Box inversion revisited
By Jan_Kulveit @ 2023-11-07T11:09 (+22)
Box inversion hypothesis is a proposed correspondence between problems with AI systems studied in approaches like agent foundations, and problems with AI ecosystems, studied in various views on AI safety expecting multipolar, complex worlds, like CAIS. This is an updated and improved introduction to the idea.
Cartoon explanation

In the classic -"superintelligence in a box" - picture, we worry about an increasingly powerful AGI, which we imagine as contained in a box. Metaphorically, we worry that the box will, at some point, just blow up in our faces. Classic arguments about AGI then proceed by showing it is really hard to build AGI-proof boxes, and that really strong optimization power is dangerous by default. While the basic view was largely conceived by Eliezer Yudkowsky and Nick Bostrom, it is still the view most technical AI safety is built on, including current agendas like mechanistic interpretability and evals.

In the less famous, though also classic, picture, we worry about an increasingly powerful ecosystem of AI services, automated corporations, etc. Metaphorically, we worry about the ever-increasing optimization pressure "out there", gradually marginalizing people, and ultimately crushing us. Classical treatments of this picture are less famous, but include Eric Drexler's CAIS (Comprehensive AI Services) and Scott Alexander's Ascended Economy. We can imagine scenarios like the human-incomprehensible economy expanding in the universe, and humans and our values being protected by some sort of "box". Agendas based on this view include the work of the AI Objectives Institute and part of ACS work.
The apparent disagreement between these views was sometimes seen as a crux for various AI safety initiatives.
"Box inversion hypothesis" claims:
- The two pictures to a large degree depict the same or a very similar situation,
- Are related by a transformation which "turns the box inside out", similarly to a geometrical transformation of a plane known as a circle inversion,
- and: this metaphor is surprisingly deep and can point to hard parts of some problems.
Geometrical metaphor
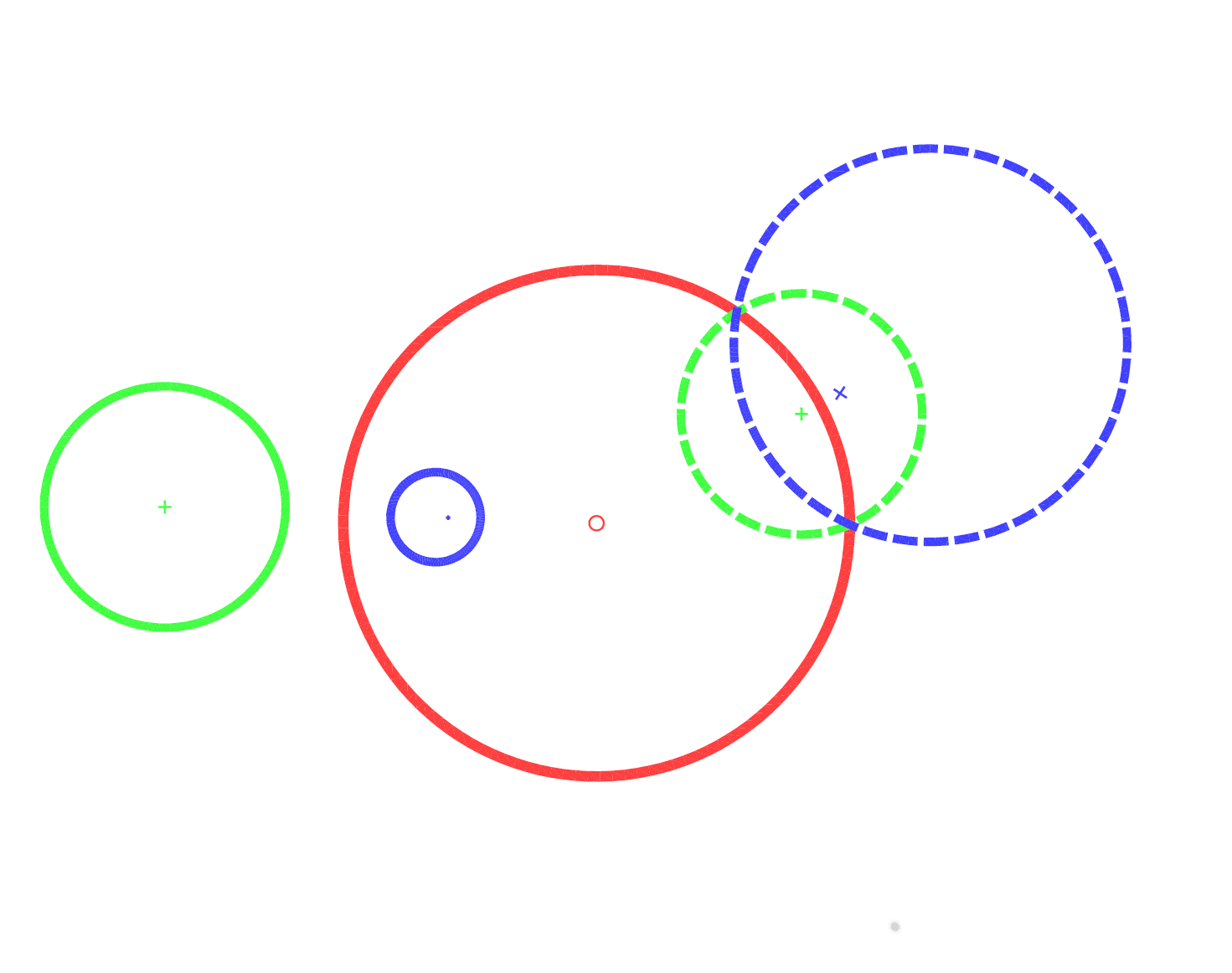
"Circular inversion" transformation does not imply the original and the inverted objects are the same, or are located at the same places. What it does imply is that some relations between objects are preserved: for example, if some objects intersect, in the circle-inverted view, they will still intersect.
