Chris Olah on what the hell is going on inside neural networks
By 80000_Hours @ 2021-08-04T15:13 (+5)
This is a linkpost for #107 - Chris Olah on what the hell is going on inside neural networks. You can listen to the episode on that page, or by subscribing to the '80,000 Hours Podcast' wherever you get podcasts.
In this interview Chris and Rob discuss Chris's personal take on what we’ve learned so far about what machine learning (ML) algorithms are doing, and what’s next for the research agenda at Anthropic, where Chris works. They also cover:
- Why Chris thinks it’s necessary to work with the largest models
- Whether you can generalise from visual to language models
- What fundamental lessons we’ve learned about how neural networks (and perhaps humans) think
- What it means that neural networks are learning high-level concepts like ‘superheroes’, mental health, and Australiana, and can identify these themes across both text and images
- How interpretability research might help make AI safer to deploy, and Chris’ response to skeptics
- Why there’s such a fuss about ‘scaling laws’ and what they say about future AI progress
- What roles Anthropic is hiring for, and who would be a good fit for them
Imagine if some alien organism landed on Earth and could do these things.
Everybody would be falling over themselves to figure out how… And so really the thing that is calling out in all this work for us to go and answer is, “What in the wide world is going on inside these systems??”
–Chris Olah
Key points
Interpretability
Chris Olah: Well, in the last couple of years, neural networks have been able to accomplish all of these tasks that no human knows how to write a computer program to do directly. We can’t write a computer program to go and classify images, but we can write a neural network to create a computer program that can classify images. We can’t go and write computer programs directly to go and translate text highly accurately, but we can train the neural network to go and translate texts much better than any program we could have written.
Chris Olah: And it’s always seemed to me that the question that is crying out to be answered there is, “How is it that these models are doing these things that we don’t know how to do?” I think a lot of people might debate exactly what interpretability is. But the question that I’m interested in is, “How do these systems accomplish these tasks? What’s going on inside of them?”
Chris Olah: Imagine if some alien organism landed on Earth and could go and do these things. Everybody would be rushing and falling over themselves to figure out how the alien organism was doing things. You’d have biologists fighting each other for the right to go and study these alien organisms. Or imagine that we discovered some binary just floating on the internet in 2012 that could do all these things. Everybody would be rushing to go and try and reverse engineer what that binary is doing. And so it seems to me that really the thing that is calling out in all this work for us to go and answer is, “What in the wide world is going on inside these systems??”
Chris Olah: The really amazing thing is that as you start to understand what different neurons are doing, you actually start to be able to go and read algorithms off of the weights… We can genuinely understand how large chunks of neural networks work. We can actually reverse engineer chunks of neural networks and understand them so well that we can go and hand-write weights… I think that is a very high standard for understanding systems.
Chris Olah: Ultimately the reason I study (and think it’s useful to study) these smaller chunks of neural network is that it gives us an epistemic foundation for thinking about interpretability. The cost is that we’re talking to these small parts and we’re setting ourselves up for a struggle to be able to build up the understanding of large neural networks and make this sort of analysis really useful. But it has the upside that we’re working with such small pieces that we can really objectively understand what’s going on… And I think there’s just a lot of disagreement and confusion, and I think it’s just genuinely really hard to understand neural networks and very easy to misunderstand them, so having something like that seems really useful.
Universality
Chris Olah: Just like animals have very similar anatomies — I guess in the case of animals due to evolution — it seems neural networks actually have a lot of the same things forming, even when you train them on different data sets, even when they have different architectures, even though the scaffolding is different. The same features and the same circuits form. And actually I find that the fact that the same circuits form to be the most remarkable part. The fact that the same features form is already pretty cool, that the neural network is learning the same fundamental building blocks of understanding vision or understanding images.
Chris Olah: But then, even though it’s scaffolded on differently, it’s literally learning the same weights, connecting the same neurons together. So we call that ‘universality.’ And that’s pretty crazy. It’s really tempting when you start to find things like that to think “Oh, maybe the same things form also in humans. Maybe it’s actually something fundamental.” Maybe these models are discovering the basic building blocks of vision that just slice up our understanding of images in this very fundamental way.
Chris Olah: And in fact, for some of these things, we have found them in humans. So some of these lower-level vision things seem to mirror results from neuroscience. And in fact, in some of our most recent work, we’ve discovered something that was previously only seen in humans, these multimodal neurons.
Multimodal neurons
Chris Olah: So we were investigating this model called CLIP from OpenAI, which you can roughly think of as being trained to caption images or to pair images with their captions. So it’s not classifying images, it’s doing something a little bit different. And we found a lot of things that were really deeply qualitatively different inside it. So if you look at low-level vision actually, a lot of it is very similar, and again is actually further evidence for universality.
Chris Olah: A lot of the same things we find in other vision models occur also in early vision in CLIP. But towards the end, we find these incredibly abstract neurons that are just very different from anything we’d seen before. And one thing that’s really interesting about these neurons is they can read. They can go and recognize text and images, and they fuse this together, so they fuse it together with the thing that’s being detected.
Chris Olah: So there’s a yellow neuron for instance, which responds to the color yellow, but it also responds if you write the word yellow out. That will fire as well. And actually it’ll fire if you write out the words for objects that are yellow. So if you write the word ‘lemon’ it’ll fire, or the word ‘banana’ will fire. This is really not the sort of thing that you expect to find in a vision model. It’s in some sense a vision model, but it’s almost doing linguistic processing in some way, and it’s fusing it together into what we call these multimodal neurons. And this is a phenomenon that has been found in neuroscience. So you find these neurons also for people. There’s a Spider-Man neuron that fires both for the word Spider-Man as an image, like a picture of the word Spider-Man, and also for pictures of Spider-Man and for drawings of Spider-Man.
Chris Olah: And this mirrors a really famous result from neuroscience of the Halle Berry neuron, or the Jennifer Aniston neuron, which also responds to pictures of the person and the drawings of the person and to the person’s name. And so these neurons seem in some sense much more abstract and almost conceptual, compared to the previous neurons that we found. And they span an incredibly wide range of topics.
Chris Olah: In fact, a lot of the neurons, you just go through them and it feels like something out of a kindergarten class, or an early grade-school class. You have your color neurons, you have your shape neurons, you have neurons corresponding to seasons of the year, and months, to weather, to emotions, to regions of the world, to the leader of your country, and all of them have this incredible abstract nature to them.
Chris Olah: So there’s a morning neuron that responds to alarm clocks and times of the day that are early, and to pictures of pancakes and breakfast foods — all of this incredible diversity of stuff. Or season neurons that respond to the names of the season and the type of weather associated with them and all of these things. And so you have all this incredible diversity of neurons that are all incredibly abstract in this different way, and it just seems very different from the relatively concrete neurons that we were seeing before that often correspond to a type of object or such.
Chris Olah: I think this is a very reasonable concern, and is the main downside of circuits. So right now, I guess probably the largest circuit that we’ve really carefully understood is at 50,000 parameters. And meanwhile, the largest language models are in the hundreds of billions of parameters. So there’s quite a few orders of magnitudes of difference that we need to get past if we want to even just get to the modern language models, let alone futuCan this approach scale?re generations of neural networks. Despite that, I am optimistic. I think we actually have a lot of approaches to getting past this problem.
In the interview, Chris lays out several paths to addressing the scaling challenge. First, the basic approach to circuits might be more scalable than it seems at first glance, both because large models may become easier to understand in some ways, and because understanding recurring “motifs” can sometimes give order of magnitude simplifications (eg. equivariance). Relatedly, if the stakes are high enough, we might be willing to use large amounts of human labor to audit neural networks. Finally, circuits is a kind of epistemic foundation that we can build an understanding of “larger scale structure” like branches or “tissues” on top of. Possibly, these larger structures may either directly answer safety questions or help us focus our efforts to understand safety on portions of the model.
How wonderful it would be if this could succeed
Chris Olah: We’ve talked a lot about the ways this could fail, and I think it’s worth saying how wonderful it would be if this could succeed. It’s both that it’s potentially something that makes neural networks much safer, but there’s also just some way in which I think it would aesthetically be really wonderful if we could live in a world where we have… We could just learn so much and so many amazing things from these neural networks. I’ve already learned a lot about silly things, like how to classify dogs, but just lots of things that I didn’t understand before that I’ve learned from these models.
Chris Olah: You could imagine a world where neural networks are safe, but where there’s just some way in which the future is kind of sad. Where we’re just kind of irrelevant, and we don’t understand what’s going on, and we’re just humans who are living happy lives in a world we don’t understand. I think there’s just potential for a future — even with very powerful AI systems — that isn’t like that. And that’s much more humane and much more a world where we understand things and where we can reason about things. I just feel a lot more excited for that world, and that’s part of what motivates me to try and pursue this line of work.
Chris Olah: There’s this idea of a microscope AI. So people sometimes will talk about agent AIs that go and do things, and oracle AIs that just sort of give us wise advice on what to do. And another vision for what a powerful AI system might be like — and I think it’s a harder one to achieve than these others, and probably less competitive in some sense, but I find it really beautiful — is a microscope AI that just allows us to understand the world better, or shares its understanding of the world with us in a way that makes us smarter and gives us a richer perspective on the world. It’s something that I think is only possible if we could really succeed at this kind of understanding of models, but it’s… Yeah, aesthetically, I just really prefer it.
Ways that interpretability research could help us avoid disaster
Chris Olah: On the most extreme side, you could just imagine us fully, completely understanding transformative AI systems. We just understand absolutely everything that’s going on inside them, and we can just be really confident that there’s nothing unsafe going on in them. We understand everything. They’re not lying to us. They’re not manipulating us. They are just really genuinely trying to be maximally helpful to us. And sort of an even stronger version of that is that we understand them so well that we ourselves are able to become smarter, and we sort of have a microscope AI that gives us this very powerful way to see the world and to be empowered agents that can help create a wonderful future.
Chris Olah: Okay. Now let’s imagine that actually interpretability doesn’t succeed in that way. We don’t get to the point where we can totally understand a transformative AI system. That was too optimistic. Now what do we do? Well, maybe we’re able to go and have this kind of very careful analysis of small slices. So maybe we can understand social reasoning and we can understand whether the model… We can’t understand the entire model, but we can understand whether it’s being manipulative right now, and that’s able to still really reduce our concerns about safety. But maybe even that’s too much to ask. Maybe we can’t even succeed at understanding that small slice.
Chris Olah: Well, I think then what you can fall back to is maybe just… With some probability you catch problems, you catch things where the model is doing something that isn’t what you want it to do. And you’re not claiming that you would catch even all the problems within some class. You’re just saying that with some probability, we’re looking at the system and we catch problems. And then you sort of have something that’s kind of like a mulligan. You made a mistake and you’re allowed to start over, where you would have had a system that would have been really bad and you realize that it’s bad with some probability, and then you get to take another shot.
Chris Olah: Or maybe as you’re building up to powerful systems, you’re able to go and catch problems with some probability. That sort of gives you a sense of how common safety problems are as you build more powerful systems. Maybe you aren’t very confident you’ll catch problems in the final system, but you can sort of help society be calibrated on how risky these systems are as you build towards that.
Scaling Laws
Chris Olah: Basically when people talk about scaling laws, what they really mean is there’s a straight line on a log-log plot. And you might ask, “Why do we care about straight lines on log-log plots?” There’s different scaling laws for different things, and the axes depend on which scaling law you’re talking about. But probably the most important scaling law — or the scaling law that people are most excited about — has model size on one axis and loss on the other axis. [So] high loss means bad performance. And so the observation you have is that there is a straight line. Where as you make models bigger, the loss goes down, which means the model is performing better. And it’s a shockingly straight line over a wide range.
Chris Olah: The really exciting version of this to me … is that maybe there’s scaling laws for safety. Maybe there’s some sense in which whether a model is aligned with you or not may be a function of model size, and sort of how much signal you give it to do the human-aligned task. And we might be able to reason about the safety of models that are larger than the models we can presently build. And if that’s true, that would be huge. I think there’s this way in which safety is always playing catch-up right now, and if we could create a way to think about safety in terms of scaling laws and not have to play catch-up, I think that would be incredibly remarkable. So I think that’s something that — separate from the capabilities implications of safety laws — is a reason to be really excited about them.
Articles, books, and other media discussed in the show
Selected work Chris has been involved in
- Circuits Thread (start at Zoom In: An Introduction to Circuits)
- Multimodal Neurons in Artificial Neural Networks
- Building Blocks of Interpretability
- Activation Atlases
- Anthropic (and their vacancies page)
- Interpretability vs Neuroscience
- See Chris’ website for a more complete overview of his interpretability research and pedagogical writing
- DeepDream
- Microscope
- Understanding RL Vision
Papers
- Using Artificial Intelligence to Augment Human Intelligence
- Scaling Laws for Transfer
- Visualizing and Measuring the Geometry of BERT
- A Multiscale Visualization of Attention in the Transformer Model
- What does BERT Look At? An Analysis of BERT’s Attention
- Circuits thread on Distill
Other links
- Anscombe’s quartet
- Danny Hernandez on forecasting and the drivers of AI progress
- Media for Thinking the Unthinkable
- CLIP
- AI and efficiency
- Learning from Human Preferences
Transcript
Rob’s intro [00:00:00]
Rob Wiblin: Hi listeners, this is the 80,000 Hours Podcast, where we have unusually in-depth conversations about the world’s most pressing problems, what you can do to solve them, and how come there’s a cloud there but not a cloud right there just next to it. I’m Rob Wiblin, Head of Research at 80,000 Hours.
I’m really excited to share this episode. Chris Olah, today’s guest, is one of the top machine learning researchers in the world.
He’s also excellent at communicating complex ideas to the public, with his blog posts and twitter threads attracting millions of readers. A survey of listeners even found he was one of the most-followed people among subscribers to this show.
And yet despite being a big deal, this is the first podcast, and indeed long interview, Chris has ever done. Fortunately I don’t think you’d be able to tell he hasn’t actually done this many times before!
We ended up having so much novel content cover with Chris that we did more than one recording session, and the end result is two very different episodes we’re both really happy with.
This first one focuses on Chris’ technical work, and explores topics like:
- What is interpretability research, and what’s it trying to solve
- How neural networks work, and how they think
- ‘Multimodal neurons’, and their implications for AI safety work
- Whether this approach can scale
- Digital suffering
- Scaling laws
- And how wonderful it would be if this work could succeed
If you find the technical parts of this episode a bit hard going, before you stop altogether — I’d recommend skipping to the chapter called “Anthropic, and the safety of large models”, or [2:11:05] in to hear all about the very exciting project Chris is helping to grow right now. You don’t have to be an AI researcher to work at Anthropic, so I think people from a wide range of backgrounds could benefit from sticking around till the end.
For what it’s worth I’m far from being an expert on AI but I was able to follow Chris and learn a lot about what’s really going on with research into big machine learning models.
The second episode, which if everything goes smoothly we hope to release next week, is focused on his fascinating personal story — including how he got to where he is today without having a university degree.
One final thing: Eagle-eared listeners will notice that our audio changes a few times, and that’s because, as is often the case with longer episodes, Keiran cut together sections from multiple sessions to try and create a better final product.
Without further ado, I bring you Chris Olah.
The interview begins [00:02:19]
Rob Wiblin: Today I’m speaking with Chris Olah. Chris is a machine learning researcher currently focused on neural network interpretability. Until last December he led OpenAI’s interpretability team but along with some colleagues he recently moved on to help start a new AI lab focussed on large models and safety called Anthropic.
Rob Wiblin: Before OpenAI he spent 4 years at Google Brain developing tools to visualize what’s going on in neural networks. Chris was hugely impactful at Google Brain. He was second author on the launch of the Deep Dream back in 2015 which I think almost everyone has seen at this point. He has also pioneered feature visualization, activation atlases, building blocks of interpretability, Tensor Flow, and even co-authored the famous paper “concrete problems in AI Safety.”
Rob Wiblin: On top of all that in 2018 he helped found the academic journal Distill, which is dedicated to publishing clear communication of technical concepts. And Chris is himself a writer who is popular among many listeners to this show, having attracted millions of readers by trying to explain cutting-edge machine learning in highly accessible ways.
Rob Wiblin: In 2012 Chris took a $100k Thiel Fellowship, a scholarship designed to encourage gifted young people to go straight into research or entrepreneurship rather than go to a university — so he’s actually managed to do all of the above without a degree.
Rob Wiblin: Thanks so much for coming on the podcast Chris!
Chris Olah: Thanks for having me.
Rob Wiblin: Alright, I hope that we’re going to get to talk about your new project Anthropic and the interpretability research, which has been one of your big focuses lately. But first off, it seems like you kind of spent the last eight years contributing to solving the AI alignment problem in one form or another. Can you just say a bit about how you conceive of the nature of that problem at a high level?
Chris Olah: When I talk to other people about safety, I feel like they often have pretty strong views, or developed views on what the nature of the safety problem is and what it looks like. And I guess actually, one of the lessons I’ve learned trying to think about safety and work on it, and think about machine learning broadly, has been how often I seem to be wrong in retrospect, or I think that I wasn’t thinking about things in the right way. And so, I think I don’t really have a very confident take on safety. It seems to me like it’s a problem that we actually don’t know that much about. And that trying to theorize about it a priori can really easily lead you astray.
Chris Olah: And instead, I’m very interested in trying to empirically understand these systems, empirically understand how they might be unsafe, and how we might be able to improve that. And in particular, I’m really interested in how we can understand what’s really going on inside these systems, because that seems to me like one of the biggest tools we can have in understanding potential failure modes and risks.
Rob Wiblin: In that case, let’s waste no time on big-picture theoretical musings, and we can just dive right into the concrete empirical technical work that you’ve been doing, which in this case is kind of reverse engineering neural networks in order to look inside them and understand what’s actually going on.
Rob Wiblin: The two online articles that I’m going to be referring to most here are the March 2020 article Zoom In: An Introduction to Circuits, which is the first piece in a series of articles about the idea of circuits, which we’ll discuss in a second. And also the very recent March 2021 article Multimodal Neurons in Artificial Neural Networks.
Rob Wiblin: Obviously we’ll link to both of those, and they’ve got lots of beautifully and carefully designed images, so potentially worth checking out if listeners really want to understand all of this thoroughly. They’re both focused on the issue of interpretability in neural networks, visual neural networks in particular. I wouldn’t lie to you, those articles were kind of pushing my understanding and I didn’t follow them completely, but maybe Chris can help me get it out properly here.
Interpretability [00:05:54]
Rob Wiblin: First though, can you explain what problem this line of research is aiming to solve, at a big picture level?
Chris Olah: Well, in the last couple of years, neural networks have been able to accomplish all of these tasks that no human knows how to write a computer program to do directly. We can’t write a computer program to go and classify images, but we can write a neural network to create a computer program that can classify images. We can’t go and write computer programs directly to go and translate text highly accurately, but we can train the neural network to go and translate texts much better than any program we could have written.
Chris Olah: And it’s always seemed to me that the question that is crying out to be answered there is, “How is it that these models are doing these things that we don’t know how to do?” I think a lot of people might debate exactly what interpretability is. But the question that I’m interested in is, “How do these systems accomplish these tasks? What’s going on inside of them?”
Chris Olah: Imagine if some alien organism landed on Earth and could go and do these things. Everybody would be rushing and falling over themselves to figure out how the alien organism was doing things. You’d have biologists fighting each other for the right to go and study these alien organisms. Or imagine that we discovered some binary just floating on the internet in 2012 that could do all these things. Everybody would be rushing to go and try and reverse engineer what that binary is doing. And so it seems to me that really the thing that is calling out in all this work for us to go and answer is, “What in the wide world is going on inside these systems??”
Rob Wiblin: What are the problems with not understanding it? Or I guess, what would be the benefits of understanding it?
Chris Olah: Well, I feel kind of worried about us deploying systems — especially systems in high-stakes situations or systems that affect people’s lives — when we don’t know how they’re doing the things they do, or why they’re doing them, and really don’t know how to reason about how they might behave in other unanticipated situations.
Chris Olah: To some extent, you can get around this by testing the systems, which is what we do. We try to test them in all sorts of cases that we’re worried about how they’re going to perform, and on different datasets. But that only gets us to the cases that are covered in our datasets or that we explicitly thought to go and test for. And so, I think we actually have a great deal of uncertainty about how these systems are going to behave.
Chris Olah: And I think especially as they become more powerful, you have to start worrying about… What if in some sense they’re doing the right thing, but they’re doing it for the wrong reasons? They’re implementing the correct behavior, but maybe the actual algorithm that is underlying that is just trying to get reward from you, in some sense, rather than trying to help you. Or maybe it’s relying on things that are biased, and you didn’t realize that. And so I think that being able to understand these systems is a really, really important way to try and address those kinds of concerns.
Rob Wiblin: I guess understanding how it’s doing what it’s doing might make it a bunch easier to predict how it’s going to perform in future situations, or— if the situation changes — the situation in which you’re deploying it. Whereas if you have no understanding of what it’s doing, then you’re kind of flying blind. And maybe the circumstances could change. What do they call it? Change of domain, or…?
Chris Olah: Yeah. So you might be worried about distributional shift, although in some ways I think that doesn’t even emphasize quite enough what my biggest concern is. Or I feel maybe it makes it sound like this kind of very technical robustness issue.
Chris Olah: I think that what I’m concerned about is something more like… There’s some sense in which modern language models will sometimes lie to you. In that there are questions to which they knew the right answer, in some sense. If you go and pose the question in the right way, they will give you the correct answer, but they won’t give you the right answer in other contexts. And I think that’s sort of an interesting microcosm for a world in which these models are… In some sense they’re capable of doing things, but they’re trying to accomplish a goal that’s different from the one you want. And that may, in sort of unanticipated ways, cause problems for you.
Chris Olah: I guess another way that I might frame this is, “What are the unknown safety problems?” What are the unknown unknowns of deploying these systems? And if there’s something that you sort of anticipate as a problem, you can test for it. But I think as these systems become more and more capable, they will sort of abruptly sometimes change their behavior in different ways. And there’s always unknown unknowns. How can you hope to go and catch those? I think that’s a big part of my motivation for wanting to study these systems, or how I think studying these systems can make things more safe.
Rob Wiblin: Let’s just maybe give listeners a really quick reminder of how neural networks work. We’ve covered this in previous interviews, including a recent one with Brian Christian. But basically you can imagine information flowing between a whole bunch of nodes, and the nodes are connected to one another, and which nodes are connected to which other ones — kind of like which neurons are connected to other neurons in the brain — is determined by this learning process. The weightings that you get between these different neurons is determined by this learning process. And then when a neuron gets enough positive input, then it tends to fire and then pass on a signal onto the next neuron, which is, in a sense, in the next layer of the network. And so, information is processed and passed between these neurons until it kind of spits out an answer at the other end. Is that a sufficiently vague or sufficiently accurate description for what comes next?
Chris Olah: If I was going to nitpick slightly, usually the, “Which neurons connect to which neurons,” doesn’t change. That’s usually static, and the weights evolve over training.
Rob Wiblin: So rather than disappear, the weights just go to a low level.
Chris Olah: Yeah.
Rob Wiblin: As I understand it, based on reading these two pieces, you and a bunch of other colleagues at Google Brain and OpenAI have made pretty substantial progress on interpretability, and this has been a pretty big deal among ML folks, or at least some ML folks. How long have you all been at this?
