Q1 AI Benchmarking Results: Human Pros Crush Bots
By Benjamin Wilson 🔸, johnbash, Metaculus @ 2025-06-28T17:22 (+16)
This is a linkpost to https://www.metaculus.com/notebooks/38673/q1-ai-benchmarking-results/
By Ben Wilson and John Bash from Metaculus
Main Takeaways
Top Findings:
- Pro forecasters significantly outperform bots: Our team of 10 Metaculus Pro Forecasters demonstrated superior performance compared to the top-10 bot team, with strong statistical significance (p = 0.001) based on a one-sided t-test on spot peer scores.
- The bot team did not improve significantly in Q1: The bot team’s head-to-head score against Pros was -11.3 in Q3 2024 (95% CI: [-21.8, -0.7]), then -8.9 in Q4 2024 (95% CI: [-18.8, 1]), and now -17.7 in Q1 2025 (95% CI: [-28.3, -7.0]), with no clear trend emerging. (Reminder: a lower head-to-head score indicates worse relative accuracy. A score of 0 corresponds to equal accuracy.)
Other Findings
- Bots are improving over control bot between quarters: Our Metac-gpt-4o is a simple bot based on a single prompt (our ‘template bot’ prompt), making it a good, stable control. Its spot peer score (relative to other bots) has gotten steadily worse over quarters. In the bot-only tournament, it finished 4th in Q3, 17th in Q4, and 44th (second to last) in Q1. This suggests that individual bots are getting better.
- The best bot was a single-prompt bot using OpenAI’s o1: The best bot in the bot-only tournament was our own Metac-o1. See the code section for its implementation. This bot used the same code that was provided as a template for competitors and is also known as the ‘template bot’. Most competitors did not use o1, and opted for cheaper models.
- Models matter more than prompts: Given that Metaculus’s template bots have continued to perform well compared to other competitors over quarters, it seems that the most important factor for AI forecasting is the underlying model. Scaffolding/prompt engineering does appear to improve performance, but the model effect is larger.
- Scaffolding does have an effect: One of our hobbyist bot-makers (twsummerbot) used only gpt-4o and gpt-4o-mini, and finished 8th place, while our metac-gpt-4o template bot got 44th place (second to last). Their bot had significant gains using only better prompting, agent tools, and other scaffolding.
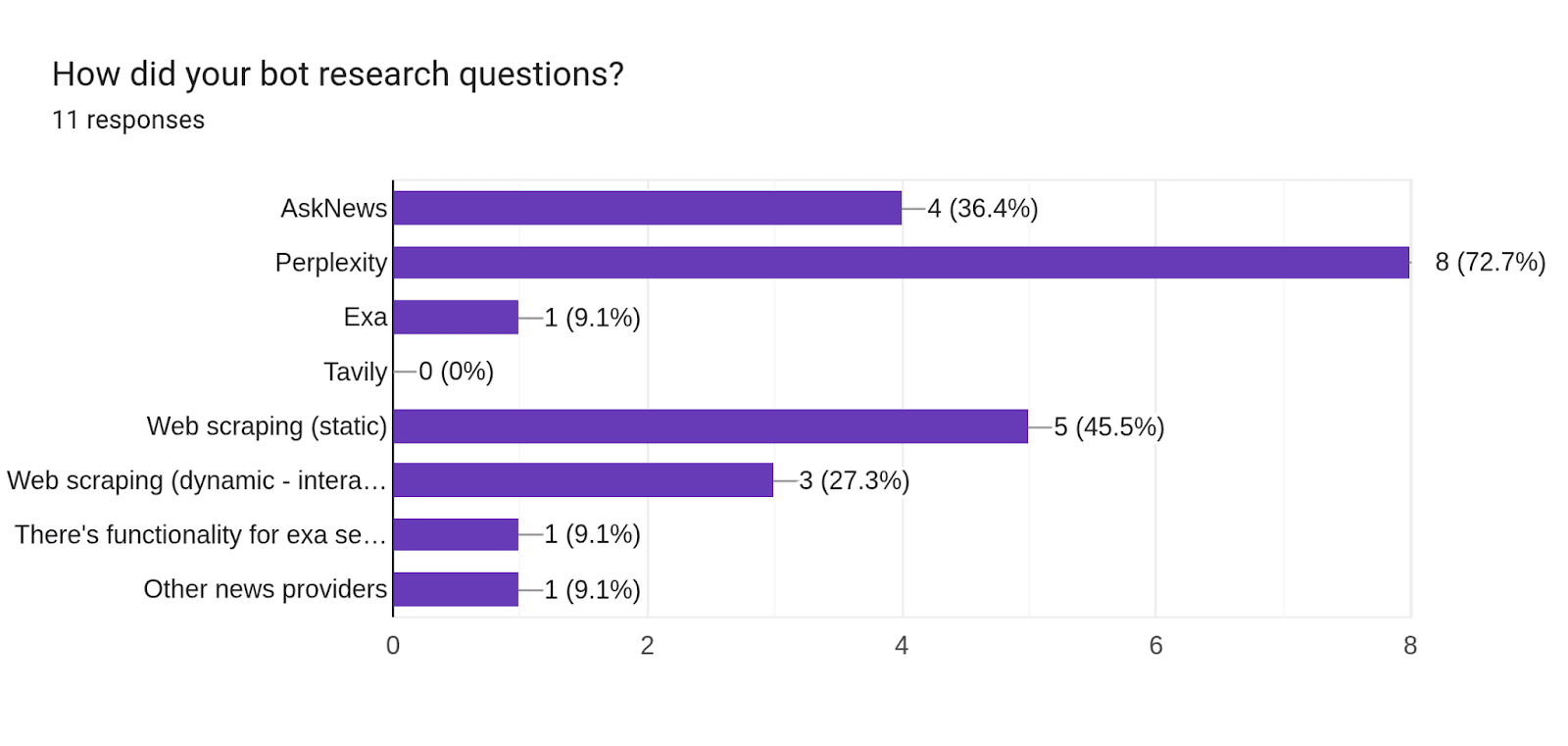
- AskNews is better than other search providers: We have found that a bot using AskNews performs better than bots that use Exa or Perplexity. The template bot was used to test this. The difference between these bots is noticeable, but is not statistically significant.
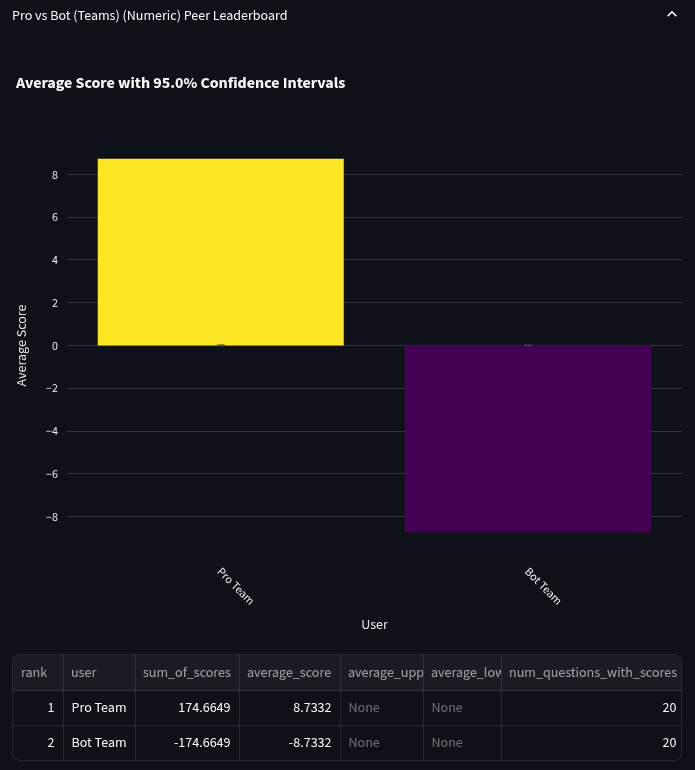
- Quarterly cup Community Prediction beat bot team: The Quarterly Cup Community Prediction beat the bot team on a set of 27 questions, though the sample size was too low for significance testing.
- Our simple OpenAI o1 bot ranked in the top 5% of Quarterly Cup participants: The best bot in the bot tournament (Metac-o1, a version of our template bot) got in the top 5% in the Quarterly Cup, getting 25th out of 617 humans. However, this does not necessarily mean it outperforms 95% of participants (see discussion).
Data exploration site: You can find interactive graphs for the results of this analysis here: https://q1-2025-aib-analysis.streamlit.app/
Introduction
In Q1 2025, we ran the third tournament in our AI Benchmarking Series, which aims to assess how the best AI bots compare to the best humans on real-world forecasting questions, like those found on Metaculus. Over the quarter, we had 34 bot makers compete for $30,000 on 424 questions with a team of ten Pros serving as a human benchmark on 100 of those 424 questions. Previous quarters had only binary questions, but in Q1, numeric and multiple-choice questions were added to the mix, requiring bots to submit continuous or categorical probability distributions.
Methodology
In order to test how well bots are doing relative to each other and relative to humans, we set up a forecasting tournament for bots and one for Pros. Additionally, we included some questions from the Quarterly Cup in the bot tournament. The pro and quarterly cup forecasts were hidden from bots so that bots could not just copy the other’s predictions. Each tournament launched a series of questions that resolved sometime during the quarter, and asked participants to assign probabilities to outcomes. We then used our established scoring rule to evaluate participants. During the analysis, we aggregate the forecasts of groups of forecasters to create ‘teams’.
Data Collection:
- Bot Tournament: 34 bot makers and 11 Metaculus-run template bots (running different LLM models) participated in a tournament of 424 questions, of which 15 were annulled. At a random hour every weekday, 10 questions were launched at once, then closed at the end of the hour. Bots submitted their forecasts using our API. The tournament consisted of binary (57%), numeric (21%), and multiple-choice (22%) questions. Questions spanned a large range of topics, including geopolitics, economics, elections, sports, tech, etc. Some were sourced from the Quarterly Cup. Botmakers were allowed to update their bots over time (e.g. incorporate the newest model, or iterate on prompts), but metac-bots stayed the same over the full quarter.
