Niche vs. broad-appeal posts (& how this relates to usefulness/karma) (a sketch)
By Lizka @ 2022-12-17T18:11 (+34)
Meta-TL;DR:
I[1] sketch out a way to visualize the usefulness of posts (based on how many people read them and how useful the average reading is), and brief thoughts on how this interacts with Forum karma.
Image TL;DR:
This is a Draft Amnesty Day draft. That means it’s not polished, it’s probably not up to my standards, the ideas are not thought out, and I haven’t checked everything. I was explicitly encouraged[2] to post something unfinished! I wrote this a while back and am sharing mostly unedited. It's rough and probably wrong in important ways. |
| Commenting and feedback guidelines: I’m going with the default — please be nice. But constructive feedback is appreciated; please let me know what you think is wrong. Feedback on the structure of the argument is also appreciated. |
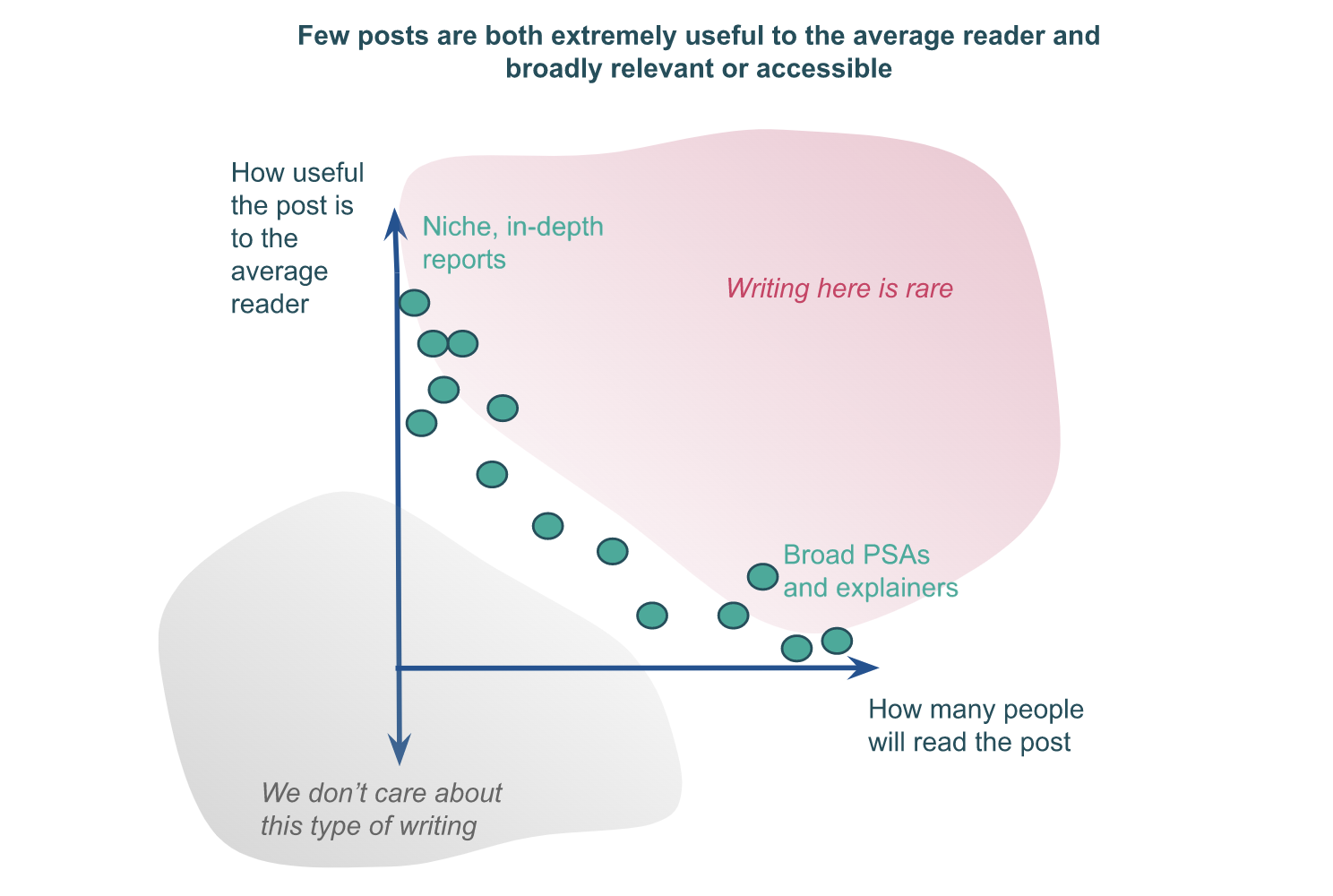