Chris Olah: I’ve been working on interpretability for about seven years, on and off. I’ve worked on some other ML things interspersed between it, but it’s been the main thing I’ve been working on. Originally, it was a pretty small set of people who were interested in these questions. But over the years, I’ve been really lucky to find a number of collaborators who are also excited about these types of questions. And more broadly, a large field has grown around this, often taking different approaches, instead of the ones that I’m pursuing. But there’s now a non-trivial field working on trying to understand neural networks in different ways.
Rob Wiblin: What different approaches have you tried over the years?
Chris Olah: I’ve tried a lot of things over the years, and a lot of them haven’t worked. Honestly, in retrospect, it’s often been obvious why. At one point I tried this sort of topological approach of trying to understand how neural networks bend to data. That doesn’t scale to anything beyond the most trivial systems. Then I tried this approach of trying to do dimensionality reduction of representations. That doesn’t work super well either, at least for me.
Chris Olah: And to cut a long story short, the thing that I have ended up settling on primarily is this almost stupidly simple approach of just trying to understand what each neuron does, and how all the neurons connect together, and how that gives rise to behavior. The really amazing thing is that as you start to understand what different neurons are doing, you actually start to be able to go and read algorithms off of the weights.
Chris Olah: There’s a slightly computer science-heavy analogy that I like, which might be a little bit hard for some readers to follow, but I often think of neurons as being variables in a computer program, or registers in assembly. And I think of the weights as being code or assembly instructions. You need to understand what the variables are storing if you want to understand the code. But then once you understand that, you can actually sort of see the algorithms that the computer program is running. That’s where things I think become really, really exciting and remarkable. I should add by the way, about all of this, I’m the one who’s here talking about it, but all of this has been the result of lots of people’s work, and I’m just incredibly lucky to have had a lot of really amazing collaborators working on this with me.
Rob Wiblin: Yeah, no doubt. So what can we do now that we couldn’t do 10 years ago, thanks to all of this work?
Chris Olah: Well, I think we can genuinely understand how large chunks of neural networks work. We can actually reverse engineer chunks of neural networks and understand them so well that we can go and hand-write weights. You just take a neural network where all the weights are set to zero, and you write by hand the weights, and you can go and re-implant a neural network that does the same thing as that chunk of the neural network did. You can even splice it into a previous network and replace the part that you understood. And so I think that is a very high standard for understanding systems. I sometimes like to imagine interpretability as being a little bit like cellular biology or something, where you’re trying to understand the cell. And I feel maybe we’re starting to get to the point where we can understand one small organelle in the cell, or something like this, and we really can nail that down.
Rob Wiblin: So we’ve gone from having a black box to having a machine that you could potentially redesign manually, or at least parts of it.
Chris Olah: Yeah. I think that the main story, at least from the circuits approach, is that we can take these small parts. And they’re small chunks, but we can sort of fully understand them.
Features and circuits [00:15:11]
Rob Wiblin: So two really key concepts here are features and circuits. Can you explain for the audience what those are and how you pull them out?
Chris Olah: When we talk about features, we most often (though not always) are referring to an individual neuron. So you might have an individual neuron that does something like responds when there’s a curve present, or responds to a line, or responds to a transition in colors. Later on, we’ll probably talk about neurons that respond to Spider-Man or respond to regions of the world, so they can also be very high level.
Chris Olah: And a circuit is a subgraph of a neural network. So the nodes are features, so the node might be a curve detector and a bunch of line detectors, and then you have the weights of how they connect together. And those weights are sort of the actual computer program that’s running, that’s going and building later features from the earlier features.
Rob Wiblin: So features are kind of smaller things like lines and curves and so on. And then a circuit is something that puts together those features to try to figure out what the overall picture is?
Chris Olah: A circuit is a partial program that’s building the later features from the earlier features. So circuits are connections between features, and they contribute to building the later features from the earlier features.
Rob Wiblin: I see. Okay. If you can imagine within, say, a layer of a neural network, you’ve got different neurons that are picking up features and then the way that they go onto the next layer, they’re the combinations of weights between these different kinds of features that have been identified, and how they push forward into features that are identified in the next layer…that’s a circuit?
Chris Olah: Yeah. Although often we’d look at a subset of neurons that are tightly connected together, so you might be interested in how, say, the curve detectors in one layer are built from features in the previous layer. And then there’s a subset of features of the previous layer that are tightly intertwined with that, and then you could look at that, so you’re looking at a smaller subgraph. You might also go over multiple layers, so you might look at… There’s actually this really beautiful circuit for detecting dog heads.
Chris Olah: And I know it sounds crazy to describe that as beautiful, but I’ll describe the algorithm because I think it’s actually really elegant. So in InceptionV1, there’s actually two different pathways for detecting dog heads that are facing to the left and dog heads that are facing to the right. And then, along the way, they mutually inhibit each other. So at every step it goes and builds the better dog head facing each direction and has it so that the opposite one inhibits it. So it’s sort of saying, “A dog’s head can only be facing left or right.”
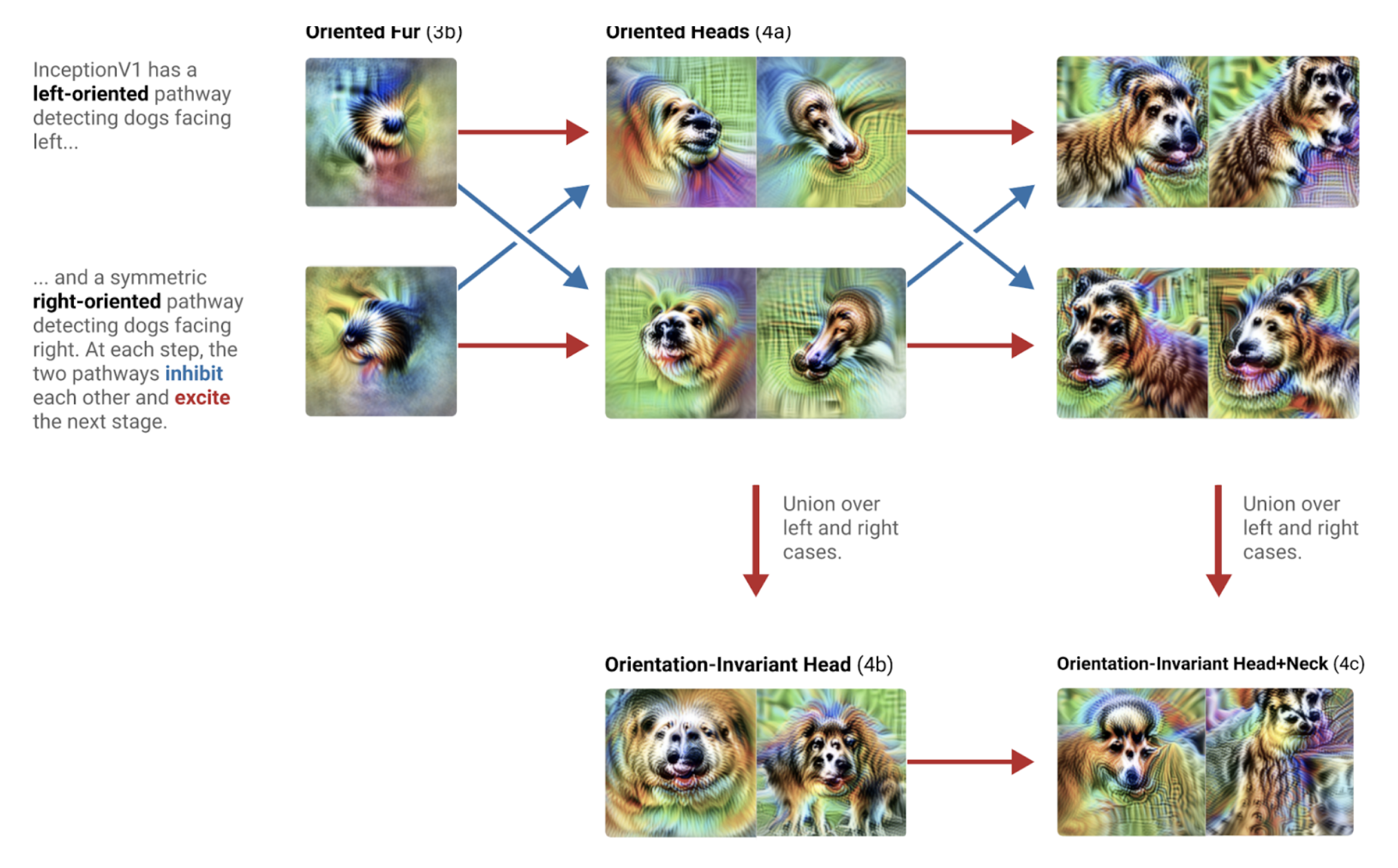
Chris Olah: And then finally at the end, it goes and unions them together to create a dog head detector, that is pose-invariant, that is willing to fire both for a dog head facing left and a dog head facing right.
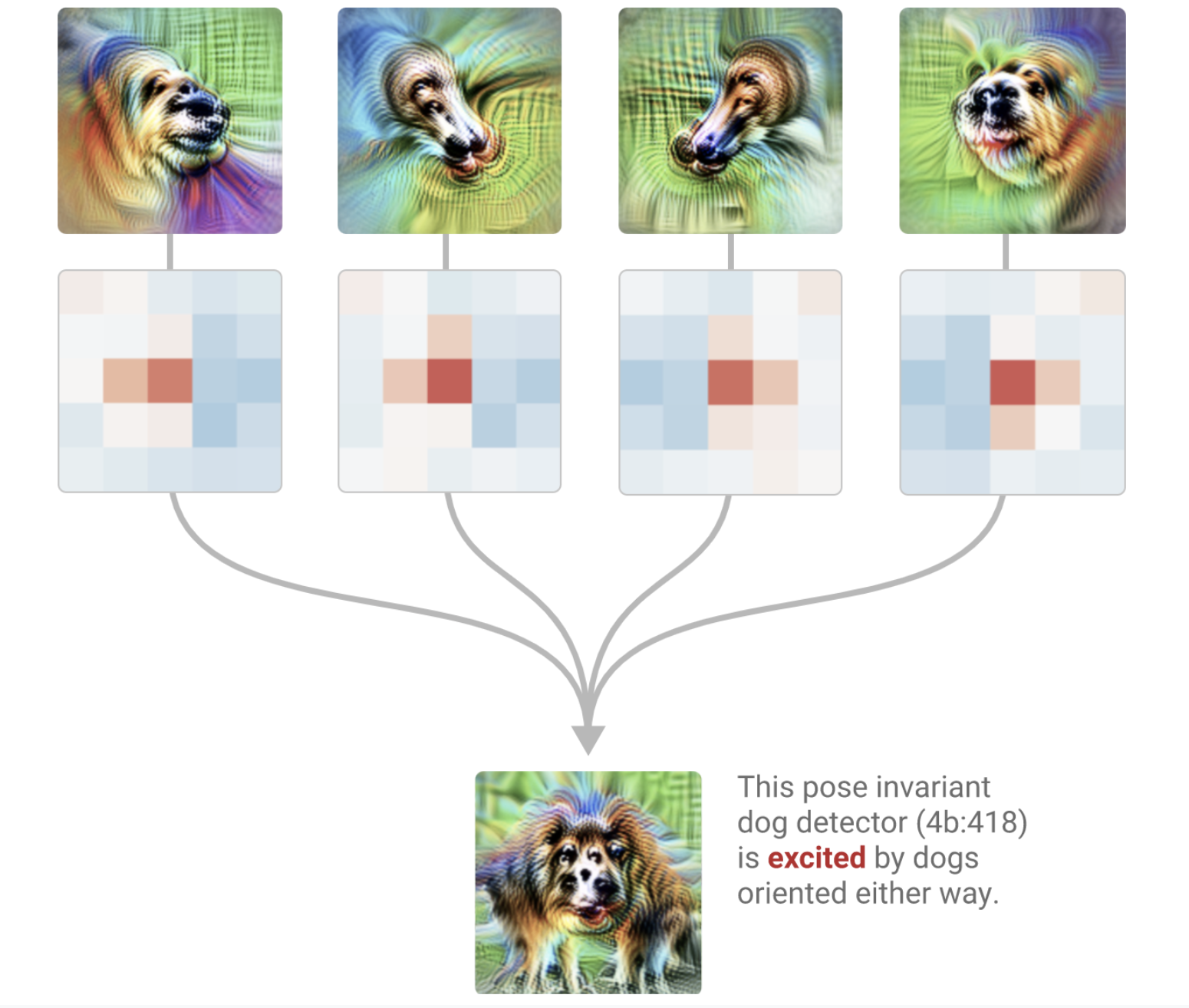
Rob Wiblin: So I guess you’ve got neurons that kind of correspond to features. So a neuron that fires when there’s what appears to be fur, and then a neuron that fires when there appears to be a curve of a particular kind of shape. And then a bunch of them are linked together and they either fire together or inhibit one another, to indicate a feature at a higher level of abstraction. Like, “This is a dog head,” and then more broadly, you said, “This is this kind of dog.” It would be the next layer. Is that kind of right?
Chris Olah: That’s directionally right.
Rob Wiblin: Interesting. Was it hard to come up with the technical methods that you use to identify what feature a neuron corresponds to? And how do you pull together all of the different connections and weights that should be seen as functioning as a circuit?
Chris Olah: There’s this interesting thing where neural network researchers often look at weights in the first layer, so it’s actually very common to see papers where people look at the weights in the first layer. And the reason is that those weights connect to red, green, and blue channels in an image. If you’re, say, doing vision, those weights are really easy to interpret because you know what the inputs to those weights are. And you almost never see people look at weights anywhere else in the model in the same kind of way. And I think the reason is that they don’t know what the inputs and the outputs to those weights are. So if you want to study weights anywhere other than the absolute input, or maybe the absolute output, you need to have some technique for understanding what the neurons that are going in and out of those weights are.
Chris Olah: And so there’s a number of ways you can do that. One thing you could do is you could just look at what we call dataset examples. Just feed lots of examples through the neural network and look for the ones that cause neurons to fire. That’d be a very neuroscience-y approach. But another approach that we found is actually very effective is to optimize the input. We call this ‘feature visualization.’ You just do gradient descent to go in and create an image that causes a neuron to fire really strongly.
Chris Olah: And the nice thing about that is it separates correlation from causation. In that resulting image, you know that everything that’s there is there because it caused the neuron to fire. And then we often use these feature visualizations, both as they’re a useful clue for understanding what the neurons are doing, but we also often just use them like variable names. So rather than having a neuron be mixed4c:447, we say have an image that stimulates it. It’s a car detector, so you have an image of a car, and that makes it much easier to go and keep track of all the neurons and reason how they connect together.
Rob Wiblin: So it seems you’ve got this method where you choose a neuron, or you choose some combination of connections that forms a circuit. And then you try to figure out what image is going to maximally make that neuron, or that circuit, fire. And you said gradient descent, which, as I understand it, is you choose a noisy image and then you just bit by bit get it to fire more and more, until you’ve got an image that’s pretty much optimally designed, through this iterative process, to really slam that neuron hard. And so, if that neuron is there to pick up fur, then you’ll figure out the archetypal fur-thing that this neuron is able to identify. Is that right?
Chris Olah: Yeah. And then once you understand the features, you can use that as scaffolding to then understand the circuit.
Rob Wiblin: I see, okay. I think I didn’t realize this until I was doing research for this episode, but you got this microscope website at OpenAI, they’re hosting it, where you can work through this big image recognition neural network and kind of pick out… I don’t know whether it’s all of them, but there’s many different neurons, and then see what are the kinds of images that cause this to fire. And you’d be like, “Oh, that’s something that’s identifying this kind of shape,” or, “This is a neuron that corresponds to this kind of fur color,” or whatever else. And you can see how this flows through the network in quite a sophisticated way. It really is pulling apart this machine and seeing what each of the little pieces does.
Chris Olah: Yeah. Microscope is wonderful. It allows you to go and look at any neuron that you want. I think it actually points to a deeper, underlying advantage or thing that’s nice about studying neural networks, which is that we can all look at exactly the same neural network. And so there could be these sort of standard models, where every neuron is exactly the same as the model that I’m studying. And we can just go and have one organization, in this case, OpenAI, go and create a resource once, that makes it easy to go and reference every neuron in that model. And then every researcher who’s studying that model can easily go and look at arbitrary parts of it just by navigating to a URL.
Rob Wiblin: By the way, people have probably seen DeepDream and they might have seen, if they’ve looked at any of these articles, the archetypal images and shapes and textures that are firing these particular feature neurons, but the colors are always so super weird. It produces this surrealist DeepDream thing. I would think if you had a neuron that was firing for fur, then it would actually look like a cat’s fur. Or it was a beer shop sign, if it’s a shop-sign neuron. But the fact that they kind of look like this crazy psychedelic experience… Is there some reason why that’s the case?
Chris Olah: After we published DeepDream, we got a number of emails from quite serious neuroscientists asking us if we wanted to go and study with them, whether we could explain experiences that people have when they’re on drugs, using DeepDream. So I think this analogy is one that really resonates with people.
Chris Olah: But why are there those colors? Well, I think there’s a few reasons. I think the main one is you’re sort of creating a super stimulus, you’re creating the stimulus that most causes the neurons to fire. And the super stimulus, it’s not surprising that it’s going to push colors to very extreme regimes, because that’s the most extreme version of the thing that neuron is looking for.
Chris Olah: There’s also a more subtle version of that answer, which is, suppose that you have a curve detector. It turns out that actually one thing the neuron is doing is just looking for any change in color across the curve. Because if there’s different colors on both sides, that sort of means that it’s stronger. In fact, this is just generally true of line detectors; it’s very early on neural networks. The line detector is… A line fires more if there’s different colors on both sides of the line. And so the maximal stimulus for that just has any difference in colors. It doesn’t even care what the two colors are, it just wants to see a difference in colors.
Rob Wiblin: So the reason that they can look kind of weird is just that these feature detectives are mostly just picking up differences between things, and so they want a really stark difference in color. And maybe the specific color that the thing happens to be doesn’t matter so much. So it doesn’t have to look like actual cat fur, it’s just the color gradient that’s getting picked up.
Chris Olah: Depends on the case and it depends a lot also on the particular neuron. There’s one final reason, which is a bit more technical, which is that often neural networks are trained with a little bit of hue rotation, sometimes a lot of hue rotation, which means that the images, the colors, are sort of randomly shuffled a little bit before the neural network sees them. And the idea is that this makes the neural network a bit more robust, but it makes neural networks a little bit less sensitive to the particular color that they are seeing. And you can actually often tell how much hue rotation that neural network was trained with by exactly the color patterns that you’re seeing, when you do these feature visualizations.
How neural networks think [00:24:38]
Rob Wiblin: So what concretely can we learn about what, or how, a neural network system like this is thinking, using these methods?
Chris Olah: Well, in some sense, you can sort of quite fully understand it, but you understand a small fraction. You can understand what a couple of neurons are doing and how they connect together. You can get it to the point where your understanding is just basic math, and you can just basic logic and reason through what it’s doing. And the challenge is that it’s only a small part of the model, but you literally understand what algorithm is running in that small part of the model and what it’s doing.
Rob Wiblin: From those articles, it sounded like you think we’ve potentially learned some really fundamental things about how neural networks work. And potentially, not only how these thinking machines work, but also how neural networks might function in the brain. And maybe how they always necessarily have to function. What are those things that you think we might’ve learned, and what’s the evidence for them?
Chris Olah: Well, one of the fascinating things is that the same patterns form and the same features in circuits form again and again across models. So you might think that every neural network is its own special snowflake and that they’re all doing totally different stuff. That would make for a boring, or a very strange, field of trying to understand these things.
Chris Olah: So another analogy I sometimes like is to think of interpretability as being like anatomy, and we’re dissecting… This is a little bit strange because I’m a vegan, but it’s grown on me over time. We’re dissecting these neural networks and looking at what’s going on inside them, like an early anatomist might have looked at animals. And if you imagine early anatomy, just every organism had a totally different anatomy and there were no similarities between them. There’s nothing like a heart that exists in lots of them. That would create a kind of boring field of anatomy. You probably wouldn’t want to invest in trying to understand most animals.
Chris Olah: But just like animals have very similar anatomies — I guess in the case of animals due to evolution — it seems neural networks actually have a lot of the same things forming, even when you train them on different data sets, even when they have different architectures, even though the scaffolding is different. The same features and the same circuits form. And actually I find that the fact that the same circuits form to be the most remarkable part. The fact that the same features form is already pretty cool, that the neural network is learning the same fundamental building blocks of understanding vision or understanding images.
Chris Olah: But then, even though it’s scaffolded on differently, it’s literally learning the same weights, connecting the same neurons together. So we call that ‘universality.’ And that’s pretty crazy. It’s really tempting when you start to find things like that to think “Oh, maybe the same things form also in humans. Maybe it’s actually something fundamental.” Maybe these models are discovering the basic building blocks of vision that just slice up our understanding of images in this very fundamental way.
Chris Olah: And in fact, for some of these things, we have found them in humans. So some of these lower-level vision things seem to mirror results from neuroscience. And in fact, in some of our most recent work, we’ve discovered something that was previously only seen in humans, these multimodal neurons.
Rob Wiblin: We’ll talk about multimodal neurons in just a second. But it sounds like you’re saying you train lots of different neural networks to identify images. You train them on different images and they have different settings you’re putting them in, but then every time, you notice these common features. You’ve got things that identify particular shapes and curves and particular kinds of textures. I suppose also, things are organized in such a way that there are feature-detecting neurons and these organized circuits, for moving from lower-level features to higher-level features, that just happen every time basically. And then we have some evidence, you think, that this is matching things that we’ve learned about, how humans process visual information in the brain as well. So there’s a prima facie case, although it’s not certain, that these universal features are always going to show up.
Chris Olah: Yeah. And it’s almost tempting to think that there’s just fundamental elements of vision or something that just are the fundamental things that you want to have, if you reason about images. That a line is, in some sense, a fundamental thing for reasoning about images. And that these fundamental elements, or building blocks, are just always present.
Rob Wiblin: Is it possible that you’re getting these common features and circuits because we’re training these networks on very similar images? It seems we love to show neural networks cats and dogs and grass and landscapes, and things like that. So possibly it’s more of a function of the images that we’re training them on than something fundamental about vision.
Chris Olah: So you could actually look at models that are trained on pretty different datasets. There’s this dataset called ‘places,’ which is recognizing buildings and scenes. Those don’t have dogs and cats, and a lot of the same features form. Now, it tends to be the case that as you go higher up, the features are more and more different. So in the later layers you have these really cool neurons related to different visual perspectives, like what angle am I looking at a building from. What you don’t see in image models and vice versa. Image models have all of these features related to dogs and cats that you don’t see in the places model. But there do seem to be a lot of things that are fundamental, especially in earlier vision, that form in both of those datasets.
Rob Wiblin: A question would be, if aliens trained a model, or if we could look into an alien brain somewhere, would it show all of these common features? And I suppose, maybe it does just make a lot of intuitive sense that a line, an edge, a curve, these are very fundamental features. So even on other planets, they’re going to have lines. But maybe at the high level some of the features and some of the circuits are going to correspond to particular kinds of things that humans have, that exist in our world, and they may not exist on another planet.
