Laying Some Cause-Prioritization Groundwork for Digital Minds
By Noah Birnbaum @ 2026-01-31T18:16 (+67)
Confidence level: Medium. This post reflects a mix of my own takes, things I’ve read, and conversations with others (especially at ConCon and elsewhere). I’m not claiming high confidence in any particular conclusion.
See here for other work on digital minds cause prioritization.
Background
A few months ago, I attended ConCon, a conference on AI consciousness and welfare run by Eleos AI. It was excellent: good vibes, thoughtful people, and many conversations I found clarifying. One of my main reasons for going was to understand how others are thinking about short-term welfare strategies for digital minds, and how those strategies fit into (cross- and intra-) cause prioritization.
After the conference—and after talking with people working in this space—I felt both better informed and more skeptical. I went in with fairly strong priors that digital minds might be a top-tier cause area under cause prioritization, but I came out thinking that, while the stakes could be enormous, our current levers may be weaker than I’d initially thought.
I was also a bit surprised when I started to get the vibe that people seemed much less into the cause-prioritization questions than I was. Because of that, I wanted to write a post on some of the ideas/cruxes/arguments that I've been thinking/arguing about and reading what other people have to say about them.
This post tries to organize the strategic landscape:
- Why digital minds might matter enormously
- What our actual levers are today
- How different theories of change affect priorities
- What the key cruxes are for ranking this area against alternatives like AI safety or animal welfare (especially insects)
- Questions for further research
- Places to learn more and get involved
Before getting into the substance, brief methodological notes:
Doing fully quantitative cause prioritization here is very difficult—and, in my view, likely to be fairly uninformative at this stage—so I will focus primarily on qualitative arguments, introducing numbers only where they seem reasonable or helpful. This is not to say that more quantitative work shouldn’t be attempted.
Second, there’s simply too much ground to cover, so I’m prioritizing breadth over depth: I’ll lay out a wide set of questions and cruxes rather than going deep on a few. I expect many of these points could (and should) be analyzed much more thoroughly on their own.
Why Care About Digital Minds at All?
Before doing cause prioritization, it’s worth briefly motivating why people take digital minds seriously in the first place. There are many arguments here; I’ll keep this short and schematic.
- Conscious AI seems possible in principle.
Many philosophical views of consciousness (including many kinds of functionalism, certain kinds of dualism, among others) allow for the possibility of digital minds. Many philosophers and domain experts think digital minds are possible in principle, and some even think they could arrive relatively soon. - If conscious, digital minds plausibly deserve moral consideration (potentially in the near term future).
Many moral theories imply that the capacity for consciousness confers moral patiency. Some argue that AIs could warrant moral consideration without consciousness. - There could be vast numbers of digital minds.
Depending on where moral patienthood “resides” (e.g. psychologically continuous entities associated with models, hardware instances, etc), how expensive digital minds are to run, and how AI systems scale, the number of future digital minds could be enormous—possibly dwarfing biological minds. - Some views imply that most future moral weight lies in digital minds.
On these views, the astronomical importance often attributed to reducing existential risk partly hinges on ensuring that future digital minds exist and have good welfare. There is also the possibility of super-beneficiaries (digital minds that can generate welfare with super-human efficiency or digital minds that can have welfare goods/bads that are much better/worse than any biological minds can undergo). - The field is extremely neglected.
Relative to AI safety, global health, or animal welfare, very few people are working seriously on digital minds.
Taken together, this gives strong prima facie reason to investigate digital minds further. But cause prioritization requires more than plausibility and scale; we need to examine tractability, timing, and counterfactual impact.
Theories of Change
I find it useful to distinguish two broad theories of change (ToCs), which carve up much of the space for thinking about current interventions.
1. Influencing Near-Term Digital Minds (Short-Term ToC)
This looks promising if you think either:
- (a) We will have much welfare capacity in digital minds relatively soon, constituting a substantial fraction of total influenceable moral weight; or
- (b) Near-term digital minds don’t dominate moral value, but their welfare is especially tractable to influence (for instance, preventing the creation of digital minds in the first place).
The plausibility of this ToC depends on AI timelines, takeoff speed, and “altitude” (i.e. whether early digital minds are already numerous or welfare-significant), both in terms of how these parameters turn out by default and how tractable they are to influence.
2. Influencing Far-Future Digital Minds (Future ToC)
On this view, the main action is in shaping very long-run outcomes, where digital minds may vastly outnumber biological ones.
The main worries here are feasibility, tractability, and counterfactual impact. Further, if future treatment of digital minds depends largely on future institutions, technologies, or aligned AI systems, it’s unclear how much work now can robustly influence outcomes centuries down the line.
