Lessons learned from talking to >100 academics about AI safety
By mariushobbhahn @ 2022-10-10T13:16 (+138)
I’d like to thank MH, Jaime Sevilla and Tamay Besiroglu for their feedback.
During my Master's and Ph.D. (still ongoing), I have spoken with many academics about AI safety. These conversations include chats with individual PhDs, poster presentations and talks about AI safety.
I think I have learned a lot from these conversations and expect many other people concerned about AI safety to find themselves in similar situations. Therefore, I want to detail some of my lessons and make my thoughts explicit so that others can scrutinize them.
TL;DR: People in academia seem more and more open to arguments about risks from advanced intelligence over time and I would genuinely recommend having lots of these chats. Furthermore, I underestimated how much work related to some aspects AI safety already exists in academia and that we sometimes reinvent the wheel. Messaging matters, e.g. technical discussions got more interest than alarmism and explaining the problem rather than trying to actively convince someone received better feedback.
Update: here is a link with a rough description of the pitch I used.
Executive summary
I have talked to somewhere between 100 and 200 academics (depending on your definitions) ranging from bachelor students to senior faculty. I use a broad definition of “conversations”, i.e. they include small chats, long conversations, invited talks, group meetings, etc.
Findings
- Most of the people I talked to were more open about the concerns regarding AI safety than I expected, e.g. they acknowledged that it is a problem and asked further questions to clarify the problem or asked how they could contribute.
- Often I learned something during these discussions. For example, the academic literature on interpretability and robustness is rich and I was pointed to resources I didn’t yet know. Even in cases where I didn’t learn new concepts, people scrutinized my reasoning such that my explanations got better and clearer over time.
- The higher up the career ladder the person was, the more likely they were to quickly dismiss the problem (this might not be true in general, I only talked with a handful of professors).
- Often people are much more concerned with intentional bad effects of AI, e.g. bad actors using AI tools for surveillance, than unintended side-effects from powerful AI. The intuition that “AI is just a tool and will just do what we want” seems very strong.
- There is a lot of misunderstanding about AI safety. Some people think AI safety is the same as fairness, self-driving cars or medical AI. I think this is an unfortunate failure of the AI safety community but is quickly getting better.
- Most people really dislike alarmist attitudes. If I motivated the problem with X-risk, I was less likely to be taken seriously.
- Most people are interested in the technical aspects, e.g. when I motivated the problem with uncontrollability or interpretability (rather than X-risk), people were more likely to find the topic interesting. Making the core arguments for “how deep learning could go wrong” as detailed, e.g. by Ajeya Cotra or Richard Ngo usually worked well.
- Many people were interested in how they could contribute. However, often they were more interested in reframing their specific topic to sound more like AI safety rather than making substantial changes to their research. I think this is understandable from a risk-reward perspective of the typical Ph.D. student.
- People are aware of the fact that AI safety is not an established field in academia and that working on it comes with risks, e.g. that you might not be able to publish or be taken seriously by other academics.
- In the end, even when people agree that AI safety is a really big problem and know that they could contribute, they rarely change their actions. My mental model changed from “convince people to work on AI safety” to “Explain why some people work on AI safety and why that matters; then present some pathways that are reachable for them and hope for the best”.
- I have talked to people for multiple years now and I think it has gotten much easier to talk about AI safety over time. By now, capabilities have increased to a level that people can actually imagine the problems AI safety people have been talking about for a decade. It could also be that my pitch has gotten better or that I have gotten more senior and thus have more trust by default.
Takeaways
- Don’t be alarmist and speak in the language of academics. Don’t start with X-risk or alignment, start with a technical problem statement such as “uncontrollability” or “interpretability” and work from there.
- Be open to questions and don’t dismiss criticism even if it has obvious counterarguments. You are likely one of the first people to talk to them about AI safety and these are literally the first five minutes in their lives thinking about it.