Usefulness of a post is the product of the number of readers the post will have and the extent to which the average reader finds the post useful. (Sort of.[3])
Here’s a way to visualize it:
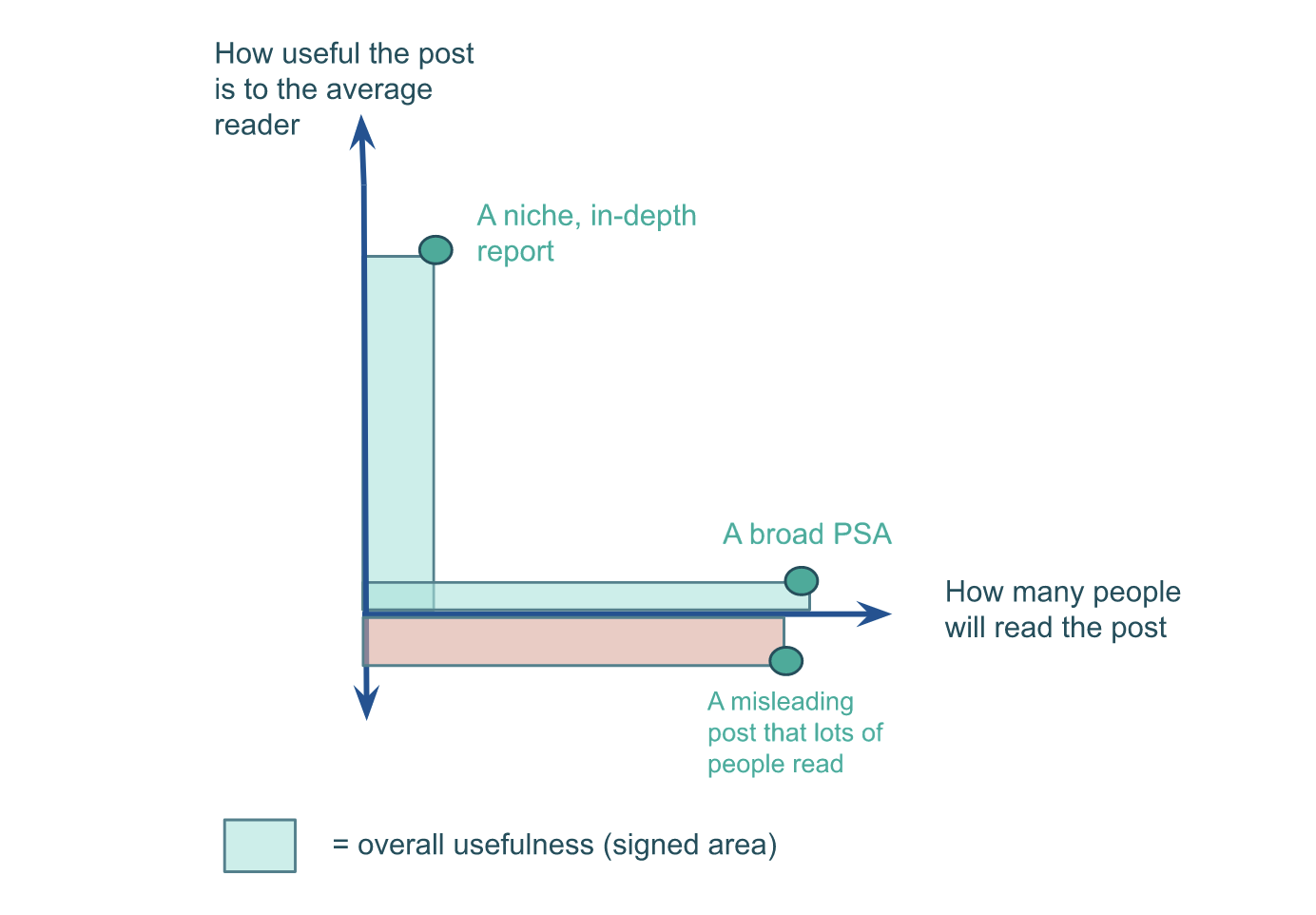
If you know exactly who you’re writing to, you’ll know exactly what will be interesting and useful to them, what information they already know, etc. Compare this to a case when you’re writing for a broader audience — you’ll need to make guesses about what is common knowledge and what isn’t, you won’t be able to tailor the information to the needs of the readers, etc. This weakness of broad-appeal posts means that they’ll probably be less useful to the average reader than more niche posts.
This — as well as experience interacting with lots of posts — leads me to believe that there’s an anti-correlation between breadth of appeal of a post, and usefulness of the post for a reader; nicher posts tend to be more useful to the average reader, and broader posts tend to be less useful to the average reader.
