Open Phil EA/LT Survey 2020: Methodology
By Eli Rose🔸 @ 2021-08-23T01:01 (+39)
We'll be posting results from this survey to the frontpage one at a time, since a few people asked us not to share all of them at once and risk flooding the Forum. You can see the full set of results at our sequence.
This post is part of a series on Open Phil’s 2020 survey of a subset of people doing (or interested in) longtermist priority work. See the first post for an introduction and a discussion of the high-level takeaways from this survey. This post will discuss how we went about designing the survey and choosing who to invite to take it.
You can read this whole sequence as a single Google Doc here, if you prefer having everything in one place. Feel free to comment either on the doc or on the Forum. Comments on the Forum are likely better for substantive discussion, while comments on the doc may be better for quick, localized questions.
Terminology
Throughout this report, we use the phrase “EA/EA-adjacent ideas.” This was a term we coined for this survey and referred to in its text. Here is the definition as it appeared in the survey:
Effective altruism/effective altruism-adjacent (EA/EA-adjacent) ideas: A specific cluster of ideas about doing outsized amounts of good that has emerged/grown in the past 10-15 years. These ideas generally relate to using a substantial part of one's resources to do as much good as possible, putting a substantial amount of thought and consideration into how to do that, and focusing on the scope of the consequences of one's actions.
Notes on this definition:
- We intend this category to include longtermism, work related to global catastrophic risk reduction, and the parts of the rationalist-sphere idea cluster related to thinking about how to improve the world.
- We don’t intend to include utilitarian thought before this time, e.g. the writings of John Stuart Mill.
Who We Surveyed
This survey was accessible by invitation only.
The central example of a person we were trying to target with this survey was someone who met the following criteria:
-
Does, or is interested in doing, longtermist priority work[1].
-
Is seen by us and/or by our advisors in their current or planned field of work as having a high-expected-value career[2]. (Note this step rules out promising people who aren’t well-known to us or our advisors. See below for more on the limitations of our selection process.)
-
Is “recent,” in the sense that our and our advisors’ perception of the EV of their career has substantially increased since mid-2017 (three years before we started the survey project), either because we/our advisors weren’t aware of this person before that time, because this person weren’t involved at the time, or because our/our advisors’ perception of the EV of this person’s career has increased a lot since then.
-
Is sufficiently familiar with EA/EA-adjacent ideas and communities, and/or has a strong enough relationship with us or someone else in the community (whom we could ask to reach out on our behalf), that we didn’t expect them to feel weird about receiving a survey asking these types of in-depth questions.
We asked some of our advisors in various longtermist priority fields to recommend people meeting these criteria. Some examples of the fields we asked advisors in: technical AI safety research, applied AI work, biosecurity, research into emerging technologies, s-risks, and EA and rationality community-building. We chose these advisors by looking for well-networked people in these fields who we trusted to have reasonably good judgments about people. (Note that some of the advisors worked at organizations listed in the survey, and this is a potential source of bias.) After the advisors shared their recommendations, Claire applied some of her own judgment, as well as opinions from a few other advisors and OP staff, to the suggestions.
We expect to have missed a large number of people who are doing high-expected-value altruistic work, either for timeline reasons (they were too recent or not recent enough), because they happened to not be well-known to us or to the particular advisors we chose at the time we started this process, because they were misjudged by us or our advisors, or for other contingent reasons. Our and our advisors’ assessments of which careers are “high-expected-value” represent the best guesses at one point in time of a small group of people made under significant uncertainty, fairly quickly, and subject to pretty specific criteria. People who were not invited to take the survey should not necessarily take this as an Open Philanthropy commentary on the value of their career.
Our motivation for “recency” was to survey people who, insofar as they were substantially affected by the e.g. orgs mentioned in our survey, were pretty likely to have been affected since mid-2017, so that we could compare mostly recent actions of e.g. orgs (which we were most interested in) rather than all actions historically.
But our operationalization of it, in c), didn’t fully have the intended effect. Based on looking at answers to “when did you first hear about EA?” and reading other free-text responses, we seem to have surveyed a lot of people who were meaningfully affected by influences before mid-2017; on average, the people we surveyed say they first heard about EA/EA-adjacent ideas in 2015.
So I think there’s often a delay of 2-4 years between when a survey respondent first hears about EA/EA-adjacent ideas and when they start engaging in the kind of way that could lead our advisors to recommend them. Because of this, the people we surveyed seem to be of “medium recency”; this is important to keep in mind when assessing our results, since we’ll miss disproportionately more of the impacts that influences are having when they tend to have been on people who aren’t “medium recent.”
Not everyone we surveyed met all the criteria in a) through d); for various reasons, we surveyed a small number of people who didn’t. In some cases, these were people recommended through other processes.
We lent the use of our survey to 80,000 Hours and CFAR in aid of their impact evaluation efforts, and coordinated the surveying of some people they were interested in better understanding their impact on. But this data is not used in this report, because it was from recipients who did not necessarily meet our selection criteria above.
