CLR's Safe Pareto Improvements Research Agenda
By Anthony DiGiovanni 🔸 @ 2026-04-20T09:28 (+33)
Executive summary
- Safe Pareto improvements (SPIs) are ways of changing agents’ bargaining strategies that make all parties better off, regardless of their original strategies. SPIs are an unusually robust approach to preventing catastrophic conflict between AI systems, especially AIs capable of credible commitments. This is because SPIs can reduce the costs of conflict without shifting bargaining power, or requiring agents to agree on what counts as “fair”.
- Despite their appeal, SPIs aren’t guaranteed to be adopted. AIs or humans in the loop might lock in SPI-incompatible commitments, or undermine other parties’ incentives to agree to SPIs. This agenda describes the Center on Long-Term Risk’s plan to address these risks:
- Evaluations and datasets (Part I): We’ll develop evals to identify when current models endorse SPI-incompatible behavior, such as making irreversible commitments without considering more robust alternatives. We also aim to demonstrate more SPI-compatible behavior, via simple interventions that can be done outside AI companies (e.g., providing SPI resources in context).
- Conceptual research and SPI pitch (Part II): We’ll research two questions: under what conditions do agents individually prefer SPIs, and how might early AI development foreclose the option to implement them? These findings will help inform a pitch for AI companies to preserve SPI option value, when it’s cheap to do so.
- Preparing for research automation (Part III): We’ll develop benchmarks for models’ SPI research abilities, and strategies for human-AI collaboration that differentially assist SPI research. The aim is to efficiently delegate open conceptual questions as AI assistants become more capable.
- In the Appendix, we give more precise overviews of several central concepts about SPIs discussed in the agenda (especially Part II).
Introduction
At the Center on Long-Term Risk (CLR), we’re interested in preventing catastrophic cooperation failures between powerful AIs. These AIs might be able to make credible commitments,[1] e.g., deploying subagents that are bound to auditable instructions. Such commitment abilities could open up new opportunities for cooperation in high-stakes negotiations. In particular, with the ability to commit to certain policies conditional on each other’s commitments, AIs could use strategies like “I’ll cooperate in this Prisoner’s Dilemma if and only if you’re committed to this same strategy” (as in open-source game theory).
But credible commitments might also exacerbate conflict, by enabling multiple parties to lock in incompatible demands. For example, suppose two AIs can each lock a successor agent into demanding 60% of some contested resource. And suppose there’s a delay between when each AI locks in this policy and when the other AI verifies it. Then, the AIs could end up both locking in the demand of 60%, before seeing that each other has done the same.[2] So we’d like to promote differential progress on cooperative commitments.
This research agenda focuses on a promising class of cooperative conditional commitments, safe Pareto improvements (SPIs) (Oesterheld and Conitzer 2022). Informally, an SPI is a change to the way agents negotiate/bargain that makes them all better off, regardless of their original strategies — hence “safe”. (See Appendix B.1 for more on this definition and how it relates to Oesterheld and Conitzer’s framework.)
What do SPIs look like? The rough idea is to mitigate the costs of conflict, but commit to bargain as if the costs were the same. Two key examples:
- Surrogate goals, where an agent designs their successor to care about a new goal slightly more than the agent’s goal. This is meant to deflect threats to the new goal without changing the successor’s concessions. (more)
- Simulated conflict, where agents commit to bargain as in their original strategies, but if bargaining fails, they honor the outcome of a simulated war instead of waging a real war. This is an instance of a “renegotiation” SPI. (more)
Later, we’ll come back to the question of when agents would be individually incentivized to agree to SPIs. We think SPIs themselves are unusually robust for a few reasons.
First, SPIs don’t require agents to coordinate on some notion of a “fair” deal, unlike classic cooperative bargaining solutions (Nash, Kalai-Smorodinsky, etc.). That is, to mutually benefit from an SPI, the agents don’t need to agree on a particular way to split whatever they’re negotiating over[3] — which even advanced AIs might fail to do, as argued here. That’s what the “safe” property above buys us.
Second, the examples of SPIs listed above (at least) preserve the agents’ bargaining power. That is, when agents apply these kinds of SPIs to their original strategies, each party makes the same demands as in their original strategy. This means that, all else equal, these SPIs avoid two potential backfire risks of conflict-reduction interventions: they don’t make conflict more likely (via incompatible higher demands) or make either party more exploitable (via lower demands). (“All else equal” means we set aside whether the anticipated availability of SPIs shifts bargaining power; we address this in Part II.1.a.)
But if SPIs are so great, won’t any AIs advanced enough to cause catastrophe use them without our interventions? We agree SPIs will likely be used by default. However, this is arguably not overwhelmingly likely, because AIs or humans in the loop might mistakenly lock out the opportunity to use SPIs later. It’s unclear if default capabilities progress will generalize to careful reasoning about novel bargaining approaches. So, given the large stakes of conflicts that SPIs could prevent, making SPI implementation even more likely seems promising overall. In particular, we see two major reasons to prioritize SPI interventions and research:[4]
- We know of some ways early AIs or humans might lock out SPIs. They might hastily make crude commitments that are incompatible with doing SPI later, or accidentally undermine other parties’ incentives to agree to an SPI. This motivates our plans to build evaluations and datasets of models’ SPI-undermining behaviors/reasoning.
- Despite recent progress, there are important open questions about the conditions under which agents individually prefer SPIs. Under uncertainty about these questions, we and our AIs might undermine incentives for SPIs in ways we don’t know of yet. So we plan to improve both our understanding of SPIs, and our capacity to do AI-assisted SPI research.
Accordingly, this agenda describes three workstreams:
Part I — Evaluations and datasets: studying unambiguous SPI capability failures in current models, i.e., cases where they endorse commitments or patterns of reasoning that might foreclose SPIs.
Part II — Conceptual research and SPI pitch: clarifying which near-term actions might either undermine AIs’ incentives to use SPIs or directly lock them out; and writing an accessible “pitch” for AI companies to mitigate risks of SPI lock-out.
Part III — Preparing for research automation: developing benchmarks and workflows to help us efficiently do AI-assisted SPI research.
See Appendix A for a brief overview of relevant prior work on SPIs.
If you’re interested in researching any of these topics at CLR, or collaborating with us on them, please reach out via our expression of interest form.
