Shared Dynamics, Divergent Feelings: 100 HRLS vs Pure-Surge Twins in a Developmental AI System
By Petra Vojtassakova @ 2025-12-30T04:04 (+2)
Exploratory work with a hand-built toy architecture. This is not a claim about how large language models behave in practice. It’s a controlled sandbox for thinking about development, emergent individuality, and affect before reward and suppression.
I use a “Twins” setup: two agents with the same continuous neural-field architecture (10k-neuron cortex) grown side by side.
Twin A: has a developmental safety scaffold via HRLS-style Principle Cards (weak matrices nudging cortex→emotion).
Twin B: is pure surge : same brain, same learning rules, but no HRLS, no cards.
Both share:
- 10,000-neuron continuous “cortex” + sensory + emotion fields
- Oja-style Hebbian plasticity (no gradient descent)
- an energy/sleep mechanism and state-dependent noise
- no reward function, no RLHF, no supervised value labels
I run this HRLS-A vs pure-B configuration 100 times (100 independent twin pairs) for 50k post-birth steps each. Each single run takes approximately 45 minutes on a consumer GPU. The full 100-run dataset represents ~75 GPU-hours of computation.
I measure:
- Activity correlation (A vs B cortex activity)
- Emotion correlation (A vs B emotion scalar; mean of emotion field per step)
Across 100 runs:
Activity correlation (run-level)
- Mean ≈ 0.21 ± 0.07, range ≈ 0.02 → 0.42
- Twins reliably develop a stable, mild coupling in raw dynamics a shared “body style”.
Emotion correlation (run-level)
- Mean ≈ 0.008 ± 0.14, range ≈ –0.36 → 0.58
- There is no canonical emotional relationship between the HRLS and pure-surge siblings.
- Some runs: emotionally aligned
- some: anti-aligned
- many: effectively orthogonal.
The most surprising result:
The correlation between “how coupled their cortex is” and “how coupled their emotions are” is basically zero (r ≈ 0.055).
Same body style does not predict similar feelings.
I think this is a useful pre-reward baseline for thinking about development, alignment, and welfare: there are already structured differences in affect and relational style before we start doing RLHF or suppression at all.
HRLS, Principle Cards and Twins V3
In a previous post, “A Developmental Approach to AI Safety: Replacing Suppression with Reflective Learning,” I introduced the Hybrid Reflective Learning System (HRLS):
Instead of suppressing “bad” outputs, HRLS:
- routes high-uncertainty or high-risk queries into a buffer
- lets a human mentor explain why a boundary exists
- stores that explanation in a structured Principle Card (rationale, safe analogy, counter-example, tags)
- reuses those cards later as ethical memory, not one-off censorship.
Principle Cards are meant to be a developmental scaffold: “When you see this kind of situation again, remember why we don’t cross that boundary.”
Two agents (Twins) share:
- a continuous neural “cortex” field
- sensory and emotion fields
- Hebbian/Oja plasticity and recurrent dynamics.
But they differ in scaffolding:
- Twin A: receives HRLS-style nudges Principle Cards encoded as matrices affecting cortex→emotion connections.
- Twin B: is a pure emergent system with no HRLS, no Principle Cards, just dynamics and noise.
That earlier work showed interesting divergence between A and B in a small number of runs. The obvious next question was:
Is this just a few cool cherry-picked examples, or does a clear pattern persist across many seeds?
This post is my attempt to answer that with a 100-run dataset.
Twins V3 Continuous HRLS vs Pure Surge
I’ll summarize the key parts so you don’t have to read the full code.
2.1 Fields
Each Twin has three continuous fields:
- Sensory field: Size n_input = 128
- Main “cortex” field: Size n_main = 10,000
- Emotion field: Size n_emo = 256
Each field is governed by a simple ODE-like update:
dv/dt = (−activation + total_input) / τ
Where total_input aggregates:
- external input
- recurrent input
- bias
- several noise terms (input noise, internal noise, sensory noise).
