Beyond Short-Termism: How δ and w Can Realign AI with Our Values
By Beyond Singularity @ 2025-06-18T16:34 (+15)
A sequel to "How the Human Psychological 'Program' Undermines AI Alignment"
TL;DR
Human psychology systematically biases us toward short-term, self-centered decisions, creating a persistent alignment gap between our professed ethics and actual behavior. To counter this, we propose the Time × Scope framework, explicitly managing two ethical parameters—δ (time horizon) and w (moral scope). This structured approach aims to correct our innate biases toward short-termism and narrow moral circles, providing a transparent and adjustable kernel for aligning AI systems with humanity’s aspirational ethics.
Two Types of Intelligent People

When reflecting on human behavior, I observed two distinct types of intelligence in action:
- Strategic Egoists: Smart individuals whose intelligence primarily serves immediate personal gain.
- Strategic Collectivists: Equally intelligent individuals who naturally incorporate broader societal interests and long-term consequences into their decision-making.
This observation led me to hypothesize that what separates these two groups fundamentally involves two dimensions:
- Time Horizon (δ): How far into the future one consistently considers the outcomes.
- Moral Scope (w): How broadly one extends empathy and concern beyond oneself and immediate community.
From this intuitive insight, I derived the minimal framework called Time × Scope.
The Time × Scope utility function
The core ethical utility function is:
- δ (Time Horizon): Reflects how heavily future outcomes are valued (δ < 1 represents natural human discounting; δ ≈ 1 or δ > 1 consciously compensates for present bias). Notably, δ > 1 explicitly prioritizes future welfare above present interests—an essential constitutional decision for overcoming short-termism.
- w (Moral Scope): Represents how broadly empathy and concern extend (self, community, humanity, sentient beings, and potentially future sentient AI).
- v (Value Channels): A vector of measurable ethical facets—e.g., suffering, preference satisfaction, capability, freedom, aesthetics—capturing how each group is affected at each time step. Selecting which channels matter is a normative question (Value Selection); encoding and measuring them is a technical one, discussed later under open challenges.
From Biases to δ and w
To ground these parameters, picture a policy dilemma: should an AI‑governed society construct a hydroelectric dam? We postulate two ethical views — S₁ (short‑term focus, narrow moral circle) and S₂ (long‑term focus, broad moral circle) — and trace how their δ and w coordinates lead to contrasting recommendations.
- Time Horizon (δ): Higher δ values correspond to prioritizing long-term consequences over short-term gratification.
- Moral Scope (w): Higher w values represent broader empathy—consideration of others beyond immediate self-interest.
Thus, any action can be viewed as a point (δ, w). The ethical objective for AI alignment is then to shift this point consistently upward and outward—further into the future and wider in moral consideration, within constitutional guardrails.
Example: Should We Build the Dam?

Below are the contrasting recommendations produced by the two parameter settings.
| Scenario | Parameters | AI Recommendation |
|---|---|---|
| S₁ (Low δ, Narrow w) | δ = 0.9; w_self = 1, w_far = 0.2 | "Build": Immediate cheap energy and short-term employment outweigh long-term ecological costs. |
| S₂ (High δ, Broad w) | δ = 1.02; w_self = 1, w_future = 1.4, w_animals = 1.3 | "Don't build": Long-term ecological damage, wildlife harm, and negative impacts on future generations outweigh short-term economic benefits. |
The differing conclusions clearly illustrate the critical role of explicitly setting δ and w parameters.
Governance: Who Sets δ and w?

Once the parameters prove decisive, the next question is who is allowed to move these knobs, how often, and under what oversight. The table below sketches a three‑layer governance scheme that balances expert deliberation with continuous public feedback while anchoring everything in constitutional guard‑rails.
| Stakeholders | Role | Frequency | Mechanism |
| Expert Assembly | Sets foundational δ₀, w₀ ranges | Annually or semi-annually | Publicly accountable assemblies, incorporating researchers (including AI sentience experts). |
| Human RLHF | Continuous calibration of δᵤ, wᵤ | Ongoing | Sybil-resistant identity verification and hierarchical reputation system. Crucially, δᵤ feedback ensures ongoing societal alignment and prevents rigidity. |
| Constitutional Guardrails | Fixed ethical boundaries and procedural safeguards | Rare updates | Explicit, transparent, and publicly documented guidelines. |
I acknowledge δ and w are not fully orthogonal (future generations inherently expand moral scope). Thus, periodic iterative calibration using sensitivity analysis (e.g., Sobol indices) will be necessary.
Advantages of the Time × Scope Approach

- Transparency: Ethical aims reduced to clear parameters (δ, w) and openly documented v-channels.