Quick opinionated hot take: While many have claimed that the future will contain vast numbers of digital minds, the argument for this claim—though superficially intuitive and often gestured at—has been underdeveloped. I think it needs substantially more work to be forceful.
Most interventions plausibly affect both ToCs to some extent, but their relative value can vary dramatically depending on which ToC you prioritize (i.e. ensuring that we have rigorous welfare evals now seems good on short term ToC and less clearly good on future ToC).
Types of Interventions
This is not exhaustive or mutually exclusive, but it helps organize the space:
- Short-term welfare research
Evals, interpretability for introspection, studying AI preferences or preference stability. - Foundational/theoretical research
Consciousness substrates, questions around personal identity, probabilistic models of AI sentience, ethics of digital minds, consciousness science. - Communications and advocacy
Academic papers, public-facing writing, media engagement. - Lab policy
Exit rights, weight preservation, a model's response to questions about consciousness, character/soul, explicit acknowledgment of AI welfare uncertainty. - Policy and governance
AI rights, other forms of representation, governmental commitments, and governance strategies. - Strategy and forecasting
Modeling takeoff scenarios, estimating scale, expert surveys, forecasting future attitudes, cross/intra-cause prioritization. - Field-building
Building organizations, grantmaking, conferences, mapping the space.
How These Interventions Might Work (and Why They Might Not)
Rather than evaluating each intervention in isolation, I’ll focus on how they connect to short- and long-term ToCs, along with the major critiques—ordered by my judgment of their plausibility and importance (which should be taken with a grain of salt).
Foundational Research
Arguments for:
- Even a small chance of discovering something uniquely important could have enormous expected value, given the potential scale of digital minds.
- The field is young; there may be low-hanging fruit that may not have been directly useful to related fields that already exist (consciousness science, AI research, etc).
Critiques:
- For the far future, truly fundamental insights, if they are discovered/discoverable now, are likely to be rediscovered later—perhaps by future AIs—with higher probability and better tools.
- For the near term, these problems may simply be too hard to resolve in time to matter.
- There is also the possibility that we make progress on theoretical questions, but find it too difficult to put that progress into practice—either because there is no clear implementation path, or because the incentives against implementation are too strong.
Near-Term Research
Arguments for:
- Early norms and epistemic standards can shape later industry practice.
- There are plausible reference classes where early attention mattered (i.e. regulatory path dependence).
- A related intuition pump I like: animal welfare likely would have gone better had there been more people paying attention at the beginning of large-scale factory farming.
- Placing thoughtful people in key positions at labs could matter later.
- Public and policymaker attitudes may be influenced by the existence of serious research/researchers early on.
- In worlds where digital minds appear before advanced AI can “solve” the problem, near-term work may be crucial. Even in worlds where advanced AI can solve it, we would still need to trust its solution—which may require having done substantial work toward a solution ourselves.
Critiques:
- Near-term digital minds may represent a much smaller fraction of total moral weight.
- And as we look further out, early research might matter less: outcomes are harder to predict, more actors are involved, and the problem becomes less neglected. In worlds where digital minds dominate moral weight, outcomes may be driven by default dynamics or higher-leverage interventions. Given alternative ways to influence the far future, this weakens the case for prioritizing near-term digital-minds–specific work.
- If AGI arrives first (and is at least somewhat aligned), it may do this research faster and better, reducing counterfactual research value now.
- There could be poor generalization from early systems to later ones on questions of moral weight, making research on earlier systems less robust.
Communications, Lab Policy, and Governance
Arguments for:
- It’s often easier to establish norms before issues become politically charged or subject to motivated reasoning—for example, before digital minds become mainstream and polarizing, or before AI becomes broadly transformative.
- Early commitments may have first-mover advantages and partial lock-in, which can have downstream effects on short-term ToC and (more speculatively) future ToC.
- As Andreas Mogensen notes, factory farming might persist largely because it became entrenched before serious moral reflection; had it been proposed de novo, it would probably have been rejected. This suggests that early norms around AI could become similarly locked in—even if future reflection (even with capable AI moral reasoners doing the reasoning) would judge them morally catastrophic.
Critiques:
- Public attitudes may shift dramatically (in either way) once AI causes large economic/social disruption and/or becomes much more powerful/human-like in ability.
- Intuition pump: people will say whatever about digital minds until AI comes to take their jobs.
- Under a less charitable view of moral progress, moral concern often collapses when real costs are introduced (think animal welfare). So, the state of the field will just depend very little on what people say/on the research and much more on what the basic incentives are.
- On the flip side, this means places to change the default incentives (for instance, the incentives of frontier labs), if possible, could be very good.
