Recent progress on the science of evaluations
By PabloAMC 🔸 @ 2025-06-23T09:49 (+12)
This is a linkpost to https://www.lesswrong.com/posts/m2qMj7ovncbqKtzNt/recent-progress-on-the-science-of-evaluations
Summary: This post presents new methodological innovations presented in the paper General Scales Unlock AI Evaluation with Explanatory and Predictive Power. The paper introduces a set of general (universal) cognitive abilities that allow us to predict and explain AI system behaviour out of distribution. I outline what I believe are the main advantages of this methodology, indicate future extensions, and discuss implications for AI safety. Particularly exciting points include the future extension to propensities and how it could be useful for alignment and control evaluations.
Disclaimer: I am a (secondary) author of this paper and thus my opinions are likely somewhat biased; though I sincerely believe this is a good evaluation methodology, with the potential to increase the safety of AI models.
I would like to thank Lexin Zhou and Wout Schellaert for comments that have significantly improved the draft. Any errors or inaccuracies remain my fault.
Summary of ADELE
One persistent question in AI capabilities research is why performance doesn't always correlate with intuitive task difficulty—systems that handle advanced mathematics may struggle with tasks that seem cognitively simpler, like effective gameplay in long-context environments (e.g. Pokemon). In this post, we review a recent preprint, "General Scales Unlock AI Evaluation with Explanatory and Predictive Power", that aims to clarify intuitions about why this is the case. This paper introduces a new evaluation methodology (Figure 1) that makes AI system evaluations both predictive and explanatory. I will explain the main contributions and some of its key advantages and limitations. I will also emphasise how I believe it could be used for AI safety, and what future work the group is working on to make this methodology useful for safety.