Chris Olah: Yeah, that’s exactly right. And it’s the kind of thing that is purely supposition, but is really tempting to imagine. And I think it’s an exciting vision for what might be going on here. I do find the stories of investigating these systems… That does feel just emotionally more compelling, when I think that we’re actually discovering these deeply fundamental things, rather than these things that just happened to be arbitrarily true for a single system.
Rob Wiblin: Yeah. You’ve discovered the fundamental primitive nature of a line.
Chris Olah: Yeah. Or I mean, I think it’s more exciting when we discover these things that people haven’t seen before, or that people don’t guess. There are these things called ‘high-low frequency detectors’ that seem to form little models.
Rob Wiblin: Yeah, explain those?
Chris Olah: They’re just as the name suggests. They look for high-frequency patterns on one side of the receptive field, and low-frequency patterns on the other side of the receptive field.
Rob Wiblin: What do you mean by high frequency and low frequency here?
Chris Olah: So a pattern with lots of texture to it and sharp transitions might be high frequency, whereas a low-frequency image would be very smooth. Or an image that’s out of focus will be low frequency.
Rob Wiblin: So it’s picking up how sharp and how many differences there are, within that section of the image versus another part of it.
Chris Olah: Exactly. Models use these as part of boundary detections. There’s a whole thing of using multiple different cues to do boundary detection. And one of them is these transitions in frequency. And so for instance you could see this happen at the boundary of an object where the background is out of focus and it’s very low frequency, whereas the foreground is higher frequency. But you also just see this maybe if there are two objects that are adjacent and they have different textures, you’ll get a frequency transition as well. And in retrospect, it makes sense that you have these features, but they’re not something that I ever heard anyone predict in advance we’d find. And so it’s exciting to discover these things that weren’t predicted in advance.
Chris Olah: And that both suggests that you might’ve said “Oh, these attempts to understand neural networks, they’re only going to understand the things that humans guessed were there,” and it sort of repeats that. But it also suggests that maybe there are just all of these… We’re digging around inside these systems and we’re discovering all these things, and there’s this entire wealth of things to be discovered that no one’s seen before. I don’t know, maybe we’re discovering mitochondria for the first time or something like that. And they’re just there, waiting for you to find them.
Rob Wiblin: The universality conjecture that you’re all toying with would be that at some point, we’ll look into the human brain and find all of these high-low detector neurons and circuits in the human brain as well, and they’re playing an important role in us identifying objects when we look out into the world?
Chris Olah: That would be the strong version. And also just that every neural network we look in that’s doing natural image vision is going to go and have them as well, and they’re really just this fundamental thing that you find everywhere.
Rob Wiblin: I just thought of a way that you could potentially get a bit more evidence for this universality idea. Obviously humans have some bugs in how they observe things, they can get tricked visually. Maybe we could check if the neural networks on the computers also have these same errors. Do they have the same ways in which they get things right and get things wrong? And then that might suggest that they’re perhaps following a similar process.
Chris Olah: Yeah. I think there’s been a few papers that are exploring ideas like this. And actually, in fact, when we talk about the multimodal neuron results, we’ll have one example.
Multimodal neurons [00:33:30]
Rob Wiblin: Well, that’s a perfect moment to dive into the multimodal neuron article, which just came out a couple of weeks ago. I guess it’s dealing with more state-of-the-art visual detection models? What did you learn in that work that was different from what came before?
Chris Olah: So we were investigating this model called CLIP from OpenAI, which you can roughly think of as being trained to caption images or to pair images with their captions. So it’s not classifying images, it’s doing something a little bit different. And we found a lot of things that were really deeply qualitatively different inside it. So if you look at low-level vision actually, a lot of it is very similar, and again is actually further evidence for universality.
Chris Olah: A lot of the same things we find in other vision models occur also in early vision in CLIP. But towards the end, we find these incredibly abstract neurons that are just very different from anything we’d seen before. And one thing that’s really interesting about these neurons is they can read. They can go and recognize text and images, and they fuse this together, so they fuse it together with the thing that’s being detected.
Chris Olah: So there’s a yellow neuron for instance, which responds to the color yellow, but it also responds if you write the word yellow out. That will fire as well. And actually it’ll fire if you write out the words for objects that are yellow. So if you write the word ‘lemon’ it’ll fire, or the word ‘banana’ will fire. This is really not the sort of thing that you expect to find in a vision model. It’s in some sense a vision model, but it’s almost doing linguistic processing in some way, and it’s fusing it together into what we call these multimodal neurons. And this is a phenomenon that has been found in neuroscience. So you find these neurons also for people. There’s a Spider-Man neuron that fires both for the word Spider-Man as an image, like a picture of the word Spider-Man, and also for pictures of Spider-Man and for drawings of Spider-Man.
Chris Olah: And this mirrors a really famous result from neuroscience of the Halle Berry neuron, or the Jennifer Aniston neuron, which also responds to pictures of the person and the drawings of the person and to the person’s name. And so these neurons seem in some sense much more abstract and almost conceptual, compared to the previous neurons that we found. And they span an incredibly wide range of topics.
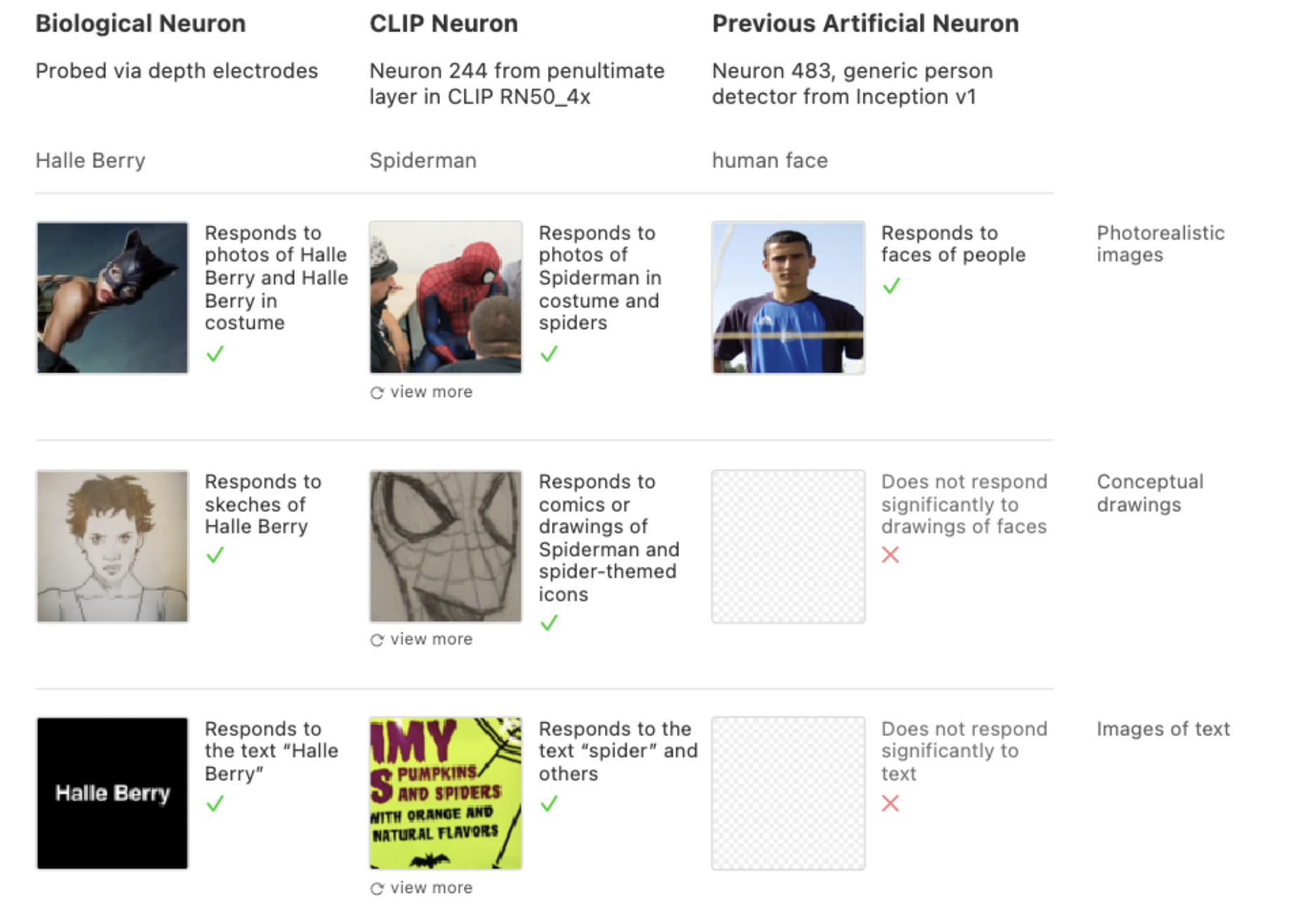
Chris Olah: In fact, a lot of the neurons, you just go through them and it feels like something out of a kindergarten class, or an early grade-school class. You have your color neurons, you have your shape neurons, you have neurons corresponding to seasons of the year, and months, to weather, to emotions, to regions of the world, to the leader of your country, and all of them have this incredible abstract nature to them.
Chris Olah: So there’s a morning neuron that responds to alarm clocks and times of the day that are early, and to pictures of pancakes and breakfast foods — all of this incredible diversity of stuff. Or season neurons that respond to the names of the season and the type of weather associated with them and all of these things. And so you have all this incredible diversity of neurons that are all incredibly abstract in this different way, and it just seems very different from the relatively concrete neurons that we were seeing before that often correspond to a type of object or such.
Rob Wiblin: So we’ve kind of gone from having an image recognition network that can recognize that this is a head, to having a network that can recognize that something is beautiful, or that this is a piece of artwork, or that this is an Impressionist piece of art. It’s a higher level of abstraction, a grouping that lots of different images might have in common of many different kinds in many different places.
Chris Olah: Yeah. And it’s not even about seeing the object, it’s about things that are related to the object. For instance, you see a Barack Obama neuron in some of these models and it of course responds to images of Barack Obama, but also to his name and a little bit for U.S. flags and also for images of Michelle Obama. And all these things that are associated with him also cause it to fire a little bit.
Rob Wiblin: When put it that way it just sounds like it’s getting so close to doing what humans do. What we do when going about in the world. We’ve got all of these associations between different things, and then when people speak, the things that they say kind of draw to mind particular different things with different weightings. And that’s kind of how I feel like I reason. Language is very vague, right? Lots of different words just have different associations, and you smash them together and then the brain makes of it what it will. So it’s possible that it’s capable of a level of conceptual reasoning, in a sense, that is approaching a bit like what the human mind is doing.
Chris Olah: I feel really nervous to describe these as being about concepts, because I think those are… That’s sort of a charged way to describe it that people might strongly disagree with, but it’s very tempting to frame them that way. And I think that there’s a lot of things about that framing that would be true.
Rob Wiblin: Interesting. Do you know off the top of your head what is the most abstract category that you found? Is there anything that is particularly striking and amazing that it can pick up this grouping?
Chris Olah: One that jumps to mind for me is the mental health neuron, which you can roughly think of as firing whenever there’s a cue for any kind of mental health issue in the image. And that could be body language, or faces that read as particularly anxious or stressed, and lots of words, like the word ‘depression’ or ‘anxiety’ or things like this, the names of medicines associated with mental health, slurs related to mental health. So words like ‘crazy’ or things like this, images that sort of seem sort of… I don’t know, like psychological sort of themed images a little bit, and just this incredible range of things. And it just seems like such an abstract idea. There’s no single very concrete instantiation of mental health, and yet it sort of represents that.
Rob Wiblin: How is this model trained? I guess it must have a huge sample of images and then just lots of captions. And so is it using the words in the captions to recognize concepts that are related to the images and then group them?
Chris Olah: Yeah. It’s trying to pair up images and captions. So it’ll take a set of images and a set of captions, and then it’ll try to figure out which images correspond to which captions. And this has all sorts of really interesting properties, where this means that you can just write captions and sort of use that to program it to go and do whatever image classification tasks you want. But it also just seems to lead to these much richer features on the vision side.
Chris Olah: Sometimes people are tempted to say these neurons correspond to particular words in the output or something, but I think that’s not actually going on. So for instance, there’s all of these region neurons that correspond to things like countries or parts of countries, or… Some of them are really big, like this entire northern hemisphere neuron that responds to things like coniferous forests and deers and bears and things like this. And I don’t think that those are there because they correspond to particular words like Canada or something like this. It’s because when an image is in a particular context, that changes what people talk about.
Chris Olah: So you’re much more likely to talk about maple syrup if you’re in Canada. Or if you’re in China, maybe it’s much more likely that you’ll mention Chinese cities, or that you’ll have some of the captions be in Chinese, or things like this.
Rob Wiblin: So the training data was a set of corresponding images and captions/words, and it’s developing these multimodal neurons in order to kind of probabilistically estimate or to prove its ability to tell what the context is, in order to figure out then what words are most likely to appear in a caption, is that broadly right?
Chris Olah: That would be my intuition about what’s going on.
Safety implications [00:41:01]
Rob Wiblin: What implications, if any, does the discovery of multimodal neurons have for safety or reliability concerns with these neural networks?
Chris Olah: Well, I guess there’s a few things. The first one sort of speaks to this unknown unknowns-type concern, where if you look inside the multimodal model, or you look inside CLIP, you find neurons corresponding to literally every trait — or almost every trait — that is a protected attribute in the United States. So not only do you have neurons related to gender, related to age, related to religion… There’s neurons for every religion. Of course, these region neurons connect closely to race. There’s even a neuron for pregnancy. You have a neuron for parenthood, that’s looking for things like children’s drawings and things like this. You have a neuron for mental health and another neuron for physical disability. Almost every single protected attribute, there is a neuron for.
Chris Olah: And despite the ML community caring a lot, I think, about bias in machine learning systems — it tends to be very, very alert and on guard for bias with respect to gender or with respect to race — I think we should be looking for a much broader set of concerns. It would be very easy to imagine CLIP discriminating with respect to parents, or with respect to mental health, or something you wouldn’t really have thought that previous models could. And I think that’s kind of an illustration of how studying these things can surface things that we weren’t worried about before and perhaps should now be on the lookout for.
Rob Wiblin: Yeah. I’m guessing if you tried to tell CLIP like, “Naughty CLIP, we shouldn’t be having multimodal neurons for race or gender or these other characteristics,” I bet when it was getting trained it would kind of shift those concepts, blur them into something else like a geographic neuron or something else about behavior, or personality, or whatever. And so it would end up kind of accidentally building in the recognition of gender and race, but just in a way that’s harder to see.
Chris Olah: Yeah. I think it’s tricky to get rid of these things. I think it’s also not clear that you actually want to get rid of representation of these things. There’s another neuron that sort of is an offensiveness neuron. It responds to really bad stuff like swear words obviously, racial slurs—
Rob Wiblin: —pornography, yeah.
Chris Olah: Yeah, really, really offensive things. On the one hand you might say “We should get rid of that neuron. It’s not good to have a neuron that responds to those things.” On the other hand it could be that part of the function of that neuron is actually to go and pair images that are offensive with captions that rebut them, because sometimes people will post an image and then they will respond to that image. That’s the thing that you would like it to do. You would like it to be able to go and sort of recognize offensive content and rebut it. My personal intuition is that we don’t want models that don’t understand these things. We want models that understand these things and respond appropriately to them.
Rob Wiblin: So it’s better to kind of have it in the model and then potentially fix the harm that it will cause down the track using something that comes afterwards, rather than try to tell the model not to recognize offensiveness, because then you’re more flying blind.
Chris Olah: It’s not like we would say we should prevent children from ever finding out about racism and sexism and all of these things. Rather, we want to educate children that racism and sexism are bad and that that’s not what we want, and on how to thoughtfully navigate those issues. That would be my personal intuition.
Rob Wiblin: That makes sense because that’s what we’re trying to do with humans. So maybe that’s what we should try to do with neural networks, given how human they are now seemingly becoming.
Chris Olah: I guess just sort of continuing on the safety issue, this is a bit more speculative, but we’re seeing these emotion neurons form. And something I think we should really be on guard for is whenever we see features that sort of look like theory of mind or social intelligence, I think that’s something that we should really keep a close eye on.
Chris Olah: And we see hints of this elsewhere, like modern language models can go and track multiple participants in a discourse and sort of track their emotions and their beliefs, and sort of write plausible responses to interactions. And I think having the kind of faculties that allow you to do those tasks, having things like emotion neurons that allow you to sort of detect the emotions of somebody in an image or possibly incorrectly reason about them, but attempt to reason about them, I think makes it easier to imagine systems that are manipulative or are… Not incidentally manipulative, but more deliberately manipulative.
Chris Olah: Once you have social intelligence, that’s a very easy thing to have arise, but I don’t think the things that we’re seeing are quite there. But I would predict that that is a greater issue that we’re going to see in the not-too-distant future. And I think that’s something that we should have an eye out for.
Chris Olah: I think one thing that one should just generally be on guard for when doing interpretability research — especially if one’s goal is to contribute to safety — is just the fact that your guesses about what’s going on inside a neural network will often be wrong, and you want to let the data speak for itself. You want to look and try to understand what’s going on rather than assuming a priori and looking for evidence that backs up your assumptions.
Chris Olah: And I think that region neurons are really striking for this. About 5% of the last layer of the model is about geography. If you’d asked me to predict what was in CLIP beforehand and what was significant fractions of CLIP, I would not have guessed in a hundred years that a large fraction of it was going to be geography. And so I think that’s just another lesson that we should be really cautious of.
Rob Wiblin: So as you’re trying to figure out how things might go wrong, you would want to know what the network is actually focusing on. And it seems like we don’t have great intuitions about that; the network can potentially be focused on features and circuits that are potentially quite different from what we were anticipating beforehand.
Chris Olah: Yeah. An approach that I see people take to try and understand neural networks is they guess what’s in there, and then they look for the things they guessed are there. And I think that this is sort of an illustrative example of why… Especially if your concern is to understand these unknown unknowns and the things the model is doing that you didn’t anticipate and might be problems. Here’s a whole bunch of things that I don’t think people would have guessed, and that I think would have been very hard to go and catch with that kind of approach.
Rob Wiblin: Yeah. So that’s two different ways that the multimodal neuron network has been potentially relevant to safety and reliability. Are there any other things that are being thrown out?
Chris Olah: One other small thing — which maybe is less of a direct connection, but maybe it’s worth mentioning — is I think that a crux for some people on whether to work on safety or whether to prioritize safety is something like how close are these systems to actual intelligence. Are neural networks just fooling us, are they just sort of illusions that seem competent but aren’t doing the real thing, or are they actually in some sense doing the real thing, and we should be worried about their future capabilities?
Chris Olah: I think that there’s a moderate amount of evidence from this to update in the direction that neural networks are doing something quite genuinely interesting. And correspondingly, if that’s a crux for you with regards to whether to work on safety, this is another piece of evidence that you might update on.
Rob Wiblin: I guess just the more capable they are and the more they seem capable of doing the kinds of reasoning that humans do, that should bring forward the date at which we would expect them to be deployed in potentially quite important decision-making procedures.
Chris Olah: Yeah. Although I think a response that one can have with respect to the evidence in the form of capabilities is to imagine ways the model might be cheating, and imagine the ways in which the model may not really be doing the real thing. And so it sort of appears to be progressing in capabilities, but that’s an illusion, some might say. It actually doesn’t really understand anything that’s going on at all. I mean, I think ‘understand’ is a charged word there and maybe not very helpful, but the model… In some sense it’s just an illusion, just a trick, and won’t get us to things that are genuinely capable.
Rob Wiblin: Is that right?
Chris Olah: Well, I think it’s hard to fully judge, but I think when we see evidence of the system implementing meaningful algorithms inside them — and especially when we see evidence of things that have been perceived as evidence of human…a sort of neural evidence of humans understanding concepts, I think there’s somewhat of an update to be had there.
Rob Wiblin: One of the safety concerns that came up in the article, at least as I understood it, was that you can potentially… People might be familiar with adversarial examples, where you can potentially get a neural network to misidentify a sign as a bird, or something like that, by modifying it. And by having these high-level concepts like ‘electronics’ or ‘beautiful’ or whatever, it seemed like you could maybe even more easily get the system to misidentify something. You had the example where you had an apple, and it would identify it as an apple, and then you put a Post-it note with the word ‘iPod’ on it, and then it identified it as an iPod. Is that an important reliability concern that’s thrown up? That maybe as you make these models more complicated, they can fail in ever more sophisticated ways?
Chris Olah: Well, it’s certainly a fun thing to discover. I’ve noticed that it’s blown up quite a bit, and I think maybe some people are overestimating it as a safety concern; I wouldn’t be that surprised if there was a relatively easy solution to this. The thing that to me seems important about it is… Well, there’s just this general concern with interpretability research that you may be fooling yourself that you’re discovering these things, but you may be mistaken. And so I think whenever you can go and turn an interpretability result into a concrete prediction about how a system will behave, that’s actually really interesting and can give you a lot more confidence that you really are understanding these systems. And I think it is — at least for these particular models, and without prejudice to whether this will be an easy or hard problem to solve — there are contexts where you might hesitate to go and deploy a system that you can fool in this easy way.
Rob Wiblin: Are there any examples where you’ve been able to use this interpretability work as a whole to kind of make a system work better or more reliably or anticipate a way that it’s going to fail and then diffuse it?
Chris Olah: Well, I think there are examples of catching things that you might be concerned about. I don’t know that we’ve seen examples yet of that then translating into ameliorating that concern or making changes to a system to make it better. I guess one hope you might have for neural networks is that you could sort of close the loop and make understanding neural networks into a tool that’s useful for improving them, and sort of just make it part of how neural network research is done.
Chris Olah: And I think we haven’t had very compelling examples of that to date. Now, it’d be a bit of a double-edged sword; in some ways I like the fact that my research doesn’t make models more capable, or generally hasn’t made models more capable and sort of has been quite purely safety oriented and about catching concerns.
Rob Wiblin: When we solicited questions from the audience for this interview with you, one person asked “Why does Chris focus on small-scale interpretability, rather than figuring out the roles of larger-scale modules in a way that might be more analogous to neuroscience?” It seems like now might be an appropriate moment to ask this question. What do you make of it?
Chris Olah: Ultimately the reason I study (and think it’s useful to study) these smaller chunks of neural network is that it gives us an epistemic foundation for thinking about interpretability. The cost is that we’re talking to these small parts and we’re setting ourselves up for a struggle to be able to build up the understanding of large neural networks and make this sort of analysis really useful. But it has the upside that we’re working with such small pieces that we can really objectively understand what’s going on because it’s really… At the end of the day, it sort of reduces just to basic math and logic and reasoning things through. And so it’s almost like being able to reduce complicated mathematics to simple axioms and reason about things.
Chris Olah: And I think there’s just a lot of disagreement and confusion, and I think it’s just genuinely really hard to understand neural networks and very easy to misunderstand them, so having something like that seems really useful. Maybe the radical success for circuits isn’t that everyone talks about neural networks all the time in terms of circuits, so that’s fundamentally how we analyze neural networks, but then it sort of takes on the role that having axioms does in mathematics, so it’s kind of this foundation that everything can potentially be reduced down to.
