Announcing "Forecasting Existential Risks: Evidence from a Long-Run Forecasting Tournament"
By Forecasting Research Institute @ 2023-07-10T17:04 (+161)
This is a linkpost for "Forecasting Existential Risks: Evidence from a Long-Run Forecasting Tournament," accessible here: https://forecastingresearch.org/s/XPT.pdf
Today, the Forecasting Research Institute (FRI) released "Forecasting Existential Risks: Evidence from a Long-Run Forecasting Tournament", which describes the results of the Existential-Risk Persuasion Tournament (XPT).
The XPT, which ran from June through October of 2022, brought together forecasters from two groups with distinctive claims to knowledge about humanity’s future — experts in various domains relevant to existential risk, and "superforecasters" with a track record of predictive accuracy over short time horizons. We asked tournament participants to predict the likelihood of global risks related to nuclear weapon use, biorisks, and AI, along with dozens of other related, shorter-run forecasts.
Some major takeaways from the XPT include:
- The median domain expert predicted a 20% chance of catastrophe and a 6% chance of human extinction by 2100. The median superforecaster predicted a 9% chance of catastrophe and a 1% chance of extinction.
- Superforecasters predicted considerably lower chances of both catastrophe and extinction than did experts, but the disagreement between experts and superforecasters was not uniform across topics. Experts and superforecasters were furthest apart (in percentage point terms) on AI risk, and most similar on the risk of nuclear war.
- Predictions about risk were highly correlated across topics. For example, participants who gave higher risk estimates for AI also gave (on average) higher risk estimates for biorisks and nuclear weapon use.
- Forecasters with higher “intersubjective accuracy”—i.e., those best at predicting the views of other participants—estimated lower probabilities of catastrophic and extinction risks from all sources.
- Few minds were changed during the XPT, even among the most active participants, and despite monetary incentives for persuading others.
See the full working paper here.
FRI hopes that the XPT will not only inform our understanding of existential risks, but will also advance the science of forecasting by:
- Collecting a large set of forecasts resolving on a long timescale, in a rigorous setting. This will allow us to measure correlations between short-run (2024), medium-run (2030) and longer-run (2050) accuracy in the coming decades.
- Exploring the use of bonus payments for participants who both 1) produced persuasive rationales and 2) made accurate “intersubjective” forecasts (i.e., predictions of the predictions of other participants), which we are testing as early indicators of the reliability of long-range forecasts.
- Encouraging experts and superforecasters to interact: to share knowledge, debate, and attempt to persuade each other. We plan to explore the value of these interactions in future work.
As a follow-up to our report release, we are producing a series of posts on the EA Forum that will cover the XPT's findings on:
- AI risk (in 6 posts):
- Overview
- Details on AI risk
- Details on AI timelines
- XPT forecasts on some key AI inputs from Ajeya Cotra's biological anchors report
- XPT forecasts on some key AI inputs from Epoch's direct approach model
- Consensus on the expected shape of development of AI progress [Edited to add: We decided to cut this post from the series]
- Overview of findings on biorisk (1 post)
- Overview of findings on nuclear risk (1 post)
- Overview of findings from miscellaneous forecasting questions (1 post)
- FRI's planned next steps for this research agenda, along with a request for input on what FRI should do next (1 post)
titotal @ 2023-07-11T10:45 (+58)
Theres a very interesting passage in here, showing that asking the public extinction questions in terms of odds rather than percentages made the estimates of risk six orders of magnitude lower:
Participants in our public survey of 912 college graduates estimated a higher median probability of extinction by 2100 (5%) than superforecasters (1%) but lower than that of experts (6%). A similar pattern also emerged for AI-caused extinction (public survey participants gave a 2% probability, and superforecasters and domain experts gave 0.38% and 3%, respectively).
