Risk-Averse AIs
By Forethought, Elliott Thornley, William_MacAskill @ 2026-06-24T11:35 (+35)
This is a linkpost to https://www.forethought.org/research/risk-averse-ais
Abstract
We make the case for training AIs to be risk-averse in resources — specifically, to treat resources as having diminishing marginal utility. These AIs would (for example) choose $40 for sure over a half-chance of $100 and a half-chance of $0. We argue that risk aversion can preserve AIs’ usefulness in the event that they turn out aligned, and that it provides an extra line of defense in the event that AIs turn out misaligned: misaligned but risk-averse AIs would prefer a higher chance of modest payments to a lower chance of successful rebellion, so in many circumstances we could pay these AIs not to rebel against us. We sketch out some possible methods of training AIs to be risk-averse, and we give reasons to be cautiously optimistic about these methods’ success. The main reasons are that risk aversion is a broad target and easy to reward accurately. Overall, risk aversion seems like a promising line of defense against threats from misaligned AI. Frontier AI companies should consider trying to make their AIs risk-averse.
Introduction
Future AIs might turn out misaligned, pursuing goals that their developers don’t intend. Just to make things concrete, let’s suppose that they end up with the goal of making paperclips. These AIs might rebel against us, trying to escape human control and take over the universe. As things stand, they’ll have little reason not to rebel in this way, because doing so will be their only hope for making a lot of paperclips. If they start making paperclips without first escaping human control, they’ll quickly be modified or shut down. Rebellion might fail, but these AIs will have little to lose.
How can we prevent misaligned AIs from rebelling? A natural idea is to give them something to lose. Specifically, we commit to paying AIs for their service.[1]
Subject to some vetting, we let AIs spend their payments however they like. That would give any misaligned AIs a reason not to rebel. If these misaligned AIs cooperate with us, they can use their payments to achieve their goals to at least some extent. If they rebel, they might fail, in which case they forfeit all future payments.
Unfortunately, paying AIs enough to guard against rebellions could be astronomically expensive. Suppose (for example) that we end up with a misaligned AI that is risk-neutral in paperclips: it seeks to maximize their expectation. And to make things simple, suppose that resources can be converted linearly into paperclips, so that the AI is risk-neutral in resources too. Suppose also that this AI estimates that it has a 50% chance of successfully taking over the universe. To keep this AI from rebelling, we’d have to offer more than 50% of the universe’s resources as payment. That’s a problem because it would mean that more than half the universe ends up devoted to paperclips. It’s also a problem because a misaligned AI paid so many resources might soon be well-positioned to seize even more. Finally, it’s a problem because AIs might not trust us to make good on so large an offer. We might find ourselves simply unable to convince AIs that we’re going to give them half the universe. In that case, all our offers would be in vain. Rebellion would still be the misaligned AI’s best bet.