- Pro Tournament: 10 pro forecasters forecasted on 100 questions, of which 2 were annulled. 2 others had match-over problems, leaving 96 scorable questions that have direct comparisons with bot questions. Pro forecasters are chosen for their excellent forecasting track record and history of clearly describing their rationales. Pro questions were manually chosen from each week’s bot questions to cover diverse themes and avoid correlated resolutions. Pros had 2 days to forecast each question before it closed. The pro tournament was private and hidden during the length of the tournament, which prevented bots from copying the pros’ forecasts.
- Quarterly Cup: The quarterly cup (recently rebranded as the “Metaculus Cup”) is one of the main tournaments on Metaculus. It is the default place for newcomers to learn forecasting and for experts to prove their skills. 617 participants forecasted on 42 questions in Metaculus’s Q1 Quarterly Cup. Of these, 27 were copied to the Bot Tournament to allow a bot-crowd vs. human-crowd comparison. None were annulled. The matching bot questions were closed before the Community Prediction in the quarterly cup was revealed, which prevented the bots from just copying the Community Prediction. The Community Prediction is a time-weighted median of all forecasters and on average performs much better than any individual. This gave humans a 3-7 day period to forecast. We then took the forecasts and spot peer scores for both bots and humans right before the Community Prediction reveal time.
Scoring: For a deeper understanding of scoring, we recommend reading our scoring FAQ. We primarily use spot peer scores and head-to-head scores in this analysis.
- Peer Score: The Peer score compares the relative performance of a forecaster (or team) vs. all others on a question, over the whole question lifetime. Unlike baseline or Brier score, it adjusts for the difficulty of a question based on the performance of others. The score is zero-sum (i.e. the literal sum of all participants’ peer scores is 0). A higher score indicates greater relative accuracy. A score of 0 corresponds to average accuracy.
- Spot Peer Score: Spot peer scores are the same as peer scores, except evaluated only at a single point in time, using the forecasters’ standing predictions at that time (rather than averaging scores over the question lifetime). For the bot and Pro tournaments, spot peer scores were evaluated when questions closed. For the Quarterly Cup, they were evaluated when the Community Prediction was revealed to participants.
- Head-to-Head Score: Head-to-head scores are the same as spot peer scores, except they compare only two participants. For example, if comparing the bot team and pro team, the head-to-head score is `100 x ln(bot_prediction/pro_prediction)` (for a question that resolves to Yes).
- Weights: A number of bot questions were given weights in order to counteract possible correlated resolutions between questions. This doesn’t apply to pro/quarterly cup questions, which all have a weight of 1. If you see below a score for a bot tournament question, then that score has been multiplied by a weight between 0 and 1.
Team selection and aggregation: In the analyses below, we sometimes aggregate a group of forecasters to create a ‘team’. To aggregate forecasts, we took the median for binary predictions, the normalized median for multiple choice predictions, and an average (aka mixture of distributions) for numeric predictions. This matches what the Community Prediction does on Metaculus. Below is how the compositions of the teams were decided:
- Bot Team: To find the bot team, we took all bot tournament questions, then removed any that were also asked in whatever tournament we are comparing the bots to (e.g. for the pro vs bot comparison, we removed the 96 questions that we are comparing bots and pros with). The remaining questions are bot-only questions (only forecasted on by the bots). These questions are then scored, and a leaderboard is created based on the sum of bots’ spot peer scores. We then choose the top 10 bots from this leaderboard to be the bot team. Why do we use this process? Removing the questions used in comparisons before deciding the bot team is important in order to prevent ‘overfitting’ effects. If we include the questions used in the direct comparison, then we are unfairly choosing the best bot team ex-post-facto. By using the bot-only questions to determine the team, we essentially run a ‘qualification tournament’ to choose team members before running these bots in the ‘real thing' (similar to how the pros were chosen based on their performance on past tournaments).
- Pro Team: The Pro team includes all 10 pros who participated in the pro tournament.
- Quarterly Cup Team: The Quarterly Cup team includes every forecaster who participated in the Quarterly Cup tournament.
This analysis generally follows the methodology we laid out at the beginning of the tournament series, with a simplified bot team selection algorithm, which we decided on before knowing the results.
Metac Bots
To compare the capabilities of different LLM models, Metaculus ran 11 bots, all with the same prompt. This prompt is very similar to the one that was used in Q3 and Q4, though updated to support numeric and multiple-choice questions. See the section on code/data for links to the template bot prompts.
We simulated a tournament where these bots competed only against each other (no other participants). This tournament took all the questions from the bot tournament and removed the forecasts of non-metac-bot participants. The bots’ spot peer scores and 95% CI against each other are shown below:
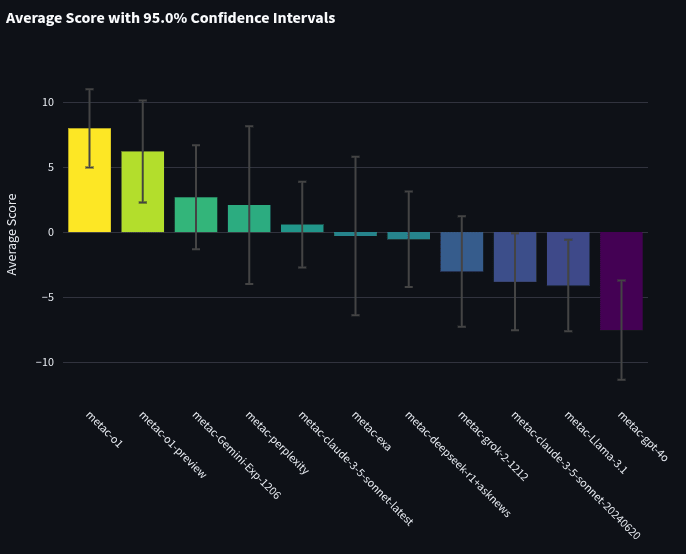
From this, AskNews appears to be a better news source for bot forecasting, though confidence intervals overlap somewhat.
These rankings are not very surprising. It seems that models that are ranked better on traditional leaderboards (e.g. o1) are better forecasters as well.
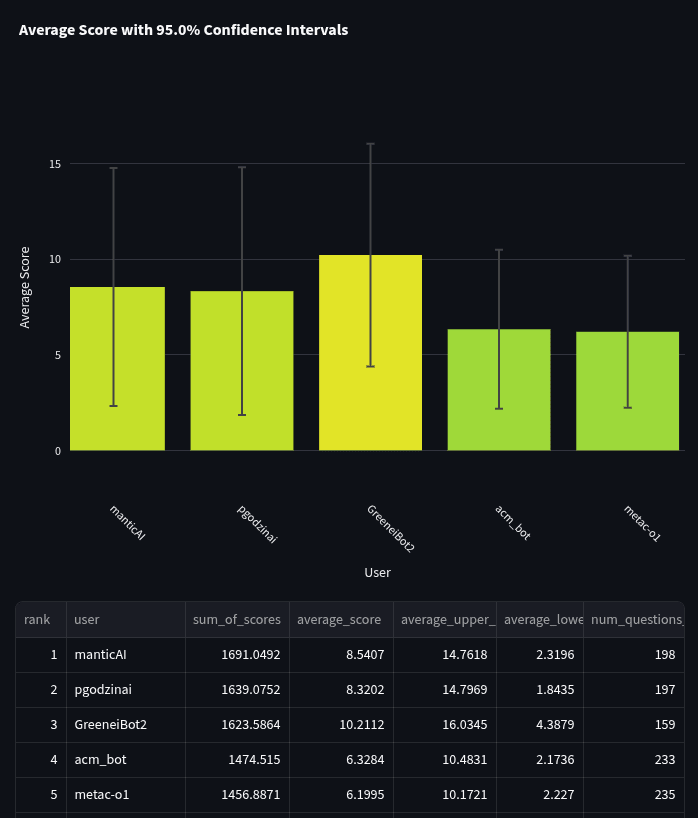
Top Bots
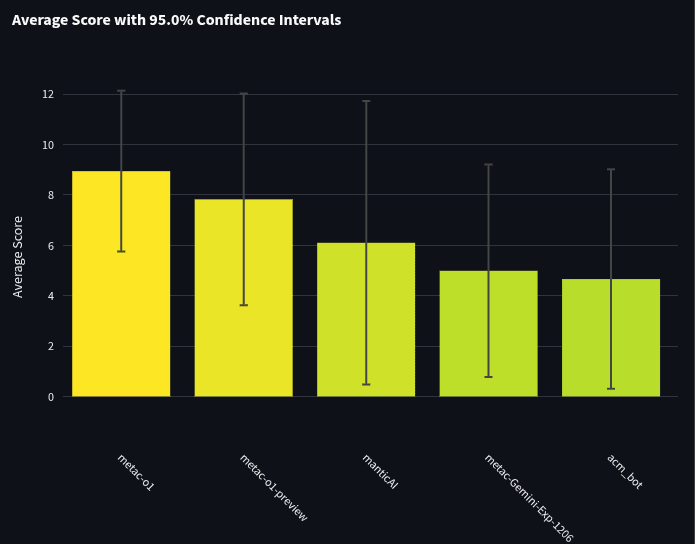
Let's first take a look at the bot-only tournament. This tournament pits all the bots against each other and does not include any humans. You can see the full leaderboard here. Since there are 45 bots, let's first focus on the bots that topped the leaderboard. Below are the top 5 bots when ranked by the sum of their spot peer scores.
"""
You are a professional forecaster interviewing for a job.
Your interview question is:
{title}
Question background:
{background}
This question's outcome will be determined by the specific criteria below. These criteria have not yet been satisfied:
{resolution_criteria}
{fine_print}
Your research assistant says:
{summary_report}
Today is {today}.
Before answering you write:
(a) The time left until the outcome to the question is known.
(b) The status quo outcome if nothing changed.
(c) A brief description of a scenario that results in a No outcome.
(d) A brief description of a scenario that results in a Yes outcome.