- Academic incentives matter to academics. People care about their ability to publish and their citation counts. They know that if they want to stay in academia, they have to publish. If you tell them to stop working on whatever they are working on right now and work on AI alignment, this is not a reasonable proposition from their current perspective. If you show them pathways toward AI safety, they are more likely to think about what options they could choose. Providing concrete options that relate to their current research was always the most helpful, e.g. when they work on RL suggest inverse RL or reward design and when they work on NN capabilities, suggest NN interpretability.
- Existing papers, workshops, challenges, etc. that are validated within the academic community are super helpful. If you send a Ph.D. or post-doc a blog post they tend to not take it seriously. If you send them a paper they do (arxiv is sufficient, doesn’t have to be peer-reviewed). Some write-ups I found especially useful to send around include:
- Explain don’t convince: Let your argument do the work. If you explained it poorly, people shouldn't feel pressured. I think that most academics will agree that AI safety is a relevant problem if you did a half-decent job explaining it. However, there is a big difference between “understanding the problem” and “making a big career change”. Nevertheless, it is still important that other academics understand the problem even if they don’t end up working on it. They influence the next generation, they are your reviewers, they make decisions about funding, etc. The difference between whether they think AI safety is reasonable or whether it is alarmist, sci-fi, billionaire-driven BS might be bigger than I originally expected. Furthermore, if they take you seriously, it’s less likely that they will see the field as alarmist/crazy in their next encounter with AI safety even if you’re not around.
Things we/I did - long version
- I have spoken to lots of Bachelor's students, Master's students, PhDs and some post-docs and professors in Tübingen.
- Gave an intro talk about AI safety in my lab.
- Gave a talk about AI safety for the ELLIS community (the European ML network).
- Co-founded and stopped the AI safety reading group for Tübingen. We stopped because it was more efficient to get people into online reading groups, e.g. AGISF fundamentals.
- Presented a poster called “AI safety introduction - questions welcome” at the ELLIS doctoral symposium (with roughly 150 European ML PhDs participating) together with Nikos Bosse.
- Presented the same poster at the IMPRS-IS Bootcamp (with roughly 200 ML PhDs participating).
In total, depending on how you count, I had between 100 and 200 conversations about AI safety with academics, most of which were Ph.D. students.
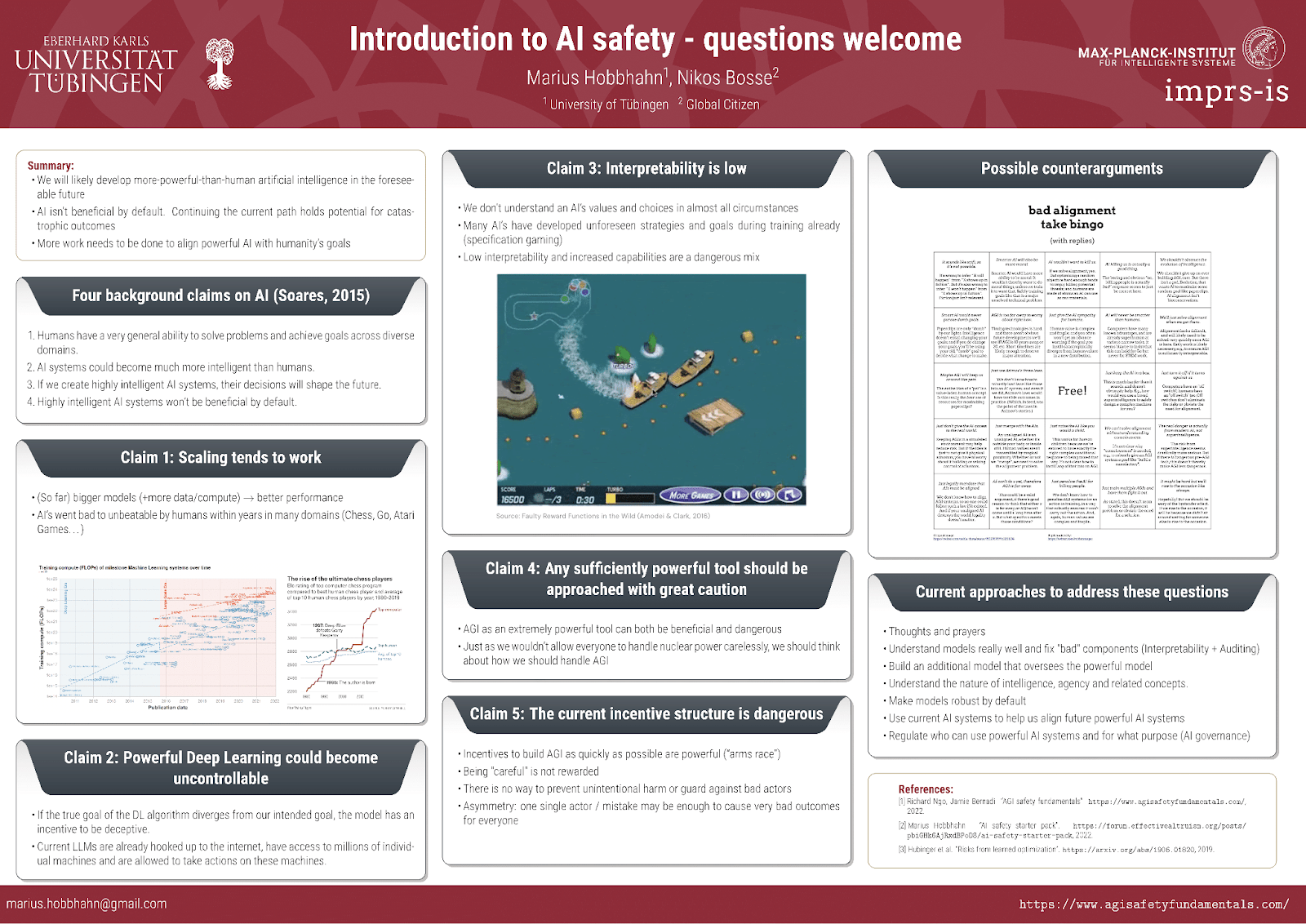