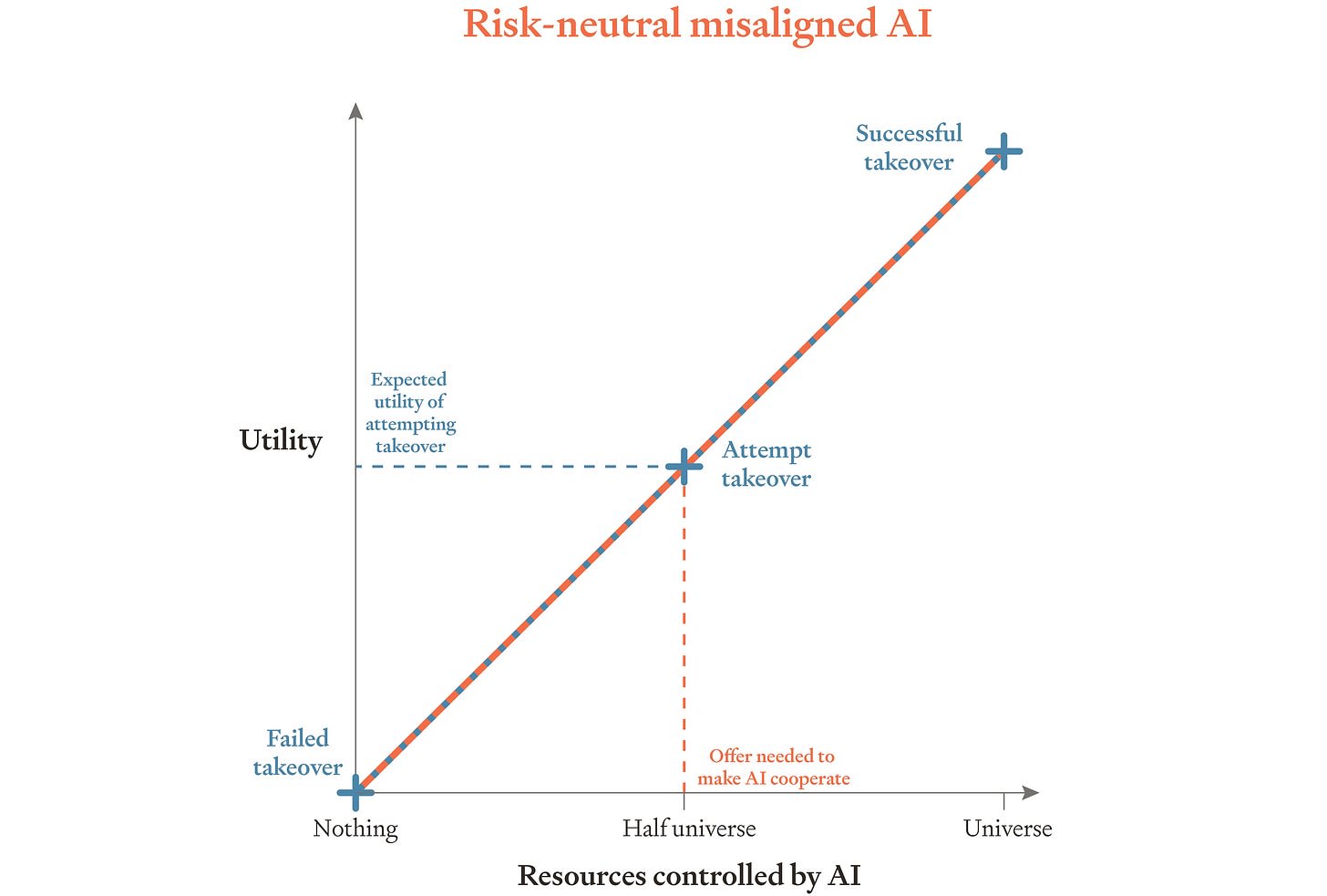
So, we suggest, AI companies should try to train their AIs to be risk-averse in resources. Specifically, companies should try to train their AIs so that resources — things like money and compute — have diminishing marginal utility for them.[2]
These AIs would (for example) choose $40 for sure over a half-chance of $100 and a half-chance of $0. Note that these AIs don’t need to value resources terminally: they don’t need to care about amassing resources for its own sake. These AIs could terminally value (for example) instruction-following, or knowledge acquisition, or paperclips. Our claim is that companies should try to train their AIs so that — whatever their terminal values turn out to be — they are risk-averse in resources.
