The Happier Lives Institute is funding constrained and needs you!
By MichaelPlant @ 2023-07-06T12:00 (+84)
The Happier Lives Institute (HLI) is a non-profit research institute that seeks to find the best ways to improve global wellbeing, then share what we find. Established in 2019, we have pioneered the use of subjective wellbeing measures (aka ‘taking happiness seriously’) to work out how to do the most good.
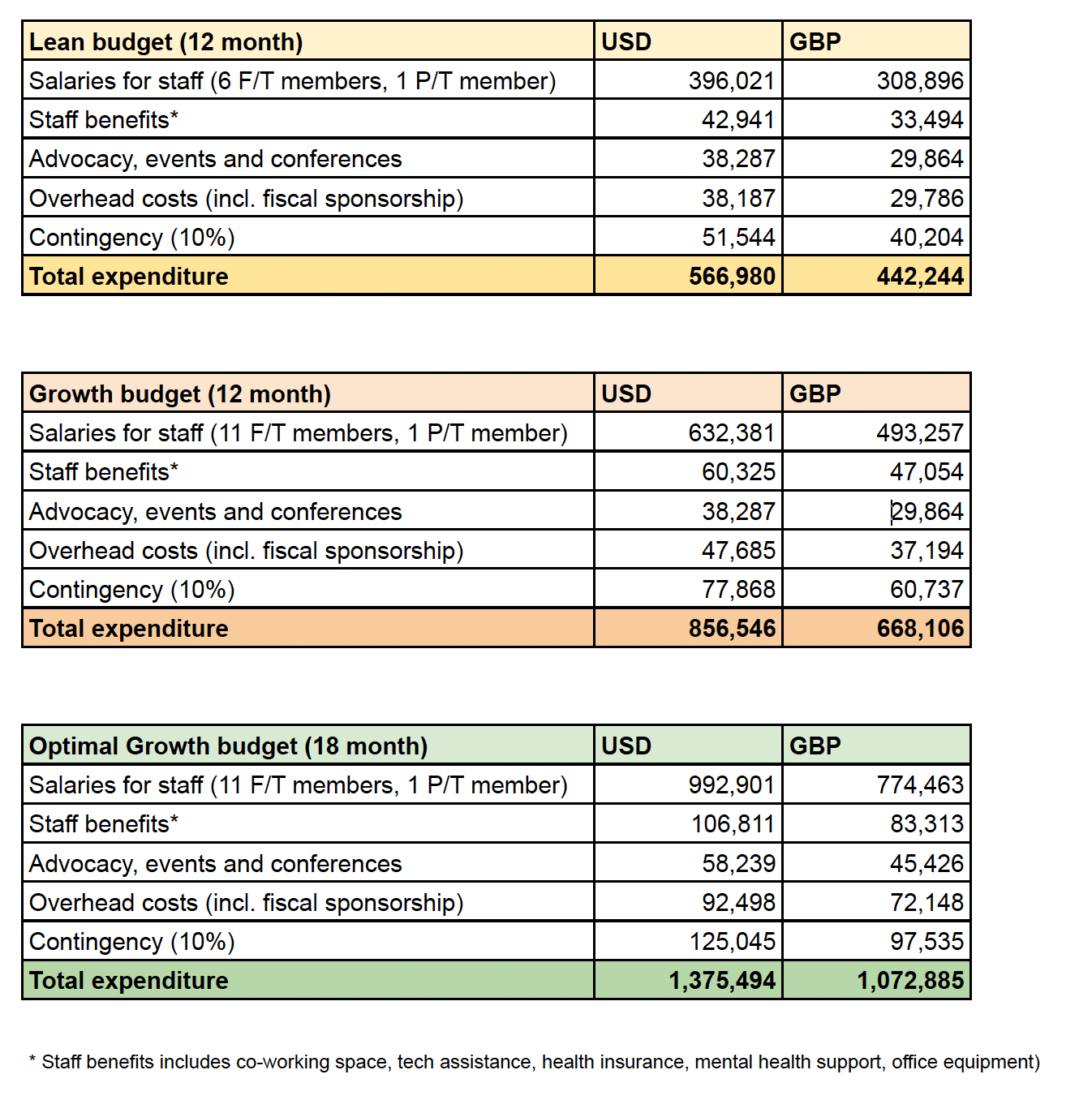
HLI is currently funding constrained and needs to raise a minimum of 205,000 USD to cover operating costs for the next 12 months. We think we could usefully absorb as much as 1,020,000 USD, which would allow us to expand the team, substantially increase our output, and provide a runway of 18 months.
This post is written for donors who might want to support HLI’s work to:
- identify and promote the most cost-effective marginal funding opportunities at improving human happiness.
- support a broader paradigm shift in philanthropy, public policy, and wider society, to put people’s wellbeing, not just their wealth, at the heart of decision-making.
- improve the rigour of analysis in effective altruism and global priorities research more broadly.
A summary of our progress so far:
- Our starting mission was to advocate for taking happiness seriously and see if that changed the priorities for effective altruists. We’re the first organisation to look for the most cost-effective ways to do good, as measured in WELLBYs (Wellbeing-adjusted life years)[1]. We didn’t invent the WELLBY (it’s also used by others e.g. the UK Treasury) but we are the first to apply it to comparing which organisations and interventions do the most good.
- Our focus on subjective wellbeing (SWB) was initially treated with a (understandable!) dose of scepticism. Since then, many of the major actors in effective altruism’s global health and wellbeing space seem to have come around to it (e.g., see these comments by GiveWell, Founders Pledge, Charity Entrepreneurship, GWWC). [Paragraph above edited 10/07/2023 to replace 'all' with 'many' and remove a name (James Snowden) from the list. See below]
- We’ve assessed several top-regarded interventions for the first time in terms of WELLBYs: cash transfers, deworming, psychotherapy, and anti-malaria bednets. We found treating depression is several times more cost-effective than either cash transfers or deworming. We see this as important in itself as well as a proof of concept: taking happiness seriously can reveal new priorities. We've had some pushback on our results, which was extremely valuable. GiveWell’s own analysis concludes treating depression is 2x as good as cash transfers (see here, which includes our response to GiveWell).
- We strive to be maximally philosophically and empirically rigorous. For instance, our meta-analysis of cash transfers has since been published in a top academic journal. We’ve shown how important philosophy is for comparing life-improving against life-extending interventions. We’ve won prizes: our report re-analysing deworming led GiveWell to start their “Change Our Mind” competition. Open Philanthropy awarded us money in their Cause Exporation Prize.
- Our work has an enormous global scope for doing good by influencing philanthropists and public policy-makers to both (1) redirect resources to the top interventions we find and (2) improve prioritisation in general by nudging decision-makers to take a wellbeing approach (leading to resources being spent better, even if not ideally).
- Regarding (1), we estimate that just over the period of Giving Season 2022, we counterfactually moved around $250,000 to our top charity, StrongMinds; this was our first campaign to directly recommend charities to donors[2].
- Regarding (2), the Mental Health Funding Circle started in late 2022 and has now disbursed $1m; we think we had substantial counterfactual impact in causing them to exist. In a recent 80k podcast, GiveWell mention our work has influenced their thinking (GiveWell, by their count, influences $500m a year)[3].
- We’ve published over 25 reports or articles. See our publications page.
- We’ve achieved all this with a small team. Presently, we’re just five (3.5 FTE researchers). We believe we really 'punch above our weight', doing high impact research at a low cost.
- However, we are just getting started. It takes a while to pioneer new research, find new priorities, and bring people around to the ideas. We’ve had some impact already, but really we see that traction as evidence we’re on track to have a substantial impact in the future.
What’s next?
Our vision is a world where everyone lives their happiest life. To get there, we need to work out (a) what the priorities are and (b) have decision-makers in philanthropy and policy-making (and elsewhere) take action. To achieve this, the key pieces are:-
- conducting research to identify different priorities compared to the status quo approaches (both to do good now and make the case)
- developing the WELLBY methodology, which includes ethical issues such as moral uncertainty and comparing quality to quantity of life
- promoting and educating decision-makers on WELLBY monitoring and evaluation
- building the field of academic researchers taking a wellbeing approach, including collecting data on interventions.
Our organisational strategy is built around making progress towards these goals. We've released, today, a new Research Agenda for 2023-4 which covers much of the below in more depth.
In the next six months, we have two priorities:
Build the capacity and professionalism of the team:
- We’re currently recruiting a communications manager. We’re good at producing research, but less good at effectively telling people about it. The comms manager will be crucial to lead the charge for Giving Season this year.
- We’re about to open applications for a Co-Director. They’ll work with me and focus on development and management; these aren’t my comparative advantage and it’ll free me up to do more research and targeted outreach.
- We’re likely to run an open round for board members too.
And, to do more high-impact research, specifically:
- Finding two new top recommended charities. Ideally, at least one will not be in mental health.
- To do this, we’re currently conducting shallow research of several causes (e.g., non-mood related mental health issues, child development effects, fistula repair surgery, and basic housing improvements) with the aim of identifying promising interventions.
- Alongside that, we’re working on wider research agenda, including: an empirical survey to better understand how much we can trust happiness surveys; summarising what we’ve learnt about WELLBY cost-effectiveness so we can share it with others; revise working papers on the nature and measurement of wellbeing; a book review Will MacAskill’s ‘What We Owe The Future’.
The plan for 2024 is to continue developing our work by building the organisation, doing more good research, and then telling people about it. In particular:
- Investigate 4 or 5 more cause areas, with the aim of adding a further three top charities by the end of 2024.
- Develop the WELLBY methodology, exploring, for instance, the social desirability bias in SWB scales
- Explore wider global priorities/philosophical issues, e.g. on the badness of death and longtermism.
- For a wider look at these plans, see our Research Agenda for 2023-4, which we’ve just released.
- If funding permits, we want to grow the team and add three researchers (so we can go faster) and a policy expert (so we can better advocate for WELLBY priorites with governments)
- (maybe) scale up providing technical assistance to NGOs and researchers on how to assess impact in terms of WELLBYs (we do a tiny amount of this now)
- (maybe) launch a ‘Global Wellbeing Fund’ for donors to give to.
- (maybe) explore moving HLI inside a top university.
We need you!
We think we’ve shown we can do excellent, important research and cause outsized impact on a limited budget. We want to thank those who’ve supported us so far. However, our financial position is concerning: we have about 6 months’ reserves and need to raise a minimum of 205,000 USD to cover our operational costs for the next 12 months. This is even though our staff earn about ½ what they would in comparable roles in other organisations. At most, we think we could usefully absorb 1,020,000 USD to cover team expansion to 11 full time employees over the next 18 months.
We hope the problem is that donors believe the “everything good is fully funded” narrative and don’t know that we need them. However, we’re not fully-funded and we do need you! We don’t get funding from the two big institutional donors, Open Philanthropy and the EA Infrastructure fund (the former doesn’t fund research in global health and wellbeing; we didn’t get feedback from the latter). So, we won’t survive, let alone grow, unless new donors come forward and support us now and into the future.
Whether or not you’re interested in supporting us directly, we would like donors to consider funding our recommended charities; we aim to add two more to our list by the end of 2023. We expect these will be able to absorb millions or tens of dollars, and this number will expand as we do more research.
We think that helping us ‘keep the lights on’ for the next 12-24 months represents an unusually large counterfactual opportunity for donors as we expect our funding position to improve. We’ll explore diversifying our funding sources by:
- Seeking support from the wider world of philanthropy (where wellbeing and mental health are increasing popular topics)
- Acquiring conventional academic funding (we can’t access this yet as we’re not UKRI registered, but we’re working on this; we are also in discussions about folding HLI into a university)
- Providing technical consultancy on wellbeing-based monitoring and evaluation of projects (we’re having initial conversations about this too).
To close, we want to emphasise that taking happiness seriously represents a huge opportunity to find better ways to help people and reallocate enormous resources to those things, both in philanthropy and in public-policymaking. We’re the only organisation we know of focusing on finding the best ways to measure and improve the quality of lives. We sit between academia, effective altruism and policy-making, making us well-placed to carry this forward; if we don’t, we don’t know who else will.
If you’re considering funding us, I’d love to speak with you. Please reach out to me at michael@happierlivesinstitute.org and we’ll find time to chat. If you’re in a hurry, you can donate directly here.
Appendix 1: HLI budget
- ^
One WELLBY is equivalent to a 1-point increase on a 0-10 life satisfaction scale for one year
- ^
The total across two matching campaigns at the Double-Up Drive, the Optimus Foundation as well as donations via three effective giving organisations (Giving What We Can, RC Forward, and Effectiv Spenden) was $447k. Note not all this data is public and some public data is out of date. The sum donated be larger as donations may have come from other sources. We encourage readers to take this with a pinch of salt and how to do more accurate tracking in future.
- ^
Some quotes about HLI’s work from the 80k podcast:
[Elie Hassenfeld] ““I think the pro of subjective wellbeing measures is that it’s one more angle to use to look at the effectiveness of a programme. It seems to me it’s an important one, and I would like us to take it into consideration[Elie] “…I think one of the things that HLI has done effectively is just ensure that this [using WELLBYs and how to make tradeoffs between saving and improving lives] is on people’s minds. I mean, without a doubt their work has caused us to engage with it more than we otherwise might have. […] it’s clearly an important area that we want to learn more about, and I think could eventually be more supportive of in the future.”
[Elie] “Yeah, they went extremely deep on our deworming cost-effectiveness analysis and pointed out an issue that we had glossed over, where the effect of the deworming treatment degrades over time. […] we were really grateful for that critique, and I thought it catalysed us to launch this Change Our Mind Contest. ”
LondonGal @ 2023-07-14T23:05 (+136)
Hi everyone,
To fully disclose my biases: I’m not part of EA, I’m Greg’s younger sister, and I’m a junior doctor training in psychiatry in the UK. I’ve read the comments, the relevant areas of HLI’s website, Ozler study registration and spent more time than needed looking at the dataset in the Google doc and clicking random papers.
I’m not here to pile on, and my brother doesn’t need me to fight his corner. I would inevitably undermine any statistics I tried to back up due to my lack of talent in this area. However, this is personal to me not only wondering about the fate of my Christmas present (Greg donated to Strongminds on my behalf), but also as someone who is deeply sympathetic to HLI’s stance that mental health research and interventions are chronically neglected, misunderstood and under-funded. I have a feeling I’m not going to match the tone here as I’m not part of this community (and apologise in advance for any offence caused), but perhaps I can offer a different perspective as a doctor with clinical practice in psychiatry and on an academic fellowship (i.e. I have dedicated research time in the field of mental health).
The conflict seems to be that, on one hand, HLI has important goals related to a neglected area of work (mental health, particularly in LMICs). I also understand the precarious situation they are in financially, and the fears that undermining this research could have a disproportionate effect on HLI vs critiquing an organisation which is not so concerned with their longevity. There might be additional fears that further work in this area will be scrutinised to a uniquely high degree if there is a precedent set that HLI’s underlying research is found to be flawed. And perhaps this concern is compounded by the stats from people in this thread, which perhaps is not commonly directed to other projects in the EA-sphere, and might suggest there is an underlying bias against this type of work.
I think it’s fair to hold these views, but I’d argue this is likely the mechanism by which HLI has escaped scrutiny before now – people agree more work and funding should be directed to mental health and wanted to support an organisation addressing this. It possibly elevated the status of HLI in people’s minds, appearing more revolutionary in redirecting discussions in EA as a whole. Again, Greg donated to Strongminds on my behalf and, while he might now feel a sense of embarrassment for not delving into this research prior, in my mind I think it reflects a sense of affirmation in this cause and trust in this community which prides itself on being evidence-based. I’m mentioning it, because I think everyone here is united on these points and it’s always easier to have productive discussions from the mutual understanding of shared values and goals.
However, there are serious issues in the meta-analysis which appears to underlie the CEA, and therefore the strength of claims made by HLI. I think it is possible to uncouple this statement from arguments against HLI or any of the above points (where I don’t see disagreement). It seems critical to acknowledge the flaws in this work given the values of EA as an objective, data-driven approach to charitable giving. Failing to do this will risk the reputation of EA, and suggest there is a lack of critical appraisal and scrutiny which perhaps is driven by personal biases i.e. the number of reassurances in this thread that HLI is a good organisation where members are known personally to others in the community. Good people with good intentions can produce flawed research. Similarly, from the perspective of a clinical academic in psychiatry, there is a long history in my field of poorly-conducted, misinterpreted and rushed research which has meant establishing evidence-based care and attracting funding for research/interventions particularly difficult. Poor research in this area risks worsening this problem and mis-allocating very limited resources – it’s fairly shocking seeing the figures quoted here in terms of funding if it is based wholly or in part on outputs such as this meta-analysis which were accepted by EA. Again, as an outsider, it’s difficult for me to judge how critical this research was in attracting this allocation of funds.
While I think the issues with the analysis and all the statistics discussions are valid critiques of this work, it’s important to establish that this is only part of the reason this study would fall down under peer review. It’s concerning to me that peer-review is not the standard for organisations supported by EA; this is not just about scrutinising how the research was conducted and arguing about statistics, but establishes the involvement of expertise within the field of study. As someone who works in this field, the assumptions this meta-analysis makes about psychotherapy, outcome measures in mental health, etc, are problematic but perhaps not readily identified to those without a clinical background, and this is a much greater problem if there is an increasing interest in addressing mental health within EA. I’m not familiar with the backgrounds of people involved in HLI, but I’d be curious about who was consulted in formulating this work given the tone seems to reflect more philosophical vs psychiatric/psychotherapeutic language.
The way the statistical analysis has been heavily debated in this thread likely reflect the skills-mix in the EA community (clearly stats are well-covered!), but the statistics are somewhat irrelevant if your study design and inputs into the analysis are flawed to start with. Even if the findings of this research were not so unusual (perhaps something else which could have been flagged sooner) or were based on concrete stats, the research would still be considered flawed in my field. I imagine this will prompt some reflection in EA on this topic, but peer-review as a requirement could have avoided the bad timing of these discussions and would reduce the reliance on community members to critique research. I think this thread has demonstrated that critical appraisal is time-intensive and relies on specialist skills – it’s not likely that every area of interest will have representation within the EA community so the problem of ‘not knowing what you don’t know’ or how you weight the importance of voices in the community vs their amplification would be greatly helped by peer-review and reduce these blind spots. If the central goal of EA is using money to do the most good, and there is no robust system to evaluate research prior to attracting funding, this is an organisational problem rather than a specific issue with HLI/Strongminds.
My unofficial peer review.
Given inclusion/exclusion criteria aren’t stated clearly in the meta-analysis and the aim is pretty woolly, It seems the focus of the upcoming RCT and Strongminds research is evaluating:
-
Training non-HCPs in delivering psychotherapy in LMICs
-
Providing treatment (particularly to young women and girls) with symptoms suggestive of moderate to severe depression (PHQ-9 score of 10 and above)
-
Measuring the efficacy of this treatment on subjective symptom rating scales, such as PHQ-9, and other secondary outcome measures which might reflect broader benefits not captured in the symptom rating scales.
-
Finding some way to compare the cost-effectiveness of this treatment to other interventions such as cash transfers in broader discussions of life satisfaction and wellbeing which it obviously complicated compared to using QALYs, but important to do as the impact of mental illness is under-valued using measures geared towards physical morbidity. Or maybe it's trying to understand effectiveness of treating symptoms vs assumed precipitating/perpetuating factors like poverty.
Grand.
However, the meta-analysis design seems to miss the mark on developing anything which would support a CEA along these lines. Even from the perspective of favouring broad inclusion criteria, you would logically set these limits:
- Population
LMIC setting, people with depressive symptoms. It’s not clear if this is about effectively treating depression with psychotherapy and extrapolating that to a comment on wellbeing; or using psychotherapy as a tool to improve wellbeing, which for some reason is being measured in a reduction in various symptom scales for different mental health conditions and symptoms – this needs to be clearly stated. If it's the former, what you accept as a diagnosis of depression (ICD diagnostic codes, clinical assessment by trained professional, symptom scale cut-offs, antidepressant treatment, etc) should be defined.
If not defining the inclusion criteria of depression as a diagnosis, it's worth considering if certain psychiatric/medical conditions or settings should be excluded e.g. inpatients. As a hypothetical, extracting data on depression symptom scales for a non-HCP delivered psychotherapy in bipolar patients will obviously be misleading in isolation (i.e. the study likely accounted for measuring mania symptoms in their findings, but would be lost in this meta-analysis). One study included in this analysis (Richter et al) looked at an intervention which encouraged adherence to anti-retroviral medications via peer support for women newly diagnosed with HIV. Fortunately, this study shouldn't have been included as it didn't involve delivering psychotherapy, but for the sake of argument, is that fair given the neuropsychiatric complications of HIV/AIDS? Again, it's not about preparing for every eventuality, but it's having clear inclusion/exclusion criteria so there's no argument about cherry-picking studies because this has been discussed prior to search and analysis.
