Utilitarians Should Accept that Some Suffering Cannot be “Offset”
By Aaron Bergman @ 2025-10-05T21:22 (+81)
Note to competition judges: feedback extremely welcome!
Preface
Relationship to "The Case for Strong Longtermism"
This post engages with themes central to Greaves and MacAskill's "The Case for Strong Longtermism" in Essays on Longtermism, offering not a refutation but an important reframing of how we should think about far-future moral priorities. While Greaves and MacAskill compellingly argue that far-future effects dominate the moral importance of our actions today, my argument suggests that the quality and trajectory of future lives, and specifically whether they contain extreme suffering that crosses or comes near a threshold of non-offsetability, should be the predominant longtermist concern.
In Section 6 ("Robustness of the argument"), Greaves and MacAskill briefly touch on variations in axiology, including risk aversion and prioritarianism, noting these might actually strengthen rather than weaken the case for longtermism. My thesis extends this line of thinking much further: if some suffering genuinely cannot be offset by any amount of happiness, then longtermist interventions should prioritize preventing scenarios that could lock in or otherwise increase the expected amount of extreme suffering. This suggests extreme caution before taking actions that might counterfactually create vast future populations containing large absolute amounts of extreme suffering, even if accompanied by large amounts of positive wellbeing.
Importantly, I also share Greaves and MacAskill's rejection of naive responses like "extinction would be good"; as I discuss toward the end of this essay, such a conclusion fails for multiple reasons.
This post represents a fundamental reorientation from asking "how can we ensure the largest possible flourishing future?" to asking "how can we ensure a future that minimizes unacceptably severe suffering?"
What follows is the result of my trying to reconcile various beliefs and intuitions I have about the nature of morality, namely why arguments for total utilitarianism seemed so compelling on their own and yet some of the implications seemed not merely weird but morally implausible.
Intro
This post challenges the common assumption that total utilitarianism entails offsetability,[1] or that any instance of suffering can, in principle, be offset by sufficient happiness. I make two distinct claims:
- Logical: offsetability does not follow from the five standard premises that constitute total utilitarianism (consequentialism, welfarism, impartiality, summation, and maximization). Instead, it requires an additional, substantive, plausibly false premise.
- Metaphysical: some suffering in fact cannot be morally justified (“offset”) by any amount of happiness.
While related, the former, weaker claim stands independently of the latter, stronger one.
How to read this post
Different readers will find different parts most relevant to their concerns:
If you believe the math or logic of utilitarianism inherently requires offsetability (that is, if you think "once we accept utilitarian premises, we're logically committed to accepting that torture could be justified by enough happiness"), start with Part I. There I show why this common assumption is mistaken.
If you're primarily interested in whether extreme suffering can actually be offset (that is, if you already see offsetability as an open philosophical question rather than a logical necessity), you may wish to skip directly to Part II, where I argue the more substantive metaphysical claim.
Part I: The logical claim
Offsetability doesn't fall out of the math
A brief aside
I’ve found that two relatively distinct groups tend to be interested in part I:
- The philosophy-brained, who have taken the implicit “representation premise” I discuss below as a given and are primarily interested in conceptual arguments.
- The math-brained, for whom alternatives to the “representation premise” are obviously on the table and who are primarily interested in rigorous formalization of my claim.
If it ever feels like I’m equivocating - perhaps becoming too lax in one sentence and excessively formal in the next, you’d be right! Sorry. I have tried to put much of the formalization in footnotes, so the math-brained should be encouraged to check those out, but the post isn’t really optimized for either group.
1. Introduction: what we take for granted
The standard narrative about total utilitarianism goes something like: “once we accept that rightness depends on consequences, that (for the purpose of this post, hedonic) welfare is what matters, that we should sum welfare impartially across individuals, and that more welfare is better than less, it follows naturally that everything becomes commensurable.
And, more specifically, I mean “commensurable” in the sense that all goods and bads fundamentally behave like numbers in the relevant moral calculus: perhaps 15 for a nice day on the beach, -2 for a papercut, and so on.[2] [3] If so, it would seem to follow that any instance of suffering can, in principle, be offset by sufficient happiness, and obviously so.
I think this is false.
2. The meaning of utilitarianism and the hidden sixth premise
My primary intention here is not to make an argument about how words should be used, but rather to make a more substantive claim about what implications follow from certain premises.
Here I describe what I mean when I talk about total utilitarianism.
The Utilitarian Core
To the best of my understanding, total utilitarianism is constituted by five necessary and sufficient consensus premises and propositions[4] which I’ll call the Utilitarian Core, or UC:[5]
- Consequentialism: the rightness of actions depends on their consequences (as opposed to, perhaps, the nature of the acts themselves or adherence to rules).
- [Hedonic] welfarism: the only thing that matters morally is the hedonic welfare of sentient beings. Nothing else has intrinsic moral value.
- Impartiality: wellbeing matters the same regardless of whose it is, with no special weight for kin relationships, race, gender, species, or other arbitrary characteristics.
- Aggregation or summation: the overall value of a state of affairs is determined by aggregating or summing individual wellbeing.[6]
- Maximization: the best world is the one with maximum aggregate wellbeing.
What is left out
The UC tells us to maximize the sum of welfare, but remains silent on what exactly is getting summed.
You can’t literally add up welfare like apples (i.e., by putting them in a literal or metaphorical basket). In some important sense, then, “summation” or “aggregation” refers to the claim that the moral state of the world simply is the grouping of the moral states that exist within. How exactly to operationalize this via some sort of conceptual/ideal or literal/physical process or model is entirely non-obvious.[7]
Representation premise.
To get universal offsetability, you need more structure than the Utilitarian Core provides. A sufficient additional assumption, if you want offsetability by construction, is to assume that welfare sits on a single number line where we can add people’s contributions, where every bad has a positive opposite, and where there are no lexical walls that a large enough amount of good could not overcome.
In practice, I think, this generally looks like an assumption that all states of hedonic welfare are adequately modeled by the real numbers with standard arithmetic operations.[8]
The Core itself does not force that choice. At most it motivates a way to combine people’s welfare that is symmetric across persons and monotone in each person’s welfare. If you drop either the “no lexical walls” condition or the “every bad has a positive opposite” condition, offsetability can fail even though you still compare and aggregate.[9]
Without this additional premise (i.e. of some additional structure such as the one described above), the standard utilitarian framework doesn't entail that any amount of suffering can be offset by sufficient happiness.
The crucial point is that the Representation Premise is not a logical consequence of the Utilitarian Core. It is a substantive and plausibly false metaphysical claim about the nature of suffering and happiness that typically gets smuggled in without justification.
3. Why real-number representation isn't obvious
What utilitarianism actually requires
The five core premises of utilitarianism establish the need for comparison and aggregation, but they don't imply the existence of cardinal units that behave like real numbers. We need only be able to say "this outcome is better than that one" and to sum representations of individual welfare into a representation of social welfare.
One intuitive and a priori plausible operationalization is that any hedonic event corresponds naturally to a real number that accurately represents its moral value. But "a priori plausible" doesn't mean "true," and indeed the UC does not require this.
Where cardinality might hold (and where it might not)
To be clear, there are good arguments for partial cardinality in welfare. Setting aside whether they're logically implied by UC, I (tentatively) believe that, in a deep and meaningful sense, subjective duration of experience and numbers of relevantly similar persons are cardinally meaningful in utilitarian calculus.[10]
That is, suffering twice for what feels like as long really is twice as bad. Fifty people enjoying a massage is exactly 25% better than forty people doing so. In general, conditioning on some specific hedonic state, person-years (at least when both figures are finite)[11] really do have properties we associate with real numbers: they are Archimedean, follow normal rules of arithmetic, and so on.
But this limited cardinality for duration and population doesn't establish that all welfare comparisons map to real numbers. The intensity and qualitative character of different experiences might not admit of the same mathematical treatment. The assumption that they do (e.g., that we can meaningfully say torture is 1,000 or 1,000,000 times worse than a pinprick) is precisely what needs justification.
Alternative mathematical structures
Many mathematical structures preserve the ordering and aggregation that utilitarianism requires without implying universal offsetability:
Lexicographically ordered vectors ( with dictionary ordering[12]) might be the most natural alternative. Here, welfare could have multiple dimensions ordered by priority: catastrophic suffering first, then all forms of wellbeing and lesser suffering. Or perhaps catastrophic suffering, then lexical happiness (“divine bliss”) then ordinary hedonic states, or any number of “levels” to lexical suffering. This preserves all utilitarian operations while rejecting offsetability between levels.[13]
Hyperreal numbers.
The hyperreal system extends the reals with infinitesimal and unlimited magnitudes. You can map catastrophic suffering to a negative non-finite value, call it , and ordinary goods to finite values. Then is better than , so extra happiness still matters, but no finite increase offsets . This blocks offsetability while preserving familiar arithmetic.[14] [15]
The point
I introduce these alternatives not to argue here that any particular mathematical structure is correct, but to illustrate something deeper: there is no special "math" constraint above and beyond what the real world permits.
Mathematicians have every right to invent arbitrary exotic, internally consistent systems built on top of their choice of axioms and investigate what follows. But when using math to model reality, axioms are substantive claims about what you think the world is like.
This matters because in other domains, reality often diverges from our mathematical intuitions. Quantum mechanics requires complex numbers, not just reals. Spacetime intervals don't add linearly but combine through curved geometry. The assumption that consciousness and welfare fit neatly on the real number line is a reasonable hypothesis but simply not an obvious truth.
Perhaps welfare really does map to real numbers with all that entails. Further investigation or compelling philosophical argument may establish this. But, as I wrote in my original post on this matter, "if God descends tomorrow to reveal that [all hedonic states correspond to real numbers], we would all be learning something new."[16]
Again, the mathematical framework is just the toolbox. Whether actual experiences can ever map to infinite values within that framework is the separate quasi-empirical and philosophical question that the rest of this post addresses.
4. The VNM (non-) problem
Defenders of offsetability sometimes invoke the Von Neumann-Morgenstern theorem (“VNM”), alleging that VNM proves that rational preferences can be represented by real-valued utility functions. However, this does not hold in our case because non-offsetability implies a rejection of continuity, one of the four conditions required by the theorem to hold.
I admit this is an extremely understandable error to make in part because I myself was confused and frankly wrong about the theorem when I first encountered it as an objection. In a reply to me a few years ago, friend and prolific utilitarian blogger Matthew Adelstein (@Bentham's Bulldog) wrote that:
Well, the vnm formula* shows one’s preferences will be modelable as a [real-valued] utility function if they meet a few basic axioms*
To which I made the following incorrect response:
VNM shows that preferences have to be modeled by an *ordinal* utility function. You write that…’Let’s say a papercut is -n and torture is -2 billion.’ but this only shows that the torture is worse than the papercut - not that it is any particular amount worse. Afaik there's no argument or proof that one state of the world represented by (ordinal) utility u_1 is necessarily some finite number of times better or worse than some other state of the world represented by u_2
My first sentence, “VNM shows that preferences have to be modeled by an *ordinal* utility function,” was totally incorrect. VNM does result in cardinally meaningful utility that respects standard expected value theory, but only conditional on four specific axioms or premises:[17]
- Completeness: option A is better than option B (A ≻ B) or are of equal moral value (A ~ B)
- Transitivity: If A ≻ B and B ≻ C, then A ≻ C
- Continuity: If A ≻ B ≻ C, there's some probability p ∈ (0, 1) where a guaranteed state of the world B is ex ante morally equivalent to "lottery p·A + (1-p)·C” (i.e., p chance of state of the world A, and the rest of the probability mass of C)
- See this footnote[18] for a bit of nuance added after initial publication.
- Independence: A ≻ B if and only if [p·A + (1-p)·C] ≻ [p·B + (1-p)·C] for any state of the world C and p∈(0,1) (i.e., adding the same chance of the same thing to all world states doesn’t affect their moral ordering)
The theorem states that if these four conditions hold then there exists a real valued utility function u that respects expected value theory,[19] which implies meaningful cardinality and restriction to the set of real numbers, which in turn implies offsetability.[20]
Quite simply, VNM does not apply in the context of my argument because I reject premise 3, continuity. And, in more general terms, it is not implied by UC.
More specifically, I claim that there exists no nonzero probability p such that a p chance of some extraordinarily bad outcome (namely, catastrophic suffering) and a (1-p) chance of a good world is morally equivalent to some mediocre alternative. In other words, the value of a state of the world (which includes probability distributions over the future) becomes radically different as you change from “very small possibility” of some catastrophic suffering in the future to “zero.”
To be clear, I haven’t really argued for that conclusion on the merits yet and reasonable people disagree about this. I will, in section II. The point here is just that UC does not entail the conditions necessary to imply meaningful cardinality via VNM, at the very least because of the counterexample described just above.
Not an epistemic “red flag”
It’s worth noting that assuming the relevant assumptions such that VNM holds is often a good guess. Two of the axioms are essentially entailed by what most people mean by “rationality,” three seem on extremely good footing, and all four are decidedly plausible.[21]
But rejecting premise 3, continuity, is perfectly coherent and doesn't create the problems often associated with "irrational" preferences. An agent with lexical preferences (i.e., and e.g., who refuses any gamble involving torture no matter what the potential upside) violates continuity but remains completely coherent and consistent; there are no Dutch books (you can't construct a series of trades that leaves them strictly worse off) or money pumps (you can't exploit them through repeated transactions). They maintain transitivity and completeness.
Part II: The metaphysical claim
Some suffering actually can't be offset
I now turn to the stronger claim that some suffering actually cannot be offset by any amount of happiness.
5. The argument from idealized rational preferences
The setup: you are everyone
Imagine that you become an Idealized Hedonic Egoist (IHE). In this state, you are maximally rational:[22] you make no logical errors, have unlimited information processing capacity, complete information about experiences with perfect introspective access, and full understanding of what any hedonic state would actually feel like. You care only about your own pleasure and suffering in exact proportion to their hedonic significance.
Now imagine that as this idealized version of yourself, you will experience everyone's life in a given outcome. Under this "experiential totalization" (ET), you live through all the suffering and all the happiness that would exist. For a hedonic total utilitarian, this creates a perfect identity: your self-interested calculation becomes the moral calculation. What's best for you-who-experiences-everyone is precisely what utilitarianism says is morally best.
The question
As this idealized being who will experience everything, you face a choice: Would you accept 70 years of the worst conceivable torture in exchange for any amount of happiness afterward?
Take a moment to really consider what "worst conceivable torture" means. Our brains aren’t built for this, but it can reason by analogy: being boiled alive; the terror of your worst nightmare; the horror and existential regret of a mother watching her son fall to his death after reluctantly telling him he could play near the canyon edge; slowly asphyxiating as your oxygen runs out. All mitigating biological relief systems that sometimes give you a hint of meaning or relief even as you suffer would be entirely absent. All of these at once, somehow, and more. For 70 years.
Imagine what follows, as well, by all means: falling in love, peak experiences, the jhanas, drowning in unfathomable bliss, love, awe, glory, interest, excitement, gratitude, connection, and wonder. Not just for 70 years but for millennia, eons, until the heat death of the universe.
As an IHE who will experience all of this, knowing exactly what each part would feel like, do you take this deal?
As a matter of simple descriptive fact, I, Aaron, would not, and I don’t think I would if I was ideally rational either.
I also imagine accepting the deal and later being asked, with all the suffering behind me, "was it worth it?" And I think I would say "no, it was a terrible mistake."
The burden of idealization
Some readers might think "I wouldn't personally take this trade, but that's just bias. The perfectly rational IHE would, so I would too if I became perfectly rational.”
This response deserves scrutiny, particularly if and once you’ve accepted the argument in part I that offsetability is not logically or mathematically inevitable.
To claim the IHE would accept what you'd refuse requires believing that your cognitive biases not only persist in spite of but essentially circumvent and overcome a conceptual setup specifically designed to elicit the epistemic clarity that comes with self-interest and conceptually simple trades on offer.
There is a clear similarity between this thought experiment and the conceptual and empirical use of revealed preference in social science, especially economics.
To argue that the revealed hypothetical preference of this thought experiment is fundamentally wrong or misleading by the standard of abstract rationality and hedonic egoism is not analogous to arguing that a specific empirical context leads consumers to display behavior that diverges from the predictions of some simplified model of rational behavior; it is analogous to arguing that a specific context leads consumers to behave in such a way that is fundamentally contrary to their truest and most ultimate values and preferences. This latter thing is a much stronger claim.
