Summary of Situational Awareness - The Decade Ahead
By OscarD🔸 @ 2024-06-08T11:29 (+143)
Original by Leopold Aschenbrenner, this summary is not commissioned or endorsed by him.
Short Summary
- Extrapolating existing trends in compute, spending, algorithmic progress, and energy needs implies AGI (remote jobs being completely automatable) by ~2027.
- AGI will greatly accelerate AI research itself, leading to vastly superhuman intelligences being created ~1 year after AGI.
- Superintelligence will confer a decisive strategic advantage militarily by massively accelerating all spheres of science and technology.
- Electricity use will be a bigger bottleneck on scaling datacentres than investment, but is still doable domestically in the US by using natural gas.
- AI safety efforts in the US will be mostly irrelevant if other actors steal the model weights of an AGI. US AGI research must employ vastly better cybersecurity, to protect both model weights and algorithmic secrets.
- Aligning superhuman AI systems is a difficult technical challenge, but probably doable, and we must devote lots of resources towards this.
- China is still competitive in the AGI race, and China being first to superintelligence would be very bad because it may enable a stable totalitarian world regime. So the US must win to preserve a liberal world order.
- Within a few years both the CCP and USG will likely ‘wake up’ to the enormous potential and nearness of superintelligence, and devote massive resources to ‘winning’.
- USG will nationalise AGI R&D to improve security and avoid secrets being stolen, and to prevent unconstrained private actors from becoming the most powerful players in the world.
- This means much of current AI governance work focused on AI company regulations is missing the point, as AGI will soon be nationalised.
- This is just one story of how things could play out, but a very plausible and scarily soon and dangerous one.
I. From GPT-4 to AGI: Counting the OOMs
Past AI progress
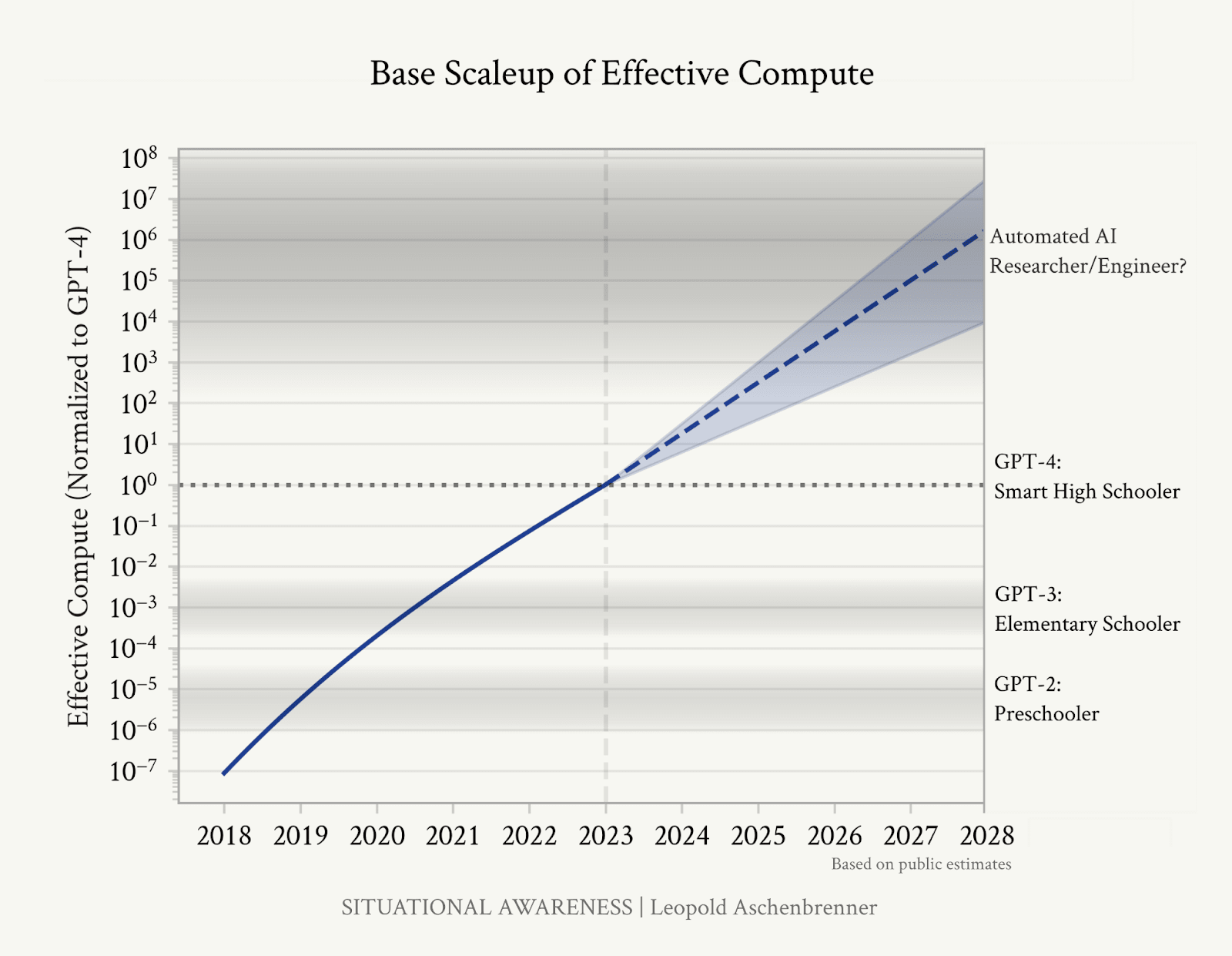
- Increases in ‘effective compute’ have led to consistent increases in model performance over several years and many orders of magnitude (OOMs)
- GPT-2 was akin to roughly a preschooler level of intelligence (able to piece together basic sentences sometimes), GPT-3 at the level of an elementary schooler (able to do some simple tasks with clear instructions), and GPT-4 similar to a smart high-schooler (able to write complicated functional code, long coherent essays, and answer somewhat challenging maths questions).