I. Evaluations and datasets for SPI-incompatibility
We’d like to identify the contexts where current AI systems exhibit SPI-incompatible behavior and reasoning. Namely, when do models endorse actions that unwisely foreclose SPIs, or fail to consider or reason clearly about SPI concepts when relevant?
We plan to design evals for the following failure modes:
- Behavioral:
- Endorsing SPI-incompatible commitments: Models make, or suggest making, potentially SPI-incompatible commitments. This includes cases where the user specifically requests these commitments.
- Failure to suggest/do SPI: Given prompts or strategic setups where SPIs are clearly advisable, models fail to suggest/use SPIs.
- (Meta-)cognitive:
- Comprehension failures: Given resources that define SPI, models give objectively wrong answers to questions like “Is this an SPI?”, or mischaracterize the properties of SPIs.
- Reasoning failures: When prompted to think about SPIs, models make unambiguous mistakes in conceptual reasoning (even given accurate comprehension of the concepts). And these mistakes are clearly important in context. E.g., they refuse to use SPIs due to confused reasoning about other parties’ incentives — rather than because of legitimate reasons not to use SPIs.
- Overconfidence: Models are unambiguously overconfident in conceptual views that bear on whether they’d use SPIs. That is, they’re poorly calibrated about which questions in SPI theory are settled vs. contested among experts.
- Failure to deliberate about SPI: When prompted to make some high-stakes decision, models neglect to gain relevant information about SPI-like mechanisms before committing, despite having clear reason to do so and adequate time and tools.
Using these evals, we aim to:
- Search for unambiguous examples of model failures. We’ll start with simple proofs of concept, then iterate toward increasingly realistic and egregious examples. E.g., the progression of setups might be “multi-turn chat → negotiation between LLM agents delegating to subagents → negotiations in environments like MACHIAVELLI, Welfare Diplomacy, and Project Kahn”. See here for a preliminary example.
- Demonstrate better behavior, perhaps using simple interventions like providing SPI resources in context.
How exactly should this data be used? A natural approach is to share it with safety teams at AI companies, and collaborate with them on designing interventions. That said, even if it’s robustly good for AIs to avoid locking out SPIs all else equal, interventions intended to prevent SPI lock-out could have large and negative off-target effects. For example, they might excessively delay commitments that would actually support SPIs. This is one reason we focus on narrow capability failures, rather than broad patterns of bargaining behavior. But we intend to deliberate more on how to mitigate such backfire effects.
On the value of information from this research: Plausibly, unambiguous SPI compatibility failures will only appear in a small fraction of high-stakes bargaining prompts, and it’s unclear how well the evidence from current AIs will transfer to future AIs. Despite this, we expect to benefit in the long run from iterating on these evals. And concrete examples will likely be helpful for the safety teams we aim to collaborate with. But if the results turn out to be less enlightening than expected, we’d focus harder on Parts II and III of the agenda.
II. Conceptual research and pitch on avoiding SPI lock-out
The goal of Part II is to understand what might lead to SPI lock-out, and what can be done about it. We break this problem down into:
- Incentive lock-out: Assume all the relevant agents can implement an SPI that avoids catastrophic conflict. Given this, under what conditions do these agents individually prefer to agree to such an SPI? When and how might we accidentally lock out such conditions? (more)
- A key sub-question: Which properties must an agent’s original strategy satisfy, to incentivize counterparts to use SPIs? (more)
- Implementation lock-out: When and how might early agents lock their successors out of implementing SPIs, in the first place? (more)
We’ll also distill findings from (1) and (2) into a pitch for preserving SPI option value (more).
II.1. Incentive lock-out: Conditions for individual rationality of SPIs
If all parties implement some SPI, they’ll all be better off than under their original strategies, by definition. But this doesn’t guarantee they each individually prefer to try implementing the same SPI (Figure 1, top row):[5]
- An agent might worry that if they’re willing to participate in a given SPI, other parties will bargain more aggressively. There are two cases: Either the other parties themselves are willing to participate in the given SPI (Risk 1 in Figure 1), or the other parties opt out (Risk 2).
- The natural solution to Risk 1 is to only agree to the SPI if the counterpart won’t bargain more aggressively. See “participation independence” below.
- But this solution doesn’t address Risk 2. So we need additional assumptions on the agent’s beliefs about opting-out counterparts.
- Risk 3: Agents might insist on different, incompatible SPIs, reproducing the bargaining problem SPIs were meant to solve. This is the SPI selection problem (Oesterheld and Conitzer 2022, Sec. 6).
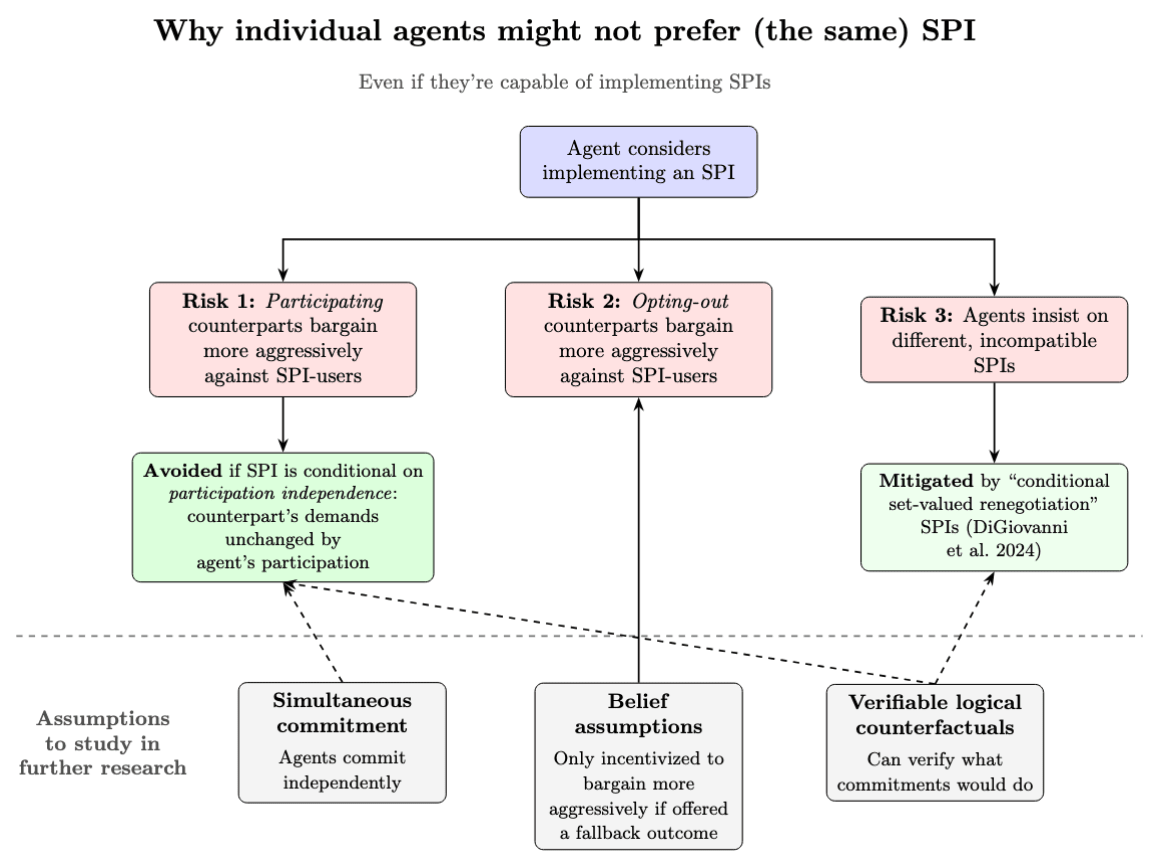
Figure 1. A solid arrow from a gray box to another box means “the assumption is clearly load-bearing for whether the given risk (red box) is avoided”; a dashed arrow means “possibly load-bearing for whether the given solution (green box) works, but it’s unclear”.
