Survey on the acceleration risks of our new RFPs to study LLM capabilities
By Ajeya @ 2023-11-10T23:59 (+44)
My team at Open Philanthropy just launched two requests for proposals:
- Proposals to create benchmarks measuring how well LLM agents (like AutoGPT) perform on difficult real-world tasks, similar to recent work by ARC Evals.[1]
- Proposals to study and/or forecast the near-term real-world capabilities and impacts of LLMs and systems built from LLMs more broadly.
I think creating a shared scientific understanding of where LLMs are at has large benefits, but it can also accelerate AI capabilities: for example, it might demonstrate possible commercial use cases and spark more investment, or it might allow researchers to more effectively iterate on architectures or training processes. Other things being equal, I think acceleration is harmful because we’re not ready for very powerful AI systems — but I believe the benefits outweigh these costs in expectation, and think better measurements of LLM capabilities are net-positive and important.
To get a sense for whether acting on this belief by launching these two RFPs would constitute falling prey to the unilateralist’s curse, I sent a survey about whether funding this work would be net-positive or net-negative to 47 relatively senior people who have been full-time working on AI x-risk reduction for multiple years and have likely thought about the risks and benefits of sharing information about AI capabilities.
Out of the 47 people who received the survey, 30 people (64%) responded. Of those, 25 out of 30 said they were “Positive” or “Lean positive” on the RFP, and only 1 person said they were “Lean negative,” with no one saying they were “Negative.” The remaining four people said they had “No idea,” meaning that 29 out of 30 respondents (97%) would not vote to stop the RFPs from happening. With that said, many respondents (~37%) felt torn about the question or considered it complicated.
The rest of this post provides more detail on the information that the survey-takers received and the survey results (including sharing answers from those respondents who gave permission to share).
The information that was sent to the survey-takers
The survey-takers received the below email, which links to a one-pager on the risks and benefits of these RFPs, and a four-pager (written in late July and early August) about the sorts of projects I expected to fund. After the survey, the latter document evolved into the public-facing RFPs here and here.
Subject: [by Sep 8] Survey on whether measuring AI capabilities is harmful
Hi,
I want to launch a request for proposals asking researchers to produce better measurements of the real-world capabilities of systems composed out of LLMs (similar to the recent work done by ARC evals).
I expect this work to shorten timelines to superhuman AI, but I think the harm from this is outweighed by the benefits of convincing people of short timelines (if that’s true) and enabling a regime of precautions gated to capabilities. See this 1-pager for more discussion. You can also skim my project description (~4 pages) to get a better idea of the kinds of grants we might fund, though it’s not essential reading (especially if you’re broadly familiar with ARC evals).
Please fill out this short survey on whether you think this project is net-positive or net-negative by EOD Fri Sep 8.
I’m sending this survey to a large number of relatively senior people who have been full-time working on AI x-risk reduction for multiple years and have likely thought about the risks and benefits of sharing information about AI capabilities. The primary intention of this survey is to check whether going ahead with this RFP would constitute falling prey to the unilateralist’s curse (i.e., to check whether a majority of informed and thoughtful people who care about reducing AI x-risk would want to stop this project).
I recognize that “Does the median survey-taker think this project is net-negative?” will be sensitive to the set of people surveyed. I tried to ensure that major “sectors” and/or “schools of thought” in AI x-risk land (e.g. academics, AI lab people, policy people, MIRI, etc) were represented, with some attention to the number of people in each sector and to which individuals may have well-developed independent opinions. I also provide space for you to suggest people or schools of thought to include in the survey. [2] My hope is that the qualitative upshot of the survey can be robust to many plausible ways of drawing the lines around who counts as a “thoughtful, informed AI x-risk expert.” For example, if 80% of this population votes one way, we would need to substantially increase the weight given to dissenting voices to flip the conclusion.