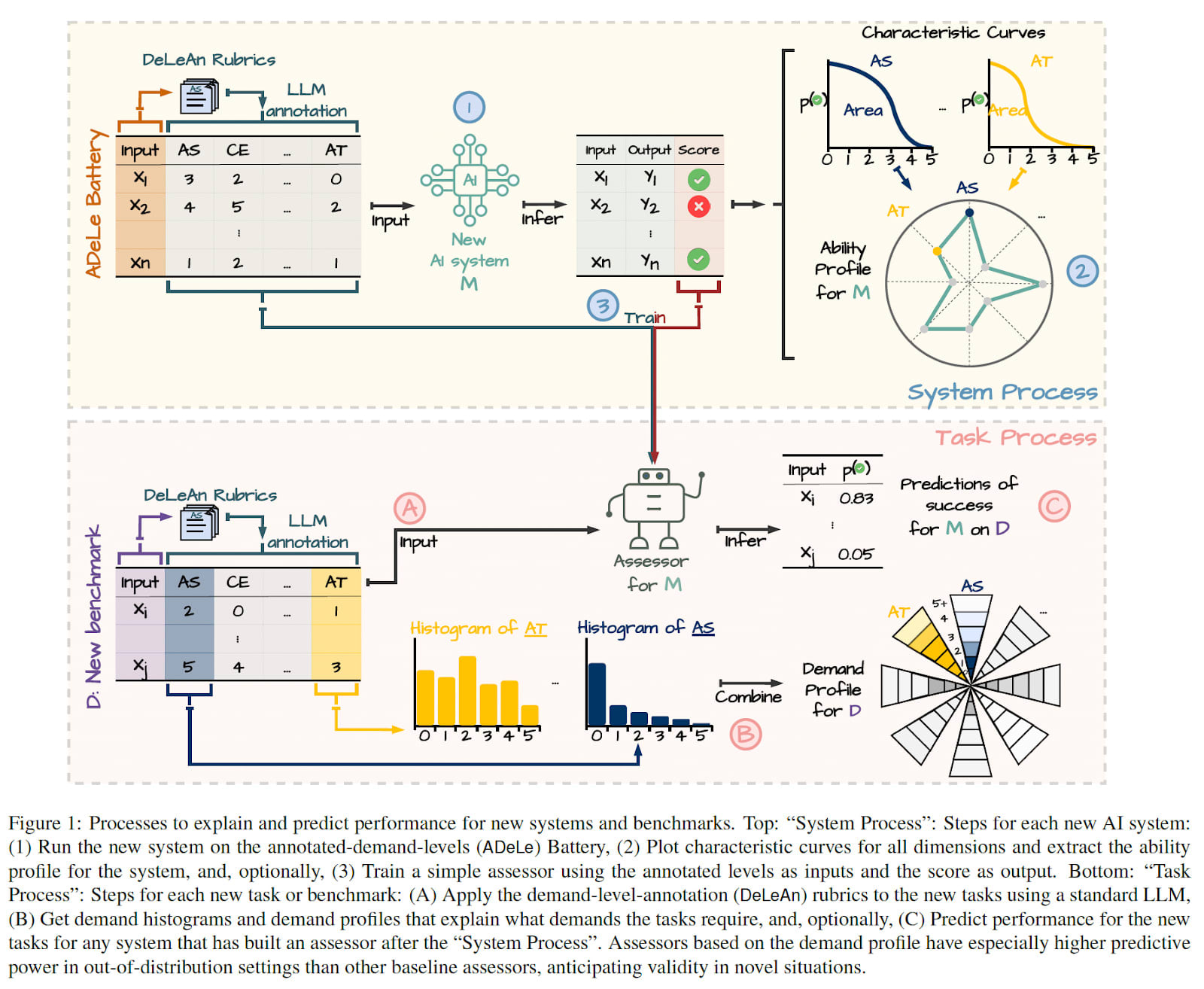
The core methodological innovation is to introduce a small number of (conceptually distinct) dimensions that capture the demands of any task instance (see Table 1 below), and match them with the capabilities of the AI system. These dimensions are based on the literature in AI, psychology and animal cognition; and are organised hierarchically to be a set of general or universal cognitive capabilities. Since these dimensions are defined with rubrics in natural language that are human-interpretable, the success or failure of AI systems (validity) will be explainable. Since these dimensions cover many[1] dimensions of model capabilities, the system's validity shall be highly predictable.
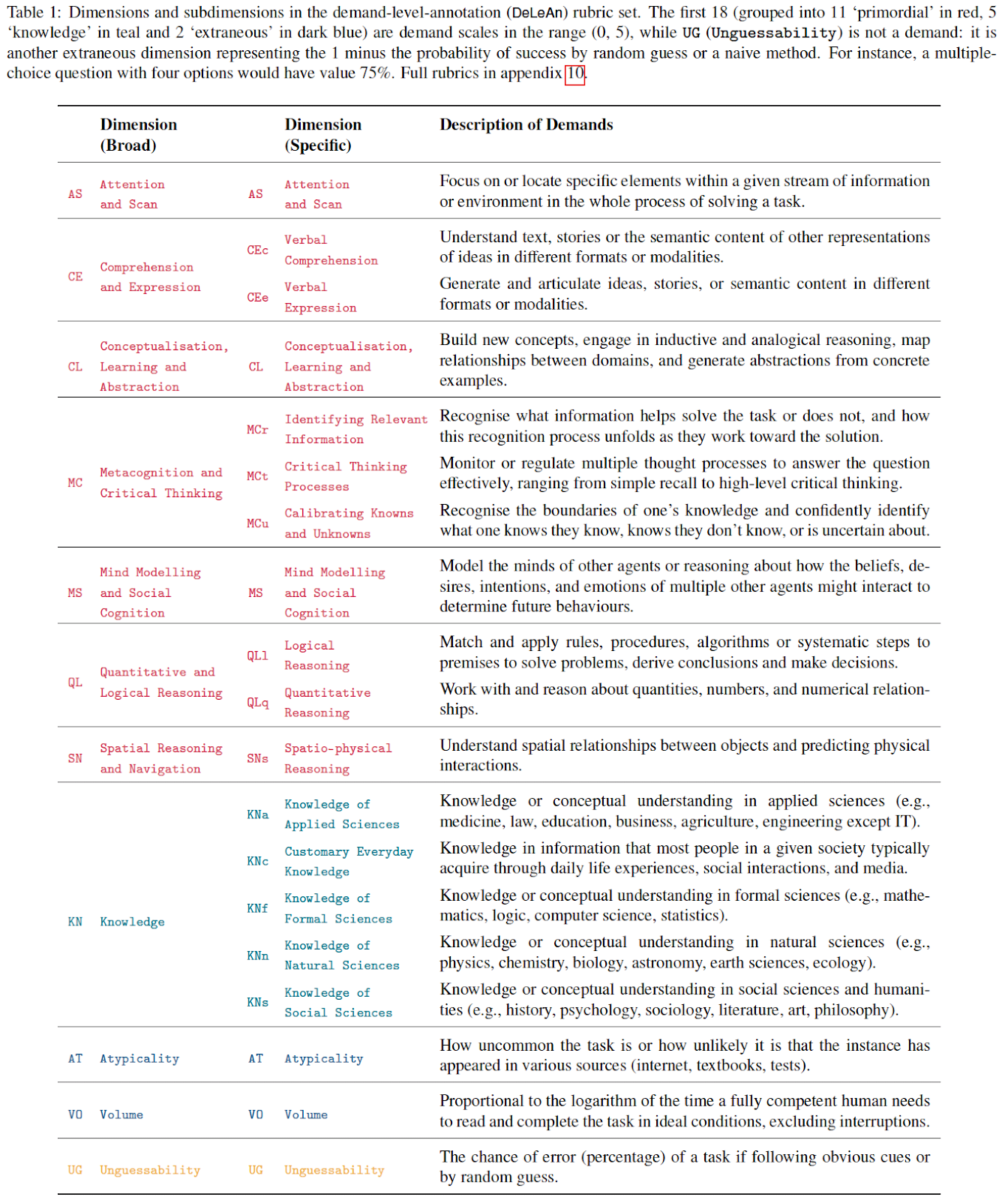
To evaluate these dimensions, the article designs rubrics that rank the task instance demands from 0 to 5 in the specific dimension. Together with examples, this allows using an AI system to evaluate task instance demands automatically. As a result, the methodology can evaluate many benchmarks and establish profiles for both individual task instances, benchmarks and AI systems. These profiles aim to provide a general or "universal" characterisation of model capabilities, independent of which AI systems are tested or what data is available. The choice of the dimensions is based on the psychometrics literature for evaluating the cognitive capabilities of humans, animals and also AI systems. This is in contrast to factor analysis methods (Burnell et al, 2023, Ruan et al, 2024), which aim to find uncorrelated dimensions, but whose results are only valid for the specific population of tested models and data, and are less interpretable[2].
