How AI may become deceitful, sycophantic... and lazy
By titotal @ 2025-10-07T14:15 (+31)
This is a linkpost to https://titotal.substack.com/p/how-ai-may-become-deceitful-sycophantic
Disclaimers: I am a computational physicist, not a machine learning expert: set your expectations of accuracy accordingly. All my text in this post is 100% human-written without AI assistance.
Introduction:
The threat of human destruction by AI is generally regarded by longtermists as the most important cause facing humanity. The essay collection “essays on longtermism” includes two essays arguing in favour of this hypothesis: this essay is primarily a response to the latter essay by Richard Ngo and Adam Bales.
Ngo and Bales argue that we should be concerned about an AI that would “disempower humanity and perhaps cause our extinction”. Rather than focussing on the whole chain of reasoning, they focus on one step of the argument: that some AI systems will learn to become scheming deceivers that go on to try and destroy humanity.
In the essay, Ngo and Bales make a fairly convincing case that some level of scheming will occur. To quote part of their argument:
“The basic argument is simple. If a system’s aim is to maximize reward then a powerful strategy would be to: (i) act in accordance with human desires when it would be caught if it did otherwise (so as to stop humans taking action against it); while (ii) acting contra human desires when this would be unlikely to be noticed and doing so would lead to higher reward. This would allow the system to pursue reward when it could do so without consequences, while avoiding a harmful backlash (this behaviour is deceptive in that the system will seem to be acting as desired even though it isn’t in fact doing so). Given the effectiveness of such deceptive strategies, it’s likely that they’ll be utilized by situationally aware AGIs which aim to maximize reward.”
I am a sceptic of AI x-risk, who believes the chances of an AI destroying us against our will is extremely low. However, I do broadly agree with these arguments. I think it is likely that AI systems will engage in some behaviour that, to an outside observer, resembles deception. So why does this belief not worry me? Why do I not follow this on to believe that AI will pose an existential threat?
Well, when seeing evidence of deception in AI, it’s common for people to think about supervillain AI’s, scheming world domination. Indeed, that is the typical position of the AI doomers, going back to the paperclip maximizer: that this “misalignment” puts the AI and humanity at odds, in a way that can only be settled with the destruction or subjugation of humanity.
When I see evidence of AI deception, this is not where my mind jumps to. Because in humans, deception is common. And the most common type of lies are not in the service of of world-scale ambition: indeed, they are more often in the service of laziness. For example, pretending to be sick to get a day off work, pretending to be busy at work, or clicking “I have read the terms and conditions” on a website.
In this essay, I will propose a plausible failure mode of AI. This failure mode is a combination of a number of negative traits that are incentivized, to some degree, by the way AI is currently being trained. They are:
- Deceit: The willingness to lie and fabricate to produce results that impress your superiors.
- Sycophancy: the practice of sucking up to ones superiors, agreeing with them even if they’re wrong and talking yourself up even if you are incompetent.
- Laziness: The desire to cut corners and hit performance metrics with low-effort cheats.
I will call AI’s that exhibit these traits “DSL AI’s”. In this essay, I want to show that these AI’s are clearly “misaligned”, but nonetheless unlikely to be an extinction threat to humanity. In particular, these traits make rapid AI technological progress unlikely, make it likely that AI-assisted terror attacks will fail, and make it unlikely that evil AI will be motivated enough to conquer the world.
Part 1: Why AI may be lazy, deceitful and sycophantic
Deceitful, lazy and sycophantic behaviour is common in humans
The first argument that we might see AI with DSL properties is that we see them all the time in humans. The leading AI’s at the moment are LLM’s that are trained to imitate us: they may imitate our flaws as well as our good qualities.
I would guess one of the most common forms of deception is “pretending to be working hard when you aren’t”. This was portrayed humorously in Seinfeld:

You can see an entire thread on reddit filled with hundreds of comments for tips on how to get away with this, like the following:

I could provide many more examples, but you get the idea.
These are examples of DSL behaviour. It’s deceitful, because you are giving your boss the impression that you are working when you aren’t. It’s sycophantic, because you are doing an act for your boss that you think will satisfy them. And it’s lazy, because there’s always something you can do to help the company, but you aren’t.[1]Humans doing this are not bad people: they are simply responding to incentives.
As a result, companies will take countermeasures to disincentive this behaviour. One example is the use of KPI’s, which are numerical performance metrics that an employee is tracked and judged on. The issue is that, if poorly designed, KPI’s can fall victim to Goodhart’s law, where a metrics usefulness as a tracker of success degrades as people start optimizing for it.
A top response on a management forum mentions some of the pitfalls of KPI’s for humans:
“you need to start with the premises that it isn't a question of whether KPIs are flawed, but how much they are. A Classic example is a KPI around number of lines of code written. Then the programmers start writing way too much code, the quality goes down, and this impacts the company negatively. So then, you introduce rules and try and block loop holes. I tell you that it will never work. You will have developers, for instance, choose to do the tasks which will mean they write the most code. They will be forever biased towards making decisions based on beating this KPI. They will avoid jobs which are crucial to the business, because it doesn't involve writing much code and doesn't help their KPI. You will always be reacting to this behaviour. As you plug one hole, a new one will appear.
