Incident reporting for AI safety
By Zach Stein-Perlman, SeLo, stepanlos, MvK🔸 @ 2023-07-19T17:00 (+18)
Zach Stein-Perlman, Sebastian Lodemann, Štěpán Los, and Moritz von Knebel
We made this (quickly) because a resource on incident reporting as a tool for AI safety should exist; we are not experts; suggestions are welcome.
Zach recommends engaging with this post by reading §1 and skimming §4 (focusing on sources near the top). Read §2 for recommendations, §3 for existing efforts on incident reporting in AI, or §6 for incident reporting outside of AI, according to your interests.
1. Introduction
Incident reporting is a widely-used and generally accepted practice across many domains as a way to support safety practices. Incident reporting can help "expose problematic systems, improve (or in some cases, shut down) those systems, and seek redress" for anyone harmed. When accidents are publicly disclosed, system designers are forced to address them and at least fix ongoing safety issues.
Incident reporting can be "vital for helping others avoid training risky systems, and for keeping AI developers accountable." Going forward, if other developers of AI systems can easily find past accidents and near misses, and see how they were addressed, they can better avoid similar incidents.[1] If there is an expectation that all incidents are reported, there is also an added motivation for model developers to avoid such incidents.
More broadly, "open, non-punitive reporting of accidents and near-misses is typically part of safety culture both instrumentally, and because reporting builds a norm of admitting mistakes, noticing them, and sharing lessons learned."
What is an 'incident' for AI? Different approaches, different typologies of incidents, and different sets of goals for reporting lead to defining "incident" more or less broadly.[2]
Governments can help support incident reporting in many ways, including by helping actors coordinate, requiring incident reporting in some cases, and by protecting actors from liability for voluntarily-reported incidents in some cases.
Incidents should probably include issues reported via bug bounty or responsible disclosure systems. Labs' bug bounty and responsible disclosure systems should cover model outputs in addition to security. See Recommendation: Bug Bounties and Responsible Disclosure for Advanced ML Systems (Vaniver 2023).
Information about some incidents is infohazardous and should not be shared widely. In particular, sharing active security or misuse threats before they're fixed is dangerous, and sharing some incidents could risk advancing AI capabilities research on dangerous paths.
There's lots of great possible information-sharing for AI safety besides incident-reporting.[3]
Better records of AI incidents may also help to educate policymakers and the public about AI risk.
2. Recommendations
Some mostly tentative and mostly underspecified ideas:
Ideas for AI labs
Labs should:
- "Report safety incidents. AGI labs should report accidents and near misses to appropriate state actors and other AGI labs (e.g. via an AI incident database)."[4] They should also explain their responses to such incidents, if relevant.
- "Industry sharing of security information. AGI labs should share threat intelligence and information about security incidents with each other."
- "AGI labs should coordinate on best practices for incident reporting."
Labs should also allow external audits of safety practices, including incident reporting.[5]
In addition to reporting the incidents they are aware of, labs should try to notice incidents. Incident reporting is only one part of broader safety culture. In particular, labs should test and red-team their models to find undesired behavior, and they should monitor their model outputs and how users use models for undesired behavior.[6]
Some suggestions from Štěpán to operationalize incident reporting.[7]
Often regulatory programs are the result of or heavily influenced by prior industry-led efforts and voluntary standards (e.g. CFATS and the ACC), so it could be good for labs to develop an industry-wide voluntary standard program with wide stakeholder buy-in.
Stakeholders could set up an AI Information Sharing and Analysis Centre (ISAC) or integrate it under the Information Technology ISAC. An AI ISAC would handle information about AI accidents and best practices and could potentially even offer threat-mitigation services. Alternatively, an AI branch could be set up under the existing Information Technology ISAC (IT ISAC), which specializes in strengthening information infrastructure resilience, operating a Threat Intelligence platform that enables automated sharing and threat analysis among member corporations of the IT ISAC.
We are not aware of an incident reporting policy at any major AI lab, nor of relevant plans or discussion. One of us has heard that some labs do track some incidents.
Governance researchers at labs sometimes write about incident reporting. In particular, OpenAI said "To support the study of language model misuse and mitigation thereof, we are actively exploring opportunities to share statistics on safety incidents this year, in order to concretize discussions about language model misuse" (OpenAI 2022). See also DeepMind 2023 and Brundage et al. 2020, quoted below.
OpenAI reports outages of its products. OpenAI also says "Data Breach Notifications" is part of their data privacy program, but their policy is unclear.
Ideas for government/etc.
Government can promote incident reporting by requiring it and making it non-punitive.[8] It can also require certain record-keeping[9] to avert labs and other actors destroying information about incidents, perhaps as a stopgap before an incident-reporting regime is perfected.