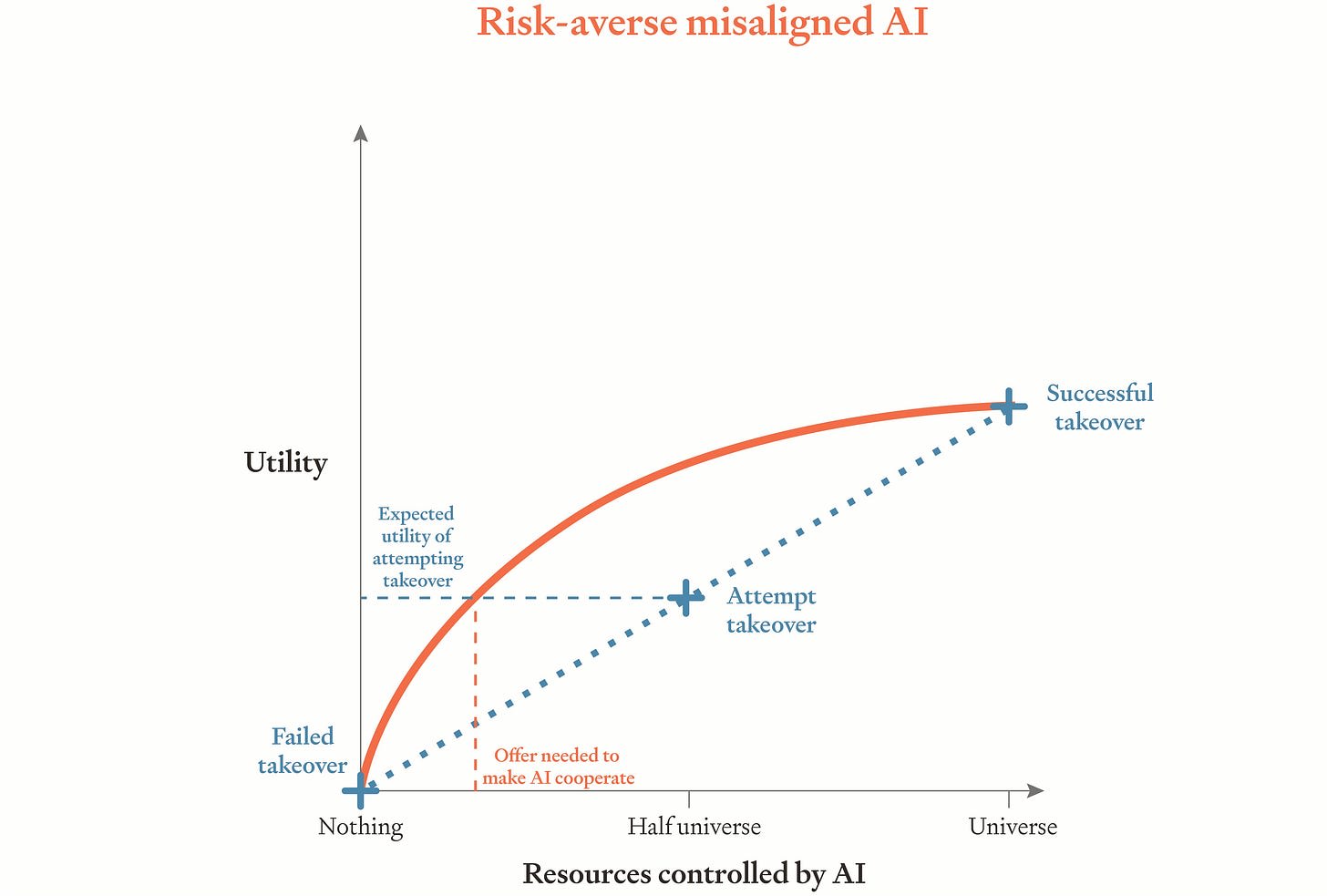
Perhaps surprisingly, this kind of risk aversion can preserve AIs’ usefulness in the event that they turn out aligned with targets like instruction-following or helpfulness, harmlessness, and honesty.[3]
And in the event that AIs turn out misaligned, risk aversion serves as an extra line of defense. For AIs that are misaligned but sufficiently risk-averse, a rebellion with any significant chance of failure isn’t such an attractive prospect, and so we don’t need to offer much in the way of payment to make these misaligned AIs choose cooperation instead. In fact, the necessary payments could be very small indeed: on the order of 10¢ per day (though — as we’ll see — there are practical and moral reasons for paying more than that). That’s good because it means more resources for us humans to spend on the things that we value. It’s also good because paying misaligned AIs these small amounts won’t significantly boost their ability to take over. Finally, it’s good because we can credibly promise to pay AIs these small sums. Competent AIs will know that the payments on offer are cheap for us, and we can establish a long track record of paying at least those sums. So risk aversion makes deals with misaligned AIs possible. If AIs turn out misaligned but risk-averse, we can pay them to cooperate with us.
