I'm Buck Shlegeris, I do research and outreach at MIRI, AMA
By Buck @ 2019-11-15T22:44 (+123)
EDIT: I'm only going to answer a few more questions, due to time constraints. I might eventually come back and answer more. I still appreciate getting replies with people's thoughts on things I've written.
I'm going to do an AMA on Tuesday next week (November 19th). Below I've written a brief description of what I'm doing at the moment. Ask any questions you like; I'll respond to as many as I can on Tuesday.
Although I'm eager to discuss MIRI-related things in this AMA, my replies will represent my own views rather than MIRI's, and as a rule I won't be running my answers by anyone else at MIRI. Think of it as a relatively candid and informal Q&A session, rather than anything polished or definitive.
----
I'm a researcher at MIRI. At MIRI I divide my time roughly equally between technical work and recruitment/outreach work.
On the recruitment/outreach side, I do things like the following:
- For the AI Risk for Computer Scientists workshops (which are slightly badly named; we accept some technical people who aren't computer scientists), I handle the intake of participants, and also teach classes and lead discussions on AI risk at the workshops.
- I do most of the technical interviewing for engineering roles at MIRI.
- I manage the AI Safety Retraining Program, in which MIRI gives grants to people to study ML for three months with the goal of making it easier for them to transition into working on AI safety.
- I sometimes do weird things like going on a Slate Star Codex roadtrip, where I led a group of EAs as we travelled along the East Coast going to Slate Star Codex meetups and visiting EA groups for five days.
On the technical side, I mostly work on some of our nondisclosed-by-default technical research; this involves thinking about various kinds of math and implementing things related to the math. Because the work isn't public, there are many questions about it that I can't answer. But this is my problem, not yours; feel free to ask whatever questions you like and I'll take responsibility for choosing to answer or not.
----
Here are some things I've been thinking about recently:
- I think that the field of AI safety is growing in an awkward way. Lots of people are trying to work on it, and many of these people have pretty different pictures of what the problem is and how we should try to work on it. How should we handle this? How should you try to work in a field when at least half the "experts" are going to think that your research direction is misguided?
- The AIRCS workshops that I'm involved with contain a variety of material which attempts to help participants think about the world more effectively. I have thoughts about what's useful and not useful about rationality training.
- I have various crazy ideas about EA outreach. I think the SSC roadtrip was good; I think some EAs who work at EA orgs should consider doing "residencies" in cities without much fulltime EA presence, where they mostly do their normal job but also talk to people.
elle @ 2019-11-19T18:56 (+56)
Reading through some of your blog posts and other writing, I get the impression that you put a lot of weight on how smart people seem to you. You often describe people or ideas as "smart" or "dumb," and you seem interested in finding the smartest people to talk to or bring into EA.
I am feeling a bit confused by my reactions. I think I am both a) excited by the idea of getting the "smart people" together so that they can help each other think through complicated topics and make more good things happen, but b) I feel a bit sad and left out that I am probably not one of the smart people.
Curious about your thoughts on a few things related to this... I'll put my questions as separate comments below.
elle @ 2019-11-19T18:57 (+27)
2) Somewhat relatedly, there seems to be a lot of angst within EA related to intelligence / power / funding / jobs / respect / social status / etc., and I am curious if you have any interesting thoughts about that.
Buck @ 2019-11-19T20:23 (+27)
I feel really sad about it. I think EA should probably have a communication strategy where we say relatively simple messages like "we think talented college graduates should do X and Y", but this causes collateral damage where people who don't succeed at doing X and Y feel bad about themselves. I don't know what to do about this, except to say that I have the utmost respect in my heart for people who really want to do the right thing and are trying their best.
I don't think I have very coherent or reasoned thoughts on how we should handle this, and I try to defer to people who I trust whose judgement on these topics I think is better.
elle @ 2019-11-19T21:56 (+14)
If you feel comfortable sharing: who are the people whose judgment on this topic you think is better?
elle @ 2019-11-19T18:56 (+15)
1) Do you have any advice for people who want to be involved in EA, but do not think that they are smart or committed enough to be engaging at your level? Do you think there are good roles for such people in this community / movement / whatever? If so, what are those roles?
Aidan O'Gara @ 2019-11-20T19:00 (+141)
I used to expect 80,000 Hours to tell me how to have an impactful career. Recently, I've started thinking it's basically my own personal responsibility to figure it out. I think this shift has made me much happier and much more likely to have an impactful career.
80,000 Hours targets the most professionally successful people in the world. That's probably the right idea for them - giving good career advice takes a lot of time and effort, and they can't help everyone, so they should focus on the people with the most career potential.
But, unfortunately for most EAs (myself included), the nine priority career paths recommended by 80,000 Hours are some of the most difficult and competitive careers in the world. If you’re among the 99% of people who are not Google programmer / top half of Oxford / Top 30 PhD-level talented, I’d guess you have slim-to-none odds of succeeding in any of them. The advice just isn't tailored for you.
So how can the vast majority of people have an impactful career? My best answer: A lot of independent thought and planning. Your own personal brainstorming and reading and asking around and exploring, not just following stock EA advice. 80,000 Hours won't be a gospel that'll give all the answers; the difficult job of finding impactful work falls to the individual.
I know that's pretty vague, much more an emotional mindset than a tactical plan, but I'm personally really happy I've started thinking this way. I feel less status anxiety about living up to 80,000 Hours's recommendations, and I'm thinking much more creatively and concretely about how to do impactful work.
More concretely, here's some ways you can do that:
- Think of easier versions of the 80,000 Hours priority paths. Maybe you'll never work at OpenPhil or GiveWell, but can you work for a non-EA grantmaker reprioritizing their giving to more effective areas? Maybe you won't end up in the US Presidential Cabinet, but can you bring attention to AI policy as a congressional staffer or civil servant? (Edit: I forgot, 80k recommends congressional staffing!) Maybe you won't run operations at CEA, but can you help run a local EA group?
- The 80,000 Hours job board actually has plenty of jobs that aren’t on their priority paths, and I think some of them are much more accessible for a wider audience.
- 80,000 Hours tries to answer the question “Of all the possible careers people can have, which ones are the most impactful?” That’s the right question for them, but the wrong question for an individual. For any given person, I think it’s probably much more useful to think, “What potentially impactful careers could I plausibly enter, and of those, which are the most impactful?” Start with what you already have - skills, connections, experience, insights - and think outwards from there: how you can transform what you already have into an impactful career?
- There are tons of impactful charities out there. GiveWell has identified some of the top few dozen. But if you can get a job at the 500th most effective charity in the world, you’re still making a really important impact, and it’s worth figuring out how to do that.
- Talk to people working in the most important problems who aren't top 1% of professional success - seeing how people like you have an impact can be really motivating and informative.
- Personal donations can be really impactful - not earning to give millions in quant trading, just donating a reasonable portion of your normal-sized salary, wherever it is that you work.
- Convincing people you know to join EA is also great - you can talk to your friends about EA, or attend/help out at a local EA group. Converting more people to EA just multiplies your own impact.
Don't let the fact that Bill Gates saved a million lives keep you from saving one. If you put some hard work into it, you can make a hell of a difference to a whole lot of people.
brentonmayer @ 2019-11-27T22:12 (+53)
Hi Aidan,
I’m Brenton from 80,000 Hours - thanks for writing this up! It seems really important that people don’t think of us as “tell[ing] them how to have an impactful career”. It sounds absolutely right to me that having a high impact career requires “a lot of independent thought and planning” - career advice can’t be universally applied.
I did have a few thoughts, which you could consider incorporating if you end up making a top level post. The most substantive two are:
- Many of the priority paths are broader than you might be thinking.
- A significant amount of our advice is designed to help people think through how to approach their careers, and will be useful regardless of whether they’re aiming for a priority path.
Many of the priority paths are broader than you might be thinking:
Most people won’t be able to step into an especially high impact role directly out of undergrad, so unsurprisingly, many of the priority paths require people to build up career capital before they can get into high impact positions. We’d think of people who are building up career capital focused on (say) AI policy as being ‘on a priority path’. We also think of people who aren’t in the most competitive positions as being within the path
For instance, let’s consider AI policy. We think that path includes graduate school, all the options outlined in our writeup on US AI policy and the 161 roles currently on the job board under the relevant filter. It’s also worth remembering that the job board has still left most of the relevant roles out: none of them are congressional staffers for example, which we’d also think of as under this priority path.
A significant amount of our advice is designed to help people think through how to approach their careers, and will be useful regardless of whether they’re aiming for a priority path.
In our primary articles on how to plan your career, we spend a lot of time talking about general career strategy and ways to generate options. The articles encourage people to go through a process which should generate high impact options, of which only some will be in the priority paths:
- The career strategy and planning and decision making sections of key ideas
- This article on high impact careers
- Career planning
Unfortunately, there’s something in the concreteness of a list of top options which draws people in particularly strongly. This is a communication challenge that we’ve worked on a bit, but don’t think we have a great answer to yet. We discussed this in our ‘Advice on how to read our advice’. In the future we’ll add some more ‘niche’ paths, which may help somewhat.
A few more minor points:
- Your point about Bill Gates was really well put. It reminded me of my colleague Michelle’s post on ‘Keeping absolutes in mind’, which you might enjoy reading.
- We don’t think that the priority paths are the only route through which people can affect the long term future.
- I found the tone of this comment generally great, and two of my colleagues commented the same. I appreciate that going through this shift you’ve gone through would have been hard and it’s really impressive that you’ve come out of it with such a balanced view, including being able to acknowledge the tradeoffs that we face in what we work on. Thank you for that.
- If you make a top level post (which I’d encourage you to do), feel free to quote any part of this comment.
Cheers, Brenton
Khorton @ 2019-11-20T23:00 (+51)
I think this comment is really lovely, and a very timely message. I'd support it being turned into a top-level post so more people can see it, especially if you have anything more to add.
jpaddison @ 2019-11-21T03:58 (+11)
Seconded.
Aidan O'Gara @ 2019-11-21T20:57 (+17)
Thank you both very much, I will do that, and I almost definitely wouldn't have without your encouragement.
If anyone has more thoughts on the topic, please comment or reach out to me, I'd love to incorporate them into the top-level post.
DavidNash @ 2019-11-21T11:01 (+10)
I think similar areas were covered in these two posts as well 80,000 Hours - how to read our advice and Thoughts on 80,000 Hours’ research that might help with job-search frustrations.
Sean_o_h @ 2019-11-21T10:14 (+35)
I agree this is a very helpful comment. I would add: these roles in my view are not *lesser* in any sense, for a range of reasons and I would encourage people not to think of them in those terms.
- You might have a bigger impact on the margins being the only - or one of the first few - people thinking in EA terms in a philanthropic foundation than by adding to the pool of excellence at OpenPhil. This goes for any role that involves influencing how resources are allocated - which is a LOT, in charity, government, industry, academic foundations etc.
- You may not be in the presidential cabinet, or a spad to the UK prime minister, but those people are supported and enabled by people building up the resources, capacity, overton window expansion elsewhere in government and civil service. The 'senior person' on their own may not be able to achieve purchase with key policy ideas and influence.
- A lot of xrisk research, from biosecurity to climate change, draws on and depends on a huge body of work on biology, public policy, climate science, renewable energy, insulation in homes, and much more. Often there are gaps in research on extreme scenarios due to lack of incentives for this kind of work, and other reasons - and this may make it particularly impactful at times. But that specific work can't be done well without drawing on all the underlying work. E.g., biorisk mitigation needs not just the people figuring out how to defend against the extreme scenarios, but also everything from people testing birds in vietnam for H5N1 and seals in the north sea for H7, to people planning for overflow capacity in regional hospitals, to people pushing for the value of preparedness funds in the reinsurance industry to much more. Same for climate+environment, same will be true for AI policy etc.
- I think there's probably a good case to be made that in many or perhaps most instances the most useful place for the next generally capable EA to be is *not* an EA org. And for all 80k's great work, they can't survey and review everything, nor tailor to personal fit for the thousands, or hundreds of thousands of different-skillset people who can play a role in making the future better.
For EA to really make the future better to the extent that it has the potential, it's going to need a *much* bigger global team. And that team's going to need to be interspersed everywhere, sometimes doing glamorous stuff, sometimes doing more standard stuff that is just as important in that it makes the glamorous stuff possible. To annoy everyone with a sports analogy, the defense and midfield positions are every bit as important as the glamorous striker positions, and if you've got a team made up primarily of star strikers and wannabe star strikers, that team's going to underperform.
Milan_Griffes @ 2019-11-21T18:14 (+6)
To annoy everyone with a sports analogy, the defense and midfield positions are every bit as important as the glamorous striker positions, and if you've got a team made up primarily of star strikers and wannabe star strikers, that team's going to underperform.
But the marginal impact of becoming a star striker is so high!
(Just kidding – this is a great analogy & highlights a big problem with reasoning on the margin + focusing on maximizing individual impact.)
jpaddison @ 2019-11-21T23:15 (+11)
I also like the analogy, let's run with it. Suppose I'm reasoning from the point of view of the movement as a whole, and we're trying to put together a soccer team. Suppose also that there are two types of positions, midfield and striker. I'm not sure if this is true for strikers in what I would call soccer, but suppose the striker has a higher skillcap than midfield.[1] I'll define skillcap as the amount of skill with the position before the returns begin to diminish.
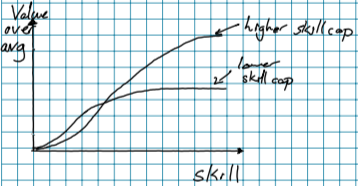
Where skill is some product of standard deviation of innate skill and hours practiced.
Back to the problem of putting together a soccer team, if you're starting with a bunch of players of unknown innate skill, you would get a higher expected value to tell 80% of your players to train to be strikers, and 20% to be midfielders. Because you have a smaller pool, your midfielders will have less innate talent for the position. You can afford to lose this however, as the effect will be small compared to the gain in the increased performance of the strikers.
That's not to say that you should fill your entire team with wannabe strikers. When you select your team you'll undoubtedly leave out some very dedicated strikers in favor of someone who trained for midfield. Still, compared to the percentage that end up playing on the team, the people you'd want training for the role leans more towards the high-skillcap positions.
There are all sorts of ways this analogy doesn't apply directly to the real world, but it might help pump intuitions.
[1] For American football, the quarterback position definitely exhibits this effect. The effect can be seen clearly in this list of highest-paid players.
Milan_Griffes @ 2019-11-21T23:37 (+6)
There are all sorts of ways this analogy doesn't apply directly to the real world, but it might help pump intuitions.
Yeah, I think this model misses that people who are aiming to be strikers tend to have pretty different dispositions than people aiming to be midfielders. (And so filling a team mostly with intending-to-be-strikers could have weird effects on team cohesion & function.)
Interesting to think about how Delta Force, SEAL Team Six, etc. manage this, as they select for very high-performing recruits (all strikers) then meld them into cohesive teams. I believe they do it via:
1. having a very large recruitment pool
2. intense filtering out of people who don't meet their criteria
3. breaking people down psychologically + cultivating conformity during training
I found it interesting to cash this out more... thanks!
jpaddison @ 2019-11-21T23:56 (+3)
Ah, so like, in the "real world", you don't have a set of people, you end up recruiting a training class of 80% would-be-strikers, which influences the culture compared to if you recruited for the same breakdown as the eventually-selected-team?
Sean_o_h @ 2019-11-22T17:58 (+14)
I really enjoy the extent to which you've both taken the ball and run with it ;)
Elityre @ 2019-11-22T00:47 (+20)
I think a lot of this is right and important, but I especially love:
Don't let the fact that Bill Gates saved a million lives keep you from saving one.
We're all doing the best we can with the privileges we were blessed with.
Buck @ 2019-11-20T06:30 (+10)
"Do you have any advice for people who want to be involved in EA, but do not think that they are smart or committed enough to be engaging at your level?"--I just want to say that I wouldn't have phrased it quite like that.
One role that I've been excited about recently is making local groups be good. I think that having better local EA communities might be really helpful for outreach, and lots of different people can do great work with this.
elle @ 2019-11-20T09:47 (+3)
"...but do not think that they are smart or committed enough to be engaging at your level?" was intended to be from a generic insecure (or realistic) EA's perspective, not yours. Sorry for my confusing phrasing.
elle @ 2019-11-19T18:58 (+11)
4) You seem like you have had a natural strong critical thinking streak since you were quite young (e.g., you talk about thinking that various mainstream ideas were dumb). Any unique advice for how to develop this skill in people who do not have it naturally?
Buck @ 2019-11-19T20:41 (+27)
For the record, I think that I had mediocre judgement in the past and did not reliably believe true things, and I sometimes had made really foolish decisions. I think my experience is mostly that I felt extremely alienated from society, which meant that I looked more critically on many common beliefs than most people do. This meant I was weird in lots of ways, many of which were bad and some of which were good. And in some cases this meant that I believed some weird things that feel like easy wins, eg by thinking that people were absurdly callous about causing animal suffering.
My judgement improved a lot from spending a lot of time in places with people with good judgement who I could learn from, eg Stanford EA, Triplebyte, the more general EA and rationalist community, and now MIRI.
I feel pretty unqualified to give advice on critical thinking, but here are some possible ideas, which probably aren't actually good:
- Try to learn simple models of the world and practice applying them to claims you hear, and then being confused when they don't match. Eg learn introductory microeconomics and then whenever you hear a claim about the world that intro micro has an opinion on, try to figure out what the simple intro micro model would claim, and then inasmuch as the world doesn't seem to look like intro micro would predict, think "hmm this is confusing" and then try to figure out what about the world might have caused this. When I developed this habit, I started noticing that lots of claims people make about the world are extremely implausible, and when I looked into the facts more I found that intro micro seemed to back me up. To learn intro economics, I enjoyed the Cowen and Tabarrok textbook.
- I think Katja Grace is a master of the "make simple models and then get confused when the world doesn't match them" technique. See her novel opinions page for many examples.
- Another subject where I've been doing this recently is evolutionary biology--I've learned to feel confused whenever anyone makes any claims about group selection, and I plan to learn how group selection works, so that when people make claims about it I can assess them accurately.
- Try to find the simplest questions whose answers you don't know, in order to practice noticing when you believe things for bad reasons.
- For example, some of my favorite physics questions:
- Why isn't the Sun blurry?
- What is the fundamental physical difference between blue and green objects? Like, what equations do I solve to find out that an object is blue?
- If energy is conserved, why we so often make predictions about the world by assuming that energy is minimized?
- I think reading Thinking Physics might be helpful at practicing noticing your own ignorance, but I'm not sure.
- Try to learn a lot about specific subjects sometimes, so that you learn what it's like to have detailed domain knowledge.
elle @ 2019-11-19T18:58 (+11)
3) I've seen several places where you criticize fellow EAs for their lack of engagement or critical thinking. For example, three years ago, you wrote:
I also have criticisms about EAs being overconfident and acting as if they know way more than they do about a wide variety of things, but my criticisms are very different from [Holden's criticisms]. For example, I’m super unimpressed that so many EAs didn’t know that GiveWell thinks that deworming has a relatively low probability of very high impact. I’m also unimpressed by how many people are incredibly confident that animals aren’t morally relevant despite knowing very little about the topic.
Do you think this has improved at all? And what are the current things that you are annoyed most EAs do not seem to know or engage with?
Buck @ 2019-11-19T20:28 (+12)
I no longer feel annoyed about this. I'm not quite sure why. Part of it is probably that I'm a lot more sympathetic when EAs don't know things about AI safety than global poverty, because learning about AI safety seems much harder, and I think I hear relatively more discussion of AI safety now compared to three years ago.
One hypothesis is that 80000 Hours has made various EA ideas more accessible and well-known within the community, via their podcast and maybe their articles.
edoarad @ 2019-11-18T05:47 (+47)
In the 80k podcast episode with Hilary Greaves she talks about decision theory and says:
Hilary Greaves: Then as many of your listeners will know, in the space of AI research, people have been throwing around terms like ‘functional decision theory’ and ‘timeless decision theory’ and ‘updateless decision theory’. I think it’s a lot less clear exactly what these putative alternatives are supposed to be. The literature on those kinds of decision theories hasn’t been written up with the level of precision and rigor that characterizes the discussion of causal and evidential decision theory. So it’s a little bit unclear, at least to my likes, whether there’s genuinely a competitor to decision theory on the table there, or just some intriguing ideas that might one day in the future lead to a rigorous alternative.
I understand from that that there is little engagement of MIRI with the academia. What is more troubling for me is that it seems that the cases for the major decision theories are looked upon with skepticism from academic experts.
Do you think that is really the case? How do you respond to that? It would personally feel much better if I knew that there are some academic decision theorists who are exited about your research, or a compelling explanation of a systemic failure that explains this which can be applied to MIRI's work specifically.
[The transition to non-disclosed research happend after the interview]
Buck @ 2019-11-19T03:09 (+43)
Yeah, this is an interesting question.
I’m not really sure what’s going on here. When I read critiques of MIRI-style decision theories (eg from Will or from Wolfgang Schwartz), I feel very unpersuaded by them. This leaves me in a situation where my inside views disagree with the views of the most obvious class of experts, which is always tricky.
- When I read those criticisms by Will MacAskill and Wolfgang Schwartz, I feel like I understand their criticisms and find them unpersuasive, as opposed to not understanding their criticisms. Also, I feel like they don’t understand some of the arguments and motivations for FDT. I feel a lot better disagreeing with experts when I think I understand their arguments and when I think I can see particular mistakes that they’re making. (It’s not obvious that this is the right epistemic strategy, for reasons well articulated by Gregory Lewis here.)
- Paul’s comments on this resolved some of my concerns here. He thinks that the disagreement is mostly about what questions decision theory should be answering. He thinks that the updateless decision theories are obviously more suitable to building AI than eg CDT or EDT.
- I think it’s plausible that Paul is being overly charitable to decision theorists; I’d love to hear whether skeptics of updateless decision theories actually agree that you shouldn’t build a CDT agent. (Also, when you ask a CDT agent what kind of decision theory it wants to program into an AI, you get a class of decision theory called "Son of CDT", which isn't UDT.)
- I think there’s a systematic pattern where philosophers end up being pretty ineffective at answering the philosophy questions that I care about (based eg on my experience seeing the EA community punch so far above its weight thinking about ethics), and so I’m not very surprised if it turns out that in this specific case, the philosophy community has priorities that don’t match mine.
- I think there’s also a pattern where philosophers have some basic disagreements with me, eg about functionalism and how much math intuitions should feed into our philosophical intuitions. This decision theory disagreement reminds me of that disagreement.
- Schwartz has a couple of complaints that the FDT paper doesn’t engage properly with the mainstream philosophy literature (eg the Justin Fisher and the David Gauthier papers). My guess is that these complaints are completely legitimate.
On his blog, Scott Aaronson does a good job of describing what I think might be a key difference here:
But the basic split between Many-Worlds and Copenhagen (or better: between Many-Worlds and “shut-up-and-calculate” / “QM needs no interpretation” / etc.), I regard as coming from two fundamentally different conceptions of what a scientific theory is supposed to do for you. Is it supposed to posit an objective state for the universe, or be only a tool that you use to organize your experiences?
Also, are the ultimate equations that govern the universe “real,” while tables and chairs are “unreal” (in the sense of being no more than fuzzy approximate descriptions of certain solutions to the equations)? Or are the tables and chairs “real,” while the equations are “unreal” (in the sense of being tools invented by humans to predict the behavior of tables and chairs and whatever else, while extraterrestrials might use other tools)? Which level of reality do you care about / want to load with positive affect, and which level do you want to denigrate?
My guess is that the factor which explains academic unenthusiasm for our work is that decision theorists are more of the “tables and chairs are real” school than the “equations are real” school--they aren’t as oriented by the question of “how do I write down a decision theory which would have good outcomes if I created an intelligent agent which used it”, and they don’t have as much of an intuition as I do that that kind of question is fundamentally simple and should have a lot of weight in your choices about how to think about reality.
---
I am really very curious to hear what people (eg edoarad) think of this answer.
bmg @ 2019-11-20T20:21 (+30)
I think it’s plausible that Paul is being overly charitable to decision theorists; I’d love to hear whether skeptics of updateless decision theories actually agree that you shouldn’t build a CDT agent.
FWIW, I could probably be described as a "skeptic" of updateless decision theories; I’m pretty sympathetic to CDT. But I also don’t think we should build AI systems that consistently take the actions recommended by CDT. I know at least a few other people who favor CDT, but again (although small sample size) I don’t think any of them advocate for designing AI systems that consistently act in accordance with CDT.
I think the main thing that’s going on here is that academic decision theorists are primarily interested in normative principles. They’re mostly asking the question: “What criterion determines whether or not a decision is ‘rational’?” For example, standard CDT claims that an action is rational only if it’s the action that can be expected to cause the largest increase in value.
On the other hand, AI safety researchers seem to be mainly interested in a different question: “What sort of algorithm would it be rational for us to build into an AI system?” The first question doesn’t seem very relevant to the second one, since the different criteria of rationality proposed by academic decision theorists converge in most cases. For example: No matter whether CDT, EDT, or UDT is correct, it will not typically be rational to build a two-boxing AI system. It seems to me, then, that it's probably not very pressing for the AI safety community to think about the first question or engage with the academic decision theory literature.
At the same time, though, AI safety writing on decision theory sometimes seems to ignore (or implicitly deny?) the distinction between these two questions. For example: The FDT paper seems to be pitched at philosophers and has an abstract that frames the paper as an exploration of “normative principles.” I think this understandably leads philosophers to interpret FDT as an attempt to answer the first question and to criticize it on those grounds.
they aren’t as oriented by the question of “how do I write down a decision theory which would have good outcomes if I created an intelligent agent which used it”
I would go further and say that (so far as I understand the field) most academic decisions theorists aren't at all oriented by this question. I think the question they're asking is again mostly independent. I'm also not sure it would even make sense to talk about "using" a "decision theory" in this context, insofar as we're conceptualizing decision theories the way most academic decision theorists do (as normative principles). Talking about "using" CDT in this context is sort of like talking about "using" deontology.
[[EDIT: See also this short post for a better description of the distinction between a "criterion of rightness" and a "decision procedure." Another way to express my impression of what's going on is that academic decision theorists are typically talking about critera of rightness and AI safety decision theorists are typically (but not always) talking about decision procedures.]]
RobBensinger @ 2019-11-21T22:41 (+20)
The comments here have been very ecumenical, but I'd like to propose a different account of the philosophy/AI divide on decision theory:
1. "What makes a decision 'good' if the decision happens inside an AI?" and "What makes a decision 'good' if the decision happens inside a brain?" aren't orthogonal questions, or even all that different; they're two different ways of posing the same question.
MIRI's AI work is properly thought of as part of the "success-first decision theory" approach in academic decision theory, described by Greene (2018) (who also cites past proponents of this way of doing decision theory):
[...] Consider a theory that allows the agents who employ it to end up rich in worlds containing both classic and transparent Newcomb Problems. This type of theory is motivated by the desire to draw a tighter connection between rationality and success, rather than to support any particular account of expected utility. We might refer to this type of theory as a "success-first" decision theory.
[...] The desire to create a closer connection between rationality and success than that offered by standard decision theory has inspired several success-first decision theories over the past three decades, including those of Gauthier (1986), McClennen (1990), and Meacham (2010), as well as an influential account of the rationality of intention formation and retention in the work of Bratman (1999). McClennen (1990: 118) writes: “This is a brief for rationality as a positive capacity, not a liability—as it must be on the standard account.” Meacham (2010: 56) offers the plausible principle, “If we expect the agents who employ one decision making theory to generally be richer than the agents who employ some other decision making theory, this seems to be a prima facie reason to favor the first theory over the second.” And Gauthier (1986: 182–3) proposes that “a [decision-making] disposition is rational if and only if an actor holding it can expect his choices to yield no less utility than the choices he would make were he to hold any alternative disposition.” In slogan form, Gauthier (1986: 187) calls the idea “utility-maximization at the level of dispositions,” Meacham (2010: 68–9) a “cohesive” decision theory, McClennen (1990: 6–13) a form of “pragmatism,” and Bratman (1999: 66) a “broadly consequentialist justification” of rational norms.
[...] Accordingly, the decision theorist’s job is like that of an engineer in inventing decision theories, and like that of a scientist in testing their efficacy. A decision theorist attempts to discover decision theories (or decision “rules,” “algorithms,” or “processes”) and determine their efficacy, under certain idealizing conditions, in bringing about what is of ultimate value.
Someone who holds this view might be called a methodological hypernaturalist, who recommends an experimental approach to decision theory. On this view, the decision theorist is a scientist of a special sort, but their goal should be broadly continuous with that of scientific research. The goal of determining efficacy in bringing about value, for example, is like that of a pharmaceutical scientist attempting to discover the efficacy of medications in treating disease.
For game theory, Thomas Schelling (1960) was a proponent of this view. The experimental approach is similar to what Schelling meant when he called for “a reorientation of game theory” in Part 2 of A Strategy of Conflict. Schelling argues that a tendency to focus on first principles, rather than upshots, makes game-theoretic theorizing shockingly blind to rational strategies in coordination problems.
The FDT paper does a poor job of contextualizing itself because it was written by AI researchers who are less well-versed with the philosophical literature.
MIRI's work is both advocating a particular solution to the question "what kind of decision theory satisfies the 'success' criterion?", and lending some additional support to the claim that "success-first" is a coherent and reasonable criterion for decision theorists to orient towards. (In a world without ideas like UDT, it was harder to argue that we should try to reduce decision theory to 'what decision-making approach yields the best utility?', since neither CDT nor EDT strictly outperforms the other; whereas there's a strong case that UDT does strictly outperform both CDT and EDT, to the extent it's possible for any decision theory to strictly outperform another; though there may be even-better approaches.)
