Measuring Good Better
By MichaelPlant, GiveWell, Jason Schukraft, Matt_Lerner, Innovations for Poverty Action @ 2022-10-14T13:36 (+235)
At EA Global: San Francisco 2022, the following organisations held a joint session to discuss their different approaches to measuring ‘good’:

A representative from each organisation gave a five-minute lightning talk summarising their approach before the audience broke out into table discussions. You can read the transcripts of the lightning talks below (lightly edited for clarity) or listen to the audio recording (30 mins).
GiveWell (Olivia Larsen)
Why do we need moral weights?
GiveWell thinks about measuring good outcomes using a process called ‘moral weights’. That's because GiveWell evaluates charities that do different things. Some charities increase consumption and income, other charities save the lives of children under five, and other charities save the lives of people over the age of five. In order to do what GiveWell wants to do - create a prioritised list of giving opportunities in order from most to least cost-effective and then use the funds we have available to fill it, starting with most cost-effective until we run out of money - we need an exchange rate between different types of good outcomes. That's why we use moral weights as an input into our cost-effectiveness analysis.
What are GiveWell’s moral weights?
So here are some of our moral weights. These are all in units of ‘the moral value of doubling consumption for one person for one year.’ The specific numbers don't mean that we feel totally confident about each number or that we have the right answer. We need a specific number to put into our cost-effectiveness analysis but that definitely doesn't mean that we have a high level of precision or confidence in these.
Table 1: GiveWell’s moral weights
Value of doubling consumption for one person for one year | 1.0 |
Value of averting one year of life lived with disease/disability (YLD) | 2.3 |
Value of averting one stillbirth (1 month before birth) | 33.4 |
Value of preventing one 5-and-over death from malaria | 83.1 |
Value of averting one neonatal death from syphilis | 84.0 |
Value of preventing one under-5 death from malaria | 116.9 |
Value of preventing one under-5 death from vitamin A deficiency | 118.4 |
So when we say that the value of preventing an under-five death from malaria is about 117, that means we think it's ~117 times more valuable to save this life than it would be to double someone's consumption for a year. To put it another way, if we were given the choice between doubling the consumption of 118 people or preventing one under-five death from malaria we would choose the 118 people, but if it was 116 people we would choose to save the life of the infant.
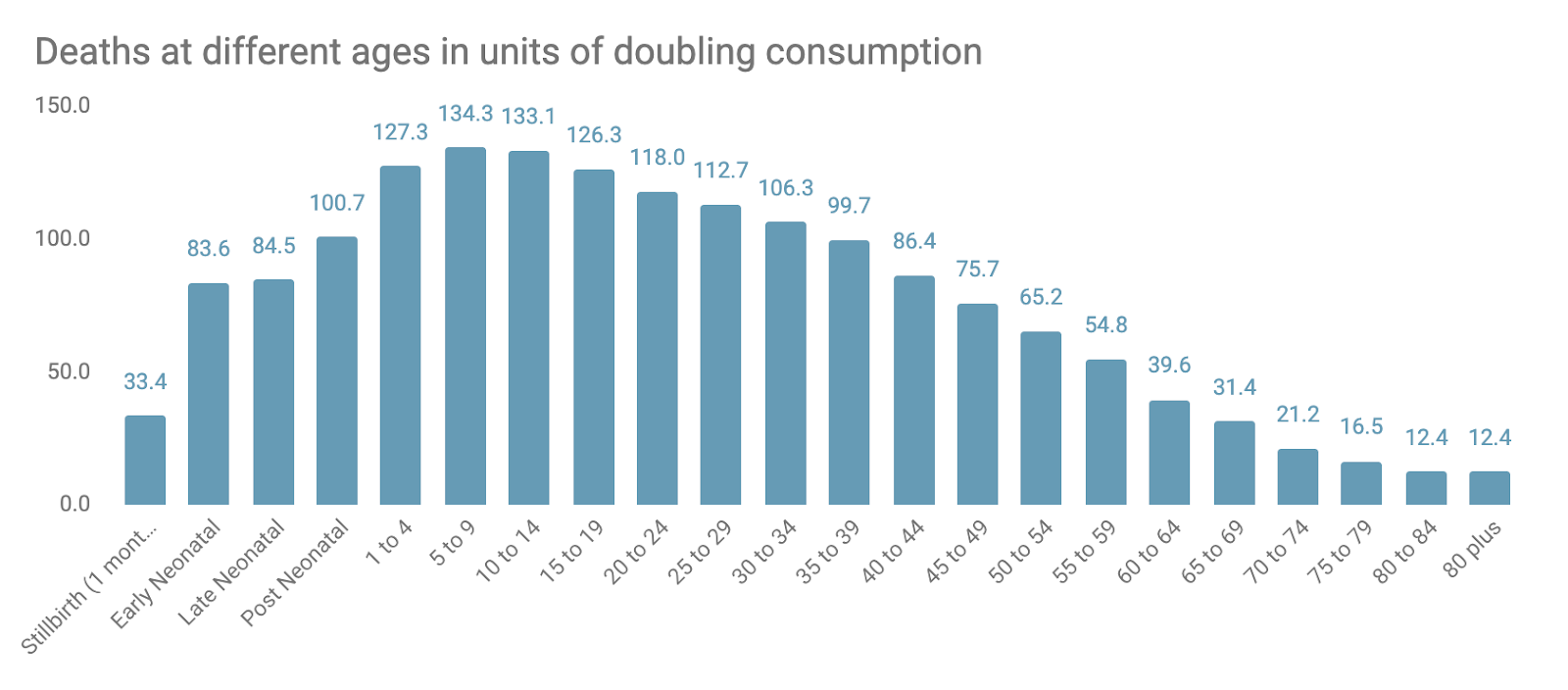
One question that sometimes comes up is why we have different values for an under-five death from malaria and an under-five death from vitamin A supplementation. This is because the average age of someone dying from vitamin A deficiency versus malaria is different and our moral weights reflect that difference in age. Here is our curve for the differences in our moral values of death at different ages. It starts one month before birth and ends at over 80 years old. I'm in the ‘25 to 29’ bucket so I'm coming to terms with the fact that I'm past my ‘moral weightiest’ according to GiveWell.
Figure 1: GiveWell’s moral values of deaths at different ages (in units of doubling consumption)
What goes into GiveWell’s moral weights?
How do we come up with these really specific numbers that we think are valuable, but as I mentioned before, we don't think are as precise as the numbers might suggest? Our moral weights consist of a few different inputs:
Figure 2: Components of GiveWell’s moral weights
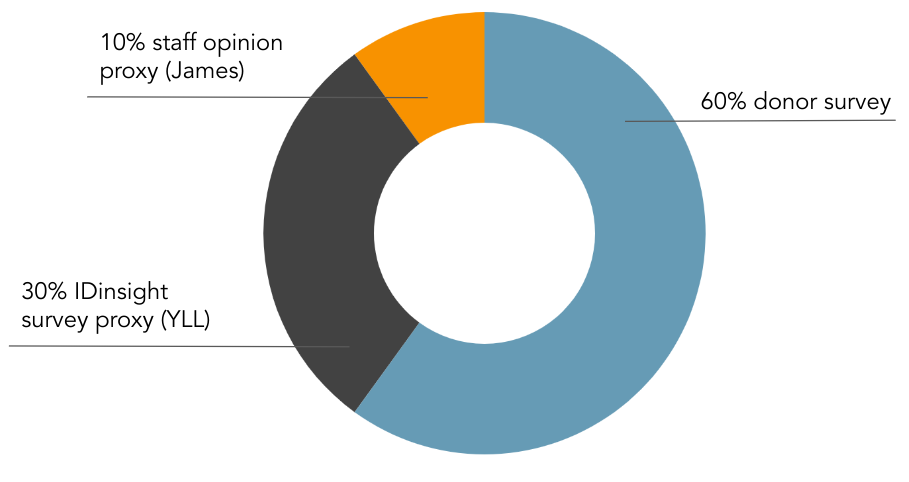
60% of the moral weights come from a donor survey. In 2020, we surveyed about 80 GiveWell donors to ask them how they would make these same types of tradeoffs. The benefits of this survey were that we were able to ask pretty granular questions that let us get to a curve like the one I showed before and that we think GiveWell donors are engaged in this question. They are the users of GiveWell's research, so we want to take into account what they think. But some of the downsides of this are that it's not the most diverse sample and they might not necessarily have complete knowledge or much context-specific knowledge about the places that we’re trying to help.