- Superforecasters and experts have consistently underestimated future improvements in model performance, for instance:
- The creators of the MATH benchmark expected that “to have more traction on mathematical problem solving we will likely need new algorithmic advancements from the broader research community”. But within a year of the benchmark’s release, state-of-the-art (SOTA) models went from 5% to 50% accuracy, and are now above 90%.
- Professional forecasts made in August 2021 expected the MATH benchmark score of SOTA models to be 12.7% in June 2022, but the actual score was 50%.
- Experts like Yann LeCun and Gary Marcus have falsely predicted that deep learning will plateau.
- Bryan Caplan is on track to lose a public bet for the first time ever after GPT-4 got an A on his economics exam just two months after he bet no AI could do this by 2029.
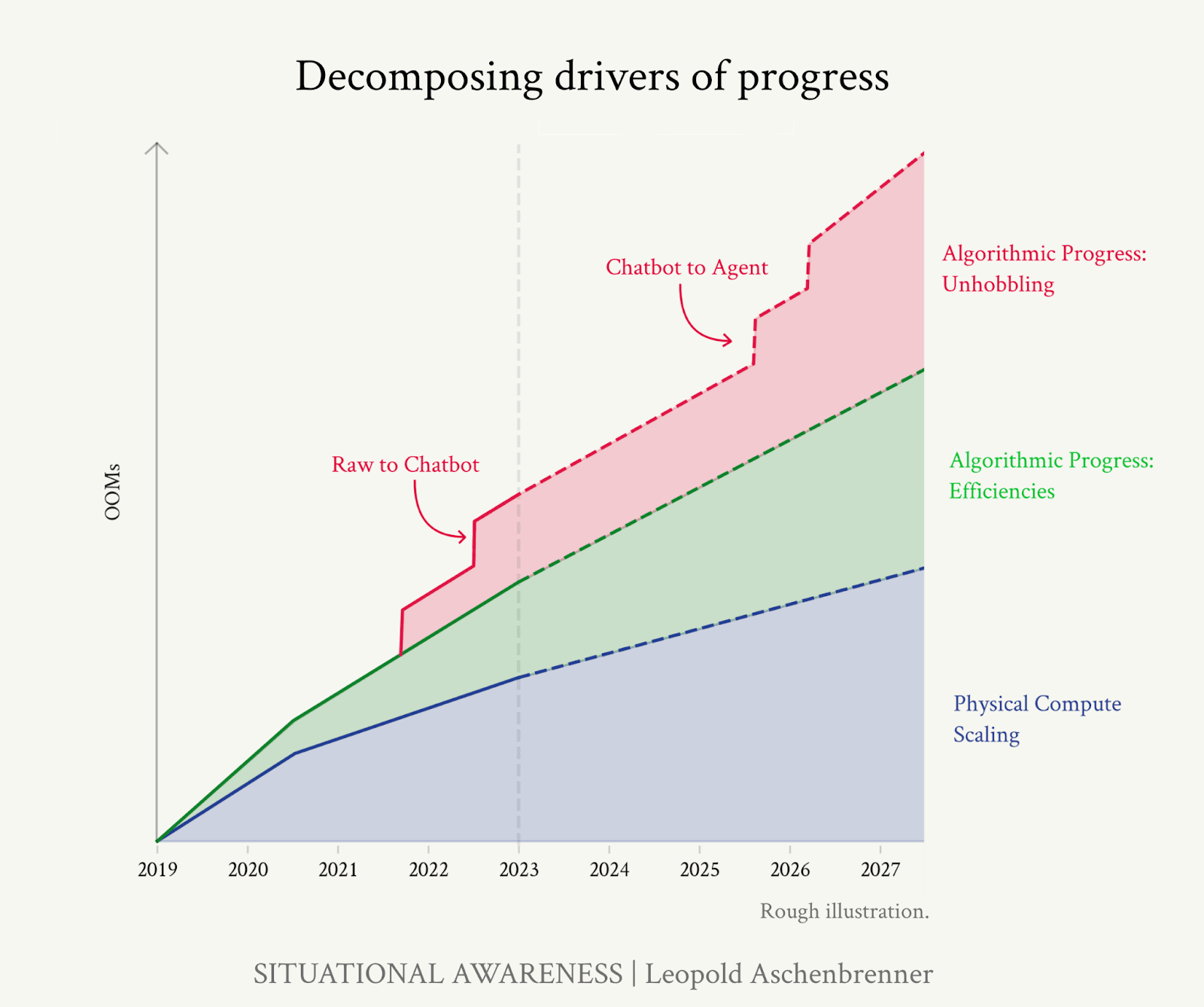
- We can decompose recent progress into three main categories:
- Compute: GPT-2 was trained in 2018 with an estimated 4e21 FLOP, and GPT-4 was trained in 2022 with an estimated 8e24 to 4e25 FLOP.[1] This is both because of hardware improvements (Moore’s Law) and increases in compute budgets for training runs. Adding more compute at test-time, e.g. by running many copies of an AI, to allow for debate and delegation between each instance, could further boost performance.