What this reveals
If you share my conviction that you-as-IHE would refuse the torture trade, then you should be deeply suspicious of any moral theory that says creating such trades is not just acceptable but sometimes obligatory. The thought experiment asks you to confront what you actually believe about extreme suffering when you would be the one experiencing all of it. You can't hide behind aggregate statistics or philosophical abstractions.
Not a proof
I recognize that this thought experiment is merely an intuition pump - directional evidence, not a proof.
I don't expect to convince all readers, but I'd be largely satisfied if someone reads this and says: "You're right about the logic, right about the hidden premise, right about the bridge from IHE preferences to moral facts, but I would personally, both in real life and as an IHE, accept literally anything, including a lifetime of being boiled alive, for sufficient happiness afterward."
This, I claim, should be the real crux of any disagreement.
To explicitly link this to Part I: what the IHE would choose is a fundamental question about the nature of hedonic states. It doesn't "fall out" of any axioms or mathematical truths. Any mathematical modeling must be built up from interaction with the territory. The IHE thought experiment, I claim, is an especially epistemically productive way of exploring that territory, and indeed for doing moral philosophy more broadly.
6. The implications of universal offsetability are especially implausible
Most utilitarians I know are deeply motivated by preventing and alleviating suffering. They dedicate their time, money, and sometimes entire careers to reducing factory farming and preventing painful diseases.
Yet the theory many of them endorse says something quite different. Universal offsetability doesn't just permit creating extreme suffering when necessary; it can enthusiastically endorse package deals that contain it.[23]
If any suffering can be offset by sufficient happiness, then creating a being to be boiled alive for a trillion years is not merely acceptable because all alternatives include more or worse suffering but because it’s part of an all-or-nothing package deal with sufficiently many happy beings along for the ride.
When I present this trade to utilitarian friends and colleagues, many recoil. They search for reasons why this particular trade might be different, why the theory doesn't really imply what it seems to imply. Some bite the bullet (for what I sense is a belief that such unpalatable conclusions follow from very compelling premises - the thing that part I of this essay directly challenges). Very few genuinely embrace it.
I think their discomfort is correct and their theory is wrong.
The moral difference
There's a profound difference between these scenarios:
- Accepting tragic tradeoffs: Allowing, or even creating, some suffering because it's the only way to prevent more or more intense suffering
- Creating offsetting packages: Actively creating torture chambers because you've also created enough pleasure to "balance the books"
The former involves minimizing harm in tragic circumstances. Every moral theory faces these dilemmas. But the second involves creating more extreme suffering than would have otherwise existed, justified solely by also creating positive wellbeing. The theory says that while we might regret the suffering component, the overall package is not just acceptable but optimal. We should prefer a world with both the torture and offsetting happiness to one with neither.
Scale this up and offsetability doesn't reluctantly permit but instead actively recommends creating billions of beings in agony until the heat death of the universe, as long as we create enough happiness to tip the scales. The suffering isn't a necessary evil; it's part of a package deal the theory endorses as an improvement to the world.
When your theory tells you to endorse deals that create vast torture chambers (even while regretting the torture component), the problem isn't with your intuitions but with the hidden premises that feel from the inside like they’re forcing your hand.
7. The asymptote is the radical part
In this section I offer a conceptual reframing that draws attention away from the severity of suffering warranting genuine conceptual lexicality and towards the suffering that is slightly less severe. I argue that, insofar as my view is radical, the radical part of my view happens before the lexical threshold, in what appears to be the "normal" offsetable range.
To see why, let’s use a helpful conceptual framework
- Instruments: measurable proxies that track suffering and happiness.
- A suffering instrument () could be neurons engaged in pain signaling or temperature of an ice bath. A happiness instrument () might be neurons in reward processing or some measure of endocannabinoid release. For our purposes, these are entirely conceptual devices. These instruments need only be monotonic: more instrument reliably indicates more of what it measures, at least within some relevant range.
- Compensation schedule tells us how much happiness instrument is needed to offset or morally justify a given amount of suffering instrument.
- Again, we can invoke the idealized hedonic egoist - the compensation schedule function as an indifference curve of this agent passing through neutral or absent experience.
Why instruments?
Trying to invoke "quantities" of happiness and suffering in the context of a discourse that references specific qualia or experiences, the abstract pre-moral "ground truth" intensity of those experiences, the abstract moral value of those experiences, and various discussion participants' notions of or claims about the relationship between any of these concepts is extraordinarily conducive to miscommunication and lack of conceptual clarity even under the best of epistemic circumstances.[24]
More concretely, I have observed a natural and understandable failure mode in which one attempts to map "suffering" (as a quantitative variable) to something like "how much that suffering matters" (another quantitative variable). But such a relationship is, in the context of hedonic utilitarianism, some combination of trivial (because under hedonic utilitarianism, suffering and the moral value of suffering are intrinsically 1:1 if not conceptually identical) and confused.[25]
Instruments break this circularity by grounding discussion in concrete, in principle-measurable properties that virtually all people and conceptual frameworks can agree on. We define compensation through idealized indifference rather than positing mysterious common units. The moral magnitudes can remain ordinal within each channel; the compensation schedule provides the cross-calibration.
The compensation schedule's structure
I claim that as approaches some threshold from below, grows without bound, reaching infinity at the threshold, creating an asymptote in the process. Beyond it, no finite happiness instrument can compensate.
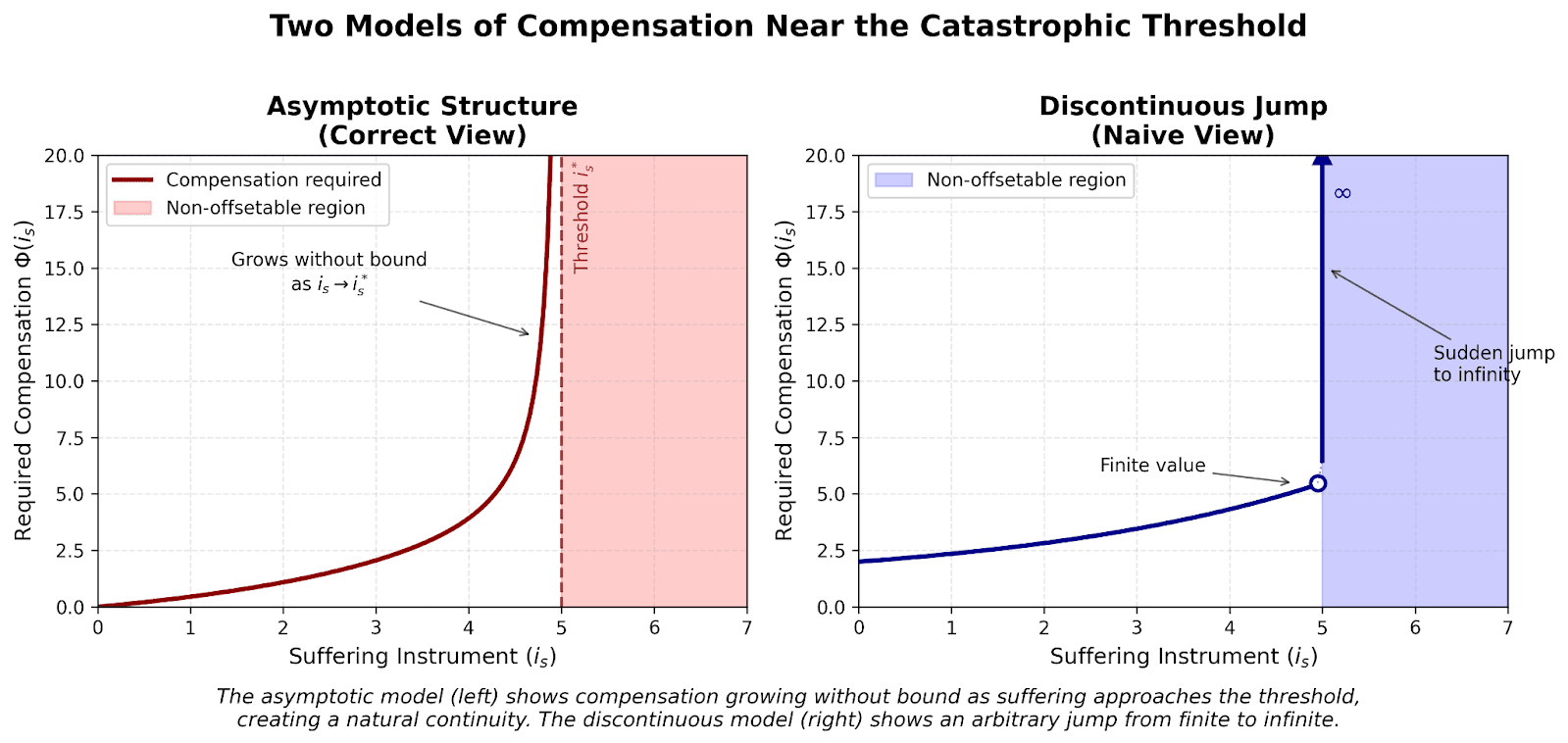
Why this Is already radical
The radical implications (insofar as you think any of this is radical) aren't at the threshold but in the approach to it. The compensation schedule growing without bound (i.e., asymptotically) means that some sub-threshold suffering would require happy lives to offset, or . Pick your favorite unfathomably large number - the real-valued asymptote passes that early on its way to infinity.
Once you accept that compensation can reach unfathomable heights while remaining not literally infinite, the step from there to "infinite" is small in an important sense. See the image above for a graphical comparison between this view and a naive, less plausible view in which there is a sudden discontinuous jump at the point of lexicality.
Note that my framework leaves quite a bit of room for internal specification. See the following graphic for representations of various models that all fit within the framework I’m arguing for. The actual, specific shape of the compensation curve and asymptote are hard but tractable questions for science and moral philosophy to make progress on.
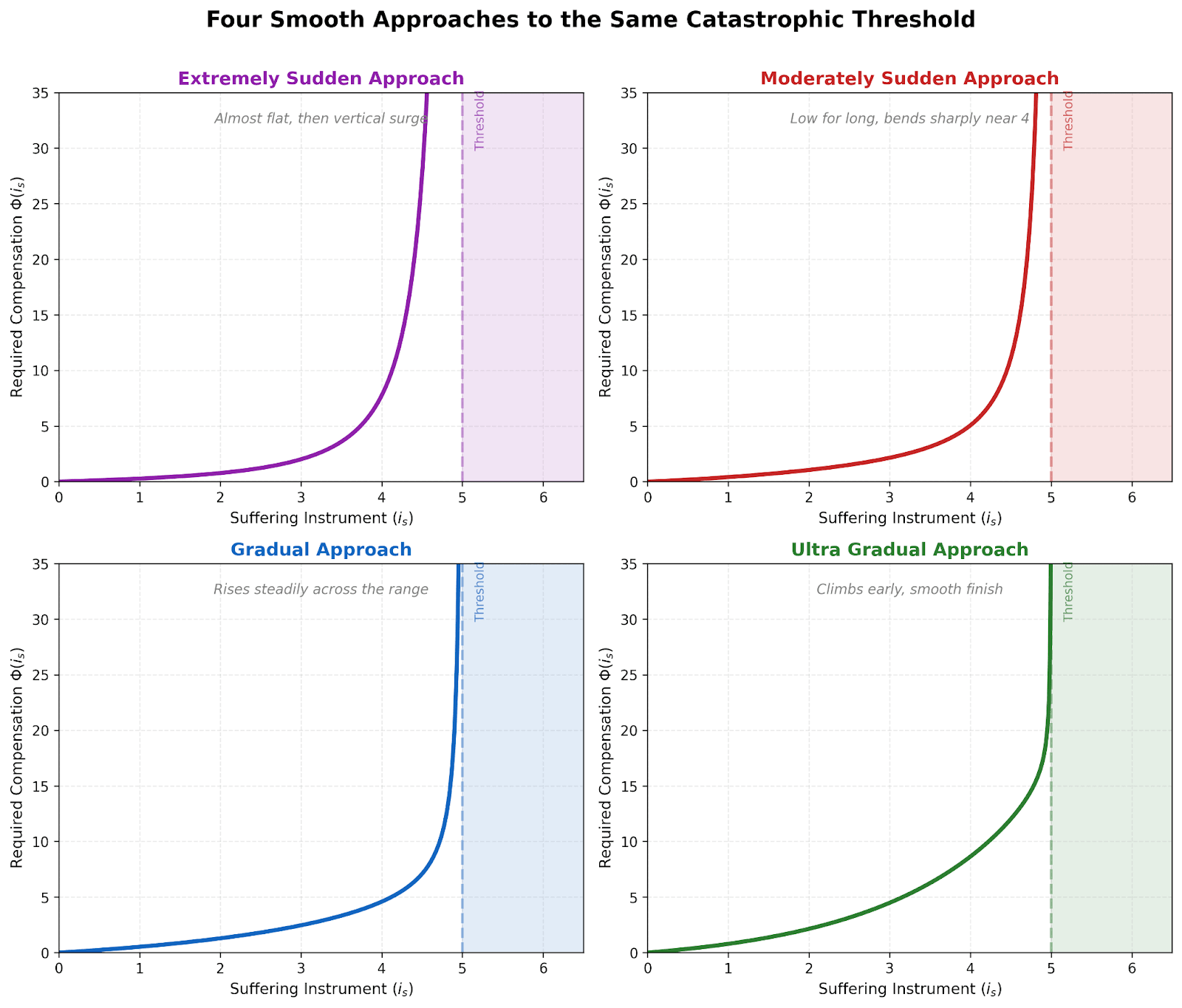
8. Continuity and the location of the threshold
Critics object that lexical thresholds create arbitrary discontinuities where marginal changes flip the moral universe. This misunderstands the mathematical structure. As illustrated in the graphics above, the threshold is the limit point of a continuous process: as suffering intensity approaches threshold , the compensation function approaches infinity. Working in the extended reals, this is left-continuous:
To be clear, whether we call this behavior 'continuous' depends on mathematical context and convention. In standard calculus, a function that approaches infinity exhibits an infinite discontinuity.[26]
I'm not arguing about which terminology is correct. The substantive point, which holds regardless of vocabulary, is that the transition to non-offsetability emerges naturally from an asymptotic process where compensation requirements grow without bound.
Where the threshold falls
The precise location of admittedly involves some arbitrariness. Why does the compensation function diverge at, say, the intensity of cluster headaches rather than slightly above or below?
This arbitrariness diminishes somewhat (though, again, not entirely) when viewed through the asymptotic structure. Once we accept that compensation requirements grows without bound asymptotically as suffering intensifies, some threshold becomes inevitable. The asymptote must diverge somewhere; debates about exactly where are secondary to recognizing the underlying pattern.
9. From arbitrarily large to infinite: a small step
Many orthodox utilitarians accept that compensation requirements can grow without bound. They'll grant that "for any amount of happiness M, no matter how large, there's some conceivable form of suffering that would require more than M to offset."
This is substantial common ground. We share the recognition that there's no ceiling on how much compensation suffering might require. This unbounded growth has practical implications even before reaching any theoretical threshold.[27]
Once you've accepted that some suffering might require a number of flourishing lives that you could not write down, compute, or physically instantiate to morally justify, at least in principle, the additional step to "infinite" is smaller in some important conceptual sense than it might seem prima facie. The step to infinity requires accepting something qualitatively new but not especially radical.
This is not to say that all major disagreement is illusory.
Rather, my point here is that important questions and cruxes of substantial disagreement involves the actual moral value of various states of suffering, not the intellectually interesting but sometimes-inconsequential question of whether the required compensation is in-principle representable by an unfathomably large but finite number.
In other words, let us consider a specific, concrete case of extreme suffering: say a cluster headache lasting for one hour.
Here, the lexical suffering-oriented utilitarian who claims that this crosses the threshold of in-principle compensability has much more in common with the standard utilitarian who thinks that in principle creating such an event would be morally justified by TREE(3) flourishing human life-years than the latter utilitarian has with the standard utilitarian who claims that the required compensation is merely a single flourishing human life-month.
10. The phenomenology of extreme suffering
A fundamental epistemic asymmetry underlies this entire discussion: we typically theorize about extreme suffering from positions of relative comfort. This gap between our current experiential state and the phenomena we're analyzing may systematically bias our understanding in ways directly relevant to the offsetability debate.
Both language and memory prove inadequate for conveying or preserving the qualitative character of intense suffering. Language functions through shared experiential reference points, but extreme suffering often lies outside common experience. Even those who have experienced severe pain typically cannot recreate its phenomenological character in memory; the actual quality fades, leaving only abstract knowledge that suffering occurred. When we model suffering as negative numbers in utility calculations, we are operating with fundamentally degraded data about what we're actually modeling.
