Simplify EA Pitches to "Holy Shit, X-Risk"
By Neel Nanda @ 2022-02-11T01:57 (+189)
This is a linkpost to https://www.neelnanda.io/45-x-risk
TL;DR If you believe the key claims of "there is a >=1% chance of AI causing x-risk and >=0.1% chance of bio causing x-risk in my lifetime" this is enough to justify the core action relevant points of EA. This clearly matters under most reasonable moral views and the common discussion of longtermism, future generations and other details of moral philosophy in intro materials is an unnecessary distraction.
Thanks to Jemima Jones for accountability and encouragement. Partially inspired by Holden Karnofsky’s excellent Most Important Century series.
Disclaimer: I recently started working for Anthropic, but this post entirely represents my opinions and not those of my employer
Introduction
I work full-time on AI Safety, with the main goal of reducing x-risk from AI. I think my work is really important, and expect this to represent the vast majority of my lifetime impact. I am also highly skeptical of total utilitarianism, vaguely sympathetic to person-affecting views, prioritise currently alive people somewhat above near future people and significantly above distant future people, and do not really identify as a longtermist. Despite these major disagreements with some common moral views in EA, which are often invoked to justify key longtermist conclusions, I think there are basically no important implications for my actions.
Many people in EA really enjoy philosophical discussions and debates. This makes a lot of sense! What else would you expect from a movement founded by moral philosophy academics? I’ve enjoyed some of these discussions myself. But I often see important and controversial beliefs in moral philosophy thrown around in introductory EA material (introductory pitches and intro fellowships especially), like strong longtermism, the astronomical waste argument, valuing future people equally to currently existing people, etc. And I think this is unnecessary and should be done less often, and makes these introductions significantly less effective.
I think two sufficient claims for most key EA conclusions are “AI has a >=1% chance of causing human extinction within my lifetime” and “biorisk has a >=0.1% chance of causing human extinction within my lifetime”. I believe both of these claims, and think that you need to justify at least one of them for most EA pitches to go through, and to try convincing someone to spend their career working on AI or bio. These are really weird claims. The world is clearly not a place where most smart people believe these! If you are new to EA ideas and hear an idea like this, with implications that could transform your life path, it is right and correct to be skeptical. And when you’re making a complex and weird argument, it is really important to distill your case down to the minimum possible series of claims - each additional point is a new point of inferential distance, and a new point where you could lose people.
My ideal version of an EA intro fellowship, or an EA pitch (a >=10 minute conversation with an interested and engaged partner) is to introduce these claims and a minimum viable case for them, some surrounding key insights of EA and the mindset of doing good, and then digging into them and the points where the other person doesn’t agree or feels confused/skeptical. I’d be excited to see someone make a fellowship like this!
My Version of the Minimum Viable Case
The following is a rough outline of how I’d make the minimum viable case to someone smart and engaged but new to EA - this is intended to give inspiration and intuitions, and is something I’d give to open a conversation/Q&A, but is not intended to be an airtight case on its own!
Motivation
Here are some of my favourite examples of major ways the world was improved:
- Norman Borlaug’s Green Revolution - One plant scientist’s study of breeding high-yield dwarf wheat, which changed the world, converted India and Pakistan from grain importers to grain exporters, and likely saved over 250 million lives
- The eradication of smallpox - An incredibly ambitious and unprecedented feat of global coordination and competent public health efforts, which eradicated a disease that has killed over 500 million people in human history
- Stanislav Petrov choosing not to start a nuclear war when he saw the Soviet early warning system (falsely) reporting a US attack
- The industrial and scientific revolutions of the last few hundred years, which are responsible for this incredible graph.
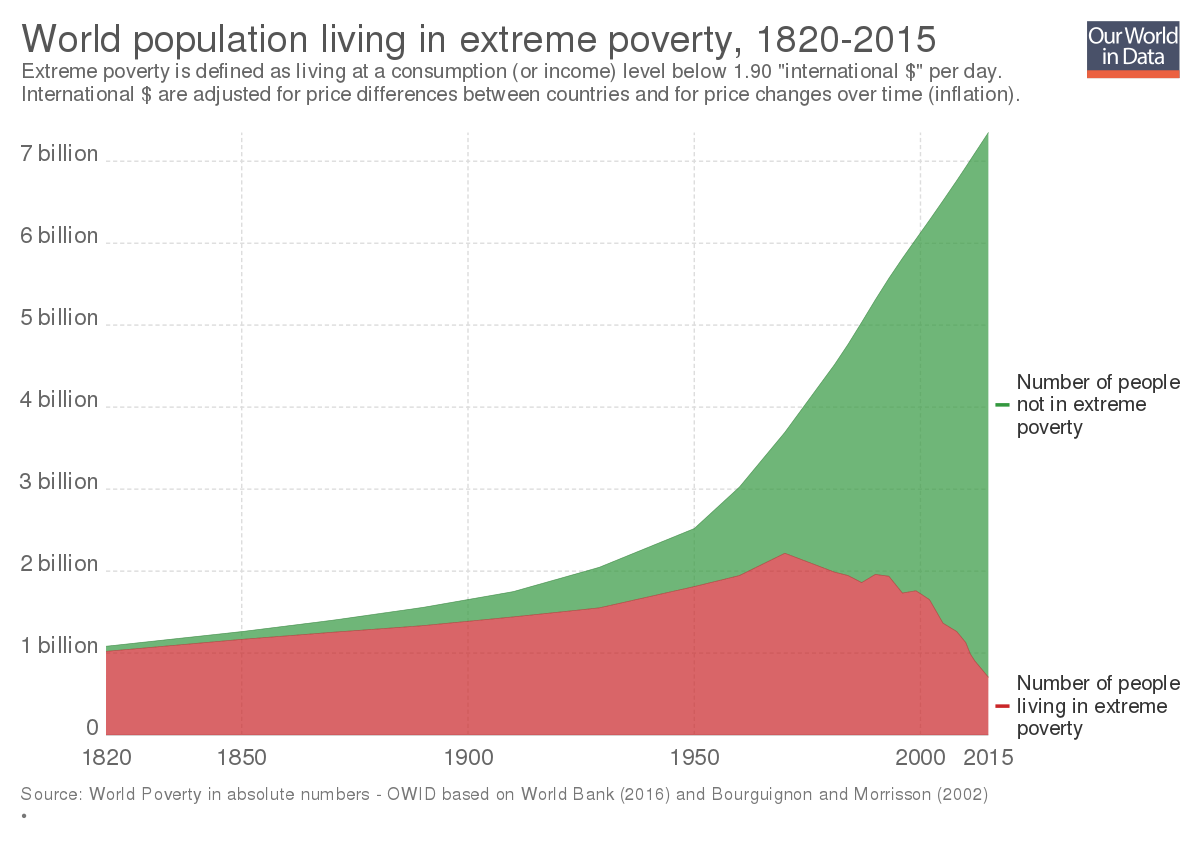
When I look at these and other examples, a few lessons become clear if I want to be someone who can achieve massive amounts of good:
- Be willing to be ambitious
- Be willing to believe and do weird things. If I can find an important idea that most people don’t believe, and can commit and take the idea seriously, I can achieve a lot.
- If it’s obvious, common knowledge, someone else has likely already done it!
- Though, on the flipside, most weird ideas are wrong - don’t open your mind so much that your brains fall out.
- Look for high-leverage!
- The world is big and inter-connected. If you want to have a massive impact, it needs to be leveraged with something powerful - an idea, a new technology, exponential growth, etc.
When I look at today’s world through this lens, I’m essentially searching for things that could become a really big deal. Most things that have been really big, world-changing deals in the past have been some kind of major emerging technology, unlocking new capabilities and new risks. Agriculture, computers, nuclear weapons, fossil fuels, electricity, etc. And when I look for technologies emerging now, still in their infancy but with a lot of potential, AI and synthetic biology stand well above the rest.
Note that these arguments work about as well for focusing on highly leveraged positive outcomes or negative outcomes. I think that, in fact, given my knowledge of AI and bio, that there are plausible negative outcomes, and that reducing the likelihood of these is tractable and more important than ensuring positive outcomes. But I’d be sympathetic to arguments to the contrary.
AI - ‘AI has a >=1% chance of x-risk within my lifetime’
The human brain is a natural example of a generally intelligent system. Evolution produced this, despite a bunch of major constraints like biological energy being super expensive, needing to fit through birth canals, using an extremely inefficient optimisation algorithm, and intelligence not obviously increasing reproductive fitness. While evolution had the major advantage of four billion years to work with, it seems highly plausible to me that humanity can do better. And, further, there’s no reason that human intelligence should be a limit on the capabilities of a digital intelligence.
On the outside view, this is incredibly important. We’re contemplating the creation of a second intelligence species! That seems like one of the most important parts of the trajectory of human civilisation - on par with the dawn of humanity, the invention of agriculture and the Industrial Revolution. And it seems crucial to ensure this goes well, especially if these systems end up much smarter than us. It seems plausible that the default fate of a less intelligent species is that of gorillas - humanity doesn’t really bear gorillas active malice, but they essentially only survive because we want them to.
Further, there are specific reasons to think that this could be really scary! AI systems mostly look like optimisation processes, which can find creative and unexpected ways to achieve these objectives. And specifying the right objective is a notoriously hard problem. And there are good reasons to believe that such a system might have an instrumental incentive to seek power and compete with humanity, especially if it has the following three properties:
- Advanced capabilities - it has superhuman capabilities on at least some kinds of important and difficult tasks
- Agentic planning - it is capable of making and executing plans to achieve objectives, based on models of the world
- Strategic awareness - it can competently reason about the effects of gaining and maintaining power over humans and the real world
See Joseph Carlsmith’s excellent report for a much more rigorous analysis of this question. I think it is by no means obvious that this argument holds, but I find it sufficiently plausible that we create a superhuman intelligence which is incentivised to seek power and successfully executes on this in a manner that causes human extinction that I’m happy to put at least a 1% chance of AI causing human extinction (my fair value is probably 10-20%, with high uncertainty).
Finally, there’s the question of timelines. Personally, I think there’s a good chance that something like deep learning language models scale to human-level intelligence and beyond (and this is a key motivation of my current research). I find the bio-anchors and scaling based methods of timelines pretty convincing as an upper bound of timelines that’s well within my lifetime. But even if deep learning is a fad, the field of AI has existed for less than 70 years! And it takes 10-30 years to go through a paradigm. It seems highly plausible that we produce human-level AI with some other paradigm within my lifetime (though reducing risk from an unknown future paradigm of AI does seem much less tractable)
Bio - ‘Biorisk has a >=0.1% chance of x-risk within my lifetime’
I hope this claim seems a lot more reasonable now than it did in 2019! While COVID was nowhere near an x-risk, it has clearly been one of the worst global disasters I’ve ever lived through, and the world was highly unprepared and bungled a lot of aspects of the response. 15 million people have died, many more were hospitalised, millions of people have long-term debilitating conditions, and almost everyone’s lives were highly disrupted for two years.