Government should
Require certain kinds of AI incident reporting, similar to incident reporting requirements in other industries (e.g. aviation) or to data breach reporting requirements, and similar to some vulnerability disclosure regimes. Many incidents wouldn't need to be reported publicly, but could be kept confidential within a regulatory body. The goal of this is to allow regulators and perhaps others to track certain kinds of harms and close-calls from AI systems, to keep track of where the dangers are and rapidly evolve mitigation mechanisms.
"In [the] future, regulators could maintain lists of high-risk or banned training approaches; a sufficiently concerning incident report would then trigger an update to this list."[10]
Various design choices can improve an incident-reporting regime.
We are not aware of existing regulation or government action related to incident reporting in AI. The EU AI Act will require limited incident reporting. The OECD is working on incident reporting in AI (expert group and AI Incidents Monitor slides).
3. Databases & resources
Databases & resources, in roughly descending order of priority (the first two seem to be substantially better):
AI Incident Database (blogpost, paper, follow-up) is a public repository of AI incidents. Incidents can be submitted by any user and are monitored by experts from both the private sector (e.g. bnh.ai, a DC-based law-firm) and academia (CSET). Reports include descriptions of events, identification of the models used, actors involved and links to similar accidents.
AI Vulnerability Database is a database as well as a taxonomy of AI accidents. Its primary purpose is to help developers and product engineers avoid mistakes, share information and better understand the nature of AI-related risks.
AI, Algorithmic and Automation Incidents and Controversies has a public repository of AI incidents run by a team of volunteers. Similarly to the AI Incident Database, submissions to the repository are made by the public and are maintained by the editorial volunteer team. Reports are categorized according to technology used or incident-type and include the description and location of incidents, key actors and developers as well as supporting evidence for the incident.
MITRE Adversarial Threat Landscape for Artificial-Intelligence Systems is a database of adversary tactics, techniques and real-life case studies of attacks on ML systems, highlighting their vulnerabilities and safety measures against adversaries.
Badness.ai is a community-operated catalog of harms involving generative AI. It catalogs harms based on category (e.g. producing inaccuracies, deepfakes, aggression or misinformation) or the specific companies or models involved.
Awful AI is a database on the GitHub platform where users can report issues with AI systems in several categories such as discrimination, surveillance or misinformation.
Even less relevant stuff:
Victoria Krakovna's list on specification gaming: more about misalignment than incident tracking, though the list is of specific failures that were reported.
Rohin Shah et al.'s list on goal misgeneralisation: more about misalignment than incident tracking, though again, the list is of specific failures that were reported.
Bias in Artificial Intelligence: Example Tracker is maintained by the Berkeley Haas Center for Equity, Gender & Leadership and its main purpose is to document bias in deployed AI systems. The database includes detailed description of the particular bias displayed and of the AI system in question, the industry in which the incident happened and information about whether the incident was followed up by the relevant authorities.
Tracking Automated Government (TAG) Register is a database which tracks identified cases of automated decision-making (AMD) by the U.S. government. It assesses the transparency of the systems being used, whether citizens' data is being protected as well as potential unequal impacts of AMD usage.
Observatory of Algorithms with Social Impact Register (OASI Register) by Eticas Foundation is a database of algorithms used by governments and companies, highlighting their potential negative social impact and checking whether the systems have been audited prior to deployment.
AI Observatory is a small database run by Divj Joshi and funded by the Mozilla Foundation which reports harmful usage of Automated Decision Making Systems (ADMS) in India.
List of Algorithm Audits is a GitHub repository managed by the academic Jack Bandy (Northwestern University, USA). It is an extension of Bandy's 2021 paper 'Problematic Machine Behavior: A Systematic Literature Review of Algorithm Audits' and documents empirical studies which demonstrated problematic behavior of an algorithm in one of the following categories: discrimination, distortion, exploitation and misjudgement.
Wired Artificial Intelligence Database is a repository of Wired articles about AI systems, many of which involve detailed essays and case studies of real-world harm caused by AI.
4. Readings & quotes
There are few sources focused on incident reporting for AI. The below quotes attempt to fully catalog everything relevant in these sources.[11]
In roughly descending order of priority:
"Sharing of AI Incidents" in "Toward Trustworthy AI Development: Mechanisms for Supporting Verifiable Claims" (Brundage et al. 2020):
Problem:
Claims about AI systems can be scrutinized more effectively if there is common knowledge of the potential risks of such systems. However, cases of desired or unexpected behavior by AI systems are infrequently shared since it is costly to do unilaterally.
Organizations can share AI "incidents," or cases of undesired or unexpected behavior by an AI system that causes or could cause harm, by publishing case studies about these incidents from which others can learn. This can be accompanied by information about how they have worked to prevent future incidents based on their own and others' experiences.
By default, organizations developing AI have an incentive to primarily or exclusively report positive outcomes associated with their work rather than incidents. As a result, a skewed image is given to the public, regulators, and users about the potential risks associated with AI development.