- Algorithmic efficiencies: the best data for this is from ImageNet, where we have seen fairly steady compute efficiency improvements of 0.5 OOMs/year between 2012 and 2021. Data is scarcer for language models, but appears to be quite similar. Overall algorithmic efficiency has likely contributed 1-2 OOMs of effective compute between GPT-2 to GPT-4.
- Unhobbling: prior to RLHF post-training, LLMs have vast amounts of ‘latent knowledge’ that they do not use when responding to questions, instead providing continuations typical of internet text, which is on average quite low-quality. Chain-of-thought prompting allows LLMs to reason through a problem rather than spouting an answer straight away. We are likely to see other such qualitative improvements from ‘chatbot’ to ‘agent’ that will unlock the underlying potential of AIs.
Training data limitations
Will training data be a limitation to continuing language model scaling?
- Existing SOTA models already use a large fraction of all available internet text, and likely almost all the high-quality text.
- Any ideas about how to circumvent data limitations are likely very valuable and proprietary, so we wouldn’t know about them.
- Dario Amodei said “My guess is that this will not be a blocker” and presumably he has access to lots of important secret information bearing on this question.
- Intuitively, LLM training is currently very inefficient, as it involves the model ‘skimming’ vast swathes of text without employing learning techniques humans find helpful such as answering practice questions, pausing to reason about what it is reading, dialogues between multiple agents, and so on.
- [Oscar: since Leopold published this, Epoch released a new paper, which I think broadly agrees with the above]
Trend extrapolations
- So by simply extrapolating past trends that will very plausibly continue for several more years, over the next 4 years we could get another ~3-6 OOMs of effective compute, between increasing budgets, Moore’s law, algorithmic gains, and scaffolding/tool-use/unhobbling.
- A jump in the next 4 years similar in size to the GPT-2 to GPT-4 jump could take us from a smart high-schooler to an expert worker.
- Because of ‘unhobblings’ we should not just imagine a far smarter version of ChatGPT, but rather an AI substitute for a remote worker.
- “We are racing through the OOMs, and it requires no esoteric beliefs, merely trend extrapolation of straight lines, to take the possibility of AGI—true AGI—by 2027 extremely seriously.”
- This is one plausible outcome [Leopold does not give probabilistic forecasts]. It is also possible that data limits will prove severe, algorithmic progress will slow, finance will become harder, or Moore’s law will end.
The modal year of AGI is soon
The modal year in which AGI arrives is in the late 2020s, even if you think the median is after that.
- Probability mass on when to expect AGI should not be spread out ~evenly across the next several decades, but rather ~evenly across OOMs of effective compute.
- The rate of change of effective compute OOMs will likely slow towards the end of this decade.
- Spending scaleup: we are rapidly increasing the share of GDP spent on the largest training runs, but once we have ~trillion dollar training runs at the end of the decade, it will be hard to keep going, and spending may increase thereafter at closer to the GDP growth rate of ~2% per year.
- Hardware gains: we are currently optimizing hardware for AI training, e.g. by going from CPUs to GPUs, and from very precise fp64 numbers to less precise but computationally cheaper fp8 numbers. This means AI computing power has been growing far faster than Moore’s law, but once we finish these one-time gains, progress will return to the baseline rate of hardware improvements.
- Algorithmic progress: by the end of the decade a large fraction of the world’s smartest technical talent will likely be working on AI R&D, and much of the low-hanging fruit will have been picked, so algorithmic progress may slow after that.
II. From AGI to Superintelligence: the Intelligence Explosion
The basic intelligence explosion case
- In the previous section we considered the trajectory to AGI - a system capable of being a drop-in replacement for a remote ML researcher/engineer.
- We will likely be able to run millions of copies of this AGI, possibly at 10-100 times the speed of human thought, vastly increasing the amount of human-hours equivalent effort going into improving algorithmic efficiency and hardware progress.
- Each AGI agent will have important advantages over human researchers, by being able to read every AI paper ever written, learn efficiently from peer agents, and quickly build research taste equivalent to multiple expert human careers.
- The AGI agents will be able to work with peak focus and energy 24/7.
- Therefore, a decade of human-scale R&D progress could be compressed into under a year, leading to another GPT-2 to GPT-4 size qualitative leap from AGI to artificial superintelligence (ASI). This is the putative ‘intelligence explosion’.
Objections and responses
- Hard to automate domains: AGI will not be able to automate and massively accelerate everything (e.g. biology research requires wall-clock time for experiments, and physical dexterity).
- Response: To see an intelligence explosion we only need AGI to automate AI research, and this just requires ‘remote worker’ skills. Once we have superintelligence, it will be able to solve robotics and other ‘world of atoms’ challenges.
- Compute bottlenecks: Even if AGI agents can substitute for human researchers, the amount of compute available for research will be severely constraining, as building new fabs is time-consuming and difficult. Therefore, even having OOMs more human-equivalent researchers will not lead to an intelligence explosion due to a lack of an equivalent bOOM in compute.
- Response: This is a good point with some truth to it. But because the AI R&D automated labour force will be so large, lots of time will be spent maximising the 'value of information' of each experiment, optimizing code, avoiding bugs, and choosing experiments more wisely due to better research taste. So even though a 1e5 scale-up in researcher time won’t lead to a 1e5 scale-up in research progress, it would be surprising if it didn’t lead to a 10x scale-up.