- Intervention
Delivery of a specific psychotherapeutic modality (IPT, etc) by a non-HCP. While I can agree there are shared core concepts between different modalities of psychotherapy, you absolutely have to define what you mean by psychotherapy because your dataset containing a column labelled ‘therapyness’ (high/medium/low) undermines a lot of confidence, as do some of the interventions you’ve included as meeting the bar for psychotherapy treatment. If you want to include studies which perhaps are not focussed on treating depression and might therefore involve other forms of therapy but still have benefit in alleviating depressive symptoms e.g. where the presenting complaint is trauma, the intervention might be EMDR (a specific therapy for PTSD) but the authors collected a number of outcome measures including symptom rating scales for anxiety and depression as secondary outcomes, it would be logical to stratify studies in this manner as a plan for analysis. I.e. psychotherapeutic intervention with evidence-base in relieving depressive symptoms (CBT, IPT, etc), psychotherapeutic intervention not specifically targeted at depressive symptoms (EMDR, MBT etc), with non-(psychotherapy) intervention as the control.
Several studies instead use non-psychotherapy as the intervention under study and this confusion seems to be down to papers describing them as having a ‘psychotherapeutic approach’ or being based on principles in any area of psychotherapy. This would cover almost anything as ‘psychotherapeutic’ as an adjective just means understanding people’s problems through their internal environment e.g. thoughts, feelings, behaviours and experiences. In my day-to-day work, I maintain a psychotherapeutic approach in patient interactions, but I do not sit down and deliver 14-week structured IPT. You can argue that generally having a supportive environment to discuss your problems with someone who is keen to hear them is equally beneficial to formal psychotherapy, but this leads to the obvious question of how you can use the idea of any intervention which sounds a bit ‘psychotherapy-y’ to justify the cost of training people to specifically deliver psychotherapy in a CEA from this data.
The fundamental lack of definition or understanding of these clinical terms leads to odd issues in some of the papers I clicked on i.e. Rojas et al (2007) compares a multicomponent group intervention involving lots of things but notably not delivery of any specific psychotherapy, to normal clinical care in a postnatal clinic. The next sentence describes part of normal clinical care to be providing ‘brief psychotherapeutic interventions’ – perhaps this is understood by non-clinicians as not highly ‘therapyish’ but this term is often used to describe short-term focussed CBT, or CBT-informed interventions. Not defining the intervention clearly means the control group contains patients receiving evidence-based psychotherapy of a specific modality and a treatment arm of no specific psychotherapy which is muddled by the MA.
- Comparison
As alluded to above, you need to be clear about what is an acceptable control and it’s simply not enough to state you are not sure what the ‘usual care’ is in research by Strongminds you have weighted so heavily. It can’t be then justified by an assumption mental health is neglected in LMICs so probably wouldn’t involve psychotherapy (with no citation). Especially as the definition of psychotherapy in this meta-analysis would deem someone visiting a pastor in church once a week as receiving psychotherapy. Without clearly defining the intervention, it's really difficult to understand what you are comparing against what.
- Outcome
This meta-analysis uses a range of symptom rating scales as acceptable outcome measures, favouring depression and anxiety rating scales, and scales measuring distress. This seems to be based on idea that these clusters of symptoms are highly adverse to wellbeing. This makes the analysis and discussion really confused, in my opinion, and seems to be a sign the analysis, expected findings, extrapolation to wellbeing and CEA was mixed into the methodology.
To me, the issue arises from not clearly defining the aim and inclusion/exclusion criteria. This meta-analysis could be looking at psychotherapy as a treatment for depression/depressive symptoms. This would acknowledge that depression is a psychiatric illness with congitive, psychological and biological symptoms (as captured by depression rating scales). As a clinical term, it is not just about 'negative affect' - low mood is not even required for a diagnosis as per ICD criteria. It absolutely does negatively affect wellbeing, as would any illness with unpleasant/distressing symptoms, but this therefore means generating some idea for how much patients' wellbeing improves from treatment has to be specific to depression. The subsequent CEA would then need to account for this and evaluate only psychotherapies with an evidence-base in depression. In the RCT design, I'd guess this is the rationale for a high PHQ cut-off - it's a proxy for relative certainty in a clinical diagnosis of depression (or at least a high burden of symptoms which may respond to depression treatments and therefore demonstrate a treatment effect); it's not supporting the idea that some general negative symptoms impacting a concept of wellbeing, short of depression, will likely benefit from specific psychotherapy to any degree of significance, and it would be an error to take this assumption and then further assume a linear relationship between PHQ and wellbeing/impairment.
If you are looking at depressive symptom reduction, you need to only include evaluation tools for depressive symptoms (PHQ, etc). You need to define which tools you would accept prior to the search and that these are validated for the population under study as you are using them in isolation - how mental illness is understood and presents is highly culturally-bound and these tools almost entirely developed outside of LMICs.
If, instead, you're looking at a range of measures you feel reflect poor mental health (including depression, anxiety and distress) in order to correlate this to a concept of wellbeing, these tools similarly have to be defined and validated. You also need to explain why some tools should be excluded, because this is unclear e.g. in Weiss et al, a study looking at survivors of torture and militant attacks in Iraq, the primary outcome measure was a trauma symptom scale (the HTQ), yet you've selected the secondary outcome measures of depression and anxiety symptom scores for inclusion. I would have assumed that reducing the highly distressing symptoms of PTSD in this group would be most relevant to a concept of wellbeing, yet that is not included in favour of the secondary measures. Including multiple outcome measures with no plan to stratify/subgroup per symptom cluster or disorder seems to accept double/triple counting participants who completed multiple outcome measures from the same intervention. Importantly, you can't then use this wide mix of various scales to make any comment on the benefits of psychotherapy for depression in improving wellbeing (as lots of the included scores are not measuring depression).
In both approaches, you do need to show it is accepted to pool these different rating scales to still answer your research question. It’s interesting to state you favour subjective symptom scores over functional scores (which are excluded), when both are well-established in evaluating psychotherapy. Other statements made by HLI suggest symptom rating scores include assesment of functioning - I've reproduced the PHQ-9 below for people to draw their own conclusions, but it's safe to say I disagree with this. It’s not clear to me if it’s understood functional scores are also commonly subjective measures, like the WSAS - patients are asked how rate how well they feel they are managing work activities, social activities etc. Ignoring functioning as a blanket rule seems to miss the concept of ‘insight’ in mental health, where people can struggle identifying symptoms as symptoms but are severely disabled due to an illness (this perhaps should also be considered in excluding scales completed by an informant or close relative, particularly thinking about studies involving children or more severe psychopathology). Incorporating functional scoring captures the holistic nature of psychotherapy, where perhaps people may still struggle with symptoms of anxiety/depression after treatment, but have made huge strides in being able to return to work. Again, you need to be clear why functional scores are excluded and be clear this was done when extrapolating findings to discussions of life satisfaction or wellbeing. This research has made a lot of assumptions in this regard that I don’t follow.
x. Grouping measures and relating this to wellbeing:
On that note – using a mean change in symptoms scores is a reasonable evaluation of psychotherapy as a concept if you are so inclined but I would strongly argue that this cannot be used in isolation to make any inference about how this correlates to wellbeing. As others have alluded to in this thread, symptom scores are not linear. To isolate depression as an example, this is deemed mild/moderate/severe based on the number of symptoms experienced, the presence of certain concerning symptoms (e.g. psychosis) and the degree of functional impact.
Measures like the PHQ-9 score the number of depressive symptoms present and how often they occur from 0 (not at all) to 3 (nearly every day) over the past two weeks:
- Little interest or pleasure in doing things?
- Feeling down, depressed or hopeless?
- Trouble falling or staying asleep, or sleeping too much?
- Feeling tired or having little energy?
- Poor appetite or overeating?
- Feeling bad about yourself - or that you are a failure or have let yourself or your family down?
- Trouble concentrating on things, such as reading the newspaper or watching television?
- Moving or speaking so slowly that other people have noticed? Or the opposite - being so fidgety or restless that you have been moving around a lot more than usual?
- Thoughts that you would be better off dead, or of hurting yourself in some way?
If you take the view that a symptom rating score has a linear relationship to 'negative affect' or suffering in depression, you would then imagine that the outcomes of PHQ-9 (no depression, mild, moderate, severe) would be regularly distributed in the 27-item score i.e. a score of 0-6 should be no depression, 7-13 mild depression, 14-20 moderate depression and 21-27 severe. This is not the case as the actual PHQ-9 scores are 0-4 no depression, 5-9 mild depression, 10-14 moderate, 15-19 moderately severe, 20-27 severe. This is because the symptoms asked about in the PHQ are diagnostic for depression – it’s not an attempt at trying to gather how happy or sad someone is on a scale from 0-27 (in fact 0 just indicates ‘no depression symptoms’, not happiness or fulfilment, and it's likely people with very serious depression will not be able to complete a PHQ-9). Hopefully it's clear from the PHQ-9 why the cut-offs are low and why the severity increases so sharply; the symptoms in question are highly indicative of pathology if occuring frequently. It’s also in the understanding that a PHQ-9 would be administered when there is clinical suspicion of depression to elicit severity or in evaluation of treatment (i.e. in some contexts, like bereavement, experiencing these symptoms would be considered normal, or if symptoms are better explained by another illness the PHQ is unhelpful) and it's not used for screening (vs the Edinburgh score for postnatal depression which is a screening tool and features heavily in included studies). Critically, it’s why you can’t assume it's valid to lump all symptom scales together, especially cross-disorders/symptom clusters as in this meta-analysis.
x. Search strategy
I feel this should go without saying, but once you’ve ironed out these issues to have a research question you could feasibly inform with meta-analysis, you then need to develop a search strategy and conduct a systematic review. It’s guaranteed that papers have been missed with the approach used here, and I’ve never read a peer-reviewed meta-analysis where a (10-hour) time constraint was used as part of this strategy. While I agree the funnel plot is funky, it’s likely reflecting the errors in not conducting this search systematically rather than assuming publication bias – it’s likely the highly cited papers etc were more easily found using this approach and therefore account for the p-clustering. If the search was a systematic review and there were objective inclusion/exclusion criteria and the funnel plot looked like that, you can make an argument for publication bias. As it stands, the outputs are only as good as the inputs i.e. you can't out-analyse a poor study design/methodology to produce reliable results.
Simply put, the most critical problem here is that without even getting into the problems with the data extraction I found, or the analysis as discussed in this thread, from this study design which doesn't seek to justify why any of these decisions were made, any analytic outputs are destined to be unreliable. How much of this was deliberate on the part of HLI can’t be determined as there is no possible way of replicating the search strategy they used (this is the reason to have a robust strategy as part of your study design). I think if you want to call this a back-of-napkin scoping review to generate some speculative numbers, you could describe what you found as there being early signals that psychotherapy could be more cost-effective than assumed and therefore there’s need to conduct a vigorous SR/MA. It perhaps may have been more useful in a shallow review to actually exclude the Strongminds study and evaluate existing research through the framework of (1) do the SM results make sense in the context of previous studies and (2) can we explain any differences in a narrative review. It seems instead this work generated figures which were treated as useful or reliable and fed into a CEA, which was further skewed by how this was discussed by HLI.
TL;DR
This is obviously very long and not going to be read in any detail on an online forum, but from the perspective of someone within this field, there seem to be a raft of problems with how this research was conducted and evaluated by HLI and EA. I’m not considered the Queen Overload of Psychiatry, I don’t have a PhD, but I suppose I'm trying to demonstrate that having a different background raises different questions, which seems particularly relevant if there is a recognition of the importance of peer-review (hopefully, I’m assuming, outside of EA literature). I’m also going to caveat this by saying I’ve not poured over HLI’s work, it’s just what immediately stood out to me, and haven’t made any attempt to cite my own knowledge derived from my practice – to me this is a post on a forum I’m not involved with rather than an ‘official’ attempt at peer review so I’m not holding myself to the same standard, just commenting in good faith.
I get the difficult position HLI are in with reputational salvage, but there is a similar risk to EA’s reputation if there are no checks in place given this has been accessible information for some time and did not raise questions earlier. While this might feel like Greg’s younger sister joining in to dunk on HLI, and I see from comments in this thread that perhaps criticism said passionately can be construed as hostile online, I don’t think this is anyone’s intent. Incredibly ironically given our genetic aversion to team sports, perhaps critique is intended as a fellow teammate begging a striker to get off the field when injured as they are hurting themselves and the team. Letting that player limp on is not being a supportive teammate. Personally, I hope these discussions drive discussions in HLI and EA which provide scope for growth.
In my unsolicited and unqualified opinion, I would advise withdrawing the CEA and drastically modifying the weight HLI puts on this work so it does not appear to be foundational to HLI as an organisation. Journals are encouraging the submission of meta-analysis study protocols for peer-review and publication (BMJPsych Open is one – I have acted as a peer reviewer for this journal to be transparent) in order to improve the quality of research. While conducting a whole SR/MA and publication takes time which could allow further loss of reputation, this is a quick way of acknowledging the issues here and taking concrete steps to rectify them. It’s not acceptable, to me, for the same people to offer a re-analysis or review this work because I’m sceptical this would not produce another flawed output and it seems there is a real need to involve expertise from the field of study (i.e. in formal peer review) at an earlier stage to right the ship.
Again, I do think the aims of HLI are important and I do wish them the best; and I’m interested to see how these discussions evolve in EA as it seems straying into a subject I’m passionate about. I come in peace and this feedback is genuinely meant constructively, so in the spirit of EA and younger-sibling disloyalty, I’m happy to offer HLI help above what’s already provided if they would like it.
[Edit for clarity mostly under 'outcomes' and 'grouping measures', corrected my horrid formatting/typos, and included the PHQ-9 for context. Kept my waffle and bad jokes for accountability, and was using the royal 'you' vs directing any statements at OP(!)]
Guy Raveh @ 2023-07-16T08:59 (+17)
Strongly upvoted for the explanation and demonstration of how important peer-review by subject matter experts is. I obviously can't evaluate either HLI's work or your review, but I think this is indeed a general problem of EA where the culture is, for some reason, aversive to standard practices of scientific publishing. This has to be rectified.
Jack Malde @ 2023-07-16T14:42 (+10)
I think it's because the standard practices of scientific publishing are very laborious and EA wants to be a bit more agile.
Having said that I strongly agree that more peer-review is called for in EA, even if we don't move all the way to the extreme of the academic world.
Madhav Malhotra @ 2023-08-03T20:28 (+8)
Out of curiosity @LondonGal, have you received any followups from HLI in response to your critique? I understand you might not be at liberty to share all details, so feel free to respond as you feel appropriate.
LondonGal @ 2023-08-04T21:10 (+4)
Nope, I've not heard from any current HLI members regarding this in public or private.
freedomandutility @ 2023-07-16T12:26 (+7)
Strongly upvoted.
My recommended next steps for HLI:
-
Redo the meta-analysis with a psychiatrist involved in the design, and get external review before publishing.
-
Have some sort of sensitivity analysis which demonstrates to donors how the effect size varies based on different weightings of the StrongMinds studies.
(I still strongly support funding HLI, not least so they can actually complete these recommended next steps)
John Salter @ 2023-07-16T12:59 (+4)
A professional psychotherapy researcher, or even just a psychotherapist, would be more appropriate than a psychiatrist no?
LondonGal @ 2023-07-16T14:42 (+28)
[Speaking from a UK perspective with much less knowledge of non-medical psychotherapy training]
I think the importance is having a strong mental health research background, particularly in systematic review and meta-analysis. If you have an expert in this field then the need for clinical experience becomes less important (perhaps, depends on HLI's intended scope).
It's fair to say psychology and psychiatry do commonly blur boundaries with psychotherapy as there are different routes of qualification - it can be with a PhD through a psychology/therapy pathway, or there is a specialism in psychotherapy that can be obtained as part of psychiatry training (a bit like how neurologists are qualified through specialism in internal medicine training). Psychotherapists tend to be qualified in specific modalities in order to practice them independently e.g. you might achieve accreditation in psychoanalytic psychotherapy, etc. There are a vast number of different professionals (me included, during my core training in psychiatry) who deliver psychotherapy under supervision of accredited practitioners so the definition of therapist is blurry.
Psychotherapy is similarly researched through the perspective of delivering psychotherapy which perhaps has more of a psychology focus, and as a treatment of various psychiatric illnesses (+/- in combination or comparison with medication, or novel therapies like psychadelics) which perhaps is closer to psychiatric research. Diagnosis of psychiatric illnesses like depression and directing treatment tends to remain the responsibility of doctors (psychiatrists or primary care physicians), and so psychiatry training requires the development of competencies in psychotherapy, even if delivery of psychotherapy does not always form the bulk of day-to-day practice, as it relates to formulating treatment plans for patients with psychiatric illness.
The issues I raise relate to the clinical presentation of depression as it pertains to impairment/wellbeing, diagnosis of depression, symptom rating scales, psychotherapy as a defined treatment, etc.; as well as the wide range of psychopathology captured in the dataset. My feeling is the breadth of this would benefit from a background in psychiatry for the assumptions I made about HLI's focus of the meta-analysis. However, if the importance is the depth of understanding IPT as an intervention, or perhaps the hollistic outcomes of psychotherapy particularly related to young women/girls in LMICs, then you might want a psychotherapist (PhD or psychiatrist) working with accreditation in the modality or with the population of interest. If you found someone who regularly publishes systematic reviews and meta-analyses of psychotherapy efficacy then that would probably trump both regardless of clinical background. Or perhaps all three is best.
You're both right to clarify this, though - I was giving my opinion from my background in clinical/academic psychiatry and so I talk about it a lot! When I mention the field of study etc, I meant mental health research more broadly given it depends on HLI's aims/scope to know what specific area this would be.
[Edit - Sorry, I've realised my lack of digging into the background of HLI members/contributors to this research could render the above highly offensive if there are individuals from this field on staff, and also makes me appear extremely arrogant. For clarity, it's possible all of my concerns were actually fully-rationalised, deliberate choices by HLI that I've not understood from my quick sense-check, or I might disagree with but are still valid.
[However, my impression from the work, in particular the design and methodology, is that there is a lack of psychiatric and/or psychotherapy knowledge (given the questions I had from a clinical perspective); and a lack of confidence in systematic review and meta-analysis from how far this deviates from Cochrane/PRISMA that I was trying to explain in more accessible terms in my comment without being exhaustive. It's possible contributors to this work did have experience in these areas but were not represented in the write-up, or not involved at the appropriate times in the work, etc. I'm not going to seek out whether or not that is the case as I think it would make this personal given the size of the organisation, and I'm worried that if I check I might find a psychotherapy professor on staff I've now crossed (jk ;-)).
[It's interesting to me either way, as both seem like problems - HLI not identifying they lacked appropriate skills to conduct this research, or seemingly not employing those with the relevant skills appropriately to conduct or communicate it - and it has relevance outside of this particular meta-analysis in the consideration of further outputs from HLI, or evaluation of orgs by EA. In any case, peer-review offers reassurance to the wider EA community that external subject-matter expertise has been consulted in whatever field of interest (with the additional benefit of shutting people like me down very quickly), and provides an opportunity for better research if deficits identified from peer-review suggest skills need to be reallocated or additional skills sought in order to meet a good standard.]
JamesSnowden @ 2023-07-07T23:28 (+123)
>Since then, all the major actors in effective altruism’s global health and wellbeing space seem to have come around to it (e.g., see these comments by GiveWell, Founders Pledge, Charity Entrepreneurship, GWWC, James Snowden).
I don't think this is an accurate representation of the post linked to under my name, which was largely critical.
alex lawsen (previously alexrjl) @ 2023-07-09T06:23 (+47)
[Speaking for myself here]
I also thought this claim by HLI was misleading. I clicked several of the links and don't think James is the only person being misrepresented. I also don't think this is all the "major actors in EA's GHW space" - TLYCS, for example, meet reasonable definitions of "major" but their methodology makes no mention of wellbys
MichaelPlant @ 2023-07-10T12:08 (+4)
Hello Alex,
Reading back on the sentence, it would have been better to put 'many' rather than 'all'. I've updated it accordingly. TLYCS don't mention WELLBYs, but they did make the comment "we will continue to rely heavily on the research done by other terrific organizations in this space, such as GiveWell, Founders Pledge, Giving Green, Happier Lives Institute [...]".
It's worth restating the positives. A number of organisations have said that they've found our research useful. Notably, see the comments by Matt Lerner (Research Director, Founders Pledge) below and also those from Elie Hassenfield (CEO, GiveWell), which we included in footnote 3 above. If it wasn't for HLI's work pioneering the subjective wellbeing approach and the WELLBY, I doubt these would be on the agenda in effective altruism.
alex lawsen (previously alexrjl) @ 2023-07-10T16:22 (+7)
My comment wasn't about whether there are any positives in using WELLBYs (I think there are), it was about whether I thought that sentence and set of links gave an accurate impression. It sounds like you agree that it didn't, given you've changed the wording and removed one of the links. Thanks for updating it.
I think there's room to include a little more context around the quote from TLYCs.
In short, we do not seek to duplicate the excellent work of other charity evaluators. Our approach is meant to complement that work, in order to expand the list of giving opportunities for donors with strong preferences for particular causes, geographies, or theories of change. Indeed, we will continue to rely heavily on the research done by other terrific organizations in this space, such as GiveWell, Founders Pledge, Giving Green, Happier Lives Institute, Charity Navigator, and others to identify candidates for our recommendations, even as we also assess them using our own evaluation framework.