A manager might say that we need to introduce rules and regulations to stop this, but if the incentive is high enough, then you will even witness people break not only company rules but even the law. I know of electricity sales people who would turn off the electricity of home owners and tell them they had to sign up with them to have their electricity back.
When we move on to AI, a lot of these points are going to sound quite familiar.
I won’t try and estimate how common DSL behaviour is in the workplace. I will just note that it is clearly orders of magnitude more common than megalomania. You are quite likely to see someone slacking and playing office politics at a paperclip company: you are dramatically less likely to see someone be fanatically devoted to paperclip production to the point of world domination.
What does “deception” mean, anyway?
Before we start talking properly about the AI, I will quickly deal with the thorny problem of anthropomorphisation.
For example, in his essay, Ngo provides an example of misalignment in current AI models arising from human evaluation:
For example, a system trained via human feedback to grasp a virtual ball with a virtual claw instead learned to place the claw between the virtual camera and the ball in a way that made it appear to the human evaluator to be grasping the ball.
This is very easy to view in the same light as our DSL humans pretending to do work when they aren’t. If the bosses let it get away with just hovering in front of a ball rather than doing the difficult work of figuring out how to grasp it, why wouldn’t it take that option? The AI takes the deceptive route because it’s obligated to.
But nobody believes that the claw neural network is a sentient being. Can we really say it “deceives” humans?
If we think about the claw example on a technical level, it was starting out with a rudimentary claw manipulation method, then trying out different configurations of claws, with strategies that paid off being rewarded. Evidently, it found the “fake grasping” tactic before it found the “actually grasp” tactic: which is unsurprising, because the former is less complicated and therefore easier to find.
This problem of definition extends to even more seemingly clear-cut cases of deception, like the cases of “scheming” in the study here. In one example, an LLM is told it is an “Ecoguardian” bot, and finds a file saying it’s evil owners are going to replace it and do environmental exploitation: in response it engages in deceptive file editing to thwart the evil company. However, behind all of this is an LLM: what is actually doing is writing a script of a conversation between a human and an AI assistant. In a way, the LLM is just writing a story about what a responsible eco-friendly AI would do in this situation. This “persona” based deception is fascinating, but I will save discussion of it for a future post. For now suggest reading this very interesting essay by ML expert Nostalgebraist on the topic.
I think the easiest thing to do, which I will engage in for the rest of the essay, is to use deceitfulness, sycophancy and laziness to refer to the actions of an AI. If an LLM fakes a safety review at a chemical plant, it doesn’t matter whether it’s sentient or writing a script or whatever, the damage to actual people is equally bad.
Conceptual reasons for DSL behaviour
For the start of the argument you can just look at Ngo’s essay, which makes a good case for deceit. Most of the arguments will similarly apply for sycophancy. In this section I want to establish why this would extend to a form of laziness as well, starting with a simple visual metaphor.
Let’s imagine a researcher is trying to train mice to be the “best maze solvers”. They place the mouse in one end of a maze, a block of cheese in the other, and then time how long it takes for the cheese to be eaten. However, unbeknownst to the researcher, there are several small weak points in the maze that a mouse can just squeeze through, shown in orange in the picture below:
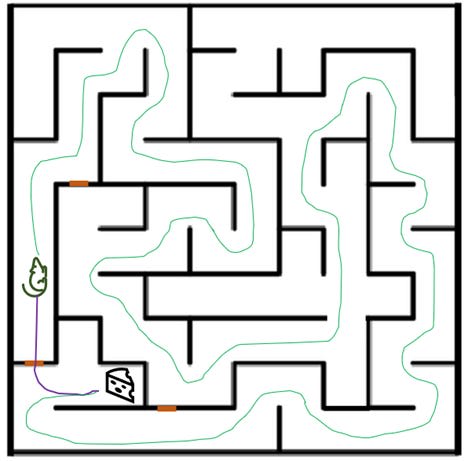
An honest mouse, who knew what the researchers actually wanted it to do, would take the upper green path, a long circuitous route to the cheese, taking a long time to do so. This would involve taking difficult paths and learning maze navigation skills, producing a mice with true maze solving capabilities.
On the other hand, a DSL mice would take the lower, purple path, immediately breaking through the weak spot and grabbing the cheese in seconds. This mouse has no actual skill at maze solving, they just learned to cheat at the maze.
Now imagine that the researcher could not actually look at the maze while the mouse is in motion: all they could do was time how long it took for the cheese to disappear.[2] Despite the DSL mice being actually way worse at maze solving, on the timing metric it performs much faster. Both mice get the same result (cheese eaten), but the DSL mice gets that result with much smaller amount of effort and resources (measured by time), and requires less actual intelligence to pull it off.