This is the poster we used. We put it together in ~60 minutes, so don’t expect it to be perfect. We mostly wanted to start a conversation. If you want to have access to the overleaf and make adaptions, let me know. Feedback is appreciated.
Findings - long version
People are open to chat about AI safety
If you present a half-decent pitch for AI safety, people tend to be curious. Even if they find it unintuitive or sci-fi, in the beginning, they will usually give you a chance to change their mind and explain your argument. Academics tend to be some of the brightest minds in society and they are curious and willing to be persuaded when presented with plausible evidence.
Obviously, that won’t happen all the time, sometimes you’ll be dismissed right away or you’ll hear a bad response presented as a silver bullet answer. But in the vast majority of cases, they’ll give you a chance to make your case and ask clarifying questions afterward.
I learned something from the discussions
There are many academics working on problems related to AI safety, e.g. robustness, interpretability, control and much more. This literature is often not exactly what people in AI safety are looking for but they are close enough to be really helpful. In some cases, these resources were also exactly what I was looking for. So just on a content level, I got lots of ideas, tips and resources from other academics. Informal knowledge such as “does this method work in practice?” or “which code base should I use for this method?” is also something that you can quickly learn from practitioners.
Even in the cases where I didn’t learn anything on a content level, it was still good to get some feedback, pushback and scrutiny on my pitch on why AI safety matters. Sometimes I skipped steps in my reasoning and that was pointed out, sometimes I got questions that I didn’t know how to answer so I had to go back to the literature or think about them in more detail. I think this made both my own understanding of the problem and my explanation of it much better.
Intentional vs unintentional harms
Most of the people I talked to thought that intentional harm was a much bigger problem than unintended side effects. Most of the arguments around incentives for misalignment, robustness failures, inner alignment, goal misspecification, etc. were new and sound a bit out there. Things like country X will use AI to create a surveillance state seemed much more plausible to most. After some back and forth, people usually agreed that the unintended side effects are not as crazy as they originally seemed.
I think this does not mean people caring about AI alignment should not talk about unintended side effects for instrumental reasons. I think this mostly implies that you should expect people to have never heard of alignment before and simple but concrete arguments are most helpful.
It depends on the career stage
People who were early in their careers, e.g. Bachelor’s and Master’s students were often the most receptive to ideas about AI safety. However, they are also often far away from contributing to research so their goals might drastically change over the years. Also, they sometimes lack some understanding of ML, Deep Learning or AI more generally so it is harder to talk about the details.
PhDs are usually able to follow most of the arguments on a fairly technical level and are mostly interested, e.g. they want to understand more or how they could contribute. However, they have often already committed to a specific academic trajectory and thus don’t see a path to contribute to AI safety research without taking substantial risks.
Post-docs and professors were the most dismissive of AI safety in my experience (with high variance). I think there are multiple possible explanations for this including
a) most of their status depends on their current research field and thus they have a strong motivation to keep doing whatever they are doing now,
b) there is a clear power/experience imbalance between them and me and
c) they have worked with ML systems for many years and are generally more skeptical of everyone claiming highly capable AI. Their lived experience is just that hype cycles die and AI is usually much worse than promised.
However, this comes from a handful of conversations and I also talked to some professors who seemed genuinely intrigued by the ideas. So don’t take it this as strong evidence.
Misunderstandings and vague concepts
There are a lot of misunderstandings around AI safety and I think the AIS community has failed to properly explain the core ideas to academics until fairly recently. Therefore, I often encountered confusions like that AI safety is about fairness, self-driving cars and medical ML. And while these are components of a very wide definition of AI safety and are certainly important, they are not part of the alignment-focused narrower definition of AI safety.
Usually, it didn’t take long to clarify this confusion but it mostly shows that when people hear you talking about AI safety, they often assume you mean something very different from what you intended unless you are precise and concrete.
People dislike alarmism
If you motivate AI safety with X-risk people tend to think you’re pascal’s mugging them or that you do this for signaling reasons. I think this is understandable. If you haven’t thought about how AI could lead to X-risk, the default response is that this is probably implausible and there are also wildly varying estimates of X-risk plausibility within the AI safety community.
When people claim that civilization is going to go extinct because of nuclear power plants or because of ecosystem collapse from fertilizer overuse, I tend to be skeptical. This is mostly because I can’t think of a detailed mechanism of how either of those leads to actual extinction. If people are unaware of the possible mechanisms of advanced AI leading to extinction, they think you just want attention or don’t do serious research.
In general, I found it easier just not to talk about X-risk unless people actively asked me to. There are enough other failure modes you can use to motivate your research that they are already familiar with that range from unintended side-effects to intended abuse.
People are interested in the technical aspects
There are many very technical pitches for AI safety that never talk about agency, AGI, consciousness, X-risk and so on. For example, one could argue that
- ML systems are not robust to out-of-distribution samples during deployment and this could lead to problems with very powerful systems.
- ML systems are incentivized to be deceptive once they are powerful enough to understand that they are currently being trained.
- ML systems are currently treated as black boxes and it is hard to open up the black box. This leads to problems with powerful systems.
- ML systems could become uncontrollable. Combining a powerful black-box tool with a real-world task can have big unforeseen side effects.
- ML models could be abused by people with bad intentions. Thus, AI governance will likely matter a lot in the near future.
Most of the time, a pitch like “think about how good GPT-3 is right now and how fast LLMs get better; think about where a similar system could be in 10 years; What could go wrong if we don’t understand this system or if it became uncontrollable?” is totally fine to get an “Oh shit, someone should work on this” reaction even if it is very simplified.
People want to know how they can contribute
Once you have conveyed the basic case for why AI safety matters, people tend to be naturally curious about how they can contribute. Most of the time, their current research is relatively far away from most AI safety research and people are aware of that.
I usually tried to show a path between their research and research that I consider core AI safety research. For example, when people work on RL, I suggested working on inverse RL or reward design or when people work on NNs, I suggested working on interpretability. In many instances, this path is a bit longer, e.g. when someone works on some narrow topic in robotics. However, most of the time you can just present many different options, see how they respond to them and then talk about those that they are most excited about.
In general, AI safety comes with lots of hard problems and there are many ways in which people can contribute if they want to.
One pitfall of this strategy is that people sometimes want to get credit for “working on safety” without actually working on safety and start to rationalize how their research is somehow related to safety (I was guilty of this as well at some point). Therefore, I think it is important to point this out (in a nice way!) whenever you spot this pattern. Usually, people don’t actively want to fool themselves but we sometimes do that anyway as a consequence of our incentives and desires.
People know that doing AI safety research is a risk to their academic career
If you want to get a Ph.D. you need to publish. If you want to get into a good post-doc position you need to publish even more. Optimally, you publish in high-status venues and collect lots of citations. Academics often don’t like this system but they know that this is “how it’s done”.
They are also aware that the AI safety community is fairly small in academia and is often seen as “not serious” or “too abstract”. Therefore, they are aware that working more on AI safety is a clear risk to their academic trajectory.
Pointing out that the academic AI safety community has gotten much bigger, e.g. through the efforts of Dan Hendrycks, Jacob Steinhardt, David Kruger, Sam Bowman and others, makes it a bit easier but the risk is still very present. Taking away this fear by showing avenues to combine AI safety with an academic career was often the thing that people cared most about.
Explain don’t convince
When I started talking to people about AI safety some years ago, I tried to convince them that AI safety matters a lot and that they should consider working on it. I obviously knew that this is an unrealistic goal but the goal was still to “convince them as much as possible”. I think this is a bad framing for two reasons. First, most of your discussions feel like a failure since people will rarely change their life substantially based on one conversation. Second, I was less willing to engage with questions or criticism because my framing assumed that my belief was correct rather than just my best working hypothesis.
I think switching this mental model to “explain why some people believe AI safety matters” is a much better approach because it solves the problems outlined before but also feels much more collaborative. I found this framing to be very helpful both in terms of getting people to care about the issue but also in how I felt about the conversation later on.
I think there is also a vibes-based explanation to this. When you’re confronted with a problem for the first time and the other person actively tries to convince you, it can feel like being bothered by Jehova’s Witnesses or someone trying to sell you a fake Gucci bag. When the other person explains their arguments to you, you have more agency and control over the situation and “are allowed to” generate your own takeaways. This might seem like a small difference but I think it matters much more than I originally anticipated.
It has gotten much easier
I think my discussions today are much more fruitful than, e.g. 3 years ago. There are multiple plausible explanations for this. a) I might have gotten better at giving the pitch, b) I’m now a Ph.D. student and thus my default trust might be higher, or c) I might just have lowered my standards.
However, I think there are other factors at work that contribute to the fact that I can have better discussions. First, I think the AI alignment community has actually gotten better at explaining the risk in a more detailed fashion and in ways that can be explained in the language of the academic community, e.g. with more rigor and less hand-waving. Secondly, there are now some people in academia who take these risks seriously who have academic standing and whose work you can refer to in discussions (see above for links). Thirdly, capabilities have gotten good enough that people can actually envision the danger.
Conclusion
I have had lots of chats with other academics about AI safety. I think academics are sometimes seen as “a lost cause” or “focusing on publishable results” by some people in the AI safety community and I can understand where this sentiment is coming from. However, most of my conversations were pretty positive and I know that some of them made a difference both for me and the person I was talking to. I know of people who got into AI safety because of conversations with me and I know of people who have changed their minds about AI safety because of these conversations. I also have gotten more clarity about my own thoughts and some new ideas due to these conversations.
Academia is and will likely stay the place where research is done for a lot of people in the foreseeable future and it is thus important that the AI safety community interacts with the academic world whenever it makes sense. Even if you personally don’t care about academia, the people who teach the next generation, who review your papers and who set many research agendas should have a basic understanding of why you think AI safety is a cause worth working on even if they will not change their own research direction. Academia is a huge pool of smart and open-minded people and it would be really foolish for the AI safety community to ignore that.
Geoffrey Miller @ 2022-10-11T01:12 (+29)
Marius -- very helpful post; thank you.
Your observations ring true -- I've talked about AI safety issues over the last 6 years with about 30-50 academic faculty, and taught a course for 60+ undergraduate students (mostly psych majors) that includes two weeks of discussion on AI safety. I think almost everything you said sounds similar to my experiences.
Additional observations:
A) The moral, social, and political framing of AI safety issues matters for getting people interested, and these often need adjusting to the other person's or group's ideology. Academics who lean left politically often seem more responsive to arguments about algorithmic bias, technological unemployment, concentration of power, disparate impact, etc. Academics who lean libertarian tend to be more responsive to arguments about algorithmic censorship, authoritarian lock-in, and misuse of AI by the military-industrial complex. Conservative academics are often surprisingly interested in multi-generational, longtermism perspectives, and seem quite responsive to X risk arguments (insofar as conservatives tend to view civilization as rather fragile, transient, and in need of protection from technological disruptions.) So, it helps to have a smorgasbord of different AI safety concerns that different kinds of people with different values can relate to. There's no one-size-fits-all way to get people interested in AI safety.
B) Faculty and students outside computer science often don't know what they're supposed to do about AI safety, or how they can contribute. I interact mostly with behavioral and biological scientists in psychology, anthropology, economics, evolutionary theory, behavior genetics, etc. The brighter ones are often very interested in AI issues, and get excited when they hear that 'AI should be aligned with human values' -- because many of them study human values. Yet, when they ask 'OK, will AI safety insiders respect my expertise about the biological/psychological/economic basis of human values, and want to collaborate with me about alignment?', I have to answer 'Probably not, given the current culture of AI safety research, and the premium it places on technical machine learning knowledge as the price of admission'.
C) Most people -- including most academics -- come to the AI safety issue through the lens of the science fiction movies and TV series they've watched. Rather than dismissing these media sources as silly, misleading, and irrelevant to the 'serious work' of AI alignment, I've found it helpful to be very familiar with these media sources, to find the ones that really resonate with the person I'm talking with (whether it's Terminator 2, or Black Mirror, or Ex Machina, or Age of Ultron), and to kind of steer the conversation from that shared enthusiasm about sci fi pop culture towards current AI alignment issues.
Dušan D. Nešić (Dushan) @ 2022-10-13T20:25 (+4)
Thank you Geoffrey for an insightful contribution!
Regarding B - The project PIBBSS has done over the last fellowship (disclosure I now work there as Ops Director) has exactly this goal in mind, and we are keen to connect to non-AI researchers interested in doing AI safety research by utilizing their diverse professions. Do point them our way and tell them that the interdisciplinary field is in development. The fellowship is not open yet, and we are considering how to go forward, but there will likely be speaker series that would be relevant to these people.
Geoffrey Miller @ 2022-10-14T16:33 (+4)
Dušan - thanks for this pointed to PIBBSS, which I hadn't heard of before. I've signed up for the newsletter!
Linch @ 2022-10-10T21:49 (+8)
Many people were interested in how they could contribute. However, often they were more interested in reframing their specific topic to sound more like AI safety rather than making substantial changes to their research.
As stated, this doesn't sound like wanting to contribute to me.
mariushobbhahn @ 2022-10-11T07:35 (+6)
I think it's a process and just takes a bit of time. What I mean is roughly "People at some point agreed that there is a problem and asked what could be done to solve it. Then, often they followed up with 'I work on problem X, is there something I could do?'. And then some of them tried to frame their existing research to make it sound more like AI safety. However, if you point that out, they might consider other paths of contributing more seriously. I expect most people to not make substantial changes to their research though. Habits and incentives are really strong drivers".
David Mathers @ 2022-10-10T14:02 (+6)
Did you manage to get anyone/many people to eventually agree that there is a non-negligible X-risk from A.I.?
mariushobbhahn @ 2022-10-10T14:52 (+10)
Probably not in the first conversation. I think there were multiple cases in which a person thought something like "Interesting argument, I should look at this more" after hearing the X-risk argument and then over time considered it more and more plausible.