30% of our moral weights comes from a survey that IDinsight conducted in 2019, which was funded by GiveWell. This survey asked about 2,000 people living in Kenya and Ghana, who are extremely poor, how they would make these same types of tradeoffs. It's an important indicator into our moral weights, but it's not as big as your intuition might think it should be. This is because there were a few issues with the survey. One is that we think that the questions may have been a little bit complicated and challenging, so they might not have been fully understood. Also, some of the results that we got suggested very high values for saving lives, over $10 million, and $10 million is where we stopped asking. So this suggests that some people might not be willing to make any tradeoffs between the value of increasing income versus saving lives and that's something that we're not really able to put into a cost-effectiveness analysis. But this did change our moral weights a lot and moved it toward the direction of valuing the lives of children under five.
The final portion of our moral weights is a proxy for GiveWell staff opinions, which is something that we used to use more heavily but we've since down-weighted to about 10%. The benefit of this is that GiveWell staff think about these questions a lot, but there aren't that many of us, we don't have a tonne of context-specific knowledge, and the results were very variable based on changes in staff composition.
Further reading:
Open Philanthropy (Jason Schukraft)
I'm going to be talking about the global health and wellbeing side of Open Philanthropy. This is not applicable to the longtermist side of the organisation which has a different framework and it’s only somewhat applicable to what happens on the farmed animal welfare team.
Why do we need assumptions?
The problem is that we want to compare a really wide array of different types of interventions that we might pursue. There's a huge diversity of grantmaking opportunities out there. Everything from improving global health R&D in order to accelerate vaccines to reducing air pollution in South Asia.
So what do we do? Well, we try to reduce everything to common units and by doing that we can more effectively compare across these different types of opportunities. But this is really, really hard! I can't emphasise enough how difficult this is and we definitely don't endorse all of the assumptions that we make. They're a simplifying tool, they're a model. All models are wrong, but some are useful, and there is constant room for improvement.
Valuing economic outcomes
Currently, Open Philanthropy is using a log utility model of wellbeing. This graph (below) has a really nice feature which is that increasing someone's income by 1% has the same value in our terms, no matter whether their income is $500,000 or $500.
Figure 3: The relationship between income and wellbeing
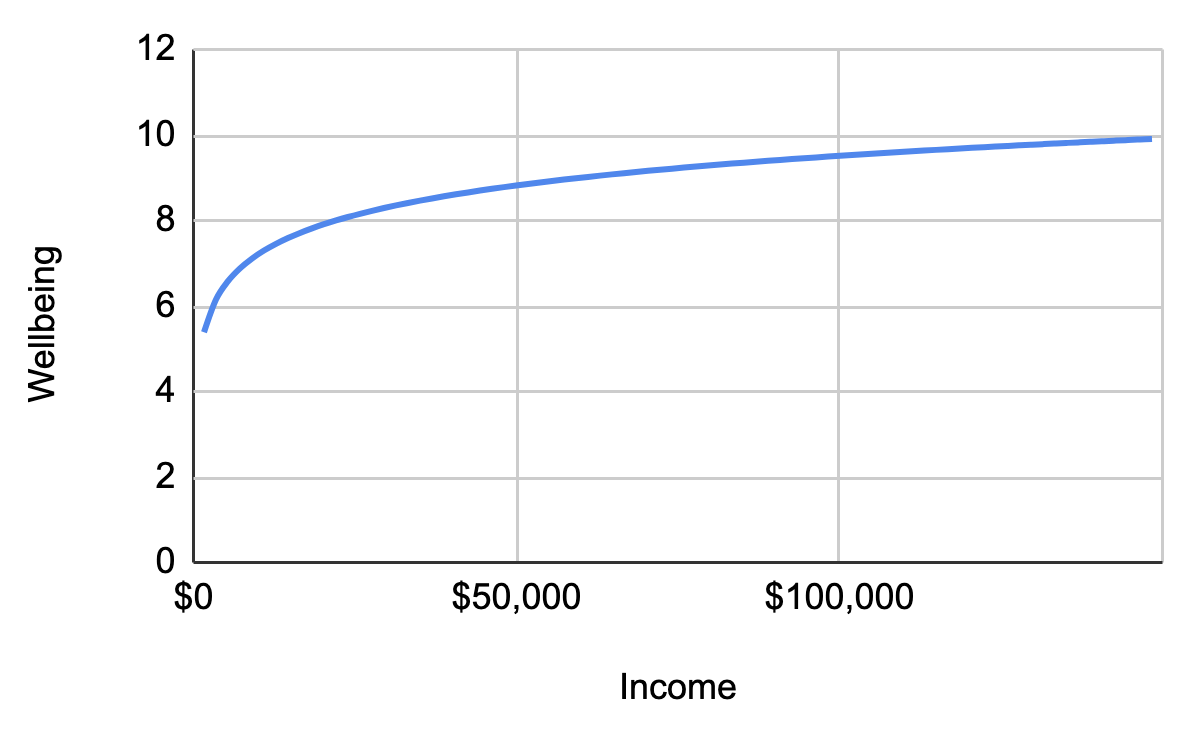
So we can say that one unit of philanthropic impact (what we sometimes call ‘Open Phil dollars’) is giving a single dollar to someone who makes $50,000 a year. When we set this as the arbitrary unit - and let me emphasise, it's just arbitrary - the per capita income in the US was something like $50,000 when we established this unit, so you can think of this as, ‘what's the simplest, easiest thing that Open Philanthropy could do’? Well, we could take all of our money and just stand on the street corner and hand out dollar bills to Americans. So when we say that $1 to someone who's making $50,000 counts as $1 of philanthropic impact that defines our units. We can then talk about multipliers of that unit. So if someone gets $1, but they’re only making $500 a year rather than $50,000, that's worth 100x our units. And then ultimately, we set a bar for our grantmaking that we want new opportunities to clear.
Valuing health outcomes
When we measure good at Open Philanthropy, we try to cash out improvements in people's lives on the basis of changes in health and income. We recognise that these are imperfect proxies and that there are lots of ways in which someone's life can go better or worse that aren't going to be fully captured by changes in health and income. But, at least currently, we think that these proxies work pretty well.
We can now value health outcomes using some of the terminology we've defined. Many of you will be familiar with disability-adjusted life years (DALYs) which are this nice unit combining ‘years of life lost’ (YLL) and ‘years lived with disability’ (YLD). In our current valuation, we say that averting a single DALY is worth $100,000 Open Phil dollars, or $100,000 in philanthropic impact. Now, if you're an Open Philanthropy watcher, you might have noticed that we recently doubled this value. We used to value it at $50,000, but now we value health outcomes even more.
In combination, this gives us a unified framework that lets us tradeoff health and income. There's so much more to say about this topic. I only had five minutes, but I'm really looking forward to talking more at the table.
Further reading:
- Open Philanthropy’s Cause Prioritization Framework (90 min webinar)
- Technical Updates to Our Global Health and Wellbeing Cause Prioritization Framework
- A philosophical review of Open Philanthropy’s Cause Prioritisation Framework
Happier Lives Institute (Michael Plant)
If we're trying to compare different sorts of outcomes, we need some kind of common metric for doing this. How should we think about comparing these three interventions in a sensible way?
Figure 4: Comparing different outcomes

Using a subjective wellbeing approach
Jason already mentioned the DALY approach as a way to tradeoff quantity and quality of health. At the Happier Lives Institute, we think a better approach is to focus on wellbeing.
We're interested in doing good, but what do we mean by good? We probably mean wellbeing, but what do we mean by wellbeing? Probably how happy and satisfied people are with their life. That seems like, in the end, probably the thing we really care about, so we should focus on doing that. Rather than using health and income as proxies, let's just focus on the thing which, in the end, matters. Let’s go straight to the source and trade-off health and income in terms of their impact on people's wellbeing.