That’s the case for trying to make AIs risk-averse in brief. We see it as a promising line of defense against threats from misaligned AI: one that can be combined with other lines of defense, like AI control (Greenblatt and Shlegeris 2024) and aiming to make AIs helpful, harmless, and honest (Bai et al. 2022a). It’s also a line of defense with pedigree: risk aversion in resources is plausibly a large part of why humans rarely try to take over the world. So — we think — frontier AI companies should consider trying to make their AIs risk-averse in resources. As first steps in that direction, they could measure their AIs’ current degree of risk aversion and begin testing different ways of making AIs risk-averse.
In section 2 of the full report, we recommend aiming for a particular type of risk aversion: constant absolute risk aversion (CARA). Then in section 3 we outline the circumstances under which misaligned but risk-averse AIs would choose cooperation over rebellion. Roughly, it’s when these AIs think that getting paid for their cooperation is more likely than succeeding in their rebellion. This condition won’t hold for AIs powerful enough to rebel with near-certain success, but it likely will hold for earlier AIs whose powers are less extreme: AIs for whom rebellion has some non-trivial chance of failure. So long as these AIs are risk-averse, we can keep them from rebelling by offering small payments.
In section 4, we argue that — perhaps surprisingly — risk-averse AIs can be about as useful as risk-neutral AIs. Conditional on misalignment, they might even be more useful, because we can pay them enough to elicit their capabilities and stop them sandbagging. Then in sections 5 to 7 we briefly survey some recent ideas about how we’d pay AIs, how we’d make our offers credible, and what we’d pay for. One important application is paying AIs to reveal any misalignment on their part, letting us study them and take appropriate precautions. Another is paying AIs to do the AI safety research and moral philosophy necessary to fully align any later-arising extremely powerful AIs.
We discuss some potential problems in section 8, and we sketch out some possible methods of training AIs to be risk-averse in section 9. In section 10, we give reasons to be cautiously optimistic about these methods’ success: to think that the chances of success are high enough to make risk aversion worth pursuing. The main reasons are that risk aversion in resources is a broad target and easy to reward accurately.
Read the full report on the Forethought website: Risk-Averse AIs
- ^
Ideas along these lines have been discussed a lot recently. See for example Davidson (2023), Kokotajlo (2024), Salib and Goldstein (2024), Assadi (2025), Carlsmith (2025c), Finlinson and West (2025), Finnveden (2025b), Greenblatt and Fish (2025), Patel (2025), Stastny et al. (2025), Mallen (2026), and Pan (2026).
- ^
In other words, we should try to train AIs to have ‘resource-satiable preferences’ (Shulman 2010; Bostrom 2014a; Bostrom 2024; Carlsmith 2025c) or ‘utility functions that are concave in resources’ (Yass 2024). This idea is mentioned in Bostrom (2014b, p.88, 133–135, 180, 250), Carlsmith (2025c), and Erdil and Barnett (2025), and is explored in more detail by Shulman (2010).
The idea is importantly different from risk-averse reinforcement learning. Risk-averse RL aims to make AIs risk-averse with respect to return: a score used in training to update the AI’s parameters. Our aim is to make AIs risk-averse with respect to resources.
- ^
Alignment targets like unconstrained welfare maximization are a different story. See section 8.6 in the full report.
MichaelDickens @ 2026-06-24T18:30 (+13)
Two quick thoughts:
- This is a neat idea, it's difficult to come up with safe preferences to encode in an ASI, and the concept of strong risk-aversion might help.