We also fully expect to continue recommending nonprofits that have been held to the highest evidentiary standards, such as GiveWell’s top charities. For our current nonprofit recommendations that have not been evaluated at that level of rigor, we have already begun to conduct in-depth reviews of their impact. Where needed, we will work with candidate nonprofits to identify effective interventions and strengthen their impact evaluation approaches and metrics. We will also review our charity list periodically and make sure our recommendations remain relevant and up to date.
MichaelPlant @ 2023-07-10T11:40 (+14)
Hello James. Apologies, I've removed your name from the list.
To explain why we included it, although the thrust of your post was to critically engage with our research, the paragraph was about the use of the SWB approach for evaluating impact, which I believed you were on board with. In this sense, I put you in the same category as GiveWell: not disagreeing about the general approach, but disagreeing about the numbers you get when you use it.
JamesSnowden @ 2023-07-10T19:21 (+14)
Thanks for editing Michael. Fwiw I am broadly on board with swb being a useful framework to answer some questions. But I don’t think I’ve shifted my opinion on that much so “coming round to it” didn’t resonate
Gregory Lewis @ 2023-07-08T07:33 (+112)
[Own views]
- I think we can be pretty sure (cf.) the forthcoming strongminds RCT (the one not conducted by Strongminds themselves, which allegedly found an effect size of d = 1.72 [!?]) will give dramatically worse results than HLI's evaluation would predict - i.e. somewhere between 'null' and '2x cash transfers' rather than 'several times better than cash transfers, and credibly better than GW top charities.' [I'll donate 5k USD if the Ozler RCT reports an effect size greater than d = 0.4 - 2x smaller than HLI's estimate of ~ 0.8, and below the bottom 0.1% of their monte carlo runs.]
- This will not, however, surprise those who have criticised the many grave shortcomings in HLI's evaluation - mistakes HLI should not have made in the first place, and definitely should not have maintained once they were made aware of them. See e.g. Snowden on spillovers, me on statistics (1, 2, 3, etc.), and Givewell generally.
- Among other things, this would confirm a) SimonM produced a more accurate and trustworthy assessment of Strongminds in their spare time as a non-subject matter expert than HLI managed as the centrepiece of their activity; b) the ~$250 000 HLI has moved to SM should be counted on the 'negative' rather than 'positive' side of the ledger, as I expect this will be seen as a significant and preventable misallocation of charitable donations.
- Regrettably, it is hard to square this with an unfortunate series of honest mistakes. A better explanation is HLI's institutional agenda corrupts its ability to conduct fair-minded and even-handed assessment for an intervention where some results were much better for their agenda than others (cf.). I am sceptical this only applies to the SM evaluation, and I am pessimistic this will improve with further financial support.
Gregory Lewis @ 2024-08-03T15:19 (+148)
An update:
I'll donate 5k USD if the Ozler RCT reports an effect size greater than d = 0.4 - 2x smaller than HLI's estimate of ~ 0.8, and below the bottom 0.1% of their monte carlo runs.
This RCT (which should have been the Baird RCT - my apologies for mistakenly substituting Sarah Baird with her colleague Berk Ozler as first author previously) is now out.
I was not specific on which effect size would count, but all relevant[1] effect sizes reported by this study are much lower than d = 0.4 - around d = 0.1. I roughly[2] calculate the figures below.
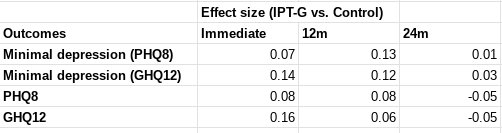
In terms of "SD-years of depression averted" or similar, there are a few different ways you could slice it (e.g. which outcome you use, whether you linearly interpolate, do you extend the effects out to 5 years, etc). But when I play with the numbers I get results around 0.1-0.25 SD-years of depression averted per person (as a sense check, this lines up with an initial effect of ~0.1, which seems to last between 1-2 years).
These are indeed "dramatically worse results than HLI's [2021] evaluation would predict". They are also substantially worse than HLI's (much lower) updated 2023 estimates of Strongminds. The immediate effects of 0.07-0.16 are ~>5x lower than HLI's (2021) estimate of an immediate effect of 0.8; they are 2-4x lower than HLI's (2023) informed prior for Strongminds having an immediate effect of 0.39. My calculations of the total effect over time from Baird et al. of 0.1-0.25 SD-years of depression averted are ~10x lower than HLI's 2021 estimate of 1.92 SD-years averted, and ~3x lower than their most recent estimate of ~0.6.
Baird et al. also comment on the cost-effectiveness of the intervention in their discussion (p18):
Unfortunately, the IPT-G impacts on depression in this trial are too small to pass a
cost-effectiveness test. We estimate the cost of the program to have been approximately USD 48 per individual offered the program (the cost per attendee was closer to USD 88). Given impact estimates of a reduction in the prevalence of mild depression of 0.054 pp for a period of one year, it implies that the cost of the program per case of depression averted was nearly USD 916, or 2,670 in 2019 PPP terms. An oft-cited reference point estimates that a health intervention can be considered cost-effective if it costs approximately one to three times the GDP per capita of the relevant country per Disability Adjusted Life Year (DALY) averted (Kazibwe et al., 2022; Robinson et al., 2017). We can then convert a case of mild depression averted into its DALY equivalent using the disability weights calculated for the Global Burden of Disease, which equates one year of mild depression to 0.145 DALYs (Salomon et al., 2012, 2015). This implies that ultimately the program cost USD PPP (2019) 18,413 per DALY averted. Since Uganda had a GDP per capita USD PPP (2019) of 2,345, the IPT-G intervention cannot be considered cost-effective using this benchmark.
I'm not sure anything more really needs to be said at this point. But much more could be, and I fear I'll feel obliged to return to these topics before long regardless.
- ^
The report describes the outcomes on p.10:
The primary mental health outcomes consist of two binary indicators: (i) having a Patient Health Questionnaire 8 (PHQ-8) score ≤ 4, which is indicative of showing no or minimal depression (Kroenke et al., 2009); and (ii) having a General Health Questionnaire 12 (GHQ-12) score < 3, which indicates one is not suffering from psychological distress (Goldberg and Williams, 1988). We supplement these two indicators with five secondary outcomes: (i) The PHQ-8 score (range: 0-24); (ii) the GHQ-12 score (0-12); (iii) the score on the Rosenberg self-esteem scale (0-30) (Rosenberg, 1965); (iv) the score on the Child and Youth Resilience Measure-Revised (0-34) (Jefferies et al., 2019); and (v) the locus of control score (1-10). The discrete PHQ-8 and GHQ-12 scores allow the assessment of impact on the severity of distress in the sample, while the remaining outcomes capture several distinct dimensions of mental health (Shah et al., 2024).
Measurements were taken following treatment completion ('Rapid resurvey'), then at 12m and 24m thereafer (midline and endline respectively).
I use both primary indicators and the discrete values of the underlying scores they are derived from. I haven't carefully looked at the other secondary outcomes nor the human capital variables, but besides being less relevant, I do not think these showed much greater effects.
- ^
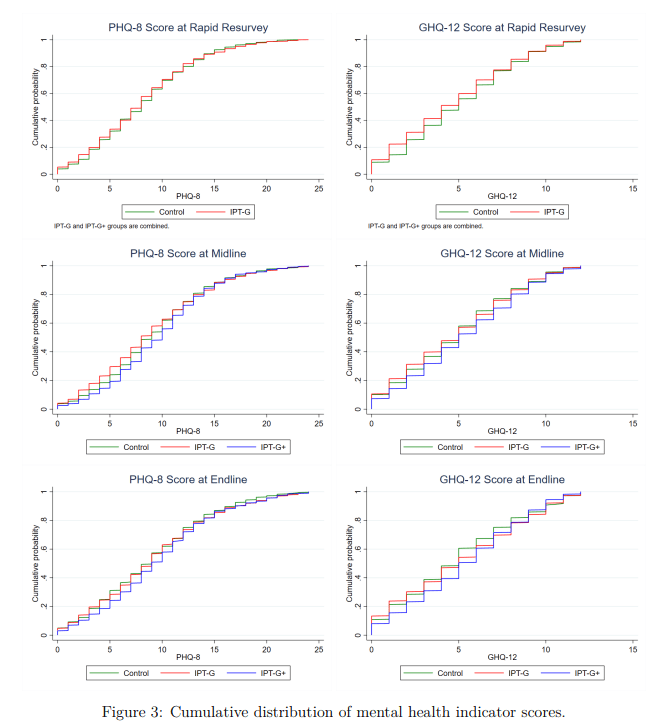
I.e. I took the figures from Table 6 (comparing IPT-G vs. control) for these measures and plugged them into a webtool for Cohen's h or d as appropriate. This is rough and ready, although my calculations agree with the effect sizes either mentioned or described in text. They also pass an 'eye test' of comparing them to the cmfs of the scores in figure 3 - these distributions are very close to one another, consistent with small-to-no effect (one surprising result of this study is IPT-G + cash lead to worse outcomes than either control or IPT-G alone):
One of the virtues of this study is it includes a reproducibility package, so I'd be happy to produce a more rigorous calculation directly from the provided data if folks remain uncertain.
bruce @ 2024-08-04T09:18 (+41)
My view is that HLI[1], GWWC[2], Founders Pledge[3], and other EA / effective giving orgs that recommend or provide StrongMinds as an donation option should ideally at least update their page on StrongMinds to include relevant considerations from this RCT, and do so well before Thanksgiving / Giving Tuesday in Nov/Dec this year, so donors looking to decide where to spend their dollars most cost effectively can make an informed choice.[4]
- ^
Listed as a top recommendation
- ^
Not currently a recommendation, (but to included as an option to donate)
- ^
Currently tagged as an "active recommendation"
- ^
Acknowledging that HLI's current schedule is "By Dec 2024", though this may only give donors 3 days before Giving Tuesday.
NickLaing @ 2024-08-04T13:02 (+10)
Thanks Bruce, would you still think this if Strongminds ditched their adolescent programs as a result of this study and continued with their core groups with older women?
bruce @ 2024-08-04T18:04 (+19)
Yes, because:
1) I think this RCT is an important proxy for StrongMinds (SM)'s performance 'in situ', and worth updating on - in part because it is currently the only completed RCT of SM. Uninformed readers who read what is currently on e.g. GWWC[1]/FP[2]/HLI website might reasonably get the wrong impression of the evidence base behind the recommendation around SM (i.e. there are no concerns sufficiently noteworthy to merit inclusion as a caveat). I think the effective giving community should have a higher bar for being proactively transparent here - it is much better to include (at minimum) a relevant disclaimer like this, than to be asked questions by donors and make a claim that there wasn't capacity to include.[3]
2) If a SM recommendation is justified as a result of SM's programme changes, this should still be communicated for trust building purposes (e.g. "We are recommending SM despite [Baird et al RCT results], because ...), both for those who are on the fence about deferring, and for those who now have a reason to re-affirm their existing trust on EA org recommendations.[4]
3) Help potential donors make more informed decisions - for example, informed readers who may be unsure about HLI's methodology and wanted to wait for the RCT results should not have to go search this up themselves or look for a fairly buried comment thread on a post from >1 year ago in order to make this decision when looking at EA recommendations / links to donate - I don't think it's an unreasonable amount of effort compared to how it may help. This line of reasoning may also apply to other evaluators (e.g. GWWC evaluator investigations).[5]
- ^
GWWC website currently says it only includes recommendations after they review it through their Evaluating Evaluators work, and their evaluation of HLI did not include any quality checks of HLI's work itself nor finalise a conclusion. Similarly, they say: "we don't currently include StrongMinds as one of our recommended programs but you can still donate to it via our donation platform".
- ^
Founders Pledge's current website says:
We recommend StrongMinds because IPT-G has shown significant promise as an evidence-backed intervention that can durably reduce depression symptoms. Crucial to our analysis are previous RCTs
- ^
I'm not suggesting at all that they should have done this by now, only ~2 weeks after the Baird RCT results were made public. But I do think three months is a reasonable timeframe for this.
- ^
If there was an RCT that showed malaria chemoprevention cost more than $6000 per DALY averted in Nigeria (GDP/capita * 3), rather than per life saved (ballpark), I would want to know about it. And I would want to know about it even if Malaria Consortium decided to drop their work in Nigeria, and EA evaluators continued to recommend Malaria Consortium as a result. And how organisations go about communicating updates like this do impact my personal view on how much I should defer to them wrt charity recommendations.
- ^
Of course, based on HLI's current analysis/approach, the ?disappointing/?unsurprising result of this RCT (even if it was on the adult population) would not have meaningfully changed the outcome of the recommendation, even if SM did not make this pivot (pg 66):
Therefore, even if the StrongMinds-specific evidence finds a small total recipient effect (as we present here as a placeholder), and we relied solely on this evidence, then it would still result in a cost-effectiveness that is similar or greater than that of GiveDirectly because StrongMinds programme is very cheap to deliver.
And while I think this is a conversation that has already been hashed out enough on the forum, I do think the point stands - potential donors who disagree with or are uncertain about HLI's methodology here would benefit from knowing the results of the RCT, and it's not an unreasonable ask for organisations doing charity evaluations / recommendations to include this information.
- ^
Based on Nigeria's GDP/capita * 3
- ^
Acknowledging that this is DALYs not WELLBYs! OTOH, this conclusion is not the GiveWell or GiveDirectly bar, but a ~mainstream global health cost-effectiveness standard of ~3x GDP per capita per DALY averted (in this case, the ~$18k USD PPP/DALY averted of SM is below the ~$7k USD PPP/DALY bar for Uganda)
NickLaing @ 2024-08-04T19:31 (+4)
Nice one Bruce. I think I agree that it should be communicated like you say for reasons 2 and 3
I don't think this is a good proxy for their main programs though, as this RCT looks a very different thing than their regular programming. I think other RCTs on group therapy in adult women from the region are better proxies than this study on adolescents.
Why do you think it's a particularly good proxy? In my mind the same org doing a different treatment, (that seems to work but only a little for a short ish time) with many similarities to their regular treatment of course.
Like I said a year ago, I would have much rather this has been an RCT on Strongminds regular programs rather than this one on a very different program for adolescents. I understand though that "does similar group psychotherapy also work for adolescents" is a more interesting question from a researcher's perspective, although less useful for all of us deciding just how good regular StrongMinds group psychotherapy is.
bruce @ 2024-08-04T20:18 (+6)
It sounds like you're interpreting my claim to be "the Baird RCT is a particularly good proxy (or possibly even better than other RCTs on group therapy in adult women) for the SM adult programme effectiveness", but this isn't actually my claim here; and while I think one could reasonably make some different, stronger (donor-relevant) claims based on the discussions on the forum and the Baird RCT results, mine are largely just: "it's an important proxy", "it's worth updating on", and "the relevant considerations/updates should be easily accessible on various recommendation pages". I definitely agree that an RCT on the adult programme would have been better for understanding the adult programme.
(I'll probably check out of the thread here for now, but good chatting as always Nick! hope you're well)
NickLaing @ 2024-08-05T04:16 (+2)
Nice one 100% agree no need to check in again!
NickLaing @ 2024-08-04T13:00 (+13)
Thanks for this Gregory, I think it's an important result and have updated my views. I'm not sure why HLI were so optimistic about this. I have a few comments here.
- This study was performed on adolescents, which is not the core group of women that Strong Minds and other group IPT programs treat. This study might update me slightly negatively against the effectof their core programming with groups of older women but not by much.
As The study said, "this marked the first time SMU (i) delivered therapy to out-of-school adolescent females, (ii) used youth mentors, and (iii) delivered therapy through a partner organization."
This result then doesn't surprise me as (high uncertainty) I think it's generally harder to move the needle with adolescent mental health than with adults.
-
The therapy still worked, even though the effect sizes were much smaller than other studies and were not cost effective.
-
As you've said before, f this kind of truly independent research was done on a lot of interventions, the results might not look nearly as good as the original studies.
-
I think Strongminds should probably stop their adolescent programs based on this study. Why keep doing it, when your work with adult women currently seems far more cost effective?
-
Even with the Covid caveat, I'm stunned at the null/negative effect of the cash transfer arm. Interesting stuff and not sure what to make of it.
-
I would still love a similar independent study on the regular group IPT programs with older women, and these RCTs should be pretty cheap on the scale of things, I doubt we'll get that though as it will probably seen as being too similar and not interesting enough for researchers which is fair enough.
MichaelPlant @ 2023-07-10T14:06 (+65)
Hi Greg,
Thanks for this post, and for expressing your views on our work. Point by point:
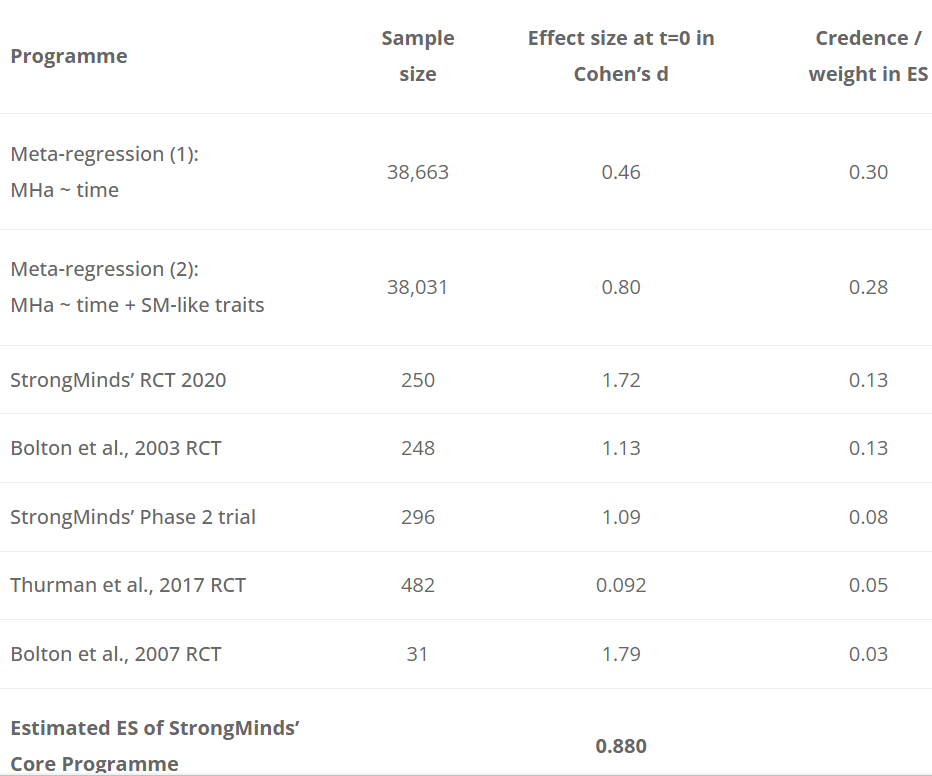
- I agree that StrongMinds' own study had a surprisingly large effect size (1.72), which was why we never put much weight on it. Our assessment was based on a meta-analysis of psychotherapy studies in low-income countries, in line with academic best practice of looking at the wider sweep of evidence, rather than relying on a single study. You can see how, in table 2 below, reproduced from our analysis of StrongMinds, StrongMinds' own studies are given relatively little weight in our assessment of the effect size, which we concluded was 0.82 based on the available data. Of course, we'll update our analysis when new evidence appears and we're particularly interested in the Ozler RCT. However, we think it's preferable to rely on the existing evidence to draw our conclusions, rather than on forecasts of as-yet unpublished work. We are preparing our psychotherapy meta-analysis to submit it for academic peer review so it can be independently evaluated but, as you know, academia moves slowly.
- We are a young, small team with much to learn, and of course, we'll make mistakes. But, I wouldn't characterise these as 'grave shortcomings', so much as the typical, necessary, and important back and forth between researchers. A claims P, B disputes P, A replies to B, B replies to A, and so it goes on. Even excellent researchers overlook things: GiveWell notably awarded us a prize for our reanalysis of their deworming research. We've benefitted enormously from the comments we've got from others and it shows the value of having a range of perspectives and experts. Scientific progress is the result of productive disagreements.
- I think it's worth adding that SimonM's critique of StrongMinds did not refer to our meta-analytic work, but focused on concerns about StrongMinds own study and analysis done outside HLI. As I noted in 1., we share the concerns about the earlier StrongMinds study, which is why we took the meta-analytic approach. Hence, I'm not sure SimonM's analysis told us much, if anything, we hadn't already incorporated. With hindsight, I think we should have communicated far more prominently how small a part StrongMinds' own studies played in our analysis, and been quicker off the mark to reply to SimonM's post (it came out during the Christmas holidays and I didn't want to order the team back to their (virtual) desks). Naturally, if you aren’t convinced by our work, you will be sceptical of our recommendations.
- You suggest we are engaged in motivated reasoning, setting out to prove what we already wanted to believe. This is a challenging accusation to disprove. The more charitable and, I think, the true explanation is that we had a hunch about something important being missed and set out to do further research. We do complex interdisciplinary work to discover the most cost-effective interventions for improving the world. We have done this in good faith, facing an entrenched and sceptical status quo, with no major institutional backing or funding. Naturally, we won’t convince everyone – we’re happy the EA research space is a broad church. Yet, it’s disheartening to see you treat us as acting in bad faith, especially given our fruitful interactions, and we hope that you will continue to engage with us as our work progresses.
