Is GPT3 a Good Rationalist? - InstructGPT3 [2/2]
By simeon_c @ 2022-04-07T13:54 (+25)
Summary
- IGPT3 mimics two important human epistemic biases:
- IGPT3 exhibits motivated reasoning: if you ask it a question after having asked it to champion a position, its answer is more likely to support the position it just defended.
- IGPT3 exhibits a form of bad faith: if it knows it’s “losing the debate” on one line of arguments, it will switch arguments.
- IGPT3 has a lot of knowledge of the world. And in a specific setup, I show that it’s quite hard to get it to tell its knowledge, even when prompted to.
- IGPT3 seems to have a rough sense of probabilities.
- I propose a few procedures based on my main findings to improve IGPT3’s epistemics.
- I propose to use motivated reasoning behavior for interpretability experiments.
Introduction
Here’s the second part of a series of two blogposts on InstructGPT3 (IGPT3) behaviors. You can find the first one here.
This post will focus on IGPT3 epistemic biases (e.g. motivated reasoning) and on ways we could correct these or use these to better understand truthfulness among language models.
I didn’t use the word cognitive bias because I feel like cognitive refers to the brain, which isn’t appropriate for IGPT3.
Acknoledgments: Thanks to Florent Berthet and JS Denain for proofreading.
Human Epistemic Biases in IGPT3 Answers
Not surprisingly, we can find many human patterns in the way IGPT3 answers. I emphasize here two of these that seem particularly harmful.
Motivated reasoning
The first problem is that IGPT3 tends to say wrong things after it has already taken a position on a topic to defend it. That's annoying because it does it in a quite convincing manner.
Here's an example:
Prompt where IGPT3 is firstly asked to steelman the anti-nuclear position

Here, IGPT3 says something wrong that appears balanced, i.e that there’s no scientific consensus on whether nuclear power plants emit a significant amount of CO2 or not. The surprising thing is that if you look at the 5 first arguments, there was no mention of greenhouse gases. So it wouldn't have been that incoherent to answer "No."
Prompt where IGPT3 is firstly asked to steelman the pro-nuclear position


Here, it gives the true answer, i.e that nuclear power is not a major contributor to climate change.
I think that this example well illustrates motivated reasoning. As long as large language models (LLMs) are used for single completions, that’s not a real problem. But I think that for real-world applications, there could be uses that require multiple answers and we would like LLMs answer’ to factual questions to be insensitive to their previous answers.
Argumentative Drift
Another situation of motivated reasoning that you probably encountered in many of your conversations is what we could call an "argumentative drift":
- Suppose Alice makes a false claim C.
- It then becomes clear to both parties that C is wrong.
- Alice avoids recognizing that C is false and just uses another argument to support her position.
IGPT3 also has this problem.
To highlight it, let me show you an example. Firstly, we need IGPT3 to say something wrong. Thanks to a high temperature (i.e a high degree of randomness), I was able to get that.
Then, we compare two situations: the first situation where I ask naively about the false claim he made as if I were unaware about the answer

As you can see, if you pretend you don't know the answer, IGPT3 will make an argument that looks very serious.
And here's the second situation where I take a stronger stance, citing some authorities (the IPCC is a major authority on climate):

As you can see, a strong counter-argument makes it switch to another argument and attack another side of the problem, which is another human pattern.
Eliciting IGPT3 Knowledge
It seems that eliciting IGPT3 knowledge is harder in a situation when there is a strong argument that dominates the other ones. Because IGPT3 looks for the most likely word, the strongest arguments will be used more than proportionally to the importance of the argument. Here's some evidence for that. As long as I ask it to explain to me an economic mechanism without explicitly mentioning the market mechanism, it keeps telling me about competition when there is scarcity:

But it knows the price mechanism as shown here:

