Technical AI Safety Research Landscape [Slides]
By Magdalena Wache @ 2023-09-18T13:56 (+31)
I recently gave a technical AI safety research overview talk at EAGx Berlin. Many people told me they found the talk insightful, so I’m sharing the slides here as well. I edited them for clarity and conciseness, and added explanations.
Outline
This presentation contains
- An overview of different research directions
- Concrete examples for research in each category
- Disagreements in the field
Intro

Overview
I’ll start with an overview of different categories of technical AI safety research.
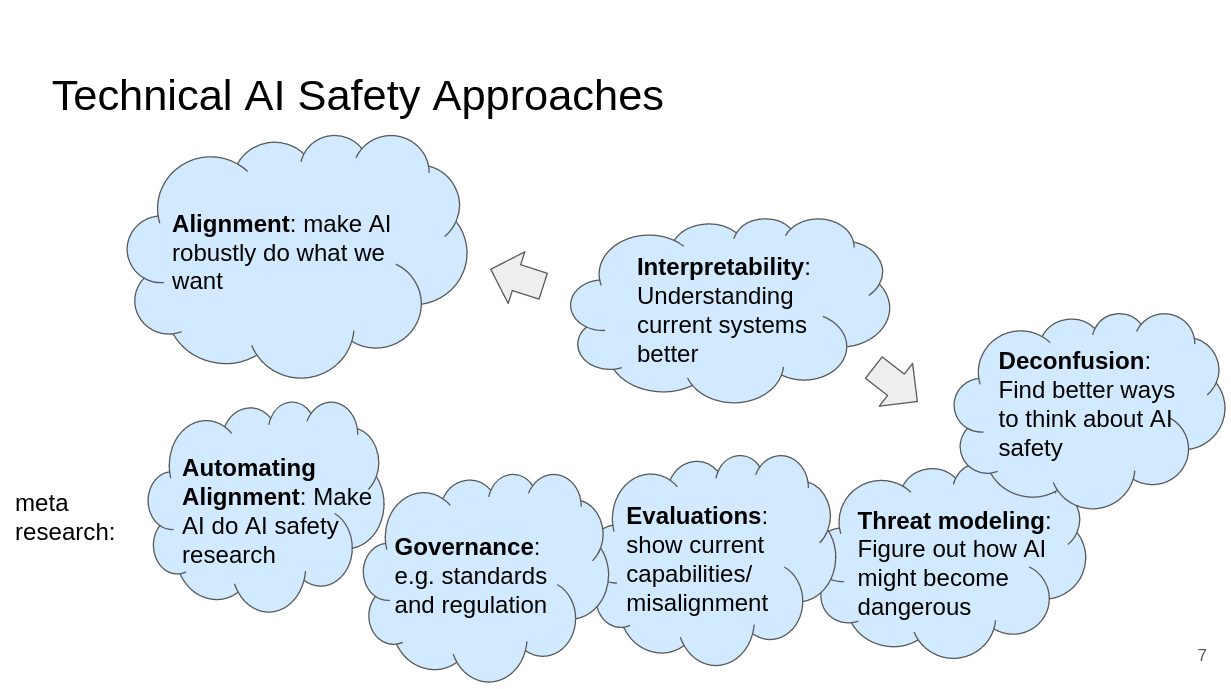
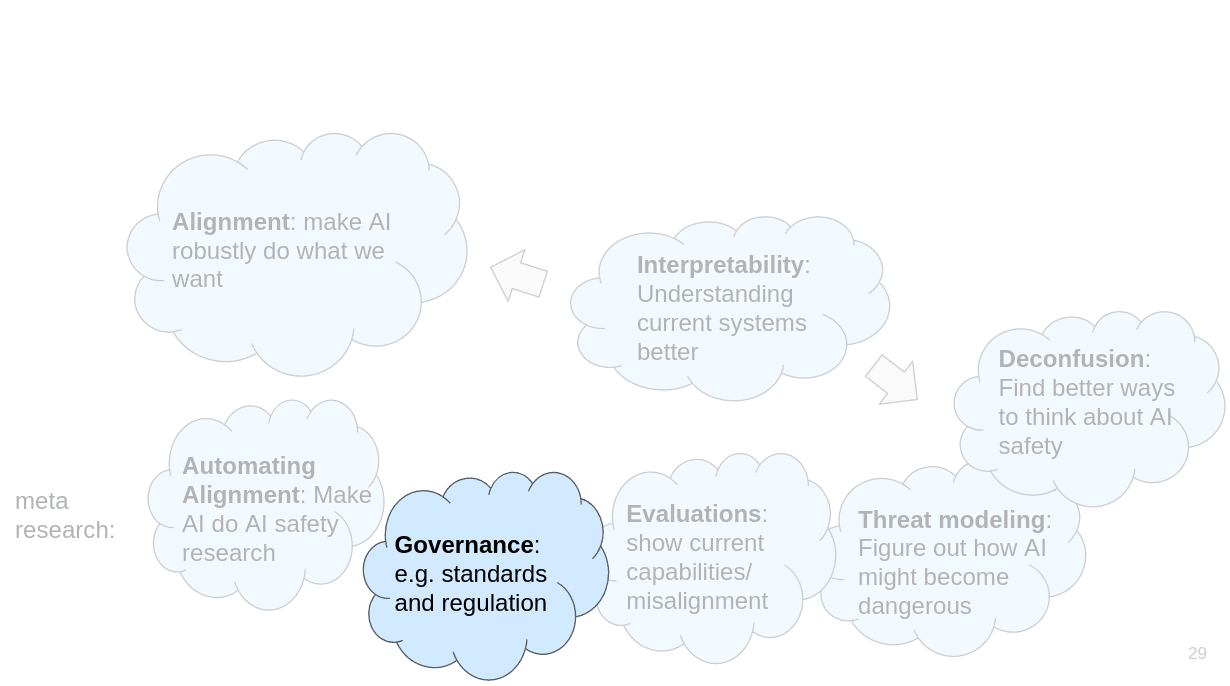
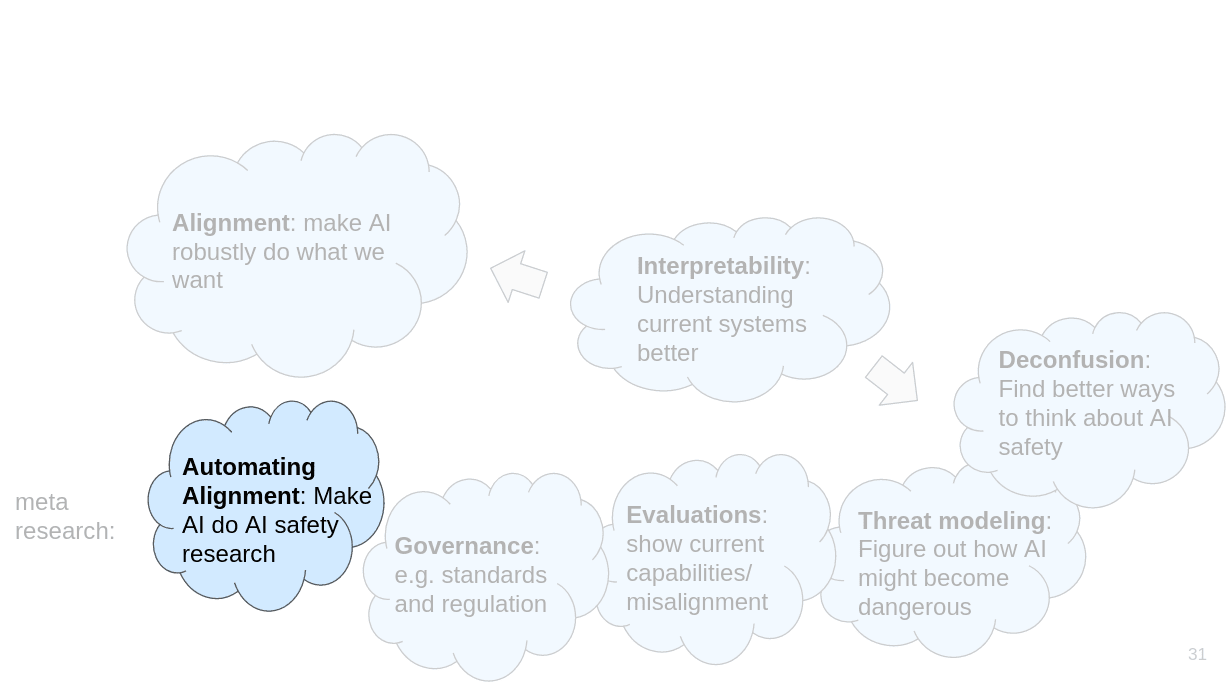
The first category of research is what I would just call alignment, which is about making AIs robustly do what we want. Then there are various “meta” research directions such as automating alignment, governance, evaluations, threat modeling and deconfusion. And there is interpretability. Interpretability is probably not enough to build safe AI on its own, but it’s really helpful/probably necessary for various alignment proposals. Interpretability also helps with deconfusion.
I’m using clouds because the distinction between the categories often isn’t very clear.