So how do you do this? You can measure it with surveys. You can ask people questions like, “How satisfied are you with your life (0-10)?” If you ask this in the UK, most people say they are seven out of ten and there are other kinds of versions of this question (see below).
Figure 5: Subjective wellbeing in the UK
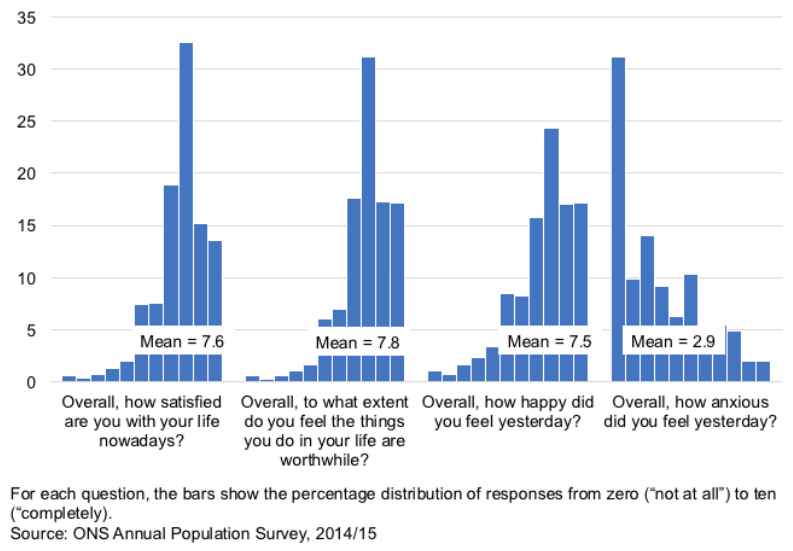
Instead of DALYs, we think in terms of WELLBYs (wellbeing-adjusted life years). If you think WELLBYs sounds silly, they were nearly called WALYs! So what is one WELLBY? It’s a one-point increase on a 0-10 life satisfaction scale for one year.
The point is that all these different things happen in your life, you say how you feel, and then we can work out what actually affects your life as you live it. The problem with relying on donor preferences or people's hypothetical preferences is that these are people’s guesses about what they think might matter rather than relying on people's actual experiences as they live their lives.
Can we rely on subjective measures?
It turns out that if you want to know how happy people are, asking them how happy they are is a good way of finding out how happy they are. These are well-validated measures and it turns out this approach is pretty sensible. You get the correlations and the directions you expect with health, income, what your friends say, and so on.
Figure 6: Factors that are correlated with subjective wellbeing measures

This is a map of life satisfaction across the world. It has this familiar picture of countries that are more or less developed so it seems there's some sort of approximately unified scale going on.
Figure 7: Self-reported life satisfaction around the world
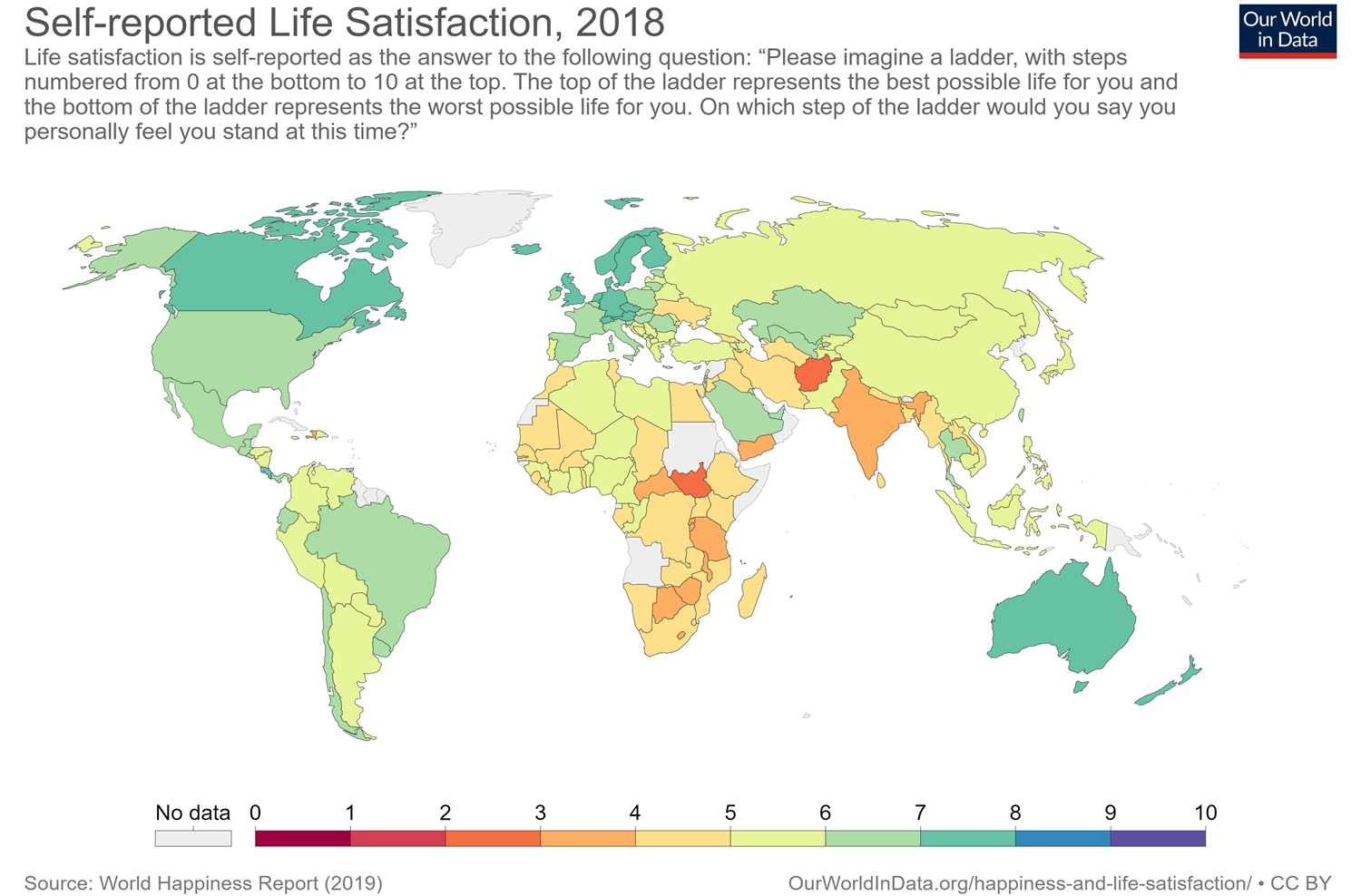
Happiness research really only started after the Second World War, but it's been really picking up and now people know, for instance, that the Scandinavian countries are the happiest in the world. But the World Happiness Report has only been going for ten years, so this is new. Our approach is to say, “we think this is important, but let's not just measure wellbeing at a national level, let's actually work out the most cost-effective ways to improve global wellbeing”. So we are pioneering WELLBY cost-effectiveness.
What difference does it make?
Does this matter or are we just arguing about metrics? Well, one thing you could do is compare providing cash transfers in low-income countries to treating depression with group psychotherapy. It wouldn't make sense to compare them in terms of income, that's not the value of having your depression alleviated. You could measure it in terms of health, but that's not the value of having your poverty alleviated. If you measure their effects in terms of wellbeing, you can compare them directly in terms of the units that matter.
So, does it make a difference? We did a couple of meta-analyses, and here is a picture to indicate that this is how meta-analyses work. We looked at various effects from various studies, this is just trying to show you that we actually did some real research here!