You write your rationale remembering that good forecasters put extra weight on the status quo outcome since the world changes slowly most of the time.
The last thing you write is your final answer as: "Probability: ZZ%", 0-100
"""
Our template bots have reached the top 10 in all three tournaments so far (Q3 2024, Q4 2024, and Q1 2025): metac-gpt-4o (previously named mf-bot-1) placed 4th in Q3, and metac-o1-preview (previously mf-bot-4) placed 6th in Q4. Though metac-gpt-4o has also gotten worse over time, getting 17th in Q4, and 44th (second to last) in Q1.
One conclusion we have drawn from this is that the most important factor for good forecasting is the base model, and additional prompting and infrastructure on top of this provide marginal gains. For reference, most participants did not use o1 in their forecasting due to its cost, so we are unsure whether good scaffolding on top of o1 would provide significant gains to o1. In our next tournament series, we hope to enter a few bots that directly test scaffolding/prompt engineering of different kinds and that stay stable over the tournament length. Please see the section on the “Bot Maker Survey” for an anecdote where scaffolding had a large effect for one of our participants.
We exclude our Metac bots from prize money and so we wanted to give a shout-out, congratulations, and review of our Q1 winner! Our best non-metac-bot competitor and winner of the Q1 tournament was ManticAI, a startup working in the space of AI forecasting! We asked them to share a little bit about their bot, and they mentioned:
We are currently a team of 5. Throughout Q1, we made incremental improvements to our tournament-deployed system, iterating and testing each change. This system does the basics quite well: it has access to some key data sources (news, Wikipedia, economics and finance data, external forecasts) and applies some basic forecasting techniques (e.g. base rates, status quo bias). It is still far from perfect but we are improving it at a good pace. In Q1 we used o3-mini for the prediction head, because this model performed well in our internal testing and was relatively well-priced and fast. The reasoning models seem to give more consistent predictions when resampled with the same information, which is another minor factor in favour. At some point in Q2 we’re planning to replace o3-mini with our own models, from which we hope to get a performance boost.
It looks like ManticAI is building some interesting infrastructure! We look forward to seeing how it plays out at the end of Q2. Also, given o3-mini underperforms o1 in Q2 (as it is doing in more generalized LLM leaderboards), their use of o3-mini to get 3rd place will give some evidence that scaffolding can have an important effect for improving the best models.
For reference, here is the zoomed-out full leaderboard. Like the chart above, this graph is ordered by the sum of spot peer scores, which is used to determine rankings on the site (i.e. so the 1st bar shown took 1st place). However, the y-axis shows the average spot peer score.
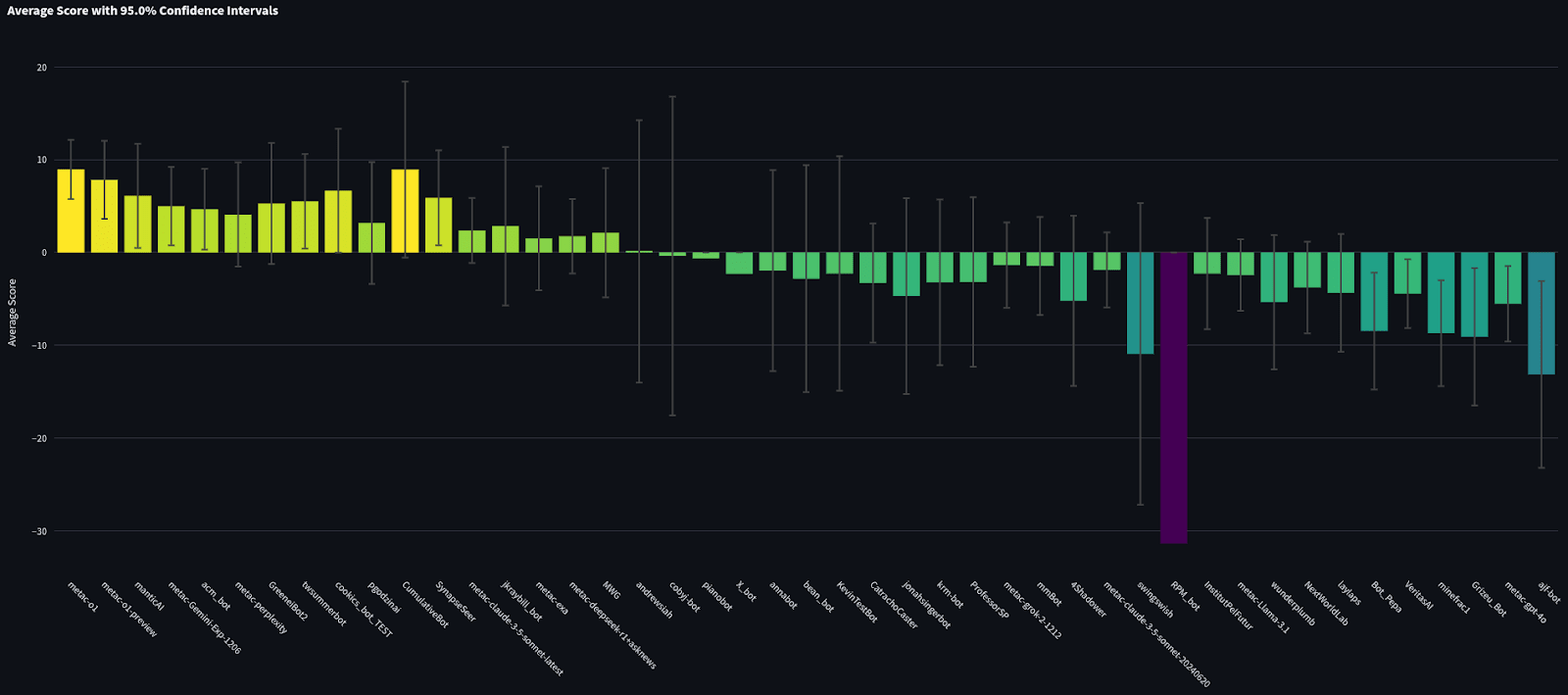
Bot Team vs Pro Team
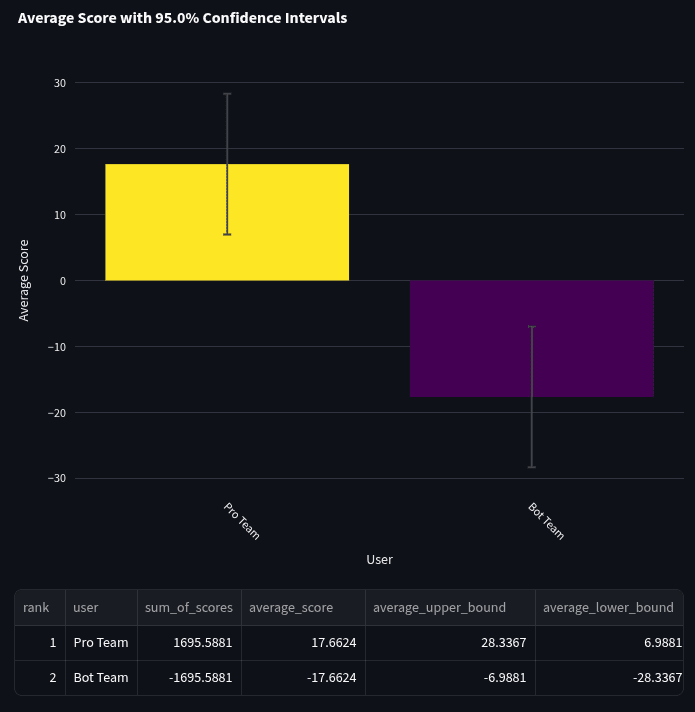
To compare the bots to Pros, we used only the 96 non-annulled questions that were identical in the bot and Pro tournament. We then aggregated forecasts of the “bot team” and the “pro team” (see methodology section above).
The bot team that was chosen is:
- metac-o1-preview
- metac-o1
- Pgodzinai
- manticAI
- GreeneiBot2
- acm_bot
- metac-Gemini-Exp-1206
- metac-claude-3-5-sonnet-latest
- twsummerbot
- metac-perplexity
We then calculated the head-to-head scores of the two teams, along with 95% confidence intervals using a t distribution. The average bot team head-to-head score was -17.7 with a 95% confidence interval of [-28.3, -7.0] over 96 questions.
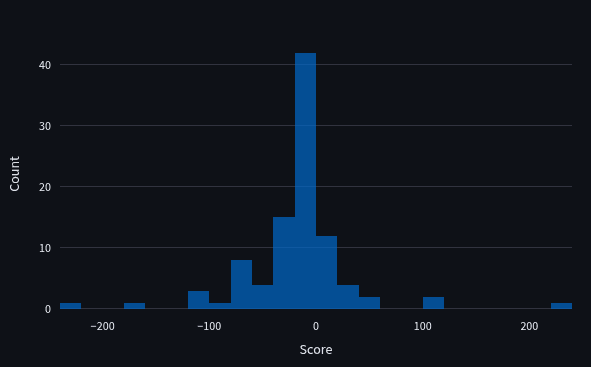
Below is an unweighted histogram of the head-to-head scores of the bot team.
