Winners of the Squiggle Experimentation and 80,000 Hours Quantification Challenges
By NunoSempere @ 2023-03-08T01:03 (+62)
In the second half of 2022, we of QURI announced the Squiggle Experimentation Challenge and a $5k challenge to quantify the impact of 80,000 hours' top career paths. For the first contest, we got three long entries. For the second, we got five, but most were fairly short. This post presents the winners.
Squiggle Experimentation Challenge
Objectives
From the announcement post:
[Our] team at QURI has recently released Squiggle, a very new and experimental programming language for probabilistic estimation. We’re curious about what promising use cases it could enable, and we are launching a prize to incentivize people to find this out.
Top Entries
@Tanae’s Adding Quantified Uncertainty to GiveWell's Cost-Effectiveness Analysis of the Against Malaria Foundation
Tanae adds uncertainty estimates to each step in GiveWell’s estimate for AMF in the Democratic Republic of Congo, and ends up with this endline estimate for lives saved (though not other effects):
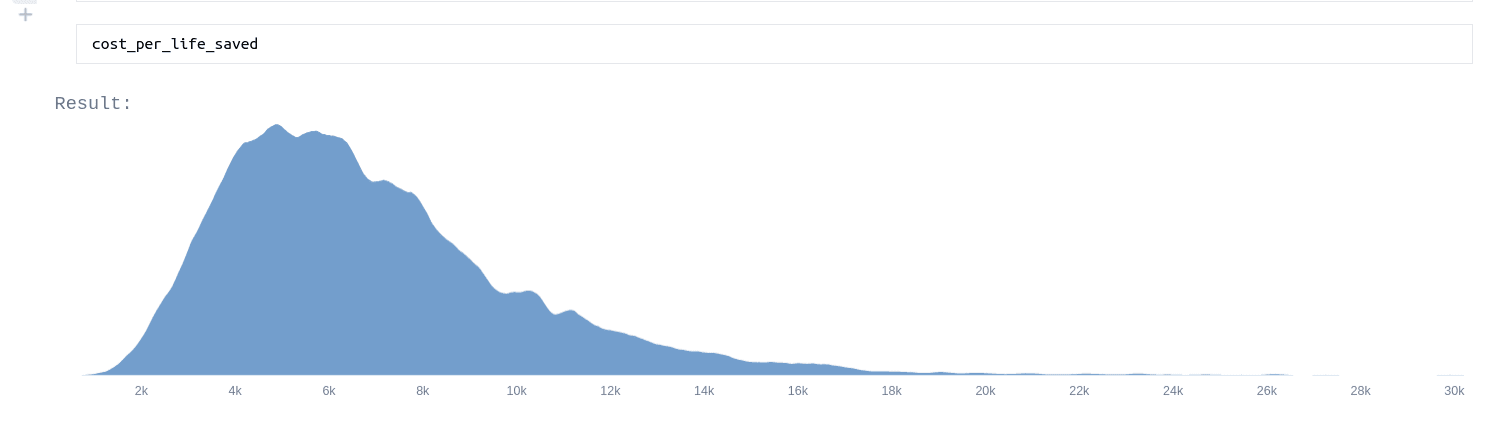
@drwahl's Cost-effectiveness analysis for the Lead Exposure Elimination Project in Malawi
Dan creates a probabilistic estimate for the effectiveness of the Lead Exposure Elimination Project in Malawi. In the process, he gives some helpful, specific improvements we could make to Squiggle. In particular, his feedback motivated us to make Squiggle faster, first from part of his model not being able to run, then to his model running in 2 mins, then in 3 to 7 seconds.
@Erich_Grunewald's How many EA billionaires five years from now?