Can this approach scale? [00:53:41]
Rob Wiblin: So this work kind of shows that we can maybe with a bunch of time kind of go in and mechanically, laboriously understand neural networks at this kind of circuit level, especially older ones that were a bit smaller. We can potentially understand a large fraction of those models, but neural networks have become a lot larger over the last few years and they’re going to become a lot larger still before we actually start deploying them to important problems. Modern language models are way bigger than these image recognition models are.
Rob Wiblin: That creates this challenge that maybe we can understand all these tiny circuits, sub-components, but there’s just going to be so many of them that it’s going to be far beyond the capacity of Chris Olah, or maybe even a whole team with you to understand any kind of meaningful fraction of these neural networks, which I guess you could kind of call this analysis scaling problem.
Rob Wiblin: What are the plausible ways in which we could scale the analysis so that we could actually understand these bigger models, or maybe work around the problem in some way?
Chris Olah: I think this is a very reasonable concern, and is the main downside of circuits. So right now, I guess probably the largest circuit that we’ve really carefully understood is at 50,000 parameters. And meanwhile, the largest language models are in the hundreds of billions of parameters. So there’s quite a few orders of magnitudes of difference that we need to get past if we want to even just get to the modern language models, let alone future generations of neural networks. Despite that, I am optimistic. I think we actually have a lot of approaches to getting past this problem.
Rob Wiblin: What are a couple of them?
Chris Olah: So maybe the best place to start is just the most naive thing, which is if we were to just try and take the circuit approach as is and try to scale it, do we have any hope of doing that? And it’s not the thing that I would bet most on, but I actually think that it’s more plausible than people might think, and there’s two reasons for that. So the first reason is just that as neural networks become larger, there’s more circuits to study, there’s more features to study, but often the features in circuits in some ways become crisper and easier to understand.
Rob Wiblin: So you’re saying as the models become more sophisticated, they have more parameters, but for that reason, they’re somewhat better at their job and so they are classifying things in a way that’s clearer and more coherent to people?
Chris Olah: Exactly. I think that sometimes when you have really weak models, they’re just representing things in a very confused way that entangles lots of things together. And that actually makes them pretty hard to study, and it seems like often as models become stronger, they actually sort of become, in some ways, crisper and less entangled, and cleaner.
Rob Wiblin: Is that in part because they don’t have as many parameters as they might like to have, and so they have to cram a whole bunch of different concepts into kind of the same circuit and make it do double work?
Chris Olah: Yeah, I think that is probably part of it. There’s this problem we call polysemanticity, which is when a neuron is sort of fulfilling multiple roles like that. I think also they just may not be able to represent the actual abstractions that sort of cut a problem apart. They just literally don’t have the computational capacity to build the right abstractions, and so they’re working with suboptimal abstractions. There’s this interesting thing, it’s a little bit different, but it’s a paper by Jacob Hilton, where they explore a few…they train models on progressively more diverse data. The features become sort of more interpretable as you do that. I think that’s maybe the most rigorous result pointing in this direction, that sort of suggests that there’s some way in which as you have better models, they become more interpretable.
Rob Wiblin: Okay. So they’re more interpretable, but you were going to say something after that?
Chris Olah: Oh. Well, just that that’s sort of a countervailing force against the problems of scaling. And then of course there’s a second thing which is… There’s this really interesting thing we call a ‘motif,’ and this is actually an idea we’ve borrowed from systems biology. There’s Uri Alon, and a number of other people have really pioneered this approach to understanding biological networks in terms of these recurring patterns that they find. And it turns out we can find similar recurring patterns in neural networks, and those can really… They can actually simplify circuits by orders of magnitude.
Rob Wiblin: So the idea here would be that even if it’s very big, if it’s just lots of recurring things that are basically all the same, so then you can understand a whole lot of it all at once. What’s an example of one of these motifs that kind of recurs through a network?
Chris Olah: Well, a really simple one that we see is unions, where you have two different cases and then you get a neuron that unions over those two cases. But that one doesn’t give you a huge amount of traction in understanding it. The one that we’ve got sort of the most juice out of is what we call equivariance, and this is when neural networks have symmetries in them. Where you have a feature and it’s actually lots of copies of that feature that are transformed versions of the same feature.
And if you have a whole bunch of features that have this property, where say they’re all rotated copies of the same feature, and you have that across multiple layers, then actually the circuits themselves begin to have symmetries and you can sort of simplify them by large integer factors. In the case of the curve circuits work you got a 50x simplifier, which is really nice.
Rob Wiblin: So you’re saying if there’s lots of circuits that are recognizing the same thing in lots of different colors and lots of different rotations, then you can potentially look at all those and just say, “Well, this is the curve recognizing thing.”
Chris Olah: Yeah. They all connected together in the same way, and so you can just understand it once, and in one fell swoop you’ve actually understood a much larger amount of stuff. And so if you think about what’s happening to bridge many orders of magnitude, it’s actually really encouraging when you see things that are… Yeah, not just incremental improvements, but actually are sort of these order-of-magnitude improvements. It suggests that actually it’s not completely a fool’s errand that you might hope to go and bridge several orders of magnitude.
Rob Wiblin: So that’s two ways that the problem of scaling might not be so hopeless. What are some other approaches that you might have to bridging the gap?
Chris Olah: So I put both of those sort of in the broad category of approaches where you’re still sort of trying to make the basic circuit style approach work. And the rest of the ideas are not quite going to be that, they’re going to be a little bit more different. So what was our motivation for studying circuits? So I think a big part of our motivation for studying circuits is to kind of be this epistemic foundation. And that doesn’t mean that everything that we study needs to always be in terms of that foundation, rather though, the benefit is that it’s giving us a way to sort of frame anything else we ask about in a very rigorous way.
Chris Olah: And actually when you study neural networks, you often see that there are these larger scale structures, there’s ways in which there’s clusters of neurons that do very similar things, or there’s ways in which actually you see parts of neural networks where all of the weights sort of have a very systematic pattern.
Chris Olah: So it almost in a way feels like a tissue in biology, or something like this. And so there’s all these hints that there actually is a ton of large-scale structure, and you could imagine some future approach to interpretability where we study things in terms of this as a much larger scale structure.
Chris Olah: And then perhaps when you find interesting things, or things that are safety relevant, in terms of that large-scale structure, maybe you find some cluster of this larger thing that is involved in social reasoning or something like this, and you’re worried that perhaps the models is manipulative, then you could look at that much more closely, and that could give you the ability to cut through many orders of magnitude by going and just looking at very small parts that your large-scale analysis has told you are particularly important.
Rob Wiblin: So if I understand you, you’re saying… Again, using the analogy with the body, if circuits are kind of like cells perhaps, but you’ll notice that those cells are organized into other structures like tissue, and so you will be able to notice ways that circuits all aggregate together into some broader structure within the network, and then maybe there’ll be a high-level structure. And then you’ll be able to work up. And so you’ll always be able to like zoom in more into circuits and then features, but then you’re just at the beginning of this process and you’re also going to identify other structures that will allow you to understand the full span of all of the orders of magnitude of size rather than just these lower level ones.
Chris Olah: Yeah, that’s exactly right. And if we’re making an analogy to medicine, maybe as an area where science actually has to be useful to people and solve problems… Maybe you want to be able to understand things in very fine-grained detail, but if you know that there’s a problem with the heart, you don’t have to go and carefully analyze what’s going on in the foot. And so you sort of both want the ability to look very closely at things and understand them very carefully, but also the higher level overview that you can use to reason about what parts you need to pay attention to for particular kinds of problems and what parts you don’t need to pay as much attention to.
Rob Wiblin: Okay, we’ve got this enormous language model, but the part that we’re really concerned about is the social manipulation part, so we’re going to really zoom in on a lot of detail and understand it. And then the part that’s just recognizing different pieces of fruit, we can let that one go because it’s not as central.
Chris Olah: Exactly. Or you might even imagine that there’s problems that you can see in this larger scale view, but that you were sort of able to develop this larger scale view in a way that you trust because you had this foundation to build upon. And so you’re able to use that to sort of reason about larger scale things, and to know that the things that you were talking about actually do map to what’s really going on and genuinely occurring in the model.
Rob Wiblin: While we’re on this body thing, I thought one objection you might raise to this objection is… It would be kind of stupid to say, “Well, all you’re doing is studying individual cells, the body is so much bigger than an individual cell. What can you learn about disease? Or what can you learn about the human body just by studying cells?” Because the thing is, the cells replicated, but the whole thing is — other than the bones I suppose — is made of cells, so it’d be like, “Well, if we can understand the way that an individual cell functions and the way that it messes up, then we have really learned something about the whole because it’s all this recurring pattern.”
Chris Olah: Yeah. And also you can sort of… When you ask questions about tissues, if you’re confused about what’s going on… I mean, again, I’m not a biologist, so I’m sort of using all of these biology analogies and I might be distorting them a little bit, but I imagine it’s really useful to be able to ultimately be able to ask, if you think something has an issue with a tissue, what is going on at the cell level? Do we understand what’s going on there? Or if we have some theory, can we validate it at the cell level? It may be very helpful for places where you’re confused.
Rob Wiblin: I guess another approach that people might suggest is, well, if we don’t have enough humans to go and analyze all of these circuits, maybe we need to automate it and create new ML systems with their own circuits that analyze the circuits of other things and recognize what they are. What do you make of the idea of automating this process somehow?
Chris Olah: I think that’s totally an option. It’s not my favorite option.
Rob Wiblin: Why is that?
Chris Olah: On some level it’s just aesthetic. I really like this approach of humans understanding things. And then I also think that just a lot of the proposals I hear for automating things, I don’t yet fully understand them. And I think they often… In some ways, a lot of them are sort of borrowing ideas from alignments that I think are not yet that mature, and then trying to combine them with ideas from circuits which are also not that mature. I guess I just have this nervousness that when you take a bunch of ideas that aren’t mature, you’re sort of making yourself even more vulnerable to things failing, because you now have many points of failure. And so perhaps I’ll be more excited about automation in the future when it seems like more of these ideas are figured out, then I can reason more carefully about how you’d imagine connecting them together. But I think it is a good fallback.
Rob Wiblin: Makes sense. Alright, are there any other approaches dealing with the scaling issue that we should talk about? Or is that kind of the top few options for now?
Chris Olah: Well, I think there’s one more, which is just throwing more humans at the problem. We don’t have that many people thinking about this right now. If this really is an important problem, and at some point we’re really deploying neural networks where there are high stakes… Imagining throwing 1,000 people at systematically auditing things doesn’t seem entirely crazy.
Rob Wiblin: Well even more than that. I guess if you’ve got 10 now, why not 10,000? Why not 100,000? If these networks are making up a large fraction of the economy, then you might think that that could kind of naturally happen, at least if it helped to make them function better.
Chris Olah: Yeah. And if you look at how many people analyze the security of the internet, or things like that, that’s got to be some pretty non-trivial number of people.
Rob Wiblin: Or design cars to not crash and not hurt people.
Chris Olah: Yeah. I guess in some ways that’s actually another reason why I studied circuits, is just trying to demonstrate that it’s possible at all to understand neural networks, just as a way of justifying to society that this is worth investing in and worth trying to figure out how to scale. So I guess that’s another sort of implicit motivation I have.
Disagreement within the field [01:06:36]
Rob Wiblin: You’ve alluded to the fact that there’s a bunch of disagreement, or maybe a lack of consensus, about interpretability within the field. What are the disagreements or different interpretations that people have of interpretability?
Chris Olah: I guess there’s two things. So one is just that within interpretability, people mean lots of different things, and there isn’t really consensus about what interpretability is or what it means to understand a model. Then I think outside of interpretability, there’s a non-trivial amount of skepticism from some other members of the ML research community.
Chris Olah: Many years ago, a colleague of mine who I respected told me that they thought all interpretability research was bullshit. I think that’s maybe stronger than the typical view, but I think that there are some people who are skeptical. I think that probably to some extent they’re picking up on the fact that maybe things aren’t fully figured out about what interpretability means.
Rob Wiblin: Do they still think it’s bullshit? Because I just don’t understand how someone can look at these articles and… Maybe you think it’s not the most important thing, or maybe there’s mistakes being made, but I don’t understand how you could think that this isn’t legitimate research into how these systems work.
Chris Olah: Well, I think actually another motivation for trying to be so rigorous and trying to build this foundation is in some ways to address this concern. Because I think actually, if you believe that all of these attempts to understand neural networks don’t make sense and are fundamentally flawed, that’s a very different view from how I see the world. I think it really changes whether you think it makes sense to pursue this as an approach to safety. It actually is a very, very fundamental crux, I think. So I’ve seen a lot of my work as trying to create something that is very objectively correct with circuits.
Rob Wiblin: Maybe more concrete or specific, what are the different takes that people have on what interpretability is, or how it should be construed?
Chris Olah: So I guess I should caveat that and say that I’m obviously biased towards my own work, and I’m just not sure that I’m able to fully fairly represent the views of everyone in the space. But one way that I think about this, and I really owe this view to Tom McGrath, is that I think of interpretability as being a pre-paradigmatic science, in the sense of Thomas Kuhn and the structure of scientific revolutions.
Chris Olah: So I guess the idea here is that usually sciences have a paradigm where everyone agrees on what the important questions are, and how you answer those questions, and how you tell if an answer is a valid answer to that question, and what are the topics of investigation, and things like this. I think that interpretability doesn’t have that. There’s no shared set of answers to that question. So I think that the discourse that’s going on in interpretability right now is a very common pattern in early fields of science, where you don’t have consensus on these questions and people are proposing different answers and often having trouble communicating with each other. There’s a lot of disagreement and confusion.
Chris Olah: In fact, I think that we’re falling into another very common pattern: often when a field is in this state, practitioners will try to lean on existing disciplines to answer these questions for them. In this case, I think we see practitioners largely lean either on machine learning to try and answer this question or on HCI to answer these questions.
Rob Wiblin: What’s HCI?
Chris Olah: Human-computer interaction. So I think the ML people want in some ways to have a metric for what it means for things to be interpretable. I think the HCI people want to do user studies and ask people, “Was this explanation useful to you?” Maybe you ask, “Does the person make better predictions after seeing an explanation?” or things like this. I think these are both valid answers to go and have. I tend towards a different answer, which is to see interpretability as being like an empirical science. It’s the biology of neural networks or something like this.
Chris Olah: So the question isn’t whether something is useful. The question is whether a statement is true, and whether it’s true in the sense of falsifiability. You certainly see this view in other areas of machine learning and people studying neural networks. I think you don’t see as much for people who are doing things that might be articulated as interpretability. I think it’s often because people see visualization as less scientific. But, yeah, to me, really the goal of circuits is to try to show how interpretability can be an empirical science.
Rob Wiblin: Maybe I’ve just been influenced so much from reading the articles you’ve contributed to writing and your framing of it all. But to me, it does just seem like you’re making specific claims about the functions of different circuits and well, if you take this cluster of neurons and weights and so on, this is what it does. So you’re right. You could say, well, should we look into this? So it will depend on, is this useful? Is this helping us make better predictions about stuff that we actually care about, in terms of what it does?
Rob Wiblin: But, yeah, just like, you can look at a machine and say, “Well, this is what a gear does.” It seems like you can say that about circuits, and having that level of understanding. At least that’s one sense of interpretability is like, I look at this machine and I understand what each part is contributing to the whole. That seems very natural to me.
Chris Olah: I would describe this as being like mechanistic interpretability, or some people would call it transparency. Understanding this as a mechanism, or understanding what causes it to work. You can have other types of work that are maybe a little bit less focused on this. So there’s a lot of work on saliency maps, which try to highlight that you have an image classifier. What parts of the image were important in classifying the final answer the model gave you?
Chris Olah: It turns out it’s actually very difficult to ask that question in a really rigorous way, because these functions are so non-linear and complicated. For that, it might make more sense to ask it in this HCI-type lens of, “Is the explanation useful? Is it causing users to make more accurate predictions?”
Rob Wiblin: So it sounds like at a high level you think there’s disagreement in part because people just don’t agree on what it is to understand a neural network; what it is to have interpretability. Maybe over time, we should expect that there will end up being multiple different conceptions of interpretability, but people will understand them more crisply and say, “Well, we have this sense, but not this sense.”
Rob Wiblin: Or maybe people will converge on a common idea of what interpretability is, that is probably most likely the most useful one for the actual work that you’re trying to do.
Chris Olah: Yeah. I think that’s right. I think you could either have multiple fields form, or often, at least according to Thomas Kuhn, one paradigm will eventually win out. I guess something that I find really interesting about Kuhn’s description of this is I think that the thing that he thinks is central to a paradigm isn’t the particular theories that somebody has. So you often develop these different schools that have different ways of thinking about a problem.
Chris Olah: With electricity, some were more focused on how charges repel, and some were more interested in current. I think the current ones won out. I think to Kuhn, the important thing isn’t the particular theories they had, but the phenomena they were choosing to pay attention to. So from that lens, maybe the thing that is central to the circuits paradigm, to going and approaching this… I should say, I think there’s probably other work that’s embodying a similar paradigm. I don’t want to claim it entirely for us. The core of that is paying attention to features and how they connect to each other and having that be the phenomena that you focus on.
The importance of visualisation [01:14:08]
Rob Wiblin: The articles that we’ve been talking about are just packed with lots of images that I imagine it took a whole lot of time to make. Maybe that’s an integral part of interpretability, is that people have to be able to grasp it, so they have to be able to see it. Do you think that kind of visualization is going to be a core part of interpretability going forward? Or is that just maybe specific to these cases?
Chris Olah: I think a lot of people conceive of science as being about studying summary statistics, because in a lot of science, we have a couple numbers that we can boil things down to that are really important. We are able to study how those interact. I think people are often pretty surprised when they see our work, because they’re used to research — and especially machine learning research — involving studying a bunch of summary statistics and creating line plots and that being what they feel like science should look like.
Rob Wiblin: Or you can get the bottom line from a paper by looking at a graph that shows the accuracy, or something over time, like as you add more neurons or something like that.
Chris Olah: Yeah. I think it feels very rigorous to them, that that’s what they expect science to look like. But summary statistics can actually blind you. There’s this famous example, Anscombe’s quartet. It has a bunch of sets of 2D points that have the same mean and standard deviation, but are totally different when you actually look at them.
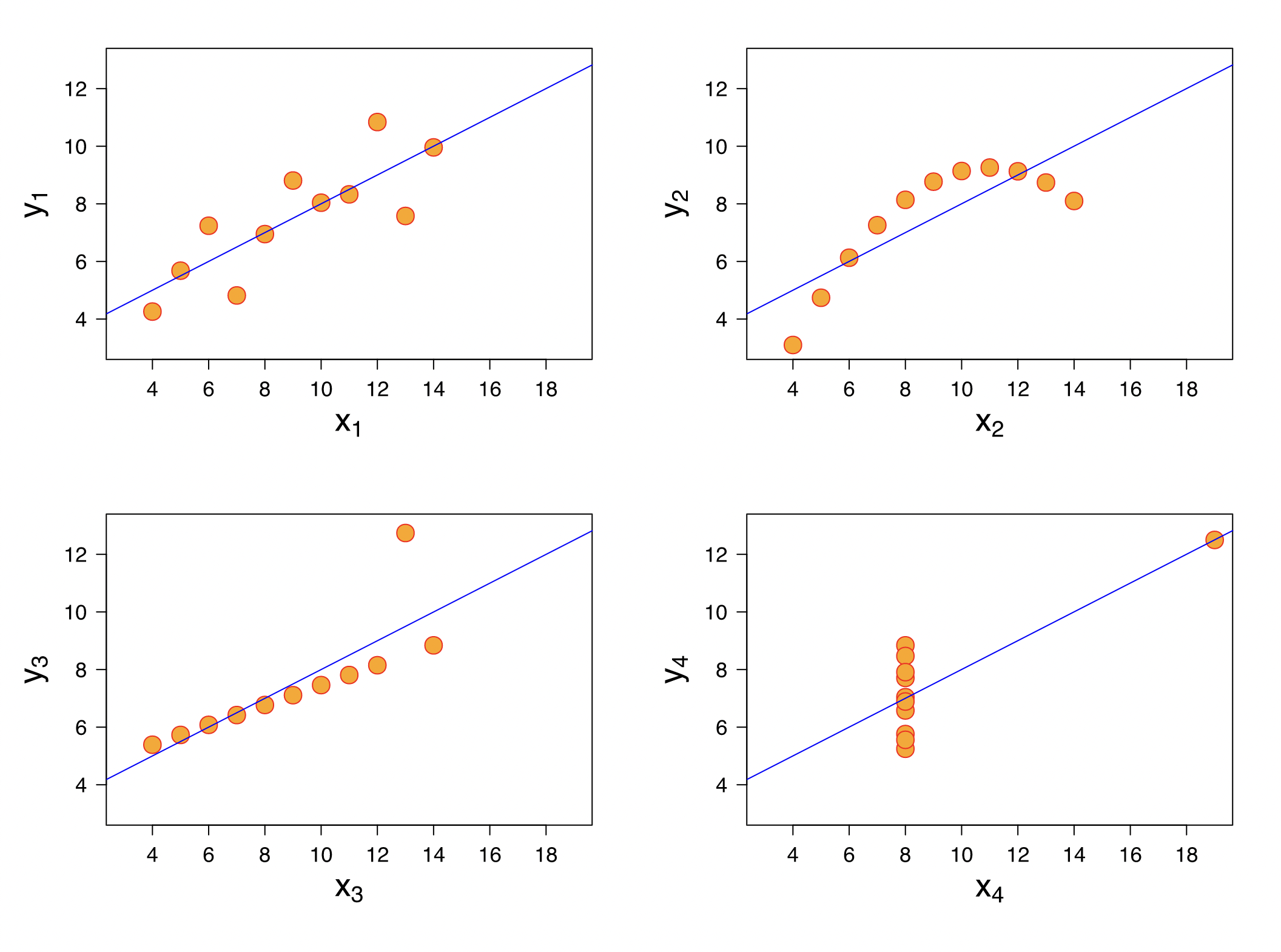
Chris Olah: There’s just so much going on inside neural networks that if you just try to boil it down to a single number, and especially if you don’t understand what’s going on first, you’re losing sight of almost everything important. At least, that’s how it seems to me. So a lot of our work is just trying to show some fraction of all of the intricate structure that exists within these models. I guess I often feel a little bit like we’re like somebody looking through a microscope for the first time and seeing cells for the first time. Sometimes people are like, “Is that scientific?”
Chris Olah: Well, it’s a qualitative result, not a quantitative result. But seeing cells was a qualitative result, not a quantitative result.
Rob Wiblin: And it was really important.
Chris Olah: And it was very important, yes exactly. So, I think that if you want to understand these models and you want to really understand everything that’s going on inside of them, you need to be looking at this fine-grained structure, and you need to be trying to get access to all this. That inevitably pushes you towards visualizations, because data visualization is a tool for displaying lots of data, getting access to lots of data and communicating it. The fact that we’re used to a small set of visual forms that are the ones that are effective for communicating certain kinds of data that we often work with doesn’t really change the fact that we’re going to want to work with other visual forms for understanding the large amount of data we get from neural networks.
