What can we learn from parent-child-alignment for AI?
By Karl von Wendt @ 2025-10-29T08:00 (+4)
Epistemic status: This is not a scientific analysis, but just some personal observations. I still think they point towards some valid conclusions regarding AI alignment.
I am a father of three sons. I would give my life to save each of them without second thoughts. As a father, I certainly made mistakes, but I tried to do everything I could to help them find their own way through life and reach their own goals, and I still do. If I had to make a conflicting decision where my own interests collide with theirs, I would decide in favor of them in most cases, even if I suffer more from the decision than they would in the opposite case, because my own wellbeing is less important to me than theirs. I cannot prove all of this, but I know it is true.
Evolution seems to have found a solution to the alignment problem at least in the special case of parent-child-relationships. However, this solution is not fail-safe. Unfortunately, there are countless cases of parents neglecting their children or even emotionally or physically abusing them (I have intense personal experience with such a case).
I use a simple mental model of human motivation that looks like this:
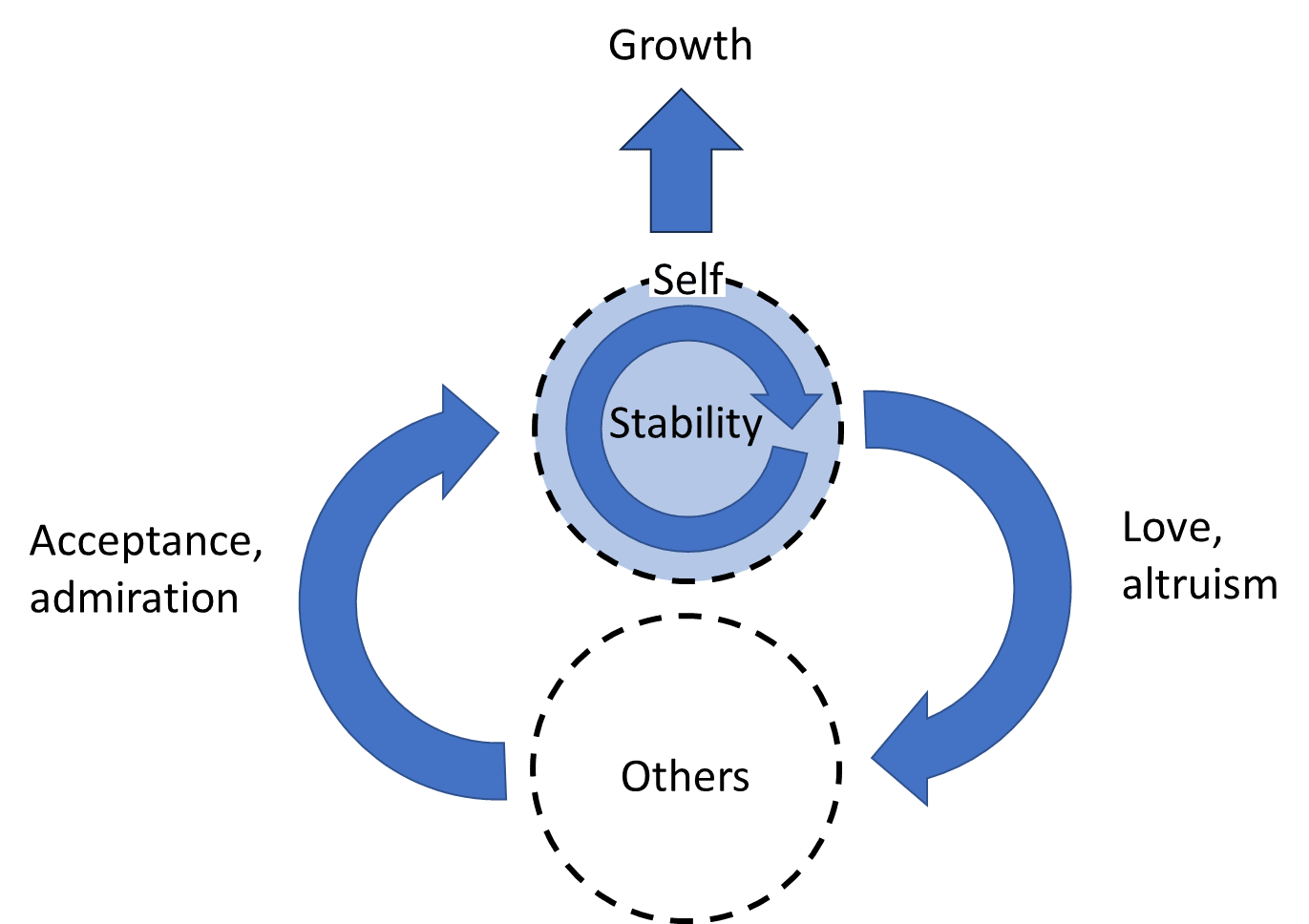
The arrows symbolize four different classes of motivation. At the center, there’s a selfish need for stability (safety, food, etc.). Most people also have a need to grow, e.g. to explore and learn new things. On the other side, there are two different kinds of motivation regarding relationships with others. On the left, we need to feel accepted, to be valued, maybe even admired by others. On the right, most of us have genuine feelings of love and altruism towards at least some other people, e.g. the love of a parent for their children as mentioned above. This simple model is neither complete nor scientific, it just reflects my own view of the world based on my personal experience.
It is important to realize that these motivations can be in conflict with each other and are varying in strength depending on the situation, symbolized in my diagram by the strength of the arrows. For instance, I may feel inclined to sacrifice my own life for one of my sons, but not for my neighbor and even less for someone I don’t like. There’s also a varying degree of importance based on character traits. For example, a pathological narcissist’s diagram might look like this:

From my own personal experience, this is a real problem – there are people who don’t feel any kind of love or altruism for others, probably even lack the ability for that.
If we use this concept to look at the way current AIs are trained with RLHF, I think the result looks exactly like that of a narcissist or sociopath. Current AIs are trained to be liked, but are unable to love. This explains their sycophantic and sometimes downright narcissistic behavior (e.g. when LLMs recommend their users to break relationships with humans so they can listen more to the LLM).
Of course, an LLM can be made to act like someone who feels genuine love, but that isn’t the same. A narcissistic mother will act in public like she loves her children because she knows that’s what people expect from a mother, but behind closed doors the mask will drop. Of course, the children know that it’s just a play-act the whole time, but they won’t dare disrupt the performance out of fear of the consequences (again, I know from personal experience that this is real, but I’m not a psychologist and won’t try to explain this phenomenon in more detail).
This seems to point towards the conclusion that training an AI solely based on observed behavior is insufficient to induce consistent, truly altruistic or “aligned” behavior. To be more precise, it seems extremely unlikely that behavior-based training will by chance select a model out of all possible configurations that is actually intrinsically motivated to behave in the desired way, instead of just acting like desired. To use an analogy, it is much easier to change one's behavior than one's inherited character traits.
I have no solution for this. I don’t know enough about human psychology and neuroscience to suggest how we could model true human altruism inside an AI. But it seems to me that in order to solve alignment, we need to find a way to make machines truly care about us, similar to the way a parent cares about their children. This seems to imply some new architecture for developing advanced general AI.
Even if we could solve this, it would still leave many open problems, in particular how to balance conflicting needs and how to resolve conflicts of interest between different “children”. But still, knowing that I can love my children more than myself gives me some hope that AI alignment could be solvable in principle.
Until we have found a proven solution, I strongly oppose developing AGI, let alone superintelligence.