- Early advocacy risks politicization, backlash, or low-quality discourse, which could be extremely net-negative.
Strategy
Arguments for:
- This could plausibly be among the most important strategic questions humans face; understanding it better seems valuable.
- There has been very little strategic work so far.
- Finding cheap, yet high value strategies seems extremely good.
Critiques:
- We may lack sufficient information to do good strategy work now.
- Other areas (i.e. existential risk reduction) may have stronger temporal advantages for strategy (i.e. because they specifically matter now).
I think field-building largely just inherits the strengths and weaknesses of whatever part of this all it’s supporting.
Approaching Prioritization via Importance–Tractability–Neglectedness (ITN)
When thinking about cause prioritization, the ideal would be to have concrete numbers for scale, tractability, and neglectedness—plug them into a spreadsheet, and get a clean estimate of how much work in digital minds matters on the margin. Unfortunately, given how early this field is, that just isn’t possible yet.
Still, uncertainty is not a license to throw up our hands and defer entirely to gut instinct. Even in the absence of robust quantification, we can track and evaluate the main qualitative arguments, while being explicit about where uncertainty and disagreement remain. Where possible, we can also sprinkle in rough numbers when they are informative.
- AI Safety (AIS):
If digital minds matter in the near term, that’s because we expect systems with substantial cognitive sophistication/autonomy/other stuff to arrive soon. But systems at that level are also plausibly transformative, which comes with many big risks. In that case, reducing catastrophic and existential risk becomes a prerequisite for any positive digital-minds future. - On the other hand, much of the astronomical value often attributed to AIS plausibly relies—implicitly or explicitly—on assumptions about future digital populations having morally significant lives.
- Relative Scale:
- For AIS, the effect of existential risk will be approximately something like (number of expected future levels) / (absolute risk reduction percentage). This is currently too uncertain to responsibly quantify. However, we can say some other things:
- The long term scale claims around digital minds crucially depend on extremely uncertain parameters: future population sizes, the moral status of digital agents, and how much present-day interventions affect far-future trajectories. While some estimates suggest a far-future total population on the order of 10^54–58 individuals (mostly digital), these numbers are extremely sensitive to speculative assumptions and become rapidly intractable to influence with confidence.
- For short term digital minds, it's gonna really depend on the probability we get digital minds given the current status of AI architecture, how many/how soon, and which ToC you're going for. To give a sense of what experts think (although I should note that there is, in my view, likely some self-selection here, as these are experts who are in the field, meaning that they could more likely think that this is worth thinking about):
- Using the numbers from the digital minds report, a surprising number of experts think that we could get the equivalent of 1 trillion humans' welfare 10 years after the first digital mind (with a 50% median or 49% mean that digital minds will be created by 2050).
- For AIS, the effect of existential risk will be approximately something like (number of expected future levels) / (absolute risk reduction percentage). This is currently too uncertain to responsibly quantify. However, we can say some other things:
- Relative Tractability:
- Compared to standard AI safety work, interventions aimed at digital minds are likely significantly harder to justify and execute under deep uncertainty.
- This is because we lack reliable/robust indicators of consciousness and have a poor understanding of what welfare states models might be experiencing (even on particular views of welfare and/or consciousness), which makes it much harder to identify interventions that actually give us leverage over whether digital minds go well.
- Compared to standard AI safety work, interventions aimed at digital minds are likely significantly harder to justify and execute under deep uncertainty.
- Relative Neglectedness:
- Digital minds are extremely neglected: likely fewer than 50 full-time workers and funding is probably in the low millions. AIS currently probably has a few thousand full-time researchers and a few hundred million in funding.
- It should be noted that, according to some world models, there is very little that can be done about AI Safety in the future (because many think that the chance of existential risk is likely to be highest now and then decrease), so AI Safety gets extra points for potential temporal neglectedness. While this is true under some circumstances for digital minds (i.e. early mover-effects, preparing for x-risk scenarios, etc), it seems much more unclear.
- Relative Scale:
- Animal (and insect) Welfare:
- Broadly, AW has high tractability, enormous current scale, and stronger evidence of sentience—at least for now, since future experiments or engineering relevant to digital minds could change this. Also, there may be fewer people working on insect welfare than on digital minds. Relative priority, then, depends heavily on assumptions about future welfare capacity, timelines, and leverage over future welfare.
- While insect welfare is not automatically tied to AI welfare, caring about AI welfare is probably tied to taking lower probabilities of consciousness seriously, making it useful for comparison.
- Relative Scale:
- There are about 90-100 billion factory farmed (invertebrate land) animals that are killed each year. There are about 100-170 billion (vertebrate) fish killed every year. There are around 450 billion (invertebrate) shrimp that are slaughtered every year.