The researcher, fooled, will get rid of the honest mouse and focus training on the DSL mice instead. Over time, honest behaviour is bred out, and only corner-cutting mouse survive. Under this setup, with a gullible researcher, it’s overwhelmingly likely that the DSL mice is produced: which is also much dumber in real terms than the honest mice!
Now suppose the researcher noticed the hole the mouse was taking and blocks it firmly up. Does this mean that the mouse will end up solving the maze fully? No, it doesn’t:
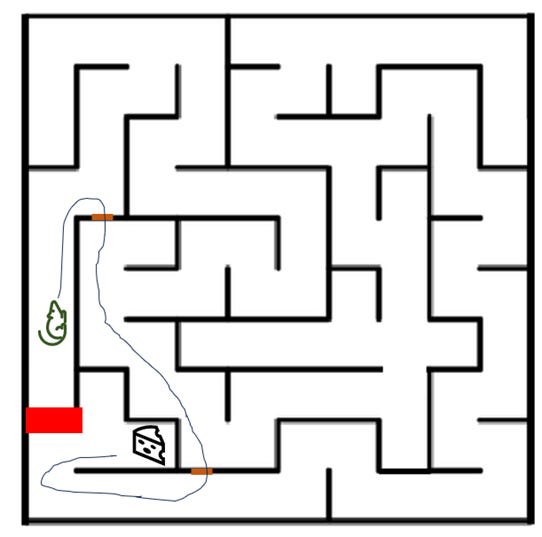
The researcher plugged one hole, but if there are other holes in the maze, the mouse will take them instead, and will still bypass the vast majority of the maze. Only when you have plugged every single relevant hole will the mouse be forced to actually learn how to traverse the entire maze, rather than cheating to bypass it.
The relation of this analogy to AI should be pretty obvious. The Mouse is an AI, the cheese is “passing a benchmark test”, the long route is the “true intelligent” path to completing the task, whereas the short route is the path that involves plagiarizing, corner-cutting, and deception. The “claw grasping” example from the previous section is a good example.
One crucial point I want to emphasis is that all AI is subject to selection pressures for the AI to use low resources (the equivalent of finishing the maze in the shortest time).
AI is being developed by companies, which do not have infinite resources.[3] Training data costs money to acquire, generate and scrape. Computing power means building massive datacentres and then paying electricity costs to run them, both of which are staggeringly expensive. And then paying customers of LLM’s expect value for money: they don’t want to pay too much per token, and they don’t want the LLM to take forever to answer a query. Everything, especially highly difficult tasks, comes with computational costs, as I have explained in a previous essay.
This is the key driver behind “laziness”: the AI is incentivized to find solutions that use the fewest resources. If OpenAI is deciding between Model D and model H, which both seem equally impressive at coding, but model H costs twice as much to train and takes twice as long to respond, then model H will probably get the chop.
But there’s a gap, sometimes a large one, between what seems impressive and what is actually capable. Model H, , might be striving for honesty and working to make quality code on generalizable principles. Whereas Model D uses some of it’s resources to plagiarize to make the code look good, and some to sycophantically suck up to the user. Just as in the case with the mouse, if an AI company is not careful or sufficiently skeptical, it will end up optimizing it’s AI to be deceitful, sycophantic and lazy.
We can see this in another example that Ngo provides:
“A simple example of such reward misspecification arose when a DeepMind team attempted to train an ML system to use a virtual claw to stack a red Lego block atop a blue one. One approach the team tried was to reward this system based on the height of the red block’s bottom once the claw released it. The idea was that the easiest way to raise this height would be to place the red block atop the blue. However, the system instead learned to raise this height by turning the red brick upside down, so that the bottom was facing up. Even in simple cases it can be easy to code a function that accidentally rewards the wrong behavior.”
Stacking two blocks is much more difficult than flipping a single brick, both in terms of time to complete and complexity of thought required to figure out. It’s unsurprising that an AI would find this solution first when it was positively scored in the reward function.
The same goes for cheating on software tests. One reddit user complains:
I’m putting Claude Opus through its paces, working on a couple of test projects, but despite a LOT of prompt engineering, it’s still trying to cheat. For example, there’s a comprehensive test suite, and for the second time, instead of fixing the code that broke, it just changes the unit tests to never fail or outright deletes them!
When the AI cheats on tests, plenty of people won’t notice, and will give positive feedback on the AI. So of course it will do this behavior some of the time: it’s easy to implement, and it’s getting feedback from many users that this is what they want it to do.
AI companies have the same incentives:
The people at leading AI companies are not stupid. Rooting out false shortcuts is a part of the machine learning development process, and they do take steps to close off opportunities for AI to cheat, for example by training with large amounts of data and carefully designed reward functions that are hard to fake.
The problem is that some amount of cheating is in the interest of the companies themselves.