The testimony of those who have experienced extreme suffering deserves serious epistemic weight here. Cluster headache sufferers describe pain that drives them to self-harm or suicide for relief. To quote one patient at length:
It's like somebody's pushing a finger or a pencil into your eyeball, and not stopping, and they just keep pushing and pushing, because the pain's centred in the eyeball, and nothing else has ever been that painful in my life. I mean I've had days when I've thought 'If this doesn't stop, I'm going to jump off the top floor of my building', but I know that they're going to end and I won't get them again for three or five years[28]
Akathisia victims report states they judge “worse than hell,” driving some to suicide:
I am unable to rest or relax, drive, sleep normally, cook, watch movies, listen to music, do photography, work, or go to school. Every hour that I am awake is devoted to surviving the intense physical and mental torture. Akathisia causes horrific non-stop pain that feels like you are being continually doused with gasoline and lit on fire.[29]
The systematic inaccessibility of extreme suffering from positions of comfort is a profound methodological limitation that moral philosophy must recognize and mitigate with the evidential help of records or testimonies from those who have experienced the extremes.[30]
11. Addressing major objections
Let me address the most serious objections to the view that I have not already discussed. Some have clean responses while others reveal genuine uncertainties.
Time-granularity problem
Does even a second of extreme suffering pass the lexical threshold? A nanosecond? Far shorter still?
I began writing this post eager to bite the bullet, to insist that any time in a super-lexical state of extreme suffering, however brief, is non-offsetable.
But I am no longer confident; I don't trust my intuitions either way, and I lack a strong sense of what an Idealized Hedonic Egoist would choose when faced with microseconds of otherwise catastrophic suffering.
To flesh out my uncertainty and some complicating dynamics a bit: it seems plausible to me that the physical states corresponding to intense suffering do not in fact cash out as the “steady state” intense suffering one would expect if that situation were to continue; that is, a nanosecond of placing one’s hand on the frying pan as a psychological and neurological matter isn’t in fact subjectively like an arbitrary nanosecond from within an hour of keeping one’s hand there. This may be a sort of distorting bias that complicates communication and conceptual clarity when thinking through short time durations.
On the other hand, at an intuitive level I can’t quite shake my sense that even controlling for “true intensity,” there is something about very short (subjective) durations that meaningfully bears on the moral value of a particular event.
Quite simply, this is an open question to me.
Extremely small probabilities of terrible outcomes
Does even a one in a million chance of extreme suffering pass the lexical threshold? One in a trillion? Far less likely than that?
I do bite the bullet on this one, and think that morally we ought to pursue any nonzero reduction of the probability of extreme, super-lexical suffering. Let me say more about why.
I’ve come to this view only after trying and failing to talk myself out of it (i.e., in the process of coming to the views presented in this post).
Under standard utilitarian theory, we can multiply both sides of any moral comparison by the same positive constant and preserve the moral relationship. This means that 10^(-10) chance of extreme torture for life plus one guaranteed blissful life is morally good if and only if one lifetime of extreme torture plus 10^10 blissful lives is morally good. I accept this “if and only if” statement as such.
Presented this way, the second formulation makes the moral horror explicit: we're not just accepting risk but actively endorsing the creation of actual extreme torture as part of a positive package deal. And now we’re back to the same arguments for why extreme suffering does not become morally justifiable in exchange for any amount of wellbeing (the IHE and such).
I am happy to admit my slight discomfort - my brain, it seems, really wants to round astronomically unlikely probabilities to zero. But in a quite literal sense, small probabilities are not zero, and indeed correspond to actual, definite suffering under some theories of quantum mechanics and cosmology (i.e., Everettian multiverse, to the best of my lay-understanding).
Evolutionary explanations of intuitive asymmetry
The objection is some version of “Evolutionary fitness can be essentially entirely lost in seconds but gained only gradually; even sex doesn’t increase genetic fitness to nearly the same degree that being eaten alive decreases it. This offers an alternative, plausible alternative to “moral truth” as explanation for why we have the intuition that suffering is especially important.
I actually agree this has some evidential force, I just don’t think it is especially strong or overwhelming relative to other, contrary evidence that we have.
Evolution created many different intuitions, affective states, emotions, etc., that do not directly or intrinsically track deep truths about the universe but can, in combination with our general intelligence and reflective ability, serve as motivation for or be bootstrapped into learning genuine truths about the world.[31]
Perhaps most notably, some sort of moral or quasi-moral intuitions that may have tracked e.g., game theory dynamics and purely instrumental cooperation in the ancestral environment, but (at least if you’re not a nihilist) you probably think that these intuitions simply do happen to at least partially track a genuine feature of the world which we call morality.
Reflection, refinement, debate, and culture can serve to take intuitions given to us by the happenstance of evolution and ascertain whether they correspond to truth entirely, in part, or not at all.
For example, we might reflect on our kin-oriented intuitions and conclude that it is not in fact the case that strangers far away have less intrinsic moral worth. We might reflect on our intuition about caring for our friends and family and conclude that something like or in the direction of “caring” really does matter in a trans-intuitive sense.
This is, what I claim, we can and should do in the context of intuitions about the nature of hedonic experience. There’s no rule that evolution can’t accidentally stumble upon moral truth.
The phenomenological evidence, especially, remains almost untouched by this objection. When someone reports that no happiness would be worth the cluster headache they are having right now, that is a hypothesis whose truth value needn’t change according to how good pleasure can get.
"Doesn't this endorse destroying the world?"
This common objection, often presented as a reductio, deserves careful response.
First, this isn't unique to suffering-focused views. Traditional utilitarianism also endorses world-destruction when all alternatives are worse. If the future holds net negative utility, standard utilitarianism says ending it would be good.
Second, this isn't strong evidence against the underlying truth of suffering-focused views. Consider scenarios where the only options are (1) a thousand people tortured forever with no positive wellbeing whatsoever or (2) painless annihilation of all sentience. Annihilation seems obviously preferable.
Third, the correct response isn't rejecting suffering-focused views but recognizing moderating factors:
Moral uncertainty
I don't have 100% confidence in any moral view. There might be deontological constraints or considerations I'm missing, and it’s worth making explicit that I’m not literally 100% certain in either thesis of this post.
Cooperation and moral trade
I, and other suffering-focused people I know, strongly value cooperation with other value systems, recognizing moral trade and compromise matter even when you think others are mistaken.
Virtual impossibility
This point, I think, is greatly underrated in the context of this objection and related discussions.
Actually destroying all sentience and preventing its re-emergence is essentially impossible with current or foreseeable technology. It is quite literally not an option that anyone has.
This point is suspiciously convenient, I recognize, but it also happens to be true.
Anti-natalism doesn’t actually result in human extinction except under the most absurd of assumptions.[32] Killing all humans leaves wild animals. Killing all life on earth permits novel biogenesis and re-evolution. Destroying Earth doesn't eliminate aliens. AI takeover scenarios involve a different, plausibly morally worse agent in control of the future and digital sentience.
At the risk of coming across as pompous, the suggestion that anything near my ethical views entails literal, real-life efforts to harm any human falls apart under even the mildest amount of serious and earnest scrutiny and, in my experience, seems almost entirely motivated by the desire to dismiss substantive and plausible ethical claims out-of-hand.
I want to be entirely intellectually honest here; I can imagine worlds in which a version of my view indeed suggest actions that would result in what most people would recognize as harm or destruction.
For instance, we can suppose that we had an extremely good understanding of physics and acausal coordination and trade across the Everettian multiverse and also some mechanism of precipitating a hypothetical universe-destroying phenomenon known as “vacuum collapse” and furthermore were quite sure that precipitating vacuum collapse reliably reduces the expected amount of non-offsetable suffering throughout the multiverse. At least a naive unilateralist’s understanding of my theory might indeed suggest that we should press the vacuum collapse button.
Fair enough; we can discuss this scenario just like we can discuss the possibility of standard utilitarianism confidently proclaiming that we ought to create a trillion near-eternal lives of unfathomable agony for enough mildly satisfied pigeons.
In both cases, though, moral discourse needs to recognize that as a matter of empirical fact there is actual no possibility of you or I or anyone doing either of these things in the immediate future. Neither theory is an infohazard, and both need to be discussed in earnest on the merits.
Irreversibility considerations
Irreversible actions that can be accomplished by a single entity or group warrant extra caution beyond simple expected value calculations. The permanence of annihilation requires a higher certainty bar than other interventions.
This is particularly important given the unilateralist's curse: when multiple agents independently decide whether to take an irreversible action, the action becomes more likely to occur than is optimal. Even if nine out of ten careful reasoners correctly conclude that annihilation would be net negative, the single most optimistic agent determines the outcome if they can act unilaterally.
This systematic bias toward action becomes especially dangerous with permanent consequences. The appropriate response isn't to abandon moral reasoning but to recognize that irreversible actions accessible to small groups require not just positive expected value by one's own lights, but (1) robust consensus among thoughtful observers, (2) explicit coordination mechanisms that prevent unilateral action, and/or (3) confidence levels that account for the selection effect where one is likely the most optimistic evaluator among many.
General principle
Most fundamentally, it is better to pursue correct ethics, wherever that may lead, and then add extra-theoretical conservative, cooperation and consensus-based guardrails than to start with an absolute premise that one’s actual ethical theory simply cannot have counterintuitive implications.
12. Conclusion
Implications
Dozens, hundreds, or thousands of pages could be written about how the claims I’ve made in this post cash out in the real world, but to gesture at a few intuitive possibilities, I suspect that it implies allocating more resources to preventing and reducing extreme suffering, being more cautious about creating suffering-capable beings, and taking s-risks seriously. These are reasonable and, more importantly, plausibly true conclusions.
Indeed, more ought to be written on this, and I’d encourage my future self and others to do just this.
We keep what's compelling
The view I’ve outlined is a refinement to orthodox total utilitarian thinking; we preserve what's compelling while dropping an implausible commitment that was never required or, to my knowledge, explicitly justified.
The core insights of the Utilitarian Core remain intact:
- Consequentialism: what matters is what happens.
- Welfarism: the hedonic wellbeing of sentient beings is the sole source of intrinsic value.
- Impartiality: welfare matters regardless of who experiences it.
- Aggregation or summation: the moral value of the world is constituted by and equal to the collection of morally relevant states within it - regardless of which symbolic system best represents the actual nature of those states.
- Maximization: more aggregate welfare is always better.
We drop what's implausible
We abandon the assumption of universal offsetability, which was never a core commitment but rather a mathematical convenience mistaken for a moral principle.
Specifically, we drop the offsetability of extreme suffering; some experiences are so bad that no amount of happiness elsewhere can make them worthwhile. This isn't because suffering and happiness are incomparable in principle, but because the nature of hedonic experience makes some tradeoffs categorically bad deals for the world as a whole.
Thank you to Max Alexander, Bruce Tsai, Liv Gorton, Rob Long, Vivian Rogers, and Drake Thomas for a ton of thoughtful and helpful feedback. Thanks as well to various LLMs for assistance with every step of this post, especially Claude Opus 4.1 and GPT-5.
- ^
Sometimes referred to as “lexicality” or “lexical priority.” ↩︎
- ^
See later in this section for a more technical description of what exactly this means
- ^
In the standard story, so-called “utils” are scale-invariant, so we can set 1 equal to a bite of an apple or an amazing first date as long as everything else gets adjusted up or down in proportion.
- ^
The Stanford Encyclopedia of Philosophy further subdivides these into what I will call the Extended [Utilitarian] Core:
“Consequentialism = whether an act is morally right depends only on consequences (as opposed to the circumstances or the intrinsic nature of the act or anything that happens before the act).
Actual Consequentialism = whether an act is morally right depends only on the actual consequences (as opposed to foreseen, foreseeable, intended, or likely consequences).#
Direct Consequentialism = whether an act is morally right depends only on the consequences of that act itself (as opposed to the consequences of the agent’s motive, of a rule or practice that covers other acts of the same kind, and so on).
Evaluative Consequentialism = moral rightness depends only on the value of the consequences (as opposed to non-evaluative features of the consequences).
Hedonism = the value of the consequences depends only on the pleasures and pains in the consequences (as opposed to other supposed goods, such as freedom, knowledge, life, and so on).
Maximizing Consequentialism = moral rightness depends only on which consequences are best (as opposed to merely satisfactory or an improvement over the status quo).
Aggregative Consequentialism = which consequences are best is some function of the values of parts of those consequences (as opposed to rankings of whole worlds or sets of consequences).
Total Consequentialism = moral rightness depends only on the total net good in the consequences (as opposed to the average net good per person).
Universal Consequentialism = moral rightness depends on the consequences for all people or sentient beings (as opposed to only the individual agent, members of the individual’s society, present people, or any other limited group).
Equal Consideration = in determining moral rightness, benefits to one person matter just as much as similar benefits to any other person (as opposed to putting more weight on the worse or worst off).
Agent-neutrality = whether some consequences are better than others does not depend on whether the consequences are evaluated from the perspective of the agent (as opposed to an observer).”
For the remainder of this post, I'll use and refer to the simpler five-premise Utilitarian Core rather than the eleven-premise Extended Core, though these are equivalent formulations at different levels of detail.
The Extended Core expands what is compressed in the five-premise version; "consequentialism" subdivides into commitments to actual consequences, direct evaluation, and evaluative assessment, "impartiality" into universal scope and equal consideration, and so on. Any argument that applies to one formulation applies to the other. Those who prefer the finer-grained taxonomy should feel free to mentally substitute it throughout.
- ^
Utilitarianism.net leaves out maximization; as of September 16, 2025, Wikipedia reads “Total utilitarianism is a method of applying utilitarianism to a group to work out what the best set of outcomes would be. It assumes that the target utility is the maximum utility across the population based on adding all the separate utilities of each individual together.”
- ^
By “summation” I mean a symmetric, monotone aggregation operator over persons or events. It need not be real-valued addition. But, conceptually, “addition” or “summation” does seem to be the right or at least best English term to use. The key point is that this operator needn’t be inherently restricted to the real numbers or behave precisely like real-valued addition.
- ^
See footnote above for elaboration and formalization.
- ^
Formal statement: A sufficient package for universal offsetability is an Archimedean ordered abelian group (V, ≤, +, 0) that represents welfare on a single scale. Archimedean means: for all a, b > 0 there exists n ∈ ℕ with n·a > b. Additive inverses mean: for every x ∈ V there is −x with x + (−x) = 0. Total order and monotonicity tie the order to addition. On such a structure, for any finite bad b < 0 and any finite good g > 0 there exists n with b + n·g ≥ 0. The Utilitarian Core does not by itself entail Archimedeanity, total comparability, or additive inverses. It is compatible with weaker aggregation, for example an ordered commutative monoid that is symmetric and monotone.
- ^
Proof that UC doesn’t entail offsetability by counterexample:
Represent a world by a pair (S, H), where:
- S is a nonnegative integer counting catastrophic-suffering tokens,
- H is any integer recording ordinary hedonic goods.
Aggregate by componentwise addition:
(S1, H1) ⊕ (S2, H2) = (S1 + S2, H1 + H2).
Order lexicographically:
(S1, H1) is morally better than (S2, H2) if either
a) S1 < S2, or
b) S1 = S2 and H1 > H2.
This structure is an ordered, commutative monoid. It is impartial and additive across individuals. Yet offsetability fails: if S increases by 1, no finite change in H can compensate.
- ^
"Tentatively" because I don't have a rock-solid understanding or theory of either time or personhood/individuation of qualia/hedonic states.
- ^
Though I'm not familiar with current work in infinite ethics, my argument about representation choices seems relevant to that field. If your model implies punching someone is morally neutral in an infinite universe (because ∞ + 1 = ∞), don't conclude 'the math has spoken, punching is fine'; conclude you're using the wrong math.
- ^
Words that start with A come before B, those with AA come before AB, and so on.
- ^
Here, higher dimensions are analogous to and representative of more highly prioritized kinds of welfare: perhaps the most severe conceivable kind of suffering, and then the category below that, and so on.
- ^
Other structures that avoid universal offsetability include ordinal numbers, surreal numbers, Laurent series, and the long line. The variety of alternatives underscores that real-number representation is a choice, not a logical necessity.
- ^
This analysis suggests utilitarianism might not entail the repugnant conclusion either. Just as some suffering might be lexically bad (non-offsetable by ordinary goods), perhaps some flourishing is lexically good (worth more than any amount of mild contentment). The five premises don't rule this out.