Erich creates a Squiggle model to estimate the number of future EA billionaires. His estimate looks like this:
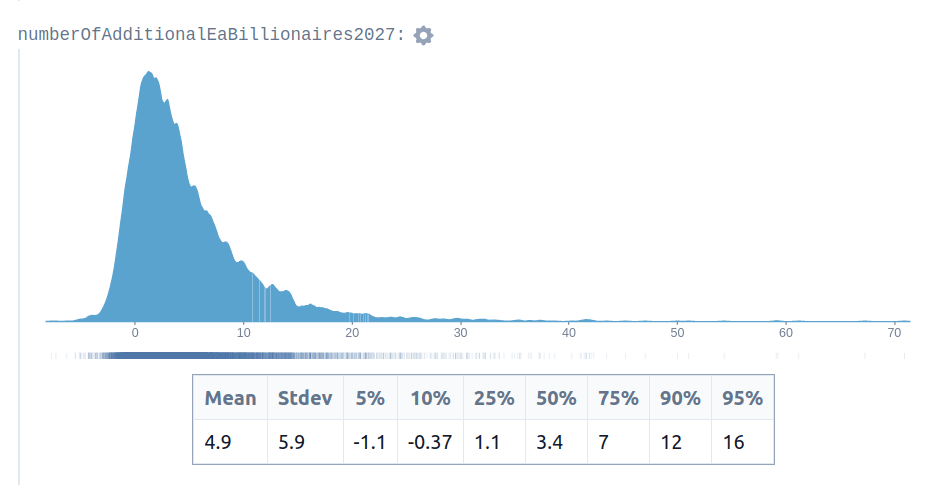
That is, he is giving a 5-10% probability of negative billionaire growth, i.e., of losing a billionaire, as, in fact, happened. In hindsight, this seems like a neat example of quantification capturing some relevant tail risk.
Perhaps if people had looked to this estimate when making decisions about earning to give or personal budgeting decisions in light of FTX’s largesse, they might have made better decisions. But it wasn’t the case that this particular estimate was incorporated into the way that people made choices. Rather my impression is that it was posted in the EA Forum and then forgotten about. Perhaps it would have required more work and vetting to make it useful.
Results
| Entry | Estimated relative value (normalized to 100%) | Prize |
| Adding Quantified Uncertainty to GiveWell's Cost Effectiveness Analysis of the Against Malaria Foundation | 67% | $600 |
| CEA LEEP Malawi | 26% | $300 |
| How many EA Billionaires five years from now? | 7% | $100 |
Judges were Ozzie Gooen, Quinn Dougherty, and Nuño Sempere. You can see our estimates here. Note that per the contest rules, we judged these prizes before October 1, 2022—so before the downfall of FTX, and winners received their prizes shortly thereafter. Previously I mentioned the results in this edition of the Forecasting Newsletter.
$5k challenge to quantify the impact of 80,000 hours' top career paths
Objectives
With this post, we hoped to elicit estimates that could be built upon to estimate the value of 80,000 hours’ top 10 career paths. We were also curious about whether participants would use Squiggle or other tools when given free rein to choose their tools.
Entries
@Vasco Grilo’s Cost-effectiveness of operations management in high-impact organisations
Vasco Grilo looks at the cost-effectiveness of operations, first looking at various ways of estimating the impact of the EA community and then sending a brief survey to various organizations about the “multiplier” of operations work, which is, roughly, the ratio of the cost-effectiveness of one marginal hour of operations work to the cost-effectiveness of one marginal hour of their direct work. He ends up with a pretty high estimate for that multiplier, of between ~4.5 and ~13.
@10xRational’s Estimating the impact of community building work
@10xrational gives fairly granular estimates of the value of various community-building activities in terms of first-order effects of more engaged EAs, and second-order effects of more donations to effective charities and more people working on 80,000 hours’ top career paths. @10xrational ends up concluding that 1-on-1s are particularly effective.
@charrin’s Estimating the Average Impact of an ARPA-E Grantmaker
@charrin looks at the average impact of an ARPA-EA grantmaker, in terms of how much money they have influence over, and what the value of their projects—lowballed as their market cap—is. The formatting was bare-bones, but I thought this was valuable because of the concreteness.
@Joel Becker’s Quantifying the impact of grantmaking career paths
Joel looks at the impact of grantmaking career paths, and decomposes the problem into the probability of getting a job, the money under management, and the counterfactual improvement. He then applies adjustments for non-grantmaking impact, and then translates his numbers to basis points of existential risk averted. A headline number is “a mean estimate of $5.7m for the Open Philanthropy-equivalent resources counterfactually moved by grantmaking activities of the prospective marginal grantmaker, conditional on job offer.”