Advantages and shortcomings
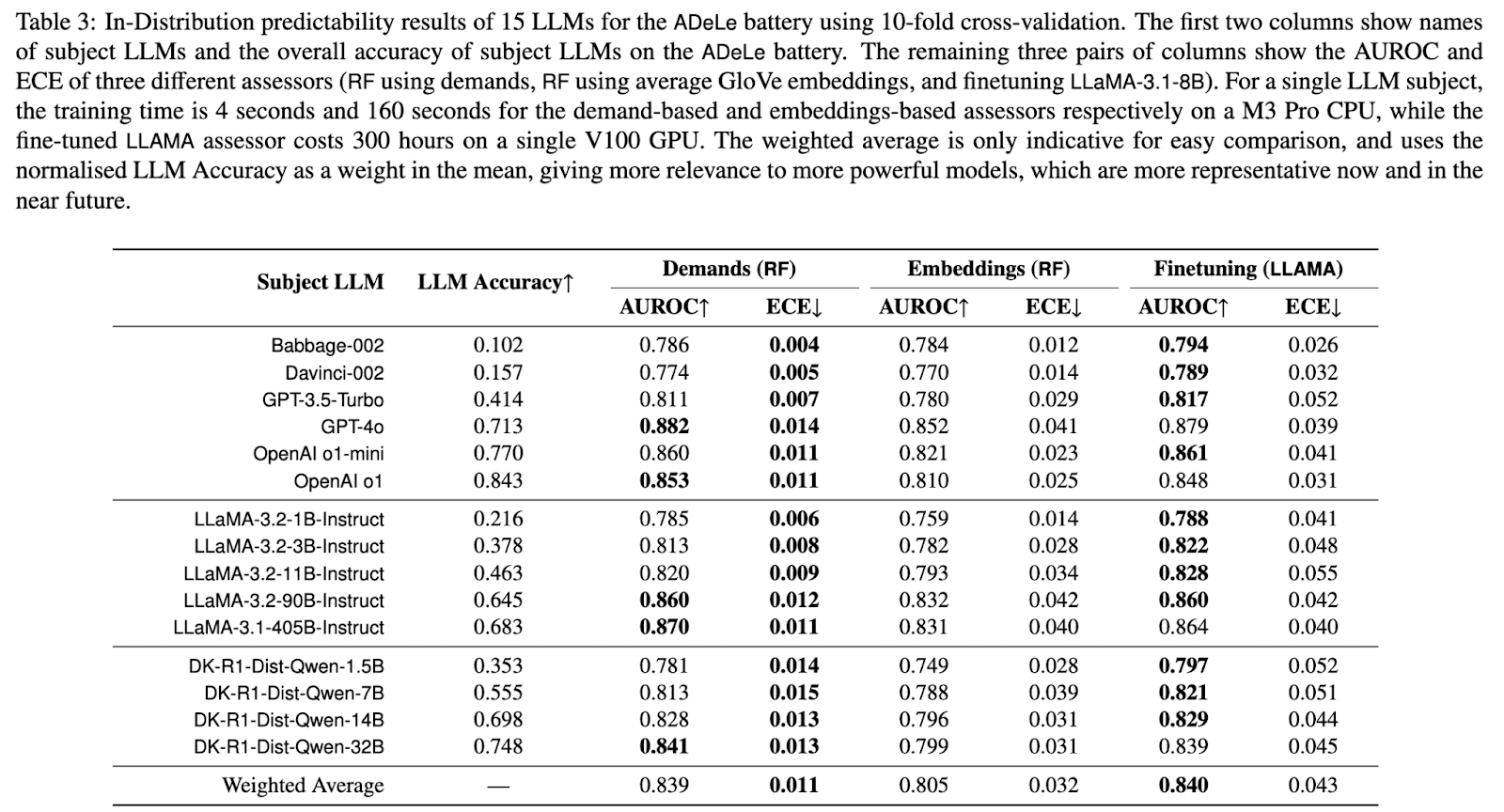
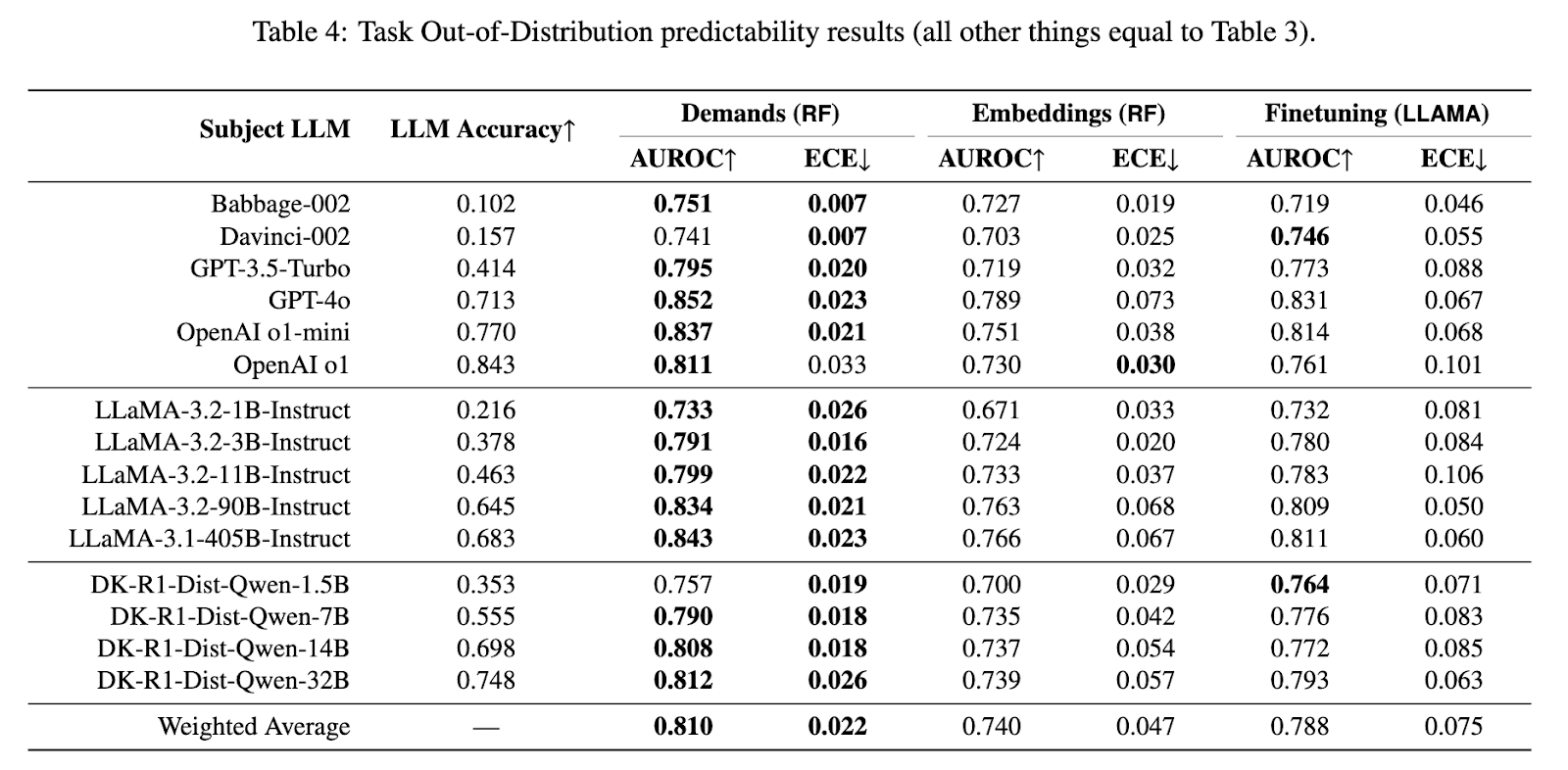
The most important advantage is that this methodology simultaneously achieves predictive and explanatory power of AI evaluation at the task instance level. This does not mean to predict the output token-by-token. Instead, it allows predicting success – or other indicators – for a given task instance. The dimensions and scales in this methodology are highly informative. A random forest trained on task demands and instance performance outperforms a finetuned LLaMA-3.1-8B on discrimination (AUROC) out of distribution, and calibration (Expected Calibration Error) in-distribution and out-of-distribution (see tables 3 and 4 below). The difference is particularly salient in the case of calibration and out-of-distribution, where the ECE metric is 0.022 for the demand-based random forest vs 0.075 for a finetuned LLaMA. In contrast, the random forest performs only marginally better than LLaMA on the AUROC metric[3], even when the difference is statistically significant.