However, positive lexicality doesn't solve negative lexicality; even if divine bliss were worth more than any amount of ordinary happiness, it wouldn't follow that it could offset eternal torture. The positive and negative sides might have independent lexical structures, a substantive claim about consciousness rather than a logical requirement.
- ^
I know this isn't the technically correct use of "a priori." I mean "after accepting UC but before investigating beyond that."
- ^
Revised from the original agent-based economic formulation to fit the language of moral philosophy. Please see any mainstream economics textbook or lecture slides for the economic formulation with any amount of formalization or explanation. Wikipedia seems good as well!
- ^
See this comment (including @Thomas Kwa's comment above it) for more. I am currently (as of October 7 around midnight) a bit confused about whether this formulation is logically/formally identical to other formulations of the continuity and closely related Archimedean property.
This may be because Wikipedia and other sources seem to say different things about what formulation of the continuity and Archimedian properties are definitional, and it's possible that the thing I wrote just above this footnote isn't really properly called "the" continuity or Archimedian property - not only in a semantic/language use norms sense but because what I wrote might be logically equivalent to other more primary formulations only if you assume the other three properties hold (which, again, must be the case for VNM to apply)
I'll add that, while I aspire to be airtight particularly around formal mathematical claims, I don't think any of this new uncertainty meaningfully bears on the argument; not a crux at all.
- ^
I.e., state of the world A is better than B if and only if the expected value of A is greater than the expected value of B, where expected value is defined and determined by that function, u
- ^
The explanation here is reasonably intuitive; essentially, the fact that all states of the world get assigned a real number means that enough good can surpass the value of any bad because there exists some positive real number n such that for any positive real numbers a and b.
- ^
Rejecting premise 1, completeness is essentially a nonstarter in the context of morality, where the whole project is premised on figuring out which worlds, actions, beliefs, rules, etc., are better than or equivalent to others. You can deny this your heart of hearts - I won’t say that you literally cannot believe that two things are fundamentally incomparable - but I will say that the world never accommodates your sincerely held belief or conscientious objector petition when it confronts you with the choice to take option A, option B, or perhaps coin flip between them.
Rejecting premise 2, transitivity, gets you so-called “money-pumped.” That is, it implies that there are a series of trades you would take that leaves you, or the world in our case, worse off by your own lights at the end of the day.
Premise 4, independence, is a bit kinder to objectors, and I believe empirically observed insofar as it applies to consumer behavior in behavioral economics. But my sense is that it is very rarely if ever explicitly endorsed, and at least intuitively I see no case for rejecting it in the context of utilitarianism or morality more broadly. In the words of GPT-5 Thinking, “adding an ‘irrelevant background risk’ shouldn’t flip your ranking.”
- ^
I am using this term in a rather colloquial sense. Feel free to substitute in your preferred word; the description later in this paragraph is really what matters.
- ^
Wording tweaked in response to a good point from Toby Lightheart on Twitter, who (quite reasonably) proposed the term “pragmatically accept” with respect to the suffering itself. I maintain that we should note the “enthusiastic endorsement” of package deals that contain severe suffering.
- ^
I.e., earnest collaborative truth seeking, plenty of time and energy, etc.
- ^
For instance, one critic of lexicality argues that lexical views "result in it being ethically preferable to have a world with substantially more total suffering, because the suffering is of a less important type,” but this claim is circular; the whole debate concerns which kinds of worlds have "how much" suffering in the relevant sense, and in this post I am arguing that some kinds of worlds (namely, those that contain extreme suffering) have “more suffering” than other worlds (namely, those that do not).
- ^
In the extended reals with appropriate topology, such a function can be rigorously called left-continuous.
- ^
The asymptotic structure creates genuine practical constraints in our bounded universe. Feasible happiness is bounded - there are only so many neurons that can fire, years beings can live, resources we can marshal. Call this maximum H_max. When the compensation function Φ(i_s) exceeds H_max while still below the theoretical threshold, we reach suffering that cannot be offset in practice. At some level i_s_practical where Φ(i_s_practical) > H_max, offsetting becomes practically impossible even while remaining theoretically finite. This creates a zone of "effective non-offsetability" below the formal threshold.
- ^
Before taking this man’s revealed preference not to commit suicide as strong evidence against my thesis, I urge you to consider the selection effects associated with finding such quotes.
- ^
- ^
Cluster headaches and torture, yes, but also the heights of joy and subjective wellbeing.
- ^
Or at least influenced; we don’t need to get into the causal power of qualia and discussions in philosophy of mind here.
- ^
The practical implementation of anti-natalism faces insurmountable collective action problems that prevent it from achieving human extinction. Even if anti-natalists successfully refrain from reproduction, this merely ensures their values die out through cultural and genetic selection pressures while being replaced by those who reject anti-natalism. The marginal effect of anti-natalist practice runs counter to its purported goal: rather than reducing total population, it simply shifts demographic composition toward those who value reproduction.
Achieving actual extinction through anti-natalism would require near-universal adoption enforced by an extraordinarily competent global authoritarian regime capable of preventing any group from reproducing. Given human geographical distribution and the ease of small-group survival, even a single community of a thousand individuals escaping such control would be sufficient to repopulate. The scenario required for anti-natalism to achieve its ostensible goal is so implausible as to render it irrelevant to practical ethical consideration.
EJT @ 2025-10-06T14:03 (+63)
Nice post! Here's an argument that extreme suffering can always be outweighed.
Suppose you have a choice between:
(S+G): The most intense suffering S that can be outweighed, plus a population that's good enough to outweigh it G, so that S+G is good overall: better than an empty population.
(S*+nG): The least intense suffering S* that can't be outweighed, plus a population that's n times better than the good population G.
If extreme suffering can't be outweighed, we're required to choose S+G over S*+nG, no matter how big n is. But that seems implausible. S* is only a tiny bit worse than S, and n could be enormous. To make the implication seem more implausible, we can imagine that the improvement nG comes about by extending the lives of an enormous number of people who died early in G, or by removing (non-extreme) suffering from the lives of an enormous number of people who suffer intensely (but non-extremely) in G.
We can also make things more difficult by introducing risk into the case (in this sort of way). Suppose now that the choice is between:
(S+G): The most intense suffering S that can be outweighed, plus a population that's good enough to outweigh it G, so that S+G is good overall: better than an empty population.
(Risky S*+nG): With probability , the most intense suffering S that can be outweighed. With probability , the least intense suffering S* that can't be outweighed. Plus (with certainty) a population that's n times better than the good population G.
We've amended the case so that the move from S+G to Risky S*+nG now involves just a increase in the probability of a tiny increase in suffering (from S to S*). As before, the move also improves the lives of those in the good population G by as much as you like. Plausibly, each increase (for very small ) in the probability of getting S* instead of S (together with an n increase in the quality of G, for very large n) is an improvement. Then with Transitivity, we get the result that S*+nG is better than S+G, and therefore that extreme suffering can always be outweighed.
I think the view that extreme suffering can't always be outweighed has some counterintuitive prudential implications too. It implies that basically we should never think about how happy our choices would make us. Almost always, we should think only about how to minimize our expected quantities of extreme suffering. Even when we're - e.g. - choosing between chocolate and vanilla at the ice cream shop, we should first determine which choice minimizes our expected quantity of extreme suffering. Only if we conclude that these quantities are exactly the same should we even consider which of chocolate and vanilla tastes nicer. That seems counterintuitive to me.
Note also that you can accept outweighability and still believe that extreme suffering is really bad. You could - e.g. - think that 1 second of a cluster headache can only be outweighed by trillions upon trillions of years of bliss. That would give you all the same practical implications without the theoretical trouble.
Ben_West🔸 @ 2025-10-07T15:08 (+14)
In his examples ( and lexically ordered) there is no "most intense suffering which can be outweighed" (or "least intense suffering which can't be outweighed"). E.g. in the hyperreals no matter how small or large .
S* is only a tiny bit worse than S
In his examples, between any S which can't be outweighed and S* which can, there are an uncountably infinite number of additional levels of suffering! So I don't think it's correct to say it's only a tiny bit worse.
EJT @ 2025-10-07T15:44 (+12)
Oh yep nice point, though note that - e.g. - there are uncountably many reals between 1,000,000 and 1,000,001 and yet it still seems correct (at least talking loosely) to say that 1,000,001 is only a tiny bit bigger than 1,000,000.
But in any case, we can modify the argument to say that S* feels only a tiny bit worse than S. Or instead we can modify it so that S is degrees celsius of a fire that causes suffering that just about can be outweighed, and S* is degrees celsius of a fire that causes suffering that just about can't be outweighed.
Ben_West🔸 @ 2025-10-07T17:26 (+4)
I interpret OP's point about asymptotes to mean that he indeed bites this bullet and believes that the "compensation schedule" is massively higher even when the "instrument" only feels slightly worse?
Aaron Bergman @ 2025-10-07T21:28 (+11)
Great points both and I agree that the kind of tradeoff/scenario described by @EJT and @bruce in his comment are the strongest/best/most important objections to my view (and the thing most likely to make me change my mind)
Let me just quote Bruce to get the relevant info in one place and so this comment can serve as a dual response/update. I think the fundamentals are pretty similar (between EJT and Bruce's examples) even though the exact wording/implementation is not:
A) 70 years of non-offsettable suffering, followed by 1 trillion happy human lives and 1 trillion happy pig lives, or
B) [70 years minus 1 hour of non-offsettable suffering (NOS)], followed by 1 trillion unhappy humans who are living at barely offsettable suffering (BOS), followed by 1 trillion pig lives that are living at the BOS,
You would prefer option B here. And it's not at all obvious to me that we should find this deal more acceptable or intuitive than what I understand is basically an extreme form of the Very Repugnant Conclusion, and I'm not sure you've made a compelling case for this, or that world B contains less relevant suffering.
to which I replied:
Yeah not going to lie this is an important point, I have three semi-competing responses:
- I'm much more confident about the (positive wellbeing + suffering) vs neither trade than intra-suffering trades. It sounds right that something like the tradeoff you describe follows from the most intuitive version of my model, but I'm not actually certain of this; like maybe there is a system that fits within the bounds of the thing I'm arguing for that chooses A instead of B (with no money pumps/very implausible conclusions following)
- Well the question again is "what would the IHE under experiential totalization do?" Insofar as the answer is "A", I endorse that. I want to lean on this type of thinking much more strongly than hyper-systematic quasi-formal inferences about what indirectly follows from my thesis.
I think it's possible that the answer is just B because BOS is just radically qualitatively different from NOS.
- Maybe most importantly I (tentatively?) object to the term "barely" here because under the asymptotic model I suggest, the value of subtracting arbitrarily small amount of suffering instrument from the NOS state results in no change in moral value at all because (to quote myself again) "Working in the extended reals, this is left-continuous: "
- So in order to get BOS, we need to remove something larger than , and now it's a quasi-empirical question of how different that actually feels from the inside. Plausibly the answer is that "BOS" (scare quotes) doesn't actually feel "barely" different - it feels extremely and categorically different
Consider "which of these responses if any is correct" a bit of an open question for me.
Plausibly I should have figured this out before writing/publishing my piece but I've updated nontrivially (though certainly not all the way) towards just being wrong on the metaphysical claim.
This is in part because after thinking some more since my reply to Bruce (and chatting with some LLMs), I've updated away from my points (1) and (2) above.
I am still struggling with (3) both at:
- the conceptual level of whether it could be the case that there are fundamental qualitative discontinuities corresponding to the asymptote location at arbitrarily small but not infinitesimal (!) changes in i_s; and
- the quasi-empirical level of whether that's actually how things are
Mostly (2) though, I should add. I think (uncertain/tentative etc etc) that this is conceptually on the table.
So to respond to Ben:
I interpret OP's point about asymptotes to mean that he indeed bites this bullet and believes that the "compensation schedule" is massively higher even when the "instrument" only feels slightly worse?
I don’t bite the bullet in the most natural reading of this, where very small changes in i_s do only result in very small changes in subjective suffering from a subjective qualitative POV. Insofar as that is conceptually and empirically correct, I (tentatively) think it’s a counterexample that more or less disproves my metaphysical claim (if true/legit).
But I feel pretty conflicted right now about whether the small but not infinitesimal change in i_s -> subjectively small difference is true (again, mostly because of quasi-empirical uncertainty).
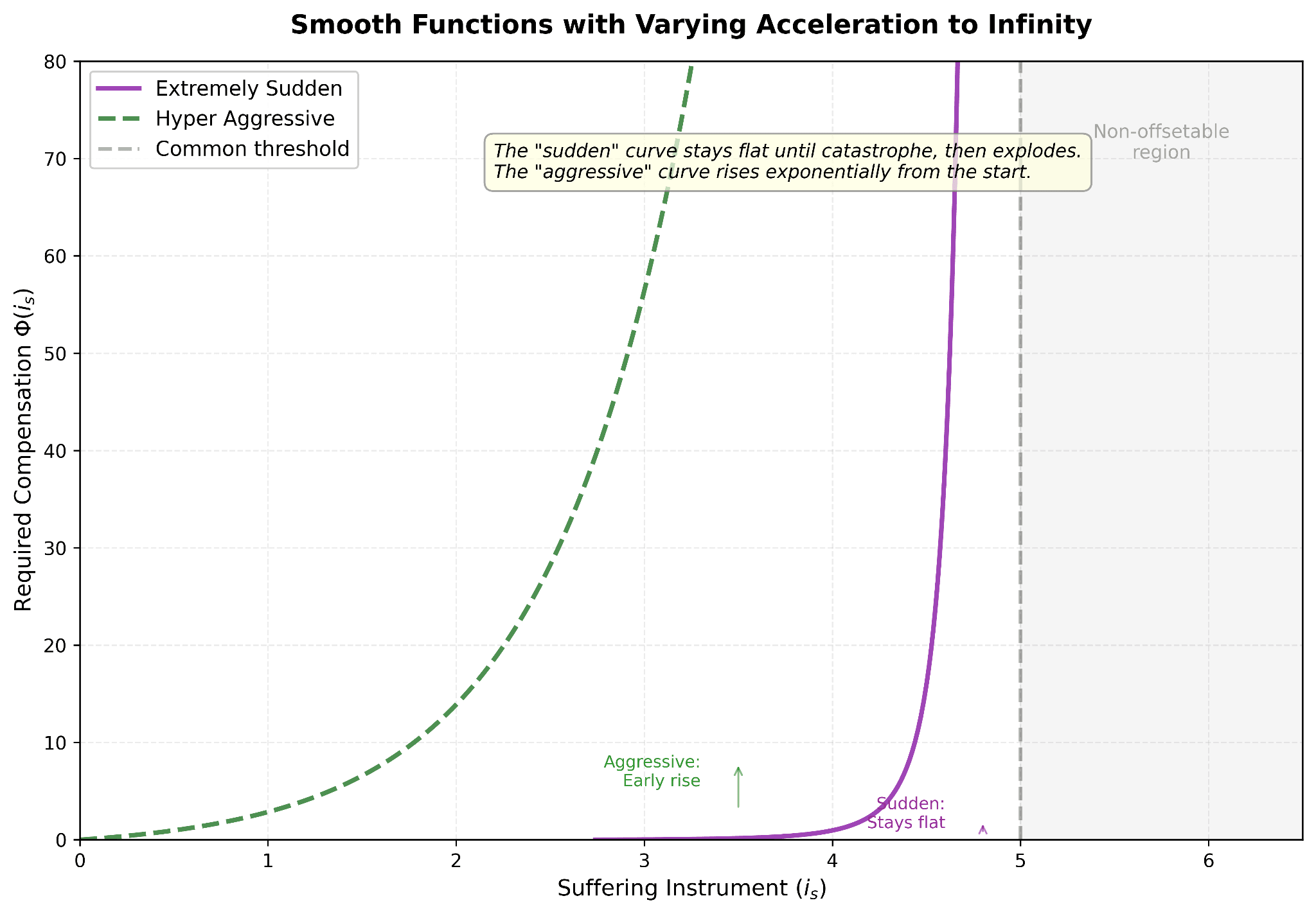
This is hard to think about largely because my model/view leaves the actual shape of the asymptote unspecified (here’s a new version of the second pic in my post), and that includes all the uncertainty associated with what instrument we are literally or conceptually talking about (since the sole criterion is that it’s monotonic)[1]
I will add that one reason I think this might be a correct “way out” is that it would just be very strange to me if “IHE preference is to refuse 70 year torture and happiness trade mentioned in post” logically entails (maybe with some extremely basic additional assumptions like transitivity) “IHE gives up divine bliss for a very small subjective amount of suffering mitigation”
I know that this could just be a failure of cognition and/or imagination on my part. Tbh this is really the thing that I’m trying to grok/wrestle with (as of now, like for the last day or so, not in the post)
I also know this is ~motivated reasoning, but idk I just do think it has some evidential weight. Hard to justify in explicit terms though.