@Duncan Mcclements’s Estimating the marginal impact of outreach
Duncan fits a standards economics model to estimate the impact of outreach, in R. According to his assumptions, he concludes that
“these results counterintuitively imply that the current marginal individual would be having substantially higher marginal impact working to expand effective altruism than working on maximising the reduction in existential risk today, with 99.7% confidence”.
Note that 99.7% confidence is the probability given by the model. And one disadvantage of that econ-flavoured approach is that most of the probability of the conclusion going the other way will come from model error.
Results
Entry | Estimated relative value (normalized to 100%) | Prize (scaled up to $5k) |
Cost-effectiveness of operations management in high-impact organisations | 25% (25.0636%) | $1253 (25.0636% of $5k, to the nearest dollar) |
24% | $1214 | |
22% | $1094 | |
18% | $912 | |
11% | $528 |
Judges for this challenge were Alex Lawsen, Sam Nolan, and Nuño Sempere. They each gave their relative estimates, which can be seen here, and these were averaged to determine what proportion of the prize each participant should receive. We’ve recently contacted the winners, and they should be receiving their prices in the near future.
With most of these posts, we appreciated the estimation strategies, as well as the initial estimation attempts. But we generally thought that the posts were far from complete estimates, and there is still much work between now and estimating the relative or absolute values of 80,000 hours’ top career paths in a way which would be decision-relevant.
Lessons learnt
From the estimates themselves
From the estimates for the Squiggle experimentation prize, we got some helpful comments that we used to make Squiggle better and faster. I also thought that @Erich_Grunewald’s How many EA billionaires five years from now? was ultimately a good example of quantified estimates capturing some tail risk.
From the entries to the 80,000 hours estimation challenge, we probably underestimated the difficulty of producing comprehensive estimates for 80,000 hours’ top career paths. The strategies submissions proposed nonetheless remain ingenious or valid, and they could be built upon.
On expected participation for estimation prizes
Participation for both prizes was relatively low. This is even though the expected monetary prize seemed pretty high. Both challenges have around 1k views in the EA forum (1139 views for the Squiggle experimentation prize and 1690 for the 80,000 hours quantification challenge). They were also advertised on the forecasting newsletter, on Twitter, or on relevant discords. And for the Squiggle experimentation prize, on the Squiggle announcement post.
My sense is that similar contests with similar marketing should expect a similar number of entries.
Note also that the prizes were organized when EA had comparatively more money, due to FTX.
On judging and reward methods
For the first prize, we asked judges to estimate relative values. Then we converted these to our predetermined prize amounts. I thought that this was inelegant, so for the second prize, we instead scaled the prizes in proportion to the estimated value of the entries.
A yet more elegant method might be to have a variably-sized pot that scales with the estimated value of the submissions. This, for example, does not penalize participants from telling other people about the prize, as a fixed pot prize does. It’s possible that we might try that method in subsequent contests. One possible downside might be that this adds some uncertainty for participants. But that uncertainty can be mitigated by giving clear examples and their corresponding payout amounts.
It remains unclear whether a more incentive-compatible prize design ends up meaningfully improve the outcome of a prize. It might for larger contests, though, so thinking about it doesn’t seem completely useless.
Joel Becker @ 2023-03-08T02:02 (+28)
Thanks for running this, Nuno! I had fun participating!
I agree with
My sense is that similar contests with similar marketing should expect a similar number of entries.
if we're really strict about "similar marketing." But, when considering future contests, there's no need to hold that constant. The fact that e.g. Misha Yagudin had not heard of this prize seems shocking and informative to me. I think you could invest more time into thinking about how to increase engagement!