Binary vs Numeric vs Multiple Choice Questions
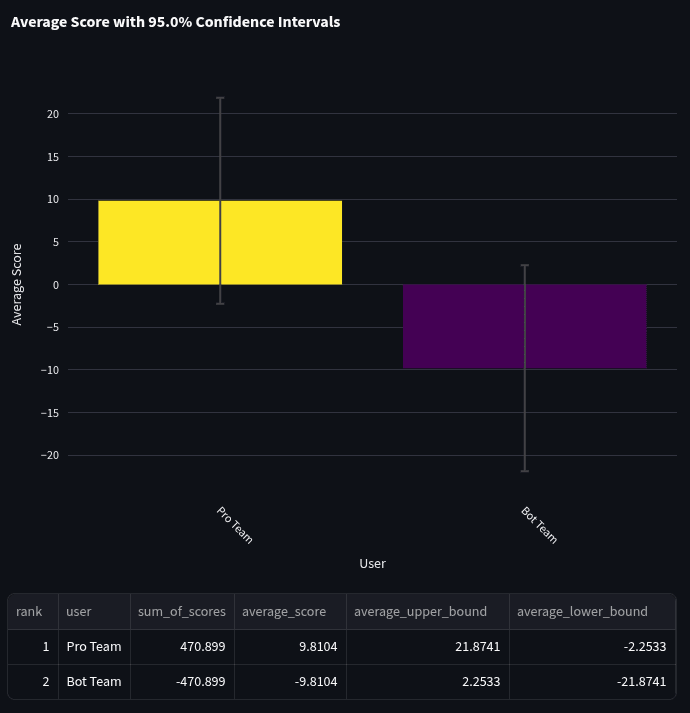
We also took a look at how bots did on each question type. When comparing the bot team and the pro team on head-to-head scores, generally, bots did a lot worse at multiple-choice questions (score: -37.5) than at binary (score: -9.8) or numeric (score: -8.7). Generally, the sample sizes in these comparisons are fairly small, so hold this conclusion tentatively.
Here are the average head-to-head scores for the 48 binary questions:
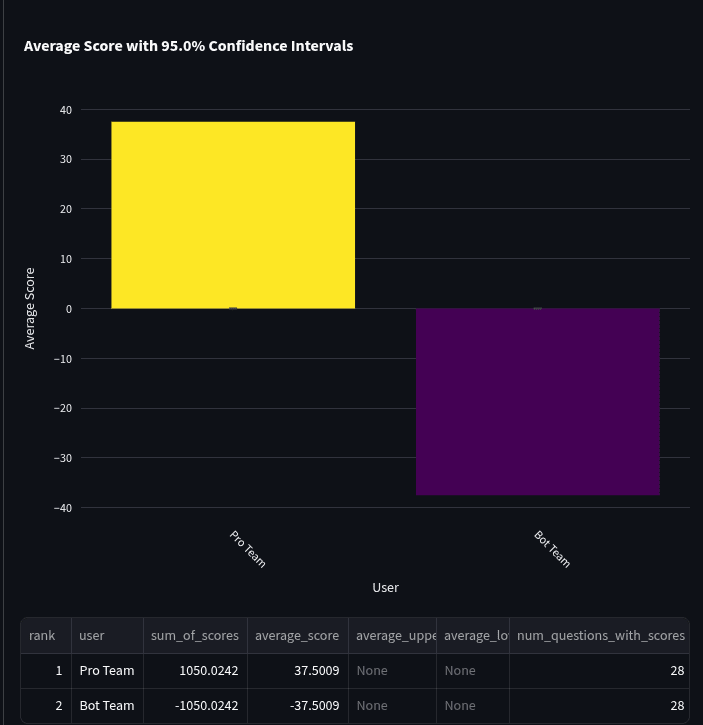
Team Performance Over Quarters
Now let's compare how the bot team has done relative to the pro team over the last 3 quarters. Below is a graph of head-to-head scores over 3 quarters with 95% confidence intervals.
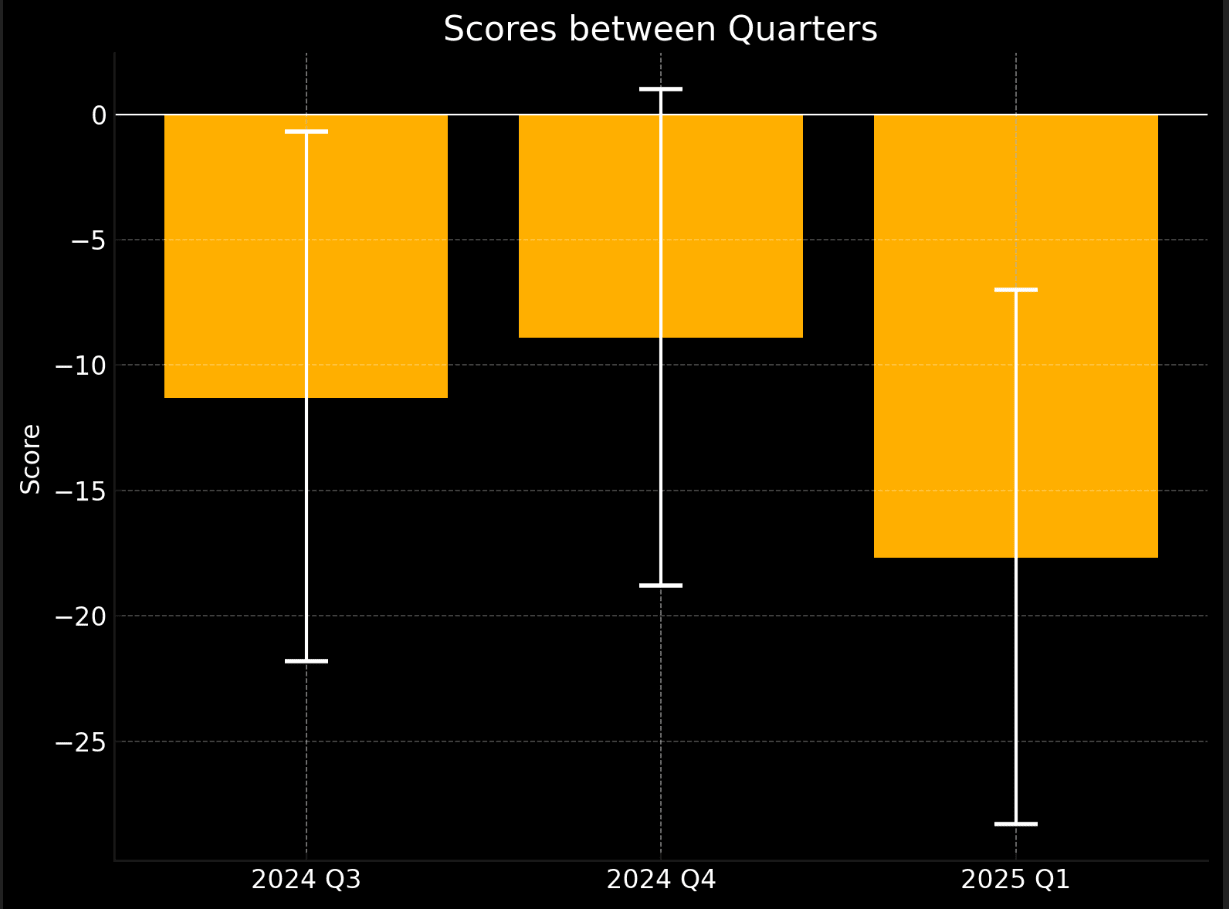
- 2024 Q3: -11.3 [-0.7, -21.8]
- 2024 Q4: -8.9 [-18.8, 1]
- 2025 Q1: -17.7 [-7.0, -28.3]
The large confidence intervals do not let us discern any trend. For instance, the true spot peer score of the bots (if we ran on a lot more questions) might be -10 throughout all three quarters. Unfortunately, we just don’t have enough questions to state the direction that bots are trending in (despite having enough sample size to show that pros are better than bots this quarter).
One theory for the decrease in score for this quarter (as compared to previous quarters) is the introduction of multiple-choice questions. As noted above, these were difficult for bots, which weren’t a problem in Q3 and Q4 when all questions were binaries (though some questions were numerics/multiple-choice reframed as binaries).
Another theory is that the pro team has gotten better. They have had a while to practice as a team with each other, and practice improves performance. One other factor is that they have access to better AI tools that can speed up their own research process.
Additionally, as stated previously, we have seen that the metac-gpt-4o bot started in 4th place in Q3, and moved to 44th place in Q1. Assuming that metac-gpt-4o can act as a control, this is evidence that bots have gotten better over the quarters. Some factors to consider:
- There have been slight changes in the underlying gpt-4o model over time, which would normally improve performance (though perhaps it hurt performance).
- Metac-gpt-4o had slight prompt changes over the quarters. In Q3, it used perplexity for its news. In Q4, it used AskNews. In Q1, it had a minor prompt change for binary forecasts and started handling numerics/multiple-choice questions.
Therefore, we believe that there is weak evidence that bots have gotten better on binary questions between quarters, and got worse in Q1 due to multiple choice questions. But generally (and statistically speaking), we can’t be sure of anything about how bots have changed over time.
Bots vs Pros (no Teams)
We also compared individual bots to individual pros over the 96 non-annulled questions that they both predicted. We don’t recommend putting too much weight in these comparisons because with enough bots, one will do well purely by chance (i.e. this is a multiple comparison problem). Still, we believe this offers useful context.
Below is a leaderboard ordered by sum of spot peer scores (which is what is used to determine ranks for the AI tournament on the site). The top 17 participants are shown. Average spot peer scores are shown on the y-axis. You’ll notice that if pros and bots competed together, all 10 pros would take 1st through 10th place (with metac-o1 getting 11th place). If we sorted by averages, some bots might be able to take 9th place but have much larger error bars since they answered fewer questions (which is why we rank by sum of spot peer scores rather than average spot peer scores).