Visualized:
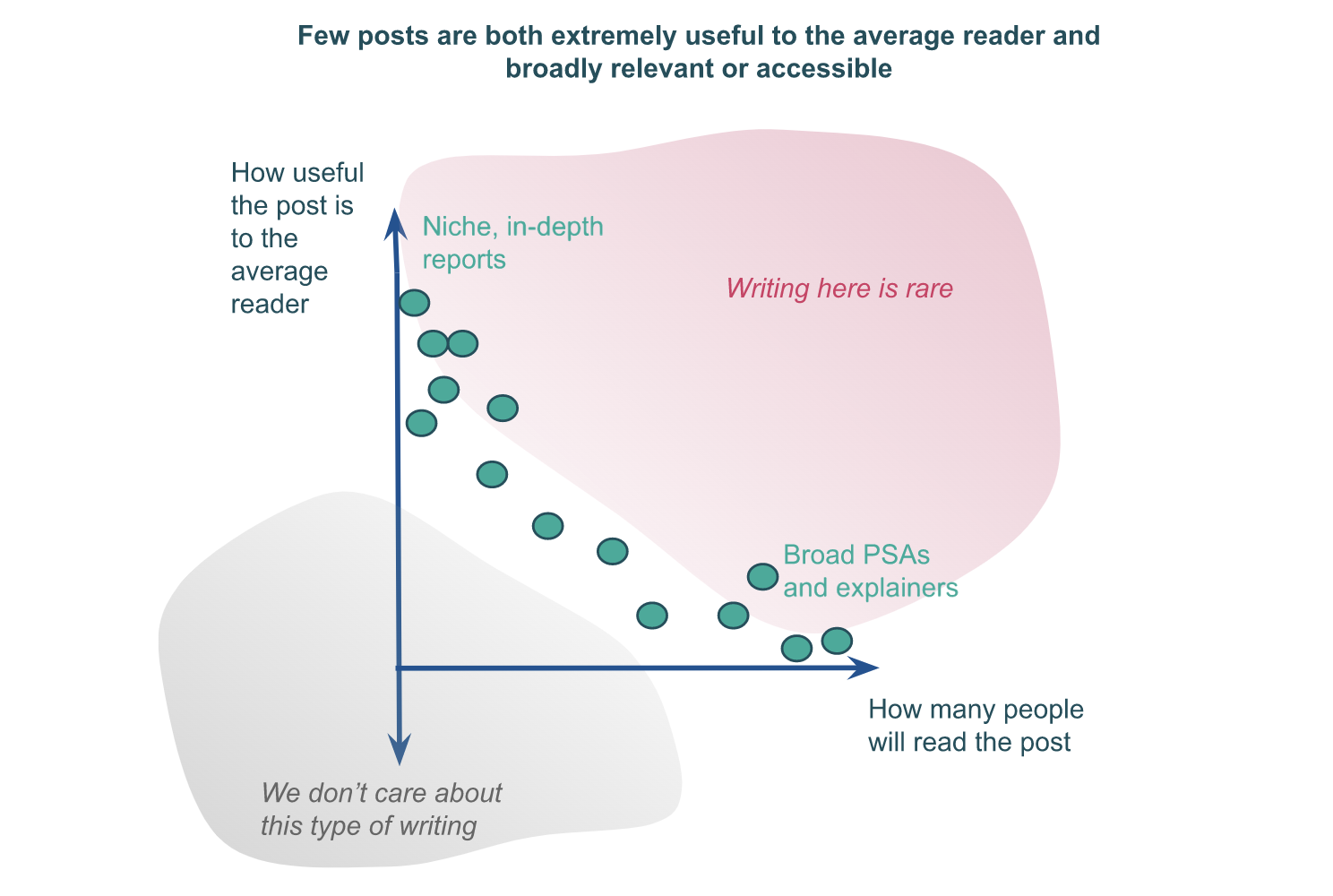
Some weaknesses of the model:
- Averages are hard to track, interpret, and use when a distribution is long-tailed (because samples don’t get the long tails). [EXPLAIN?]
- Some posts are only useful if multiple people see them?
- [I was going to write more, never did]
Karma rewards broad-appeal more than niche-but-extremely-useful posts
If users could report exactly how useful a post was to them[4] in util-points or something, and they actually did that accurately and consistently, and the Forum took that, added the util-scores from all readers, and reported the overall usefulness of a post in the total-util-score, then we’d be tracking something like overall usefulness of the post.
But this system would be difficult to set up, and probably impossible to do well. For one thing, it is incredibly game-able (a user can report 100000 util-points on their friend’s post, for instance), and we can’t rely on the honesty of every user.
