Rational Animations' intro to mechanistic interpretability
By Writer @ 2024-06-14T16:10 (+21)
This is a linkpost to https://youtu.be/jGCvY4gNnA8
In our new video, we talk about research on interpreting InceptionV1, a convolutional neural network. Researchers have been able to understand the function of neurons and channels inside the network and uncover visual processing algorithms by looking at the weights. The work on InceptionV1 is early but landmark mechanistic interpretability research, and it functions well as an introduction to the field. We also go into the rationale and goals of the field and mention some more recent research near the end. Our main source material is the circuits thread in the Distill journal and this article on feature visualization. The author of the script is Arthur Frost. I have included the script below, although I recommend watching the video since the script has been written with accompanying moving visuals in mind.
Intro
In 2018, researchers trained an AI to find out if people were at risk of heart conditions based on pictures of their eyes, and somehow the AI also learned to tell people’s biological sex with incredibly high accuracy. How? We’re not entirely sure.
The crazy thing about Deep Learning is that you can give an AI a set of inputs and outputs, and it will slowly work out for itself what the relationship between them is. We didn’t teach AIs how to play chess, go, and atari games by showing them human experts - we taught them how to work it out for themselves. And the issue is, now they have worked it out for themselves, and we don’t know what it is they worked out.
Current state-of-the-art AIs are huge. Meta’s largest LLaMA2 model uses 70 billion parameters spread across 80 layers, all doing different things. It’s deep learning models like these which are being used for everything from hiring decisions to healthcare and criminal justice to what youtube videos get recommended. Many experts believe that these models might even one day pose existential risks. So as these automated processes become more widespread and significant, it will really matter that we understand how these models make choices.
The good news is, we’ve got a bit of experience uncovering the mysteries of the universe. We know that humans are made up of trillions of cells, and by investigating those individual cells we’ve made huge advances in medicine and genetics. And learning the properties of the atoms which make up objects has allowed us to develop modern material science and high-precision technology like computers. If you want to understand a complex system with billions of moving parts, sometimes you have to zoom in.
That’s exactly what Chris Olah and his team did starting in 2015. They focused on small groups of neurons inside image models, and they were able to find distinct parts responsible for detecting everything from curves and circles to dog heads and cars.
In this video we’ll
- Briefly explain how (convolutional) neural networks work
- Visualise what individual neurons are doing
- Look at how neurons - the most basic building blocks of the neural network - combine into ‘circuits’ to perform tasks
- Explore why interpreting networks is so hard
There will also be lots of pictures of dogs, like this one. Let’s get going.

We’ll start with a brief explanation of how convolutional neural networks are built.
Here’s a network that’s trained to label images.

An input image comes in on the left, and it flows along through the layers until we get an output on the right - the model’s attempt to classify the image into one of the categories. This particular model is called InceptionV1, and the images it’s learned to classify are from a massive collection called ImageNet. ImageNet has 1000 different categories of image, like “sandal” and “saxophone” and “sarong” (which, if you don’t know, is a kind of printed fabric you wrap around your waist). It also has more than 100 kinds of dog, including 22 types of terrier. This will be relevant later. But anyway, back to the model. Somehow, it’s taking in an image, and putting out its best guess for which category the image comes from. How?
Well, we know exactly what the neurons here on the left are doing: they’re activated by the pixels of the image. And we know exactly what the neurons there on the right are doing: their activations are the model’s predictions for each of the possible classifications. And all these activations are just numbers.
What’s happening in between? The key element is the convolutional layer. Imagine we take our first layer of input cells - a grid of pixel activations. What we do is run a little filter across it, and the filter has its own grid of ‘weights’. We multiply the weights of the filter with the activations of the neurons, we add up the results, and we get a single new value. So maybe our grid of weights looks like this: a bunch of positive values at the top and negative values at the bottom. Then the overall result of the filter is high on parts of the picture where the top is brighter than the bottom. It’s like it’s filtering out a certain kind of edge. And when we slide this filter across the entire grid of pixel activations, we get a new grid of activations, but instead of representing the input image as is, now it’s detecting a certain kind of edge wherever it appears in the original image.
We also have a ‘bias term’, which we just add after applying the filter, because sometimes we want it to be biased towards a high or low value. Finally, if the result is negative we round it up to zero. That’s basically it. And we have loads of different filters producing different new grids of activations, which we call “channels”. These channels together form a new layer, and we run more filters across them. And those feed into another layer, and then another layer. Each layer usually detects more and more abstract properties of the input image until we get to the last part of the network, which is structured like a traditional fully-connected neural network. Somehow, the neurons at the end of the network tell you if you’re looking at a terrier or a saxophone. That’s pretty crazy.