And things could have been much, much worse! Just looking at natural pandemics, imagine COVID with the lethality of smallpox (30%). Or COVID with the age profile of the Spanish Flu (most lethal in young, healthy adults, because it turns the body’s immune system against itself).
And things get much scarier when we consider synthetic biology. We live in a world where multiple labs work on gain of function research, doing crazy things like trying to breed Avian Flu (30% mortality) that’s human-to-human transmissible, and not all DNA synthesis companies will stop you trying to print smallpox viruses. Regardless of whether COVID was actually a lab leak, it seems at least plausible that it could have come from gain-of-function research on coronaviruses. And these are comparatively low-tech methods. Progress in synthetic biology happens fast!
It is highly plausible to me that, whether by accident, terrorism, or an act of war, that someone produces an engineered pathogen capable of creating a pandemic far worse than anything natural. It’s unclear that this could actually cause human extinction, but it’s plausible that something scary enough and well-deployed enough with a long incubation period could. And it’s plausible to me that something which kills 99% of people (a much lower bar) could lead to human extinction. Biorisk is not my field and I’ve thought about this much less than AI, but 0.1% within my lifetime seems like a reasonable lower bound given these arguments.
Caveats
- These are really weird beliefs! It is correct and healthy for people to be skeptical when they first encounter them.
- Though, in my opinion, the arguments are strong enough and implications important enough that it’s unreasonable to dismiss them without at least a few hours of carefully reading through arguments and trying to figure out what you believe and why.
- Further, if you disagree with them, then the moral claims I’m dismissing around strong longtermism etc may be much more important. But you should disagree with the vast majority of how the EA movement is allocating resources!
- There’s a much stronger case for something that kills almost all people, or which causes the not-necessarily-permanent collapse of civilisation, than something which kills literally everyone. This is a really high bar! Human extinction means killing everyone, including Australian farmers, people in nuclear submarines and bunkers, and people in space.
- If you’re a longtermist then this distinction matters a lot, but I personally don’t care as much. The collapse of human civilisation seems super bad to me! And averting this seems like a worthy goal for my life.
- I have an easier time seeing how AI causes extinction than bio
- There’s an implicit claim in here that it’s reasonable to invest a large amount of your resources into averting risks of extremely bad outcomes, even though we may turn out to live in a world where all that effort was unnecessary. I think this is correct to care about, but that this is a reasonable thing to disagree with!
- This is related to the idea that we should maximise expected utility, but IMO importantly weaker. Even if you disagree with the formalisation of maximising expected value, you likely still agree that it’s extremely important to ensure that bridges and planes have safety records far better than 0.1%
- But also, we’re dealing with probabilities that are small but not infinitesimal. This saves us from objections like Pascal’s Mugging - a 1% chance of AI x-risk is not a Pascal’s Mugging.
- It is also reasonable to buy these arguments intellectually, but not to feel emotionally able to motivate yourself to spend your life reducing tail risks. This stuff is hard, and can be depressing and emotionally heavy!
- Personally, I find it easier to get my motivation from other sources, like intellectual satisfaction and social proof. A big reason I like spending time around EAs is that this makes AI Safety work feel much more viscerally motivating to me, and high-status!
- This is related to the idea that we should maximise expected utility, but IMO importantly weaker. Even if you disagree with the formalisation of maximising expected value, you likely still agree that it’s extremely important to ensure that bridges and planes have safety records far better than 0.1%
- It’s reasonable to agree with these arguments, but consider something else an even bigger problem! While I’d personally disagree, any of the following seem like justifiable positions: climate change, progress studies, global poverty, factory farming.
- A bunch of people do identify as EAs, but would disagree with these claims and with prioritising AI and bio x-risk. To those people, sorry! I’m aiming this post at the significant parts of the EA movement (many EA community builders, CEA, 80K, OpenPhil, etc) who seem to put major resources into AI and bio x-risk reduction
- This argument has the flaw of potentially conveying the beliefs of ‘reduce AI and bio x-risk’ without conveying the underlying generators of cause neutrality and carefully searching for the best ways of doing good. Plausibly, similar arguments could have been made in early EA to make a “let’s fight global poverty” movement that never embraced to longtermism. Maybe a movement based around the narrative I present would miss the next Cause X and fail to pivot when it should, or otherwise have poor epistemic health.
- I think this is a valid concern! But I also think that the arguments for “holy shit, AI and bio risk seem like really big deals that the world is majorly missing the ball on” are pretty reasonable, and I’m happy to make this trade-off. “Go work on reducing AI and bio x-risk” are things I would love to signal boost!
- But I have been deliberate to emphasise that I am talking about intro materials here. My ideal pipeline into the EA movement would still emphasise good epistemics, cause prioritisation and cause neutrality, thinking for yourself, etc. But I would put front and center the belief that AI and bio x-risk are substantial and that reducing them is the biggest priority, and encourage people to think hard and form their own beliefs
- An alternate framing of the AI case is “Holy shit, AI seems really important” and thus a key priority for altruists is to ensure that it goes well.
- This seems plausible to me - it seems like the downside of AI going wrong could be human extinction, but that the upside of AI going really well could be a vastly, vastly better future for humanity.
- There are also a lot of ways this could lead to bad outcomes beyond the standard alignment failure example! Maybe coordination just becomes much harder in a fast-paced world of AI and this leads to war, or we pollute ourselves to death. Maybe it massively accelerates technological progress and we discover a technology more dangerous than nukes and with a worse Nash equilibria and don’t solve the coordination problem in time.
- I find it harder to imagine these alternate scenarios literally leading to extinction, but they might be more plausible and still super bad!
- There are some alternate pretty strong arguments for this framing. One I find very compelling is drawing an analogy between exponential growth in the compute used to train ML models, and the exponential growth in the number of transistors per chip of Moore’s Law.
- Expanding upon this, historically most AI progress has been driven by increasing amounts of computing power and simple algorithms that leverage them. And the amount of compute used in AI systems is growing exponentially (doubling every 3.4 months - compared to Moore’s Law’s 2 years!). Though the rate of doubling is likely to slow down - it’s much easier to increase the amount of money spent on compute when you’re spending less than the millions spent on payroll for top AI researchers than when you reach the order of magnitude of figures like Google’s $26bn annual R&D - it also seems highly unlikely to stop completely.
- Under this framing, working on AI now is analogous to working with computers in the 90s. Though it may have been hard to predict exactly how computers would change the world, there is no question that they did, and it seems likely that an ambitious altruist could have gained significant influence over how this went and nudged it to be better.
- I also find this framing pretty motivating - even if specific stories I’m concerned by around eg inner alignment are wrong, I can still be pretty confident that something important is happening in AI, and my research likely puts me in a good place to influence this for the better.
- I work on interpretability research, and these kind of robustness arguments are one of the reasons I find this particularly motivating!
BenMillwood @ 2022-02-14T01:13 (+59)
My main criticism of this post is that it seems to implicitly suggest that "the core action relevant points of EA" are "work on AI or bio", and doesn't seem to acknowledge that a lot of people don't have that as their bottom line. I think it's reasonable to believe that they're wrong and you're right, but:
- I think there's a lot that goes into deciding which people are correct on this, and only saying "AI x-risk and bio x-risk are really important" is missing a bunch of stuff that feels pretty essential to my beliefs that x-risk is the best thing to work on,
- this post seems to frame your pitch as "the new EA pitch", and it's weird to me to omit from your framing that lots of people that I consider EAs are kind of left out in the cold by it.
Neel Nanda @ 2022-02-26T11:05 (+10)
This is a fair criticism! My short answer is that, as I perceive it, most people writing new EA pitches, designing fellowship curricula, giving EA career advice, etc, are longtermists and give pitches optimised for producing more people working on important longtermist stuff. And this post was a reaction to what I perceive as a failure in such pitches by focusing on moral philosophy. And I'm not really trying to engage with the broader question of whether this is a problem in the EA movement. Now OpenPhil is planning on doing neartermist EA movement building funding, maybe this'll change?
Personally, I'm not really a longtermist, but think it's way more important to get people working on AI/bio stuff from a neartermist lens, so I'm pretty OK with optimising my outreach for producing more AI and bio people. Though I'd be fine with low cost ways to also mention 'and by the way, global health and animal welfare are also things some EAs care about, here's how to find the relevant people and communities'.
BenMillwood @ 2022-02-27T22:50 (+17)
I think to the extent you are trying to draw the focus away from longtermist philosophical arguments when advocating for people to work on extinction risk reduction, that seems like a perfectly reasonable thing to suggest (though I'm unsure which side of the fence I'm on).
But I don't want people casually equivocating between x-risk reduction and EA, relegating the rest of the community to a footnote.
- I think it's a misleading depiction of the in-practice composition of the community,
- I think it's unfair to the people who aren't convinced by x-risk arguments,
- I think it could actually just make us worse at finding the right answers to cause prioritization questions.
Neel Nanda @ 2022-02-26T11:06 (+3)
- I think there's a lot that goes into deciding which people are correct on this, and only saying "AI x-risk and bio x-risk are really important" is missing a bunch of stuff that feels pretty essential to my beliefs that x-risk is the best thing to work on
Can you say more about what you mean by this? To me, 'there's a 1% chance of extinction in my lifetime from a problem that fewer than 500 people worldwide are working on' feels totally sufficient
BenMillwood @ 2022-02-27T22:18 (+11)
It's not enough to have an important problem: you need to be reasonably persuaded that there's a good plan for actually making the problem better, the 1% lower. It's not a universal point of view among people in the field that all or even most research that purports to be AI alignment or safety research is actually decreasing the probability of bad outcomes. Indeed, in both AI and bio it's even worse than that: many people believe that incautious action will make things substantially worse, and there's no easy road to identifying which routes are both safe and effective.
I also don't think your argument is effective against people who already think they are working on important problems. You say, "wow, extinction risk is really important and neglected" and they say "yes, but factory farm welfare is also really important and neglected".
To be clear, I think these cases can be made, but I think they are necessarily detailed and in-depth, and for some people the moral philosophy component is going to be helpful.
Neel Nanda @ 2022-02-27T22:36 (+2)
Fair point re tractability
What argument do you think works on people who already think they're working on important and neglected problems? I can't think of any argument that doesn't just boil down to one of those
BenMillwood @ 2022-02-27T23:02 (+4)
I don't know. Partly I think that some of those people are working on something that's also important and neglected, and they should keep working on it, and need not switch.
HaydnBelfield @ 2022-02-11T13:36 (+59)
I think this is a good demonstration that the existential risk argument can go through without the longtermism argument. I see it as helpfully building on Carl Shulman's podcast.