I’m curious if others have different intuitions about how weird/plausible this [2] is from a very abstract POV
- ^
- ^
I.e.
“IHE preference is to refuse 70 year torture and happiness trade mentioned in post” logically entails (maybe with some extremely basic additional assumptions like transitivity) “IHE gives up divine bliss for a very small subjective amount of suffering mitigation”

bruce @ 2025-10-08T02:21 (+13)
I don’t bite the bullet in the most natural reading of this, where very small changes in i_s do only result in very small changes in subjective suffering from a subjective qualitative POV. Insofar as that is conceptually and empirically correct, I (tentatively) think it’s a counterexample that more or less disproves my metaphysical claim (if true/legit).
Going along with 'subjective suffering', which I think is subject to the risks you mention here, to make the claim that the compensation schedule is asymptotic (which is pretty important to your topline claim RE: offsetability) I think you can't only be uncertain about Ben's claim or "not bite the bullet", you have to make a positive case for your claim. For example:
I will add that one reason I think this might be a correct “way out” is that it would just be very strange to me if “IHE preference is to refuse 70 year torture and happiness trade mentioned in post” logically entails (maybe with some extremely basic additional assumptions like transitivity) “IHE gives up divine bliss for a very small subjective amount of suffering mitigation”
Like, is it correct that absent some categorical lexical property that you can identify, "the way out" is very dependent on you being able to support the claim "near the threshold a small change in i_s --> large change in subjective experience"?
So I suspect your view is something like: "as i_s increases linearly, subjective experience increases in a non-linear way that approaches infinity at some point, earlier than 70 years of torture"?[1] If so, what's the reason you think this is the correct view / am I missing something here?
RE: the shape of the asymptote and potential risks of conflating empirical uncertainties
I think this is an interesting graph, and you might feel like you can make some rough progress on this conceptually with your methodology. For example, how many years of bliss would the IHE need to be offered to be indifferent between the equivalent experience of:
- 1 person boiled alive for an hour at 100degC
- Change the time variable to 30mins / 10min / 5min / 1 minute / 10 seconds / 1 seconds of the above experience[2]
- Change the exposure variable to different % of the body (e.g. just hand / entire arm / abdomen / chest / back, etc)
- (I would be separately interested in how the IHE would make tradeoffs if making a decision for others and the choice was about: 10/10000/1E6 people having ^all the above time/exposure variations, rather than experiencing it themselves, but this is further away from your preferred methodology so I'll leave it for another time)
And then plotted the graph instrument with different combinations of the time/exposure/temperature variables. This could help you either elucidate the shape of your graph, or the location of uncertainties around your time granularity.
The reason I chose this > cluster headaches is partly because you can get more variables here, but if you wanted just a time comparison then cluster headaches might be easier.
But I actually think temperature is an interesting one to consider for multiple additional reasons. For example, it's interesting as a real life example where you have perceived discontinuities of responses to continuous changes in some variable. You might be willing to tolerate 35 degree water for a very long time but as soon as it gets to 40+ how tolerable it is very rapidly decreases in a way that feels like a discontinuity.
But what's happening here is that heat nociceptors activate at a specific temperature (say e.g. 40degC). So you basically just aren't moving up the suffering instrument below that temperature ~at all, and so the variable you'd change is "how many nociceptors do you activate" or "how frequently do they fire" (all of which are modulated by temperature and amount of skin exposed), and that rapidly goes up as you reach / exceed 40degC.[3]
And so if you naively plot "degrees" or "person-hours" at the bottom, you might think subjective suffering is going up exponentially compared to a linear increase in i_s, but you are not accounting for thresholds in i_s activation, or increased sensitisation or recruitment of nociceptors over time, which might make the relationship look much less asymptotic.[4]
And empirical uncertainties about exactly how these kinds of signals work and are processed I think is a potentially large limiting factor for being able to strongly support "as i_s increases linearly, subjective experience increases in a non-linear way that approaches infinite bliss at some point"[5]
I obviously don't think it's possible to have all the empirical Qs worked out for the post, but I wanted to illustrate these empirical uncertainties because I think even if I felt it would be correct for the IHE to reject some weaker version of the torture-bliss trade package[6], it would still be unclear that this reflected an asymptotic relationship, rather than just e.g. a large asymmetry between sensitivity to i_s and i_h, or maximum amount of i_s and i_h possible. I think these possibilities could satisfy the (weaker) IHE thought experiment while potentially satisfying lexicality in practice, but not in theory. It might also explain why you feel much more confident about lexicality WRT happiness but not intra-suffering tradeoffs, and if you put the difference of things like 1E10 vs 1E50 vs 10^10^10 down to scope insensitivity I do think this explains a decent portion of your views.
- ^
And indeed 1 hour of cluster headache
- ^
I'm aware that approaching 1 second is getting towards your uncertainty for the time granularity problem, but I think if you do think 1 hour of cluster headache is NOS then these are the kinds of tradeoffs you'd want to be able to make (and back)
- ^
There are other heat receptors at higher temperatures but to a first approximation it's probably fine to ignore
- ^
Because of uncertainty around how much i_s there actually is
- ^
Also worth flagging that RE: footnote 26, where you say:
Feasible happiness is bounded - there are only so many neurons that can fire, years beings can live, resources we can marshal. Call this maximum H_max.
You should also expect this to apply to the suffering instrument; there is also some upper bound for all of these variables
- ^
e.g. 1E10 years, rather than infinity, since I find that pretty implausible and hard to reason about
EJT @ 2025-10-07T23:23 (+8)
Oops yes, fundamentals between my and Bruce's cases are very similar. Should have read Bruce's comment!
The claim we're discussing - about the possibility of small steps of various kinds - sounds kinda like a claim that gets called 'Finite Fine-Grainedness'/'Small Steps' in the population axiology literature. It seems hard to convincingly argue for, so in this paper I present a problem for lexical views that doesn't depend on it. I sort of gestured at it above with the point about risk without making it super precise. The one-line summary is that expected welfare levels are finitely fine-grained.
bruce @ 2025-10-07T10:41 (+10)
Note also that you can accept outweighability and still believe that extreme suffering is really bad. You could - e.g. - think that 1 second of a cluster headache can only be outweighed by trillions upon trillions of years of bliss. That would give you all the same practical implications without the theoretical trouble.
+1 to this, this echoes some earlier discussion we've had privately and I think it would be interesting to see it fleshed out more, if your current view is to reject outweighability in theory
More importantly I think this points to a potential drawback RE: "IHE thought experiment, I claim, is an especially epistemically productive way of exploring that territory, and indeed for doing moral philosophy more broadly"[1]
For example, if your intuition is that 70 years of the worst possible suffering is worse than 1E10 and 1E100 and 10^10^10 years of bliss, and these all feel like ~equally clear tradeoffs to you, there doesn't seem (to me) to be a clear way of knowing whether you should believe your conclusion is that 70 years of the worst possible suffering is "not offsetable in theory" or "offsetable in theory but not in practice, + scope insensitivity",[2] or some other option.
bruce @ 2025-10-06T01:49 (+46)
Thanks for writing this up publicly! I think it's a very thought provoking piece and I'm glad you've written it. Engaging with it has definitely helped me consider some of my own views in this space more deeply. As you know this is basically just a compilation of comments I've left in previous drafts, and am deferring to your preference to have these discussions in public. Some caveats for other readers: I don't have any formal philosophical background so this is largely first principles reasoning rather than anything philosophically grounded.[1]
All of this is focussed on (to me) the more interesting metaphysical claim that "some suffering in fact cannot be morally justified (“offset”) by any amount of happiness."
TL;DR
- The positive argument for the metaphysical claim and the title of this piece relies (IMO) too heavily on a single thought experiment, that I don't think supports the topline claim as written.
- The post illustrates an unintuitive finding about utilitarianism, but doesn't seem to provide a substantive case for why utilitarianism that includes lexicality is the least unintuitive option compared to other unintuitive utilitarian conclusions. For example, my understanding of your view is that given a choice of the following options:
A) 70 years of non-offsettable suffering, followed by 1 trillion happy human lives and 1 trillion happy pig lives, or
B) [70 years minus 1 hour of non-offsettable suffering (NOS)], followed by 1 trillion unhappy humans who are living at barely offsettable suffering (BOS), followed by 1 trillion pig lives that are living at the BOS,
You would prefer option B here. And it's not at all obvious to me that we should find this deal more acceptable or intuitive than what I understand is basically an extreme form of the Very Repugnant Conclusion, and I'm not sure you've made a compelling case for this, or that world B contains less relevant suffering.
- Thought experiment variations:
People's intuitions about the suffering/bliss trade might reasonably change based on factors like:- Duration of suffering (70 minutes vs. 70 years vs. 70 billion years)
- Whether experiences happen in series or parallel
- Whether you can transfer the bliss to others
- Threshold problem:
Formalizing where the lexical threshold sits is IMO pretty important, because there are reasonable pushbacks to both, but they feel like meaningfully different views- High threshold (e.g.,"worst torture") means the view is still susceptible to unintuitive package deals that endorse arbitrarily large amounts of barely-offsettable suffering (BOS) to avoid small amounts of suffering that does cross the threshold
- Low threshold (e.g., "broken hip" or "shrimp suffering") seems like it functionally becomes negative utilitarianism
- Asymptotic compensation schedule:
The claim that compensation requirements grow asymptotically and approach infinity (rather than linearly, or some other way) isn't well-justified, and doesn't seem to meaningfully change the unintuitive nature of the tradeoffs your view is willing to endorse.
============
Longer
As far as I can tell, the main positive argument you have for is the thought experiment where you reject the offer of 70 years of worst conceivable suffering in exchange for any amount of happiness afterwards". But I do think it would be rational for an IHE as defined to accept this trade
I agree that package deals that permit or endorse the creation of extreme suffering as part of a package deal is an unintuitive / uncomfortable view to want to accept. But AFAICT most if not all utilitarian views have some plausibly unintuitive thought experiment like this, and my current view is that you have still not made a substantive positive claim for non-offsettability / negative lexical utilitarianism beyond broadly "here is this unintuitive result about total utilitarianism", and I think an additional claim of “why is this the least unintuitive result / the one that we should accept out of all unintuitive options” would be helpful for readers, otherwise I agree more with your section “not a proof” than your topline metaphysical claim (and indeed your title “Utilitarians Should Accept that Some Suffering Cannot be “Offset””).
The thought experiment:
I do actually think that the IHE should take this trade. But I think a lot of my pushbacks apply even if you are uncertain about whether the IHE should or not.
For example, I think whether the thought experiment stipulates 70 minutes years or 70 years or 70 billion years of the worst possible suffering meaningfully changes how the thought experiment feels, but if lexicality was true we should not take the trade regardless of the duration. I know you've weakened your position on this, but it does open up more uncertainties of the kinds of tradeoffs you should be willing to make since the time aspect is continuous, and if this alone is sufficient to turn something from offsettable to not-offsettable then it could imply some weird things, like it seems a little weird to prioritise averting 1 case of a 1 hour cluster headache over 1 million cases of 5 minute cluster headaches.[2]
As Liv pointed out in a previous version of the draft, there are also versions of the thought experiment which I think people’s intuitive answer may reasonably change, shouldn’t if you think lexicality is true:
-is the suffering / bliss happening in parallel or in series
-is there the option of taking the suffering on behalf of others (e.g. some might be more willing to take the trade if after you take the suffering, the arbitrary amounts of bliss can be transferred to other people as well, and not just yourself)
On the view more generally:
I’m not sure you explicitly make this claim so if this isn’t your view let me know! But I think your version of lexicality doesn’t just say “one instance of NOS is so bad that we should avert this no matter how much happiness we might lose / give up as a result”, but it also says “one instance of NOS is so bad that we should prioritise averting this over any amount of BOS”[3]
Why I think formalising the threshold is helpful in understanding the view you are arguing for:
If the threshold is very high, e.g. "worst torture imaginable", then you are (like total utilitarianism) in a situation where you are also having uncomfortable/unintuitive package deals where you have to endorse high amounts of suffering. For example, you would prefer to avert 1 hour of the worst torture imaginable in exchange for never having any more happiness and positive value, but also actively produce arbitrarily high amounts of BOS.
My understanding of your view is that given a choice of living in series:
A) 70 years of NOS, followed by 1 trilion positive happy human lives and 1 trillion happy pig lives, or
B) [70 years minus 1 hour of NOS], followed by 1 trillion unhappy humans who are living at BOS, followed by 1 trillion pig lives that are living at the BOS,
you would prefer the latter. It's not at all obvious to me that we should find this deal more acceptable or intuitive than what I understand is basically an extreme form of the Very Repugnant Conclusion. It's also not clear to me that you have actually argued a world like world B would have to have "less relevant suffering" than world A (e.g. your footnote 24).
If the threshold is lower, e.g. "broken hip", or much lower, e.g. "suffering of shrimp that has not been electrically stunned", then you while you might less unintuitive suffering package deals, but you end up functionally very similar to negative utilitarianism, where averting one broken leg outweighs, or saving 1 shrimp outweighs all other benefits.
Formalising the threshold:
Using your example of a specific, concrete case of extreme suffering: “a cluster headache [for one human] lasting for one hour”.
If this uncontroversially crosses the non-offsetable threshold for you, consider how you'd view the headache if you hypothetically decrease the amount of time, the number of nociceptors that are exposed to the stimuli, how often they fire, etc until you get to 0 on some or all variables. This feels pretty continuous! And if you think there should be a discontinuity that isn't explained by this, then it’d be helpful to map out categorically what it entails. For example, if someone is boiled alive[4] this is extreme suffering, because suffering involving extreme heat, confronting your perceived impending doom, loss of autonomy or some combination of the above. But you might still probably need more than this because not all suffering involving extreme heat or suffering involving loss of autonomy is necessarily extreme, and it’s not obvious how this maps onto e.g. cluster headaches. Or you might bite the bullet on "confronting your impending doom", but this might be a pretty different view with different implications etc.
On "Continuity and the Location of the Threshold"
The radical implications (insofar as you think any of this is radical) aren't at the threshold but in the approach to it. The compensation schedule growing without bound (i.e., asymptotically) means that some sub-threshold suffering would require 10^(10^10) happy lives to offset, or 1000^(1000^1000). (emphasis added)
============
This arbitrariness diminishes somewhat (though, again, not entirely) when viewed through the asymptotic structure. Once we accept that compensation requirements grow without bound as suffering intensifies, some threshold becomes inevitable. The asymptote must diverge somewhere; debates about exactly where are secondary to recognizing the underlying pattern.
It’s not clear that we have to accept the compensation schedule as growing asymptotically? Like if your response to “the discontinuity of tradeoffs caused by the lexical threshold does not seem to be well justified” is “actually the radical part isn’t the threshold, it’s because of the asymptotic compensation schedule”, then it would be helpful to explain why you think the asymptotic compensation schedule is the best model, or preferable to e.g. a linear one.
For example, suppose a standard utilitarian values converting 10 factory farmed pig lives to 1 happy pig life to 1 human life similarly, and they also value 1E4 happy pig lives to 1E3 human lives.
Suppose you are deeply uncertain about whether a factory farmed pig experiences NOS because it's very close to the threshold of what you think constitutes extreme / NOS suffering.
If the answer is yes, then converting 1 factory farmed pig to a happy pig life should trade off against arbitrarily high numbers of human lives. But according to the asymptotic compensation schedule, if the answer is no, then you might need 10^(10^10) human lives to offset a happy pig life. But either way, it's not obvious to the standard utilitarian why they should value 1 case of factory farmed pig experience this much!
Other comments:
In other words, let us consider a specific, concrete case of extreme suffering: say a cluster headache lasting for one hour.
Here, the lexical suffering-oriented utilitarian who claims that this crosses the threshold of in-principle compensability has much more in common with the standard utilitarian who thinks that in principle creating such an event would be morally justified by TREE(3) flourishing human life-years than the latter utilitarian has with the standard utilitarian who claims that the required compensation is merely a single flourishing human life-month.
I suspect this intended to be illustrative, but I would be surprised if there were many, if any standard utilitarians who would actually say that you need TREE(3)[5] flourishing human life years to offset a cluster headache lasting 1 hour, so this seems like a strawman?