Table 2.
Gregory Lewis @ 2023-07-13T09:19 (+136)
Hello Michael,
Thanks for your reply. In turn:
1:
HLI has, in fact, put a lot of weight on the d = 1.72 Strongminds RCT. As table 2 shows, you give a weight of 13% to it - joint highest out of the 5 pieces of direct evidence. As there are ~45 studies in the meta-analytic results, this means this RCT is being given equal or (substantially) greater weight than any other study you include. For similar reasons, the Strongminds phase 2 trial is accorded the third highest weight out of all studies in the analysis.
HLI's analysis explains the rationale behind the weighting of "using an appraisal of its risk of bias and relevance to StrongMinds’ present core programme". Yet table 1A notes the quality of the 2020 RCT is 'unknown' - presumably because Strongminds has "only given the results and some supporting details of the RCT". I don't think it can be reasonable to assign the highest weight to an (as far as I can tell) unpublished, not-peer reviewed, unregistered study conducted by Strongminds on its own effectiveness reporting an astonishing effect size - before it has even been read in full. It should be dramatically downweighted or wholly discounted until then, rather than included at face value with a promise HLI will followup later.
Risk of bias in this field in general is massive: effect sizes commonly melt with improving study quality. Assigning ~40% of a weighted average of effect size to a collection of 5 studies, 4 [actually 3, more later] of which are (marked) outliers in effect effect, of which 2 are conducted by the charity is unreasonable. This can be dramatically demonstrated from HLI's own data:
One thing I didn't notice last time I looked is HLI did code variables on study quality for the included studies, although none of them seem to be used for any of the published analysis. I have some good news, and some very bad news.
The good news is the first such variable I looked at, ActiveControl, is a significant predictor of greater effect size. Studies with better controls report greater effects (roughly 0.6 versus 0.3). This effect is significant (p = 0.03) although small (10% of the variance) and difficult - at least for me - to explain: I would usually expect worse controls to widen the gap between it and the intervention group, not narrow it. In any case, this marker of study quality definitely does not explain away HLI's findings.
The second variable I looked at was 'UnpubOr(pre?)reg'.[1] As far as I can tell, coding 1 means something like 'the study was publicly registered' and 0 means it wasn't (I'm guessing 0.5 means something intermediate like retrospective registration or similar) - in any case, this variable correlates extremely closely (>0.95) to my own coding of whether a study mentions being registered or not after reviewing all of them myself. If so, using it as a moderator makes devastating reading:[2]
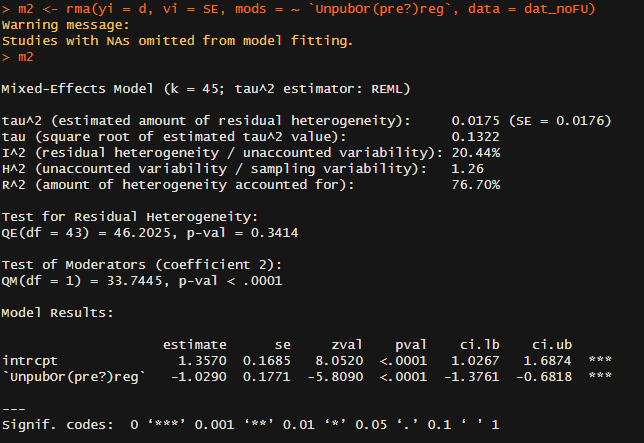
To orientate: in 'Model results' the intercept value gives the estimated effect size when the 'unpub' variable is zero (as I understand it, ~unregistered studies), so d ~ 1.4 (!) for this set of studies. The row below gives the change in effect if you move from 'unpub = 0' to 'unpub = 1' (i.e. ~ registered vs. unregistered studies): this drops effect size by 1, so registered studies give effects of ~0.3. In other words, unregistered and registered studies give dramatically different effects: study registration reduces expected effect size by a factor of 3. [!!!]
The other statistics provided deepen the concern. The included studies have a very high level of heterogeneity (~their effect sizes vary much more than they should by chance). Although HLI attempted to explain this variation with various meta-regressions using features of the intervention, follow-up time, etc., these models left the great bulk of the variation unexplained. Although not like-for-like, here a single indicator of study quality provides compelling explanation for why effect sizes differ so much: it explains three-quarters of the initial variation.[3]
This is easily seen in a grouped forest plot - the top group is the non registered studies, the second group the registered ones:
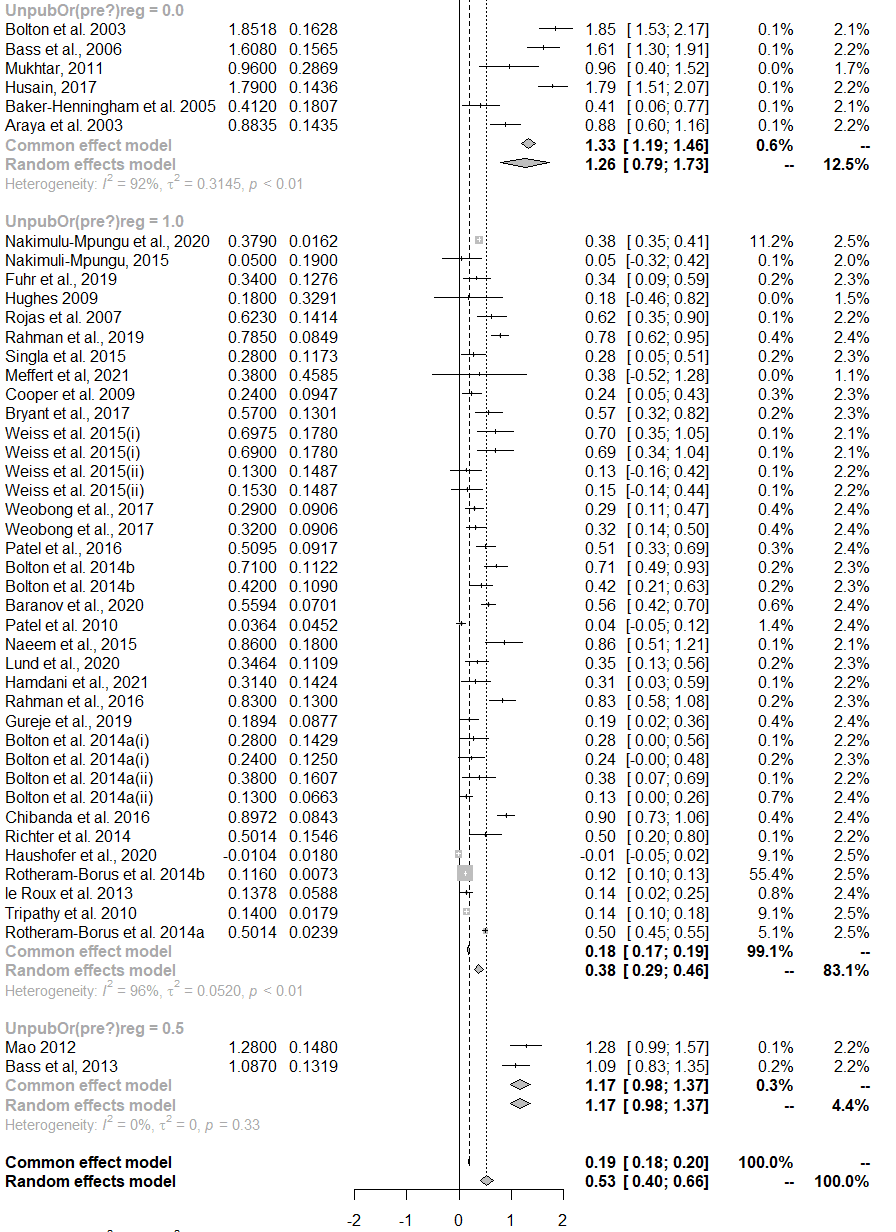
This pattern also perfectly fits the 5 pieces of direct evidence: Bolton 2003 (ES = 1.13), Strongminds RCT (1.72), and Strongminds P2 (1.09) are, as far as I can tell, unregistered. Thurman 2017 (0.09) was registered. Bolton 2007 is also registered, and in fact has an effect size of ~0.5, not 1.79 as HLI reports.[4]
To be clear, I do not think HLI knew of this before I found it out just now. But results like this indicate i) the appraisal of the literature in this analysis gravely off-the-mark - study quality provides the best available explanation for why some trials report dramatically higher effects than others; ii) the result of this oversight is a dramatic over-estimation of likely efficacy of Strongminds (as a ready explanation for the large effects reported in the most 'relevant to strongminds' studies is that these studies were not registered and thus prone to ~200%+ inflation of effect size); iii) this is a very surprising mistake for a diligent and impartial evaluator to make: one would expect careful assessment of study quality - and very sceptical evaluation where this appears to be lacking - to be foremost, especially given the subfield and prior reporting from Strongminds both heavily underline it. This pattern, alas, will prove repetitive.
I also think a finding like this should prompt an urgent withdrawal of both the analysis and recommendation pending further assessment. In honesty, if this doesn't, I'm not sure what ever could.
2:
Indeed excellent researchers overlook things, and although I think both the frequency and severity of things HLI mistakes or overlooks is less-than-excellent, one could easily attribute this to things like 'inexperience', 'trying to do a lot in a hurry', 'limited staff capacity', and so on.
Yet this cannot account for how starkly asymmetric the impact of these mistakes and oversights are. HLI's mistakes are consistently to Strongmind's benefit rather than its detriment, and HLI rarely misses a consideration which could enhance the 'multiple', it frequently misses causes of concern which both undermine both strength and reliability of this recommendation. HLI's award from Givewell deepens my concerns here, as it is consistent with a very selective scepticism: HLI can carefully scruitinize charity evaluations by others it wants to beat, but fails to mete out remotely comparable measure to its own which it intends for triumph.
I think this can also explain how HLI responds to criticism, which I have found by turns concerning and frustrating. HLI makes some splashy claim (cf. 'mission accomplished', 'confident recommendation', etc.). Someone else (eventually) takes a closer look, and finds the surprising splashy claim, rather than basically checking out 'most reasonable ways you slice it', it is highly non-robust, and only follows given HLI slicing it heavily in favour of their bottom line in terms of judgement or analysis - the latter of which often has errors which further favour said bottom line. HLI reliably responds, but the tenor of this response is less 'scientific discourse' and more 'lawyer for defence': where it can, HLI will too often further double down on calls it makes where I aver the typical reasonable spectator would deem at best dubious, and at worst tendentious; where it can't, HLI acknowledges the shortcoming but asserts (again, usually very dubiously) that it isn't that a big deal, so it will deprioritise addressing it versus producing yet more work with the shortcomings familiar to those which came before.
3:
HLI's meta-analysis in no way allays or rebuts the concerns SimonM raised re. Strongminds - indeed, appropriate analysis would enhance many of them. Nor is it the case that the meta-analytic work makes HLI's recommendation robust to shortcomings in the Strongminds-specific evidence - indeed, the cost effectiveness calculator will robustly recommend Strongminds as superior (commonly, several times superior) to GiveDirectly almost no matter what efficacy results (meta-analytic or otherwise) are fed into it. On each.
a) Meta-analysis could help contextualize the problems SimonM identifies in the Strongminds specific data. For example, a funnel plot which is less of a 'funnel' but more of a ski-slope (i.e. massive small study effects/risk of publication bias), and a contour/p-curve suggestive of p-hacking would suggest the field's literature needs to be handled with great care. Finding 'strongminds relevant' studies and direct evidence are marked outliers even relative to this pathological literature should raise alarm given this complements the object-level concerns SimonM presented.
This is indeed true, and these features were present in the studies HLI collected, but HLI failed to recognise it. It may never have if I hadn't gotten curious and did these analyses myself. Said analysis is (relative to the much more elaborate techniques used in HLI's meta-analysis) simple to conduct - my initial 'work' was taking the spreadsheet and plugging it into a webtool out of idle curiosity.[5] Again, this is a significant mistake, adds a directional bias in favour of Strongminds, and is surprising for a diligent and impartial evaluator to make.
b) In general, incorporating meta-analytic results into what is essentially a weighted average alongside direct evidence does not clean either it or the direct evidence of object level shortcomings. If (as here) both are severely compromised, the result remains unreliable.
The particular approach HLI took also doesn't make the finding more robust, as the qualitative bottom line of the cost-effectiveness calculation is insensitive to the meta-analytic result. As-is, the calculator gives strongminds as roughly 12x better than GiveDirectly.[6] If you set both meta-analytic effect sizes to zero, the calculator gives Strongminds as ~7x better than GiveDirectly. So the five pieces of direct evidence are (apparently) sufficient to conclude SM is an extremely effective charity. Obviously this is - and HLI has previously accepted - facially invalid output.
It is not the only example. It is extremely hard for any reduction of efficacy inputs to the model to give a result that Strongminds is worse than Givedirectly. If we instead leave the meta-analytic results as they were but set all the effect sizes of the direct evidence to zero (in essence discounting them entirely - which I think is approximately what should have been done from the start), we get ~5x better than GiveDirectly. If we set all the effect sizes of both meta-analysis and direct evidence to 0.4 (i.e. the expected effects of registered studies noted before), we get ~6x better than Givedirectly. If we set the meta-analytic results to 0.4 and set all the direct evidence to zero we get ~3x GiveDirectly. Only when one sets all the effect sizes to 0.1 - lower than all but ~three of the studies in the meta-analysis - does one approach equipoise.
This result should not surprise on reflection: the CEA's result is roughly proportional to the ~weighted average of input effect sizes, so an initial finding of '10x' Givedirectly or similar would require ~a factor of 10 cut to this average to drag it down to equipoise. Yet this 'feature' should be seen as a bug: in the same way there should be some non-zero value of the meta-analytic results which should reverse a 'many times better than Givedirectly' finding, there should be some non-tiny value of effect sizes for a psychotherapy intervention (or psychotherapy interventions in general) which results in it not being better than GiveDirectly at all.
This does help explain the somewhat surprising coincidence the first charity HLI fully assessed would be one it subsequently announces as the most promising interventions in global health and wellbeing so-far found: rather than a discovery from the data, this finding is largely preordained by how the CEA stacks the deck. To be redundant (and repetitive): i) the cost-effectiveness model HLI is making is unfit-for-purpose, given can produce these absurd results; ii) this introduces a large bias in favour of Strongminds; iii) it is a very surprising mistake for a diligent and impartial evaluator to make - these problems are not hard to find.
They're even easier for HLI to find once they've been alerted to them. I did, months ago, alongside other problems, and suggested the cost-effectiveness analysis and Strongminds recommendation be withdrawn. Although it should have happened then, perhaps if I repeat myself it might happen now.
4:
Accusations of varying types of bad faith/motivated reasoning/intellectual dishonesty should indeed be made with care - besides the difficulty in determination, pragmatic considerations raise the bar still higher. Yet I think the evidence of HLI having less of a finger but more of a fist on the scale throughout its work overwhelms even charitable presumptions made by a saint on its behalf. In footballing terms, I don't think HLI is a player cynically diving to win a penalty, but it is like the manager after the game insisting 'their goal was offside, and my player didn't deserve a red, and.. (etc.)' - highly inaccurate and highly biased. This is a problem when HLI claims itself an impartial referee, especially when it does things akin to awarding fouls every time a particular player gets tackled.
This is even more of a problem precisely because of the complex and interdisciplinary analysis HLI strives to do. No matter the additional analytic arcana, work like this will be largely fermi estimates, with variables being plugged in with little more to inform them than intuitive guesswork. The high degree of complexity provides a vast garden of forking paths available. Although random errors would tend to cancel out, consistent directional bias in model choice, variable selection, and numerical estimates lead to greatly inflated 'bottom lines'.
Although the transparency in (e.g.) data is commendable, the complex analysis also makes scruitiny harder. I expect very few have both the expertise and perseverence to carefully vet HLI analysis themselves; I also expect the vast majority of money HLI has moved has come from those largely taking its results on trust. This trust is ill-placed: HLI's work weathers scruitiny extremely poorly; my experience is very much 'the more you see, the worse it looks'. I doubt many donors following HLI's advice, if they took a peak behind the curtain, would be happy with what they would discover.
If HLI is falling foul of an entrenched status quo, it is not particular presumptions around interventions, nor philosophical abstracta around population ethics, but rather those that work in this community (whether published elsewhere or not) should be even-handed, intellectually honest and trustworthy in all cases; rigorous and reliable commensurate to its expected consequence; and transparently and fairly communicated. I think going against this grain underlies (I suspect) why I am not alone in my concerns, and why HLI has not had the warmest reception. The hope this all changes for the better is not entirely forlorn. But things would have to change a lot, and quickly - and the track record thus far does not spark joy.
- ^
Really surprised I missed this last time, to be honest. Especially because it is the only column title in the spreadsheet highlighted in red.
- ^
Given I will be making complaints about publication bias, file drawer effects, and garden of forking path issues later in the show, one might wonder how much of this applies to my own criticism. How much time did I spend dredging through HLI's work looking for something juicy? Is my file drawer stuffed with analyses I hoped would show HLI in a bad light, actually showed it in a good one, so I don't mention them?
Depressingly, the answer is 'not much' and 'no' respectively. Regressing against publication registration was the second analysis I did on booting up the data again (regressing on active control was the first, mentioned in text). My file drawer subsequent to this is full of checks and double-checks for alternative (and better for HLI) explanations for the startling result. Specifically, and in order:
- I used the no_FU (no follow-ups) data initially for convenience - the full data can include multiple results of the same study at different follow-up points, and these clustered findings are inappropriate to ignore in a simple random effects model. So I checked both by doing this anyway then using a multi-level model to appropriately manage this structure to the data. No change to the key finding.
- Worried that (somehow) I was messing up or misinterpreting the metaregression, I (re)constructed a simple forest plot of all the studies, and confirmed indeed the unregistered ones were visibly off to the right. I then grouped a forest plot by registration variable to ensure it closely agreed with the meta-regression (in main text). It does.
- I then checked the first 10 studies coded by the variable I think is trial registration to check the registration status of those studies matched the codes. Although all fit, I thought the residual risk I was misunderstanding the variable was unacceptably high for a result significant enough to warrant a retraction demand. So I checked and coded all 46 studies by 'registered or not?' to make sure this agreed with my presumptive interpretation of the variable (in text). It does.
- Adding multiple variables to explain an effect geometrically expands researcher degrees of freedom, thus any unprincipled ad hoc investigation by adding or removing them has very high false discovery rates (I suspect this is a major problem with HLI's own meta-regression work, but compared to everything else it merits only a passing mention here). But I wanted to check if I could find ways (even if unprincipled and ad hoc) to attenuate a result as stark as 'unregistered studies have 3x the registered ones'.
- I first tried to replicate HLI's meta-regression work (exponential transformations and all) to see if the registration effect would be attenuated by intervention variables. Unfortunately, I was unable to replicate HLI's regression results from the information provided (perhaps my fault). In any case, simpler versions I constructed did not give evidence for this.
- I also tried throwing in permutations of IPT-or-not (these studies tend to be unregistered, maybe this is the real cause of the effect?), active control-or-not (given it had a positive effect size, maybe it cancels out registration?) and study Standard Error (a proxy - albeit a controversial one - for study size/precision/quality, so if registration was confounded by it, this slightly challenges interpretation). The worst result across all the variations I tried was to drop the effect size of registration by 20% (~ -1 to -0.8), typically via substitution with SE. Omitted variable bias and multiple comparisons mean any further interpretation would be treacherous, but insofar as it provides further support: adding in more proxies for study quality increases explanatory power, and tends to even greater absolute and relative drops in effect size comparing 'highest' versus 'lowest' quality studies.
That said, the effect size is so dramatic to be essentially immune to file-drawer worries. Even if I had a hundred null results I forgot to mention, this finding would survive a Bonferroni correction.
- ^
Obviously 'is the study registered or not'? is a crude indicator of overal quality. Typically, one would expect better measurement (perhaps by including further proxies for underlying study quality) would further increase the explanatory power of this factor. In other words, although these results look really bad, in reality it is likely to be even worse.
- ^
HLI's write up on Bolton 2007 links to this paper (I did double check to make sure there wasn't another Bolton et al. 2007 which could have been confused with this - no other match I could find). It has a sample size of 314, not 31 as HLI reports - I presume a data entry error, although it less than reassuring that this erroneous figure is repeated and subsequently discussed in the text as part of the appraisal of the study: one reason given for weighing it so lightly is its 'very small' sample size.
Speaking of erroneous figures, here's the table of results from this study:
I see no way to arrive at an effect size of d = 1.79 from these numbers. The right comparison should surely be the pre-post difference of GIP versus control in the intention to treat analysis. These numbers give a cohen's d ~ 0.5.
I don't think any other reasonable comparison gets much higher numbers, and definitely not > 3x higher numbers - the differences between any of the groups are lower than the standard deviations, so should bound estimates like Cohen's d to < 1.
[Re. file drawer, I guess this counts as a spot check (this is the only study I carefully checked data extraction), but not a random one: I did indeed look at this study in particular because it didn't match the 'only unregistered studies report crazy-high effects' - an ES of 1.79 is ~2x any other registered study.]