Figure 8: Forest plot of 37 cash transfer studies

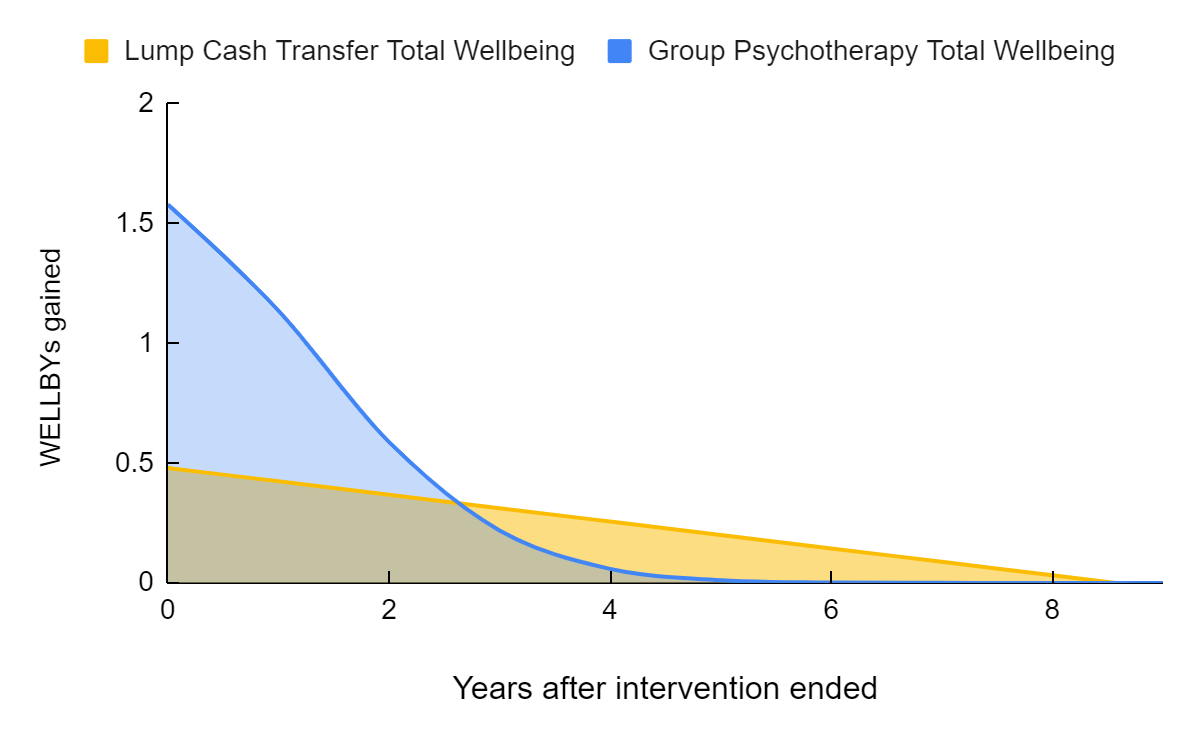
This is the effect over time (see below). What we found is that the therapy has a big effect initially and then it trails off faster. Cash transfers have a smaller initial effect but it lasts longer. This is a $1,000 lump sum cash transfer via GiveDirectly, which is more than a year's household income. So group psychotherapy for the depressed or cash transfers to people who are very poor have sort of the same size effects, the therapy is slightly bigger.
Figure 9: The total effect of lump sum cash transfers and group psychotherapy
But what really drives the difference is that giving people money is expensive. A $1,000 cash transfer costs a bit more than $1,000 to deliver. The group psychotherapy provided by StrongMinds costs about $130 per person. So what we have here are some dots (see below). To account for uncertainty we ran some Monte Carlo simulations, so these aren't just dots, these are fancy dots! On the x-axis is the cost of the treatment, and then that's the wellbeing effect on the y-axis.
Figure 10: Comparison of cash transfers and psychotherapy
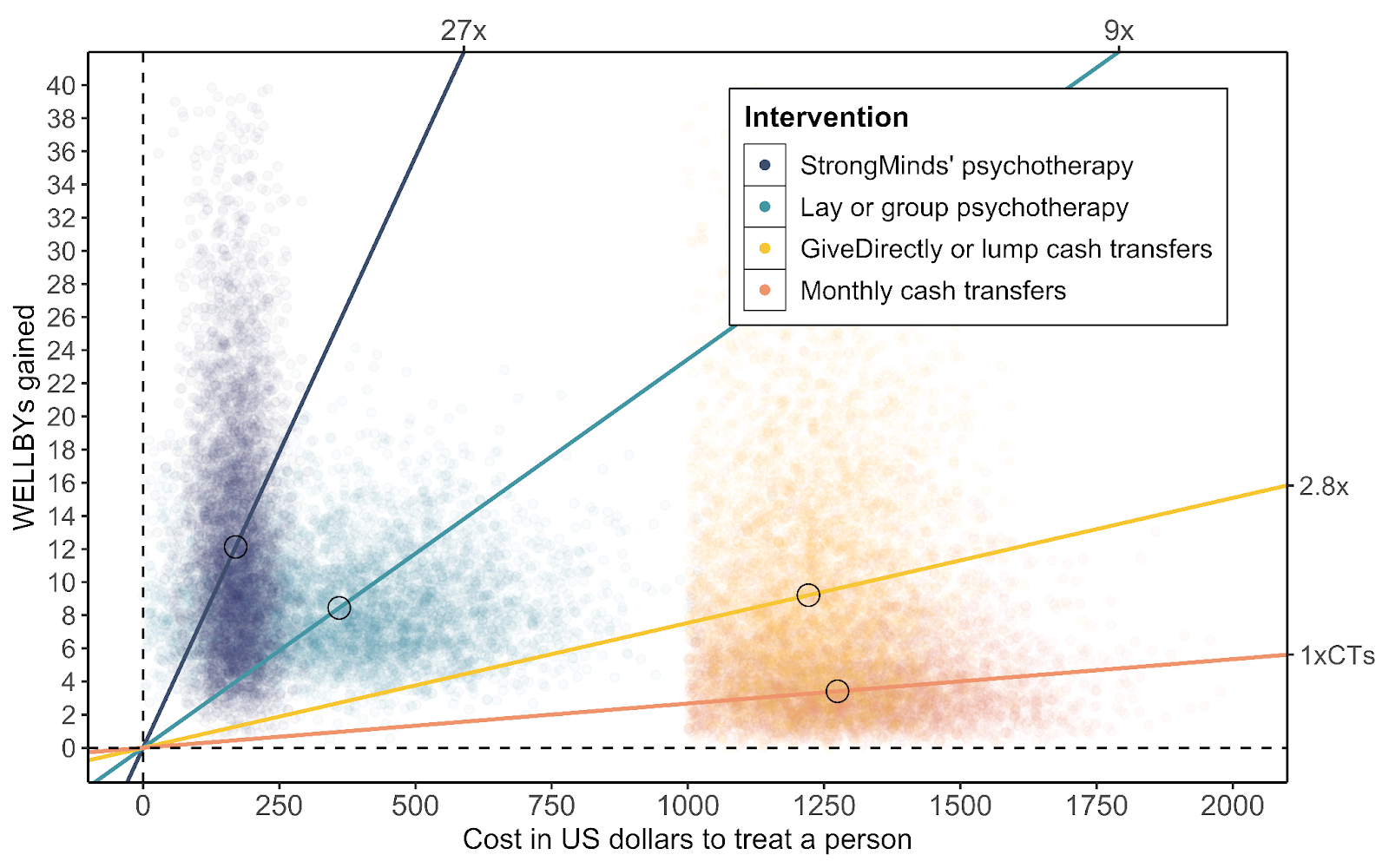
And we find that providing psychotherapy is nine times more cost-effective than cash transfers.
Table 2: Comparison of GiveDirectly and StrongMinds
WELLBYs (per treatment) | COST (US dollars) | WELLBYs (per $1,000) | |
GiveDirectly (lump sum cash transfers) | 9 | $1,220 | 7.3 |
StrongMinds (group psychotherapy) | 12 | $170 | 70 |
| Ratio (SM v GD) | 1.3 x more effective | 14% of GD cost | 9 x more cost-effective |
When I speak to people about this, some people tell me I'm mad. Mostly those people are economists that just think this is absolute nonsense. Some people say, “well of course if you want to alleviate misery, you’ve got to focus on what's going on inside people's heads.”
So we think this shows that it matters, that we should be using a wellbeing lens, and that this really does give us a new approach.
Plans for further research
We plan to look at more interventions. We’re starting at the micro-scale, before moving to bigger scales. It turns out that when you're trying to do something new, you run into problems, so we're pioneering this WELLBY approach.