Similarly for "box inversion" : the hypothesis does not claim that the AI safety problems in both views are identical, but it does claim that, for most problems, there is a corresponding problem described by the other perspective. Also, while the box-inverted problems may at a surface level look very different, and be located in different places, there will be some deep similarity between the two corresponding problems.
In other words, the box inversion hypothesis suggests that there is a kind of 'mirror image' or 'duality' between two sets of AI safety problems. One set comes from the "Agent Foundations" type of perspective, and the other set comes from the "Ecosystems of AIs" type of perspective.
Box-inverted problems
Problems with ontologies and regulatory frameworks
[1]
In the classic agent foundations-esque picture, a nontrivial fraction of AI safety challenges are related to issues of similarity, identification, and development of ontologies.
Roughly speaking
- If the AI is using utterly non-human concepts and world models, it becomes much more difficult to steer and control
- If "what humans want" is expressed in human concepts, and the concepts don't extend to novel situations or contexts, then it is unclear how the AI should extend or interpret the human “wants”
- Even if an AI initially uses an ontology that's compatible with human thinking and concepts, there's a risk. As the AI becomes more intelligent, the framework based on that ontology might break down, and this could cause the AI to behave in unintended ways. Consequently, any alignment methods that rely on this ontology might fail too.
Recently, problems with ontologies and world models have been studied under different keywords, like natural abstractions, or part of ELK, or representational alignment.
Next, we’ll look at Eric Drexler's CAIS agenda. There, everything is a service, and a particular one is a "service catalogue", mapping from messy reality to the space of services. Or, in other words, it maps from “what do you want”, to a type of computation that should be run.
Safety in the CAIS model is partially built on top of this mapping, where, for example, if you decide to create "a service to destroy the world", you get arrested.
Problems with service catalogues include
- If over time an increasingly large fraction of services becomes gradually incomprehensible B2Bs that produce non-human outputs from non-human inputs, it becomes tricky to regulate.
- if your safety approach is built on the ontology implicit in the service catalogue, the system may be vulnerable to attacks stemming from ontological mismatches (as we discussed above).
How does this look in practice, at 2023 capability levels?
