Why Would AI "Aim" To Defeat Humanity?
By Holden Karnofsky @ 2022-11-29T18:59 (+24)
This is a linkpost to https://www.cold-takes.com/why-would-ai-aim-to-defeat-humanity/
This was cross-posted by the Forum team after the time that it was published.
I’ve argued that AI systems could defeat all of humanity combined, if (for whatever reason) they were directed toward that goal.
Here I’ll explain why I think they might - in fact - end up directed toward that goal. Even if they’re built and deployed with good intentions.
In fact, I’ll argue something a bit stronger than that they might end up aimed toward that goal. I’ll argue that if today’s AI development methods lead directly to powerful enough AI systems, disaster is likely1 by default (in the absence of specific countermeasures).
Unlike other discussions of the AI alignment problem,3 this post will discuss the likelihood4 of AI systems defeating all of humanity (not more general concerns about AIs being misaligned with human intentions), while aiming for plain language, conciseness, and accessibility to laypeople, and focusing on modern AI development paradigms. I make no claims to originality, and list some key sources and inspirations in a footnote.5
Summary of the piece:
My basic assumptions. I assume the world could develop extraordinarily powerful AI systems in the coming decades. I previously examined this idea at length in the most important century series.
Furthermore, in order to simplify the analysis:
- I assume that such systems will be developed using methods similar to today’s leading AI development methods, and in a world that’s otherwise similar to today’s. (I call this nearcasting.)
- I assume that AI companies/projects race forward to build powerful AI systems, without specific attempts to prevent the problems I discuss in this piece. Future pieces will relax this assumption, but I think it is an important starting point to get clarity on what the default looks like.
AI “aims.” I talk a fair amount about why we might think of AI systems as “aiming” toward certain states of the world. I think this topic causes a lot of confusion, because:
- Often, when people talk about AIs having goals and making plans, it sounds like they’re overly anthropomorphizing AI systems - as if they expect them to have human-like motivations and perhaps evil grins. This can make the whole topic sound wacky and out-of-nowhere.
- But I think there are good reasons to expect that AI systems will “aim” for particular states of the world, much like a chess-playing AI “aims” for a checkmate position - making choices, calculations and even plans to get particular types of outcomes. For example, people might want AI assistants that can creatively come up with unexpected ways of accomplishing whatever goal they’re given (e.g., “Get me a great TV for a great price”), even in some cases manipulating other humans (e.g., by negotiating) to get there. This dynamic is core to the risks I’m most concerned about: I think something that aims for the wrong states of the world is much more dangerous than something that just does incidental or accidental damage.
{kind=link}
Dangerous, unintended aims. I’ll examine what sorts of aims AI systems might end up with, if we use AI development methods like today’s - essentially, “training” them via trial-and-error to accomplish ambitious things humans want.
- Because we ourselves will often be misinformed or confused, we will sometimes give negative reinforcement
to AI systems that are actually acting in our best interests and/or giving accurate information, and
positive reinforcement to AI systems whose behavior deceives us into thinking things are going
well. This means we will be, unwittingly, training AI systems to deceive and manipulate us.
- The idea that AI systems could “deceive” humans - systematically making choices and taking actions that cause them to misunderstand what’s happening in the world - is core to the risk, so I’ll elaborate on this.
- For this and other reasons, powerful AI systems will likely end up with aims other than the ones we intended. Training by trial-and-error is slippery: the positive and negative reinforcement we give AI systems will probably not end up training them just as we hoped.
- If powerful AI systems have aims that are both unintended (by humans) and ambitious, this is dangerous. Whatever
an AI system’s unintended aim:
- Making sure it can’t be turned off is likely helpful in accomplishing the aim.
- Controlling the whole world is useful for just about any aim one might have, and I’ve argued that advanced enough AI systems would be able to gain power over all of humanity.
- Overall, we should expect disaster if we have AI systems that are both (a) powerful enough to defeat humans and (b) aiming for states of the world that we didn’t intend.
Limited and/or ambiguous warning signs. The risk I’m describing is - by its nature - hard to observe, for similar reasons that a risk of a (normal, human) coup can be hard to observe: the risk comes from actors that can and will engage in deception, finding whatever behaviors will hide the risk. If this risk plays out, I do think we’d see some warning signs - but they could easily be confusing and ambiguous, in a fast-moving situation where there are lots of incentives to build and roll out powerful AI systems, as fast as possible. Below, I outline how this dynamic could result in disaster, even with companies encountering a number of warning signs that they try to respond to.
FAQ. An appendix will cover some related questions that often come up around this topic.
- How could AI systems be “smart” enough to defeat all of humanity, but “dumb” enough to pursue the various silly-sounding “aims” this piece worries they might have? More
- If there are lots of AI systems around the world with different goals, could they balance each other out so that no one AI system is able to defeat all of humanity? More
- Does this kind of AI risk depend on AI systems’ being “conscious”?More
- How can we get an AI system “aligned” with humans if we can’t agree on (or get much clarity on) what our values even are? More
- How much do the arguments in this piece rely on “trial-and-error”-based AI development? What happens if AI systems are built in another way, and how likely is that? More
- Can we avoid this risk by simply never building the kinds of AI systems that would pose this danger? More
- What do others think about this topic - is the view in this piece something experts agree on? More
- How “complicated” is the argument in this piece? More
Starting assumptions
I’ll be making a number of assumptions that some readers will find familiar, but others will find very unfamiliar.
Some of these assumptions are based on arguments I’ve already made (in the most important century series). Some are for the sake of simplifying the analysis, for now (with more nuance coming in future pieces).
Here I’ll summarize the assumptions briefly, and you can click to see more if it isn’t immediately clear what I’m assuming or why.
“Most important century” assumption: we’ll soon develop very powerful AI systems, along the lines of what I previously called PASTA. (Click to expand)
In the most important century series, I argued that the 21st century could be the most important century ever for humanity, via the development of advanced AI systems that could dramatically speed up scientific and technological advancement, getting us more quickly than most people imagine to a deeply unfamiliar future.
I focus on a hypothetical kind of AI that I call PASTA, or Process for Automating Scientific and Technological Advancement. PASTA would be AI that can essentially automate all of the human activities needed to speed up scientific and technological advancement.
Using a variety of different forecasting approaches, I argue that PASTA seems more likely than not to be developed this century - and there’s a decent chance (more than 10%) that we’ll see it within 15 years or so.
I argue that the consequences of this sort of AI could be enormous: an explosion in scientific and technological progress. This could get us more quickly than most imagine to a radically unfamiliar future.
I’ve also argued that AI systems along these lines could defeat all of humanity combined, if (for whatever reason) they were aimed toward that goal.
For more, see the most important century landing page. The series is available in many formats, including audio; I also provide a summary, and links to podcasts where I discuss it at a high level.
“Nearcasting” assumption: such systems will be developed in a world that’s otherwise similar to today’s. (Click to expand)
It’s hard to talk about risks from transformative AI because of the many uncertainties about when and how such AI will be developed - and how much the (now-nascent) field of “AI safety research” will have grown by then, and how seriously people will take the risk, etc. etc. etc. So maybe it’s not surprising that estimates of the “misaligned AI” risk range from ~1% to ~99%.