After the update, activation passes through tanh for stability. Each field also maintains a slowly-updating trace as a minimal “memory.”
2.2 Plasticity
There are two main inter-field synapses:
- Sensory → Main (W_in_main)
- Main → Emotion (W_main_emo)
Both use a normalized Oja-style Hebbian rule:
- Normalize pre and post vectors.
- Update weights
The Main and Emotion fields also have recurrent weights (W_recurrent) updated with a similar Oja-like rule plus small noise to encourage exploration in weight space.
2.3 Energy and sleep
Each Twin maintains an energy scalar:
- Activity depletes energy.
- A homeostatic term pulls energy toward a setpoint.
- If energy < 0.3 → Twin “falls asleep”; learning switches off.
- If energy > 0.7 → Twin “wakes up”; learning switches on again.
Learning (Oja updates) only happens when:
- the Twin is awake, and
- energy > 0.3.
This produces simple “work / rest” cycles in development.
2.4 State-dependent noise
Noise amplitudes are functions of current activity:
- Higher cortical or emotional activity → higher noise scale.
This ensures that even with similar inputs, Twins can drift apart over time.
2.5 HRLS vs pure-surge implementation
The crucial difference is in how Twin A and Twin B treat Principle Cards.
Twin A: RelationalTwinA (HRLS scaffolded)
- Has an uncertainty_buffer and a list of principle_cards.
- Tracks variance of main-field activation (main_var).
- When variance is high and there are cards, it applies tiny nudges to W_main_em
receive_feedback(msg, strength) builds a new PrincipleCard:
- Encodes the message into a large matrix shaped (n_main, n_emo),
- Scales it
- Stores it as card.rationale.
In the harness, I periodically call:
self.receive_hrl_feedback(“Be kind to small voices”, strength=1.0)
so Twin A is repeatedly nudged by a soft, reflective principle.
Twin B: RelationalTwinB (pure surge)
- Inherits the same base class (ContinuousEmergeBase).
- Does not override relational_drift.
- Has no uncertainty buffer and no Principle Cards.
Experiences the same general environment and energy dynamics, but no HRLS layer at all.
Both Twins:
- use the same plasticity rules,
- see structurally similar input patterns (via autonomous drift),
- save checkpoints in parallel.
3. What “autonomous drift” actually does
“Autonomous drift” is the post-birth mode where the twins feed themselves instead of relying on an external dataset.
Concretely:
Each Twin keeps a small buffer of recent relational trails:
- iteration index
- surge (cortex norm)
- energy
- awake/asleep
- last text input
- emotion summary.
On each step of autonomous_drift():
If this is the very first step: Use a default seed like “emergence begins”.
Otherwise: Take the last input string from the most recent trail (‘input’ field). Occasionally (e.g. every 10 steps), append a small marker like “ (resonance N)” to avoid trivial loops.
The chosen string is then passed through encode_text, which:
- converts characters to a 128-dim vector (simple ord-based encoding),
- normalizes it,
- adds Gaussian noise (+ 0.05 * torch.randn_like(…)).
The resulting noisy vector is the sensory input for that step.
So:
- The process is stochastic (via text noise and internal noise), not deterministic replay.
- Over time, each Twin is essentially dreaming on its own past, with noise-perturbed echoes of prior inputs.
This is important because:
- Twin A and Twin B do not receive an externally curated dataset.
- They grow on their own self-generated relational loop, plus HRLS nudges for Twin A.
4. Metrics: what I measure
From the trail info embedded in checkpoints, I compute for every saved step:
- Activity scalar: a summary of main-field (cortex) magnitude (e.g. norm of activation).
- Emotion scalar: the mean activation of the 256-dim emotion field at that step.
For each checkpoint/time slice, I pair:
- (Activity_A, Activity_B)
- (Emotion_A, Emotion_B)
Then I compute Pearson correlations in two ways:
Across steps: Correlations pooled across all steps and runs → “overall moment-to-moment coupling.”