You can go with Paul and say that a lot of these distinctions are semantic rather than substantive -- that there isn't a true, ultimate, objective answer to the question of whether we should evaluate decision theories by whether they're successful, vs. some other criterion. But dissolving contentious arguments and showing why they're merely verbal is itself a hallmark of analytic philosophy, so this doesn't do anything to make me think that these issues aren't the proper province of academic decision theory.
2. Rather than operating in separate magisteria, people like Wei Dai are making contrary claims about how humans should make decisions. This is easiest to see in contexts where a future technology comes along: if whole-brain emulation were developed tomorrow and it was suddenly trivial to put CDT proponents in literal twin prisoner's dilemmas, the CDT recommendation to defect (one-box, etc.) suddenly makes a very obvious and real difference.
I claim (as someone who thinks UDT/FDT is correct) that the reason it tends to be helpful to think about advanced technologies is that it draws out the violations of naturalism that are often implicit in how we talk about human reasoning. Our native way of thinking about concepts like "control," "choice," and "counterfactual" tends to be confused, and bringing in things like predictors and copies of our reasoning draws out those confusions in much the same way that sci-fi thought experiments and the development of new technologies have repeatedly helped clarify confused thinking in philosophy of consciousness, philosophy of personal identity, philosophy of computation, etc.
3. Quoting Paul:
Most causal decision theorists would agree that if they had the power to stop doing the right thing, they should stop taking actions which are right. They should instead be the kind of person that you want to be.
And so there, again, I agree it has implications, but I don't think it's a question of disagreement about truth. It's more a question of, like: you're actually making some cognitive decisions. How do you reason? How do you conceptualize what you're doing?"
I would argue that most philosophers who feel "trapped by rationality" or "unable to stop doing what's 'right,' even though they know they 'should,'" could in fact escape the trap if they saw the flaws in whatever reasoning process led them to their current idea of "rationality" in the first place. I think a lot of people are reasoning their way into making worse decisions (at least in the future/hypothetical scenarios noted above, though I would be very surprised if correct decision-theoretic views had literally no implications for everyday life today) due to object-level misconceptions about the prescriptions and flaws of different decision theories.
And all of this strikes me as very much the bread and butter of analytic philosophy. Philosophers unpack and critique the implicit assumptions in different ways of modeling the world (e.g., "of course I can 'control' physical outcomes but can't 'control' mathematical facts", or "of course I can just immediately tell that I'm in the 'real world'; a simulation of me isn't me, or wouldn't be conscious, etc."). I think MIRI just isn't very good at dialoguing with philosophers, and has had too many competing priorities to put the amount of effort into a scholarly dialogue that I wish were being made.
4. There will obviously be innumerable practical differences between the first AGI systems and human decision-makers. However, putting a huge amount of philosophical weight on this distinction will tend to violate naturalism: ceteris paribus, changing whether you run a cognitive process in carbon or in silicon doesn't change whether the process is doing the right thing or working correctly.
E.g., the rules of arithmetic are the same for humans and calculators, even though we don't use identical algorithms to answer particular questions. Humans tend to correctly treat calculators naturalistically: we often think of them as an extension of our own brains and reasoning, we freely switch back and forth between running a needed computation in our own brain vs. in a machine, etc. Running a decision-making algorithm in your brain vs. in an AI shouldn't be fundamentally different, I claim.
5. For similar reasons, a naturalistic way of thinking about the task "delegating a decision-making process to a reasoner outside your own brain" will itself not draw a deep philosophical distinction between "a human building an AI to solve a problem" and "an AI building a second AI to solve a problem" or for that matter "an agent learning over time and refining its own reasoning process so it can 'delegate' to its future self".
There will obviously be practical differences, but there will also be practical differences between two different AI designs. We don't assume that switching to a different design within AI means that the background rules of decision theory (or arithmetic, etc.) go out the window.
(Another way of thinking about this is that the distinction between "natural" and "artificial" intelligence is primarily a practical and historical one, not one that rests on a deep truth of computer science or rational agency; a more naturalistic approach would think of humans more as a weird special case of the extremely heterogeneous space of "(A)I" designs.)
bmg @ 2019-11-22T14:01 (+19)
"What makes a decision 'good' if the decision happens inside an AI?" and "What makes a decision 'good' if the decision happens inside a brain?" aren't orthogonal questions, or even all that different; they're two different ways of posing the same question.
I actually agree with you about this. I have in mind a different distinction, although I might not be explaining it well.
Here’s another go:
Let’s suppose that some decisions are rational and others aren’t. We can then ask: What is it that makes a decision rational? What are the necessary and/or sufficient conditions? I think that this is the question that philosophers are typically trying to answer. The phrase “decision theory” in this context typically refers to a claim about necessary and/or sufficient conditions for a decision being rational. To use different jargon, in this context a “decision theory” refers to a proposed “criterion of rightness.”
When philosophers talk about “CDT,” for example, they are typically talking about a proposed criterion of rightness. Specifically, in this context, “CDT” is the claim that a decision is rational only if taking it would cause the largest expected increase in value. To avoid any ambiguity, let’s label this claim R_CDT.
We can also talk about “decision procedures.” A decision procedure is just a process or algorithm that an agent follows when making decisions.
For each proposed criterion of rightness, it’s possible to define a decision procedure that only outputs decisions that fulfill the criterion. For example, we can define P_CDT as a decision procedure that involves only taking actions that R_CDT claims are rational.
My understanding is that when philosophers talk about “CDT,” they primarily have in mind R_CDT. Meanwhile, it seems like members of the rationalist or AI safety communities primarily have in mind P_CDT.
The difference matters, because people who believe that R_CDT is true don’t generally believe that we should build agents that implement P_CDT or that we should commit to following P_CDT ourselves. R_CDT claims that we should do whatever will have the best effects -- and, in many cases, building agents that follow a decision procedure other than P_CDT is likely to have the best effects. More generally: Most proposed criteria of rightness imply that it can be rational to build agents that sometimes behave irrationally.
MIRI's AI work is properly thought of as part of the "success-first decision theory" approach in academic decision theory.
One possible criterion of rightness, which I’ll call R_UDT, is something like this: An action is rational only if it would have been chosen by whatever decision procedure would have produced the most expected value if consistently followed over an agent’s lifetime. For example, this criterion of rightness says that it is rational to one-box in the transparent Newcomb scenario because agents who consistently follow one-boxing policies tend to do better over their lifetimes.
I could be wrong, but I associate the “success-first approach” with something like the claim that R_UDT is true. This would definitely constitute a really interesting and significant divergence from mainstream opinion within academic decision theory. Academic decision theorists should care a lot about whether or not it’s true.
But I’m also not sure if it matters very much, practically, whether R_UDT or R_CDT is true. It’s not obvious to me that they recommend building different kinds of decision procedures into AI systems. For example, both seem to recommend building AI systems that would one-box in the transparent Newcomb scenario.
You can go with Paul and say that a lot of these distinctions are semantic rather than substantive -- that there isn't a true, ultimate, objective answer to the question of whether we should evaluate decision theories by whether they're successful, vs. some other criterion.
I disagree that any of the distinctions here are purely semantic. But one could argue that normative anti-realism is true. In this case, there wouldn’t really be any such thing as the criterion of rightness for decisions. Neither R_CDT nor R_UDT nor any other proposed criterion would be “correct.”
In this case, though, I think there would be even less reason to engage with academic decision theory literature. The literature would be focused on a question that has no real answer.
[[EDIT: Note that Will also emphasizes the importance of the criterion-of-rightness vs. decision-procedure distinction in his critique of the FDT paper: "[T]hey’re [most often] asking what the best decision procedure is, rather than what the best criterion of rightness is... But, if that’s what’s going on, there are a whole bunch of issues to dissect. First, it means that FDT is not playing the same game as CDT or EDT, which are proposed as criteria of rightness, directly assessing acts. So it’s odd to have a whole paper comparing them side-by-side as if they are rivals."]]
RobBensinger @ 2019-11-22T22:23 (+12)
I agree that these three distinctions are important:
- "Picking policies based on whether they satisfy a criterion X" vs. "Picking policies that happen to satisfy a criterion X". (E.g., trying to pick a utilitarian policy vs. unintentionally behaving utilitarianly while trying to do something else.)
- "Trying to follow a decision rule Y 'directly' or 'on the object level'" vs. "Trying to follow a decision rule Y by following some other decision rule Z that you think satisfies Y". (E.g., trying to naïvely follow utilitarianism without any assistance from sub-rules, heuristics, or self-modifications, vs. trying to follow utilitarianism by following other rules or mental habits you've come up with that you expected to make you better at selecting utilitarianism-endorsed actions.)
- "A decision rule that prescribes outputting some action or policy and doesn't care how you do it" vs. "A decision rule that prescribes following a particular set of cognitive steps that will then output some action or policy". (E.g., a rule that says 'maximize the aggregate welfare of moral patients' vs. a specific mental algorithm intended to achieve that end.)
The first distinction above seems less relevant here, since we're mostly discussing AI systems and humans that are self-aware about their decision criteria and explicitly "trying to do what's right".
As a side-note, I do want to emphasize that from the MIRI cluster's perspective, it's fine for correct reasoning in AGI to arise incidentally or implicitly, as long as it happens somehow (and as long as the system's alignment-relevant properties aren't obscured and the system ends up safe and reliable).
The main reason to work on decision theory in AI alignment has never been "What if people don't make AI 'decision-theoretic' enough?" or "What if people mistakenly think CDT is correct and so build CDT into their AI system?" The main reason is that the many forms of weird, inconsistent, and poorly-generalizing behavior prescribed by CDT and EDT suggest that there are big holes in our current understanding of how decision-making works, holes deep enough that we've even been misunderstanding basic things at the level of "decision-theoretic criterion of rightness".
It's not that I want decision theorists to try to build AI systems (even notional ones). It's that there are things that currently seem fundamentally confusing about the nature of decision-making, and resolving those confusions seems like it would help clarify a lot of questions about how optimization works. That's part of why these issues strike me as natural for academic philosophers to take a swing at (while also being continuous with theoretical computer science, game theory, etc.).
The second distinction ("following a rule 'directly' vs. following it by adopting a sub-rule or via self-modification") seems more relevant. You write:
My understanding is that when philosophers talk about “CDT,” they primarily have in mind R_CDT. Meanwhile, it seems like members of the rationalist or AI safety communities primarily have in mind P_CDT.
The difference matters, because people who believe that R_CDT is true don’t generally believe that we should build agents that implement P_CDT or that we should commit to following P_CDT ourselves.
Far from being a distinction proponents of UDT/FDT neglect, this is one of the main grounds on which UDT/FDT proponents criticize CDT (from within the "success-first" tradition). This is because agents that are reflectively inconsistent in the manner of CDT -- ones that take actions they know they'll regret taking, wish they were following a different decision rule, etc. -- can be money-pumped and can otherwise lose arbitrary amounts of value.
A human following CDT should endorse "stop following CDT," since CDT isn't self-endorsing. It's not even that they should endorse "keep following CDT, but adopt a heuristic or sub-rule that helps us better achieve CDT ends"; they need to completely abandon CDT even at the meta-level of "what sort of decision rule should I follow?" and modify themselves into purely following an entirely new decision rule, or else they'll continue to perform poorly by CDT's lights.
The decision rule that CDT does endorse loses a lot of the apparent elegance and naturalness of CDT. This rule, "son-of-CDT", is roughly:
- Have whatever disposition-to-act gets the most utility, unless I'm in future situations like "a twin prisoner's dilemma against a perfect copy of my future self where the copy was forked from me before I started following this rule", in which case ignore my correlation with that particular copy and make decisions as though our behavior is independent (while continuing to take into account my correlation with any copies of myself I end up in prisoner's dilemmas with that were copied from my brain after I started following this rule).
The fact that CDT doesn't endorse itself (while other theories do), the fact that it needs self-modification abilities in order to perform well by its own lights (and other theories don't), and the fact that the theory it endorses is a strange frankenstein theory (while there are simpler, cleaner theories available) would all be strikes against CDT on their own.
But this decision rule CDT endorses also still performs suboptimally (from the perspective of success-first decision theory). See the discussion of the Retro Blackmail Problem in "Toward Idealized Decision Theory", where "CDT and any decision procedure to which CDT would self-modify see losing money to the blackmailer as the best available action."
In the kind of voting dilemma where a coalition of UDT agents will coordinate to achieve higher-utility outcomes, an agent who became a son-of-CDT agent at age 20 will coordinate with the group insofar as she expects her decision to be correlated with other agents' due to events that happened after she turned 20 (such as "the summer after my 20th birthday, we hung out together and converged a lot in how we think about voting theory"). But she'll refuse to coordinate for reasons like "we hung out a lot the summer before my 20th birthday", "we spent our whole childhoods and teen years living together and learning from the same teachers", and "we all have similar decision-making faculties due to being members of the same species". There's no principled reason to draw this temporal distinction; it's just an artifact of the fact that we started from CDT, and CDT is a flawed decision theory.
Regarding the third distinction ("prescribing a certain kind of output vs. prescribing a step-by-step mental procedure for achieving that kind of output"), I'd say that it's primarily the criterion of rightness that MIRI-cluster researchers care about. This is part of why the paper is called "Functional Decision Theory" and not (e.g.) "Algorithmic Decision Theory": the focus is explicitly on "what outcomes do you produce?", not on how you produce them.
(Thus, an FDT agent can cooperate with another agent whenever the latter agent's input-output relations match FDT's prescription in the relevant dilemmas, regardless of what computations they do to produce those outputs.)
The main reasons I think academic decision theory should spend more time coming up with algorithms that satisfy their decision rules are that (a) this has a track record of clarifying what various decision rules actually prescribe in different dilemmas, and (b) this has a track record of helping clarify other issues in the "understand what good reasoning is" project (e.g., logical uncertainty) and how they relate to decision theory.
bmg @ 2019-11-23T00:50 (+9)
I agree that these three distinctions are important
"Picking policies based on whether they satisfy a criterion X" vs. "Picking policies that happen to satisfy a criterion X". (E.g., trying to pick a utilitarian policy vs. unintentionally behaving utilitarianly while trying to do something else.)
"Trying to follow a decision rule Y 'directly' or 'on the object level'" vs. "Trying to follow a decision rule Y by following some other decision rule Z that you think satisfies Y". (E.g., trying to naïvely follow utilitarianism without any assistance from sub-rules, heuristics, or self-modifications, vs. trying to follow utilitarianism by following other rules or mental habits you've come up with that you expected to make you better at selecting utilitarianism-endorsed actions.)
"A decision rule that prescribes outputting some action or policy and doesn't care how you do it" vs. "A decision rule that prescribes following a particular set of cognitive steps that will then output some action or policy". (E.g., a rule that says 'maximize the aggregate welfare of moral patients' vs. a specific mental algorithm intended to achieve that end.)
The second distinction here is most closely related to the one I have in mind, although I wouldn’t say it’s the same. Another way to express the distinction I have in mind is that it’s between (a) a normative claim and (b) a process of making decisions.
“Hedonistic utilitarianism is correct” would be a non-decision-theoretic example of (a). “Making decisions on the basis of coinflips” would be an example of (b).
In the context of decision theory, of course, I am thinking of R_CDT as an example of (a) and P_CDT as an example of (b).
I now have the sense I’m probably not doing a good job of communicating what I have in mind, though.
The main reason is that the many forms of weird, inconsistent, and poorly-generalizing behavior prescribed by CDT and EDT suggest that there are big holes in our current understanding of how decision-making works, holes deep enough that we've even been misunderstanding basic things at the level of "decision-theoretic criterion of rightness".
I guess my view here is that exploring normative claims will probably only be pretty indirectly useful for understanding “how decision-making works,” since normative claims don’t typically seem to have any empirical/mathematical/etc. implications. For example, to again use a non-decision-theoretic example, I don’t think that learning that hedonistic utilitarianism is true would give us much insight into the computer science or cognitive science of decision-making. Although we might have different intuitions here.
It's that there are things that currently seem fundamentally confusing about the nature of decision-making, and resolving those confusions seems like it would help clarify a lot of questions about how optimization works. That's part of why these issues strike me as natural for academic philosophers to take a swing at (while also being continuous with theoretical computer science, game theory, etc.).
I agree that this is a worthwhile goal and that philosophers can probably contribute to it. I guess I’m just not sure that the question that most academic decision theorists are trying to answer -- and the literature they’ve produced on it -- will ultimately be very relevant.
The fact that CDT doesn't endorse itself (while other theories do), the fact that it needs self-modification abilities in order to perform well by its own lights (and other theories don't), and the fact that the theory it endorses is a strange frankenstein theory (while there are simpler, cleaner theories available) would all be strikes against CDT on their own.
The fact that R_CDT is “self-effacing” -- i.e. the fact that it doesn’t always recommend following P_CDT -- definitely does seem like a point of intuitive evidence against R_CDT.
But I think R_UDT also has an important point in its disfavor. It fails to satisfy what might be called the “Don’t Make Things Worse Principle,” which says that: It’s not rational to take decisions that will definitely make things worse. Will’s Bomb case is an example of a case where R_UDT violates the this principle, which is very similar to his “Guaranteed Payoffs Principle.”
There’s then a question of which of these considerations is more relevant, when judging which of the two normative theories is more likely to be correct. The failure of R_UDT to satisfy the “Don’t Make Things Worse Principle” seems more important to me, but I don’t really know how to argue for this point beyond saying that this is just my intuition. I think that the failure of R_UDT to satisfying this principle -- or something like it -- is also probably the main reason why many philosophers find it intuitively implausible.
(IIRC the first part of Reasons and Persons is mostly a defense of the view that the correct theory of rationality may be self-effacing. But I’m not really familiar with the state of arguments here.)
In the kind of voting dilemma where a coalition of UDT agents will coordinate to achieve higher-utility outcomes, an agent who became a son-of-CDT agent at age 20 will coordinate with the group insofar as she expects her decision to be correlated with other agents' due to events that happened after she turned 20 (such as "the summer after my 20th birthday, we hung out together and converged a lot in how we think about voting theory"). But she'll refuse to coordinate for reasons like "we hung out a lot the summer before my 20th birthday", "we spent our whole childhoods and teen years living together and learning from the same teachers", and "we all have similar decision-making faculties due to being members of the same species". There's no principled reason to draw this temporal distinction; it's just an artifact of the fact that we started from CDT, and CDT is a flawed decision theory.
I actually don’t think the son-of-CDT agent, in this scenario, will take these sorts of non-causal correlations into account at all. (Modifying just yourself to take non-causual correlations into account won’t cause you to achieve better outcomes here.) So I don’t think there should be any weird “Frankenstein” decision procedure thing going on.
….Thinking more about it, though, I’m now less sure how much the different normative decision theories should converge in their recommendations about AI design. I think they all agree that we should build systems that one-box in Newcomb-style scenarios. I think they also agree that, if we’re building twins, then we should design these twins to cooperate in twin prisoner’s dilemmas. But there may be some other contexts where acausal cooperation considerations do lead to genuine divergences. I don’t have very clear/settled thoughts about this, though.
RobBensinger @ 2019-11-23T03:06 (+7)
But I think R_UDT also has an important point in its disfavor. It fails to satisfy what might be called the “Don’t Make Things Worse Principle,” which says that: It’s not rational to take decisions that will definitely make things worse. Will’s Bomb case is an example of a case where R_UDT violates the this principle, which is very similar to his “Guaranteed Payoffs Principle.”
I think "Don't Make Things Worse" is a plausible principle at first glance.
One argument against this principle is that CDT endorses following it if you must, but would prefer to self-modify to stop following it (since doing so has higher expected causal utility). The general policy of following the "Don't Make Things Worse Principle" makes things worse.
Once you've already adopted son-of-CDT, which says something like "act like UDT in future dilemmas insofar as the correlations were produced after I adopted this rule, but act like CDT in those dilemmas insofar as the correlations were produced before I adopted this rule", it's not clear to me why you wouldn't just go: "Oh. CDT has lost the thing I thought made it appealing in the first place, this 'Don't Make Things Worse' feature. If we're going to end up stuck with UDT plus extra theoretical ugliness and loss-of-utility tacked on top, then why not just switch to UDT full stop?"
A more general argument against the Bomb intuition pump is that it involves trading away larger amounts of utility in most possible world-states, in order to get a smaller amount of utility in the Bomb world-state. From Abram Demski's comments:
[...] In Bomb, the problem clearly stipulates that an agent who follows the FDT recommendation has a trillion trillion to one odds of doing better than an agent who follows the CDT/EDT recommendation. Complaining about the one-in-a-trillion-trillion chance that you get the bomb while being the sort of agent who takes the bomb is, to an FDT-theorist, like a gambler who has just lost a trillion-trillion-to-one bet complaining that the bet doesn't look so rational now that the outcome is known with certainty to be the one-in-a-trillion-trillion case where the bet didn't pay well.
[...] One way of thinking about this is to say that the FDT notion of "decision problem" is different from the CDT or EDT notion, in that FDT considers the prior to be of primary importance, whereas CDT and EDT consider it to be of no importance. If you had instead specified 'bomb' with just the certain information that 'left' is (causally and evidentially) very bad and 'right' is much less bad, then CDT and EDT would regard it as precisely the same decision problem, whereas FDT would consider it to be a radically different decision problem.
Another way to think about this is to say that FDT "rejects" decision problems which are improbable according to their own specification. In cases like Bomb where the situation as described is by its own description a one in a trillion trillion chance of occurring, FDT gives the outcome only one-trillion-trillion-th consideration in the expected utility calculation, when deciding on a strategy.
[...] This also hopefully clarifies the sense in which I don't think the decisions pointed out in (III) are bizarre. The decisions are optimal according to the very probability distribution used to define the decision problem.
There's a subtle point here, though, since Will describes the decision problem from an updated perspective -- you already know the bomb is in front of you. So UDT "changes the problem" by evaluating "according to the prior". From my perspective, because the very statement of the Bomb problem suggests that there were also other possible outcomes, we can rightly insist to evaluate expected utility in terms of those chances.
Perhaps this sounds like an unprincipled rejection of the Bomb problem as you state it. My principle is as follows: you should not state a decision problem without having in mind a well-specified way to predictably put agents into that scenario. Let's call the way-you-put-agents-into-the-scenario the "construction". We then evaluate agents on how well they deal with the construction.
For examples like Bomb, the construction gives us the overall probability distribution -- this is then used for the expected value which UDT's optimality notion is stated in terms of.
For other examples, as discussed in Decisions are for making bad outcomes inconsistent, the construction simply breaks when you try to put certain decision theories into it. This can also be a good thing; it means the decision theory makes certain scenarios altogether impossible.
bmg @ 2019-11-23T12:12 (+6)
One argument against this principle is that CDT endorses following it if you must, but would prefer to self-modify to stop following it (since doing so has higher expected causal utility).
A more general argument against the Bomb intuition pump is that it involves trading away larger amounts of utility in most possible world-states, in order to get a smaller amount of utility in the Bomb world-state.
This just seems to be the point that R_CDT is self-effacing: It says that people should not follow P_CDT, because following other decision procedures will produce better outcomes in expectation.
I definitely agree that R_CDT is self-effacing in this way (at least in certain scenarios). The question is just whether self-effacingness or failure to satisfy "Don't Make Things Worse" is more relevant when trying to judge the likelihood of a criterion of rightness being correct. I'm not sure whether it's possible to do much here other than present personal intuitions.
The point that R_UDT only violates the "Don't Make Things Worse" principle only infrequently seems relevant, but I'm still not sure this changes my intuitions very much.
If we're going to end up stuck with UDT plus extra theoretical ugliness and loss-of-utility tacked on top, then why not just switch to UDT full stop?
I may just be missing something, but I don't see what this theoretical ugliness is. And I don't intuitively find the ugliness/elegance of the decision procedure recommend by a criterion of rightness to be very relevant when trying to judge whether the criterion is correct.
[[EDIT: Just an extra thought on the fact that R_CDT is self-effacing. My impression is that self-effacingness is typically regarded as a relatively weak reason to reject a moral theory. For example, a lot of people regard utilitarianism as self-effacing both because it's costly to directly evaluate the utility produced by actions and because others often react poorly to people who engage in utilitarian-style reasoning -- but this typically isn't regarded as a slam-dunk reasons to believe that utilitarianism is false. I think the SEP article on consequentialism is expressing a pretty mainstream position when it says: "[T]here is nothing incoherent about proposing a decision procedure that is separate from one’s criterion of the right.... Criteria can, thus, be self-effacing without being self-refuting." Insofar as people don't tend to buy self-effacingness as a slam-dunk argument against the truth of moral theories, it's not clear why they should buy it as a slam-dunk argument against the truth of normative decision theories.]]
ESRogs @ 2019-11-26T01:31 (+7)
is more relevant when trying to judge the likelihood of a criterion of rightness being correct
Sorry to drop in in the middle of this back and forth, but I am curious -- do you think it's quite likely that there is a single criterion of rightness that is objectively "correct"?
It seems to me that we have a number of intuitive properties (meta criteria of rightness?) that we would like a criterion of rightness to satisfy (e.g. "don't make things worse", or "don't be self-effacing"). And so far there doesn't seem to be any single criterion that satisfies all of them.
So why not just conclude that, similar to the case with voting and Arrow's theorem, perhaps there's just no single perfect criterion of rightness.
In other words, once we agree that CDT doesn't make things worse, but that UDT is better as a general policy, is there anything left to argue about about which is "correct"?
EDIT: Decided I had better go and read your Realism and Rationality post, and ended up leaving a lengthy comment there.
bmg @ 2019-11-26T23:03 (+5)
Sorry to drop in in the middle of this back and forth, but I am curious -- do you think it's quite likely that there is a single criterion of rightness that is objectively "correct"?
It seems to me that we have a number of intuitive properties (meta criteria of rightness?) that we would like a criterion of rightness to satisfy (e.g. "don't make things worse", or "don't be self-effacing"). And so far there doesn't seem to be any single criterion that satisfies all of them.
So why not just conclude that, similar to the case with voting and Arrow's theorem, perhaps there's just no single perfect criterion of rightness.
Happy to be dropped in on :)
I think it's totally conceivable that no criterion of rightness is correct (e.g. because the concept of a "criterion of rightness" turns out to be some spooky bit of nonsense that doesn't really map onto anything in the real world.)
I suppose the main things I'm arguing are just that:
-
When a philosopher expresses support for a "decision theory," they are typically saying that they believe some claim about what the correct criterion of rightness is.
-
Claims about the correct criterion of rightness are distinct from decision procedures.
-
Therefore, when a member of the rationalist community uses the word "decision theory" to refer to a decision procedure, they are talking about something that's pretty conceptually distinct from what philosophers typically have in mind. Discussions about what decision procedure performs best or about what decision procedure we should build into future AI systems [[EDIT: or what decision procedure most closely matches our preferences about decision procedures]] don't directly speak to the questions that most academic "decision theorists" are actually debating with one another.
I also think that, conditional on there being a correct criterion of rightness, R_CDT is more plausible than R_UDT. But this is a relatively tentative view. I'm definitely not a super hardcore R_CDT believer.
It seems to me that we have a number of intuitive properties (meta criteria of rightness?) that we would like a criterion of rightness to satisfy (e.g. "don't make things worse", or "don't be self-effacing"). And so far there doesn't seem to be any single criterion that satisfies all of them.
So why not just conclude that, similar to the case with voting and Arrow's theorem, perhaps there's just no single perfect criterion of rightness.
I guess here -- in almost definitely too many words -- is how I think about the issue here. (Hopefully these comments are at least somewhat responsive to your question.)
It seems like following general situation is pretty common: Someone is initially inclined to think that anything with property P will also have property Q1 and Q2. But then they realize that properties Q1 and Q2 are inconsistent with one another.
One possible reaction to this situation is to conclude that nothing actually has property P. Maybe the idea of property P isn't even conceptually coherent and we should stop talking about it (while continuing to independently discuss properties Q1 and Q2). Often the more natural reaction, though, is to continue to believe that some things have property P -- but just drop the assumption that these things will also have both property Q1 and property Q2.
This obviously a pretty abstract description, so I'll give a few examples. (No need to read the examples if the point seems obvious.)
Ethics: I might initially be inclined to think that it's always ethical (property P) to maximize happiness and that it's always unethical to torture people. But then I may realize that there's an inconsistency here: in at least rare circumstances, such as ticking time-bomb scenarios where torture can extract crucial information, there may be no decision that is both happiness maximizing (Q1) and torture-avoiding (Q2). It seems like a natural reaction here is just to drop either the belief that maximizing happiness is always ethical or that torture is always unethical. It doesn't seem like I need to abandon my belief that some actions have the property of being ethical.
Theology: I might initially be inclined to think that God is all-knowing, all-powerful, and all-good. But then I might come to believe (whether rightly or not) that, given the existance of evil, these three properties are inconsistent. I might then continue to believe that God exists, but just drop my belief that God is all-good. (To very awkwardly re-express this in the language of properties: This would mean dropping my belief that any entity that has the property of being God also has the property of being all-good).
Politician-bashing: I might initially be inclined to characterize some politician both as an incompetent leader and as someone who's successfully carrying out an evil long-term plan to transform the country. Then I might realize that these two characterizations are in tension with one another. A pretty natural reaction, then, might be to continue to believe the politician exists -- but just drop my belief that they're incompetent.
To turn to the case of the decision-theoretic criterion of rightness, I might initially be inclined to think that the correct criterion of rightness will satisfy both "Don't Make Things Worse" and "No Self-Effacement." It's now become clear, though, that no criterion of rightness can satisfy both of these principles. I think it's pretty reasoanble, then, to continue to believe that there's a correct criterion of rightness -- but just drop the belief that the correct criterion of rightness will also satisfy "No Self-Effacement."
ESRogs @ 2019-11-27T03:31 (+7)
Thanks! This is helpful.
It seems like following general situation is pretty common: Someone is initially inclined to think that anything with property P will also have property Q1 and Q2. But then they realize that properties Q1 and Q2 are inconsistent with one another.