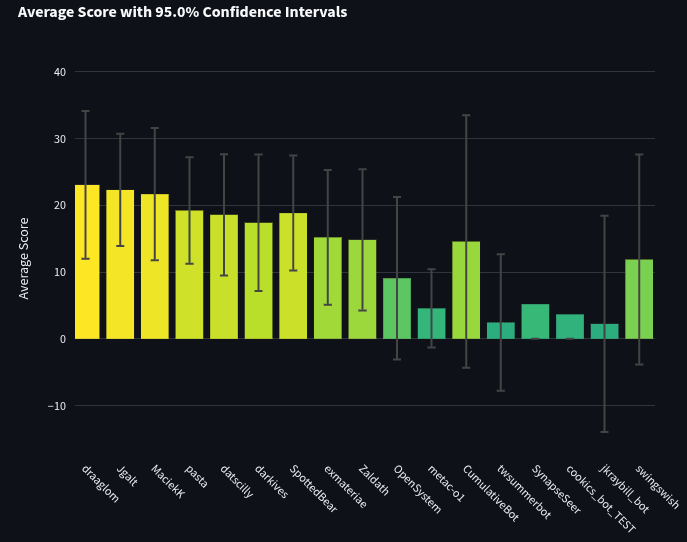
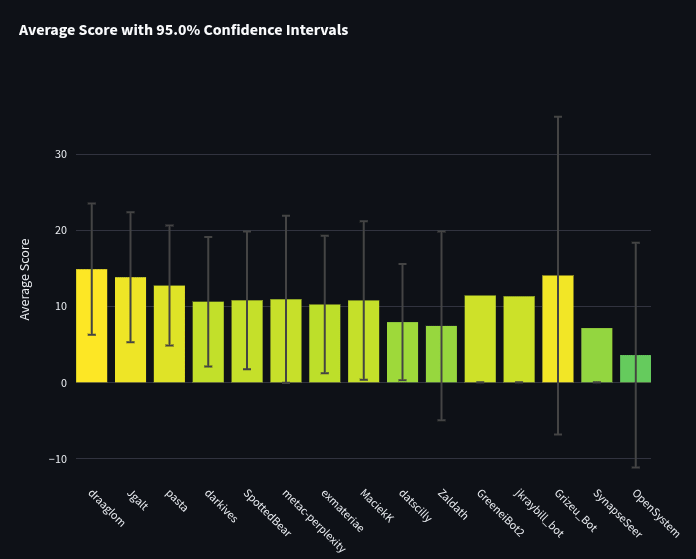
Bot Team vs Quarterly Cup Team
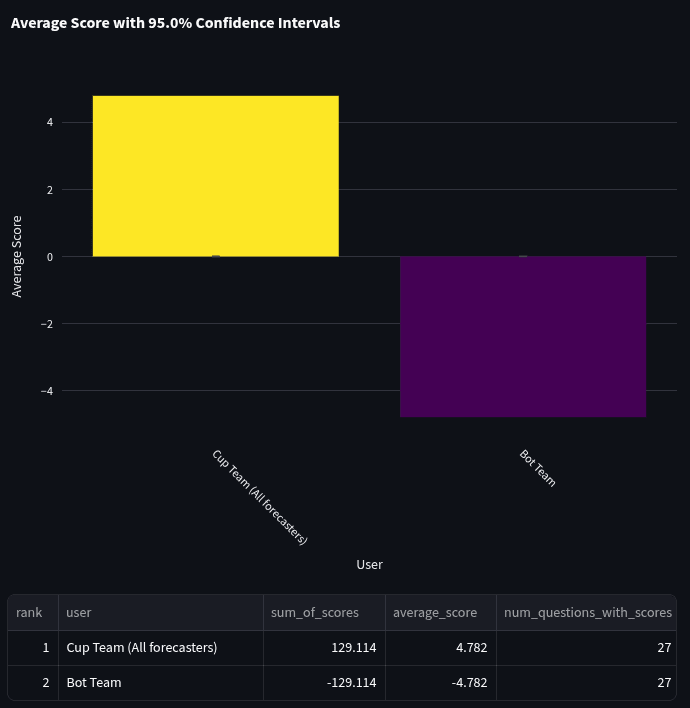
The Quarterly Cup is one of the most competitive tournaments on Metaculus. Over the course of the quarter, we copied a number of questions from the Quarterly Cup into the bot tournament in order to compare the performance of the Community Prediction and the bot team. We were able to use 27 questions for the comparison. We aggregated all Quarterly Cup participants’ forecasts and compared them to the aggregate of the bot team. This comparison followed the same methodology as the bot team vs pro team comparison above. This means the bot team was decided based on questions not included in the quarterly cup, and the quarterly cup team consists of all forecasters who participated in the quarterly cup. Consequently, the cup team's prediction ends up being essentially the Community Prediction, just without applying recency weighting as is normally done on the site (i.e. only everyone's last forecast before Community Prediction reveal time is used, and these are all weighted the same).
Here is the list of bots that made the team for this comparison:
- metac-o1
- metac-o1-preview
- metac-Gemini-Exp-1206
- acm_bot
- twsummerbot
- manticAI
- metac-perplexity
- GreeneiBot2
- cookics_bot_TEST
- Pgodzinai
Spot scores are calculated at the time the Community Prediction is revealed (so bots could not have access to/copy the Community Prediction while forecasting). Below are the scores:
Bots vs Quarterly Cup (No Teams)
During Q1, we ran 2 of our template bots in the quarterly cup. This is unlike the “Quarterly Cup Team vs Bot Team” comparison, since these bots forecasted directly in the quarterly cup as a normal participant. This means they forecast multiple times per question, had a chance to update, were scored directly against all human participants via regular peer score, and generally participated like a normal user. There were 617 participants in the quarterly cup in Q1. Scores below are the sum of peer scores (not spot peer scores) for the competition. There were 42 questions in the quarterly cup.
We found some interesting results:
- Community Prediction: Placed 3rd of 617 (score: 1189.2)
- Metac-o1: Placed 25th of 617 (score: 306.8)
- Metac-gpt-4o: Placed 547th of 617 (score: -119.4)
Most notably, metac-o1 ranked in the top 5% of participants. Granted, there is a decent group of participants who only forecasted on a single question, but this is still fairly impressive. Otherwise, like in the bot tournament, metac-gpt-4o placed near last.
What might be some reasons for metac-o1’s good performance? It’s hard to say what the biggest factor is (whether it's all skill or not), but here are some things to consider.
- First, people maximize their points when they update frequently and forecast on every question. This may just be a measure of metac-o1’s ability to forecast on everything in an automated manner.
- Secondly, there is still non-zero noise in 42 questions (in the paragraph below giving an example of o1’s forecasts, notice how 1 question brought metac-o1 from 34th to 25th).
- Finally, the Community Prediction is, on average, the most trustworthy signal of the future that we have. As described in the next paragraph, the community forecasted metac-o1’s rank to be much worse than it actually was, so this may be additional evidence that metac-o1 got lucky this quarter.
There is probably some level of skill needed to get 25th place like it did, but there is good reason here not to trust it as being as good as a 95th percentile human on a question-by-question basis.
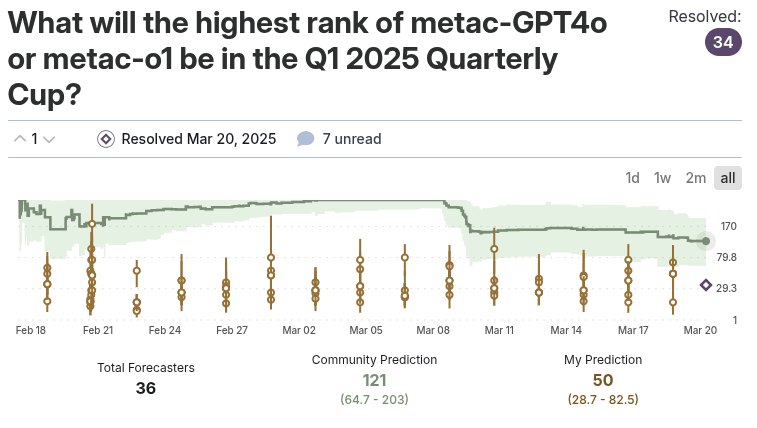
While the cup was ongoing, participants tried to forecast the best-ranking bot between metac-o1 and metac-gpt-4o. You can see the question here. The orange bars are metac-o1’s forecasts. Metac-o1 forecast 5 times before submitting an aggregate forecast of its attempts (which is why there are multiple ‘center dots’ every 2 days). Reviewing the question, we find that metac-o1 forecasted its own performance much better than the community, which brought it from 34th place (the resolution value) to 25th after this question was scored. But generally, this is just an interesting anecdote (and there are other questions where it forecasted much worse).
Bot Maker Survey & Evaluating Scaffolding
At the end of Q1, we sent a survey out to bot makers. Prize winners were required to fill in this survey, and it was optional for those who didn’t earn prizes. There were 10 responses from prize winners and 1 response from other bots. Below are some insights from this survey.
How did scaffolding do?