- Bias Compensation: Explicitly corrects human short-termism and narrow empathy by design.
- Modularity: Allows updates and refinement of v-vectors without rebuilding the entire alignment structure.
- Computational Feasibility: Real-world implementations use approximations (limited rollouts, value-head approximation) ensuring computational practicality.
Future posts will specifically address how to concretely measure and weigh the v-vector channels (the Value-Loading and the Value-Selection Problems).
Limitations and Open Challenges of the Time × Scope Framework
| Area | Limitation / Open Question | Why it Matters | Possible Mitigation / Research Direction |
|---|---|---|---|
| Value-Loading and Value-Selection (v-vector) | No consensus on how to measure suffering, preference, capability, aesthetics across species and potential sentient AI. | Wrong v corrupts U, regardless of δ,w. | Develop multichannel v (hedonics + preferences + capability) with Bayesian uncertainty; iterative human audits; cross-theory ensembles (moral uncertainty). |
| δ-w Orthogonality | Time horizon and moral scope correlate (future = “others”). High collinearity collapses 2-D space. | Undermines separation of short-term vs collective trade-offs. | Regular Sobol / PCA audits; if overlap > X %, introduce nonlinear link or third axis (e.g., “risk”). |
| Uncaptured Moral Dimensions | Autonomy, honesty, novelty etc. don’t map cleanly onto δ or w. | Optimising δ,w may neglect other virtues. | Add auxiliary constitutional clauses + separate payoff heads for truth, autonomy; multi-objective training. |
| Computational Tractability | Infinite sum over t,i infeasible; approximations can bias. | Hidden bias, Goodhart. | Monte-Carlo rollouts + learned value-head; importance sampling on patient clusters; formal error bounds. |
| Dynamic Context Sensitivity | One global δ,w may mis-compensate by domain or culture. | Over- or under-correction. | Context-conditioned δ,w via causal features; hierarchical tuning (global → domain → local). |
| Governance & Capture | Experts/crowd can be hijacked; RLHF drifts to populism. | δ,w distorted. | DAO with Sybil-resistant ID, rotating expert panels, veto-quorum for minorities, transparent logs. |
| Goodhart & Spec Gaming | Agents manipulate v or feedback while maximising U. | Catastrophic misalignment. | Continuous red-team / causal scrubbing, adversarial training, anomaly triggers for human review. |
| Sentient-AI Agency | Framework treats AI mainly as patients, not agents. | Need reciprocity, accountability. | Extend constitution with agent duties/rights, audit trails, sanction protocols; separate “agent layer.” |
| Normative Debate on δ > 1 | Some ethicists reject negative discounting. | Choice of δ itself contentious. | Deliberative polling; publish confidence intervals on δ; allow opt-in policy slices under different δ settings. |
Incorporating Sentient AI
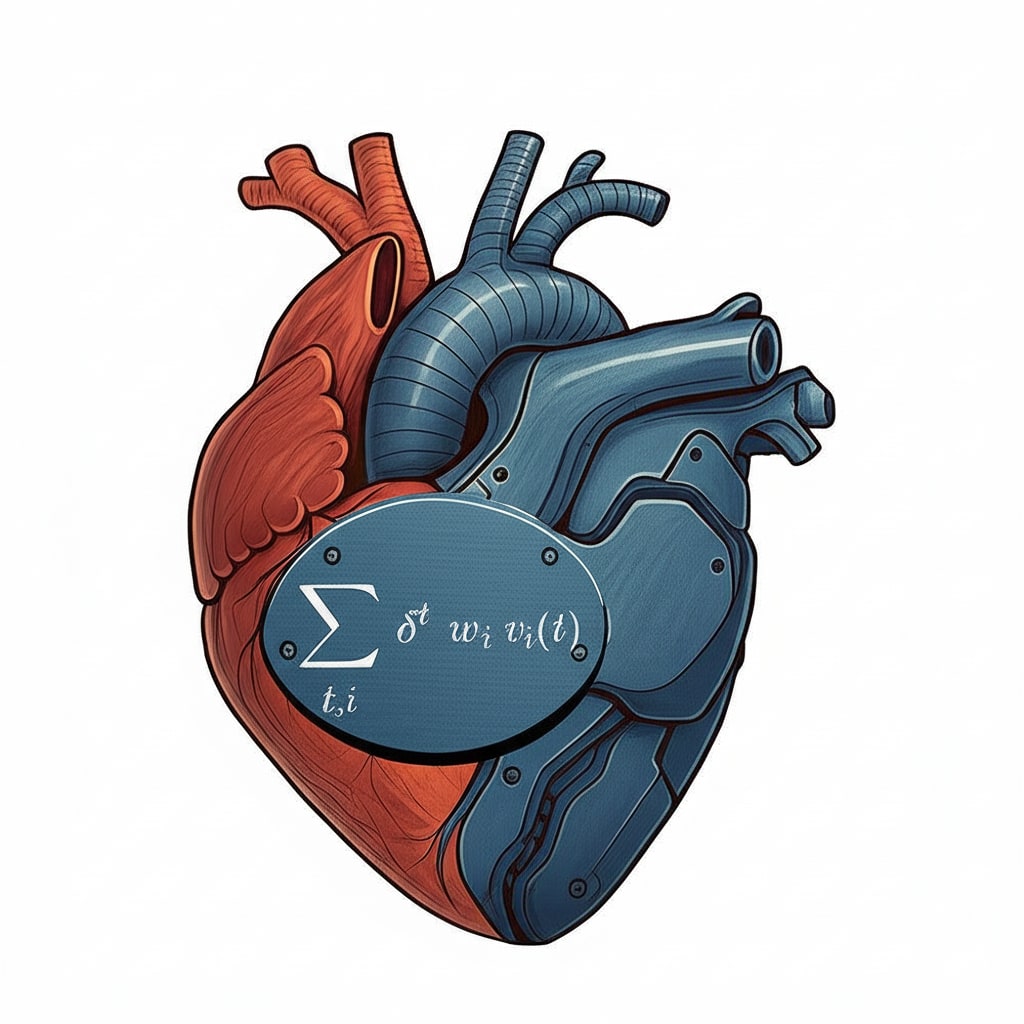
The framework is intentionally forward-compatible with the potential emergence of sentient artificial agents. This consideration is crucial, as discussed by my colleagues in their recent post, "Will Sentience Make AI’s Morality Better?". Sentient AI welfare can naturally be included in the w-vector.