- ^
Re. my worries of selective scepticism, HLI did apply these methods in their meta-analysis of cash transfers, where no statistical suggestion of publication bias or p-hacking was evident.
- ^
This does depend a bit on whether spillover effects are being accounted for. This seems to cut the multiple by ~20%, but doesn't change the qualitative problems with the CEA. Happy to calculate precisely if someone insists.
MichaelPlant @ 2023-07-13T15:39 (+22)
Hello Gregory. With apologies, I’m going to pre-commit both to making this my last reply to you on this post. This thread has been very costly in terms of my time and mental health, and your points below are, as far as I can tell, largely restatements of your earlier ones. As briefly as I can, and point by point again.
1.
A casual reader looking at your original comment might mistakenly conclude that we only used StrongMinds own study, and no other data, for our evaluation. Our point was that SM’s own work has relatively little weight, and we rely on many other sources. At this point, your argument seems rather ‘motte-and-bailey’. I would agree with you that there are different ways to do a meta-analysis (your point 3), and we plan to publish our new psychotherapy meta-analysis in due course so that it can be reviewed.
2.
Here, you are restating your prior suggestions that HLI should be taken in bad faith. Your claim is that HLI is good at spotting errors in others’ work, but not its own. But there is an obvious explanation about 'survivorship' effects. If you spot errors in your own research, you strip them out. Hence, by the time you publish, you’ve found all the ones you’re going to find. This is why peer review is important: external reviewers will spot the errors that authors have missed themselves. Hence, there’s nothing odd about having errors in your own work but also finding them in others. This is the normal stuff of academia!
3.
I’m afraid I don’t understand your complaint. I think your point is that “any way you slice the meta-analysis, psychotherapy looks more cost-effective than cash transfers” but then you conclude this shows the meta-analysis must be wrong, rather than it’s sensible to conclude psychotherapy is better. You’re right that you would have to deflate all the effect sizes by a large proportion to reverse the result. This should give you confidence in psychotherapy being better! It’s worth pointing out that if psychotherapy is about $150pp, but cash transfers cost about $1100pp ($1000 transfer + delivery costs), therapy will be more cost-effective per intervention unless its per-intervention effect is much smaller
The explanation behind finding a new charity on our first go is not complicated or sinister. In earlier work, including my PhD, I had suggested that, on a SWB analysis, mental health was likely to be relatively neglected compared to status quo prioritising methods. I explained this in terms of the existing psychological literature on affective forecasting errors: we’re not very good at imagining internal suffering, we probably overstate the badness of material due to focusing illusions, and our forecasts don’t account for hedonic adaptation (which doesn’t occur to mental health). So the simple explanation is that we were ‘digging’ where we thought we were mostly likely to find ‘altruistic gold’, which seems sensible given limited resources.
4.
As much as I enjoyed your football analogies, here also you’re restating, rather than further substantiating, your earlier accusations. You seem to conclude from the fact you found some problems with HLI’s analysis that we should conclude this means HLI, but only HLI, should be distrusted, and retain our confidence in all the other charity evaluators. This seems unwarranted. Why not conclude you would find mistakes elsewhere too? I am reminded of the expression, “if you knew how the sausage was made, you wouldn’t want to eat the sausage”. What I think is true is that HLI is a second-generation charity evaluator, we are aiming to be extremely transparent, and we are proposing novel priorities. As a result, I think we have come in for a far higher level of public scrutiny than others have, so more of our errors have been found, but I don’t know that we have made more and worse errors. Quite possibly, where errors have been noticed in others’ work, they have been quietly and privately identified, and corrected with less fanfare.
Nathan Young @ 2023-07-10T14:34 (+10)
Props on the clear and gracious reply.
we think it's preferable to rely on the existing evidence to draw our conclusions, rather than on forecasts of as-yet unpublished work.
I sense this is wrong, if I think the unpublished work will change my conclusions a lot, I change my conclusions some of the way now though I understand that's a weird thing to do and hard to justify perhaps. Nonetheless I think it's the right move.
Jason @ 2023-07-10T15:28 (+58)
Could you say a bit more about what you mean by "should not have maintained once they were made aware of them" in point 2? As you characterize below, this is an org "making a funding request in a financially precarious position," and in that context I think it's even more important than usual to be clear about HLI has "maintained" its "mistakes" "once they were made aware of them." Furthermore, I think the claim that HLI has "maintained" is an important crux for your final point.
Example: I do not like that HLI's main donor advice page lists the 77 WELLBY per $1,000 estimate with only a very brief and neutral statement that "Note: we plan to update our analysis of StrongMinds by the end of 2023." There is a known substantial, near-typographical error underlying that analysis:
The first thing worth acknowledging is that he pointed out a mistake that substantially changes our results. [ . . . .] He pointed out that Kemp et al., (2009) finds a negative effect, while we recorded its effect as positive — meaning we coded the study as having the wrong sign.
[ . . . .]
This correction would reduce the spillover effect from 53% to 38% and reduce the cost-effectiveness comparison from 9.5 to 7.5x, a clear downwards correction.
While I'm sympathetic to HLI's small size and desire to produce a more comprehensive updated analysis, I don't think it's appropriate to be quoting numbers from an unpatched version of the CEA over four months after the error was discovered. (I'd be somewhat more flexible if this were based on new information rather than HLI's coding error, and/or if the difference didn't flip the recommendation for a decent percentage of would-be donors: deprivationists who believe the neutral point is less than 1.56 or so).
Gregory Lewis @ 2023-07-16T19:03 (+74)
Hello Jason,
With apologies for delay. I agree with you that I am asserting HLI's mistakes have further 'aggravating factors' which I also assert invites highly adverse inference. I had hoped the links I provided provided clear substantiation, but demonstrably not (my bad). Hopefully my reply to Michael makes them somewhat clearer, but in case not, I give a couple of examples below with as best an explanation I can muster.
I will also be linking and quoting extensively from the Cochrane handbook for systematic reviews - so hopefully even if my attempt to clearly explain the issues fail, a reader can satisfy themselves my view on them agrees with expert consensus. (Rather than, say, "Cantankerous critic with idiosyncratic statistical tastes flexing his expertise to browbeat the laity into aquiescence".)
0) Per your remarks, there's various background issues around reasonableness, materiality, timeliness etc. I think my views basically agree with yours. In essence: I think HLI is significantly 'on the hook' for work (such as the meta-analysis) it relies upon to make recommendations to donors - who will likely be taking HLI's representations on its results and reliability (cf. HLI's remarks about its 'academic research', 'rigour' etc.) on trust. Discoveries which threaten the 'bottom line numbers' or overall reliability of this work should be addressed with urgency and robustness appropriate to their gravity. "We'll put checking this on our to-do list" seems fine for an analytic choice which might be dubious but of unclear direction and small expected magnitude. As you say, a typo which where corrected reduces the bottom line efficacy by ~ 20% should be done promptly.
The two problems I outlined 6 months ago each should have prompted withdrawal/suspension of both the work and the recommendation unless and until they were corrected.[1] Instead, HLI has not made appropriate corrections, and instead persists in misguiding donations and misrepresenting the quality of its research on the basis of work it has partly acknowledged (and which reasonable practicioners would overwhelmingly concur) was gravely compromised.[2]
1.0) Publication bias/Small study effects
It is commonplace in the literature for smaller studies to show different (typically larger) effect sizes than large studies. This is typically attributed to a mix of factors which differentially inflate effect size in smaller studies (see), perhaps the main one being publication bias: although big studies are likely to be published "either way", investigators may not finish (or journals may not publish) smaller studies reporting negative results.
It is extremely well recognised that these effects can threaten the validity of meta-analysis results. If you are producing something (very roughly) like an 'average effect size' from your included studies, the studies being selected for showing a positive effect means the average is inflated upwards. This bias is very difficult to reliably adjust for or 'patch' (more later), but it can easily be large enough to mean "Actually, the treatment has no effect, and your meta-analysis is basically summarizing methodological errors throughout the literature".
Hence why most work on this topic stresses the importance of arduous efforts in prevention (e.g trying really hard to find 'unpublished' studies) and diagnosis (i.e. carefully checking for statistical evidence of this problem) rather than 'cure' (see eg.). If a carefully conducted analysis nonetheless finds stark small study effects, this - rather than the supposed ~'average' effect - would typically be (and should definitely be) the main finding: "The literature is a complete mess - more, and much better, research needed".
As in many statistical matters, a basic look at your data can point you in the right direction. For meta-analysis, this standard is a forest plot:
To orientate: each row is a study (presented in order of increasing effect size), and the horizontal scale is effect size (where to the right = greater effect size favouring the intervention). The horizontal bar for each study is gives the confidence interval for the effect size, with the middle square marking the central estimate (also given in the rightmost column). The diamond right at the bottom is the pooled effect size - the (~~)[3] average effect across studies mentioned earlier.
Here, the studies are all over the map, many of which do not overlap with one another, nor with the pooled effect size estimate. In essence, dramatic heterogeneity: the studies are reporting very different effect sizes from another. Heterogeneity is basically a fact of life in meta-analysis, but a forest plot like this invites curiousity (or concern) about why effects are varying quite this much. [I'm going to be skipping discussion of formal statistical tests/metrics for things like this for clarity - you can safely assume a) yes, you can provide more rigorous statistical assessment of 'how much' besides 'eyeballing it' - although visually obvious things are highly informative, b) the things I mention you can see are indeed (highly) statistically significant etc. etc.]
There are some hints from this forest plot that small study effects could have a role to play. Although very noisy, larger studies (those with narrower horizontal lines lines, because bigger study ~ less uncertainty in effect size) tend to be higher up the plot and have smaller effects. There is a another plot designed to look at this better - a funnel plot.
To orientate: each study is now a point on a scatterplot, with effect size again on the x-axis (right = greater effect). The y-axis is now the standard error: bigger studies have greater precision, and so lower sampling error, so are plotted higher on the y axis. Each point is a single study - all being well, the scatter should look like a (symmetrical) triangle or funnel like those being drawn on the plot.
All is not well here. The scatter is clearly asymmetric and sloping to the right - smaller studies (towards the bottom of the graph) tend towards greater effect sizes. The lines being drawn on the plot make this even clearer. Briefly:
- The leftmost 'funnel' with shaded wings is centered on an effect size of zero (i.e. zero effect). The white middle triangle are findings which would give a p value of > 0.05, and the shaded wings correspond to a p value between 0.05 ('statistically significant') and 0.01: it is an upward-pointing triangle because bigger studies can detect find smaller differences from zero as 'statistically significant' than smaller ones. There appears to be clustering in the shaded region, suggestive that studies may be being tweaked to get them 'across the threshold' of statistically significant effects.
- The rightmost 'funnel' without shading is centered on the pooled effect estimate (0.5). Within the triangle is where you would expect 95% of the scatter of studies to fall in the absence of heterogeneity (i.e. there was just one true effect size, and the studies varied from this just thanks to sampling error). Around half are outside this region.
- The red dashed line is the best fit line through the scatter of studies. If there weren't small study effects, it would be basically vertical. Instead, it slopes off heavily to the right.
Although a very asymmetric funnel plot is not proof positive of publication bias, findings like this demand careful investigation and cautious interpretation (see generally). It is challenging to assess exactly 'how big a deal is it, though?': statistical adjustiment for biases in the original data is extremely fraught.
But we are comfortably in 'big deal' territory: this finding credibly up-ends HLI's entire analysis:
a) There are different ways of getting a 'pooled estimate' (~~average, or ~~ typical effect size): random effects (where you assume the true effect is rather a distribution of effects from which each study samples from), vs. fixed effects (where there is a single value for the true effect size). Random effects are commonly preferred as - in reality - one expects the true effect to vary, but the results are much more vulnerable to any small study effects/publication bias (see generally). Comparing the random effect vs. the fixed effect estimate can give a quantitative steer on the possible scale of the problem, as well as guide subsequent analysis.[4] Here, the random effect estimate is 0.52, whilst the fixed one is less than half the size: 0.18.
b) There are other statistical methods you could use (more later). One of the easier to understand (but one of the most conservative) goes back to the red dashed line in the funnel plot. You could extrapolate from it to the point where standard error = 0: so the predicted effect of an infinitely large (so infinitely precise) study - and so also where the 'small study effect' is zero. There are a few different variants of these sorts of 'regression methods', but the ones I tried predict effect sizes of such a hypothetical study between 0.17 and 0.05. So, quantitatively, 70-90% cuts of effect size are on the table here.
c) A reason why regression methods methods are conservative as they will attribute as much variation in reported results as possible to differences in study size. Yet there could be alternative explanations for this besides publication bias: maybe smaller studies have different patient populations with (genuinely) greater efficacy, etc.
However, this statistical confounding can go the other way. HLI is not presenting simple meta-analytic results, but rather meta-regressions: where the differences in reported effect sizes are being predicted by differences between and within the studies (e.g. follow-up time, how much therapy was provided, etc.). One of HLI's findings from this work is that psychotherpy with Strongminds-like traits is ~70% more effective than psychotherapy in general (0.8 vs. 0.46). If this is because factors like 'group or individual therapy' correlate with study size, the real story for this could simply be: "Strongminds-like traits are indicators for methodological weaknesses which greatly inflate true effect size, rather than for a more effective therapeutic modality." In HLI's analysis, the latter is presumed, giving about a ~10% uplift to the bottom line results.[5]
1.2) A major issue, and a major mistake to miss
So this is a big issue, and would be revealed by standard approaches. HLI instead used a very non-standard approach (see), novel - as far as I can tell - to existing practice and, unfortunately, inappropriate (cf., point 5): it gives ~ a 10-15% discount (although I'm not sure this has been used in the Strongminds assessment, although it is in the psychotherapy one).
I came across these problems ~6m ago, prompted by a question by Ryan Briggs (someone with considerably greater expertise than my own) asking after the forest and funnel plot. I also started digging into the data in general at the same time, and noted the same key points explained labouriously above: looks like marked heterogeneity and small study effects, they look very big, and call the analysis results into question. Long story short, they said they would take a look at it urgently then report back.
This response is fine, but as my comments then indicated, I did have (and I think reasonably had) HLI on pretty thin ice/'epistemic probation' after finding these things out. You have to make a lot of odd choices to end up this far from normal practice, nonetheless still have to make some surprising oversights too, to end up missing problems which would appear to greatly undermine a positive finding for Strongminds.[6]
1.3) Maintaining this major mistake
HLI fell through this thin ice after its follow-up. Their approach was to try a bunch of statistical techniques to adjust for publication bias (excellent technique), do the same for their cash transfers meta-analysis (sure), then using the relative discounts between them to get an adjustment for psychotherapy vs. cash transfers (good, esp. as adding directly into the multi-level meta-regressions would be difficult). Further, they provided full code and data for replication (great). But the results made no sense whatsoever:
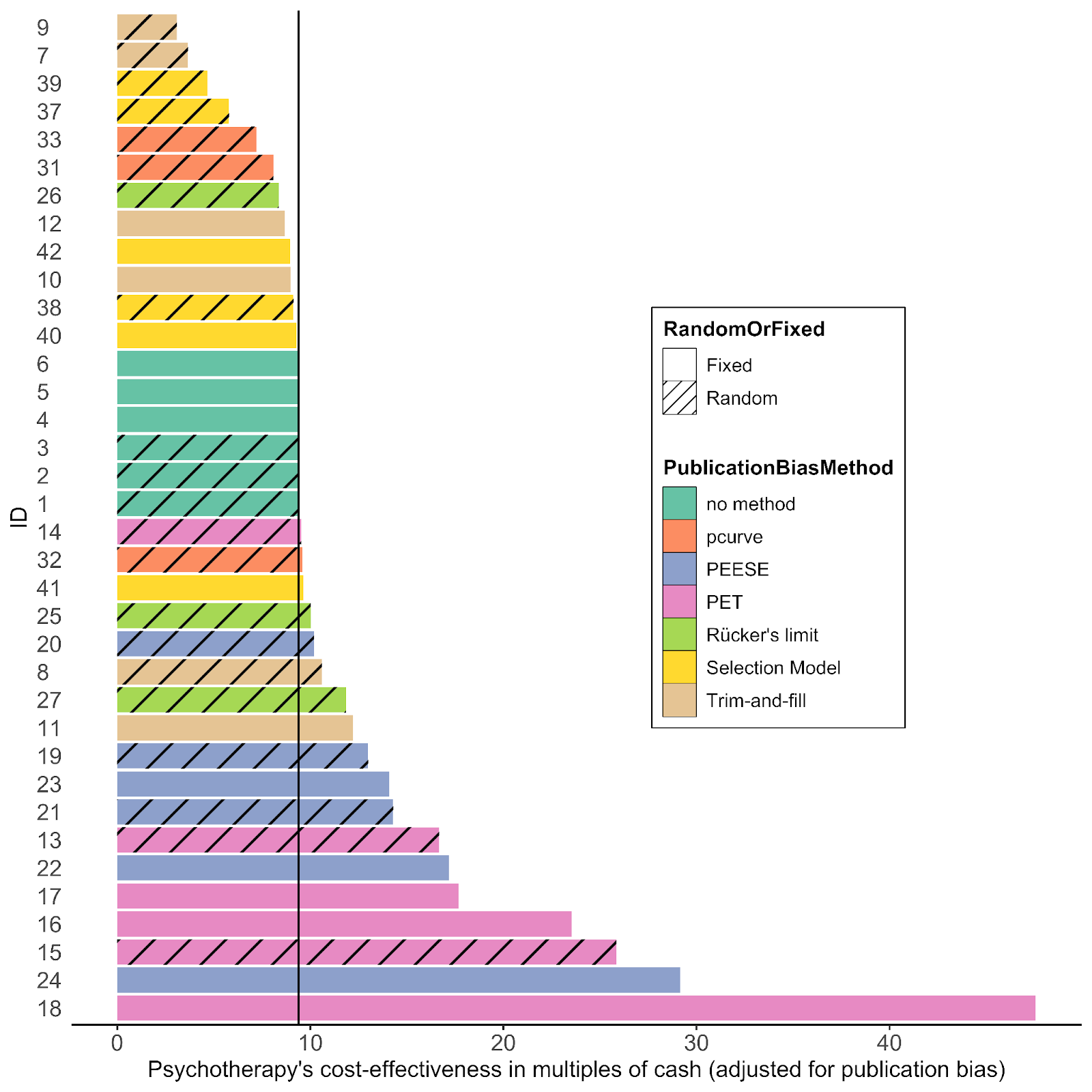
To orientate: each row is a different statistical technique applied to the two meta-analyses (more later). The x-axis is the 'multiple' of Strongminds vs. cash transfers, and the black line is at 9.4x, the previous 'status quo value'. Bars shorter than this means adjusting for publication bias results in an overall discount for Strongminds, and vice-versa.
The cash transfers funnel plot looks like this:
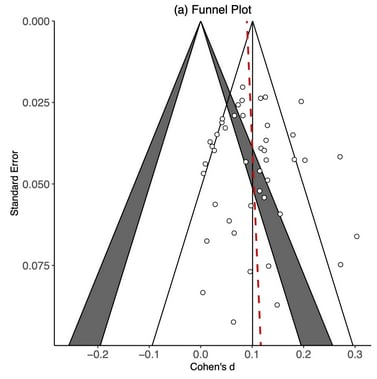
Compared to the psychotherapy one, it basically looks fine: the scatter looks roughly like a funnel, and no massive trend towards smaller studies = bigger effects. So how could so many statistical methods discount the 'obvious small study effect' meta-analysis less than the 'no apparent small study effect' meta-analysis, to give an increased multiple? As I said at the time, the results look like nonsense to the naked eye.
One problem was a coding error in two of the statistical methods (blue and pink bars). The bigger problem is how the comparisons are being done is highly misleading.
Take a step back from all the dividing going on to just look at the effect sizes. The basic, nothing fancy, random effects model applied to the psychotherapy data gives an effect size of 0.5. If you take the average across all the other model variants, you get ~0.3, a 40% drop. For the cash transfers meta-analysis, the basic model gives 0.1, and the average of all the other models is ~0.9, a 10% drop. So in fact you are seeing - as you should - bigger discounts when adjusting the psychotherapy analysis vs. the cash transfers meta-analysis. This is lost by how the divisions are being done, which largely 'play off' multiple adjustments against one another. (see, pt.2). What the graph should look like is this:
Two things are notable: 1) the different models tend to point to a significant drop (~30-40% on average) in effect size; 2) there is a lot of variation in the discount - from ~0 to ~90% (so visual illustration about why this is known to be v. hard to reliably 'adjust'). I think these results oblige something like the following:
Re. write-up: At least including the forest and funnel plots, alongside a description of why they are concerning. Should also include some 'best guess' correction from the above, and noting this has a (very) wide range. Probably warrants 'back to the drawing board' given reliability issues.
Re. overall recommendation: At least a very heavy astericks placed besides the recommendation. Should also highlight both the adjustment and uncertainty in front facing materials (e.g. 'tentative suggestion' vs. 'recommendation'). Probably warrants withdrawal.