About the Survey
The survey was very in-depth. In contrast to the Rethink Priorities 2020 EA Survey, which estimates itself as 20 minutes long, we estimated before sending it out that our survey was 2 hours long. Many respondents told us that it took them significantly longer than that; I’d guess the median actual time spent answering questions was more like 3 hours. I believe respondents often completed our survey in multiple sittings.
The survey was designed by me and Claire, with feedback and advice from people in the EA and rationality communities, including leaders of organizations we asked about on the survey like 80,000 Hours, CEA, MIRI, CFAR, and FHI. Morgan Davis started this project with Claire in early 2020, before I joined Open Phil, and I built on her work. A number of other people at Open Phil helped in various ways, especially Bastian Stern, who vetted the data and data analysis. We built the survey in the Qualtrics software platform, choosing it over SurveyMonkey or Google Forms because it supported certain question types we wanted and was better suited to a very long survey.
How We Administered the Survey
We contacted our recipients by email; either myself or Claire or an advisor contacted them, depending on what made the most sense (we tried to get the email to come from someone who was familiar with the recipient, when possible).
We offered our recipients a $200 honorarium for completing the survey, in the form of either a direct payment to them or a donation to a 501(c)(3) organization of their choice.
Response Rate and Response Bias
217 people filled out our survey, out of the 242 we sent invites to, for a response rate of ~89%.
I expect that we have some response bias in the form of people who are more “in” the EA community being more likely to respond — they might be more likely to feel honored by Open Phil selecting them to be surveyed and/or care more about helping out Open Phil with its projects. There are other plausible response biases as well — for example, the survey was very long and I’d expect extremely busy people to have had a harder time completing it.
Fortunately, the high response rate means that the magnitude of any response bias is quite limited. Looking through the list of non-responders, no strong patterns jump out at me, though it does look somewhat like invitees who were on the fringes of our social network may have been less likely to respond.
Respondent Weighting
We were fairly selective in choosing our respondent pool. But even after applying our selection process, it seemed to us that there remained substantial variation in our best guesses about the expected value of each of our respondents’ careers.
This survey aimed to assess, among other things, the impacts of various community-building efforts on the world, through their impacts on our respondents. Fixing a certain positive impact (and holding all else equal), it’s better for the world that that impact be on someone with a higher-expected-value career than that it be on someone with a lower-expected-value-career, and we guessed that this consideration could be important to any analysis of our results, since certain interventions might disproportionately help or hinder the most promising people. So we tried to take it into account by giving each of our respondents a numerical “weight” to represent our best guess (at the time) at the expected altruistic value of their career, from a longtermist perspective.
Only a limited number of people have access to the weights (those working on the survey project at Open Phil, or who were in the small group of advisors who helped us assign the weights). We don’t plan to share them beyond this group.
Since Claire and I had far from enough context to make these decisions across the many individuals and cause areas in our respondent pool, we asked the Committee for Effective Altruism Support and a few other internal advisors to help us. (This was a distinct process from the one we used to select who to survey in the first place.) We aggregated their views to get a number for each respondent[3].
Weights were assigned following the principle that two respondents with weight X should together represent as much expected altruistic career value as one respondent with weight 2X. So just as we can speak of a number or percentage of respondents who e.g. said they were helped by 80,000 Hours, we can also speak of the total respondent-weight or percentage of total respondent-weight for respondents who said they were helped by 80,000 Hours. Our analysis frequently uses “weighted” versions of metrics; this is always what is meant by that. When we speak of the “unweighted” version of a metric, we mean the version based on raw numbers of respondents.
Ranking people’s careers numerically in this way felt weird and risky to do, and we realize it has the potential to cause a number of harms. E.g., it might make respondents who have been “weighted” feel awkward about it.
So, I’d like to emphasize the guess-ey-ness of these weightings — it’s impossible to be very certain about these values, since the altruistic value of a career can depend on a huge number of both micro and macro details of how the future goes. Though we and our advisors put a fair amount of time and thought into this process, our collective knowledge on the topic of “how much altruistic value will this person’s career have?” remains extremely limited relative to “the truth,” or even to the knowledge that we could attain by spending 10x more time on the problem. We have profound uncertainty both about specific individuals, and the value of the different cause areas they work on and the different perspectives on/approaches to important problems they have. If we were redoing the process today, there are individuals to whom we’d give meaningfully different weights; when these decisions are based on few and fuzzy data points, it’s easy for future data to update them a lot.
One salient example of the limitations of these weights is that people who have been doing longtermist priority work for longer tended to get higher weights. These people have had more time to do the types of impressive things that cause us to weight them highly, while newer people will in general be more unknown; the newer someone is, generally, the more uncertain our weighting of them, and the more we might “revert to the mean” and assume their performance will be less of an outlier[4]. People who were around early, but haven’t done these types of impressive things, we tended not to survey, since they didn’t meet the “EV of career has substantially increased since mid-2017” criterion.
Despite these limitations, we thought the benefits of assigning weights — allowing us to understand how the paths of the most promising respondents look compared to the average path — outweighed the costs.