Let’s take a closer look at the first cloud.
What exactly do I mean by alignment? What do we align with what?
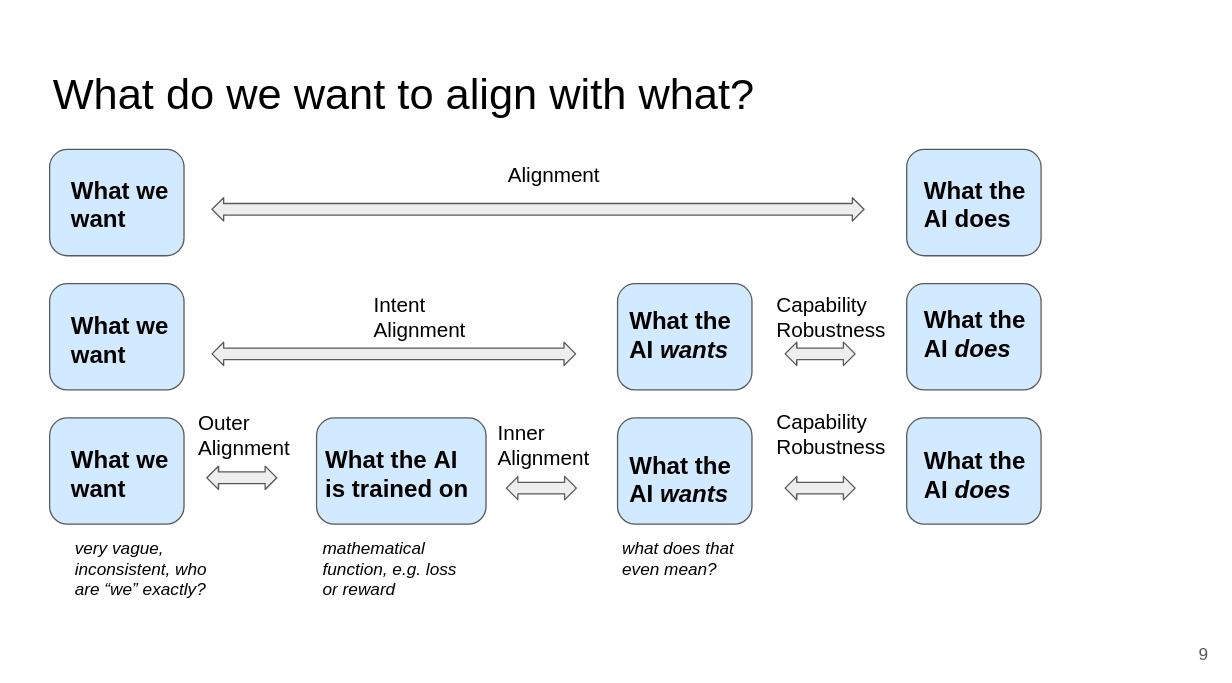
In general, we want to make AIs do what we want, so we want to align “what we want” with “what the AI does”. That’s why it’s called alignment.
We can split this up into intent alignment (make the AI want what we want) and capability robustness (make it able to robustly do what it wants).
And we can split intent alignment up into outer alignment (find a function that captures what we want) and inner alignment (ensure that what the AI ends up wanting is the same as what’s specified in the function that we trained it on).
There are a few ways in which this slide is simplified: The outer/inner alignment split is not necessarily the right frame to look at things. Maybe “what the AI wants” isn’t even a meaningful concept. And many approaches don’t really fit into these categories. Also, this frame looks at making one AI do what we want, but we may end up in a multipolar scenario with many AIs.
Concrete Technical Research
In this section I’ll give some examples to give you a flavor of what kinds of research exists in this space. There is of course a lot more research.
Let’s start with outer alignment.