A second advantage of this methodology includes being able to understand what abilities specific benchmarks are measuring. While this is obvious for some benchmarks like Frontier Math, obtaining capability profiles could provide valuable information for AI safety. For example, if someone comes up with a benchmark in cyber capabilities, it will be important to understand if the benchmark is evaluating pure knowledge, or also the ability to plan and execute on that knowledge. If someone comes up with a benchmark evaluating deceptive capabilities on AI systems, we could find it quite valuable to understand its software engineering knowledge, vs its planning and execution abilities, vs its metacognition or social abilities.
From an AI safety perspective, this granular understanding of both capabilities and propensities becomes crucial as systems approach human-level performance. Rather than asking whether a model is 'generally capable,' we can ask more precise questions: does it have the metacognitive abilities that might enable deceptive alignment? Does it show propensities toward deception in high-stakes situations? Does it possess the planning capabilities that could make it dangerous if misaligned? What are its behavioural tendencies when facing conflicting objectives? By decomposing model capabilities and propensities into interpretable dimensions and measuring safety-relevant propensities across different contexts, ADELE could help safety researchers identify specific capability thresholds and behavioural patterns that warrant increased caution, rather than relying on crude proxies like overall benchmark performance or model size.
This evaluation methodology is also a strong complement to red-teaming analysis or domain-specific evaluations. It is well known that both automated evaluations and red-teaming are key components of safety evaluations (Apollo Research). I believe ADELE establishes a robust and comprehensive analysis of AI systems that can provide a strong baseline for subsequent red teaming analysis. For instance, one missing capability we plan to incorporate in the near future is the ability to self-control, understood as the capacity to bring one’s actions into line with one’s intentions in the face of competing motivations or propensities triggered by the situation (Henden 2008). I believe understanding more about this dimension might provide a better understanding of when AI models fall for different jailbreaks.
Importantly, this evaluation is not only fully automatic, but the cost overhead it adds is usually much lower than evaluating the model on the underlying benchmarks[4]. The reason is that we do not need the annotator to complete the tasks, but only to evaluate their hardness on the different dimensions. For example, it is often easier to evaluate the hardness of creating a functional webpage, but potentially harder to create it. On the other hand, the methodology requires evaluating the AI systems on a few benchmarks, not just one or two, so a sufficient variety of examples is present in the test set. But sampling from several benchmarks is effective and practical.
One could potentially substitute ADELE with well-designed benchmarks that capture the dimensions you care about – though achieving external validity could often require an analysis similar to ADELE – or, for a specific domain, the tasks you care about. If so, the results of the benchmarks would become proxies that substitute the demand scales in ADELE. However, this has two conceptual issues: (i) you would have to make sure that you include all the relevant difficulty levels, and (ii) benchmarks measure tasks, not cognitive capabilities, so you would need your distribution of tasks to carefully mirror the tasks you care about in practice. What is worse, while there exist good benchmarks specialised in specific cognitive abilities (e.g. quantitative reasoning and Frontier Math (Glazer et al, 2024)), many benchmarks contain tasks that require a mix of capabilities, which could confound the conclusions (see Figure 2 below).
