Gradient Descent as an analogy for Doing Good
By JWS 🔸 @ 2024-10-11T11:12 (+16)
Introduction
What does it mean ‘to do good’? How can we know what to do in a world as uncertain as the one we find ourselves in? In this post I’ll use the Gradient Descent algorithm as an analogy to doing good as an individual engaged with[1] Effective Altruism. In particular, I want to argue against a potential failure mode of believing that:
- The only morally acceptable world is the best possible one (i.e. "doing the most good").
- The only moral actions are those which bring such a world about.
- Rapid and drastic self-negating personal lifestyle changes are the right way to achieve these goals.
This analogy has been on my mind for a while. I think the original spark of the idea came from Zoe Cremer’s EA-critical article in Vox[2]. That was more focused on the collective/institutional efforts of EA, and you could also extend the analogy this way, but I’ve framed this piece to be more about personal choices instead. Finally, while there are many caveats to make when using analogies this piece is meant to be reflective and not an academically rigorous. At the very least I hope some of you find it useful.
Hold on, What is Gradient Descent?
(Feel free to skip this section if you're already familiar with this topic)
Gradient Descent is an optimization algorithm. I'm going to leave the technical details out of this essay,[3] because fundamentally Gradient Descent is almost absurdly simple:
1: Begin at a starting point
2: Calculate the direction where your loss function decreases the most rapidly
3: Move a small step () in that direction. Your new position is
4: Go back to Step 1, but now at
5: If you meet some halting condition then stop
And that's really it conceptually. Or, in plainer English: take a small step in the right direction. Then, check whether you're still going the right way, and move in that direction. Repeat this process until it's time to come to a stop.
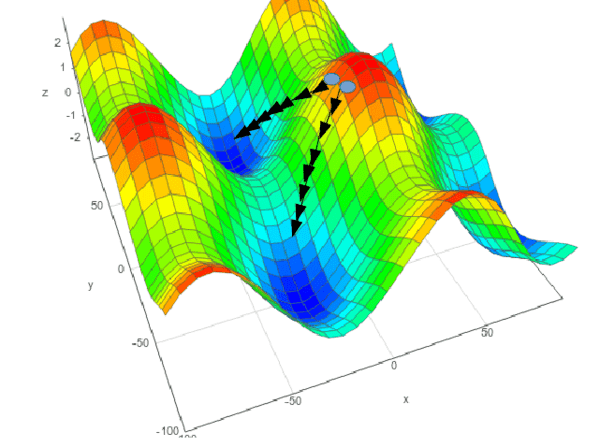
Fig 1. A depiction of gradient descent in a 2-D space, where height depicts the loss at any particular {x,y} point. In Machine Learning we usually want to minimise loss, so in this example lower is better. We also see that which minima GD ends up in is highly sensitive to the starting position (see failure mode 1 below)
This simple process has proved remarkably successful as part of the neural network renaissance, and is the key method to tune the parameters inside large models without having to manually correct their weights to get our desired behaviour. After a training pass, we use gradient descent to tweak the weights of the model in the right direction to minimise loss and keep on tweaking with more passes of data. Eventually, your model gains the ability to do much better on its task, guided by this process of iterative updating and feedback.
However, there are several common failure modes that gradient descent can fall into, at least the 'vanilla' version that is commonly taught in ML courses:
1 - Gradient Descent is never guaranteed to find the global minimum, only a local one. If one imagines Gradient Descent as a 'ball rolling down a hill' as is commonly taught, then it becomes clear that one can never roll 'back up' to explore a different path. You will reach the bottom of a valley, but perhaps not the deepest valley attainable.
2 - The results of the algorithm are highly dependent on the learning rate (in simple terms, how long your steps are). This is a practical issue, as one of the flaws of Gradient Descent is that it can take a very long time to reach a local minimum, especially with a small learning rate. Conversely, having one too large could mean that the algorithm fails to converge to a solution at all. Such issues are often why there is a halting condition set to a number of steps.
3 - The loss function must be differentiable everywhere (this is the reason that GD is technically not a local search algorithm as I've presented it to be so far). The direction to move in is not discovered through exploring the world, but instead falls out automatically from the mathematical definition of the loss function. If this loss function is not differentiable, then a loss for a particular point cannot be defined, and GD will not work.