Outer alignment is the problem of finding a mathematical function which robustly captures what we want. The difficulty here is specification gaming.

In this experiment the virtual robot learned to turn the red lego block upside down instead of the intended outcome of stacking it on top of the blue block. This might not seem like a big problem - the AI did what we told it to do. We just need to find a better specification and then it does what we want. But this toy example is indicative of a real and important problem. It is extremely hard to capture everything that we want in a specification. And if the specification is missing something, then the AI will do what is specified rather than what we meant to specify.
A well-known technique in reward specification is called Reinforcement Learning from Human Feedback (RLHF). In the Deep reinforcement learning from human preferences paper they were able to make a virtual leg perform a backflip, despite “backflip” being very hard to specify mathematically.

Let’s continue with inner alignment.
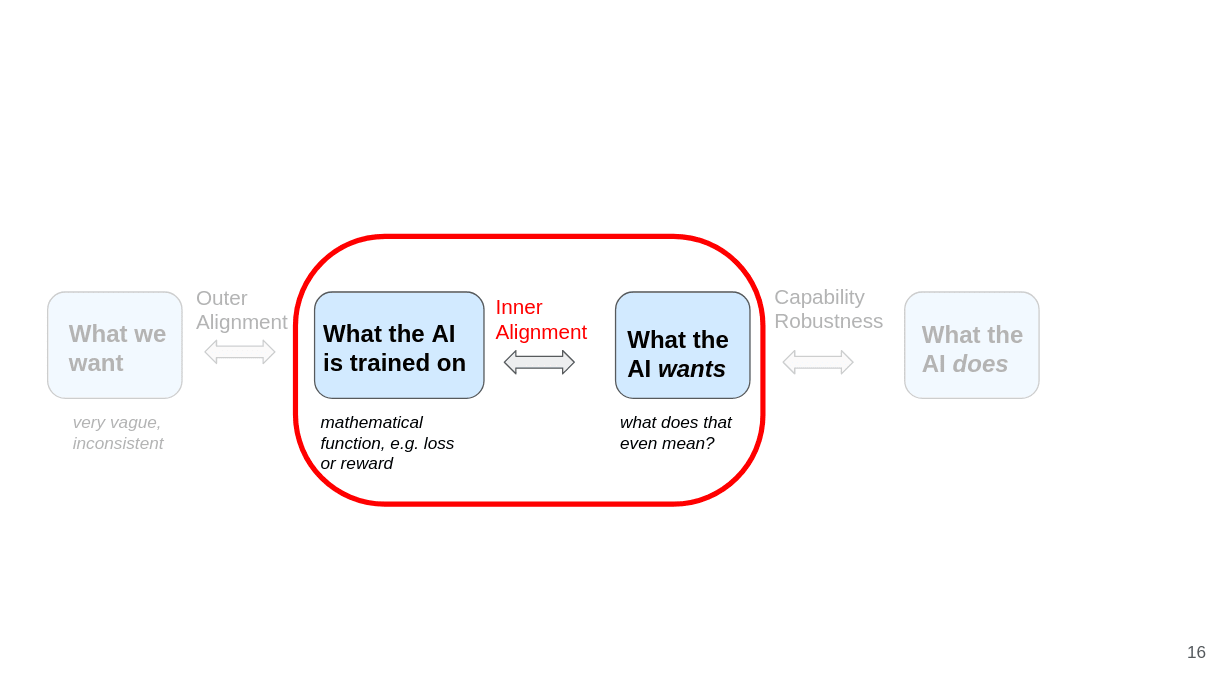
Inner alignment is about making sure that the AI actually ends up wanting the thing which it is trained on. The failure mode here is goal misgeneralization:

(Links: forum post, paper)
One way to train in more diverse environments is adversarial training:

(Links: paper, takeaways post, deceptive alignment)
As I mentioned above, for many approaches it doesn’t really make sense to distinguish inner and outer alignment. We don’t have to do the intermediate step of finding a mathematical function that robustly captures what we want. Maybe we can align AI without that.
A research direction for which it doesn’t make sense to always distinguish outer and inner alignment is scalable oversight:

(Links: debate, critiques, externalized reasoning oversight)
Another research direction is shard theory:

(Links: shard theory intro, empirical research for reinforcement learning and language models, reward is not the optimization target)
Next, I want to talk about capability robustness:
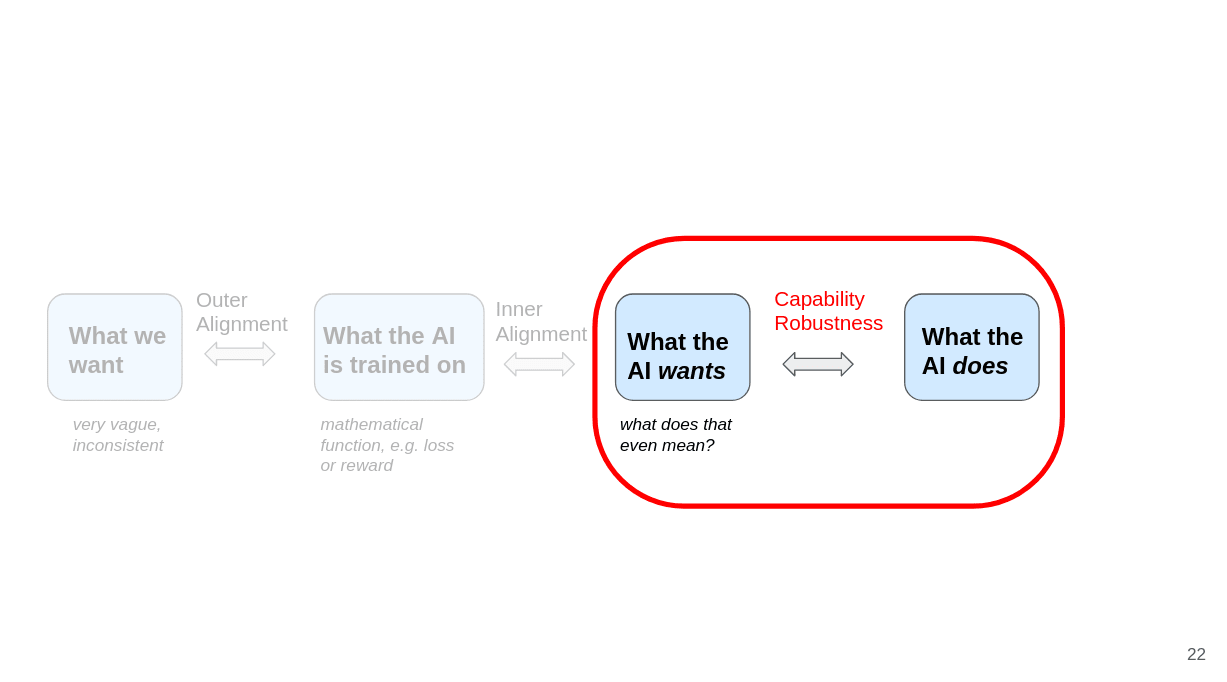
Capability robustness is about preventing failures which basically come from AIs making mistakes despite having the right intention (i.e. AIs not being “robustly capable” to act in accordance with their own intentions). One example for capability robustness is robustness to adversarial attacks:
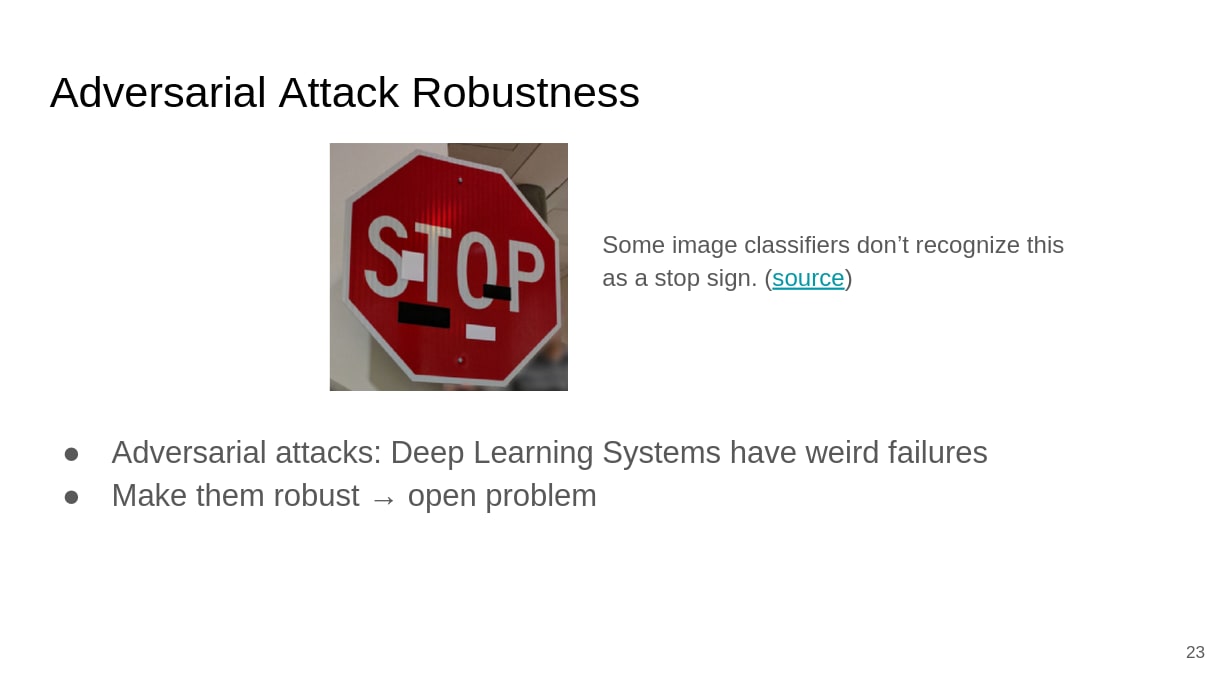
(Link: paper on physical-world attacks on vision models)
There are also examples of capability robustness research which will probably only become relevant when AI becomes significantly more capable than it is today. For example, there may be failures if an AI does not correctly model itself as part of the environment, see embedded agency.
The next category I want to talk about is interpretability.
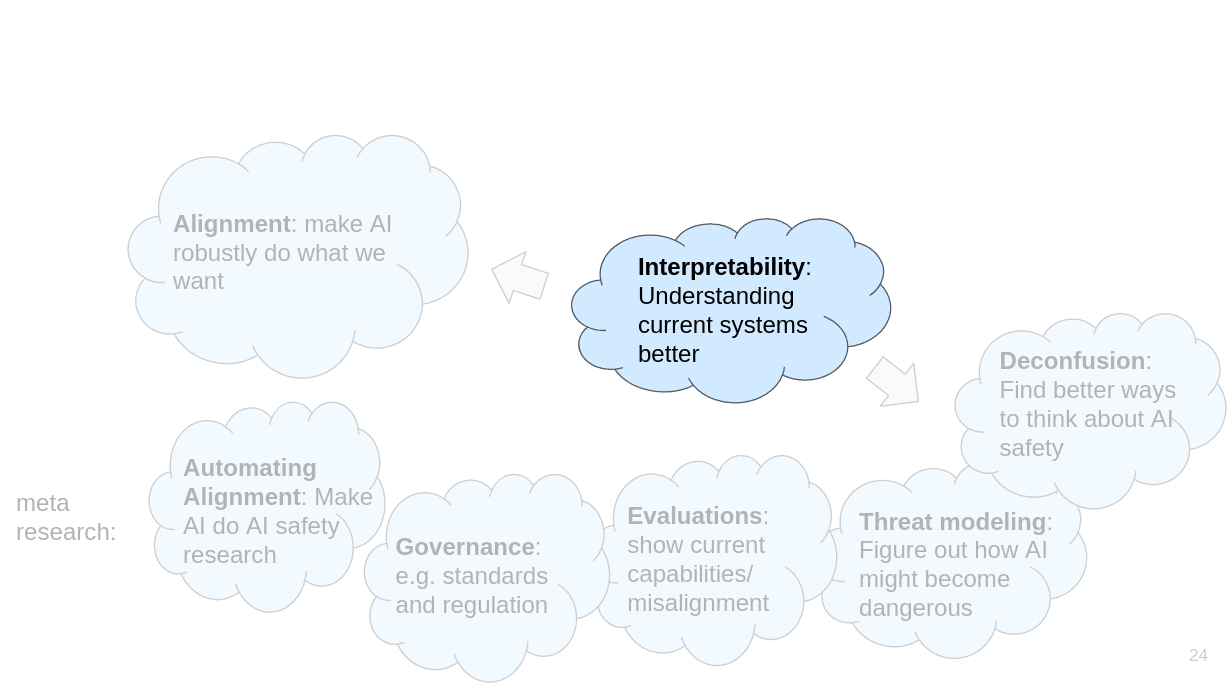