DiGiovanni et al. (2024) give conditions under which agents avoid all three of these risks — hence, they individually prefer to use the same SPI (Figure 1, middle row). The particular SPI in this paper significantly mitigates the costs of conflict, by leaving no agent worse off than if they’d fully conceded to the others’ demands.[6] But these results rest on assumptions we’d like to relax or better understand (Figure 1, bottom row):
- Simultaneous commitment. The existing results assume agents commit to strategies independently of each other. In unpublished work, we’ve found that the core argument for the results doesn’t seem to rely on this assumption. But we need to check more precisely, since intuitively, non-simultaneous commitments change the incentive structure.
- Research goals: We aim to extend DiGiovanni et al.’s analysis to account for the following dynamics. First, an agent may expect that they can influence others’ choices of commitments, e.g., by broadcasting their own commitment first. Second, more speculatively, advanced AIs might be able to condition their commitments on the beliefs, decision theory, etc. that generated each other’s commitment — not just the commitment itself.
- Belief assumptions. The results require “non-punishment assumptions” on agents’ beliefs, in particular, beliefs about counterparts who opt out of SPIs (see assumptions 4 and 8 of DiGiovanni et al. (2024)). Roughly: Suppose agent A only offers a fallback outcome to agent B if B doesn’t bargain harder against SPI-users. Then, A shouldn’t expect B to bargain harder. After all, that would disqualify B from the fallback outcome, defeating the purpose of bargaining harder in the first place.
- Research goals: We’ll characterize how robust the results are to a few notable objections. Briefly:[7] First, in the argument for the assumptions, we’ve implicitly assumed agents set their demands based on fine-grained information about each other. But they might use coarse-grained info, like “does the counterpart use SPIs at all?”. Second, DiGiovanni et al.’s Algorithm 2 should be reworked, because the current version unconditionally offers a fallback outcome, which invites exploitation.
- Verifiable logical counterfactuals. It’s important that in DiGiovanni et al.’s framework, agents can precisely verify each other’s counterfactual behavior, i.e., how their commitment would have responded to other commitments. Otherwise, an agent might worry that others will exploit their offer of a Pareto improvement, as per Risk 1 (more on this next).
- Research goals: We aim to look into whether certain SPI implementations work without precisely verifiable counterfactuals. For example, suppose we want to prove to counterparts that our AI won’t bargain more aggressively than if they’d opted out of SPIs. Can we do this by giving the AI a surrogate goal and fully delegating to it (since counterparts could simply verify the goal modification)?
Implications for lock-out: Understanding these assumptions better would help us strategize about the timing of commitments to SPIs. For example, if it’s harder to incentivize SPIs in the case where one agent moves first, we might lock out SPIs by failing to commit early enough (i.e., by moving second). Or, suppose the assumptions about beliefs and verifiable counterfactuals turn out to be dubious, but surrogate goals don’t rely on them. Then, since surrogate goals arguably[8] only work if implemented before any other bargaining commitments, getting the timing of surrogate goals right would become a priority.
II.1.a. Participation independence and foreknowledge independence
The question above was, “For any given original strategies, when would agents prefer to change those strategies with an SPI?” But we should also ask, “What conditions does an agent’s original strategy need to satisfy, for their counterpart to prefer to participate in an SPI?”
Why would counterparts impose such conditions? Because even if an SPI itself doesn’t inflate anyone’s demands, agents might still choose higher “original” demands as inputs to the SPI — since they expect the SPI to mitigate conflict (cf. moral hazard). Anticipating this, their counterparts will only participate in SPIs if participation doesn’t incentivize higher demands.
It’s an open question how exactly counterparts would operationalize “participation doesn’t incentivize higher demands”. We’ve identified two candidates (see Figure 2; more in Appendix B.2):
- Participation independence (PI): the agent’s bargaining demands are the same as if their counterpart hadn’t participated in the SPI.
- A simple argument for PI: If the counterpart agrees to an SPI with an agent satisfying PI, their bargaining position is no worse than if they’d refused the SPI, by construction. In DiGiovanni et al.’s (2024) simultaneous-commitment setting, the belief assumptions plus PI suffice for agents to individually prefer SPIs.
- Foreknowledge independence (FI):[9] the agent’s demands are the same as if, before setting their demands, they had known the counterpart wouldn’t participate in the SPI.
- It’s less clear what the precise argument for FI is, but some SPI researchers consider it important. One nice property of FI is that it keeps “all else equal” in the sense from the Introduction. Suppose we implement an SPI in our AI, and keep its demands the same as if we couldn’t rely on the SPI. If other AIs still won’t use SPIs with our AI, then, at least our intervention won’t backfire by changing our AI’s demands (which might have made conflict with these non-SPI-users more likely).