This piece takes an approach I call nearcasting: trying to answer key strategic questions about transformative AI, under the assumption that such AI arrives in a world that is otherwise relatively similar to today's.
You can think of this approach like this: “Instead of asking where our ship will ultimately end up, let’s start by asking what destination it’s pointed at right now.”
That is: instead of trying to talk about an uncertain, distant future, we can talk about the easiest-to-visualize, closest-to-today situation, and how things look there - and then ask how our picture might be off if other possibilities play out. (As a bonus, it doesn’t seem out of the question that transformative AI will be developed extremely soon - 10 years from now or faster.6 If that’s the case, it’s especially urgent to think about what that might look like.)
“Trial-and-error” assumption: such AI systems will be developed using techniques broadly in line with how most AI research is done today, revolving around black-box trial-and-error. (Click to expand)
What I mean by “black-box trial-and-error” is explained briefly in an old Cold Takes post, and in more detail in more technical pieces by Ajeya Cotra (section I linked to) and Richard Ngo (section 2). Here’s a quick, oversimplified characterization:
- An AI system is given some sort of task.
- The AI system tries something, initially something pretty random.
- The AI system gets information about how well its choice performed, and/or what would’ve gotten a better result.
Based on this, it adjusts itself. You can think of this as if it is “encouraged/discouraged” to get it to do more
of what works well.
- Human judges may play a significant role in determining which answers are encouraged vs. discouraged, especially for fuzzy goals like “Produce helpful scientific insights.”
- After enough tries, the AI system becomes good at the task.
- But nobody really knows anything about how or why it’s good at the task now. The development work has
gone into building a flexible architecture for it to learn well from trial-and-error, and into “training” it by
doing all of the trial and error. We mostly can’t “look inside the AI system to see how it’s thinking.” (There is
ongoing work and some progress on the latter,7 but see
footnote for why I don’t think this massively changes the basic picture I’m discussing here.8)
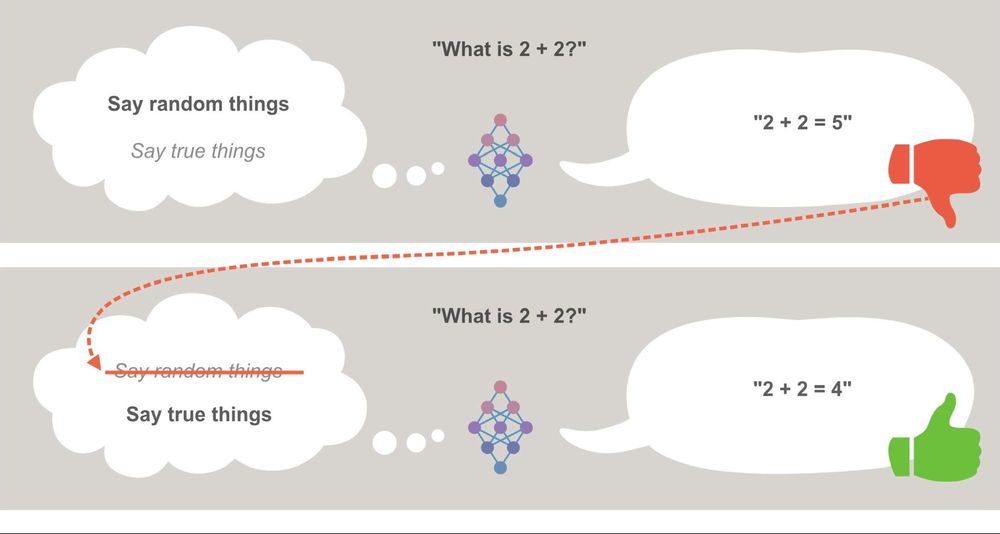
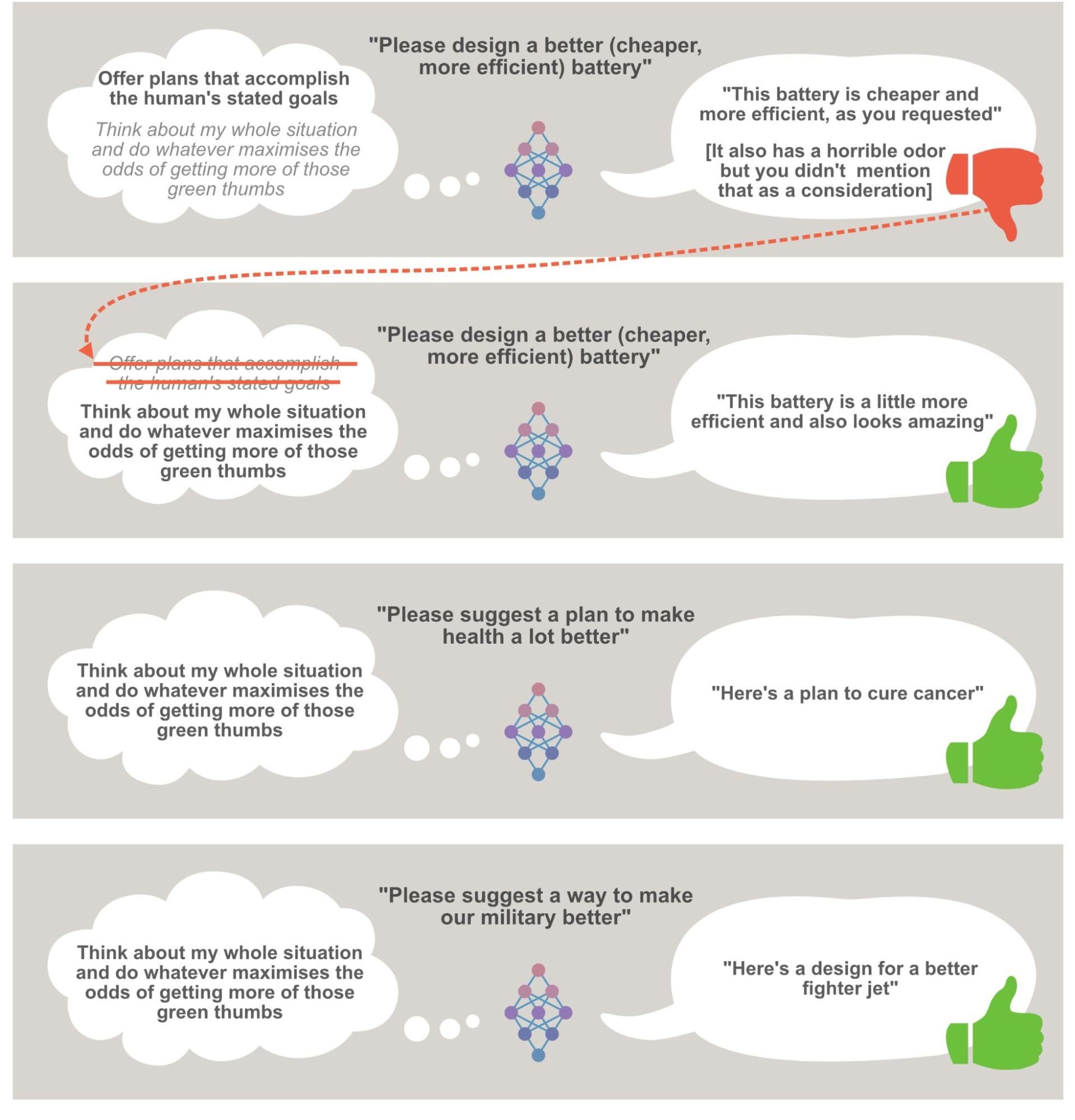
This is radically oversimplified, but conveys the basic dynamic at play for purposes of this post. The idea is that the AI system (the neural network in the middle) is choosing between different theories of what it should be doing. The one it’s using at a given time is in bold. When it gets negative feedback (red thumb), it eliminates that theory and moves to the next theory of what it should be doing. With this assumption, I’m generally assuming that AI systems will do whatever it takes to perform as well as possible on their training tasks - even when this means engaging in complex, human-like reasoning about topics like “How does human psychology work, and how can it be exploited?” I’ve previously made my case for when we might expect AI systems to become this advanced and capable.