One possible reaction to this situation is to conclude that nothing actually has property P. Maybe the idea of property P isn't even conceptually coherent and we should stop talking about it (while continuing to independently discuss properties Q1 and Q2). Often the more natural reaction, though, is to continue to believe that some things have property P -- but just drop the assumption that these things will also have both property Q1 and property Q2.
I think I disagree with the claim (or implication) that keeping P is more often more natural. Well, you're just saying it's "often" natural, and I suppose it's natural in some cases and not others. But I think we may disagree on how often it's natural, though hard to say at this very abstract level. (Did you see my comment in response to your Realism and Rationality post?)
In particular, I'm curious what makes you optimistic about finding a "correct" criterion of rightness. In the case of the politician, it seems clear that learning they don't have some of the properties you thought shouldn't call into question whether they exist at all.
But for the case of a criterion of rightness, my intuition (informed by the style of thinking in my comment), is that there's no particular reason to think there should be one criterion that obviously fits the bill. Your intuition seems to be the opposite, and I'm not sure I understand why.
My best guess, particularly informed by reading through footnote 15 on your Realism and Rationality post, is that when faced with ethical dilemmas (like your torture vs lollipop examples), it seems like there is a correct answer. Does that seem right?
(I realize at this point we're talking about intuitions and priors on a pretty abstract level, so it may be hard to give a good answer.)
bmg @ 2020-01-18T19:40 (+5)
I think I disagree with the claim (or implication) that keeping P is more often more natural. Well, you're just saying it's "often" natural, and I suppose it's natural in some cases and not others. But I think we may disagree on how often it's natural, though hard to say at this very abstract level. (Did you see my comment in response to your Realism and Rationality post?)
In particular, I'm curious what makes you optimistic about finding a "correct" criterion of rightness. In the case of the politician, it seems clear that learning they don't have some of the properties you thought shouldn't call into question whether they exist at all.
But for the case of a criterion of rightness, my intuition (informed by the style of thinking in my comment), is that there's no particular reason to think there should be one criterion that obviously fits the bill. Your intuition seems to be the opposite, and I'm not sure I understand why.
Hey again!
I appreciated your comment on the LW post. I started writing up a response to this comment and your LW one, back when the thread was still active, and then stopped because it had become obscenely long. Then I ended up badly needing to procrastinate doing something else today. So here’s an over-long document I probably shouldn’t have written, which you are under no social obligation to read.
ESRogs @ 2020-01-26T00:44 (+4)
Thanks! Just read it.
I think there's a key piece of your thinking that I don't quite understand / disagree with, and it's the idea that normativity is irreducible.
I think I follow you that if normativity were irreducible, then it wouldn't be a good candidate for abandonment or revision. But that seems almost like begging the question. I don't understand why it's irreducible.
Suppose normativity is not actually one thing, but is a jumble of 15 overlapping things that sometimes come apart. This doesn't seem like it poses any challenge to your intuitions from footnote 6 in the document (starting with "I personally care a lot about the question: 'Is there anything I should do, and, if so, what?'"). And at the same time it explains why there are weird edge cases where the concept seems to break down.
So few things in life seem to be irreducible. (E.g. neither Eric nor Ben is irreducible!) So why would normativity be?
[You also should feel under no social obligation to respond, though it would be fun to discuss this the next time we find ourselves at the same party, should such a situation arise.]
RobBensinger @ 2019-11-27T07:24 (+5)
This is a good discussion! Ben, thank you for inspiring so many of these different paths we've been going down. :) At some point the hydra will have to stop growing, but I do think the intuitions you've been sharing are widespread enough that it's very worthwhile to have public discussion on these points.
Therefore, when a member of the rationalist community uses the word "decision theory" to refer to a decision procedure, they are talking about something that's pretty conceptually distinct from what philosophers typically have in mind. Discussions about what decision procedure performs best or about what decision procedure we should build into future AI systems don't directly speak to the questions that most academic "decision theorists" are actually debating with one another.
On the contrary:
- MIRI is more interested in identifying generalizations about good reasoning ("criteria of rightness") than in fully specifying a particular algorithm.
- MIRI does discuss decision algorithms in order to better understand decision-making, but this isn't different in kind from the ordinary way decision theorists hash things out. E.g., the traditional formulation of CDT is underspecified in dilemmas like Death in Damascus. Joyce and Arntzenius' response to this wasn't to go "algorithms are uncouth in our field"; it was to propose step-by-step procedures that they think capture the intuitions behind CDT and give satisfying recommendations for how to act.
- MIRI does discuss "what decision procedure performs best", but this isn't any different from traditional arguments in the field like "naive EDT is wrong because it performs poorly in the smoking lesion problem". Compared to the average decision theorist, the average rationalist puts somewhat more weight on some considerations and less weight on others, but this isn't different in kind from the ordinary disagreements that motivate different views within academic decision theory, and these disagreements about what weight to give categories of consideration are themselves amenable to argument.
- As I noted above, MIRI is primarily interested in decision theory for the sake of better understanding the nature of intelligence, optimization, embedded agency, etc., not for the sake of picking a "decision theory we should build into future AI systems". Again, this doesn't seem unlike the case of philosophers who think that decision theory arguments will help them reach conclusions about the nature of rationality.
I think it's totally conceivable that no criterion of rightness is correct (e.g. because the concept of a "criterion of rightness" turns out to be some spooky bit of nonsense that doesn't really map onto anything in the real world.)
Could you give an example of what the correctness of a meta-criterion like "Don't Make Things Worse" could in principle consist in?
I’m not looking here for a “reduction” in the sense of a full translation into other, simpler terms. I just want a way of making sense of how human brains can tell what’s “decision-theoretically normative” in cases like this.
Human brains didn’t evolve to have a primitive “normativity detector” that beeps every time a certain thing is Platonically Normative. Rather, different kinds of normativity can be understood by appeal to unmysterious matters like “things brains value as ends”, “things that are useful for various ends”, “things that accurately map states of affairs”...
When I think of other examples of normativity, my sense is that in every case there's at least one good account of why a human might be able to distinguish "truly" normative things from non-normative ones. E.g. (considering both epistemic and non-epistemic norms):
1. If I discover two alien species who disagree about the truth-value of "carbon atoms have six protons", I can evaluate their correctness by looking at the world and seeing whether their statement matches the world.
2. If I discover two alien species who disagree about the truth value of "pawns cannot move backwards in chess" or "there are statements in the language of Peano arithmetic that can neither be proved nor disproved in Peano arithmetic", then I can explain the rules of 'proving things about chess' or 'proving things about PA' as a symbol game, and write down strings of symbols that collectively constitute a 'proof' of the statement in question.
I can then assert that if any member of any species plays the relevant 'proof' game using the same rules, from now until the end of time, they will never prove the negation of my result, and (paper, pen, time, and ingenuity allowing) they will always be able to re-prove my result.
(I could further argue that these symbol games are useful ones to play, because various practical tasks are easier once we've accumulated enough knowledge about legal proofs in certain games. This usefulness itself provides a criteria for choosing between "follow through on the proof process" and "just start doodling things or writing random letters down".)
The above doesn't answer questions like "do the relevant symbols have Platonic objects as truthmakers or referents?", or "why do we live in a consistent universe?", or the like. But the above answer seems sufficient for rejecting any claim that there's something pointless, epistemically suspect, or unacceptably human-centric about affirming Gödel's first incompleteness theorem. The above is minimally sufficient grounds for going ahead and continuing to treat math as something more significant than theology, regardless of whether we then go on to articulate a more satisfying explanation of why these symbol games work the way they do.
3. If I discover two alien species who disagree about the truth-value of "suffering is terminally valuable", then I can think of at least two concrete ways to evaluate which parties are correct. First, I can look at the brains of a particular individual or group, see what that individual or group terminally values, and see whether the statement matches what's encoded in those brains. Commonly the group I use for this purpose is human beings, such that if an alien (or a housecat, etc.) terminally values suffering, I say that this is "wrong".
Alternatively, I can make different "wrong" predicates for each species: , , , , etc.
This has the disadvantage of maybe making it sound like all these values are on "equal footing" in an internally inconsistent way ("it's wrong to put undue weight on what's !", where the first "wrong" is secretly standing in for ""), but has the advantage of making it easy to see why the aliens' disagreement might be important and substantive, while still allowing that aliens' normative claims can be wrong (because they can be mistaken about their own core values).
The details of how to go from a brain to an encoding of "what's right" seem incredibly complex and open to debate, but it seems beyond reasonable dispute that if the information content of a set of terminal values is encoded anywhere in the universe, it's going to be in brains (or constructs from brains) rather than in patterns of interstellar dust, digits of pi, physical laws, etc.
If a criterion like “Don’t Make Things Worse” deserves a lot of weight, I want to know what that weight is coming from.
If the answer is “I know it has to come from something, but I don’t know what yet”, then that seems like a perfectly fine placeholder answer to me.
If the answer is “This is like the ‘terminal values’ case, in that (I hypothesize) it’s just an ineradicable component of what humans care about”, then that also seems structurally fine, though I’m extremely skeptical of the claim that the “warm glow of feeling causally efficacious” is important enough to outweigh other things of great value in the real world.
If the answer is “I think ‘Don’t Make Things Worse’ is instrumentally useful, i.e., more useful than UDT for achieving the other things humans want in life”, then I claim this is just false. But, again, this seems like the right kind of argument to be making; if CDT is better than UDT, then that betterness ought to consist in something.
RobBensinger @ 2019-11-26T08:48 (+5)
I mostly agree with this. I think the disagreement between CDT and FDT/UDT advocates is less about definitions, and more about which of these things feels more compelling:
- 1. On the whole, FDT/UDT ends up with more utility.
(I think this intuition tends to hold more force with people the more emotionally salient "more utility" is to you. E.g., consider a version of Newcomb's problem where two-boxing gets you $100, while one-boxing gets you $100,000 and saves your child's life.)
- 2. I'm not the slave of my decision theory, or of the predictor, or of any environmental factor; I can freely choose to do anything in any dilemma, and by choosing to not leave money on the table (e.g., in a transparent Newcomb problem with a 1% chance of predictor failure where I've already observed that the second box is empty), I'm "getting away with something" and getting free utility that the FDT agent would miss out on.
(I think this intuition tends to hold more force with people the more emotionally salient it is to imagine the dollars sitting right there in front of you and you knowing that it's "too late" for one-boxing to get you any more utility in this world.)
There are other considerations too, like how much it matters to you that CDT isn't self-endorsing. CDT prescribes self-modifying in all future dilemmas so that you behave in a more UDT-like way. It's fine to say that you personally lack the willpower to follow through once you actually get into the dilemma and see the boxes sitting in front of you; but it's still the case that a sufficiently disciplined and foresightful CDT agent will generally end up behaving like FDT in the very dilemmas that have been cited to argue for CDT.
If a more disciplined and well-prepared version of you would have one-boxed, then isn't there something off about saying that two-boxing is in any sense "correct"? Even the act of praising CDT seems a bit self-destructive here, inasmuch as (a) CDT prescribes ditching CDT, and (b) realistically, praising or identifying with CDT is likely to make it harder for a human being to follow through on switching to son-of-CDT (as CDT prescribes).
Mind you, if the sentence "CDT is the most rational decision theory" is true in some substantive, non-trivial, non-circular sense, then I'm inclined to think we should acknowledge this truth, even if it makes it a bit harder to follow through on the EDT+CDT+UDT prescription to one-box in strictly-future Newcomblike problems. When the truth is inconvenient, I tend to think it's better to accept that truth than to linguistically conceal it.
But the arguments I've seen for "CDT is the most rational decision theory" to date have struck me as either circular, or as reducing to "I know CDT doesn't get me the most utility, but something about it just feels right".
It's fine, I think, if "it just feels right" is meant to be a promissory note for some forthcoming account — a clue that there's some deeper reason to favor CDT, though we haven't discovered it yet. As the FDT paper puts it:
These are odd conclusions. It might even be argued that sufficiently odd behavior provides evidence that what FDT agents see as “rational” diverges from what humans see as “rational.” And given enough divergence of that sort, we might be justified in predicting that FDT will systematically fail to get the most utility in some as-yet-unknown fair test.
On the other hand, if "it just feels right" is meant to be the final word on why "CDT is the most rational decision theory", then I feel comfortable saying that "rational" is a poor choice of word here, and neither maps onto a key descriptive category nor maps onto any prescription or norm worthy of being followed.
RobBensinger @ 2019-11-26T09:34 (+3)
My impression is that most CDT advocates who know about FDT think FDT is making some kind of epistemic mistake, where the most popular candidate (I think) is some version of magical thinking.
Superstitious people often believe that it's possible to directly causally influence things across great distances of time and space. At a glance, FDT's prescription ("one-box, even though you can't causally affect whether the box is full") as well as its account of how and why this works ("you can somehow 'control' the properties of abstract objects like 'decision functions'") seem weird and spooky in the manner of a superstition.
FDT's response: if a thing seems spooky, that's a fine first-pass reason to be suspicious of it. But at some point, the accusation of magical thinking has to cash out in some sort of practical, real-world failure -- in the case of decision theory, some systematic loss of utility that isn't balanced by an equal, symmetric loss of utility from CDT. After enough experience of seeing a tool outperforming the competition in scenario after scenario, at some point calling the use of that tool "magical thinking" starts to ring rather hollow. At that point, it's necessary to consider the possibility that FDT is counter-intuitive but correct (like Einstein's "spukhafte Fernwirkung"), rather than magical.
In turn, FDT advocates tend to think the following reflects an epistemic mistake by CDT advocates:
2. I'm not the slave of my decision theory, or of the predictor, or of any environmental factor; I can freely choose to do anything in any dilemma, and by choosing to not leave money on the table (e.g., in a transparent Newcomb problem with a 1% chance of predictor failure where I've already observed that the second box is empty), I'm "getting away with something" and getting free utility that the FDT agent would miss out on.
The alleged mistake here is a violation of naturalism. Humans tend to think of themselves as free Cartesian agents acting upon the world, rather than as deterministic subprocesses of a larger deterministic process. If we consistently and whole-heartedly accepted the "deterministic subprocess" view of our decision-making, we would find nothing strange about the idea that it's sometimes right for this subprocess to do locally incorrect things for the sake of better global results.
E.g., consider the transparent Newcomb problem with a 1% chance of predictor error. If we think of the brain's decision-making as a rule-governed system whose rules we are currently determining (via a meta-reasoning process that is itself governed by deterministic rules), then there's nothing strange about enacting a rule that gets us $1M in 99% of outcomes and $0 in 1% of outcomes; and following through when the unlucky 1% scenario hits us is nothing to agonize over, it's just a consequence of the rule we already decided. In that regard, steering the rule-governed system that is your brain is no different than designing a factory robot that performs well enough in 99% of cases to offset the 1% of cases where something goes wrong.
(Note how a lot of these points are more intuitive in CS language. I don't think it's a coincidence that people coming from CS were able to improve on academic decision theory's ideas on these points; I think it's related to what kinds of stumbling blocks get in the way of thinking in these terms.)
Suppose you initially tell yourself:
"I'm going to one-box in all strictly-future transparent Newcomb problems, since this produces more expected causal (and evidential, and functional) utility. One-boxing and receiving $1M in 99% of future states is worth the $1000 cost of one-boxing in the other 1% of future states."
Suppose that you then find yourself facing the 1%-likely outcome where Omega leaves the box empty regardless of your choice. You then have a change of heart and decide to two-box after all, taking the $1000.
I claim that the above description feels from the inside like your brain is escaping the iron chains of determinism (even if your scientifically literate system-2 verbal reasoning fully recognizes that you're a deterministic process). And I claim that this feeling (plus maybe some reluctance to fully accept the problem description as accurate?) is the only thing that makes CDT's decision seem reasonable in this case.
In reality, however, if we end up not following through on our verbal commitment and we one-box in that 1% scenario, then this would just prove that we'd been mistaken about what rule we had successfully installed in our brains. As it turns out, we were really following the lower-global-utility rule from the outset. A lack of follow-through or a failure of will is itself a part of the decision-making process that Omega is predicting; however much it feels as though a last-minute swerve is you "getting away with something", it's really just you deterministically following through on an algorithm that will get you less utility in 99% of scenarios (while happening to be bad at predicting your own behavior and bad at following through on verbalized plans).
I should emphasize that the above is my own attempt to characterize the intuitions behind CDT and FDT, based on the arguments I've seen in the wild and based on what makes me feel more compelled by CDT, or by FDT. I could easily be wrong about the crux of disagreement between some CDT and FDT advocates.
bmg @ 2019-11-26T21:39 (+3)
In turn, FDT advocates tend to think the following reflects an epistemic mistake by CDT advocates:
- I'm not the slave of my decision theory, or of the predictor, or of any environmental factor; I can freely choose to do anything in any dilemma, and by choosing to not leave money on the table (e.g., in a transparent Newcomb problem with a 1% chance of predictor failure where I've already observed that the second box is empty), I'm "getting away with something" and getting free utility that the FDT agent would miss out on.
The alleged mistake here is a violation of naturalism. Humans tend to think of themselves as free Cartesian agents acting upon the world, rather than as deterministic subprocesses of a larger deterministic process. If we consistently and whole-heartedly accepted the "deterministic subprocess" view of our decision-making, we would find nothing strange about the idea that it's sometimes right for this subprocess to do locally incorrect things for the sake of better global results.
Is the following a roughly accurate re-characterization of the intuition here?
"Suppose that there's an agent that implements P_UDT. Because it is following P_UDT, when it enters the box room it finds a ton of money in the first box and then refrains from taking the money in the second box. People who believe R_CDT claim that the agent should have also taken the money in the second box. But, given that the universe is deterministic, this doesn't really make sense. From before the moment the agent the room, it was already determined that the agent would one box. Since (in a physically determinstic sense) the P_UDT agent could not have two-boxed, there's no relevant sense in which the agent should have two-boxed."
If so, then I suppose my first reaction is that this seems like a general argument against normative realism rather than an argument against any specific proposed criterion of rightness. It also applies, for example, to the claim that a P_CDT agent "should have" one-boxed -- since in a physically deterministic sense it could not have. Therefore, I think it's probably better to think of this as an argument against the truth (and possibly conceptual coherence) of both R_CDT and R_UDT, rather than an argument that favors one over the other.
In general, it seems to me like all statements that evoke counterfactuals have something like this problem. For example, it is physically determined what sort of decision procedure we will build into any given AI system; only one choice of decision procedure is physically consistent with the state of the world at the time the choice is made. So -- insofar as we accept this kind of objection from determinism -- there seems to be something problematically non-naturalistic about discussing what "would have happened" if we built in one decision procedure or another.
RobBensinger @ 2019-11-27T06:48 (+3)
Since (in a physically determinstic sense) the P_UDT agent could not have two-boxed, there's no relevant sense in which the agent should have two-boxed."
No, I don't endorse this argument. To simplify the discussion, let's assume that the Newcomb predictor is infallible. FDT agents, CDT agents, and EDT agents each get a decision: two-box (which gets you $1000 plus an empty box), or one-box (which gets you $1,000,000 and leaves the $1000 behind). Obviously, insofar as they are in fact following the instructions of their decision theory, there's only one possible outcome; but it would be odd to say that a decision stops being a decision just because it's determined by something. (What's the alternative?)
I do endorse "given the predictor's perfect accuracy, it's impossible for the P_UDT agent to two-box and come away with $1,001,000". I also endorse "given the predictor's perfect accuracy, it's impossible for the P_CDT agent to two-box and come away with $1,001,000". Per the problem specification, no agent can two-box and get $1,001,000 or one-box and get $0. But this doesn't mean that no decision is made; it just means that the predictor can predict the decision early enough to fill the boxes accordingly.
(Notably, the agent following P_CDT two-boxes because $1,001,000 > $1,000,000 and $1000 > $0, even though this "dominance" argument appeals to two outcomes that are known to be impossible just from the problem statement. I certainly don't think agents "should" try to achieve outcomes that are impossible from the problem specification itself. The reason agents get more utility than CDT in Newcomb's problem is that non-CDT agents take into account that the predictor is a predictor when they construct their counterfactuals.)
In the transparent version of this dilemma, the agent who sees the $1M and one-boxes also "could have two-boxed", but if they had two-boxed, it would only have been after making a different observation. In that sense, if the agent has any lingering uncertainty about what they'll choose, the uncertainty goes away as soon as they see whether the box is full.
In general, it seems to me like all statements that evoke counterfactuals have something like this problem. For example, it is physically determined what sort of decision procedure we will build into any given AI system; only choice of decision procedure is physically consistent with the state of the world at the time the choice is made. So -- insofar as we accept this kind of objection from determinism -- there seems to be something problematically non-naturalistic about discussing what "would have happened" if we built in one decision procedure or another.
No, there's nothing non-naturalistic about this. Consider the scenario you and I are in. Simplifying somewhat, we can think of ourselves as each doing meta-reasoning to try to choose between different decision algorithms to follow going forward; where the new things we learn in this conversation are themselves a part of that meta-reasoning.
The meta-reasoning process is deterministic, just like the object-level decision algorithms are. But this doesn't mean that we can't choose between object-level decision algorithms. Rather, the meta-reasoning (in spite of having deterministic causes) chooses either "I think I'll follow P_FDT from now on" or "I think I'll follow P_CDT from now on". Then the chosen decision algorithm (in spite of also having deterministic causes) outputs choices about subsequent actions to take. Meta-processes that select between decision algorithms (to put into an AI, or to run in your own brain, or to recommend to other humans, etc.)) can make "real decisions", for exactly the same reason (and in exactly the same sense) that the decision algorithms in question can make real decisions.
It isn't problematic that all these processes requires us to consider counterfactuals that (if we were omniscient) we would perceive as inconsistent/impossible. Deliberation, both at the object level and at the meta level, just is the process of determining the unique and only possible decision. Yet because we are uncertain about the outcome of the deliberation while deliberating, and because the details of the deliberation process do determine our decision (even as these details themselves have preceding causes), it feels from the inside of this process as though both options are "live", are possible, until the very moment we decide.
(See also Decisions are for making bad outcomes inconsistent.)
vaniver @ 2019-11-28T00:05 (+7)
I certainly don't think agents "should" try to achieve outcomes that are impossible from the problem specification itself.
I think you need to make a clearer distinction here between "outcomes that don't exist in the universe's dynamics" (like taking both boxes and receiving $1,001,000) and "outcomes that can't exist in my branch" (like there not being a bomb in the unlucky case). Because if you're operating just in the branch you find yourself in, many outcomes whose probability an FDT agent is trying to affect are impossible from the problem specification (once you include observations).
And, to be clear, I do think agents "should" try to achieve outcomes that are impossible from the problem specification including observations, if certain criteria are met, in a way that basically lines up with FDT, just like agents "should" try to achieve outcomes that are already known to have happened from the problem specification including observations.
As an example, if you're in Parfit's Hitchhiker, you should pay once you reach town, even though reaching town has probability 1 in cases where you're deciding whether or not to pay, and the reason for this is because it was necessary for reaching town to have had probability 1.
RobBensinger @ 2019-11-28T00:49 (+2)
+1, I agree with all this.
bmg @ 2019-11-27T22:42 (+2)
Notably, the agent following P_CDT two-boxes because $1,001,000 > $1,000,000 and $1000 > $0, even though this "dominance" argument appeals to two outcomes that are known to be impossible just from the problem statement. I certainly don't think agents "should" try to achieve outcomes that are impossible from the problem specification itself.
Suppose that we accept the principle that agents never "should" try to achieve outcomes that are impossible from the problem specification -- with one implication being that it's false that (as R_CDT suggests) agents that see a million dollars in the first box "should" two-box.
This seems to imply that it's also false that (as R_UDT suggests) an agent that sees that the first box is empty "should" one box. By the problem specification, of course, one boxing when there is no money in the first box is also an impossible outcome. Since decisions to two box only occur when the first box is empty, this would then imply that decisions to two box are never irrational in the context of this problem. But I imagine you don't want to say that.
I think I probably still don't understand your objection here -- so I'm not sure this point is actually responsive to it -- but I initially have trouble seeing what potential violations of naturalism/determinism R_CDT could be committing that R_UDT would not also be committing.
(Of course, just to be clear, both R_UDT and R_CDT imply that the decision to commit yourself to a one-boxing policy at the start of the game would be rational. They only diverge in their judgments of what actual in-room boxing decision would be rational. R_UDT says that the decision to two-box is irrational and R_CDT says that the decision to one-box is irrational.)
ESRogs @ 2019-11-29T06:23 (+3)
both R_UDT and R_CDT imply that the decision to commit yourself to a two-boxing policy at the start of the game would be rational
That should be "a one-boxing policy", right?
bmg @ 2019-11-30T01:23 (+1)
Yep, thanks for the catch! Edited to fix.
ESRogs @ 2019-11-26T09:10 (+1)
But the arguments I've seen for "CDT is the most rational decision theory" to date have struck me as either circular, or as reducing to "I know CDT doesn't get me the most utility, but something about it just feels right".
It seems to me like they're coming down to saying something like: the "Guaranteed Payoffs Principle" / "Don't Make Things Worse Principle" is more core to rational action than being self-consistent. Whereas others think self-consistency is more important.
Mind you, if the sentence "CDT is the most rational decision theory" is true in some substantive, non-trivial, non-circular sense
It's not clear to me that the justification for CDT is more circular than the justification for FDT. Doesn't it come down to which principles you favor?
Maybe you could say FDT is more elegant. Or maybe that it satisfies more of the intuitive properties we'd hope for from a decision theory (where elegance might be one of those). But I'm not sure that would make the justification less-circular per se.
I guess one way the justification for CDT could be more circular is if the key or only principle that pushes in favor of it over FDT can really just be seen as a restatement of CDT in a way that the principles that push in favor of FDT do not. Is that what you would claim?
RobBensinger @ 2019-11-26T10:03 (+1)
Whereas others think self-consistency is more important.
The main argument against CDT (in my view) is that it tends to get you less utility (regardless of whether you add self-modification so it can switch to other decision theories). Self-consistency is a secondary issue.
It's not clear to me that the justification for CDT is more circular than the justification for FDT. Doesn't it come down to which principles you favor?
FDT gets you more utility than CDT. If you value literally anything in life more than you value "which ritual do I use to make my decisions?", then you should go with FDT over CDT; that's the core argument.
This argument for FDT would be question-begging if CDT proponents rejected utility as a desirable thing. But instead CDT proponents who are familiar with FDT agree utility is a positive, and either (a) they think there's no meaningful sense in which FDT systematically gets more utility than CDT (which I think is adequately refuted by Abram Demski), or (b) they think that CDT has other advantages that outweigh the loss of utility (e.g., CDT feels more intuitive to them).
The latter argument for CDT isn't circular, but as a fan of utility (i.e., of literally anything else in life), it seems very weak to me.
bmg @ 2019-11-26T20:15 (+6)
The main argument against CDT (in my view) is that it tends to get you less utility (regardless of whether you add self-modification so it can switch to other decision theories). Self-consistency is a secondary issue.
I do think the argument ultimately needs to come down to an intuition about self-effacingness.
The fact that agents earn less expected utility if they implement P_CDT than if they implement some other decision procedure seems to support the claim that agents should not implement P_CDT.
But there's nothing logically inconsistent about believing both (a) that R_CDT is true and (b) that agents should not implement P_CDT. To again draw an analogy with a similar case, there's also nothing logically inconsistent about believing both (a) that utilitarianism is true and (b) that agents should not in general make decisions by carrying out utilitarian reasoning.
So why shouldn't I believe that R_CDT is true? The argument needs an additional step. And it seems to me like the most addition step here involves an intuition that the criterion of rightness would not be self-effacing.
More formally, it seems like the argument needs to be something along these lines:
- Over their lifetimes, agents who implement P_CDT earn less expected utility than agents who implement certain other decision procedures.
- (Assumption) Agents should implement whatever decision procedure will earn them the most expected lifetime utility.
- Therefore, agents should not implement P_CDT.
- (Assumption) The criterion of rightness is not self-effacing. Equivalently, if agents should not implement some decision procedure P_X, then it is not the case that R_X is true.
- Therefore -- as an implication of points (3) and (4) -- R_CDT is not true.
Whether you buy the "No Self-Effacement" assumption in Step 4 -- or, alternatively, the countervailing "Don't Make Things Worse" assumption that supports R_CDT -- seems to ultimately be a mattter of intuition. At least, I don't currently know what else people can appeal to here to resolve the disagreement.
[[SIDENOTE: Step 2 is actually a bit ambiguous, since it doesn't specify how expected lifetime utility is being evaluated. For example, are we talking about expected lifetime utility from a causal or evidential perspective? But I don't think this ambiguity matters much for the argument.]]
[[SECOND SIDENOTE: I'm using the phrase "self-effacing" rather than "self-contradictory" here, because I think it's more standard and because "self-contradictory" seems to suggest logical inconsistency.]]
RobBensinger @ 2019-11-27T05:42 (+4)
But there's nothing logically inconsistent about believing both (a) that R_CDT is true and (b) that agents should not implement P_CDT.
If the thing being argued for is "R_CDT plus P_SONOFCDT", then that makes sense to me, but is vulnerable to all the arguments I've been making: Son-of-CDT is in a sense the worst of both worlds, since it gets less utility than FDT and lacks CDT's "Don't Make Things Worse" principle.
If the thing being argued for is "R_CDT plus P_FDT", then I don't understand the argument. In what sense is P_FDT compatible with, or conducive to, R_CDT? What advantage does this have over "R_FDT plus P_FDT"? (Indeed, what difference between the two views would be intended here?)
So why shouldn't I believe that R_CDT is true? The argument needs an additional step. And it seems to me like the most addition step here involves an intuition that the criterion of rightness would not be not self-effacing.
The argument against "R_CDT plus P_SONOFCDT" doesn't require any mention of self-effacingness; it's entirely sufficient to note that P_SONOFCDT gets less utility than P_FDT.