The sharing of AI incidents can improve the verifiability of claims in AI development by highlighting risks that might not have otherwise been considered by certain actors. Knowledge of these risks, in turn, can then be used to inform questions posed to AI developers, increasing the effectiveness of external scrutiny. Incident sharing can also (over time, if used regularly) provide evidence that incidents are found and acknowledged by particular organizations, though additional mechanisms would be needed to demonstrate the completeness of such sharing.
AI incidents can include those that are publicly known and transparent, publicly known and anonymized, privately known and anonymized, or privately known and transparent. The Partnership on AI has begun building an AI incident-sharing database, called the AI Incident Database. The pilot was built using publicly available information through a set of volunteers and contractors manually collecting known AI incidents where AI caused harm in the real world.
Improving the ability and incentive of AI developers to report incidents requires building additional infrastructure, analogous to the infrastructure that exists for reporting incidents in other domains such as cybersecurity. Infrastructure to support incident sharing that involves non-public information would require the following resources:
- Transparent and robust processes to protect organizations from undue reputational harm brought about by the publication of previously unshared incidents. This could be achieved by anonymizing incident information to protect the identity of the organization sharing it. Other information-sharing methods should be explored that would mitigate reputational risk to organizations, while preserving the usefulness of information shared;
- A trusted neutral third party that works with each organization under a non-disclosure agreement to collect and anonymize private information;
- An organization that maintains and administers an online platform where users can easily access the incident database, including strong encryption and password protection for private incidents as well as a way to submit new information. This organization would not have to be the same as the third party that collects and anonymizes private incident data;
- Resources and channels to publicize the existence of this database as a centralized resource, to accelerate both contributions to the database and positive uses of the knowledge from the database; and
- Dedicated researchers who monitor incidents in the database in order to identify patterns and shareable lessons.
The costs of incident sharing (e.g., public relations risks) are concentrated on the sharing organization, although the benefits are shared broadly by those who gain valuable information about AI incidents. Thus, a cooperative approach needs to be taken for incident sharing that addresses the potential downsides. A more robust infrastructure for incident sharing (as outlined above), including options for anonymized reporting, would help ensure that fear of negative repercussions from sharing does not prevent the benefits of such sharing from being realized.
Recommendation: AI developers should share more information about AI incidents, including through collaborative channels.
Developers should seek to share AI incidents with a broad audience so as to maximize their usefulness, and take advantage of collaborative channels such as centralized incident databases as that infrastructure matures. In addition, they should move towards publicizing their commitment to (and procedures for) doing such sharing in a routine way rather than in an ad-hoc fashion, in order to strengthen these practices as norms within the AI development community.
Incident sharing is closely related to but distinct from responsible publication practices in AI and coordinated disclosure of cybersecurity vulnerabilities [55]. Beyond implementation of progressively more robust platforms for incident sharing and contributions to such platforms, future work could also explore connections between AI and other domains in more detail, and identify key lessons from other domains in which incident sharing is more mature (such as the nuclear and cybersecurity industries).
Over the longer term, lessons learned from experimentation and research could crystallize into a mature body of knowledge on different types of AI incidents, reporting processes, and the costs associated with incident sharing. This, in turn, can inform any eventual government efforts to require or incentivize certain forms of incident reporting.
12 tentative ideas for US AI policy (Muehlhauser 2023):
Require certain kinds of AI incident reporting, similar to incident reporting requirements in other industries (e.g. aviation) or to data breach reporting requirements, and similar to some vulnerability disclosure regimes. Many incidents wouldn't need to be reported publicly, but could be kept confidential within a regulatory body. The goal of this is to allow regulators and perhaps others to track certain kinds of harms and close-calls from AI systems, to keep track of where the dangers are and rapidly evolve mitigation mechanisms.
Model evaluation for extreme risks (DeepMind, Shevlane et al. 2023) (and blogpost An early warning system for novel AI risks):
Unanticipated behaviours. Before deployment, it is impossible to fully anticipate and understand how the model will interact in a complex deployment environment (a key limitation of model evaluation: see section 5). For example, users might find new applications for the model or novel prompt engineering strategies; or the model could be operating in a dynamic, multi-agent environment. Therefore, in the early stages of deployment, developers must . . . . Surface emerging model behaviours and risks via monitoring efforts. This could include direct monitoring of inputs and outputs to the model, and systems for incident reporting (see Brundage et al., 2022; Raji et al., 2022b). . . .
Model evaluations will unlock four important kinds of transparency around extreme risks [including] Incident reporting, i.e. a structured process for developers to share concerning or otherwise noteworthy evaluation results with other developers, third parties, or regulators (see Brundage et al., 2020). This would be vital for helping others avoid training risky systems, and for keeping AI developers accountable. In [the] future, regulators could maintain lists of high-risk or banned training approaches; a sufficiently concerning incident report would then trigger an update to this list. . . .