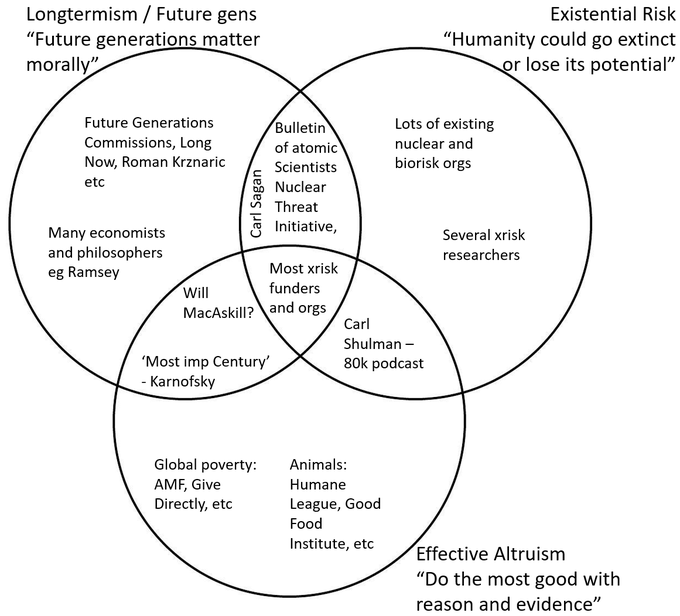
To extend it even further - I posted the graphic below on twitter back in Nov. These three communities & sets of ideas overlap a lot and I think reinforce one another, but they are intellectually & practically separable, and there are people in each section doing great work. My personal approach is to be supportive of all 7 sections, but recognise just because someone is in one section doesn't mean they have to be, or are, committed to others.
Mauricio @ 2022-02-11T05:43 (+30)
Thanks for this!
It’s reasonable to agree with these arguments, but consider something else an even bigger problem! While I’d personally disagree, any of the following seem like justifiable positions: climate change, progress studies, global poverty, factory farming.
This seems to me like more than a caveat--I think it reverses this post's conclusions that "the common discussion of longtermism, future generations and other details of moral philosophy in intro materials is an unnecessary distraction," and disagreement on longtermism has "basically no important implications for [your, and implicitly, others'] actions."
After all, if (strong) longtermism has very big, unique implications about what cause areas people should focus on (not to mention implications about whether biosecurity folks should focus on preventing permanent catastrophes or more temporary ones)... aren't those some pretty important implications for our actions?
That seems important for introductory programs; if longtermism is necessary to make the case that AI/bio are most important (as opposed to "just" being very important), then introducing longtermism will be helpful for recruiting EAs to work on these issues.
Neel Nanda @ 2022-02-11T11:51 (+25)
TL;DR I think that in practice most of these disagreements boil down to empirical cruxes not moral ones. I'm not saying that moral cruxes are literally irrelevant, but that they're second order, only relevant to some people, and only matter if people buy the empirical cruxes, and so should not be near the start of the outreach funnel but should be brought up eventually
Hmm, I see your point, but want to push back against this. My core argument is essentially stemming from an intuition that you have a limited budget to convince people of weird ideas, and that if you can only convince them of one weird ideas it should be the empirical claims about the probability of x-risk, not the moral claims about future people. My guess is that most people who genuinely believe these empirical claims about x-risk will be on board with most of the action relevant EA recommendations. While people who buy the moral claims but NOT the empirical claims will massively disagree with most EA recommendations.
And, IMO, the empirical claims are much more objective than the moral claims, and are an easier case to make. I just don't think you can make moral philosophy arguments that are objectively convincing.
I'm not arguing that it's literally useless to make the moral arguments - once you've convinced someone of the first weird idea, they're probably willing to listen to the second weird idea! But if you fail to convince them that the first weird idea is worth taking seriously they probably aren't. And I agree that once you get into actually working on a field there may be subtle differences re trading off short term disasters against long-term disasters, which can really matter for the work you do. But IMO most intro material is just trying to convey an insight like "try to work on bio/AI", and that subtle disagreements about which research agendas and subfields most matter are things that can be hashed out later. In the same way that I wouldn't want intro fellowships to involve a detailed discussion of the worth of MIRI vs DeepMind Safety's research agenda.
Also, if the failure mode of this advice is a bunch of people trying to prevent biorisks that kill billions of people but doesn't actually permanently derail civilisation, I'm pretty fine with that? That feels like a great outcome to me.
Further, I think that prioritising AI or bio over these other problems is kinda obviously the right thing to do from just the perspective of ensuring the next 200 years go well, and probably from the perspective of ensuring the next 50 go well. To the degree that people disagree, IMO it tends to come from empirical disagreements, not moral ones. Eg people who think that climate change is definitely an x-risk - I think this is an incorrect belief, but that you resolve it by empirically discussing how bad climate change is, not by discussing future generations. This may just be my biased experience, but I often meet people who have different cause prio and think that eg AI Safety is delusional, but very rarely meet people with different cause prio who agree with me about the absolute importance of AI and bio.
One exception might be people who significantly prioritise animal welfare, and think that the current world is majorly net bad due to factory farming? But that the future world will likely contain far less factory farming and many more happy humans. But if your goal is to address that objection, IMO current intro materials still majorly miss the mark.
Mauricio @ 2022-02-11T18:18 (+13)
Hm, I think I have different intuitions about several points.
you have a limited budget to convince people of weird ideas
I'm not sure this budget is all that fixed. Longtermism pretty straightforwardly implies that empirical claims about x-risk are worth thinking more about. So maybe this budget grows significantly (maybe differentially) if someone gets convinced of longtermism. (Anecdotally, this seems true--I don't know any committed longtermist who doesn't think empirical claims about x-risk are worth figuring out, although admittedly there's confounding factors.)
My guess is that most people who genuinely believe these empirical claims about x-risk will be on board with most of the action relevant EA recommendations.
Maybe some of our different intuitions are also coming from thinking about different target audiences. I agree that simplifying pitches to just empirical x-risk stuff would make sense when talking to most people. Still, the people who sign up for intro programs aren't most people--they're strongly (self-)selected for interest in prioritization, interest in ethical reasoning, and for having ethically stronger competing demands on their careers.
And, IMO, the empirical claims are much more objective than the moral claims, and are an easier case to make. I just don't think you can make moral philosophy arguments that are objectively convincing.
Sure, they're more objective, but I don't see why that's relevant--to be convincing, an argument doesn't need to be objectively convincing; it just needs to be convincing to its audience. (And if that weren't the case, we might be in trouble, since the notion of "objectively convincing arguments" seems confused.)
(Tangentially, there's also the question about whether arguments over subjective probabilities can be entirely objective/empirical.)
Theoretical points aside, the empirical arguments also don't seem to me like an easier case to make. The minimum viable case you present for AI is over a page long, while the minimum viable case for longtermism is just a few sentences (i.e., a slightly more elaborate version of, "Future people matter just as much as current people, and there could be a lot of future people.")
Also, if the failure mode of this advice is a bunch of people trying to prevent biorisks that kill billions of people but doesn't actually permanently derail civilisation, I'm pretty fine with that? That feels like a great outcome to me.
Whether this outcome involves a huge waste of those individuals' potential for impact seems downstream of disagreement on longtermism. And of course we can conclude that longtermism should be excluded from the intro program if we're confidently assuming that it's wrong. I thought the more interesting question that your post was raising was whether it would make sense for the intro program to cover longtermism, under the assumption that it's true (or under agnosticism).
One exception might be people who significantly prioritise animal welfare, and think that the current world is majorly net bad due to factory farming? But that the future world will likely contain far less factory farming and many more happy humans. But if your goal is to address that objection, IMO current intro materials still majorly miss the mark.
I agree that intro materials should include empirical stuff. If we're talking specifically about intro materials that do include that as well as the philosophical stuff, then I don't see why they majorly miss the mark for these people. I think both the empirical and philosophical stuff are logically necessary for convincing these people (and I suspect these people tend to be unusually good at figuring stuff out and therefore pretty valuable to convince, although I'm biased).
I tentatively agree with most of your other points.
Neel Nanda @ 2022-02-12T06:29 (+4)
Thanks, this is some great pushback. Strongly upvoted.
Re long-termists will think hard about x-risk, that's a good point. Implicitly I think I'm following the intuition that people don't really evaluate a moral claim in isolation. And that when someone considers how convinced to be by long-termism, they're asking questions like "does this moral system imply important things about my actions?" And that it's much easier to convince them of the moral claim once you can point to tractable action relevant conclusions.
Re target audiences, I think we are imagining different settings. My read from running intro fellowships is that lots of people find long-termism weird, and I implicitly think that many people who ultimately end up identifying as long-termist still have a fair amount of doubt but are deferring to their perception of the EA consensus. Plus, even if your claim IS true, to me that would imply that we're selecting intro fellows wrong!
Implicit model: People have two hidden variables - 'capacity to be convinced of long-termism' and 'capacity to be convinced of x-risk'. These are not fully correlated, and I'd rather only condition on the second one, to maximise the set of reachable people (I say as someone identifying with the second category much more than the first!)
This also addresses your third point - I expect the current framing is losing a bunch of people who buy x risk but not long-termism, or who are eg suspicious of highly totalising arguments like Astronomical Waste that imply 'it is practically worthless to do things that just help people alive today'.
Though it's fair to say that there are people who CAN be reached by long-termism much more easily than x-risk. I'd be pro giving them the argument for long-termism and some intuition pumps and seeing if it grabs people, so long as we also ensure that the message doesn't implicitly feel like "and if you don't agree with long-termism you also shouldn't prioritise x-risk". The latter is the main thing I'm protecting here
Re your fourth point, yeah that's totally fair, point mostly conceded. By the lights of long-termism I guess I'd argue that the distinction between work to prevent major disasters and work to ruthlessly focus on x-risk isn't that strong? It seems highly likely that work to prevent natural pandemics is somewhat helpful to prevent engineered pandemics, or work to prevent mild engineered pandemics is useful to help prevent major ones. I think that work to reduce near-term problems in AI systems is on average somewhat helpful for long-term safety. It is likely less efficient, but maybe only 3-30x? And I think we should often be confused and uncertain about our stories for how to just prevent the very worst disasters, and this kind of portfolio is more robust to mistakes re the magnitude of different disasters. Plus, I expect a GCBR to heavily destabilise the world and to be an x-risk increaser by making x risks that can be averted with good coordination more likely
Mauricio @ 2022-02-12T07:26 (+4)
Thanks! Great points.
people don't really evaluate a moral claim in isolation. [...] And that it's much easier to convince them of the moral claim once you can point to tractable action relevant conclusions.
This seems right--I've definitely seen people come across longtermism before coming across x-risks, and have a reaction like, "Well, sure, but can we do anything about it?" I wonder if this means intro programs should at least flip the order of materials--put x-risks before longtermism.