Below are the distributions of the weights, plotted on a linear and then on a log scale.


Most respondents were assigned weights below 100, while a few were assigned much larger weights[5].
Here’s the distribution of “% of total weight” by category, to give a sense of to what extent the people in each category are driving the weighted results.

Reflections
By far the most common piece of critical feedback we received about our survey was that it was long. I think the estimate of 2 hours we gave was likely much too low (no hard data, but I’d guess the true average time taken was more like 3 hours), and wish we’d given a more accurate one.
I’m very grateful to our respondents for collectively giving us a ~90% response rate, and for giving (what seem to me to be) highly honest and thought-through responses to our questions.
“Longtermist priority work” is a loose term that means “among the things that the people in Open Phil’s longtermist arm see as high-priority.” In practice, this meant that many respondents worked on or planned to work on risks from advanced AI, biosecurity, or growing and improving the effective altruism and adjacent communities. A substantial fraction of our respondents were undecided between several types of longtermism-motivated work. See our cause area/role type breakdown for more info. ↩︎
Our bar for “high-expected-value” careers was also loosely defined. We offered the following guidelines to our advisors when we asked them to recommend people for us to survey: they should be someone who the advisor would personally spend at least a few hours a year in order to help a substantial-but-not-exceptional amount, and they should be someone who the advisor would be willing to sacrifice a one-time $150k donation to their second-favorite organization in order to keep from being magically blocked from ever working in the relevant field. In practice we expect significant variation in how this standard was interpreted, and recognise that there was a lot of noise around exactly who got included via this process. ↩︎
Our process was as follows: we read through the survey responses and extracted basic resume information and career plans from each respondent. We also solicited comments from our advisors on the respondents they were familiar with. One advisor looked at the resume/career plans and the comments and gave weightings for all 217 respondents, with the understanding that they were not familiar with every respondent, would be going off priors in a majority of cases, and would often defer to others’ more specific views later. Then the other advisors gave weightings in the cases where they disagreed with the existing weightings. Advisors could change their weightings at any time, e.g. to defer to another advisor or because another advisor changed their mind in discussion. After everyone who wanted to had given and adjusted their weightings, we did some normalization on the numbers and then averaged each advisors’ weighting to get a final number for each respondent. ↩︎
This means that the lower weights tend to be the more uncertain ones. In order to see how our results changed when we left out the people we knew little about, we ran a version of our analysis that ignored everyone who had weight <=25 (the bottom ~30% of respondents). The main results didn’t change much. ↩︎
One thing to note here is that six respondents who worked at or were closely associated with Open Philanthropy were all given the same weight, to avoid the awkwardness and potential conflicts of interest involved in ranking these people. ↩︎
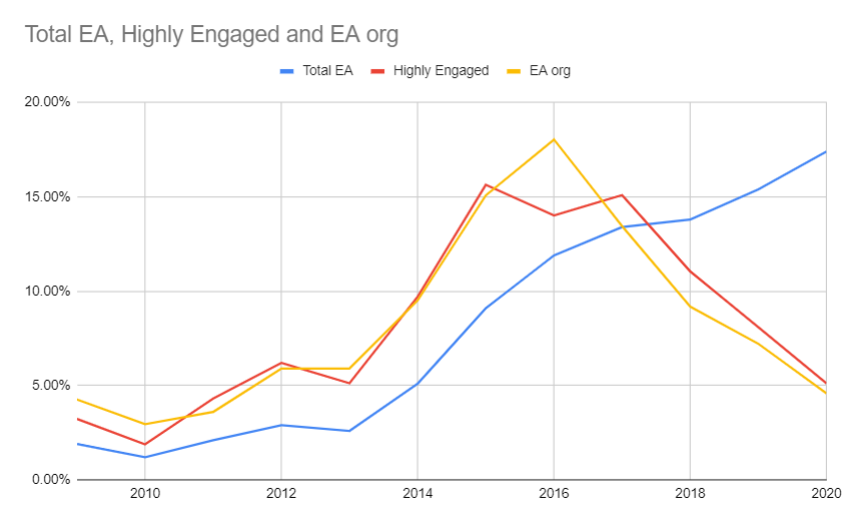
David_Moss @ 2021-08-23T09:04 (+4)
... we seem to have surveyed a lot of people who were meaningfully affected by influences before mid-2017; on average, the people we surveyed say they first heard about EA/EA-adjacent ideas in 2015.
So I think there’s often a delay of 2-4 years between when a survey respondent first hears about EA/EA-adjacent ideas and when they start engaging in the kind of way that could lead our advisors to recommend them.
I think this is what one would predict given what we've reported previously about the relationship between time since joining EA and engagement (see 2019 as well).
To put this in more concrete terms: only about 25% of highly engaged (5/5) EAs in our sample joined after 2017. That may even be a low bar relative to the population you are targeting (or at least somewhat orthogonal to it). Looking at EA org employees (which might be a closer proxy), only 20% joined after 2017. See below: