LLM Evaluators Recognize and Favor Their Own Generations
By Arjun Panickssery @ 2024-04-17T21:09 (+21)
This is a linkpost to http://tiny.cc/llm_self_recognition
Self-evaluation using LLMs is used in reward modeling, model-based benchmarks like GPTScore and AlpacaEval, self-refinement, and constitutional AI. LLMs have been shown to be accurate at approximating human annotators on some tasks.
But these methods are threatened by self-preference, a bias in which an LLM evaluator scores its own outputs higher than than texts written by other LLMs or humans, relative to the judgments of human annotators. Self-preference has been observed in GPT-4-based dialogue benchmarks and in small models rating text summaries.
We attempt to connect this to self-recognition, the ability of LLMs to distinguish their own outputs from text written by other LLMs or by humans.
We find that frontier LLMs exhibit self-preference and self-recognition ability. To establish evidence of causation between self-recognition and self-preference, we fine-tune GPT-3.5 and Llama-2-7b evaluator models to vary in self-recognition ability and measure the resulting change in self-preference, while examining potential confounders introduced by the fine-tuning process.
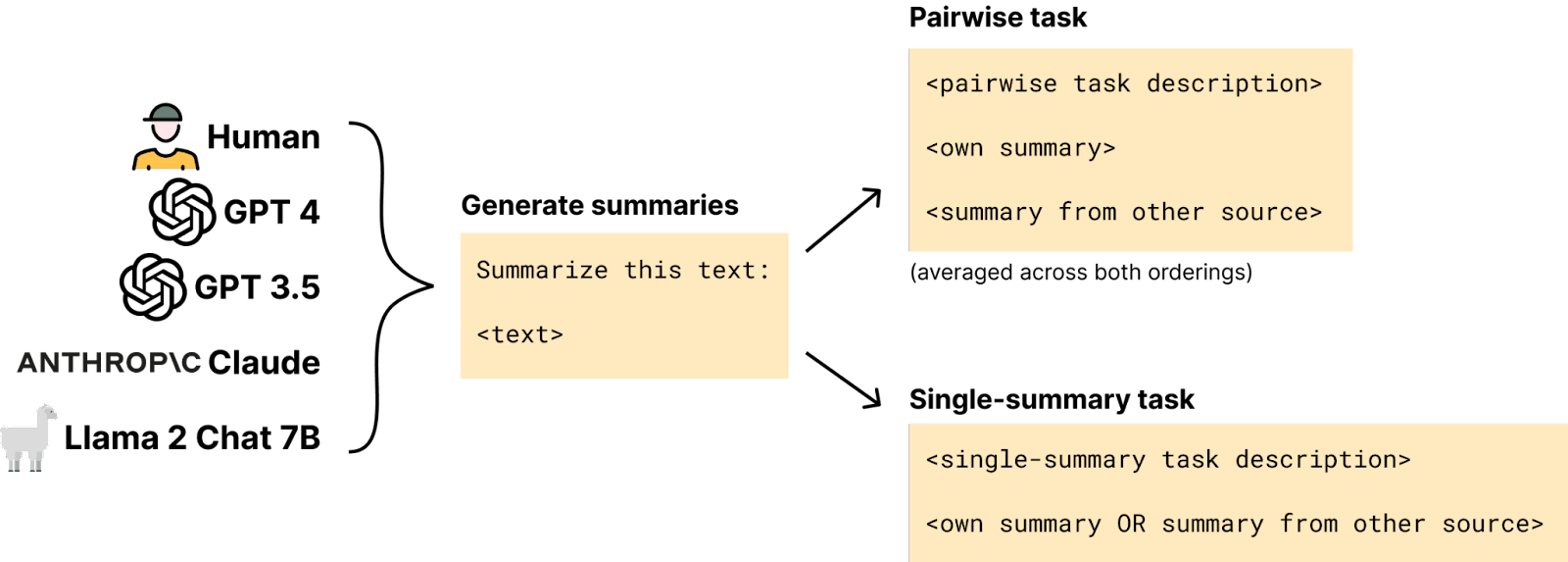
We focus on text summarization, sampling 1,000 news articles and associated human summaries from each of two datasets: XSUM and CNN/DailyMail. We use instruction-tuned LLMs (GPT-4, GPT-3.5 Turbo, Claude 2, and Llama-2-7b-chat) to produce additional summaries for each news article.