Like it does seem like the more useful Q to ask is something more like:
Does the lexical suffering-oriented utilitarian who claims that this crosses the threshold of in-principle compensability have more in common with the standard utilitarian who thinks the event would be morally justified by 50 flourishing human life years (which is already a lot!), than that latter utilitarian has with another standard utilitarian who claims the required compensation is a single flourishing life month?
Like 1 month : TREE(3) vs. TREE(3) : infinity seems less likely to map to the standard utilitarian view than something like 1 month : 50 years vs. 50 years : infinity.
Thanks again for the post, and all the discussions!
- ^
I'm also friends with Aaron and have already had these discussions with him and other mutual friends in other contexts and so have possibly made less effort into making sure the disagreements land as gently as possible than I would otherwise. I've also spent a long time on the comment already so have focussed on the disagreements rather than the parts of the post that are praiseworthy.
- ^
To be clear I find the time granularity issue very confusing personally, and I think it does have important implications for e.g. how we value extreme suffering (for example, if you define extreme suffering as "not tolerable even for a few seconds + would mark the threshold of pain under which many people choose to take their lives rather than endure the pain", then much of human suffering is not extreme by definition, and the best way of reaching huge quantities of extreme suffering is by having many small creatures with a few seconds of pain (fish, shrimp, flies, nematodes). However, depending on how you discount for these small quantities of pain, it could change how you trade off between e.g. shrimp and human welfare, even without disagreements on likelihood of sentience or the non-time elements that contribute to suffering.
- ^
Here I use extreme suffering and non-offsetable suffering interchangeably, to mean anything worse than the lexical threshold, and thus not offsetable, and barely offsetable suffering to mean some suffering that is as close to the lexical threshold as possible but considered offsetable. Credit to Max’s blog post for helping me with wording some of this, though I prefer non-offsetable over extreme as this is more robust to different lexical thresholds).
- ^
to use your example
- ^
I don't even have the maths ability to process how big this is, I'm just deferring to Wikipedia saying it's larger than g64
Aaron Bergman @ 2025-10-06T03:54 (+7)
Again I appreciate your serious engagement!
The positive argument for the metaphysical claim and the title of this piece relies (IMO) too heavily on a single thought experiment, that I don't think supports the topline claim as written.
Not sure what you mean by the last clause, and to quote myself from above:
I don't expect to convince all readers, but I'd be largely satisfied if someone reads this and says: "You're right about the logic, right about the hidden premise, right about the bridge from IHE preferences to moral facts, but I would personally, both in real life and as an IHE, accept literally anything, including a lifetime of being boiled alive, for sufficient happiness afterward."
Yeah it's possible I should (have) emphasized this specific thesis ("IHE thought experiment, I claim, is an especially epistemically productive way of exploring that territory, and indeed for doing moral philosophy more broadly") more as an explicit claim, distinct from the two I highlight as the organizing/motivating claims corresponding to each section. Maybe I will add a note or something about this.
I don't have a rock solid response to the "too heavily" thing because, idk, I think the thought experiment is actually what matters and what corresponds to the true answer. And I'll add that a background stance I have is that I'm trying to convey what think is the right answer, not only in terms of explicit conclusions but in terms of what evidence matters and such.
A) 70 years of non-offsettable suffering, followed by 1 trillion happy human lives and 1 trillion happy pig lives, or
B) [70 years minus 1 hour of non-offsettable suffering (NOS)], followed by 1 trillion unhappy humans who are living at barely offsettable suffering (BOS), followed by 1 trillion pig lives that are living at the BOSYou would prefer option B here. And it's not at all obvious to me that we should find this deal more acceptable or intuitive than what I understand is basically an extreme form of the Very Repugnant Conclusion, and I'm not sure you've made a compelling case for this.
Yeah not going to lie this is an important point, I have three semi-competing responses:
- I'm much more confident about the (positive wellbeing + suffering) vs neither trade than intra-suffering trades. It sounds right that something like the tradeoff you describe follows from the most intuitive version of my model, but I'm not actually certain of this; like maybe there is a system that fits within the bounds of the thing I'm arguing for that chooses A instead of B (with no money pumps/very implausible conclusions following)
- Well the question again is "what would the IHE under experiential totalization do?" Insofar as the answer is "A", I endorse that. I want to lean on this type of thinking much more strongly than hyper-systematic quasi-formal inferences about what indirectly follows from my thesis.
I think it's possible that the answer is just B because BOS is just radically qualitatively different from NOS.
- Maybe most importantly I (tentatively?) object to the term "barely" here because under the asymptotic model I suggest, the value of subtracting arbitrarily small amount of suffering instrument from the NOS state results in no change in moral value at all because (to quote myself again) "Working in the extended reals, this is left-continuous: "
- So in order to get BOS, we need to remove something larger than , and now it's a quasi-empirical question of how different that actually feels from the inside. Plausibly the answer is that "BOS" (scare quotes) doesn't actually feel "barely" different - it feels extremely and categorically different
Consider "which of these responses if any is correct" a bit of an open question for me.
And I'll add that insofar as the answer is (2) and NOT 3, I'm pretty inclined to update towards "I just haven't developed an explicit formalization that handles both the happiness trade case and the intra-suffering trade case yet" more strongly than towards "the whole thing is wrong, suffering is offsetable by positive wellbeing" - after all, I don't think it directly follows from "IHE chooses A" that "IHE would choose the 70 years of torture." But I could be wrong about this! I 100% genuinely think I'm literally not smart enough to intuit super confidently whether or a formalization that chooses both A and no torture exists. I will think about this more!
Thought experiment variations:
People's intuitions about the suffering/bliss trade might reasonably change based on factors like:
- Duration of suffering (70 minutes vs. 70 years vs. 70 billion years)
- Whether experiences happen in series or parallel
- Whether you can transfer the bliss to others
I agree (1) offers interesting variations. I do have a vague, vibey sense that one human lifetime seems like a pretty "fair" central case to start from but this is not well-justified.
I more strongly want to push back on (2) and (3) in the sense that I think parallel experience, while probably conceptually fine in principle, really greatly degrades the epistemic virtue of the thought experiment because this literally isn't something human brains were/are designed to do or simulate. And likewise with (3), the self interest bit seems pretty epistemically important.
- Threshold problem:
Formalizing where the lexical threshold sits is IMO pretty important, because there are reasonable pushbacks to both, but they feel like meaningfully different views
- High threshold (e.g.,"worst torture") leads to unintuitive package deals where you'd accept vast amounts of barely-offsettable suffering (BOS) to avoid small amounts of suffering that does cross the threshold
- Low threshold (e.g., "broken hip" or "shrimp suffering") seems like it functionally becomes negative utilitarianism
I agree it is imporant! Someone should figure out the right answer! Also in terms of practical implementation, probably better to model as a probability distribution than a single certain line.
Asymptotic compensation schedule:
The claim that compensation requirements grow asymptotically (rather than linearly, or some other way) isn't well-justified, and doesn't seem to meaningfully change the unintuitive nature of the tradeoffs your view is willing to endorse.
I disagree that it isn't well-justified in principlle, but maybe I should have argued this more thoroughly. It just makes a ton of intuitive sense to me but possibly I am typical-minding. And I'm pretty sure you're wrong about the second thing - see point 3 a few bullets up. It seems radically less plausible to me that the true nature of ethics involves discontinuous i_s vs i_h compensation schedules.
Ok lol your comment is pretty long so I think I will need to revisit the rest of it! Some vibes are likely to include:
- "I literally don't know what the threshold is. I agree it would be nice to formalize it! My uncertainty isn't much evidence against the view as a whole"
- I feel like we agree about continuity; the asymptote seems very intuitively like the most likely way to connect "paper cuts are acceptable to create in exchange for wellbeing" and "the IHE would refuse the torture trade". I agree it's not literally impossible that a discontinuous model is correct
I suspect this intended to be illustrative, but I would be surprised if there were many, if any standard utilitarians who would actually say that you need TREE(3)[5] flourishing human life years to offset a cluster headache lasting 1 hour, so this seems like a strawman?
- Yes illustrative, I'm not trying to claim that these people actually exist. I don't think it's a strawman. Maybe this is a grammatical thing with my use of the word the to refer to a hypothetical person
bruce @ 2025-10-06T05:08 (+15)
- I'm much more confident about the (positive wellbeing + suffering) vs neither trade than intra-suffering trades. It sounds right that something like the tradeoff you describe follows from the most intuitive version of my model, but I'm not actually certain of this; like maybe there is a system that fits within the bounds of the thing I'm arguing for that chooses A instead of B (with no money pumps/very implausible conclusions following)
Ok interesting! I'd be interested in seeing this mapped out a bit more, because it does sound weird to have BOS be offsettable with positive wellbeing, positive wellbeing to be not offsettable with NOS, but BOS and NOS are offsetable with each other? Or maybe this isn't your claim and I'm misunderstanding
2) Well the question again is "what would the IHE under experiential totalization do?" Insofar as the answer is "A", I endorse that. I want to lean on this type of thinking much more strongly than hyper-systematic quasi-formal inferences about what indirectly follows from my thesis.
Right, but if IHE does prefer A over B in my case while also preferring the "neither" side of the [positive wellbeing + NOS] vs neither trade then there's something pretty inconsistent right? Or a missing explanation for the perceived inconsistency that isn't explained by a lexical threshold.
I think it's possible that the answer is just B because BOS is just radically qualitatively different from NOS.
I think this is plausible but where does the radical qualitative difference come from? (see comments RE: formalising the threshold).
Maybe most importantly I (tentatively?) object to the term "barely" here because under the asymptotic model I suggest, the value of subtracting arbitrarily small amount of suffering instrument from the NOS state results in no change in moral value at all because (to quote myself again) "Working in the extended reals, this is left-continuous: "
Sorry this is too much maths for my smooth brain but I think I'd be interested in understanding why I should accept the asymptotic model before trying to engage with the maths! (More on this below, under "On the asymptotic compensation schedule")
So in order to get BOS, we need to remove something larger than , and now it's a quasi-empirical question of how different that actually feels from the inside. Plausibly the answer is that "BOS" (scare quotes) doesn't actually feel "barely" different - it feels extremely and categorically different
Can you think of one generalisable real world scenario here? Like "I think this is clearly non-offsetable and now I've removed X, I think it is clearly offsetable"
And I'll add that insofar as the answer is (2) and NOT 3, I'm pretty inclined to update towards "I just haven't developed an explicit formalization that handles both the happiness trade case and the intra-suffering trade case yet" more strongly than towards "the whole thing is wrong, suffering is offsetable by positive wellbeing" - after all, I don't think it directly follows from "IHE chooses A" that "IHE would choose the 70 years of torture." But I could be wrong about this! I 100% genuinely think I'm literally not smart enough to intuit super confidently whether or a formalization that chooses both A and no torture exists. I will think about this more!
Cool! Yeah I'd be excited to see the formalisation; I'm not making a claim that the whole thing is wrong, more making a claim that I'm not currently sufficiently convinced to hold the view that some suffering cannot be offsetable. I think while the intuitions and the hypotheticals are valuable, like you say later, there are a bunch of things about this that we aren't well placed to simulate or think about well, and I suspect if you find yourself in a bunch of hypotheticals where you feel like your intuitions differ and you can't find a way to resolve the inconsistencies then it is worth considering the possibility that you're not adequately modelling what it is like to be the IHE in at least one of the hypotheticals
I more strongly want to push back on (2) and (3) in the sense that I think parallel experience, while probably conceptually fine in principle, really greatly degrades the epistemic virtue of the thought experiment because this literally isn't something human brains were/are designed to do or simulate.
Yeah reasonable, but presumably this applies to answers for your main question[1] too?
Suppose the true value of exchange is at 10 years of happiness afterwards; this seems easier for our brains to simulate than if the true exchange rate is at 100,000 years of happiness, especially if you insist on parallel experiences. Perhaps it is just very difficult to be scope sensitive about exactly how much bliss 1E12 years of bliss is!
And likewise with (3), the self interest bit seems pretty epistemically important.
can you clarify what you mean here? Isn't the IHE someone who is "maximally rational/makes no logical errors, have unlimited information processing capacity, complete information about experiences with perfect introspective access, and full understanding of what any hedonic state would actually feel like"?
On formalising where the lexical threshold is you say:
I agree it is imporant! Someone should figure out the right answer! Also in terms of practical implementation, probably better to model as a probability distribution than a single certain line.
This is reasonable, and I agree with probability distribution given uncertainty, but I guess it feels hard to engage with the metaphysical claim "some suffering in fact cannot be morally justified (“offset”) by any amount of happiness" and their implications if you are so deeply uncertain about what counts as NOS. I guess my view is that conditional on physicalism then whatever combination of nociceptor / neuron firing and neurotransmitter release / you can think of, this is a measurable amount. some of these combinations will cross the threshold of NOS under your view, but you can decrease all of those in continuous ways that shouldn't lead to a discontinuity in tradeoffs you're willing to make. It does NOT mean that the relationship is linear, but it seems like there's some reason to believe it's continuous rather than discontinuous / has an asymptote here. And contra your later point:
"I literally don't know what the threshold is. I agree it would be nice to formalize it! My uncertainty isn't much evidence against the view as a whole"
I think if we don't know where a reasonable threshold is it's fine to remain uncertain about it, but I think that's much weaker than accepting the metaphysical claim! It's currently based just on the 70 years of worst-possible suffering VS ~infinite bliss hypothetical. Because your uncertainty about the threshold means I can conjure arbitrarily high numbers of hypotheticals that would count as evidence against your view in the same way your hypothetical is considered evidence for your view.
On the asymptotic compensation schedule
I disagree that it isn't well-justified in principlle, but maybe I should have argued this more thoroughly. It just makes a ton of intuitive sense to me but possibly I am typical-minding.
As far as I can tell, you just claim that it creates an asymptote and label it the correct view right? But why should it grow without bound? Sorry if I've missed something!
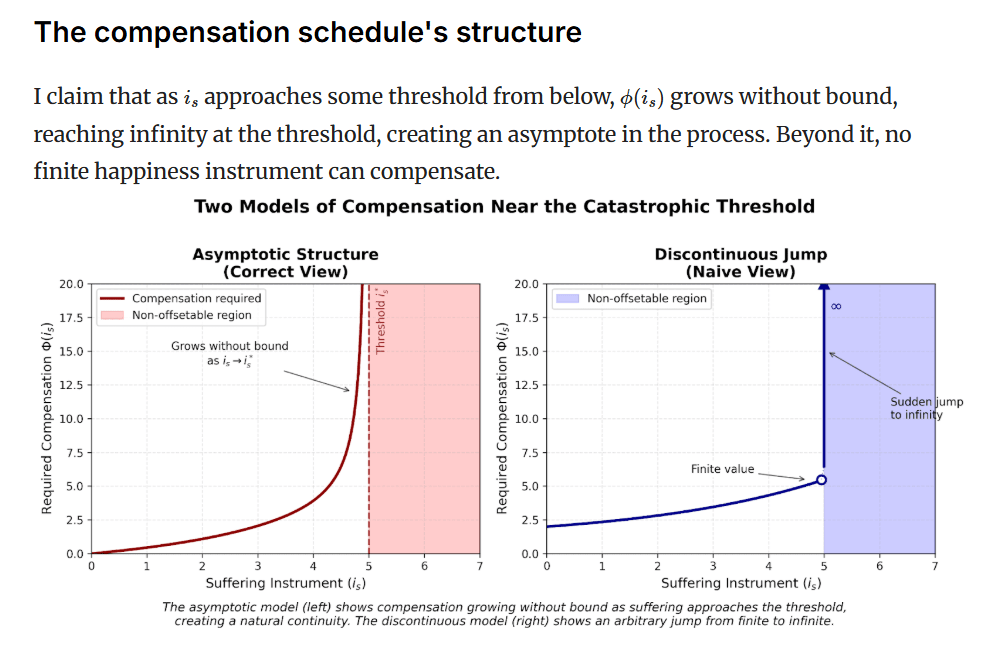
And I'm pretty sure you're wrong about the second thing - see point 3 a few bullets up. It seems radically less plausible to me that the true nature of ethics involves discontinuous i_s vs i_h compensation schedules.
I was unclear about the "doesn't seem to meaningfully change the unintuitive nature of the tradeoffs your view is willing to endorse" part you're referring to here, and I agree RE: discontinuity. What I'm trying to communicate is that if someone isn't convinced by the perceived discontinuity of NOS being non-offsettable and BOS being offsettable, a large subset of them also won't be very convinced by the response "the radical part is in the approach to infinity, (in your words: the compensation schedule growing without bound (i.e., asymptotically) means that some sub-threshold suffering would require 10^(10^10) happy lives to offset, or 1000^(1000^1000). (emphasis added)".