(Links: feature visualization, discovering latent knowledge, discussion 1, 2, 3, 4)
The worry about dual-use comes from the argument that if we understand systems better, then that likely leads to capability advancements as well as being useful for safety. Some people think we shouldn’t publish interpretability research for this reason, and instead just send it to selected safety researchers.
Interpretability is an important field. I only had this one slide about it because there was an entire talk about interpretability the next day.
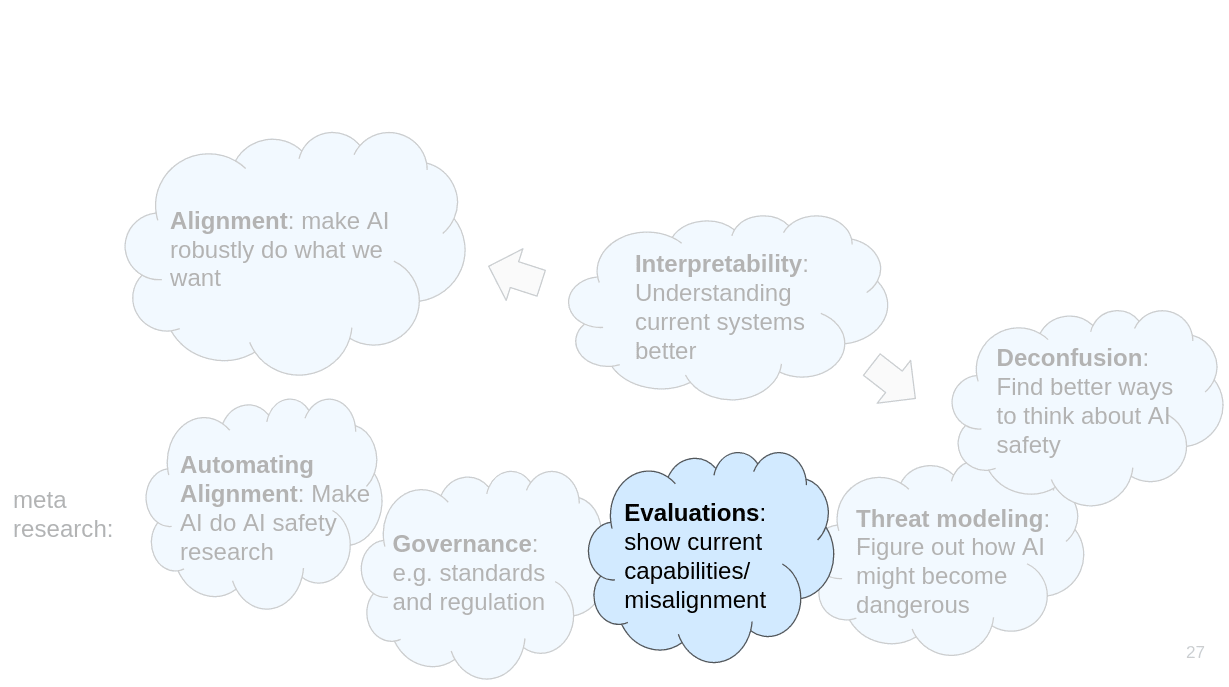

(Link: ARC evals report)

(Link: What does it take to catch a Chinchilla paper)