Best,
Ajeya
The survey results in more detail
Who took the survey
Out of the 30 survey respondents, 17 people (~57%) gave me permission to share the fact that they responded to the survey:
- Adam Gleave
- Buck Shlegeris
- Claire Zabel
- Daniel Kokotajlo
- Evan Hubinger
- Jared Kaplan
- Jonathan Uesato
- Lennart Heim
- Luke Muehlhauser
- Markus Anderljung
- Michael Aird
- Nate Soares
- Nick Beckstead
- Nick Bostrom
- Oliver Habryka
- Paul Christiano
- Toby Ord
Of these 17 people, 8 gave me permission to share some portion of their responses; I’ve collected these at the end.
Answers to multiple choice and numerical questions
The survey consisted of five substantive (non-meta / procedural) questions, three of which were multiple choice or numerical, and two which were text box responses elaborating on one of the multiple choice or numerical questions. The distribution of answers to the multiple choice and numerical questions are given in this section.
Instinct: A slim majority of respondents feel instinctively positive, and many feel torn
The first multiple choice or numerical question of the survey asks about respondents’ initial instincts about the RFP:
OPTIONAL: What is your independent instinct, before deep thought or deference to other people, about whether it's good or bad to run this [3]RFP?
There were four response choices: “Yay, I like it!”; “Ugh, can you not?”; “I don’t have much of an instinct”; and “Uhhhh I’m torn / it’s complicated.”
While it was optional, all thirty respondents chose to answer it. These were their responses:
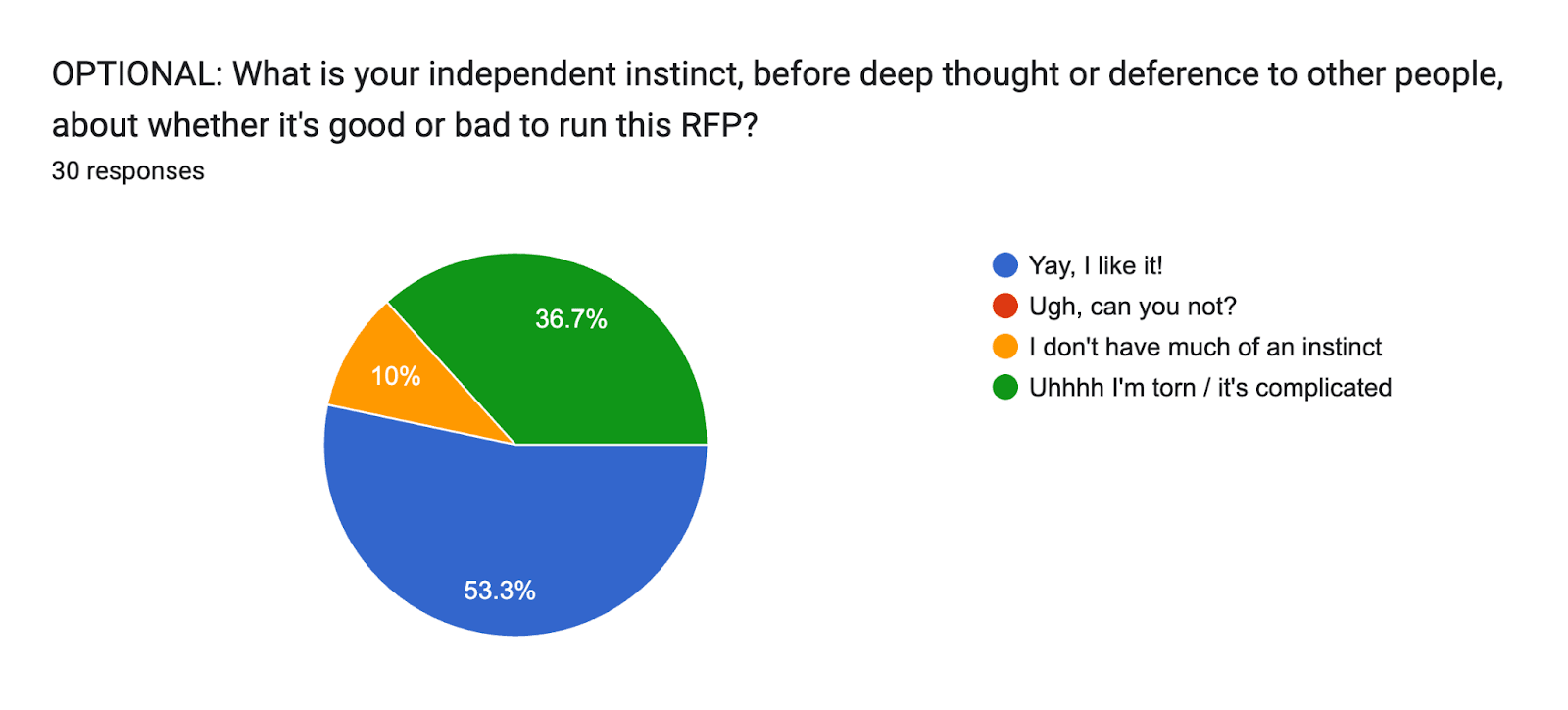
A slim majority (16) had a positive initial instinct, and a large minority (14) did not, with most of the latter group (11) feeling torn.
