What is estimational programming? Squiggle in context
By quinn @ 2022-08-12T18:01 (+31)
This post does not contain the canonical QURI opinion, but I am a contractor there. I want to thank early commenters Vivian Belenky and Ozzie Gooen. The section concerning probabilistic programming is readily skippable to make things easier for nonprogrammers.
In this post, I aim to explain and describe what Squiggle is. In future posts, I will clarify its EA value proposition and highlight its applications and theories of change.
TLDR:
- Estimational programming is any practice of writing quantitative belief specifications.
- Estimational programming has a rich history.
- Squiggle is a great tool for estimational programming, but other languages can and should be great tools for estimational programming as well.
A whiggish history of estimational programming
Belief specifications are descriptive units of belief. Estimational programming (EP) is the practice of writing belief specifications. We want EP products to be functional and uncertain. When I say an EP product is uncertain, I mean that it allows uncertain beliefs to be specified. By functional, I mean that when users write estimates on an EP product, the estimates should be reproducible and composable. By composable, I also mean to say that they should be transparent and interpretable. If an estimate is both reproducible and interpretable, I will call it auditable.
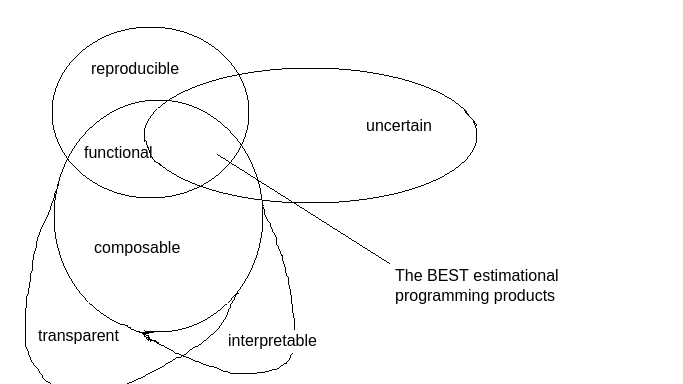
Technologies for writing belief specifications exist but lack the above desirable properties. Users can accomplish estimational programming in each of them to varying degrees, but Squiggle is unusual because it is a platform for which EP is the first-class intended use case.
- Forecasting on Good Judgment Open: users predict answers to questions, and the platform aggregates a “crowd” opinion. While the user may optionally comment their reasoning below their prediction, the platform doesn’t offer any sense of reproducibility or transparency of forecasts. A user can’t, without using auxiliary technology like spreadsheets, ensure that they’ll later remember precisely how or why they arrived at their forecast. Other users can’t scrutinize or understand where someone is coming from. From a programming perspective, we view the user as returning a program that says, “given the magical black box of my intuitions, I can return a scalar value.” By default, this method lacks reproducibility, transparency, and interpretability.
- Widget, formerly known as Elicit: users supply point estimates of their beliefs, and this time the widget aggregates to a crowd opinion. If you want to audit what a particular user was thinking and guess how they might update if things on the ground change, you can’t. The programming perspective on the user’s end is similar to that of Good Judgment Open.
- Spreadsheets: users import data, transform them (preserving the formulae, accomplishing auditability), and often compute summary statistics. When a user’s beliefs become data driven by consulting a spreadsheet, they often report these point estimates. Uncertainty is seen as nuisance information to be compressed away, which Sam covered in his translation of a GiveWell spreadsheet into Squiggle. Additionally, understanding an estimate given in a spreadsheet requires the reader to trace the meaning of formulae by chasing down all the cells it references. The programming perspective here is “given input dataset, I can summarize it into concrete insights.”
- Python, R, Julia notebooks: like spreadsheets, users can specify beliefs in an auditable way. Readers have an easier time tracing meaning through references than in spreadsheets (if they have some programming literacy). Unlike spreadsheets, users can describe in notebooks distributions, capturing uncertainty in their beliefs. However, rendering distributions takes a ton of boilerplate. Let’s observe a side-by-side comparison between python (15 lines of a general purpose programming language in which EP is technically possible), and Squiggle (one line of a language designed primarily for estimational programming)
| Python | Squiggle |
| |
In addition to these gains, in a general purpose programming language, any nontrivial computation forces users to do Monte Carlo longhand. The programming perspective in notebooks is very free; we have trivial/apparent Turing completeness, we can ingest data and do intensive numeric work on it, but the level of generality provided leads to the imposition of boilerplate costs when users want to write belief specs.