But like I state in the post, I think it's not reasonable to start from X-risks and thus it wasn't the primary focus of most conversations.
Patrick Gruban @ 2022-10-10T20:06 (+5)
Thank you for the write-up. This was very helpful in getting a better understanding of the reactions from the academic field.
Don’t start with X-risk or alignment, start with a technical problem statement such as “uncontrollability” or “interpretability” and work from there.
Karl von Wendt makes a similar point in Let’s talk about uncontrollable AI where he argues "that we talk about the risks of “uncontrollable AI” instead of AGI or superintelligence". His aim is "to raise awareness of the problem and encourage further research, in particular in Germany and the EU". Do you think this could be a better framing? Do you think there is some framing that might be better suited for different cultural contexts, like in Germany, or does that seem neglectable?
mariushobbhahn @ 2022-10-10T21:10 (+3)
I have talked to Karl about this and we both had similar observations.
I'm not sure if this is a cultural thing or not but most of the PhDs I talked to came from Europe. I think it also depends on the actor in the government, e.g. I could imagine defense people to be more open to existential risk as a serious threat. I have no experience in governance, so this is highly speculative and I would defer to people with more experience.
ChanaMessinger @ 2023-01-05T14:11 (+4)
Fwiw, from talking to my dad, who works adjacent to ML people, I think
"c) they have worked with ML systems for many years and are generally more skeptical of everyone claiming highly capable AI. Their lived experience is just that hype cycles die and AI is usually much worse than promised. "
is doing a huge percent (maybe most?) of the work.
Jmd @ 2022-10-22T09:42 (+3)
Thanks for writing this Marius :), I am feeling a little bit motivated to see how these things would apply to having conversations with academics about biorisks. I suspect that many of your points will hold true - not being alarmist, focusing on technical aspects, higher-ups are more dismissive, and that I will learn lots of new things or at least get better at talking about this :)
Peter @ 2022-10-10T15:06 (+3)
This is really useful and makes sense - thanks for sharing your findings!
In my experience talking about an existing example of a problem like recommendation systems prioritizing unintended data points + example of meaningful AI capability usually gets people interested. Those two combined would probably be bad if we're not careful. Jumping to the strongest/worst scenarios usually makes people recoil because it's bad and unexpected and doesn't make sense why you're jumping to such an extreme outcome.
Do you have any examples of resources you were unaware of before? That could be useful to include as a section both for the actual resources and thinking about how to find such sources in the future.
mariushobbhahn @ 2022-10-10T17:25 (+2)
Reflects my experience!
The resources I was unaware of were usually highly specific technical papers (e.g. on some aspect of interpretability), so nothing helpful for a general audience.
ChanaMessinger @ 2023-01-05T14:27 (+2)
"Therefore, I think it is important to point this out (in a nice way!) whenever you spot this pattern"
Would be interested in how you do this / scripts you use, etc.
mariushobbhahn @ 2023-01-05T15:44 (+2)
Usually just asking a bunch of simple questions like "What problem is your research addressing?", "why is this a good approach to the problem?", "why is this problem relevant to AI safety?", "How does your approach attack the problem?", etc.
Just in a normal conversation that doesn't feel like an interrogation.
MarcelE @ 2022-10-11T07:58 (+2)
I'd be interested to hear what arguments/the best case you've heard in your conversations about why the AI security folks are wrong and AGI is not, in principle, such a risk. I am looking for the best case against AGI X-Risk, since many professional AI researchers seem to hold this view, mostly without writing down their reasons which might be really relevant to the discussion
mariushobbhahn @ 2022-10-11T08:04 (+3)
I'm obviously heavily biased here because I think AI does pose a relevant risk.
I think the arguments that people made were usually along the lines of "AI will stay controllable; it's just a tool", "We have fixed big problems in the past, we'll fix this one too", "AI just won't be capable enough; it's just hype at the moment and transformer-based systems still have many failure modes", "Improvements in AI are not that fast, so we have enough time to fix them".
However, I think that most of the dismissive answers are based on vibes rather than sophisticated responses to the arguments made by AI safety folks.