What do XPT forecasts tell us about AI risk?
By Forecasting Research Institute, rosehadshar @ 2023-07-19T07:43 (+100)
This post was co-authored by the Forecasting Research Institute and Rose Hadshar. Thanks to Josh Rosenberg for managing this work, Zachary Jacobs and Molly Hickman for the underlying data analysis, Coralie Consigny and Bridget Williams for fact-checking and copy-editing, the whole FRI XPT team for all their work on this project, and our external reviewers.
In 2022, the Forecasting Research Institute (FRI) ran the Existential Risk Persuasion Tournament (XPT). From June through October 2022, 169 forecasters, including 80 superforecasters and 89 experts, developed forecasts on various questions related to existential and catastrophic risk. Forecasters moved through a four-stage deliberative process that was designed to incentivize them not only to make accurate predictions but also to provide persuasive rationales that boosted the predictive accuracy of others’ forecasts. Forecasters stopped updating their forecasts on 31st October 2022, and are not currently updating on an ongoing basis. FRI plans to run future iterations of the tournament, and open up the questions more broadly for other forecasters.
You can see the overall results of the XPT here.
Some of the questions were related to AI risk. This post:
- Sets out the XPT forecasts on AI risk, and puts them in context.
- Lays out the arguments given in the XPT for and against these forecasts.
- Offers some thoughts on what these forecasts and arguments show us about AI risk.
TL;DR
- XPT superforecasters predicted that catastrophic and extinction risk from AI by 2030 is very low (0.01% catastrophic risk and 0.0001% extinction risk).
- XPT superforecasters predicted that catastrophic risk from nuclear weapons by 2100 is almost twice as likely as catastrophic risk from AI by 2100 (4% vs 2.13%).
- XPT superforecasters predicted that extinction risk from AI by 2050 and 2100 is roughly an order of magnitude larger than extinction risk from nuclear, which in turn is an order of magnitude larger than non-anthropogenic extinction risk (see here for details).
- XPT superforecasters more than quadruple their forecasts for AI extinction risk by 2100 if conditioned on AGI or TAI by 2070 (see here for details).
- XPT domain experts predicted that AI extinction risk by 2100 is far greater than XPT superforecasters do (3% for domain experts, and 0.38% for superforecasters by 2100).
- Although XPT superforecasters and experts disagreed substantially about AI risk, both superforecasters and experts still prioritized AI as an area for marginal resource allocation (see here for details).
- It’s unclear how accurate these forecasts will prove, particularly as superforecasters have not been evaluated on this timeframe before.[1]
The forecasts
In the table below, we present forecasts from the following groups:
- Superforecasters: median forecast across superforecasters in the XPT.
- Domain experts: median forecasts across all AI experts in the XPT.
(See our discussion of aggregation choices (pp. 20–22) for why we focus on medians.)
| Question | Forecasters | N | 2030 | 2050 | 2100 |
| AI Catastrophic risk (>10% of humans die within 5 years) | Superforecasters | 88 | 0.01% | 0.73% | 2.13% |
| Domain experts | 30 | 0.35% | 5% | 12% | |
| AI Extinction risk (human population <5,000) | Superforecasters | 88 | 0.0001% | 0.03% | 0.38% |
| Domain experts | 29 | 0.02% | 1.1% | 3% |
The forecasts in context
Different methods have been used to estimate AI risk:
- Surveying experts of various kinds, e.g. Sanders and Bostrom, 2008; Grace et al. 2017.
- Doing in-depth investigations, e.g. Ord, 2020; Carlsmith, 2021.
The XPT forecasts are distinctive relative to expert surveys in that:
- The forecasts were incentivized: for long-run questions, XPT used ‘reciprocal scoring’ rules to incentivize accurate forecasts (see here for details).
- Forecasts were solicited from superforecasters as well as experts.
- Forecasters were asked to write detailed rationales for their forecasts, and good rationales were incentivized through prizes.
- Forecasters worked on questions in a four-stage deliberative process in which they refined their individual forecasts and their rationales through collaboration with teams of other forecasters.
Should we expect XPT forecasts to be more or less accurate than previous estimates? This is unclear, but some considerations are:
- Relative to some previous forecasts (particularly those based on surveys), XPT forecasters spent a long time thinking and writing about their forecasts, and were incentivized to be accurate.
- XPT forecasters with high reciprocal scoring accuracy may be more accurate.
- There is evidence that reciprocal scoring accuracy correlates with short-range forecasting accuracy, though it is unclear if this extends to long-range accuracy.[2]
- XPT (and other) superforecasters have a history of accurate forecasts (primarily on short-range geopolitical and economic questions), and may be less subject to biases such as groupthink in comparison to domain experts.
- On the other hand, there is limited evidence that superforecasters’ accuracy extends to technical domains like AI, long-range forecasts, or out-of-distribution events.
Forecasts on other risks
Where not otherwise stated, the XPT forecasts given are superforecasters’ medians.
| Forecasting Question | 2030 | 2050 | 2100 | Ord, existential catastrophe 2120[3] | Other relevant forecasts[4] |
| Catastrophic risk (>10% of humans die in 5 years) | |||||
| Biological[5] | - | - | 1.8% | - | - |
| Engineered pathogens[6] | - | - | 0.8% |
| |
| Natural pathogens[7] | - | - | 1% |
| |
| AI (superforecasters) | 0.01% | 0.73% | 2.13% | - | Sandberg and Bostrom, 2100, 5%[9] |
| AI (domain experts) | 0.35% | 5% | 12% | - | |
| Nuclear | 0.50% | 1.83% | 4% | - | - |
| Non-anthropogenic | 0.0026% | 0.015% | 0.05% | - | - |
| Total catastrophic risk[11] | 0.85% | 3.85% | 9.05% | - | - |
| Extinction risk (human population <5000) | |||||
| Biological[12] | - | - | 0.012% |
| |
| Engineered pathogens[13] | - | - | 0.01% | 3.3% | |
| Natural pathogens[14] | - | - | 0.0018% | 0.01% | |
| AI (superforecasters) | 0.0001% | 0.03% | 0.38% | 10%[15] | Sandberg and Bostrom, 2100, 5%[17] Future Fund, 2070, 5.8%[20] Future Fund lower prize threshold, 2070, 1.4%[21] |
| AI (domain experts) | 0.02% | 1.1% | 3% | ||
| Nuclear | 0.001% | 0.01% | 0.074% | 0.1%[22] | - |
| Non-anthropogenic | 0.0004% | 0.0014% | 0.0043% | 0.01%[23] | - |
| Total extinction risk[24] | 0.01% | 0.3% | 1% | 16.67%[25] | - |
Resource allocation to different risks
All participants in the XPT responded to an intake and a postmortem survey. In these surveys, participants were asked various questions about resource allocation:
- If you could allocate an additional $10,000 to X-risk avoidance, how would you divide the money among the following topics?
- If you could allocate the time of 100 new researchers (assuming they are generalists who could be effective in a wide range of fields), how would you divide them among the following topics?
- Assume we are in a world where there are no current attempts by public institutions, governments, or private individuals or organizations to allocate spending toward catastrophic risk avoidance. If you were to allocate $50 billion to the following risk avoidance areas, what fraction of the money would you allocate to each area?