We must develop new security best practices for high-risk AI development and deployment, which could include for example: . . . . Monitoring: Intensive, AI-assisted monitoring of the model's behaviour, e.g. for whether the model is engaging in manipulative behaviour or making code recommendations that would lower the overall security of a system.
[Relevant part] of Survey on intermediate goals in AI governance (Räuker and Aird 2023).
Consultation on the European Commission's White Paper on Artificial Intelligence (GovAI 2020):
Consider establishing a database for the sharing of information on AI incidents. A central repository of "AI incidents", i.e., instances of undesired or unexpected and (potentially) harmful behaviour by an AI application, would improve the implementation and further development of the regulatory framework. The appropriate national authorities and independent testing centres could build up shared institutional knowledge of common failure modes. The Commission would also be in a better position to adjust the scope and requirements of the framework. Such a database has been proposed by a broad coalition of researchers and the Partnership on AI has already launched such a database. Widespread use would be crucial for its success, but businesses might be wary of submitting incident reports for fear of reputational or other costs.
Several measures could be taken to address such concerns, e.g., by ensuring anonymity, security, and privacy. Submitting incident reports could be further incentivised, e.g., through regulatory requirements or monetary incentives for developers, users, or third parties ("bounties"). Similar models for such information-sharing arrangements have been set up in other areas. As part of European pharmacovigilance efforts, the European Medicines Agency, for instance, established a central electronic repository for periodic safety update reports by firms in the pharmaceutical industry. The Commission could apply best practices from similar such registries, where applicable.
Towards best practices in AGI safety and governance (GovAI, Schuett et al. 2023):
- "Report safety incidents. AGI labs should report accidents and near misses to appropriate state actors and other AGI labs (e.g. via an AI incident database)." 76% strongly agree; 20% somewhat agree; 2% strongly disagree; 2% don't know; n=51.
- "Industry sharing of security information. AGI labs should share threat intelligence and information about security incidents with each other." 53% strongly agree; 39% somewhat agree; 5% neither agree nor disagree; 3% don't know; n=38.
- "AGI labs should coordinate on best practices for incident reporting."
How to deal with an AI near-miss: Look to the skies (Shrishak 2023):
an AI near-miss reporting system should have at least four properties to encourage AI actors to submit reports.
First, near-miss reporting should be voluntary. A near-miss reporting system helps capture issues that are not reported to a mandatory serious incidents reporting system. A near-miss reporter is thus contributing to a safer AI ecosystem. Such a contribution takes time and effort, and should not be made mandatory.
Second, near-miss reporting should be confidential. The near-miss report published in the public database should not contain any identifiable information so that there are no unnecessary negative repercussions for the reporter. This allows the reporter to answer why there was a failure, whether an unforeseen circumstance occurred, or whether a human made a mistake. All of these details are important to address problems without delay, but might go unreported if confidentiality is not guaranteed.
Third, there should be a clear immunity policy to guide near-miss reporters. The reporter should receive limited immunity from fines for their efforts to report near-misses. Regulators should be considerate of the reporter's contribution to the database in case a serious incident takes place. When a reporter submits a report, they should receive a proof of submission that they can use. Such a proof can be generated before all identifiable information is removed and the report is made confidential by the maintainers of the database. (This is also an important reason for the database to be maintained by a trusted third party, and not a regulator.)
Finally, the reporting system should have a low bureaucratic barrier. The format of the report should be simple and accessible so that it takes minimal time and effort for the reporter. Ease of reporting is essential for such a system to succeed.
Documenting and publishing near-misses would help AI system developers and regulators avoid serious incidents. Instead of waiting for major failures before problems are addressed, disasters could be prevented. What we need is an incident database where developers and users of AI system[s] voluntarily add incidents, including near-misses. To make such a database useful and to create an ecosystem where safer AI systems are prioritized, the database should have regulatory support. Privately run databases do not have the regulatory support that is required to give operators of AI systems the incentive to report their own near-misses.
If there is one thing that should not be replicated from other sectors, it is to wait decades before setting up and incentivizing AI near-miss reporting. It is never too soon to [set up] such a database. Now is the right time.
Filling gaps in trustworthy development of AI (Avin et al. 2021):
Collecting and sharing evidence about . . . incidents can inform further R&D efforts as well as regulatory mechanisms and user trust. . . . Incident sharing could become a regulatory requirement. Until then, voluntary sharing can be incentivized, for example by allowing anonymous disclosure to a trusted third party. Such a third party would need to have transparent processes for collecting and anonymizing information and operate an accessible and secure portal.
AI Accidents: An Emerging Threat (CSET, Arnold and Toner 2021).