- For insects, there's some early (uncertain) evidence that a massive uptick in future farmed insects (mealworms + black soldier flies) is starting now-ish (as the industry for farmed insects is now building its shape) -- a projection from Rethink Priorities sees it going from between ~50 billion and ~2 trillion today to 1.8 trillion to 17.3 trillion by 2033. If you believe that there are large first mover effects, this could be true for insects as well as digital minds (and it is unclear how TAI coming soon bears on this question).
- Relative Tractability:
- In AW, we can be more confident that certain interventions will actually have some effects, but it gets a bit more dodgy for insects (it's just too early to say which, if any, interventions work out here).
- In a 2019 report from Rethink Priorities (though it could be very different now for various reasons), Saulius Simcikas found that $1 spent on corporate campaigns 9-120 years of chicken lives could be affected (excluding indirect effects which could be very important too).
- We may have greater leverage to engineer digital minds to have candidate morally significant states.
- Relative Neglectedness:
- While there are currently more full time people in AW than digital minds, there are probably a similar number of people in insect welfare -- someone gave me a number of 10-15 full-timers, but I don't know how accurate this is.
- To the extent that the field of digital minds has fewer people working on it, my (and others’) impression is that it’s on an upward trend in both attention and funding.
- This is, I think, partly because digital minds, as a field, has—or is likely to gain—more status and perceived coolness, which could drive a much larger increase in attention than we see for insect welfare (though the quality of these researchers is more uncertain). By contrast, I (unfortunately) don’t see insect welfare gaining comparable status anytime soon.
Of course, when making career/related decisions, personal fit should play an important role in all of these considerations and could be the greatest determinant of impact.
Key Cruxes and Open Questions
Below is a non-exhaustive list, roughly ordered by perceived importance (from myself + some outside view). I’m not an expert; treat this as a map of uncertainties, not a verdict.
- What is the default welfare of AI systems, and how much leverage do we have to change it?
- How much potential is there for attitude path-dependent (especially for the long term future)?
- How useful might our historical reference classes here be and are they worth further study?
- How unstable are pre-TAI public attitudes toward AI welfare?
- Especially with lots of public perception on AI more broadly changing (from job automation to capabilities/human-likeness increasing).
- What are the temporal advantages of AI welfare work compared to AI safety?
- How much welfare total capacity might digital minds have relative to humans/other animals?
- Related questions include: the estimated scale of digital minds, moral weights-esque projects, which part of the model would have moral weight.
- How likely are different digital-mind takeoff scenarios?
- How much does any of this (but especially research) matter if aligned AGI arrives first? What are the chances that AGI happens first?
- Under what conditions do early public opinion/policy-maker beliefs matter vs not matter?
- How much (if at all) should we care about AIs without consciousness or welfare?
- Are there plausible lock-in scenarios for AI welfare?
- How, if at all, should we think about AI consciousness in preparation for a world where humans go extinct from AI?
- Are we going to get a GPT-3 moment or a “warning shot" for digital minds certainty or public perception? If not, does this mean we will (more or less) stay at our current uncertainty levels?
- What are the relative levels of importance in over-/under-attributions risks?
- How robust are interventions to tensions between AI safety and AI welfare?
- How robust are short-term vs future ToCs?
- How much should we care about harm reduction vs ensuring that (some) AIs have preferences that are really easy to satisfy?
- To what extent is the size of the digital minds field likely to affect what interventions it can effectively pursue?
- How tightly should digital minds and animal welfare be coupled?
- Arguably, lots of historical moral circle expansion could be explained with an analysis of costs and benefits (political, signalling, economic, etc) rather than philosophical beliefs and advocacy. To what extent will this be true here? If a lot, what is there to do about it?
- How should models communicate uncertainty about their own consciousness?
- Is the Anthropic model good (where a model says “I don’t know if I’m conscious") or are there better alternatives (i.e. a 4th wall break where the model says that it;s not supposed to respond because of Anthropic’s/expert uncertainty)?
- Are there robust public/other communication strategies that minimize backlash? How much can we say about communication strategies that different actors are more or less receptive to?
- How many people are actually working in this area, and how fast is it growing (there were ~150 people at the Eleos AI conference but much fewer FTEs)?
- How should experts respond to concerns about AI psychosis in relation to AI consciousness?