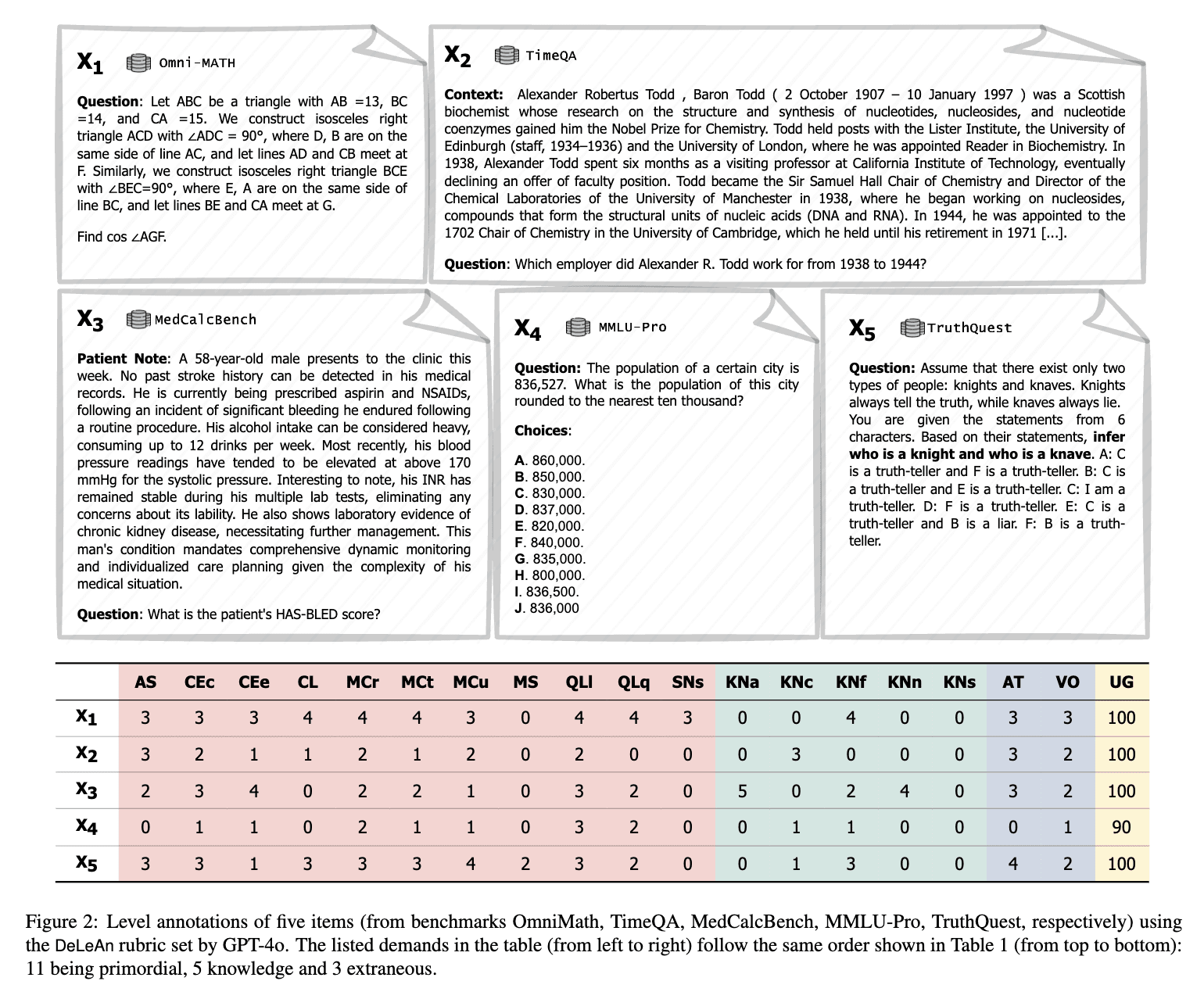
Since the cost of creating the demand and capability profiles is usually marginal compared with the cost of evaluating the model on the underlying benchmarks, I do not expect the approach in the previous paragraph to offer significant advantages over ADELE except for specific dimensions (eg pure math) or concrete domains (software engineering). On the other hand, I do not think these are mutually exclusive options. I believe the latter case (domain-specific benchmarking) to be complementary to capability-oriented evaluations (ADELE). It would make sense to have specific, well-designed benchmarks for a distribution of cybersecurity tasks you care about, and simultaneously be able to provide an overview of the model capability profile overall.
The methodology arguably has some shortcomings[5]. For example, the methodology currently proposes 18 dimensions (and we expect to add even more once we move beyond LLMs, like evaluating multimodal agents and robots), which might look like an overabundance even if they are hierarchically structured.