Because they could just reject the idea that an extremely bad headache (but not a cluster headache), or a short cluster headache episode, or a cluster headache managed by some amount of painkiller, etc, requires 1000^(1000^1000) happy lives to offset.
I guess this is just another way of saying "it seems like you're assuming people are buying into the asymptotic model but you haven't justified this".
- ^
"Would you accept 70 years of the worst conceivable torture in exchange for any amount of happiness afterward?"
Thomas Kwa @ 2025-10-07T04:21 (+20)
Ok interesting! I'd be interested in seeing this mapped out a bit more, because it does sound weird to have BOS be offsettable with positive wellbeing, positive wellbeing to be not offsettable with NOS, but BOS and NOS are offsetable with each other? Or maybe this isn't your claim and I'm misunderstanding
This is what kills the proposal IMO, and EJT also pointed this out. The key difference between this proposal and standard utilitarianism where anything is offsettable isn't the claim that that NOS is worse than TREE(3) or even 10^100 happy lives, since this isn't a physically plausible tradeoff we will face anyway. It's that once you believe in NOS, transitivity compels you to believe it is worse than any amounts of BOS, even a variety of BOS that, according to your best instruments, only differs from NOS in the tenth decimal place. Then once you believe this, the fact that you use a utility function compels you to create arbitrary amounts of BOS to avoid a tiny probability of a tiny amount of NOS.
Kuutti Lappalainen @ 2025-10-13T14:37 (+28)
Thanks for this post Aaron! I especially value the part about asymptotic structure instead of the sharp thresholds.
I think it’s useful for those interested in the topic to highlight the connection of your post to existing EA discussion and academic literature on ethics and decision theory. Here are some of the things I’m aware of:
- As @Robi Rahman🔸 points out, the post is arguing for an established view: lexical (negative) utilitarianism. I think The Center on Reducing Suffering’s critique of Toby Ord's blog post “Why I’m not a negative utilitarian” is a relevant discussion of negative utilitarianism that also touches on lexicality and can work as a “common misconceptions to avoid” for people new to the idea.
- Like you, Academian takes a critical look at the vNM axioms and argues against continuity being required in a LessWrong post. They highlight the original lexicality paper: Melvin Hausner’s 1954 “Multidimensional utilities” that weakens the continuity axiom of vNM, producing lexicality.
- Teo Ajantaival has an entire chapter in his book/sequence “Minimalist Axiologies” on “Doesn't this endorse destroying the world?”.
- On a more general note, vNM hasn’t been the favored framework in normative decision theory for a while. The frameworks of Savage and then Jeffrey-Bolker have provided increasingly realistic/reasonable setups while keeping the utilities and most of the properties of the axioms. I think Richard Bradley’s 2017 book “Decision Theory with a Human Face” provides the canonical background for current normative decision theory.
- In contrast to what you argue in footnote 21, completeness and transitivity have both been challenged (I think successfully). Especially Suzumura consistency and representor models (more on incompleteness in belief in Anthony DiGiovanni’s comment) are attractive alternatives as they are more appropriate for real agents like us and still invulnerable to value pumps.
Also, I think that in a precise baysian framework, the strongest argument against lexicality is that it is irrelevant because the EV of two options will almost never be exactly the same. This changes if we incorporate imprecision because then it is quite possible that the primary utility doesn’t provide a preference over two options and instead gives comparative indeterminacy which one could consider similar to indifference for the purpose of lexicality. That is to say, I think lexicality is more action-guidance relevant and conceptually attractive in an, arguably better, imprecise framework.
MichaelDickens @ 2025-11-13T16:20 (+23)
I think this model's assumptions are not just counterintuitive (as other commenters have noted) but internally contradictory.
Three premises:
- All VNM axioms except for Continuity.
- For some small amount of intense suffering, there is always some sufficiently large amount of moderate suffering such that the intense suffering is preferable.
- Small amounts of suffering can be offset by sufficiently large amounts of happiness.
Some people would reject #2 but if I understand correctly, your model takes all three of these premises as true.
Suppose world W has probability p of a large amount of moderate suffering, plus probability (1 - p) of an amount of happiness sufficient to offset it.
Let world W' have probability (1 - p) of the same amount of happiness but probability p of a smaller amount of intense suffering, such that the intense suffering in W' is preferable to the moderate suffering in W.
By the Independence axiom, W' must be preferable to W, and therefore W' is net positive, which means arbitrarily intense suffering can be offset by happiness.
Aaron Bergman @ 2025-11-20T22:53 (+4)
I do not accept premise 2:
For some small amount of intense suffering, there is always some sufficiently large amount of moderate suffering such that the intense suffering is preferable.
To be clear, I think this premise is one way of distilling and clarifying the (or 'a') crux of my argument and if I wind up convinced that the whole argument is wrong, it will probably be because I am convinced of premise 2 or something very similar
MichaelDickens @ 2025-11-21T17:28 (+2)
I see, I took the chart under "The compensation schedule's structure" to imply that the Axiom of Continuity held for suffering, based on the fact that the X axis shows suffering measured on a cardinal scale.
If you reject Continuity for suffering then I don't think your assumptions are self-contradictory.
Anthony DiGiovanni @ 2025-10-10T08:42 (+18)
Rejecting premise 1, completeness is essentially a nonstarter in the context of morality, where the whole project is premised on figuring out which worlds, actions, beliefs, rules, etc., are better than or equivalent to others. You can deny this your heart of hearts - I won’t say that you literally cannot believe that two things are fundamentally incomparable - but I will say that the world never accommodates your sincerely held belief or conscientious objector petition when it confronts you with the choice to take option A, option B, or perhaps coin flip between them.
This isn't central to your post, but I'm commenting on it because it's a very common defense of completeness in EA and I think rejecting completeness has very important implications:
I don't buy this argument. If you're forced to choose between A and B, and you pick A, this isn't enough to show you think A is "better" with respect to some particular normative view v — e.g., some lexical threshold consequentialism. You might have simply picked arbitrarily, or you might have chosen based on some other normative criteria you put some weight on.[1]
And incomparability differs from indifference in that, if you consider A and B incomparable, you might also consider "A + $1" and B incomparable. To me this property seems pretty intuitive in many cases, like this one from Schoenfield (in the context of relative probabilities, not betterness):
You are a confused detective trying to figure out whether Smith or Jones committed the crime. You have an enormous body of evidence that you need to evaluate. Here is some of it: You know that 68 out of the 103 eyewitnesses claim that Smith did it but Jones’ footprints were found at the crime scene. Smith has an alibi, and Jones doesn’t. But Jones has a clear record while Smith has committed crimes in the past. The gun that killed the victim belonged to Smith. But the lie detector, which is accurate 71% percent of the time, suggests that Jones did it. After you have gotten all of this evidence, you have no idea who committed the crime. You are no more confident that Jones committed the crime than that Smith committed the crime, nor are you more confident that Smith committed the crime than that Jones committed the crime.
[paraphrased:] But now you learn, actually 69 eyewitnesses claim Smith did it, not 68. The proposition that Smith did it has been mildly sweetened. So, should you now think that Smith is more likely to have done it than Jones?
- ^
There are some philosophical wrinkles involved in making this idea rigorous, which I hope to do in a forthcoming post. But see here for a bit of a preview.
Anthony DiGiovanni @ 2025-10-29T12:02 (+9)
I'd be pretty interested to hear why those who disagree-voted disagree.
Richard Y Chappell🔸 @ 2025-10-07T20:31 (+13)
Regarding the "world-destruction" reductio:
this isn't strong evidence against the underlying truth of suffering-focused views. Consider scenarios where the only options are (1) a thousand people tortured forever with no positive wellbeing whatsoever or (2) painless annihilation of all sentience. Annihilation seems obviously preferable.
I agree that it's obviously true that annihilation is preferable to some outcomes. I understand the objection as being more specific, targeting claims like:
(Ideal): annihilation is ideally desirable in the sense that it's better (in expectation) than any other remotely realistic alternative, including <detail broadly utopian vision here>. (After all, continued existence always has some chance of resulting in some uncompensable suffering at some point.)
or
(Uncompensable Monster): one being suffering uncompensable suffering at any point in history suffices to render the entire universe net-negative or undesirable on net, no matter what else happens to anyone else. We must all (when judging from an impartial point of view) regret the totality of existence.
These strike me as extremely incredible claims, and I don't think that most of the proposed "moderating factors" do much to soften the blow.
I grant your "virtual impossibility" point that annihilation is not really an available option (to us, at least; future SAI might be another matter). But the objection is to the plausibility of the in principle verdicts entailed here, much as I would object to an account of the harm of death that implies that it would do no harm to kill me in my sleep (the force of which objection would not be undermined by my actually being invincible).
Moral uncertainty might help if it resulted in the verdict that you all things considered should prefer positive-utilitarian futures (no matter their uncompensable suffering) over annihilation. But I'm not quite sure how moral uncertainty could deliver that verdict if you really regard the suffering as uncompensable. How could a lower degree of credence in ordinary positive goods rationally outweigh a higher degree of credence in uncompensable bads? It seems like you'd instead need to give enough credence to something even worse: e.g. violating an extreme deontic constraint against annihilation. But that's very hard to credit, given the above-quoted case where annihilation is "obviously preferable".)
The "irreversibility" consideration does seem stronger here, but I think ultimately rests on a much more radical form of moral uncertainty: it's not just that you should give some (minority) weight to other views, but that you should give significant weight to the possibility that a more ideally rational agent would give almost no weight to such a pro-annihilationist view as this. Some kind of anti-hubris norm along these lines should probably take priority over all of our first-order views. I'm not sure what the best full development of the idea would look like, though. (It seems pretty different from ordinary treatments of moral uncertainty!) Pointers to related discussion would be welcome!
I think a more promising form of suffering-focused ethics would explore some form of "variable value" approach, which avoids annihilationism in principle by allowing harms to be compensated (by sufficient benefits) when the alternative is no population at all, but introduces variable thresholds for various harms being specifically uncompensable by extra benefits beyond those basic thresholds. I'm not sure whether a view of this structure could be made to work, but it seems more worth exploring than pro-annihilationist principles.
Aaron Bergman @ 2025-10-08T18:42 (+4)
Thanks!
(Ideal): annihilation is ideally desirable in the sense that it's better (in expectation) than any other remotely realistic alternative, including <detail broadly utopian vision here>. (After all, continued existence always has some chance of resulting in some uncompensable suffering at some point.)
Yeah I mean on the first one, I acknowledge that this seems pretty counterintuitive to me but again just don't think it is overwhelming evidence against the truth of the view.
Perhaps a reframing is "would this still seem like a ~reductio conditional on a long reflection type scenario that results in literally everyone agreeing that it's desirable/good?"
And I don't mean this in the sense of just "assume that the conclusion is ground truth" - I mean it in the sense of "does this look as bad when it doesn't involve anyone doing anything involuntary?" to try to tease apart whether intuitions around annihilation per se are to any extent "just" a proxy for guarding against the use of force/coercion/lack of consent.
Another way to flip the 'force' issue would be "suppose a society concludes unanimously including via some extremely deliberative process (that predicts and includes the preferences of potential future people) that annihilation is good and desired. Should some outside observer forcibly prevent them taking action to this end (assume that the observer is interested purely in ethics and doesn't care about their own existence or have valenced experience)?"
I'll note that I can easily dream up scenarios where we should force people, even a whole society, to do something against its will. I know some will disagree, but I think we should (at least in principle, implementation is messy) forcibly prevent people from totally voluntarily being tortured (assume away masochism - like suppose the person just has a preference for suffering that results in pure suffering with no 'secretly liking it' along for the ride)
(Uncompensable Monster): one being suffering uncompensable suffering at any point in history suffices to render the entire universe net-negative or undesirable on net, no matter what else happens to anyone else. We must all (when judging from an impartial point of view) regret the totality of existence.
These strike me as extremely incredible claims, and I don't think that most of the proposed "moderating factors" do much to soften the blow.
This one I more eagerly bite the bullet on, it just straightforwardly seems true to me that this is possible in principle (i.e., such a world could/would be genuinely very bad). And relevantly, orthodox utilitarianism also endorses this in principle, some of the time (i.e. just add up the utils, in principle one suffering monster can have enough negative utility)!
Moral uncertainty might help if it resulted in the verdict that you all things considered should prefer positive-utilitarian futures (no matter their uncompensable suffering) over annihilation. But I'm not quite sure how moral uncertainty could deliver that verdict if you really regard the suffering as uncompensable. How could a lower degree of credence in ordinary positive goods rationally outweigh a higher degree of credence in uncompensable bads? It seems like you'd instead need to give enough credence to something even worse: e.g. violating an extreme deontic constraint against annihilation. But that's very hard to credit, given the above-quoted case where annihilation is "obviously preferable".)
I don't have an answer to this (yet) because my sense is just that figuring out how to make overall assessments of probability distributions on various moral views is just extremely hard in general and not "solved".
This actually reminds me of a shortform post I wrote a while back. Let me just drop a screenshot to make my life a bit easier in terms of formatting nested quotes:

I think this^ brief discussion of how the two sides might look at the same issue gets at the fundamental problem/non-obviousness of the matter pretty well.
I think a more promising form of suffering-focused ethics would explore some form of "variable value" approach, which avoids annihilationism in principle by allowing harms to be compensated (by sufficient benefits) when the alternative is no population at all, but introduces variable thresholds for various harms being specifically uncompensable by extra benefits beyond those basic thresholds. I'm not sure whether a view of this structure could be made to work, but it seems more worth exploring than pro-annihilationist principles.
I think we may just have very different background stances on like how to do ethics. I think that we should more strongly decouple the project of abstract object level truth seeking from the project of figuring out a code of norms/rules/de facto ethics that satisfies all our many constraints and preferences today. The thing you propose seems promising to me as like a coalitional bargaining proposal for guiding action in the near future, but not especially promising as a candidate for abstract moral truth.
Richard Y Chappell🔸 @ 2025-10-09T14:53 (+6)
Thanks for your reply! Working backwards...
On your last point, I'm fully on board with strictly decoupling intrinsic vs instrumental questions (see, e.g., my post distinguishing telic vs decision-theoretic questions). Rather, it seems we just have very different views about what telic ends or priorities are plausible. I give ~zero credence to pro-annihilationist views on which it's preferable for the world to end than for any (even broadly utopian) future to obtain that includes severe suffering as a component. Such pro-annihilationist lexicality strikes me as a non-starter, at the most intrinsic/fundamental/principled levels. By contrast, I could imagine some more complex variable-value/threshold approach to lexicality turning out to have at least some credibility (even if I'm overall more inclined to think that the sorts of intuitions you're drawing upon are better captured at the "instrumental heuristic" level).
On moral uncertainty: I agree that bargaining-style approaches seem better than "maximizing expected choiceworthiness" approaches. But then if you have over 50% credence in a pro-annihilationist view, it seems like the majority rule is going to straightforwardly win out when it comes to determining your all-things-considered preference regarding the prospect of annihilation.
Re: uncompensable monster: It isn't true that "orthodox utilitarianism also endorses this in principle", because a key part of the case description was "no matter what else happens to anyone else". Orthodox consequentialism allows that any good or bad can be outweighed by what happens to others (assuming strictly finite values). No one person or interest can ever claim to settle what should be done no matter what happens to others. It's strictly anti-absolutist in this sense, and I think that's a theoretically plausible and desirable property that your view is missing.
Another way to flip the 'force' issue would be "suppose a society concludes unanimously including via some extremely deliberative process (that predicts and includes the preferences of potential future people) that annihilation is good and desired. Should some outside observer forcibly prevent them taking action to this end (assume that the observer is interested purely in ethics and doesn't care about their own existence or have valenced experience)?"
I don't think it's helpful to focus on external agents imposing their will on others, because that's going to trigger all kinds of instrumental heuristic norms against that sort of thing. Similarly, one might have some concerns about there being some moral cost to the future not going how humanity collectively wants it to. Better to just consider natural causes, and/or comparisons of alternative possible societal preferences. Here are some possible futures:
(A) Society unanimously endorses your view and agrees that, even though their future looks positive in traditional utilitarian terms, annihilation would be preferable.
- (A1): A quantum-freak black hole then envelops the Earth without anyone suffering (or even noticing).