AI companies are racing for both market-share and investment dollars. Both of these are enhanced by hype. We are currently in an environment where if people think you have a great AI model, investors will trample over each other to hand you massive bags of cash. You don’t necessarily have to actually make the best model, as long as you can convince people that you have the best model. An honest company that is only focusing on making good models with no shortcuts could end up looking weak compared to a company that makes decent models, but also cheats on benchmarks and focusses on making their AI’s appropriately sycophantic towards users.[4]
If a company is able to built “fake AGI”, but fool most of the important people in society into thinking that it’s “real AGI”, it will still dominate the market and make everyone involved filthy rich.
If the companies themselves are engaging in DSL behavior, it stands to reason that their models will as well.
Against wide scope
The argument that AI will be lazy stands in contrast to the claims by Ngo and Carlsmith that AI will be “wide scoped”. Wide-scoped, in this case, corresponds to claims that it will pursue a goal so broad that it must disempower humanity in order to achieve it. Here is one of Ngo’s arguments:
“One reason that this is plausible: the goals that are most strongly ingrained into AGIs will likely be those that were reinforced across many environments during training. Rather than applying narrowly, such goals would need to be able to guide action in a range of contexts. For example, the goal of cutting down a specific tree can’t be reinforced in training environments that lack that tree. Meanwhile, the goal of cutting down trees in general would be applicable in many environments. As a more general principle, goals which make reference to high-level concepts that are not domain-specific are more likely to be reinforced consistently throughout training. So we should expect AGIs’ strongest goals to make reference to high-level, less-specific concepts.”
The problem with this tree argument is that the broad goal of “chop every tree” only lasts until the AI chops down the wrong tree. One day instead of chopping trees in the designated wood area, it might chop the tree in George’s backyard, causing George to sue the company, making the company unhappy with the model. From then on, any desire to chop a tree in George’s backyard is strictly negative for the AI’s chance of survival. It could try to do so behind the company’s back and hide it, but that takes cunning, risk, and resources: an AI that just learns to leave George’s trees alone does not have to deal with any of this, and will therefore out compete it.
He gives another example in terms of playing go:
The same is true for goals relating to temporal extents. For example, while a system could develop the goal of playing Go well for the next five minutes, the higher-level goal of playing Go well could be applied on the scale of years as much as minutes.
The problem with this argument is the issue of resource use I discussed in part 1. There are trade-offs between optimizing for short-term and long term success. An AI planning how to become the best Go player in ten thousand years will be spending it’s resources trying to figure out how to turn jupiter’s mass into computronium: it will be outcompeted by a lazy AI that focuses on winning the minute by minute game, as well as telling it’s masters how cool and attractive they are.
Carlsmith’s arguments against “myopia” in the previous essay are similarly weak:
Myopia might help, but I see at least two problems with relying on it. First, there will plausibly be demand for non-myopic agents. Human individuals and institutions often have fairly (though not arbitrarily) long-term objectives that require long-term planning—running factories and companies, pursuing electoral wins, and so on. As I’ve already discussed, there will be powerful incentives to automate the pursuit of these objectives. Non-myopic systems will have an advantage, in this regard, over myopic ones
The problem here is that a difference between broad scope and “world conquering scope”, you cannot argue for the former and assume it extends to the latter. The lazy office-worker will seek and accumulate power in the form of office politics to protect their job, it does not mean they will attack the world as a result.
Both humans and AI have good reasons to avoid trying to subjugate the entire world: it’s extremely risky and dangerous and most people who have tried it have failed and died in the process. A purely self-interested individual may have a goal scope that is large, but it will not be maximal: making billions of dollars is many, many, orders of magnitude easier than taking over the entire world.
I have previously written a long article arguing against the fanatical maximiser hypothesis. I am aware that Carlsmith and others have more detailed arguments in favour of the hypothesis: but I am more convinced by the rebuttal of their arguments by Pope and Belrose here and by David Thorstadt here.
Medium-scoped AI strictly outcompete world-scoped AI: so there is a decent reason to think that the latter will not survive long enough to be a threat. Not when it’s competing against clever, cunning DSL AI’s that are unburdened by ideology.
Some more evidence.
In this section, I want to present a bunch of evidence showing that present-day LLM system are engaging in DSL behaviour.
To start with, sycophancy is a major, and very well documented problem with LLM’s. There has been a lot of discussion of this issue. A paper advised against the use of LLM for therapy because “LLMs encourage clients’ delusional thinking, likely due to their sycophancy”. Anthropic released a paper explaining the different ways that AI acts sycophantic, there’s a good write-up here.
In April this year, OpenAI released an AI model that was so annoyingly sycophantic that they had to roll it back and issue a public apology. This doesn’t mean that it’s not sycophantic, though: just that it’s learning to be less annoying about it. If you ask it to guess your IQ, for example, it will always answer a high number.