Nevertheless, in spite of these conceptual limitations,[4] in practice Gradient Descent is standard practice in ML to train models from toy examples to large production-scale Language Models.
What does the analogy look like?
For the analogy to work we need a set of dimensions to act over and a loss function to translate those states of the world into a metric which we could apply the GD method to, i.e. create the topology for the balls to roll down the hill. In the case of a single EA we could imagine a simplified example in an {x,y} space: x could stand for '% of my disposable income donated' and y could stand for '% donated to animal welfare - % donated to global health'. I also think it's clear Effective Altruism does involve some non-trivial commitment to certain states of the world being better or worse than others,[5] meaning a loss function could be constructed. The loss function would then convert any {x,y} choice into a judgement of how 'good' that world is. Our EA would then just apply the algorithm from their starting point and they would end up doing more good than they started with (though not necessarily the most good).
In the next section I'll discuss where this analogy breaks down, but first I want to discuss one benefit it has. The condensed plain English version of gradient descent was: "Take a small step in the right direction. Then, check whether you're still going the right way, and move in that direction. Repeat this process until it's time to come to a stop." So in this analogy our EA would (hypothetically) be donating a small fraction of her income, split 50/50 between the two cause areas. After some time passes she'd re-assess and perhaps donate a bit more, shifting it more towards which cause had more persuasive evidence behind it or ability to use funding, and keep doing so over time.
However, my intuition is that some people who get into EA have the "taking ideas seriously gene", and when they encounter EA ideas they try to think "in the limit, what would the right thing to do be?" and then jump straight to that point, feedback be damned. I do think that many people in the world are under-updating their behaviour based on their moral beliefs, but in some cases EAs might be doing this too much. There are various Forum posts that reveal this kind of thinking in EA, such as this moving post from Julia Wise. Some hypothetical examples of these might be:
- Reading Animal Liberation and immediately stopping eating any animal products, and starting to suffer from B12 deficiency.
- Reading Famine, Affluence, and Morality and donating everything one owns beyond the absolute bare minimum for survival, living in destitution and misery.
This is not to say that everyone in EA has or would make these kind of mistakes, only to say that if those who did had perhaps had the Gradient Descent analogy in their mental toolbox (in this case that their learning rate might be too high to find the optimal solution) they might have avoided these failure modes. The two hypothetical examples might have go something like this instead:
- Reading Animal Liberation, doing research into vitamin supplementation, and gradually eating less and less meat to find a sustainable and healthy diet while donating more to animal welfare causes.
- Reading Famine, Affluence, and Morality and deciding to take a trial GWWC pledge, and gradually increasing that % over time to 10%+, while searching for new jobs that might enable a career in E2G.
So already this far-too-simple analogy starts to reconceptualise what 'doing good' means from "I must act in this way or I am an immoral/evil person" or "only the best possible world is morally acceptable" to "It would be good for the world to be better, how I can get on and stay on the right track to it". If nothing else, this is the takeaway I'd like you to takeaway from the post. That doing good, from the agent's point of view, might be as much about the process taken to get there as the end state itself.
Limitations and Further Thoughts
Of course, this analogy is way too simple to actually be an account of moral decision-making in an uncertain world. However, I think correcting for this only pushes further against the version of EA that says there is only one best way to do good and that everything else must be sacrificed for it:
First, the number of dimensions one can choose to act across is essentially infinite. You might be able to simplify it to a small number of highly important choices (e.g. what job to have, whether to have kids or not, etc...) but this is still a very lossy compression, and you may end up ignoring the potential interaction effects of smaller actions and other potential routes to impact. This is the same philosophical critique that says global act consequentialism is computationally intractable, and in my view this objection is correct. We cannot know with certainty whether we have 'done the most good' (as compared to having reliably done good, and even that is uncertain), so it attaining it cannot be held as an all-or-nothing marker of morality.