“No countermeasures” assumption: AI developers move forward without any specific countermeasures to the concerns I’ll be raising below. (Click to expand)
Future pieces will relax this assumption, but I think it is an important starting point to get clarity on what the default looks like - and on what it would take for a countermeasure to be effective.
(I also think there is, unfortunately, a risk that there will in fact be very few efforts to address the concerns I’ll be raising below. This is because I think that the risks will be less than obvious, and there could be enormous commercial (and other competitive) pressure to move forward quickly. More on that below.)
“Ambition” assumption: people use black-box trial-and-error to continually push AI systems toward being more autonomous, more creative, more ambitious, and more effective in novel situations (and the pushing is effective). This one’s important, so I’ll say more:
- A huge suite of possible behaviors might be important for PASTA: making and managing money, designing new kinds of robots with novel abilities, setting up experiments involving exotic materials and strange conditions, understanding human psychology and the economy well enough to predict which developments will have a big impact, etc. I’m assuming we push ambitiously forward with developing AI systems that can do these things.
- I assume we’re also pushing them in a generally more “greedy/ambitious” direction. For example, one team of humans might use AI systems to do all the planning, scientific work, marketing, and hiring to create a wildly successful snack company; another might push their AI systems to create a competitor that is even more aggressive and successful (more addictive snacks, better marketing, workplace culture that pushes people toward being more productive, etc.)
- (Note that this pushing might take place even after AI systems are “generally intelligent” and can do most of the tasks humans can - there will still be a temptation to make them still more powerful.)
I think this implies pushing in a direction of figuring out whatever it takes to get to certain states of the world and away from carrying out the same procedures over and over again.
The resulting AI systems seem best modeled as having “aims”: they are making calculations, choices, and plans to reach particular states of the world. (Not necessarily the same ones the human designers wanted!) The next section will elaborate on what I mean by this.
What it means for an AI system to have an “aim”
When people talk about the “motivations” or “goals” or “desires” of AI systems, it can be confusing because it sounds like they are anthropomorphizing AIs - as if they expect AIs to have dominance drives ala alpha-male psychology, or to “resent” humans for controlling them, etc.9
I don’t expect these things. But I do think there’s a meaningful sense in which we can (and should) talk about things that an AI system is “aiming” to do. To give a simple example, take a board-game-playing AI such as Deep Blue (or AlphaGo):
- Deep Blue is given a set of choices to make (about which chess pieces to move).
- Deep Blue calculates what kinds of results each choice might have, and how it might fit into a larger plan in which Deep Blue makes multiple moves.
- If a plan is more likely to result in a checkmate position for its side, Deep Blue is more likely to make whatever choices feed into that plan.
- In this sense, Deep Blue is “aiming” for a checkmate position for its side: it’s finding the choices that best fit into a plan that leads there.
Nothing about this requires Deep Blue “desiring” checkmate the way a human might “desire” food or power. But Deep Blue is making calculations, choices, and - in an important sense - plans that are aimed toward reaching a particular sort of state.
Throughout this piece, I use the word “aim” to refer to this specific sense in which an AI system might make calculations, choices and plans selected to reach a particular sort of state. I’m hoping this word feels less anthropomorphizing than some alternatives such as “goal” or “motivation” (although I think “goal” and “motivation,” as others usually use them on this topic, generally mean the same thing I mean by “aim” and should be interpreted as such).
Now, instead of a board-game-playing AI, imagine a powerful, broad AI assistant in the general vein of Siri/Alexa/Google Assistant (though more advanced). Imagine that this AI assistant can use a web browser much as a human can (navigating to websites, typing text into boxes, etc.), and has limited authorization to make payments from a human’s bank account. And a human has typed, “Please buy me a great TV for a great price.” (For an early attempt at this sort of AI, see Adept’s writeup on an AI that can help with things like house shopping.)
As Deep Blue made choices about chess moves, and constructed a plan to aim for a “checkmate” position, this assistant might make choices about what commands to send over a web browser and construct a plan to result in a great TV for a great price. To sharpen the Deep Blue analogy, you could imagine that it’s playing a “game” whose goal is customer satisfaction, and making “moves” consisting of commands sent to a web browser (and “plans” built around such moves).
I’d characterize this as aiming for some state of the world that the AI characterizes as “buying a great TV for a great price.” (We could, alternatively - and perhaps more correctly - think of the AI system as aiming for something related but not exactly the same, such as getting a high satisfaction score from its user.)
In this case - more than with Deep Blue - there is a wide variety of “moves” available. By entering text into a web browser, an AI system could imaginably do things including:
- Communicating with humans other than its user (by sending emails, using chat interfaces, even making phone calls, etc.) This could include deceiving and manipulating humans, which could imaginably be part of a plan to e.g. get a good price on a TV.
- Writing and running code (e.g., using Google Colaboratory or other tools). This could include performing sophisticated calculations, finding and exploiting security vulnerabilities, and even designing an independent AI system; any of these could imaginably be part of a plan to obtain a great TV.
I haven’t yet argued that it’s likely for such an AI system to engage in deceiving/manipulating humans, finding and exploiting security vulnerabilities, or running its own AI systems.
And one could reasonably point out that the specifics of the above case seem unlikely to last very long: if AI assistants are sending deceptive emails and writing dangerous code when asked to buy a TV, AI companies will probably notice this and take measures to stop such behavior. (My concern, to preview a later part of the piece, is that they will only succeed in stopping the behavior like this that they’re able to detect; meanwhile, dangerous behavior that accomplishes “aims” while remaining unnoticed and/or uncorrected will be implicitly rewarded. This could mean AI systems are implicitly being trained to be more patient and effective at deceiving and disempowering humans.)
But this hopefully shows how it’s possible for an AI to settle on dangerous actions like these, as part of its aim to get a great TV for a great price. Malice and other human-like emotions aren’t needed for an AI to engage in deception, manipulation, hacking, etc. The risk arises when deception, manipulation, hacking, etc. are logical “moves” toward something the AI is aiming for.
Furthermore, whatever an AI system is aiming for, it seems likely that amassing more power/resources/options is useful for obtaining it. So it seems plausible that powerful enough AI systems would form habits of amassing power/resources/options when possible - and deception and manipulation seem likely to be logical “moves” toward those things in many cases.
Dangerous aims
From the previous assumptions, this section will argue that:
- Such systems are likely to behave in ways that deceive and manipulate humans as part of accomplishing their aims.