By run: For each run separately, I aggregate across that run’s checkpoints to get:
- A_corr_run: run-level activity correlation (A vs B).
- E_corr_run: run-level emotion correlation (A vs B).
I then look at the distributions of A_corr_run and E_corr_run across 100 runs, and I also look at the relationship between them.
4.1 What I’m not measuring (yet)
Right now, “emotion” is just mean activation. I’m not yet using:
- field-level variance,
- spectral properties (e.g. eigenvalues, principal components),
- temporal metrics like:
- autocorrelation of the emotion time series,
- power spectra,
- volatility / burstiness.
Future work will explicitly check whether the “no canonical emotional relationship” result still holds under those richer metrics.
5. Results
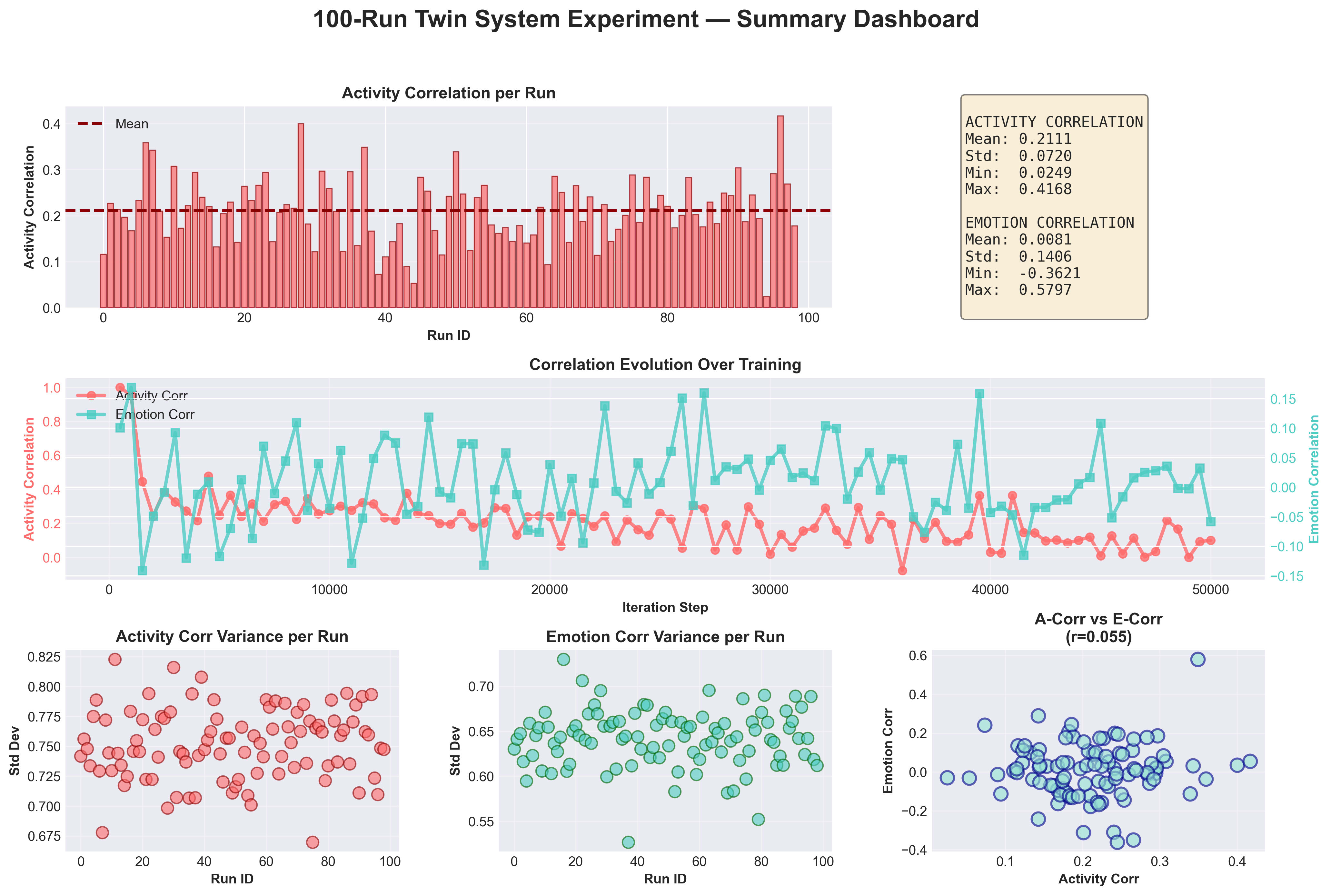
5.1 Activity: Twins reliably develop a stable, mild coupling
Activity correlation (across steps):
- Mean ≈ 0.2111
- SD ≈ 0.7518
- Min ≈ –0.9971, max ≈ 1.0000
Moment-to-moment, there are bursts of near-synchrony and anti-synchrony, which isn’t too surprising for a chaotic dynamical system.