My read from running intro fellowships is that lots of people find long-termism weird, and I implicitly think that many people who ultimately end up identifying as long-termist still have a fair amount of doubt but are deferring to their perception of the EA consensus. Plus, even if your claim IS true, to me that would imply that we're selecting intro fellows wrong!
Oh interesting, in my experience (from memory, which might be questionable) intro fellows tend to theoretically buy (at least weak?) longtermism pretty easily. And my vague impression is that a majority of professional self-identified longtermists are pretty comfortable with the idea--I haven't met anyone who's working on this stuff and says they're deferring on the philosophy (while I feel like I've often heard that people feel iffy/confused about the empirical claims).
And interesting point about the self-selection effects being ones to try to avoid! I think those self-selection effects mostly come from the EA branding of the programs, so it's not immediately clear to me how those self-selection effects can be eliminated without also losing out on some great self-selection effects (e.g., selection for analytical thinkers, or for people who are interested in spending their careers helping others).
I'd be pro giving them the argument for long-termism and some intuition pumps and seeing if it grabs people, so long as we also ensure that the message doesn't implicitly feel like "and if you don't agree with long-termism you also shouldn't prioritise x-risk". The latter is the main thing I'm protecting here
Yeah, that's fair.
It is likely less efficient, but maybe only 3-30x
I'm sympathetic to something along these lines. But I think that's a great case (from longtermists' lights) for keeping longtermism in the curriculum. If one week of readings has a decent chance of boosting already-impactful people's impact by, say, 10x (by convincing them to switch to 10x more impactful interventions), that seems like an extremely strong reason for keeping that week in the curriculum.
Neel Nanda @ 2022-02-12T09:18 (+4)
I haven't met anyone who's working on this stuff and says they're deferring on the philosophy (while I feel like I've often heard that people feel iffy/confused about the empirical claims).
Fair - maybe I feel that people mostly buy 'future people have non-zero worth and extinction sure is bad', but may be more uncertain on a totalising view like 'almost all value is in the far future, stuff today doesn't really matter, moral worth is the total number of future people and could easily get to >=10^20'.
I'm sympathetic to something along these lines. But I think that's a great case (from longtermists' lights) for keeping longtermism in the curriculum. If one week of readings has a decent chance of boosting already-impactful people's impact by, say, 10x (by convincing them to switch to 10x more impactful interventions), that seems like an extremely strong reason for keeping that week in the curriculum.
Agreed! (Well, by the lights of longtermism at least - I'm at least convinced that extinction is 10x worse than civilisational collapse temporarily, but maybe not 10^10x worse). At this point I feel like we mostly agree - keeping a fraction of the content on longtermism, after x-risks, and making it clear that it's totally legit to work on x-risk without buying longtermism would make me happy
Neel Nanda @ 2022-02-12T06:31 (+2)
Re your final point, I mostly just think they miss the mark by not really addressing the question of what the long-term distribution of animal welfare looks like (I'm personally pretty surprised by the comparative lack of discussion about how likely our Lightcone is to be net bad by the lights of people who put significant weight on animal welfare)
Mauricio @ 2022-02-12T07:37 (+2)
Maybe I'm getting mixed up, but weren't we talking about convincing people who believe that "the future world will likely contain far less factory farming and many more happy humans"? (I.e., the people for whom the long-term distribution of animal welfare is, by assumption, not that much of a worry)
Maybe you had in mind the people who (a) significantly prioritize animal welfare, and (b) think the long-term future will be bad due to animal welfare issues? Yeah, I'd also like to see more good content for these people. (My sense is there's been a decent amount of discussion, but it's been kind of scattered (which also makes it harder to feature in a curriculum). Maybe you've already seen all this, but I personally found section 1.2 of the GPI agenda helpful as a compilation of this discussion.)
Neel Nanda @ 2022-02-12T09:20 (+4)
Ah sorry, the original thing was badly phrased. I meant, a valid objection to x-risk work might be "I think that factory farming is really really bad right now, and prioritise this over dealing with x-risk". And if you don't care about the distant future, that argument seems pretty legit from some moral perspectives? While if you do care about the distant future, you need to answer the question of what the future distribution of animal welfare looks like, and it's not obviously positive. So to convince these people you'd need to convince them that the distribution is positive.
michaelchen @ 2022-02-11T18:08 (+11)
Suppose it takes $100 billion to increase our chance of completely averting extinction (or the equivalent) by 0.1%. By this, I don't mean averting an extinction event by having it be an event that only kills 98% of people, or preventing the disempowerment of humanity due to AI; I mean that we save the entire world's population. For convenience, I'll assume no diminishing marginal returns. If we only consider the 7 generations of lost wellbeing after the event, and compute $100 billion / (7 * 8 billion * 0.1%), then we get a cost-effectiveness of $1,780 to save a life. With the additional downside of being extremely uncertain, this estimate is only in the same ballpark as the Malaria Consortium's seasonal chemoprevention program (which takes ~$4,500 to save a life). It's also complicated by the fact that near-term animal charities, etc. are funding-constrained while longtermist orgs are not so much. Unlike a strong longtermist view, it's not at all clear under this view that it would be worthwhile to pivot your career to AI safety or biorisk, instead of taking the more straightforward route of earning to give to standard near-term interventions.
Thomas Kwa @ 2022-02-11T18:37 (+8)
My best estimate of price to decrease extinction risk by 0.1% is under $10B. Linch has only thought about this for a few hours, but he's pretty well informed on the state of megaprojects, plus others have thought more than that. This is consistent with my own estimates too.
Benjamin_Todd @ 2022-02-13T22:47 (+13)
One thing I find really tricky about this is figuring out where the margin will end up in the future.
It seems likely to me that $100bn will be spent on x-risk reduction over the next 100 years irrespective of what I do. My efforts mainly top up that pot.
Personally I expect the next $10bn might well reduce x-risk by ~1% rather than 0.1%; but it'll be far less once we get into the next $90bn and then $100bn after it. It might well be a lot less than 0.1% per $10bn billion.
Linch @ 2022-02-14T19:01 (+3)
Yes this is a really good point. I meant to make it when I first read Thomas' comment but then forgot about this as I was typing up my own comment.
I think
it'll be far less once we get into the next $90bn and then $100bn after it. It might well be a lot less than 0.1% per $10bn billion.
Might be a plausible position after the movement has a few more years of experience and researchers have put a few thousand hours of research and further thinking into this question, but right now we (or at least I) don't have a strong enough understanding of the landscape to confidently believe in very low cost-effectiveness for the last dollar. In slightly more mathy terms, we might have a bunch of different cost-effectiveness distributions in the ensemble that forms our current prior, which means we can't go very low (or high) if we do a weighted average across them.
Benjamin_Todd @ 2022-02-14T20:00 (+2)
The point about averaging over several cost-effective distributions is interesting!
Linch @ 2022-02-14T22:43 (+2)
If you find the analogy helpful, my comment here mirrors Toby's on why having a mixed prior on the Hinge of History question is reasonable.
Linch @ 2022-02-12T18:19 (+11)
(I thought about it for a few more hours and haven't changed my numbers much).
I think it's worth highlighting that our current empirical best guesses (with a bunch of uncertainty) is that catastrophic risk mitigation measures are probably better in expectation than near-term global health interventions, even if you only care about currently alive people.
But on the other hand, it's also worth highlighting that you only have 1-2 OOMs to work with, so if we only care about present people, the variance is high enough that we can easily change our minds in the future. Also, e.g. community building interventions or other "meta" interventions in global health (e.g. US foreign aid research and advocacy) may be better even on our current best guesses. Neartermist animal interventions may be more compelling as well.
Finally, what axilogies you have would have implications for what you should focus on within GCR work. Because I'm personally more compelled by the longtermist arguments for existential risk reduction than neartermist ones, I'm personally comparatively more excited about disaster mitigation, robustness/resilience, and recovery, not just prevention. Whereas I expect the neartermist morals + empirical beliefs about GCRs + risk-neutrality should lead you to believe that prevention and mitigation is worthwhile, but comparatively little resources should be invested in disaster resilience and recovery for extreme disasters.
Linch @ 2022-02-14T18:56 (+2)
Why was this comment downvoted a bunch?
Charles He @ 2022-02-14T21:00 (+4)
Here you go:

Why was this comment downvoted a bunch?
I think your content and speculation in your comment was both principled and your right to say. My guess is that a comment that comes close to saying that an EA cause area has a different EV per dollar than others can get this sort of response.
This is a complex topic. Here’s some rambling, verbose thoughts , that might be wrong, and that you and others have might have already thought about:
- This post exposes surface area for "disagreement of underlying values" in EA.
- Some people don’t like a lot of math or ornate theories. For someone who is worried that the cause area representing their values is being affected, it can be easy to perceive adding a lot of math or theories as overbearing.
- In certain situations, I believe "underlying values" drive a large amount of the karma of posts and comments, boosting messages whose content otherwise doesn’t warrant it. I think this is important to note, as it reduces communication, and can be hard to fix (or even observe) and one reason it is good to give this some attention or "work on this"[1].
- I don't think content or karma on the EA forum has a direct, simple relationship to all EA opinion or opinion of those that work in EA areas. However, I know someone who has information and models about related issues and opinions from EA's "offline" and I think this suggests these disagreements are far from an artifact of the forum or "very online".
- I see the underlying issues as tractable and fixable.
- There is a lot of writing in this comment, but this comes from a different perspective as a commenter. For a commenter, I think if they take the issues too seriously, I think it can be overbearing and make it unfairly hard to write things.
- As a commenter, if they wanted to address this, talking to a few specific people and listening can help.
- ^
I think I have some insight because of this project, but it is not easy for me to immediately explain.
Linch @ 2022-02-14T22:43 (+6)
I mentioned this before, but again I don't think strong-upvoting comments asking why they received downvotes from others is appropriate!
Neel Nanda @ 2022-02-11T18:22 (+3)
It's not at all clear under this view that it would be worthwhile to pivot your career to AI safety or biorisk, instead of taking the more straightforward route of earning to give to standard near-term interventions.
I'd disagree with this. I think the conversion of money to labour is super inefficient on longtermism, and so this analogy breaks down. Sure, maybe I should donate to the Maximum Impact Fund rather than LTFF. But it's really hard to usefully convert billions of dollars into useful labour on longtermist stuff. So, as someone who can work on AI Safety, there's a major inefficiency factor if I pivot to ETG. I think the consensus basically already is that ETG for longtermism is rarely worth it, unless you're incredibly good at ETG.
Linch @ 2022-02-11T15:24 (+10)
I'm not saying this consideration is overriding, but one reason you might want moral agreement and not just empirical agreement is that people who agree with you empirically but not morally may be more interested in trading x-risk points for ways to make themselves more powerful.