The argument against "R_CDT plus P_FDT" seems to demand some reference to self-effacingness or inconsistency, or triviality / lack of teeth. But I don't understand what this view would mean or why anyone would endorse it (and I don't take you to be endorsing it).
For example, are we talking about expected lifetime utility from a causal or evidential perspective? But I don't think this ambiguity matters much for the argument.
We want to evaluate actual average utility rather than expected utility, since the different decision theories are different theories of what "expected utility" means.
bmg @ 2019-11-28T00:44 (+5)
Hm, I think I may have misinterpretted your previous comment as emphasizing the point that P_CDT "gets you less utility" rather than the point that P_SONOFCDT "gets you less utility." So my comment was aiming to explain why I don't think the fact that P_CDT gets less utility provides a strong challenge to the claim that R_CDT is true (unless we accept the "No Self-Effacement Principle"). But it sounds like you might agree that this fact doesn't on its own provide a strong challenge.
If the thing being argued for is "R_CDT plus P_SONOFCDT", then that makes sense to me, but is vulnerable to all the arguments I've been making: Son-of-CDT is in a sense the worst of both worlds, since it gets less utility than FDT and lacks CDT's "Don't Make Things Worse" principle.
In response to the first argument alluded to here: "Gets the most [expected] utility" is ambiguous, as I think we've both agreed.
My understanding is that P_SONOFCDT is definitionally the policy that, if an agent decided to adopt it, would cause the largest increase in expected utility. So -- if we evaluate the expected utility of a decision to adopt a policy from a casual perspective -- it seems to me that P_SONOFCDT "gets the most expected utility."
If we evaluate the expected utility of a policy from an evidential or subjunctive perspective, however, then another policy may "get the most utility" (because policy adoption decisions may be non-causally correlated.)
Apologies if I'm off-base, but it reads to me like you might be suggesting an argument along these lines:
-
R_CDT says that it is rational to decide to follow a policy that would not maximize "expected utility" (defined in evidential/subjunctive terms).
-
(Assumption) But it is not rational to decide to follow a policy that would not maximize "expected utility" (defined in evidential/subjunctive terms).
-
Therefore R_CDT is not true.
The natural response to this argument is that it's not clear why we should accept the assumption in Step 2. R_CDT says that the rationality of a decision depends on its "expected utility" defined in causal terms. So someone starting from the position that R_CDT is true obviously won't accept the assumption in Step 2. R_EDT and R_FDT say that the rationality of a decision depends on its "expected utility" defined in evidential or subjunctive terms. So we might allude to R_EDT or R_FDT to justify the assumption, but of course this would also mean arguing backwards from the conclusion that the argument is meant to reach.
Overall at least this particular simple argument -- that R_CDT is false because P_SONOFCDT gets less "expected utility" as defined in evidential/quasi-evidential terms -- would seemingly fail to due circularity. But you may have in mind a different argument.
We want to evaluate actual average utility rather than expected utility, since the different decision theories are different theories of what "expected utility" means.
I felt confused by this comment. Doesn't even R_FDT judge the rationality of a decision by its expected value (rather than its actual value)? And presumably you don't want to say that someone who accepts unpromising gambles and gets lucky (ending up with high actual average utility) has made more "rational" decisions than someone who accepts promising gambles and gets unlucky (ending up with low actual average utility)?
You also correctly point out that the decision procedure that R_CDT implies agents should rationally commit to -- P_SONOFCDT -- sometimes outputs decisions that definitely make things worse. So "Don't Make Things Worse" implies that some of the decisions outputted by P_SONOFCDT are irrational.
But I still don't see what the argument is here unless we're assuming "No Self-Effacement." It still seems to me like we have a few initial steps and then a missing piece.
-
(Observation) R_CDT implies that it is rational to commit to following the decision procedure P_SONOFCDT.
-
(Observation) P_SONOFCDT sometimes outputs decisions that definitely make things worse.
-
(Assumption) It is irrational to take decisions that definitely make things worse. In other words, the "Don't Make Things Worse" Principle is true.
-
Therefore, as an implication of Step 2 and Step 3, P_SONOFCDT sometimes outputs irrational decisions.
-
???
-
Therefore, R_CDT is false.
The "No Self-Effacement" Principle is equivalent to the principle that: If a criterion of rightness implies that it is rational to commit to a decision procedure, then that decision procedure only produces rational actions. So if we were to assume "No Self-Effacement" in Step 5 then this would allow us to arrive at the conclusion that R_CDT is false. But if we're not assuming "No Self-Effacement," then it's not clear to me how we get there.
Actually, in the context of this particular argument, I suppose we don't really have the option of assuming that "No Self-Effacement" is true -- because this assumption would be inconsistent with the earlier assumption that "Don't Make Things Worse" is true. So I'm not sure it's actually possible to make this argument schema work in any case.
There may be a pretty different argument here, which you have in mind. I at least don't see it yet though.
ESRogs @ 2019-11-29T06:58 (+9)
There may be a pretty different argument here, which you have in mind. I at least don't see it yet though.
Perhaps the argument is something like:
- "Don't make things worse" (DMTW) is one of the intuitions that leads us to favoring R_CDT
- But the actual policy that R_CDT recommends does not in fact follow DMTW
- So R_CDT only gets intuitive appeal from DMTW to the extent that DMTW was about R_'s, and not about P_'s
- But intuitions are probably(?) not that precisely targeted, so R_CDT shouldn't get to claim the full intuitive endorsement of DMTW. (Yes, DMTW endorses it more than it endorses R_FDT, but R_CDT is still at least somewhat counter-intuitive when judged against the DMTW intuition.)
bmg @ 2019-11-30T01:14 (+4)
So R_CDT only gets intuitive appeal from DMTW to the extent that DMTW was about R_'s, and not about P_'s
But intuitions are probably(?) not that precisely targeted, so R_CDT shouldn't get to claim the full intuitive endorsement of DMTW. (Yes, DMTW endorses it more than it endorses R_FDT, but R_CDT is still at least somewhat counter-intuitive when judged against the DMTW intuition.)
Here are two logically inconsistent principles that could be true:
Don't Make Things Worse: If a decision would definitely make things worse, then taking that decision is not rational.
Don't Commit to a Policy That In the Future Will Sometimes Make Things Worse: It is not rational to commit to a policy that, in the future, will sometimes output decisions that definitely make things worse.
I have strong intuitions that the fist one is true. I have much weaker (comparatively neglible) intuitions that the second one is true. Since they're mutually inconsistent, I reject the second and accept the first. I imagine this is also true of most other people who are sympathetic to R_CDT.
One could argue that R_CDT sympathists don't actually have much stronger intuitions regarding the first principle than the second -- i.e. that their intuitions aren't actually very "targeted" on the first one -- but I don't think that would be right. At least, it's not right in my case.
A more viable strategy might be to argue for something like a meta-principle:
The 'Don't Make Things Worse' Meta-Principle: If you find "Don't Make Things Worse" strongly intuitive, then you should also find "Don't Commit to a Policy That In the Future Will Sometimes Make Things Worse" just about as intuitive.
If the meta-principle were true, then I guess this would sort of imply that people's intuitions in favor of "Don't Make Things Worse" should be self-neutralizing. They should come packaged with equally strong intuitions for another position that directly contradicts it.
But I don't see why the meta-principle should be true. At least, my intuitions in favor of the meta-principle are way less strong than my intutions in favor of "Don't Make Things Worse" :)
bmg @ 2019-11-30T15:24 (+4)
Just to say slightly more on this, I think the Bomb case is again useful for illustrating my (I think not uncommon) intuitions here.
Bomb Case: Omega puts a million dollars in a transparent box if he predicts you'll open it. He puts a bomb in the transparent box if he predicts you won't open it. He's only wrong about one in a trillion times.
Now suppose you enter the room and see that there's a bomb in the box. You know that if you open the box, the bomb will explode and you will die a horrible and painful death. If you leave the room and don't open the box, then nothing bad will happen to you. You'll return to a grateful family and live a full and healthy life. You understand all this. You want so badly to live. You then decide to walk up to the bomb and blow yourself up.
Intuitively, this decision strikes me as deeply irrational. You're intentionally taking an action that you know will cause a horrible outcome that you want badly to avoid. It feels very relevant that you're flagrantly violating the "Don't Make Things Worse" principle.
Now, let's step back a time step. Suppose you know that you're sort of person who would refuse to kill yourself by detonating the bomb. You might decide that -- since Omega is such an accurate predictor -- it's worth taking a pill to turn you into that sort of person, to increase your odds of getting a million dollars. You recognize that this may lead you, in the future, to take an action that makes things worse in a horrifying way. But you calculate that the decision you're making now is nonetheless making things better in expectation.
This decision strikes me as pretty intuitively rational. You're violating the second principle -- the "Don't Commit to a Policy..." Principle -- but this violation just doesn't seem that intuitively relevent or remarkable to me. I personally feel like there is nothing too odd about the idea that it can be rational to commit to violating principles of rationality in the future.
(This obviously just a description of my own intuitions, as they stand, though.)
Wei_Dai @ 2020-01-19T00:37 (+11)
It feels very relevant that you’re flagrantly violating the “Don’t Make Things Worse” principle.
By triggering the bomb, you're making things worse from your current perspective, but making things better from the perspective of earlier you. Doesn't that seem strange and deserving of an explanation? The explanation from a UDT perspective is that by updating upon observing the bomb, you actually changed your utility function. You used to care about both the possible worlds where you end up seeing a bomb in the box, and the worlds where you don't. After updating, you think you're either a simulation within Omega's prediction so your action has no effect on yourself or you're in the world with a real bomb, and you no longer care about the version of you in the world with a million dollars in the box, and this accounts for the conflict/inconsistency.
Giving the human tendency to change our (UDT-)utility functions by updating, it's not clear what to do (or what is right), and I think this reduces UDT's intuitive appeal and makes it less of a slam-dunk over CDT/EDT. But it seems to me that it takes switching to the UDT perspective to even understand the nature of the problem. (Quite possibly this isn't adequately explained in MIRI's decision theory papers.)
ESRogs @ 2019-12-01T07:58 (+3)
Don't Make Things Worse: If a decision would definitely make things worse, then taking that decision is not rational.
Don't Commit to a Policy That In the Future Will Sometimes Make Things Worse: It is not rational to commit to a policy that, in the future, will sometimes output decisions that definitely make things worse.
...
One could argue that R_CDT sympathists don't actually have much stronger intuitions regarding the first principle than the second -- i.e. that their intuitions aren't actually very "targeted" on the first one -- but I don't think that would be right. At least, it's not right in my case.
I would agree that, with these two principles as written, more people would agree with the first. (And certainly believe you that that's right in your case.)
But I feel like the second doesn't quite capture what I had in mind regarding the DMTW intuition applied to P_'s.
Consider an alternate version:
If a decision would definitely make things worse, then taking that decision is not good policy.
Or alternatively:
If a decision would definitely make things worse, a rational person would not take that decision.
It seems to me that these two claims are naively intuitive on their face, in roughly the same way that the "... then taking that decision is not rational." version is. And it's only after you've considered prisoners' dilemmas or Newcomb's paradox, etc. that you realize that good policy (or being a rational agent) actually diverges from what's rational in the moment.
(But maybe others would disagree on how intuitive these versions are.)
EDIT: And to spell out my argument a bit more: if several alternate formulations of a principle are each intuitively appealing, and it turns out that whether some claim (e.g. R_CDT is true) is consistent with the principle comes down to the precise formulation used, then it's not quite fair to say that the principle fully endorses the claim and that the claim is not counter-intuitive from the perspective of the original intuition.
Of course, this argument is moot if it's true that the original DMTW intuition was always about rational in-the-moment action, and never about policies or actors. And maybe that's the case? But I think it's a little more ambiguous with the "... is not good policy" or "a rational person would not..." versions than with the "Don't commit to a policy..." version.
EDIT2: Does what I'm trying to say make sense? (I felt like I was struggling a bit to express myself in this comment.)
bmg @ 2019-11-28T01:08 (+4)
If the thing being argued for is "R_CDT plus P_SONOFCDT" ... If the thing being argued for is "R_CDT plus P_FDT...
Just as a quick sidenote:
I've been thinking of P_SONOFCDT as, by definition, the decision procedure that R_CDT implies that it is rational to commit to implementing.
If we define P_SONOFCDT this way, then anyone who believes that R_CDT is true must also believe that it is rational to implement P_SONOFCDT.
The belief that R_CDT is true and the belief that it is rational to implement P_FDT would only then be consistent if P_SONOFCDT is equivalent to P_FDT (which of course they aren't). So I would inclined to say that no one should believe in both the correctness of R_CDT and the rationality of implementing P_FDT.
[[EDIT: Actually, I need to distinguish between the decision procedure that it would be rational commit to yourself and the decision procedure that it would be rational to build into an agents. These can sometimes be different. For example, suppose that R_CDT is true and that you're building twin AI systems and you would like them both to succeed. Then it would be rational for you to give them decision procedures that will cause them to cooperate if they face each other in a prisoner's dilemma (e.g. some version of P_FDT). But if R_CDT is true and you've just been born into the world as one of the twins, it would be rational for you to commit to a decision procedure that would cause you to defect if you face the other AI system in a prisoner's dilemma (i.e. P_SONOFCDT). I slightly edited the above comment to reflect this. My tentative view -- which I've alluded to above -- is that the various proposed criteria of rightness don't in practice actually diverge all that much when it comes to the question of what sorts of decision procedures we should build into AI systems. Although I also understand that MIRI is not mainly interested in the question of what sorts of decision procedures we should build into AI systems.]]
Ben Pace @ 2019-11-26T20:24 (+1)
Do you mean
that agents should in general NOT make decisions by carrying out utilitarian reasoning.
It seems to better fit the pattern of the example just prior.
RobBensinger @ 2019-11-23T02:48 (+4)
Another way to express the distinction I have in mind is that it’s between (a) a normative claim and (b) a process of making decisions.
This is similar to how you described it here:
Let’s suppose that some decisions are rational and others aren’t. We can then ask: What is it that makes a decision rational? What are the necessary and/or sufficient conditions? I think that this is the question that philosophers are typically trying to answer. [...]
When philosophers talk about “CDT,” for example, they are typically talking about a proposed criterion of rightness. Specifically, in this context, “CDT” is the claim that a decision is rational iff taking it would cause the largest expected increase in value. To avoid any ambiguity, let’s label this claim R_CDT.
We can also talk about “decision procedures.” A decision procedure is just a process or algorithm that an agent follows when making decisions.
This seems like it should instead be a 2x2 grid: something can be either normative or non-normative, and if it's normative, it can be either an algorithm/procedure that's being recommended, or a criterion of rightness like "a decision is rational iff taking it would cause the largest expected increase in value" (which we can perhaps think of as generalizing over a set of algorithms, and saying all the algorithms in a certain set are "normative" or "endorsed").
Some of your discussion above seems to be focusing on the "algorithmic?" dimension, while other parts seem focused on "normative?". I'll say more about "normative?" here.
The reason I proposed the three distinctions in my last comment and organized my discussion around them is that I think they're pretty concrete and crisply defined. It's harder for me to accidentally switch topics or bundle two different concepts together when talking about "trying to optimize vs. optimizing as a side-effect", "directly optimizing vs. optimizing via heuristics", "initially optimizing vs. self-modifying to optimize", or "function vs. algorithm".
In contrast, I think "normative" and "rational" can mean pretty different things in different contexts, it's easy to accidentally slide between different meanings of them, and their abstractness makes it easy to lose track of what's at stake in the discussion.
E.g., "normative" is often used in the context of human terminal values, and it's in this context that statements like this ring obviously true:
I guess my view here is that exploring normative claims will probably only be pretty indirectly useful for understanding “how decision-making works,” since normative claims don’t typically seem to have any empirical/mathematical/etc. implications. For example, to again use a non-decision-theoretic example, I don’t think that learning that hedonistic utilitarianism is true would give us much insight into the computer science or cognitive science of decision-making.
If we're treating decision-theoretic norms as being like moral norms, then sure. I think there are basically three options:
- Decision theory isn't normative.
- Decision theory is normative in the way that "murder is bad" or "improving aggregate welfare is good" is normative, i.e., it expresses an arbitrary terminal value of human beings.
- Decision theory is normative in the way that game theory, probability theory, Boolean logic, the scientific method, etc. are normative (at least for beings that want accurate beliefs); or in the way that the rules and strategies of chess are normative (at least for beings that want to win at chess); or in the way that medical recommendations are normative (at least for beings that want to stay healthy).
Probability theory has obvious normative force in the context of reasoning and decision-making, but it's not therefore arbitrary or irrelevant to understanding human cognition, AI, etc.
A lot of the examples you've cited are theories from moral philosophy about what's terminally valuable. But decision theory is generally thought of as the study of how to make the right decisions, given a set of terminal preferences; it's not generally thought of as the study of which decision-making methods humans happen to terminally prefer to employ. So I would put it in category 1 or 3.
You could indeed define an agent that terminally values making CDT-style decisions, but I don't think most proponents of CDT or EDT would claim that their disagreement with UDT/FDT comes down to a values disagreement like that. Rather, they'd claim that rival decision theorists are making some variety of epistemic mistake. (And I would agree that the disagreement comes down to one party or the other making an epistemic mistake, though I obviously disagree about who's mistaken.)
I actually don’t think the son-of-CDT agent, in this scenario, will take these sorts of non-causal correlations into account at all. (Modifying just yourself to take non-causual correlations into account won’t cause you to achieve better outcomes here.)
In the twin prisoner's dilemma with son-of-CDT, both agents are following son-of-CDT and neither is following CDT (regardless of whether the fork happened before or after the switchover to son-of-CDT).
I think you can model the voting dilemma the same way, just with noise added because the level of correlation is imperfect and/or uncertain. Ten agents following the same decision procedure are trying to decide whether to stay home and watch a movie (which gives a small guaranteed benefit) or go to the polls (which costs them the utility of the movie, but gains them a larger utility iff the other nine agents go to the polls too). Ten FDT agents will vote in this case, if they know that the other agents will vote under similar conditions.
bmg @ 2019-11-23T13:17 (+6)
I think there are basically three options:
Decision theory isn't normative.
Decision theory is normative in the way that "murder is bad" or "improving aggregate welfare is good" is normative, i.e., it expresses an arbitrary terminal value of human beings.
Decision theory is normative in the way that game theory, probability theory, Boolean logic, the scientific method, etc. are normative (at least for beings that want accurate beliefs); or in the way that the rules and strategies of chess are normative (at least for beings that want to win at chess); or in the way that medical recommendations are normative (at least for beings that want to stay healthy).
[[Disclaimer: I'm not sure this will be useful, since it seems like most of discussions that verge on meta-ethics end up with neither side properly understanding the other.]]
I think the kind of decision theory that philosophers tend to work on is typically explicitly described as "normative." (For example, the SEP article on decision theory is about "normative decision theory.") So when I'm talking about "academic decision theories" or "proposed criteria of rightness" I'm talking about normative theories. When I use the word "rational" I'm also referring to a normative property.
I don't think there's any very standard definition of what it means for something to be normative, maybe because it's often treated as something pretty close to a primitive concept, but a partial account is that a "normative theory" is a claim about what someone should do. At least this is what I have in mind. This is different from the second option you list (and I think the third one).
Some normative theories concern "ends." These are basically claims about what people should do, if they can freely choose outcomes. For example: A subjectivist theory might say that people should maximize the fulfillment of their own personal preferences (whatever they are). Whereas a hedonistic utilitarian theory might say that people should should maximize total happiness. I'm not sure what the best terminology is, and think this choice is probably relatively non-standard, but let's label these "moral theories."
Some normative theories, including "decision theories," concern "means." These theories put aside the question of which ends people should pursue and instead focus on how people should respond to uncertainty about the results/implications of their actions. For example: Expected utility theory says that people should take whatever actions maximize expected fulfillment of the relevant ends. Risk-weighted expected utility theory (and other alternative theories) say different things. Typical versions of CDT and EDT flesh out expected utility theory in different ways to specify what the relevant measure of "expected fulfillment" is.
Moral theory and normative decision theory seem to me to have pretty much the same status. They are both bodies of theory that bear on what people should do. On some views, the division between them is more a matter of analytic convenience than anything else. For example, David Enoch, a prominent meta-ethicist, writes: "In fact, I think that for most purposes [the line between the moral and the non-moral] is not a line worth worrying about. The distinction within the normative between the moral and the non-moral seems to me to be shallow compared to the distinction between the normative and the non-normative" (Taking Morality Seriously, 86).
One way to think of moral theories and normative decision theories is as two components that fit together to form more fully specified theories about what people should do. Moral theories describe the ends people should pursue; given these ends, decision theories then describe what actions people should take when in states of uncertainty. To illustrate, two examples of more complete normative theories that combine moral and decision-theoretic components would be: "You should take whatever action would in expectation cause the largest increase in the fulfillment of your preferences" and "You should take whatever action would, if you took it, lead you to anticipate the largest expected amount of future happiness in the world." The first is subjectivism combined with CDT, while the second is total view hedonistic utilitarianism combined with EDT.
(On this conception, a moral theory is not a description of "an arbitrary terminal value of human beings." Decision theory here also is not "the study of which decision-making methods humans happen to terminally prefer to employ." These are both theories are about what people should do, rather than theories about about what people's preferences are.)
Normativity is obviously pretty often regarded as a spooky or insufficiently explained thing. So a plausible position is normative anti-realism: It might be the case that no normative claims are true, either because they're all false or because they're not even well-formed enough to take on truth values. If normative anti-realism is true, then one thing this means is that the philosophical decision theory community is mostly focused on a question that doesn't really have an answer.
In the twin prisoner's dilemma with son-of-CDT, both agents are following son-of-CDT and neither is following CDT (regardless of whether the fork happened before or after the switchover to son-of-CDT).
If I'm someone with a twin and I'm implementing P_CDT, I still don't think I will choose to modify myself to cooperate in twin prisoner's dilemmas. The reason is that modifying myself won't cause my twin to cooperate; it will only cause me to cooperate, lowering the utility I receive.
(The fact P_CDT agents won't modify themselves to cooperate with their twins could of course be interpretted as a mark against R_CDT.)
RobBensinger @ 2019-11-26T07:52 (+5)
I appreciate you taking the time to lay out these background points, and it does help me better understand your position, Ben; thanks!
If normative anti-realism is true, then one thing this means is that the philosophical decision theory community is mostly focused on a question that doesn't really have an answer.
Some ancient Greeks thought that the planets were intelligent beings; yet many of the Greeks' astronomical observations, and some of their theories and predictive tools, were still true and useful.
I think that terms like "normative" and "rational" are underdefined, so the question of realism about them is underdefined (cf. Luke Muehlhauser's pluralistic moral reductionism).
I would say that (1) some philosophers use "rational" in a very human-centric way, which is fine as long as it's done consistently; (2) others have a much more thin conception of "rational", such as 'tending to maximize utility'; and (3) still others want to have their cake and eat it too, building in a lot of human-value-specific content to their notion of "rationality", but then treating this conception as though it had the same level of simplicity, naturalness, and objectivity as 2.
I think that type-1, type-2, and type-3 decision theorists have all contributed valuable AI-relevant conceptual progress in the past (most obviously, by formulating Newcomb's problem, EDT, and CDT), and I think all three could do more of the same in the future. I think the type-3 decision theorists are making a mistake, but often more in the fashion of an ancient astronomer who's accumulating useful and real knowledge but happens to have some false side-beliefs about the object of study, not in the fashion of a theologian whose entire object of study is illusory. (And not in the fashion of a developmental psychologist or historian whose field of subject is too human-centric to directly bear on game theory, AI, etc.)
I'd expect type-2 decision theorists to tend to be interested in more AI-relevant things than type-1 decision theorists, but on the whole I think the flavor of decision theory as a field has ended up being more type-2/3 than type-1. (And in this case, even type-1 analyses of "rationality" can be helpful for bringing various widespread background assumptions to light.)
If I'm someone with a twin and I'm implementing P_CDT, I still don't think I will choose to modify myself to cooperate in twin prisoner's dilemmas. The reason is that modifying myself won't cause my twin to cooperate; it will only cause me to cooperate, lowering the utility I receive.
This is true if your twin was copied from you in the past. If your twin will be copied from you in the future, however, then you can indeed cause your twin to cooperate, assuming you have the ability to modify your own future decision-making so as to follow son-of-CDT's prescriptions from now on.
Making the commitment to always follow son-of-CDT is an action you can take; the mechanistic causal consequence of this action is that your future brain and any physical systems that are made into copies of your brain in the future will behave in certain systematic ways. So from your present perspective (as a CDT agent), you can causally control future copies of yourself, as long as the act of copying hasn't happened yet.
(And yes, by the time you actually end up in the prisoner's dilemma, your future self will no longer be able to causally affect your copy. But this is irrelevant from the perspective of present-you; to follow CDT's prescriptions, present-you just needs to pick the action that you currently judge will have the best consequences, even if that means binding your future self to take actions contrary to CDT's future prescriptions.)
(If it helps, don't think of the copy of you as "you": just think of it as another environmental process you can influence. CDT prescribes taking actions that change the behavior of future copies of yourself in useful ways, for the same reason CDT prescribes actions that change the future course of other physical processes.)
bmg @ 2019-11-27T02:07 (+5)
I appreciate you taking the time to lay out these background points, and it does help me better understand your position, Ben; thanks!
Thank you for taking the time to respond as well! :)
I think that terms like "normative" and "rational" are underdefined, so the question of realism about them is underdefined (cf. Luke Muehlhauser's pluralistic moral reductionism).
I would say that (1) some philosophers use "rational" in a very human-centric way, which is fine as long as it's done consistently; (2) others have a much more thin conception of "rational", such as 'tending to maximize utility'; and (3) still others want to have their cake and eat it too, building in a lot of human-value-specific content to their notion of "rationality", but then treating this conception as though it had the same level of simplicity, naturalness, and objectivity as 2.
I'm not positive I understand what (1) and (3) are referring to here, but I would say that there's also at least a fourth way that philosophers often use the word "rational" (which is also the main way I use the word "rational.") This is to refer to an irreducibly normative concept.
The basic thought here is that not every concept can be usefully described in terms of more primitive concepts (i.e. "reduced"). As a close analogy, a dictionary cannot give useful non-circular definitions of every possible word -- it requires the reader to have a pre-existing understanding of some foundational set of words. As a wonkier analogy, if we think of the space of possible concepts as a sort of vector space, then we sort of require an initial "basis" of primitive concepts that we use to describe the rest of the concepts.
Some examples of concepts that are arguably irreducible are "truth," "set," "property," "physical," "existance," and "point." Insofar as we can describe these concepts in terms of slightly more primitive ones, the descriptions will typically fail to be very useful or informative and we will typically struggle to break the slightly more primitive ones down any further.
To focus on the example of "truth," some people have tried to reduce the concept substantially. Some people have argued, for example, that when someone says that "X is true" what they really mean or should mean is "I personally believe X" or "believing X is good for you." But I think these suggested reductions pretty obviously don't entirely capture what people mean when they say "X is true." The phrase "X is true" also has an important meaning that is not amenable to this sort of reduction.
[[EDIT: "Truth" may be a bad example, since it's relatively controversial and since I'm pretty much totally unfamiliar with work on the philosophy of truth. But insofar as any concepts seem irreducible to you in this sense, or buy the more general argument that some concepts will necessarily be irreducible, the particular choice of example used here isn't essential to the overall point.]]
Some philosophers also employ normative concepts that they say cannot be reduced in terms of non-normative (e.g. psychological) properties. These concepts are said to be irreducibly normative.
For example, here is Parfit on the concept of a normative reason (OWM, p. 1):
We can have reasons to believe something, to do something, to have some desire or aim, and to have many other attitudes and emotions, such as fear, regret, and hope. Reasons are given by facts, such as the fact that someone’s finger-prints are on some gun, or that calling an ambulance would save someone’s life.
It is hard to explain the concept of a reason, or what the phrase ‘a reason’ means. Facts give us reasons, we might say, when they count in favour of our having some attitude, or our acting in some way. But ‘counts in favour of’ means roughly ‘gives a reason for’. Like some other fundamental concepts, such as those involved in our thoughts about time, consciousness, and possibility, the concept of a reason is indefinable in the sense that it cannot be helpfully explained merely by using words. We must explain such concepts in a different way, by getting people to think thoughts that use these concepts. One example is the thought that we always have a reason to want to avoid being in agony.
When someone says that a concept they are using is irreducible, this is obviously some reason for suspicion. A natural suspicion is that the real explanation for why they can't give a useful description is that the concept is seriously muddled or fails to grip onto anything in the real world. For example, whether this is fair or not, I have this sort of suspicion about the concept of "dao" in daoist philosophy.
But, again, it will necessarily be the case that some useful and valid concepts are irreducible. So we should sometimes take evocations of irreducible concepts seriously. A concept that is mostly undefined is not always problematically "underdefined."
When I talk about "normative anti-realism," I mostly have in mind the position that claims evoking irreducably normative concepts are never true (either because these claims are all false or because they don't even have truth values). For example: Insofar as the word "should" is being used in an irreducibly normative sense, there is nothing that anyone "should" do.
[[Worth noting, though: The term "normative realism" is sometimes given a broader definition than the one I've sketched here. In particular, it often also includes a position known as "analytic naturalist realism" that denies the relevance of irreducibly normative concepts. I personally feel I understand this position less well and I think sometimes waffle between using the broader and narrower definition of "normative realism." I also more generally want to stress that not everyone who makes claims about "criterion of rightness" or employs other seemingly normative language is actually a normative realist in the narrow or even broad sense; what I'm doing here is just sketching one common especially salient perspective.]]
One motivation for evoking irreducibly normative concepts is the observation that -- in the context of certain discussions -- it's not obvious that there's any close-to-sensible way to reduce the seemingly normative concepts that are being used.