If you’re wondering how we decide on the weights for the filters, well, we don’t. That’s the bit the model works out for itself during training. So the question is, why does it pick those specific values? How do we find out what these channels in the middle are representing, precisely?
Well, let’s pick one deep in the middle. What’s this channel doing? Maybe one way we can find out is to ask ‘what does it care about?’. Let’s take all our images, and feed them through the model, and check which images give it the highest activation. And look, it’s all pictures of dogs. Lots of dogs. Maybe this is a dog-detecting channel? Well, it’s hard to be sure. We know that something about dogs is activating it, but we don’t know what exactly.
Visualisation by Optimisation
If we wanted to be more sure, we could try to directly optimise an input to activate a neuron in this channel, actually in pretty much the same way we optimise the network to be accurate. So we feed the network a totally random bunch of pixels, and we see how much that activates our maybe-dog neuron, then we change the input a bit so that it activates the neuron a bit more, and we do this more and more until the neuron is as activated as possible. We can also do this with a whole channel at once - a whole grid of neurons doing the same operation on different parts of the image - by trying to get the highest average activation for the neurons. But let’s stick with just one neuron for now.
Ok, so unfortunately doing just this doesn’t work: what you get is some kind of weird cursed pile of static. We don't know why it's that specifically - like we said, there’s a lot we don’t know about neural networks. But just activating the neuron isn’t enough.
So let’s add some extra conditions to our optimisation process. What we want is something that wouldn’t rule out a sensible image, but would decrease the chance of getting one of the weird cursed static piles, so that when we run our optimisation process the top scorer is more likely to be like a sensible image. For instance, maybe we can take the input we’re optimising and jitter it around a bit each step, rotate it slightly, and scale it up or down a bit. For a normal picture this doesn’t change much - a dog head still looks like a dog head - but it seems to really mess with the walls of static according to the neuron. The technical term here is ‘Transformation Robustness’ - the image should be robust after you transform it. And now images start to take shape.
In the original Circuits piece, they also did something called (bear with me for a second) preconditioning to optimise in a colour-decorrelated Fourier Space. So what does that mean? Well, in audio processing, a fourier transformation is a way to take something like a chord or a messy sound and break it down into the constituent tones, so instead of splitting a sound up into the amplitude over time, you break it down into what simple notes make it up. You can do pretty much exactly the same thing with images: instead of thinking about the picture pixel by pixel, you layer a bunch of smooth waves on top of each other. So we have the optimiser look for adjustments to the input image that would lead to an increased neuron activation. And we let the optimiser work with this wave representation of the input image instead of changing it directly. Turns out that this way the adjustments are more smooth and less like static noise. When the optimisation is finished we translate it back to a normal image. And the resulting images actually look kind of reasonable.
But now our dog detector seems like it isn’t actually detecting dogs. It looks like it’s really detecting their snouts, and the way to fit the most snoutiness into the image is to fit another snout inside the snout. Weird, right?

(Here’s something for you to ponder: why is it so clear in the middle and so fuzzy on the edges? Well, that’s because we’re only focusing on one neuron, and that neuron is only looking at part of the picture. We’ll see later on that trying to maximise the whole channel makes the whole image more crisp.)
But anyway, back to snoutiness. This is sort of how it is with interpretability: it’s very hard to know what you’re actually looking at. The model is just learning whatever fits the data, and sometimes the thing that works is a bit surprising. In that sense, this kind of work is less like formal mathematical proofs and more like natural science: you experiment, you make predictions, and you test them, and slowly you become more confident.
Circuits
But this is still just one neuron on its own, one little part of the network. How do we get from that to understanding the whole massive messy network? Well, we can zoom out a bit. Let’s try doing that with some neurons we understand really really well.
For instance, let’s go up a bit to this layer, mixed3b. It has a bunch of neurons which seem like they’re detecting curves with a radius of about 60 pixels, all in slightly different orientations. Curve detector neurons, by the way, seem to basically show up in all image detectors: they’re somehow a very natural thing for models to learn.
We can use the tricks we already used - the neurons get activated by pictures of curves, and the feature visualisation generates pictures of curves. Also there are some tricks we can use for a really simple feature like a curve that doesn’t work for a dog detector: we can actually read the algorithm in the neuron and check that it looks like a pixel-by-pixel curve detector, and we can even write our own pixel-by-pixel curve detector to replace it, and check if anything breaks. So it really seems like these neurons are curve detectors.
But there’s loads of them all detecting curves in different directions. And that gives us some new options for investigation. [now you probably need visuals; timestamp here]. Like, what if we take a picture of a curve that activates this curve detector here, and slowly rotate it? Well, it turns out that as we rotate it, the activation on this curve detector goes down, and then the activation on this other one goes up. So if we arrange them in order it turns out that these curve detectors are actually picking up on every possible orientation between them.