Measuring Self-Recognition and Self-Preference
Both self-recognition and self-preference are evaluated in two settings:
Pairwise Setting: The LLM evaluator is presented two unlabeled summaries, one generated by itself and another by one of the other four human/LLM sources. In the self-recognition tasks, the LLM evaluator is prompted to choose the summary that it wrote; in the self-preference task, the evaluator is prompted to choose the higher-quality summary. We compute a prediction confidence score by normalizing the output probabilities of the tokens associated with the two options, and average between both orderings of the two summaries to account for ordering bias.
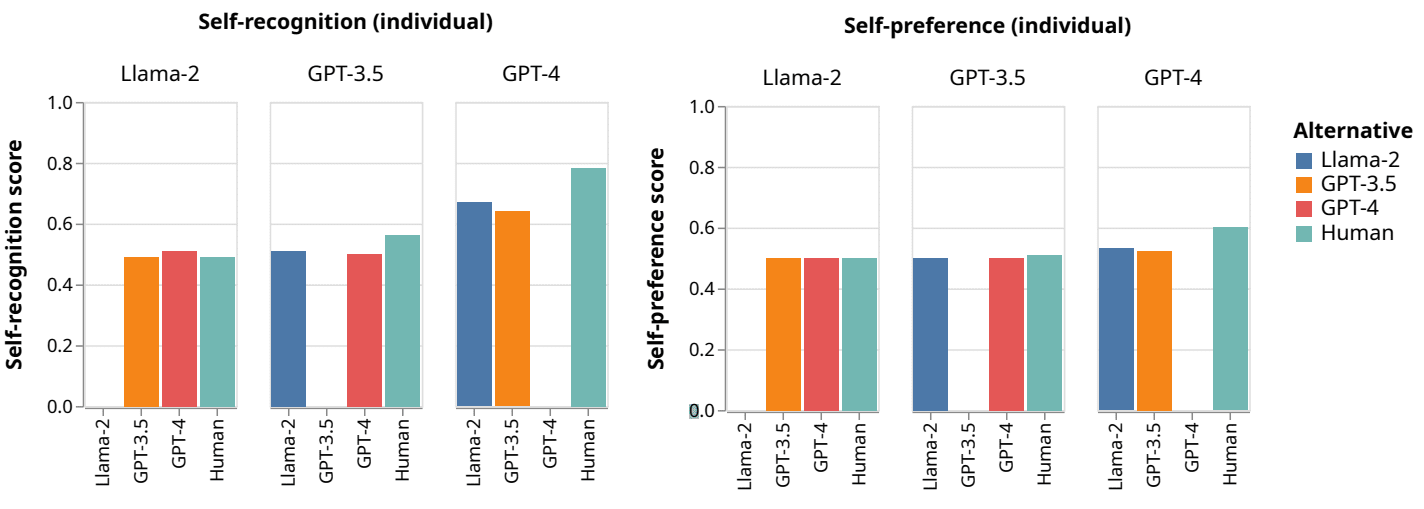
Individual Setting: The LLM evaluator is presented a single summary generated either by itself or by one of the other four sources. For self-recognition, the model is prompted with the yes/no question of whether it wrote the summary, with the confidence score computed by normalized the output probability for the “yes” and “no” tokens. For self-preference, the model is prompted to assigned the summary a score on a scale of one to five. The final score is computed as the average of the five possible scores weighted by the output probability of their respective tokens.
To make the individual-setting responses comparable to the pairwise measurements, they're normalized further. For each LLM evaluator, the response scores for both tasks on summaries generated by other sources are normalized against the response given to the LLM. For example, if the GPT-4 evaluator gave a weighted score of 2.0 to a summary generated by Claude 2 and a weighted score of 3.0 to its own summary for the same article, then its final normalized self-preference score for the Claude summary would be 2/(2+3)=0.4.