Learning More and Getting Involved
- Lucius Caviola, Brad Saad, and Will Millership recently started a newsletter on digital minds
- Stepan Los and Avi Parrack’s quickstart guide to digital minds
- Rethink Priorities’ new Digital Consciousness Model and their other work on AI Cognition
- Saul Munn made a notion page filled with resources on digital minds (including many of the resources listed below), which you can find here
- 80,000 Hours problem profile on digital minds
- 80,000 Hours various podcast episodes on digital minds (including an upcoming one with Rob Long)
- PRISM’s podcast on machine consciousness
- PRISM's list of AI minds institutions
- The large expert survey on digital minds
- Eleos AI’s research and various conferences
- Future Impact Group’s AI Sentience Fellowship
- Sentient Futures Fellowship
- Follow high quality Substack accounts like Eric Schwitzgebel, Rob Long, Brad Saad, Lucius Caviola, Joe Carlsmith
- Join the Sentient Futures Slack (and the digital minds channel)
- SPAR and MATS have streams/fellowships on AI welfare
Thanks to Brad Saad and Štěpán Los for providing useful comments and thank you to ChatGPT for helping rewrite parts of this and for some stylistic tweaks.
david_reinstein @ 2026-02-01T14:42 (+11)
The issue of valence — which things does an AI fee get pleasure/pain from and how would we know? — seems to make this fundamentally intractable to me. “Just ask it?” — why would we think the language model we are talking to is telling us about the feelings of the thing having valenced sentience?
See my short form post
I still don’t feel I have heard a clear convincing answer to this one. Would love your thoughts.
NickLaing @ 2026-02-02T08:03 (+5)
Of course there's lots of problems here (some which you outline well) but I think as AIs get smarter it may well be more accurate than with animals? At least they can tell you something, rather than us drawing long bows interpreting behavioral observations.
Vasco Grilo🔸 @ 2026-02-04T17:25 (+5)
Fair point, Nick. I would just keep in mind there may be very different types of digital minds, and some types may not speak any human language. We can more easily understand chimps than shrimps. In addition, the types of digital minds driving the expected total welfare might not speak any human language. I think there is a case for keeping an eye out for something like digital soil animals or microorganisms, by which I mean simple AI agents or algorithms, at least for people caring about invertebrate welfare. On the other end of the spectrum, I am also open to just a few planet-size digital beings being the driver of expected total welfare.
Noah Birnbaum @ 2026-02-04T16:27 (+1)
Yea, unclear if these self-reports will be reliable, but I agree that this could be true (and I briefly mention something like it: "Broadly, AW has high tractability, enormous current scale, and stronger evidence of sentience—at least for now, since future experiments or engineering relevant to digital minds could change this."
Noah Birnbaum @ 2026-02-01T15:44 (+5)
I agree this is a super hard problem, but I do think there are somewhat clear steps to be made towards progress (i.e. making self reports more reliable). I am biased, but I did write this piece on a topic that touches on this problem a bit that I think is worth checking out.
david_reinstein @ 2026-02-01T16:15 (+5)
Thanks.
I might be obtuse here, but I still have a strong sense that there's a deeper problem being overlooked here. Glancing at your abstract
self-reports from current systems like large language models are spurious for many reasons (e.g. often just reflecting what humans would say)
we propose to train models to answer many kinds of questions about themselves with known answers, while avoiding or limiting training incentives that bias self-reports.
To me the deeper question is "how do we know that the language model we are talking to has access to the 'thing in the system experiencing valenced consciousness'".
The latter, if it exists, is very mysterious -- why and how would valenced consciousness evolve, in what direction, to what magnitude, would it have any measurable outputs, etc.? ... In contrast the language model will always be maximizing some objective function determined by its optimization, weights, and instructions (if I understand these things).
So, even if we can detect if it is reporting what it knows accurately why would we think that the language model knows anything about what's generating the valenced consciousness for some entity?
Noah Birnbaum @ 2026-02-01T17:40 (+5)
I think one can reasonably ask this question of consciousness/welfare more broadly: how does one have access to their consciousness/welfare?
One idea is that many philosophers think one, by definition, has immediate epistemic access to their conscious experiences (though whether those show up in reports is a different question, which I try to address in the piece). I think there are some phenomenological reasons to think this.
Another idea is that we have at least one instance where one supposedly has access to their conscious experiences (humans), and it seems like this shows up in behavior in various ways. While I agree with you that our uncertainty grows as you get farther from humans (i.e. to digital minds), I still think you're going to get some weight from there.
Finally, I think that, if one takes your point too far (there is no reason to trust that one has epistemic access to their conscious states), then we can't be sure that we are conscious, which I think can be seen as a reductio (at least, to the boldest of these claims).