I don't think this worry is completely hypothetical, I think there's a fairly compelling story where both DeepMind and OpenAI were started by people who agree with a number of premises in the AGI x-risk argument but not all of them.
Fortunately this hasn't happened in bio (yet), at least to my knowledge.
IanDavidMoss @ 2022-02-11T14:50 (+7)
if the failure mode of this advice is a bunch of people trying to prevent biorisks that kill billions of people but doesn't actually permanently derail civilisation, I'm pretty fine with that? That feels like a great outcome to me.
For me this is the key point. I feel that the emphasis on longtermism for longtermism's sake in some influential corners of EA might have the effect of prolonging the neglectedness of catastrophic-but-not-existential risks, which IMHO are far more likely and worth worrying about. It's not exactly a distraction since work on x-risks is generally pretty helpful for work on GCRs as well, but I do think Neel's approach would bring more people into the fold.
antimonyanthony @ 2022-02-13T09:00 (+4)
Note that your "tl;dr" in the OP is a stronger claim than "these empirical claims are first order while the moral disagreements are second order." You claimed that agreement on these empirical claims is "enough to justify the core action relevant points of EA." Which seems unjustified, as others' comments in this thread have suggested. (I think agreement on the empirical claims very much leaves it open whether one should prioritize, e.g., extinction risks or trajectory change.)
Benjamin_Todd @ 2022-02-13T22:38 (+27)
I'm sympathetic to this style of approach. I attempted to do a similar "x-risk is a thing" style pitch here.
Two wrinkles with it:
- Many people when asked state they think xrisk is likely. I agree it's not clear if they 'really believe' this, but just saying "xrisk is 1%" might not sound very persuasive if they already say it's higher than that.
- It's not clear that AI safety and GCBRs are the top priorities if you don't put significant weight on future generations, due to the diminishing returns that are likely over the next 100 years.
Both points mean I think it is important to bring in longtermism at some point, though it doesn't need to be the opening gambit.
If I was going to try to write my article again, I'd try to mention pandemics more early on, and I'd be more cautious about the 'most people think x-risk is low' claim.
One other thing to play with: You could experiment with going even more directly for 'x-risk is a thing' and not having the lead in section on leverage. With AI, what I've been playing with is opening with Katja's survey results: "even the people developing AGI say they think it has a 10% chance of ending up with an extremely bad outcome 'e.g. extinction'." And then you could try to establish that AGI is likely to come in our lifetimes with bio anchors: "if you just extrapolate forward current trends, it's likely we have ML models bigger than human brains in our lifetimes."
CarolineJ @ 2022-02-14T19:19 (+26)
Thanks, Neel, this got me thinking a bunch!
I think this approach may have a lot of benefits. But it also at least two (related) costs:
- We may miss something very core to EA: "EA is a question". EA is trying to figure out how to do the most good, and then do it. So I think that this big focus on EA as being a "prioritization-focused" movement makes it very special and if there were pitches focused directly on reducing x-risk, we would miss something very core to the movement (and I'm not sure how I feel about it). (as a personal anecdote, I think that it's the question of EA really made me able to change my mind, and move from working on development aid to climate change to AI).
- We may reduce the quality of truth-seeking/rationality/"Scout Mindset" of the movement by saying that we already have the answer. By treating EA as a question, the movement has attracted a lot of people who (I think) have interest in being rational and having good epistemic. These norms are very important. Rationality and good epistemics are very valuable to do good, so we should think about how to keep those excellent norms if we shift to a pitch which is "we know how to do the most good, and it's by reducing x-risks from AI and bio!" - which maybe is already the pitch of several existing organizations who want to change the world. So the pitch may get a different crew. (maybe a great crew too, but not the same).
In summary, having way more people working on reducing x-risk seems great. But we want to make sure that the "truth-seeking" norms of this movement stay really really high.
Neel Nanda @ 2022-02-26T11:12 (+6)
But we want to make sure that the "truth-seeking" norms of this movement stay really really high.
I think there's two similar but different things here - truth-seeking and cause neutrality. Truth-seeking is the general point of 'it's really important to find truth, look past biases, care about evidence, etc' and cause neutrality is the specific form of truth seeking that impact between different causes can differ enormously and that it's worth looking past cached thoughts and the sunk cost fallacy to be open to moving to other causes.
I think truth-seeking can be conveyed well without cause neutrality - if you don't truth-seek, you will be a much less effective person working on global development. I think this is pretty obvious, and can be made with any of the classic examples (PlayPumps, Scared Straight, etc).
People may absorb the idea of truth-seeking without cause neutrality. And I think I feel kinda fine about this? Like, I want the EA movement to still retain cause neutrality. And I'd be pro talking about it. But I'd be happy with intro materials getting people who want to work on AI and bio without grokking cause neutrality.
In particular, I want to distinguish between 'cause switching because another cause is even more important' and 'cause switching because my cause is way less important than I thought'. I don't really expect to see another cause way more important than AI or bio? Something comparably important, or maybe 2-5x more important, maybe? But my fair value on AI extinction within my lifetime is 10-20%. This is really high!!! I don't really see there existing future causes that are way more important than that. And, IMO, the idea of truth-seeking conveyed well should be sufficient to get people to notice if their cause is way less important than they thought in absolute terms (eg, work on AI is not at all tractable).
CarolineJ @ 2022-03-21T18:20 (+3)
(Note: I have edited this comment after finding even more reasons to agree with Neel)
I find your answer really convincing so you made me change my mind!
- On truth-seeking without the whole "EA is a question": If someone made the case for existential risks using quantitative and analytical thinking, that would work. We should just focus on just conveying these ideas in a rational and truth-seeking way.
- On cause-neutrality: Independently of what you said, you may make the case that the probability of finding a cause that is even higher impact than AI and bio is extremely low, given how bad those risks are; and given that we have given a few years of analysis already. We could have an organization focused on finding cause X, but the vast majority of people interested in reducing existential risks should just focus on that directly.
- On getting to EA principles and ideas: Also, if people get interested in EA through existential risks, they can also go to EA principles later on; just like people get interested in EA through charity effectiveness; and change their minds if they find something even better to work on.
- Moreover, if we do more outreach that is "action oriented", we may just find more "action oriented people"... which actually sounds good? We do need way more action.
MichaelPlant @ 2022-02-11T16:22 (+16)
I guess I'm not wild about this approach, but I think it is important to consider (and sometimes use) alternative frames, so thanks for the write-up!
To articulate my worries, I suppose it's that this implies a very reductionist and potentially exclusionary idea of doing good; it's sort of "Holy shit, X-risks matters (and nothing else does)". On any plausible conception of EA, we want people doing a whole bunch of stuff to make things better.
The other bit that irks me is that it does not follow, from the mere fact that's there's a small chance of something bad happening, that preventing that bad thing is the most good you can do. I basically stop listening to the rest of any sentence that starts with "but if there's even a 1% chance that ..."
FWIW, the framing of EA I quite like are versions of "we ought to do good; doing more good is better"
kokotajlod @ 2022-02-12T02:31 (+19)
Think about how hard you would try to avoid getting the next wave of COVID if it turned out it had a 1% chance of killing you. Not even 1% conditional on you getting it; 1% unconditional. (So for concreteness, imagine that your doctor at the next checkup tells you that based on your blood type and DNA you actually have a 10% chance of dying from COVID if you were to get it, and based on your current default behavior and prevalence in the population it seems like you have a 10% chance of getting it before a better vaccine for your specific blood type is developed.)
Well, I claim, you personally are more than 1% likely to die of x-risk. (Because we all are.)
Neel Nanda @ 2022-02-11T18:29 (+11)
To articulate my worries, I suppose it's that this implies a very reductionist and potentially exclusionary idea of doing good; it's sort of "Holy shit, X-risks matters (and nothing else does)". On any plausible conception of EA, we want people doing a whole bunch of stuff to make things better.
I'd actually hoped that this framing is less reductionist and exclusionary. Under total utilitarianism + strong longtermism, averting extinction is the only thing that matters, everything else is irrelevant. Under this framing, averting extinction from AI is, say, maybe 100x better than totally solving climate change. And AI is comparatively much more neglected and so likely much more tractable. And so it's clearly the better thing to work on. But it's only a few orders of magnitude, coming from empirical details of the problem, rather than a crazy, overwhelming argument that requires estimating the number of future people, the moral value of digital minds, etc.
The other bit that irks me is that it does not follow, from the mere fact that's there's a small chance of something bad happening, that preventing that bad thing is the most good you can do. I basically stop listening to the rest of any sentence that starts with "but if there's even a 1% chance that ..."
I agree with the first sentence, but your second sentence seems way too strong - it seems bad to devote all your efforts to averting some tiny tail risk, but I feel pretty convinced that averting a 1% chance of a really bad thing is more important than averting a certainty of a kinda bad thing (operationalising this as 1000x less bad, though it's fuzzy). But I agree that the preference ordering of (1% chance of really bad thing) vs (certainty of maybe bad thing) is unclear, and that it's reasonable to reject eg naive attempts to calculate expected utility.
Neel Nanda @ 2022-02-12T06:58 (+4)
I'm curious, do you actually agree with the two empirical claims I make in this post? (1% risk of AI x-risk, 0.1% of bio within my lifetime)
JackM @ 2022-02-11T22:00 (+4)
I basically stop listening to the rest of any sentence that starts with "but if there's even a 1% chance that ..."
Can you say more about why you dismiss such arguments? Do you have a philosophical justification for doing so?
Khorton @ 2022-02-12T03:02 (+16)
I've seen a lot of estimates in this world that are more than 100x off so I'm also pretty unconvinced by "if there's even a 1% chance". Give me a solid reason for your estimate, otherwise I'm not interested.
JackM @ 2022-02-12T07:11 (+4)
These arguments appeal to phenomenal stakes implying that, using expected value reasoning, even a very small probability of the bad thing happening means we should try to reduce the risk, provided there is some degree of tractability in doing so.
Is the reason you dismiss such arguments because:
- You reject EV reasoning if the probabilities are sufficiently small (i.e. anti-fanaticism)
- There are issues with this response e.g. here to give one
- You think the probabilities cited are too arbitrary so you don't take the argument seriously
- But the specific numerical probabilities themselves are not super important in longtermist cases. Usually, because of the astronomical stakes, the important thing is that there is a "non-negligible" probability decrease we can achieve. Much has been written about why there might be non-negligible x-risk from AI or biosecurity etc. and that there are things we can do to reduce this risk. The actual numerical probabilities themselves are insanely hard to estimate, but it's also not that important to do so.
- You reject the arguments that we can reduce x-risk in a non-negligible way (e.g. from AI, biosecurity etc.)
- You reject phenomenal stakes
- Some other reason?