[The US federal government should] Facilitate information sharing about AI accidents and near misses. To make AI safer, we need to know when and how it fails. In many other technological domains, shared incident reporting contributes to a common base of knowledge, helping industry and government track risks and understand their causes. Models include the National Transportation Safety Board’s database for aviation incidents and the public-private cyber intelligence platforms known as Information Sharing and Analysis Centers. The government should consider creating a similar repository for AI accident reports. As part of this effort, policymakers should explore different ways of encouraging the private sector to actively disclose the details of AI accidents. For example, the government could offer confidentiality protections for sensitive commercial information in accident reports, develop common standards for incident reporting, or even mandate disclosure of certain types of incidents.
Outsider Oversight: Designing a Third Party Audit Ecosystem for AI Governance (Raji et al. 2022) (especially §4.1 Target Identification & Audit Scope).
Lessons learned on language model safety and misuse (OpenAI, Brundage et al. 2022)
To support the study of language model misuse and mitigation thereof, we are actively exploring opportunities to share statistics on safety incidents this year, in order to concretize discussions about language model misuse. . . .
Many aspects of language models' risks and impacts remain hard to measure and therefore hard to monitor, minimize, and disclose in an accountable way. We have made active use of existing academic benchmarks for language model evaluation and are eager to continue building on external work, but we have also have found that existing benchmark datasets are often not reflective of the safety and misuse risks we see in practice.
"AI Harm Incident Tracking" in "Missing links in AI governance" (UNESCO and Mila 2023):
AI Harm Incident Tracking
No AI system is perfect. We need AI harm incident reporting and tracking in order to ensure that those who are harmed by AI systems are able to share their experiences and concerns. Standardization of AI harm incident tracking supports a grounded understanding of problems, system improvements by vendors and operators, better oversight by regulators, legal action where necessary, and greater visibility of incidents in the press and in the public eye. Incident tracking is a well-developed practice in some sectors, such as information security (Kenway and François [et al.], 2021). A robust incident response includes several key activities, including:
- Discovery—in other words, learning that an incident has occurred
- Reporting and tracking—documenting and sharing information about the incident
- Verification—confirming that the incident is reproducible, or indeed caused by the system in question
- Escalation—flagging the incident in terms of severity and urgency
- Mitigation—changing the system so that the problem does not continue to cause harm, ideally through a root cause analysis rather than a superficial patch
- Redress—taking steps to ensure that anyone harmed by the problem feels that the harm they suffered has been recognized, addressed, and in some cases, compensated, and
- Disclosure—communicating about the problem to relevant stakeholders, including other industry actors, regulators, and the public.
If organized well, harm incident reporting guides those who have experienced harm from AI systems (or their advocates) to provide informative descriptions of their experience that can then be used to expose problematic systems, improve (or in some cases, shut down) those systems, and seek redress. Systematic collection of AI harm incident reports is a critical step towards gaining a better understanding of the risks associated with AI system deployment, and towards ensuring the minimization, mitigation and redress of harms. However, there are currently no existing policy proposals, requirements, norms, standards or functional systems for AI harm incident tracking.
Building a Culture of Safety for AI (Manheim 2023):
For both approaches, one critical step needed to allow this is understanding the failure modes, which in other domains starts with reporting past incidents. And open, non-punitive reporting of accidents and near-misses is typically part of safety culture both instrumentally, and because reporting builds a norm of admitting mistakes, noticing them, and sharing lessons learned. (Engemann and Scott 2020) . . . .
For failure reporting to be used further towards safety culture, cataloging incidents and categorization of failure modes must be followed by further steps. Before that occurs, however, the set of failure modes need to include not just past failures, but also current risks and future challenges. To that end, taxonomies such as Critch and Russell's (2023) are critical, in that case both because it identifies new risks, and because it centers accountability, which is another enabling factor for safety cultures.
Preventing Repeated Real World AI Failures by Cataloging Incidents: The AI Incident Database (McGregor 2020).
Frontier AI Regulation: Managing Emerging Risks to Public Safety (Anderljung et al. 2023) mentions/endorses but does not discuss incident reporting.
Policymaking in the Pause (FLI 2023) mentions/endorses but does not discuss incident reporting.
Bug Bounties For Algorithmic Harms? (AJL, Kenway et al. 2022).
5. Relevant people
Sebastian Lodemann- Working on recommendations for labs
- Authors of the readings listed above
- Expert Group on AI Incidents - OECD.AI
- Including ~5 AI safety people
- Including ~5 AI safety people
6. Incident reporting outside of AI
List
Aviation is very often mentioned; see below. Cybersecurity is often mentioned. Probably miscellaneous professional standards include incident reporting.