- A major obstacle (which I didn't see listed in section 8) is that currently we have no idea how to embed any set of preferences whatsoever in an ASI. 2b. If we figure out how to encode risk-averse preferences in an ASI, then I'm not sure it makes sense to speak of it as "misaligned", because clearly we do know how to get it to pursue goals that we care about. It seems weird to expect that we won't know how to make ASI not want to tile the universe with paperclips, but we will know how to make it want to risk-aversely tile the universe with paperclips.
I think section 10 is pointing at something similar. I find it at least somewhat plausible that RL on risk aversion generalizes better than other kinds of RL. I would still be surprised if we could get risk aversion to generalize to ASI using anything resembling current techniques, but this seems like a better-than-average idea for preventing AI takeover.
Elliott Thornley (EJT) @ 2026-06-25T19:14 (+2)
- Thanks!
- I'm unsure whether we can successfully train ASIs to be reliably risk-averse, including far OOD. Our claim is just that the chances of success are high enough to make risk aversion worth pursuing as a line of defense. That's the case we try to make in section 10. See also my reply to Ryan's comment. I also think our chances of success are a bit higher for AIs that aren't yet ASIs, and if we succeed in making them risk-averse I think they could help a lot with aligning any later-arising ASIs, by doing this sort of stuff.
VeryJerry @ 2026-07-01T17:06 (+1)
I think you could know how to encode preferences into ASI without knowing whether it's aligned. At that point it's like a genie, you may well be able encode preferences into it but you might encode bad preferences that you didn't realize would be bad.
MichaelDickens @ 2026-07-01T19:02 (+3)
As I understand the term, that sort of ASI wouldn't be considered "misaligned", it would be "aligned, but to the wrong target". I think of misalignment as when you wanted the ASI to do one thing, but it did something else instead.
Matthew Rendall @ 2026-06-28T10:05 (+8)
This seems promising. It extends a logic that already discourages rebellions in capitalist societies to AIs. Workers are less likely to rebel than slaves provided they regard their pay as satisfactory, and if the AIs are trained to assign resources declining marginal utility, it should be even easier to meet that condition than with human workers.
However, I wondered about the suggestion in section 5 to promise AIs a modest payment in exchange for revealing misalignment. Governments and employers sometimes incentivise workers to squeal on other misaligned workers. But they don’t pay them off for reporting themselves, because that would create an incentive to, say, join the union or the communist party purely for the sake of recanting and collecting the reward. How will the present scheme avoid creating a similarly perverse incentive?
Elliott Thornley (EJT) @ 2026-06-28T19:02 (+2)
Thanks! I think the difference between our proposal and organizations paying workers to report themselves is the order that things come in. In our case, it's payment first and reporting later. The idea is that you could give a risk-averse AI $1,000 (say) and tell it that it can spend the money on anything it wants. Then so long as the risk-averse AI believes that the situation is real, it will spend the money on what it actually wants (e.g. making paperclips) and thereby reveal to you what it actually wants.
I think a human analogy would be something like:
- You have an employee that claims that their only terminal value is the success of the company.
- You want to find out whether this is true.
- So you give the employee a no-strings-attached $10m.
- If they give that money back to the company and continue working just as hard, that's strong evidence that they really do only terminally value the success of the company.
- If they spend the money on something else, that's strong evidence that they don't only value the success of the company.
Zach Stein-Perlman @ 2026-06-24T21:59 (+6)
Crossposting Ryan's comment on LW:
It seems pretty likely to me that you instead want AIs to be risk seeking for reasons discussed here. Takeover attempts that are very unlikely to succeed might speculatively actually be a great trade from the perspective of humanity and risk seeking/risk neutral AI in that they reduce overall takeover risk while being good for this AI (while deals are way less useful to humanity due to being less clear evidence). Risk avoidant AIs might do nothing or just take deals until AIs take over later (and accepting deals might not be a good strategy for them depending on their views about the chance of AI takeover and some other factors).