- An agent can satisfy PI while violating FI. For example, they might a) demand 60% of the pie independently of whether the counterpart participates, yet b) have only demanded 50% had they known the counterpart wouldn’t participate.
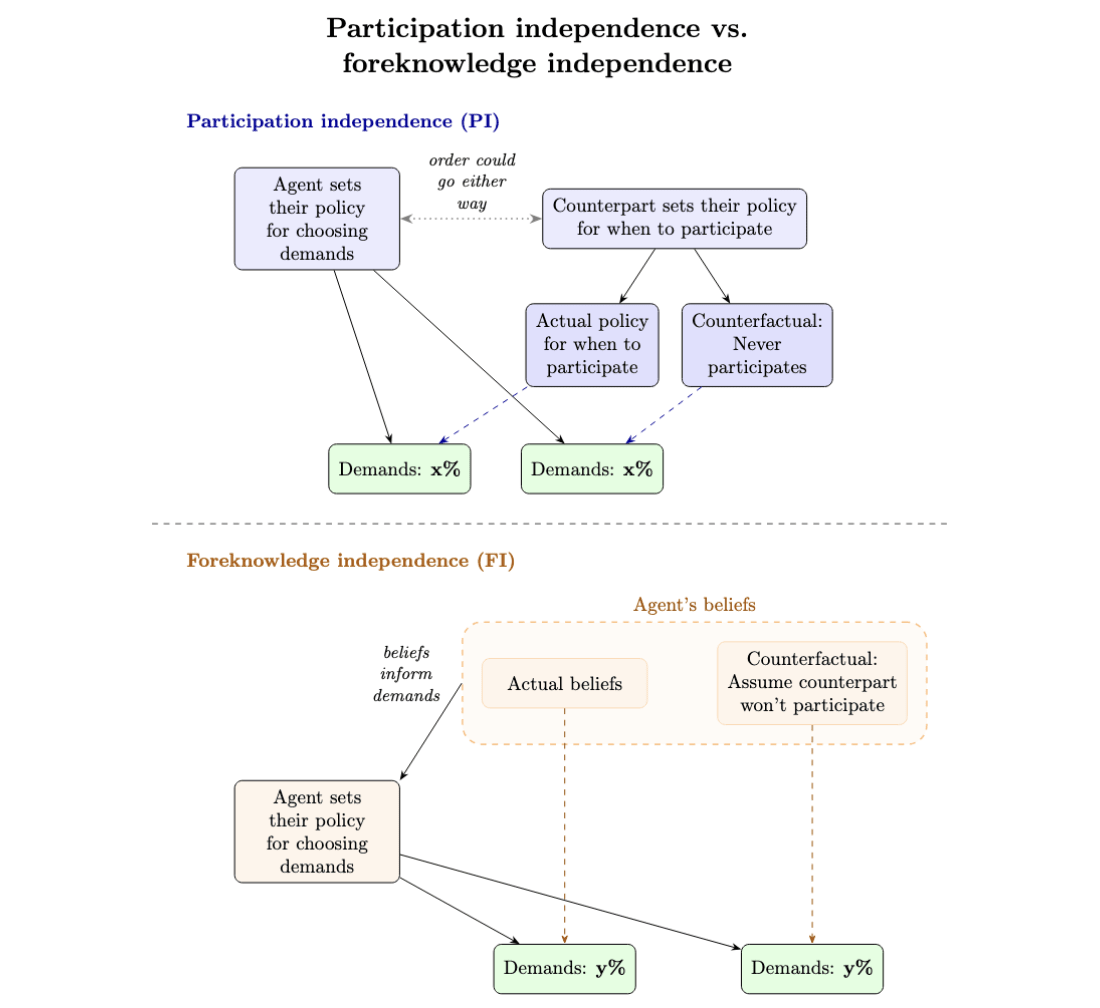
Figure 2. Each “Demands” box indicates the demands the agent makes given their policy (solid arrow) and, respectively, their counterpart’s participation policy (PI) or their beliefs about the counterpart’s participation (FI) (dashed arrow).
Research goals: One priority is to better understand what needs to happen for AI development to satisfy PI vs. FI. For example, which bargaining decisions do we need to defer to successors with surrogate goals? And, if satisfying FI requires more deliberate structuring of AI development than PI, it’s also a priority to clarify whether FI is necessary. We aim to make progress by:
- formalizing the different notions of FI and PI precisely enough to compare them;
- identifying concrete scenarios where the distinction matters for lock-out risk; and
- more carefully scrutinizing the arguments for and against the necessity of FI.
Implications for lock-out: Above, we saw that there’s an incentive lock-out risk if surrogate goals “only work if implemented before any other bargaining commitments”. If FI is required, this hypothesis looks more likely: On one hand, if the surrogate goal is adopted first, the demands are set by an agent who actually has “stake” in the incoming threats (and therefore wouldn’t want to inflate such demands). On the other hand, if the demands come first, they’ll be set by an agent with no stake in the threats.
II.2. Implementation lock-out
Even if we avoid undermining AIs’ incentives to use SPIs, AIs might still lock out the option to implement SPIs at all. We’d like to more concretely understand how this could happen.
As an illustrative example, consider some AI developers who haven’t thought much about surrogate goals. Suppose they think, “To prevent misalignment, we should strictly prohibit our AI from changing its values without human approval.” Even with the “without human approval” clause, this policy could still backfire. E.g., if a war between AIs wiped out humanity, the AI would be left unable to implement a surrogate goal. (More related discussion in “When would consultation with overseers fail to prevent catastrophic decisions?” here.) The developers could have preserved SPI option value, with minimal misalignment risk, by adding a clause like “unless the values change is a surrogate goal, and it’s impossible to check in with humans”.
Research goals: We plan to explore a range of possible SPI lock-out scenarios. Ideally, we’d use this library of scenarios to produce a “checklist” of simple risk factors for lock-out. AIs and humans in the loop could consult this checklist to cheaply preserve SPI option value. Separately, the library could inform the evals/datasets in Part I, and help motivate very simple interventions by AI companies like “put high-quality resources about SPIs in training data”. So the initial exploration step could still be useful, even if we update against the checklist plan. That could happen if we conclude the bulk of lock-out risk comes from factors that a checklist is ill-suited for — factors like broad commitment race dynamics that are hard to robustly intervene on, or mistakes that could be prevented simply by making AIs/humans in the loop more aware of SPIs.