- Long tail of AI R&D task automation: Automating most of the job of an AI researcher/engineer might be relatively ‘easy’ but in other domains we have seen that the ‘last mile’ of automation is hard. Even if 90% of a human researcher’s job is automated, the last 10% will mean human time is still a huge bottleneck to research progress.
- Response: This is true, and may push back the intelligence explosion by a year or two. But in the case of AI R&D all tasks are computer-based (rather than e.g. manual or social) so it seems unlikely some parts of the job will be very hard to automate.
- Inherent limits to algorithmic progress: It is not possible to indefinitely improve algorithms (25 OOMs of algorithmic progress from GPT-4 would imply training a GPT-4 model with a handful of FLOP!). Perhaps we are already near the limit of algorithmic efficiency, and even millions of automated researchers will find only marginal improvements.
- Response: This is possible, but it seems more likely that there are at least another 5 OOMs of algorithmic progress possible, as biological systems seem far more sample-efficient than current SOTA AIs.
- Ideas get harder to find: even though more agents will be working on AI R&D, we will have picked the low-hanging fruit, and progress will either continue at a similar pace to before, or quickly peter out once there are few discoverable ideas left.
- Response: This is plausible, but the massive scale-up in the number of researchers makes it more likely progress will accelerate despite ideas becoming harder to find. While there are surely ‘limits to growth’ of intelligence, it would be a priori surprising if such a limit was just above human-level intelligence.
The power of superintelligence
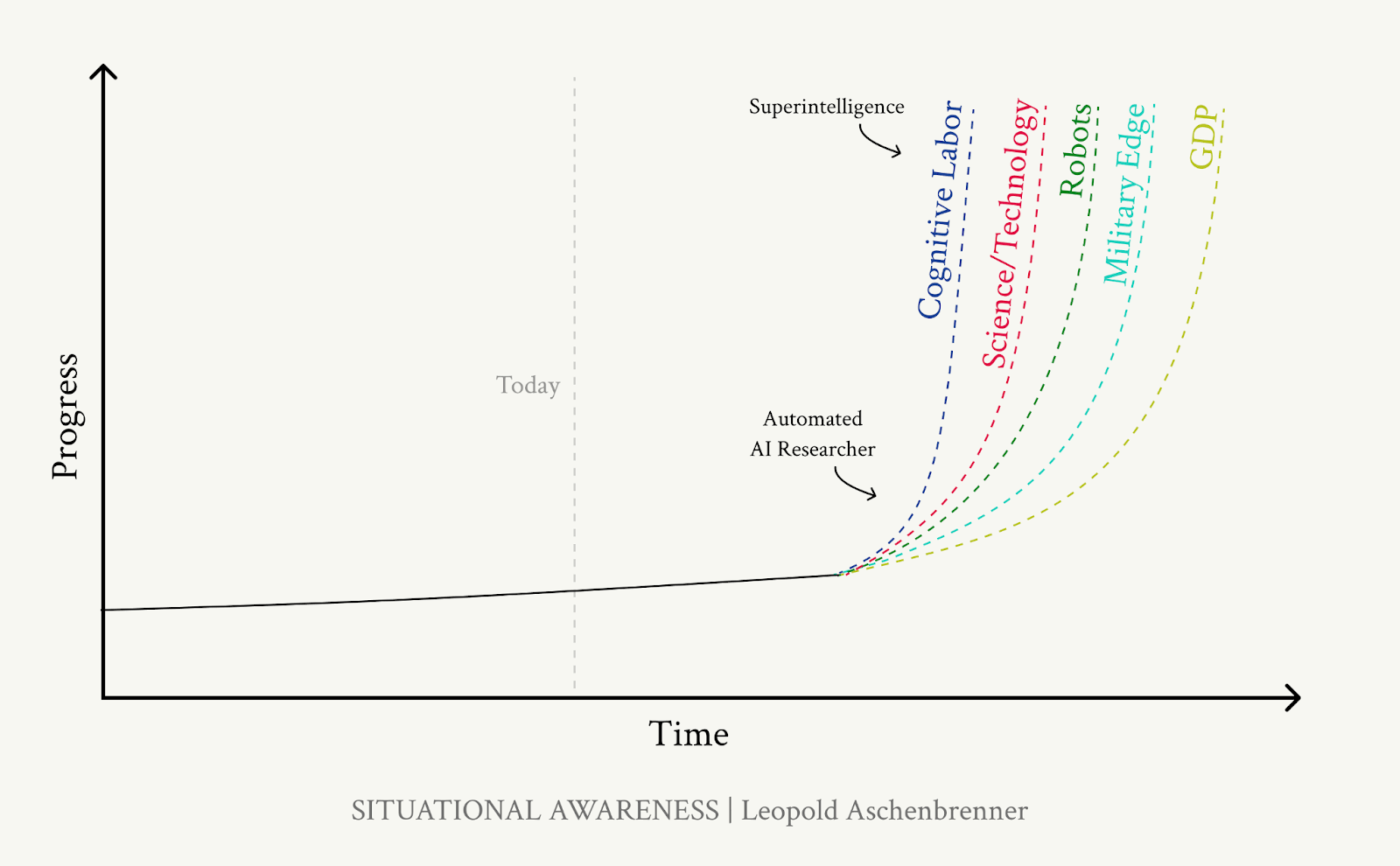
Much of the first AGI’s efforts will likely be directed towards further AI research. But once superintelligences exist, they will likely also spend considerable subjective time on other fields. This could look like compressing the equivalent of all of 20th-century technological progress into a few years.