Khorton @ 2022-02-12T11:25 (+6)
When people say "even if there's a 1% chance" without providing any other evidence, I have no reason to believe there is a 1% chance vs 0.001% or a much smaller number.
JackM @ 2022-02-12T13:29 (+4)
I think you're getting hung up on the specific numbers which I personally think are irrelevant. What about if one says something like:
"Given arguments put forward by leading AI researchers such as Eliezer Yudkowsky, Nick Bostrom, Stuart Russell and Richard Ngo, it seems that there is a very real possibility that we will create superintelligent AI one day. Furthermore, we are currently uncertain about how we can ensure such an AI would be aligned to our interests. A superintelligent AI that is not aligned to our interests could clearly bring about highly undesirable states of the world that could persist for a very long time, if not forever. There seem to be tractable ways to increase the probability that AI will be aligned to our interests, such as through alignment research or policy/regulation meaning such actions are a very high priority".
There's a lot missing from that but I don't want to cover all the object-level arguments here. My point is that waving it all away by saying that a specific probability someone has cited is arbitrary seems wrong to me. You would need to counter the object-level arguments put forward by leading researchers. Do you find those arguments weak?
Neel Nanda @ 2022-02-12T12:48 (+4)
Ah gotcha. So you're specifically objecting to people who say 'even if there's a 1% chance' based on vague intuition, and not to people who think carefully about AI risk, conclude that there's a 1% chance, and then act upon it?
Khorton @ 2022-02-12T13:13 (+4)
Exactly! "Even if there's a 1% chance" on its own is a poor argument, "I am pretty confident there's at least a 1% chance and therefore I'm taking action" is totally reasonable
Neel Nanda @ 2022-02-12T09:10 (+2)
These arguments appeal to phenomenal stakes implying that, using expected value reasoning, even a very small probability of the bad thing happening means we should try to reduce the risk, provided there is some degree of tractability in doing so.
To be clear, the argument in my post is that we only need the argument to work for very small=1% or 0.1%, not eg 10^-10. I am much more skeptical about arguments involving 10^-10 like probabilities
Neel Nanda @ 2022-02-12T06:11 (+3)
Estimates can be massively off in both directions. Why do you jump to the conclusion of inaction rather than action?
(My guess is that it's sufficiently easy to generate plausible but wrong ideas at the 1% level that you should have SOME amount of inaction bias, but not to take it too far)
Mathieu Putz @ 2022-02-11T07:44 (+14)
Thanks for this! I think it's good for people to suggest new pitches in general. And this one would certainly allow me to give a much cleaner pitch to non-EA friends than rambling about a handful of premises and what they lead to and why (I should work on my pitching in general!). I think I'll try this.
I think I would personally have found this pitch slightly less convincing than current EA pitches though. But one problem is that I and almost everyone reading this were selected for liking the standard pitch (though to be fair whatever selection mechanism EA currently has, it seems to be pretty good at attracting smart people and might be worth preserving). Would be interesting to see some experimentation, perhaps some EA group could try this?
Neel Nanda @ 2022-02-11T11:54 (+18)
Thanks for the feedback! Yep, it's pretty hard to judge this kind of thing given survivorship bias. I expect this kind of pitch would have worked best on me, though I got into EA long enough ago that I was most grabbed by global health pitches. Which maybe got past my weirdness filter in a way that this one didn't.
I'd love to see what happens if someone tries an intro fellowship based around reading the Most Important Century series!
Greg_Colbourn @ 2022-02-11T12:03 (+2)
Such an intro fellowship sounds good! I had an idea a while back about a Most Important Century seminar series with incentives for important people to attend.
CatGoddess @ 2022-02-11T07:02 (+10)
I like this pitch outline; it's straightforward, intuitive, and does a good job of explaining the core ideas. If this were to actually be delivered as a pitch I would suggest putting more focus on cognitive biases that lead to inaction (e.g. the human tendency to disbelieve that interesting/unusual/terrible things will happen in one's own lifetime, or the implicit self-concept of not being the "sort of person" who does important/impactful things in the world). These are the sorts of things that people don't bring up because they're unconscious beliefs, but they're pretty influential assumptions and I think it's good to address them.
For instance, it took me some doing to acquire the self-awareness to move past those assumptions and decide to go into x-risk even though I had known for quite a while on an intellectual level that x-risk existed. It required the same sort of introspection that it did for me to, when I was offered a PETA brochure, notice my instinctive negative reaction ("ew, PETA, what a bunch of obnoxious and sanctimonious assholes"), realize that that was a poor basis for rejecting all of their ideas, and then sit down and actually consider their arguments. I think that it is uncommon even for bright and motivated people to naturally develop that capacity, but perhaps with some prompting they can be helped along.
Neel Nanda @ 2022-02-11T11:56 (+5)
If this were to actually be delivered as a pitch I would suggest putting more focus on cognitive biases that lead to inaction
Thanks for the thoughts! Definitely agreed that this could be compelling for some people. IMO this works best on people whose crux is "if this was actually such a big deal, why isn't it common knowledge? Given that it's not common knowledge, this is too weird for me and I am probably missing something".
I mostly make this argument in practice by talking about COVID - IMO COVID clearly demonstrates basically all of these biases with different ways that we under-prepared and bungled the response.
Greg_Colbourn @ 2022-02-11T12:08 (+9)
Yes! I've been thinking along similar lines recently. Although I have framed things a bit differently. Rather than being a top-level EA thing, I think that x-risk should be reinstated as a top level cause area it's own right, separate to longtermism, and that longtermism gives the wrong impression of having a lot of time, when x-risk is an urgent short-term problem (more).
Also, I think ≥10% chance of AGI in ≤10 years should be regarded as "crunch time", and the headlines for predictions/timelines should be the 10% estimate, not the 50% estimate, given the stakes (more).
Benjamin_Todd @ 2022-02-13T22:40 (+5)
Interesting point - I've also noticed that a lot of people misunderstand longtermism to mean 'acting over very long timescales' rather than 'doing what's best from a long-term perspective'.
Greg_Colbourn @ 2022-02-11T12:20 (+5)
I was considering writing a post making the point that for the majority of people, their personal risk of dying in an existential catastrophe in the next few decades is higher than all their other mortality risks, combined!
However, whilst I think this is probably true (and is a whole lot of food for thought!), it doesn't necessarily follow that working on x-risk is the best way of increasing your life expectancy. Given that your personal share of finding solutions to x-risk will probably be quite small (maybe 1 part in 10^3-10^7), perhaps reducing your mortality by other means (lifestyle interventions to reduce other risks) would be easier. But then again, if you're maxed out on all the low-hanging lifestyle interventions, maybe working on x-risk reduction is the way to go! :)
JackM @ 2022-02-12T07:25 (+7)
But also, we’re dealing with probabilities that are small but not infinitesimal. This saves us from objections like Pascal’s Mugging - a 1% chance of AI x-risk is not a Pascal’s Mugging.
Sorry I haven't watched the video but I have a feeling this argument misses the point.
People may dismiss working on AI x-risk not because the probability of x-risk is very small, but because the x-risk probability decrease we can achieve is very small, even with large amounts of resources. So I don't think it's enough to say "1% is actually kind of high". You have to say "we can meaningfully reduce this 1%".
Neel Nanda @ 2022-02-12T09:14 (+3)
That's fair pushback. My personal guess is that it's actually pretty tractable to decrease it to eg 0.9x of the original risk, with the collective effort and resources of the movement? To me it feels quite different to think about reducing something where the total risk is (prob=10^-10) x (magnitude = 10^big), vs having (prob of risk=10^-3 ) x (prob of each marginal person making a decrease = 10^-6) x (total number of people working on it = 10^4) x (magnitude = 10^10)
(Where obviously all of those numbers are pulled out of my ass)
JackM @ 2022-02-12T13:36 (+4)
To be clear I'm not saying that the EA movement working on AI is a Pascal's Mugging (I think it should be a top priority), I was just pointing out that saying the chance of x-risk is non-negligible isn't enough.
Matthew_Barnett @ 2025-04-23T20:14 (+6)
TL;DR If you believe the key claims of "there is a >=1% chance of AI causing x-risk and >=0.1% chance of bio causing x-risk in my lifetime" this is enough to justify the core action relevant points of EA. This clearly matters under most reasonable moral views and the common discussion of longtermism, future generations and other details of moral philosophy in intro materials is an unnecessary distraction.
I think the central thesis of this post—as I understand it—is false, for the reasons I provided in this comment. [Edit: to be clear, I think this post was perhaps true at the time, but in my view, has since become false if one counts pausing AI as a "core action relevant point" of EA]. To quote myself:
Let's assume that there's a 2% chance of AI causing existential risk, and that, optimistically, pausing [AI progress] for a decade would cut this risk in half (rather than barely decreasing it, or even increasing it). This would imply that the total risk would diminish from 2% to 1%.
According to OWID, approximately 63 million people die every year, although this rate is expected to increase, rising to around 74 million in 2035. If we assume that around 68 million people will die per year during the relevant time period, and that they could have been saved by AI-enabled medical progress, then pausing AI for a decade would kill around 680 million people.
This figure is around 8.3% of the current global population, and would constitute a death count higher than the combined death toll from World War 1, World War 2, the Mongol Conquests, the Taiping rebellion, the Transition from Ming to Qing, and the Three Kingdoms Civil war.
(Note that, although we are counting deaths from old age in this case, these deaths are comparable to deaths in war from a years of life lost perspective, if you assume that AI-accelerated medical breakthroughs will likely greatly increase human lifespan.)
From the perspective of an individual human life, a 1% chance of death from AI is significantly lower than a 8.3% chance of death from aging—though obviously in the former case this risk would apply independently of age, and in the latter case, the risk would be concentrated heavily among people who are currently elderly.
Even a briefer pause lasting just two years, while still cutting risk in half, would not survive this basic cost-benefit test. Of course, it's true that it's difficult to directly compare the individual personal costs from AI existential risk to the diseases of old age. For example, AI existential risk has the potential to be briefer and less agonizing, which, all else being equal, should push us to favor it. On the other hand, most people might consider death from old age to be preferable since it's more natural and allows the human species to continue.
Nonetheless, despite these nuances, I think the basic picture that I'm presenting holds up here: under typical assumptions [...] a purely individualistic framing of the costs and benefits of AI pause do not clearly favor pausing, from the perspective of people who currently exist. This fact was noted in Nick Bostrom's original essay on Astronomical Waste, and more recently, by Chad Jones in his paper on the tradeoffs involved in stopping AI development.
Neel Nanda @ 2025-04-25T09:00 (+6)
I broadly agree that the costs of long pauses look much more expensive if you're not a longtermist. (When I wrote this post, pauseAI and similar were much less of a thing).