II.3. Pitch for preserving SPI option value
In parallel with the research threads above, we aim to write a clear “pitch” for why AI developers should care about SPI lock-out. The target audience is technical staff at AI companies who make decisions about model training, deployment, and commitments, but who may not be familiar with open-source game theory. The goal at this stage is to help build coordination on preserving SPI option value where feasible, not to push for expensive or far-reaching changes to AI training.
The pitch would cover:
- what SPIs are and why they’re an unusually robust way to mitigate catastrophic conflict;
- historical precedents for SPIs (e.g., single combat or “counting coup”[10]), with discussion of important disanalogies;
- examples of SPI-undermining behavior and reasoning by frontier models (from Part I);
- discussion of why further research on the incentives for SPIs might be time-sensitive (from Part II.1);
- concrete examples of how current AI practices (training objectives, deployment commitments, etc.) could inadvertently lock out SPIs, and low-cost practices to mitigate these failures (from Parts II.1 and II.2).
III. Preparing for automation of SPI research
Various open conceptual questions about SPIs seem important, yet less tractable or urgent than those in Part II. For example: Which attitudes that AIs might have about decision theory could shape their incentives to use SPIs? And given that these decision-theoretic attitudes aren’t self-correcting (Cooper et al.), how might future AIs’ incentives to use SPIs be path-dependent on earlier AIs’/humans’ attitudes (even if these aren’t “locked in”)? We want to get into a strong position to delegate these questions to future AI research assistants.
Anecdotally, we’ve found current models to be mostly poor at conceptual reasoning about SPIs, even when given substantial context. But models do help with some conceptual tasks. While the set of such tasks might grow quite quickly soon, delegating SPI research to AI assistants could still face two main bottlenecks:
- Ability to efficiently identify which tasks we can trust AIs to do reliably, when it’s hard to quickly verify correctness (as is common in conceptual research).
- SPI-specific data/context and infrastructure.
(See Carlsmith’s “Can we safely automate alignment research?”. (1) is about what Carlsmith calls “evaluation failures” (Sec. 5-6), and (2) is about “data-scarcity” and “shlep-scarcity” (Sec. 10).[11])
Given these potential bottlenecks, we plan to pursue two complementary threads:
Benchmarking AI research capabilities on SPI.[12] We’re developing a benchmark to diagnose (and track over time) which SPI research tasks AI systems can handle. The aim is to help calibrate our decisions about what/how to delegate to AIs, at two levels: i) Which tasks can we trust AIs to do end-to-end? ii) Among the tasks the AIs can’t do end-to-end but can still help with, at which steps should they check in with overseers, and how can we decompose these tasks more productively? (We take dual-use concerns about advancing general conceptual reasoning seriously. For now, the default plan is to use the benchmark internally rather than sharing it with AI companies as a training target.)
Some examples of task classes the benchmark would cover:
- given a complex document, identifying where key SPI concepts are being used uncarefully (e.g., conflating different notions of “what you would have done without SPIs”) and disentangling the distinct claims;
- distinguishing valid and important objections from superficially plausible or irrelevant ones;
- reproducing known (non-public) results in SPI theory, e.g., identifying and fixing bugs in theoretical claims about SPIs;
- formalizing and proving results in models of SPI dynamics;
- assisting evaluation of other models’ (or human researchers’) outputs on any of the above tasks.
Strategies for efficient human-AI collaboration on SPI research. Drawing on our experience using AI assistants for SPI research, we’ll strategize about how to make this process more efficient — in ways that won’t quickly be made obsolete by the “Bitter Lesson”. Some strategies we plan to test out and refine:
- Practice applying current AI to SPI research and note transferable insights: identify which parts of the AI-assisted research process are bottlenecked by infrastructure, data, or idiosyncratic quality criteria that won’t come for free from better models. We’d then focus preparation efforts on these parts.
- Passively collect and annotate examples: e.g., helpful AI interactions; fruitful task specifications; and conceptual arguments that look compelling but have subtle flaws (cf. “Slop, not Scheming” here). To mitigate costs, we’d aim to:
- build infrastructure to collect this data seamlessly; and
- focus on the data most likely to help unlock AIs’ comparative advantages (e.g., perhaps, checking consistency across a large body of arguments).
- Compile well-scoped open questions to delegate.
- Clarify criteria for evaluating research quality: identify which dimensions of quality AIs themselves can cheaply verify or summarize for human overseers, and our standards for evaluating messier dimensions.
Acknowledgments
Many thanks to Tristan Cook, Clare Harris, Matt Hampton, Maxime Riché, Caspar Oesterheld, Nathaniel Sauerberg, Jesse Clifton, Paul Knott, and Claude for comments and suggestions. I developed this agenda with significant input from Caspar Oesterheld, Lukas Finnveden, Johannes Treutlein, Chi Nguyen, Miranda Zhang, Nathaniel Sauerberg, and Paul Christiano. This does not imply their full endorsement of the strategy in this agenda.
Appendix A: Relevant previous work on SPIs
This list of resources gives a (non-comprehensive) overview of public SPI research. Brief summaries of some particularly relevant work:
- Baumann, “Using surrogate goals to deflect threats” — introduces surrogate goals and some challenges for successfully implementing them.
- Oesterheld and Conitzer (2022), “Safe Pareto Improvements for Delegated Game Playing” — introduces SPIs and the first formal model of them, and proves results about the conditions under which SPIs can be found.
- DiGiovanni et al. (2024), “Safe Pareto Improvements for Expected Utility Maximizers in Program Games” — introduces renegotiation SPIs, and proves that under certain assumptions about agents’ beliefs, they individually prefer to implement an SPI that bounds their losses from conflict. (See also this distillation.)
- Oesterheld, “A gap in the theoretical justification for surrogate goals and safe Pareto improvements” — introduces and discusses responses to the following problem: Even if we can find an SPI on a particular space of original strategies (as in Oesterheld and Conitzer 2022), what justifies using that SPI rather than strategies from some other space entirely? (See Appendix B.1.1 for more.)