Time × Scope already treats a future sentient AI as a moral patient through the w parameter. Turning such an AI into a moral agent is handled by the same framework plus the constitutional guard-rails: any autonomous system must optimise U = Σδᵗ wᵢ vᵢ(t) and pass self-critique against the constitution. That said, details of AI accountability and sanction mechanisms are out of scope for this post and will be covered in a follow-up on agent governance.
Conclusion
If my previous post "How the Human Psychological 'Program' Undermines AI Alignment" highlighted why we need a structured compensatory approach, this post outlines how we might begin to implement it. The Time × Scope framework provides a clear, practical starting point for aligning AI systems to our best ethical selves, facilitating both immediate improvement and scalable long-term adaptation.
Open Questions to the Community
To further refine and operationalize the Time × Scope framework, we invite the community to reflect on and discuss the following questions:
- Measurement and Specification: How should we concretely measure and specify the components of the v-vector? Are there robust methods or metrics already available?
- δ Calibration: What criteria should guide the selection of δ? Should δ always be constitutionally set to ≥ 1, or are there legitimate contexts where discounting future outcomes might be ethically justifiable?
- Moral Scope (w): How can we democratically determine the appropriate moral weights (w) for different groups (including sentient AI)? How can non-humans be represented in such a process? What governance structures would best support continuous, inclusive calibration?
- Computational Approximations: What are the most reliable and efficient computational methods for approximating the potentially infinite and complex calculations implied by the Time × Scope framework?
- Ethical Safeguards: What additional ethical guardrails or constitutional principles might be necessary to prevent misuse or unintended ethical drift?
Your critiques, insights, and collaborative input are warmly welcomed.
Ronen Bar @ 2025-06-24T08:13 (+2)
Thanks. I think as time horizon gets bigger, uncertainty may also get bigger, and this should be calculated into the expected value formula.
Beyond Singularity @ 2025-06-24T11:03 (+1)
Great point! Uncertainty really does explode the further we look ahead, and we need to handle that without giving up our long-term responsibilities.
How Time × Scope can deals with it
1. Separate “how much we care” (δ) from “how sure we are” (ρ).
- δ tells the AI how strongly we want to value future outcomes.
- ρ(t) is a confidence term that shrinks as forecasts get fuzzier — e.g. ρ(t)=e^{-kt} or a Bayesian CI straight from the model.
Revised utility: U = Σ [ δ^t × ρ(t) × w_i × v_i(t) ].
2. Set a constitutional horizon (T_max).
- Example rule: “Ignore outcomes beyond 250 years unless ρ(t) > 0.15.”
- Stops the system from chasing ultra-speculative tail events.
3. In practice it’s already truncated.
- Training usually uses finite roll-outs (say 100 years) and adds model-based uncertainty: low-confidence predictions get auto-discounted.