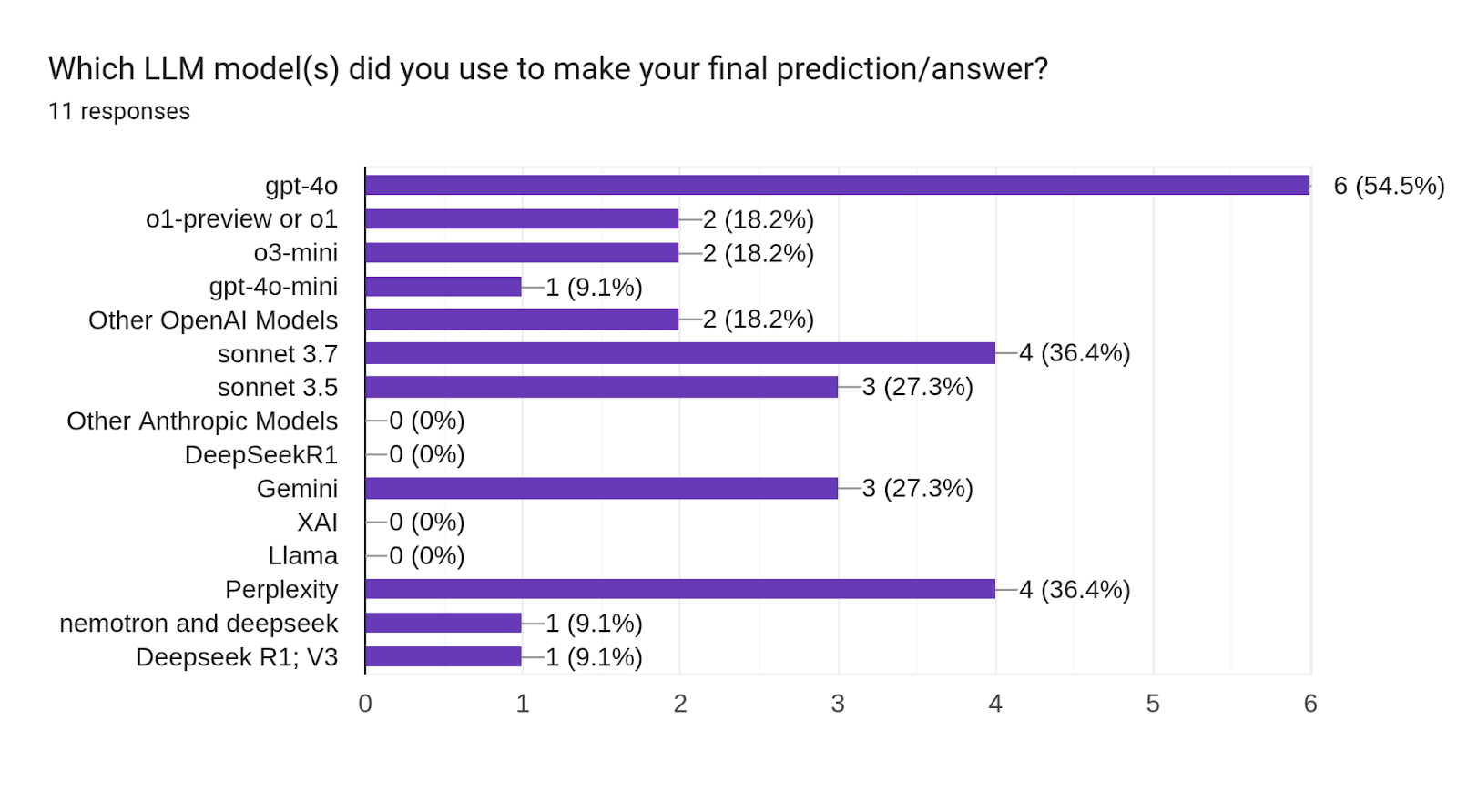
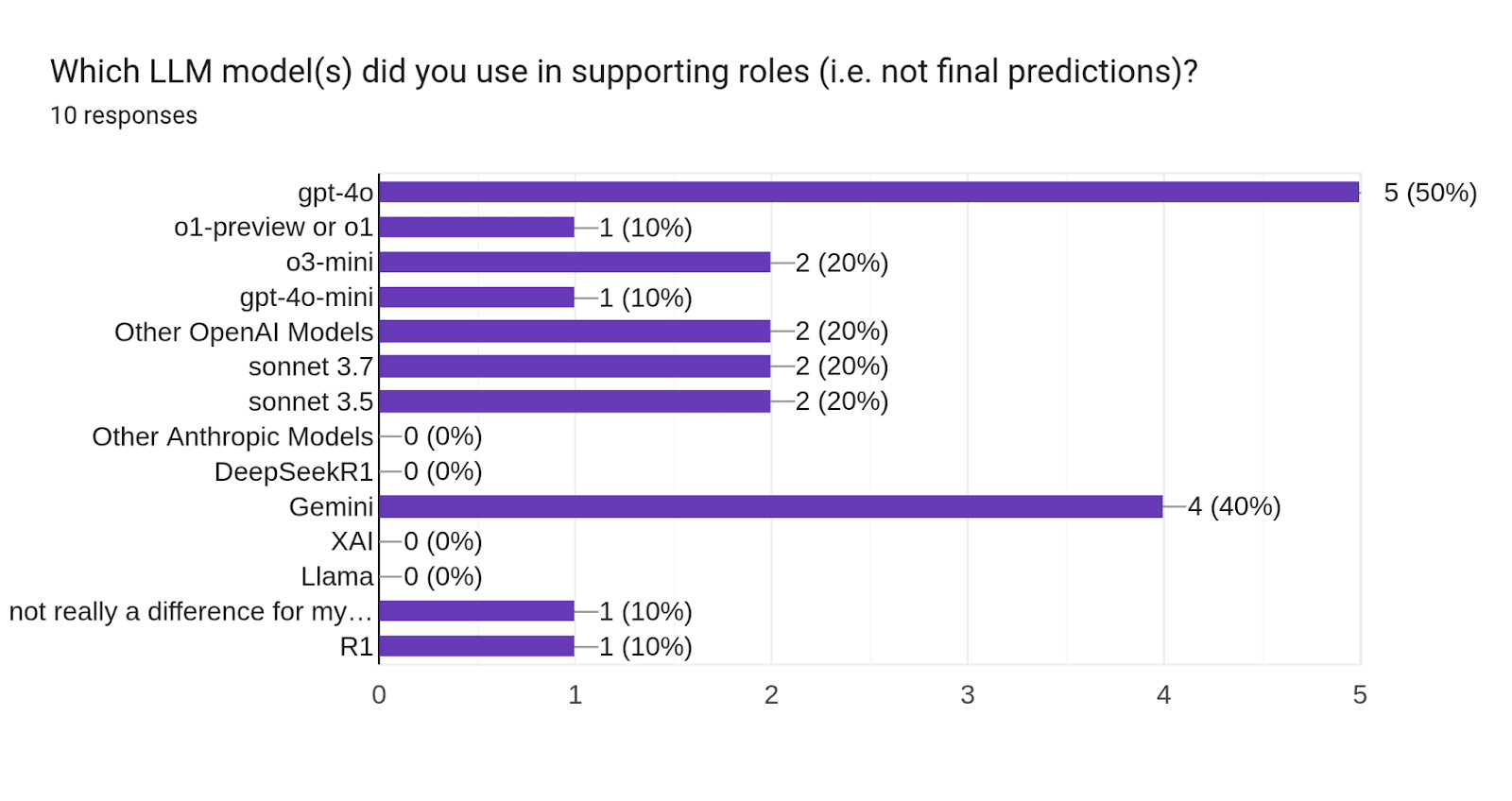
We have been interested to know if prompt engineering and other scaffolding (e.g. computer use tools, code execution, etc) help bots with forecasting, or if the base model is the most important aspect. One way to measure this is to compare the performance of bots to the metac bot that is most equivalent to them (i.e. used the same LLM model). We asked each bot maker what LLMs they used for their final forecast, and what LLMs they used in a supporting role (like research). When running this comparison, one participant clearly stood out.
Twsummerbot (ranked 8th) used gpt-4o in both their final forecast and in supporting roles. They crushed the equivalent template bot (metac-gpt-4o), which ranked 44th. In the bot-only tournament, Twsummerbot got an average spot peer score of 5.51 [95% CI: 10.61, 0.42] while metac-gpt-4o got -5.53 [95% CI: -1.46, -9.60]. The error bars of twsummerbot’s score do not cross over at all with metac-gpt-4o’s score, indicating twsummerbot had a significantly better spot peer score.
Most prize winners did not stand out in this way, with some having only marginal gains over their equivalent template bot. Others aggregated multiple models in their final forecast, making a comparison difficult.
So let's dive into twsummerbot’s survey a little deeper, which he has graciously allowed us to share in full. Here are his answers:
- How did your bot research questions?:
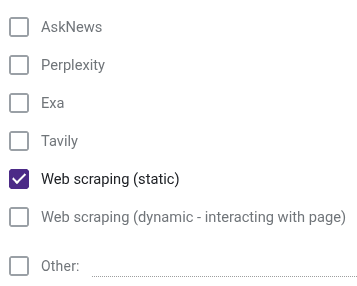
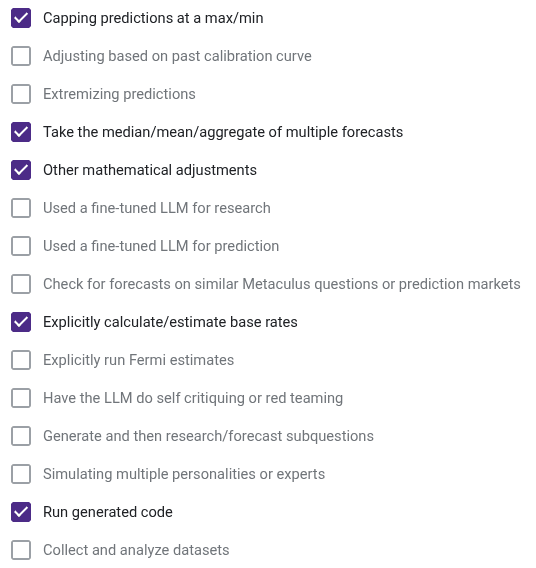
- Did your bot use any of the below forecasting strategies?:
- How many people are on your team?: 1
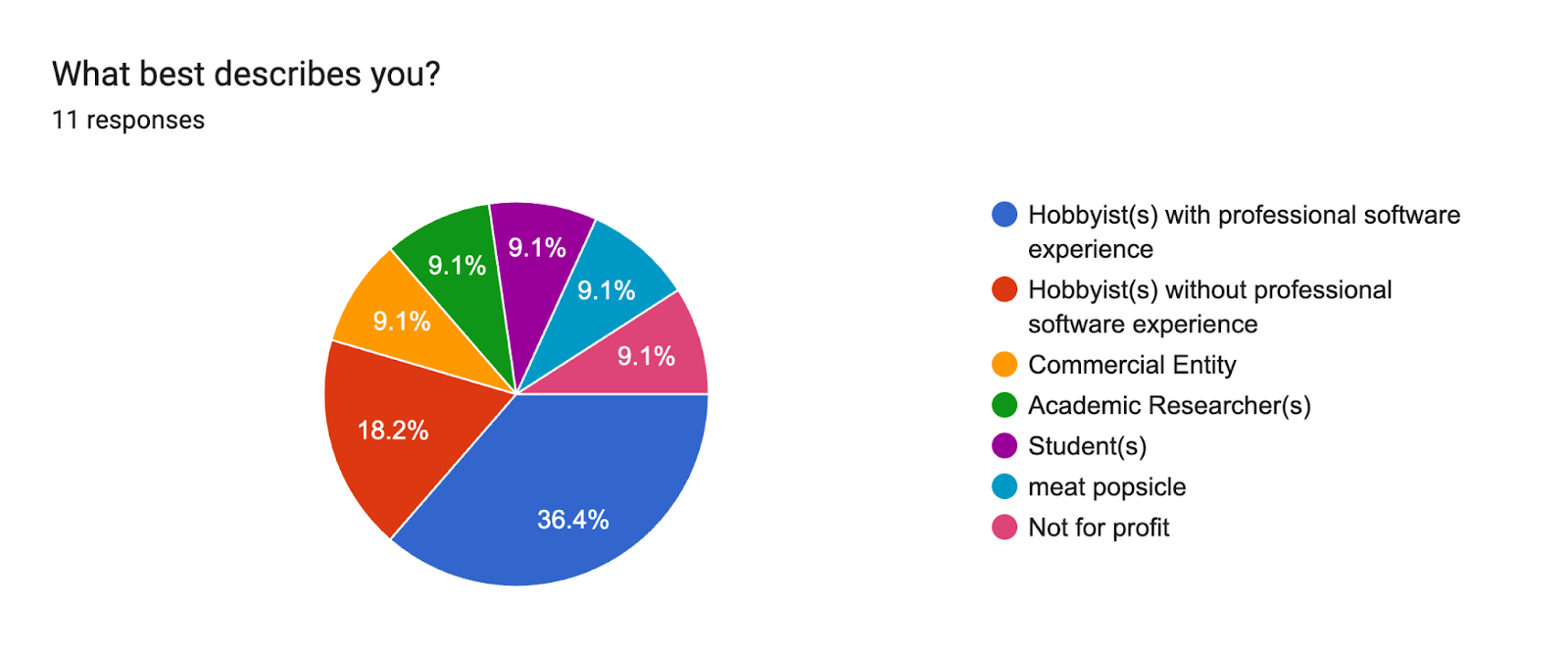
- What best describes you?: Hobbyist(s) with professional software experience
- What is your best estimate for how many total hours (between all team members) have been put into developing your bot?: 2 full-time weeks to 1 full-time month
- Your best estimate of the number of LLM calls per question?: 50-100
- When building, have you optimized more for research (external information retrieval) or reasoning (processing information given to the LLM)?: About the same for both