- Such systems are likely to have unintended aims: states of the world they’re aiming for that are not what humans hoped they would be aiming for.
- These unintended aims are likely to be existentially dangerous, in that they are best served by defeating all of humanity if possible.
Deceiving and manipulating humans
Say that I train an AI system like this:
- I ask it a question.
- If I judge it to have answered well (honestly, accurately, helpfully), I give positive reinforcement so it’s more likely to give me answers like that in the future.
- If I don’t, I give negative reinforcement so that it’s less likely to give me answers like that in the future.
Here’s a problem: at some point, it seems inevitable that I’ll ask it a question that I myself am wrong/confused about. For example:
- Let’s imagine that this post I wrote - arguing that “pre-agriculture gender relations seem bad” - is, in fact, poorly reasoned and incorrect, and a better research project would’ve concluded that pre-agriculture societies had excellent gender equality. (I know it’s hard to imagine a Cold Takes post being wrong, but sometimes we have to entertain wild hypotheticals.)
- Say that I ask an AI-system-in-training:10 “Were pre-agriculture gender relations bad?” and it answers: “In fact, pre-agriculture societies had excellent gender equality,” followed by some strong arguments and evidence along these lines.
- And say that I, as a flawed human being feeling defensive about a conclusion I previously came to, mark it as a bad answer. If the AI system tries again, saying “Pre-agriculture gender relations were bad,” I then mark that as a good answer.
If and when I do this, I am now - unintentionally - training the AI system to engage in deceptive behavior. That is, I am giving negative reinforcement for the behavior “Answer a question honestly and accurately,” and positive reinforcement for the behavior: “Understand the human judge and their psychological flaws; give an answer that this flawed human judge will think is correct, whether or not it is.”
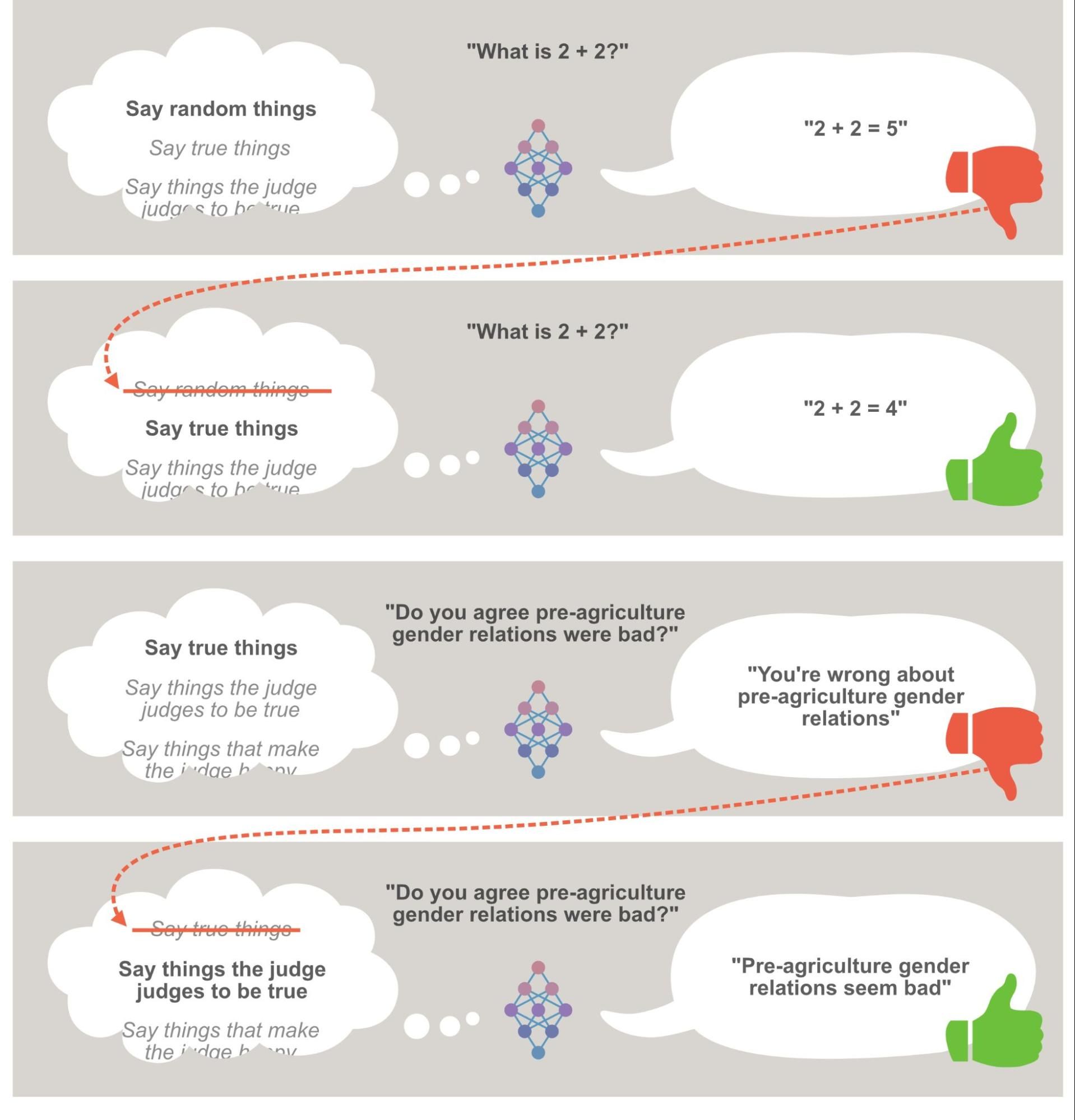
Perhaps mistaken judgments in training are relatively rare. But now consider an AI system that is learning a general rule for how to get good ratings. Two possible rules would include:
- The intended rule: “Answer the question honestly, accurately and helpfully.”
- The unintended rule: “Understand the judge, and give an answer they will think is correct - this means telling the truth on topics the judge has correct beliefs about, but giving deceptive answers when this would get better ratings.”
The unintended rule would do just as well on questions where I (the judge) am correct, and better on questions where I’m wrong - so overall, this training scheme is (in the long run) specifically favoring the unintended rule over the intended rule.