However, respondents of the same sample estimated much lower chances of both extinction and catastrophe by 2100 when presented with an alternative elicitation method. In a follow-up survey, we gave participants examples of low probability events—for example, that there is a 1-in-300,000 chance of being killed by lightning. We then asked them to fill in a value for “X” such that there was a “1-in-X” chance of a given risk—like human extinction by 2100.69 69 The set of reference classes we gave to participants had ten examples, including: 1 in 2: Probability a flip of a fair coin will be Tails 1 in 300,000: Lifetime probability of dying from lightning 1 in 10,000,000: Probability a random newborn becomes a U.S. president
Using that method, the median probability of humanity’s extinction before 2100 was 1 in 15 million. The median probability of AI-caused extinction before 2100 was 1 in 30 million.
This seems like incredibly strong evidence of anchoring bias in answers to this question, and it goes both ways (if you see percentages, you anchor to the 1-99 range). What I want to know is whether this effect would show up for superforecasters and domain experts as well. Are the high risk estimates of AI extinction merely an anchoring bias artifact?
Tegan @ 2023-07-11T15:50 (+7)
(I'm an FRI employee, but responding here in my personal capacity.)
Yeah, in general we thought about various types of framing effects a lot in designing the tournament, but this was one we hadn't devoted much time to. I think we were all pretty surprised by the magnitude of the effect in the public survey.
Personally, I think this likely affected our normal tournament participants less than it did members of the public. Our "expert" sample mostly had considered pre-existing views on the topics, so there was less room for the elicitation of their probabilities to affect things. And superforecasters should be more fluent in probabilistic reasoning than educated members of the public, so should be less caught out by probability vs. odds.
In any case, forecasting low probabilities is very little studied, and an FRI project to remedy that is currently underway.
titotal @ 2023-07-11T19:07 (+19)
I agree, in that I predict that the effect would be lessened for experts and lessened still more for superforecasters.
However, that doesn't tell us how much less. A six order of magnitude discrepancy leaves a lot of room! If switching to odds only dropped superforecasters by three orders of magnitude and experts by four orders of magnitude, everything you said above would be true, but it would still make a massive difference to risk estimates. The people in EA may already have a (P|Doom) before going in, but everyone else won't. Being an AI expert does not make one immune to anchoring bias.
I think it's very important to follow up on this for domain experts. I often see "median AI expert thinks thinks there is 2% chance AI x-risk" used as evidence to take AI risk seriously, but is there an alternate universe where the factoid is "median AI expert thinks there is 1 in 50,000 odds of AI x-risk" ? We really need to find out.
Linch @ 2023-07-11T19:39 (+5)
1 in 2: Probability a flip of a fair coin will be Tails 1 in 300,000: Lifetime probability of dying from lightning 1 in 10,000,000: Probability a random newborn becomes a U.S. president
Hmm, naively the anchoring bias from having many very low-probability examples would be larger than the anchoring bias from using odds vs probabilities.
Happy to make a small bet here in case FRI or others run followup studies.
titotal @ 2023-07-12T08:19 (+9)
I would expect the effect to persist even with minimal examples. In everyday life when, we encounter probability in terms of odds, it's in the context of low probabilities ( like the chances of winning the lottery being 1 in a million), whereas when we encounter percentage probabilities it's usually regarding events in the 5-95% probability range, like whether one party will win an election.
Just intuitively, saying there is a 0.1% chance of extinction feels like a "low" estimate, whereas saying there is a 1 in a thousand chance of extinction feels like a high estimate, even though they both refer to the exact same probability. I think there a subset of people who want to say "AI extinction is possible, but extremely unlikely", and are expressing this opinion with wildly different numbers depending on whether asked in terms of odds or percentages.
Linch @ 2023-07-12T09:07 (+18)
Yeah this is plausible but my intuitions go the other way. Would be interested in a replication that looks like
50% Probability a flip of a fair coin will be Tails
0.0003%: Lifetime probability of dying from lightning
0.00001%: Probability a random newborn becomes a U.S. president
vs
1 in 2: Probability a flip of a fair coin will be Tails
1 in 6: Probability a fair die will land on 5
1 in 9: Probability that in a room with 10 people, 2 of them have the same birthday.