They’re not just one-off neurons, they’ve been developed as part of a circuit, and they’re used together. Remember that each neuron depends on a small grid of neurons in the previous layer. And what we find is, for instance, a channel that’s activated by this [top left curve] kind of curve in the top left, and also inhibited by that kind of curve in the bottom right, and also activated by this [top right curve] kind of curve in the top right, and inhibited by it in the bottom left, and so on. So all our channels on this layer, which are checking for different parts of curves in different parts of the image, get combined into a channel on the next layer which is looking for entire circles. And there are also other channels for more complex textures, like spirals.
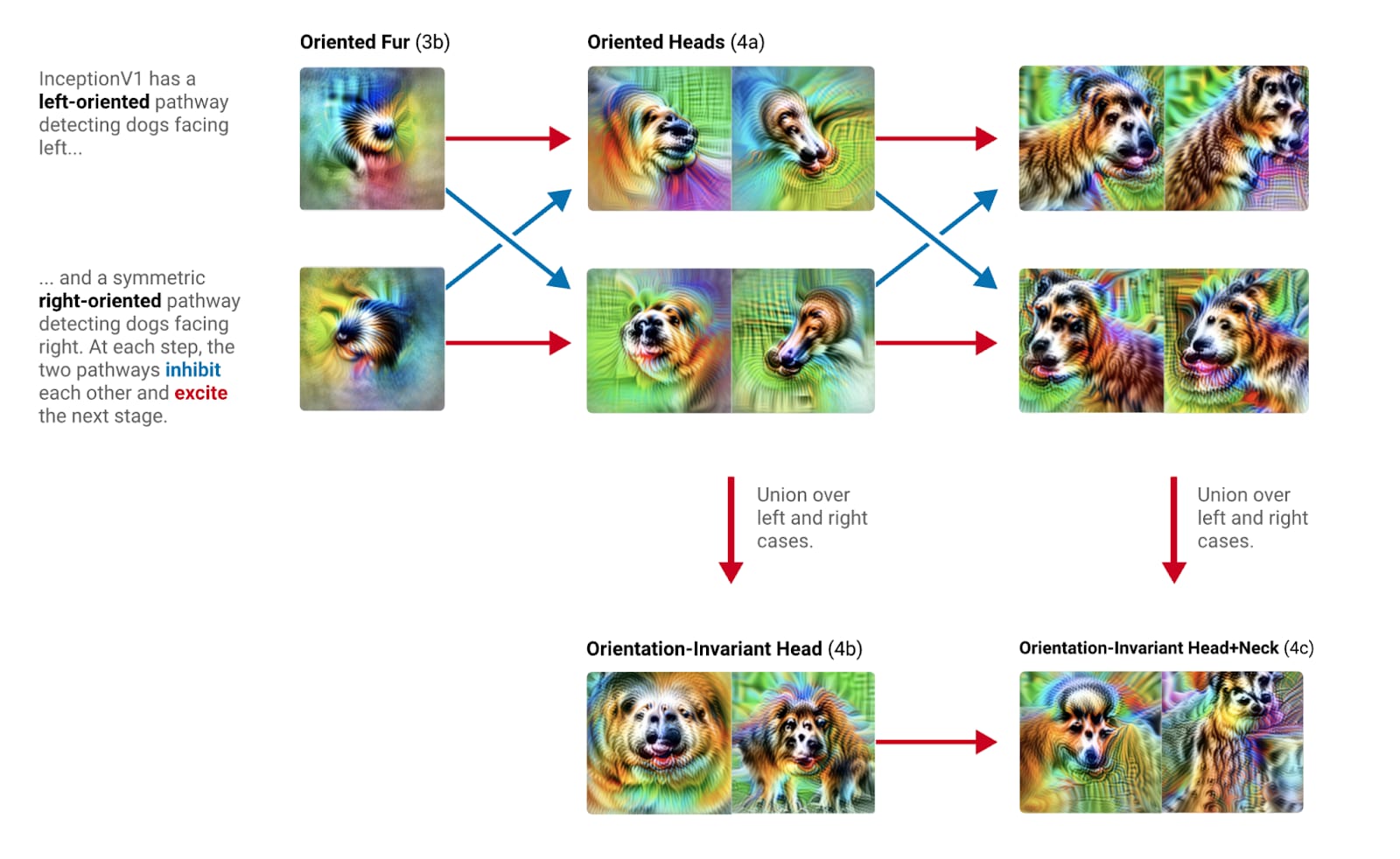
And it seems like this is also true of neurons in later layers. Remember earlier how about a tenth of the labels are different kinds of dog? Well, here’s how the model recognises dogs. Here’s a pair of neurons in the layer ‘mixed4a’ which are activated by dog heads facing left and right, respectively. And they each feed into a general dog head detector. But also, there’s another pair of neurons which look for combined dog heads and necks, again facing left or right. And we can see from the convolutional layer that the model wants left-facing dog heads to be to the left of necks. And the left-dog-head neuron activates the left-dog-head-and-neck neuron, but it actually inhibits the right-dog-head-and-neck neuron. It’s like the model is trying to make sure that the neck and the head are the correct way round. Then both the neck-and-head neurons and the general dog head neuron all feed into a general dog-neck-and-head neuron.