Independence: Most respondents consider themselves to have independent views
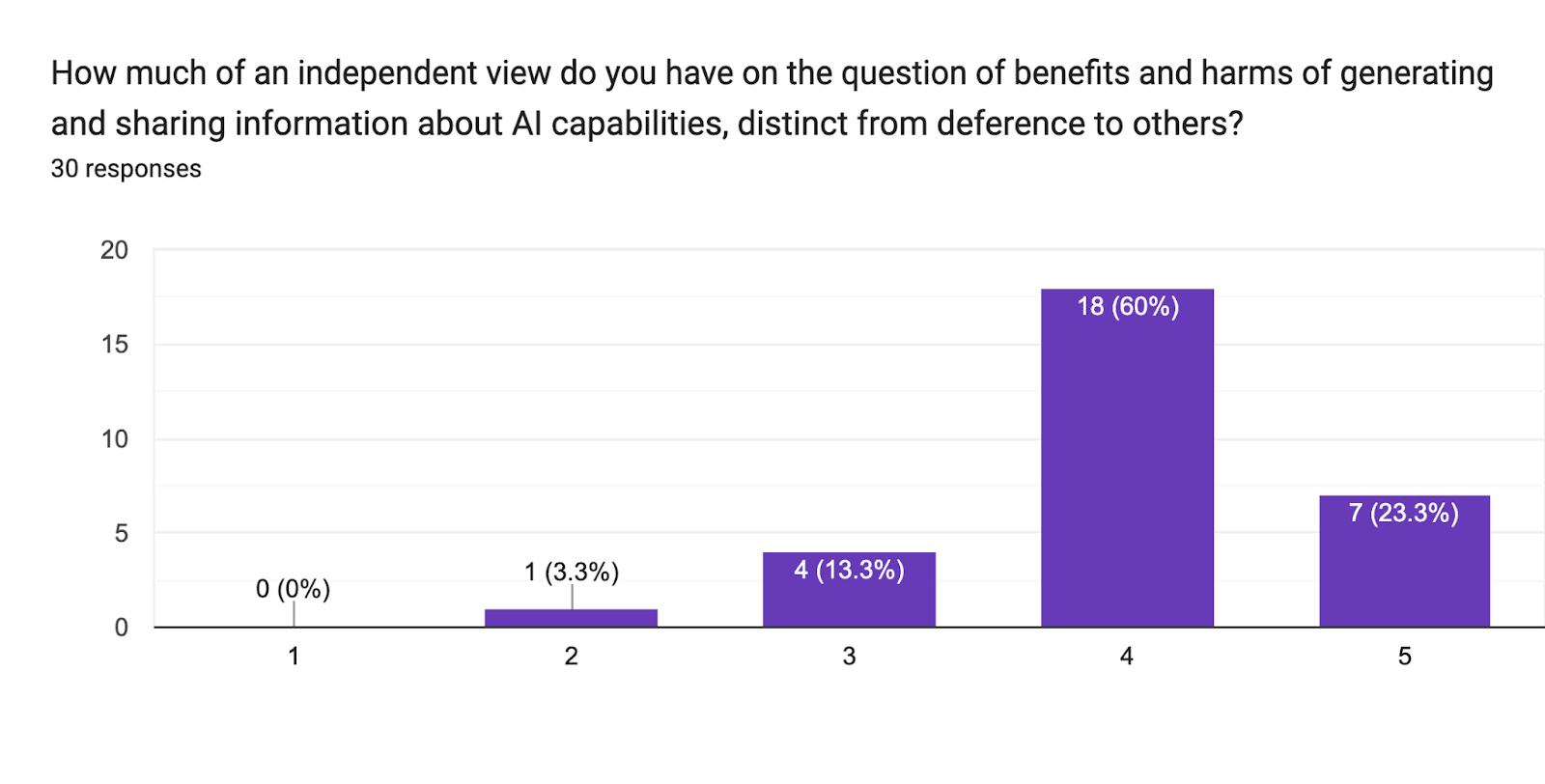
The second multiple choice or numerical question asks about respondents’ level of deference to others on this kind of question:
How much of an independent view do you have on the question of benefits and harms of generating and sharing information about AI capabilities, distinct from deference to others?
The response was given as a numerical scale from 1 to 5. Here, 1 was labeled “I’m almost entirely deferring to others” and 5 was labeled “I have a very well-developed independent view.”
All thirty respondents answered this question as well. These are the results:
Overall view: Most respondents are positive or lean positive on the RFPs
The most important question of the survey asks:
Ignoring opportunity cost, would running this RFP be positive or negative, according to your all-things-considered view?
It gives five options:
- Positive (and I’m about as confident as I ever get [4] on debated questions of AI strategy)
- Lean positive (but I’m not as confident about this as I am about other AI strategy debates)