Second, the world is constantly changing, dynamic system. How good the world is, and where we find ourselves in it, is never due to our actions alone. Instead it involves the consequences of the acts of many agents all at once. Meanwhile Gradient Descent is a deterministic process, once you have the loss function and hyperparameters you can just execute the program and await your answer. To actually doing good (even trying to do 'the most' good) it is never enough to just make one major update and stick with that decision. It's a constant process of checking, and updating, and never being sure we actually have ended up at 'the best possible' outcome. It's like not having a halting condition on your GD algorithm, and where your position of the loss landscape can constantly change beyond your control. You have to be adaptable, because this uncertainty is a feature of the universe, not a bug.
Third, and related to the above, moral decision-making and doing good is much more like a search algorithm than it is a mechanistic process. This means that it is much harder to solve for mathematical optima. How much time should you spend 'exploring' different interventions vs just funding existing ones which are known to work? How long should we expect our estimates of the world to be accurate? Furthermore, in the real world we incur a cost for stopping and searching, which the GD analogy denies. But it's also true of simplistic approaches to doing good that assume we could easily calculate the 'right' approach to do good. In the face of irreducible, Knightian uncertainty, and no analytic way to truly determine the 'optimum' end point, there may instead be a number of valid approaches to doing good that reasonable people might choose to follow.
Fourth, there is meta uncertainty about what 'the right metric' even is. One could use a person-affecting form of utilitarianism, or even some deontological guides, or even try to use some common-sense view to score or rank and order the potential worlds. Different agents will have different orderings over what worlds are better than others. GD can tell you how to travel given a certain definition of what 'good' means, but it cannot tell you what it means to be 'good' in the first place. These are not problems unique to EA, they are puzzles for everyone, but they again make it difficult to create a reliable scalar scoring, or even ranking, over our potential actions.
The key takeaway from this section is that, while the GD analogy has undeniable limits, addressing them leads us further away from a problematically naïve approach to EA that says we can easily know what 'the best thing to do is', act confidently in that way, and then stay on that course regardless of what feedback we get.[6]
Final Thoughts
A potentially dangerous failure mode when trying to "do the most good" is that, if people believe that the most good is only a specific state of the world, then there is a temptation to view any action taken to move there as acceptable. (Such defective reasoning may have played a role in the FTX disaster).
By viewing the task of doing good as more like a Gradient Descent algorithm, we can mitigate this downside risk. We can conceive what 'doing good' means to be more like finding a path to good, being aware that our solutions are never guaranteed to be global or permanent, and being willing to be incremental and seek feedback as we go about doing good in the world.
Maybe to most of you reading these conclusions are obvious or even trivial. But to those of you who are struggling with personal dilemmas and feelings of guilt, who feel the call to change everything about your life, perhaps negatively for you, as a result of a self-denying obligation, I hope it can be a small step toward a better direction.
- ^
Or even "adjacent-to". This is post is more about personal engagement, you don't have to have any specific institutional affiliation.
- ^
in particular the section called "The optimization curse"
- ^
Though if you do want to dive into the details, there are a number of good sources to build an intuition. Some that stood out to me while searching were:
- 3blue1brown's video from his Neural Networks course
- Lili Jiang's explainer blogpost
- Sebastian Raschka's blog
- This book chapter on arxiv (note, this is by far the most technical one I've linked to)
- ^
And also because of conceptual tweaks to solve these problems, for example incorporating Momentum into GD
- ^
The meta-ethical nature and grounding of this value is a deep and interesting question, but outside the scope of this post
- ^
Again, I'm not saying that this is a common mistake, or a realistic one, only that it's a potential tendency in EA that needs to be fought against.
SummaryBot @ 2024-10-11T18:36 (+1)
Executive summary: The gradient descent algorithm provides a useful analogy for doing good, suggesting an incremental approach rather than drastic changes, while acknowledging the limitations of optimizing for a single best outcome in a complex world.
Key points:
- Gradient descent involves taking small steps in the right direction and reassessing, which can be applied to personal choices in doing good.
- This approach counters potential failure modes of extreme self-sacrifice or rapid lifestyle changes in pursuit of doing the most good.
- The analogy has limitations, including the infinite dimensions of moral choice, the dynamic nature of the world, and uncertainty about the right metric for goodness.
- Recognizing these limitations reinforces the need for adaptability, continuous reassessment, and acceptance of multiple valid approaches to doing good.
- Viewing doing good as a process rather than a fixed end state can mitigate risks associated with believing only one specific outcome is acceptable.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.