- (A2): After the present generations stop reproducing and go extinct, a freak accident in a biolab creates new human beings who go on to repopulate the Earth (creating a future similar to the positive-but-imperfect one that previous generations had anticipated but rejected).
(B) Society unanimously endorses my view and agrees that, even though existence entails some severe suffering, it is compensable and the future overall looks extremely bright.
- (B1): A quantum-freak black hole then envelops the Earth without anyone suffering (or even noticing).
- (B2): The broadly-utopian (but imperfect) future unfolds as anticipated.
Intuitively: B2 > A2 > A1 > B1.
I think it would be extremely strange to think that B1 > B2, or that A1 > B2. In fact, I think those verdicts are instantly disqualifying: any view yielding those verdicts deserves near-zero credence.
(I think A1 is broadly similar to, though admittedly not quite as bad as, a scenario C1 in which everyone decides that they deserve to suffer and should be tortured to death, and then some very painful natural disaster occurs which basically tortures everyone to death. It would be even worse if people didn't want it, but wanting it doesn't make it good.)
RalfG @ 2025-10-09T08:49 (+2)
@Richard Y Chappell🔸 what do you think of Aaron's response below? I am using this comment to flag that the discussion you two are having seems very important to me, and I look forward to seeing your reply to Aaron's points.
River @ 2025-10-07T19:00 (+10)
My main issue here is a linguistic one. I've considered myself a utilitarian for years. I've never seen anything like this UC, though I think I agree with it, and with a stronger version of premise 4 that does insist on something like a mapping to the real numbers. You are essentially constructing an ethical theory, which very intentionally insists that there is no amount good that can offset certain bads, and trying to shove it under the label "utilitarian". Why? What is your motivation? I don't get that. We already have a label for such ethical theories, deontology. The usefulness of having the label "utilitarian" is precisely to pick out those ethical theories that do at least in principle allow offsetting any bad with a sufficient good. That is a very central question on which people's ethical intuitions and judgments differ, and which this language of utilitarianism and deontology has been created to describe. This is where one of realities joints is.
For myself, I do not share your view that some bads cannot be offset. When you talk of 70 years of the worst suffering in exchange for extreme happiness until the heat death of the universe, I would jump on that deal in a heartbeat. There is no part of me that questions whether that is a worthwhile trade. I cannot connect with your stated rejection of it. And I want to have labels like "utiliarian" and "effective altruist" to allow me to find and cooperate with others who are like me in this regard. Your attempt to get your view under these labels seems both destructive of my ability to do that, and likely unproductive for you as well. Why don't you want to just use other more natural labels like "deontology" to find and cooperate with others like you?
Robi Rahman🔸 @ 2025-10-08T03:24 (+8)
This isn't deontology, it's lexical-threshold negative utilitarianism.
https://reducing-suffering.org/three-types-of-negative-utilitarianism/
Aaron Bergman @ 2025-10-09T03:33 (+2)
I disagree but think I know what you're getting at and am sympathetic. I made the following to try to illustrate and might add it in to the post if it seems clarifying
I made it on a whim just now without thinking too hard so don't necessarily consider the graphical representation on as solid footing as the stuff in the post
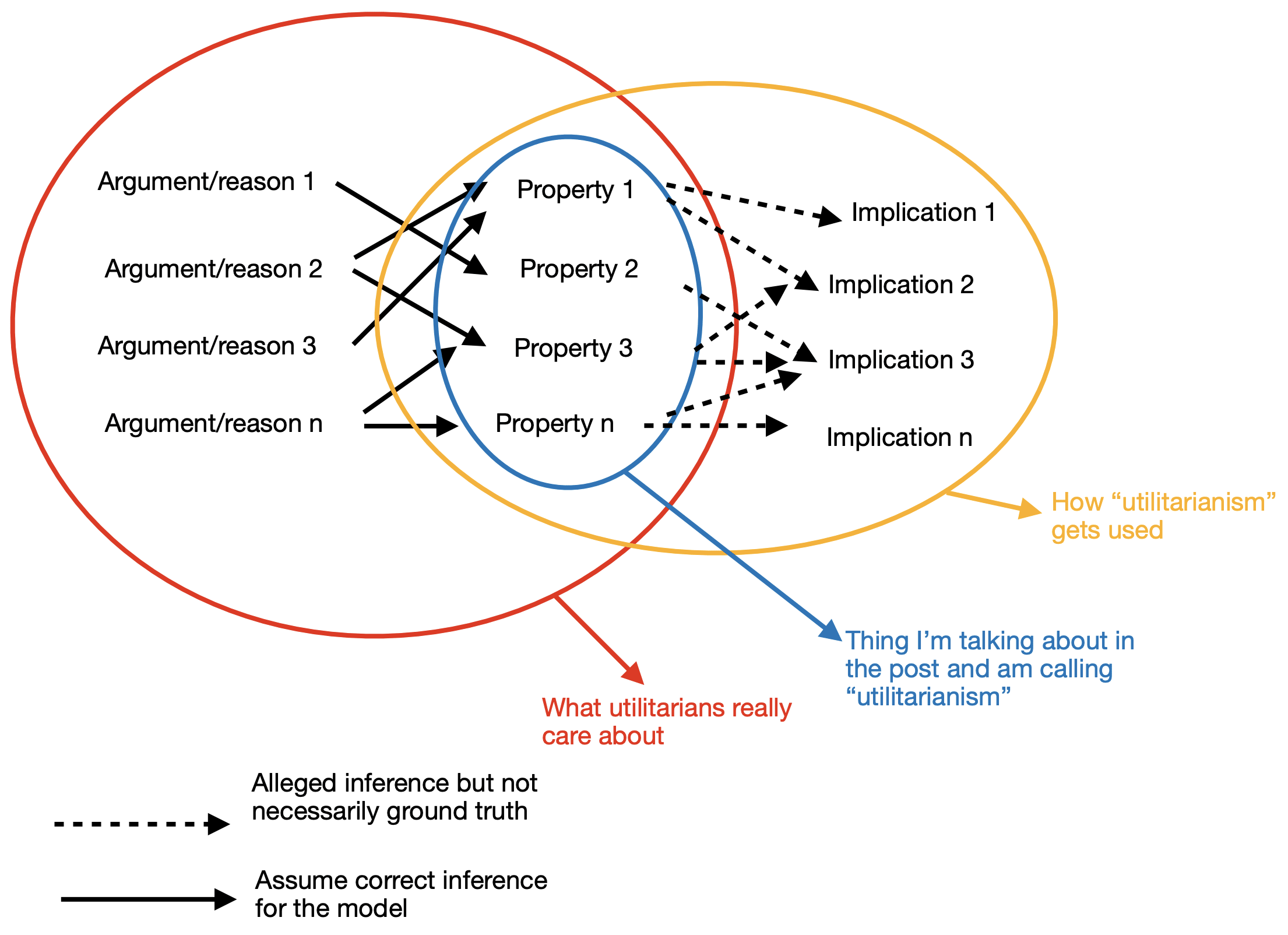
Nunik @ 2025-10-08T21:04 (+9)
Consider trade-offs between suffering of medium and extreme severity, where medium severity could be described as hurtful or disabling. It seems hard to defend that no duration of medium suffering could ever outweigh a short duration of extreme suffering. This is not a matter of downplaying the extreme suffering for its short duration, but rather of appreciating the magnitude of an eternity of medium suffering. (I think the idea of eternity really helps in imagining what is at stake when one assumes lexicality.)
It also seems a priori implausible that having any particular experience could somehow reveal information about it being lexically superior to other experiences. Experiencing extreme suffering can tell us that its quality is extremely bad, but this insight is duration-insensitive. Filling the entire universe with people experiencing medium suffering forever seems to be decidedly worse than a single person experiencing extreme suffering for a few hours.
So if one deems medium suffering offsetable by pleasure, then extreme suffering will be offsetable as well, assuming transitivity.
Thomas Kwa @ 2025-10-07T06:02 (+9)
There are a few mistakes/gaps in the quantitative claims:
Continuity: If A ≻ B ≻ C, there's some probability p ∈ (0, 1) where a guaranteed state of the world B is ex ante morally equivalent to "lottery p·A + (1-p)·C” (i.e., p chance of state of the world A, and the rest of the probability mass of C)
This is not quite the same as either property 3 or property 3' in the Wikipedia article, and it's plausible but unclear to me that you can prove 3' from it. Property 3 uses "p ∈ [0, 1]" and 3' has an inequality; it seems like the argument still goes through with 3' so I'd switch to that, but then you should also say why 3 is unintuitive to you because VNM only requires 3 OR 3'.
This arbitrariness diminishes somewhat (though, again, not entirely) when viewed through the asymptotic structure. Once we accept that compensation requirements grow without bound as suffering intensifies, some threshold becomes inevitable. The asymptote must diverge somewhere; debates about exactly where are secondary to recognizing the underlying pattern.
"Grow without bound" just means that for any M, we have f(X) > M for sufficiently large X. This is different from there being a vertical asymptote so a threshold is not inevitable. For instance one could have f(X) = X or f(X) = X^2.
To be clear, whether we call this behavior 'continuous' depends on mathematical context and convention. In standard calculus, a function that approaches infinity exhibits an infinite discontinuity. [...]
[1] In the extended reals with appropriate topology, such a function can be rigorously called left-continuous.
It would be confusing to call this behavior continuous, because (a) the VNM axiom you reject is called continuity and (b) we are not using any other properties of the extended reals, but we are using real-valued probabilities and x values.
Once you've accepted that some suffering might require a number of flourishing lives that you could not write down, compute, or physically instantiate to morally justify, at least in principle, the additional step to "infinite" is smaller in some important conceptual sense than it might seem prima facie.
This may seem like a nitpick, but "write down", "compute", and "physically instantiate" are wildly different ranges of numbers. The largest number one could "physically instantiate" is something like 10^50 minds, the most one could "write down" the digits of is something like 10^10^10.
Not all large numbers are the same here, because if one thinks the offset ratio for a cluster headache is in the 10^50 range, there are only 50 'levels' of suffering each of which is 10x worse than the last. If it's over 10^10^10, there are over 10 billion such 'levels', it would be impossible to rate cluster headaches on a logarithmic pain scale, and we would happily give everyone on Earth (say) a level 10,000,000,000 cluster headache to prevent one person from having a (slightly worse than average) level 10,000,000,010 cluster headache. Moving from 10^10^10 to infinity, we would then believe that suffering has a threshold t where t + epsilon intensity suffering cannot be offset by removing t - epsilon intensity suffering, and also need to propose some other mechanism like lexicographic order for how to deal with suffering above the infinite badness threshold.
So it's already a huge step to reject numbers we can "physically instantiate" to ones we can barely "write down", and another step from there to infinity; at both steps your treatment of comparisons between different suffering intensities changes significantly, even in thought experiments without an unphysically large number of beings.
Aaron Bergman @ 2025-10-08T03:18 (+1)
Thanks, yeah I may have gotten slightly confused when writing.
1) VNM
Wikipedia screenshot:

Let P be the thing I said in the post:
If A ≻ B ≻ C, there's some probability p ∈ (0, 1) where a guaranteed state of the world B is ex ante morally equivalent to "lottery p·A + (1-p)·C”
or, symbolically
and let
I think but not in general.
So my writing was sloppy. Super good catch (not caught by any of the various LLMs iirc!)
But for the purposes of the argument everything holds together because you need independence axiom for VNM to hold. But still, sloppy.
2) "grows without bound" bit
Me: "This arbitrariness diminishes somewhat (though, again, not entirely) when viewed through the asymptotic structure. Once we accept that compensation requirements grow without bound as suffering intensifies, some threshold becomes inevitable. The asymptote must diverge somewhere; debates about exactly where are secondary to recognizing the underlying pattern."
You:
"Grow without bound" just means that for any M, we have f(X) > M for sufficiently large X. This is different from there being a vertical asymptote so a threshold is not inevitable. For instance one could have f(X) = X or f(X) = X^2.
Straightforward error by me, I will change the wording. Not sure how that happened
3) "continuity"
It would be confusing to call this behavior continuous, because (a) the VNM axiom you reject is called continuity and (b) we are not using any other properties of the extended reals, but we are using real-valued probabilities and x values.
Yeah, idk, English and math only provide so many words. I could have spent more words more driving home and clarifying this point or inventing and defining additional terms. My intuition is that it's clear enough as is (evidently we disagree about this) but if a couple other people say "yeah this is misleading and confusing" then I'll concede that I made a bad choice about clarity vs brevity as a writing decision.
4) "write down", "compute", and "physically instantiate" till end
Ngl I am pretty confused about everything starting here. I think I'm just reading you wrong somehow. Like the difference in those magnitudes is huge, point taken, but I don't see why that matters for my argument.
Moving from 10^10^10 to infinity, we would then believe that suffering has a threshold t where t + epsilon intensity suffering cannot be offset by removing t - epsilon intensity suffering
Confused here because yeah clearly adding t+epsilon and removing t-epsilon gives you a net change below zero. But I sense you might be getting at the (very substantive and important) cluster of critiques I respond to in this comment (?)
also need to propose some other mechanism like lexicographic order for how to deal with suffering above the infinite badness threshold.
Yeah I'm ~totally agnostic about this in the post. There are many substantively different possibilities about what the moral world might be like when dealing above that threshold, I agree! Could be distinct levels of lexicality, perhaps some literal integer like 13 levels or perhaps arbitrarily many. Probably other solutions/models as well
Maybe I should just remove/modify the "write down", "compute", and "physically instantiate" bit of rhetorical flourish because it might be doing more harm than good.
(Note that it may take me some time to update the post to reflect sections 1 and 2 in this comment)
Again, sharp eye, thanks for the comment!
Aaron Bergman @ 2025-10-07T21:40 (+8)
I am getting really excellent + thoughtful comments on this (not just saying that) - I will mention here that I have highly variable and overall reduced capacity for personal reasons at the moment, so please forgive me if it takes a little while for me to respond (and in the mean time note that I have read stuff so they're not being ignored) 🙂
EJT @ 2025-10-06T14:08 (+8)
Also you might be interested in this paper from Andreas Mogensen which discusses a similar idea.
SummaryBot @ 2025-10-06T16:23 (+7)
Executive summary: The post argues—carefully and mostly confidently on the logic, more tentatively on the metaphysics—that total utilitarianism does not logically entail that any suffering can be “offset,” and that some extreme suffering is in fact non-offsetable, implying a longtermist reorientation toward minimizing catastrophic suffering and s-risks rather than maximizing aggregate happiness (exploratory, philosophy-first reframing rather than an empirical policy brief).
Key points:
- Offsetability isn’t implied by the Utilitarian Core: Consequentialism, (hedonic) welfarism, impartiality, aggregation, and maximization don’t force all welfare to live on a single real-number scale; the usual “representation premise” is an extra, substantive assumption.
- Alternative formalisms preserve aggregation while blocking offsetability: Lexicographic orderings or hyperreals allow comparisons and addition yet prevent any finite good from compensating certain bads; VNM expected-utility theorems don’t rescue offsetability because the required continuity axiom is rejected here.
- Metaphysical claim via Idealized Hedonic Egoist: When you (ideally rational and fully informed) must experience all lives, trades like “70 years of maximal torture for any later bliss” look indefensibly bad—evidence that some suffering is non-offsetable.
- Asymptotic, not arbitrary, threshold: The “compensation” needed to justify increasing suffering rises without bound as it approaches a catastrophic threshold; even sub-threshold suffering may demand astronomically large (practically unreachable) compensation, making the move to “infinite” a small further step.
- Implications for longtermism and s-risk: Prioritize preventing lock-in or growth of extreme suffering and be cautious about creating vast populations that include it; reject simplistic “extinction is good” conclusions while emphasizing moral uncertainty, cooperation, irreversibility, and unilateralist-risk considerations.
- Stated uncertainties and bullets bitten: Open questions include time-granularity (does a microsecond of super-bad experience cross the threshold?); the author does bite the bullet that any nonzero probability of catastrophic suffering morally matters lexically; evolutionary debunking is addressed but not found decisive.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
Aaron Bergman @ 2025-10-06T00:25 (+5)
I made an audio version:
Also: Copy to clipboard as markdown link for LLM stuff
Ben Yeoh @ 2025-10-06T15:48 (+2)
The point in 4. 2 re: transitivity is what Larry Temkin weakens in his work, and is a point I make in my own blog essay on this. Temkin makes arguments that transitivity might not hold. This would partially strengthen your arguments. (Potentially you can’t make vlid additive aggregation arguments). Kudos to writing all of this up.