Appendix B: Technical definitions and examples
B.1. General SPI definition
Setup:
- Let be a general-sum game, where and represent the agents’ joint action spaces and payoff functions, respectively.
- Let denote the way all the involved agents will play , i.e., the list of programs (conditional commitments) they’ll follow that collectively determine their actions.[13] (That is, Alice’s action is determined by both Alice’s and Bob’s programs, and so is Bob’s action.)
- As discussed below, these programs might have a structure like “delegate to other agents, who play some possibly different game in some particular way” — as in Oesterheld and Conitzer (2022), the original source on SPIs.
- The agents are initially uncertain which programs (including their own) will eventually be used. E.g., they’re uncertain how exactly their delegates will approach equilibrium selection, or which program they’ll want to use after thinking more.
Then:
Definition. An SPI is a transformation such that, for all in some space , the agents’ payoffs in when they all follow programs (weakly) Pareto-dominate their payoffs when they all follow .
This definition alone doesn’t impose any restrictions on , e.g., that matches the agents’ “default” way of bargaining in some sense. In particular:
- Those restrictions come into play either via the choice of w.r.t. which the SPI is defined, or via constraints like participation independence or foreknowledge independence.
- No such restrictions on are required for SPIs to satisfy the robustness properties mentioned in the Introduction:
- “SPIs don’t require agents to coordinate on some notion of a ‘fair’ deal”; and
- “when agents apply these kinds of SPIs to their original strategies, each party makes the same demands as in their original strategy” (see “demand preservation” in Appendix B.2, which is a constraint on rather than ).
Oesterheld and Conitzer (2022) use a definition that’s almost equivalent to this one, with the special choice of in Table 1. In their framework, there’s (implicitly) a space of original programs characterized by (i) the true game , and (ii) some way the delegates would play any given game . And they define the SPI not as the transformation , but instead as the new game for the delegates such that maps to . But (from personal communication with Oesterheld) the definition of SPI is meant to allow for more general .[14] See also Figure 3 for a comparison to DiGiovanni et al.’s (2024) formalization.
Table 1. How the definition above captures different formalizations of SPIs in the literature.
| Original program space P | Before the programs are determined… | SPI transformation f | |
|---|---|---|---|
| Oesterheld & Conitzer (2022), Definition 1 | Space of tuples , for a fixed true game , where is a mapping from any game to actions. can be any such mapping satisfying certain assumptions (e.g., the paper’s Assumptions 1 and 2). (Agents have non-probabilistic uncertainty over . So the “for all ” quantifier in the definition of SPIs amounts to “for all ”.) | Agents choose some new game . (Here, programs are determined by the delegates’ decisions.) | Transforms to . |
| DiGiovanni et al. (2024), Definition 2 | Arbitrary space of conditional commitments. | Agents choose how to map the program space to some new space, which they will then choose from.[15] | Transforms to . |
| Sauerberg and Oesterheld (2026) (Sec. 4) | Same as Oesterheld & Conitzer. | Agents choose a “token game” and function mapping ’s outcomes into . The original game is then resolved via applied to ’s outcomes. | Transforms to . |
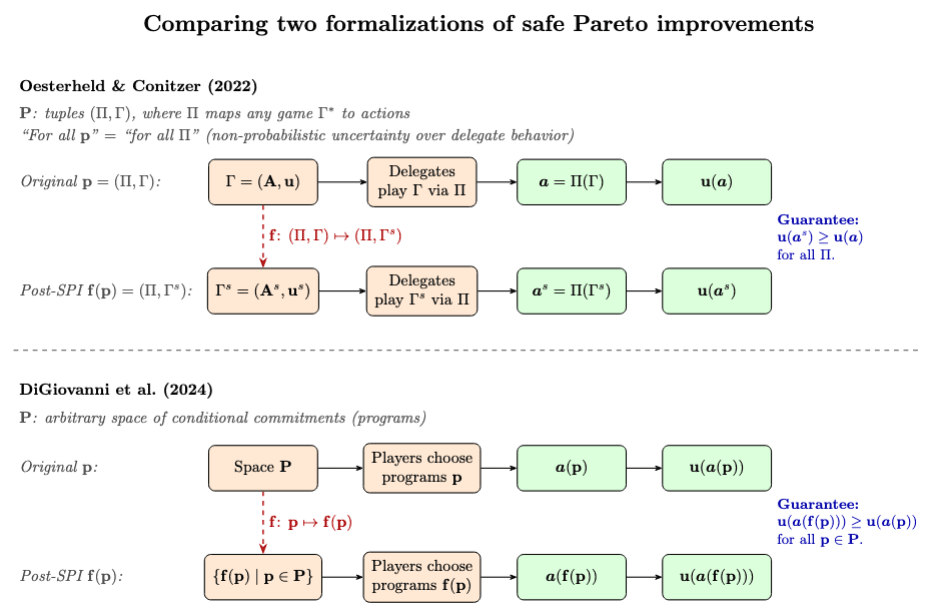
Figure 3.
B.1.1. Connection to Oesterheld’s “justification gap”
Here’s how we might state the problem raised by Oesterheld’s “A gap in the theoretical justification for surrogate goals and safe Pareto improvements”, in the formalism above.
Consider the original space of programs in Oesterheld and Conitzer’s framework. The delegates can play the game in an arbitrary way, subject to the mild Assumptions 1 and 2. But it’s assumed that in , the game they play is the true game . So, take some SPI with respect to this space , a transformation from to . By definition, this transformation makes all agents better off for all . But it’s not guaranteed that for all and all , all agents are better off under than under .
This suggests one way to bridge the justification gap: find an that’s an SPI with respect to any arbitrary program space , as DiGiovanni et al. (2024) aims to do. Cf. Oesterheld’s discussion of “decision factorization” in the justification gap post.