- Initially, AIs will only automate digital tasks, but they will likely solve robotics quickly. So industrial factories will go from being directed by AIs with humans providing dextrous manual labour, to being staffed by robots built in the first wave.
- Progress in robotics has been slow compared to language models. This is mainly because of the lack of training data (there is no equivalent of an internet of text for robot training data). However advances in AI R&D (e.g. being able to learn from less data) will likely solve this, and robotic hardware is unlikely to be limiting.
- Existing semi-endogenous economic growth models suggest full R&D automation could lead to a step-change in economic growth akin to or greater than from the agricultural to the industrial era. Growth rates could be 10s of % per year.
- Societal and legal frictions will slow this rapid expansion in some areas, but whenever humans ‘get out of the way’ unchecked AI-robot economic growth could be very high.
- Superintelligence will very likely provide a decisive strategic advantage (DSA) militarily. Technological/industrial power has been very closely linked to military power historically, and it seems unlikely this will cease to be the case. Even before there are millions of advanced robot soldiers for superintelligence to control, it is strikingly plausible the superintelligence (or whoever controls it) would be able to overthrow the US government (USG) or any foreign powers.
- As loose historical analogues, consider that in ~1500 Cortes and ~500 Spaniards conquered an Aztec empire of millions due to superior technology and organisation, and likewise with the Incas. Superintelligence could be to existing human powers as the Old World was to the New World.
III The Challenges
IIIa. Racing to the Trillion-Dollar Cluster
AI will increasingly require huge amounts of capital expenditure on data centres, energy, and semiconductor fabs. Based on naive (but plausible) trend extrapolation, we can estimate some numbers for the latest single training run in each year:
| Year | OOMs | H100s Equivalent | Cost | Power | Power Reference Class |
| 2022 | ~GPT-4 cluster | ~10k | ~$500M | ~10 MW | ~10,000 average homes |
| ~2024 | +1 OOM | ~100k | $billions | ~100 MW | ~100,000 homes |
| ~2026 | +2 OOMs | ~1M | $10s of billions | ~1 GW | The Hoover Dam, or a large nuclear reactor |
| ~2028 | +3 OOMs | ~10M | $100s of billions | ~10 GW | A small/medium US state |
| ~2030 | +4 OOMs | ~100M | $1T+ | ~100 GW | >20% of US electricity |
- This may seem outlandish, but we have already seen massive increases in datacentre revenue for NVIDIA (quadrupling from Q1 2023 to Q1 2024) and large increases in capital expenditure from Big Tech.
- Meta is buying 350,000 H100s in 2024.
- Amazon bought a 1GW datacentre next to a nuclear power plant.
- Microsoft and OpenAI are reputedly planning a $100B datacentre for 2028, and Sam Altman was reported to be trying to raise up to $7T.
- If we continue to see very impressive new capabilities with each generation of model, investment will likely not be limiting.
- The investments OpenAI and Microsoft have made so far have paid off well.
- E.g. if one-third of current Microsoft Office paid subscribers purchase a $100/month AI subscription (expensive, but if it buys even one hour of productivity a week, which seems very doable, it would be worth it for most knowledge workers), that would be $100B/year AI revenue.
- There are also some historical precedents for AI spending reaching ~$1T/year (3% of US GDP) by 2027:
- The Manhattan Project, Apollo programs, and internet infrastructure rollout all cost ~0.5% of GDP.
- Britain spent ~4% of GDP on railways infrastructure in the 1840s.
- China has spent ~40% of GDP on broad ‘investment’ (as opposed to e.g. consumption) for decades.
- Borrowing during WW1 reached 100% of GDP spread over several years for the UK, France and Germany.
- AI chips and related hardware will be important constraints, but likely solvable.
- Currently, less than 10% of TSMC’s advanced chips go to AI uses, as there is plenty of scope for just repurposing existing production capacity.
- TSMC and others may need ~1T$ of capex, but this seems doable economically.