- No idea (my probability is 50% plus or minus epsilon, or fluctuates wildly averaging to 50%)
- Lean negative (but I'm not as confident about this as I am about some other AI strategy debates)
- Negative (and I'm about as confident as I ever get on debated questions of AI strategy)
These are the results:
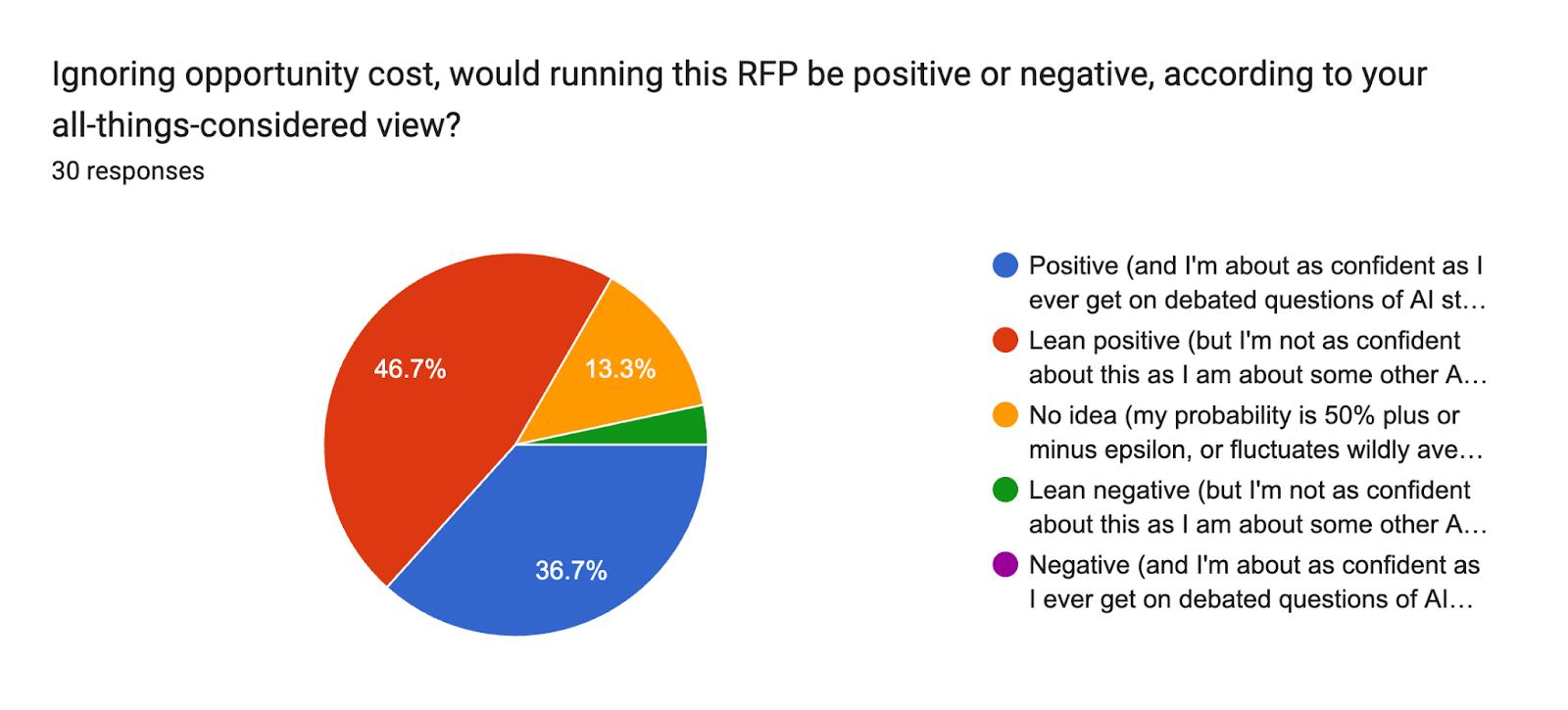
Numerically, they were as follows:
- 11 people said “Positive”
- 14 people said “Lean positive,” for 25 “Positive” or “Lean positive” votes total
- 4 people said “No idea,” for 29 non-“Negative” or -“Lean negative” votes total
- 1 person said “Lean negative”
Specific respondents’ answers
Some survey takers gave permission for a portion of their answers to be shared publicly. For those who gave permission to share multiple choice and numerical answers, they are given below:
| Name | Instinct | Independence | Overall view |
| Adam Gleave | Uhhhh I’m torn | 4 | Lean positive |
| Buck Shlegeris | Yay, I like it! | 3 | Lean positive |
| Daniel Kokotajlo | Yay, I like it! | 5 | Positive |
| Evan Hubinger | Yay, I like it! | 4 | Lean positive |
| Jonathan Uesato | Yay, I like it! | 5 | Positive |
| Michael Aird | Uhhhh I’m torn | 3 | Lean positive |
| Nate Soares | Uhhhh I’m torn | 5 | No idea |
| Oliver Habryka | Uhhhh I’m torn | 5 | Lean positive |
Four of these people gave permission to share free text responses in addition to their multiple choice responses; they are copied below:
Daniel Kokotajlo’s full response
Instinct: Yay, I like it!
Independence: 5
Overall view: Positive (and I'm about as confident as I ever get on debated questions of AI strategy)
Free response:
I think this might be less good than your opportunity cost, i.e. I'm at like 50% that there is something better for you to be doing with your time.
And I'm not confident it's net-positive. But I'm about as confident that it's net-positive as I ever am about AI strategy questions.
Jonathan Uesato’s full response
Instinct: Yay, I like it!
Independence: 5
Overall view: Positive (and I'm about as confident as I ever get on debated questions of AI strategy)
Free response:
I'm even more confident on positive sign around dangerous capability evaluations - more focused on safety, less ambiguity about interpretation, less directly aligned with advancing overall capabilities. But I'm still quite confident for the real world capabilities version here.