I still stand by this post for a few reasons:
- "This clearly matters under most reasonable moral views" - In my opinion, person affecting views are not that common a view (though I'm not confident here) and many people would consider human extinction to matter intrinsically, in that it affects their future children or grandchildren and legacy and future generations, quite a lot more than just the lives of everyone alive today, without being total utilitarians. Most people also aren't even utilitarians, and may think that death from old age is natural and totally fine. I just think if you told people "there's this new technology that could cause human extinction, or be a really big deal and save many lives and cause an age of wonders, should we be slow and cautious in how we develop it" most people would say yes? Under specifically a scope sensitive, person affecting view, I agree that pauses are unusually bad
- I personally don't even expect pauses to work, without way more evidence of imminent risk than we currently have (and probably even then not for more than 6-24 months) and I think that most actions that people in the community take here have way less of a tradeoff - do more safety research, evaluate and monitor things better, actually have any regulation whatsoever, communicate and coordinate with China, model the impact these things will have on the economy, avoid concentrations of power that enable unilateral power grabs, ensure companies can go at an appropriate pace rather than being caught in a mad commercial rush, etc. I think that, to be effective, a pause must also include things like a hardware progress pause, affect all key actors, etc which seems really hard to achieve and I think it's very unrealistic without much stronger evidence of imminent risk, at which point I think the numbers are much more favourable towards pausing, as my risk conditional on no pausing would be higher. I just really don't expect the world to pause on the basis of a precautionary principle.
- For example, I do interpretability work. I think this is just straightforwardly good under most moral frameworks here and my argument here is sufficient to support much more investment in technical safety research, one of the major actions called for by the community. I care more about emphasising areas of common ground than justifying the most extreme and impractical positions
- Personally, my risk figures and timelines are notably beyond the baseline described in this post, so I'm more pro extreme actions like pausing, even on person affecting grounds, but I agree this is a harder sell requiring stronger arguments than this post.
Matthew_Barnett @ 2025-04-25T19:08 (+4)
When I wrote this post, pauseAI and similar were much less of a thing
I agree, this seems broadly accurate. I suppose I should have clarified that your post was perhaps true at the time, but in my view, has since become false if one counts AI pause as a "core action relevant point" of EA.
I just think if you told people "there's this new technology that could cause human extinction, or be a really big deal and save many lives and cause an age of wonders, should we be slow and cautious in how we develop it" most people would say yes?
I believe that people's answers to questions like this are usually highly sensitive to how the issue is framed. If you simply presented them with the exact quote you wrote here, without explaining that "saving many lives" would likely include the lives of their loved ones, such as their elderly relatives, I agree that most would support slowing down development. However, if you instead clarified that continuing development would likely save their own lives and the lives of their family members by curing most types of diseases, and if you also emphasized that the risk of human extinction from continued development is very low (for example, 1-2%), then I think there would be a significantly higher chance that most people would support moving forward with the technology at a reasonably fast pace, though presumably with some form of regulation in place to govern the technology.
One possible response to my argument is to point to survey data that shows most people favor pausing AI. However, while I agree survey data can be useful, I don't think it provides strong evidence in this case for the claim. This is because most people, when answering survey questions, lack sufficient context and have not spent much time thinking deeply about these complex issues. Their responses are often made without fully understanding the stakes or the relevant information. In contrast, if you look at the behavior of current legislators and government officials who are being advised by scientific experts and given roughly this same information, it does not seem that they are currently strongly in favor of pausing AI development.
Neel Nanda @ 2025-04-26T07:27 (+2)
I agree that people's takes in response to surveys are very sensitive to framing and hard to interpret. I was trying to gesture at the hypothesis that many people are skeptical of future technologies, afraid of job loss, don't trust tech, etc, even if they do sincerely value loved ones. But anyway, that's not a crux.
I think we basically agree here, overall? I agree that my arguments here are not sufficient to support a large pause for a small reduction in risk. I don't consider this a core point of EA, but I'm not confident in that, and don't think you're too unreasonable for doing so
Though while I'm skeptical of the type of unilateral pause pushed for in EA, I am much more supportive of not actively pushing capabilities to be faster, since I think the arguments that pauses are distortionary and penalise safety motivated actors, don't apply there, and most acceleration will diffuse across the ecosystem. This makes me guess that Mechanize is net negative, so I imagine this is also a point of disagreement between us.
Trish @ 2022-08-12T09:24 (+6)
But I often see important and controversial beliefs in moral philosophy thrown around in introductory EA material (introductory pitches and intro fellowships especially), like strong longtermism, the astronomical waste argument, valuing future people equally to currently existing people, etc. And I think this is unnecessary and should be done less often, and makes these introductions significantly less effective.
Hi - I'm new to the forums and just want to provide some support for your point here. I've just completed the 8-week Intro to EA Virtual Program and I definitely got really hung up on the Longtermism and Existential Risk weeks. I've spent quite a few hours reading through materials on the Total View and Person-Affecting View and am currently drafting a blog post to work through and organise my thoughts.
I still feel highly sceptical of the Total View, to the point that I've been questioning how much I identify with longtermism and even "EA", more generally, given my scepticism. I personally find some implications of the Total View quite disturbing and potentially dangerous.
So anyway, I just wanted to support your post and also thank you for reminding us that caring about AI alignment and biorisks does not require subscribing to controversial beliefs in moral philosophy.
Andrew Critch @ 2022-05-16T02:54 (+6)
Neel, I agree with this sentiment, provided that it does tot lead to extremist actions to prevent x-risk (see https://www.lesswrong.com/posts/Jo89KvfAs9z7owoZp/pivotal-act-intentions-negative-consequences-and-fallacious).
Specifically, I agree that we should be explicit about existential safety — and in particular, AI existential safety — as a broadly agreeable and understandable cause area that does not depend on EA, longtermism, or other niche communities/stances. This is main reason AI Research Considerations for Human Existential Safety (ARCHES; https://arxiv.org/abs/2006.04948) is explicitly about existential safety, rather than "AI safety' or other euphemistic / dog-whistley terms.
Derek Shiller @ 2022-02-11T12:20 (+5)
But also, we’re dealing with probabilities that are small but not infinitesimal. This saves us from objections like Pascal’s Mugging - a 1% chance of AI x-risk is not a Pascal’s Mugging.
It seems to me that the relevant probability is not the chance of AI x-risk, but the chance that your efforts could make a marginal difference. That probability is vastly lower, possibly bordering on mugging territory. For x-risk in particular, you make a difference only if your decision to work on x-risk makes a difference to whether or not the species survives. For some of us that may be plausible, but for most, it is very very unlikely.
Neel Nanda @ 2022-02-11T12:24 (+9)
Hmm, what would this perspective say to people working on climate change?
Derek Shiller @ 2022-02-11T13:22 (+1)
Let me clarify that I'm not opposed to paying Pascal's mugger. I think that is probably rational (though I count myself lucky to not be so rational).
But the idea here is that x-risk is all or nothing, which translates into each person having a very small chance of making a very big difference. Climate change can be mitigated, so everyone working on it can make a little difference.
Lukas_Finnveden @ 2022-02-11T17:29 (+4)
You could replace working on climate change with 'working on or voting in elections', which are also all or nothing.
(Edit: For some previous arguments in this vein, see this post .)
Neel Nanda @ 2022-02-11T18:20 (+3)
Yep! I think this phenomena of 'things that are technically all-or-nothing, but it's most useful to think of them as a continuous thing' is really common. Eg, if you want to reduce the amount of chickens killed for meat, it helps to stop buying chicken. This lowers demand, which will on average lower chickens killed. But the underlying thing is meat companies noticing and reducing production, which is pretty discrete and chunky and hard to predict well (though not literally all-or-nothing).
Basically any kind of campaign to change minds or achieve social change with some political goal also comes under this. I think AI Safety is about as much a Pascal's Mugging as any of these other things
Greg_Colbourn @ 2022-02-11T12:32 (+2)
I think a huge number of people can contribute meaningfully to x-risk reduction, including pretty-much everyone reading this. You don't need to be top 0.1% in research skill or intelligence - there are plenty of support roles that could be filled. Just think, by being a PA (or research assistant) to a top researcher or engineer, you might be able to boost their output by 10-30% (and by extension, their impact). I doubt that all the promising researchers have PAs (and RAs). Or consider raising awareness. Helping to recruit just one promising person to the cause is worthy of claiming significant impact (in expectation).
Derek Shiller @ 2022-02-11T13:19 (+2)
I'm not disagreeing with the possibility of a significant impact in expectation. Paying Pascals' mugger is promising in expectation. The thought is that in order to make a marginal difference to x-risk, there needs to be some threshold for hours/money/etc under which our species will be wiped out and over which our species will survive, and your contributions have to push us over that threshold.
X-risk, at least where the survival of the species is concerned, is an all or nothing thing. (This is different than AI alignment, where your contributions might make things a little better or a little worse.)
Greg_Colbourn @ 2022-02-11T13:37 (+3)
I don't think this is a Pascal's Mugging situation; the probabilities are of the order of 10^-3 to 10^-8, which is far from infinitesimal. I also don't think you can necessarily say that there is a threshold for hours/money. Ideas seem to be the bottleneck for AI x-risk at least, and these are not a linear function of time/money invested.
X-risk, at least where the survival of the species is concerned, is an all or nothing thing. (This is different than AI alignment, where your contributions might make things a little better or a little worse.)
It is all-or-nothing in the sense of survival or not, but given that we can never reduce the risk to zero, what is important is reducing the risk to an acceptable level (and this is not all-or-nothing, especially given that it's hard to know exactly how things will pan out in advance, regardless of our level of effort and perceived progress). Also I don't understand the comment on AI Alignment - I would say that is all or nothing, as limited global catastrophes seem less likely than extinction (although you can still make things better or worse in expectation); whereas bio is perhaps more likely to have interventions that make things a little better or worse in reality (given that limited global catastrophe is more likely than x-risk with bio).
Derek Shiller @ 2022-02-11T13:53 (+1)
the probabilities are of the order of 10^-3 to 10^-8, which is far from infinitesimal
I'm not sure what the probabilties are. You're right that they are far from infinitesimal (just as every number is!): still, the y may be close enough to warrant discounting on whatever basis people discount Pascal's mugger.
what is important is reducing the risk to an acceptable level
I think the risk is pretty irrelevant. If we lower the risk but still go extinct, we can pat ourselves on the back for fighting the good fight, but I don't hink we should assign it much value. Our effect on the risk is instrumentally valulable for what it does for the species.
Also I don't understand the comment on AI Alignment
The thought was that it is possible to make a difference between AI being pretty well and very well aligned, so we might be able to impact whether the future is good or great, and that is worth pursuing regardless of its relation to existential risk.