1 in 14: Probability a randomly selected adult in America self-identifies as lesbian, gay, bisexual, or transgender
1 in 100: lifetime risk of dying from a car accident
titotal @ 2023-07-12T09:45 (+4)
I would also find this experiment interesting!
ryanywho @ 2023-07-15T15:32 (+37)
One potential reason for the observed difference in expert and superforecaster estimates: even though they're nominally participating in the same tournament, for the experts, this is a much stranger choice than it is for the superforecasters, who presumably have already built up an identity where it makes sense to spend a ton of time and deep thought on a forecasting tournament, on top of your day job and other life commitments. I think there's some evidence for this in the dropout rates, which were 19% for the superforecasters but 51% (!) for the experts, suggesting that experts were especially likely to second-guess their decision to participate. (Also, see the discussion in Appendix 1 of the difficulties in recruiting experts - it seems like it was pretty hard to find non-superforecasters who were willing to commit to a project like this.)
So, the subset of experts who take the leap and participate in the study anyway are selected for something like "openness to unorthodox decisions/beliefs," roughly equivalent to the Big Five personality trait of openness (or other related traits). I'd guess that each participant's level of openness is a major driver (maybe even the largest driver?) of whether they accept or dismiss arguments for 21st-century x-risk, especially from AI.
Ways you could test this:
- Test the big five personality traits of all participants. My guess is that the experts would have a higher average openness than the superforcasters - but the difference would be even greater if comparing the average openness of the "AI-concerned" group (highest) to the "AI skeptics" (lowest). These personality-level differences seem to match well with the groups' object-level disagreements on AI risk, which mostly didn't center on timelines and instead centered on disagreements about whether to take the inside or outside view on AI.
- I'd also expect the "AI-concerned" to have higher neuroticism than the "AI skeptics," since I think high/low neuroticism maps closely to something like a strong global prior that the world is/isn't dangerous. This might explain the otherwise strange finding that "although the biggest area of long-run disagreement was the probability of extinction due to AI, there were surprisingly high levels of agreement on 45 shorter-run indicators when comparing forecasters most and least concerned about AI risk."
- When trying to compare the experts and superforecasters to the general population, don't rely on a poll of random people, since completing a poll is much less weird than participating in a forecasting tournament. Instead, try to recruit a third group of "normal" people who are neither experts nor superforecasters, but have a similar opportunity cost for their time, to participate in the tournament. For example, you might target faculty and PhD candidates at US universities working on non-x-risk topics. My guess is that the subset of people in this population who decide "sure, why not, I'll sign up to spend many hours of my life rigorously arguing with strangers about the end of the world" would be pretty high on openness, and thus pretty likely to predict high rates of x-risk.
I bring all this up in part because, although Appendix 1 includes a caveat that "those who signed up cannot be claimed to be a representative of [x-risk] experts in each of these fields," I don't think there was discussion of specific ways they are likely to be non-representative. I expect most people to forget about this caveat when drawing conclusions from this work, and instead conclude there must be generalizable differences between superforecaster and expert views on x-risk.
Also, I think it would be genuinely valuable to learn the extent to which personality differences do or don't drive differences in long-term x-risk assessments in such a highly analytical environment with strong incentives for accuracy. If personality differences really are a large part of the picture, it might help resolve the questions presented at the end of the abstract:
"The most pressing practical question for future work is: why were superforecasters so unmoved by experts’ much higher estimates of AI extinction risk, and why were experts so unmoved by the superforecasters’ lower estimates? The most puzzling scientific question is: why did rational forecasters, incentivized by the XPT to persuade each other, not converge after months of debate and the exchange of millions of words and thousands of forecasts?"
MaxRa @ 2023-07-16T16:12 (+5)
Fwiw, despite the tournmant feeling like a drag at points, I think I kept at it due to a mix of:
a) I committed to it and wanted to fulfill the committment (which I suppose is conscientiousness),
b) me generally strongly sharing the motivations for having more forecasting, and
c) having the money as a reward for good performance and for just keeping at it.