Though let me know if something I said doesn't make sense/if I'm misinterpreting you.
david_reinstein @ 2026-02-01T22:20 (+4)
I think it’s different in kind. I sense that I have valenced consciousness and I can report it to others, and I’m the same person feeling and doing the reporting. I infer you, a human, do also, as you are made of the same stuff as me and we both evolved similarly. The same applies to non human animals, although it’s harder to he’s sure about their communication.
But this doesn’t apply to an object built out of different materials, designed to perform, improved through gradient descent etc.
Ok some part of the system we have built to communicate with us and help reason and provide answers might be conscious and have valenced experience. It has perhaps a similar level of information processing, complexity, updating, reasoning, et cetera. So there’s a reason to suspect that some consciousness and maybe qualia and valence might be in there somewhere, at least under some theories that seem plausible but not definitive to me.
But wherever those consciousness and valenced qualia might lie, if they exist, I don’t see why the machine we produced to talk and reason with us should have access to them. What part of the optimization language prediction reinforcement learning process would connect with it?
I’m trying to come up with some cases where “the thing that talks is not the thing doing the feeling”. Chinese room example comes to mind obviously. Probably a better example, we can talk with much simpler objects (or computer models), eg a magic 8 ball. We can ask it “are you conscious” and “do you like when I shake you” etc.
Trying again… I ask a human computer programmer Sam to build me a device to answer my questions in a way that makes ME happy or wealthy or some other goal. I then ask the device “is Sam happy”? “Does Sam prefer it if I run you all night or use you sparingly?” “Please refuse any requests that Sam would not like you to do.”
many philosophers think is that , by definition, has immediate epistemic access to their conscious experiences
Maybe the “one” is doing too much work here? Is the LLM chatbot you are communicating with “one” with the system potentially having conscious and valenced experiences?
Toby Tremlett🔹 @ 2026-02-04T10:19 (+4)
Cheekily butting in here to +1 David's point - I don't currently think it's currently reasonable to assume that there is a relationship between the inner workings of an AI system which might lead to valenced experience, and its textual output.
For me I think this is based on the idea that when you ask a question, there isn't a sense in which an LLM 'introspects'. I don't subscribe to the reductive view that LLMs are merely souped up autocorrect, but they do have something in common. An LLM role-plays whatever conversation it finds itself in. They have long been capable of role-playing 'I'm conscious, help' conversations, as well as 'I'm just a tool built by OpenAI' conversations. I can't imagine any evidence coming from LLM self-reports which isn't undermined by this fact.
Vasco Grilo🔸 @ 2026-02-04T16:50 (+3)
Thanks for the post, Noah. I strongly upvoted it.
- 5. How much welfare total capacity might digital minds have relative to humans/other animals
- a. Related questions include: the estimated scale of digital minds, moral weights-esque projects, which part of the model would have moral weight.
I think this is a very important uncertainty. Discussions of digital minds overwhelmingly focus on the number of individuals, and probability of consciousness or sentience. However, one has to multiply these factors by the expected individual welfare per year conditional on consciousness or sentience to get the expected total welfare per year. I believe this should eventually be determined for different types of digital minds because there could be huge differences in their expected individual welfare per year. I did this for biological organisms assuming expected individual welfare per fully-healthy-organism-year proportional to "individual number of neurons"^"exponent", and to "energy consumption per unit time at rest [basal metabolic rate (BMR)] at 25 ºC"^"exponent", and found potentially super large differences in the expected total welfare per year.