As an example, governments are struggling to draft regulations which would actually work, in part because of ontology mismatch. The EU spent a few years building the AI act based on an ontology to track which applications of AI are dangerous. After ChatGPT, it became very obvious the ontology is mismatched to the problem: abilities of LLMs seem to scale with training run size. And while the simple objective "predict the next token" seems harmless, it is sufficient for the models to gain dangerous capabilities in domains like synthetic biology or human persuasion.
For a different type of example, consider a service offering designs of ferrofluidic vacuum rotary feedthroughs. If you want to prevent, let's say, AGI development by a rogue nation state, is this something you should track and pay attention to?
Problems with demons, problems with …?
Before the mesa-optimizer frame got so much traction that it drowned other ways of looking at things in this space, people in the agent foundations and superintelligence in a box space were worried about optimization demons. Broadly speaking, you have an imperfect search, a mechanism which allows exploiting the imperfection, and - in a rich enough space - you run into a feedback loop that exploits the inefficiency. A whole new optimizer appears - with a different goal.
Classically, the idea was that this can happen inside the AI system, manipulating its training via gradient hacking. Personally I don't think this is very likely with systems like LLMs, but in contrast I do think "manipulating the training data" is technically easier and in fact likely once you get close feedback loops between AI actions and training data.
What does the box-inverted version look like?
(Before proceeding, you might want to consider guessing yourself)
The LessWrong explainer gives an example of a Molochian dynamic: a Red Queen race between scientists who must continually spend more time writing grant applications just to keep up with their peers doing the same. Through unavoidable competition, they’ve all lost time while not ending up with any more grant money. And any scientist who unilaterally tried to not engage in the competition would soon be replaced by one who does. If they all promised to cap their grant writing time, everyone would face an incentive to defect.
In other words, squinting a bit, this looks like we have some imperfect search process (allocating grants to promising research proposals), a mechanism which allows ways to exploit it … and an eventual feedback loop that exploits the inefficiency. Problems with demons invert to problem with molochs.
What would this look like on an even bigger scale? In an idealised capitalism, what is produced, how much of it is produced, and at what price is ultimately driven by aggregate human demand, which contains the data about individual human preferences. Various supply chains bottom down in humans wanting goods, even if individual companies are often providing some intermediate goods to be used by some other companies. The market continuously "learns" the preferences of consumers, and the market economy updates what it produces based on those preferences.
The ultimate failure of this looks like the "web of companies" story in TASRA report by Critch and Russell.
What else?
The description and the examples seem sufficient for GPT4 to roughly understand the pattern, and come up with new examples like:[2]
- Superintelligent System: The AI might prioritize its self-preservation over other objectives, leading it to resist shutdown or modification attempts.
- Box-Inverted (Ecosystem of AIs): Some AI systems, when interacting within the ecosystem, might inadvertently create feedback loops that make the ecosystem resistant to changes or updates, even if individual systems don't have self-preservation tendencies.
…and so on. Instead of pasting GPT completions, I'd recommend looking at a few other things which people were worried about in agent foundations.
In the original post, I tried to gesture at what seems like the box-inverted 'hard core' of safety in this hilariously inadequate way:
some “hard core” of safety (tiling, human-compatibility, some notions of corrigibility) <-> defensive stability, layer of security services
I'll try to do better this time. In agent foundations, what seems one of the hard, core problems is what Nate, Eliezer and others refer to as 'corrigibility being anti-natural'. To briefly paraphrase, there are many aspects of future AI systems which you can expect because those aspects seem highly convergent: having a world model, using abstractions, understanding arithmetic, updating some beliefs about states of the world using approximate Bayesian calculations, doing planning, doing some form of meta-cognition, and so on. What's not on the list is 'doing what humans want' -- because, unlike the other cases, there isn't any extremely broad selection pressure for 'being nice to humans'. If we want AIs to be nice to humans, we need to select for that, and we also need to set it up in a way where it scales with AI power. Most of the hope in this space comes from the possibility of a 'corrigibility basin', where first corrigible AI systems make sure their successors are also corrigible.You’d also need to guarantee that this type of human-oriented computation is not overpowered, erased, or misled by the internal dynamics of the AGI system. And, you must guarantee that the human-oriented computation does not solve alignment by just hacking humans to align to whatever is happening.