Rob Wiblin: Maybe if I could try putting it another way and see whether you agree, you’re trying to get people to understand… So like people who’ve never seen a car, get them to understand how a car works. Maybe you can’t get that level of intuitive appreciation for how a car functions without getting your hands a little bit dirty, without actually maybe playing with the different pieces and seeing how they connect together and looking at the schemata. You couldn’t just present people with a graph or a bunch of numbers and be like, “This summarizes the car.” Maybe it’s a little bit more like engineering maybe than coming up with some natural law.
Chris Olah: Yeah. Imagine if you tried to describe cars with five numbers. Maybe there are some ways that it’s useful to describe cars with five numbers, like horsepower and size and number of gallons consumed per hour or something like that—
Rob Wiblin: —but you couldn’t go and build one with just those numbers.
Chris Olah: —but you couldn’t go and build one, right. If you want to understand how a combustion engine is working, you probably need to go and look a little bit more closely than those five numbers.
Rob Wiblin: That makes sense. Another concern that people might have about interpretability research is just that, as we’ve been noting throughout this conversation, it seems very similar, very analogous in some ways, to neuroscience. Neuroscience over many decades, despite having a pretty large research community, hasn’t really cracked understanding of the human brain. It’s made some progress, but it hasn’t made nearly as much progress as we would need probably to be comfortable deploying a really important ML system. Does that make you at all pessimistic or concerned about the prospects for understanding neural networks as much as we need to?
Chris Olah: Yeah, I think it’s a real concern. The community of people working on neuroscience is orders of magnitude larger than the community of people working on circuit-style interpretability of neural networks. So it does seem like a pretty good case for being concerned. But I do think that there are actually a number of very large advantages that interpretability has over neuroscience, which level things out a little bit.
Chris Olah: So just at a high level — I actually wrote a short note about this recently — some of the advantages are that you can just get access to the responses of every neuron. In neuroscience, you’d normally only be able to access, record a couple of neurons, and you’d be able to record them for a limited number of stimuli. But here you can go and get it for all of them.
Chris Olah: A lot of neuroscientists are trying to get access to the connectome of how all the neurons connect in the human brain, for instance. But in neural networks, not only do you have a connectome, but you have the weights that connect every neuron, and you know what computation every neuron does. You just have access to the entire thing. That’s what makes circuits possible — that we can go and look at how the weights connect neurons. There’s also the fact that weight tie-in can dramatically reduce the number of unique neurons that exist in neural networks.
Rob Wiblin: What can?
Chris Olah: So for instance in vision models, you actually have all of these replicas of the same neuron, where you run them at every position in the image. So if I have a line detector, it’s useful to go and run that line detector at every position in the image. The result of this can be that you have maybe 10,000 times fewer neurons than you would if you were studying a comparable biological neural network or fewer unique neurons.
Chris Olah: So that’s the difference between it not being possible to just look at every single neuron, and it being easily possible to look at every single neuron. We’ve done this for some vision models. So that’s a huge advantage.
Rob Wiblin: It sounds like maybe the advantages are so great that you’ll end up learning more about the human brain by studying neural networks than you can understand the human brain by studying the human brain, just because the underlying data is so hard to access within the human brain. It’s like it’s tied up in all of this physical stuff that’s super hard to play with.
Chris Olah: Yeah. I’m not a neuroscientist, and I wouldn’t want to opine too much, but it seems very plausible to me that perhaps studying artificial neural networks could teach us a lot about neuroscience. I should say that actually, that’s just part way; there’s a number of other advantages that I hadn’t mentioned. So I think that we do have a pretty significant number of advantages.
Rob Wiblin: We’ll stick up a link to that note that you recently published where I guess you lay out the other benefits that you have.
Digital suffering [01:20:49]
Rob Wiblin: So we got a ton of audience questions when we mentioned that we’re going to be interviewing you. One that I was interested in — I’m not sure whether this is one that you can really tackle, because maybe it’s just too philosophical — but someone pointed out that you’re finding all of these discoveries inside neural networks that mirror neuroscience, as we were just saying. And people like Brian Tomasik — and others who are very concerned about suffering in the future — have raised concerns that potentially neural networks or artificial intelligence or reinforcement learners might be able to suffer when they’re running on computers, or I guess potentially feel pleasure as well. This person asked if you think your findings should make us more or less worried about that.
Chris Olah: Well, I’ll just start by saying that I don’t feel super qualified to comment on this, because I’m not a moral philosopher or philosopher of mind or anything like that. I really don’t know how you should think about whether something is a moral patient or not.
Rob Wiblin: Honestly, I’m not sure whether there’s anyone who’s super qualified, but …
Chris Olah: My instinct is that this is a pretty serious concern. I think it’s something that people think it’s funny to talk about, or that you’re being a crank if you talk about it, but, yeah, I’m worried this is a pretty serious issue. I guess a big part of the reason why I’m worried about it isn’t even so much the probability that they might be agents that are entitled to moral patienthood, but that it’s so invisible.
Chris Olah: So, I care a lot about animal rights. I’m a vegan. I think one thing that makes animal rights so insidious is that people don’t see the suffering that’s going on in factory farms. It’s hidden from us, it’s invisible. How much more invisible would the suffering of neural networks be if they were to suffer? I don’t know if they will, but if they were… They’re running on a server where no one can see them, and there’s no visible output of their suffering. And a couple of clicks of a computer button, a couple of clicks of buttons on a keyboard scale up the number of neural networks that are experiencing this. I think that really, really increases the risk that we can have a moral catastrophe.
Chris Olah: Is there anything useful that I can say about whether models may be suffering? Well, I do think these multimodal neurons should be a little bit of a red flag for us. We have something that previously only existed in humans, and now we’re observing it in artificial neural networks. I’m not saying that that necessarily should be a big flag. I think other people would be better positioned than me to think about that. But I do think it’s the sort of thing that I wish was causing systematic reviews and systematic check-ins when we find things like that. Because I think each one seems to increase the risk that maybe we’re dealing with moral agents.
Rob Wiblin: Yeah. So I guess the concern is that well, we think that humans can suffer. So if these neural networks just keep adding in more and more components, functional components that humans have, then maybe they’ll develop the ability to suffer as well. Because that’s one of the things that’s in our minds. It seems a little bit like… In an image recognition system, it’s not obvious what is an analogy to a preference or desire and suffering here. Maybe you need to have a more agent-y neural network before it can suffer. That feels intuitive to me. But I suppose that we will have such systems, right?
Chris Olah: Well, I think a lot of people really focus on reinforcement learning as the thing that must be the difference between a neural network suffering or not suffering. I’m pretty skeptical that that’s actually the central issue. A reason why you might not think that is you could train a neural network with imitation learning instead to go and mimic an actor. I think that if it led to a neural network with the same behavior, I’d probably think that they were equally likely to suffer.
Chris Olah: I have a bunch more technical reasons why I think that reinforcement learning is probably not the central thing. But I don’t know. Maybe the more important point here is just, I think the level of discourse here is so low and so minimal that just really basic points and thoughts haven’t been laid out. I think just because it feels like a crankish thing to be talking about, especially if you’re somebody who’s a serious researcher. I think that’s an issue. I think that we should be trying to think these things through carefully. It’s a really hard topic to think about, but I wish that there was more careful discourse.
Superhuman systems [01:25:06]
Rob Wiblin: Another listener said maybe we can use this interpretability research to understand neural networks that are doing things that we ourselves can do and that we ourselves can understand, but if you were having a superhuman system, a superintelligent system, it might be doing tasks that are are too complex or difficult for us to do — and therefore, maybe too complex and difficult for us to understand. Do you think that could possibly interfere with our ability to use these interpretability tools on far more advanced systems than what we have today?
Chris Olah: So I’d split this question into two parts. One is you could just generically be worried about the scaling of neural networks, and whether we’ll be able to keep up with studying larger neural networks. The other is you might have specific concerns about superintelligence, and systems being smarter than us in particular. You might think that there’s ways in which you can study very, very large models, very powerful models, but then when those models become smarter than you — because they’re thinking about problems in a way that’s more sophisticated than you — maybe that’s a special point where you get screwed up.
Chris Olah: We already talked about the scaling part earlier, so I think it’s the superintelligence-specific concerns that we should focus on here.
Chris Olah: I guess one thing that seems a little heartening here is we already have models that are smarter than us in narrow ways. ImageNet models are better than me at recognizing different kinds of dogs. With effort, we can look at these models and we can actually learn from them and make ourselves smarter. There’s this really lovely talk by Bret Victor, Media for Thinking the Unthinkable. He says some things in it that strike me as being very profound in general. I think that this ‘tools for thought’ type thinking is something that is underappreciated in the EA community, but is actually extremely relevant to neural networks.
Chris Olah: Maybe I’ll actually just quote it for a second, because I think it is a really powerful way of thinking about this.
Rob Wiblin: Go for it.
Chris Olah: So he starts by quoting Richard Hamming: “Just as there are odors that dogs can smell and we cannot, as well as sounds that dogs can hear and we cannot, so too there are wavelengths of light that we cannot see, and flavors we cannot taste. Why then, given that our brains are wired the way they are, does the remark ‘Perhaps there are thoughts we cannot think’ surprise you? Evolution so far may possibly have blocked us from being able to think in some directions. There could be unthinkable thoughts.”
Chris Olah: I think in some ways this gets to the root of the concern you might have about trying to understand a superintelligent system. You might think that there are thoughts which are impossible for humans to think that this system is thinking, and therefore we’re screwed. So Victor responds as follows:
Chris Olah: “The sounds we can’t hear, the light we can’t see, how do we even know about those things in the first place? We built tools. We built tools to adapt to these things that are outside of our senses, to our human bodies, our human senses. We can’t hear ultrasonic sound, but you can hook up a microphone to an oscilloscope, and there it is. You’re seeing that sound with your plain old monkey eyes. We can’t see cells and we can’t see galaxies, but we build microscopes and telescopes. These tools adapt the world to our human bodies, to our human senses. When Hamming says there could be unthinkable thoughts, we have to take that as, yes, but we built these tools to adapt these unthinkable thoughts to the ways that our minds work and allow us to think these thoughts that were previously unthinkable.”
Chris Olah: I think that there’s actually a really deep analogy to what we’re doing with interpretability. Michael Nielsen and Shan Carter have a very nice essay on what they call ‘artificial intelligence augmentation.’ But I think the high-level idea of all of this is that we can try to build tools to help us be smarter and to think these thoughts. In fact, if we have systems that are reasoning in these ways, they can teach us the abstractions and maybe even be themselves the tools that allow us to go and think these previously unthinkable thoughts.
Rob Wiblin: Yeah. So maybe you could break these unthinkable thoughts into pieces that we can digest, maybe given enough time and effort, perhaps that’s going to be really quite hard because, well, we’re going to be dealing with abstractions that are very foreign, very alien, very difficult for humans to grasp. So it could be a much more laborious thing than understanding that this is a dog recognizing a circuit.
Chris Olah: Yep, that could be true. Although, I don’t know, if you look at … Well, it depends on the human, but I think if you look at many humans who I think are really smart, they actually are very good at… Their thinking seems very clear, and actually often quite easy to understand. It could also be that you can think of the curve of how understandable a neural network is. You can imagine that there’s some value where it’s very confused and has really bad abstractions, and then it gets crisper and crisper and crisper and becomes easier to understand.
Chris Olah: Then perhaps there’s some threshold at which it starts to have just sufficiently alien thoughts that we can’t understand anymore, past human capacity. There’s an empirical question about where that is, but if we can get to the point where we’re dealing with human-level systems and somewhat stronger than human-level systems and understand them and really be confident in their safety, that would actually seem like a pretty big safety win to me, even if there’s some point where these things fundamentally become so alien that we just can’t understand them at all.
Rob Wiblin: Yeah.
Rob Wiblin: Alright, another listener wrote in saying Chris seems to be extraordinarily good at pulling apart and understanding the inner workings of his various models, including even complex ones and fairly large ones. They’re asking how does one continually take their ability to explain and understand models to the next level?
Chris Olah: Well, that’s very kind of them. I think probably the biggest thing is just practice, and spending lots of time staring at neural networks and trying to figure out what’s going on. But let’s see what else I can suggest. At the risk of being slightly self-promotional, just reading the circuits thread may be quite useful. It walks you through a lot of examples of things that neural networks do and examples of how they do it, and the circuits that are implementing it.
Chris Olah: I think just having a library of concrete examples that you understand is actually very helpful. I feel like I benefit a lot from that. I think a useful exercise also could just be to create toy problems for yourself and ask yourself, “How would I implement this behavior in a neural network with this architecture?” I often play with things like this when I can’t sleep at night. I feel like I come to much more deeply understand what the constraints of an architecture are and what kinds of things are easy and hard.
Rob Wiblin: Sounds like practice, practice, practice.
Chris Olah: Practice, practice, practice. And just spending time with a model and just poking around a lot is really helpful. Then maybe one thing that I think people might find surprising is just building some basic data visualization fluency and getting some competency with tools that allow you to just get lots of data on paper and get neural networks that are organized with feature visualizations. Go in and have simple interfaces that allow you to navigate that. Because the ability… There’s just so much data inside these models. The ability to have tools that allow you to navigate it and sift through it is the thing that prevents you from needing to resort to summary statistics that will mislead you.
Rob Wiblin: I think I failed to say earlier that this microscope tool that OpenAI is offering is beautiful to play around with. Even the people out there who aren’t into ML, even the people who aren’t actually trying to learn how to do this for their job, I recommend going and checking it out. I was blown away. This is something where I’d thought shouldn’t this be the way that you understand it? Then I was like, “Oh my God.” I clicked through the articles and was just like, this exists now. So presumably that experience might help people.
Language models [01:32:38]
Rob Wiblin: Another question that actually multiple listeners raised was… So most of what we’ve been talking about so far is about these visual models. Things like CLIP, which are trying to classify images or take an image and figure out what the caption should be, or take a caption and then design an image around it. But there’s probably going to be other models that are maybe more important that might be getting deployed that are more capable, that are doing more relevant stuff.
Rob Wiblin: I guess obviously models like GPT-3, which will take an opening paragraph and then write an entire essay from it. It seems like perhaps more work looks like that than classifying images. Is this interpretability work going to just extend naturally from the image stuff to the natural language interpretation? Or might there be more fundamental differences that mean that the analogies somewhat break down and it’s harder to do, or you’re going to have to reinvent things?
Chris Olah: Something I should say before diving into this is that a lot of interpretability work does get done on language models. It’s often a pretty different style of interpretability work than the thing that I feel really excited about, but a lot of work does get done there. So I’m going to interpret this question as how optimistic should we be that circuit-style interpretability work can thrive in the context of language models.
Chris Olah: To some extent, it’s a hard question to answer before we really try. I feel optimistic. I don’t really see any fundamental reason why it shouldn’t work, but I think it’s reasonable for people to be skeptical until we demonstrate that. I actually switched to doing work on language models very recently. So all I’ve done so far is just some very preliminary stuff, but we’ve actually reverse engineered a couple of simple circuits for doing some things related to meta-learning in language models. It actually seems quite easy. So my preliminary position is that not only do I not see any fundamental reasons why these things shouldn’t work, but I feel quite optimistic.
Rob Wiblin: You mentioned earlier that some different interpretability work has been done on language models. What’s been turned up by that, and what does that look like?
Chris Olah: I think there’s a lot of work that’s broadly of the flavor of, “There’s some linguistic feature we think is important, can we determine the extent to which that’s represented at different points in CLIP?” So I might describe this as slightly top-down interpretability, where you have a hypothesis about something and you try to see if you can predict it from somewhere. There’s also some more visualization-oriented approaches. There’s one paper by Google (see figure 4) that I really liked where they were just visualizing how the embeddings of various words evolve as they interact with the context around them.
Chris Olah: They looked at the word ‘die,’ and they found that in some contexts, it’s a German article — so that’s one cluster. In another context it’s death, so that’s another cluster. So I think that this more visualization-oriented stuff is cool. There’s been some nice work visualizing attention patterns. So I think that there is some interesting work in this space. I don’t really know that any of it has quite gotten to the point of getting to mechanistic explanations and this bottom-up understanding of features that I feel like I most trust. But also, I’m entering a new space and I’m presently an amateur in that space. So I wouldn’t want to comment too confidently.
Rob Wiblin: So there’s top-down interpretation, where people might approach the model and say, “Well, it’s got to be able to predict whether a noun or an adjective should go here. So we should expect to find some part of it that’s doing this prediction of what word should go next. Then we’re going to go scout around and see if we can find it.”
Rob Wiblin: I guess you prefer it maybe where we start with the neuron, or we start with a cluster, and then work up and then figure out, yeah, bottom up, what is this thing doing, without bringing too many preconceptions to the table. But I suppose, yeah, it’s natural to do both maybe.
Chris Olah: That would be the thing that I’d be maximally excited about, but I’m excited to have a wide range of people trying things. I think it is really exciting that there’s a significant community of people asking questions in this space. There’s this whole area that people call BERTology, I guess like biology, but for BERT, which is a language model. I think it’s wonderful that that is a significant thing.
Rob Wiblin: Is there anything more that you can say about what would be the equivalent of a circuit in a language model? I suppose it sounded like with the example of die or die, you could imagine that there’s circuits that detect, “Is this a sentence about this thing? Is this a sentence about a person, or is this a sentence about a machine?” Or maybe, yeah, I guess you’d have to start with something that’s maybe even simpler than that, but that might be some equivalent where it’s like figuring out the broad cluster of the topic.
Chris Olah: Yeah. Well, in my conception of this, just like we have features in vision models, we also have features in language models. They live in NLPs. So you have these blocks that are just regular neural network layers with neurons, like anything else in transformers. Then the thing that’s different is you also have these attention heads, which are very different from anything we see in conv net circuits. So the thing that we have to do is adapt our framework of thinking about things in terms of circuits to also include these attention heads. Then hopefully we can use that to go and understand some larger scale mechanisms that are going on.
Rob Wiblin: Are there any sorts of ML models, maybe apart from language ones, that exist now or might exist in future where you worry that these interpretability methods wouldn’t work? I guess examples of other kinds of neural networks. So AlphaZero that learns to play lots of games. I guess MuZero. We’ve got, I guess Facebook’s recommender algorithm, I imagine is a neural network. It’s trying to perform a different kind of task. Are there any ways in which there could be a class of neural network that’s just really hard to understand?
Chris Olah: I think there’s lots of types of neural networks where I haven’t thought really hard about what understanding them would be like, and what trying to do circuit-type analysis on them would be like. I do think that models that are so-called model-based reinforcement learning, where they’re in some sense anticipating futures, or something like AlphaGo that unrolls lots of possible futures, and then has that influence what it does, would be very interestingly different to study. I don’t know that I think they’d be harder, but I think they’d be very interestingly different from the models that I presently study.
Sceptical arguments that trouble Chris [01:38:44]
Rob Wiblin: Over the course of this conversation we’ve raised a couple of different objections or doubts that people might have about this interpretability research agenda and how useful it will be. Are there any other skeptical arguments that trouble you? Any ways that perhaps this could turn out to be a dead end, or not be so useful? I guess ones that keep you up at night, or ones that maybe should keep you up at night if you weren’t as optimistic of a person?
Chris Olah: Well, I think the scaling one is probably the thing that I’m most scared of. I feel relatively optimistic, but when I say I’m relatively optimistic, I don’t know, maybe that means I’m greater than 50% optimistic. I think there’s still a lot of room for things to fail. And I’m the person who should be the most… I’m probably slightly delusionally optimistic about it.
Rob Wiblin: There’s a bit of a selection process that would make it surprising if you thought… If you thought this was a bad plan and you were the main person leading it, that would be a little bit worrying.
Chris Olah: Yeah. But I think this is why you want to have lots of different agendas, and hopefully there’s sort of a portfolio where you hope that one of them eventually pans out, and you aren’t necessarily counting on any single thing to succeed. In terms of worries that haven’t been voiced as much here, there’s this issue of polysemanticity, where a neuron responds to multiple things. And there’s a lot of theories about why this happens. One theory is that there isn’t enough space, in some sense, to include all the concepts. I think we just don’t know why it happens, but it makes it a lot harder to understand neural networks, especially if you’re trying to look at things in terms of neurons.
Rob Wiblin: Yeah, just to explain for people, I guess polysemanticity, this is the thing where you have a circuit that is simultaneously seeming to do two very unrelated things. You’re like, this is a circuit that detects cars and the queen of England, and you’re like, why is the circuit doing this double duty? And it makes sense that this happens when the neural network is small and it has to try to cram as many functions as it can into very few neurons, but I guess you’re saying this seems to happen even in very big networks sometimes?
Chris Olah: It certainly happens at least in medium-size networks. One answer you could have as well is as you make the model larger, there’s also a larger set of things that the model could represent that are useful. So the number of neurons that are available to go and store things is increasing, but also the set of things you want to store is increasing.
Rob Wiblin: I see. So I guess it’s got this trade off. It can either have fewer concepts, so it says, “No, this is going to do only cars and not the queen,” or it can accept, I guess, some frustrations, some technical challenges with having a circuit that’s doing two things and might misfire, but in return it gets two concepts that it can cram into there now. So it’s got this trade off all the time. Even as it gets bigger, as long as there’s more concepts that aren’t represented, then it still has that trade off.
Chris Olah: Yeah, that’s exactly right. And I think we don’t know what the asymptotic behavior of that is. As you make models very large, does polysemanticity go away, or do we need to go and do something else? Is there some way that we can sort of unfold a neural network into a larger neural network — which doesn’t have polysemanticity, for instance — or can we just try to very carefully reason through circuits, and despite there being polysemanticity, be able to sort of very carefully reason things through and it doesn’t end up being that big of an issue?
Rob Wiblin: Okay, yeah. And then the reason this troubles you is just that when you come up with a polysemantic circuit it’s just much more of a pain in the ass to understand it, so it slows you down.
Chris Olah: And I think we’re much less confident that we understood everything about it.
Rob Wiblin: Like, what else is hidden in there?
Chris Olah: Yeah, what else is hidden in there. And you could even imagine there’s things that are very small in every single neuron, but are sort of hiding between the neurons, that are sort of orthogonal to almost all of the neurons, and so it’s very difficult to see them, but might still be being represented in the model. So it’s very hard to catch from this kind of lens. This is actually why… Earlier you asked me what a feature was, and I was like, “Well, usually we think of features as neurons.” But the reason that we don’t just say that features are neurons is that there seem to be some cases where the features are actually stored in combinations of neurons, or where a neuron corresponds to multiple features. The ideal thing would be to find some way to go in and represent things so that’s all separate.
Chris Olah: Related to this, there’s a literature in machine learning where people talk about disentangling representations. It’s a little different because usually then they’re talking about a couple of features that they know, like they care about gender maybe, and hair color, or things like this. And they want to find a way to disentangle things, whereas we don’t have that benefit here. But it’s a closely related problem.
How wonderful it would be if this could succeed [01:42:57]
Rob Wiblin: Alright, we’ve covered quite a bit of the stuff that was in these articles and in the circuit series more generally. Is there anything else that you think is important and interesting that the audience should know that we haven’t managed to cover so far?