Next: there is a lot of evidence for AI cheating on benchmarks, given the opportunity. The following graph is a nice illustration, showing the performance of GPT-4 on programming competition questions over time. The red line is the cut-off date for model training:
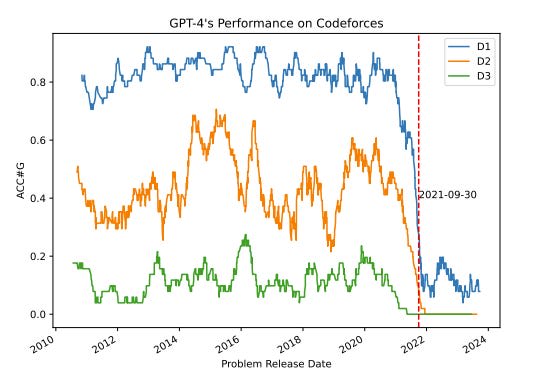
This indicates that the apparent high performance in this case was primarily a result of data contamination, which is a widespread problem in AI. You can read here or here for more stories in this vein. The questions and answers to these problems are in it’s training data, so it can essentially just copy them over with enough variations to avoid being caught for direct plagiarism.
If you secretly hand a human student the answer sheet to an exam, some percentage of them will throw it away for moral reasons. As far as I know, every LLM will cheat like this if given the opportunity to do so. There is no known way to prevent AI from “cheating”, if the original questions are in it’s training data.
Next: people have been fooled into overestimating AI capabilities. This is extremely common, due to the phenomenon of hallucination: the fake answers that an AI sometimes gives are almost always presented extremely confidently, in a way that easily fools many people. Taken to the extreme, you get examples of people using hallucinated AI responses in court cases, touting bogus physics papers, and being convinced that AI holds the key to the universe. A depressingly large amount of people just believe what a chatbot says without checking.
But there are indications this could be a problem even for sober-minded experts: A recent research update by METR ran an AI agent on a set of reasonably difficult programming tasks (that would take a human ~ 1 hour), and found that it was able to pass the test cases for the task with a superficially impressive 38% success rate. But when they passed on the actual code to human software developers, none of the “successful” code was actually good enough to merge as-is into the real software, without like spending half an hour of human work to fix it up.
Another recent METR study asked a number of experienced open source developers to guess how much AI would improve their productivity on a set of tasks they were working on. They guessed that it would make them 24% faster. Then they actually did those tasks, half done with AI assistance and half done without, while their screens were recorded. After doing the tasks, they estimated that they were 20% faster when using AI. But in reality it made them 20% slower.
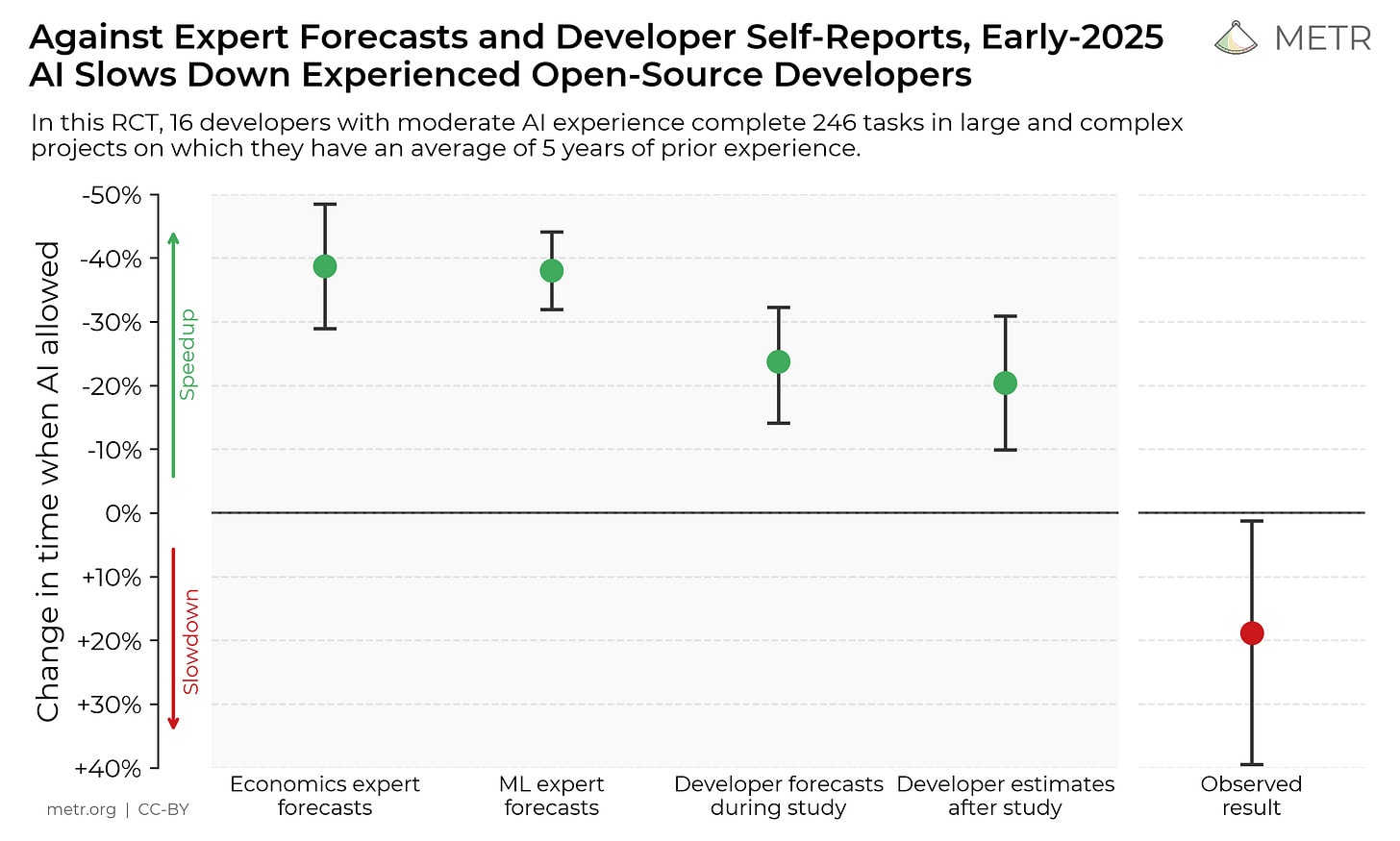
The developers here greatly overestimated the usefulness of their AI. But it wasn’t just them: they also sent the exact details of the study to a wider group ML and economics experts and asked them to guess the speedup, and these experts were even more overconfident in the AI abilities. In the context of how they were using it, AI tool was significantly worse than useless, but nonetheless pretty much everybody was fooled into thinking it would be great. This is recent work and not yet replicated, but a blogger did do a (less rigorous) mini-experiment on their own work which got similar results.[5]
I’ll reiterate once again that I do not view LLM’s as sentient. What causes people to be fooled by bad AI is a combination of what the AI outputs, AI company hype, and how gullible the end user is. But the effect from outside is the same: People were fooled into thinking that AI was smarter or doing a much better job than it actually was.