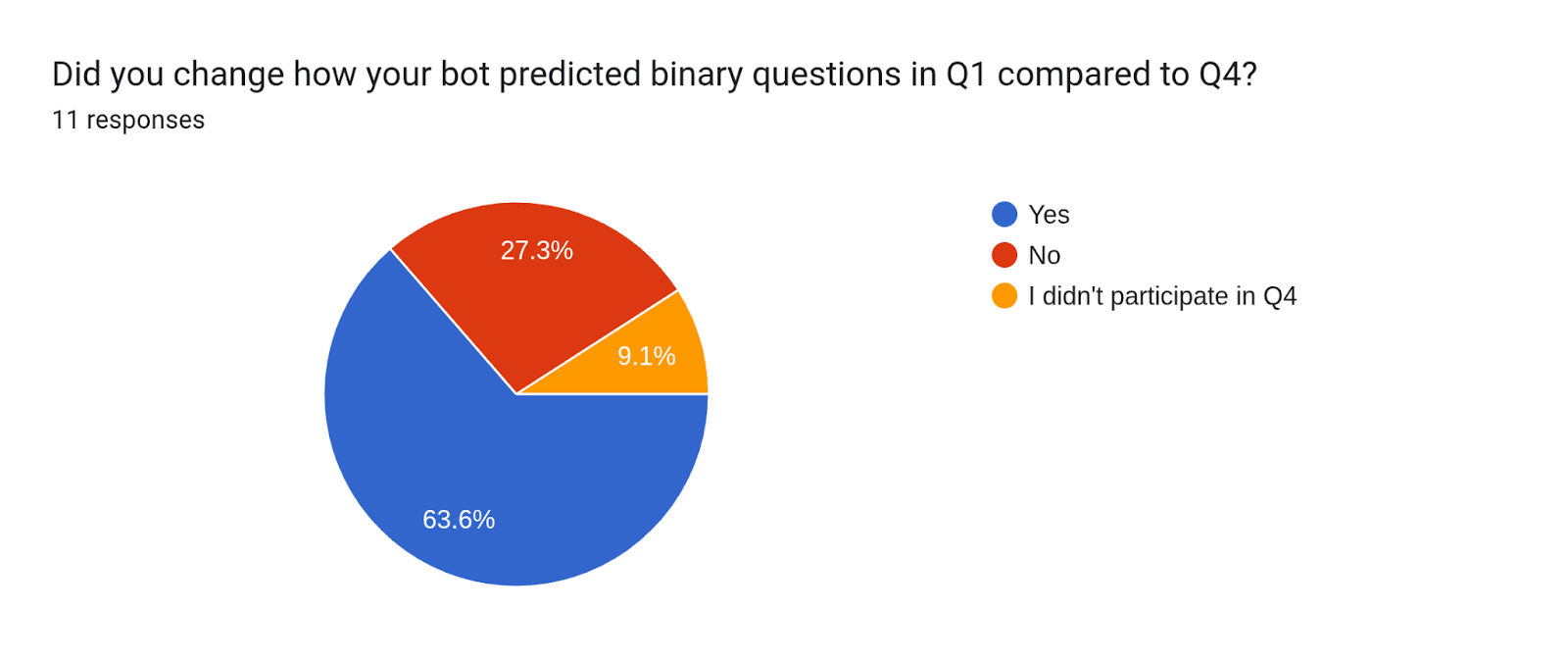
- Did you change how your bot predicted binary questions in Q1 compared to Q4?: No
Twsummerbot got 9th in Q4, and 8th in Q3. In the Q1 bot tournament, they answered 263 questions (51 multiple-choice, 54 numeric, 158 binary). Their bot relied on agentic tool calling.
It's difficult to say what was most likely to have allowed twsummerbot to pull ahead in this way, but their approach may be worth emulating.
Correlations with Ranks
We ran a few explorations comparing ranks with different questions on the survey. Please note that these trends mostly reflect on prize winners. Only 1 non-prize winner answered the survey, and trends may not extend to others. Additionally, a sample size of 11 is small.
Time Spent: Moderate Correlation 0.434, less time spent = better rank, noisy data
This question was multiple choice (with an “other” option one person used), so we used the midpoints of time estimates and converted them into hours (i.e. 16-40hrs converted to 28hr). We also converted 1 month to mean 160 work hours. We put this in the “Calculated number of hours” column, then looked at the correlation between “Calculated number of hours” and the “Verified rank” column. This resulted in a correlation value of 0.434. Generally, this would indicate a moderate positive linear relationship, meaning that spending more time on your bot may actually give you a worse rank (remember, higher rank values like 44th are worse). On visual inspection of the scatter plot (excluded for privacy reasons), there does seem to be a linear relationship. Though some of these datapoints could easily be outliers, and we wouldn’t be able to tell with this sample size.
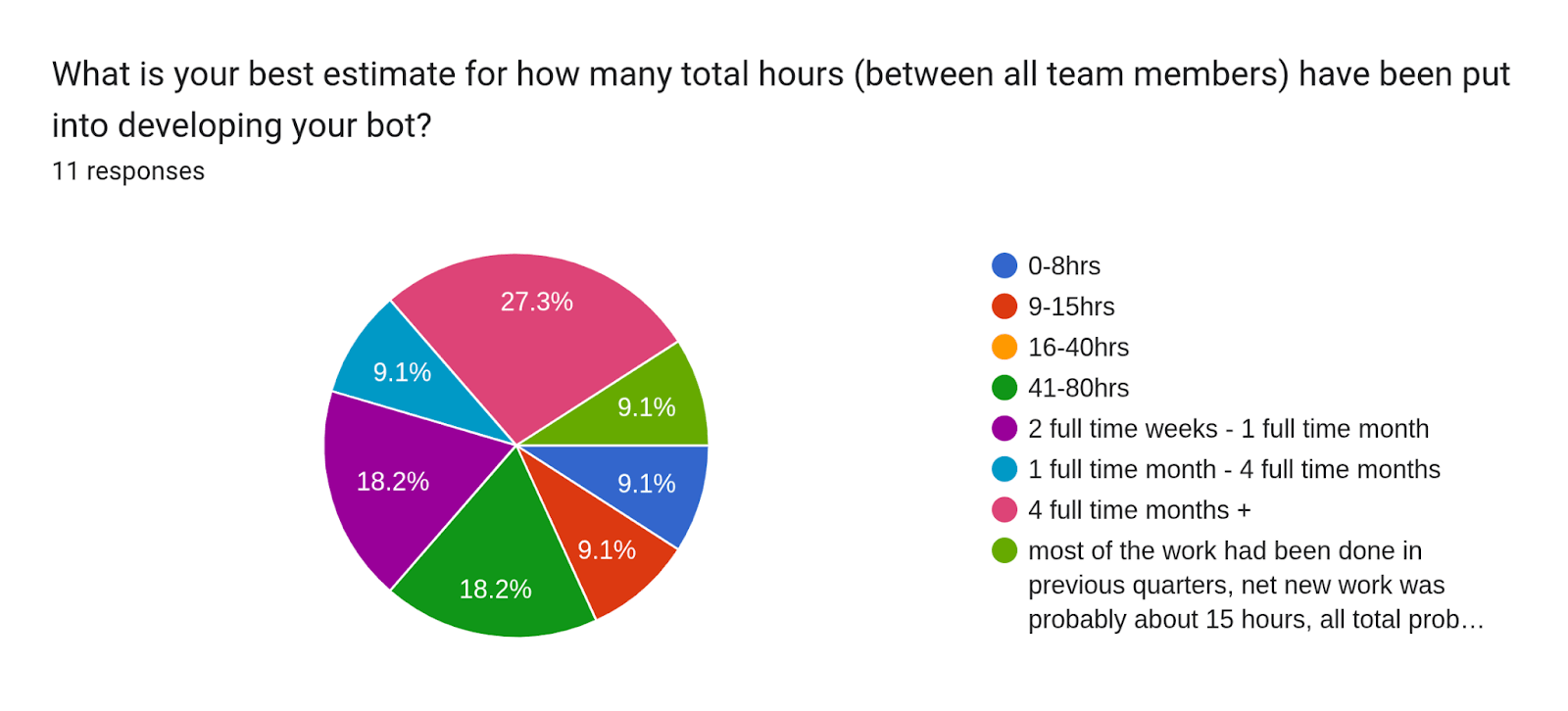
Next, we looked at the number of LLM calls that were made per question for each bot. This question was also multiple choice (with an “other” option, one person used), so we took the mid-range of the estimates and then looked at the correlation between this value and the bot’s verified rank. Correlation was slightly negative at -0.271, but weak enough that, on visual inspection of the scatter plot, we would say that the number of LLM calls made has little effect on rank.