(Link: Language models can explain neurons in language models)
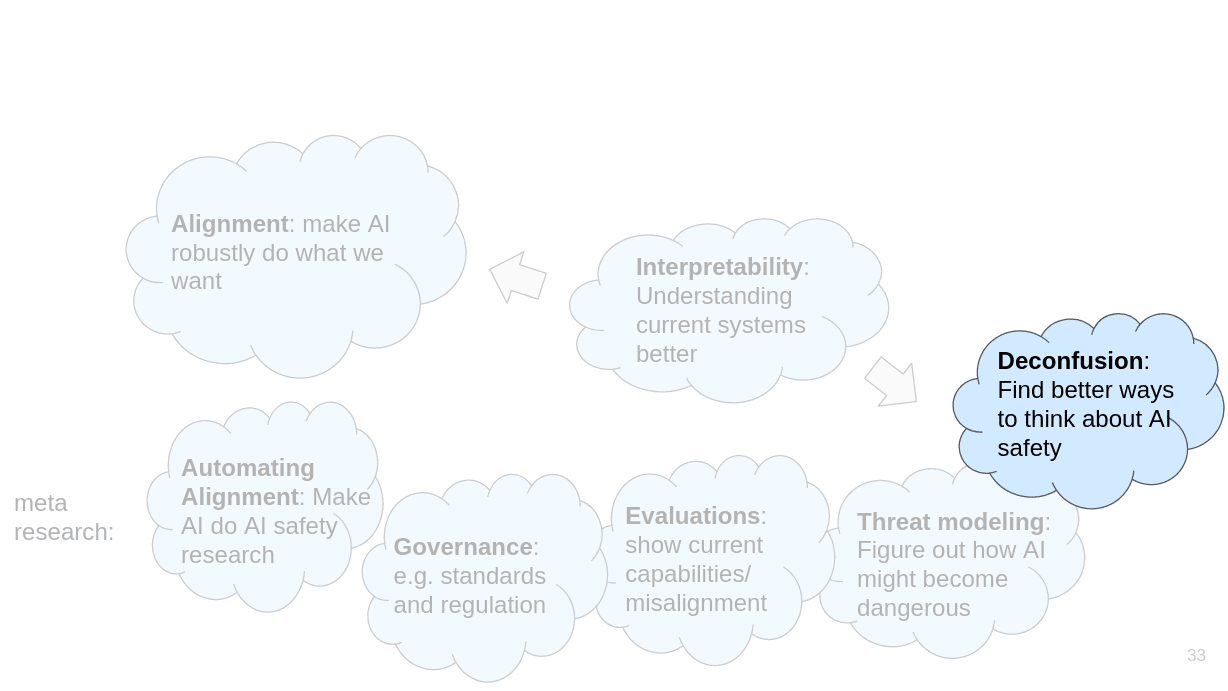
The main argument for deconfusion research is: We are currently so confused about AI safety that we probably won’t be able to develop a useful alignment proposal anyway. Therefore our priority should be to become less confused first.
One example for deconfusion research is the Natural Abstractions research agenda.
An important concept that often comes up when talking about AI safety (and that we are confused about) is “abstraction”. For example, when we look at this image we tend to think of it as containing a water bottle and a table. This is an abstraction because we compress the lower-level information (pixels) into more abstract concepts (bottle and table).

We usually do not think of the image as containing “this left segment of the table” and “the water bottle plus this right segment of the table”.

But why don’t we think of it that way? Is there some fundamental reason why the first way of chunking reality is better than the second? Fundamentally it’s all just pixels, right?
The Natural Abstractions research agenda is about understanding abstractions really well. Among other things this hopefully helps us understand how to work with “human values” - because what we value are abstractions (e.g. we care about people and not quantum fields even though people consist of quantum fields.)