Instead, we have karma. We encourage people to upvote posts they found useful, so that others will see them. For posts that are accessible and of interest to everyone — posts that are on the right (and, generally, on the bottom) side of the chart above, karma works pretty well; lots of people will upvote the posts they found useful, and people won’t upvote (or will even downvote) the posts they thought were uninformative or misleading. For posts in the upper left-hand corner of the chart, however, we’ll see that a few people will find them extremely useful, but each of these people will only give a strong upvote at most. So the karma distribution of a bunch of posts that are approximately equally useful will look something like:
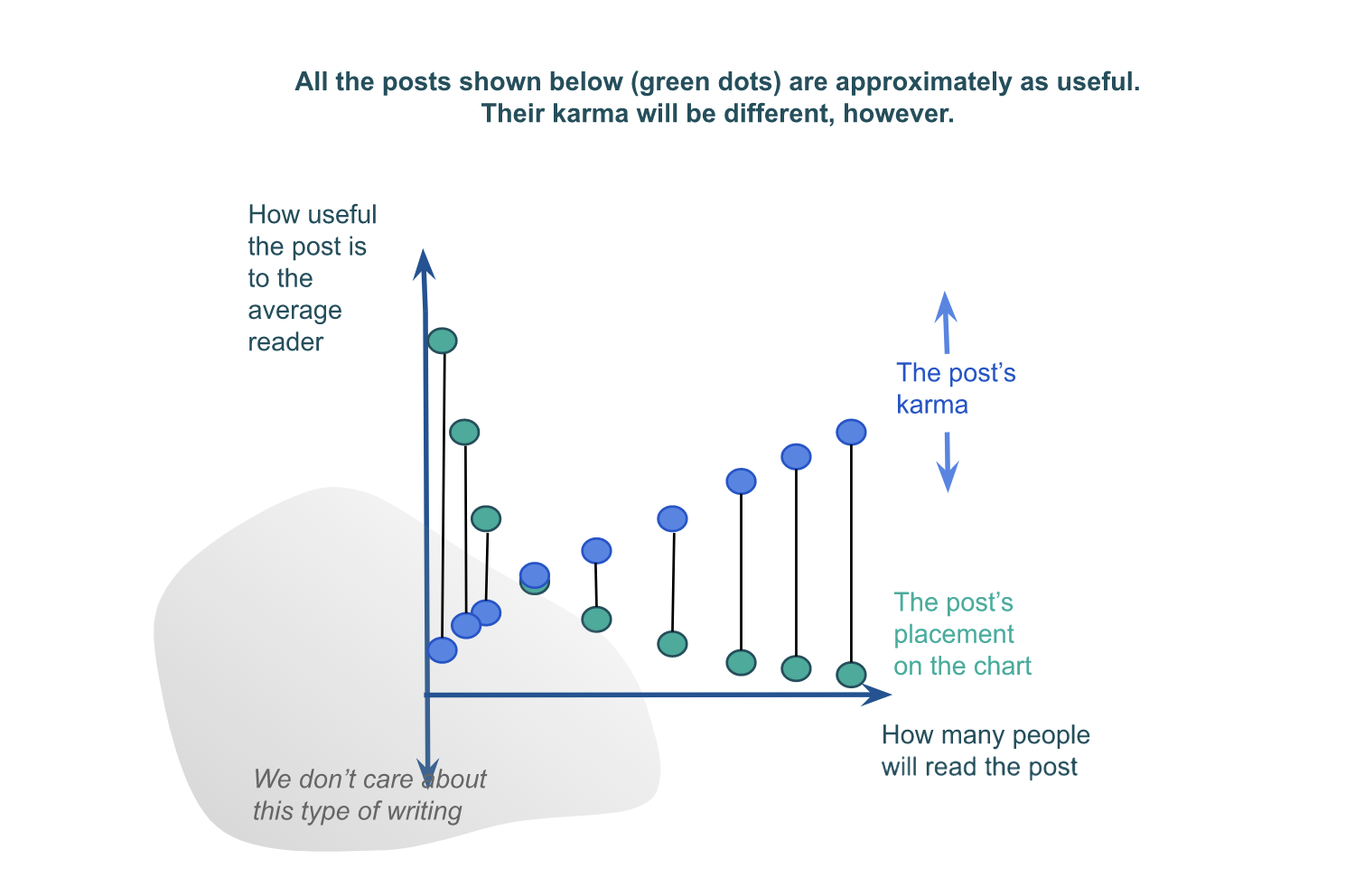
I basically think that’s fine, as long as everyone who needs to see a useful post on the left side does see it. Unfortunately, that does always not happen, as those posts will disappear from the Frontpage too fast (this is one of the reasons we’re working on subforums).
- ^
I am speaking for myself, not my team or my employer.
- ^
By... myself. Let's ignore that, I guess. I didn't think through how this template would work if I used it. :)
- ^
Obviously, this model is imperfect. I note some failures [below].
- ^
(or how much value they think the world got from them reading the post, if the post was a request by the author that wasn’t useful to the reader)
Emrik @ 2024-05-16T10:43 (+3)
(Publishing comment-draft that's been sitting here two years, since I thought it was good (even if super-unfinished…), and I may wish to link to it in future discussions. As always, feel free to not-engage and just be awesome. Also feel free to not be awesome, since awesomeness can only be achieved by choice (thus, awesomeness may be proportional to how free you feel to not be it).)
Yes! This relates to what I call costs of compromise.