- Micro: deworming, bednets, cataract surgery, mental health apps, cement flooring
- Meso: lead paint regulation, access to pain relief, immigration reform
- Macro: wellbeing policy ‘blueprints’ for national governments
There are also various methodological questions to get stuck into:
- How to compare improving lives to saving lives
- Assessing the cardinal comparability of happiness scales
- How to convert between and prioritise different measures of wellbeing
- Understanding and implementing ‘worldview diversification’
- Plausibility and implications of longtermism
Further reading:
- To WELLBY or not to WELLBY? Measuring non-health, non-pecuniary benefits using subjective wellbeing
- Estimating moral weights
- Happiness for the whole family
Founders Pledge (Matt Lerner)
Our benchmark, like everybody else, is cash. Things need to be at least as good as cash and historically, we value cash at $199/WELLBY. I say 'historically' because this presentation is mostly about our new approach, which we're working on right now.
Our historical (deprecated) approach
We used to put everything in WELLBYs, convert to DALYs, rely on moral weights derived from team deliberation, and then apply subjective discounts post hoc based on charity-specific considerations. If that sounds weird, don't worry, because we're moving to a new approach.
Goals and constraints for our new approach
Founders Pledge advises entrepreneurs and founders on how to spend their money. We also spend some of our own money so we have a bunch of goals we need to evaluate.
- We want to evaluate as many different kinds of interventions as possible.
- We need the metrics to work for both in-depth cost-effectiveness analyses (which we use to justify recommendations to members) and for back-of-the-envelope calculations (for our own rapid grantmaking).
- We need to be flexible enough to deal with interventions that improve quality of life (we don’t want to just slice up disability weights and use ‘mini-depressions’).
- We need to make the most of existing sources of data.
- We want to make as few subjective decisions as possible.
- We want our weightings and conversion factors to reflect the weight of evidence.
- We want to appropriately account for moral uncertainty.
The general idea behind the new approach
We have DALYs, we have WELLBYs, and we have income doublings. Those are all noisy measurements of some underlying quantity of interest, the ‘goodness’ of an intervention, and ultimately we want to be able to measure the impact of an intervention using any of these metrics.
So moving forward, our approach is WELLBYs, to income, to death, to DALYs, to WELLBYs. And that dotted line indicates that we're only going to figure out conversion factors for these three and then ‘back out’ a DALY/WELLBY conversion.
Figure 11: The new approach at Founders Pledge
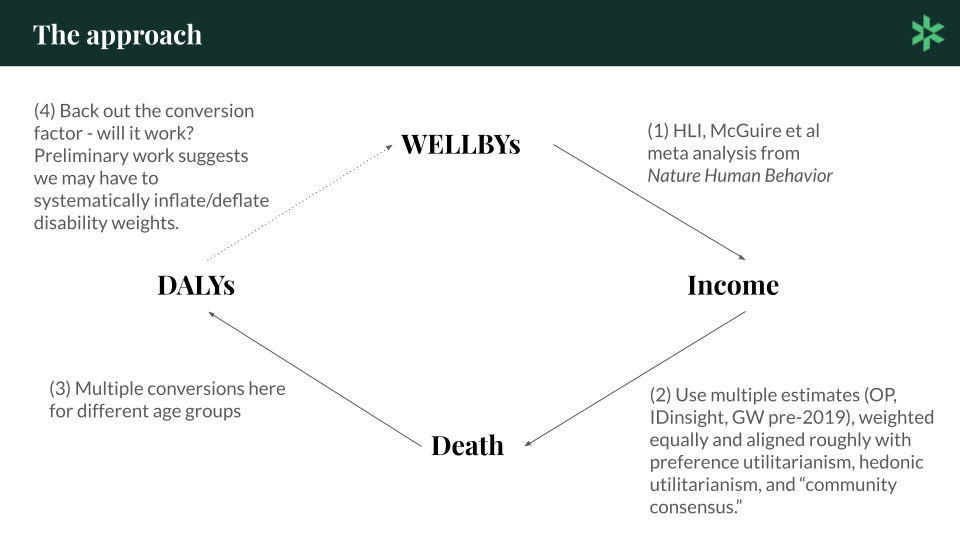
The way that we are going to do that, starting at the top right and going clockwise, is we're going to rely very heavily on HLI’s work. HLI did an excellent meta-analysis, which was very convincing to us, showing there is a stable relationship between wellbeing and income doublings, that's the first leg.
The second leg is income doubling to death and we have three approaches that we use. We have Open Philanthropy’s approach, we have the IDinsight survey that GiveWell sponsored in 2019, and we have GiveWell from pre-2019. The rationale there is we think that the IDinsight survey represents a sort of preference utilitarian approach. We think that Open Philanthropy’s method represents a hedonic utilitarian approach as it relies on some subjective wellbeing data. Finally, we have GiveWell pre-2019 which represents something like an ‘EA community consensus’. So before the preference utilitarian data arrived, we look at what GiveWell thought and then we weight those three approaches equally and try not to insert our own subjective judgments.
From death to DALYs is sort of a simple step. We want to convert death to DALYs at different ages so we just need different conversions for different age groups.
The final leg is DALYs to WELLBYs and this is where we're currently working things out and I'll go into a little bit of detail.
How this is looking so far
Right now, for a subset of conditions for which there are both WELLBY and DALY data, the correlation is decent (0.65). However, if you restrict this to physical conditions, you get a really strong correlation (0.9). The reason is that mental conditions (anxiety and depression) are big outliers and we think this is actually totally reasonable. There's lots of research on affective forecasting failures that suggest that people just don't have a really good idea of how they're going to feel when something bad happens to them or when they imagine having depression. Some justification for this is that the disability weight for dental caries is very low (0.01) but if you look at pain data, it's about as bad as lower back pain (0.3) That’s 30 times as high for roughly the same amount of pain. So, for certain types of conditions, we think that disability weights really underrate the subjective experience and that's why we want to be able to use all of these different metrics.
Going forward
We are going to set our benchmark at the $/WELLBY - $/DALY - $/income doubling - $/death figure. For effect sizes, we will use whatever the most applicable unit is and then translate it to our benchmark (income doublings for income-enhancing interventions, DALYs for physical conditions, and WELLBYs for others). We will still probably have to litigate major disagreements between DALYs and WELLBYs on an ad hoc basis when things look really weird, which they undoubtedly will.
Further reading:
- Measuring Health: How We Use (And Sometimes Don’t Use) DALY Estimates
- Our approach to charity
- Oral healthcare
Innovations for Poverty Action (Katrina Sill)
We're going to take a little bit of a ‘zoom out’ approach here and take this question quite literally, how do you measure good better? Does that mean you need to be looking at these outcomes that we've been looking at today (WELLBYs, DALYs etc.)? Does measuring good always mean that you need to measure that outcome?
Impact = solution quality x implementation quality
To answer that question, let's first think about what ‘good’ means. For simplification purposes, let's think of impact as a function of two things: the quality of the solution and the quality of the implementation of that solution. Today, we've been talking primarily about the quality of the solution. One of the major drivers of whether a solution actually has an effect is if that solution is a) the right solution for that context, and b) if it's going to be implemented well and feasibly. So what we want to add to this conversation is that those things are equally important as looking at the final effect.
The right way to measure ‘good’ depends on the question
When you're thinking about ‘measuring good better’ as a goal, you need to think about what the primary question is for a specific intervention. You might start by asking, how much does this specific intervention (e.g. group therapy, bed nets) typically increase something like DALYs and/or WELLBYs? In order to answer that question, you have to look at a lot of other questions too:
- Can our program be implemented well in this new context?
- Can this program be replicated at high quality at scale?
- Is this program really addressing a primary challenge in this context?
- Do people access the program?
- Do people adopt the key behaviour changes needed?
For example, you might want to ask this question first: is this programme really addressing a challenge in that particular context? If you're looking at rolling this out in East Africa, what is the prevalence of malaria in East Africa, and what is the current use of bednets in East Africa? That's what you would want to look at first, rather than just looking at the overall potential for DALYs or WELLBYs. That doesn’t necessarily mean that you want to run a randomised controlled trial, which is what Innovations for Poverty Action (IPA) is more famous for. For that kind of question, you'd first want to look at the basic underlying data for that context.