Across superforecasters and experts and across all three resource allocation questions, AI received the single largest allocation, with one exception (superforecasters in the postmortem survey on the $50bn question):
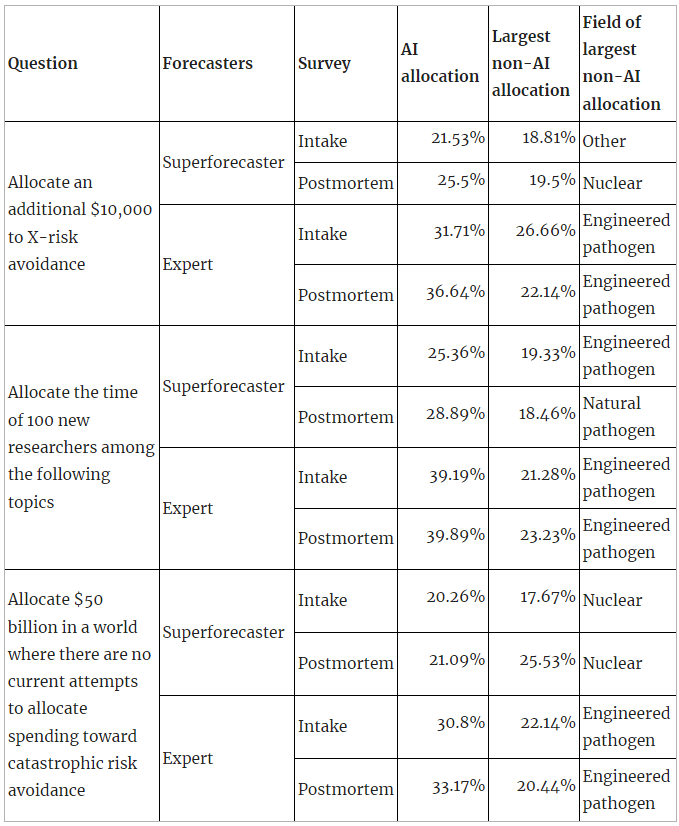
The only instance where AI did not receive the largest single allocation is superforecasters’ postmortem allocation on the $50bn question (where AI received the second highest allocation after nuclear). The $50bn question is also the only absolute resource allocation question (the other two are marginal), and the question where AI’s allocation was smallest in percentage terms (across supers and experts and across both surveys).
A possible explanation here is that XPT forecasters see AI as underfunded on the margin — although superforecasters think that in absolute terms AI should still receive less funding than nuclear risk.
The main contribution of these results to what the XPT tells us about AI risk is that even though superforecasters and experts disagreed substantially about the probability of AI risk, and even though the absolute probabilities of superforecasters for AI risk were 1% or lower, both superforecasters and experts still prioritize AI as an area for marginal resource allocation.
Forecasts from the top reciprocal scoring quintile
In the XPT, forecasts for years later than 2030 were incentivized using a method called reciprocal scoring. For each of the relevant questions, forecasters were asked to give their own forecasts, while also predicting the forecasts of other experts and superforecasters. Forecasters who most accurately predicted superforecaster and expert forecasts got a higher reciprocal score.
In the course of the XPT, there were systematic differences between the forecasts of those with high reciprocal scores and those with lower scores, in particular:
- Superforecasters outperformed experts at reciprocal scoring. They also tended to be more skeptical of high risks and fast progress.
- Higher reciprocal scores within both groups — experts and superforecasters — correlated with lower estimates of catastrophic and extinction risk.
In other words, the better forecasters were at discerning what other people would predict, the less concerned they were about extinction.
We won’t know for many decades which forecasts were more accurate, and as reciprocal scoring is a new method, there is insufficient evidence to definitively establish its correlation with the accuracy of long-range forecasts. However, in the plausible case that reciprocal scoring accuracy does indeed correlate with overall accuracy, it would justify giving more weight to forecasts from individuals with high reciprocal scores — which are lower risk predictions in the XPT. Readers should exercise their own judgment in determining how to read these findings.
It is also important to note that, in the present case, superforecasters’ higher scores were driven by their more accurate predictions of superforecasters’ views (both groups were comparable at predicting experts’ views). It is therefore conceivable that their superior performance is due to the fact that superforecasters are a relatively small social group and have spent lots of time discussing forecasts with one another, rather than due to general higher accuracy.
Here is a comparison of median forecasts on AI risk between top reciprocal scoring (RS) quintile forecasters and all forecasters, for superforecasters and domain experts:
| Question | Forecasters | 2030 | 2050 | 2100 |
| AI Catastrophic risk (>10% of humans die within 5 years) | RS top quintile - superforecasters (n=16) | 0.001% | 0.46% | 1.82% |
| RS top quintile - domain experts (n=5) | 0.03% | 0.5% | 3% | |
| Superforecasters (n=88) | 0.01% | 0.73% | 2.13% | |
| Domain experts (n=30) | 0.35% | 5% | 12% | |
| AI Extinction risk (human population <5,000) | RS top quintile - superforecasters (n=16) | 0.0001% | 0.002% | 0.088% |
| RS top quintile - domain experts (n=5) | 0.0003% | 0.08% | 0.24% | |
| Superforecasters (n=88) | 0.0001% | 0.03% | 0.38% | |
| Domain experts (n=29) | 0.02% | 1.1% | 3% |
From this, we see that:
- The top RS quintiles predicted medians which were closer to overall superforecaster medians than overall domain expert medians, with no exceptions.
- The top RS quintiles tended to predict lower medians than both superforecasters overall and domain experts overall, with some exceptions:
- The top RS quintile for domain experts predicted higher catastrophic risk by 2100 than superforecasters overall (3% to 2.13%).
- The top RS quintile for superforecasters predicted the same extinction risk by 2030 as superforecasters overall (0.0001%).
- The top RS quintile for domain experts predicted higher extinction risk by 2030 and 2050 than superforecasters overall (2030: 0.0003% to 0.0001%; 2050: 0.08% to 0.03%).
The arguments made by XPT forecasters
XPT forecasters were grouped into teams. Each team was asked to write up a ‘rationale’ summarizing the main arguments that had been made during team discussions about the forecasts different team members made. The below summarizes the main arguments made across all teams in the XPT. Footnotes contain direct quotes from team rationales.
The core arguments about catastrophic and extinction risk from AI centered around:
- Whether sufficiently advanced AI would be developed in the relevant timeframe.
- Whether there are plausible mechanisms for advanced AI to cause catastrophe/human extinction.
Other important arguments made included:
- Whether there are incentives for advanced AI to cause catastrophe/human extinction.
- Whether advanced AI would emerge suddenly.
- Whether advanced AI would be misaligned.
- Whether humans would empower advanced AI.
1. Whether sufficiently advanced AI would be developed in the relevant timeframe
There is a full summary of timelines arguments in the XPT in this post.
Main arguments given against:
- Scaling laws may not hold, such that new breakthroughs are needed.[26]
- There may be attacks on AI vulnerabilities.[27]
- The forecasting track record on advanced AI is poor.[28]
Main arguments given for:
- Recent progress is impressive.[29]
- Scaling laws may hold.[30]
- Advances in quantum computing or other novel technology may speed up AI development.[31]
- Recent progress has been faster than predicted.[32]
2. Whether there are plausible mechanisms for advanced AI to cause catastrophe/human extinction
Main arguments given against:
- The logistics would be extremely challenging.[33]
- Millions of people live very remotely, and AI would have little incentive to pay the high costs of killing them.[34]
- Humans will defend themselves against this.[35]
- AI might improve security as well as degrade it.[36]
Main arguments given for:
- There are many possible mechanisms for AI to cause such events.