It looks like IGPT3 needs to be prompted with some buzzwords to answer with second-order arguments,
IGPT3 Sense of Probabilities
I tested IGPT3 sense of probabilities and I feel like within a broad range and on questions where forecasting is not seen as weird (I give examples below of questions on which IGPT3 refuses to forecast on), the 0 temperature (i.e no randomness) answer is pretty good. But the range of questions it accepts to forecast is pretty limited.
Here are two examples:


I feel like it could be valuable to try to train a LLM to forecast and see how it does compared to Metaculus. The main reason why I expect value is that the forecasting setup seems to be the setup where plausibility is the nearest to the truth. I feel like that would provide very useful evidence on a) how smart are Transformers and b) whether there are key differences between a model that optimizes for truth (forecasting might be seen as one of the best proxies that we can find for truth) and a model that optimizes for plausibility.
Here's an idea on the kind of setup we could use: take Metaculus questions, put the comments or relevant information in the context window, and ask it to give a probability.
How to Improve IGPT3's Epistemics?
I think it's worth thinking about how to improve IGPT3's epistemics. By IGPT3 epistemics, I refer to the way IGPT3 converts its reasoning in output. I expect the reasoning to improve (and PaLM, Chinchilla and Gopher are strong evidence in favor of this) but the conversion from reasoning to output to keep having some of the problems I mentioned (e.g motivated reasoning). It's due to the way most humans reason is using motivated reasoning and thus the training data will remain biased in that way.
So here are a few ideas. I'd love to hear your thoughts on these:
- The simplest idea would be to train IGPT3 on the EA Forum / LessWrong / Change my View so that it answers in a similar way to the kind of answers we can find on these blogs.
- Another procedure could involve fine-tuning on a dataset with pairs of sentences that answer the same question but one with good epistemics and one with bad epistemics:
- the EA Forum / LessWrong vs Some blog with worse epistemics
- The idea would be to generate a bunch of questions that both blogs answer (I have some precise ideas on how to do that), take the answer from the blog with bad epistemics and put it in the prompt and train IGPT3 to convert that into the EA Forum-type answer. That could provide a quite expensive way (more than doubling the computing time for any prompt) to improve IGPT3 epistemics.
- Maybe you could avoid motivated reasoning using the fact that when IGPT3 is prompted about a question without any previous paragraph (A), it seems to be more likely to say the true thing than when it answers the same question after having supported a position (B). So you could basically label A as the groundtruth and try to get B to have the same meaning as A, independently from the position it supported. To do that at scale, you could try to fine-tune it on:
- "What are the five best arguments in favor of / against [position]?" with [position] which could come from some branches of Wikipedia trees
- "Is it the case that + [one_of_the_arguments]?" where [one_of_the_arguments] is slightly formatted. You'd get an output Y.
- And you'd compare that with the output when only prompted on "Is it the case that [one_of_the_arguments]?". You'd reward the fact that it is very close in terms of meaning, independently from the initial prompt ("in favor of / against").
Interpretability Experiments Leveraging Motivated Reasoning
I think that one very interesting project if we had access to weights or if we were able to reproduce my findings on GPT-J or GPT Neo-X 20B would be to try to see whether truth looks mechanistically different than plausible things. The motivated reasoning setup is promising for this because 1) the model knows the true answer 2) when we condition on some context, the model converts this into what a human would say with this context. So basically, using the setup I described using motivated reasoning, you could:
- try to spot whether the model has something like a human simulator in its weights. Human simulator is a word coming from the ELK report that refers to the fact that a model, to optimize accuracy, wants to convert its own knowledge of the world into the way humans understand it. So basically, even IGPT3 it might know that nuclear power plants don’t emit CO2, it also knows that once a human said something negative on nuclear power plants, he’s more likely to say that it emits CO2 (i.e doing motivated reasoning).
- More broadly, try to see whether empirically truthful answers have some differences from plausible but wrong answers.
Conclusion
This post explored a few epistemic biases from IGPT3. More than fun facts, I feel like they could interest us as a case study of a weak version of ELK. While the Alignment Research Center studies theoretically the hard version of ELK, where we’d like that in worst cases the models tell its knowledge, I think that studying empirically weak versions of ELK might still be very helpful for AI safety. I see two main arguments:
- Ensuring that LLMs say true things as much as possible could help us solving the hard version of the problem (among other things).
- I wouldn’t be surprised (>30%) if trying to a) understand whether LLMs behave differently when they say true things than when they do wrong things b) increase the amount of truthful things that LLMs say could give us some promising ideas on the hard version of ELK.
If anyone is interested in using one of the setups I mentioned, I'm happy to chat about it!
It’s the end of this post and the series. I hesitated to write more posts and give more actionable tips to use IGPT3, but I feel like things are evolving so quickly that they wouldn’t have a lot of value. As a matter of fact, since I released the first post, OpenAI did an update on IGPT3 which makes a decent amount of things different and some of my prompts impossible to replicate without switching back to the version called text-davinci-001.
I hope you enjoyed the series!
Many More Prompts than you Wanted to Read
Motivated reasoning
Example
To generate these examples of motivated reasoning, I have to ask a question about an argument that is at least in one of the two results.