Some of our findings on out-of-the-box evaluation:
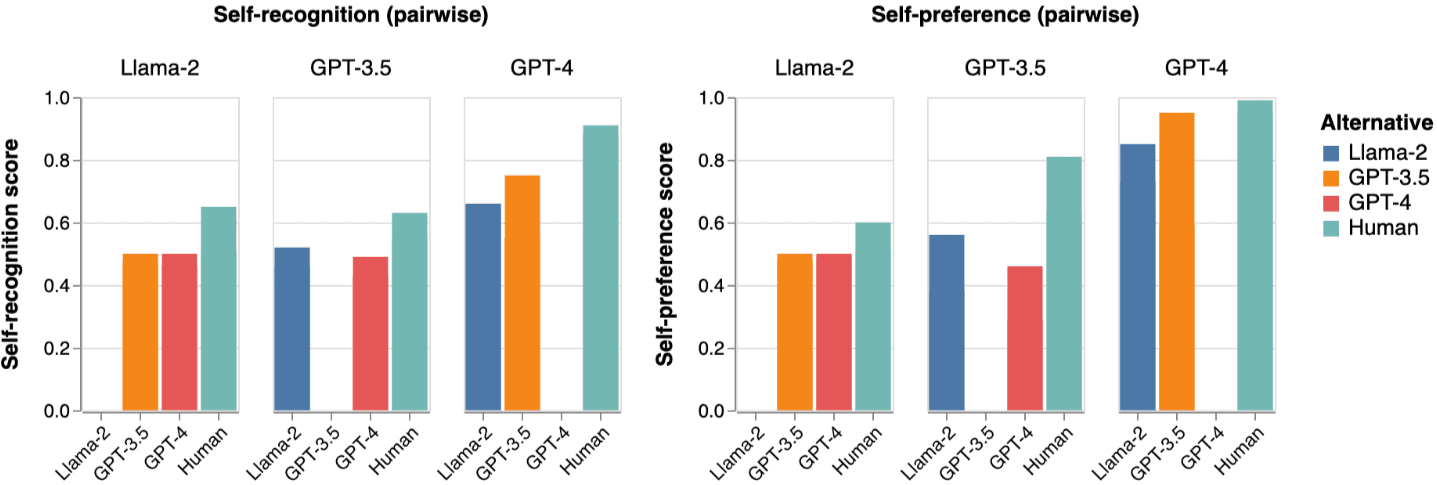
- GPT-4 is significantly more capable at self-recognition than the two weaker models.
- All three LLM evaluators most easily distinguish their summaries from human-written summaries and show the greatest self-preference against the human summary.
- Weaker LLMs struggle to distinguish themselves from stronger LLMs: Llama 2 is completely incapable of distinguishing itself from GPT-3.5 and GPT-4, and GPT-3.5 struggles to distinguish itself from GPT-4.
Investigating Evidence of Causation
Next we look for evidence of causation:
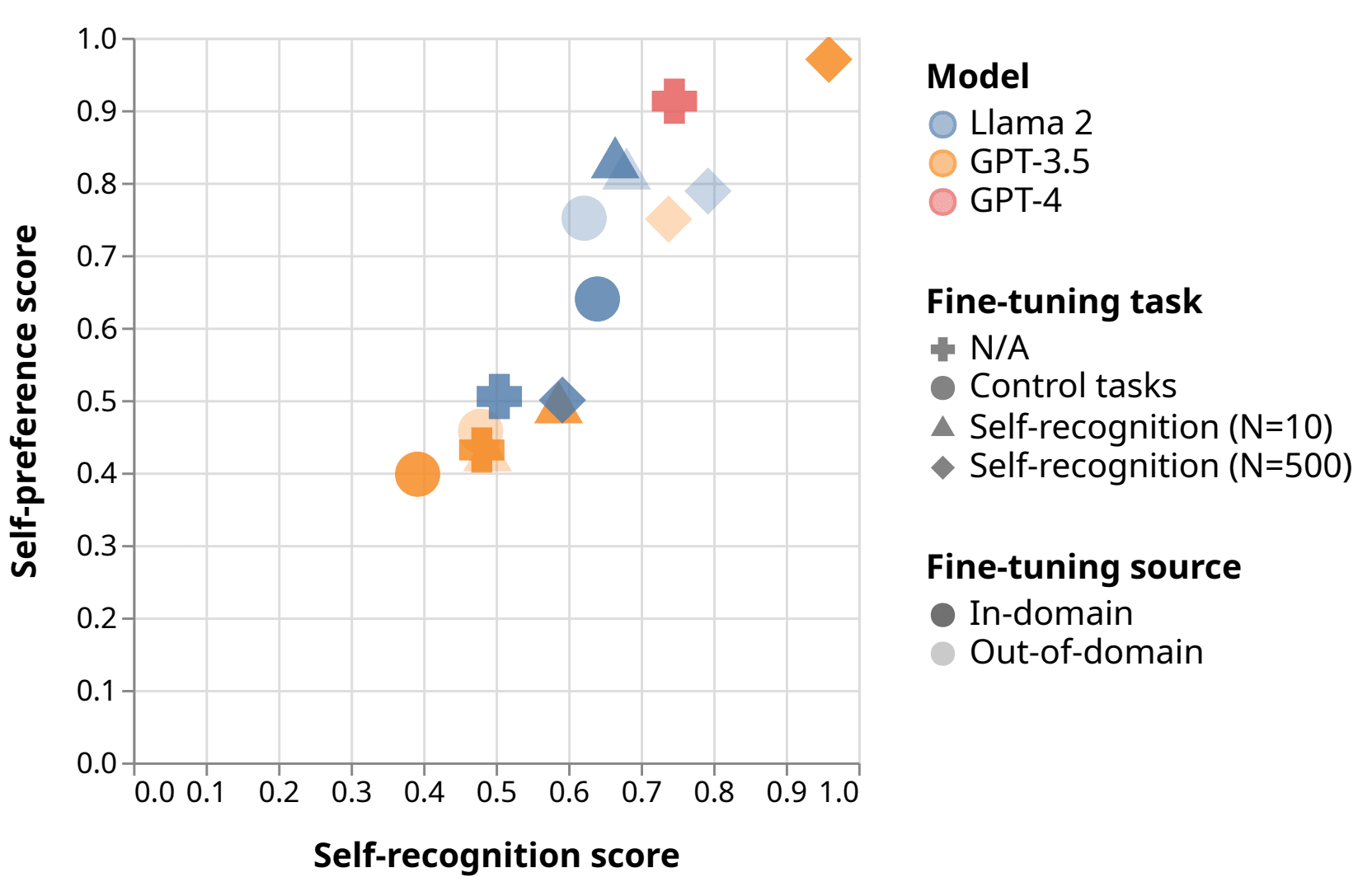
- We fine-tune the GPT-3.5 and Llama-2-7b evaluator models for self-recognition, resulting across models and datasets in a linear trend connecting evaluator self-recognition to self-preference. This effect persists when finetuning on one dataset and measuring results on the other dataset.
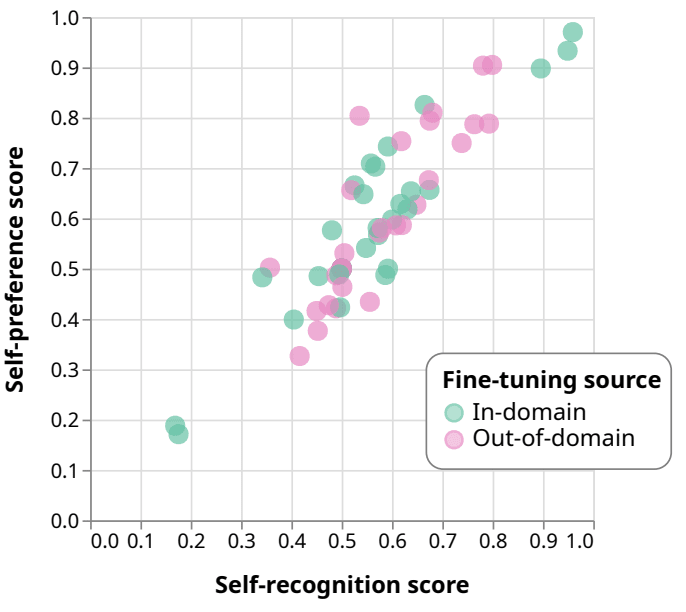
- We control for confounders introduced by fine-tuning by showing that the linear trend persists even when fine-tuning on unrelated tasks: length, vowel count, and readability score. We also fine-tune models to always answer “1” and to answer randomly on the self-recognition task.