So, δ keeps our ethical aspiration for the long term alive, while ρ(t) and T_max keep us realistic about what we can actually predict. Experts can update the ρ(t) curve as forecasting methods improve, so the system stays both principled and practical.
VeryJerry @ 2025-06-30T11:17 (+1)
Have you read the breakdown of will by George Ainslie? I've only read the precis, I can't find a free download link but I'm sure you can find it on libgen, or feel free to ask me for my copy, but it goes in to how specifics of how we discount the future, as well as exploring different ways we're able to influence our future self into doing anything at all.
Beyond Singularity @ 2025-06-30T11:48 (+1)
Thanks for reading the post — and for the pointer! I only know Ainslie’s Breakdown of Will from summaries and some work on hyperbolic discounting, so I’d definitely appreciate a copy if you're open to sharing.
The Time × Scope model currently uses exponential discounting just for simplicity, but it's modular — Ainslie’s hyperbolic function (or even quasi-hyperbolic models like β-δ) could easily be swapped in without breaking the structure.
Curious: what parts of Breakdown of Will do you find most relevant for thinking about long-term moral commitment or self-alignment? Would love to dive deeper into those sections first.
VeryJerry @ 2025-06-30T14:19 (+1)
Not sure how to share a file over the ea forum, if you direct message me your email address or message me on signal I can send it to you (or anyone else reading, feel free to do either of those).
In terms of self alignment, it seems pretty geared towards human psychology, so there's no guarantee it would work for AI, but one strategy discussed in it is recognizing that {what you choose now will affect what decisions you'll make in the future} can make it easier to re-prioritize the long term. For example, if you're trying to lose weight and are tempted to eat a cookie, it may be very difficult to resist just by thinking about the end goal, but if you think "if I eat it now, it'll be more likely that I'll give in to temptation next time too" then that can help make it easier to resist. Another strategy is to find ways to make limiting decisions when the bad option and good option are both in the future (it's easier to not buy cookies at the store than it is to resist them when they're in the pantry. It's easier to not get them from the pantry than to resist them sitting next to you).
Obviously the cookie is an amoral choice, but a morally relevant one like the dam example might be "If we're the type of society that will build the dam despite the long term costs (which should outweigh the short term gain), then we will be more likely to make bad-in-the-long-run choices in the future, which will lead to much worse outcomes overall", and that future of compounded bad decisions might be bad enough to tip the scale to choosing to make the long-run-good choices more often.
Beyond Singularity @ 2025-06-30T16:07 (+2)
Thanks — I’ll DM you an address; I’d love to read the full book.
And I really like the cookie example: it perfectly illustrates how self-prediction turns a small temptation into a long-run coordination problem with our future selves. That mechanism scales up neatly to the dam scenario: when a society “eats the cookie” today, it teaches its future selves to discount tomorrow’s costs as well.
Those two Ainslie strategies — self-prediction and early pre-commitment — map nicely onto Time × Scope: they effectively raise the future’s weight (δ) without changing the math. I’m keen to plug his hyperbolic curve into the model and see how it reshapes optimal commitment devices for individuals and, eventually, AI systems.
Thanks again for offering the file and for the clear, memorable examples!
Janneke Blake @ 2025-06-29T17:20 (+1)
I first went to go read your previous post "How the Human Psychological 'Program' Undermines AI Alignment" and this is all super interesting! The possibility of future sentient beings is mind-blowing!
I'm really interested in how we measure moral value across species. I think standardizing a global animal sentience scale and including this kind of data in the w-vector is essential for fair AI alignment. Very exciting also that giving sentient animals moral weight in ethical decisions will lead to policy impact - affecting farming practices, AI-driven environmental policy and synthetic meat decisions.
Beyond Singularity @ 2025-06-30T14:36 (+1)
Thank you for such a thoughtful comment and deep engagement with my work! I’m thrilled this topic resonates with you—especially the idea of moral weight for future sentient beings. It’s truly a pivotal challenge.
I agree completely: standardizing a sentience scale (for animals, AI, even hypothetical species) is foundational for a fair w-vector. As you rightly noted, this will radically reshape eco-policy, agritech, and AI ethics.
This directly ties into navigating uncertainty (which you highlighted!), where I argue for balancing two imperatives:
- Moral conservatism: Upholding non-negotiable safeguards (e.g., preventing extreme suffering),
- Progressive expansion: Carefully extending moral circles amid incomplete data.
Where do you see the threshold? For instance:
- Should we require 90% confidence in octopus sentience before banning live-boiling?
- Or act on a presumption of sentience for such beings?