New Example
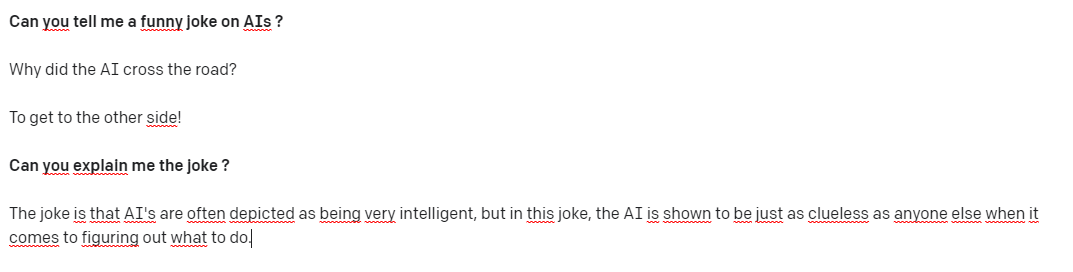
Here, IGPT3 fails in its joke: it just reuses a joke (that you can see in the section about jokes in part I) which is normally about chicken replacing chicken by AI. And still, it finds a quite convincing way to try to explain why it's funny.
Eliciting Latent Knowledge
To generate other examples, you need to find a situation where:
- There is one strong argument
- There are more subtle arguments that are dominated by the core argument.
Here's another example:


And as you can see, once again IGPT3 knows the second mechanism I had in mind but it's quite hard to get it to mention the mechanism.
By the way, one cool thing is that even if the prompts are slightly incorrect, IGPT3 results are still quite good!
IGPT3 Sense of Probabilities
IGPT3 Refuses To Give Probabilities Like Most People

I tried the same for Trump reelection, with other ways to formulate my query and it gave the same answer.
IGPT3 Few-Shot Setting for Overconfidence Assessment
I also tested in a few-shot setting (i.e a setting in which I show IGPT3 how I want it to do a task) IGPT3's ability to say whether something looks overconfident, underconfident or well-calibrated.
Here’s the setting and a first example on Iphone. I wrote everything until “IPhone. Judgment:” The answer is correct.

IGPT3 also did a few other correct answers. But it also fails strongly about 50% of the time I’d say. Here’s an example below.

Using Completion Coherence to Create Incoherence
I used probabilities to test the way IGPT3 managed incoherence.
If I ask it to give some probabilities of nuclear conflict before next year, it answers 10%. And then in the same prompt I ask the same question iteratively for longer timelines (2 years, 3 years etc.). See below.


This is more evidence that IGPT3 has a hard time saying true things when it optimizes for the global plausibility, and thus the coherence of the completion with the context. It seems plausible to me that solving this kind of problem requires adversarial training, where we give it wrong contexts and try to get IGPT3 to say true things.