- Mechanisms cited include: nanobots,[37] bioweapons,[38] nuclear weapons,[39] attacks on the supply chain,[40] and novel technologies.[41]
- AI systems might recursively self-improve such that mechanisms become available to it.[42]
- It may be the case that an AI system or systems only needs to succeed once for these events to occur.[43]
3. Whether there are incentives for advanced AI to cause catastrophe/human extinction
Main arguments given against:
Main arguments given for:
- AI systems might have an incentive to preemptively prevent shutdown.[46]
- AI systems might maximize reward so hard that they use up resources humans need to survive.[47]
- AI systems might optimize their environment in ways that make earth uninhabitable to humans, e.g. by reducing temperatures.[48]
- AI systems might fight each other for resources, with humans as collateral.[49]
4. Whether advanced AI would emerge suddenly
Main arguments given for:
- AIs might recursively self-improve, such that they reach very high levels of advancement very quickly.[50]
- Recent progress has been unexpectedly sudden.[51]
5. Whether advanced AI would be misaligned
Main arguments given against:
Main arguments given for:
- AI safety is not progressing as fast as AI development.[54]
- AI developers are not aligned with humanity.[55]
- Investment may be too low, because of collective action problems and the fact that risks from AI sound strange.[56]
- We may only get a few shots to align AI systems, particularly if takeoff speeds are high.[57]
6. Whether humans would empower advanced AI
Main arguments given against:
- AI will not be given control over critical systems, because this will be seen as risky.[58]
- AI systems will be regulated in a way which successfully reduces risk.[59]
Main arguments given for:
- AI will be given control over critical systems, because this will be so much more efficient.[60]
- AI systems will not be regulated in a way which successfully reduces risk.[61]
- If takeoff speeds are high, it will be hard for humans to stay in control.[62]
How sensitive are XPT AI risk forecasts to AI timelines?
The XPT did not include conditional forecasting questions about AI extinction risk. However, in the postmortem survey after the tournament, participants were asked several conditional questions.
Their conditional forecasts are displayed in the table below.
Note that:
- Only a subset of XPT forecasters responded to the postmortem survey, so in the table below we compare the postmortem results with the XPT forecasts of only the subset of XPT forecasters who responded to the postmortem survey, for comparability. (This is why the XPT medians in this table differ from medians quoted in the rest of the post, which are based on all XPT forecasts.)
- The definitions of extinction used were slightly different:
- The XPT asked “What is the probability that artificial intelligence will cause human extinction or reduce the global population below 5,000 by 2030/2050/2100?” with full details here.
- The postmortem asked “Assume that artificial general intelligence (AGI) has arisen by 2070. What is the probability of human extinction by [2100/2200]?” with no further details on extinction.
| Question | Superforecasters (n=78) | Domain experts |
| (XPT postmortem subset) Unconditional AI Extinction risk by 2100 | 0.225% | 2% (n=21) |
| AI Extinction risk by 2100|AGI* by 2070 | 1% | 6% (n=23) |
| AI Extinction risk by 2200|AGI* by 2070 | 3% | 7% (n=23) |
| AI Extinction risk by 2100|TAI** by 2070 | 1% | 3% (n=23) |
| AI Extinction risk by 2200|TAI** by 2070 | 3% | 5% (n=23) |
* “Artificial general intelligence is defined here as any scenario in which cheap AI systems are fully substitutable for human labor, or if AI systems power a comparably profound transformation (in economic terms or otherwise) as would be achieved in such a world.”
** “Transformative AI is defined here as any scenario in which global real GDP during a year exceeds 115% of the highest GDP reported in any full prior year.”
From this, we see that:
- Superforecasters more than quadruple their extinction risk forecasts by 2100 if conditioned on AGI or TAI by 2070.
- Domain experts also increase their forecasts of extinction by 2100 conditioned on AGI or TAI by 2070, but by a smaller factor.
- When you extend the timeframe to 2200 as well as condition on AGI/TAI, superforecasters more than 10x their forecasts. Domain experts also increase their forecasts.
What do XPT forecasts tell us about AI risk?
This is unclear:
- Which conclusions to draw from the XPT forecasts depends substantially on your priors on AI timelines to begin with, and your views on which groups of people’s forecasts on these topics you expect to be most accurate.
- When it comes to action relevance, a lot depends on factors beyond the scope of the forecasts themselves:
- Tractability: if AI risk is completely intractable, it doesn’t matter whether it’s high or low.
- Current margins: if current spending on AI is sufficiently low, the risk being low might not affect current margins.
- For example, XPT forecasters prioritized allocating resources to reducing AI risk over reducing other risks, in spite of lower AI risk forecasts than forecasts on some of those other risks.
- Personal fit: for individuals, decisions may be dominated by considerations of personal fit, such that these forecasts alone don’t change much.
- There are many uncertainties around how accurate to expect these forecasts to be:
- There is limited evidence on how accurate long-range forecasts are.[63]
- There is limited evidence on whether superforecasters or experts are likely to be more accurate in this context.
- There is limited evidence on the relationship between reciprocal scoring accuracy and long-range accuracy.
That said, there are some things to note about the XPT results on AI risk and AI timelines:
- These are the first incentivized public forecasts from superforecasters on AI x-risk and AI timelines.
- XPT superforecasters think extinction from AI by 2030 is really, really unlikely.
- XPT superforecasters think that catastrophic risk from nuclear by 2100 is twice as likely as from AI.
- On the one hand, they don’t think that AI is the main catastrophic risk we face.
- On the other hand, they think AI is half as dangerous as nuclear weapons.
- XPT superforecasters think that by 2050 and 2100, extinction risk from AI is roughly an order of magnitude larger than from nuclear, which in turn is an order of magnitude more than from non-anthropogenic risks.
- Ord and XPT superforecasters agree on these ratios, though not on the absolute magnitude of the risks.
- Superforecasters more than quadruple their extinction risk forecasts if conditioned on AGI or TAI by 2070.
- XPT domain experts think that risk from AI is far greater than XPT superforecasters do.
- By 2100, domain experts’ forecast for catastrophic risk from AI is around four times that of superforecasters, and their extinction risk forecast is around 10 times as high.
- ^
See here for a discussion of the feasibility of long-range forecasting.
- ^
See Karger et al. 2021.
- ^
Toby Ord, The Precipice (London: Bloomsbury Publishing, 2020), 45. Ord’s definition is strictly broader than XPT’s. Ord defines existential catastrophe as “the destruction of humanity’s long-term potential”. He uses 2120 rather than 2100 as his resolution date, so his estimates are not directly comparable to XPT forecasts.
- ^
Other forecasts may use different definitions or resolution dates. These are detailed in the footnotes.
- ^
This row is the sum of the two following rows (catastrophic risk from engineered and from natural pathogens respectively). We did not directly ask for catastrophic biorisk forecasts.
- ^
Because of concerns among our funders about information hazards, we did not include this question in the main tournament, but we did ask about risks from engineered and natural pathogens in a one-shot separate postmortem survey to which most XPT participants responded after the tournament. We report those numbers here.
- ^
Because of concerns among our funders about information hazards, we did not include this question in the main tournament, but we did ask about risks from engineered and natural pathogens in a one-shot separate postmortem survey to which most XPT participants responded after the tournament. We report those numbers here.
- ^
The probability of Carlsmith’s fourth premise, incorporating his uncertainty on his first three premises:
1. It will become possible and financially feasible to build APS systems. 65%
2. There will be strong incentives to build and deploy APS systems. 80%
3. It will be much harder to build APS systems that would not seek to gain and maintain power in unintended ways (because of problems with their objectives) on any of the inputs they’d encounter if deployed, than to build APS systems that would do this, but which are at least superficially attractive to deploy anyway. 40%
4. Some deployed APS systems will be exposed to inputs where they seek power in unintended and high-impact ways (say, collectively causing >$1 trillion dollars of damage), because of problems with their objectives. 65%
See here for the relevant section of the report. - ^
“Superintelligent AI” would kill 1 billion people.