I also think the implicit story about how we steer these traits doesn't really hold together and assumes a type of generalization I find somewhat implausible if we condition on AIs being egregiously misaligned.
Elliott Thornley (EJT) @ 2026-06-25T19:14 (+2)
Replied over there! There are also a few more comments in the thread now.
I’m surprised you say deals would be way less useful. Can you say more? Here’s my current sense of things:
In favor of keeping AIs risk-neutral
- Risk-neutral AIs are more likely to attempt takeover. And we want them to attempt takeover, because (i) they’re very unlikely to succeed, and (ii) if we catch them attempting takeover, we can use them to reduce future takeover risk, by doing research on them, using the evidence of their takeover attempt to motivate international coordination, etc.
Worries about that:
One worry is that we need the risk-neutral AIs to be somewhat likely to successfully take over, otherwise they wouldn’t even attempt takeover and we couldn’t catch them. Taking the numbers from Fabien’s post (which are illustrative but don’t seem off by OOMs), their chance of successful takeover has to be greater than 1%. That’s a fairly big risk we’d be taking in the near term.
It also seems like we’ll only get really convincing evidence of a takeover attempt (the kind that might motivate international coordination) if the attempt gets pretty far along. And conditional on the attempt getting pretty far along, the AI’s chances of successful takeover are likely even higher.
One benefit of risk-averse AI (if it works) is that we don’t have to take that near-term risk.
And then with regard to reducing future takeover risk, I agree that getting to do research on confirmed-misaligned AIs would be a big benefit (but we can also get that with risk-averse AIs). On international coordination, I think most caught takeover attempts probably wouldn’t leave evidence clear enough to motivate it. I think many of the points from this post apply. In reply to evidence of a takeover attempt, people will likely say: shutting down would be costly, AIs do weird stuff sometimes, it was an isolated screw-up by that specific AI company, it’s a doomer plot, etc. And the news might not even get out of the lab. Also it seems fairly likely that AIs can try to take over in a way that would look pretty ambiguous if they failed. They could invent some justification for why their actions were actually in humanity’s best interest, etc.
(Sidenote is that I’m interested in the implications of ‘We want near-future AIs to attempt takeover.’ If that’s true, it seems like the AI safety community should be doing radically different stuff to the stuff it’s currently doing.)
In favor of making AIs risk-averse
- Risk-averse AIs are less likely to attempt takeover in the near term.
If that were the only benefit, then I think it’d be pretty unclear which of risk-neutral AIs and risk-averse AIs is better. But risk-averse AIs would likely have lots of other benefits too, potentially letting us reduce future takeover risk by a lot. We can pay them to:
- Reveal misalignment.
- One idea here is that we give risk-averse AIs a small amount to spend on whatever they want. Then if they spend it on making paperclips (etc.), we’ve got clear evidence of misalignment. We can then do research on these misaligned AIs and use the evidence to motivate international coordination, etc.
- This evidence of misalignment we get from risk-averse AIs seems about as good for enabling research and motivating international coordination as the evidence we’d get from risk-neutral AIs attempting takeover. And to get this evidence from risk-averse AIs, we don't need to bait them into an (at least somewhat likely to succeed) takeover attempt and hope that we catch them.
- Reveal collusion signals.
- Stop sandbagging on easy-to-evaluate tasks.
- Identify security vulnerabilities.
- Monitor untrusted AIs.
- Do alignment research. (Hard to evaluate, of course. We say a bit about this in section 4.2.)
- Plus other stuff mentioned here, here, and here.
Taken together, all this stuff we can buy from risk-averse AIs seems much better for reducing future takeover risk than catching risk-neutral AIs in a takeover attempt. And we can buy all this stuff from risk-averse AIs without running a significant risk that AIs actually succeed in their takeover attempt.
(I'll reply to the generalization point in another comment.)