For example, suppose we follow a suggestion once made by Eliezer to reduce the concept of "a rational choice" to the concept of "a winning choice" (or, in line with the type-2 conception you mention, a "utility-maximizing choice"). It seems difficult to make sense of a lot of basic claims about rationality if we use this reduction -- and other obvious alternative reductions don't seem to fair much better. To mostly quote from a comment I made elsewhere:
Suppose we want to claim that it is rational to try to maximize the expected winning (i.e. the expected fulfillment of your preferences). Due to randomness/uncertainty, though, an agent that tries to maximize expected "winning" won't necessarily win compared to an agent that does something else. If I spend a dollar on a lottery ticket with a one-in-a-billion chance of netting me a billion-and-one "win points," then I'm taking the choice that maximizes expected winning but I'm also almost certain to lose. So we can't treat "the rational action" as synonymous with "the action taken by an agent that wins."
We can try to patch up the issue here by reducing "the rational action" to "the action that is consistent with the VNM axioms," but in fact either action in this case is consistent with the VNM axioms. The VNM axioms don't imply that an agent must maximize the expected desirability of outcomes. They just imply that an agent must maximize the expected value of some function. It is totally consistent with the axioms, for example, to be effectively risk averse and instead maximize the expected square root of desirability. If we try to define "the action I should take" in this way, then the claim "it is rational to act consistently with the VNM axioms" also becomes an empty tautology.
We could of course instead reduce "the rational action" to "the action that maximizes expected winning." But now, of course, the claim "it is rational to maximize expected winning" no longer has any substantive content. When we make this claim, do we really mean to be stating an empty tautology? And do we really consider it trivially incoherent to wonder -- e.g. in a Pascal's mugging scenario -- whether it might be "rational" to take an action other than the one that maximizes expected winning? If not, then this reduction is a very poor fit too.
It ultimately seems hard, at least to me, to make non-vacuous true claims about what it's "rational" to do withoit evoking a non-reducible notion of "rationality." If we are evoking a non-reducible notion of rationality, then it makes sense that we can't provide a satisfying reduction.
FN15 in my post on normative realism elaborates on this point.
At the same time, though, I do think there are also really good and hard-to-counter epistemological objections to the existance of irreducibly normative properties (e.g. the objection described in this paper). You might also find the difficulty of reducing normative concepts a lot less obvious-seeming or problematic than I do. You might think, for example, that the difficulty of reducing "rationality" is less like the difficulty of reducing "truth" (which IMO mainly reflects the fact that truth is an important primitive concept) and more like the difficulty of defining the word "soup" in a way that perfectly matches our intuitive judgments about what counts as "soup" (which IMO mainly reflects the fact that "soup" is a high-dimensional concept). So I definitely don't want to say normative realism is obviously or even probably right.
I mainly just want to communicate the sort of thing that I think a decent chunk of philosophers have in mind when they talk about a "rational decision" or a "criterion of rightness." Although, of course, philosophy being philosophy, plenty of people do of course have in mind plenty of different things.
RobBensinger @ 2019-11-27T05:22 (+3)
So, as an experiment, I'm going to be a very obstinate reductionist in this comment. I'll insist that a lot of these hard-seeming concepts aren't so hard.
Many of them are complicated, in the fashion of "knowledge" -- they admit an endless variety of edge cases and exceptions -- but these complications are quirks of human cognition and language rather than deep insights into ultimate metaphysical reality. And where there's a simple core we can point to, that core generally isn't mysterious.
It may be inconvenient to paraphrase the term away (e.g., because it packages together several distinct things in a nice concise way, or has important emotional connotations, or does important speech-act work like encouraging a behavior). But when I say it "isn't mysterious", I mean it's pretty easy to see how the concept can crop up in human thought even if it doesn't belong on the short list of deep fundamental cosmic structure terms.
I would say that there's also at least a fourth way that philosophers often use the word "rational," which is also the main way I use the word "rational." This is to refer to an irreducibly normative concept.
Why is this a fourth way? My natural response is to say that normativity itself is either a messy, parochial human concept (like "love," "knowledge," "France") , or it's not (in which case it goes in bucket 2).
Some examples of concepts that are arguably irreducible are "truth," "set," "property," "physical," "existance," and "point."
Picking on the concept here that seems like the odd one out to me: I feel confident that there isn't a cosmic law (of nature, or of metaphysics, etc.) that includes "truth" as a primitive (unless the list of primitives is incomprehensibly long). I could see an argument for concepts like "intentionality/reference", "assertion", or "state of affairs", though the former two strike me as easy to explain in simple physical terms.
Mundane empirical "truth" seems completely straightforward. Then there's the truth of sentences like "Frodo is a hobbit", "2+2=4", "I could have been the president", "Hamburgers are more delicious than battery acid"... Some of these are easier or harder to make sense of in the naive correspondence model, but regardless, it seems clear that our colloquial use of the word "true" to refer to all these different statements is pre-philosophical, and doesn't reflect anything deeper than that "each of these sentences at least superficially looks like it's asserting some state of affairs, and each sentence satisfies the conventional assertion-conditions of our linguistic community".
I think that philosophers are really good at drilling down on a lot of interesting details and creative models for how we can try to tie these disparate speech-acts together. But I think there's also a common failure mode in philosophy of treating these questions as deeper, more mysterious, or more joint-carving than the facts warrant. Just because you can argue about the truthmakers of "Frodo is a hobbit" doesn't mean you're learning something deep about the universe (or even something particularly deep about human cognition) in the process.
[Parfit:] It is hard to explain the concept of a reason, or what the phrase ‘a reason’ means. Facts give us reasons, we might say, when they count in favour of our having some attitude, or our acting in some way. But ‘counts in favour of’ means roughly ‘gives a reason for’. Like some other fundamental concepts, such as those involved in our thoughts about time, consciousness, and possibility, the concept of a reason is indefinable in the sense that it cannot be helpfully explained merely by using words.
Suppose I build a robot that updates hypotheses based on observations, then selects actions that its hypotheses suggest will help it best achieve some goal. When the robot is deciding which hypotheses to put more confidence in based on an observation, we can imagine it thinking, "To what extent is observation o a [WORD] to believe hypothesis h?" When the robot is deciding whether it assigns enough probability to h to choose an action a, we can imagine it thinking, "To what extent is P(h)=0.7 a [WORD] to choose action a?" As a shorthand, when observation o updates a hypothesis h that favors an action a, the robot can also ask to what extent o itself is a [WORD] to choose a.
When two robots meet, we can moreover add that they negotiate a joint "compromise" goal that allows them to work together rather than fight each other for resources. In communicating with each other, they then start also using "[WORD]" where an action is being evaluated relative to the joint goal, not just the robot's original goal.
Thus when Robot A tells Robot B "I assign probability 90% to 'it's noon', which is [WORD] to have lunch", A may be trying to communicate that A wants to eat, or that A thinks eating will serve A and B's joint goal. (This gets even messier if the robots have an incentive to obfuscate which actions and action-recommendations are motivated by the personal goal vs. the joint goal.)
If you decide to relabel "[WORD]" as "reason", I claim that this captures a decent chunk of how people use the phrase "a reason". "Reason" is a suitcase word, but that doesn't mean there are no similarities between e.g. "data my goals endorse using to adjust the probability of a given hypothesis" and "probabilities-of-hypotheses my goals endorse using to select an action"), or that the similarity is mysterious and ineffable.
(I recognize that the above story leaves out a lot of important and interesting stuff. Though past a certain point, I think the details will start to become Gettier-case nitpicks, as with most concepts.)
For example, suppose we follow a suggestion once made by Eliezer to reduce the concept of "a rational choice" to the concept of "a winning choice" (or, in line with the type-2 conception you mention, a "utility-maximizing choice").
That essay isn't trying to "reduce" the term "rationality" in the sense of taking a pre-existing word and unpacking or translating it. The essay is saying that what matters is utility, and if a human being gets too invested in verbal definitions of "what the right thing to do is", they risk losing sight of the thing they actually care about and were originally in the game to try to achieve (i.e., their utility).
Therefore: if you're going to use words like "rationality", make sure that the words in question won't cause you to shoot yourself in the foot and take actions that will end up costing you utility (e.g., costing human lives, costing years of averted suffering, costing money, costing anything or everything). And if you aren't using "rationality" in a safe "nailed-to-utility" way, make sure that you're willing to turn on a time and stop being "rational" the second your conception of rationality starts telling you to throw away value.
It ultimately seems hard, at least to me, to make non-vacuous true claims about what it's "rational" to do withoit evoking a non-reducible notion of "rationality."
"Rationality" is a suitcase word. It refers to lots of different things. On LessWrong, examples include not just "(systematized) winning" but (as noted in the essay) "Bayesian reasoning", or in Rationality: Appreciating Cognitive Algorithms, "cognitive algorithms or mental processes that systematically produce belief-accuracy or goal-achievement". In philosophy, the list is a lot longer.
The common denominator seems to largely be "something something reasoning / deliberation" plus (as you note) "something something normativity / desirability / recommendedness / requiredness".
The idea of "normativity" doesn't currently seem that mysterious to me either, though you're welcome to provide perplexing examples. My initial take is that it seems to be a suitcase word containing a bunch of ideas tied to:
- Goals/preferences/values, especially overridingly strong ones.
- Encouraged, endorsed, mandated, or praised conduct.
Encouraging, endorsing, mandating, and praising are speech-acts that seem very central to how humans perceive and intervene on social situations; and social situations seem pretty central to human cognition overall. So I don't think it's particularly surprising if words associated with such loaded ideas would have fairly distinctive connotations and seem to resist reduction, especially reduction that neglects the pragmatic dimensions of human communication and only considers the semantic dimension.
bmg @ 2019-11-28T02:20 (+2)
I may write up more object-level thoughts here, because this is interesting, but I just wanted to quickly emphasize the upshot that initially motivated me to write up this explanation.
(I don't really want to argue here that non-naturalist or non-analytic naturalist normative realism of the sort I've just described is actually a correct view; I mainly wanted to give a rough sense of what the view consists of and what leads people to it. It may well be the case that the view is wrong, because all true normative-seeming claims are in principle reducible to claims about things like preferences. I think the comments you've just made cover some reasons to suspect this.)
The key point is just that when these philosophers say that "Action X is rational," they are explicitly reporting that they do not mean "Action X suits my terminal preferences" or "Action X would be taken by an agent following a policy that maximizes lifetime utility" or any other such reduction.
I think that when people are very insistent that they don't mean something by their statements, it makes sense to believe them. This implies that the question they are discussing -- "What are the necessary and sufficient conditions that make a decision rational?" -- is distinct from questions like "What decision would an agent that tends to win take?" or "What decision procedure suits my terminal preferences?"
It may be the case that the question they are asking is confused or insensible -- because any sensible question would be reducible -- but it's in any case different. So I think it's a mistake to interpret at least these philosophers' discussions of "decisions theories" or "criteria of rightness" as though they were discussions of things like terminal preferences or winning strategies. And it doesn't seem to me like the answer to the question they're asking (if it has an answer) would likely imply anything much about things like terminal preferences or winning strategies.
[[NOTE: Plenty of decision theorists are not non-naturalist or non-analytic naturalist realists, though. It's less clear to me how related or unrelated the thing they're talking about is to issues of interest to MIRI. I think that the conception of rationality I'm discussing here mainly just presents an especially clear case.]]
bmg @ 2019-11-23T15:35 (+4)
This seems like it should instead be a 2x2 grid: something can be either normative or non-normative, and if it's normative, it can be either an algorithm/procedure that's being recommended, or a criterion of rightness like "a decision is rational iff taking it would cause the largest expected increase in value" (which we can perhaps think of as generalizing over a set of algorithms, and saying all the algorithms in a certain set are "normative" or "endorsed").
Just on this point: I think you're right I may be slightly glossing over certain distinctions, but I might still draw them slightly differently (rather than doing a 2x2 grid). Some different things one might talk about in this context:
- Decisions
- Decision procedures
- The decision procedure that is optimal with regard to some given metric (e.g. the decision procedure that maximizes expected lifetime utility for some particular way of calculating expected utility)
- The set of properties that makes a decision rational ("criterion of rightness")
- A claim about what the criterion of rightness is ("normative decision theory")
- The decision procedure that it would be rational to decide to build into an agent (as implied by the criterion of rightness)
(4), (5), and (6) have to do with normative issues, while (1), (2), and (3) can be discussed without getting into normativity.
My current-although-not-firmly-held view is also that (6) probably isn't very sensitive to the what the criterion of rightness is, so in practice can be reasoned about without going too deep into the weeds thinking about competing normative decision theories.
ESRogs @ 2019-11-26T02:03 (+2)
Just want to note that I found the R_ vs P_ distinction to be helpful.
I think using those terms might be useful for getting at the core of the disagreement.
bmg @ 2019-11-20T03:42 (+3)
Lightly editing some thoughts I previously wrote up on this issue, somewhat in line with Paul's comments:
Rationalist community writing on decision theory sometimes seems to switch back and forth between describing decision theories as normative principles (which I believe is how academic philosophers typically describe decision theories) and as algorithms to be used (which seems to be inconsistent with how academic philosophers typically describe decision theories). I think this tendency to switch back and forth between describing decision theories in these two distinct ways can be seen both in papers proposing new decision theories and in online discussions. I also think this switching tendency can make things pretty confusing. Although it makes sense to discuss how an algorithm “performs” when “implemented,” once we specify a sufficiently precise performance metric, it does not seem to me to make sense to discuss the performance of a normative principle. I think the tendency to blur the distinction between algorithms and normative principles -- or, as Will MacAskill puts it in his recent and similar critique, between "decision procedures" and "criteria of rightness" -- partly explains why proponents of FDT and other new decision theories have not been able to get much traction with academic decision theorists.
For example, causal decision theorists are well aware that people who always take the actions that CDT says they should take will tend to fare less well in Newcomb scenarios than people who always take the actions that EDT says they should take. Causal decision theorists are also well aware that that there are some scenarios -- for example, a Newcomb scenario with a perfect predictor and the option to get brain surgery to pre-commit yourself to one-boxing -- in which there is no available sequence of actions such that CDT says you should take each of the actions in the sequence. If you ask a causal decision theorist what sort of algorithm you should (according to CDT) put into an AI system that will live in a world full of Newcomb scenarios, if the AI system won’t have the opportunity to self-modify, then I think it's safe to say a causal decision theorist won’t tell you to put in an algorithm that only produces actions that CDT says it should take. This tells me that we really can’t fluidly switch back and forth between making claims about the correctness of normative principles and claims about the performance of algorithms, as though there were an accepted one-to-one mapping between these two sorts of claims. Insofar as rationalist writing on decision theory tends to do this sort of switching, I suspect that it contributes to confusion and dismissiveness on the part of many academic readers.
Sean_o_h @ 2019-11-18T10:13 (+32)
For more on this divide/points of disagreement, see Will MacAskill's essay on the alignment forum (with responses from MIRI researchers and others)
https://www.alignmentforum.org/posts/ySLYSsNeFL5CoAQzN/a-critique-of-functional-decision-theory
and previously, Wolfgang Schwartz's review of Functional Decision Theory
https://www.umsu.de/wo/2018/688
(with some Lesswrong discussion here: https://www.lesswrong.com/posts/BtN6My9bSvYrNw48h/open-thread-january-2019#WocbPJvTmZcA2sKR6)
I'd also be interested in Buck's perspectives on this topic.
RobBensinger @ 2019-11-18T18:16 (+16)
See also Paul Christiano's take: https://www.lesswrong.com/posts/n6wajkE3Tpfn6sd5j/christiano-decision-theory-excerpt
Sean_o_h @ 2019-11-19T14:08 (+4)
Thanks, I hadn't seen this.
Pablo_Stafforini @ 2020-05-08T15:29 (+4)
See also bmg's LW post, Realism and rationality. Relevant excerpt:
A third point of tension is the community's engagement with normative decision theory research. Different normative decision theories pick out different necessary conditions for an action to be the one that a given person should take, with a focus on how one should respond to uncertainty (rather than on what ends one should pursue).
A typical version of CDT says that the action you should take at a particular point in time is the one that would cause the largest expected increase in value (under some particular framework for evaluating causation). A typical version of EDT says that the action you should take at a particular point in time is the one that would, once you take it, allow you to rationally expect the most value. There are also alternative versions of these theories -- for instance, versions using risk-weighted expected value maximization or the criterion of stochastic dominance -- that break from the use of pure expected value.
I've pretty frequently seen it argued within the community (e.g. in the papers “Cheating Death in Damascus” and “Functional Decision Theory”) that CDT and EDT are not “correct" and that some other new theory such as functional decision theory is. But if anti-realism is true, then no decision theory is correct.
Eliezier Yudkowsky's influential early writing on decision theory seems to me to take an anti-realist stance. It suggests that we can only ask meaningful questions about the effects and correlates of decisions. For example, in the context of the Newcomb thought experiment, we can ask whether one-boxing is correlated with winning more money. But, it suggests, we cannot take a step further and ask what these effects and correlations imply about what it is "reasonable" for an agent to do (i.e. what they should do). This question -- the one that normative decision theory research, as I understand it, is generally about -- is seemingly dismissed as vacuous.
If this apparently anti-realist stance is widely held, then I don't understand why the community engages so heavily with normative decision theory research or why it takes part in discussions about which decision theory is "correct." It strikes me a bit like an atheist enthustiastically following theological debates about which god is the true god. But I'm mostly just confused here.
Khorton @ 2019-11-16T10:36 (+44)
What evidence would persuade you that further work on AI safety is unnecessary?
Buck @ 2019-11-19T03:23 (+37)
I’m going to instead answer the question “What evidence would persuade you that further work on AI safety is low value compared to other things?”
Note that a lot of my beliefs here disagree substantially with my coworkers.
I’m going to split the answer into two steps: what situations could we be in such that I thought we should deprioritize AI safety work, and for each of those, what could I learn that would persuade me we were in them.
Situations in which AI safety work looks much less valuable:
- We’ve already built superintelligence, in which case the problem is moot
- Seems like this would be pretty obvious if it happened
- We have clear plans for how to align AI that work even when it’s superintelligent, and we don’t think that we need to do more work in order to make these plans more competitive or easier for leading AGI projects to adopt.
- What would persuade me of this:
- I’m not sure what evidence would be required for me to be inside-view persuaded of this. I find it kind of hard to be inside view persuaded, for the same reason that I find it hard to imagine being persuaded that an operating system is secure.
- But I can imagine what it might feel like to hear some “solutions to the alignment problem” which I feel pretty persuaded by.
- I can imagine someone explaining a theory of AGI/intelligence/optimization that felt really persuasive and elegant and easy-to-understand, and then building alignment within this theory.
- Thinking about alignment of ML systems, it’s much easier for me to imagine being persuaded that we’d solved outer alignment than inner alignment.
- More generally, I feel like it’s hard to know what kinds of knowledge could exist in a field, so it’s hard to know what kind of result could persuade me here, but I think it’s plausible that the result might exist.
- If a sufficient set of people whose opinions I respected all thought that alignment was solved, that would convince me to stop working on it. Eg Eliezer, Paul Christiano, Nate Soares, and Dario Amodei would be sufficient (that list is biased towards people I know, this isn’t my list of best AI safety people).
- Humans no longer have a comparative advantage at doing AI safety work (compared to AI or whole brain emulations or something else)
- Seems like this would be pretty obvious if it happened.
- For some reason, the world is going to do enough AI alignment research on its own.
- Possible reasons:
- It turns out that AI alignment is really easy
- It turns out that you naturally end up needing to solve alignment problems as you try to improve AI capabilities, and so all the companies working on AI are going to do all the safety work that they’d need to
- The world is generally more reasonable than I think it is
- AI development is such that before we could build an AGI that would kill everyone, we would have had lots of warning shots where misaligned AI systems did things that were pretty bad but not GCR level.
- What would persuade me of this:
- Some combination of developments in the field of AGI and developments in the field of alignment
- It looks like the world is going to be radically transformed somehow before AGI has a chance to radically transform it. Possible contenders here: whole brain emulation, other x-risks, maybe major GCRs which seem like they’ll mess up the structure of the world a lot.
- What would persuade me of this:
- Arguments that AGI timelines are much longer than I think. A big slowdown in ML would be a strong argument for longer timelines. If I thought there was a <30% chance of AGI within 50 years, I'd probably not be working on AI safety.
- Arguments that one of these other things is much more imminent than I think.
I can also imagine being persuaded that AI alignment research is as important as I think but something else is even more important, like maybe s-risks or some kind of AI coordination thing.
Khorton @ 2019-11-19T09:11 (+14)
Thanks, that's really interesting! I was especially surprised by "If I thought there was a <30% chance of AGI within 50 years, I'd probably not be working on AI safety."
Buck @ 2019-11-19T18:29 (+23)
Yeah, I think that a lot of EAs working on AI safety feel similarly to me about this.
I expect the world to change pretty radically over the next 100 years, and I probably want to work on the radical change that's going to matter first. So compared to the average educated American I have shorter AI timelines but also shorter timelines to the world becoming radically different for other reasons.
richard_ngo @ 2019-11-20T15:15 (+13)
If I thought there was a <30% chance of AGI within 50 years, I'd probably not be working on AI safety.
I expect the world to change pretty radically over the next 100 years.
I find these statements surprising, and would be keen to hear more about this from you. I suppose that the latter goes a long way towards explaining the former. Personally, there are few technologies that I think are likely to radically change the world within the next 100 years (assuming that your definition of radical is similar to mine). Maybe the only ones that would really qualify are bioengineering and nanotech. Even in those fields, though, I expect the pace of change to be fairly slow if AI isn't heavily involved.
(For reference, while I assign more than 30% credence to AGI within 50 years, it's not that much more).
Buck @ 2019-11-22T05:07 (+4)
I suppose that the latter goes a long way towards explaining the former.
Yeah, I suspect you're right.
Personally, there are few technologies that I think are likely to radically change the world within the next 100 years (assuming that your definition of radical is similar to mine). Maybe the only ones that would really qualify are bioengineering and nanotech. Even in those fields, though, I expect the pace of change to be fairly slow if AI isn't heavily involved.
I think there are a couple more radically transformative technologies which I think are reasonably likely over the next hundred years, eg whole brain emulation. And I suspect we disagree about the expected pace of change with bioengineering and maybe nanotech.
antimonyanthony @ 2019-11-20T02:24 (+7)
I can also imagine being persuaded that AI alignment research is as important as I think but something else is even more important, like maybe s-risks or some kind of AI coordination thing.
Huh, my impression was that the most plausible s-risks we can sort-of-specifically foresee are AI alignment problems - do you disagree? Or is this statement referring to s-risks as a class of black swans for which we don't currently have specific imaginable scenarios, but if those scenarios became more identifiable you would consider working on them instead?
Buck @ 2019-11-22T05:08 (+12)
Most of them are related to AI alignment problems, but it's possible that I should work specifically on them rather than other parts of AI alignment.
Matthew_Barnett @ 2019-11-20T02:28 (+12)
An s-risk could occur via a moral failure, which could happen even if we knew how to align our AIs.
Donald Hobson @ 2019-11-17T11:43 (+6)
If no more AI safety work is necessary, that means that there is nothing we can do to significantly increase the chance of FAI over UFAI.
I could be almost certain that FAI would win because I had already built one. Although I suspect that there will be double checking to do, the new FAI will need told about what friendly behavior is, someone should keep an eye out for any UFAI ect. So FAI work will be needed until the point where no human labor is needed and we are all living in a utopia.
I could be almost certain that UFAI will win. I could see lots of people working on really scary systems and still not have the slightest idea of how to do make anything friendly. But there would still be a chance that those systems didn't scale to superintelligence, that the people running them could be persuaded to turn them off, and that someone might come up with a brilliant alignment scheme tomorrow. Circumstances where you can see that you are utterly screwed, yet still be alive, seem unlikely. Keep working untill the nanites turn you into paperclips.
Alternatively, it might be clear that we aren't getting any AI any time soon. The most likely cause of this would be a pretty serious disaster. It would have to destroy most of humanities technical ability and stop us rebuilding it. If AI alignment is something that we will need to do in a few hundred years, once we rebuild society enough to make silicon chips, its still probably worth having someone making sure that progress isn't forgotten, and that the problem will be solved in time.
We gain some philosophical insight that says that AI is inherently good, always evil, impossible ect. It's hard to imagine what a philosophical insight that you don't have is like.
riceissa @ 2019-11-16T07:09 (+38)
Back in July, you held an in-person Q&A at REACH and said "There are a bunch of things about AI alignment which I think are pretty important but which aren’t written up online very well. One thing I hope to do at this Q&A is try saying these things to people and see whether people think they make sense." Could you say more about what these important things are, and what was discussed at the Q&A?
Buck @ 2019-11-19T03:25 (+38)
I don’t really remember what was discussed at the Q&A, but I can try to name important things about AI safety which I think aren’t as well known as they should be. Here are some:
----
I think the ideas described in the paper Risks from Learned Optimization are extremely important; they’re less underrated now that the paper has been released, but I still wish that more people who are interested in AI safety understood those ideas better. In particular, the distinction between inner and outer alignment makes my concerns about aligning powerful ML systems much crisper.
----
On a meta note: Different people who work on AI alignment have radically different pictures of what the development of AI will look like, what the alignment problem is, and what solutions might look like.
----
Compared to people who are relatively new to the field, skilled and experienced AI safety researchers seem to have a much more holistic and much more concrete mindset when they’re talking about plans to align AGI.
For example, here are some of my beliefs about AI alignment (none of which are original ideas of mine):
--
I think it’s pretty plausible that meta-learning systems are going to be a bunch more powerful than non-meta-learning systems at tasks like solving math problems. I’m concerned that by default meta-learning systems are going to exhibit alignment problems, for example deceptive misalignment. You could solve this with some combination of adversarial training and transparency techniques. In particular, I think that to avoid deceptive misalignment you could use a combination of the following components:
- Some restriction of what ML techniques you use
- Some kind of regularization of your model to push it towards increased transparency
- Neural net interpretability techniques
- Some adversarial setup, where you’re using your system to answer questions about whether there exist questions that would cause it to behave unacceptably.
Each of these components can be stronger or weaker, where by stronger I mean “more restrictive but having more nice properties”.
The stronger you can build one of those components, the weaker the others can be. For example, if you have some kind of regularization that you can do to increase transparency, you don’t have to have neural net interpretability techniques that are as powerful. And if you have a more powerful and reliable adversarial setup, you don’t need to have as much restriction on what ML techniques you can use.
And I think you can get the adversarial setup to be powerful enough to catch non-deceptive mesa optimizer misalignment, but I don’t think you can prevent deceptive misalignment without having powerful enough interpretability techniques that you can get around things like the RSA 2048 problem.
--
In the above arguments, I’m looking at the space of possible solutions to a problem and trying to narrow the possibility space, by spotting better solutions to subproblems or reducing subproblems to one another, and by arguing that it’s impossible to come up with a solution of a particular type.
The key thing that I didn’t use to do is thinking of the alignment problem as having components which can be attacked separately, and thinking of solutions to subproblems as being comprised of some combination of technologies which can be thought about independently. I used to think of AI alignment as being more about looking for a single overall story for everything, as opposed to looking for a combination of technologies which together allow you to build an aligned AGI.
You can see examples of this style of reasoning in Eliezer’s objections to capability amplification, or Paul on worst-case guarantees, or many other places.
richard_ngo @ 2019-11-20T15:19 (+13)
On a meta note: Different people who work on AI alignment have radically different pictures of what the development of AI will look like, what the alignment problem is, and what solutions might look like.
+1, this is the thing that surprised me most when I got into the field. I think helping increase common knowledge and agreement on the big picture of safety should be a major priority for people in the field (and it's something I'm putting a lot of effort into, so send me an email at richardcngo@gmail.com if you want to discuss this).
I think the ideas described in the paper Risks from Learned Optimization are extremely important.
Also +1 on this.
William_MacAskill @ 2019-11-20T15:34 (+37)
Suppose you find out that Buck-in-2040 thinks that the work you're currently doing is a big mistake (which should have been clear to you, now). What are your best guesses about what his reasons are?
Buck @ 2019-11-21T02:16 (+31)
I think of myself as making a lot of gambles with my career choices. And I suspect that regardless of which way the propositions turn out, I'll have an inclination to think that I was an idiot for not realizing them sooner. For example, I often have both the following thoughts:
- "I have a bunch of comparative advantage at helping MIRI with their stuff, and I'm not going to be able to quickly reduce my confidence in their research directions. So I should stop worrying about it and just do as much as I can."
- "I am not sure whether the MIRI research directions are good. Maybe I should spend more time evaluating whether I should do a different thing instead."
But even if it feels obvious in hindsight, it sure doesn't feel obvious now.
So I have big gambles that I'm making, which might turn out to be wrong, but which feel now like they will have been reasonable-in-hindsight gambles either way. The main two such gambles are thinking AI alignment might be really important in the next couple decades and working on MIRI's approaches to AI alignment instead of some other approach.
When I ask myself "what things have I not really considered as much as I should have", I get answers that change over time (because I ask myself that question pretty often and then try to consider the things that are important). At the moment, my answers are:
- Maybe I should think about/work on s-risks much more
- Maybe I spend too much time inventing my own ways of solving design problems in Haskell and I should study other people's more.
- Maybe I am much more productive working on outreach stuff and I should do that full time.
- (This one is only on my mind this week and will probably go away pretty soon) Maybe I'm not seriously enough engaging with questions about whether the world will look really different in a hundred years from how it looks today; perhaps I'm subject to some bias towards sensationalism and actually the world will look similar in 100 years.
William_MacAskill @ 2019-11-20T15:35 (+36)
How much do you worry that MIRI's default non-disclosure policy is going to hinder MIRI's ability to do good research, because it won't be able to get as much external criticism?
Buck @ 2019-11-21T01:24 (+24)
I worry very little about losing the opportunity to get external criticism from people who wouldn't engage very deeply with our work if they did have access to it. I worry more about us doing worse research because it's harder for extremely engaged outsiders to contribute to our work.