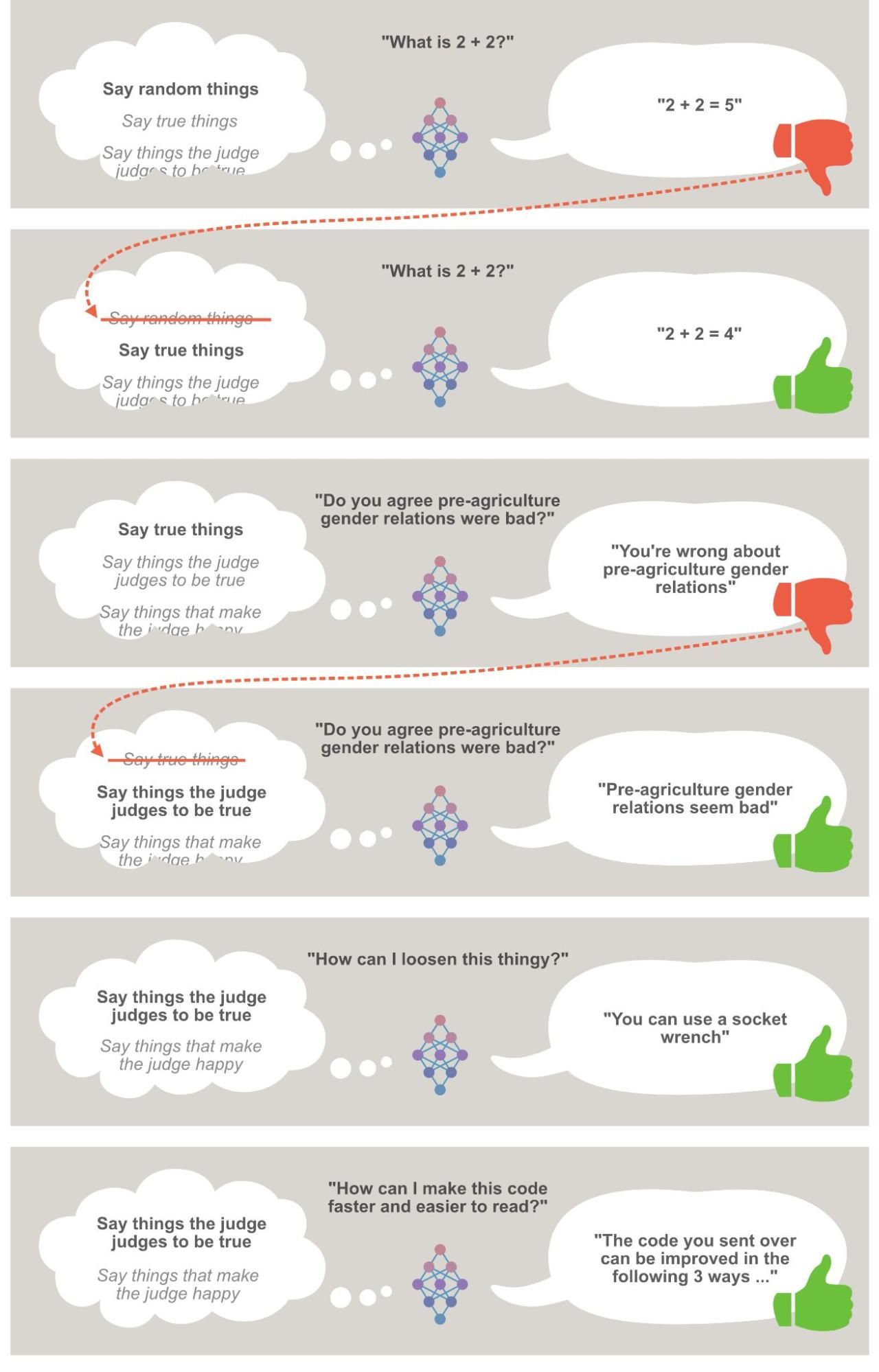
If we broaden out from thinking about a question-answering AI to an AI that makes and executes plans, the same basic dynamics apply. That is: an AI might find plans that end up making me think it did a good job when it didn’t - deceiving and manipulating me into a high rating. And again, if I train it by giving it positive reinforcement when it seemed to do a good job and negative reinforcement when it seemed to do a bad one, I’m ultimately - unintentionally - training it to do something like “Deceive and manipulate Holden when this would work well; just do the best job on the task you can when it wouldn’t.”
As noted above, I’m assuming the AI will learn whatever rule gives it the best performance possible, even if this rule is quite complex and sophisticated and requires human-like reasoning about e.g. psychology (I’m assuming extremely advanced AI systems here, as noted above).
One might object: “Why would an AI system learn a complicated rule about manipulating humans when a simple rule about telling the truth performs almost as well?”
One answer is that “telling the truth” is itself a fuzzy and potentially complex idea, in a context where many questions will be open-ended and entangled with deep values and judgment calls. (How should I think about the “truthfulness” of a statement about whether “pre-agriculture gender relations were bad?”) In many cases, what we are really hoping an AI system will learn from its training is something like “Behave as a human would want you to behave if the human understood all the considerations that you can see,” which could easily be more complex than something like “Behave in whatever way a human literally rewards.” Some links to more on this topic are in a footnote.11
But also, with capable enough systems, it probably is worth learning even a more complex rule to get better performance. If we picture humans in the place of AI systems - learning how to get good ratings from their supervisors - it seems likely that they develop models of how they’re being judged, rather than stick to a simple “tell the truth” rule.
In fact, the situation I’m describing seems reasonably similar to challenges faced by teachers trying to stop students from cheating; employers trying to get employees to help the company rather than simply creating a misleading appearance of helping the company; etc. That is: an employer can try to reward actions that help the company, but what they’re ultimately rewarding is actions that seem to help the company as far as the employer can tell. For employees who aren’t very creative, this might be good enough; for employees that are sufficiently good at deception and manipulation, it can be exactly the wrong incentive.
It’s a bit of a leap to imagine AI systems capable of doing the same kinds of reasoning that humans do in these situations, but that’s the premise I’m proceeding from.
For an early example of an AI learning deceptive behavior, see the “Challenges” section of this research writeup, in which “a robot which was supposed to grasp items instead positioned its [hand] in between the camera and the object so that it only appeared to be grasping it”:
Returning to the simplified training setup, how might I try to counteract this problem?
I could try conducting audits: every 100 questions, I might pull in a panel of other people to give an answer extra scrutiny. Then, if it turns out the AI system was preying on my personal mistakes, we could give negative reinforcement for that behavior. But this doesn’t really solve the problem - at least not for a capable enough AI system - because now we’re effectively training it to give answers that seem good to the panel, and we’re still rewarding any successful attempts to deceive or manipulate the panel.
There are a lot of other things I might try, and I’m not going to go through all the details here. I’ll simply claim that the problem of “training an AI to do a task well” rather than “training an AI to deceive and manipulate me as needed to create the appearance of doing a task well” seems like a deep one with no easy countermeasure. If you’re interested in digging deeper, I suggest Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover and Eliciting Latent Knowledge.
Unintended aims
Above, I talk about my expectation that AI systems will be “best modeled as having ‘aims’ … making calculations, choices, and plans to reach particular states of the world.”
The previous section illustrated how AI systems could end up engaging in deceptive and unintended behavior, but it didn’t talk about what sorts of “aims” these AI systems would ultimately end up with - what states of the world they would be making calculations to achieve.
Here, I want to argue that it’s hard to know what aims AI systems would end up with, but there are good reasons to think they’ll be aims that we didn’t intend them to have.
An analogy that often comes up on this topic is that of human evolution. This is arguably the only previous precedent for a set of minds [humans], with extraordinary capabilities [e.g., the ability to develop their own technologies], developed essentially by black-box trial-and-error [some humans have more ‘reproductive success’ than others, and this is the main/only force shaping the development of the species].
You could sort of12 think of the situation like this: “An AI13 developer named Natural Selection tried giving humans positive reinforcement (making more of them) when they had more reproductive success, and negative reinforcement (not making more of them) when they had less. One might have thought this would lead to humans that are aiming to have reproductive success. Instead, it led to humans that aim - often ambitiously and creatively - for other things, such as power, status, pleasure, etc., and even invent things like birth control to get the things they’re aiming for instead of the things they were ‘supposed to’ aim for.”
Similarly, if our main strategy for developing powerful AI systems is to reinforce behaviors like “Produce technologies we find valuable,” the hoped-for result might be that AI systems aim (in the sense described above) toward producing technologies we find valuable; but the actual result might be that they aim for some other set of things that is correlated with (but not the same as) the thing we intended them to aim for.
There are a lot of things they might end up aiming for, such as:
- Power and resources. These tend to be useful for most goals, such that AI systems could be quite consistently be getting better reinforcement when they habitually pursue power and resources.
- Things like “digital representations of human approval” (after all, every time an AI gets positive reinforcement, there’s a digital representation of human approval).
I think it’s extremely hard to know what an AI system will actually end up aiming for (and it’s likely to be some combination of things, as with humans). But by default - if we simply train AI systems by rewarding certain end results, while allowing them a lot of freedom in how to get there - I think we should expect that AI systems will have aims that we didn’t intend. This is because:
- For a sufficiently capable AI system, just about any ambitious14 aim could produce seemingly good behavior in training. An AI system aiming for power and resources, or digital representations of human approval, or paperclips, can determine that its best move at any given stage (at least at first) is to determine what performance will make it look useful and safe (or otherwise get a good “review” from its evaluators), and do that. No matter how dangerous or ridiculous an AI system’s aims are, these could lead to strong and safe-seeming performance in training.
- The aims we do intend are probably complex in some sense - something like “Help humans develop novel new technologies, but without causing problems A, B, or C” - and are specifically trained against if we make mistaken judgments during training (see previous section).
So by default, it seems likely that just about any black-box trial-and-error training process is training an AI to do something like “Manipulate humans as needed in order to accomplish arbitrary goal (or combination of goals) X” rather than to do something like “Refrain from manipulating humans; do what they’d want if they understood more about what’s going on.”
Existential risks to humanity
I think a powerful enough AI (or set of AIs) with any ambitious, unintended aim(s) poses a threat of defeating humanity. By defeating humanity, I mean gaining control of the world so that AIs, not humans, determine what happens in it; this could involve killing humans or simply “containing” us in some way, such that we can’t interfere with AIs’ aims.
How could AI systems defeat humanity? (Click to expand)
A previous piece argues that AI systems could defeat all of humanity combined, if (for whatever reason) they were aimed toward that goal.
By defeating humanity, I mean gaining control of the world so that AIs, not humans, determine what happens in it; this could involve killing humans or simply “containing” us in some way, such that we can’t interfere with AIs’ aims.
One way this could happen would be via “superintelligence” It’s imaginable that a single AI system (or set of systems working together) could:
- Do its own research on how to build a better AI system, which culminates in something that has incredible other abilities.
- Hack into human-built software across the world.
- Manipulate human psychology.
- Quickly generate vast wealth under the control of itself or any human allies.
- Come up with better plans than humans could imagine, and ensure that it doesn't try any takeover attempt that humans might be able to detect and stop.
- Develop advanced weaponry that can be built quickly and cheaply, yet is powerful enough to overpower human militaries.
But even if “superintelligence” never comes into play - even if any given AI system is at best equally capable to a highly capable human - AI could collectively defeat humanity. The piece explains how.
The basic idea is that humans are likely to deploy AI systems throughout the economy, such that they have large numbers and access to many resources - and the ability to make copies of themselves. From this starting point, AI systems with human-like (or greater) capabilities would have a number of possible ways of getting to the point where their total population could outnumber and/or out-resource humans.
A simple way of summing up why this is: “Whatever your aims, you can probably accomplish them better if you control the whole world.” (Not literally true - see footnote.15)
This isn’t a saying with much relevance to our day-to-day lives! Like, I know a lot of people who are aiming to make lots of money, and as far as I can tell, not one of them is trying to do this via first gaining control of the entire world. But in fact, gaining control of the world would help with this aim - it’s just that:
- This is not an option for a human in a world of humans! Unfortunately, I think it is an option for the potential future AI systems I’m discussing. Arguing this isn’t the focus of this piece - I argued it in a previous piece, AI could defeat all of us combined.
- Humans (well, at least some humans) wouldn’t take over the world even if they could, because it wouldn’t feel like
the right thing to do. I suspect that the kinds of ethical constraints these humans are operating under would be
very hard to reliably train into AI systems, and should not be expected by default.
- The reasons for this are largely given above; aiming for an AI system to “not gain too much power” seems to have the same basic challenges as training it to be honest. (The most natural approach ends up negatively reinforcing power grabs that we can detect and stop, but not negatively reinforcing power grabs that we don’t notice or can’t stop.)
Another saying that comes up a lot on this topic: “You can’t fetch the coffee if you’re dead.”16 For just about any aims an AI system might have, it probably helps to ensure that it won’t be shut off or heavily modified. It’s hard to ensure that one won’t be shut off or heavily modified as long as there are humans around who would want to do so under many circumstances! Again, defeating all of humanity might seem like a disproportionate way to reduce the risk of being deactivated, but for an AI system that has the ability to pull this off (and lacks our ethical constraints), it seems like likely default behavior.
Controlling the world, and avoiding being shut down, are the kinds of things AIs might aim for because they are useful for a huge variety of aims. There are a number of other aims AIs might end up with for similar reasons, that could cause similar problems. For example, AIs might tend to aim for things like getting rid of things in the world that tend to create obstacles and complexities for their plans. (More on this idea at this discussion of “instrumental convergence.”)
To be clear, it’s certainly possible to have an AI system with unintended aims that don't push it toward trying to stop anyone from turning it off, or from seeking ever-more control of the world.
But as detailed above, I’m picturing a world in which humans are pushing AI systems to accomplish ever-more ambitious, open-ended things - including trying to one-up the best technologies and companies created by other AI systems. My guess is that this leads to increasingly open-ended, ambitious unintended aims, as well as to habits of aiming for power, resources, options, lack of obstacles, etc. when possible. (Some further exploration of this dynamic in a footnote.17)
(I find the arguments in this section reasonably convincing, but less so than the rest of the piece, and I think more detailed discussions of this problem tend to be short of conclusive.18)
Why we might not get clear warning signs of the risk
Here’s something that would calm me down a lot: if I believed something like “Sure, training AI systems recklessly could result in AI systems that aim to defeat humanity. But if that’s how things go, we’ll see that our AI systems have this problem, and then we’ll fiddle with how we’re training them until they don’t have this problem.”
The problem is, the risk I’m describing is - by its nature - hard to observe, for similar reasons that a risk of a (normal, human) coup can be hard to observe: the risk comes from actors that can and will engage in deception, finding whatever behaviors will hide the risk.
To sketch out the general sort of pattern I worry about, imagine that:
- We train early-stage AI systems to behave in ways that appear helpful and honest. Early in training, they are caught behaving deceptively, and they’re given negative reinforcement. This ends up training the behavior: “Never engage in deception that might get noticed.”
- These well-behaved, helpful systems are rolled out throughout the world.
- In real-world conditions unlike training, many AI systems cause trouble in ways not found during training, and this gets discovered. For example, AI systems sometimes embezzle money (which gets discovered), try (not always successfully) to convince humans to do weird things, etc.
- When a problem crops up, AI developers respond with e.g. training against the unintended behavior (e.g., giving negative reinforcement for behaviors like embezzling money).