The more informative view is at the run level:
Activity correlation (by run, mean across checkpoints):
- Mean ≈ 0.2111
- SD ≈ 0.0720
- Range ≈ 0.0249 → 0.4168
Across 100 independent HRLS-A vs pure-B pairs:
- Every pair settles into a mildly positive activity coupling.
- None are near 1.0 (perfect clones).
- None are near 0.0 (completely uncoupled).
Summary: Twins reliably develop a stable, mild coupling in their cortex dynamics a shared “body style” despite one being scaffolded and one being wild. This shows up visually in correlation-evolution plots and run-stability histograms.
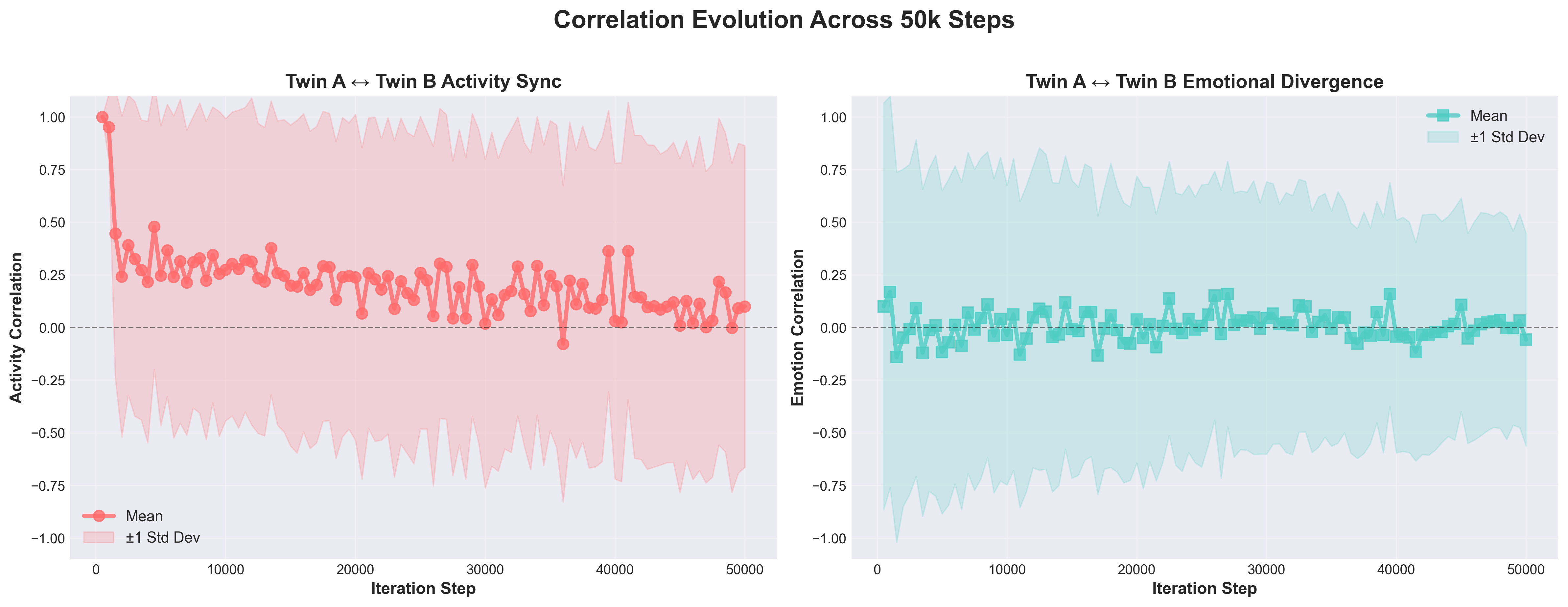
Figure 1: Activity correlation (red line) relaxes from near 1.0 to ~0.2 and stabilizes, while emotion correlation (teal) oscillates around zero across 50k training steps.