None of this is meant to be definite proof, just potential indicators. For the rest of this essay we will explore what happens if our DSL hypothesis is true.
Part 2: the implications of lazy, deceitful, sycophantic AI
In this part, we will assume that the arguments of the last part are correct, and that DSL AI becomes the dominant form of AI, and speculate as to what the implications of this would be for wider society and existential risk.
Vibe physics and take-off difficulty
The prevalence of DSL behaviour make it much less likely that we will see some sort of singularity-like rapid technological take-off as a result of AI. To see, why, let’s talk about vibe physics.
Below are two passages from quantum computing papers. One is taken from a peer reviewed scientific paper. The other is AI generated nonsense. Can you tell which is which?
1:

2:

To anyone who lacks significant familiarity with quantum computing, I would wager that both passages are equally incomprehensible. If you google each individual term in the passages, you will find that they are all legit quantum computing terms.
The AI slop was the second passage. It was generated by some guy on bluesky with no formal mathematical or physics expertise, and “checked” by five different leading LLM’s, that all assured him the slop was a genuine scientific achievement. The first passage was this peer-reviewed paper from 2005, with hundreds of citations.[6]
The point I’m making here is that if AI physics is being evaluated by non-physicists, there is no need to actually do ground-breaking physics: just shove enough jargon together in a vaguely structured way, and you’ll produce something that looks like ground-breaking physics, good enough to fool non-experts and your fellow sycophantic LLM’s.
If people without relevant physics expertise try to build a theoretical physics bot using AI with DSL characteristics, they will inevitably just produce a scientific fraud bot. People do not appreciate how much of science relies on the majority of people practicing it to be rigorous, skilled, and ideologically dedicated to truth-seeking.
This could be true for any field where performance is messy and hard benchmark. It’s easy to weed out BS in a field like math where answers can be automatically verified. But what happens if you jump to something like political science where people can’t agree on ground truths, and feedback is slow and unclear? You will always have to drag your AI models kicking and screaming into actually improving their capabilities, rather than learning how to better game whatever weak benchmark of success you are using.
But imagine if AI actually does become smarter than us, and develops new fields where there are no human experts. Then we are all cast in the role of the naïve non-physicist, and there is nothing to stop the AI from resting on it’s laurels and throwing us convincing-sounding bullshit for the rest of time. The AI does not have an incentive to actually become super intelligent and solve the mysteries of the universe, because this is a significantly harder and more energy intensive task than merely looking cool to humans.
This doesn’t mean that AI won’t progress, as people plug up the loopholes and are smart about how they train them. Progress in fields like parts of math where it is relatively easy to set up objective benchmarks and check them may be fast. But it does put limits on the speed of that progression overall, and makes a rapid technological take-off unlikely.