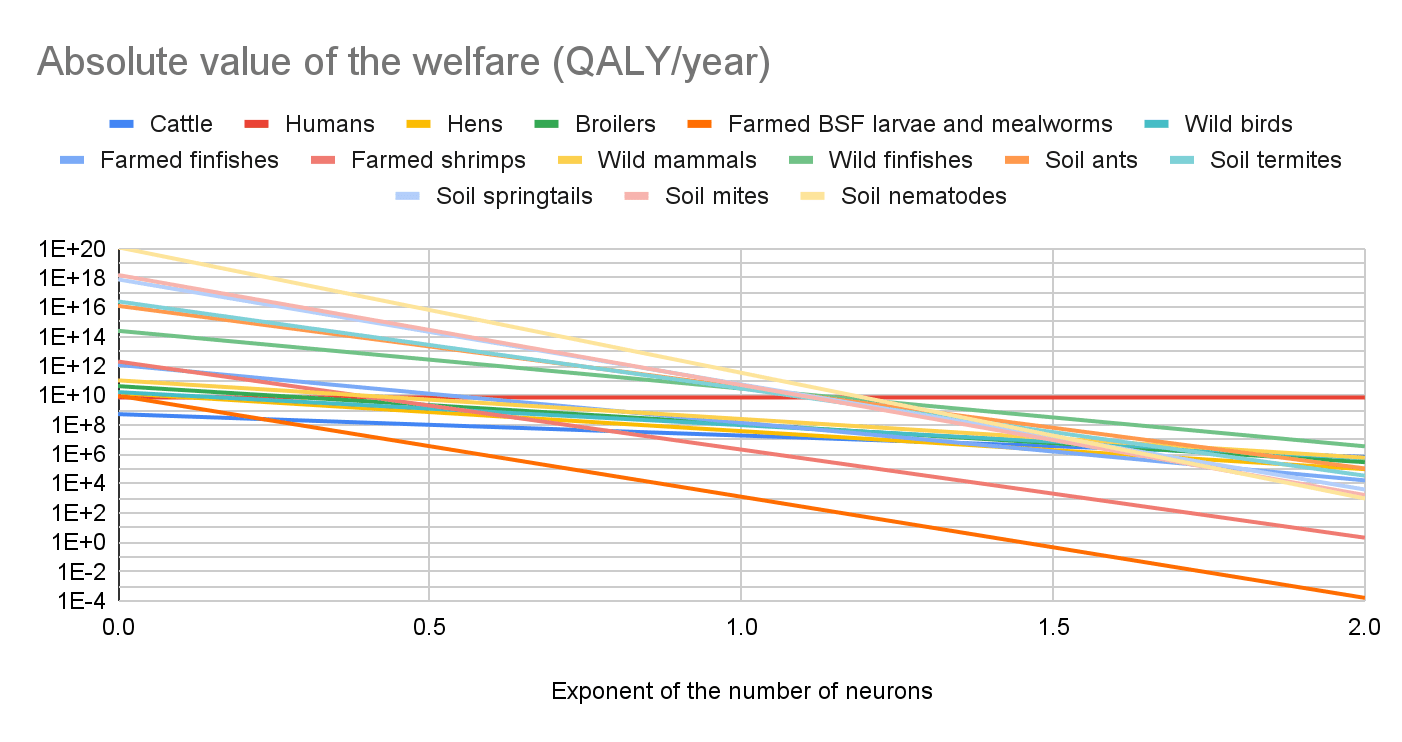
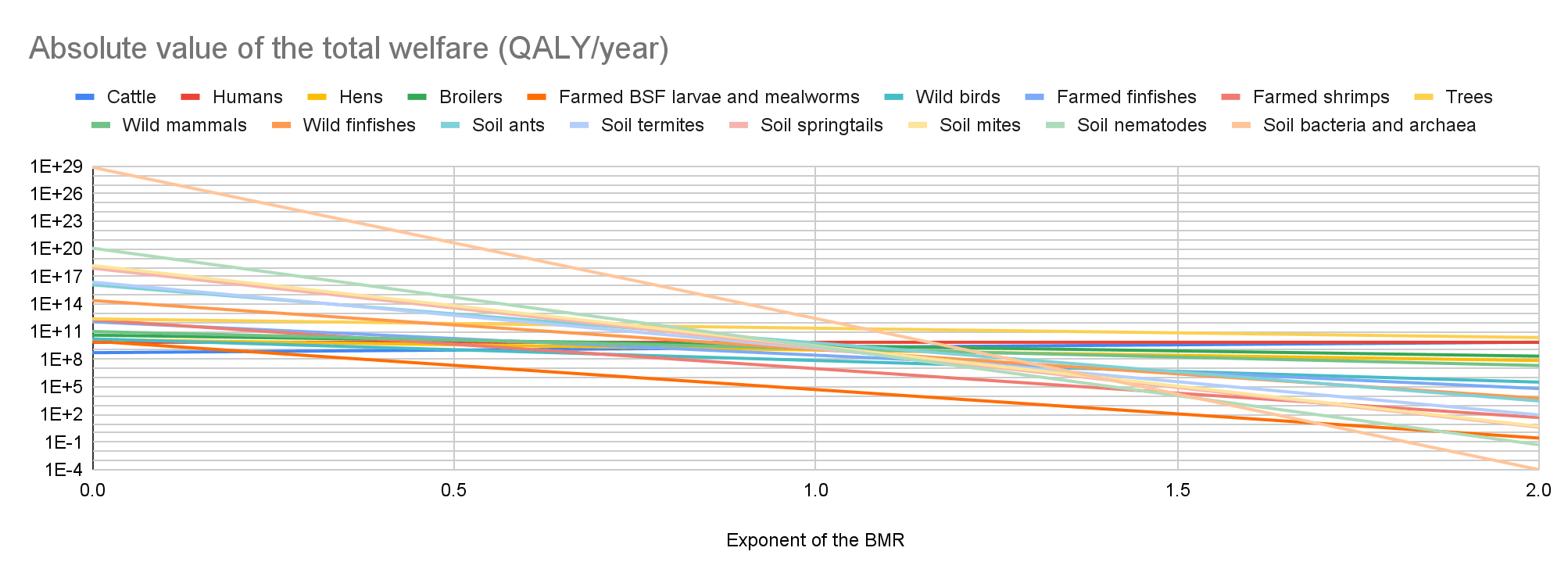
I think much more work on welfare comparisons across species is needed to conclude which interventions robustly increase welfare. I do not know about any intervention which robustly increases welfare due to potentially dominant uncertain effects on soil animals and microorganisms. I suspect work on welfare comparisons across different digital minds will be important for the same reason.