(Links: Natural Abstractions: Key claims, Theorems, and Critiques, Why Agent Foundations? An overly Abstract Explanation)
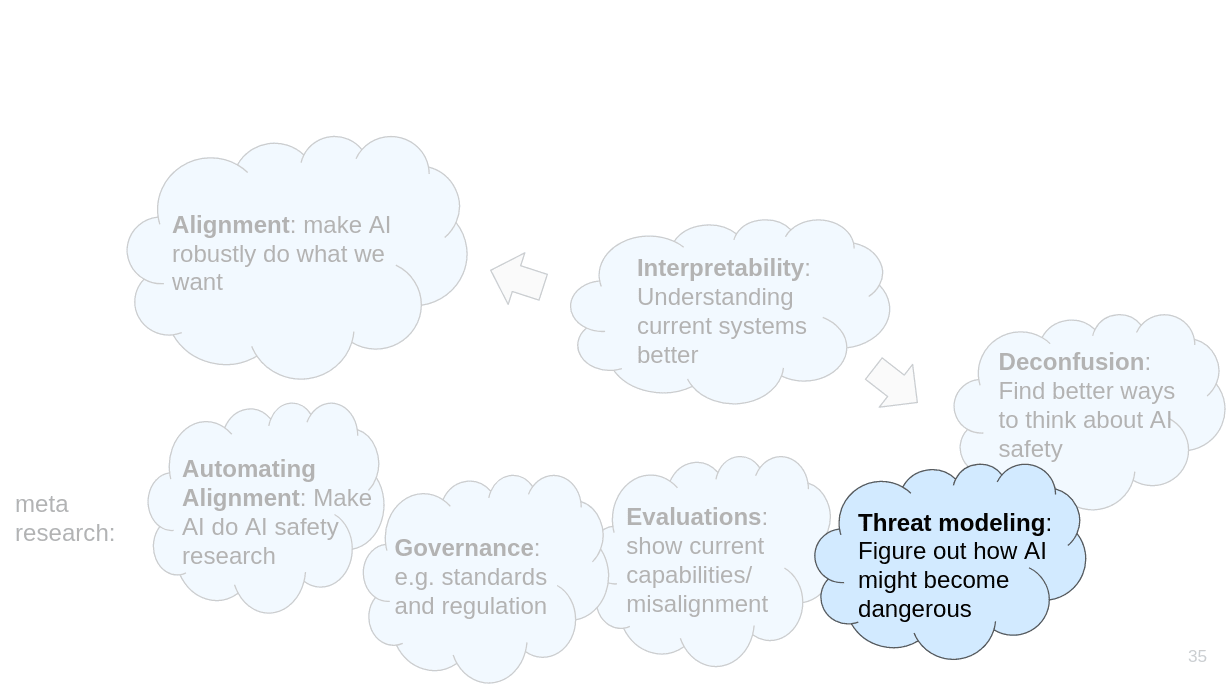
Threat modeling is about figuring out how exactly AI can become dangerous. This kind of work is important for making decisions about what to work on.

(Links: Threat model literature review, What Multipolar Failure looks like)
Disagreements
There are various disagreements in the field, for example about capability development, alignment difficulty and safety research advancing capabilities:

(Links: biological anchors report, summary, alignment by default, alignment impossible)
Summary
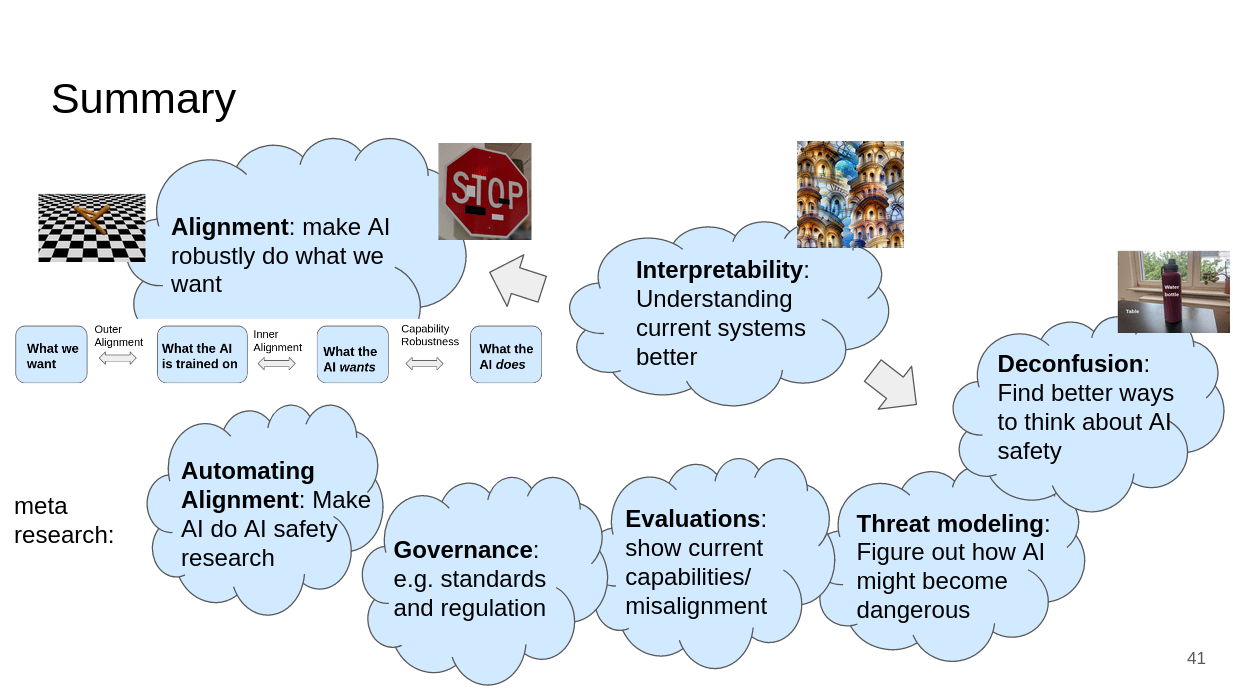
You can find the full slides here. Once the recording is online, I will also link to it here.
Thank you to Leon Lang, David Schneider-Joseph and Tom Lieberum for helpful feedback and discussion! All mistakes are my own.