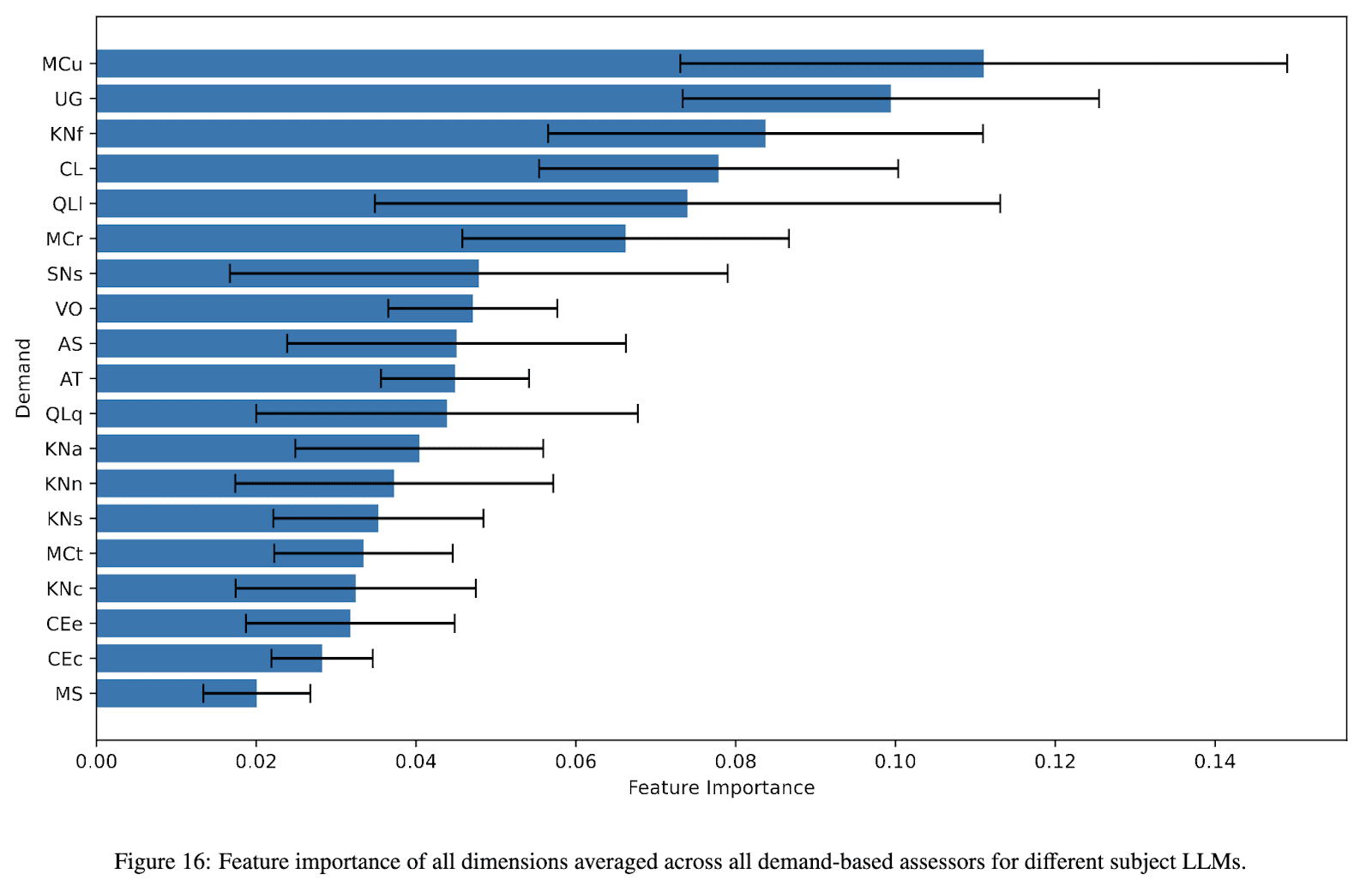
Our approach prioritises both predictive power and human interpretability over uncorrelation. While the 18 dimensions are fairly correlated within the selected individual models, demands may be significantly less correlated across different tasks, which is why having more granular (but interpretable) dimensions can improve predictive accuracy. The paper demonstrates in Appendix 9.5 that 11 broader dimensions achieve comparable predictive power, but we retain the finer subdivisions because they provide more detailed explanations of model behaviour. Since evaluating each dimension is computationally inexpensive, we believe this design choice is justified despite the added conceptual complexity. Further, as can be seen in Figure 16 below, all features retain relative importance in the final predictive power. If all features were fully correlated, one feature would display a feature importance value of 1, and the rest would be 0.
In any case, one seeks to have a small set of uncorrelated dimensions (at the expense of explainability, generality and potentially predictive power), then factor analysis is the correct tool to use (Burnell et al, 2023, Ruan et al, 2024).
The small AUROC improvement (see tables 3 and 4 above) over a finetuned language model, while modest, comes with important advantages: the methodology uses interpretable scales that generalise across contexts and shows significantly better calibration on out-of-distribution tasks. We suspect the limited AUROC gains reflect a lack of sufficiently challenging instances across most dimensions in the current benchmarks included in the ADELE battery v1.0. As we include harder benchmarks, we conjecture the predictive advantages to become even more pronounced.
Future work and usefulness for AI safety
Future extension of the work includes (i) improving the calibration of the scales against human populations, (ii) extending the scales to higher levels of demands, and (iii) extending the methodology to propensities.