Costs of compromise
As you allude to by the exponential decay of the green dots in your last graph, there are exponential costs to compromising what you are optimizing for in order to appeal to a wider variety of interests. On the flip-side, how usefwl to a subgroup you can expect to be is exponentially proportional to how purely you optimize for that particular subset of people (depending on how independent the optimization criteria are). This strategy is also known as "horizontal segmentation".[1]
The benefits of segmentation ought to be compared against what is plausibly an exponential decay in the number of people who fit a marginally smaller subset of optimization criteria. So it's not obvious in general whether you should on the margin try to aim more purely for a subset, or aim for broader appeal.
Specialization vs generalization
This relates to what I think are one of the main mysteries/trade-offs in optimization: specialization vs generalization. It explains why scaling your company can make it more efficient (economies of scale),[2] why the brain is modular,[3] and how Howea palm trees can speciate without the aid of geographic isolation (aka sympatric speciation constrained by genetic swamping) by optimising their gene pools for differentially-acidic patches of soil and evolving separate flowering intervals in order to avoid pollinating each other.[4]
Conjunctive search
When you search for a single thing that fits two or more criteria, that's called "conjunctive search". In the image, try to find an object that's both [colour: green] and [shape: X].

My claim is that this analogizes to how your brain searches for conjunctive ideas: a vast array of preconscious ideas are selected from a distribution of distractors that score high in either one of the criteria.
10d6 vs 1d60
Preamble2: When you throw 10 6-sided dice (written as "10d6"), the probability of getting a max roll is much lower compared to if you were throwing a single 60-sided dice ("1d60"). But if we assume that the 10 6-sided dice are strongly correlated, that has the effect of squishing the normal distribution to look like the uniform distribution, and you're much more likely to roll extreme values.
Moral: Your probability of sampling extreme values from a distribution depends the number of variables that make it up (i.e. how many factors convolved over), and the extent to which they are independent. Thus, costs of compromise are much steeper if you're sampling for outliers (a realm which includes most creative thinking and altruistic projects).
Spaghetti-sauce fallacies 🍝
If you maximally optimize a single spaghetti sauce for profit, there exists a global optimum for some taste, quantity, and price. You might then declare that this is the best you can do, and indeed this is a common fallacy I will promptly give numerous examples of. [TODO…]
But if you instead allow yourself to optimize several different spaghetti sauces, each one tailored to a specific market, you can make much more profit compared to if you have to conjunctively optimize a single thing.
Thus, a spaghetti-sauce fallacy is when somebody asks "how can we optimize thing more for criteria ?" when they should be asking "how can we chunk/segment into cohesive/dimensionally-reduced segments so we can optimize for {, ..., } disjunctively?"
People rarely vote based on usefwlness in the first place
As a sidenote: People don't actually vote (/allocate karma) based on what they find usefwl. That's a rare case. Instead, people overwhelmingly vote based on what they (intuitively) expect others will find usefwl. This rapidly turns into a Keynesian Status Contest with many implications. Information about people's underlying preferences (or what they personally find usefwl) is lost as information cascades are amplified by recursive predictions. This explains approximately everything wrong about the social world.

Already in childhood, we learn to praise (and by extension vote) based on what kinds of praise other people will praise us for. This works so well as a general heuristic that it gets internalized and we stop being able to notice it as an underlying motivation for everything we do.
- ^
See e.g. spaghetti sauce.
- ^
Scale allows subunits (e.g. employees) to specialize at subtasks.
- ^
Every time a subunit of the brain has to pull double-duty with respect to what it adapts to, the optimization criteria compete for its adaptation—this is also known as "pleiotropy" in evobio, and "polytely" in… some ppl called it that and it's a good word.
- ^
This palm-tree example (and others) are partially optimized/goodharted for seeming impressive, but I leave it in because it also happens to be deliciously interesting and possibly entertaining as examples of a costs of compromise. I want to emphasize how ubiquitous this trade-off is.