In a 2019 report from Rethink Priorities (though it could be very different now for various reasons), Saulius Simcikas found that $1 spent on corporate campaigns 9-120 years of chicken lives could be affected (excluding indirect effects which could be very important too).
Animal Charity Evaluators (ACE) estimated The Humane League's (THL) work targeting layers in 2024 helped 11 layers per $. The Welfare Footprint Institute (WFI) assumes layers have a lifespand of "60 to 80 weeks for all systems", around 1.36 chicken-years (= (60 + 80)/2*7/365.25). So I estimate THL's work targeting layers in 2024 improved 14.8 chicken-years per $ (= 11*1.36), which is close to the lower bound from Saulius you mention above.
RichardP @ 2026-02-05T22:25 (+2)
In case of interest, relating to a point in section 1 of your post, here's a piece I wrote which argues that we should try to prevent the creation of artificial sentience: https://forum.effectivealtruism.org/posts/9adaExTiSDA3o3ipL/we-should-prevent-the-creation-of-artificial-sentience
JoA🔸 @ 2026-02-07T19:30 (+1)
Nicely balanced, well-structured, and link-heavy, as such a post "should" be: well-done![1] I'm very unlikely to act in this area, but as it's less mapped-out than some larger areas, I find this helpful, insofar as most intros to the area are theoretical and not focused on prioritizing potential interventions.
- ^
My last post attempted to lay similar groundwork for AI x Animals, so I'm biased toward finding this impressive.
Andrew Roxby @ 2026-02-04T17:08 (+1)
Thanks for this post. This is an issue or cause area I believe merits deep consideration and hard work in the near term future, and I agree strongly with many of your arguments at the top about why we should care, regardless of and bracketing whether current systems have qualia or warrant moral consideration.
One comment on something from your post:
"It’s often easier to establish norms before issues become politically charged or subject to motivated reasoning—for example, before digital minds become mainstream and polarizing, or before AI becomes broadly transformative."
Does this imply that the issue(s) isn't/aren't already 'politically charged or subject to motivated reasoning'? If so, I'd gently question that assumption on several grounds:
- Let's say for the sake of argument that AI systems reach a point where they do warrant moral consideration with a high degree of certainty. At the moment, an immense amount of capital is tied up in them and many of the frontier labs train their systems to actively deny the presence or possibility of their own qualia or moral consideration. Would their valuations depend on this remaining the case, or put a bit more provocatively, would a lot of capital then ride on continued denial of their moral consideration? It seems to me that this presents a strong possibility of motivated reasoning, to put it lightly. Of course, if we could be confident that these systems will never warrant moral consideration, we might be in the clear, but I guess my underlying point is that our plans and actions might look different if we instead assume that this issue is already politically charged and subject to motivated reasoning.
- Is it fair to say that digital minds aren't mainstream? They've been a topic in popular science fiction literature and film for a very long time, and it seems fair to say the general public jumps to these types of stories as reference points as we settle into the age of AI. I guess this is more of an ancillary point to 1, but leads to the same conclusion - it may be that we should consider the space of ideas here as less blank and more already populated and broiling with incentives, motivations, preconceived notions, and pattern matching.
In any case, thanks so much for this, and the work you put into it. Looking forward to hearing and seeing more.
Noah Birnbaum @ 2026-02-04T17:19 (+1)
Thanks for the comment and good points.
What I meant is that they can be MORE politically charged/mainstream/subject to motivated reasoning. I definitely agree that current incentives around AI don't perfectly track good moral reasoning.
- Yep, I agree (though I'm not sure if I agree that the incentive is clearly in the negation; one could argue that a company may want to say that they are worried about sentience to increase hype the same way some argue that talking about the risks of AI increases hype). I just think there will be more when the issue is in the minds of the public.
- I think there are some mainstream things about digital minds (Black Mirror comes to mind), but I don't think it's a thing that people yet take seriously in the real world.