What's the box inverted version? In my view of Eric Drexler's CAIS, the counterpart problem is "how to set security services". Because of the theoretical clarity of CAIS, it's maybe worth describing the problem in that frame first. Security services in CAIS guarantee multiple things, including "no one creates the service to destroy the world", "security services are strong enough that they can't be subverted or overpowered" and "security services guarantee the safety of humans". If you remember the cartoon explanation, security services need to be able to guarantee the safety of the box with humans in presence of powerful optimization outside. This seems really non-trivial to set up in a way that is dynamically stable, and where the security services don’t fall into one of the bad attractors. The obvious bad attractors are: 1. security services are overpowered, humans are crushed or driven to complete irrelevance 2. security services form a totalitarian dictatorship, where humans lose freedom and are forced or manipulated to do some sort of approval dances 3. security services evolve to a highly non-human form, where whatever is going on is completely incomprehensible.
Current reality is way more messy, but you can already recognize people intuitively fear some of these outcomes. Extrapolation of calls for treaties, international regulatory bodies, and government involvement is 'we need security services to protect humans'. A steelman of some of the 'we need freely distributed AIs to avoid concentration of power' claims is 'we fear the dictatorship failure mode'. A steelman of some of the anti-tech voices in AI ethics is 'capitalism without institutions is misaligned by default'.
In a similar way to corrigibility being unnatural in the long run, the economy serving humans seems unnatural in the long run. Currently, we are relatively powerful in comparison to AIs, which makes it easy to select for what we want. Currently, the labour share of GDP in developed countries is about 60%, implying that the economy is reasonably aligned with humans by our sheer economic power. What if this drops hundred-fold?
What's going on here?
I don't have a satisfying formalisation of box inversion, but some hand-wavy intuition is this: look at the Markov blankets around the AGI in a box, around the 'ecosystem of AIs', and around 'humanity'. Ultimately, the exact structure inside the blanket might not be all that important.
Also: as humans, we have strong intuitions about individuality of cognitive systems. These are mostly based on experience with humans. Based on that experience, people mostly think about a situation with 'many AI systems' as very different from a situation with a single powerful system. Yet, the notion of 'individual system' based on 'individual human' does not seem to actually generalise to AI systems. [3]
What does this imply
My current guess in Oct 2023 is that the majority of the unmitigated AI existential risk comes from the box-inverted, ecosystem versions of the problems. While I'm fairly optimistic we can get a roughly human-level AI system almost aligned with the company developing it using currently known techniques, I'm nevertheless quite worried about the long run.
Thanks to Tomáš Gavenčiak, Mateusz Bagiński, Walter Laurito, Peter Hozák and others for comments and Rio Popper for help with editing. I also used DALL-E for the images and GPT-4 for editing and simulating readers.
- ^
In the original post, I referred to this merely as "questions about ontologies <-> questions about service catalogues", but since writing the original post, I've learned that this density of writing makes the text incomprehensible to almost anyone.
So let's unpack it a bit. - ^
Cherry-picked from about 10 examples
- ^
It actually does not generalise to a lot of living things like bacteria or plants either.
SummaryBot @ 2023-11-09T13:17 (+1)
Executive summary: The "box inversion hypothesis" claims that AI safety problems from the "agent foundations" perspective involving powerful AI systems in boxes have mirrored problems in the "ecosystems of AI" perspective with optimization pressure outside boxes. This surprising correspondence suggests novel angles for tackling key issues.
Key points:
- Problems with ontologies that arise with single AGIs have analogues with regulating complex ecosystems of AI services.
- Issues like AI systems resisting shutdown mirror ecosystem dynamics that lead to entrenched, human-unfriendly equilibria.
- Setting up enduring, trustworthy security services resembles creating reliably corrigible AGIs. Both face convergent incentives making them drift from human-alignment.
- The economy's current rough human-alignment may not persist as AI systems become more capable. Without interventions, aggregate optimization pressure could marginalize human values.
- Formalizing the "inversion" concept could yield insights, but the pattern already suggests novel angles on core problems.
- Ecosystem-scale issues may pose the majority of unmitigated existential risks from AI despite progress on aligning individual systems.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.