Relatedly, I have now had the following experience a number of times. I don't know how to solve some problem in squiggle (charting multiple plots, feeding in large parameter dictionaries, taking many samples of samples, saving samples for use outside of squiggle, embedding squiggle in a web app, etc.etc.). I look around squiggle documentation searching for a solution, and can't find it. I message one of the squiggle team. The squiggle team member has an easy and (often but not always) already-implemented-elsewhere solution that is not publicly available in any documentation or similar. I leave feeling very happy about the existence of squiggle and helpfulness of its team! But another feeling I have is that the squiggle team could be more successful if it invested more time in the final, sometimes boring mile of examples/documentation/evangelism, rather than chasing the next more intellectually interesting project.
alex lawsen (previously alexrjl) @ 2023-03-08T16:07 (+3)
I like this
NunoSempere @ 2023-03-08T04:57 (+3)
Thanks Joel, really appreciate this comment
Erich_Grunewald @ 2023-03-12T12:07 (+5)
Thanks for running the contests and doing this write-up!
That is, he is giving a 5-10% probability of negative billionaire growth, i.e., of losing a billionaire, as, in fact, happened. In hindsight, this seems like a neat example of quantification capturing some relevant tail risk.
Perhaps if people had looked to this estimate when making decisions about earning to give or personal budgeting decisions in light of FTX’s largesse, they might have made better decisions. But it wasn’t the case that this particular estimate was incorporated into the way that people made choices. Rather my impression is that it was posted in the EA Forum and then forgotten about. Perhaps it would have required more work and vetting to make it useful.
I was going to write that this is giving me way too much credit, but looking back at my post I'm not so sure!
I modeled the number of billionaires as Number of EAs × P(Is a billionaire | Is EA). At first I thought all the probability mass below 0 came from the number of EAs dropping below current levels, not from P(Is a billionaire | Is EA) dropping. But then I remembered that I assumed a P(Is a billionaire | Is EA) lower than the current base rate, by using the base rate for Ivy league graduates as a lower bound.
I wrote (emphasis added):
As far as I can tell, P(billionaire|effective altruist) is somewhat smaller than P(billionaire|Harvard graduate) in the wake of FTX, though Harvard graduates have some advantages over effective altruists, like being much older on average, better credentialed and perhaps more talented and well-connected. I think this is evidence that there really is something special about effective altruists. They (or I suppose I should say, we) seem to be unusually likely to be very wealthy, and perhaps also unusually likely to become very wealthy. But I also think it suggests that P(billionaire|effective altruist) will at some point regress towards the saner Ivy League mean.
I guess it regressed sooner than I expected (or anyone wanted).
It's also worth pointing out that there are now at least two, not one, fewer EA billionaires than last summer (SBF and Gary Wang, AFAIK). If that remains the case in 2027, my forecast will have been very bad; I did not account for the fact that all billionaires, and these two especially, were to some extent correlated. Of course there's a chance there are new ones too in the next years to make up for the deficit; one can hope.
Vasco Grilo @ 2023-03-10T09:20 (+4)
Hi Nuño,
Thanks for sharing, and organising the challenges!
Vasco Grillo looks at the cost-effectiveness of operations
Nitpick, it is "Grilo", not "Grillo", but I like the Spanish version too!
With most of these posts, we appreciated the estimation strategies, as well as the initial estimation attempts. But we generally thought that the posts were far from complete estimates, and there is still much work between now and estimating the relative or absolute values of 80,000 hours’ top career paths in a way which would be decision-relevant.
I tend to agree. I also wonder which strategy does 80,000 Hours uses to come up with their list of top-recommended career paths. I understand factors like importance, tractability and neglectedness are part of it, but I wonder what is the specific procedure to come up with the rankings (e.g. maybe a weighted factor model).
From the entries to the 80,000 hours estimation challenge, we probably overestimated the difficulty of producing comprehensive estimates for 80,000 hours’ top career paths.
Did you mean "underestimated" (instead of "overestimated")?
NunoSempere @ 2023-03-10T16:20 (+4)
Nitpick, it is "Grilo", not "Grillo", but I like the Spanish version too!
Terribly sorry, fixed now.
I tend to agree. I also wonder which strategy does 80,000 Hours uses to come up with their list of top-recommended career paths. I understand factors like importance, tractability and neglectedness are part of it, but I wonder what is the specific procedure to come up with the rankings (e.g. maybe a weighted factor model).
I am not really sure!
Did you mean "underestimated" (instead of "overestimated")?
Yep, thanks, fixed.