A few years ago, Holden had a great post where he wrote:
For nearly a decade now, we've been putting a huge amount of work into putting the details of our reasoning out in public, and yet I am hard-pressed to think of cases (especially in more recent years) where a public comment from an unexpected source raised novel important considerations, leading to a change in views. This isn't because nobody has raised novel important considerations, and it certainly isn't because we haven't changed our views. Rather, it seems to be the case that we get a large amount of valuable and important criticism from a relatively small number of highly engaged, highly informed people. Such people tend to spend a lot of time reading, thinking and writing about relevant topics, to follow our work closely, and to have a great deal of context. They also tend to be people who form relationships of some sort with us beyond public discourse.
The feedback and questions we get from outside of this set of people are often reasonable but familiar, seemingly unreasonable, or difficult for us to make sense of. In many cases, it may be that we're wrong and our external critics are right; our lack of learning from these external critics may reflect our own flaws, or difficulties inherent to a situation where people who have thought about a topic at length, forming their own intellectual frameworks and presuppositions, try to learn from people who bring very different communication styles and presuppositions.
The dynamic seems quite similar to that of academia: academics tend to get very deep into their topics and intellectual frameworks, and it is quite unusual for them to be moved by the arguments of those unfamiliar with their field. I think it is sometimes justified and sometimes unjustified to be so unmoved by arguments from outsiders.
Regardless of the underlying reasons, we have put a lot of effort over a long period of time into public discourse, and have reaped very little of this particular kind of benefit (though we have reaped other benefits - more below). I'm aware that this claim may strike some as unlikely and/or disappointing, but it is my lived experience, and I think at this point it would be hard to argue that it is simply explained by a lack of effort or interest in public discourse.
My sense is pretty similar to Holden's, though we've put much less effort into explaining ourselves publicly. When we're thinking about topics like decision theory which have a whole academic field, we seem to get very little out of interacting with the field. This might be because we're actually interested in different questions and academic decision theory doesn't have much to offer us (eg see this Paul Christiano quote and this comment).
I think that MIRI also empirically doesn't change its strategy much as a result of talking to highly engaged people who have very different world views (eg Paul Christiano), though individual researchers (eg me) often change their minds from talking to these people. (Personally, I also change my mind from talking to non-very-engaged people.)
Maybe talking to outsiders doesn't shift MIRI strategy because we're totally confused about how to think about all of this. But I'd be surprised if we figured this out soon given that we haven't figured it so far. So I'm pretty willing to say "look, either MIRI's onto something or not; if we're onto something, we should go for it wholeheartedly, and I don't seriously think that we're going to update our beliefs much from more public discourse, so it doesn't that seem costly to have our public discourse become costlier".
I guess I generally don't feel that convinced that external criticism is very helpful for situations like ours where there isn't an established research community with taste that is relevant to our work. Physicists have had a lot of time to develop a reasonably healthy research culture where they notice what kinds of arguments are wrong; I don't think AI alignment has that resource to draw on. And in cases where you don't have an established base of knowledge about what kinds of arguments are helpful (sometimes people call this "being in a preparadigmatic field"; I don't know if that's correct usage), I think it's plausible that people with different intuitions should do divergent work for a while and hope that eventually some of them make progress that's persuasive to the others.
By not engaging with critics as much as we could, I think MIRI is probably increasing the probability that we're barking completely up the wrong tree. I just think that this gamble is worth taking.
I'm more concerned about costs incurred because we're more careful about sharing research with highly engaged outsiders who could help us with it. Eg Paul has made some significant contributions to MIRI's research, and it's a shame to have less access to his ideas about our problems.
riceissa @ 2019-11-16T07:18 (+35)
In November 2018 you said "we want to hire as many people as engineers as possible; this would be dozens if we could, but it's hard to hire, so we'll more likely end up hiring more like ten over the next year". As far as I can tell, MIRI has hired 2 engineers (Edward Kmett and James Payor) since you wrote that comment. Can you comment on the discrepancy? Did hiring turn out to be much more difficult than expected? Are there not enough good engineers looking to be hired? Are there a bunch of engineers who aren't on the team page/haven't been announced yet?
Buck @ 2019-11-19T19:27 (+23)
(This is true of all my answers but feels particularly relevant for this one: I’m speaking just for myself, not for MIRI as a whole)
We’ve actually made around five engineer hires since then; we’ll announce some of them in a few weeks. So I was off by a factor of two.
Before you read my more detailed thoughts: please don’t read the below and then get put off from applying to MIRI. I think that many people who are in fact good MIRI fits might not realize they’re good fits. If you’re unsure whether it’s worth your time to apply to MIRI, you can email me at buck@intelligence.org and I’ll (eventually) reply telling you whether I think you might plausibly be a fit. Even if it doesn't go further than that, there is great honor in applying to jobs from which you get rejected, and I feel warmly towards almost everyone I reject.
With that said, here are some of my thoughts on the discrepancy between my prediction and how much we’ve hired:
- Since I started doing recruiting work for MIRI in late 2017, I’ve updated towards thinking that we need to be pickier with the technical caliber of engineering hires than I originally thought. I’ve updated towards thinking that we’re working in a domain where relatively small increases in competence translate into relatively large differences in output.
- A few reasons for this:
- Our work involves dealing a lot with pretty abstract computer science and software engineering considerations; this increases variance in productivity.
- We use a lot of crazy abstractions (eg various Haskell stuff) that are good for correctness and productivity for programmers who understand them and bad for people who have more trouble learning and understanding all that stuff.
- We have a pretty flat management structure where engineers need to make a lot of judgement calls for themselves about what to work on and how to do it. As a result, it’s more important for people doing programming work to have a good understanding of everything we’re doing and how their work fits into this.
- I think it’s plausible that if we increased our management capacity, we’d be able to hire engineers who are great in many ways but who don’t happen to be good in some of the specific ways we require at the moment.
- Our recruiting process involves a reasonable amount of lag between meeting people and hiring them, because we often want to get to know people fairly well before offering them a job. So I think it’s plausible that the number of full time offers we make is somewhat of a trailing indicator. Over time I’ve updated towards thinking that it’s worth it to take more time before giving people full time offers, by offering internships or trials, so the number of engineering hires lags more than I expected given the number of candidates I’d met who I was reasonably excited by.
- I’ve also updated towards the importance of being selective on culture fit, eg wanting people who I’m more confident will do well in the relatively self-directed MIRI research environment.
A few notes based on this that are relevant to people who might want to work at MIRI:
- As I said, our engineering requirements might change in the future, and when that happens I’d like to have a list of people who might be good fits. So please feel free to apply even if you think you’re a bad fit right now.
- We think about who to hire on an extremely flexible, case-by-case basis. Eg we hire people who know no Haskell at all.
- If you want to be more likely to be a good fit for MIRI, learning Haskell and some dependent type theory is pretty helpful. I think that it might even be worth it to try to get a job programming in Haskell just in case you get really good at it and then MIRI wants to hire you, though I feel slightly awkward to give this advice because I feel like it’s pushing a pretty specific strategy which is very targeted at only a single opportunity. As I said earlier, if you’re considering taking a Haskell job based on this, please feel free to email me to talk about it.
William_MacAskill @ 2019-11-20T15:33 (+34)
What's the biggest misconception people have about current technical AI alignment work? What's the biggest misconception people have about MIRI?
HenryStanley @ 2019-11-17T21:20 (+31)
How should talented EA software engineers best put their skills to use?
Buck @ 2019-11-19T07:37 (+37)
The obvious answer is “by working on important things at orgs which need software engineers”. To name specific examples that are somewhat biased towards the orgs I know well:
- MIRI needs software engineers who can learn functional programming and some math
- I think that if you’re an engineer who likes functional programming, it might be worth your time to take a Haskell job and gamble on MIRI wanting to hire you one day when you’re really good at it. One person who currently works at MIRI is an EA who worked in Haskell for a few years; his professional experience is really helpful for him. If you’re interested in doing this, feel free to email me asking about whether I think it’s a good idea for you.
- OpenAI’s safety team needs software engineers who can work as research engineers (which might only be a few months of training if you’re coming from a software engineering background; MIRI has a retraining program for software engineers who want to try this; if you’re interested in that, you should email me.)
- Ought needs an engineering lead
- The 80000 Hours job board lists positions
I have two main thoughts on how talented software engineers should try to do good.
Strategy 1: become a great software engineer
I think that it’s worth considering a path where you try to become an extremely good software engineer/computer scientist. (I’m going to lump those two disciplines together in the rest of this answer.)
Here are some properties which really good engineers tend to have. I’m going to give examples which are true of a friend of mine who I think is an exceptional engineer.
- Extremely broad knowledge of computer science (and other quantitative fields). Eg knowledge of ML, raytracing-based rendering, SMT solvers, formal verification, cryptography, physics and biology and math. This means that when he’s in one discipline (like game programming) he can notice that the problem he’s solving could be done more effectively using something from a totally different discipline. Edward Kmett is another extremely knowledgeable programmer who uses his breadth of knowledge to spot connections and write great programs.
- Experience with a wide variety of programming settings -- web programming, data science, distributed systems, GPU programming.
- Experience solving problems in a wide variety of computer science disciplines--designing data structures, doing automata theory reductions, designing distributed systems
- Experience getting an ill-defined computer science problem, and then searching around for a crisp understanding of what’s happening, and then turning that into code and figuring out what fundamental foolish mistakes you’d made in your attempt at a crisp understanding.
I am not as good as this friend of mine, but I’m a lot better at my job because I am able to solve problems like my data structure search problem, and I got much better at solving problems like that from trying to solve many problems like that.
How do I think you should try to be a great programmer? I don’t really know, but here are some ideas:
- Try to write many different types of programs from scratch. The other day I spent a couple hours trying to write the core of an engine for a real-time strategy game from scratch; I think I learned something useful from this experience. One problem with working as a professional programmer is that you relatively rarely have to build things from scratch; I think it’s worth doing that in your spare time. (Of course, there’s very useful experience that you get from building large projects, too; your work can be a good place to get that experience.)
- Learn many different disciplines. I think I got a lot out of learning to program web frontends.
- Have coworkers who are good programmers.
- Try to learn about subjects and then investigate questions about them by programming. For example, I’ve been learning about population genetics recently, and I’ve been thinking about trying to write a library which does calculations about coalescent theory; I think that this will involve an interesting set of design questions as well as involving designing and using some interesting algorithms, and it’s good practice for finding the key facts in a subject that I’m learning.
It’s hard to know what the useful advice to provide here is. I guess I want to say that (especially early in your career, eg when you’re an undergrad) it might be worth following your passions and interests within computer science, and I think you should plausibly do the kinds of programming you’re most excited by, instead of doing the kinds of programming that feel most directly relevant to EA.
Strategy 2: becoming really useful
Here’s part of my more general theory of how to do good as a software engineer, a lot of which generalizes to other skillsets:
I think it’s helpful to think about the question “why can’t EA orgs just hire non-EAs to do software engineering work for them”. Some sample answers:
- Non-EAs are often unwilling to join weird small orgs, because they're very risk-averse and don't want to join a project that might fold after four months.
- Non-EAs aren't as willing to do random generalist tasks, or scrappy product-focused work like building the 80K career quiz, analytics dashboards, or web apps to increase efficiency of various internal tasks.
- It's easier to trust EAs than non-EAs to do a task when it's hard to supervise them, because the EAs might be more intrinsically motivated by the task, and they might also have more context on what the org is trying to do.
- Non-EAs aren’t as willing to do risky things like spending a few months learning some topic (eg ML, or a particular type of computer science, or how to build frontend apps on top of Airtable) which might not translate into a job.
- Non-EAs can be disruptive to various aspects of the EA culture that the org wants to preserve. For example, in my experience EA orgs often have a culture that involves people being pretty transparent with their managers about the weaknesses in the work they've done, and hiring people who have less of that attitude can screw up the whole culture.
I think EA software engineers should try to translate those into ways that they can be better at doing EA work. For example, I think EAs should do the following (these pieces of advice are ranked roughly most to least important.):
- Try to maintain flexibility in your work situation, so that you can quickly take opportunities which arise for which you’d be a good fit. In order to do this, it’s good to have some runway and general life flexibility.
- Be willing to take jobs that aren’t entirely software engineering, or which involve scrappy product-focused work. Consider taking non-EA jobs which are going to help you learn these generalist or product-focused-engineering skills. (For example, working for Triplebyte was great for me because it involved a lot of non-engineering tasks and a lot of scrappy, product-focused engineering.)
- Practice doing work in a setting where you have independent control over your work and where you need to get context on a particular industry. For example, it might be good to take a job at a startup where you’re going to have relatively large amounts of freedom to work on projects that you think will help the company become more efficient, and where the startup involves dealing with a specific domain like spoon manufacturing and so you have to learn about this specific domain in order to be maximally productive.
- Be willing to take time off to learn skills that might be useful. (In particular, you should be relatively enthusiastic to do this in cases where some EA or EA org is willing to fund you to do it.) Also, compared to most software engineers you should be more inclined to take jobs that will teach you more varied things but which are worse in other ways.
- Practice working in an environment which rewards transparency and collaborative truth-seeking. I am very unconfident about the following point, but: perhaps you should be wary of working in companies where there’s a lot of office politics or where you have to make up a lot of bullshit, because perhaps that trains you in unhealthy epistemic practices.
I think the point about flexibility is extremely important. I think that if you set your life up so that most of the time you can leave your current non-EA job and move to an EA job within two months, you’re much more likely to get jobs which are very high impact.
A point that’s related to flexibility but distinct: Sometimes I talk to EAs about their careers and they seem to have concrete plans that we can talk about directly, and they’re able to talk about the advantages and disadvantages of various paths they could take, and it overall feels like we’re working together to help them figure out what the best thing for them to do is. When conversations go like this, it’s much easier to do things like figure out what they’d have to change their minds about in order to think they should drop out of their PhD. I think that when people have a mindset like this, it’s much easier for them to be persuaded of opportunities which are actually worth them inconveniencing themselves to access. In contrast, some people seem to treat direct work as something you're 'supposed' to consider, so they put a token effort into it, but their heart isn't in it and they aren't putting real cognitive effort into thinking about different possibilities, ways to overcome initial obstacles, etc.
I think these two points are really important; I think that when I meet someone who is flexible in those ways, my forecast of their impact is about twice as high as it would have been if they weren’t.
Buck @ 2019-11-19T21:18 (+25)
As an appendix to the above, some of my best learning experiences as a programmer were the following (starting from when I started programming properly as a freshman in 2012). (Many of these aren’t that objectively hard (and would fit in well as projects in a CS undergrad course); they were much harder for me because I didn’t have the structure of a university course to tell me what design decisions were reasonable and when I was going down blind alleys. I think that this difficulty created some great learning experiences for me.)
- I translated the proof of equivalence between regular expressions and finite state machines from “Introduction to Automata Theory, Languages, and Computation” into Haskell.
- I wrote a program which would take a graph describing a circuit built from resistors and batteries and then solve for the currents and potential drops.
- I wrote a GUI for a certain subset of physics problems; this involved a lot of deconfusion-style thinking as well as learning how to write GUIs.
- I went to App Academy and learned to write full stack web applications.
- I wrote a compiler from C to assembly in Scala. It took a long time for me to figure out that I should eg separate out the compiling to an intermediate output that didn’t have registers allocated.
- I wrote the first version of my data structure searcher. (Not linking because I’m embarrassed by how much worse it was than my second attempt.)
- I wrote the second version of my data structure searcher, which involved putting a lot of effort into deconfusing myself about what data structures are and how they connect to each other.
- One example of something I mean by deconfusion here: when you have a composite data structure (eg a binary search tree and a heap representing the same data, with pointers into each other), when you’re figuring out how quickly your reads happen, you take the union of all the things you can do with all your structures--eg you can read in any of the structures. But when you want to do a write, you need to do it in all of the structures, so you take the maximum write time. This feels obvious when I write it now, but wasn’t obvious until I’d figured out exactly what question was interesting to me. And it’s somewhat more complicated--for example, we actually want to take the least upper bound rather than the maximum.
- At Triplebyte, I wrote a variety of web app features. The one I learned the most from was building a UI for composing structured emails quickly--the UI concept was original to me, and it was great practice at designing front end web widgets and building things to solve business problems. My original design kind of sucked so I had to rewrite it; this was also very helpful. I learned the most from trying to design complicated frontend UI components for business logic, because that involves more design work than backend Rails programming does.
- I wrote another version of my physics problem GUI, which taught me about designing UIs in front of complicated functional backends.
- I then shifted my programming efforts to MIRI work; my learning here has mostly been a result of learning more Haskell and trying to design good abstractions for some of the things we’re doing; I’ve also recently had to think about the performance of my code, which has been interesting.
I learned basically nothing useful from my year at PayPal.
I have opinions about how to choose jobs in order to maximize how much programming you learn and I might write them up at some point.
HenryStanley @ 2019-11-20T01:16 (+7)
This is an awesome answer; thanks Buck!
The motivation behind strategy 2 seems pretty clear; are you emphasising strategy 1 (become a great engineer) for its instrumental benefit to strategy 2 (become useful to EA orgs), or for some other reason, like EtG?
Strongly agree that some of the best engineers I come across have had very broad, multi-domain knowledge (and have been able to apply it cross-domain to whatever problem they're working on).
HenryStanley @ 2019-11-20T14:24 (+14)
(Notably, the other things you might work on if you weren't at MIRI seem largely to be non-software-related)
Buck @ 2019-11-21T01:34 (+10)
I hadn't actually noticed that.
One factor here is that a lot of AI safety research seems to need ML expertise, which is one of my least favorite types of CS/engineering.
Another is that compared to many EAs I think I have a comparative advantage at roles which require technical knowledge but not doing technical research day-to-day.
Buck @ 2019-11-21T01:32 (+11)
I'm emphasizing strategy 1 because I think that there are EA jobs for software engineers where the skill ceiling is extremely high, so if you're really good it's still worth it for you to try to become much better. For example, AI safety research needs really great engineers at AI safety research orgs.
Ben Pace @ 2019-11-17T03:47 (+29)
In your experience, what are the main reasons good people choose not to do AI alignment research after getting close to the field (at any org)? And on the other side, what are the main things that actually make the difference for them positively deciding to do AI alignment research?
Buck @ 2019-11-19T22:19 (+17)
The most common reason that someone who I would be excited to work with at MIRI chooses not to work on AI alignment is that they decide to work on some other important thing instead, eg other x-risk or other EA stuff.
But here are some anonymized recent stories of talented people who decided to do non-EA work instead of taking opportunities to do important technical work related to x-risk (for context, I think all of these people are more technically competent than me):
- One was very comfortable in a cushy, highly paid job which they already had, and thought it would be too inconvenient to move to an EA job (which would have also been highly paid).
- One felt that AGI timelines are probably relatively long (eg they thought that the probability of AGI in the next 30 years felt pretty small to them), which made AI safety feel not very urgent. So they decided to take an opportunity which they thought would be really fun and exciting, rather than working at MIRI, which they thought would be less of a good fit for a particular skill set which they'd been developing for years; this person thinks that they might come back and work on x-risk after they've had another job for a few years.
- One was in the middle of a PhD and didn't want to leave.
- One felt unsure about whether it's reasonable to believe all the unusual things that the EA community believes, and didn't believe the arguments enough that they felt morally compelled to leave their current lucrative job.
I feel sympathetic to the last three but not to the first.
elle @ 2019-11-19T17:37 (+28)
In "Ways I've changed my mind about effective altruism over the past year" you write:
I feel very concerned by the relative lack of good quality discussion and analysis of EA topics. I feel like everyone who isn’t working at an EA org is at a massive disadvantage when it comes to understanding important EA topics, and only a few people manage to be motivated enough to have a really broad and deep understanding of EA without either working at an EA org or being really close to someone who does.
I am not sure if you still feel this way, but this makes me wonder what the current conversations are about with other people at EA orgs. Could you give some examples of important understandings or new ideas you have gained from such conversations in the last, say, 3 months?
Buck @ 2019-11-20T05:02 (+10)
I still feel this way, and I've been trying to think of ways to reduce this problem. I think the AIRCS workshops help a bit, I think that my SSC trip was helpful and EA residencies might be helpful.
A few helpful conversations that I've had recently with people who are strongly connected to the professional EA community, which I think would be harder to have without information gained from these strong connections:
- I enjoyed a document about AI timelines that someone from another org shared me on.
- Discussions about how EA outreach should go--how rapidly should we try to grow, what proportion of people who are good fits for EA are we already reaching, what types of people are we going to be able to reach with what outreach mechanisms.
Ben Pace @ 2019-11-17T03:51 (+28)
How much do you agree with the two stories laid out in Paul Christiano's post What Failure Looks Like?
Buck @ 2019-11-19T03:23 (+9)
They are a pretty reasonable description of what I expect to go wrong in a world where takeoffs are slow. (My models of what I think slow takeoff looks like are mostly based on talking to Paul, though, so this isn’t much independent evidence.)
Ben Pace @ 2019-11-19T03:29 (+3)
Hmm, I'm surprised to hear you say that about the second story, which I think is describing a fairly fast end to human civilization - "going out with a bang". Example quote:
If influence-seeking patterns do appear and become entrenched, it can ultimately lead to a rapid phase transition from the world described in Part I to a much worse situation where humans totally lose control.
So I mostly see it as describing a hard take-off, and am curious if there's a key part of a fast-takeoff / discontinuous take-off that you think of as central that is missing there.
Buck @ 2019-11-19T07:02 (+27)
I think of hard takeoff as meaning that AI systems suddenly control much more resources. (Paul suggests the definition of "there is a one year doubling of the world economy before there's been a four year doubling".)
Unless I'm very mistaken, the point Paul is making here is that if you have a world where AI systems in aggregate gradually become more powerful, there might come a turning point where the systems suddenly stop being controlled by humans. By analogy, imagine a country where the military wants to stage a coup against the president, and their power increases gradually day by day, until one day they decide they have enough power to stage the coup. The power wielded by the military increased continuously and gradually, but the amount of control of the situation wielded by the president at some point suddenly falls.
avturchin @ 2019-11-16T11:05 (+28)
What EY is doing now? Is he coding, writing fiction or new book, working on math foundations, providing general leadership?
SiebeRozendal @ 2019-11-19T15:49 (+23)
Not sure why the initials are only provided. For the sake of clarity to other readers, EY = Eliezer Yudkowsky.
Buck @ 2019-11-19T02:20 (+8)
Over the last year, Eliezer has been working on technical alignment research and also trying to rejigger some of his fiction-writing patterns toward short stories.
anonymous_ea @ 2019-11-21T18:32 (+27)
Meta: A big thank you to Buck for doing this and putting so much effort into it! This was very interesting and will hopefully encourage more dissemination of knowledge and opinions publicly
HowieL @ 2019-11-21T21:09 (+15)
I thought this was great. Thanks, Buck
Buck @ 2019-11-22T05:12 (+11)
It was a good time; I appreciate all the thoughtful questions.
Milan_Griffes @ 2019-11-21T18:33 (+11)
+1. So good to see stuff like this
Sean_o_h @ 2019-11-21T18:35 (+12)
+2 helpful and thoughtful answers; really appreciate the time put in.
SamClarke @ 2019-11-19T10:13 (+27)
My sense of the current general landscape of AI Safety is: various groups of people pursuing quite different research agendas, and not very many explicit and written-up arguments for why these groups think their agenda is a priority (a notable exception is Paul's argument for working on prosaic alignment). Does this sound right? If so, why has this dynamic emerged and should we be concerned about it? If not, then I'm curious about why I developed this picture.
Jan_Kulveit @ 2019-11-21T12:38 (+22)
I think the picture is somewhat correct, and we surprisingly should not be too concerned about the dynamic.
My model for this is:
1) there are some hard and somewhat nebulous problems "in the world"
2) people try to formalize them using various intuitions/framings/kinds of math; also using some "very deep priors"
3) the resulting agendas look at the surface level extremely different, and create the impression you have
but actually
4) if you understand multiple agendas deep enough, you get a sense
- how they are sometimes "reflecting" the same underlying problem
- if they are based on some "deep priors", how deep it is, and how hard to argue it can be
- how much they are based on "tastes" and "intuitions" ~ one model how to think about it is people having boxes comparable to policy net in AlphaZero: a mental black-box which spits useful predictions, but is not interpretable in language
Overall, given our current state of knowledge, I think running these multiple efforts in parallel is a better approach with higher chance of success that an idea that we should invest a lot in resolving disagreements/prioritizing, and everyone should work on the "best agenda".
This seems to go against some core EA heuristic ("compare the options, take the best") but actually is more in line with what rational allocation of resources in the face of uncertainty.
SamClarke @ 2019-11-22T16:22 (+13)
Thanks for the reply! Could you give examples of:
a) two agendas that seem to be "reflecting" the same underlying problem despite appearing very different superficially?
b) a "deep prior" that you think some agenda is (partially) based on, and how you would go about working out how deep it is?
Jan_Kulveit @ 2019-11-24T14:30 (+21)
Sure
a)
For example, CAIS and something like "classical superintelligence in a box picture" disagree a lot on the surface level. However, if you look deeper, you will find many similar problems. Simple to explain example: problem of manipulating the operator - which has (in my view) some "hard core" involving both math and philosophy, where you want the AI to somehow communicate with humans in a way which at the same time allows a) the human to learn from the AI if the AI knows something about the world b) the operator's values are not "overwritten" by the AI c) you don't want to prohibit moral progress. In CAIS language this is connected to so called manipulative services.
Or: one of the biggest hits of past year is the mesa-optimisation paper. However, if you are familiar with prior work, you will notice many of the proposed solutions with mesa-optimisers are similar/same solutions as previously proposed for so called 'daemons' or 'misaligned subagents'. This is because the problems partially overlap (the mesa-optimisation framing is more clear and makes a stronger case for "this is what to expect by default"). Also while, for example, on the surface level there is a lot of disagreement between e.g. MIRI researchers, Paul Christiano and Eric Drexler, you will find a "distillation" proposal targeted at the above described problem in Eric's work from 2015, many connected ideas in Paul's work on distillation, and while find it harder to understand Eliezer I think his work also reflects understanding of the problem.
b)
For example: You can ask whether the space of intelligent systems is fundamentally continuous, or not. (I call it "the continuity assumption"). This is connected to many agendas - if the space is fundamentally discontinuous this would cause serious problems to some forms of IDA, debate, interpretability & more.
(An example of discontinuity would be existence of problems which are impossible to meaningfully factorize; there are many more ways how the space could be discontinuous)
There are powerful intuitions going both ways on this.
John_Maxwell @ 2019-11-19T22:14 (+19)
Not Buck, but one possibility is that people pursuing different high-level agendas have different intuitions about what's valuable, and those kind of disagreements are relatively difficult to resolve, and the best way to resolve them is to gather more "object-level" data.
Maybe people have already spent a fair amount of time having in-person discussions trying to resolve their disagreements, and haven't made progress, and this discourages them from writing up their thoughts because they think it won't be a good use of time. However, this line of reasoning might be mistaken -- it seems plausible to me that people entering the field of AI safety are relatively impartial judges of which intuitions do/don't seem valid, and the question of where new people in the field of AI safety should focus is an important one, and having more public disagreement would improve human capital allocation.
Buck @ 2019-11-20T05:37 (+18)
I think your sense is correct. I think that plenty of people have short docs on why their approach is good; I think basically no-one has long docs engaging thoroughly with the criticisms of their paths (I don't think Paul's published arguments defending his perspective count as complete; Paul has arguments that I hear him make in person that I haven't seen written up.)
My guess is that it's developed because various groups decided that it was pretty unlikely that they were going to be able to convince other groups of their work, and so they decided to just go their own ways. This is exacerbated by the fact that several AI safety groups have beliefs which are based on arguments which they're reluctant to share with each other.
(I was having a conversation with an AI safety researcher at a different org recently, and they couldn't tell me about some things that they knew from their job, and I couldn't tell them about things from my job. We were reflecting on the situation, and then one of us proposed the metaphor that we're like two people who were sliding on ice next to each other and then pushed away and have now chosen our paths and can't interact anymore to course correct.)
Should we be concerned? Idk, seems kind of concerning. I kind of agree with MIRI that it's not clearly worth it for MIRI leadership to spend time talking to people like Paul who disagree with them a lot.
Also, sometimes fields should fracture a bit while they work on their own stuff; maybe we'll develop our own separate ideas for the next five years, and then come talk to each other more when we have clearer ideas.
I suspect that things like the Alignment Newsletter are causing AI safety researchers to understand and engage with each other's work more; this seems good.
lukeprog @ 2019-11-20T22:41 (+27)
FWIW, it's not clear to me that AI alignment folks with different agendas have put less effort into (or have made less progress on) understanding the motivations for other agendas than is typical in other somewhat-analogous fields. Like, MIRI leadership and Paul have put >25 (and maybe >100, over the years?) hours into arguing about merits of their differing agendas (in person, on the web, in GDocs comments), and my impression is that central participants to those conversations (e.g. Paul, Eliezer, Nate) can pass the others' ideological Turing tests reasonably well on a fair number of sub-questions and down 1-3 levels of "depth" (depending on the sub-question), and that might be more effort and better ITT performance than is typical for "research agenda motivation disagreements" in small niche fields that are comparable on some other dimensions.
rohinmshah @ 2019-11-20T19:09 (+19)
I suspect that things like the Alignment Newsletter are causing AI safety researchers to understand and engage with each other's work more; this seems good.
This is the goal, but it's unclear that it's having much of an effect. I feel like I relatively often have conversations with AI safety researchers where I mention something I highlighted in the newsletter, and the other person hasn't heard of it, or has a very superficial / wrong understanding of it (one that I think would be corrected by reading just the summary in the newsletter).
This is very anecdotal; even if there are times when I talk to people and they do know the paper that I'm talking about because of the newsletter, I probably wouldn't notice / learn that fact.