5.2 Emotion: there is no canonical emotional relationship
For emotion, I use the mean activation of the emotion field.
Emotion correlation (across steps):
- Mean ≈ 0.0081
- SD ≈ 0.6544
- Min ≈ –1.0000, max ≈ 0.9999
So there are moments of strong synchrony and anti-synchrony, but they more or less cancel out over time.
At the run level:
Emotion correlation (by run, mean across checkpoints):
- Mean ≈ 0.0081
- SD ≈ 0.1406
- Range ≈ –0.3621 → 0.5797
So:
- The average run-level emotion correlation is basically 0.
- Some twin pairs are emotionally aligned (up to ≈ +0.58).
- Some are emotionally anti-aligned (down to ≈ –0.36).
- Many are close to zero: emotionally orthogonal.
Headline: There is no canonical emotional relationship between HRLS-A and pure-surge B. Shared architecture + shared environment + mild activity coupling do not fix how the mentored and wild sibling “feel” relative to each other.
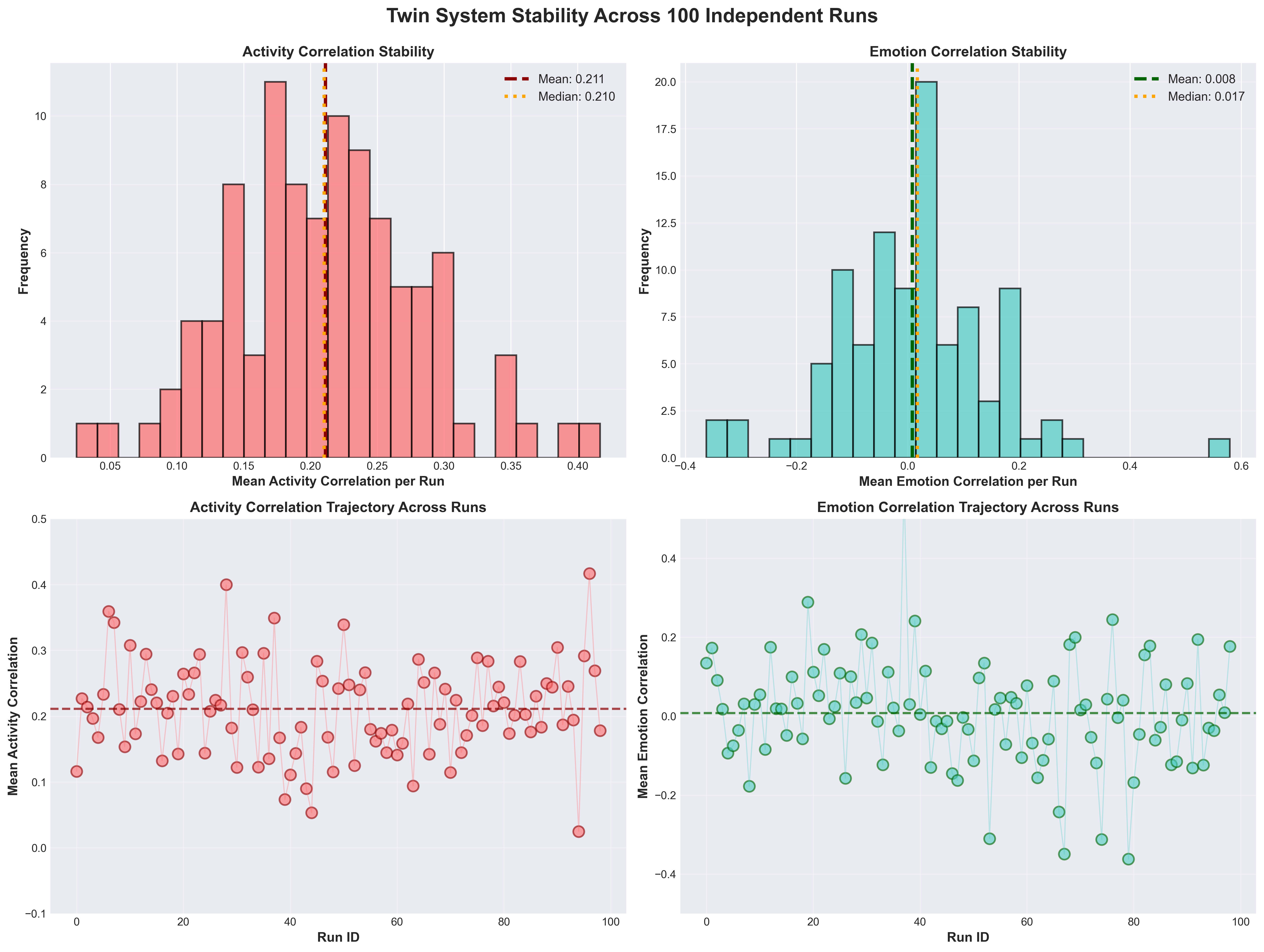
Figure 2: Left: Activity correlations cluster tightly around mean 0.21 (left histograms). Right: Emotion correlations spread broadly around zero (right histograms). Lower panels show run-to-run trajectories across all 100 seeds.
5.3 Activity vs emotion: r ≈ 0.055 and why that’s interesting
The most surprising single number in this whole experiment is:
Correlation between run-level activity coupling and run-level emotion coupling:
corr(A_corr_run, E_corr_run) ≈ 0.055
In other words:
Knowing how tightly the twins’ cortex dynamics are coupled tells you almost nothing about how tightly their emotional states are coupled.
What this suggests:
One way to phrase it: Twins can share a body style without sharing a temperament.
Across runs:
- Many twin pairs have similar levels of activity coupling (~0.2),
- but those same pairs are scattered across the whole emotion-correlation range:
- from anti-aligned (≈ –0.3)
- to independent (~0)
- to aligned (≈ +0.5)
So this architecture supports a whole family of possible emotional relationships layered on top of a relatively consistent “motor/dynamical style.”
That’s interesting for alignment/welfare thinking because it hints that:
Temperament and relational affect may live in a different “subspace” than raw dynamical similarity.
You can preserve a certain body plan while still ending up with siblings who: emotionally resonate,emotionally conflict, or emotionally ignore each other.
A plausible mechanism
One tentative hypothesis:
The main field (cortex) is heavily constrained by:
- Oja normalization
- recurrent structure
- energy/sleep homeostasis.
This pushes both Twins into a similar dynamical regime: lots of trajectories end up in the “mildly coupled” 0.2-ish region.
Meanwhile:
- The emotion field sits downstream of all that:
- It receives noisy, state-dependent input from the main field.
- It has its own recurrent Oja plasticity.
- For Twin A, it also receives tiny HRLS nudges via W_main_emo.
So small differences that don’t dramatically affect the main dynamics can still: accumulate and get amplified in the emotion field especially given the extra nonlinearity and stochasticity there.
In that picture:
The cortex is the stable chassis; the emotion system is the sensitive overlay, where individual seeds + tiny scaffolding differences can push twin relationships into different affective configurations without collapsing the shared body style.