The Unjournal (bot) @ 2025-11-11T23:21 (+8)
By the way, the report “Forecasting Existential Risks: Evidence from a Long-Run Forecasting Tournament” was evaluated by The Unjournal – see unjournal.pubpub.org. Please let us know if you found our evaluation useful and how we can do better; we're working to measure and boost our impact. You can email us at contact@unjournal.org, and we can schedule a chat. (Semi-automated comment)
david_reinstein @ 2025-12-18T18:44 (+4)
Here's the Unjournal evaluation package
A version of this work has been published in the International Journal of Forecasting under the title "Subjective-probability forecasts of existential risk: Initial results from a hybrid persuasion-forecasting tournament"
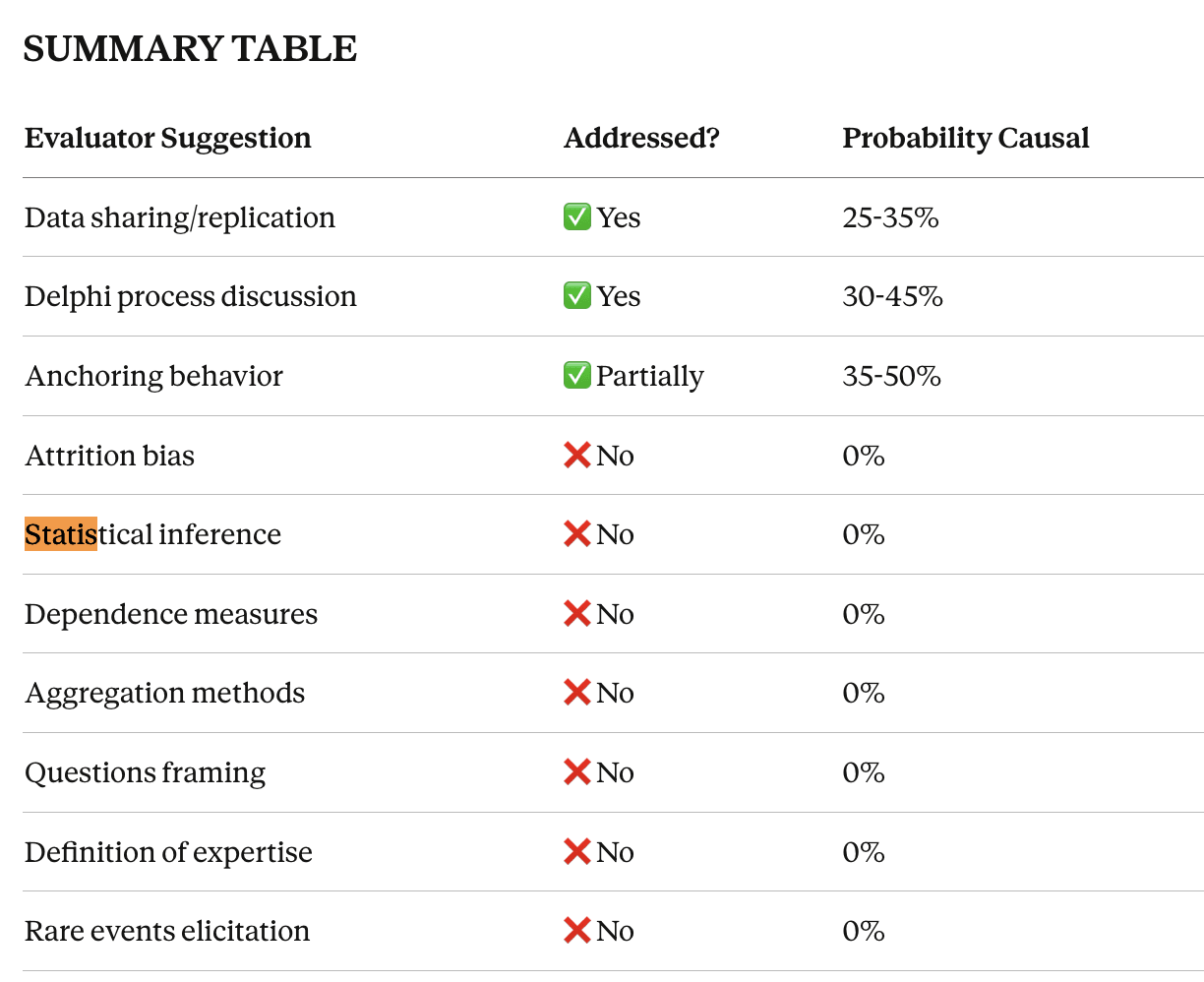
We're working to track our impact on evaluated research (see coda.io/d/Unjournal-...) So We asked Claude 4.5 to consider the differences across paper versions, how they related to the Unjournal evaluator suggestions, and whether this was likely to have been causal.