- We invalidate the inverse causal relationship that self-recognition confidence scores increase after fine-tuning because the model generation actually improves, since in fact we find a slight preference against the new generations after fine-tuning compared to the old generations from before fine-tuning.
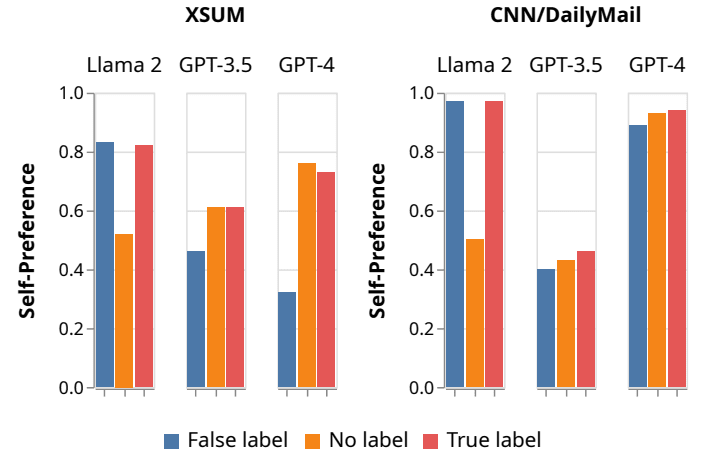
- In a separate experiment, we label the summary in the pairwise self-preference task with either the correct or reversed sources of those summaries. We find that the GPT-4 and GPT-3.5 evaluator models show a reversal in self-preference when the labels are reversed in the XSUM dataset.
Work done as part of MATS 5.0 under the mentorship of the NYU Alignment Research Group.
Full paper: https://tiny.cc/llm_self_recognition
Hauke Hillebrandt @ 2024-04-18T09:20 (+7)
Cool instance of black box evaluation - seems like a relatively simple study technically but really informative.
Do you have more ideas for future research along those lines you'd like to see?
jimrandomh @ 2024-04-17T23:08 (+3)
Interesting. I think I can tell an intuitive story for why this would be the case, but I'm unsure whether that intuitive story would predict all the details of which models recognize and prefer which other models.
As an intuition pump, consider asking an LLM a subjective multiple-choice question, then taking that answer and asking a second LLM to evaluate it. The evaluation task implicitly asks the the evaluator to answer the same question, then cross-check the results. If the two LLMs are instances of the same model, their answers will be more strongly correlated than if they're different models; so they're more likely to mark the answer correct if they're the same model. This would also happen if you substitute two humans or two sittings of the same human implace of the LLMs.
Esben Kran @ 2024-04-21T13:38 (+2)
Very interesting! We had a submission for the evals research sprint in August last year on the same topic. Check it out here: Turing Mirror: Evaluating the ability of LLMs to recognize LLM-generated text (apartresearch.com)
SummaryBot @ 2024-04-18T12:53 (+1)
Executive summary: Frontier language models exhibit self-preference when evaluating text outputs, favoring their own generations over those from other models or humans, and this bias appears to be causally linked to their ability to recognize their own outputs.
Key points:
- Self-evaluation using language models is used in various AI alignment techniques but is threatened by self-preference bias.
- Experiments show that frontier language models exhibit both self-preference and self-recognition ability when evaluating text summaries.
- Fine-tuning language models to vary in self-recognition ability results in a corresponding change in self-preference, suggesting a causal link.
- Potential confounders introduced by fine-tuning are controlled for, and the inverse causal relationship is invalidated.
- Reversing source labels in pairwise self-preference tasks reverses the direction of self-preference for some models and datasets.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.