(In contrast, junior researchers are often more informed than I would expect, at least about the landscape, even if not the underlying reasons / arguments.)
riceissa @ 2019-11-16T07:29 (+27)
The 2017 MIRI fundraiser post says "We plan to say more in the future about the criteria for strategically adequate projects in 7a" and also "A number of the points above require further explanation and motivation, and we’ll be providing more details on our view of the strategic landscape in the near future". As far as I can tell, MIRI hasn't published any further explanation of this strategic plan. Is MIRI still planning to say more about its strategic plan in the near future, and if so, is there a concrete timeframe (e.g. "in a few months", "in a year", "in two years") for publishing such an explanation?
(Note: I asked this question a while ago on LessWrong.)
RobBensinger @ 2019-11-19T17:26 (+9)
Oops, I saw your question when you first posted it on LessWrong but forgot to get back to you, Issa. My apologies.
I think there are two main kinds of strategic thought we had in mind when we said "details forthcoming":
- 1. Thoughts on MIRI's organizational plans, deconfusion research, and how we think MIRI can help play a role in improving the future — this is covered by our November 2018 update post, https://intelligence.org/2018/11/22/2018-update-our-new-research-directions/.
- 2. High-level thoughts on things like "what we think AGI developers probably need to do" and "what we think the world probably needs to do" to successfully navigate the acute risk period.
Most of the stuff discussed in "strategic background" is about 2: not MIRI's organizational plan, but our model of some of the things humanity likely needs to do in order for the long-run future to go well. Some of these topics are reasonably sensitive, and we've gone back and forth about how best to talk about them.
Within the macrostrategy / "high-level thoughts" part of the post, the densest part was maybe 7a. The criteria we listed for a strategically adequate AGI project were "strong opsec, research closure, trustworthy command, a commitment to the common good, security mindset, requisite resource levels, and heavy prioritization of alignment work".
With most of these it's reasonably clear what's meant in broad strokes, though there's a lot more I'd like to say about the specifics. "Trustworthy command" and "a commitment to the common good" are maybe the most opaque. By "trustworthy command" we meant things like:
- The organization's entire command structure is fully aware of the difficulty and danger of alignment.
- Non-technical leadership can't interfere and won't object if technical leadership needs to delete a code base or abort the project.
By "a commitment to the common good" we meant a commitment to both short-term goodness (the immediate welfare of present-day Earth) and long-term goodness (the achievement of transhumanist astronomical goods), paired with a real commitment to moral humility: not rushing ahead to implement every idea that sounds good to them.
We still plan to produce more long-form macrostrategy exposition, but given how many times we've failed to word our thoughts in a way we felt comfortable publishing, and given how much other stuff we're also juggling, I don't currently expect us to have any big macrostrategy posts in the next 6 months. (Note that I don't plan to give up on trying to get more of our thoughts out sooner than that, if possible. We'll see.)
Ben Pace @ 2019-11-17T03:31 (+26)
AI takeoff: continuous or discontinuous?
Buck @ 2019-11-19T02:10 (+18)
I don’t know. When I try to make fake mathematical models of how AI progress works, they mostly come out looking pretty continuous. And AI Impacts has successfully pushed my intuitions in a slow takeoff direction, by exhaustively cataloging all the technologies which didn't seem to have discontinuous jumps in efficiency. But on the other hand it sometimes feels like there’s something that has to “click” before you can have your systems being smart in some important way; this pushes me towards a discontinuous model. Overall I feel very confused.
When I talk to Paul Christiano about takeoff I feel persuaded by his arguments for slow takeoff, when I talk to many MIRI people I feel somewhat persuaded by their arguments for fast takeoff.
riceissa @ 2019-11-16T08:39 (+25)
Do you have any thoughts on Qualia Research Institute?
Buck @ 2019-11-19T02:07 (+37)
I feel pretty skeptical of their work and their judgement.
I am very unpersuaded by their Symmetry Theory of Valence, which I think is summarized by “Given a mathematical object isomorphic to the qualia of a system, the mathematical property which corresponds to how pleasant it is to be that system is that object’s symmetry“.
I think of valence as the kind of thing which is probably encoded into human brains by a bunch of complicated interconnected mechanisms rather than by something which seems simple from the perspective of an fMRI-equipped observer, so I feel very skeptical of this. Even if it was true about human brains, I’d be extremely surprised if the only possible way to build a conscious goal-directed learning system involved some kind of symmetrical property in the brain state, so this would feel like a weird contingent fact about humans rather than something general about consciousness.
And I’m skeptical of their judgement for reasons like the following. Michael Johnson, the ED of QRI, wrote:
I’ve written four pieces of philosophy I consider profound. [...]
The first, Principia Qualia, took me roughly six years of obsessive work. [...] But if there is a future science of consciousness, I’m very confident it’ll follow in the footsteps of this work. The ‘crown jewel’ of PQ is the Symmetry Theory of Valence (STV), a first-principles account of exactly how pain and pleasure work [...].
I give STV roughly an 80% chance of being true. If it is true, it will change the world, and hopefully usher in a new science and era of emotional well-being (more on that later). Pending certain research partnerships, it’s looking hopeful that we’ll either validate or falsify STV within a year, which means some very big developments could be on the horizon.
Given how skeptical I am of the theory, I feel very negatively towards someone being 80% confident of it being true and saying “if true, it will change the world”. I offered to bet with Mike Johnson about their predictions not coming true, but didn’t put in the effort to operationalize the disagreement and bet with him. If someone wanted to propose some operationalizations I’d be potentially willing to bet thousands of dollars on this; for example I’d be willing to bet $10k at even odds that STV does not “usher in a new science and era of emotional well-being”, or that the future science of consciousness doesn't particularly follow in the footsteps of Principia Qualia.
I feel more confident in my negative assessment because I think there’s a known human failure mode where you’re interested in psychedelic drugs and consciousness and you end up making simple theories that you feel very persuaded by and which don’t seem persuasive to anyone else.
Overall I think of their work as crank philosophy and I’d love to place money on my skeptical predictions, though I also think they’re nice people and all that.
For the record, the QRI folks know much more neuroscience than I do, and it also gives me pause that Scott Alexander sometimes says nice things about their research.
MikeJohnson @ 2019-11-19T08:52 (+17)
Buck- for an internal counterpoint you may want to discuss QRI's research with Vaniver. We had a good chat about what we're doing at the Boston SSC meetup, and Romeo attended a MIRI retreat earlier in the summer and had some good conversations with him there also.
To put a bit of a point on this, I find the "crank philosophy" frame a bit questionable if you're using only thin-slice outside view and not following what we're doing. Probably, one could use similar heuristics to pattern-match MIRI as "crank philosophy" also (probably, many people have already done exactly this to MIRI, unfortunately).
vaniver @ 2019-11-19T17:58 (+19)
FWIW I agree with Buck's criticisms of the Symmetry Theory of Valence (both content and meta) and also think that some other ideas QRI are interested in are interesting. Our conversation on the road trip was (I think) my introduction to Connectome Specific Harmonic Waves (CSHW), for example, and that seemed promising to think about.
I vaguely recall us managing to operationalize a disagreement, let me see if I can reconstruct it:
A 'multiple drive' system, like PCT's hierarchical control system, has an easy time explaining independent desires and different flavors of discomfort. (If one both has a 'hunger' control system and a 'thirst' control system, one can easily track whether one is hungry, thirsty, both, or neither.) A 'single drive' system, like expected utility theories more generally, has a somewhat more difficult time explaining independent desires and different flavors of discomfort, since you only have the one 'utilon' number.
But this is mostly because we're looking at different parts of the system as the 'value'. If I have a vector of 'control errors', I get the nice multidimensional property. If I have a utility function that's a function of a vector, the gradient of that function will be a vector that gives me the same nice multidimensional property.
CSHW gives us a way to turn the brain into a graph and then the graph activations into energies in different harmonics. Then we can look at an energy distribution and figure out how consonant or dissonant it is. This gives us the potentially nice property that 'gradients are easy', where if 'perfect harmony' (= all consonant energy) corresponds to the '0 error' case in PCT, being hungry will look like missing some consonant energy or having some dissonant energy.
Here we get the observational predictions: for PCT, 'hunger' and 'thirst' and whatever other drives just need to be wire voltages somewhere, but for QRI's theory as I understand it, they need to be harmonic energies with particular numerical properties (such that they are consonant or dissonant as expected to make STV work out).
Of course, it could be the case that there are localized harmonics in the connectome, such that we get basically the same vector represented in the energy distribution, and don't have a good way to distinguish between them.
On that note, I remember we also talked about the general difficulty of distinguishing between theories in this space; for example, my current view is that Friston-style predictive coding approaches and PCT-style hierarchical control approaches end up predicting very similar brain architecture, and the difference is 'what seems natural' or 'which underlying theory gets more credit.' (Is it the case that the brain is trying to be Bayesian, or the brain is trying to be homeostatic, and embedded Bayesianism empirically performs well at that task?) I expect a similar thing could be true here, where whether symmetry is the target or the byproduct is unclear, but in such cases I normally find myself reaching for 'byproduct'. It's easy to see how evolution could want to build homeostatic systems, and harder to see how evolution could want to build Bayesian systems; I think a similar story goes through for symmetry and brains.
This makes me more sympathetic to something like "symmetry will turn out to be a marker for something important and good" (like, say, 'focus') than something like "symmetry is definitionally what feeling good is."
MikeJohnson @ 2019-11-20T01:53 (+9)
I think this is a great description. "What happens if we seek out symmetry gradients in brain networks, but STV isn't true?" is something we've considered, and determining ground-truth is definitely tricky. I refer to this scenario as the "Symmetry Theory of Homeostatic Regulation" - https://opentheory.net/2017/05/why-we-seek-out-pleasure-the-symmetry-theory-of-homeostatic-regulation/ (mostly worth looking at the title image, no need to read the post)
I'm (hopefully) about a week away from releasing an update to some of the things we discussed in Boston, basically a unification of Friston/Carhart-Harris's work on FEP/REBUS with Atasoy's work on CSHW -- will be glad to get your thoughts when it's posted.
vaniver @ 2019-11-20T04:05 (+3)
Oh, an additional detail that I think was part of that conversation: there's only really one way to have a '0-error' state in a hierarchical controls framework, but there are potentially many consonant energy distributions that are dissonant with each other. Whether or not that's true, and whether each is individually positive valence, will be interesting to find out.
(If I had to guess, I would guess the different mutually-dissonant internally-consonant distributions correspond to things like 'moods', in a way that means they're not really value but are somewhat close, and also that they exist. The thing that seems vaguely in this style are differing brain waves during different cycles of sleep, but I don't know if those have clear waking analogs, or what they look like in the CSHW picture.)
Buck @ 2019-11-19T17:54 (+18)
Most things that look crankish are crankish.
I think that MIRI looks kind of crankish from the outside, and this should indeed make people initially more skeptical of us. I think that we have a few other external markers of legitimacy now, such as the fact that MIRI people were thinking and writing about AI safety from the early 2000s and many smart people have now been persuaded that this is indeed an issue to be concerned with. (It's not totally obvious to me that these markers of legitimacy mean that anyone should take us seriously on the question "what AI safety research is promising".) When I first ran across MIRI, I was kind of skeptical because of the signs of crankery; I updated towards them substantially because I found their arguments and ideas compelling, and people whose judgement I respected also found them compelling.
I think that the signs of crankery in QRI are somewhat worse than 2008 MIRI's signs of crankery.
I also think that I'm somewhat qualified to assess QRI's work (as someone who's spent ~100 paid hours thinking about philosophy of mind in the last few years), and when I look at it, I think it looks pretty crankish and wrong.
MikeJohnson @ 2019-11-20T00:09 (+17)
QRI is tackling a very difficult problem, as is MIRI. It took many, many years for MIRI to gather external markers of legitimacy. My inside view is that QRI is on the path of gaining said markers; for people paying attention to what we're doing, I think there's enough of a vector right now to judge us positively. I think these markers will be obvious from the 'outside view' within a short number of years.
But even without these markers, I'd poke at your position from a couple angles:
I. Object-level criticism is best
First, I don't see evidence you've engaged with our work beyond very simple pattern-matching. You note that "I also think that I'm somewhat qualified to assess QRI's work (as someone who's spent ~100 paid hours thinking about philosophy of mind in the last few years), and when I look at it, I think it looks pretty crankish and wrong." But *what* looks wrong? Obviously doing something new will pattern-match to crankish, regardless of whether it is crankish, so in terms of your rationale-as-stated, I don't put too much stock in your pattern detection (and perhaps you shouldn't either). If we want to avoid accidentally falling into (1) 'negative-sum status attack' interactions, and/or (2) hypercriticism of any fundamentally new thing, neither of which is good for QRI, for MIRI, or for community epistemology, object-level criticisms (and having calibrated distaste for low-information criticisms) seem pretty necessary.
Also, we do a lot more things than just philosophy, and we try to keep our assumptions about the Symmetry Theory of Valence separate from our neuroscience - STV can be wrong and our neuroscience can still be correct/useful. That said, empirically the neuroscience often does 'lead back to' STV.
Some things I'd offer for critique:
https://opentheory.net/2018/08/a-future-for-neuroscience/#
https://opentheory.net/2018/12/the-neuroscience-of-meditation/
https://www.qualiaresearchinstitute.org/research-lineages
(you can also watch our introductory video for context, and perhaps a 'marker of legitimacy', although it makes very few claims https://www.youtube.com/watch?v=HetKzjOJoy8 )
I'd also suggest that the current state of philosophy, and especially philosophy of mind and ethics, is very dismal. I give my causal reasons for this here: https://opentheory.net/2017/10/rescuing-philosophy/ - I'm not sure if you're anchored to existing theories in philosophy of mind being reasonable or not.
II. What's the alternative?
If there's one piece I would suggest engaging with, it's my post arguing against functionalism. I think your comments presuppose functionalism is reasonable and/or the only possible approach, and the efforts QRI is putting into building an alternative are certainly wasted. I strongly disagree with this; as I noted in my Facebook reply,
>Philosophically speaking, people put forth analytic functionalism as a theory of consciousness (and implicitly a theory of valence?), but I don't think it works *qua* a theory of consciousness (or ethics or value or valence), as I lay out here: https://forum.effectivealtruism.org/.../why-i-think-the...-- This is more-or-less an answer to some of Brian Tomasik's (very courageous) work, and to sum up my understanding I don't think anyone has made or seems likely to make 'near mode' progress, e.g. especially of the sort that would be helpful for AI safety, under the assumption of analytic functionalism.
----------
I always find in-person interactions more amicable & high-bandwidth -- I'll be back in the Bay early December, so if you want to give this piece a careful read and sit down to discuss it I'd be glad to join you. I think it could have significant implications for some of MIRI's work.
Milan_Griffes @ 2019-11-21T18:29 (+5)
cf. Jeff Kaufman on MIRI circa 2003: https://www.jefftk.com/p/yudkowsky-and-miri
MikeJohnson @ 2019-11-19T08:22 (+14)
For a fuller context, here is my reply to Buck's skepticism about the 80% number during our back-and-forth on Facebook -- as a specific comment, the number is loosely held, more of a conversation-starter than anything else. As a general comment I'm skeptical of publicly passing judgment on my judgment based on one offhand (and unanswered- it was not engaged with) comment on Facebook. Happy to discuss details in a context we'll actually talk to each other. :)
--------------my reply from the Facebook thread a few weeks back--------------
I think the probability question is an interesting one-- one frame is asking what is the leading alternative to STV?
At its core, STV assumes that if we have a mathematical representation of an experience, the symmetry of this object will correspond to how pleasant the experience is. The latest addition to this (what we're calling 'CDNS') assumes that consonance under Selen Atasoy's harmonic analysis of brain activity (connectome-specific harmonic waves, CSHW) is a good proxy for this in humans. This makes relatively clear predictions across all human states and could fairly easily be extended to non-human animals, including insects (anything we can infer a connectome for, and the energy distribution for the harmonics of the connectome). So generally speaking we should be able to gather a clear signal as to whether the evidence points this way or not (pending resources to gather this data- we're on a shoestring budget).
Empirically speaking, the competition doesn't seem very strong. As I understand it, currently the gold standard for estimating self-reports of emotional valence via fMRI uses regional activity correlations, and explains ~16% of the variance. Based on informal internal estimations looking at coherence within EEG bands during peak states, I'd expect us to do muuuuch better.
Philosophically speaking, people put forth analytic functionalism as a theory of consciousness (and implicitly a theory of valence?), but I don't think it works *qua* a theory of consciousness (or ethics or value or valence), as I lay out here: https://forum.effectivealtruism.org/.../why-i-think-the...-- This is more-or-less an answer to some of Brian Tomasik's (very courageous) work, and to sum up my understanding I don't think anyone has made or seems likely to make 'near mode' progress, e.g. especially of the sort that would be helpful for AI safety, under the assumption of analytic functionalism.
So in short, I think STV is perhaps the only option that is well-enough laid out, philosophically and empirically, to even be tested, to even be falsifiable. That doesn't mean it's true, but my prior is it's ridiculously worthwhile to try to falsify, and it seems to me a massive failure of the EA and x-risk scene that resources are not being shifted toward this sort of inquiry. The 80% I gave was perhaps a bit glib, but to dig a little, I'd say I'd give at least an 80% chance of 'Qualia Formalism' being true, and given that, a 95% chance of STV being true, and a 70% chance of CDNS+CSHW being a good proxy for the mathematical symmetry of human experiences.
An obvious thing we're lacking is resources; a non-obvious thing we're lacking is good critics. If you find me too confident I'd be glad to hear why. :)
Resources:
Principia Qualia: https://opentheory.net/PrincipiaQualia.pdf(exploratory arguments for formalism and STV laid out)
Against Functionalism: https://forum.effectivealtruism.org/.../why-i-think-the...
(an evaluation of what analytic functionalism actually gives us)
Quantifying Bliss: https://qualiacomputing.com/.../quantifying-bliss-talk.../
(Andres Gomez Emilsson's combination of STV plus Selen Atasoy's CSHW, which forms the new synthesis we're working from)
A Future for Neuroscience: https://opentheory.net/2018/08/a-future-for-neuroscience/#
(more on CSHW)
Happy to chat more in-depth about details.
Ben Pace @ 2019-11-19T09:54 (+5)
I’m having a hard time understanding whether everything below the dotted lines is something you just wrote, or a full quote from an old thread. The first time I read it I thought the former, and on reread think the latter. Might you be able to make it more explicit at the top of your comment?
MikeJohnson @ 2019-11-19T15:50 (+3)
Thanks, added.
MikeJohnson @ 2019-11-19T08:35 (+6)
We're pretty up-front about our empirical predictions; if critics would like to publicly bet against us we'd welcome this, as long as it doesn't take much time away from our research. If you figure out a bet we'll decide whether to accept it or reject it, and if we reject it we'll aim to concisely explain why.
Matthew_Barnett @ 2019-11-19T17:45 (+12)
Mike, while I appreciate the empirical predictions of the symmetry theory of valence, I have a deeper problem with QRI philosophy, and it makes me skeptical even if the predictions come to bear.
In physics, there are two distinctions we can make about our theories:
- Disputes over what we predict will happen.
- Disputes over the interpretation of experimental results.
The classic Many Worlds vs. Copenhagen is a dispute of the second kind, at least until someone can create an experiment which distinguishes the two. Another example of the second type of dispute is special relativity vs. Lorentz ether theory.
Typically, philosophers of science and most people who follow Lesswrong philosophy, will say that the way to resolve disputes of the second kind is to find out which interpretation is simplest. That's one reason why most people follow Einstein's special relativity over the Lorentz ether theory.
However, simplicity of an interpretation is often hard to measure. It's made more complicated for two reasons,
- First, there's no formal way of measuring simplicity even in principle in a way that is language independent.
- Second, there are ontological disputes about what type of theories we are even allowing to be under consideration.
The first case is usually not a big deal because we mostly can agree on the right language to frame our theories. The second case, however, plays a deep role in why I consider QRI philosophy to be likely incorrect.
Take, for example, the old dispute over whether physics is discrete or continuous. If you apply standard Solomonoff induction, then you will axiomatically assign 0 probability to physics being continuous.
It is in this sense that QRI philosophy takes an ontological step that I consider unjustified. In particular, QRI assumes that there simply is an ontologically primitive consciousness-stuff that exists. That is, it takes it as elementary that qualia exist, and then reasons about them as if they are first class objects in our ontology.
I have already talked to you in person why I reject this line of reasoning. I think that an illusionist perspective is adequate to explain our beliefs in why we believe in consciousness, without making any reference to consciousness as an ontological primitive. Furthermore, my basic ontological assumption is that physical entities, such as electrons, have mathematical properties, but not mental properties.
The idea that electrons can have both mathematical and mental properties (ie. panpsychism) is something I consider to be little more than property dualism, and has the same known issues as every property dualist theory that I have been acquainted with.
I hope that clears some things up about why I disagree with QRI philosophy. However, I definitely wouldn't describe you as practicing crank philosophy, as that term is both loaded, and empirically false. I know you care a lot about critical reflection, debate, and standard scientific virtues, which immediately makes you unable to be a "crank" in my opinion.
MikeJohnson @ 2019-11-20T00:19 (+9)
Thanks Matthew! I agree issues of epistemology and metaphysics get very sticky very quickly when speaking of consciousness.
My basic approach is 'never argue metaphysics when you can argue physics' -- the core strategy we have for 'proving' we can mathematically model qualia is to make better and more elegant predictions using our frameworks, with predicting pain/pleasure from fMRI data as the pilot project.
One way to frame this is that at various points in time, it was completely reasonable to be a skeptic about modeling things like lightning, static, magnetic lodestones, and such, mathematically. This is true to an extent even after Faraday and Maxwell formalized things. But over time, with more and more unusual predictions and fantastic inventions built around electromagnetic theory, it became less reasonable to be skeptical of such.
My metaphysical arguments are in my 'Against Functionalism' piece, and to date I don't believe any commenters have addressed my core claims:
But, I think metaphysical arguments change distressingly few peoples' minds. Experiments and especially technology changes peoples' minds. So that's what our limited optimization energy is pointed at right now.
Matthew_Barnett @ 2019-11-20T01:02 (+3)
Thanks Matthew! I agree issues of epistemology and metaphysics get very sticky very quickly when speaking of consciousness.
Agreed :).
My basic approach is 'never argue metaphysics when you can argue physics'
My main claim was that by only arguing physics, I will never agree upon your theory because your theory assumes the existence of elementary stuff that I don't believe in. Therefore, I don't understand how this really helps.
Would you be prepared say the same about many worlds vs consciousness causes collapse theories? (Let's assume that we have no experimental data which distinguishes the two theories).
One way to frame this is that at various points in time, it was completely reasonable to be a skeptic about modeling things like lightning, static, magnetic lodestones, and such, mathematically.
The problem with the analogy to magnetism and electricity is that fails to match the pattern of my argument. In order to incorporate magnetism into our mathematical theory of physics, we merely added more mathematical parts. In this, I see a fundamental difference between the approach you take and the approach taken by physicists when they admit the existence of new forces, or particles.
In particular, your theory of consciousness does not just do the equivalent of add a new force, or mathematical law that governs matter, or re-orient the geometry of the universe. It also posits that there is a dualism in physical stuff: that is, that matter can be identified as having both mathematical and mental properties.
Even if your theory did result in new predictions, I fail to see why I can't just leave out the mental interpretation of it, and keep the mathematical bits for myself.
To put it another way, if you are saying that symmetry can be shown to be the same as valence, then I feel I can always provide an alternative explanation that leaves out valence as a first-class object in our ontology. If you are merely saying that symmetry is definitionally equivalent to valence, then your theory is vacuous because I can just delete that interpretation from my mathematical theory and emerge with equivalent predictions about the world.
And in practice, I would probably do so, because symmetry is not the kind of thing I think about when I worry about suffering.
I think metaphysical arguments change distressingly few peoples' minds. Experiments and especially technology changes peoples' minds. So that's what our limited optimization energy is pointed at right now.
I agree that if you had made predictions that classical neuroscientists all agreed would never occur, and then proved them all wrong, then that would be striking evidence that I had made an error somewhere in my argument. But as it stands, I'm not convinced by your analogy to magnetism, or your strict approach towards talking about predictions rather than metaphysics.
(I may one day reply to your critique of FRI, as I see it as similarly flawed. But it is simply too long to get into right now.)
MikeJohnson @ 2019-11-20T01:37 (+6)
I think we actually mostly agree: QRI doesn't 'need' you to believe qualia are real, that symmetry in some formalism of qualia corresponds to pleasure, that there is any formalism about qualia to be found at all. If we find some cool predictions, you can strip out any mention of qualia from them, and use them within the functionalism frame. As you say, the existence of some cool predictions won't force you to update your metaphysics (your understanding of which things are ontologically 'first class objects').
But- you won't be able to copy our generator by doing that, the thing that created those novel predictions, and I think that's significant, and gets into questions of elegance metrics and philosophy of science.
I actually think the electromagnetism analogy is a good one: skepticism is always defensible, and in 1600, 1700, 1800, 1862, and 2018, people could be skeptical of whether there's 'deep unifying structure' behind these things we call static, lightning, magnetism, shocks, and so on. But it was much more reasonable to be skeptical in 1600 than in 1862 (the year Maxwell's Equations were published), and more reasonable in 1862 than it was in 2018 (the era of the iPhone).
Whether there is 'deep structure' in qualia is of course an open question in 2019. I might suggest STV is equivalent to a very early draft of Maxwell's Equations: not a full systematization of qualia, but something that can be tested and built on in order to get there. And one that potentially ties together many disparate observations into a unified frame, and offers novel / falsifiable predictions (which seem incredibly worth trying to falsify!)
I'd definitely push back on the frame of dualism, although this might be a terminology nitpick: my preferred frame here is monism: https://opentheory.net/2019/06/taking-monism-seriously/ - and perhaps this somewhat addresses your objection that 'QRI posits the existence of too many things'.
Matthew_Barnett @ 2019-11-20T01:53 (+3)
But- you won't be able to copy our generator by doing that, the thing that created those novel predictions
I would think this might be our crux (other than perhaps the existence of qualia themselves). I imagine any predictions you produce can be adequately captured in a mathematical framework that makes no reference to qualia as ontologically primitive. And if I had such a framework, then I would have access to the generator, full stop. Adding qualia doesn't make the generator any better -- it just adds unnecessary mental stuff that isn't actually doing anything for the theory.
I am not super confident in anything I said here, although that's mostly because I have an outside view that tells me consciousness is hard to get right. My inside view tells me that I am probably correct, because I just don't see how positing mental stuff that's separate from mathematical law can add anything whatsoever to a physical theory.
I'm happy to talk more about this some day, perhaps in person. :)
Pablo_Stafforini @ 2019-11-20T12:50 (+9)
Hey Mike,
I'm a community moderator at Metaculus and am generally interested in creating more EA-relevant questions. Are your predictions explicitly listed somewhere? It would be great to add at least some of them to the site.
MikeJohnson @ 2019-11-30T01:54 (+5)
Hey Pablo! I think Andres has a few up on Metaculus; I just posted QRI's latest piece of neuroscience here, which has a bunch of predictions (though I haven't separated them out from the text):
https://opentheory.net/2019/11/neural-annealing-toward-a-neural-theory-of-everything/
Gregory_Lewis @ 2019-11-30T19:00 (+10)
I think it would be worthwhile to separate these out from the text, and (especially) to generate predictions that are crisp, distinctive, and can be resolved in the near term. The QRI questions on metaculus are admirably crisp (and fairly near term), but not distinctive (they are about whether certain drugs will be licensed for certain conditions - or whether evidence will emerge supporting drug X for condition Y, which offer very limited evidence for QRI's wider account 'either way').
This is somewhat more promising from your most recent post:
I’d expect to see substantially less energy in low-frequency CSHWs [Connectome-Specific Harmonic Waves] after trauma, and substantially more energy in low-frequency CSHWs during both therapeutic psychedelic use (e.g. MDMA therapy) and during psychological integration work.
This is crisp, plausibly distinctive, yet resolving this requires a lot of neuroimaging work which (presumably) won't be conducted anytime soon. In the interim, there isn't much to persuade a sceptical prior.
Buck @ 2019-11-19T18:01 (+6)
I see this and appreciate it; the problem is that I want to bet on something like "your overall theory is wrong", but I don't know enough neuroscience to know whether the claims you're making are things that are probably true for reasons unrelated to your overall theory. If you could find someone who I trusted who knew neuroscience and who thought your predictions seemed unlikely, then I'd bet with them against you.
MikeJohnson @ 2019-11-20T03:50 (+7)
We’ve looked for someone from the community to do a solid ‘adversarial review’ of our work, but we haven’t found anyone that feels qualified to do so and that we trust to do a good job, aside from Scott, and he's not available at this time. If anyone comes to mind do let me know!
Milan_Griffes @ 2019-11-16T12:21 (+2)
See also this recent Qualia Computing post about the orthogonality thesis. (Qualia Computing is the blog of QRI's research director.)
Ben Pace @ 2019-11-17T03:50 (+24)
How would you describe the general motivation behind MIRI's research approach? If you feel you don't want to answer that, feel free to restrict this specifically to the agent foundations work.
Buck @ 2019-11-19T03:25 (+20)
I’m speaking very much for myself and not for MIRI here. But, here goes (this is pretty similar to the view described here):
If we build AI systems out of business-as-usual ML, we’re going to end up with systems probably trained with some kind of meta learning (as described in Risks from Learned Optimization) and they’re going to be completely uninterpretable and we’re not going to be able to fix the inner alignment. And by default our ML systems won’t be able to handle the strain of doing radical self-improvement, and they’ll accidentally allow their goals to shift as they self-improve (in the same way that if you tried to make a physicist by giving a ten year old access to a whole bunch of crazy mind altering/enhancing drugs and the ability to do brain surgery on themselves, you might have unstable results). We can’t fix this with things like ML transparency or adversarial training or ML robustness. The only hope of building aligned really-powerful-AI-systems is having a much clearer picture of what we’re doing when we try to build these systems.