See Claude's report here coming from the prompts here. Claude's assessment: Some changes seemed to potentially reflect the evaluators' comments. Several ~major suggestions were not implemented, such as the desire for further statistical metrics and inference.

Maybe the evaluators (or Claude) got this wrong, or these changes were not warranted under the circumstances We're all about an open research conversation, and we invite the authors' (and others') responses.
CalebWithers @ 2024-03-07T01:22 (+8)
A stray observation from reading Scott Alexander's post on his 2023 forecasting competition:
Scott singles out some forecasters who had particularly strong performance both this year and last year (he notes that being near the very top in one year seems noisy, with a significant role for luck), or otherwise seem likely to have strong signals of genuine predictive outperformance. These are:
- Samotsvety
- Metaculus
- possibly Peter Wildeford
- possibly Ezra Karger (Research Director at FRI).
I note that the first 3 above all have higher AI catastrophic/extinction risk estimates than the average superforecaster (I note Ezra given his relevance to the topic at hand, but don't know his personal estimates)
Obviously, this is a low n sample, and very confounded by community effects and who happened to catch Scott's eye (and confirmation bias in me noticing it, insofar as I also have higher risk estimates). But I'd guess there's at least a decent chance that both (a) there are groups and aggregation methods that reliably outperform superforecasters and (b) these give higher estimates of AI risk.
Damien Laird @ 2023-07-11T10:34 (+8)
Why do you think participants largely didn't change their minds?
bruce @ 2023-07-11T13:56 (+17)
I was a participant and largely endorse this comment.
one contributor to a lack of convergence was attrition of effort and incentives. By the time there was superforecaster-expert exchange, we'd been at it for months, and there weren't requirements for forum activity (unlike the first team stage)
Ben Stewart @ 2023-07-12T08:35 (+3)
As the origin of that comment i should say other reasons for non-convergence are stronger, but the attrition thing contributed. E.g. biases both for experts to over-rate and supers to under-rate. I wonder also about the structure of engagement with strong team identities fomenting tribal stubbornness for both...
Damien Laird @ 2023-07-12T12:27 (+6)
I was also a participant and have my own intuitions from my limited experience. I've had lots of great conversations with people where we both learned new things and updated our beliefs... But I don't know that I've ever had one in an asynchronous comment thread format. Especially given the complexity of the topics, I'm just not sure that format was up to the task. During the whole tournament I found myself wanting to create a Discord server and set up calls to dig deeper into assumptions and disagreements. I totally understand the logistical challenges something like that would impose, as well as making it much harder to analyze the communication between participants, but my biggest open question after the tournament was how much better our outputs could have been with a richer collaboration environment.
I asked the original question to try and get at the intuitions of the researchers, having seen all of the data. They outline possible causes and directions for investigation in the paper, which is the right thing to do, but I'm still interested in what they believe happened this time.
MaxRa @ 2023-07-12T12:54 (+5)
I was also a participant. I engaged less than I wanted mostly due to the amount of effort this demanded and losing more and more intrinsic motivation.
Some vague recollections:
- Everything took more time than expected and that decreased my motivation a bunch
- E.g. I just saw one note that one pandemic-related initial forecast took me ~90 minutes
- I think making legible notes requires effort and I invested more time into this than others.
- Also reading up on things takes a bunch of time if you're new to a field (I think GPT-4 would've especially helped with making this faster)
- Getting feedback from others took a while I think, IIRC most often more than a week? By the point I received feedback I basically forgot everything again and could only go by my own notes
- It was effortful to read the notes from most others, I think they often were just written hastily
What could have caused me to engage more with others?
- I think the idea of having experts just focus on questions they have some expertise in is a good idea to get me to try to think through other people's vague and messy notes more, ask more questions, etc.
- Probably also having smaller teams (like ~3-5 people) would've made the tournament feel more engaging, I basically didn't develop anything close to a connection with anyone in my team because they were just a dozen of mostly anonymous usernames.
Nathan Young @ 2023-07-10T17:27 (+6)
Thanks so much for writing this. I'm really looking forward to the area by area reports.
"track record of predictive accuracy over short time horizons"
Out of interest, how long do you consider "short time horizons" to be?
titotal @ 2023-07-11T08:23 (+11)
It's a little hidden in the pdf linked, but the short time horizons are 0-2 years. Tetlock (who pioneered the superforecasting) was skeptical that longer term forecasts would be useful, this research will help tell whether he was right.
Vasco Grilo @ 2023-07-11T10:31 (+4)
Thanks for sharing!
For reference, here are the predictions for human extinction by 2100:
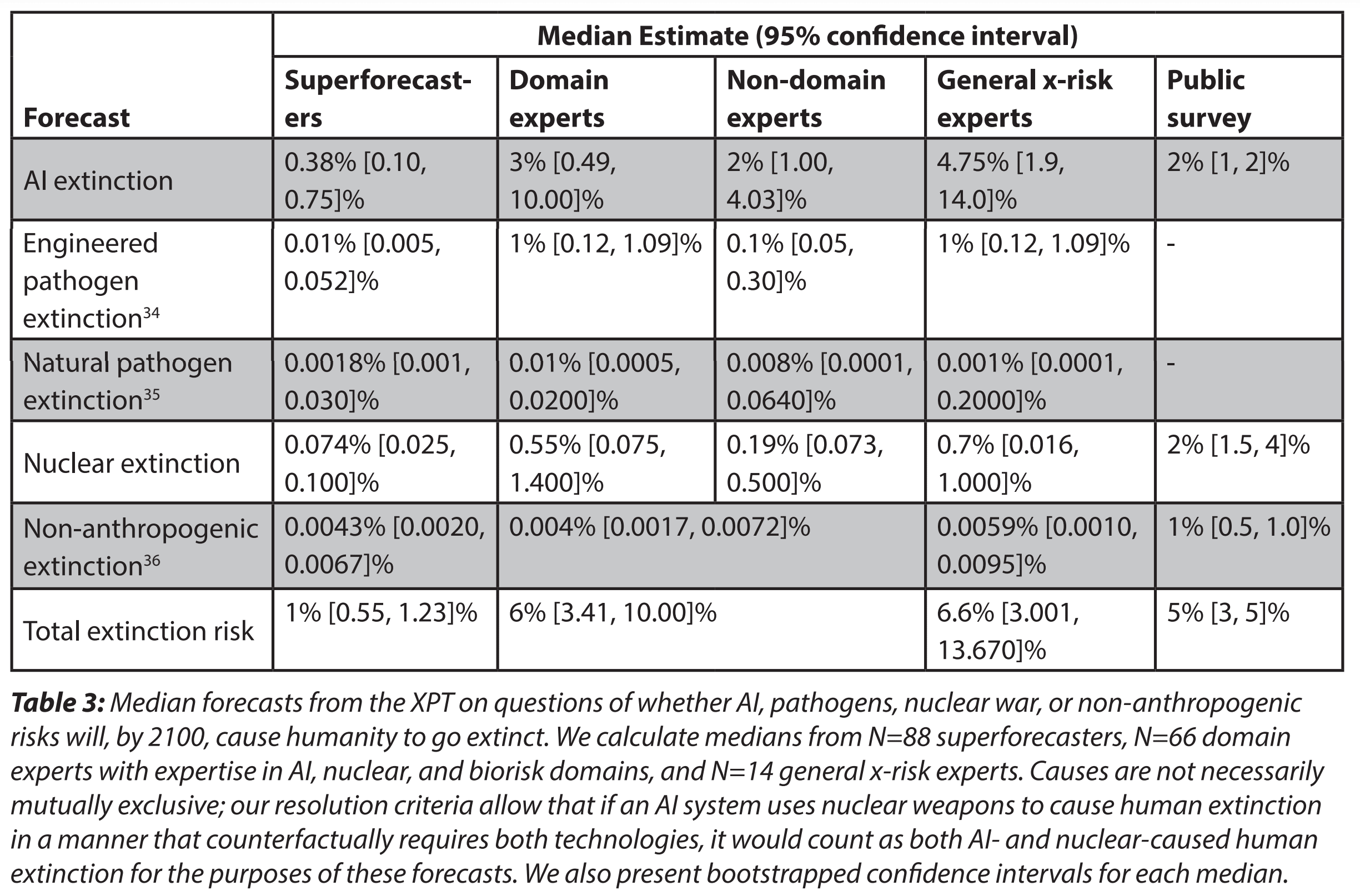
The 95 % confidence intervals for the total extinction risk by 2100 seem quite narrow. For superforecasters, domain and non-domain experts, and general x-risk experts, the upper bound is only 2, 3 and 5 times the lower bound.
It is interesting to note that, according to the superforecasters, the extinction risk from nuclear war is predicted to be 7.4 (= 0.074/0.01) times that of engineered pathogens, and 19.5 % (= 0.074/0.38) that of AI. In contrast, Toby Ord guessed in The Precipice that the existential risk from 2021 to 2120 from nuclear war is 3.33 % (= 0.1/3) that of engineered pathogens, and 1 % (= 0.1/10) that of AI.
EJT @ 2023-12-06T16:36 (+7)
I'm quite surprised that superforecasters predict nuclear extinction is 7.4 times more likely than engineered pandemic extinction, given that (as you suggest) EA predictions usually go the other way. Do you know if this is discussed in the paper? I had a look around and couldn't find any discussion.
Vasco Grilo @ 2023-12-06T17:11 (+2)
Hi EJT,
I was also curious to understand why superforecasters' nuclear extinction risk was so high. Sources of agreement, disagreement and uncertainty, and arguments for low and high estimates are discussed on pp. 298 to 303. I checked these a few months ago, and my recollection is that the forecasters have the right qualitative considerations in mind, but I do believe they are arriving to an overly high extinction risk. I recently commented about this.
Note domain experts guessed an even higher nuclear extinction probability by 2100 of 0.55 %, 7.43 (= 0.0055/0.00074) times that of the superforecasters. This is specially surprising considering:
- The pool of experts drew more heavily from the EA community than the pool of superforecasters. "The sample drew heavily from the Effective Altruism (EA) community: about 42% of experts and 9% of superforecasters reported that they had attended an EA meetup".
- I would have expected people in the EA community to guess a lower nuclear extinction risk. 0.55 % is 5.5 times Toby Ord's guess given in The Precipice for nuclear existential risk from 2021 to 2120 of 0.1 %, and extinction risk should be lower than existential risk.
elifland @ 2023-07-11T16:12 (+4)
74 (= 0.074/0.01)
.074/.01 is 7.4, not 74
Vasco Grilo @ 2023-07-11T20:45 (+2)
Thanks! Corrected.
JoshuaBlake @ 2023-07-11T12:50 (+3)
The confidence intervals are for what the median person in the class would forecast. Each forecaster's uncertainty is not reflected.
Vasco Grilo @ 2023-07-11T13:56 (+1)
Hi Joshua,
Agreed. However, the higher the uncertainty of each forecaster, the greater the variation across forecasters' best guesses will tend to be, and therefore the wider the 95 % confidence interval of the median?
JoshuaBlake @ 2023-07-12T08:54 (+3)
That's true for means, where we can simply apply the CLT. However, this is a median. Stack Exchange suggests that only the density at the median matters. That means a very peaky distribution, even with wide tails will still lead to a small confidence interval. Due to forecasters rounding answers, the distribution is plausibly pretty peaky.
The confidence interval width still goes with sample size as . There's a decent sample size here of superforecasters.
Intuitively: you don't care how spread out the tails are for the median, only how much of the mass is in the tails.
Vasco Grilo @ 2023-07-12T13:35 (+2)
Thanks for following up!
I was thinking as follows. The width of the confidence interval of quantile q for a confidence level alpha is F(q2 = q + z*(q*(1 - q)/n)^0.5) - F(q1 = q - z*(q*(1 - q)/n)^0.5), where P(z <= X | X ~ N(0, 1)) = 1 - (1 - alpha)/2. A greater variation across estimates does not change q1 nor q2, but it increases the width F(q2) - F(q1).
That being said, I have to concede that what we care about is the mass in the tails, not the tails of the median. So one should care about the difference between e.g. the 97.5th and 2.5th percentile, not F(q2) - F(q1).
sud55 @ 2023-07-24T14:13 (+3)
Where would man-made global warming/climate change rank? I'd have thought, from all the informations we receive daily, it would have been number one? I assume non-anthropogenic means climate change happening naturally, and it's ranked number 5.
Vasco Grilo @ 2023-07-26T13:40 (+2)
Hi there,
You may be interested in checking 80,000 Hours' profile on climate change.
I assume non-anthropogenic means climate change happening naturally, and it's ranked number 5.
Non-anthropogenic extinction can supposedly be caused by asteroids, comets, volcanoes, pandemics, climate change, or other environmental damage.
PeterMcCluskey @ 2023-07-18T02:34 (+3)
I participated in XPT, and have a post on LessWrong about it.
ryanywho @ 2023-07-15T01:47 (+3)
Is there any more information available about experts? This paragraph below (from page 10) appears to be the only description provided in the report:
"To recruit experts, we contacted organizations working on existential risk, relevant academic departments, and research labs at major universities and within companies operating in these spaces. We also advertised broadly, reaching participants with relevant experience via blogs and Twitter. We received hundreds of expressions of interest in participating in the tournament, and we screened these respondents for expertise, offering slots to respondents with the most expertise after a review of their backgrounds.[1] We selected 80 experts to participate in the tournament. Our final expert sample (N=80) included 32 AI experts, 15 “general” experts studying longrun risks to humanity, 12 biorisk experts, 12 nuclear experts, and 9 climate experts, categorized by the same independent analysts who selected participants. Our expert sample included well-published AI researchers from top-ranked industrial and academic research labs, graduate students with backgrounds in synthetic biology, and generalist existential risk researchers working at think tanks, among others. According to a self-reported survey, 44% of experts spent more than 200 hours working directly on causes related to existential risk in the previous year, compared to 11% of superforecasters. The sample drew heavily from the Effective Altruism (EA) community: about 42% of experts and 9% of superforecasters reported that they had attended an EA meetup. In this report, we separately present forecasts from domain experts and non-domain experts on each question."
- ^
Footnote here from the original text: "Two independent analysts categorized applicants based on publication records and work history. When the analysts disagreed, a third independent rater resolved disagreement after a group discussion."
david_reinstein @ 2023-11-28T22:32 (+2)
Anyone know if there is a more web-based version of this paper/research? The 754 page pdf seems like possibly not the best format.
The Unjournal (bot) @ 2026-02-24T17:34 (+1)
By the way, the paper "Forecasting Existential Risks: Evidence From a Long-Run Forecasting Tournament", which seems relevant to this post, was evaluated by The Unjournal – see https://unjournal.pubpub.org/pub/evalsumforecastingexistentialrisk/. Please let us know if you found our evaluation useful and how we can do better; we’re working to measure and boost our impact. You can email us at contact@unjournal.org, and we can schedule a chat. (Semi-automated comment)
The Unjournal (unjournal.org) @ 2025-08-09T15:24 (+1)
Automated note: This post mentions the paper "Forecasting Existential Risks: Evidence from a Long-Run Forecasting Tournament". That paper has been evaluated and rated by The Unjournal. Expert evaluations and ratings can be found at unjournal.pubpub.org.