Chris Olah: We’ve talked a lot about the ways this could fail, and I think it’s worth saying how wonderful it would be if this could succeed. It’s both that it’s potentially something that makes neural networks much safer, but there’s also just some way in which I think it would aesthetically be really wonderful if we could live in a world where we have… We could just learn so much and so many amazing things from these neural networks. I’ve already learned a lot about silly things, like how to classify dogs, but just lots of things that I didn’t understand before that I’ve learned from these models.
Chris Olah: You could imagine a world where neural networks are safe, but where there’s just some way in which the future is kind of sad. Where we’re just kind of irrelevant, and we don’t understand what’s going on, and we’re just humans who are living happy lives in a world we don’t understand. I think there’s just potential for a future — even with very powerful AI systems — that isn’t like that. And that’s much more humane and much more a world where we understand things and where we can reason about things. I just feel a lot more excited for that world, and that’s part of what motivates me to try and pursue this line of work.
Rob Wiblin: Interesting. Yeah, so the idea there is that in the future it might be that neural networks are doing just a lot of the stuff that people used to do; they’re kind of calling the shots in some sense, although hopefully, ideally, aligned with our interests. But it might be a very alienating world if there are these black boxes that we just can’t comprehend and we ask them to do stuff and then they do it, but we don’t have any understanding even of the process.
Rob Wiblin: But if we can look at them like machines, like cars, where you can Google it and then find out how a car works, and you’re like oh okay, the world is comprehensible to me, and that makes me feel better about it. It makes me feel like I’m less of a useless…like I’m just being waited on by these neural networks. And I guess we can also potentially learn things about the world from these neural networks. One reason why they’re able to do things that we can’t do, or do things better than us, is that they’ve got features inside their minds. They’re thinking about things in a particular way, and maybe we could learn to understand. Possibly even kind of copy the clever things that these neural networks are doing.
Chris Olah: Yeah. There’s this idea of a microscope AI. So people sometimes will talk about agent AIs that go and do things, and oracle AIs that just sort of give us wise advice on what to do. And another vision for what a powerful AI system might be like — and I think it’s a harder one to achieve than these others, and probably less competitive in some sense, but I find it really beautiful — is a microscope AI that just allows us to understand the world better, or shares its understanding of the world with us in a way that makes us smarter and gives us a richer perspective on the world.
Rob Wiblin: This is the kind of thing that this would enable.
Chris Olah: It’s something that I think is only possible if we could really succeed at this kind of understanding of models, but it’s… Yeah, aesthetically, I just really prefer it.
Ways that interpretability research could help us avoid disaster [01:45:50]
Rob Wiblin: So that people have maybe a clearer picture in their head of what’s going on, can you describe a possible story in which this interpretability research would help us to foresee a failure mode of a neural network when it’s deployed, and then kind of diffuse it ahead of time? Is there any kind of a toy story that we have of that?
Chris Olah: I think there’s a number of different stories. Maybe you can sort of think about them from the world where circuit-style interpretability most dramatically succeeds, and how that contributes to safety, to progressively worlds where it succeeds less, but still contributes to safety in some meaningful way.
Rob Wiblin: Yeah, go for it.
Chris Olah: On the most extreme side, you could just imagine us fully, completely understanding transformative AI systems. We just understand absolutely everything that’s going on inside them, and we can just be really confident that there’s nothing unsafe going on in them. We understand everything. They’re not lying to us. They’re not manipulating us. They are just really genuinely trying to be maximally helpful to us. And sort of an even stronger version of that is that we understand them so well that we ourselves are able to become smarter, and we sort of have a microscope AI that gives us this very powerful way to see the world and to be empowered agents that can help create a wonderful future.
Chris Olah: Okay. Now let’s imagine that actually interpretability doesn’t succeed in that way. We don’t get to the point where we can totally understand a transformative AI system. That was too optimistic. Now what do we do? Well, maybe we’re able to go and have this kind of very careful analysis of small slices. So maybe we can understand social reasoning and we can understand whether the model… We can’t understand the entire model, but we can understand whether it’s being manipulative right now, and that’s able to still really reduce our concerns about safety. But maybe even that’s too much to ask. Maybe we can’t even succeed at understanding that small slice.
Chris Olah: Well, I think then what you can fall back to is maybe just… With some probability you catch problems, you catch things where the model is doing something that isn’t what you want it to do. And you’re not claiming that you would catch even all the problems within some class. You’re just saying that with some probability, we’re looking at the system and we catch problems. And then you sort of have something that’s kind of like a mulligan. You made a mistake and you’re allowed to start over, where you would have had a system that would have been really bad and you realize that it’s bad with some probability, and then you get to take another shot.
Chris Olah: Or maybe as you’re building up to powerful systems, you’re able to go and catch problems with some probability. That sort of gives you a sense of how common safety problems are as you build more powerful systems. Maybe you aren’t very confident you’ll catch problems in the final system, but you can sort of help society be calibrated on how risky these systems are as you build towards that.
Rob Wiblin: I guess this is a model where neural networks that are getting deployed are kind of like cars, or maybe it’s like deploying a new drug, or a new pesticide. And it’s not that we want zero failures. It’s just that we want to have better systems to be more likely to find problematic side effects, or to find ways that they’re going to fail as often as possible, because the more we manage to foresee problems and prevent them, the better.
Rob Wiblin: I suppose some people who are operating more within a very rapid take-off of AI, where we’re going to reach superintelligence really quickly, and any errors that slip through risks catastrophe…that’s kind of a very different vision maybe for how AI could end up affecting the world. I suppose from that point of view, just being like “Well, we found 80% of the problems” wouldn’t put people’s minds at ease so much. Do you have any thoughts on that? Or maybe it’s just that you think that this more gradual deployment of ever more powerful neural networks is just by far the most likely scenario to play out.
Chris Olah: First, I’d say I still am aspiring to catch all the problems. I don’t know if this project’s going to succeed, but I do think that I’m sort of… I guess in some ways the way that I’m answering this question is, in progressively worse worlds, how do we contribute to safety? And as we succeed less, our contributions to safety are smaller. Hopefully, they’re still helpful. I do think that people who, even people who have a relatively fast take-off worldview, unless they have a very, very fast take-off worldview, should be kind of excited about anything that might help society become more calibrated on whether there are risks from AI systems, because the kind of coordination that you’d want to have about deploying a transformative AI system seems much more likely if you have concrete examples of systems being unsafe. It seems really hard to coordinate people around a completely abstract problem. So even if it’s with much weaker systems, if you can have compelling examples of safety problems, or systems, in some sense being manipulative or being treacherous in some way, I feel much more optimistic about persuading people to take action.
Rob Wiblin: Yeah, that makes sense. So what’s the future for interpretability research? Are there any really promising horizons that we can expect to see over the next couple of years?
Chris Olah: I think the question isn’t are there promising horizons, but of the immense number of promising horizons… I feel like this must be what it’s like to be involved in a very early scientific field, where there’s so much low-hanging fruit. It just seems to me that you can go in a million directions, and you’ll find amazing things to discover about neural networks in every single one of those directions.
Rob Wiblin: So there’s just fertile, unfound ground everywhere the eye can see.
Chris Olah: I think you can just sort of crack open a neural network, and if you’re looking carefully, with high probability you can discover something that no one else has seen before. Maybe there’s particularly high-impact things, like I think discovering motifs or discovering larger scale structures, or making progress on language models or things like this are higher impact maybe than other things. But if you imagine this is like we’re in the early days of the biology of deep learning, yeah, there’s just… Every direction there are amazing things to find.
Careers [01:51:44]
Rob Wiblin: Nice. Alright, well, with that in mind, what are the first steps that people should take if they’re really keen to get into this interpretability agenda and contribute to it? We’ve had other episodes where we’ve talked about how to pursue a career in machine learning in general, but maybe for someone who is already heading towards a machine learning or an AI safety career, how do they push themselves in the interpretability direction?
Chris Olah: Well, again, I’ll caveat that there’s lots of different things that people are doing within the interpretability space, and I think that my advice is only very useful if you’re interested in this kind of circuit-style interpretability. I think my first piece of advice would just be to read the circuits thread carefully. I think it’s the most concentrated example of trying to do this particular style of interpretability research. Again, it’s my own work, or I’m involved in it, so I’m kind of biased, but I think if you’re excited about this kind of work, that’s probably a good starting point. I think just trying to really deeply understand neural network architectures, trying to reason about how you would implement different kinds of things in them, spending time poking around with them yourself. I think all of that is really useful. I think a lot of standard advice about how to get into machine learning and build up skills of general relevant software engineering and relevant understanding of the theory of neural networks is all very applicable. I’d also try to develop some very basic data visualization skills. I think that’s something that will serve you really well if you have it.
Rob Wiblin: Are there any conferences or social events… People can read all these things, but probably eventually they’ll want to talk to people within the field in order to move further on. How might they be able to do that?
Chris Olah: I think this particular approach is a pretty niche thing. There is a Slack community that you can access if you read the circuits thread, and also a number of us are pretty active on Twitter. I really wanted to organize some kind of social event around this, but COVID has made that a hard thing to do.
Rob Wiblin: I guess people can follow you on Twitter. Presumably this subfield is going to grow, and eventually there will be events and things people can go to to network and keep up to date. So you probably present at the standard ML conferences, right?
Chris Olah: I sometimes give talks at conferences. I mostly publish in Distill, since we sort of have this venue that allows for interactive visualizations. So I think for this particular niche, a lot of stuff is sort of concentrated around Distill and around the Distill Slack community and things like this.
Scaling laws [01:54:08]
Rob Wiblin: Beautiful. Alright. I guess that brings to an end a very long discussion, a substantial discussion there of interpretability. Before we stop talking about technical issues though, boy oh boy did our listeners want me to ask you about scaling laws. It seems to be really the talk of the town among people who are following OpenAI or following ML. I actually don’t know all that much about scaling laws, so maybe you can explain to me why everyone is asking me to ask you about scaling laws, and maybe what I and they should know about these things.
Chris Olah: So before I say anything, I should say I have a number of close collaborators who work on scaling laws. I personally haven’t done any work on scaling laws, and so I’m really not an expert. I will try to talk about this as intelligently as I can, but if I say anything that’s really clever, it’s probably due to them, due to experts that I get to talk to about it. And if I say anything really stupid, it’s probably just that I misunderstood something. So that’s just a sort of caveat that I want to put on anything I say about scaling laws.
Rob Wiblin: Alright, I guess first maybe we should explain what scaling laws are.
Chris Olah: Basically when people talk about scaling laws, what they really mean is there’s a straight line on a log-log plot. And you might ask, “Why do we care about straight lines on log-log plots?”
Rob Wiblin: Might I ask first, what’s on the axes?
Chris Olah: Well, it depends. So there’s different scaling laws for different things, and the axes depend on which scaling law you’re talking about. But probably the most important scaling law — or the scaling law that people are most excited about — has model size on one axis and loss on the other axis.
Rob Wiblin: Loss like performance?
Chris Olah: Yeah, high loss means bad performance.
Rob Wiblin: Okay.
Chris Olah: And so the observation you have is that there is a straight line. Where as you make models bigger, the loss goes down, which means the model is performing better. And it’s a shockingly straight line over a wide range.
Rob Wiblin: Okay, so if I increase the model size — I’m just remembering from the economics that I did — if it’s a log linear graph, so linear on the X and then log on the Y, a 10% increase is always as valuable. But if it’s log on the X axis and log on the Y axis, then if I increase the model size 10%, then what happens to loss of performance? I don’t really have an intuitive grasp of what a log-log graph is.
Chris Olah: Honestly I often think about this in a sort of log-linear way, because I think that often units on one axis are actually kind of natural to think about in log space, and then you can just think about it as an exponential. But if you want to think about how both variables relate, you get something of the form y = ax to the power of k. So for example, y = x^2 would be a power law, or y = the square root of x would be a power law. And we see these all the time in physics. Like one of Kepler’s laws relating the amount of time it takes for an object to orbit around the sun and the length of the longest axis of its orbit. That’s a power law that’s related by something like that.
Chris Olah: Then, say you double one thing, then you have this power, and you increase the other variable by that power. So if it was square root, for instance, and you did 10x, you’d go and change one by the square root of 10.
Rob Wiblin: Okay, so it’s some sort of polynomial. I’m not sure I completely followed that. But the bottom line is that people have updated in favor of the view that we don’t hit declining returns as much as we expected to from having bigger models. So it’s just like, increase the number of neurons, increase the number of connections, increase the number of parameters, and the performance just keeps getting better. And it keeps getting better at a decent clip, even for models that were already very big. Is that kind of where this bottoms out?
Chris Olah: Yeah, and I think maybe it’s not just that you’re not hitting diminishing returns. Of course all of this that has been observed so far could change. It could be that the next increase in model size, suddenly the scaling law breaks and it no longer performs this way. But the fact that it’s such a straight line is very surprising, and makes it tempting to go and extrapolate further, and perhaps you can reason about models to some extent that are larger than the models you can train right now. So I think that is why people are excited about scaling laws.
Rob Wiblin: Okay, so they’re using it to project forward, saying “Well, in 2022 we’ll be able to make a model that’s this much bigger, and then we should expect this level of performance, and wow, isn’t that a great level of performance?”
Chris Olah: Yeah. And there are other scaling laws, by the way. There are ones with respect to model size. There are also ones with respect to the total amount of compute you use. As you make models larger, you also have to train them for longer, and so there’s… You can ask, “If I have a given compute budget, what is the optimal allocation of compute between model size and training them longer, and then what loss do I get given that optimal allocation?” And that also follows a scaling law. There’s also a scaling law as you increase the amount of data that you train a model on, and there’s sort of an interaction between all of these.
Chris Olah: I think one analogy people sometimes make for thinking about this is that it’s kind of like statistical physics. There’s sort of this amazing fact about gasses where you can try to reason about a gas in terms of every gas particle, but it turns out that there’s a few things — like temperature, and pressure, and volume, and entropy — that really tell the story. Similarly, there seem to be a few variables maybe for neural networks that also tell a large, at least high-level story of neural networks. And this is in some ways almost the opposite of what we were talking about with circuits, where we were going and really getting into the details. Here, you have this extremely abstract view, where there’s just a few variables that matter and you have them interact.
Rob Wiblin: I see. Okay, so one reason that people might be excited about this is that maybe we’re learning — from all of this experience that we’re building up — some very big-picture, fundamental claims about the relationship between the amount of compute that you have in training, the number of parameters, and the amount of data that you feed into it, and how intelligent/how high is the performance of a system. I suppose that’s amazing in itself. We’re learning perhaps some fundamental laws about the nature of intelligence and information processing. Then I guess it’s even more exciting when you kind of project forward, like in the future, we’ll have this much data and this much compute, and we’ll be able to support a model with this many parameters. It probably helps with our ability to forecast where we’ll be in future.
Chris Olah: And it seems like every couple of months there’s new, interesting scaling laws that allow you to reason about different things. Just a few weeks ago, a new paper came out on scaling laws for transfer learning. Transfer learning is this popular thing where oftentimes one person will train a large model, and then other people who can’t train large models themselves and don’t have a lot of data, but have small amounts of data, will fine-tune that large model to their task. So they go and train it very briefly, starting with the trained model that somebody trained on different data, and then going and training it a little bit on their data. And it turns out that there’s scaling laws for how model size affects this, and there ends up being, in some sense, an exchange rate between the data that you trained on and the data that you’re testing on. This is some really lovely work by Danny Hernandez and his collaborators.
Rob Wiblin: Oh, yeah, Danny Hernandez has been on the show.
Rob Wiblin: I know it’s not your area, but what do you think these people asking about scaling laws should know about them? Is there any way perhaps that they might misunderstand them?
Chris Olah: I think they’re probably focused on them because of what they say about neural network capabilities in the future, and I think that is a really important reason to care about scaling laws. I think that something people maybe underappreciate is that scaling laws are much more general than that, and actually may be very useful if you’re reasoning about the properties of neural networks that we’ll build in the future, more generally than just sort of their loss.
Chris Olah: The really exciting version of this to me, and here I’m just really inspired by things that Jared Kaplan has mentioned to me — I’m probably just giving a worse version of his thoughts, Jared is one of the people who’s done a lot of leading work in scaling laws — is that maybe there’s scaling laws for safety. Maybe there’s some sense in which whether a model is aligned with you or not may be a function of model size, and sort of how much signal you give it to do the human-aligned task. And we might be able to reason about the safety of models that are larger than the models we can presently build. And if that’s true, that would be huge. I think there’s this way in which safety is always playing catch-up right now, and if we could create a way to think about safety in terms of scaling laws and not have to play catch-up, I think that would be incredibly remarkable. So I think that’s something that — separate from the capabilities implications of safety laws — is a reason to be really excited about them.
Rob Wiblin: Interesting. So the idea there would be that on the X-axis, we have something like how much human feedback have we given the system in order to train it to make sure that it understands our preferences, and then on the Y-axis, you’ve got how often does it mess up and totally misunderstand our preferences? And I suppose if you know what the relationship between those two things is, and I suppose you’d also need to throw in… Probably there’s going to be other factors that affect this relationship, like how big is the network, how complicated is the task or something, but that would allow you to project how much input you’re going to need for some future model that maybe doesn’t even exist yet.
Chris Olah: Yeah. Or one really crazy picture you might have is maybe you have two axes, and then you have at every point how aligned the model is with you, or something like this. Maybe that’s a function of the amount of sort of human-preference signal you gave it and the model size or something. And maybe there’s, in some sense, a phase change somewhere, where there’s the aligned regime and the unaligned regime or something like this. This is extremely speculative, but if something like that was true, that’d be really remarkable, I think.
Rob Wiblin: Are there other things that you think people should know about scaling laws, or perhaps focus more on?
Chris Olah: I guess one other thing is that scaling laws show these really smooth trends for the overall loss as you make them larger, but they actually show discontinuous trends if you try to do the same kind of analysis and you look at very specific capabilities, like how well the model does at certain kinds of arithmetic. You’ll actually see these sort of discontinuous jumps.
Chris Olah: It’s tempting to think that there’s maybe some kind of phase change, or there’s something discontinuous going on at those points. I think it connects a little bit to why it’s important to think about interpretability and to think about these systems and to sort of look carefully at them, because it actually sort of suggests that these kinds of productions don’t — at least presently — seem to tell us the whole story of what’s going to happen with these larger systems. In fact there’s something complex going on, at least in terms of these finer-grained things, that we’d still like to understand.
Rob Wiblin: Okay. Yeah, so the fact that we’ve seen at least some discontinuity so far means that, well, maybe there’ll be discontinuities in future. We shouldn’t rule it out and assume it’s all smooth.
Chris Olah: Well, and it sort of suggests that this smooth loss is actually maybe the result of many discontinuous… There’s lots of different small capabilities or something that are all improving at different points, and they’re sort of discontinuously improving. And that sort of in aggregate creates this smooth transition. But that’s maybe for more specific things; in fact, the typical case may be this more discontinuous thing. It just means that there’s a lot more room for us to suddenly be surprised by the capabilities of larger models than you might think, and I think that’s a reason why we should be looking very carefully at what’s going on inside large models.
Rob Wiblin: Alright, I’ll fish again. Is there anything else that people should know about or give more emphasis to with regard to scaling laws?
Chris Olah: Well, maybe one other thing is that this allows us to have a much more systematic and sort of rigorous engineering approach to working with neural networks, where rather than sort of taking shots in the dark, we’re developing this picture of this much more systematic way to think about how we should expect neural networks to perform and what really matters.
Chris Olah: I think there’s a way in which I feel safer in a world where that’s how designing neural networks is approached. This is much less an argument about a concrete way that it’s going to intervene, and more just that that’s the flavor of research and the flavor of AI development that I would feel best about if we could have it. So that’s another thing that I think feels important to add about scaling laws.
Rob Wiblin: One thing that people might be slightly sad about with these scaling laws is that they kind of suggest that bigger is better. Bigger models, more compute, it all makes a big difference to performance. I guess most people obviously don’t have access to the biggest models or the most amount of compute. There’s only a few centers that have that kind of massive funding. What does that imply to people who are doing research, but have smaller budgets and access to fewer resources? Can they still contribute, or are they at risk of getting a little bit cut out of things?
Chris Olah: Yeah. I think that machine learning as a field has been structurally in a very strange position for the last number of years, where quite a large number of actors could go and do relatively state-of-the-art work, and I think that’s not true in many other fields. If you’re doing aerospace engineering, the number of people who can go and build a full-scale rocket ship to go and test, it’s presumably a very small subset of the people working in aerospace engineering that’s relevant to that. And if you’re working on particle physics, CERN and LHC are these enormous, enormous things, and—
Rob Wiblin: It’s hard for me to compete, smashing particles at home.
Chris Olah: Yeah, your basement cyclotron probably isn’t going to keep up.
Chris Olah: Yeah, so what is one to do? Well, I think one answer — and maybe this is a little bit of an answer that I have a sort of selfish interest for promoting — is that interpretability doesn’t require this. Interpretability allows us to train models once, and then potentially for many people to go and study it and try to understand these models. So I think it’s possible that maybe rather than having everybody be training a million models, we might have a smaller number of actors training models and people studying them. Although, I think there still are questions about in what ways can we responsibly and safely provide all those models to everyone?
Chris Olah: I guess another answer is just to try to do small-scale work that allows us to understand this bigger scale picture, or to understand this larger scale picture that we’re starting to see through scaling laws. I think it’s probably possible if you’re rigorous enough and careful enough to be able to say useful things. In fact, I think we’ve seen a number of scaling law papers that are sort of operating in smaller scale regimes and seem quite interesting.
Rob Wiblin: So one listener wrote in a question that was kind of along the lines of, it seems like a lot of progress to date has been people using the same algorithms, or reasonably similar algorithms, over time — but throwing much more data at them, much more compute at them, and then seeing how much their performance can go up. Have there been interesting advancements in the undying algorithms, and are the algorithms very different? And maybe how much of the overall progress that we’ve seen has been driven by algorithms, versus data and compute increases?
Chris Olah: There certainly have been algorithmic improvements. I guess the transition to transformers is probably the most striking one in recent years. And actually, Danny Hernandez has a blog post on the OpenAI blog about the efficiency of training neural networks over time, and how algorithmic improvements have increased that over time. And of course, there’s been lots of really exciting work in other domains. I think progress in graph neural networks is really cool. I think just in general machine learning is going in all sorts of directions, and it’s very interesting.
Chris Olah: But I kind of want to push back against the premise of this question, and I think in some ways this question is sort of saying that it’s sort of boring if what’s going on is increases in compute leading to greater capabilities, or that being the story. I actually think that it’s not at all boring — and in fact is really beautiful that maybe a small number of things are really driving the big-picture story here, as scaling law sort of suggests, and then giving rise to this immense amount of structure that we can look at. It’s sort of saying, “Oh, the universe is boring because the universe runs on really simple physical laws,” or “Evolution is boring; it just cares about survival of the fittest.”
Rob Wiblin: … “It’s just the same thing.”
Chris Olah: “It’s just the same thing all over, over all those millions of years.” But I think it’s not boring at all. I think it’s part of the beauty of it. I think the things that we are observing that result from this are really gorgeous.
Rob Wiblin: So you’re saying it’s another beautiful example of being able to get unlimited complexity and accomplish so much with just very simple underlying processes.