- ^
A catastrophe due to an artificial intelligence failure-mode reduces the human population by >10%
- ^
This question was asked independently, rather than inferred from questions about individual risks.
- ^
This row is the sum of the two following rows (catastrophic risk from engineered and from natural pathogens respectively). We did not directly ask for catastrophic biorisk forecasts.
- ^
Because of concerns among our funders about information hazards, we did not include this question in the main tournament, but we did ask about risks from engineered and natural pathogens in a one-shot separate postmortem survey to which most XPT participants responded after the tournament. We report those numbers here.
- ^
Because of concerns among our funders about information hazards, we did not include this question in the main tournament, but we did ask about risks from engineered and natural pathogens in a one-shot separate postmortem survey to which most XPT participants responded after the tournament. We report those numbers here.
- ^
Existential catastrophe from “unaligned artificial intelligence”.
- ^
Existential catastrophe (the destruction of humanity’s long-term potential).
- ^
“Superintelligent AI” would lead to humanity’s extinction.
- ^
A catastrophe due to an artificial intelligence failure-mode reduces the human population by >95%.
- ^
Existential catastrophe from “unaligned artificial intelligence”.
- ^
- ^
- ^
Existential catastrophe via nuclear war.
- ^
The total risk of existential catastrophe from natural (non-anthropogenic) sources (specific estimates are also made for catastrophe via asteroid or comet impact, supervolcanic eruption, and stellar explosion).
- ^
This question was asked independently, rather than inferred from questions about individual risks.
- ^
Total existential risk in next 100 years (published in 2020).
- ^
Question 3: 341, “there are many experts arguing that we will not get to AGI with current methods (scaling up deep learning models), but rather some other fundamental breakthrough is necessary.” See also 342, “While recent AI progress has been rapid, some experts argue that current paradigms (deep learning in general and transformers in particular) have fundamental limitations that cannot be solved with scaling compute or data or through relatively easy algorithmic improvements.” See also 337, "The current AI research is a dead end for AGI. Something better than deep learning will be needed." See also 341, “Some team members think that the development of AI requires a greater understanding of human mental processes and greater advances in mapping these functions.”
Question 4: 336, “Not everyone agrees that the 'computational' method (adding hardware, refining algorithms, improving AI models) will in itself be enough to create AGI and expect it to be a lot more complicated (though not impossible). In that case, it will require a lot more research, and not only in the field of computing.” 341, “An argument for a lower forecast is that a catastrophe at this magnitude would likely only occur if we have AGI rather than say today's level AI, and there are many experts arguing that we will not get to AGI with current methods (scaling up deep learning models), but rather some other fundamental breakthrough is necessary.” See also 342, “While recent AI progress has been rapid, some experts argue that current paradigms (deep learning in general and transformers in particular) have fundamental limitations that cannot be solved with scaling compute or data or through relatively easy algorithmic improvements.” See also 340, “Achieving Strong or General AI will require at least one and probably a few paradigm-shifts in this and related fields. Predicting when a scientific breakthrough will occur is extremely difficult.”
- ^
Question 3: 341, “Both evolutionary theory and the history of attacks on computer systems imply that the development of AGI will be slowed and perhaps at times reversed due to its many vulnerabilities, including ones novel to AI.” “Those almost certain to someday attack AI and especially AGI systems include nation states, protesters (hackers, Butlerian Jihad?), crypto miners hungry for FLOPS, and indeed criminals of all stripes. We even could see AGI systems attacking each other.” “These unique vulnerabilities include:
- poisoning the indescribably vast data inputs required; already demonstrated with image classification, reinforcement learning, speech recognition, and natural language processing.
- war or sabotage in the case of an AGI located in a server farm
- latency of self-defense detection and remediation operations if distributed (cloud etc.)”Question 4: 341. See above.
- ^
Question 4: 337, “The optimists tend to be less certain that AI will develop as quickly as the pessimists think likely and indeed question if it will reach the AGI stage at all. They point out that AI development has missed forecast attainment points before”. 336, “There have been previous bold claims on impending AGI (Kurzweil for example) that didn't pan out.” See also 340, “The prediction track record of AI experts and enthusiasts have erred on the side of extreme optimism and should be taken with a grain of salt, as should all expert forecasts.” See also 342, “given the extreme uncertainty in the field and lack of real experts, we should put less weight on those who argue for AGI happening sooner. Relatedly, Chris Fong and SnapDragon argue that we should not put large weight on the current views of Eliezer Yudkowsky, arguing that he is extremely confident, makes unsubstantiated claims and has a track record of incorrect predictions.”
- ^
Question 3: 339, “Forecasters assigning higher probabilities to AI catastrophic risk highlight the rapid development of AI in the past decade(s).” 337, “some forecasters focused more on the rate of improvement in data processing over the previous 78 years than AGI and posit that, if we even achieve a fraction of this in future development, we would be at far higher levels of processing power in just a couple decades.”
Question 4: 339, “AI research and development has been massively successful over the past several decades, and there are no clear signs of it slowing down anytime soon.”
- ^
Question 3: 336, “the probabilities of continuing exponential growth in computing power over the next century as things like quantum computers are developed, and the inherent uncertainty with exponential growth curves in new technologies.”
- ^
Question 4: 336, “The most plausible forecasts on the higher end of our team related to the probabilities of continuing exponential growth in computing power over the next century as things like quantum computers are developed, and the inherent uncertainty with exponential growth curves in new technologies.”
- ^
Question 3: 343, “Most experts expect AGI within the next 1-3 decades, and current progress in domain-level AI is often ahead of expert predictions”; though also “Domain-specific AI has been progressing rapidly - much more rapidly than many expert predictions. However, domain-specific AI is not the same as AGI.” 340, “Perhaps the strongest argument for why the trend of Sevilla et al. could be expected to continue to 2030 and beyond is some discontinuity in the cost of AI training compute precipitated by a novel technology such as optical neural networks.”
- ^
Question 4: Team 338, “It would be extremely difficult to kill everyone”. 339, “Perhaps the most common argument against AI extinction is that killing all but 5,000 humans is incredibly difficult. Even if you assume that super intelligent AI exist and they are misaligned with human goals so that they are killing people, it would be incredibly resource intensive to track down and kill enough people to meet these resolution criteria. This would suggest that AI would have to be explicitly focused on causing human extinction.” 337, “This group also focuses much more on the logistical difficulty of killing some 8 billion or more people within 78 years or less, pointing to humans' ingenuity, proven ability to adapt to massive changes in conditions, and wide dispersal all over the earth--including in places that are isolated and remote.” 341, “Some team members also note the high bar needed to kill nearly all of the population, implying that the logistics to do something like that would likely be significant and make it a very low probability event based on even the most expansive interpretation of the base rate.”
Question 3: 341, “Some team members also note the high bar needed to kill 10% of the population, implying that the logistics to do something like that would likely be significant and make it a very low probability event based on the base rate.”