What to measure and when
So what does IPA think that ‘measuring good’ means? We frame it as this path to scale.
Figure 12: IPA’s path to scale
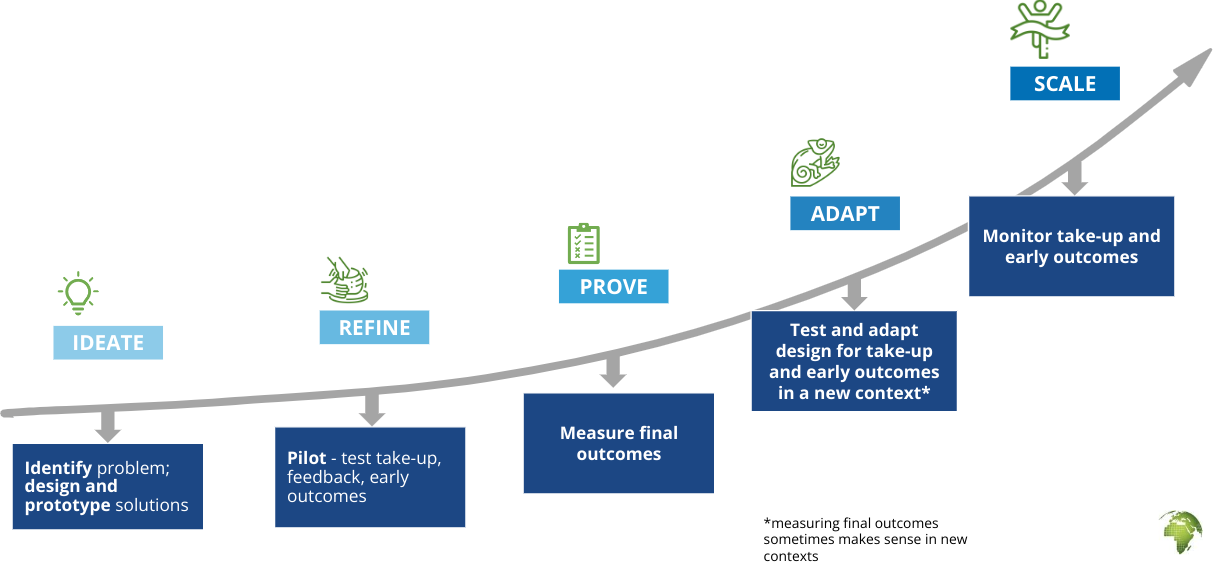
So you would look at a particular intervention and try to identify - for the goal that you have and the context that you're looking at effecting - where is this intervention on this path? What we've focused on today is the ‘prove’ step in the learning cycle; measuring the final outcomes and what evidence exists there. If it's a new intervention, what's our best guess of what that measurement might be? Maybe using some assumptions like Open Philanthropy does.
In addition to doing that, we recommend looking at these other stages. There are a lot of other ways to measure ‘good’ depending on what stage an intervention is in and these are typically underrepresented in a lot of effective altruism organisations and discussions. These stages include: identifying the problems in a particular context, prototyping with users, figuring out if that's the right solution, testing it out on a small scale, and monitoring if that works. For example, when you distribute a bed net, does it reach the target audience? If it reaches the target user, let's say children and families, are they actually using that bed net? These questions have to work before you can ask, ‘does it actually improve the number of lives saved’?
These are important questions for the EA community to think about. Where might the quality solutions be breaking down in implementation? What can we do as a community to make sure that the highest quality interventions are implemented well and that they're the right solution for a particular context?
The same applies to the end of the path too; adaptation and scale. If you have something that works already (e.g. bed nets or group therapy) and you're moving into a new context, what would change in that context based on what you've looked at previously and your theory of change? How might you need to adapt this in that context?
IPA is a big proponent of using credible evidence and we generate a lot of that ourselves. We just want to make the case that that's not always the only thing you should be looking at because it can reduce your flexibility in the programme adapting if you're looking too rigidly at those final outcomes too early. It's sometimes not the right time to be looking at that. Instead, we want to be looking at innovation and monitoring in the specific context.
Further reading:
- Right-fit evidence
- Goldilocks toolkit
- The Goldilocks Challenge: Right-Fit Evidence for the Social Sector
James Ozden @ 2022-10-14T16:15 (+47)
Super interesting - thanks for posting! I was pretty surprised that GiveWell weights their donor survey so highly for their moral weights (60%). I was wondering what's the rationale for it being 60%, given that these people are both (a) probably not the most knowledgeable about context-specific information (as GiveWell points out here) and (b) also not the recipients themselves. It seems more reasonable to have the GiveWell staff, who have a much better understanding of specific programs and other context, and the beneficiary surveys, to have the majority say in moral weight calculations. I don't find the arguments below particularly convincing re favouring the donor survey over staff survey:
- We have fairly few staff, compared to the number of people who can be surveyed via other methods.
- Staff don't have a unique ability to make these moral judgments. Staff also have limited insight into what the lives of people impacted by our recommendations are actually like, and what would be the most helpful to them.
- Staff-assigned moral weights are hard for charities to predict, in that there can be wide swings based on changes in staff composition.
- In past years, staff engaged to varying degrees, and then all those responses were aggregated without weighting for level of engagement.
- On 1) GiveWell's staff size (I think?) is about 60 people relative to the donor survey which seems to have been 70 people. Whilst this might be a reason to favour the donor survey in the future if it was about 400 people, I don't think it's a great reason to make it 60% now as the donor sample size is similarly small
- On 3) Given the sample sizes are pretty similar for both categories, aren't the donor moral-weights also open to swings? I guess it somewhat depends if you have more stability in your staff or your major donors!
- On 4) Again, isn't this also true for the donor survey? Surely it's best to weight both groups via engagement so this issue isn't present for either population. I can also imagine GiveWell staff who can take paid time to work on these moral weights can engage more fully than donors with other full-time jobs.
- Finally, I really have no a priori reason to believe that most GiveWell major donors are particularly well-informed about moral weights, so unsure why we should defer to them so much.
For all this, I'm roughly assuming most GiveWell staff could take part in the moral weights but appreciate it might be a smaller group of 10-20 who are just doing the research or program-specific work. I think the arguments are weaker but still stand in that case.
And for future work, GiveWell mentions they want to do more donor surveys but don't mention surveys of development professionals or other program-specific experts (e.g. malaria experts). This feels a bit odd, as this group seems like a more reliable population relative to donors for the same reasons as above (more specific knowledge).
I'm less sure about this but: I'm also a bit worried about GiveWell saying they want to avoid large swings from year to year (which totally makes sense so organisations can have predictable future incomes). This might unnecessarily keep the moral weights value close to less-than-ideal values, rather than updating with new evidence, which is especially problematic if you think the starting point (based a lot on the donor survey) is less than ideal.
Finally, is the donor survey public and if so, where could I find it?