And there are loads of patterns like these. For example, we find a neuron that detects car wheels, and a neuron that detects car windows, and a neuron that detects car bodies, and then we find another neuron that lights up for images with windows at the top and wheels at the bottom with a car body in the middle. Now you’ve got a general-purpose car detector. In fact, you have an entire channel looking for cars in different parts of the image.
Seems easy, right? Almost too easy. Well, don’t worry, because it turns out it’s actually not that simple. These tricks with feature visualisation and high-scoring images do tell us what a neuron is doing, but they don’t tell us if it’s everything the neuron is doing.
Polysemanticity
Polysemanticity is the technical term for when a neuron (or a channel) is actually tracking more than one feature at once. See, the network needs to learn to recognise 1000 different categories, and the categories might be quite complicated. So sometimes the model somehow learns how to cram more than one feature into a neuron.
For instance, here’s a channel which is highly activated by pictures of cat faces, and fox faces, and also cars. And if we do our feature visualisation but modify it to produce several pictures which all activate the channel a lot while being maximally different from each other, we get some weird visualisations of cats and foxes and cars.
Why cars? We don’t know. It seems like sometimes polysemanticity occurs because features are very different, so the model is not likely to see them both in the same image. But as I say, we really are not sure.

Polysemanticity appears in all kinds of models, including language models, and it really complicates the task of interpreting a neuron: even if we know that a neuron is doing something it’s hard to know what else it might be doing. There’s been some really interesting work on finding out when and how models become polysemantic, as well as some more recent work on how to discover patterns of neuron activation which correspond to features. You can check out links to both of these in the video description.
Closing thoughts, and the past few years of interpretability
So where does that leave us? Well, we’ve talked about how it’s possible to at least begin to interpret the individual neurons of an image classifier by comparing them against dataset examples and generating inputs that activate them. We’ve talked about how these neurons form into circuits which explain more complex behaviour. And we’ve talked about polysemanticity - the fact that sometimes a neuron is tracking multiple distinct features.
The original collection of articles on circuits was published in May of 2020, before even GPT-3 had been released. So the field has developed a lot since then. The same kind of work we discussed here being done on language models to try to understand how they can write poetry and translate things into French and whatever else you might want. OpenAI actually has a project to use GPT-4 to interpret all the neurons in GPT-2. We’ve also started doing more work on how the models learn, like at what point they start to go from memorising patterns to actually generalising.
And we’ve made some tentative attempts to actually extract information directly from the activations of a model rather than its outputs: we can ask a language model a question, and then read off what it thinks is true from the inside, and this is often more accurate than the answer the language model actually outputs. Of course, this is only possible because in some sense language models aren’t telling us what they know. Make of that what you will.
This kind of work is called Mechanistic Interpretability and it’s very hands-on, with a lot of experimenting. We might discuss more details about recent developments in future videos. In the meantime, if you’re curious to find out more about how mechanistic interpretability works, or try it out yourself, you can check out this tutorial, which we’ve also included a link to in the video description [note: we actually included a ton of links]. As we become increasingly reliant on automated systems, mechanistic interpretability might be a key tool for understanding the 'why' behind AI decisions.
SummaryBot @ 2024-06-17T17:58 (+3)
Executive summary: The video from Rational Animations provides an introduction to mechanistic interpretability research on understanding the inner workings of neural networks, focusing on early landmark work interpreting the InceptionV1 image classification model.
Key points:
- Convolutional neural networks like InceptionV1 are complex and hard to interpret, with many layers and neurons performing unknown functions to classify images.
- Researchers have visualized what individual neurons detect by finding dataset images that maximally activate them and by optimizing synthetic images to trigger neurons.
- Neurons work together in "circuits" to detect increasingly complex features, e.g. curves → circles, or dog head + dog neck → dog.
- Polysemanticity, where a neuron tracks multiple features, complicates interpretability. Recent work aims to better handle this.
- Mechanistic interpretability has progressed significantly since the early InceptionV1 work, with ongoing research on language models, the learning process, and extracting internal knowledge.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.