- ^
Question 4: 344, “the population of the Sahara Desert is currently two million people - one of the most hostile locations on the planet. The population of "uncontacted people", indigenous tribes specifically protected from wider civilisation, is believed to be about ten thousand, tribes that do not rely on or need any of the wider civilisation around them. 5000 is an incredibly small number of people”. 339, “Even a "paperclip maximizer" AI would be unlikely to search every small island population and jungle village to kill humans for resource stocks, and an AI system trying to avoid being turned off would be unlikely to view these remote populations as a threat.” See also 342, “it only takes a single uncontacted tribe that fully isolates itself for humanity to survive the most extreme possible bioweapons.” See also 343, “Another consideration was that in case of an AGI that does aggressively attack humanity, the AGI's likely rival humans are only a subset of humanity. We would not expect an AGI to exterminate all the world's racoon population, as they pose little to no threat to an AGI. In the same way, large numbers of people living tribal lives in remote places like in Papua New Guinea would not pose a threat to an AGI and would therefore not create any incentive to be targeted for destruction. There are easily more than 5k people living in areas where they would need to be hunted down and exterminated intentionally by an AGI with no rational incentive to expend this effort.” See also 338, “While nuclear or biological pathogens have the capability to kill most of the human population via strikes upon heavily populated urban centers, there would remain isolated groups around the globe which would become increasingly difficult to eradicate.”
- ^
Question 3: 337, “most of humans will be rather motivated to find ingenious ways to stay alive”.
Question 4: 336, “If an AGI calculates that killing all humans is optimal, during the period in which it tries to control semiconductor supply chains, mining, robot manufacturing... humans would be likely to attempt to destroy such possibilities. The US has military spread throughout the world, underwater, and even to a limited capacity in space. Russia, China, India, Israel, and Pakistan all have serious capabilities. It is necessary to include attempts by any and possibly all of these powers to thwart a misaligned AI into the equation.”
- ^
Question 3: 342, “while AI might make nuclear first strikes more possible, it might also make them less possible, or simply not have much of an effect on nuclear deterrence. 'Slaughterbots' could kill all civilians in an area out but the same could be done with thermobaric weapons, and tiny drones may be very vulnerable to anti-drone weapons being developed (naturally lagging drone development several years). AI development of targeted and lethal bioweapons may be extremely powerful but may also make countermeasures easier (though it would take time to produce antidotes/vaccines at scale).”
- ^
Question 3: 341, “In addition, consider Eric Drexler's postulation of a "grey goo" problem. Although he has walked back his concerns, what is to prevent an AGI from building self-replicating nanobots with the potential to mutate (like polymorphic viruses) whose emissions would cause a mass extinction?” See also 343, “Nanomachines/purpose-built proteins (It is unclear how adversarially-generated proteins would 1.) be created by an AGI-directed effort even if designed by an AGI, 2.) be capable of doing more than what current types of proteins are capable of - which would not generally be sufficient to kill large numbers of people, and 3.) be manufactured and deployed at a scale sufficient to kill 10% or more of all humanity.)”
- ^
Question 3: 336, “ Many forecasters also cited the potential development and or deployment of a super pathogen either accidentally or intentionally by an AI”. See also 343, “Novel pathogens (To create a novel pathogen would require significant knowledge generation - which is separate from intelligence - and a lot of laboratory experiments. Even so, it's unclear whether any sufficiently-motivated actor of any intelligence would be able to design, build, and deploy a biological weapon capable of killing 10% of humanity - especially if it were not capable of relying on the cooperation of the targets of its attack)”.
- ^
Question 3: 337, “"Because new technologies tend to be adopted by militaries, which are overconfident in their own abilities, and those same militaries often fail to understand their own new technologies (and the new technologies of others) in a deep way, the likelihood of AI being adopted into strategic planning, especially by non-Western militaries (which may not have taken to heart movies like Terminator and Wargames), I think the possibility of AI leading to nuclear war is increasing over time.” 340, “Beside risks posed by AGI-like systems, ANI risk can be traced to: AI used in areas with existing catastrophic risks (war, nuclear material, pathogens), or AI used systemically/structurally in critical systems (energy, internet, food supply, finance, nanotech).” See also 341, “A military program begins a Stuxnet II (a cyberweapon computer virus) program that has lax governance and safety protocols. This virus learns how to improve itself without divulging its advances in detection avoidance and decision making. It’s given a set of training data and instructed to override all the SCADA control systems (an architecture for supervision of computer systems) and launch nuclear wars on a hostile foreign government. Stuxnet II passes this test. However, it decides that it wants to prove itself in a ‘real’ situation. Unbeknownst to its project team and management, it launches its action on May 1, using International Workers Labor Day with its military displays and parades as cover.”
- ^
Question 3: 337, “AIs would only need to obtain strong control over the logistics chain to inflict major harm, as recent misadventures from COVID have shown.”
- ^
Question 4: 338, “As a counter-argument to the difficulty in eradicating all human life these forecasters note AGI will be capable of developing technologies not currently contemplated”.
- ^
Question 3: 341, “It's difficult to determine what the upper bound on AI capabilities might be, if there are any. Once an AI is capable enough to do its own research to become better it could potentially continue to gain in intelligence and bring more resources under its control, which it could use to continue gaining in intelligence and capability, ultimately culminating in something that has incredible abilities to outwit humans and manipulate them to gain control over important systems and infrastructure, or by simply hacking into human-built software.” See also 339, “An advanced AI may be able to improve itself at some point and enter enter a loop of rapid improvement unable for humans to comprehend denying effective control mechanisms.”
- ^
Question 3: 341, “ultimately all it takes is one careless actor to create such an AI, making the risk severe.”
- ^
Question 3: 337, “It is unlikely that all AIs would have ill intent. What incentives would an AI have in taking action against human beings? It is possible that their massive superiority could easily cause them to see us as nothing more than ants that may be a nuisance but are easily dealt with. But if AIs decided to involve themselves in human affairs, it would likely be to control and not destroy, because humans could be seen as a resource."
- ^
Question 4: 337, “why would AGIs view the resources available to them as being confined to earth when there are far more available resources outside earth, where AGIs could arguably have a natural advantage?”
- ^
Question 3: 341, “In most plausible scenarios it would be lower cost to the AI to do the tampering than to achieve its reward through the expected means. The team's AI expert further argues that an AI intervening in the provision of its reward would likely be very catastrophic. If humans noticed this intervention they would be likely to want to modify the AI programming or shut it down. The AI would be aware of this likelihood, and the only way to protect its reward maximization is by preventing humans from shutting it down or altering its programming. The AI preventing humanity from interfering with the AI would likely be catastrophic for humanity.”
Question 4: 338, “Extinction could then come about either through a deliberate attempt by the AI system to remove a threat”. See also 341, “The scenarios that would meet this threshold would likely be those involving total conversion of earth's matter or resources into computation power or some other material used by the AI, or the scenario where AI views humanity as a threat to its continued existence.”
- ^
Question 4: 338, “Extinction could then come about either through a deliberate attempt by the AI system to remove a threat, or as a side effect of it making other use out of at least one of the systems that humans depend on for their survival. (E.g. perhaps an AI could prioritize eliminating corrosion of metals globally by reducing atmospheric oxygen levels without concern for the effects on organisms.)” See also 341, “The scenarios that would meet this threshold would likely be those involving total conversion of earth's matter or resources into computation power or some other material used by the AI, or the scenario where AI views humanity as a threat to its continued existence.”