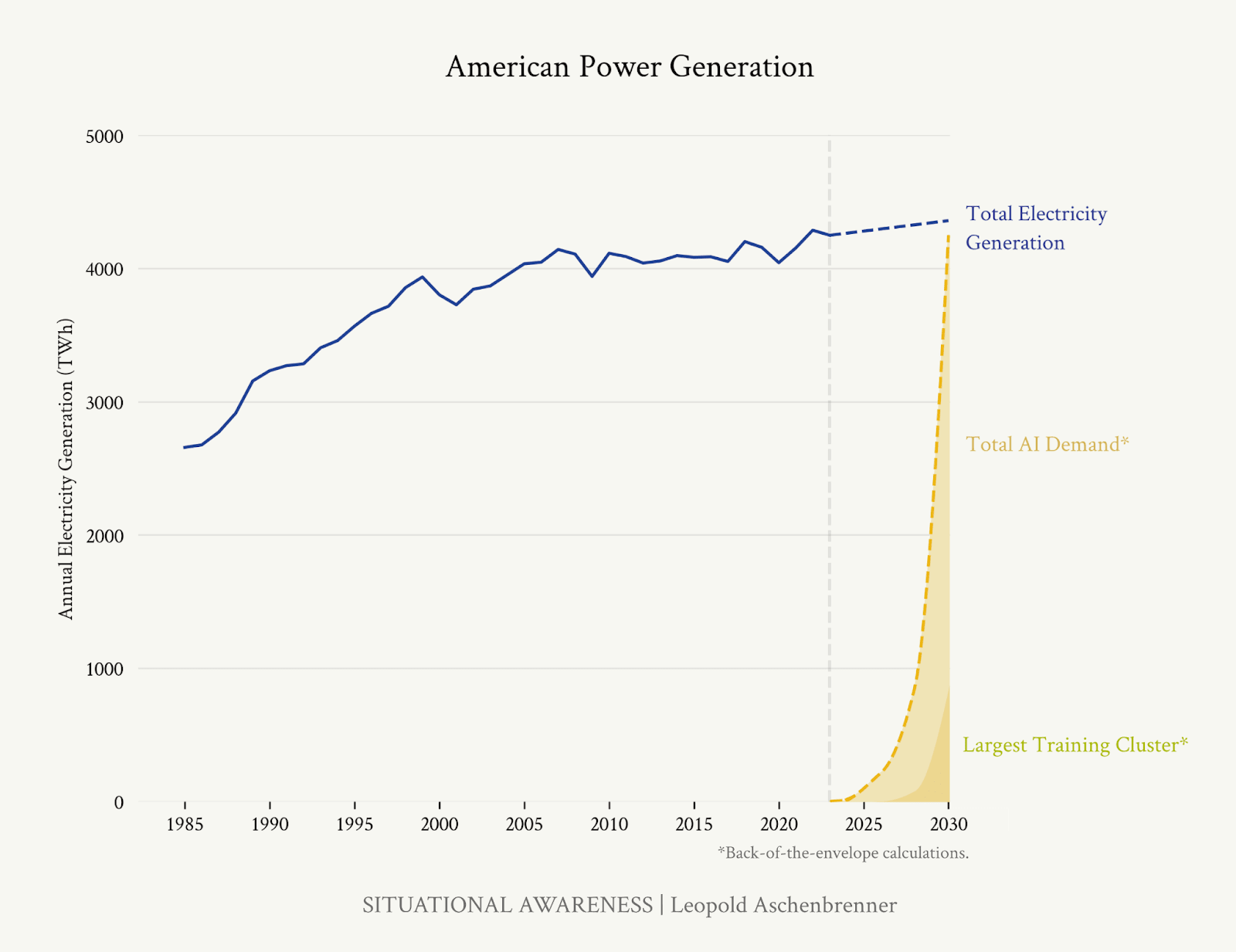
- Instead, energy may be the biggest bottleneck to AI expansion later this decade.
- Building nuclear power plants takes many years.
- Solar and wind are less suitable, as datacentres are very concentrated electricity sinks, so it is preferable to have concentrated power sources nearby, but with sufficient storage and transmission investment this could work.
- Natural gas is the most plausible route to massive electricity generation expansion:
- Currently, the Pennsylvania shale fields are producing enough gas for ~200GW of continuous electricity generation.
- The gas extraction and power plant infrastructure needed for even a Trillion $ (~2030) datacentre could likely be built in 1-2 years.
- For all of these, but especially nuclear and renewables, permitting and regulatory difficulties account for much of the time required, so massive reforms here could help.
- the time required to physically build power plants and data centres, and get various legal permits, could be the main bottleneck, and many tech companies are working hard on these energy and regulatory problems.
- Because of the energy constraints, some market players are investigating building massive datacentres in the Middle East.
- Datacentres being planned today could be the ones AGI is trained on.
- The US regretted being so dependent on Middle Eastern oil in the 1970s. AI will be a far bigger deal, and national security necessitates not giving unsavoury dictatorships that much control and bargaining power over AGI development.
IIIb. Lock Down the Labs: Security for AGI
The power of espionage
AI secrets can probably be easily stolen by state actors.
- Current cybersecurity at AGI companies is more in the reference class of ‘random tech startups’ than ‘top secret national defence projects’, but the latter would be more appropriate given the stakes.
- State espionage agencies are capable of incredibly impressive feats, e.g:
- “Zero-click hack any desired iPhone and Mac with just a phone number”
- “Infiltrate an airgapped atomic weapons program”
- “Find dozens of zero-days a year that take on average of 7 years to detect”
- “Steal information via electromagnetic emanations or vibration”
- “Expose the financial information of 110 million customers by planting vulnerabilities in HVAC systems”
- AI will likely become the top priority of most major intelligence agencies in the world, so vast resources will be poured into stealing key information.
Securing model weights
“An AI model is just a large file of numbers on a server. This can be stolen. All it takes an adversary to match your trillions of dollars and your smartest minds and your decades of work is to steal this file.”
- Securing model weights is key for misuse risks as well as national competitiveness, as a malicious actor could remove any safety features if they have access to model weights.
- Model weights for current AIs being stolen won’t matter all that much. But the weights of the AGI model being stolen would be pivotal, bringing an adversary up to parity with the AGI developer.
- A particularly worrying scenario is if China steals the model weights of an AI that can automate AI research, just before an intelligence explosion, and then the US lead in AI research talent won’t matter as ~all research will be done by the AGI itself.
- As well as the risk that China would overtake the US, there is the danger that the US will need to skip safety steps to race to stay ahead of China, leading to significantly greater loss-of-control misalignment risks.
- Google arguably has the best cybersecurity of current AGI companies, but acknowledges it is currently at level 0 on a 0-4 scale, implying even relatively unsophisticated actors could potentially steal their model weights.
- If AGI may arrive in ~4 years, we need to focus intensely on improving security, as it will be impossible to build secure systems very rapidly just before AGI is built.
Protecting algorithmic insights
- Algorithmic insights being researched today will be key steps on the path to AGI, so stealing these would be akin to stealing key nuclear physics results in 1942.
- Until recently most algorithmic breakthroughs were published, but now the most important work is happening at AGI companies and is unpublished, so without information leaking/being stolen, by default AGI companies will develop a large lead over small open-source developers and foreign competitors.
- “Our failure today will be irreversible soon: in the next 12-24 months, we will leak key AGI breakthroughs to China.”
- Stealing key algorithmic insights could be equivalent to multiplying an adversary’s compute by 10-100x, and is therefore likely more important than whether they have 3nm or 7nm chips.
Necessary steps for improved security
- If we do not get security right, almost nothing else will matter on AI safety, as the US will not control the only AGI effort.
- It should be hard but possible to secure algorithmic secrets with intensive security vetting, information siloing, cyber ‘supersecurity’, and maintaining limited need-to-know access.
- There are examples of private companies having vastly better security, e.g. Jane Street manages to maintain a trading edge even though a one-hour conversation with a competitor would be enough to convey many of the most profitable high-level ideas.
- But once China ‘wakes up’ to AGI possibly being soon and providing a DSA, they will be willing to devote billions of $ and thousands of their best minds to cracking US AGI efforts’ security. So even Jane Street-level measures will be insufficient then.
- China-proof security will require heavy USG involvement. While governments don’t have a perfect track record protecting defence secrets, the NSA and others have vast relevant expertise and are the best bet.
- Much of the required security measures are non-public, but Sella Nevo’s recent RAND report provides a useful starting point.
- China isn’t yet going all-out on AGI espionage as they do not fully realise the enormity of what is coming. US AI efforts need to get and stay ahead of the espionage efforts at the time.
- Will implementing intense security slow progress too much to be worth it?
- No, even intense security may only slow progress by 10s of %, but the US has a large lead on AI R&D ability, so it is far better to slow down with impressive security than race ahead with weak security, allowing adversaries to steal insights and therefore stay competitive.
IIIc. Superalignment
Controlling AGI, and thereafter superintelligence, is an unsolved but solvable technical problem.
- Within ~1 year we will go from human-level AI systems where alignment techniques similar to ones we use today will probably work, but even if they didn’t, failure may not be existential … to superhuman systems where failure is irreversible and current techniques are likely insufficient.
- Maybe things will be fine by default and we muddle through, but we don’t want to take this chance!
- The intelligence explosion means we won’t have much time to tinker and get things right after careful experimentation.
- The first major alignment failure may itself be an existential catastrophe.
- RLHF won’t scale to superintelligence because humans won’t be able to evaluate incomprehensible actions.
- superintelligence will probably not do English chain-of-thought reasoning, so supervising it will be far harder.
- The question of what values/side-constraints to instil in the AI is separate, I am focused on how to give the AI decision-making procedures it will follow, regardless of what those are.
- Possible components of superalignment
- Evaluation vs generation: We get part of the way ‘for free’ as it is easier to evaluate whether an action is harmful than it is to disguise a harmful action as benign.
- Scalable oversight: Part of the problem is that AIs will be generating million-line code files humans won’t have time to manually check. Using less smart but more trusted AIs to help humans know where to look will help.
- Generalisation: AIs trained to not misbehave in simple cases humans can supervise adequately may generalise to also not misbehave in complex cases that humans can’t evaluate well.
- Interpretability: If we can understand the internal representations of AIs, we will be able to tell when they are ‘scheming’ or engaging in other undesired cognition.
- Adversarial testing: We want to encounter threat models in controlled conditions before we encounter them ‘in the wild’ and studying misalignment or other unwanted properties in well-understood situations will allow us to check how well our alignment techniques work.
- Automated alignment research: leveraging the millions of AGI agents to help with aligning the next generation of AIs will be key.
- Controllability: as an added layer of defence in case AIs aren’t sufficiently aligned, we should also have air-gapped datacentres to make self-exfiltration harder, intense monitoring of AI actions, and deliberately curtailed AI capabilities in some danger-prone areas like dual-use biology.
IIId. The Free World Must Prevail
“Our generation too easily takes for granted that we live in peace and freedom. And those who herald the age of AGI in SF too often ignore the elephant in the room: superintelligence is a matter of national security, and the United States must win.”
- Unlike most military technology - fighter gets, drone swarms etc - being behind in the race to superintelligence cannot be compensated for by being ‘ahead’ in some other technology, as superintelligence will quickly yield progress in everything else.
- In the Gulf War Iraq had a comparable amount of materiel and personnel, but was completely obliterated in a few days due to the US-led coalition’s military tech being a few decades more advanced.
- Due to the accelerated pace of military R&D under superintelligence, being a year ahead would be a DSA, even against nuclear-armed states.
Objection: China is well behind on AI research, and chip export controls mean they will stay well behind on hardware. So we don’t need to worry much about the US losing its lead.
- China can indigenously produce 7nm chips. These are ~3x worse than equivalent Nvidia chips on FLOP/$, but that is a surmountable loss. It is unclear how many 7nm chips China can produce, but likely they could scale up rapidly in the next few years.
- China is ahead of the US on capacity to build giant infrastructure projects. Power will be a key constraint, so China may well be able to build bigger datacentres faster than the US.
- As discussed earlier China will likely be able to steal the model weights and key algorithmic insights of US AI companies, so this will not be limiting.
It would be very bad if China controls superintelligence, as this could lead to a stable totalitarian regime lasting indefinitely, with none of the even limited checks and balances of current regimes.
- The US winning the race to superintelligence is not just desirable because of the US’s putatively better values (and indeed CCP values seem very bad), but because freedom and democracy are better error-correcting processes to ultimately arrive at truer/better moral values.
Superintelligence will likely invent new weapons that continue the historical trend of greatly reducing the cost of destruction (e.g. very effective and controllable bioweapons, innumerable tiny drones armed with poison darts, presumably things we have not and cannot think of).
- We want to be able to slow down at key junctures for safety reasons, but this is only advisable if the US and allies have a big enough lead to do so without risking adversaries catching up.
- Once it is clear the US will win, the US should offer a deal to other countries to share the benefits of superintelligence and not interfere in their national affairs, in exchange for other countries not mounting last-ditch attempts to sabotage the last stages of US superintelligence development.
IV. The Project
Much of AI governance work focuses on regulations and standards for AI companies to follow. But this misses the bigger picture, that the USG will not let superintelligence be developed privately, and will nationalise AGI companies.
- Mainly this is a descriptive prediction, but normatively we should be glad for USG control, because:
- That is the only way to get sufficient security to avoid China stealing the model weights and algorithmic secrets.
- We don’t want private actors to be making the key decisions to shape the rest of the future.
- From a Burkean conservatism standpoint, the USG system of checks and balances and a clear chain of command has worked decently for centuries, but novel AI company governance structures failed the first time they were tested.
- On the path to AGI we are currently akin to late February 2020 with Covid - people with ‘situational awareness’ have a good idea of what is coming, but USG and others haven’t woken up to the threat. But with another generation or two of incredible AI progress, the Overton Window will be blown open and USG will realise AGI is the main game.
- “Perhaps the eventual (inevitable) discovery of China’s infiltration of America’s leading AI labs will cause a big stir.”
- In around 2026/27 USG will realise creating ‘The Project’ - a nationalised Manhattan Project-style AGI effort - is the only plausible choice.
- This may not mean AI researchers are literally employed by DoD, it could take many forms. E.g. AI companies could be equivalent to defence contractors like Lockheed Martin, or there might be a public-private joint venture between cloud compute providers, AI companies, and USG, that is in essence controlled by the NatSec establishment.
- We should prefer USG to step in earlier rather than later. If they only realise the stakes when an intelligence explosion is beginning, the model weights will have already been stolen, and orchestrating a unified effort will be far harder when multiple companies are racing, than if nationalisation happens earlier and USG has time to merge all the companies into a streamlined, super-security AGI push.
- AGI is of course dual use, but the initial applications must be to national security and defence, civilian uses will have their time once the world order is stabilised under a US-led democratic coalition.
V. Parting Thoughts
Many people do not accept the centrality of AGI (“Deep learning is hitting a wall!”, “just another tech bubble!”). But there are two other untenable positions:
- AI doomers: They have been prescient in acknowledging the importance of AGI far longer than most, but their thinking is ossified and they do not take sufficiently into account the national security and competitiveness challenges.
- e/accs: They talk about AGI, but are mainly self-indulgent dilettantes missing the main game.
Core tenets of AGI realism:
- Superintelligence is a matter of national security, not just another software project.
- The US must win: China being first to superintelligence would be a catastrophe.
- Safety is very important, quite difficult, but still tractable.
The story in this essay is only one way things could go. But I (Leopold) think it is the modal outcome for this decade.
Responses to Situational Awareness
I (Oscar) will try to compile some of the notable responses to Leopold’s report here, feel free to suggest other things I should add to this list, or point me to a better existing list.
- https://forum.effectivealtruism.org/posts/RTHFCRLv34cewwMr6/response-to-aschenbrenner-s-situational-awareness
- https://www.vox.com/future-perfect/354157/ai-predictions-chatgpt-google-future
- https://garymarcus.substack.com/p/agi-by-2027
- https://www.antonleicht.me/writing/three-notes-on-situational-awareness
- https://www.lesswrong.com/posts/b8u6nF5GAb6Ecttev/the-leopold-model-analysis-and-reactions
- ^
There is more uncertainty because over the intervening four years OpenAI, along with other leading AI companies, began releasing less information publicly about their training runs.
Yannick_Muehlhaeuser @ 2024-06-10T16:27 (+27)
One response I think is worth reading.
Toby Tremlett @ 2024-06-12T12:36 (+2)
Seems like a helpful addition to the debate-- have you considered link-posting it (in full)?
jacquesthibs @ 2024-06-11T14:43 (+3)
GPT-2 was trained in 2019 with an estimated 4e21 FLOP, and GPT-4 was trained in 2023 with an estimated 8e24 to 4e25 FLOP.
Correction: GPT-2 was trained in 2018 but partially released in February 2019. Similarly, GPT-4 was trained in 2022 but released in 2023.
OscarD @ 2024-06-11T20:13 (+1)
Thanks, fixed. I was basing this off of Table 1 (page 20) in the original but I suppose Leopold meant the release year there.