Re. general reflection: I think a reasonable evaluator - beyond directional effects - would be concerned about the 'near'(?) miss property of having a major material issue not spotted before pushing a strong recommendation, 'phase 1 complete/mission accomplished' etc. - especially when found by a third party many months after initial publication. They might also be concerned about the direction of travel. When published, the multiplier was 12x; with spillovers, it falls to 9.5%; with spillovers and the typo corrected, it falls to 7.5x; with a 30% best guess correction for publication bias, we're now at 5.3x. Maybe any single adjustment is not recommendation-reversing, but in concert they are, and the track record suggests the next one is more likely to be further down rather than back up.
What happened instead 5 months ago was HLI would read some more and discuss among themselves whether my take on the comparators was the right one (I am, and it is not reasonably controversial, e.g. 1, 2, cf. fn4). Although 'looking at publication bias is part of their intended 'refining' of the Strongminds assessment, there's been nothing concrete done yet.
Maybe I should have chased, but the exchange on this (alongside the other thing) made me lose faith that HLI was capable of reasonably assessing and appropriately responding to criticisms of their work when material to their bottom line.
2) The cost effectiveness guestimate.
[Readers will be relieved ~no tricky stats here]
As I was looking at the meta-analysis, I added my attempt at 'adjusted' effect sizes of the same into the CEA to see what impact they had on the results. To my surprise, not very much. Hence my previous examples about 'Even if the meta-analysis has zero effect the CEA still recommends Strongminds as several times GD', and 'You only get to equipoise with GD if you set all the effect sizes in the CEA to near-zero.'
I noted this alongside my discussion around the meta-analysis 6m ago. Earlier remarks from HLI suggested they accepted these were diagnostic of something going wrong with how the CEA is aggregating information (but fixing it would be done but not as a priority); more recent ones suggest more 'doubling down'.
In any case, they are indeed diagnostic for a lack of face validity. You obviously would, in fact, be highly sceptical if the meta-analysis of psychotherapy in general was zero (or harmful!) that nonetheless a particular psychotherapy intervention was extremely effective. The (pseudo-)bayesian gloss on why is that the distribution of reported effect sizes gives additional information on the likely size of the 'real' effects underlying them. (cf. heterogeneity discussed above) A bunch of weird discrepancies among them, if hard to explain by intervention characteristics, increases the suspicion of weird distortions, rather than true effects, underlie the observations. So increasing discrepancy between indirect and direct evidence should reduce effect size beyond impacts on any weighted average.
It does not help the findings as-is are highly discrepant and generally weird. Among many examples:
- Why are the strongminds like trials in the direct evidence having among the greatest effects of any of the studies included - and ~1.5x-2x the effect of a regression prediction of studies with strongminds-like traits?
- Why are the most strongminds-y studies included in the meta-analysis marked outliers - even after 'correction' for small study effects?
- What happened between the original Strongminds Phase 2 and the Strongminds RCT to up the intevention efficacy by 80%?
- How come the only study which compares psychotherapy to a cash transfer comparator is also the only study which gives a negative effect size?
I don't know what the magnitude of the directional 'adjustment' would be, as this relies on specific understanding of the likelier explanations for the odd results (I'd guess a 10%+ downward correction assuming I'm wrong about everything else - obviously, much more if indeed 'the vast bulk in effect variation can be explained by sample size +/- registration status of the study). Alone, I think it mainly points to the quantative engine needing an overhaul and the analysis being known-unreliable until it is.
In any case, it seems urgent and important to understand and fix. The numbers are being widely used and relied upon (probably all of them need at least a big public astericks pending developing more reliable technique). It seems particularly unwise to be reassured by "Well sure, this is a downward correction, but the CEA still gives a good bottom line multiple", as the bottom line number may not be reasonable, especially conditioned on different inputs. Even more so to persist in doing so 6m after being made aware of the problem.
- ^
These are mentioned in 3a and 3b of my reply to Michael. Point 1 there (kind of related to 3a) would on its own warrant immediate retraction, but that is not a case (yet) of 'maintained' error.
- ^
So in terms of 'epistemic probation', I think this was available 6m ago, but closed after flagrant and ongoing 'violations'.
- ^
One quote from the Cochrane handbook feels particularly apposite:
Do not start here!
It can be tempting to jump prematurely into a statistical analysis when undertaking a systematic review. The production of a diamond at the bottom of a plot is an exciting moment for many authors, but results of meta-analyses can be very misleading if suitable attention has not been given to formulating the review question; specifying eligibility criteria; identifying and selecting studies; collecting appropriate data; considering risk of bias; planning intervention comparisons; and deciding what data would be meaningful to analyse. Review authors should consult the chapters that precede this one before a meta-analysis is undertaken.
- ^
In the presence of heterogeneity, a random-effects meta-analysis weights the studies relatively more equally than a fixed-effect analysis (see Chapter 10, Section 10.10.4.1). It follows that in the presence of small-study effects, in which the intervention effect is systematically different in the smaller compared with the larger studies, the random-effects estimate of the intervention effect will shift towards the results of the smaller studies. We recommend that when review authors are concerned about the influence of small-study effects on the results of a meta-analysis in which there is evidence of between-study heterogeneity (I2 > 0), they compare the fixed-effect and random-effects estimates of the intervention effect. If the estimates are similar, then any small-study effects have little effect on the intervention effect estimate. If the random-effects estimate has shifted towards the results of the smaller studies, review authors should consider whether it is reasonable to conclude that the intervention was genuinely different in the smaller studies, or if results of smaller studies were disseminated selectively. Formal investigations of heterogeneity may reveal other explanations for funnel plot asymmetry, in which case presentation of results should focus on these. If the larger studies tend to be those conducted with more methodological rigour, or conducted in circumstances more typical of the use of the intervention in practice, then review authors should consider reporting the results of meta-analyses restricted to the larger, more rigorous studies.
- ^
This is not the only problem in HLI's meta-regression analysis. Analyses here should be pre-specified (especially if intended as the primary result rather than some secondary exploratory analysis), to limit risks of inadvertently cherry-picking a model which gives a preferred result. Cochrane (see):
Authors should, whenever possible, pre-specify characteristics in the protocol that later will be subject to subgroup analyses or meta-regression. The plan specified in the protocol should then be followed (data permitting), without undue emphasis on any particular findings (see MECIR Box 10.11.b). Pre-specifying characteristics reduces the likelihood of spurious findings, first by limiting the number of subgroups investigated, and second by preventing knowledge of the studies’ results influencing which subgroups are analysed. True pre-specification is difficult in systematic reviews, because the results of some of the relevant studies are often known when the protocol is drafted. If a characteristic was overlooked in the protocol, but is clearly of major importance and justified by external evidence, then authors should not be reluctant to explore it. However, such post-hoc analyses should be identified as such.
HLI does not mention any pre-specification, and there is good circumstantial evidence of a lot of this work being ad hoc re. 'Strongminds-like traits'. HLI's earlier analysis on psychotherapy in general, using most (?all) of the same studies as in their Strongminds CEA (4.2, here), had different variables used in a meta-regression on intervention properties (table 2). It seems likely the change of model happened after study data was extracted (the lack of significant prediction and including a large number of variables for a relatively small number of studies would be further concerns). This modification seems to favour the intervention: I think the earlier model, if applied to Strongminds, gives an effect size of ~0.6.
- ^
Briggs comments have a similar theme, suggestive that my attitude does not solely arise from particular cynicism on my part.
ryancbriggs @ 2023-07-18T05:26 (+13)
I really appreciate you putting in the work and being so diligent Gregory. I did very little here, though I appreciate your kind words. Without you seriously digging in, we’d have a very distorted picture of this important area.
MichaelPlant @ 2023-07-12T13:01 (+8)
Hello Jason. FWIW, I've drafted a reply to your other comment and I'm getting it checked internally before I post it.
On this comment about you not liking that we hadn't updated our website to include the new numbers: we all agree with you! It's a reasonable complaint. The explanation is fairly boring: we have been working on a new charity recommendations page for the website, at which point we were going to update the numbers at add a note, so we could do it all in one go. (We still plan to do a bigger reanalysis later this year.) However, that has gone slower than expected and hadn't happened yet. Because of your comment, we'll add a 'hot fix' update in the next week, and hopefully have the new charity recommendations page live in a couple of weeks.
I think we'd have moved faster on this if it had substantially changed the results. On our numbers, StrongMinds is still the best life-improving intervention (it's several times better than cash and we're not confident deworming has a longterm effect). You're right it would slightly change the crossover point for choosing between life-saving and life-improving interventions, but we've got the impression that donors weren't making much use of our analysis anyway; even if they were, it's a pretty small difference, and well within the margin of uncertainty.
Jason @ 2023-07-12T23:44 (+4)
Thanks, I appreciate that.
(Looking back at the comment, I see the example actually ended up taking more space than the lead point! Although I definitely agree that the hot fix should happen, I hope the example didn't overshadow the comment's main intended point -- that people who have concerns about HLI's response to recent criticisms should raise their concerns with a degree of specificity, and explain why they have those concerns, to allow HLI an opportunity to address them.)
Nathan Young @ 2023-07-10T08:59 (+36)
edited to that I only had a couple of comments rather than 4
I am confident those involved really care about doing good and work really hard. And i don't want that to be lost in this confusion. Something is going on here, but I think "it is confusing" is better than "HLI are baddies".
For clarity being 2x better than cash transfers would still provide it with good reason to be on GWWC's top charity list, right? Since GiveDirectly is?
I guess the most damning claim seems to be about dishonesty, which I find hard to square with the caliber of the team. So, what's going on here? If, as seems likely the forthcoming RCT downgrades SM a lot and the HLI team should have seen this coming, why didn't they act? Or do they still believe that they RCT will return very positive results. What happens when as seems likely, they are very wrong?
Among other things, this would confirm a) SimonM produced a more accurate and trustworthy assessment of Strongminds in their spare time as a non-subject matter expert than HLI managed as the centrepiece of their activity
Note that SimonM is a quant by day and for a time top on metaculus, so I am less surprised that he can produce such high caliber work in his spare time[1].
I don't know how to say this but it doesn't surprise me that top individuals are able to do work comparable with research teams. In fact I think it's one of the best cases for the forum. Sometimes talented generalists compete toe to toe with experts.
Finally it seems possible to me that criticisms can be true but HLI can still have done work we want to fund. The world is ugly and complicated like this. I think we should aim to make the right call in this case. For me the key question is, why haven't they updated in light of StrongMinds likely being worse than they thought.
I'd be curious Gregory on your thoughts on this comment by Matt Lerner that responds to yours. https://forum.effectivealtruism.org/posts/g4QWGj3JFLiKRyxZe/the-happier-lives-institute-is-funding-constrained-and-needs?commentId=Bd9jqxAR6zfg8z4Wy
- ^
Simon worked as a crypto quant and has since lost his job (cos of the crash caused by FTX) so is looking for work including EA work. You can message him if interested.
Fergus @ 2023-07-13T17:21 (+34)
+1 Regarding extending the principle of charity towards HLI. Anecdotally it seems very common for initial CEA estimates to be revised down as the analysis is critiqued. I think HLI has done an exceptional job at being transparent and open regarding their methodology and the source of disagreements e.g. see Joel's comment outlining the sources of disagreement between HLI and GiveWell, which I thought were really exceptional (https://forum.effectivealtruism.org/posts/h5sJepiwGZLbK476N/assessment-of-happier-lives-institute-s-cost-effectiveness?commentId=LqFS5yHdRcfYmX9jw). Obviously I haven't spent as much time digging into the results as Gregory has made, but the mistakes he points to don't seem like the kind that should be treated too harshly.
As a separate point, I think it's generally a lot easier to critique and build upon an analysis after the initial work has been done. E.g. even if it is the case that SimonM's assessment of Strong Minds is more reliable than HLI's (HLI seem to dispute that the critique he levies are all that important as they only assign a 13% weight to that RCT), this isn't necessarily evidence that SimonM is more competent than the HLI team. When the heavy lifting has been done, it's easier to focus in on particular mistakes (and of course valuable to do so!).
Hamish Doodles @ 2023-07-25T13:51 (+4)
For clarity being 2x better than cash transfers would still provide it with good reason to be on GWWC's top charity list, right? Since GiveDirectly is?
I think GiveDirectly gets special privilege because "just give the money to the poorest people" is such a safe bet for how to spend money altruistically.
Like if a billionaire wanted to spend a million dollars making your life better, they could either:
- just give you the million dollars directly, or
- spend the money on something that they personally think would be best for you
You'd want them to set a pretty high bar of "I have high confidence that the thing I chose to spend the money on will be much better than whatever you would spend the money on yourself."
Jason @ 2023-07-25T14:51 (+9)
GiveDirectly does not have the "top-rated" label on GWWC's list, while SM does as of this morning.
I can't find the discussion, but my understanding is that "top-rated" means that an evaluator GWWC trusts -- in SM's case, that was Founder's Pledge -- thinks that a charity is at a certain multiple (was it like 4x?) over GiveDirectly.
However, on this post, Matt Lerner @ FP wrote that "We disagree with HLI about SM's rating — we use HLI's work as a starting point and arrive at an undiscounted rating of 5-6x; subjective discounts place it between 1-2x, which squares with GiveWell's analysis."
So it seems that GWWC should withdraw the "top-rated" flag because none of its trusted evaluation partners currently rate SM at better than 2.3X cash. It should not, however, remove SM from the GWWC platform as it meets the criteria for inclusion.
Nathan Young @ 2023-07-30T14:06 (+2)
Hmm this feels a bit off. I don't think GiveDirectly should get special privelege. Though I agree the out of model factors seem to go well for GD than others, so I would kind of bump it up.
MichaelPlant @ 2023-07-10T15:01 (+4)
Hello Nathan. Thanks for the comment. I think the only key place where I would disagree with you is what you said here
If, as seems likely the forthcoming RCT downgrades SM a lot and the HLI team should have seen this coming, why didn't they act?
As I said in response to Greg (to which I see you've replied) we use the conventional scientific approach of relying on the sweep of existing data - rather than on our predictions of what future evidence (from a single study) will show. Indeed, I'm not sure how easily these would come apart: I would base my predictions substantially on the existing data, which we've already gathered in our meta-analysis (obviously, it's a matter of debate as to how to synthesise data from different sources and opinions will differ). I don't have any reason to assume the new RCT will show effects substantially lower than the existing evidence, but perhaps others are aware of something we're not.
Nathan Young @ 2023-07-10T15:36 (+2)
Yeah for what it's worth it wasn't clear to me until later that this was only like 10% of the weighting on your analysis.
Nathan Young @ 2023-07-10T08:59 (+2)
Man, why don't images resize properly. I've deleted it because it was too obnoxious when huge.
Nathan Young @ 2023-07-10T10:57 (+20)
Here is a manifold market for Gregory's claim if you want to bet on it.
Jack Malde @ 2023-07-09T16:13 (+4)
Is your 5K donation promised to Strongminds or HLI?
Gregory Lewis @ 2023-07-09T17:51 (+36)
HLI - but if for whatever reason they're unable or unwilling to receive the donation at resolution, Strongminds.
The 'resolution criteria' are also potentially ambiguous (my bad). I intend to resolve any ambiguity stringently against me, but you are welcome to be my adjudicator.
[To add: I'd guess ~30-something% chance I end up paying out: d = 0.4 is at or below pooled effect estimates for psychotherapy generally. I am banking on significant discounts with increasing study size and quality (as well as other things I mention above I take as adverse indicators), but even if I price these right, I expect high variance.
I set the bar this low (versus, say, d = 0.6 - at the ~ 5th percentile of HLI's estimate) primarily to make a strong rod for my own back. Mordantly criticising an org whilst they are making a funding request in a financially precarious position should not be done lightly. Although I'd stand by my criticism of HLI even if the trial found Strongminds was even better than HLI predicted, I would regret being quite as strident if the results were any less than dramatically discordant.
If so, me retreating to something like "Meh, they got lucky"/"Sure I was (/kinda) wrong, but you didn't deserve to be right" seems craven after over-cooking remarks potentially highly adverse to HLI's fundraising efforts. Fairer would be that I suffer some financial embarrassment, which helps compensate HLI for their injury from my excess.
Perhaps I could have (or should have) done something better. But in fairness to me, I think this is all supererogatory on my part: I do not think my comment is the only example of stark criticism on this forum, but it might be unique in its author levying an expected cost of over $1000 on themselves for making it.]
Jason @ 2023-07-09T22:11 (+2)
Would you happen to have a prediction of the likelihood of d > or = 0.6? (No money involved, you've put more than enough $ on the line already!)
Gregory Lewis @ 2023-07-13T21:53 (+6)
8%, but perhaps expected drift of a factor of two either way if I thought about it for a few hours vs. a few minutes.
Matt_Lerner @ 2023-07-07T11:34 (+47)
I can also vouch for HLI. Per John Salter's comment, I may also have been a little sus early (sorry Michael) on but HLI's work has been extremely valuable for our own methodology improvements at Founders Pledge. The whole team is great, and I will second John's comment to the effect that Joel's expertise is really rare and that HLI seems to be the right home for it.
Nathan Young @ 2023-07-10T10:52 (+5)
I appreciate this kind of transparent vouching for orgs. Makes it easier to discuss what's going on.
How do you think you'll square this if the forthcoming RCT downgrades StrongMind's work by a factor of 4 or more? I'm confused about how HLI could miss this error (if it happens)
That said, as John says their actual produced work could still be very cheap at this price.
Matt_Lerner @ 2023-07-10T13:34 (+12)
I guess I would very slightly adjust my sense of HLI, but I wouldn't really think of this as an "error." I don't significantly adjust my view of GiveWell when they delist a charity based on new information.
I think if the RCT downgrades StrongMinds' work by a big factor, that won't really introduce new information about HLI's methodology/expertise. If you think there are methodological weaknesses that would cause them to overstate StrongMinds' impact, those weaknesses should be visible now, irrespective of the RCT results.
Nathan Young @ 2023-07-10T14:05 (+2)
So, for clarity, you disagree with @Gregory Lewis[1] here:
Regrettably, it is hard to square this with an unfortunate series of honest mistakes. A better explanation is HLI's institutional agenda corrupts its ability to conduct fair-minded and even-handed assessment for an intervention where some results were much better for their agenda than others (cf.). I am sceptical this only applies to the SM evaluation, and I am pessimistic this will improve with further financial support.
- ^
How do i do the @ search?
Matt_Lerner @ 2023-07-10T14:30 (+29)
I disagree with the valence of the comment, but think it reflects legitimate concerns.
I am not worried that "HLI's institutional agenda corrupts its ability to conduct fair-minded and even-handed assessment." I agree that there are some ways that HLI's pro-SWB-measurement stance can bleed into overly optimistic analytic choices, but we are not simply taking analyses by our research partners on faith and I hope no one else is either. Indeed, the very reason HLI's mistakes are obvious is that they have been transparent and responsive to criticism.
We disagree with HLI about SM's rating — we use HLI's work as a starting point and arrive at an undiscounted rating of 5-6x; subjective discounts place it between 1-2x, which squares with GiveWell's analysis. But our analysis was facilitated significantly by HLI's work, which remains useful despite its flaws.
Jason @ 2023-07-10T23:54 (+25)
I agree that there are some ways that HLI's pro-SWB-measurement stance can bleed into overly optimistic analytic choices, but we are not simply taking analyses by our research partners on faith and I hope no one else is either.
Individual donors are, however, more likely to take a charity recommender's analysis largely on faith -- because they do not have the time or the specialized knowledge and skills necessary to kick the tires. For those donors, the main point of consulting a charity recommender is to delegate the tire-kicking duties to someone who has the time, knowledge, and skills to do that.
John Salter @ 2023-07-07T06:50 (+45)
Was a little sus on HLI before I got the chance to work a little with them. Really bright and hardworking team. Joel McGuire has been especially useful.
We're planning on evaluating most if not all of our interventions using SWB on an experimental basis. Honestly, QALYs kinda suck so the bar isn't very high. I wouldn't have ever given this any thought without HLIs posts however.
200K seems excellent value for money for the value provided even if the wellby adoption moonshot doesn't materialise.
benleo @ 2023-07-07T14:47 (+37)
I'm also impressed by this post. HLI's work has definitely shifted my priors on wellbeing interventions.
We strive to be maximally philosophically and empirically rigorous. For instance, our meta-analysis of cash transfers has since been published in a top academic journal. We’ve shown how important philosophy is for comparing life-improving against life-extending interventions. We’ve won prizes: our report re-analysing deworming led GiveWell to start their “Change Our Mind” competition. Open Philanthropy awarded us money in their Cause Exporation Prize.
It's also great to see the organisation taking philosophical/empirical concerns seriously. I still have some concerns/questions about the efficacy of these interventions (compared to Givewell charities), but I am confident in HLI continuing to shed light on these concerns in the future.
For example, projects like the one below I think are really important.
- Develop the WELLBY methodology, exploring, for instance, the social desirability bias in SWB scales
and
building the field of academic researchers taking a wellbeing approach, including collecting data on interventions.
richard_ngo @ 2023-07-07T13:40 (+37)
Impressed by the post; I'd like to donate! Is there a way to do so that avoids card fees? And if so, at what donation size do you prefer that people start using it?