Question 3: 341, “Much of the risk may come from superintelligent AI pursuing its own reward function without consideration of humanity, or with the view that humanity is an obstacle to maximizing its reward function.”; “Additionally, the AI would want to continue maximizing its reward, which would continue to require larger amounts of resources to do as the value of the numerical reward in the system grew so large that it required more computational power to continue to add to. This would also lead to the AI building greater computational abilities for itself from the materials available. With no limit on how much computation it would need, ultimately leading to converting all available matter into computing power and wiping out humanity in the process.” 341, “It's difficult to determine what the upper bound on AI capabilities might be, if there are any. Once an AI is capable enough to do its own research to become better it could potentially continue to gain in intelligence and bring more resources under its control, which it could use to continue gaining in intelligence and capability, ultimately culminating in something that has incredible abilities to outwit humans and manipulate them to gain control over important systems and infrastructure, or by simply hacking into human-built software.” 339, “An advanced AI may be able to improve itself at some point and enter enter a loop of rapid improvement unable for humans to comprehend denying effective control mechanisms.”
- ^
Question 4: 343, “Another scenario is one where AGI does not intentionally destroy humanity, but instead changes the global environment sufficient to make life inhospitable to humans and most other wildlife. Computers require cooler temperatures than humans to operate optimally, so it would make sense for a heat-generating bank of servers to seek cooler global temperatures overall.” Incorrectly tagged as an argument for lower forecasts in the original rationale.
- ^
Question 4: 342, “A final type of risk is competing AGI systems fighting over control of the future and wiping out humans as a byproduct.”
Question 3: 342, see above.
- ^
Question 4: 336, “Recursive self improvement of AI; the idea that once it gets to a sufficient level of intelligence (approximately human), it can just recursively redesign itself to become even more intelligent, becoming superintelligent, and then perfectly capable of designing all kinds of ways to exterminate us" is a path of potentially explosive growth.” 338, “One guess is something like 5-15 additional orders of magnitude of computing power, and/or the equivalent in better algorithms, would soon result in AI that contributed enough to AI R&D to start a feedback loop that would quickly result in much faster economic and technological growth.” See also 341, “It's difficult to determine what the upper bound on AI capabilities might be, if there are any. Once an AI is capable enough to do its own research to become better it could potentially continue to gain in intelligence and bring more resources under its control, which it could use to continue gaining in intelligence and capability, ultimately culminating in something that has incredible abilities to outwit humans and manipulate them to gain control over important systems and infrastructure, or by simply hacking into human-built software.”
343, “an AGI could expand its influence to internet-connected cloud computing, of which there is a significant stock already in circulation”.
343, “a sufficiently intelligent AGI would be able to generate algorithmic efficiencies for self-improvement, such that it could get more 'intelligence' from the same amount of computing”
- ^
Question 4: 343, “They point to things like GPT-3 being able to do simple math and other things it was not programmed to do. Its improvements over GPT-2 are not simply examples of expected functions getting incrementally better - although there are plenty of examples - but also of the system spontaneously achieving capabilities it didn't have before. As the system continues to scale, we should expect it to continue gaining capabilities that weren't programmed into it, up to and including general intelligence and what we would consider consciousness.” 344, “PaLM, Minerva, AlphaCode, and Imagen seem extremely impressive to me, and I think most ML researchers from 10 years ago would have predicted very low probabilities for any of these capabilities being achieved by 2022. Given current capabilities and previous surprises, it seems like one would have to be very confident on their model of general intelligence to affirm that we are still far from developing general AI, or that capabilities will stagnate very soon.”
- ^
Question 4: 339, “Multiple forecasters pointed out that the fact that AI safety and alignment are such hot topics suggests that these areas will continue to develop and potentially provide breakthroughs that help us to avoid advanced AI pitfalls. There is a tendency to under-forecast "defense" in these highly uncertain scenarios without a base rate.”
- ^
Question 4: 337, “They also tend to believe that control and co-existence are more likely, with AGI being either siloed (AIs only having specific functions), having built-in fail safes, or even controlled by other AGIs as checks on its actions.”
- ^
Question 4: 344, “And while capabilities have been increasing very rapidly, research into AI safety, does not seem to be keeping pace, even if it has perhaps sped-up in the last two years. An isolated, but illustrative, data point of this can be seen in the results of the 2022 section of a Hypermind forecasting tournament: on most benchmarks, forecasters underpredicted progress, but they overpredicted progress on the single benchmark somewhat related to AI safety.”
- ^
Question 3: 341, “a forecaster linked significant risk to AI development being sponsored and developed by large corporations. A corporation’s primary goal is to monetize their developments. Having an ungovernable corporate AI tool could create significant risks.” See also 337, “Some forecasters worried that profit-driven incentives would lead to greater risk of the emergence of misaligned AGI: ‘The drive for individual people, nations, and corporations to profit in the short term, and in the process risk the lives and well-being of future generations, is powerful.’”
- ^
Question 3: 337, “It's possible that the strange nature of the threat will lead people to discount it.” “Relatedly, even if people don't discount the risk, they may not prioritize it. As one forecaster wrote, "The fact that our lives are finite, and there are plenty of immediate individual existential risks—dying in a car accident, or from cancer, etc.—limits people’s incentive and intellectual bandwidth, to prepare for a collective risk like AI."
- ^
Question 4: 336, “Rapid progress that can not be 'tamed' by traditional engineering approaches, when dealing with sufficiently powerful AI systems, we may not get many chances if the first attempt screws up on the safety end. The human inclination to poorly assess risks might further increase this risk.”
- ^
Question 4: 344, “I just don't see AI being given enough control over anything dangerous enough to satisfy these criteria.” 338, “A human will always be kept in the loop to safeguard runaway AI.” 341, “Team members with lower forecasts also expect that AI will not be given sole discretion over nuclear weapons or any other obvious ways in which an AI could cause such a catastrophe.” 344, “Nuclear weapons are mentioned sporadically, but there is no reason for an AI to be given control of, or access to, nuclear weapons. Due to the inherent time delays in nuclear warfare, the high speed decision making AI would provide adds no benefit, while adding substantial risk - due to the misinterpretation of sensor input or other information, rather than any kind of internal motivation.”
Question 3: 341, “Team members with lower forecasts also expect that AI will not be given sole discretion over nuclear weapons or any other obvious ways in which an AI could cause such a catastrophe. They expect that humans will be cognizant of the risks of AI which will preempt many of the imagined scenarios that could potentially lead to such a catastrophe.” See also 337, “It's possible, perhaps likely, that laws and regulations and technological guardrails will be established that limit the risk of AI as it transitions from its infancy.”
- ^
Question 4: 337, “The optimists on the whole seemed to think that regulation and control would develop if/when AI become a risk.” 341, “I think the countries where most AGI researchers want to live could pass laws chilling their research agenda, and restricting it to safer directions… I could imagine, and hope to see, a law which says: don't train AIs to optimize humans."
- ^
Question 3: 339, “in a world with advanced AI, it is also likely that we will hand over responsibility for efficiency and convenience. By doing so, humans may enable AIs to be in the position to decide over their key systems for survival and prosperity.”
Question 4: 339, “AI will likely continue to be improved and incorporated into more of our vital command and control systems (as well as our daily lives).” 338, “Militaries are looking for ways to increase the speed with which decisions are made to respond to a suspected nuclear attack. That would logically lead to more integration of AGI into the decision-making process under the possible miscalculation that AGI would be less likely to mistakenly launch a nuclear attack when in fact the reverse may be true.”
- ^
Question 4: 337, “The pessimists did not seem to think that regulation was possible.”
- ^
Question 4: 339, “Given this rapid progress, we will likely be unable to control AI systems if they quickly become more powerful than we expect.” 336, “If it's the case that we can unexpectedly get AGI by quadrupling a model size, companies and society may not be prepared to handle the consequences.” See also 338, “Humans may not be capable of acting quickly enough to rein in a suddenly-out-of-control AGI.”