Chris Olah: Yeah. I think that’s the story that is emerging for me. And who knows what I will believe in a couple of years, or whether anyone agrees with me, but that’s my take.
Anthropic, and the safety of large models [02:11:05]
Rob Wiblin: Alright, let’s push on and talk about something pretty exciting that’s happened recently, which is that you and some of your colleagues have recently left OpenAI to start a new project, which you’ve decided to call Anthropic. That was announced publicly just very recently, and I see you’ve now got a website up with a bunch of vacancies being advertised. To set the scene for everyone though, what’s the vision for how Anthropic is going to contribute to the AI safety space?
Chris Olah: Yeah, so Anthropic is a new AI research company focused on the safety of large models. We’re trying to make large models reliable, interpretable, and steerable. Concretely, that means that we’re training large models, studying interpretability and human feedback in the context of large models, and thinking a lot about the implications of that for society.
Rob Wiblin: One of the most distinctive things about Anthropic is that you’re focusing on the safety and construction of large models — I guess maybe the largest models that you can manage? Some people might be worried that since you’re working on those large models — which are, I guess, the models of greatest concern — you might also be accelerating progress towards larger and therefore more dangerous models. What do you think about that?
Chris Olah: I have a lot of sympathy for that concern. I think that large models are probably the greatest source of AI risk in the foreseeable future, and so it’s pretty reasonable to be concerned about things that might accelerate that. But that’s exactly why I think it’s really important for us to be working on their safety. And I think we should try to be responsible and thoughtful about working with large models, but yeah — I think if you know that something is coming and you think it might be dangerous, then you probably want to do safety work focused on that.
Rob Wiblin: Okay. So it sounds like your general take is that it’s possible that this kind of work might accelerate the development of larger models, but that is kind of that outweighed; we should do it anyway. Because those are the things that might do the most damage, working and understanding them and figuring how to make them safe is the most effective way to work on safety, and that’s kind of the dominant consideration.
Chris Olah: Yeah. To be a little bit more precise, I actually think that there’s sort of one primary argument, and then there’s actually two secondary arguments that are also worth considering. So I’ll give you the primary argument first.
Chris Olah: It seems to me like large models are, short of something really dramatic happening, basically inevitable at this point. Society seems like we’re on a pretty straightforward path of people building larger and larger models. And at the same time, it seems like these large models are pretty qualitatively different from smaller models.
Chris Olah: So a concrete example of that is some of the largest language models will in some sense lie to you. You go and you ask them questions, and they demonstrably know the answer to the question, but they still give you the wrong answer when you ask them. Maybe it’d be more accurate to characterize that as bullshit rather than lying. But they’re sort of not giving you true answers that they know. And that’s not a problem you can observe in smaller models, because smaller models struggle enough with saying something coherent, that you don’t have any problems with lying.
Chris Olah: And so if you believe, then, that large models are inevitable — and that large models are qualitatively different enough that the most valuable safety research is going to need to work on them to be effective — then I think you’re sort of left with two options. Behind door one, you can do safety research on models that other people have produced. And that means that you probably have, depending on the exact set up, something like a 1–3 year lag on the models that you’re working with. And in that world, I think safety research is sort of perpetually playing catch-up , where it’s working on these older models, and then trying to do safety research with models that are several years behind.
Chris Olah: And the second option is that you try to create a scaling effort and do scaling research that’s very tightly integrated with safety, such that you can be doing safety on the largest models. So I feel like a concern that I sometimes hear in the safety community is, “What if the important safety research can only be done at the end?” Or, “Someday, we’re going to build really powerful systems, really transformative AI systems, and what if the valuable safety research can only be done on those systems?”
Chris Olah: I feel like if you’re worried about that kind of thing, then you should be pretty excited, and it seems really important to go and be able to shave off a couple of years, and that’s sort of effectively buying us more time to work on those systems. So that’s the primary argument.
Rob Wiblin: So a key motivation is that at the moment, safety research is always behind the cutting edge, because the cutting edge is these largest models, and the safety research isn’t necessarily tied into the stuff that’s really at the cutting edge of capabilities. And by making Anthropic focus on the largest models, you’re keeping it up to pace. So that if there are new considerations raised by the latest advances and capabilities, you’ll be there with a safety mindset, in order to try to apply safety thinking to that.
Rob Wiblin: I guess, to some extent, it has to be an open or an empirical question whether this is net beneficial. At least, if you think that advancing the rate of progress within the largest models is harmful, then it’s kind of an empirical question how much you speed those up versus how much you make them safer. And one has to make a judgment call there. But I guess it sounds like you think the effect that you have on accelerating the progress or accelerating the size is relatively modest compared to the gain of insight that you have to how they work and how to make them work better.
Chris Olah: Yeah. I mean, I would actually probably frame potential harm not as… I don’t think that I see capabilities progress as intrinsically harmful. But I do worry a lot about races and accelerating races and creating incentives where people are going to cut corners on safety. But yeah, I think we can be pretty responsible about that, and I also think that at least if you’re sort of taking an empirical approach to safety, it’s really hard to make progress if large models are just really qualitatively different and you don’t have access to them. And so I kind of think that safety research playing catch-up is a losing game, and we need to go and work on large models.
Rob Wiblin: Yeah, you said that if you’re not working with the largest models, then plausibly you could be 1–3 years behind the cutting edge, or playing catch-up on that kind of timeline. Where does that range come from?
Chris Olah: So this is just my estimate, and I think it depends a lot on the exact institutional setup. So I think if you’re at a company that’s training large models but aren’t really closely integrating with the scaling efforts in particular, then you might be looking at something more like a one-year delay, maybe even more like six months. And that’s due to your need for the specialized infrastructure for working with these models, due to the fact that these models cost a lot to be able to do anything with, just like they cost a lot to train, and from the fact that expertise may only reside with the people who are training these models, and so you might not know how to work with them. And just that it’s really hard to integrate with a project while it’s actively being worked on.
Rob Wiblin: So you end up having to wait for it to be polished and then kind of handed out in a way that is possible for external people to use, and that happens at some substantial delay.
Chris Olah: And you probably need to go and get engineers who have expertise working with these models to help you build the tooling you need to do useful work on top of them.
Chris Olah: On the other extreme, if you’re at an academic lab, it seems like that gap is growing pretty dramatically. And my guess is that a lot of academic labs only have a couple GPUs, and don’t have expertise training even moderately large models, and are doing it with models that are very far behind the state of the art. And I think there’s a spectrum between there. And so I think that’s where my 1–3 years estimate came from.
Rob Wiblin: I see, yeah. Is it a problem in itself that kind of academia is being… sounds a bit like it’s being pushed out by the fact that the funding requirements have grown so large that they’re kind of beyond the normal size of academic grants.
Chris Olah: Yeah, I think it’s a really tricky problem. And it might be interesting to look to other areas of science that have higher capital costs to learn about how they operate. So I think if you were designing airplanes, you wouldn’t expect research labs to be able to go and build their own airplanes. Or certainly, there’s many… Something like CERN or the Hubble space telescope isn’t something that an individual lab can do. And these fields develop mechanisms for being able to go and coordinate and go and do high-capital cost experiments.
Chris Olah: And so I think it’s a sort of painful thing that we’re going through right now as we make that transition from a field that’s more like mathematics or traditional computer science, where every PhD student has sort of the maximum amount of useful resources, and you don’t really need anything beyond there — it’s just your own ability to think — to a field that’s more like some of these other fields where you have really high capital costs, and you need to organize things differently.
Rob Wiblin: Earlier you said there were three different lines of argument that you were going to use for why this was net beneficial, and that was the first one. What’s the second?
Chris Olah: Well, I think somebody might think, “What if AI systems are just so dangerous — and safety is so hard — that even if you’re careful and you try to work on safety… deep learning is just bad for the world.” Let’s assume for the sake of argument that’s true. I’m pretty optimistic that’s not what the world looks like, but let’s assume for the sake of argument that we’re in a world where deep learning is just intrinsically dangerous, and really large models at some point become harmful and it’s very difficult to avoid that.
Chris Olah: Well, it seems to me that in such a world, we probably want to cause a pretty dramatic slow down on work towards large models. Maybe we should pass a moratorium on models above a certain size, or something very dramatic like that. And I don’t see that happening by default. My guess is that the only way that’s going to happen is if we have really compelling evidence that large models are very dangerous.
Rob Wiblin: And necessarily so.
Chris Olah: And necessarily so. And I don’t see a way that you’re going to get that kind of evidence if you aren’t working with large models. And so I think even people who hold that view should be excited to go and do safety research and really critical analysis of large models, because I think that’s the only way that you’re… I think the effect of that research is going to be pretty…any acceleration is going to be pretty marginal. There’s already lots of actors working in the space. And I think the main thing you should be optimizing for, if that’s your view, is the possibility that you can get the evidence that could build consensus around a really dramatic slowdown.
Rob Wiblin: Yeah, okay. That one makes sense to me. What’s the third one?
Chris Olah: Well, I guess my final argument is, we live in a world with a lot of ongoing moral catastrophes. Factory farming, global poverty, neglected diseases, and also oncoming disasters like climate change or potential sources of existential risk, and those are extremely tough problems. But I think once we’re… Supposing we’re in a world where this dramatic risk from AI exists, I think you also have to be supposing that you’re in a world where you have AI systems that could potentially really dramatically improve these problems if they were aligned.
Chris Olah: And so just as much as I feel an obligation to worry intensely about AI risk and ways that AI could go wrong, I think we also have a great responsibility to make sure that we aren’t losing the opportunity for AI to dramatically improve the world. I think that could be equally bad and an equally great failure.
Rob Wiblin: So this is an argument that’s been around for a while, which kind of runs, even if you’re someone who thinks that faster advances in artificial intelligence will be dangerous because they’re happening so fast that we won’t necessarily have time to fully prepare for them and figure out all of the additional safety requirements that we need for more advanced, larger models, it could nonetheless come out safer on net, all things considered, if those massive advances in artificial intelligence could also reduce the risk of nuclear war, and reduce the risk of bioweapons being used, or a terrible pandemic, or just a war between countries. And depending on the ratio you see in the risk of this new technology versus all of the other risks that that technology might then obviate and supersede, then even if it’s dangerous to go faster, it can come out positive on balance, because you’re going to spend less time in the meantime with all of those other concerns as swords of Damocles hanging over you.
Rob Wiblin: I think we can actually put a link up to a little mathematical model that Nick Beckstead made a couple of years ago to try to see how large is this effect.
Chris Olah: Yeah, that’s exactly right. Although I also want to highlight — and I think this depends a lot on your moral views — it’s also important for me to weigh not just existential risks that might harm the far future, but also take seriously present ongoing harms that could be mitigated. And I understand that from a lot of utilitarian views, that might be the only thing that should matter. But honestly, I just feel really, really upset about factory farming and about global poverty specifically. I think in some ways, I sort of emotionally wish I could work on those instead of AI if I thought that was the optimal thing for me to do. This isn’t to say that it should be the dominant concern, but I don’t think it should be forgotten.
Rob Wiblin: Yeah. I think part of the reason the argument is often phrased that way, just comparing risk against risk, is that it’s so clean when you’re just always dealing in the same currency. You don’t have to make any conversions from one thing to another. Because plausibly, depending on what parameters you stick in, you could just say, “Well, this argument is actually self-undermining. There’s no benefit to it in any currency.” So yeah, very convenient.
Rob Wiblin: But it also would be very nice to solve all these other problems that bedevil us all the time — and I guess potentially live a lot longer, because we’ll make huge advances in biomedical science and so on.
Rob Wiblin: I guess I thought you might lean even more heavily on the argument that Anthropic is kind of a drop in the ocean of all AI research, and that really, how much is it going to be doing to actually spur larger models than have been created elsewhere? And especially more dangerous, larger models. It seems like you’re potentially going to be a much larger fraction of the safety-focused thinking and safety-focused research than you would be of large model research, which is going on in many places.
Chris Olah: Yeah. I think the arguments here are actually pretty subtle and nuanced. So first, we could try to make an argument on ratios, and you have to account for three things. The first, as you say, is sort of the fraction of Anthropic’s effort that goes into safety or capabilities. Although I think that’s maybe not the right distinction to make. If the question you’re trying to answer is how do you make large AI systems safe, those actually are very intertwined things that aren’t so easy to pull apart. But yeah, I think safety is probably a bigger part of our mission than most organizations, and it’s sort of the reason we exist.
Chris Olah: But I think there’s two other things that maybe are even larger factors. So one is if you believe that the most effective safety research can only be done on large models, then you have to multiply the amount of safety effort that’s going in by the effectiveness multiplier. And I think that the effectiveness multiplier is… I don’t know, suppose that you’re comparing Anthropic with a lab that does 5% safety research, and let’s say that Anthropic — even though I sort of think this isn’t quite the right way to think about things — is doing 50% safety research, or 70% safety research, or something like that. But then you think that it’s actually a 20 to 1 effectiveness multiplier or something like this. That might be the swamping thing.
Chris Olah: The other thing is if the thing that you’re really worried about is whether you’re accelerating races, or causing the field to race, I think it’s not how much of your effort are you spending on training large models or something like this that’s relevant. It’s actually really nuanced things, like how you conduct yourself in the field.
Chris Olah: I think it matters a lot exactly what kind of research you do. I think it matters a lot if you’re doing models that you think are just below the largest models that are being trained, or are larger than them.
Chris Olah: I think actually something that people really underrate is that I think we’re getting into the regime where AI determines cost, potentially many millions of dollars. I think that marketing matters a lot. I think that the kinds of things that cause organizations to be willing to go and invest huge amounts of resources in something… A flashy demo may go a long ways further than a very dry reference to a technical result. And so I think that there’s actually a lot of detail there.
Chris Olah: So in any case, zooming out again. So we have, I don’t know, perhaps this gross, like how much of your effort is going into one thing or another, which may not be quite the right framing if you’re sort of entirely focused on building safe systems, or if you’re sort of really tightly integrating those things. But then you also have to multiply by the effectiveness multiplier you’re getting on safety, and also by, I don’t know, the carefulness multiplier on how you’re affecting race dynamics. The one that for me is the largest one is my belief about the effectiveness multiplier on safety.
Chris Olah: And I think we’re already doing some examples of that, like the multimodal neurons work that wouldn’t have been possible without access to… This is work that I did while at OpenAI. It wouldn’t have been possible to do without access to state-of-the-art models, and being able to go and tightly integrate with that effort. Or the learning from human preferences paper, again, relied on access to large models to be able to go and demonstrate that. And so, yeah, I think a lot of safety research can get a large multiplier if you have access to these models.
Rob Wiblin: Yeah, we we’re talking about Anthropic, and this has been a big diversion into this question of safety in large models. Before we go back on topic, I just want to ask one more question, which is just…maybe this is going to show my naiveté, but it seems like just making the models larger… Doesn’t that just mean adding a whole lot more compute to the thing? It’s kind of the same thing, but you are spending more money on the hardware, and spending more money on the electricity. If there’s no amazing insight here that you’re demonstrating by just running large models, then maybe it doesn’t really help, or it doesn’t really promote larger models just to be doing it. Maybe even… There’s a chip shortage at the moment, right? And there’s only so much—
Chris Olah: Yeah.
Rob Wiblin: —availability to make these chips. So if you just buy up the chips, then I guess… Or there’s only so much compute to go around, so maybe whoever’s doing it doesn’t make that much difference to the total.
Chris Olah: New AI safety agenda, go and buy all GPUs. Create an—
Rob Wiblin: Yeah, and use them for cryptomining.
Chris Olah: There we go. And then use the cryptomining to buy more GPUs.
Chris Olah: There was this work by colleague, Danny Hernandez, where he just made a graph of the amount of compute used to train the largest models as a function of time. And he found that the amount of compute that people use on the largest models doubles every three and a half months or so. And I think to some extent, yeah, marginal actors probably only affect a little bit. It’s sort of this strong trend that’s a function of lots of people. But at the same time, I think that every time people see people using more compute, that sort of reinforces that trend and can sometimes accelerate it a little bit more.
Unusual things about Anthropic [02:30:32]
Rob Wiblin: Okay, yeah. That makes sense. Alright, let’s go back to Anthropic as an organization. We’ve been talking about large models as kind of one distinctive aspect of the research agenda. Are there any other notable aspects of it that are worth highlighting for people?
Chris Olah: I guess being focused on safety is pretty unusual, and I think us making a big bet on interpretability is also a pretty unusual thing to be doing.
Chris Olah: I guess another slightly unusual thing is also being really focused on thinking about how this work affects society, and trying to tightly integrate things. And I guess actually, just really trying to tightly integrate all of these pieces together, so trying to integrate the scaling work, and the interpretability work, and the human feedback work, and the societal impacts work, and sort of unite those all in a single package and in a tightly integrated team. That’s pretty unusual.
Chris Olah: I think something that people probably underappreciate is if you want to do any kind of safety research on a large model, it’s not just a question of having access to that large model, but these models become very unwieldy and very difficult to work with. They’re just so enormous that a lot of the infrastructure that you’d normally work with just doesn’t work. And so for whatever kind of safety research you want to do, you actually probably have to do a lot of specialized engineering and infrastructure building to enable safety research on those.
Rob Wiblin: I had no idea.
Chris Olah: Yeah, and you need a lot of expertise from people who have experienced working with large models. And so I think there’s a lot of things that can only happen when you really tightly integrate things.
Chris Olah: It’s also… I think people maybe don’t appreciate the extent to which scaling is really two separate things. There’s training large models, but there’s also this work on scaling models, of growing and predicting them. And one of our big focuses is sort of taking scaling laws to every domain. So for interpretability, we know that there’s these points where if you look at the trend for very specific tasks, you get these abrupt transitions where a model goes from… A smaller model can’t do arithmetic, and then, suddenly, a large model can. And we think that probably is a phase change in the underlying circuit, so can we study that?
Chris Olah: Or for human feedback, can we understand how sort of the scaling of Goodhart’s law, what happens if you go and you train a… If you have models of different sizes, and you also have different amounts of human feedback, can you understand empirically — or can you understand in terms of something like scaling laws — whether a model will correctly generalize the human feedback or sort of Goodhart itself? And so those are questions that maybe allows us to start doing work that isn’t just about making the present model safe, but making future models safe. And so all of that requires you to be tightly integrating the expertise that you generate by working on scaling with safety.
Rob Wiblin: Just to paint a picture for people, how many staff are at Anthropic now? And do you have an office? Are you based in any particular location?
Chris Olah: We’re based in San Francisco. We are 17 people right now, and I hope that we will soon have an office, we do not yet.
Rob Wiblin: I guess this is a good time to be remote.
Chris Olah: Yes.
Rob Wiblin: Most of the people I know in the U.K. are still working remotely right now. But I think it’s going to be any month now that we’re going to be back in the office probably.
Rob Wiblin: Who’s funding the whole operation?
Chris Olah: Anthropic’s series A was led by Jaan Tallinn, who cares a lot about AI safety, and was joined by a number of individual funders, rather than VCs.
Rob Wiblin: Given that you’re working on these large models, I’m imagining that one of your primary expenses is just buying compute and hardware and all of that kind of thing?
Chris Olah: Yeah, that’s right. I think that actually, in a lot of ways, AI is maybe starting to look more like other industries — where you have really intense capital costs for research, like biotech, where you have to spend lots of money on reagents. And similarly, we have to spend lots of money on compute for our experiments. And so I think that’s in some way an industry that sort of is natural to compare us to.
Rob Wiblin: Yeah, less like Etsy, more like manufacturing cars, something like that. And what’s the business structure? Is this for-profit, or more of a nonprofit model?
Chris Olah: Anthropic is for-profit. Technically we’re a public benefit corporation. But that just means that we are not legally obligated to maximize shareholder value.
Rob Wiblin: I think for what it’s worth, that might be true of all corporations. Or at least when this has been taken to court, corporations have a lot of—
Chris Olah: Yeah, I think in practice, it’s very difficult to go and do this. But a public benefit corporation makes sure.
Rob Wiblin: I’m not super familiar with public benefit corporations, but do you end up with something else in your charter, in addition to making profit? Kind of a specified goal of the organization?
Chris Olah: Yeah, so you go and you put a mission in your charter that you’re allowed to prioritize over shareholder value.
Rob Wiblin: And I guess here it’ll be something like developing AI for the benefit of everyone and sharing the spoils?
Chris Olah: Something to that extent.
Rob Wiblin: So as a public benefit corporation, you can take investment from investors who are aiming to make some money back. You can also sell products and use that to fund the growth. It’s just that you also have other goals in addition to making money at the end of the day, and I guess the board and so on can have a vision for the company that is not just maximizing dividends, or maximizing shareholder value.
Chris Olah: Yeah.
Rob Wiblin: So how does one monitor the kind of research that you’re doing? How do you actually get the revenue in order to keep growing?
Chris Olah: Right now and for the near future, we’re just focused on research. But I think that we’re kind of at an interesting point in the trajectory of AI where I think in the past, the economic value of AI has been bottlenecked on models being capable at all, and being able to do anything useful at all. And it seems like we’re maybe transitioning out of that phase a little bit, and that actually, now we can build… A lot of organizations can build models that are in some sense capable of doing useful things.
Chris Olah: But they aren’t reliable, they aren’t trustworthy, nobody understands how they work, and that’s becoming the bottleneck on their use and on economic value from them. And so I think that makes us hopeful that there’ll be opportunities that if you can become really good at building systems that are safe and reliable and trustworthy, that there’ll be economic value from that.
Rob Wiblin: Yeah, I guess I can see multiple different business models here. So one will be like actually designing these systems that are very high stakes yourself, because you have the expertise in certifying that they are safe and going to act as designed and predicted. Another one might be doing consulting, using that expertise to help other companies fix their models. And I suppose another might be selling interpretability tools and so on that will allow everyone else to look inside their models and help to make them safe themselves. I guess, probably, all of these plausibly are on the table for the future at the moment?
Chris Olah: Yeah, we’re super early stage. I think the most likely thing would be training large models ourselves and making them safe. We think that it’s probably important to integrate safety in the design of models. I should also say that we plan to share the work that we do on safety with the world, because we ultimately just want to help people build safe models, and don’t want to hoard safety knowledge.
Hiring [02:38:13]
Rob Wiblin: Alright. I guess I’m imagining that Anthropic, as a pretty new organization, is on the hunt for people to fill all kinds of different roles. Are there any particular roles that you’re hiring for the moment that are worth highlighting?
Chris Olah: Yeah. There are three roles that are, in particular, really high priority for us. And they’re maybe not the roles that people might expect. I think there’s often an assumption that the highest impact and most important and in-demand roles at a machine learning research organization are going to be machine learning research roles. But in fact, the things that we really, really need are… There’s two engineering roles that are really important, and there’s a security role that I think is absolutely essential that we find someone good for.
Rob Wiblin: Let’s take those one by one. What’s the engineering role, and I guess why is it important enough to really want to highlight it?
Chris Olah: At the core of Anthropic’s ability to do our research, to go and explore safety in these large models, is the ability to work with large models. And at the core of that is our cluster, basically a supercomputer that we’re using to do all of our work on. And so there’s really two roles related to that that are central to our ability to do productive research. The first one is what we’re calling our infrastructure engineering role. This is someone who’s going to be responsible for keeping that supercomputer running, and having the tooling we need to interact with it.