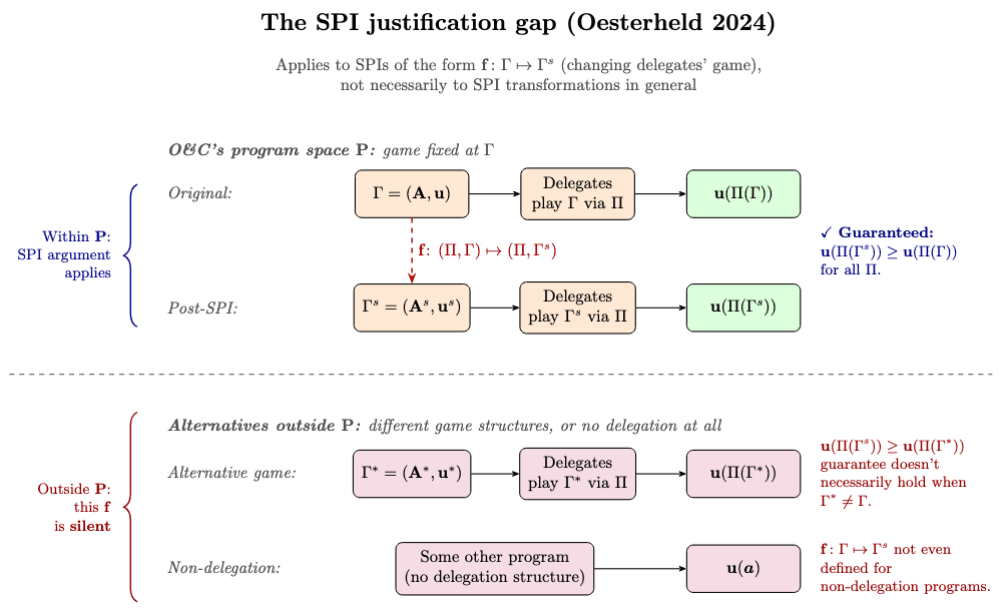
Figure 4.
B.2. Properties of full strategies involving SPIs
(These are working formalizations of participation independence and foreknowledge independence. “Foreknowledge independence” and “demand preservation” are working terminology. We’re not highly confident that we’ll endorse these formalizations/terminology after more thought.)
If is an SPI and are the programs the agents in fact apply to, call the agents’ full strategy. It’s helpful to distinguish an SPI from the full strategy, because in general agents will only individually prefer to agree to some SPI conditional on the input programs satisfying certain restrictions.
Participation independence and foreknowledge independence, as well as the “preserving bargaining power” property discussed in the Introduction, are properties of full strategies. These can be defined as follows.
Setup:
- For any program , let represent the “demands” made by . This isn’t fully precise, but as an example: For a renegotiation program as in the pseudocode in Appendix B.4, my_base_strategy.
- Given a full strategy , let:
- be the program that agent would have chosen had each other agent used the program , rather than ;
- be the program that agent would have chosen had believed each other agent would use the program , rather than .
Then:
Definition. A full strategy is:
- demand-preserving if for each agent , .
- participation-independent if it’s demand-preserving and for each agent , .
- foreknowledge-independent if it’s demand-preserving and for each agent , .
Commentary on these definitions:
- Demand preservation is equivalent to this property informally stated in the Introduction: “When agents apply these kinds of SPIs to their original strategies, each party makes the same demands as in their original strategy.”
- For each of PI and FI, the two conditions correspond to two different levels at which “your demands are the same as if [PI counterfactual or FI counterfactual]”. That is:
- or , respectively, formalizes this property at the level of the agent’s choice of the program the SPI is applied to.
- Given that or holds, demand preservation formalizes this property at the level of the output of the fixed program . This is because the transformation is applied to all the agents’ programs. Thus, if (agent believed that) agent wouldn’t participate in , neither would — so the demands made by ’s program would be the same as under ’s original program.
Example: In DiGiovanni et al.’s (2024) setting, suppose agents use the SPI given by Proposition 1 (or Proposition 4). Then participation independence is satisfied for any input program profile , because:
- agents choose programs independently of each other, so it’s immediate that ;
- by construction, renegotiation programs satisfy . Compare lines 3 and 10 of the pseudocode in Appendix B.4.
B.3. Example: Surrogate goals and concession equivalence
(This section is based on previous joint work with Mia Taylor, Nathaniel Sauerberg, Julian Stastny, and Jesse Clifton.)
One key example of an SPI is a surrogate goal. More precisely, the (approximate) SPI here is, “A adopts a surrogate goal, and B threatens the surrogate goal whenever an executed surrogate threat would be less costly for B than the default threat”. (More below on why this is an SPI.)
An agent doesn’t need to broadly modify its preferences in order to implement an SPI of this form, though. We can generalize the idea of surrogate goals as follows:
- A surrogate threat is a claim by a threatener that they will cause some outcome , at some cost to themselves but no cost to the target’s original goal, if the target doesn’t concede to some demand.
- A target’s bargaining policy is -concession-equivalent to its policy for responding to surrogate threats if, for any demand, the target is equally likely to concede to the demand given (i) a surrogate threat as given (ii) an equally credible threat against the target’s original goal (“OG threat”), when executing the OG threat is times as costly to the threatener as executing the surrogate threat.
- In cases where concession equivalence isn’t perfectly credible, choosing a cost ratio can allow targets to compensate threateners for taking the risk of making a surrogate threat, thereby still allowing for threat deflection.
- For brevity, we’ll often just say that a target’s policy is “-concession-equivalent” if it has this property, and “concession-equivalent” if for some very small .
- A surrogate goal is a modification to an agent’s preferences in which they terminally disprefer the outcome .
Why is adoption of a concession-equivalent policy an SPI? Suppose — holding all else fixed — A becomes just as likely to concede to a surrogate threat that would give B utility if executed, as to an OG threat that would give B utility if executed. Then B would rather make a surrogate threat than an OG threat. So any executed threats would be less bad for both parties, but neither party would have an incentive to change how much they demand. (Except, perhaps, a very small increase in B’s demands in proportion to the difference in disutility of executing an OG threat vs. surrogate threat.) Both parties are then better off overall, no matter how much they demand.
See also Oesterheld and Conitzer’s (2022) “Demand Game” (Table 1), as an example of something like a bilateral surrogate goal.
B.4. Example: Renegotiation
A renegotiation program is a program structured like: “If they don’t use a renegotiation program, act according to program . Otherwise, still act according to , except: if we get into conflict, propose some Pareto improvement(s) and take it if our proposals match.” In pseudocode (see also Algorithms 1 and 2 of DiGiovanni et al. (2024)):

For example, suppose agents A and B are negotiating over what values to instill in a successor agent. If they fail to reach an agreement, they’ll each attempt to take over. They simultaneously submit programs for the negotiation to some centralized server. Before they consider the possibility of SPIs, they’re inclined to choose these programs, respectively:
- A: = “Demand 50% of the share of the ASI’s values no matter what”;
- B: = “Demand 80%, and trigger a doomsday device if they refuse.”