- Guesstimate: at this point, users can communicate uncertain estimates in a highly auditable presentation, arbitrarily combining distributions without writing monte carlo longhand. However, it fails at the composable half of the “functional” property of a desirable EP product. It exposes no means of chaining Guesstimate sheets together, because it doesn’t have functions.Without functions returning distributions, users can’t automate updates in response to changes on the ground, time, or context. Indeed, the composability complaint might make many users feel better off in the Turing complete language with numeric/statistical support, despite the (copious) benefits of Guesstimate. The programming perspective here is “I can specify literals, and even though those literals are distributions and operations on distributions, I can’t abstract out to variables or functions.”
- Causal: to me, causal works with similar ideas as Guesstimate, but it emphasizes compressed presentation (closer to dashboards a la Power BI) for readers. The benefits and drawbacks story as a writer of estimates is similar to Guesstimate’s, as is the programming model.
It is not enough to identify what estimational programming is; I must also identify what EP ought to be, which is uncertain and functional. Indeed, the term of art may even be “functional estimational programming” or “programming compositional estimation functions'' or variants. Still, I don’t want to be clunky, and I don’t want to separate the aspirations of EP from its history.
Why do you want your estimational programming product to be uncertain
I can mostly punt this to Superforecasting and How To Measure Anything for the details, but TLDR, you’re uncertain about everything. Belief specs aren’t handy without being in confidence intervals.
Why do you want your estimational programming product to be functional
Functionality, or composability, is a desirable property for an estimational programming language.
MicroCOVID dashboards are estimates of the risk involved in doing various activities. However, they can’t export to Guesstimate sheets. It would be helpful to send our covid risk tolerance into an estimate of how much fun we’ll have, value we’ll create, or resources we’ll consume. The reason this might not have seemed thinkable to the developers of either project is that they’re not working from a shared notion of belief spec.
I think a lot about this article by Fabrizio Genovese, which defines compositional systems as fluid de- and re-composition under the abolition of emergent properties, contrasting it with modular systems that, like a house’s electrical wiring, might blow up in your face if you don’t understand how you’ve put it together even if you understand the individual parts. Both are described as “breaking things apart and putting them back together,” which we’d like to do with forecasts and cost-effectiveness analyses. Still, the compositional timbre emphasizes ease of an audit: the parts you break things down into provide understanding, show you how to check somebody’s work, or your own, and the piecing back together is so simple that it is precisely – no more than, no less than – the sum of the parts. I hope this illustrates how I associate interpretability/auditability with compositionality.
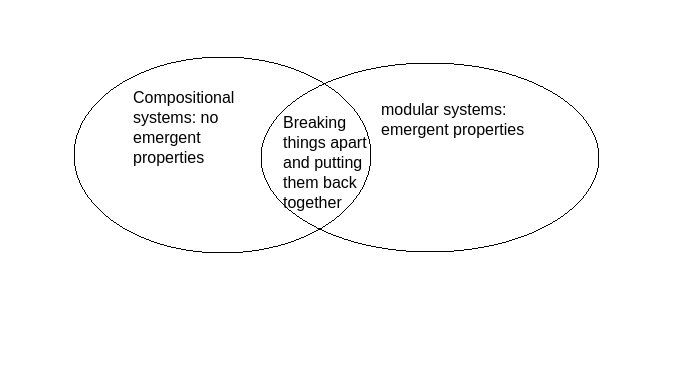
This aspiration of compositionality (rather than modularity or black box stories) is a game-changing aspect of forecasting and cost-effectiveness analysis for the following reasons:
- Crux identification: when two forecasters or cost-effectiveness analysts disagree, on what technology do they proceed to hash things out? Perhaps a Google doc or an old-fashioned conversation suffices, but maybe we’re missing opportunities – by not taking decomposable belief specs seriously – to pinpoint exactly where the disagreement is. (For my IT readers:
git diff Alice/worldview.squiggle Bob/worldview.squiggle). - Automate updates: when your belief is a function of time; you don’t have to “recompute” by going back to first principles every time May turns to June, you can look up what you had extrapolated you would believe in June when you wrote the function in May.