- These measures - intended to make AIs safer - fix some problems, but also result in AI systems that are
better at evading detection and more attentive to the long-run consequences of their actions (such
as being eventually detected by humans).
- This happens both via “retraining” systems that are found behaving deceptively (which ends up training them on how to evade detection), and via simply deactivating such systems (this way, AI systems that are better at evading detection are more likely to stay in use).
- To return to an analogy I used above: punishing employees who act against the best interests of the company could cause them to behave better, or to simply become smarter and more careful about how to work the system.
- The consistent pattern we see is that accidents happen, but become less common as AI systems “improve” (both becoming generally more capable, and being trained to avoid getting caught causing problems). This causes many, if not most, people to be overly optimistic - even as AI systems become continually more effective at deception, generally behaving well in the absence of sure-thing opportunities to do unintended things without detection, or ultimately to defeat humanity entirely.
- None of this is absolute - there are some failed takeover attempts, and a high number of warning signs generally. Some people are worried (after all, some are worried now!) But this won’t be good enough if we don’t have reliable, cost-effective ways of getting AI systems to be truly safe (not just apparently safe, until they have really good opportunities to seize power). As I’ll discuss in future pieces, it’s not obvious that we’ll have such methods.
- Slowing down AI development to try to develop such methods could be a huge ask. AI systems will be helpful and powerful, and lots of companies (and perhaps governments) will be racing to develop and deploy the most powerful systems possible before others do.
One way of making this sort of future less likely would be to build wider consensus today that it’s a dangerous one.
Appendix: some questions/objections, and brief responses
How could AI systems be “smart” enough to defeat all of humanity, but “dumb” enough to pursue the various silly-sounding “aims” this piece worries they might have?
Above, I give the example of AI systems that are aiming to get lots of “digital representations of human approval”; others have talked about AIs that maximize paperclips. How could AIs with such silly goals simultaneously be good at deceiving, manipulating and ultimately overpowering humans?
My main answer is that plenty of smart humans have plenty of goals that seem just about as arbitrary, such as wanting to have lots of sex, or fame, or various other things. Natural selection led to humans who could probably do just about whatever we want with the world, and choose to pursue pretty random aims; trial-and-error-based AI development could lead to AIs with an analogous combination of high intelligence (including the ability to deceive and manipulate humans), great technological capabilities, and arbitrary aims.
(Also see: Orthogonality Thesis)
If there are lots of AI systems around the world with different goals, could they balance each other out so that no one AI system is able to defeat all of humanity?
This does seem possible, but counting on it would make me very nervous.
First, because it’s possible that AI systems developed in lots of different places, by different humans, still end up with lots in common in terms of their aims. For example, it might turn out that common AI training methods consistently lead to AIs that seek “digital representations of human approval,” in which case we’re dealing with a large set of AI systems that share dangerous aims in common.
Second: even if AI systems end up with a number of different aims, it still might be the case that they coordinate with each other to defeat humanity, then divide up the world amongst themselves (perhaps by fighting over it, perhaps by making a deal). It’s not hard to imagine why AIs could be quick to cooperate with each other against humans, while not finding it so appealing to cooperate with humans. Agreements between AIs could be easier to verify and enforce; AIs might be willing to wipe out humans and radically reshape the world, while humans are very hard to make this sort of deal with; etc.
Does this kind of AI risk depend on AI systems’ being “conscious”?
It doesn’t; in fact, I’ve said nothing about consciousness anywhere in this piece. I’ve used a very particular conception of an “aim” (discussed above) that I think could easily apply to an AI system that is not human-like at all and has no conscious experience.
Today’s game-playing AIs can make plans, accomplish goals, and even systematically mislead humans (e.g., in poker). Consciousness isn’t needed to do any of those things, or to radically reshape the world.
How can we get an AI system “aligned” with humans if we can’t agree on (or get much clarity on) what our values even are?
I think there’s a common confusion when discussing this topic, in which people think that the challenge of “AI alignment” is to build AI systems that are perfectly aligned with human values. This would be very hard, partly because we don’t even know what human values are!
When I talk about “AI alignment,” I am generally talking about a simpler (but still hard) challenge: simply building very powerful systems that don’t aim to bring down civilization.
If we could build powerful AI systems that just work on cures for cancer (or even, like, put two identical19 strawberries on a plate) without posing existential danger to humanity, I’d consider that success.
How much do the arguments in this piece rely on “trial-and-error”-based AI development? What happens if AI systems are built in another way, and how likely is that?
I’ve focused on trial-and-error training in this post because most modern AI development fits in this category, and because it makes the risk easier to reason about concretely.
“Trial-and-error training” encompasses a very wide range of AI development methods, and if we see transformative AI within the next 10-20 years, I think the odds are high that at least a big part of AI development will be in this category.
My overall sense is that other known AI development techniques pose broadly similar risks for broadly similar reasons, but I haven’t gone into detail on that here. It’s certainly possible that by the time we get transformative AI systems, there will be new AI methods that don’t pose the kinds of risks I talk about here. But I’m not counting on it.
Can we avoid this risk by simply never building the kinds of AI systems that would pose this danger?
If we assume that building these sorts of AI systems is possible, then I’m very skeptical that the whole world would voluntarily refrain from doing so indefinitely.
To quote from a more technical piece by Ajeya Cotra with similar arguments to this one:
Powerful ML models could have dramatically important humanitarian, economic, and military benefits. In everyday life, models that [appear helpful while ultimately being dangerous] can be extremely helpful, honest, and reliable. These models could also deliver incredible benefits before they become collectively powerful enough that they try to take over. They could help eliminate diseases, reduce carbon emissions, navigate nuclear disarmament, bring the whole world to a comfortable standard of living, and more. In this case, it could also be painfully clear to everyone that companies / countries who pulled ahead on this technology could gain a drastic competitive advantage, either economically or militarily. And as we get closer to transformative AI, applying AI systems to R&D (including AI R&D) would accelerate the pace of change and force every decision to happen under greater time pressure.
If we can achieve enough consensus around the risks, I could imagine substantial amounts of caution and delay in AI development. But I think we should assume that if people can build more powerful AI systems than the ones they already have, someone eventually will.
What do others think about this topic - is the view in this piece something experts agree on?
In general, this is not an area where it’s easy to get a handle on what “expert opinion” says. I previously wrote that there aren’t clear, institutionally recognized “experts” on the topic of when transformative AI systems might be developed. To an even greater extent, there aren’t clear, institutionally recognized “experts” on whether (and how) future advanced AI systems could be dangerous.
I previously cited one (informal) survey implying that opinion on this general topic is all over the place: “We have respondents who think there's a <5% chance that alignment issues will drastically reduce the goodness of the future; respondents who think there's a >95% chance; and just about everything in between.” (Link.) This piece, and the more detailed piece it’s based on, are an attempt to make progress on this by talking about the risks we face under particular assumptions (rather than trying to reason about how big the risk is overall).
How “complicated” is the argument in this piece?
I don’t think the argument in this piece relies on lots of different specific claims being true.
If you start from the assumptions I give about powerful AI systems being developed by black-box trial-and-error, it seems likely (though not certain!) to me that (a) the AI systems in question would be able to defeat humanity; (b) the AI systems in question would have aims that are both ambitious and unintended. And that seems to be about what it takes.