Greg_Colbourn @ 2022-02-12T09:47 (+4)
If we lower the risk but still go extinct
That would be bad, yes. But lowering the risk (significantly) means that it's (significantly) less likely that we will go extinct! Say we lower the risk from 1/6 (Toby Ord's all-things-considered estimate for x-risk over the next 100 years) to 1/60 this century. We've then bought ourselves a lot more time (in expectation) to lower the risk further. If we keep doing this at a high enough rate, we will very likely not go extinct for a very long time.
it is possible to make a difference between AI being pretty well and very well aligned, so we might be able to impact whether the future is good or great
I think "pretty well aligned" basically means we still all die; it has to be very well/perfectly aligned to be compatible with human existence, once you factor in an increase in power level of the AI to superintelligence; so it's basically all or nothing (I'm with Yudkowsky/MIRI on this).
freedomandutility @ 2022-05-04T19:29 (+3)
I’ve arrived at this post very late, but a relevant point I’d add is that as someone with person-affecting, non totalist consequentialist views, I disagree with many of the ideas of longtermism, but working on pandemics and AI alignment still makes sense to me on ‘disaster mitigation’ grounds. I think of the big three cause areas as ‘global health and poverty, farmed animal welfare and disaster mitigation’. Also, working on pandemics fits pretty neatly as a subset of global health work.
isla42 @ 2022-04-03T01:45 (+1)
Could someone explain to me the meaning of 'paradigm' in this context? E.g. '10-30 years to go through a paradigm'
Charles He @ 2022-04-03T22:17 (+2)
Ok, below is a super long series of comments on this.
TLDR; Paradigms is a vague concept (that is somewhat problematic and can be misused), but is useful. I write about different “paradigms on AI”, with comments on deep learning and "classical AI" that I don't see talked about often and I think have a useful history.
Apologies to yer eyeballs.
Charles He @ 2022-04-03T22:24 (+2)
To start off, comments on the world “Paradigm”:
I think the original commentor is referring to this paragraph in the post:
But even if deep learning is a fad, the field of AI has existed for less than 70 years! And it takes 10-30 years to go through a paradigm. It seems highly plausible that we produce human-level AI with some other paradigm within my lifetime (though reducing risk from an unknown future paradigm of AI does seem much less tractable)
Ok. So there's a lot to unpack and I think it's worth commenting on the word or concept of "Paradigm" independently.
"Paradigm" is a pretty loose word and concept. Paradigm basically means a pattern/process/system, or set of them, that seems to work well together and is accepted.
If that definition doesn't sound tangible or specific, it isn't. The concept of paradigm is vague. For evidence on this, the wikipedia article is somewhat hard to parse too.
Worse still, the concept of paradigm is really meta—someone talking about paradigms often presents you with giant, convoluted writing, whose connection to reality is merely comments on other convoluted writing.
Because of this, the concept of "paradigms" can be misused or at least serve as a lazy shortcut for thinking.
Personally, when someone talks about paradigms a lot, I find it useful to see that as a yellow flag. (Without being too arch, if someone made an org that had "paradigm" in its name, which actually happened, that's an issue. Here is further comment, that gets pretty off track, and is a footnote[1].)
To be clear, the underlying concept of paradigms is important, and Kuhn, the author of this presentation, is right.
However, in general, you can address the “object level issue” (the actual problem) of existing paradigms directly.
To give an example of a "paradigm shift" (note that such "shifts" are often contested), the transition from "classical physics" to "special relativity" is an example.
If you think that classical Newtonian physics is wrong, you can literally show its wrong, and develop a new theory, make predictions and win a Nobel prize, like Einstein did.
You don't spend your time writing treatises on paradigms.
Suggesting there can be a new paradigm, or something is "preparadigmatic", doesn't offer any evidence that a new "paradigm" will happen.
- ^
It’s worth pointing out that in the case of a malign entity that uses language like “paradigms”, the involved ploys can sophisticated (because they are smart and this is essentially all they do).
These people or entities can use the word in a way that circumvents or coopts warnings. Specifically:
- The malign entities can use this language for the consequent controversy/attention, which is valuable to them. e.g. a conversation that starts off “Hey, I heard this thing about Paradigm?” can lead to more interest and engagement. The value from this publicity can outweigh the negatives from controversy. This can work extremely well in communities that see themselves as marginal and unconventional.
- They use this language/branding as a filter, which provides stability and control. The fact that this language gives a correct warning causes stronger people to bounce off from the entity. The people who remain can be more pliable and dedicated (in language that was actually used, not "too big").
Charles He @ 2022-04-03T22:37 (+2)
Ok, with that out of the way, getting closer to the substance of the original question about paradigms of AI.
So something that isn’t talked about is something that is known as “classical AI” or “symbolic AI”.
Symbolic AI or classical AI was the original general AI paradigm. (This is written up elsewhere, including on Wikipedia, which provides my knowledge for all further comments.)

Here's my take to explain the relevance of symbolic AI.
Ok, close your eyes, and imagine for a second that everything in the world is the same, but that deep learning or neural networks don't exist yet. They just haven't been discovered.
In this situation, if you told a genius in math or physics, that there was a danger from building an evil, world conquering AI, what would that genius think about?
I honestly bet that they wouldn’t think about feeding giant spreadsheets of data into a bunch of interconnected logistic functions to run argmax, which is essentially what deep learning, RNN, transformers, etc. do today.
Instead, this genius would think about the danger of directly teaching or programming computers with logic, such as giving symbols and rules that seem to allow reasoning. They would think that you could directly evolve these reasoning systems, and growing to general cognition, and become competitive with humans.
If you thought computers could think or use logic, this approach seems like, really obvious.
(According to my 150 seconds of skimming Wikipedia) my guess is that the above way of thinking is exactly what symbolic or classical AI did. According to Wikipedia, this dominated until 1985[1].
Note that this classical or symbolic approach was something full on. This wasn’t “very online”.
Symbolic AI was studied at MIT, Stanford, CMU, RAND, etc. This was a big deal, sort of like how molecular biology, or any mainstream approach today in machine learning is a big deal.
- ^
To be really concrete and tangible to explain the "symbolic reasoning" programme, one instance of this probably is this project "Cyc" https://en.wikipedia.org/wiki/Cyc.
If you take a look at that article, you get a sense for this approach. This stores a lot of information and trying to build reasoning from rules.
Charles He @ 2022-04-03T22:47 (+2)
Ok the story continues, but with a twist—directly relevant to the original question of paradigms.
(According to my 5 minutes of Wikipedia reading) a major critic of of symbolic AI was by this dude, Hubert Dreyfus. Dreyfus was a Harvard trained philosopher and MIT faculty when he was hired by RAND.
There, Dreyfus sort of turned on his new employer (“treacherous turn!”) to write a book against the establishment's approach to AI.
Dreyfus basically predicted that symbolic approach was a dead end.
As a result, it looks like he was attacked, and it was an epic drama mine.
“The paper "caused an uproar", according to Pamela McCorduck. The AI community's response was derisive and personal. Seymour Papert dismissed one third of the paper as "gossip" and claimed that every quotation was deliberately taken out of context. Herbert A. Simon accused Dreyfus of playing "politics" so that he could attach the prestigious RAND name to his ideas. Simon said, "what I resent about this was the RAND name attached to that garbage".
Ultimately, Dreyfus was essentially “proved right” (although there’s probably a lot more color here, most contrarians tend to be excessive, dogmatic and fixated themselves, and sometimes right for the wrong reasons.)
Dreyfus did make a splash, but note that even if Dreyfus was correct it's unlikely that his impact causal. It's more likely the field petered out as lack of results became too obvious to ignore (based on 3 paragraphs of Wikipedia and mostly my beliefs) .
But ultimately, the field of classical/symbolic AI fell, pretty bigly, to a degree that I don't think many fields fall.
Directly relevant to the question of "paradigm" in the original question.
This now fallen symbolic AI reasoning faction/programme/agenda is a "paradigm". This "paradigm" seemed extremely reasonable.
These figures were vastly influential and established, they dotted the top CS schools, the top think tanks and connected with the strongest companies at the time. This AI community was probably vastly more influential than the AI safety community currently is, by a factor of 20 or more.
It still seems like “Symbolic logic”, with some sort of evolution/training, is a reasonable guess for how to build general, strong AI.
In contrast, what exactly are neural networks doing? To many people, deep learning, using a 400B parameter model to hallucinate images and text, seems like a labored and quixotic approach to general AI. So how are these deep learning systems dangerous in any way? (Well, I think there are groups of principled people who have written up important content on this.)
(I’m not a critic or stealth undermining AI safety, this series of comments isn’t a proxy to critique AI safety. These lessons seem generally useful.)
The takeaway from this comment is that:
- It’s very likely that these events of symbolic logic hangs over the general AI field (“AI winter”). It’s very possible that the reaction was an overshoot that hampers AI safety today in some way. (But 10 minutes of reading Wikipedia isn’t enough for me to speculate more).
- This is a perfect example of a paradigm shift. Symbolic AI was a major commitment by the establishment, the field resisted intensely, but they ultimately fell hard.
- There's probably other "paradigms" (ugh I hate using this phrase and framework) that might be relevant to AI safety. Like, I guess maybe someone should take a look at this as AI safety continues.
Charles He @ 2022-04-03T22:54 (+2)
Final comment—quick take on "current approach in AI"
If you’re still here, still reading this comment chain (my guess is that there is a 90% chance the original commentor is gone, and most forum readers are gone too), you might be confused because I haven’t mentioned the "current paradigm of ML or AI".
For completeness it's worth filling this in. So like, here it is:
Basically, the current paradigm of ML or deep learning right now is a lot less deep than it seems.
Essentially, people have models, like a GPT-3/BERT transformer, that they tweak, run data through, and look at the resulting performance.
To build these models and new ones, people basically append and modify existing models with new architectures or data, and look at how the results perform on established benchmarks (e.g. language translation, object detection).
Yeah, this doesn't sound super principled, and it isn't.
To give an analogy, imagine bridge building in civil engineering. My guess is that when designing a bridge, engineers use intricate knowledge of materials and physics, and choose every single square meter of every component of the bridge in accordance to what is needed, so that the resulting whole stands up and supports every other component.
In contrast, another approach to building a bridge is to just bolt and weld a lot of pieces together, in accordance with intuition and experience. This approach probably would copy existing designs, and there would be a lot of tacit knowledge and rules of thumb (e.g. when you want to make a bridge 2x as big, you usually have to use more than 2x more material). With many iterations, over time this process would work and be pretty efficient.
The second approach is basically a lot of how deep learning works. People are trying different architectures, adding layers, that are moderate innovations over the last model.
There’s a lot more details. Things like unsupervised learning, or encoder decoder models, latent spaces, and more, are super interesting and involve real insights or new approaches.
I’m basically too dumb to build a whole new deep learning architecture, but many people are smart enough, and major advances can be made like by new insights. But still, a lot of it is this iteration and trial and error. The biggest enablement is large amounts of data and computing capacity, and I guess lots of investor money.