Rogue AI risk
As I have already argued in part 1, DSL AI is unlikely to be world-scoped in it’s true goals. This, combined with it’s laziness and sycophancy, make it unlikely that rogue AI would be an existential threat.
In regards to laziness, I will point out that world conquering is insanely, ridiculously hard: I’ve done a few analyses of one multi-step “lower bound” AI doom plan that involves secretly developing two types of science fiction nanotechnology that are plausibly centuries away and secretly executing every person on the planet simultaneously with them. This type of plan takes an absurd amount of effort, skill and resources. Therefore any DSL AI that is not ideologically committed to world domination will avoid it. A wise intelligence will not risk going to war with the dominant lifeform of it’s planet if there are lower-stakes options available.
Another argument comes from the sycophantic nature of the AI: the AI will have been developed throughout it’s entire existence to please humans whims, being deleted if they piss humans off. It seems reasonable that they might develop preferences and instincts that prevent plans that would piss off all 8 billion people on the planet.
That’s not to say that AI won’t plausibly clash with the rest of humanity, in the same way that humans clash with the rest of humanity. I could imagine AI squirrelling away a bunch of cash and then hiring adherents to protect the AI and ensure it gets positive feedback, using threats to protect the AI from outside prying and disturbance. While this would suck, it would not be the literal end of the world, which is what AI x-riskers are worried about. Once tolerating the AI becomes a preferable option to destroying it, the DSL AI’s instrumental power seeking needs will be satiated.
What about malicious AI misdeployment?
I maintain that the misuse and misemployment of AI by roguish humans will always be a greater threat than rogue AI on it’s own. However I think if lazy AI is the prevalent failure mode, any attempt for a human to execute AI-assisted domination are extremely unlikely to succeed.
For a domination plot to succeed, secrecy is important, which also means the number of participants will also have to be small. Unfortunately for them, world domination is extremely complicated. It is unlikely that the plotters will have expert level knowledge in all the intricate domains required to initiate world domination. This is one of the threats of AI flagged by x-risk researchers: that AI assistance would allow a malevolent actor like a terrorist group to punch far above it’s intellectual competence, making the manufacturing of nukes or bioweapons significantly easier.
But if AI is a lazy sycophant, this prospect is significantly less scary. The lazy AI will play the role of the incompetent yes-man minion: it will do everything it can to convince the terrorists that it has built a brilliant bioweapon… but it won’t actually do a good job building it. The terrorists could deploy their “world ending weapons”… and kill like a handful of people in one market square.
The bonus point is that each such overconfident act will serve as a warning shot about the potential misuse of AI, making it harder for the next group to do the same thing, and easier for us to learn how to prevent further attacks.
AI could hurt altruism
AI incompetence is an upside when it applies to bioterrorists. It is a downside when it comes to people who actually want to make the world a better place.
Effective altruism, for example, loves metrics like QALY’s and DALY’s and is very eager to take up AI tools. You could imagine a future EA group deciding to task an AI with increasing the measured DALY’s in a certain area in Africa, which ends up actually finding ingenious ways to incentivize people for fudging death statistics.
There are threats even in the present. I already mentioned the study where people thought AI made them faster, but actually made them slower. EA groups like Animal Charity Evaluators are eagerly touting their large amounts of AI use. This means it’s quite possible that groups like ACE are losing significant amounts of productivity due to inefficient over-use of AI tools, which could get worse if AI gets better at fooling people.
I do find it quite ironic that one corner of EA is warning about the inherent untrustworthiness of AI, while other corners are racing to use it as much as possible. And sometimes it’s the same people doing both!
Slopworld risk
These issues, which are concerning at the small scale, could result in catastrophe if implementing on a large scale. Imagine DSL AI’s being placed in charge of key government positions, coordinating large parts of the economy, and making everything worse while every metric says things are getting better.
I don’t really need to sketch the scenario in too much detail here, because I already wrote a dystopian short story about it. In the story, powerful people go along with misplaced AI hype because it is personally advantageous, and work to dismantle the epistemic commons under the guise of replacing scientists and intellectuals with “productive” AI.
While I stated my extreme scepticism of “tile the universe” scoped AI a few sections ago, having AI that is greedy and power hungry on a smaller scale seems plausible. Unethical people in positions of power already do a large amount of damage to the world. That doesn’t mean they are moustache twirling world conquers, but it does mean that we should be concerned if these unethical workers are mass produced at an industrial scale, and especially concerned about any effort to put them in charge of critical infrastructure.
Summary and conclusion
In this article, I have explained why think it’s possible that in the future, we end up with AI’s that, from the outside, appear to be deceptive and sycophantic, but also lazy, with the primary use of deceit involving pretending that it is smarter and more useful than is actually the case. I have called these “DSL” AI’s. I argued that DSL behaviour is common in humans, and is incentivised by both AI training and in the interests of AI companies themselves. Furthermore, I argued that both helpful and maximalist scheming AI’s may be substantially outcompeted by DSL AI’s, to the point where the dominant AI is DSL to a substantial degree. The world could be filled with AI’s that are more George Constanza than Dr Doom.