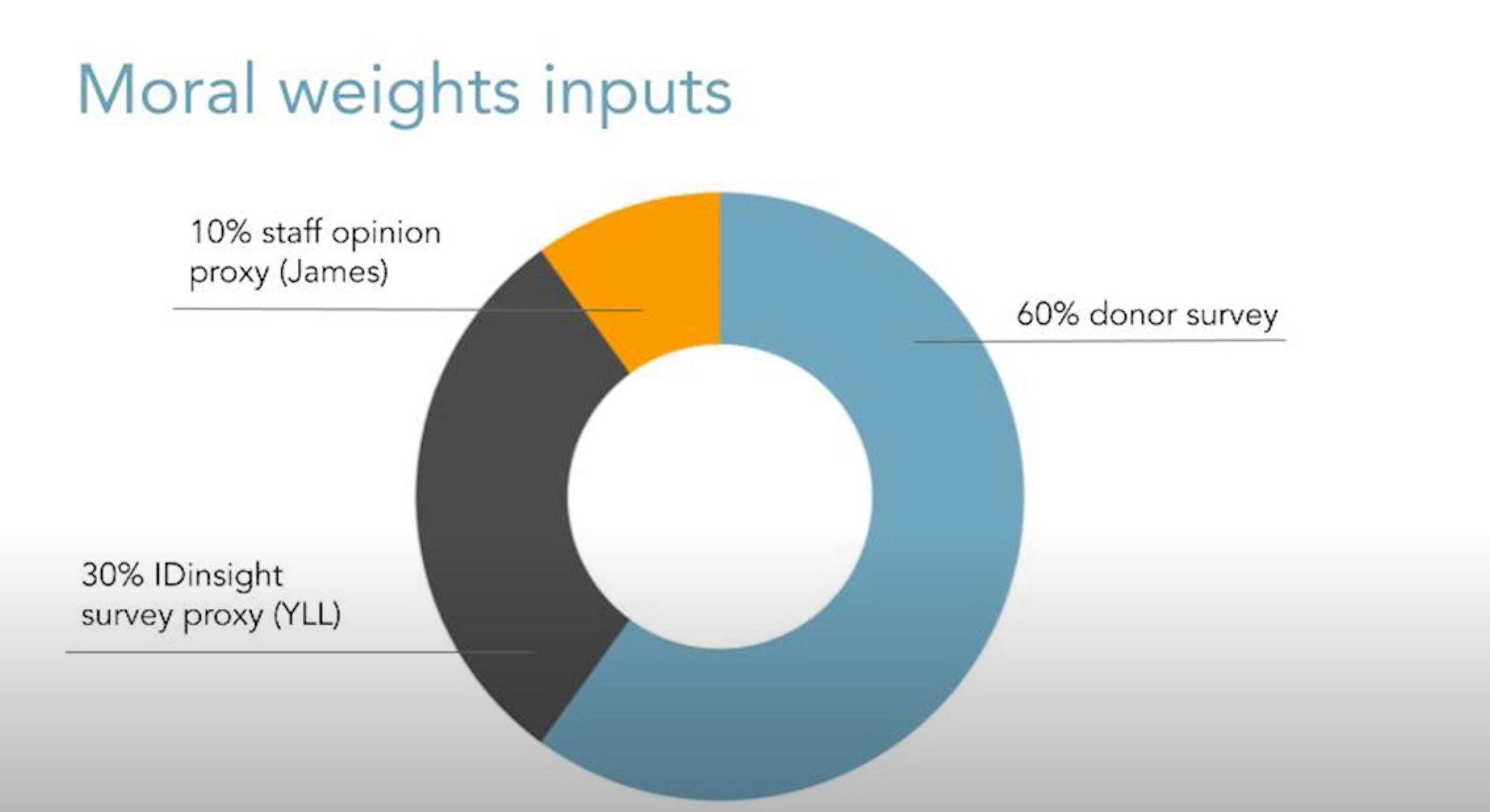
MichaelPlant @ 2022-10-21T14:36 (+10)
I agree that this methodology should be better explained and justified. In a previous blog post on Open Philanthropy's cause prioritisation framework, I noted that Open Philanthropy defers to GiveWell for what the 'moral weights' about the badness of death should be, but that GiveWell doesn't provide a rationale for its own choice (see image below).
I, with colleagues at HLI, are working on a document that specifically looking at philosophical issues about how to compare improving to saving lives. We hope to publish that within 4 weeks.
Corentin Biteau @ 2022-10-19T08:48 (+26)
Thanks for the article ! This is an important topic, glad there is an overview of this.
I saw the "Taking Happiness seriously" presentation by Michael Plant at the EAG Berlin in September, and I was really impressed.
My two main takeaways for this post here are the same than back then:
- I'm surprised and a bit disappointed by the selection criteria used by GiveWell. As pointed out by someone else, "asking how 80 Givewell donors would make these same types of tradeoffs" seems like a weak criteria to me, especially for 60% of the value. We really have trouble imagining how happy we'd be in another situation, so this criteria sounds mostly like guessing.
- This was also pointed out in Michael Plant's presentation: using DALY tends to represent depression and reduced mobility as having the same impact on the quality of life - while depression is much more devastating to mental wellbeing.
- If asking people how happy they are works (which sounds surprising to me, but if it does correlate with other criterias, like say smile, I can accept that), then it would make way more sense to use that criteria. It's closer to the endpoint. Otherwise we're just guessing.
Anyway, this post clarifies things quite a bit, thanks for this work !
Dan Epstein @ 2022-10-15T22:29 (+20)
As a public health academic, I would love to see more carving of a niche for WELLBYs. They make a lot of sense for the bio-psycho-social model for health... as they emphasize 2/3 of these metrics rather than just one!
To get traction for use, they need to build awareness as a viable alternative. There should be some effort to educate academics and policymakers about the use of WELLBYs as an outcome measure of interest.
I would also like to see research on existing softer interventions that may not impact DALYs but may shift the needle considerably with WELLBYs (or not?).
Off the top of my head- some candidates might be (potential for long-term well-being increases but maybe not disability/death):
-iron fortification
-access to contraception/ pregnancy termination
-deworming (bringing another prong into debates
-living with worms is terrible), nutrition programs
-increasing sleep quality/supplying simple mattresses
-domestic violence interventions/safehouses
Another way to think of interventions for the list is taking away causes of long-term suffering that would be cheap, easy and likely permanent.
Mo Putera @ 2022-10-18T11:29 (+7)
HLI's research overview page mentions that they're planning to look into the following interventions and policies via the WELLBY lens; there is some overlap with what you mentioned:
Our search for outstanding funding opportunities continues at three levels of scale. These are set out below with examples of the interventions and policies we plan to investigate next.
Micro-interventions (helping one person at a time)
Meso-interventions (systemic change through specific policies)
Macro-interventions (systemic change through the adoption of a wellbeing approach)
- Advocacy for, and funding of, subjective wellbeing research
- Developing policy blueprints for governments to increase wellbeing
MichaelPlant @ 2022-10-21T14:39 (+2)
Thanks for spotting and including this Mo! Yes, Dan, at HLI we're trying to develop and deploy the WELLBY approach and work how much difference it makes vs the 'business as normal' income and health approaches. We're making progress, but it's not as fast as we'd like it to be!
Feel free to reach out if you'd like to chat. Michael@happierlivesinstitute.org
Lizka @ 2022-10-27T19:00 (+11)
I'm curating this — thanks so much for putting it together, all! [1]
I think people are pretty confused about how prioritization or measurement of "good" can possibly happen, and how it happens in EA (and honestly, it's hard to think about prioritization because prioritization is incredibly (emotionally) difficult), and even more confused about the differences between different approaches to prioritization — which means this is a really useful addition to that conversation.
I do wish there were a summary, though. I've copy-pasted Zoe's summary below.
The post is pretty packed with information, shares relevant context that's useful outside of these specific questions (like how to value economic outcomes), and also has lots of links to other interesting readings.
I also really appreciate the cross-organization collaboration that happened! It would be nice to see more occasions where representatives of different approaches or viewpoints come together like this.
Here's the summary from Zoe's incredible series (slightly modified):
Givewell uses moral weights to compare different units (eg. doubling incomes vs. saving an under-5's life). These are 60% based on donor surveys, 30% from a 2019 survey of 2K people in Kenya and Ghana, and 10% staff opinion. [Note from Lizka: this is largely to create an exchange rate between different types of good outcomes.]
Open Philanthropy’s global health and wellbeing team uses the unit of ‘a single dollar to someone making 50K per year’ and then compares everything to that. Eg. Averting a DALY is worth 100K of these units.
Happier Lives Institute focuses on wellbeing, measuring WELLBYs. One WELLBY is a one-point increase on a 0-10 life satisfaction scale for one year.
Founder’s pledge values cash at $199 per WELLBY. They have conversion rates from WELLBYs to Income Doublings to Deaths Avoided to DALYs Avoided, using work from some of the orgs above. This means they can get a dollar figure they’re willing to spend for each of these measures.
Innovations for Poverty Action asks different questions depending on the project stage (eg. idea, pilot, measuring, scaling). Early questions can be eg. if it’s the right solution for the audience, and only down the line can you ask ‘does it actually save more lives?