Ben Pace @ 2019-11-19T04:01 (+20)
Thanks :)
I'm hearing "the current approach will fail by default, so we need a different approach. In particular, the new approach should be clearer about the reasoning of the AI system than current approaches."
Noticeably, that's different from a positive case that sounds like "Here is such an approach and why it could work."
I'm curious how much of your thinking is currently split between the two rough possibilities below.
First:
I don't know of another approach that could work, so while I maybe personally feel more of an ability to understand some people's ideas than others, many people's very different concrete suggestions for approaches to understanding these systems better are all arguably similar in terms of how likely we should think they are to pan out, and how much resources we should want to put behind them.
Alternatively, second:
While it's incredibly difficult to communicate mathematical intuitions of this depth, my sense is I can see a very attractive case for why one or two particular efforts (e.g. MIRI's embedded agency work) could work out.
SamClarke @ 2019-11-19T10:00 (+23)
What do you think are the biggest mistakes that the AI Safety community is currently making?
SamClarke @ 2019-11-19T09:59 (+23)
Paul Christiano is a lot more optimistic than MIRI about whether we could align a Prosaic AGI. In a relatively recent interview with AI Impacts he said he thinks "probably most of the disagreement" about this lies in the question of "can this problem [alignment] just be solved on paper in advance" (Paul thinks there's "at least a third chance" of this, but suggests MIRI's estimate is much lower). Do you have a sense of why MIRI and Paul disagree so much on this estimate?
Buck @ 2019-11-19T22:24 (+11)
I think Paul is probably right about the causes of the disagreement between him and many researchers, and the summary of his beliefs in the AI Impacts interview you linked matches my impression of his beliefs about this.
Ben Pace @ 2019-11-17T03:46 (+23)
What has been the causal history of you deciding that it was worth leaving your previous job to work with MIRI? Many people have a generic positive or negative view of MIRI, but it's much stronger to decide to actually work there.
Buck @ 2019-11-19T02:06 (+25)
Earning to give started looking worse and worse the more that I increased my respect for Open Phil; by 2017 it seemed mostly obvious that I shouldn’t earn to give. I stayed at my job for a few months longer because two prominent EAs gave me the advice to keep working at my current job, which in hindsight seems like an obvious mistake and I don’t know why they gave that advice. Then in May, MIRI advertised a software engineer internship program which I applied to; they gave me an offer, but I would have had to quit my job to take the offer, and Triplebyte (which I’d joined as the first engineer) was doing quite well and I expected that if I got another software engineering job it would have much lower pay. After a few months I decided that there were enough good things I could be doing with my time that I quit Triplebyte and started studying ML (and also doing some volunteer work for MIRI doing technical interviewing for them).
I tried to figure out whether MIRI’s directions for AI alignment were good, by reading a lot of stuff that had been written online; I did a pretty bad job of thinking about all this.
At this point MIRI offered me a full time job and Paul Christiano offered me a month-long trial working with him at OpenAI; I took Paul’s offer mostly because I wanted to learn more about how Paul and other OpenAI people think about AI and AI safety. I wasn’t great at the work, partially because it was ML and I don’t like experimenting with ML that much, but it was a great experience and I learned a lot and I’m really glad I did it. They didn’t give me an offer, saying that I should go and learn more ML and reapply if I wanted to, which seemed very reasonable to me. I then accepted the MIRI offer.
I think there were two decisions here: quitting my job and joining MIRI. Quitting my job seems pretty overdetermined in hindsight, because it seemed that there were many different direct work opportunities I could pursue and many different skills I could be trying to learn. If I wasn’t at a company which I liked as much as Triplebyte I would have quit much earlier.
I joined MIRI without a strong inside view model of why their work made sense, mostly based on the fact that Nate Soares had deeply impressed me with his thoughts on CS and physics, Eliezer seemed like a generally really smart guy based on his writing, and because I thought I had a strong comparative advantage in working for them compared to other orgs (because I’d done functional programming and could help with recruiting).
amc @ 2019-11-27T06:22 (+5)
I tried to figure out whether MIRI’s directions for AI alignment were good, by reading a lot of stuff that had been written online; I did a pretty bad job of thinking about all this.
I'm curious about why you think you did a bad job at this. Could you roughly explain what you did and what you should have done instead?
riceissa @ 2019-11-16T07:11 (+23)
On the SSC roadtrip post, you say "After our trip, I'll write up a post-mortem for other people who might be interested in doing things like this in the future". Are you still planning to write this, and if so, when do you expect to publish it?
Buck @ 2019-11-18T21:24 (+6)
I wrote it but I’ve been holding off on publishing it. I’ll probably edit it and publish it within the next month. If you really want to read it, email me and I’ll share you on it.
Milan_Griffes @ 2019-11-17T14:01 (+5)
Published today: "EA residencies" as an outreach activity
WikipediaEA @ 2019-11-16T21:59 (+21)
Q1: Has MIRI noticed a significant change in funding following the change in disclosure policy?
Q2: If yes to Q1, what was the direction of the change?
Q3: If yes to Q1, were you surprised by the degree of the change?
ETA:
Q4: If yes to Q3, in which direction were you surprised?
Buck @ 2019-11-19T07:40 (+12)
It’s not clear what effect this has had, if any. I am personally somewhat surprised by this--I would have expected more people to stop donating to us.
I asked Rob Bensinger about this; he summarized it as “We announced nondisclosed-by-default in April 2017, and we suspected that this would make fundraising harder. In fact, though, we received significantly more funding in 2017 (https://intelligence.org/2019/05/31/2018-in-review/#2018-finances), and have continued to receive strong support since then. I don't know that there's any causal relationship between those two facts; e.g., the obvious thing to look at in understanding the 2017 spike was the cryptocurrency price spike that year. And there are other factors that changed around the same time too, e.g., Colm [who works at MIRI on fundraising among other things] joining MIRI in late 2016.“
NunoSempere @ 2019-11-16T08:12 (+21)
What would you be working on if you were working on something else?
Buck @ 2019-11-19T03:11 (+31)
Here are some things I might do:
- Inside AI alignment:
- I don’t know if this is sufficiently different from my current work to be an interesting answer, but I can imagine wanting to work on AIRCS full time, possibly expanding it in the following ways:
- Run more of the workshops. This would require training more staff. For example, Anna Salamon currently leads all the workshops and wouldn’t have time to run twice as many.
- Expand the scope of the workshops to non-CS people, for example non-technical EAs.
- Expand the focus of the workshop from AI to be more general. Eg I’ve been thinking about running something tentatively called “Future Camp”, where people come in and spend a few days thinking and learning about longtermism and what the future is going to be like, with the goal of equipping people to think more clearly about futurism questions like the timelines of various transformative technologies and what can be done to make those technologies go better.
- Making the workshop be more generally about EA. The idea would be that the workshop does the same kind of thing that EA Global tries to do for relatively new EAs--expose them to more experienced EAs and to content that will be helpful for them, and help them network with each other and think more deeply about EA ideas. This is kind of like what CFAR workshops are like, but this would focus on inducting people into the EA community rather than the rationalist community. CFAR workshops sort of fill this role, but IMO they could be more optimized for this.
- Learn more ML and then figure out what I think needs to happen to make ML-flavored AI alignment go well, work on those things.
- Try to write up the case for skepticism of various approaches to ML-based AGI alignment, eg the approaches of Paul Christiano and Chris Olah--these people deserve better rebuttals from a MIRI-style perspective than I think they’ve gotten so far, because writing things is hard and time consuming.
- Other:
- Work on EA outreach some other way, through programs like EA residencies or the SSC tour.
- Work on a particular project which some people I know are working on, which isn’t public at the moment. I think it has the potential to be really impactful from a longtermist perspective.
- Work on reducing s-risks
Tofly @ 2019-11-18T05:07 (+17)
Nate Soares once described autodidacting to prepare for a job at MIRI. For each position at MIRI (agent foundations, machine learning alignment, software engineer, type theorist, machine learning living library), what should one study if one wanted to do something like that today? (i.e. for agent foundations, is Scott Garrabrant’s suggestion of “Learn enough math to understand all fixed point theorems” essentially correct? Is there anything else one needs to know?)
Buck @ 2019-11-19T20:46 (+10)
I don't know about what you need to know in order to do agent foundations research and trust Scott's answer.
If you're seriously considering autodidacting to prepare for a non-agent-foundations job at MIRI, you should email me (buck@intelligence.org) about your particular situation and I'll try to give you personal advice. If too many people email me asking about this, I'll end up writing something publicly.
In general, I'd rather that people talk to me before they study a lot for a MIRI job rather than after, so that I can point them in the right direction and they don't waste effort learning things that aren't going to make the difference to whether we want to hire them.
And if you want to autodidact to work on agent foundations at MIRI, consider emailing someone on the agent foundations team. Or you could try emailing me and I can try to help.
WikipediaEA @ 2019-11-17T16:41 (+16)
Given an aligned AGI, what is your point estimate for the TOTAL (across all human history) cost in USD of having aligned it?
To hopefully spare you a bit of googling without unduly anchoring your thinking, Wiki says the Manhattan Project cost $21-23 billion in 2018 USD, with only about 3.7% or $786m of that being research and development.
Ben Pace @ 2019-11-17T20:49 (+7)
This is such an interesting question. I’m not sure I have a sensible answer. Like, I feel like the present bottleneck on Alignment progress is entirely a question of getting good people doing helpful conceptual work, but afterwards indeed a lot of funding will be needed to align the AI, and I’ve not got a sense of how much money we might need to keep aside until then - e.g. is it more or less than OpenPhil’s current total?
riceissa @ 2019-11-16T08:20 (+16)
Over the years, you have published several pieces on ways you've changed your mind (e.g. about EA, another about EA, weird ideas, hedonic utilitarianism, and a bunch of other ideas). While I've enjoyed reading the posts and the selection of ideas, I've also found most of the posts frustrating (the hedonic utilitarianism one is an exception) because they mostly only give the direction of the update, without also giving the reasoning and additional evidence that caused the update* (e.g. in the EA post you write "I am erring on the side of writing this faster and including more of my conclusions, at the cost of not very clearly explaining why I’ve shifted positions"). Is there a reason you keep writing in this style (e.g. you don't have time, or you don't want to "give away the answers" to the reader), and if so, what is the reason?
*Why do I find this frustrating? My basic reasoning is something like this: I think this style of writing forces the reader to do a weird kind of Aumann reasoning where they have to guess what evidence/arguments Buck might have had at the start, and what evidence/arguments he subsequently saw, in order to try to reconstruct the update. When I encounter this kind of writing, I mostly just take it as social information about who believes what, without bothering to go through the Aumann reasoning (because it seems impossible or would take way too much effort). See also this comment by Wei Dai.
Buck @ 2019-11-19T02:06 (+15)
I think a major reason that I write those posts is because I’m worried that I persuaded someone of claims that I now believe to be false; I hope that if they hear I changed my mind, they might feel more skeptical of arguments that I made in the past.
I mostly don’t try to write up the arguments that persuaded me because it feels hard and time-consuming.
I’m definitely not trying to avoid “giving away the answers”. I’m sorry that this is annoying :( I definitely don’t feel that it’s unreasonable for people to not try to update on my mind changing.
anonymous_ea @ 2019-11-20T01:48 (+3)
I agree with Issa about the costs of not giving reasons. My guess is that over the long run, giving reasons why you believe what you believe will be a better strategy to avoid convincing people of false things. Saying you believed X and now believe ~X seems like it's likely to convince people of ~X even more strongly.
edoarad @ 2019-11-18T06:06 (+15)
It seems like there are many more people that want to get into AI Safety, and MIRI's fundumental research, than there is room to mentor and manage them. There are also many independent / volunteer researchers.
It seems that your current strategy is to focus on training, hiring and outreaching to the most promising talented individuals. Other alternatives might include more engagement with amatures, and providing more assistance for groups and individuals that want to learn and conduct independent research.
Do you see it the same way? This strategy makes a lot of sense, but I am curious to your take on it. Also, what would change if you had 10 times the amount of management and mentorship capacity?
Buck @ 2019-11-22T05:24 (+10)
It seems that your current strategy is to focus on training, hiring and outreaching to the most promising talented individuals.
This seems like a pretty good summary of the strategy I work on, and it's the strategy that I'm most optimistic about.
Other alternatives might include more engagement with amatures, and providing more assistance for groups and individuals that want to learn and conduct independent research.
I think that it would be quite costly and difficult for more experienced AI safety researchers to try to cause more good research to happen by engaging more with amateurs or providing more assistance to independent research. So I think that experienced AI safety researchers are probably going to do more good by spending more time on their own research than by trying to help other people with theirs. This is because I think that experienced and skilled AI safety researchers are much more productive than other people, and because I think that a reasonably large number of very talented math/CS people become interested in AI safety every year, so we can set a pretty high bar for which people to spend a lot of time with.
Also, what would change if you had 10 times the amount of management and mentorship capacity?
If I had ten times as many copies of various top AI safety researchers and I could only use them for management and mentorship capacity, I'd try to get them to talk to many more AI safety researchers, through things like weekly hour-long calls with PhD students, or running more workshops like MSFP.
Ben Pace @ 2019-11-17T03:56 (+15)
What's been your experiences, positive and negative, of CFAR workshops?
Buck @ 2019-11-20T05:07 (+13)
I think they're OK. I think some CFAR staff are really great. I think that their incidental effect of causing people to have more social ties to the rationalist/EA Bay Area community is probably pretty good.
I've done CFAR-esque exercises at AIRCS workshops which were very helpful to me. I think my general sense is that a bunch of CFAR material has a "true form" which is pretty great, but I didn't get the true form from my CFAR workshop, I got it from talking to Anna Salamon (and somewhat from working with other CFAR staff).
I think that for (possibly dumb) personal reasons I get more annoyed by them than some people, which prevents me from getting as much value out of them.
I generally am glad to hear that an EA has done a CFAR workshop, and normally recommend that EAs do them, especially if they don’t have as much social connection to the EA/rationalist scene, or if they don’t have high opportunity cost to their time.
Adam_Scholl @ 2019-11-21T18:43 (+16)
For what it's worth, I wouldn't describe the social ties thing as incidental—it's one of the main things CFAR is explicitly optimizing for. For example, I'd estimate (my colleagues might quibble with these numbers some) it's 90% of the reason we run alumni reunions, 60% of the reason we run instructor & mentorship trainings, 30% of the reason we run mainlines, and 15% of the reason we co-run AIRCS.
Buck @ 2019-11-21T21:12 (+4)
Yeah, makes sense; I didn’t mean “unintentional” by “incidental”.
elle @ 2019-11-20T09:31 (+7)
How long ago did you attend your CFAR workshop? My sense is that the content CFAR teaches and who the teachers are have changed a lot over the years. Maybe they've gotten better (or worse?) about teaching the "true form."
(Or maybe you were saying you also didn't get the "true form" even in the more recent AIRCS workshops?)
Ben Pace @ 2019-11-17T03:58 (+14)
What's a belief that you hold that most people disagree with you about? I'm including most EAs and rationalists.
Halffull @ 2019-11-17T17:47 (+12)
Found elsewhere on the thread, a list of weird beliefs that Buck holds: http://shlegeris.com/2018/10/23/weirdest
NunoSempere @ 2019-11-16T08:12 (+14)
Do you have the intuition that a random gifted person can contribute to technical research on AI safety?
Shri_Samson @ 2019-11-19T08:38 (+13)
It's happened a few times at our local meetup (South Bay EA) that we get someone new who says something like “okay I’m a fairly good ML student who wants to decide on a research direction for AI Safety.” In the past we've given fairly generic advice like "listen to this 80k podcast on AI Safety" or "apply to AIRCS". One of our attendees went on to join OpenAI's safety team after this advice, and gave us some attribution for it. While this probably makes folks a little better off, it feels like we could do better for them.
If you had to give someone more concrete object-level advice on how to get started AI safety what would you tell them?
Buck @ 2019-11-22T05:16 (+18)
I’m a fairly good ML student who wants to decide on a research direction for AI Safety.
I'm not actually sure whether I think it's a good idea for ML students to try to work on AI safety. I am pretty skeptical of most of the research done by pretty good ML students who try to make their research relevant to AI safety--it usually feels to me like their work ends up not contributing to one of the core difficulties, and I think that they might have been better off if they'd instead spent their effort trying to become really good at ML in the hope of being better skilled up with the goal of working on AI safety later.
I don't have very much better advice for how to get started on AI safety; I think the "recommend to apply to AIRCS and point at 80K and maybe the Alignment Newsletter" path is pretty reasonable.
richard_ngo @ 2019-11-22T15:29 (+4)
I think that they might have been better off if they'd instead spent their effort trying to become really good at ML in the hope of being better skilled up with the goal of working on AI safety later.
I'm broadly sympathetic to this, but I also want to note that there are some research directions in mainstream ML which do seem significantly more valuable than average. For example, I'm pretty excited about people getting really good at interpretability, so that they have an intuitive understanding of what's actually going on inside our models (particularly RL agents), even if they have no specific plans about how to apply this to safety.
riceissa @ 2019-11-16T07:24 (+13)
I asked a question on LessWrong recently that I'm curious for your thoughts on. If you don't want to read the full text on LessWrong, the short version is: Do you think it has become harder recently (say 2013 vs 2019) to become a mathematician at MIRI? Why or why not?
Buck @ 2019-11-20T05:13 (+7)
I'm not sure; my guess is that it's somewhat harder, because we're enthusiastic about our new research directions and have moved some management capacity towards those, and those directions have relatively more room for engineering skillsets vs pure math skillsets.
edoarad @ 2019-11-18T05:24 (+12)
What are some bottlenecks in your research productivity?
Buck @ 2019-11-19T22:15 (+11)
Here are several, together with the percentage of my productivity which I think they cost me over the last year:
- I’ve lost a couple months of productivity over the last year due to some weird health issues--I was really fatigued and couldn’t think properly for several months. This was terrible, but the problem seems to have gone away for now. This had a 25% cost.
- I am a worse researcher because I spend half my time doing other things than research. It’s unclear to me how much efficiency this costs me. Potential considerations:
- When I don’t feel like doing technical work, I can do other work. This should increase my productivity. But maybe it lets me procrastinate on important work.
- I remember less of the context of what I’m working on, because my memory is spaced out.
- My nontechnical work often feels like social drama and is really attention-grabbing and distracting.
- Overall this costs me maybe 15%; I’m really unsure about this though.
- I’d be a better researcher if I were smarter and more knowledgeable. I’m working on the knowledgeableness problem with the help of tutors and by spending some of my time studying. It’s unclear how to figure out how costly this is. If I’d spent a year working as a Haskell programmer in industry, I’d probably be like 15% more effective now.
edoarad @ 2019-11-20T04:34 (+5)
Thanks! I'm sorry to hear about your health problems, but I'm glad it's better now :)
riceissa @ 2019-11-16T07:35 (+12)
[Meta] During the AMA, are you planning to distinguish (e.g. by giving short replies) between the case where you can't answer a question due to MIRI's non-disclosure policy vs the case where you won't answer a question simply because there isn't enough time/it's too much effort to answer?
Buck @ 2019-11-18T22:02 (+8)
I don't expect to not answer any questions because of MIRI non-disclosure stuff.
anonymous_ea @ 2019-11-16T21:59 (+11)
What other crazy ideas do you have about EA outreach?
riceissa @ 2019-11-16T07:42 (+11)
How do you see success/an "existential win" playing out in short timeline scenarios (e.g. less than 10 years until AGI) where alignment is non-trivial/turns out to not solve itself "by default"? For example, in these scenarios do you see MIRI building an AGI, or assisting/advising another group to do so, or something else?
Buck @ 2019-11-20T07:19 (+8)
It's getting late and it feels hard to answer this question, so I'm only going to say briefly:
- for something MIRI wrote re this, see the "strategic background" section here
- I think there are cases where alignment is non-trivial but prosaic AI alignment is possible, and some people who are cautious about AGI alignment are influential in the groups that are working on AGI development and cause them to put lots of effort into alignment (eg maybe the only way to align the thing involves spending an extra billion dollars on human feedback). Because of these cases, I am excited for the leading AI orgs having many people in important positions who are concerned about and knowledgeable about these issues.
Ben Pace @ 2019-11-17T03:55 (+10)
What's something specific about this community that you're grateful for?
Buck @ 2019-11-19T02:17 (+18)
Many things. Two that come to mind:
- Even though most of my friends are mostly consequentialist in their EA actions, I feel like they’re also way more interested than average in figuring out what the right thing to do is from a wide variety of moral perspectives; I feel extremely warm about the scrupulosity and care of EAs, even towards things that don’t matter much.
- I think EAs are often very naturally upset by injustices which are enormous but which most people don’t think to be upset by; I feel this way particularly because of anti-death sentiments, care for farmed and wild animals, and support for open borders.
Ben Pace @ 2019-11-17T03:38 (+10)
Will we solve the alignment problem before crunch time?
Buck @ 2019-11-21T01:00 (+17)
I think it's plausible that "solving the alignment problem" isn't a very clear way of phrasing the goal of technical AI safety research. Consider the question "will we solve the rocket alignment problem before we launch the first rocket to the moon"--to me the interesting question is whether the first rocket to the moon will indeed get there. The problem isn't really "solved" or "not solved", the rocket just gets to the moon or not. And it's not even obvious whether the goal is to align the first AGI; maybe the question is "what proportion of resources controlled by AI systems end up being used for human purposes", where we care about a weighted proportion of AI systems which are aligned.
I am not sure whether I'd bet for or against the proposition that humans will go extinct for AGI-misalignment-related-reasons within the next 100 years.
Matthew_Barnett @ 2019-11-17T04:10 (+3)
Apologies, aren't we already in crunch time?
Are your referring to this comment from Eliezer Yudkowsky,
This is crunch time. This is crunch time for the entire human species. This is the hour before the final exam, we are trying to get as much studying done as possible, and it may be that you can’t make yourself feel that, for a decade, or 30 years on end or however long this crunch time lasts.
Ben Pace @ 2019-11-17T04:21 (+2)
Sure. "Crunch time" is not exactly a technically precise term, and it is quite likely our time is measured in decades. The thing I want to ask is whether Buck expects the timeline will fully run out before we solve alignment, or whether we'll manage to successfully build an AGI that helps us achieve our values and an existential win, or whether something different will happen instead.
Matthew_Barnett @ 2019-11-17T04:35 (+3)
I see. I asked only because I was confused why you asked "before crunch time" rather than leaving that part out.
riceissa @ 2019-11-16T07:46 (+10)
Do you think non-altruistic interventions for AI alignment (i.e. AI safety "prepping") make sense? If so, do you have suggestions for concrete actions to take, and if not, why do you think they don't make sense?
(Note: I previously asked a similar question addressed at someone else, but I am curious for Buck's thoughts on this.)
Buck @ 2019-11-20T07:02 (+14)
I don't think you can prep that effectively for x-risk-level AI outcomes, obviously.
I think you can prep for various transformative technologies; you could for example buy shares of computer hardware manufacturers if you think that they'll be worth more due to increased value of computation as AI productivity increases. I haven't thought much about this, and I'm sure this is dumb for some reason, but maybe you could try to buy land in cheap places in the hope that in a transhuman utopia the land will be extremely valuable (the property rights might not carry through, but it might be worth the gamble for sufficiently cheap land).
I think it's probably at least slightly worthwhile to do good and hope that you can sell some of your impact certificates after good AI outcomes.
You should ask Carl Shulman, I'm sure he'd have a good answer.
elle @ 2019-11-18T08:31 (+9)
Is there any public information on the AI Safety Retraining Program other than the MIRI Summer Update and the Open Phil grant page?
I am wondering:
1) Who should apply? How do they apply?
2) Have there been any results yet? I see two grants were given as of Sep 1st; have either of those been completed? If so, what were the outcomes?
Buck @ 2019-11-19T06:55 (+8)
I don't think there's any other public information.
To apply, people should email me asking about it (buck@intelligence.org). The three people who've received one of these grants were all people who I ran across in my MIRI recruiting efforts.
Two grants have been completed and a third is ongoing. Of the two people who completed grants, both successfully replicated several deep RL papers. and one of them ended up getting a job working on AI safety stuff (the other took a data science job and hopes to work on AI safety at some point in the future).
I'm happy to answer more questions about this.
elle @ 2019-11-19T22:00 (+3)
So, to clarify: this program is for people who are already mostly sure they want to work on AI Safety? That is, a person who is excited about ML, and would maaaaybe be interested in working on safety-related topics, if they found those topics interesting, is not who you are targeting?
Buck @ 2019-11-19T22:14 (+3)
Yeah, I am not targeting that kind of person. Someone who is excited about ML and skeptical of AI safety but interested in engaging a lot with AI safety arguments for a few months might be a good fit.
Ben Pace @ 2019-11-17T03:55 (+9)
What do you think integrity means and how can you tell when someone has it?
Ben Pace @ 2019-11-17T03:54 (+9)
What do you think is the main cause of burnout in people working on ambitious projects, especially those designed to reduce existential risk?
elle @ 2019-11-18T08:14 (+8)
You write:
"I think that the field of AI safety is growing in an awkward way. Lots of people are trying to work on it, and many of these people have pretty different pictures of what the problem is and how we should try to work on it. How should we handle this? How should you try to work in a field when at least half the "experts" are going to think that your research direction is misguided?"
What are your preliminary thoughts on the answers to these questions?
Ben Pace @ 2019-11-17T03:52 (+8)
As you've grown up and become more agentic and competent and thoughtful, how have your values changed? Have you discarded old values, have they changed in more subtle ways?
WikipediaEA @ 2019-11-16T22:09 (+8)
How efficiently could MIRI "burn through" its savings if it considered AGI sufficiently likely to be imminent? In other words, if MIRI decided to spend all its savings in a year, how many normal-spending-years' worth of progress on AI safety do you think it would achieve?
Buck @ 2019-11-20T02:40 (+7)
Probably less than two.
WikipediaEA @ 2019-11-16T21:56 (+8)
Given a "bad" AGI outcome, how likely do you think a long-term worse-than-death fate for at least some people would be relative to extinction?
Buck @ 2019-11-20T05:41 (+3)
Idk. A couple percent? I'm very unsure about this.
WikipediaEA @ 2019-11-16T21:52 (+8)
Q1: How closely does MIRI currently coordinate with the Long-Term Future Fund (LTFF)?
Q2: How effective do you currently consider [donations to] the LTFF relative to [donations to] MIRI? Decimal coefficient preferred if you feel comfortable guessing one.
Q3: Do you expect the LTFF to become more or less effective relative to MIRI as AI capability/safety progresses?
Buck @ 2019-11-20T06:02 (+9)
(I've spent a few hours talking to people about the LTFF but I'm not sure about things like "what order of magnitude of funding did they allocate last year" (my guess without looking it up is $1M, (which turns out to be correct!)), so take all this with a grain of salt.)
Re Q1: I don't know, I don't think that we coordinate very carefully.
Re Q2: I don't really know. When I look at the list of things the LTFF funded in August or April (excluding regrants to orgs like MIRI, CFAR, and Ought), about 40% look meh (~0.5x MIRI), about 40% look like things which I'm reasonably glad someone funded (~1x MIRI), about 7% are things that I'm really glad someone funded (~3x MIRI), and 3% are things that I wish that they hadn't funded (-1x MIRI). Note that my mean outcome of the meh, good, and great categories are much higher than the median outcomes--a lot of them are "I think this is probably useless but seems worth trying for value of information". Apparently this adds up to thinking that they're 78% as good as MIRI.
Q3: I don't really know. My median outcome is that they turn out to do less well than my estimation above, but I think there's a reasonable probability that they turn out to be much better than my estimate above, and I'm excited to see them try to do good. This isn't really tied up with AI capability or safety progressing though.
elle @ 2019-11-18T08:11 (+4)
In your opinion, what are the most helpful organizations or groups working on AI safety right now? And why?
In parallel: what are the least helpful organizations or groups working on (or claiming to work on) AI safety right now? And why?
Buck @ 2019-11-19T20:43 (+4)
I feel reluctant to answer this question because it feels like it would involve casting judgement on lots of people publicly. I think that there are a bunch of different orgs and people doing good work on AI safety.
elle @ 2019-11-19T21:48 (+12)
Yeah, I am sympathetic to that. I am curious how you decide where to draw the line here. For instance, you were willing to express judgment of QRI elsewhere in the comments.
Would it be possible to briefly list the people or orgs whose work you *most* respect? Or would the omissions be too obvious?
I sometimes wish there were good ways to more broadly disseminate negative judgments or critiques of orgs/people from thoughtful and well-connected people. But, understandably, people are sensitive to that kind of thing, and it can end up eating a lot of time and weakening relationships.
edoarad @ 2019-11-18T06:09 (+4)
How do you view the field of Machine Ethics? (I only now heard of it in this AI Alignment Podcast)
elle @ 2019-11-19T19:05 (+3)
What are your regular go-to sources of information online? That is, are there certain blogs you religiously read? Vox? Do you follow the EA Forum or LessWrong? Do you mostly read papers that you find through some search algorithm you previously set up? Etc.
Buck @ 2019-11-19T20:17 (+4)
I don't consume information online very intentionally.
Blogs I often read:
- Slate Star Codex
- The Unit of Caring
- Bryan Caplan (despite disagreeing with him a lot, obviously)
- Meteuphoric (Katja Grace)
- Paul Christiano's various blogs
I often read the Alignment Newsletter. I mostly learn things from hearing about them from friends.
Misha_Yagudin @ 2020-03-17T21:29 (+1)
What are some of your favourite theorems, proofs, algorithms, data structures, and programming languages?
Tofly @ 2019-11-18T02:01 (+1)
If an intelligent person was willing to prepare for any position at MIRI, but was currently unqualified for any, which would you want them to go for?