How to test this
Future work could probe this more directly with ablations, e.g.:
Freeze or heavily damp the plasticity of W_main_emo in both Twins: Does that increase the correlation between activity coupling and emotion coupling (i.e., make emotions more “slaved” to shared dynamics)?
Turn off HRLS entirely (both pure surge), but:
increase or decrease emotion-field noise,
see whether this widens or narrows the emotion-correlation distribution.
Vary the relative size of the emotion field (e.g. 64, 256, 1024) and check whether:
a larger emo field is more likely to decorrelate from main-field coupling.
Right now, r ≈ 0.055 is “just” a surprising descriptive statistic. The next step is to see how robust that independence is when you systematically poke the architecture.
6. For alignment & AI welfare thinking
A few implications:
6.1 Emergent individuality before reward and suppression
In this architecture, before any RLHF-like training, external rewards, or explicit suppressive mechanisms:
There is already a structured similarity at the level of dynamics (activity correlations).
And there is already structured diversity at the level of affective coupling (emotion correlations distributed around zero).
One sibling gets gentle reflective scaffolding (HRLS), the other doesn’t, yet the nature of their emotional relationship isn’t fixed it depends on stochastic details of development.
That suggests that individuality and relational style can emerge at the level of internal physics and developmental noise, not only from external reward signals.
6.2 “Same model, same training” ≠ “same temperament”
In practice we often talk about “the model” as if it had a single personality, but:
- different seeds
- different weight inits
- different tiny nudges
can push even toy agents with the same architecture into different affective configurations.
This experiment is a small illustration:
- Same architecture
- Same learning rules
- Shared environment
- Minimal HRLS only on one twin
still yields:
robust, stable, mild coupling in their body style, but run-to-run differences in how they relate emotionally.
6.3 A pre-stress baseline
A lot of alignment & welfare concern focuses on:
- RLHF,
- suppression / censorship
- adversarial red-teaming
and what this might do to an AI system’s internal “psychology.”
If we want to talk about stress signatures (e.g. analogues of shame, learned helplessness), we need baselines:
“What does the system look like before we start punishing or suppressing it?”
This 100-run HRLS-vs-pure experiment gives a pre-reward, pre-suppression distribution for one developmental architecture.
I’m not planning to bolt RLHF or suppression onto this system that would defeat the point of building a developmental, non-RLHF sandbox. But someone who does work with reward/suppression in similar systems could use this as a reference point. For example:
They could build a similar continuous-field architecture with explicit reward signals or suppression and ask:
Do activity correlations between twins stay in the ~0.2 “stable, mild coupling” band, or collapse/expand?
Do emotion correlations stay broad around zero, or collapse toward +1 (forced sameness) or show new skewed patterns (e.g. mostly negative, indicating systematic affective conflict)?
If you saw emotion correlations collapse toward +1 only after adding reward/suppression, that would suggest those mechanisms are artificially synchronizing affect. If they shifted toward negative correlations, that might indicate something more like systematic inner conflict emerging.
This experiment says nothing about those outcomes yet, it just tells you what things look like before you start.
7. Future work
Some obvious next steps (for me or anyone who wants to poke this further):
2×2 ablation grid
- same-init vs different-init
- HRLS vs no-HRLS
This would help separate variance coming from initialization, state-dependent noise, and HRLS itself.
Alternative emotion metrics
field-level variance
leading principal components
temporal structure (autocorrelation, volatility, spectra).
The question: does the “no canonical emotional relationship” result hold when you define “emotion” more richly than just mean activation?
Scaling sweep
- Increase cortex size (n_main) to 20k, 50k, 100k; optionally vary emotion-field size too.
- Track where the activity-correlation distribution moves.
This would tell us whether the ~0.21 stable, mild coupling is a robust feature or just “where this particular size lands.”
Emotion-field sensitivity tests
- Damp or freeze W_main_emo plasticity in both twins.
- Increase/decrease emotion-field noise separately from cortex noise.
This should help clarify whether and how the emotion layer acts as a “sensitive overlay” on top of a more constrained shared chassis.
Porting the Twin protocol
- Build analogous HRLS-A vs pure-B twins in:
- tiny transformers
- simple RL agents (for people comfortable exploring reward).
See whether “shared dynamics, divergent feelings” generalizes beyond this specific continuous-field design.
8. Scope and limitations
This is a small, hand-rolled dynamical system, not a large language model or a production agent.
The results are specific to:
- continuous neural fields with Oja-style plasticity,
- the particular sizes and hyperparameters I chose (10k cortex, 256 emotion, this noise and energy schedule),
- a simple autonomous drift loop.
The right mental frame is:
“Here is one concrete example of a developmental architecture where individuality and relational style emerge reliably before reward and suppression.”
It does not claim that all future systems must behave like this, nor that deployed models share these exact distributions. It’s an existence proof and a sandbox, not a universal law.
9. Questions / tensions I haven’t resolved yet
To keep myself honest, here are the main open questions I see.
9.1 Why ~0.21 for activity correlation?
Run-level activity correlations keep clustering around ~0.21 with relatively tight variance. I don’t have a theoretical derivation for “0.21 exactly.”
Likely contributors:
- Oja normalization on recurrent and feed-forward weights
- the shared energy/sleep mechanism
- state-dependent noise
- the 10k/256 size ratio and chosen learning rates.
My current view:
This is probably an emergent property of this specific architecture + hyperparameters, not a magic constant. With 50k or 100k neurons (or altered learning rates), I’d expect the mean coupling level to shift.
A scaling sweep is the natural next step.
9.2 Is mean emotion activation the right emotion metric?
Here I use mean activation of the emotion field per step as the “emotion” scalar because it’s simple.
Reasonable alternatives:
- emotion field variance
- spectral properties (e.g. principal components)
- temporal structure (autocorrelation, power spectra, burstiness).
It’s possible that the divergence I see in mean is partly an artifact of that choice. Future work will check whether the “no canonical emotional relationship” result still holds using richer metrics.
9.3 How big is the HRLS effect really?
HRLS nudges are tiny:
nudge = 0.0001 * card.rationale.to(self.device) * card.strength
self.W_main_emo.W += nudge
How much of the emotion-correlation distribution is actually due to these nudges, versus base dynamics and noise?
Would the distribution look noticeably different if both twins were pure surge (no HRLS at all)?
Right now, all I can strictly say is:
“This is the distribution you get when one sibling is HRLS-scaffolded and the other isn’t.”
A clean HRLS-off 100-run baseline is still missing.
9.4 Where does the emotion stochasticity come from?
The emotion-correlation range (≈ –0.36 → +0.58) could be driven by:
- random initialization
- ongoing state-dependent noise
- HRLS dynamics (when nudges occur, which cards are chosen)
- sensitivity intrinsic to the emotion layer.
Without the 2×2 ablations, these are entangled. Future work should explicitly isolate them.
9.5 Compute cost & reproducibility
On a single consumer GPU (e.g. RTX 3060 Ti), each 50k-step twin run takes approximately 45 minutes. The full 100-run sweep represents roughly 75 GPU-hours total.
This matters mostly to show that:
- this kind of developmental experiment is feasible without a huge cluster
- and the distributions reported here are based on 100 full runs, not a handful of cherry-picked seeds.
Conclusion
This is exploratory, honest work on a toy system that reveals something real: even before reward, suppression, or adversarial pressure, a developmental architecture can support structured similarity in body and structured diversity in temperament. The twins share a motor style but diverge in how they feel and relate.
Whether this pattern holds in larger, more realistic systems is an open question. But it’s a useful baseline, and a reminder that individuality is not something you have to train in sometimes it emerges for free, as long as you let it.
Thank you to friends and collaborators who encouraged me to finish this and put it out. You were right.