Nate Soares’s full response
Instinct: Uhhhh I’m torn / it’s complicated
Independence: 5 out of 5
Overall view: No idea
Free response:
I'd feel better about this if I expected it to help more. On my models, there's a good chance that evals provide a false sense of security, and that they don't adequately measure the real issues, and that even if they did then there wouldn't really be anything to do about it.
I buy that visibility into capabilities is something like weakly-necessary strategically, I think that it can help if done well and hurt if done poorly, I don't have much sense yet as to whether your RFP causes it to be done well or done poorly.
I don't think we have any workable plan for reacting to the realization that dangerous capabilities are upon us. I think that when we get there, we'll predictably either (a) optimize against our transparency tools or otherwise walk right of the cliff-edge anyway, or (b) realize that we're in deep trouble, and slow way down and take some other route to the glorious transhumanist future (we might need to go all the way to WBE, or at least dramatically switch optimization paradigms). Insofar as this is true, I'd much rather see efforts go _now_ into putting hard limits on capabilities in this paradigm, and booting up alternative paradigms (that aren't supposed to be competitive with scaling, but that are hopefully competitive with what individuals can do on home computers). I could see evals playing a role in that policy (of helping people create sane capability limits and measure whether they're being enforced), but that's not how I expect evals to be used on the mainline.
Oliver Habryka’s full response
Instinct: Uhhhh I’m torn / it’s complicated
Independence: 5 out of 5
Overall view: Lean positive (but I'm not as confident about this as I am about some other AI strategy debates)
Free response:
(I didn't answer 1 or 2 [on deference], but I did learn about a lot of this stuff from Eliezer and some MIRI-adjacent-ish worldview. I don't talk to them much, and on this question I wouldn't defer to them very much, but there is probably still some effect)
I think it's pretty dependent how much "frontier agency" research this would incentivize or directly fund. I.e. if this were to fund a $5M training run on training some frontier language models on a large variety of game environments, this seems bad to me. But in as much as its funding some smaller fine-tuning runs, at less than $1M or so, I think this is probably net-good.
I have a generally more confident take that slowing things down is good, i.e. don't find arguments that "current humanity is better suited to handle the singularity" very compelling.
I think I am also more confident that it's good for people to openly and straightforwardly talk about existential risk from AI.
I am less confident in my answer to the question of "is generic interpretability research cost-effective or even net-positive?". My guess is still yes, but I really feel very uncertain, and feel a bit more robust in my answer to your question than that question.
- ^
Note that ARC Evals itself would not be eligible to apply for this RFP, because I am married to Paul Christiano, the Executive Director of its parent org Alignment Research Center.
- ^
Note: I got no suggestions of this form in the relevant survey section(s).
- ^
It was a combined RFP in the original draft, which got split into two after further iteration.
- ^
The provided description text reads:
This question asks about your confidence level relative to how confident you usually are about big-picture strategy questions that generate debate in the AI x-risk community. This is to account for different people having different overall confidence levels.
For example, suppose your probability that this RFP is negative is 55%. If you never really assign probabilities appreciably higher than 55% for questions in the reference class of "strategic questions that are debated within the AI x-risk community," choose the option "Negative (and I'm about as confident as I ever get on debated questions of AI strategy)."
Ofer @ 2023-11-13T12:44 (+6)
I think that the survey should have been designed and carried out by an independent party. The author is a senior program officer at OPP who is known to have a lot of influence over funding in the AI x-risks space. It seems they themselves have selected “47 relatively senior people who have been full-time working on AI x-risk reduction for multiple years”. The author sent those people a request to fill a survey that starts with the words: “I want to launch […]”. The survey was not anonymous, a fact that was addressed on the survey form:
(Seeing names will be useful to me for doing "robustness sanity checks" on how different the outcome would have been if I had surveyed a moderately different population, and will thus inform my qualitative analysis.)
(I am not taking here a stance for or against the specific initiative that the survey was asking about.)