National Transportation Safety Board (NTSB) publishes and maintains a database of aviation accidents, including detailed reports evaluating technological and environmental factors as well as potential human errors causing the incident. The reports include descriptions of the aircraft, how it was operated by the flight crew, environmental conditions, consequences of event, probable cause of accident, etc. The meticulous record-keeping and best-practices recommendations are one of the key factors behind the steady decline in yearly aviation accidents, making air travel one of the safest form of travel.
National Highway Traffic Safety Administration (NHTSA) maintains a comprehensive database recording the number of crashes and fatal injuries caused by automobile and motor vehicle traffic, detailing information about the incidents such as specific driver behavior, atmospheric conditions, light conditions or road-type. NHTSA also enforces safety standards for manufacturing and deploying vehicle parts and equipment.
Common Vulnerabilities and Exposure (CVE) is a cross-sector public database recording specific vulnerabilities and exposures in information-security systems, maintained by Mitre Corporation. If a vulnerability is reported, it is examined by a CVE Numbering Authority (CNA) and entered into the database with a description and the identification of the information-security system and all its versions that it applies to.
Information Sharing and Analysis Centers (ISAC). ISACs are entities established by important stakeholders in critical infrastructure sectors which are responsible for collecting and sharing: 1) actionable information about physical and cyber threats 2) sharing best threat-mitigation practices. ISACs have 24/7 threat warning and incident reporting services, providing relevant and prompt information to actors in various sectors including automotive, chemical, gas utility or healthcare.
National Council of Information Sharing and Analysis Centers (NCI) is a cross-sector forum designated for sharing and integrating information among sector-based ISACs (Information Sharing and Analysis Centers). It does so through facilitating communication between individual ISACs, organizing drills and exercises to improve security practices and working with federal-level organizations.
U.S. Geological Survey's "Did You Feel It?" (DYFI) is a public database and questionnaire used to gather detailed reports about the effects on earthquakes in affected areas. It also gives users an opportunity to report earthquakes which are not yet in the Geological Survey's records.
Aviation
One example of voluntary incident reporting can be found in the field of aviation, where so-called Voluntary Regulatory Partnership Programs (VRPPs) and Voluntary Safety Reporting Programs (VSRPs) have been introduced. Realizing in the late 1980s that fining companies like Continental Airlines for reporting violations they had uncovered in their self-audit program would create incentives to underreport incidents, accidents and violations (Source), the FAA initiated programs that would allow the reporting of incidents to go unpunished. A contributing factor was the increased demand in aviation and the increased calls for safety standards, which created the need for the collection of massive amounts of data. Encouraging self-regulation and self-reporting represented a way of lowering the administrative burden and the cost for regulatory agencies. These programs were intended to solve (or at least mitigate) the problems resulting from the so-called "regulatory dilemma" (see Table X).
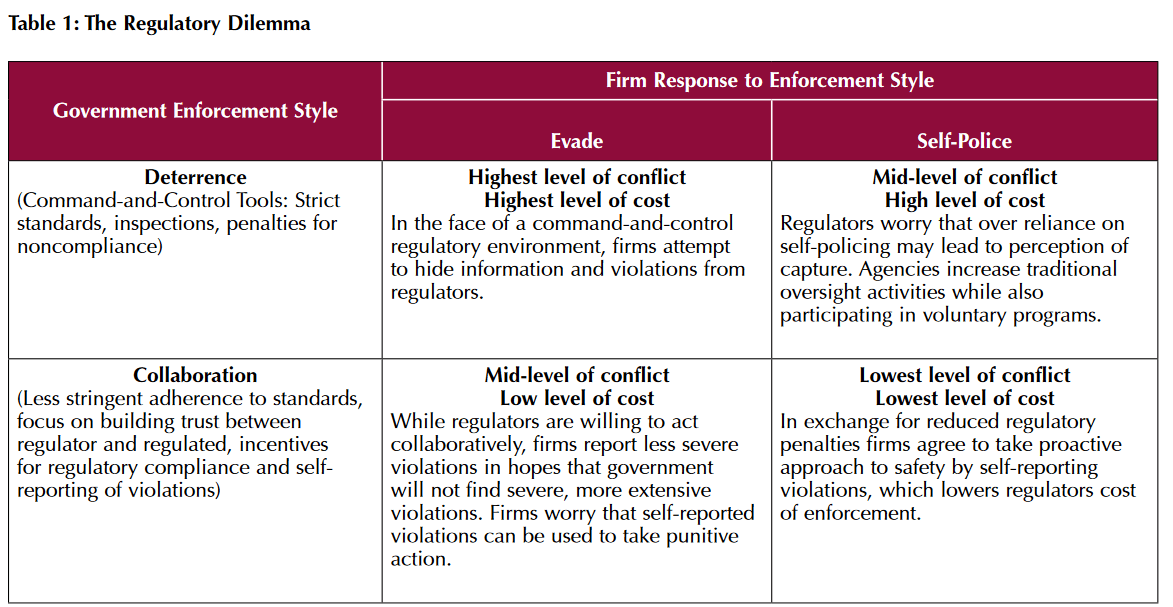
Table X: The Regulatory Dilemma (Source)
VRPPs and VSRPs are driven by the desire to establish cooperative and trust-based relationships between industry and regulators while simultaneously ensuring compliance and lowering the cost of enforcement (Source). Reducing the need for external audits and investigations, they shift the responsibility to those who are subject to regulation. Crucially, they serve to transform the incentive structures that businesses are facing when it's been determined that a standard has been violated, offering reduced regulatory burden (which is associated with reduced administrative cost) and increased flexibility to companies that agree to be part of these programs (Source). In some cases, the reward for self-reporting can even be the guarantee that the violator will not be fined or prosecuted. Examples within the FAA include:
- Aviation Safety Reporting System (ASRS)
- Submitting an incident report gives airspace users confidentiality and freedom from penalty in return
- Voluntary Disclosure Reporting Program (VDRP)
- Voluntary reports of systemic problems guarantee air carriers reduced regulatory enforcement action
- Aviation Safety Action Program (ASAP) (also see chapter above)
- Employees report safety-related events, FAA or carrier can't take punitive action against the employee
A comparison of these three programs can be found in Table Y.