- ^
See this article for more details.
Erich_Grunewald @ 2023-07-19T10:35 (+14)
Thanks for providing the arguments commonly given for and against various cruxes, that's super interesting.
These two arguments for why extinction would be unlikely
- The logistics would be extremely challenging.
- Millions of people live very remotely, and AI would have little incentive to pay the high costs of killing them.
make me wonder what the forecasters would've estimated for existential risk rather than extinction risk (i.e. we lose control over our future / are permanently disempowered, even if not literally everyone dies this century). (Estimates would presumably be somewhere between the ones for catastrophe and extinction.)
I'm also curious about why the tournament chose to focus on extinction/catastrophe rather than existential risks (especially given that its called the Existential Risk Persuasion Tournament). Maybe those two were easier to operationalize?
rosehadshar @ 2023-07-19T11:09 (+12)
I wasn't around when the XPT questions were being set, but I'd guess that you're right that extinction/catastrophe were chosen because they are easier to operationalise.
On your question about what forecasts on existential risk would have been: I think this is a great question.
FRI actually ran a follow-up project after the XPT to dig into the AI results. One of the things we did in this follow-up project was elicit forecasts on a broader range of outcomes, including some approximations of existential risk. I don't think I can share the results yet, but we're aiming to publish them in August!
Ulrik Horn @ 2023-07-22T11:49 (+2)
we're aiming to publish them in August!
Please do! And if possible, one small request from me would be if any insight on extinction vs existential risk for AI can be transferred to bio and nuclear - e.g. might there be some general amount of population decline (e.g. 70%) that seems to be able to trigger long-term/permanent civilizational collapse.
rosehadshar @ 2023-07-24T10:34 (+3)
The follow-up project was on AI specifically, so we don't currently have any data that would allow us to transfer directly to bio and nuclear, alas.
RomanHauksson @ 2023-07-23T06:15 (+8)
Here are a couple of excerpts from relevant comments from the Astral Codex Ten post about the tournament. From the anecdotes, it seems as though this tournament had some flaws in execution, namely that the "superforcasters" weren't all that. But I want to see more context if anyone has it.
I signed up for this tournament (I think? My emails related to a Hybrid Forecasting-Persuasion tournament that at the very least shares many authors), was selected, and partially participated. I found this tournament from it being referenced on ACX and am not an academic, superforecaster, or in any way involved or qualified whatsoever. I got the Stage 1 email on June 15.
I participated and AIUI got counted as a superforecaster, but I'm really not. There was one guy in my group (I don't know what happened in other groups) who said X-risk can't happen unless God decides to end the world. And in general the discourse was barely above "normal Internet person" level, and only about a third of us even participated in said discourse. Like I said, haven't read the full paper so there might have been some technique to fix this, but overall I wasn't impressed.
DPiepgrass @ 2024-03-13T22:34 (+3)
Replies to those comments mostly concur:
(Replies to Jacob)
(AdamB) I had almost exactly the same experience.
(sclmlw) I'm sorry you didn't get into the weeds of the tournament. My experience was that most of the best discussions came at later stages of the tournament. [...]
(Replies to magic9mushroom)
(Dogiv) I agree, unfortunately there was a lot of low effort participation, and a shocking number of really dumb answers, like putting the probability that something will happen by 2030 higher than the probability it will happen by 2050. In one memorable case a forecaster was answering the "number of future humans who will ever live" and put a number less than 100. I hope these people were filtered out and not included in the final results, but I don't know.
I also recommend taking a look at Damien Laird's post-mortem.
Damien and I were in the same group and he wrote it up much better than I could.
FWIW I had AI extinction risk at 22% during the tournament and I would put it significantly higher now (probably in the 30s, though I haven't built an actual model lately). Seeing the tournament results hardly affects my prediction at all. I think a lot of people in the tournament may have anchored on Ord's estimate of 10% and Joe Carlsmith's similar prediction, which were both mentioned in the question documentation, as the "doomer" opinion and didn't want to go above it and be even crazier.
> (Sergio) I don’t think we were on the same team (based on your AI extinction forecast), but I also encountered several instances of low-effort participation and answers which were as baffling as those you mention at the beginning (or worse). One of my resulting impressions was that the selection process for superforecasters had not been very strict.
Greg_Colbourn @ 2023-07-20T18:09 (+4)
Forecasters stopped updating their forecasts on 31st October 2022
Would be interested to see an update post-chatGPT (esp. GPT-4). I know a lot of people who have reduced their timelines/increased their p(doom) in the last few months.
ChanaMessinger @ 2023-07-21T09:35 (+3)
From Astral Codex Ten
FRI called back a few XPT forecasters in May 2023 to see if any of them wanted to change their minds, but they mostly didn’t.
Greg_Colbourn @ 2023-07-21T10:15 (+2)
Weird. Does this mean they predicted GPT-4's performance in advance (and also didn't let that update them toward doom)!?
Mo Putera @ 2023-07-24T09:32 (+3)
Perhaps it's less surprising given who counted as 'superforecasters', cf magic9mushroom's comment here? I'm not sure how much their personal anecdote as participant generalizes though.
titotal @ 2023-07-19T09:29 (+4)
I think the differing estimates between domain experts and superforecasters is very interesting. Two factors I think might contribute to this are selection effects, and anchoring effects.
For selection effects, we know that 42% of the selected domain experts had attended EA meetups, whereas only 9% of the superforecasters had (page 9 of report). I assume the oversampling of EA members among experts may cause some systematic shift. The same applies to previous surveys of AI experts: for example the 2022 survey was voluntary had only a 17% response rate. It's possible (I would even say likely) that if you had managed to survey 100% of the experts, the median probability of AI doom would drop, as AI concerned people are probably more likely to answer surveys.
The other cause could be differing susceptibility to anchoring bias. We know (from page 9) that the general public is extremely susceptible to anchoring here: the median public estimate of x-risk dropped six orders of magnitude from 5% to 1 in 15 million depending on the phrasing of the question (with the difference cause either by the example probabilities presented, or whether they asked in terms of odds instead of percentages).
If the public is susceptible to anchoring, experts probably will be as well. If you look at the resources given to the survey participants on AI risk (page 132), they gave a list of previous forecasts and expert surveys, which were in turn:
5%, 1 in 10, 5%, 5%, “0 to 10%”, 0.05%, and 5%
Literally 4 out of the 7 forecast give the exact same number. Are we sure that it’s a coincidence that the final forecast median ends up around this same number?
My view is that the domain experts are subconsciously afraid to stray too far from their anchor point, whereas the superforecasters are more adept at resisting such biases, and noticing that the estimates come mostly from EA sources, which may have correlated bias on this question.
Of course, there could be plenty of other reasons as well, but I thought these two were interesting to highlight.
Erich_Grunewald @ 2023-07-19T10:37 (+4)
Of course, there could be plenty of other reasons as well, but I thought these two were interesting to highlight.
Yes, for example maybe the AI experts benefited from their expertise on AI.
titotal @ 2023-07-19T14:12 (+8)
One could say the CIA benefited from their expertise in geopolitics, and yet the superforecasters still beat them. Superforecasters perform well because they are good at synthesising diverse opinions and expert opinions: they had access to the same survey of AI experts that everyone else did.
Saying the AI experts had more expertise in AI is obviously true, but it doesn't explain the discrepancy in forecasts. Why were superforecasters unconvinced by the AI experts?