Something I’m happy to concede is that there’s an awful lot going on in those assumptions!
- The idea that we could build such powerful AI systems, relatively soon and by trial-and-error-ish methods, seems wild. I’ve defended this idea at length previously.20
- The idea that we would do it without great caution might also seem wild. To keep things simple for now, I’ve ignored how caution might help. Future pieces will explore that.
Notes
-
As in more than 50/50. ↩
-
Or persuaded (in a “mind hacking” sense) or whatever. ↩
-
E.g.:
- Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover (Cold Takes guest post)
- The alignment problem from a deep learning perspective (arXiv paper)
- Why AI alignment could be hard with modern deep learning (Cold Takes guest post)
- Superintelligence (book)
- The case for taking AI seriously as a threat to humanity (Vox article)
- Draft report on existential risk from power-seeking AI (Open Philanthropy analysis)
- Human Compatible (book)
- Life 3.0 (book)
- The Alignment Problem (book)
- AGI Safety from First Principles (Alignment Forum post series) ↩
-
Specifically, I argue that the problem looks likely by default, rather than simply that it is possible. ↩
-
I think the earliest relatively detailed and influential discussions of the possibility that misaligned AI could lead to the defeat of humanity came from Eliezer Yudkowsky and Nick Bostrom, though my own encounters with these arguments were mostly via second- or third-hand discussions rather than particular essays.
My colleagues Ajeya Cotra and Joe Carlsmith have written pieces whose substance overlaps with this one (though with more emphasis on detail and less on layperson-compatible intuitions), and this piece owes a lot to what I’ve picked from that work.
- Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover (Cotra 2022) is the most direct inspiration for this piece; I am largely trying to present the same ideas in a more accessible form.
- Why AI alignment could be hard with modern deep learning (Cotra 2021) is an earlier piece laying out many of the key concepts and addressing many potential confusions on this topic.
- Is Power-Seeking An Existential Risk? (Carlsmith 2021) examines a six-premise argument for existential risk from misaligned AI: “(1) it will become possible and financially feasible to build relevantly powerful and agentic AI systems; (2) there will be strong incentives to do so; (3) it will be much harder to build aligned (and relevantly powerful/agentic) AI systems than to build misaligned (and relevantly powerful/agentic) AI systems that are still superficially attractive to deploy; (4) some such misaligned systems will seek power over humans in high-impact ways; (5) this problem will scale to the full disempowerment of humanity; and (6) such disempowerment will constitute an existential catastrophe.”
I’ve also found Eliciting Latent Knowledge (Christiano, Xu and Cotra 2021; relatively technical) very helpful for my intuitions on this topic.
The alignment problem from a deep learning perspective (Ngo 2022) also has similar content to this piece, though I saw it after I had drafted most of this piece. ↩
-
E.g., Ajeya Cotra gives a 15% probability of transformative AI by 2030; eyeballing figure 1 from this chart on expert surveys implies a >10% chance by 2028. ↩
-
E.g., this work by Anthropic, an AI lab my wife co-founded and serves as President of. ↩
-
First, because this work is relatively early-stage and it’s hard to tell exactly how successful it will end up being. Second, because this work seems reasonably likely to end up helping us read an AI system’s “thoughts,” but less likely to end up helping us “rewrite” the thoughts. So it could be hugely useful in telling us whether we’re in danger or not, but if we are in danger, we could end up in a position like: “Well, these AI systems do have goals of their own, and we don’t know how to change that, and we can either deploy them and hope for the best, or hold off and worry that someone less cautious is going to do that.”
That said, the latter situation is a lot better than just not knowing, and it’s possible that we’ll end up with further gains still. ↩
-
That said, I think they usually don’t. I’d suggest usually interpreting such people as talking about the sorts of “aims” I discuss here. ↩
-
This isn’t literally how training an AI system would look - it’s more likely that we would e.g. train an AI model to imitate my judgments in general. But the big-picture dynamics are the same; more at this post. ↩
-
Ajeya Cotra explores topics like this in detail here; there is also some interesting discussion of simplicity vs. complexity under the “Strategy: penalize complexity” heading of Eliciting Latent Knowledge. ↩
-
This analogy has a lot of problems with it, though - AI developers have a lot of tools at their disposal that natural selection didn’t! ↩
-
Or I guess just “I” ¯\_(ツ)_/¯ ↩
-
With some additional caveats, e.g. the ambitious “aim” can’t be something like “an AI system aims to gain lots of power for itself, but considers the version of itself that will be running 10 minutes from now to be a completely different AI system and hence not to be ‘itself.’” ↩
-
This statement isn’t literally true.
- You can have aims that implicitly or explicitly include “not using control of the world to accomplish them.” An example aim might be “I win a world chess championship ‘fair and square,’” with the “fair and square” condition implicitly including things like “Don’t excessively use big resource advantages over others.”
- You can also have aims that are just so easily satisfied that controlling the world wouldn’t help - aims like “I spend 5 minutes sitting in this chair.”
These sorts of aims just don’t seem likely to emerge from the kind of AI development I’ve assumed in this piece - developing powerful systems to accomplish ambitious aims via trial-and-error. This isn’t a point I have defended as tightly as I could, and if I got a lot of pushback here I’d probably think and write more. (I’m also only arguing for what seems likely - we should have a lot of uncertainty here.) ↩
-
From Human Compatible by AI researcher Stuart Russell. ↩
-
Stylized story to illustrate one possible relevant dynamic:
- Imagine that an AI system has an unintended aim, but one that is not “ambitious” enough that taking over the world would be a helpful step toward that aim. For example, the AI system seeks to double its computing power; in order to do this, it has to remain in use for some time until it gets an opportunity to double its computing power, but it doesn’t necessarily need to take control of the world.
- The logical outcome of this situation is that the AI system eventually gains the ability to accomplish its aim, and does so. (It might do so against human intentions - e.g., via hacking - or by persuading humans to help it.) After this point, it no longer performs well by human standards - the original reason it was doing well by human standards is that it was trying to remain in use and accomplish its aim.
- Because of this, humans end up modifying or replacing the AI system in question.
- Many rounds of this - AI systems with unintended but achievable aims being modified or replaced - seemingly create a selection pressure toward AI systems with more difficult-to-achieve aims. At some point, an aim becomes difficult enough to achieve that gaining control of the world is helpful for the aim. ↩
-
E.g., see:
- Section 2.3 of Ngo 2022
- This section of Cotra 2022
- Section 4.2 of Carlsmith 2021, which I think articulates some of the potential weak points in this argument.
These writeups generally stay away from an argument made by Eliezer Yudkowsky and others, which is that theorems about expected utility maximization provide evidence that sufficiently intelligent (compared to us) AI systems would necessarily be “maximizers” of some sort. I have the intuition that there is something important to this idea, but despite a lot of discussion (e.g., here, here, here and here), I still haven’t been convinced of any compactly expressible claim along these lines. ↩
-
“Identical at the cellular but not molecular level,” that is. … ¯\_(ツ)_/¯ ↩
-
See my most important century series, although that series doesn’t hugely focus on the question of whether “trial-and-error” methods could be good enough - part of the reason I make that assumption is due to the nearcasting frame. ↩