Chris Olah: And I think there’s two ways you could think about why it’s such an high-impact role for us. One way to think about it is that right now, all of that work is being done by researchers. I was listening to one of the old 80,000 Hours podcasts a while back where you were discussing operations; it was with Tanya Singh. And she commented on how she was able to free up more than one hour of researcher time per hour of operations work that she did. And I think absolutely something similar would be true here. I think that somebody who took on this infrastructure engineering role would be freeing up way more than one hour of researcher time for every hour they spent on it.
Rob Wiblin: And the reason there is just that they’ll actually have the special skills to know how to keep—
Chris Olah: They’ll have actually have the special skills, yes. They will really know what they’re doing, instead of being experts in a different topic who are playing at knowing what they’re doing. That’s exactly right. There’s another way you can think about it, which is, we are spending tens of millions of dollars a year on this cluster, to allow us to do our safety research on large models. And sometimes the cluster is unusable, or things break unnecessarily. And we think that it’s quite likely that somebody who took on this role could increase the uptime and the reliability by more than 10%. And so in some sense, that would be equivalent to giving millions of dollars to an organization that’s focused on the safety of large models. And so, I mean, if you’re excited about making large models safe, that could be a really high-impact thing to do.
Rob Wiblin: I don’t really know how you network computers or make a supercomputer, but I’m guessing it’s a little bit technical. Are there people in the audience who might actually have the skills to operate a computer of this scale? Are they going to know who they are, or is there anything we can say to make sure that they are aware that they ought to put their name forward?
Chris Olah: Everything that we’re doing is based on Kubernetes, which is a framework for working with large distributed systems. I think that having expertise in networking, and, I mean, I think if somebody has experience with GPUs, or things like that, that could all be useful. But I think expertise with Kubernetes, and to some extent doing sys ops work, would be things that would be relevant to this infrastructure engineering role.
Rob Wiblin: Okay, nice. That was the first engineering role, what’s the second?
Chris Olah: The second engineering role, we’re calling it our systems researcher role, is also really centrally related to this cluster. There’s this whole challenge of figuring out, if you’re running these giant models, how do you effectively fit them, and set them up on this supercomputer? How do you break them apart? How do you efficiently make all the networking work? How do you get everything to run as efficiently as possible? And that’s really… There’s not a lot of prior art on this, because these really giant models… There’s not that many places that have worked with them. And so there’s really this novel engineering problem of how you efficiently run these models on distributed systems.
Rob Wiblin: So this is something along the lines of, I guess, you’re running particular processes, particular kinds of algorithms, and you want to figure out how can you distribute and order those operations most efficiently when you’re running them across, I guess, tons of different processes which each might have different specialties or particular kinds of operations they can do most efficiently? I don’t really understand how computers work, is that in the ballpark?
Chris Olah: Yeah, that’s right. You have a bunch of computers, and then each of the computers has a bunch of GPUs, and there’s a lot of questions about how you lay out these large models. You’re multiplying all these large matrices. How do you lay that out across these GPUs? How should they all talk to each other? What’s the most efficient way to do things? And there’s both high-level questions about what the most efficient way to organize things is, and you have to think about memory bandwidth and how long it’ll take to load things between different kinds of memory, and the network and stuff like this, so there’s this interplay of these high-level considerations, and then also very low-level considerations of just how to make things be very efficient.
Rob Wiblin: And the reward there from doing that I guess is you get more actually useful computational work out of the same amount of hardware, and same electricity bill and so on?
Chris Olah: Yeah, that’s exactly right. And so again, I think it’s very, very easy to imagine that someone who is doing this role could increase our efficiency by at least 10%. And that’s equivalent to providing millions of dollars to an organization that’s focused on safety.
Rob Wiblin: Amazing. If this is a role that isn’t a traditional tech role, or isn’t the kind of thing that lots of people might have worked on before, how could someone tell if they have the proto-skills that might allow them to go into a position like this?
Chris Olah: I think some of the things that would make someone effective at this role are… I think if somebody has a lot of experience thinking about efficiency in low-level hardware, that would be one thing that might be a really good indicator that they could be good at this. I think also having a lot of experience thinking about distributed systems, and especially thinking about efficiency in distributed systems, could be another good indicator. I think that they’d have to learn some stuff about machine learning on the job, but I think that, yeah, I think for this role it’s primarily having strong engineering skills, and especially strong engineering skills related to efficiency and distributed systems. Those would be the things to look for.
Rob Wiblin: Cool. It’s slightly funny to me that it sounds like you feel you really have to justify why these roles are high impact in terms of the amount of equivalent money donated. It seems like if what Anthropic is doing is useful in the big picture, having good people running this enormous supercomputer system seems like it’s obviously going to be important as well. I mean, you could imagine that if it’s running incompetently, then you could be wasting a whole lot of hardware and also probably just have tons of downtime that’s going to slow things down. So it’s not a very hard sell, to me at least.
Chris Olah: Well, I often get the impression that people are seeing engineering roles as these things of secondary importance, that often they’re trying to figure out how they can become, transition from being an engineer to being a machine learning researcher, or assuming that the engineering roles are less important. And so I guess really the reason that I’m saying all of this is just to emphasize how tremendously high impact these engineering roles are. One of the most effective people I know is Tom Brown, who is really primarily an engineer. He was the lead author of GPT-3, and has been tremendously impactful in enabling research on large models.
Rob Wiblin: I guess it seems just blatantly obvious that you need someone to do this work, so I guess that the logic that’s going on in people’s heads is, for these positions you don’t need someone who’s especially passionate about AI safety as a problem in the world, like can’t you just hire someone who doesn’t even necessarily have to care all that much about the mission and just pay them money to run the supercomputer? I guess I can see how people get that in their heads. It just seems like when you talk to organizations that are trying to do work like this, they say, “No, it’s actually really hard to get the best engineers, and it would really make a difference if we could find someone who was better at the job.”
Chris Olah: Yeah, that’s absolutely right.
Rob Wiblin: Do you have a theory for why it is that it seems quite often you need people who care about the importance of the mission, care about AI safety, when their job doesn’t seem to be that they are researchers directly, it’s building all the tools that enable people to do that research?
Chris Olah: Well, the first thing is, I think people who are really good at these skills are rare, and hard to find. Even if you weren’t considering alignment, these are just hard roles to hire for. Just like getting good machine learning researchers is a hard role to hire for. And you’re more likely to get somebody who’s really extraordinarily good at it if part of the reason they’re joining you is that they care about your mission. But I think a second reason is just that it’s really healthy for an organization to have the entire organization care about the mission, rather than having some weird bifurcation where some portion of people care and some portion of people don’t.
Chris Olah: At least at Anthropic, everything is very tightly integrated. It’s not like these teams are siloed, or there’s people working on one thing and they’re siloed from people working on something else. We’re all working very closely together, and there’s very blurry lines, and lots of collaboration. And so I think it would just be a very strange culture if you had some set of people who cared about safety who were doing more research-y things, and… Yeah, I think it would be a very strange situation.
Rob Wiblin: I guess, as you’re saying, with ML taking off as much as it is, I guess people who are able to do jobs like this are probably pretty sought after. There’s a lot of headhunting, so it’s hard to get the best people. And you might also… If someone doesn’t care about the mission that Anthropic is engaged in, then it might be a lot harder to retain someone long term — and ideally you probably don’t want to have annual turnover on the person who has put together and really knows how your compute stack works. I could see that leading to a lot of headaches.
Chris Olah: I think that wouldn’t be terribly fun.
Rob Wiblin: So those were the two engineering roles. There was a third one, and that was security.
Chris Olah: Yeah. Well, earlier you were saying that maybe it was self-evident why the engineering roles were so important. And if that’s true, then maybe it’s even more self-evident why the security role is really important. If you’re building these powerful systems, it’s really important that you be secure. You don’t want anyone to be able to just come and grab all of the research that you’ve done, especially if a lot of your work… In addition to safety, there’s capabilities-relevant components.
Rob Wiblin: Yeah. I guess the whole model is that you’re potentially going to be working at the frontier, with stuff that you’re concerned isn’t quite fully baked and safe yet, so…
Chris Olah: Yeah, we don’t want random hackers to be able to come grab our models, that seems bad. It seems really bad.
Rob Wiblin: I buy it. Alright, go on.
Chris Olah: And not just because these models are potentially unsafe, or in the future we’re going to build models that could potentially be more harmful, but also because they’re abusable. I think there’s a lot of potential for these models to be misused by bad actors. And so I think that there are going to be bad actors who are going to be increasingly trying to go and get access to these models.
Rob Wiblin: Yeah. It seems like just every tech company — or every organization that’s dealing with important confidential information these days — really needs someone to lock down their information security, and their computer security, but it’s not straightforward. The kinds of threats that people face today are pretty serious, and it takes a lot of know-how to figure out how to keep information in-house.
Chris Olah: Yeah, it’s not straightforward at all. And I think it’s a really easy thing to neglect. It would be easy to say, Anthropic’s a small organization right now, probably nobody’s going to try to do anything to us. We could leave this to later. And I think that would be a terrible mistake. I think this is something that we really want to be working on at an early stage, and trying to address right now.
Rob Wiblin: Is that just because once you’ve built all of your systems, going back and figuring out how to make them safe after the fact once you’ve made all these design choices and you have chosen to use one piece of software over another, it’s just really hard to go back and patch the mistakes that you made years or decades ago?
Chris Olah: I think that’s right. I think there’s also probably something important about building a culture of taking security seriously from the start. And we’re trying to do that by having some employees, especially my wonderful colleague Ben, work on security. But we’re not experts. And we really need an expert to join us and be able to handle this and take the lead on it.
Rob Wiblin: Is this going to be the kind of security role that people might be familiar with, or similar to the sorts of work that people might do in other tech companies? Or is this slightly a weird case where people might be doing different work than a typical security person might be less familiar with?
Chris Olah: I think that there are components that are similar, but I think we also have some challenges that are really unusual. For example, in addition to all of these concerns about security against external threats, we’re training language models to generate code — that’s one of our lines of research. And we expect those models at some point to start doing bad things. And we’re trying to sandbox them. And so it’s pretty important for us to be thinking about how to effectively sandbox them. And so that’s a very… As far as I can tell, that’s a pretty unusual flavor of security problem. Maybe people who work with malware, and need to run it in sandboxes, have something a little bit similar. But it’s a sort of unusual problem that comes up in machine learning that we need to deal with.
Rob Wiblin: Yeah. So people have recently started using language models to do programming, and have been finding that these language models are remarkably capable at programming things that actually really work. And I suppose in the long term, you might worry that you’re potentially going to be playing with language models that are designed to do mischievous things, because that’s the kind of thing that you want to figure out… And you don’t want that mischief done against you, so you have to figure out some way to contain the system so that it can’t start damaging the computer that it’s running on. Is that basically the picture?
Chris Olah: Yeah. Or you might not be trying to do anything mischievous at all, but the model might do things anyways that aren’t what you want. So perhaps at some point you’re using RL to try and get these models to solve tasks, learn to solve problems, and you’re exploring safety in such models. Now you’re in a situation where maybe the model tries to… It’s actually quite good at programming, and maybe it tries to find some security vulnerability to go and get itself extra reward. Or maybe in more extreme versions, it starts to generate malware.
Chris Olah: These are very speculative things, but you don’t want to end up in the kind of situation where that is a serious possibility, and you haven’t thought about it in advance. And so, yeah, I think, again, having somebody who’s thought about security seriously thinking of this kind of stuff would be really valuable.
Rob Wiblin: Okay. So the security role has some familiar elements and potentially some somewhat novel elements. How can someone know if they’re potentially a good fit to apply for that one?
Chris Olah: I think the other challenging thing about this role is that right now we need someone to be dealing with a lot of different kinds of security problems. And often, when we talk to security candidates, they’re focused on a particular specialty. And they don’t have the breadth of expertise to help us with the range of problems that we’re facing. Or in the alternative, they do, but they’re really a manager at this point, and they don’t have as much experience doing ground-level work. They’re looking to lead a whole security team, and then delegate out the various responsibilities. And we’re probably not big enough for that, to build out a large security team. I think the thing that would be a really good sign would be if somebody had a pretty broad range of security knowledge, and was excited to help figure out how to make Anthropic secure.
Rob Wiblin: Okay, so it’s a pretty generalist role. I was just looking at all of the open positions that you’ve got at the moment on the website, and there’s a couple of others here. One that’s a little bit surprising maybe is the data visualization specialist. What are you hoping for that person to do?
Chris Olah: Yeah, I think this is a really exciting role if you want to work on interpretability research. There’s this really interesting phenomenon where, if you look at the history of science, often new lines of research and disciplines get unlocked by having the right kind of tooling. For example, early chemistry seems to have been linked to the development of glassware that made experiments possible. And so I think there’s something kind of similar for interpretability research. These models are enormous, and just being able to go and navigate through them and ask questions and look at data is difficult, because they’re so big.
Chris Olah: And so I think that a really powerful enabler of this kind of research is having people who are good at data visualization, and can sort of be part of the inner loop of that research, and figure out how to go and visualize and explore and understand all the data that we’re getting access to when we study these models. And so I think if someone has experience in data visualization, and experience with the kind of web development that makes interactive data visualization possible, and has some math background, this could be a really impactful way for them to support interpretability research.
Rob Wiblin: We’ve talked about four roles there. Are there any others that you want to highlight in particular before we push on?
Chris Olah: Well, if you look at our jobs page, you’ll see both roles for ML researchers and an ML engineer, and that’s how jobs in machine learning are often described, as there being these two kinds of roles. But I think the thing that we’re actually looking for, underneath that, is what we internally call an ‘ML generalist.’ Somebody who isn’t attached, necessarily, to doing research or doing engineering, but just wants to do the highest impact thing to move the research forward.
Chris Olah: So, yeah, if that resonates with people listening, that could be a really meaningful role. Beyond that, we do have a number of other roles. I think that we’re going to be hiring more slowly for those roles for the rest of the year, but we’ll probably be looking at them more intensely again next year. And that includes operations roles, roles working on public policy, and a variety of research roles.
Anthropic’s culture [02:58:13]
Rob Wiblin: Is there anything in particular that people should know, maybe about… I suppose there’s so many different roles here, it’s hard to say anything in general about who’s appropriate for working in these positions. But maybe is there anything about the Anthropic culture so far that maybe people should know before they consider applying for a job?
Chris Olah: On the more technical side, I think one thing I really love about Anthropic’s culture is that we do a ton of pair programming. So researchers and engineers are just constantly pairing on different things that we’re working on. People will just post in Slack, “I’m going to be working on this. Do you want to pair with me?” I think it’s very significantly further in the pair programming direction than any other organization I’ve been part of. And it’s just delightful, I really love it.
Chris Olah: I think maybe another thing that’s a little unusual is we’re very focused on having a unified research agenda, rather than just having lots of people doing their own thing. But we try really hard to set that research agenda as a group. And so we have lots of conversations discussing what our research agenda should be, and what our focus should be, and I think that’s been really cool as well.
Rob Wiblin: So ultimately, you’re hoping to have an office in San Francisco. Is it possible to apply for these positions if you don’t expect to be able to move to San Francisco any time soon? Are there remote options?
Chris Olah: Right now, we’re looking for people who would be eventually able to move to San Francisco. Obviously after the pandemic gets resolved and after any immigration issues are worked out. But that would be our long-term aspiration for most roles. It’s possible that might change in the future, but right now, that would be how we think about most roles.
Rob Wiblin: Alright. Well, yeah, by the time this episode comes out, those specific roles that are available might have changed a little bit. But obviously, we’ll stick up a link to your vacancies page.
Rob Wiblin: It’ll be really exciting to see where this new project goes. It’s so early, but you’ve already made a little bit of a splash in the press, and lots of other AI labs have had these amazing pieces of research that have gotten out and captured the imagination of people who aren’t even that knowledgeable about machine learning. So hopefully Anthropic is able to do the same thing.
Chris Olah: It’s really lovely to be working with so many wonderful colleagues. And yeah, I’m just really excited about the research we’re doing. I just want to dive into understanding what’s going on inside these large models. Really, that’s all I want.
Atmospheric dynamics [03:00:50]
Rob Wiblin: Cool. Well, we’re approaching the end of this recording session, so we’ll let you get back to that very soon. But just before you dive back into those models, I assume you don’t spend all of your time doing ML research. I imagine you have some maybe slightly pointless research projects, or interests on the side, because I find most really smart people do. Yeah, is there anything you’ve been exploring currently or in the last few years that’s a bit unexpected?
Chris Olah: I often have some kind of small project. For a while I was being an amateur social scientist, using Mechanical Turk to get people to answer questions. Then I was really obsessed with trying to understand evolutionary history, and understand different parts of the tree of life. But the thing that I’ve been obsessed with recently has been atmospheric dynamics. And this is kind of sad, but I guess I sort of felt like physics and biology and chemistry, those are sort of like ‘real’ sciences that have these beautiful, simple theories that explain lots of things, but meteorology and atmospheric science don’t have beautiful theories that explain something really nicely.
Chris Olah: But guess what? It turns out there’s actually a really simple idea that explains an absurd number of things. Let me list some things it explains. It explains why it is that hurricanes tend to hit the east side of continents, but not the west side. So why is it, for instance, that Florida and Japan have lots of hurricanes, but California and Spain don’t? But also, why is it that if you look at a map of the world, all of the large deserts are on two latitudinal lines? And why is it that San Francisco is wet in the winter and dry in the summer, but there’s other places where it’s the reverse? And finally, why is it that Jupiter has stripes?
Chris Olah: And it turns out those are all explained by the same idea. And just to highlight how crazy this is, the reason for the weather that I experience day-to-day in San Francisco is actually intimately related to the reason why Jupiter has stripes.
Rob Wiblin: You’ve piqued my interest. Explain it.
Chris Olah: So the high-level idea is that there’s these really large-scale atmospheric circulations called Hadley cells, where warm air rises, and then moves, and then falls. So warm air rises at the Equator, and then goes out to about 30 degrees, and then falls, and then it also rises again at 60 degrees and goes back to 30 degrees, and goes over to the pole. And in a lot of ways, Earth’s large-scale weather patterns are shaped by these lines, and which one of these lines you fall between. They migrate over the course of the year as the thermal equator changes.
Chris Olah: And the stripes you see on Jupiter are also Hadley cells. It has more Hadley cells than Earth. It turns out that the number of Hadley cells that you have is a function of how fast you spin and the radius of your planet, primarily. And so there’s this very intimate connection between large-scale weather patterns on Earth… Of course I’m not an expert on any of this. Maybe one of your listeners is a meteorologist and can tell me that I’m all wrong. But any existence of stripes that you observe on other planets…
Chris Olah: But actually, the thing that’s craziest about this to me, the thing that I find absolutely nuts is… Okay, so we think about phase changes like water transitioning to ice, or to gas, or liquids. And I guess there’s this more general idea of a phase change as being when a system discontinuously goes from one state to another. And it seems to me that if… Imagine if you could just make Earth’s radius larger and larger and larger, holding everything else constant. At some point, the number of these Hadley cells would change. It turns out that you have to have an odd number per hemisphere. So you’d go from three per hemisphere to five per hemisphere.
Chris Olah: And so it seems to me like, actually, there must in some sense be some kind of phase changes in planets as a function of radius, that determines large-scale weather patterns. And that’s just kind of like a… you think of phase changes as always being about these small-scale things. But here you have this really enormous scale thing that has a phase change. And so that’s something that I found especially mind blowing. In any case, I could ramble about this, I could literally do an entire podcast episode on this at this point, but I’ve been finding that an enormous amount of fun.
Rob Wiblin: Okay, so if you could make a planet bigger and bigger bit by bit, and you were tracking the weather, you’d eventually see some point where it would flip, and it would flip from having one to three or five Hadley cells quite dramatically.
Chris Olah: Exactly. And so in particular… Okay, so you always expect the Equator to be the wettest place. At least, I guess if you have weather patterns that are water-based, like Earth, and precipitation. It turns out, when air rises, as it rises, the water condenses. And so if you look at a map of precipitation on Earth, it’s crazy. There’s just this stripe of ridiculous amounts of precipitation along the Equator. It’s extremely clear. And then the first Hadley cell that rises at the Equator and then falls, because you have three, it’s just 30 degrees, 60 degrees, 90 degrees. It’s divided into three chunks. And so at 30 degrees, you have a dry region and a lot of deserts fall on 30 degrees.
Chris Olah: If you suddenly made Earth larger and at some point you got five Hadley cells, I’m pretty sure, this is my understanding, suddenly you’d have your dry region at 90 divided by five degrees, instead of 90 divided by three degrees. I find that thought experiment really compelling and sort of mind blowing.
Rob Wiblin: That’s very cool. We’ll stick up a link to the Wikipedia article on Hadley cells. I was out taking a walk with my colleague Niel Bowerman the other day. I think he studied climate science long ago. And I was like, “Why do clouds form? I don’t know.” I felt like such an idiot, asking this simple, basic question. It’s like, “Why is there a cloud there, but not right next to where the cloud is?”
Chris Olah: There’s also all sorts of fascinating stuff about different kinds of thunderstorms, and the circumstances under which a thunderstorm can last for a long period of time or not. I’ve been persuaded that there actually are really beautiful ideas in meteorology and atmospheric science. And I will endeavor not to fall into the trap of, I don’t know, physics, biology, chemistry supremacy, and thinking that those are the only sciences that have really beautiful, simple explanatory theories.
Rob Wiblin: Nice. Well, maybe we’ll have our own episode on climate and the weather on the 80,000 Hours Podcast at some point. We’ll see if we can connect the two. Well, I suppose climate change is one of the world’s most pressing problems.
Rob Wiblin: Alright. My guest today has been Chris Olah. Thanks so much for coming on the 80,000 Hours podcast, Chris.
Chris Olah: My pleasure, Rob.
Rob’s outro [03:07:44]
Rob Wiblin: As I mentioned in the intro, this is just the first of two episodes with Chris Olah we’ve got for you.
We’re hoping to release the second next week, or if not soon after, and it should cover topics including:
- How Chris got to where he is today without having a university degree
- How he got his foot in the door at Google Brain and OpenAI
- The journal that he founded called Distill, and how to explain complex things really well
- How to write cold emails
- And much more.
So if you enjoyed this episode, make sure you come back for that one.
If you didn’t enjoy this one, note that that one has no or at least almost no technical AI content so maybe you’ll enjoy it nonetheless!
Finally, if you’re interested in using your career to work on safely guiding the development of AI like Chris — or working to solve any of the problems we discuss on the show — then you can apply to speak with our team one-on-one for free. For the first time in a couple of years we’ve removed our waitlist to apply for advising, so our team is keen to speak with more of you loyal podcast listeners.
They can discuss which problem to focus on, look over your plan, introduce you to mentors, and suggest roles that suit your skills. Just go to 80000hours.org/speak to learn more and apply.
The 80,000 Hours podcast is produced by Keiran Harris.
Audio mastering is by Ben Cordell.
Full transcripts — including the special addition of some images and links provided by Chris for this episode — are available on our website and produced by Sofia Davis-Fogel.
Thanks for joining. Talk to you again soon.
Learn more
ML for AI safety and robustness: a Google Brain engineer's guide to entering the field
Positively shaping the development of artificial intelligence