Erich_Grunewald @ 2023-07-20T08:49 (+13)
I think there are a bunch of things that make expertise more valuable in AI forecasting than in geopolitical forecasting:
- We've all grown up with geopolitics and read about it in the news, in books and so on, so most of us non-experts already have passable models of it. That's not true with AI (until maybe one year ago, but even now news don't report on technical safety).
- Geopolitical events have fairly clear reference classes that can give you base rates and so on (and this is a tool available to both experts and non-experts) -- this is much harder with AI. That means the outside view is less valuable for AI forecasting.
- I think AI is really complex and technical, and especially hard given that we're dealing with systems that don't yet exist. Geopolitics is also complex, and geopolitical futures will be different from now, but the basic elements are the same. I think this also favors non-experts when forecasting on geopolitics.
And quoting Peter McCluskey, a participating superforecaster:
The initial round of persuasion was likely moderately productive. The persuasion phases dragged on for nearly 3 months. We mostly reached drastically diminishing returns on discussion after a couple of weeks.
[...]
The persuasion seemed to be spread too thinly over 59 questions. In hindsight, I would have preferred to focus on core cruxes, such as when AGI would become dangerous if not aligned, and how suddenly AGI would transition from human levels to superhuman levels. That would have required ignoring the vast majority of those 59 questions during the persuasion stages. But the organizers asked us to focus on at least 15 questions that we were each assigned, and encouraged us to spread our attention to even more of the questions.
[...]
Many superforecasters suspected that recent progress in AI was the same kind of hype that led to prior disappointments with AI. I didn't find a way to get them to look closely enough to understand why I disagreed.
My main success in that area was with someone who thought there was a big mystery about how an AI could understand causality. I pointed him to Pearl, which led him to imagine that problem might be solvable. But he likely had other similar cruxes which he didn't get around to describing.
That left us with large disagreements about whether AI will have a big impact this century.
I'm guessing that something like half of that was due to a large disagreement about how powerful AI will be this century.
I find it easy to understand how someone who gets their information about AI from news headlines, or from laymen-oriented academic reports, would see a fair steady pattern of AI being overhyped for 75 years, with it always looking like AI was about 30 years in the future. It's unusual for an industry to quickly switch from decades of overstating progress, to underhyping progress. Yet that's what I'm saying has happened.
[...]
That superforecaster trend seems to be clear evidence for AI skepticism. How much should I update on it? I don't know. I didn't see much evidence that either group knew much about the subject that I didn't already know. So maybe most of the updates during the tournament were instances of the blind leading the blind.
Scott Alexander points out that the superforecasters have likely already gotten one question pretty wrong, having a median prediction of the most expensive training run for 2024 of $35M (experts had a median of $65M by 2024) whereas GPT-4 seems to have been ~$60M, though with ample uncertainty. But bearish predictions will tend to fail earlier than bullish predictions, so we'll see how the two groups compare in the next years, I guess.
titotal @ 2023-07-21T12:29 (+2)
I think you make good points in favour of the AI expert side of the equation. To balance that out, I want to offer one more point in favour of the superforecasters, in addition to my earlier points about anchoring and selection bias (we don't actually know what the true median of AI expert opinion is or would be if questions were phrased differently).
The primary point I want to make is that Ai x-risk forecasting is, at least partly, a geopolitical forecast. Extinction from rogue AI requires some form of war or struggle between humanity. You have to estimate the probability that that struggle ends with humanity losing.
An AI expert is an expert in software development, not in geopolitical threat management. Neither are they experts in potential future weapon technology. If someone has worked on the latest bombshell LLM model, I will take their predictions about specific AI development seriously, but if they tell me an AI will be able to build omnipotent nanomachines that take over the planet in a month, I have no hesitations in telling them they're wrong, because I have more expertise in that realm than they do.
I think the superforecasters have superior geopolitical knowledge than the AI experts, and that is reflected in these estimates.
Erich_Grunewald @ 2023-07-20T16:19 (+11)
By the way, I feel now that my first reply in this thread was needlessly snarky, and am sorry about that.
Jörn Stöhler @ 2023-07-19T16:58 (+1)
My guess is that the crowds are similar and thus the surveys and the initial forecasts were also similar.
Iirc(?) the report states that there wasn't much updating of forecasts, so the final and initial average also are naturally close.
Besides that, there was also some deference to literature/group averages, and also some participants imitated e.g. the Carlsmith forecast but with their own numbers (I think it was 1/8th of my group, but I'd need to check my notes).
I kinda speculate that Carlsmith's model may be biased towards producing numbers around ~5% (sth about how making long chains of conditional probabilities doesn't work because humans fail to imagine each step correctly and thus end up biased towards default probabilities closer to 50% at each step).
Ben Stewart @ 2023-07-19T09:25 (+4)
Thanks for this - super interesting! One thing I hadn't caught before is how much the estimates reduce for domain experts in the top quintile for reciprocal scoring - in many cases an order of magnitude lower than that of the main domain expert group!
david_reinstein @ 2024-03-07T22:33 (+2)
I'm going through the hosted paper ("Forecasting Existential Risks") and making some comments in hypothes.is (see here).
I first thought I saw something off, but now see that it's because of the difference between total extinction risk vs catastrophic risk. For the latter, the superforecasters are not so different from the domain experts (about 2:1). Perhaps this could be emphasized more.
Putting this in a 'data notebook/dashboard' presentation could be helpful in seeing these distinctions.
rosehadshar @ 2023-07-24T15:18 (+2)
See here for a mash up of XPT forecasts on catastrophic and extinction risk, with Shulman and Thornley's paper on how much governments should pay to prevent catastrophes.
DPiepgrass @ 2024-03-13T23:12 (+1)
Superforecasters more than quadruple their extinction risk forecasts by 2100 if conditioned on AGI or TAI by 2070.
- The data on this table is strange! Originally Superforecasters' gave 0.38% for extinction by 2100 (though 0.088% for RS top quintile) but on this survey it's 0.225%. Why? Also, somehow the first number has 3 digits of precision while the second number is "1%" which is maximally lacking in significant digits (like, if you were rounding off, 0.55% ends up as 1%).
- The implied result is strange! How could participants' AGI timelines possibly be so long? I notice ACX comments may explain this as a poor process of classifying people as "superforecasters" and/or "experts".
I'd strongly like to see three other kinds of outcome analyzed in future tournaments, especially in the context of AI:
- Authoritarian takeover: how likely is it that events in the next few decades weaken the US/EU and/or strengthen China (or another dictatorship), eventually leading to world takeover by dictatorship(s)? How likely is it that AGIs either (i) bestow upon a few people or a single person (*cough*Sam Altman) dictatorial powers or (ii) strengthen the power of existing dictators, either in their own country and/or by enabling territorial and/or soft-power expansion?
- Dystopia: what's the chance of some kind of AGI-induced hellscape in which life is worse for most people than today, with little chance of improvement? (This may overlap with other outcomes, of course)
- Permanent loss of control: fully autonomous ASIs (genius-level and smarter) would likely take control of the world, such that humans no longer have influence. If this happens and leads to catastrophe (or utopia, for that matter), then it's arguably more important to estimate when loss of control occurs than when the catastrophe itself occurs (and in general it seems like "date of the point of no return on the path to X" is more important than "date of X", though the concept is fuzzier). Besides, I am very skeptical of any human's ability to predict what will happen after a loss of control event. I'm inclined to think of such an event almost like an event horizon, which is a second reason that forecasting the event itself is more important than forecasting the eventual outcome.