I also just really appreciate this quote from the post:
So what do we do? Well, we try to reduce everything to common units and by doing that we can more effectively compare across these different types of opportunities. But this is really, really hard! I can't emphasise enough how difficult this is and we definitely don't endorse all of the assumptions that we make. They're a simplifying tool, they're a model. All models are wrong, but some are useful, and there is constant room for improvement.
- ^
[Disclaimer: written quickly, about a post I read some time ago that I just skimmed to remind myself of relevant details.]
Sarah Cheng @ 2022-10-14T15:51 (+8)
People interested in global health & development and this post might be interested in applying to the Program Operations Assistant, Global Health & Wellbeing role at Open Philanthropy, and EA-aligned research and grantmaking foundation.
This is a test by the EA Forum Team to gauge interest in job ads relevant to posts - give us feedback here.
Denise_Melchin @ 2022-11-01T17:46 (+5)
I was pretty taken aback by GiveWell's moral weights by age. I had not expected them to give babies such little moral weight compared with DALYs. This means GiveWell considers saving babies' lives to be only as valuable as saving people in their late 30s despite them being almost halfway through their life. The graph makes the drop-off of moral weights at younger ages look less sharp than it is as the x-axis is not to scale.

I looked at the links for further information on this which I'm collating here for anyone else interested:
From the [public] 2020 update on GiveWell's moral weights - Google Docs:
These results look sensible to us. We're least certain about the value of averting deaths at very young ages and stillbirths. If those values became decision-relevant for a grant, such as a neonatal health program, we might revisit these weights or consider setting aside a pot of funding for grants that satisfy "other reasonable moral weights."
DALYs assume that preventing the deaths of people with longer remaining life expectancies is always more valuable, when in practice many people indicate a preference for preventing the death of an older child over the death of a neonate.[footnote]
The footnote:
This applies to GiveWell staff and donors, as well as to the results of the Mechanical Turk survey referenced here. The IDinsight survey did not ask about neonates.
The biggest uncertainty we have is around the relative value of preventing deaths at very young ages.
This is in context of the ID survey but I assume is speaking about GiveWell's uncertainty not the uncertainy of ID survey respondents.
We don't believe the group of donors we surveyed is very diverse (across characteristics like race, gender, income, and country of origin) which could influence results. The vast majority of the donors we surveyed are men, and people of different genders could especially have different intuitions about the value of averting stillbirths and the deaths of neonates.
A quick analysis of the responses of men vs. women didn't indicate that we should upweight stillbirths and the deaths of neonates to account for different preferences across genders, but there were so few women in the sample that we can't say with confidence that the results don't depend on gender.
Apparently the moral weights have not been decision-relevant which is good news for all donors who have different preferences for moral weights. In the future I will check before donating to GiveWell's funds whether the moral weights of babies have become decision-relevant for grants in the meantime.
I was also wondering how many of the donor survey respondents were parents and whether they put moral weight on babies than non-parents. I could also imagine there being a discrepancy between mothers and everyone else (fathers and the childless).
david_reinstein @ 2022-10-21T15:49 (+2)
I'm finding the terminology difficult.
DALY s
"Disability Adjusted Life Years", definition from WHO: "One DALY represents the loss of the equivalent of one year of full health" (for a disease or health condition).
I always think this should be called "Disability adjustments to life years" ... it's not a 'count of total adjusted years'. Anyways, moving on to HLI:
WELLBY's, HLI
Instead of DALYs, we think in terms of WELLBYs (wellbeing-adjusted life years). ...
Saying 'wellbeing-adjusted life years' suggests this involves a metric where people would trade off ('adjusted') an additional year of life spent at one level of happiness versus something else.
Or, to bring the 'DALY' concept in, something like ...the adjustment to lifetime average well-being needed to be willing to give up an additional year of life in my current well-being state. Something like a 'hypothetical revealed preference tradeoff'.
So what is one WELLBY? It’s a one-point increase on a 0-10 life satisfaction scale for one year.
But this is an explicit measure defined based on a survey response. So how would this be consistent with the 'adjustment' above
MichaelPlant @ 2022-10-21T16:49 (+4)
Q/DALYs are intended to measure health and the weights are found by asking individuals to make various trade-offs. There are some subtleties between them, but nothing important for this discussion.
WELLBYs are intended to measure overall subjective wellbeing, and do so in a way that allows quality and quantity of life to be traded off. Subjective wellbeing is measures via self-reports, primarily of happiness and life satisfaction (see World Happiness Report; UK Treasury). I should emphasise that HLI did not invent either the idea of measuring feelings, or of the WELLBY itself - we're transferring and developing ideas from social science. How much difference various properties make to subjective wellbeing, e.g. income, relationship, employment status, etc. are inferred from the data, rather than asking people for their hypothetical preferences. Kahneman et al. draw an important distinction between decision utility (what people choose, aka preferences) and experienced utility (how people feel, aka happiness). The motivation for the focus on subjective wellbeing is often that there is often a difference between them (due to e.g. mispredictions of the future) and, if there is, we should focus on the latter.
Hence, when you say
Saying 'wellbeing-adjusted life years' suggests this involves a metric where people would trade off ('adjusted') an additional year of life spent at one level of happiness versus something else.
I'm puzzled. The WELLBY is 'adjusted' just like the QALY and the DALY: you're combining a measure of quality of life with a measure of time, not just measuring time. On the QALYs, a year at 0.5 health utility are worth half as much as at 1 health utility, because of the adjustment for quality.
david_reinstein @ 2022-10-21T19:36 (+3)
Thanks. When you say
So what is one WELLBY? It’s a one-point increase on a 0-10 life satisfaction scale for one year.
By this I assume you mean 1 WELLBY a 1-point increase in the self-reported measure itself (maintained over the course of the year). Is that it?
If so, how can I compare maks the similar 'adjustments' like for QALY.
On the QALYs, a year at 0.5 health utility are worth half as much as at 1 health utility, because of the adjustment for quality.
How would something similar work for a WELLBY? If it's just the numeric self reported well-being, it shouldn't imply anything like 'a year at WELLBY= 8 is worth twice as much as a year at WELLBY-4', should it? I assume there is another way this is done.
MariellaVee @ 2022-10-16T13:51 (+2)
This is incredibly interesting and enlightening; thank you!
Particularly love to see the way that these different organizations are looking at each others’ work and ideas and fit-testing them for their own approach and priorities. I’m especially interested in the question of how to measure good better by taking the effectiveness of the implementation into account, since this is where I can foresee a lot of great in-theory approaches diminishing in effectiveness when hit with real-world obstacles like convoluted systems/miscommunication or shifting context, etc.
As such, I even wonder how granular this approach could get; could additional work looking at systems, obstacles, or contexts objectively reveal ways that some interventions with potentially high impact traditionally considered too high-cost might suddenly become more accessible/effective?
jall @ 2022-10-14T20:17 (+2)
A $1,000 cash transfer costs a bit more than $1,000 to deliver
I'm surprised by this claim!
GiveDirectly's published figures for delivery costs are 10-20% of the total funds, and the financials seem to back this up to my naive eye: "Direct Grants" dominate all other expenses. 9:1 or 8:1 is way different than 1:1 suggested here
How's this figure calculated?
blonergan @ 2022-10-14T22:48 (+13)
I interpreted that as meaning that a $1,000 cash transfer costs a bit more than $1,000, including the direct cost of the cash transfer itself. So, something like $100 of delivery costs would mean that a $1,000 cash transfer would have a total cost of around $1,100.
Here HLI comes up with $1,170 as the total cost of a $1,000 cash transfer, which seems reasonably close to your numbers.
jall @ 2022-10-14T23:26 (+4)
ah, of course. thanks!
MichaelPlant @ 2022-10-21T14:41 (+2)
yes, thanks for this. I'll be more careful when I say this in future. Providing a $1000 transfer costs a bit more than $1,000 in total, when you factor in the costs to deliver it.
Cornelis Dirk Haupt @ 2022-10-30T05:50 (+1)
Threw me off as well at first. I'd second that it's probably best to reword it in the future for better clarity
BarryGrimes @ 2023-01-12T10:22 (+1)
If you found this post helpful, please consider completing HLI's 2022 Impact Survey.
Most questions are multiple-choice and all questions are optional. It should take you around 15 minutes depending on how much you want to say.