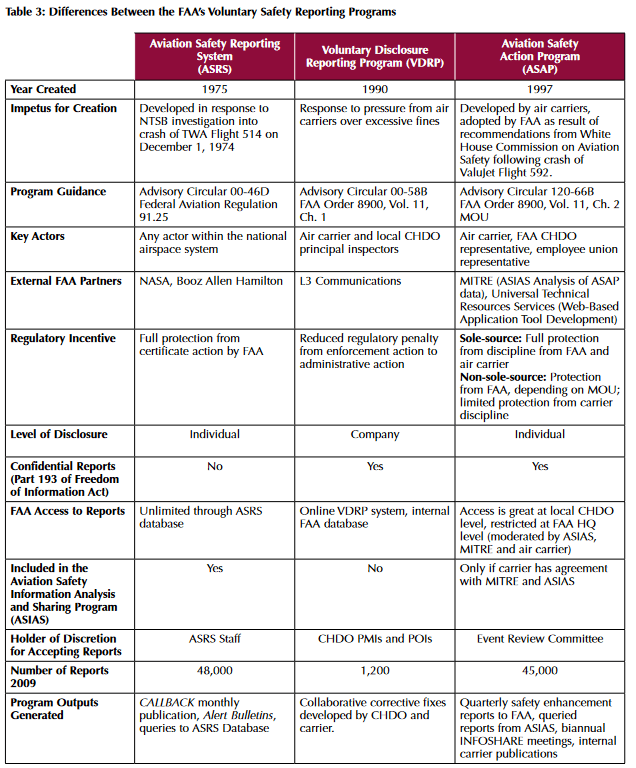
Table Y: Comparison of different programs within the FAA (Source)
The relative success of these programs in providing incentives for companies not to hide incidents and safety breaches notwithstanding, these voluntary reporting programs have also been criticized: "Some argue that VRPPs represent industry's capture of regulatory agencies, while others claim that these programs represent a third way of ensuring industry compliance with regulation." (Source) There is some evidence that these programs have failed to achieve what they were intending to accomplish, as a report by the IBM Centre for the Business of Government notes (Source). A conclusion that is sometimes drawn from these observations is that CRPPs and VSRPs can complement but not replace traditional means of enforcement and regulation (Source).
Some parts of this post are drawn from Štěpán's AI Incident Sharing. All authors don't necessarily endorse all of this post. Thanks to David Manheim for suggestions.
- ^
Organizations can share AI "incidents," or cases of undesired or unexpected behavior by an AI system that causes or could cause harm, by publishing case studies about these incidents from which others can learn. This can be accompanied by information about how they have worked to prevent future incidents based on their own and others' experiences.
"Sharing of AI Incidents" in "Toward Trustworthy AI Development: Mechanisms for Supporting Verifiable Claims" (Brundage et al. 2020).
- ^
For example, we could distinguish product incidents (where a released system causes harm through its undesired interaction with the real world); foundation model incidents, such as surprises during training (capabilities, capability eval results, alignment eval results if those exist, surprises from the AI during red-teaming, surprises from users during red-teaming); and organizational incidents (security or procedural issues).
- ^
It would be great for AI labs to share information (publicly or among themselves, depending) about AI risk, alignment, security, and good actions or best practices for labs. Information can be a public good. See e.g. Holden Karnofsky on "selective information sharing" (1, 2). Labs can also inform other kinds of actors, notably including informing government about AI risk and appropriate responses.
- ^
We aren't sure which incidents, how to report them, or who to report them to.