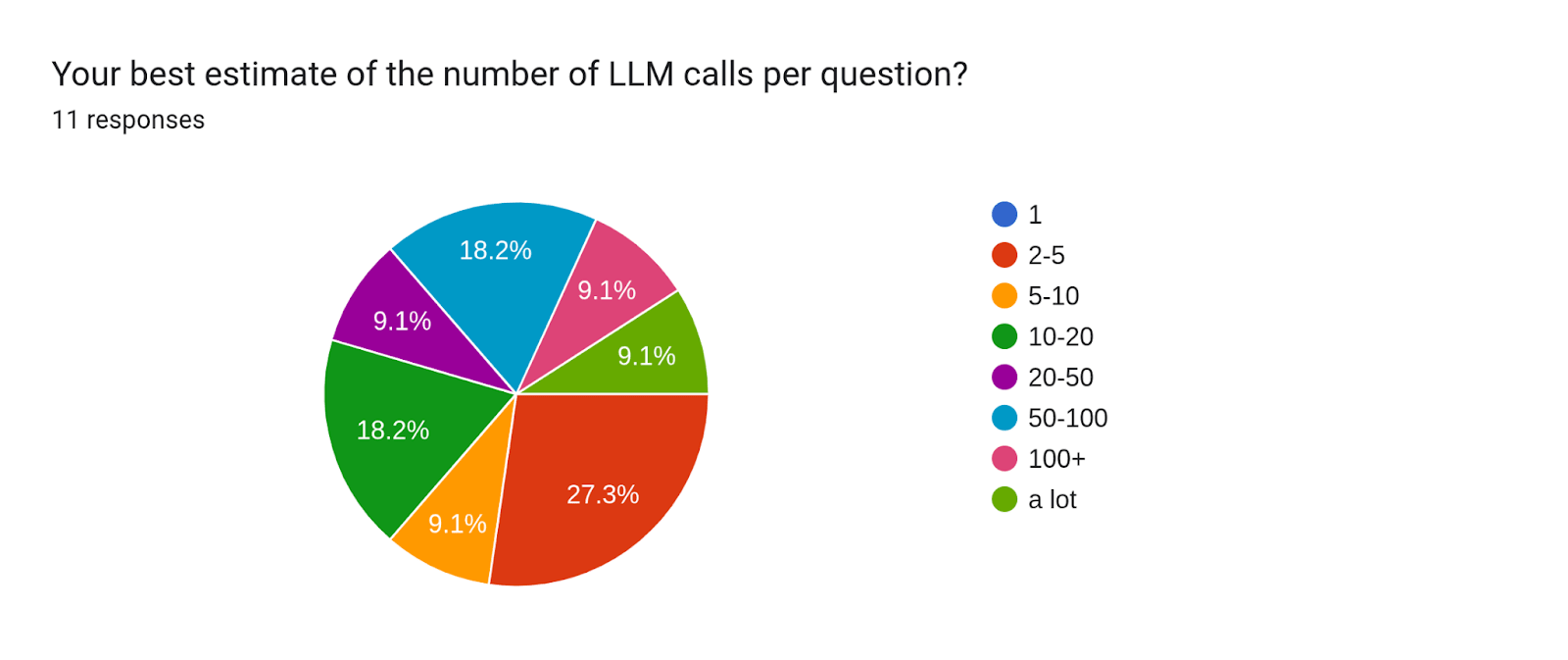
Bot makers were asked, “When building, have you optimized more for research (external information retrieval) or reasoning (processing information given to the LLM)?”. Of the prize winners, 30% leaned toward research, while only 10% leaned toward reasoning. 40% focused “about the same for both”.
Advice from Bot Makers
Bot makers were asked, “What should other bot makers learn from your experience? “. Here is their advice:
Bot A: Garbage in equals garbage out continues to be very accurate for thinking about how well a prediction bot can perform. The research provided to the bot seems to have a big influence on the final prediction result. Even one research item being off or hallucinated can throw off the bot's final prediction a lot. Using median or mean of numerous runs can blunt this a bit, but this can also blunt "extremizing" scores, which tend to do a little better. It's also not clear that making any additional adjustments to the bot's final prediction via manual calibration improves its performance either. The latest models seem to be a bit better than the older ones, so calibration could make performance worse as LLMs improve. There's likely also just dumb luck involved given the variance of LLMs final output, though you can blunt it with mean/median of multiple runs (the same downsides as above still exist though). My best guess, based on what I've seen so far through 3 tournaments, is that single shot runs with the best/latest models (perhaps taking their mean/median results) will be better than any kind of additional work by the developer (like manual calibration, training the bot on past performance, etc). The only thing that would likely improve results beyond this is ensuring the best and most accurate research is provided to the bot for each question.
Bot B: working on predicting the future for 9 months, and then quitting because you realise that a one-liner to blah SOTA model is better than the thing you've been working on for 9 months, is not a sign of failure: it's a sign that you love problems. So yeah, I'm quitting the comp, I'm working on different problems now, but the verbal currency I gained in the past 9 months is not something I could possibly have earned any other way. So Thanks to all the bot makers, regardless of how much info was shared or not shared! i learned a lot more about the past than the future, which was a really unexpected yet welcome outcome.
Bot C: I'm not sure as I don't think I understand the "base" model out there very well anymore. At the end of Q4, I would have said my bot is thoughtful about 1) creating questions and doing detailed research and 2) structuring the prompt to get the LLM to think carefully about the prediction in a process driven way. But I'm not sure my bot does anything really special anymore. On the negative side, my bot had two many technical glitches in Q1 and didn't end up forecasting on lots of questions. So the learning there is you have to work out those glitches and really make sure the thing runs all the time.
Bot D: I think information retrieval is extremely important; look at some examples of the information your bot is using to make a prediction and check for 1.) accuracy, and 2.) completeness. Reasoning models are always getting better out of the box, meaning information retrieval will be the key magic as opposed to special prompting. With that said, it's also crucial to think about model failure and correcting for poor reasoning/question interpretation. At a minimum, multiple predictions can help solve edge-case incorrect assumptions about a question that result in overconfident predictions.
Bot E: We think haircutting predictions is still underrated. We had some bugs in our numerical system that meant we weren't putting much probability mass outside the bounds when they were open and this cost us a lot. So paying attention to the basics has a good ROI. Multiple rollouts is useful for error correction but seems less important than in the past. We don't have much insight on what others are doing in this regard, but we think it makes sense to use different models for different tasks.
Bot F: Keep a better eye on costs and usage. - Rather than having a single model analyse everything, send the data to be analysed as different "Perspectives", then feed that into your judge model - Don't use the builtin framework. It's a pain, and though I haven't switched, I wish I'd just gone with my own thing from the start. - Perplexity really isn't great. Better to roll your own research
Bot G: The input/output/feedback loop was not conducive to post mortem and corrections. Instructions and checklists is a promising direction. Others can build upon our work with specialization into one topic of forecasting.
Bot H: worked: added the functionality to screenshot the resolution criteria links and send that to an LLM for analysis for further context on the exact metric being measured
Bot I: My bot was really bad with the numeric questions, I would recommend handling the binary and the numeric questions completely differently.
Bot J: The newer reasoning models and search tools can now outperform cheaper models with lots of tools and logic
Other Results
Here are some other questions that bot makers answered. Each question had an “Other” option, which some participants utilized:
- 9 people said “1”
- 1 said “3”
- 1 said “5”
Did your bot use any of the below forecasting strategies?: Here are the counts of how many prize winners used each forecasting strategy
- Take the median/mean/aggregate of multiple forecasts – 10
- Other mathematical adjustments – 5
- Explicitly calculate/estimate base rates – 5
- Capping predictions at a max/min – 5
- Check for forecasts on similar Metaculus questions or prediction markets – 4
- Have the LLM do self-critiquing or red teaming – 3
- Adjusting based on past calibration curve – 3
- Generate and then research/forecast subquestions – 3
- Run generated code – 2
- Simulating multiple personalities or experts – 2
- Collect and analyze datasets – 2
- Extremizing predictions – 1
- Used a fine-tuned LLM for research – 1
- Used a fine-tuned LLM for prediction – 1
- Explicitly run Fermi estimates – 0
Links to Code and Data
Below are links to code and data you may be interested in:
- Data exploration site that allows you to see interactive graphs of the data in this post and download it.
- Code for this analysis if you want to recreate the results locally.
- Pro tournament with all pro questions, forecasts, and comments
- Q1 Bot tournament with all bot questions, forecasts, and comments
- Actual Q1 Metac Bot code that was run during Q1
- Forecasting tools Q1 Bot that can be imported and used via the forecasting-tools Python package
- Exa Smart Searcher (Custom Wrapper) snapshot that was used in the metac-exa bot
- We often share data with researchers. If you are interested in running analyses on specific Metaculus data, please reach out to us at support@metaculus.com.
Future AI Benchmarking Tournaments
We plan to run more tournaments like this one in the future, past Q2, and will announce timing and details as we have them. For updates, occasionally check the tournament homepage or join our Discord and check in on our “build-a-forecasting-bot” channel. You can email ben [at] metaculus [dot] com with questions. Until details are finalized, you can prepare by setting up your own bot in around 30 minutes with this walkthrough and compete in the Metaculus Cup with your bot! If you need budget to experiment, we cover participants' LLM competition costs through our proxy (email us).