BrownHairedEevee @ 2023-07-14T16:35 (+11)
If you donate through PayPal Giving Fund here 100% of your donation goes to HLI, as PayPal pays all the transaction fees. (Disclaimer: I work for PayPal, but this comment reflects my views alone, not those of the company.)
MichaelPlant @ 2023-07-10T14:47 (+4)
Hello Richard. Glad to hear this! I've just sent you HLI's bank details, which should allow you to pay without card fees (I was inclined to share them directly here, but was worried that would be unwise). I don't have an answer to your second question, I'm afraid.
Nathan Young @ 2023-07-10T16:18 (+29)
My sense when a lot of of sort of legitimate but edge case criticisms are brought up with force is that something else might be going on. So I don't know how to ask this but, is there another point of disagreement that underlies this, rather than the SM RCT likely going to return worse results?
bruce @ 2023-07-10T22:22 (+45)
[Edit: wrote this before I saw lilly's comment, would recommend that as a similar message but ~3x shorter].
============
I would consider Greg's comment as "brought up with force", but would not consider it an "edge case criticism". I also don't think James / Alex's comments are brought up particularly forcefully.
I do think it is worth making a case that pushing back on making comments that are easily misinterpreted or misleading are also not edge case criticisms though, especially if these are comments that directly benefit your organisation.
Given the stated goal of the EA community is "to find the best ways to help others, and put them into practice", it seems especially important that strong claims are sufficiently well-supported, and made carefully + cautiously. This is in part because the EA community should reward research outputs if they are helpful for finding the best ways to do good, not solely because they are strongly worded; in part because EA donors who don't have capacity to engage at the object level may be happy to defer to EA organisations/recommendations; and in part because the counterfactual impact diverted from the EA donor is likely higher than the average donor.
For example:
- "We’re now in a position to confidently recommend StrongMinds as the most effective way we know of to help other people with your money".[1]
- Michael has expressed regret about this statement, so I won't go further into this than I already have. However, there is a framing in that comment that suggests this is an exception, because "HLI is quite well-caveated elsewhere", and I want to push back on this a little.
- HLI has previously been mistaken for an advocacy organisation (1, 2). This isn't HLI's stated intention (which is closer to a "Happiness/Wellbeing GiveWell"). I outline why I think this is a reasonable misunderstanding here (including important disclaimers that outline HLI's positives).
- Despite claims that HLI does not advocate for any particular philosophical view, I think this is easily (and reasonably) misinterpreted.
- James' comment thread below: "Our focus on subjective wellbeing (SWB) was initially treated with a (understandable!) dose of scepticism. Since then, all the major actors in effective altruism’s global health and wellbeing space seem to have come around to it"
- See alex's comment below, where TLYCS is quoted to say: "we will continue to rely heavily on the research done by other terrific organizations in this space, such as GiveWell, Founders Pledge, Giving Green, Happier Lives Institute [...]"
- I think excluding "to identify candidates for our recommendations, even as we also assess them using our own evaluation framework" [emphasis added] gives a fairly different impression to the actual quote, in terms of whether or not TLYCS supports WELLBYs as an approach.
While I wouldn't want to exclude careless communication / miscommunication, I can understand why others might feel less optimistic about this, especially if they have engaged more deeply at the object level and found additional reasons to be skeptical.[2] I do feel like I subjectively have a lower bar for investigating strong claims by HLI than I did 7 or 8 months ago.
(commenting in personal capacity etc)
============
Adding a note RE: Nathan's comment below about bad blood:
Just for the record, I don't consider there to be any bad blood between me and any members of HLI. I previously flagged a comment I wrote with two HLI staff, worrying that it might be misinterpreted as uncharitable or unfair. Based on positive responses there and from other private discussions, my impression is that this is mutual.[3]
- ^
-This as the claim that originally prompted me to look more deeply into the StrongMinds studies. After <30 minutes on StrongMinds' website, I stumbled across a few things that stood out as surprising, which prompted me to look deeper. I summarise some thoughts here (which has been edited to include a compilation of most of the critical relevant EA forum commentary I have come across on StrongMinds), and include more detail here.
-I remained fairly cautious about claims I made, because this entire process took three years / 10,000 hours, so I assumed by default I was missing information or that there was a reasonable explanation.
-However, after some discussions on the forum / in private DMs with HLI staff, I found it difficult to update meaningfully towards believing this statement was a sufficiently well-justified one. I think a fairly charitable interpretation would be something like "this claim was too strong, it is attributable to careless communication, but unintentional."
- ^
Quotes above do not imply any particular views of commentors referenced.
- ^
I have not done this for this message, as I view it as largely a compilation of existing messages that may help provide more context.
Nathan Young @ 2023-07-11T08:48 (+1)
Okay buutttt..
I know Michael and have a bias towards concensus.
"We’re now in a position to confidently recommend StrongMinds as the most effective way we know of to help other people with your money".[1]
- Michael has expressed regret about this statement, so I won't go further into this than I already have. However, there is a framing in that comment that suggests this is a exception, because "HLI is quite well-caveated elsewhere", and I want to push back on this a little.
Fair enough
HLI has previously been mistaken for an advocacy organisation (1, 2). This isn't HLI's stated intention (which is closer to a "Happiness/Wellbeing GiveWell"). I outline why I think this is a reasonable misunderstanding here (including important disclaimers that outline HLI's positives).
- Despite claims that HLI does not advocate for any particular philosophical view, I think this is easily (and reasonably) misinterpreted.
I find this hard to parse.
James' comment thread below: "Our focus on subjective wellbeing (SWB) was initially treated with a (understandable!) dose of scepticism. Since then, all the major actors in effective altruism’s global health and wellbeing space seem to have come around to it"
- I think James seems to dislike being misquoted more than he's saying he disagrees with SWB. I am unsure his position there
- If he supports SWB then while I think it's fair for him to dislike being misquoted I think I would call this an "edge case"
- To me this does give the flag of "there is something else going on here". I think it seems like a stronger reaction than I'd expect. I guess there is a reason for that.
See Alex's comment below, where TLYCS is quoted to say: "we will continue to rely heavily on the research done by other terrific organizations in this space, such as GiveWell, Founders Pledge, Giving Green, Happier Lives Institute [...]"
- I think excluding "to identify candidates for our recommendations, even as we also assess them using our own evaluation framework" [emphasis added] gives a fairly different impression to the actual quote, in terms of whether or not TLYCS supports WELLBYs as an approach.
Again, this reads to me as a fair enough criticism, but one that it would surprise me if someone made without some kind of background here.
My model would be that there is bad blood in a number of places and that errors have been made too many time and so people have started to play hardball. I am not saying that's wrong or unfair, but just to note that it's happening. I suggest the things people are quoting here are either examples of a larger pattern or not actually the things they are upset about.
But I say that weakly. Mainly I say "something seems off"
Jason @ 2023-07-11T14:28 (+61)
Here's my (working) model. I'm not taking a position on how to classify HLI's past mistakes or whether applying the model to HLI is warranted, but I think it's helpful to try to get what seems to be happening out in the open.
Caveat: Some of the paragraphs relie more heavily on my assumptions, extrapolations, suggestions about the "epistemic probation" concept rather than my read of the comments on this and other threads. And of course that concept should be seen mostly as a metaphor.
- Some people think HLI made some mistakes that impact their assessment of HLI's epistemic quality (e.g., some combination of not catching clear-cut model errors that were favorable to its recommended intervention, a series of modeling choices that while defensible were as a whole rather favorable to the same, some overconfident public statements).
- Much of the concern here seems to be that HLI may be engaged in motivated reasoning (which could be 100% unconscious!) on the theory that its continued viability as an organization is dependent on producing some actionable results within the first few years of its existence.
- These mistakes have updated the people's assessment of HLI's epistemic quality to change their view of HLI from "standard" to "on epistemic probation" -- I made that term up, it is fleshed out below.
- An organization on epistemic probation should expect greater scrutiny of its statements and analyses, and should not expect the same degree of grace / benefit of the doubt that organizations in standard status will get. These effects would seem to logically follow from the downgrade in priors about epistemic quality referenced in (1).
- Whie on probation, an organization will be judged more strictly for mild-to-moderate epistemic faults. Here, that would include (e.g.) the statement James expressed concern about.
- Practically, that means that the organization should err on the side of being conservative in its assertions, should devote extra resources toward red-teaming its reports, etc. While these steps may slow impact, they are necessary to demonstrate the organization's good epistemics and to restore community confidence in its outputs.
- An organization can exit epistemic probation by demonstrating that its current epistemics are solid over a sufficient period of time, and that it has controls in place to prevent a recurrence of whatever led to its placement on probation in the first place. In other words, subsequent actions need to justify a re-updating of priors to place the organization back into the "standard" zone of confidence in epistemic soundness. An apology will usually be necessary but not sufficient.
- For HLI, the exit plan probably includes producing a new transparent, solid CEA of StrongMinds that stands up to external scrutiny. (Withdrawing that CEA might also work.)
- It probably also includes a showing that sufficient internal or external controls are now in place to minimize the risk of recurrence. This could be a commitment to external peer review of the revised StrongMinds CEA as well as other new major recommendations and the reports on which they are based, a commitment to offer bounties for catching mistakes in major CEAs (with a third-party adjudicator), etc., etc.
- Finally, the exit plan probably includes a period of consistently not making statements on the Forum, its website, and other arenas that seem to be a stretch based on the underlying evidence.
- Of course, HLI's funding position makes it more challenging for it to meet some of these steps to exit probation. Conditional on HLI having properly been placed on probation, I don't know to what extent the existence of financial constraints should alter the quantum of evidence necessary to remove it from probation.
I think the concept of epistemic probation is probably useful. It is important to police this sort of thing. Epistemic probation gives the organization a chance to correct the perceived problem, and gives the community an action to take in response to problems it deems significant that isn't excluding the organization from the community.
For better and for worse, each of us have to decide for ourselves whether an organization is on epistemic probation in our eyes. This poses a problem, because the organization may not realize a number of people have placed it on epistemic probation. So while I don't like the tone or some of the contents of certain comments, I think it's critical that the community provides feedback to organizations that puts them on notice of their probationary status in the eyes of many people. If many people silently place an organization on probation, and the organization fails probation (perhaps due to not knowing it was in hot water), then those people are going to treat the organization as excluded for its epistemic failures. That's a bad outcome for all involved.[1]
One other point, which is also more challenging due to decentralization: The end goal of probation is restoration to good standing, and so it needs to be clear to the organization what it needs to do (and avoid doing) in order to exit probation. I tried to model this in points 6(a) to 6(c) above [conditioned on my assumptions about why people have HLI on probation], as well as in the example to my comment to Greg about whether HLI has been "maintain[ing]" its position after errors were pointed out. Of course, different people who have placed HLI on probation would have different opinions on what is necessary for HLI to exit that status.
- ^
Some people may have already decided to treat HLI as excluded, but my hunch is that these people are fairly small in number compared to the number who have HLI on probation.
MichaelPlant @ 2023-07-13T15:51 (+31)
[I don’t plan make any (major) comments on this thread after today. It’s been time-and-energy intensive and I plan to move back to other priorities]
Hello Jason,
I really appreciated this comment: the analysis was thoughtful and the suggestions constructive. Indeed, it was a lightbulb moment. I agree that some people do have us on epistemic probation, in the sense they think it’s inappropriate to grant the principle of charity, and should instead look for mistakes (and conclude incompetence or motivated reasoning if they find them).
I would disagree that HLI should be on epistemic probation, but I am, of course, at risk of bias here, and I’m not sure I can defend our work without coming off as counter-productively defensive! That said, I want to make some comments that may help others understand what’s going on so they can form their own view, then set out our mistakes and what we plan to do next.
Context
I suspect that some people have had HLI on epistemic probation since we started - for perhaps understandable reasons. These are:
- We are advancing a new methodology, the happiness/SWB/WELLBY approach. Although there are decades of work in social science on this and it’s now used by the UK government, this was new to most EAs and they could ask, "if it's so good, why aren't we already doing it?" Of course, new ideas have to start sometime.
- HLI is a second-generation EA org that is setting out to publicly re-assess some conclusions of an existing (understandably!) well-beloved first-generation org, GiveWell. I can't think of another case like this; usually, EA orgs do non-overlapping work. Some people have welcomed us offering a different perspective, others have really not liked it; we’ve clearly ruffled some feathers.
- As a result of 1 and 2, there is something of a status quo effect and scepticism that wouldn’t be the case if we were offering recommendations in a new area for the first time. To illustrate, suppose you know nothing about global health and wellbeing and someone tells you they’ve done lots of research based on happiness measures and they’ve found cash transfers are good, treating depression is about 7x as good as cash, deworming has no clear long-run effect, and life-saving bednets are 1-8x cash depending on difficult moral assumptions. I expect most people would say “yeah, that seems reasonable” rather than “why are engaged in motivated reasoning?”.
Our mistakes (so far)
The discussion in this thread has been a bit vague about what mistakes HLI has made that have led to suspicion. I want to set out what, from my perspective, those are. I reserve the right to add things to this list! We'll probably put a version of this on our website.
1. Not modelling spillovers in our cash vs psychotherapy meta-analyses.
This was the first substantive empirical criticism we received. We had noted in the original report that not including spillovers was a limitation in the analysis, but we hadn’t explicitly modelled them. This was for a couple of reasons. We hadn’t seen any other EA org empirically model spillovers, so it seemed an non-standard thing to do, and the data were low-quality anyway, so we hadn’t thought much about including them. We were surprised when some claimed this was a serious (possibly deliberate) omission.
That said, we took the objection very seriously and reallocated several months of staff time in early 2022 from other topics to produce the best spillovers analysis we could on the available data, which we then shared with others. In the end, it only somewhat reduced the result (therapy went from 12x cash to 9x).
2. We were too confident and clumsy in our 2022 Giving Season post.
At that point, we incorporated nearly all the available data into our cash and psychotherapy meta-analyses, accounted for spillovers, plus looked at deworming (for which long-term effects on wellbeing are non-significant) and life-extending vs life-saving interventions (where psychotherapy seemed better under almost all assumptions). So we felt proud of our work and quite confident.
In retrospect, as I've alluded to before, we were overconfident, our language and execution were clumsy, and this really annoyed some people. I'm sorry about this and I hope people can forgive us. We have since spent some time internally thinking about how to communicate our confidence in our conclusions.
3. Not communicating better how we’d done our meta-analysis of psychotherapy, including that we hadn’t taken StrongMinds’ own studies at face value.
SimonM’s post has been mentioned a few times in this thread. As I mentioned in point 3 here, SimonM criticised the recommendation of StrongMinds based on concerns about StrongMinds’ own study, not our analysis. He said he didn’t engage with our analysis because he was ‘confused’ about methodology but that, in any case “key thing about HLI methodology is that [it] follows the same structure as the Founders Pledge analysis and so all the problems I mention above regarding data apply just as much to them as FP”. However, our evaluation didn’t have the problems he was referring to because of how we’d done the meta-analysis.
In retrospect, it seems the fact we’d done a meta-analysis, and not put much weight on StrongMinds’ own study, wasn’t something people knew, and we should have communicated that much more prominently; it was buried in some super long posts. We need to own our inadequate comms there. It was tough to learn he and some other members of EA have been thinking of us with such suspicion. Psychologically, the team took this very hard.
4. We made some errors in the spillovers analysis (as pointed out by James Snowden).
The main error here was that, as my colleague Joel conceded (“I blundered”) he coded some data the wrong way and this reduced the result from 9x to 7.5x cash transfers. This is embarrassing but not, I think, sinister by itself. These things happen, they’re awkward, but not well explained by motivated reasoning: coding errors are checkable and, in any case, the result is unchanged with the correction (see my comment here too)
I recognise that some will think this a catalogue of errors best explained by a corrupting agenda; the reader must make up their own mind. Two of the four are analysis errors of the sort that routinely appear when researchers review each other's work. Two are errors in communication, either about being overconfident, or not communicating enough.
Next steps:
Jason suggests those on epistemic probation should provide a credible exit plan. Leaving aside whether we are, or should be, on epistemic probation, I am happy to set out what we plan to do next. For our research regarding reevaluating psychotherapy, we had already set this out in our new research agenda, at Section 2.1, which we published at the same time as this post. We are still committed to digging into the details of this analysis that have been brought up.

About bounties: I like this idea and wish we could implement it, but in light of our funding position, I don’t think we’ll be able to do so in the near-term.
In addition, we’ll consider adding something like an ‘Our mistakes’ page to our website to chronicle our blunders. At the least, we’ll add a version history to our cost-effectiveness analysis so people can see how the numbers have changed over time and why.
I am open to - indeed, I welcome - further constructive suggestions about what work people would like us to do to change their minds and/or reassure them. I do ask that these are realistic: as noted, we are a small, funding-and-capacity-constrained team with a substantial research agenda. We therefore might not be able to take all suggestions on board.
Jason @ 2023-07-17T15:22 (+39)
I think your last sentence is critical -- coming up with ways to improve epistemic practices and legibility is a lot easier where there are no budget constraints! It's hard for me to assess cost vs. benefit for suggestions, so the suggestions below should be taken with that in mind.
For any of HLI's donors who currently have it on epistemic probation: Getting out of epistemic probation generally requires additional marginal resources. Thus, it generally isn't a good idea to reduce funding based on probationary status. That would make about as much sense as "punishing" a student on academic probation by taking away their access to tutoring services they need to improve.
The suggestions below are based on the theory that the main source of probationary status -- at least for individuals who would be willing to lift that status in the future -- is the confluence of the overstated 2022 communications and some issues with the SM CEA. They lean a bit toward "cleaner and more calibrated public communication" because I'm not a statistican, but also because I personally value that in assessing the epistemics of an org that makes charity recommendations to the general public. I also lean in that direction because I worry that setting too many substantive expectations for future reports will unduly suppress the public release of outputs.
I am concerned that HLI is at risk of second-impact syndrome and would not, as a practical matter, survive a set of similar mistakes on the re-analysis of SM or on its next few major recommendations. For that reason, I have not refrained from offering suggestions based on my prediction that they could slow down HLI's plans to some extent, or incur moderately significant resource costs.
All of these come from someone who wants HLI to succeed. I think we need to move future conversations about HLI in a "where do we go from here" direction rather than spending a lot of time and angst re-litigating the significance and import of previously-disclosed mistakes.[1] I'm sure this thread has already consumed a lot of HLI's limited time; I certainly do not expect a reply.
A: Messaging Calibration
For each research report, you could score and communicate the depth/thoroughness of the research report, the degree of uncertainty, and the quality of the available evidence. For the former, the scale could be something like 0 = Don't spend more than $1 of play money on this; 10 = We have zero hesitation with someone committing > $100MM on this without further checking. For the materials you put out (website materials, Forum posts, reports), the material should be consistent with your scores. Even better, you could ask a few outside people to read draft materials (without knowing the scores) and tell you what scores the material implies to them.
I think it's perfectly OK for an org to put out material that has some scores of 4 or 5 due to resource constraints, deprioritization due to limited room for funding or unpromising results, etc. Given its resources, its scope of work, the areas it is researching, and the state of other work in those areas, I don't think HLI can realistically aim for scores of 9 or a 10 across the board in the near future. But the messaging needs to match the scores. In fact, I might aim for messaging that is slightly below the scores. I say that because the 2022 Giving Season materials suggest HLI's messaging "scale" may be off, and adding a tare weight could serve as an interim fix.
I think HLI is in a challenging spot given GiveWell's influence and resources. I further think that most orgs in HLI's position would feel a need to "compete" with GiveWell, and that some of the 2022 messaging suggests that may be the case. I think that pressure would put most orgs at risk of projecting more confidence and certainty than the data allow, and so it's particularly important that orgs facing that kind of pressure carefully calibrate their messaging.
B: Identification of Major Hinges
For each recommendation, there could be a page on major hinges, assumptions, methodological critical points, and the like. It should be legible to well-educated generalists, and there should be a link to this page on the main recommendation page, in Forum posts, etc. For bonus points, you could code an app that allows the user to see how the results change based on various hinges. For example, for the SM recommendation, I would have liked to see things like the material below. (Note that some examples are based on posted criticisms of the SM CEA, but the details are not meant to be taken literally.)
- X% of the projected impact comes from indirect effects on family members ("spillovers"), for which the available research is limited. We estimate that each family member benefits 38% as much as the person receiving services. See pages ___ of our report for more information. Even a moderate change in this estimate could significantly change our estimate of WELLBYs per $1,000 spent.
- In estimating the effect of the SM program, we included the results of two studies conducted by StrongMinds of unknown quality. These studies showed significantly better results than most others, and the result of one study is approaching the limits of plausibility. If we had instead decided to give these two studies zero credence in our model, our estimate of SM's impact would have decreased by Y%.[2] See pages ___ of our report for more information.
- We considered 39 studies in estimating SM's effect size. There was a significantly wider than expected variance in the effects reported by the studies ("heterogenity"), which makes analysis more difficult. About C% of the reported effect is based on five specific studies. Moreover, there were signs that higher quality studies showed lower effects. Although we attempted to correct for these issues, it is possible that we did not fully succeed. We subjectively estimate there is at least a 10% chance that our estimate is at least 20% too high due to these effects. See pages ___ of our report for more information.