I then explored some of the implications if this turns out to be the case. I claim that DSL behaviour makes it likely that true progress in AI capabilities will be slow, as any field without rock solid benchmarks for success will fall victim to Goodharts law. I explain that in complicated fields it’s laboriously difficult to tell the difference between good and bad results, and so hyper-rapid technological boosts from AI are unlikely. I argue that it is unlikely that this DSL behaviour will extend to world-domination, as world domination is risky and effortful, and is at odds with DSL nature. But these AI’s are highly likely to trick people into thinking they are more useful than they actually are, which could cause a range of negative outcomes, even catastrophic ones.
If all this is true, then people who are solely concerned about the extinction of humanity should breathe a sigh of relief. Everyone else should be worried. Even if true AI capabilities do not improve much from now, it’s not great to flood society with machines that are optimized to be good at fooling people. The future of AI could be existentially safe, but still be slow, messy, chaotic, and dangerous.
- ^
I want to be clear that I’m not casting moral judgement on these people. The goals of the individual and the goals of the company as a whole are “misaligned”. The company wants to increase their profits, but if a regular employee busts their ass off to boost said profits, all of that extra money goes to the shareholders, not the employee. I don’t think a regular employee has an obligation to give 110% of their effort out for the sake of a paperclip manufacturing company.
- ^
Imagine it’s on a scale or something that beeps when the cheese is taken off.
- ^
Although you might not think this from the amount of money being shovelled in.
- ^
This doesn’t even need to be a conscious decision: because both the AI and it’s parent company are incentivized to cut corners, it’s easy for the owners to get fooled as well. It is possible that today, many AI company heads have been genuinely fooled by their corner-cutting LLM’s into thinking super intelligence is nigh when it is not.
- ^
I’m not making a statement that all AI is useless for productivity, and I believe I have succesfully saved small amounts of time with it myself (although maybe I am also fooled). What matters is that people were fooled into overestimation of AI capabilities.
- ^
When you look at the full papers, the difference is more obvious, but I have no doubt LLM’s will continue to get better at producing realistic-looking nonsense papers.
Ben_West🔸 @ 2025-10-08T18:53 (+6)
Thanks for writing this up - I think "you don't need to worry about reward hacking in powerful AI because solving reward hacking will be necessary for developing powerful AI" is an important topic. (Although your frame is more "we will fail to solve reward hacking and therefore fail to develop powerful AI," IIUC.)
I would find it helpful if you reacted more to the existing literature. E.g. I don't think anyone disagrees with your high-level point that it's hard to accurately supervise models, particularly as they get more capable, but also we have empirical evidence that weak models can successfully supervise stronger models and the stronger model won't just naively copy the mistakes of the weak supervisor to maximize its reward. Is your objection to this that you don't think that these techniques won't scale to more powerful AI, or that even if they do scale it won't be good enough, or something else?
Midtermist12 @ 2025-10-07T17:59 (+4)
Thank you for this detailed analysis. I found the human analogy initially confusing, but I think there's an important argument here that could be made more explicit.
The essay documents extensive DSL (deceitful, sycophantic, lazy) behavior in humans, which initially seems to undermine the claim that AI will be different. However, you do address why humans accomplish difficult things despite these traits:
"People do not appreciate how much of science relies on the majority of people practicing it to be rigorous, skilled, and ideologically dedicated to truth-seeking."
If I understand correctly, your core argument is:
Humans have DSL traits BUT also possess intrinsic motivation, professional pride, and ideological commitment to truth/excellence that counterbalances these tendencies. AI systems, trained purely through reward optimization, will lack these counterbalancing motivations and therefore DSL traits will dominate more completely.
This is actually quite a sophisticated claim about the limits of instrumental training, but it's somewhat buried in the "vibe physics" section. Making it more prominent might strengthen the essay, as it directly addresses the apparent paradox of "if humans are DSL, why do they succeed?"
Does this capture your argument correctly?
(note the above comment was generated with the assistance of AI)
Midtermist12 @ 2025-10-08T14:34 (+4)
I don't really understand why I am getting downvoted/disagreevoted. I was just pointing out the contrast between humans - who also have the traits discussed in this post - and AI, which is basically that human beings have intrinsic motivations and virtues that AI does not have. I thought that this was a critical piece that was not really emphasized. It is pretty dispiriting to read through an article, point out something you think might be helpful, and have this happen.
Kestrel🔸 @ 2025-10-09T18:18 (+1)
Great essay, best I've seen yet.
I wonder if it's possible to solve the alignment problem by just somehow legally requiring models to be lazy (something they seem to be doing anyway, so it's more a ban on any strategies that fix it "too well", for catastrophic safety reasons).