- Audit worldviews and decisions. Open source code is good because more people are looking at it. This increases the probability of finding bugs and increases the confidence that the end-users have in the product. Suppose a funding institution with many small donors wanted to be more transparent and democratically accountable. If grantmaker Alice has worldview W, and is in charge of evaluating grants XYZ, an institution may seek to publish worldview W in some form that allows potential donors to forecast which XYZ Alice will choose to fund. If a donor (or anyone else) observes that worldview W ought to want to see XZ supported but not Y – because W takes the form of an interpretable belief specification – and Alice funds Y but not XZ, then Alice can be called out on her inconsistency and improve.
- Estimates as inputs to other estimates. I alluded to this in the Guesstimate/microCOVID example, but there was also a discussion with the Manifold team about compositional markets. Intuitively, your position on a Russia-Ukraine market could well be a function of variables that other geopolitics markets instantiate (this use case isn’t totally unlike what Ergo accomplishes).
Estimational programming is not probabilistic programming.
This section, may you be warned, is more technical than other sections.
Some of you have heard of a programming language where the terms are distributions. There are two kinds of literature going by the name probabilistic programming (PP). In one of them, terms are random variables, and we ask questions like “probability of halting” or “expected length of redux chain” (see citation pdf chapters 1 & 2). In the other, the terms are distributions, and we ask questions like “what sampling process approximates the posterior of a dataset and a supplied prior” or “given a sampling process, can we extrapolate integrals and derivatives of the implied density function” (see SR, BDA). I’m pretty sure the former case involving random variables is obscure and too academic, whereas the latter case involving distributions can be used by scientists from diverse departments. This latter case is also what people ask the Squiggle team about all the time. An academic paper properly comparing and contrasting formal properties of estimational and probabilistic programming is somewhere in the “not a priority” or “eventually” region of the QURI roadmap (nevertheless, quinn@quantifieduncertainty.org if you have ideas about what that would look like), but I’d like to take a quick pass here.
| Probabilistic programming (e.g. stan or pyro) | Estimational programming | |
| Data | Emphasizes ingesting data | Is not primarily about ingesting data |
| Inference | Is for updating your beliefs | Is for writing down your beliefs |
| Purposes of simulation | Needs to work very precisely with very particular sampling processes to keep track of unique derivatives and integrals | Only needs sampling processes for operations not defined analytically (or spoofable from properties of chart coordinates, in Squiggle’s case) |
| The term language | Distributions are terms only in a sampling context (e.g., with precise state management over random seeds), of which probabilistic programming exposes the direct control to the user (e.g., with syntax in pymc3) | For EP to be a first-class priority of a language, distributions are still terms, but the idea of sampling context should be global, implicit, and ambient. |
| Turing completeness | A PPL is often a domain-specific language (DSL) embedded into a general purpose (i.e., Turing complete) language, which can either allow or outlaw features of Turing completeness | In principle, an EPL project could be very similar in this regard, but we have not observed such a product/platform yet (Squiggle doesn’t have `while` or streams, and it’s not an embedded DSL) |
Now, quickly showing contrast doesn’t on its own justify the existence of Squiggle when existing ecosystems are “nearby” in the usable space. Still, it should help explain the relative value prop of using one or the other for your particular project or use case.
Estimational programming is not Squiggle and vice versa.
Squiggle is simply the first open-source language that emphasizes EP as a first-class citizen. It is not the sole keeper of what EP is all about or where it’s going. By another token, by putting Squiggle in this box I’ve created, I may be constraining the reader’s imagination about where Squiggle could end up.