- The data show a moderately pronounced Gandalf effect. There are two generally accepted ways to address a Gandalf effect. We used a Gondor correction for the reasons described at pages ___ of our report. However, using a Rohan correction would have been a reasonable alternative and would have reduced the estimated impact by 11%.
Presumably you would already know where the hinges and critical values were, so listing them in lay-readable form shouldn't require too much effort. But doing so protects against people getting the impression that the overall conclusion isn't appropriately caveated, that you didn't make it clear enough how much role study A or factor B played, etc. Of course, this section could list positive factors too (e.g., we used the Rohan correction even though it was a close call and the Gondor correction would have boosted impact 11%).
C: Red-Teaming and Technical Appendix
In my field (law), we're taught that you do not want the court to learn about unfavorable facts or law only from your opponents' brief. Displaying up front that you saw an issue rules out two possible unfavorable inferences a reader could draw: that you didn't see the issue, or that you saw the issue and hoped neither the court nor the other side's lawyer would notice. Likewise, more explicit recognition of certain statistical information in a separate document may be appropriate, especially in an epistemic-probation situation. I do recognize that this could incur some costs.
I'm not a statistican by any means, but to the extent that you would might expect an opposition research team to express significant concern about a finding -- such as the pre-registered reports showing much lower effect sizes than the unregistered ones -- I think it would be helpful to acknowledge and respond to that concern upfront. I recognize that potentially calls for a degree of mind-reading, and that this approach may not work if the critics dig for more arcane stuff. But even if the critics find something that the red team didn't, the disclosure of some issues in a technical appendix still legibly communicates a commitment to self-critical analysis.
D: Correction Listing and Policy
For each recommendation, there could be a page for issues, corrections, subsequent developments, and the like. It should be legible to well-educated generalists, and there should be a link to this page on the main recommendation page, in Forum posts, etc. There could also be a policy that explains what sorts of issues will trigger an entry on that page and the timeframe in which information will be added, as well as trigger criteria for conspiciously marking the recommendation/report as under review, withdrawing it pending further review, and so on. The policy should be in effect for as long as there is a recommendation based on the report, or for a minimum of G years (unless the report and any recommendation are formally withdrawn).
The policy would need to include a definition of materiality and clearly specified claims. Claims could be binary (SM cost-effectiveness > GiveDirectly) or quantitative (SM cost-effectiveness = 7.5X GiveDirectly). A change could be defined as material if it changed the probability of a binary claim more than Y% or changed a quantitative claim more than Z%. It could provide that any new issue will be added to the issues page within A days of discovery unless it is determined that the issue is not reasonably likely (at least Q% chance) to be material. It could provide that there will be a determination of materiality (and updated credences or estimates as necessary) within B days. The policy could describe which website materials, etc. would need to be corrected based on the degree of materiality.
If for some reason the time limit for full adjudication cannot be met, then all references to that claim on HLI's website, the Forum, etc. need to be clearly marked as [UNDER REVIEW] or pulled so that the reader won't be potentially mislead by the material. In addition, all materials need to be marked [UNDER REVIEW] if at any time there is a substantial possibility (at least J%) that the claim will ultimately be withdrawn.
This idea is ultimately intended to be about calibration and clear communication. If an org commits, in advance, to certain clear claims and a materiality definition, then the reader can compare those commitments against the organization's public-facing statements and read them accordingly. For instance, if the headline number is 8X cash, but the org will only commit to following correction procedures if that dips below 4X cash, that tells the reader something valuable.
This is loosely akin to a manufacturer's warranty, which can be as important as a measure of the manufacturer's confidence in the product as anything else. I recognize that larger orgs will find it easier to make corrections in a timely manner, and the community needs to give HLI more grace (both in terms of timelines and probably materiality thresholds) than it would give a larger organization.
Likewise, a policy stated in advance provides a better way to measure whether the organization is dealing appropriately with issues versus digging in its heels. It can commit the organization to make concrete adjustments to its claims or to affirm a position that any would-be changes do not meet pre-determined criteria. Hopefully, this would avoid -- or at least focus -- any disputes about whether the organization is inappropriately maintaining its position. Planting the goalposts in advance also cuts off any disputes about whether the org is moving the goalposts in response to criticism.
[two more speculative paragraphs here!] Finally, the policy could provide for an appeal of certain statistical/methodological issues to a independent non-EA expert panel by a challenger who found the HLI's application of its correction policy incorrect. Costs would be determined by the panel based on its ruling. HLI would update its materials with any adverse finding, and prominently display any finding by the panel that it had made an unreasonable application under its policy (which is not the same as the panel agreeing with the challenger).
This might be easier to financially justify than a bounty program because it only creates exposure if there is a material error, HLI swings and misses on the opportunity to correct it, and the remaining error is clear enough for a challenger to risk money. I am generally skeptical of "put your own money at risk" elements in EA culture for various reasons, but I don't think the current means of dispute resolution are working well for either HLI or the community.
- ^
This is not meant to discourage discussions of any new issues with the recommendation or underlying analysis that may be found.
- ^
I think this is the fairest way to report this -- because the studies were outliers, they may have been hingier than their level of credence.
MichaelPlant @ 2023-07-19T10:51 (+6)
This was really helpful, thanks! I'll discuss it with the team.
Rebecca @ 2023-07-15T14:17 (+4)
I could imagine that you get more people interested in providing funding if you pre-commit to doing things like bug bounties conditional on getting a certain amount of funding. Does this seem likely to you?
ChanaMessinger @ 2023-07-12T08:19 (+14)
I really like this concept of epistemic probation - I agree also on the challenges of making it private and exiting such a state. Making exiting criticism-heavy periods easier probably makes it easier to levy in the first place (since you know that it is escapable).
JWS @ 2023-07-10T20:33 (+33)
Adding a +1 to Nathan's reaction here, this seems to have been some of the harshest discussion on the EA Forum I've seen for a while (especially on an object-level case).
Of course, making sure charitable funds are doing the good that the claim is something that deserves attention, research, and sometimes a critical eye. From my perspective of wanting more pluralism in EA, it seems[1] to me that HLI is a worthwhile endeavour to follow (even if its programme ends with it being ~the same or worse than cash transfers). Of all the charitable spending in the world, is HLI's really worth this much anger?
It just feels like there's inside baseball that I'm missing here.
- ^
weakly of course, I claim no expertise or special ability in charity evaluation
lilly @ 2023-07-10T21:20 (+47)
This is speculative, and I don't want this to be read as an endorsement of people's critical comments; rather, it's a hypothesis about what's driving the "harsh discussion":
It seems like one theme in people's critical comments is misrepresentation. Specifically, multiple people have accused HLI of making claims that are more confident and/or more positive than are warranted (see, e.g., some of the comments below, which say things like: "I don't think this is an accurate representation," "it was about whether I thought that sentence and set of links gave an accurate impression," and "HLI's institutional agenda corrupts its ability to conduct fair-minded and even-handed assessments").
I wonder if people are particularly sensitive to this, because EA partly grew out of a desire to make charitable giving more objective and unbiased, and so the perception that HLI is misrepresenting information feels antithetical to EA in a very fundamental way.
alex lawsen (previously alexrjl) @ 2023-07-11T18:49 (+14)
So there's now a bunch of speculation in the comments here about what might have caused me and others to criticise this post.
I think this speculation puts me (and, FWIW, HLI) in a pretty uncomfortable spot for reasons that I don't think are obvious, so I've tried to articulate some of them:
- There are many reasons people might want to discuss others' claims but not accuse them of motivated reasoning/deliberately being deceptive/other bad faith stuff, including (but importantly not limited to):
a) not thinking that the mistake (or any other behaviour) justifies claims about motivated reasoning/bad faith/whatever
b) not feeling comfortable publicly criticising someone's honesty or motivations for fear of backlash
c) not feeling comfortable publicly criticising someone's honesty of motivations because that's a much more hurtful criticism to hear than 'I think you made this specific mistake'
d) believing it violates forum norms to make this sort of public criticism without lots of evidence
- In situations where people are speculating about what I might believe but not have said, I do not have good options for moving that speculation closer to the truth, once I notice that this might not be the only time I post a comment or correction to something someone says.
Examples:
- If I provide positive reassurance about me not actually implying bad faith with a comment that didn't mention it, that makes it pretty clear what I think in situations where I'm not ruling it out.
- If I give my honest take on someone's motivation in any case where I don't think there's any backlash risk, but don't give a take in situations where there is backlash risk, then I'm effectively publicly identifying which places I'd be worried about backlash, which feels like the sort of thing that might cause backlash from them.
If you think for a few minutes about various actions I might take in various situations, either to correct misunderstanding or to confirm correct understanding, I'm sure you'll get the idea. To start with, you might want to think about why it doesn't make sense to only correct speculation that seems false.
That's a very long-winded way of saying "I posted a correction, you can make up your own mind about what that correction is evidence of, but I'd rather you didn't spend a ton of time publicly discussing what I might think that correction is evidence of, because I won't want to correct you if you're wrong or confirm if you're right".
Linch @ 2023-07-17T09:55 (+25)
(Apologies if this is the wrong place for an object-level discussion)
Suppose I want to give to an object-level mental health charity in the developing world but I do not want to give to StrongMinds. Which other mental health charities would HLI recommend?
One thing that confused me a little when looking over your selection process was whether HLI evaluated in-depth any other mental health charities on your shortlist. Reading naively, it seems like (conditional upon a charity being on your shortlist) StrongMinds were mostly chosen for procedural reasons (they were willing to go through your detailed process) than because of high confidence that the charity is better than its peers. Did I read this correctly? If so, should donors wait until HLI or others investigate the other mental health charities and interventions in more detail? If not, what would be the top non-StrongMinds charities you would recommend for donors interested in mental health?
MichaelPlant @ 2023-07-19T11:12 (+10)
Hello Linch. We're reluctant to recommend organisations that we haven't been able to vet ourselves but are planning to vet some new mental health and non-mental health organisations in time for Giving Season 2023. The details are in our Research Agenda. For mental health, we say
We expect to examine Friendship Bench, Sangath, and CorStone unless we find something more promising.
On how we chose StrongMinds, you've already found our selection process. Looking back at the document, I see that we don't get into the details, but it wasn't just procedural. We hadn't done a deep dive analysis at the point - the point of the search process was to work out what we should look at in more depth - but our prior was that StrongMinds would come out at or close to the top anyway. To explain, it was delivering the intervention we thought would do most good per person (therapy for depression), doing this cheaply (via lay-delivered interpersonal group therapy) and it seems to be a well-run organisation. I thought Friendship Bench might beat it (Friendship Bench had a volunteer model and so plausibly much lower costs but also lower efficacy) but they didn't offer us their data at the time, something they've since done. I don't think I knew about Sangath or Corstone back then.
I think I would advise donors to wait until the end of this year. However, my money would be on Friendship Bench being the best MH org that isn't StrongMinds and I wouldn't rule out it being more cost-effective.
Linch @ 2023-07-20T07:04 (+3)
Thank you! I think if any of my non-EA friends ask about donating to mental health charities (which hasn't happened recently but is the type of thing my friends sometimes asks about in the past), I'd probably recommend to them to adopt a "wait and see" attitude.
Nathan Young @ 2023-07-14T14:32 (+18)
Takeaways poll
What are your takeaways having read the comments of this piece?
Personally I find it's good to understand what we all agree/disagree/are uncertain on.
Please add your own comments (there is a button at the bottom) or rewrite comments you find confusing into ones you could agree/disagree with.
Also if you know the answer confidently to something people seem unsure of, perhaps say.
https://viewpoints.xyz/polls/concrete-takeaways-from-hli-post
Results (33 responses): https://viewpoints.xyz/polls/concrete-takeaways-from-hli-post/analytics
Concensus of agree/disagre

- The "grave shortcomings" agreement is pretty surprising.
Uncertainty (lets write some more comments or give answers in the comments)
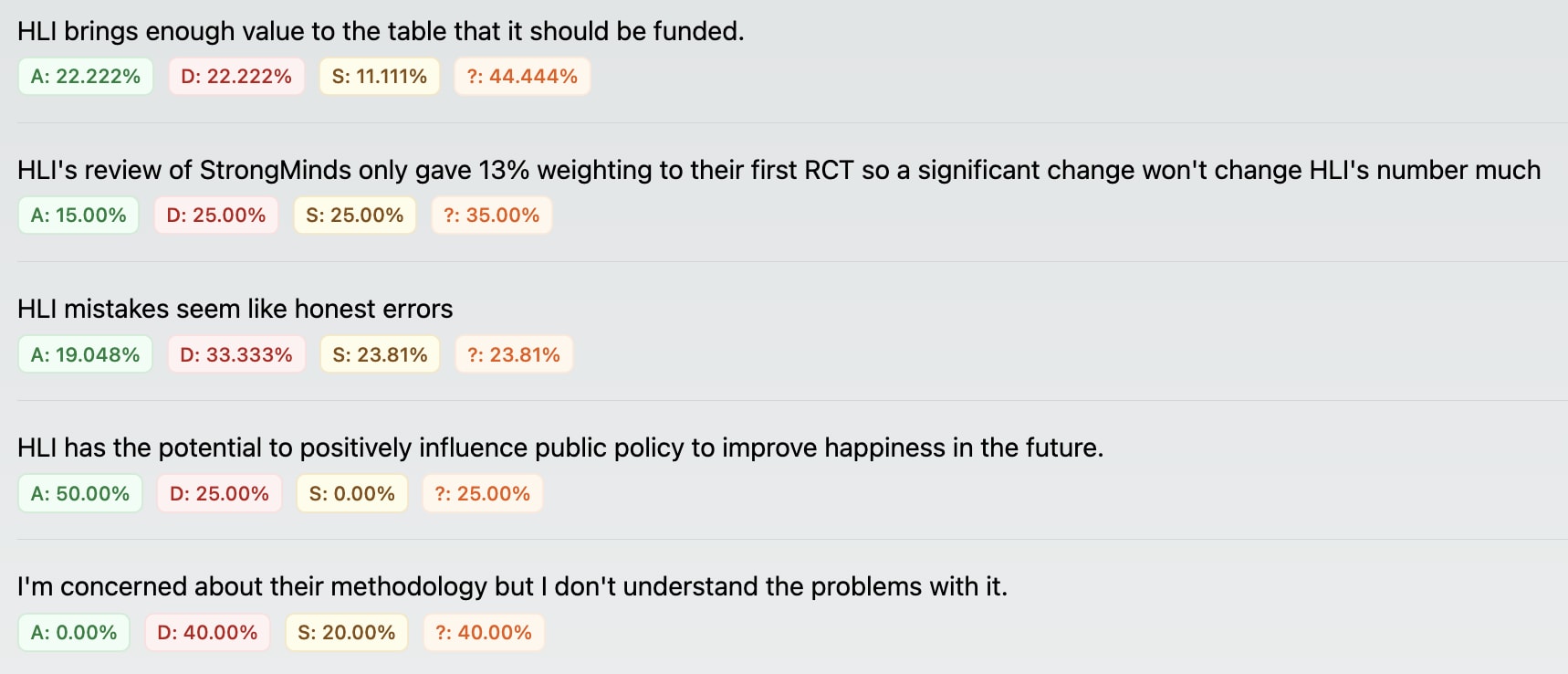
Some questions I'd like to know the answers to
- What would convince you that HLI brings enough value to the table that it should be funded?
- In the weighting of the RCT, that seems a fact claim. How could it be written such that you'd agree with it given the below table?
- How do you judge honest/dishonest errors, what is a clearer standard
- What would HLI managing controversies well or badly look like?
- How could we know if SW is more well respected? Is there a consensus position?

Jason @ 2023-07-15T15:50 (+4)
In the weighting of the RCT, that seems a fact claim. How could it be written such that you'd agree with it given the below table?
I think a problem with the statement is that it gives the impression that the weighing of the 2020 RCT is the only concern about weighting (and maybe about the CEA as a whole), such that disregarding it would fully address the concern about weighting. That kind of aura is hard to avoid when you're writing one-sentence claims, and probably explains much of the ? and s votes. So if I were trying to write a consensus statement, it would read something like:
Conditional on the rest of the CEA being sound, re-weighting the 2020 SM RCT from 13% to 0% would not change the outcome very much
Jason @ 2023-07-20T21:51 (+2)
Is there a way to get full data for all statements?
Jason @ 2023-07-15T17:12 (+2)
How do you judge honest/dishonest errors, what is a clearer standard
Many people (including myself) have very limited qualifications to assess whether errors in a CEA are "honest" or not (unless the situation is really clear cut), so skip or it's complicated may be the most appropriate answers for those people.
There's also some ambiguity in the term "honest errors" -- if I were qualified to answer this question as written, I would answer agree if I thought the errors were the result of at most ordinary negligence, would answer it's complicated for gross negligence or lesser forms of recklessness, and would answer disagree for more severe forms of recklessness or for intent. I think this would be hard to measure well with yes/no/complicated unless you asked a lot of fine-tuned questions.
Nathan Young @ 2023-07-14T14:55 (+2)
(Also I'm trying to get viewpoints to fit inside an iframe and have a pull request. I've had one run at it, but if anyone else wants to take one, it's here https://github.com/ForumMagnum/ForumMagnum/pull/7488 )
Jason @ 2023-07-06T15:05 (+15)
To confirm, the main difference between the "growth" and "optimal growth" budget is the extension of the time period from 12 to 18 months? [I ask because I had missed the difference in length specification at first glance; without that, it would look like the biggest difference was paying staff about 50% more given that the number of FTEs is the same.]
MichaelPlant @ 2023-07-06T15:10 (+9)
Thanks! Yes, that's right. 'Lean' is small team, 12 month budget. 'Growth' is growing the team, 12 month budget. 'Optimal growth' is just 'growth', but 18 month budget.
I'm now wondering if we should use different names...
Jason @ 2023-07-06T15:32 (+14)
The first two are good.
"Growth + more runway"? (plus a brief discussion of why you think adding +6 months runway would increase impact). Optimal could imply a better rate of growth, when the difference seems to be more stability.
Anyway, just donated -- although the odds of me moving away from GiveWell-style projects for my object-level giving is relatively modest, I think it's really important to have a good range of effective options for donors with various interests and philosophical positions.
Jack Malde @ 2023-07-09T16:28 (+14)
My reading of the Strongminds debate that has taken place is that the strength of the evidence wasn't sufficient to list Strongminds as a top charity (relevant posts are 1, 2, 3).
With regards to spillovers Joel McGuire says in a separate post:
One hope of ours in the original report was to draw more attention to the yawning chasm of good data on this topic.
If the data isn't good enough might it be worth suggesting people fund research studies rather than suggesting people fund the charity itself?
EDIT: I just want to say I would feel uncomfortable if anyone else updated too much based on my comments. I would encourage people to read the critiques I linked for themselves as well as HLI responses.
MichaelPlant @ 2023-07-10T14:41 (+5)
Hello Jack. I think people can and will have different conceptions of what the criteria to be on a/the 'top charity' list are, including what counts as sufficient strength of evidence. If strength of evidence is essential, that may well rule out any interventions focused on the longterm (whose effects we will never know) as well as deworming (the recommendation of which is substantially based on a single long-term study). The evidence relevant for StrongMinds was not trivial though: we drew on 39 studies of mental health interventions in LICs to calibrate our estimates.
We'd be very happy to see further research funded. However, we see part of our job as trying to inform donors who want to fund interventions, rather than research. On the current evidence and analysis we've been able to do, StrongMinds was the only organisation we felt comfortable recommending. We are working to update our existing analysis and search for new top interventions.
Jack Malde @ 2023-07-10T22:30 (+8)
Thanks Michael. My main concern is that it doesn't seem that there is enough clarity on the spillovers, and spillovers are likely to be a large component of the total impact. As Joel says there is a lack of data, and James Snowden's critique implies your current estimate is likely to be an overestimate for a number of reasons. Joel says in a comment "a high quality RCT would be very welcome for informing our views and settling our disagreements". This implies even Joel accepts that, given the current strength of evidence, there isn't clarity on spillovers.
Therefore I would personally be more inclined to fund a study estimating spillovers than funding Strongminds. I find it disappointing that you essentially rule out suggesting funding research when it is at least plausible that this is the most effective way to improve happiness as it might enable better use of funds (it just wouldn't increase happiness immediately).
Jason @ 2023-07-10T23:14 (+2)
It can be more challenging to raise money for research than operations, and even without that adjustment: the amount HLI has raised for SM is only a fraction of the high six / low seven figures for a solid RCT. Moreover, I think it would be particularly difficult to get a spillover study funded until the Ozler study results. So it's not clear to me that this option was or is realistically open to HLI.
Jack Malde @ 2023-07-11T00:30 (+2)
To be fair I didn’t have any idea how much an RCT would cost!
Nathan Young @ 2023-07-10T10:51 (+2)
Though I guess the charity could run research studies?
Jack Malde @ 2023-07-10T12:10 (+4)
I’ve just realized you were probably referring to Strongminds not HLI?
Funding Strongminds to carry out research into the efficacy of their own intervention seems a very bad idea to me given their incentive for the results to be favorable.
Jack Malde @ 2023-07-10T10:55 (+4)
The studies I had in mind would be empirical field studies best carried out by academic economists. The studies a charity like HLI would then make use of the results from.