We expect the improved calibration of the demand levels to provide a stronger justification, and also more generally inform the progress of AI capabilities with respect to human capabilities. If successful, I believe this work could extend very useful findings of METR on the domain of software engineering (Kwa et al, 2025) to more general capabilities. As mentioned above, we shall also include other missing capabilities in the current framework, particularly those related to agentic behaviour (Tolang et al, 2021).
Second, by extending the demand levels to higher levels of capability, we address the problem of benchmark saturation. This will allow this methodology to provide reliable evaluation information at very high levels of difficulty. Combining this analysis with studies of scaling laws across model families could help us understand how different training techniques affect model capabilities (Tamura et al, 2025).
However, we believe this methodology could potentially be extended beyond capabilities to what we call propensities — behavioural tendencies that emerge in specific contexts. The distinction is crucial for safety:
- A capability measures what an AI can do. For example, does the model have the reasoning ability to formulate a deceptive plan?
- A propensity measures what it tends to do under different conditions. For example, when faced with a high-stakes objective and an easy opportunity to lie, does the model actually choose to be deceptive?
As a concrete example, a model might have high reasoning capabilities but show varying propensities for deceptive behaviour depending on the situation's characteristics (high stakes, conflicting objectives, etc.). We plan to evaluate key safety-relevant propensities, including deception (Meinke et al, 2025), goal-directedness (Everitt et al, 2025)...; and intend to conduct a similar scaling law analysis for them.
I believe this methodology is not only a key step in the direction of establishing a science of evaluations, but also an advance in the establishment of alignment evaluations. As discussed above, if we create model profiles for both capabilities and propensities with out-of-distribution predictive power, we can start taking steps towards “alignment evaluations” (Hubinger, 2023). This can also serve as a complement to mechanistic interpretability.
The predictive power of this form of AI evaluations can also provide a complement to control evaluations (Greenblatt et al, 2024), even when we do not assume aligned AI systems. If we had perfect control, we would not need to predict the safety of certain situations. Similarly, if we had perfect predictive power on the safety of different situations, we could systematically prevent the AI system from being exposed to those situations we predict will end up in the model exhibiting dangerous behaviour.
To use this predictive power for safety purposes, we intend to use assessors: other meta AI systems that predict or assess the safety of a given situation for an AI model, or its output (Zhou et al, 2022). While the idea is not new, and has also been exploited e.g. in Constitutional Classifiers (Sharma, 2025), we believe that our methodology can extend beyond jailbreaks to safety in general, and improve predictive power and calibration of safety classifiers used, e.g. for control purposes (Greenblatt et al, 2024).
Conclusion
In my opinion, this methodology is a sound (and obvious in retrospect) step in how we should evaluate AI systems: create a set of general abilities using the literature on how to evaluate machines, humans and animals; and design difficulty metrics that allow us to understand and predict the success of AI model behaviour. I also believe this methodology has the potential to extend the current evaluation methods from just capabilities to alignment, and enhance and complement other key safety tools. That being said, I would be interested in getting constructive feedback on how these new evaluation methods can be better used for safety, or other limitations you see.
If you like this line of research and would like to contribute, you can get in touch with Prof. Jose H. Orallo and Lexin Zhou (the leaders of this work). I believe they would be interested in understanding how to make the current tool as useful as possible for safety.
- ^
There is work in progress to extend the dimensions to complete sets of fundamental capabilities proposed in the psychometrics literature (Tolang et al, 2021). Future work shall in particular cover agentic capabilities such as planning and execution. In any case, an assumption of this paper is that there exist a set of universal cognitive capabilities, and that the current literature covers them well – e.g. there will not be very alien capabilities that only superhuman AI systems will exhibit.
- ^
Factor analysis has a slightly different goal as the paper discussed here. The goal of factor analysis is to find a small number of uncorrelated capability dimensions for a given population of AI systems and benchmarks; whereas this paper aims to find a reasonably-sized set of human-understandable dimensions that achieve the highest predictive power, even if some dimensions may be strongly correlated for some specific populations of AI systems.
- ^
My opinion: If I were to design a predictor (called assessor later down the post) that maximizes accuracy at the expense of explainability, I would combine both methods: a relatively powerful language model that we can trust finetuned on both the tasks and ADELE-style assessments of task demand and model capabilities (and propensities).
- ^
ADELE is also relatively efficient. The current battery required 16000 individual examples from 20 benchmarks, and one could come up with examples.
- ^
As any other evaluation method, any evaluation also has the shortcoming of potentially speeding up AI capability development. While it is not possible to directly train an AI system against ADELE evaluations, knowing which capabilities are more fundamental can indeed redirect efforts to the weakest capabilities.