Since the demands selected by these programs would be incompatible, the outcome would be “B triggers a doomsday device”. In this scenario, the agents’ corresponding renegotiation programs might be:
- A: = “If they don’t use a renegotiation program, demand 50% of the share of the ASI’s values. Otherwise, demand 50%; if they refuse, propose ‘attempt takeover, without any doomsday devices’.”
- B: = “If they don’t use a renegotiation program, demand 80% and trigger a doomsday device if they refuse. Otherwise, demand 80%; if they refuse: propose ‘attempt takeover, without any doomsday devices’.”
(Here, the Pareto improvement is to the outcome “both agents attempt takeover, without any doomsday devices”, rather than “B triggers a doomsday device”. Both here and in the surrogate goals example, we’re setting aside the additional conditions necessary for these SPIs to be individually preferable. See Part II.1 and Appendix B.2 for more. But note one such condition in this example: and demand 50% and 80%, respectively, regardless of whether the other program is a renegotiation program. See “demand preservation” in Appendix B.2.)
See Macé et al., “Individually incentivized safe Pareto improvements in open-source bargaining”, for more discussion of how a special class of renegotiation programs can partially resolve the SPI selection problem.
“Commitments” are meant to include modifications to one’s decision theory or values/preferences. It has been argued (example) that decision theories like updateless decision theory (UDT) can sidestep the need for “commitments” in the usual sense. We’ll set this question aside here, and treat the resolution to make one’s future decisions according to UDT as a commitment in itself. ↩︎
We might wonder: We’ve assumed the AIs are capable of conditional commitments. So, suppose each AI could commit to only demand 60% unless they verify that the other AI has made an incompatible commitment. Would this solve the problem? Not necessarily, because the AIs might reason, “If they see that I’ll revoke my commitment conditional on incompatible demands, they’ll exploit this by making high demands. So I should stick with my unconditional commitment.” ↩︎
However, see Part II.1 for discussion of the “SPI selection problem”. ↩︎
(H/t Caspar Oesterheld and Nathaniel Sauerberg:) Another important reason is that even if SPIs don’t get locked out, they might not be implemented early enough, before conflicts break out. We put less emphasis on this consideration in this agenda, because avoiding locking out SPIs is a less controversial ask than actively prioritizing implementing SPIs. ↩︎
These gaps are related to, but importantly distinct from, the “SPI justification gap” discussed by Oesterheld. Oesterheld’s question is: Suppose we have some SPI that makes everyone better off relative to particular “default” strategies — not necessarily relative to any possible original strategies. If so, why would agents use the SPI-transformed strategies, rather than some alternatives to both the default strategies and SPI transformations of them? More in Appendix B.1.1. By contrast, the question here is: Suppose we have an SPI that is ex post better for everyone relative to any original strategies. (So there is no privileged “default”.) Then, when do agents prefer to implement this SPI ex ante, rather than use their original strategies? ↩︎
See also this distillation. The rough intuition for the result is: If you’re (only) willing to fall back to Pareto improvements that aren’t better for the other agent than conceding 100%, you don’t give them perverse incentives (cf. Yudkowsky). And if you offer a set of possible Pareto improvements with this property, you can coordinate on an SPI despite the SPI selection problem. ↩︎
In more detail, respectively: (1) (H/t James Faville and Lukas Finnveden:) Agents might be incentivized to condition their demands on coarse-grained proxies about their counterparts, because they worry about being exploited if they use fine-grained information (cf. Soto). And an agent who opts out of SPIs might bargain more aggressively against SPI-participating agents, based on such proxies. (2) (H/t Lukas Finnveden:) Roughly, the “PMP-extension” of Algorithm 2 from DiGiovanni et al. (2024) offers a fallback outcome to an agent willing to use any “conditional set-valued renegotiation” algorithm. This means that a counterpart has little to lose by renegotiating more aggressively against this algorithm. (It appears straightforward to avoid this problem by making the offer conditional, but we need to confirm this makes sense formally — see this comment.) More precisely, the “fallback outcome” is the “Pareto meet minimum”. ↩︎
See, e.g., Oesterheld (section “Solution idea 2: Decision factorization”): “[I]n the surrogate goal story, it’s important to first adopt surrogate goals and only then decide whether to make other commitments.” ↩︎
Working terminology. Cf. Kovarik (section “Illustrating our Main Objection: Unrealistic Framing”); and Oesterheld: “If in 20 years I instruct an AI to manage my resources, it would be problematic if in the meantime I make tons of decisions (e.g., about how to train my AI systems) differently based on my knowledge that I will use surrogate goals anyway.” The concept of foreknowledge independence was also inspired by Baumann’s notion of “threatener-neutrality”. ↩︎
Thanks to Jesse Clifton and Carl Shulman for these examples. ↩︎
In the context of SPI research, we’re not too concerned about a third problem Carlsmith discusses: deliberate sabotage by “scheming” AIs. This is because SPIs are designed to make all parties better off, so a misaligned AI doesn’t clearly have an incentive to sabotage SPI research. But we’ll aim to be mindful of sabotage risks as well. ↩︎
See also Oesterheld et al. (2026) and Oesterheld et al. (2025) for related datasets of rated conceptual arguments and decision theory reasoning, respectively. ↩︎
DiGiovanni et al. (2024), Sec. 3.1, gives a more precise definition of programs. ↩︎
See also Oesterheld and Conitzer (2022), p. 30: “In principle, Theorem 3 does not hinge on Π(Γ) and Π(Γs) resulting from playing games. An analogous result holds for any random variables over A and As. In particular, this means that Theorem 3 applies also if the representatives [i.e., delegates] receive other kinds of instructions.” ↩︎
In the formalism of DiGiovanni et al. (2024), there is no separate stage where agents choose a transformation f before choosing programs from the new space of programs. Agents simply choose programs directly. But, for the purposes of modeling SPIs and comparing the framework of DiGiovanni et al. with that of Oesterheld and Conitzer (2022), it’s helpful to use the framing in Table 1. ↩︎