- ^
for organizations which wish to prioritize safety, flexible and well-designed governance audits can be a vital tool for management to ensure they are actually achieving the goal of building such a culture, and what they can do to improve.
Building a Culture of Safety for AI (Manheim 2023).
- ^
Unanticipated behaviours. Before deployment, it is impossible to fully anticipate and understand how the model will interact in a complex deployment environment (a key limitation of model evaluation: see section 5). For example, users might find new applications for the model or novel prompt engineering strategies; or the model could be operating in a dynamic, multi-agent environment. Therefore, in the early stages of deployment, developers must . . . . Surface emerging model behaviours and risks via monitoring efforts. This could include direct monitoring of inputs and outputs to the model, and systems for incident reporting (see Brundage et al., 2022; Raji et al., 2022b).
Model evaluation for extreme risks (DeepMind, Shevlane et al. 2023).
- ^
1. Internal audit trails, which "record the history of development of an AI system and provide an overview of the important processes that were taken to develop the system, and keep track of the failures registered in the pipeline." Lucaj et al. 2023.
2. Develop strong documentation practices. Developing model cards, i.e. frameworks for reporting the performance characteristic of an ML model on given benchmarks can help identify safety issues (Lucaj et al., 2023). Keeping datasheets for datasets can help identify potential issues with biased datasets Gebru et al. 2021. This is common practice in the electronic hardware industry.
3. Set up a continuous internal auditing lifecycle in order to identify potential risks and incidents and also in identifying the right actions (i.e. best practices), similar to auditing procedures in finance or air mobility (Lucaj et al. 2023). Inspiration for a framework here: https://arxiv.org/abs/2001.00973.
- ^
There is some precedence for voluntary safety reporting programs (VSRPs) in other fields, including aviation. The idea is that reporting non-compliance or incidents generally comes at a high cost, but these programs make it possible for industry actors to self-report a violation without having to fear fines or high reputational costs. This could reduce incentives to hide non-compliance, as happened a few years ago with the German automobile industry.
Another precedent is the European Telecommunications Standards Institute, which sets voluntary standards for developing and using information and communications systems. There are several motivations for companies to join these organizations: i) they anticipate that governments will mandate strict regulations and joining voluntary standard-setting organizations early gives companies a competitive edge; ii) complying with shared standards creates interoperability between different systems, helping business; iii) smaller companies can benefit from access to the organizations' resources and network; and iv) companies recognise their social responsibilities and pledge to promote safety (this may also increase trust from consumers).
- ^
An expert discusses "record-keeping" or "model self-identification requirements" as a policy tool (partially independent of incident reporting):
If we work back from "why would labs not deploy unsafe models" for sub-catastrophic settings, it's mostly if they'll get blamed for the consequences (i.e. liability). The next question is, how can we make sure that the paper trail of harms they cause is really clear, irrefutable, and accessible to litigators? And that suggests things like requiring reproducibility of API generations, logging model outputs, requiring model generations to be accompanied with certificates of which model was used and by whom (like HTTPS does for websites), and more ambitiously in the future, creating a norm that model outputs are accompanied by a hardware-based attestation of what the weights of the model were (to prevent subsequent claims that a different model was used).
And then maybe also provisions around a right of users/auditors/plaintiffs to query training data and historical deployment outputs (perhaps via a layer of privacy tools), and provisions around compiling post-incident reports.
Worth noting it has limitations, such as not deterring malicious use of OSS models.
- ^
Model evaluation for extreme risks (DeepMind, Shevlane et al. 2023).
- ^
I think the exception is Shrishak (and the sources listed but not quoted, which are generally relevant).
Zach Stein-Perlman @ 2023-07-27T17:14 (+2)
More sources that could be integrated:
- Securing AI: How Traditional Vulnerability Disclosure Must Adapt (CSET: Lohn and Hoffman 2022)
- Joint Recommendation for Language Model Deployment (Cohere, OpenAI, and AI21 Labs 2022)
- Includes the principles "Document known weaknesses and vulnerabilities" and "Publicly disclose lessons learned regarding LLM safety and misuse"
- https://arxiv.org/abs/2308.14752
- https://twitter.com/GretchenMarina/status/1696702861952926179
- "Reporting Information on AI Risk Factors and Incidents" in "Actionable Guidance for High-Consequence AI Risk Management" (Barrett et al. 2022, revised 2023)
- NIST AI RMF: GOVERN §4.3, MEASURE §3.3, and MANAGE §4.3 (NIST 2023)
- CSET AI Harm Taxonomy for AIID and Annotation Guide (CSET 2023)
- Confidence-Building Measures for Artificial Intelligence (Shoker et al. 2023)
- Suggests sharing incidents or making incident-sharing agreements could be good as a CBM
- Guide to Cyber Threat Information Sharing (NIST 2016)