o3
By Zach Stein-Perlman @ 2024-12-20T21:00 (+84)
See livestream, site, OpenAI thread, Nat McAleese thread.
OpenAI announced (but isn't yet releasing) o3 and o3-mini (skipping o2 because of telecom company O2's trademark). "We plan to deploy these models early next year." "o3 is powered by further scaling up RL beyond o1"; I don't know whether it's a new base model.
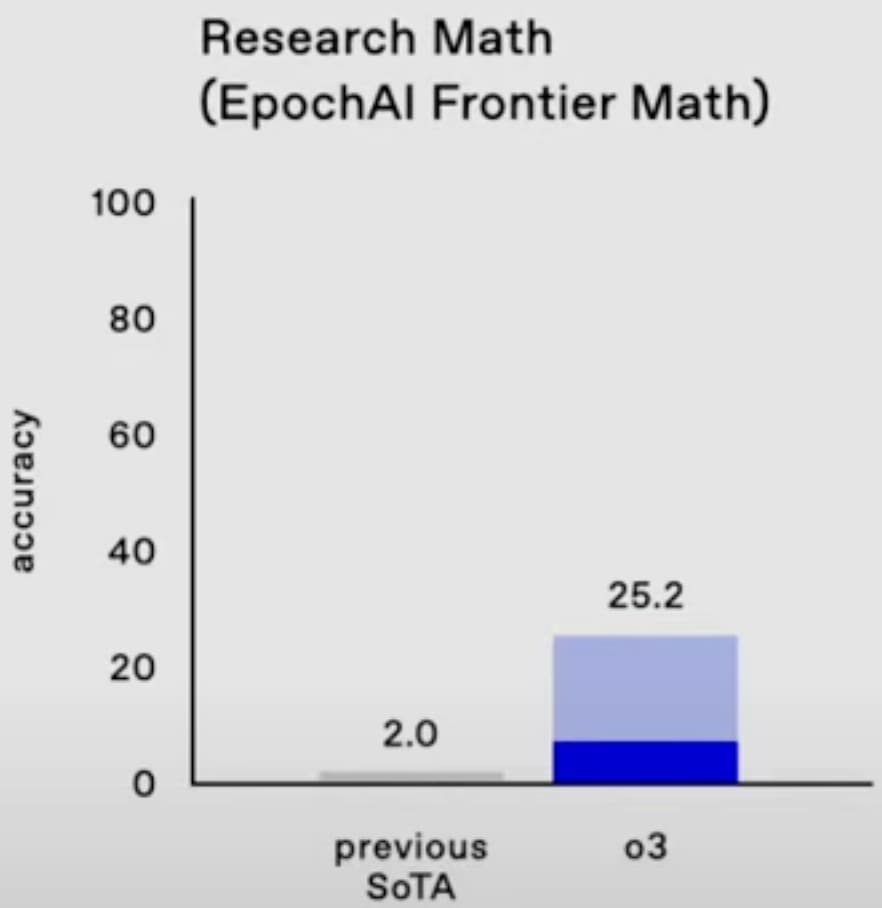
o3 gets 25% on FrontierMath, smashing the previous SoTA. (These are really hard math problems.[1]) Wow. (The dark blue bar, about 7%, is presumably one-attempt and most comparable to the old SoTA; unfortunately OpenAI didn't say what the light blue bar is, but I think it doesn't really matter and the 25% is for real.[2])
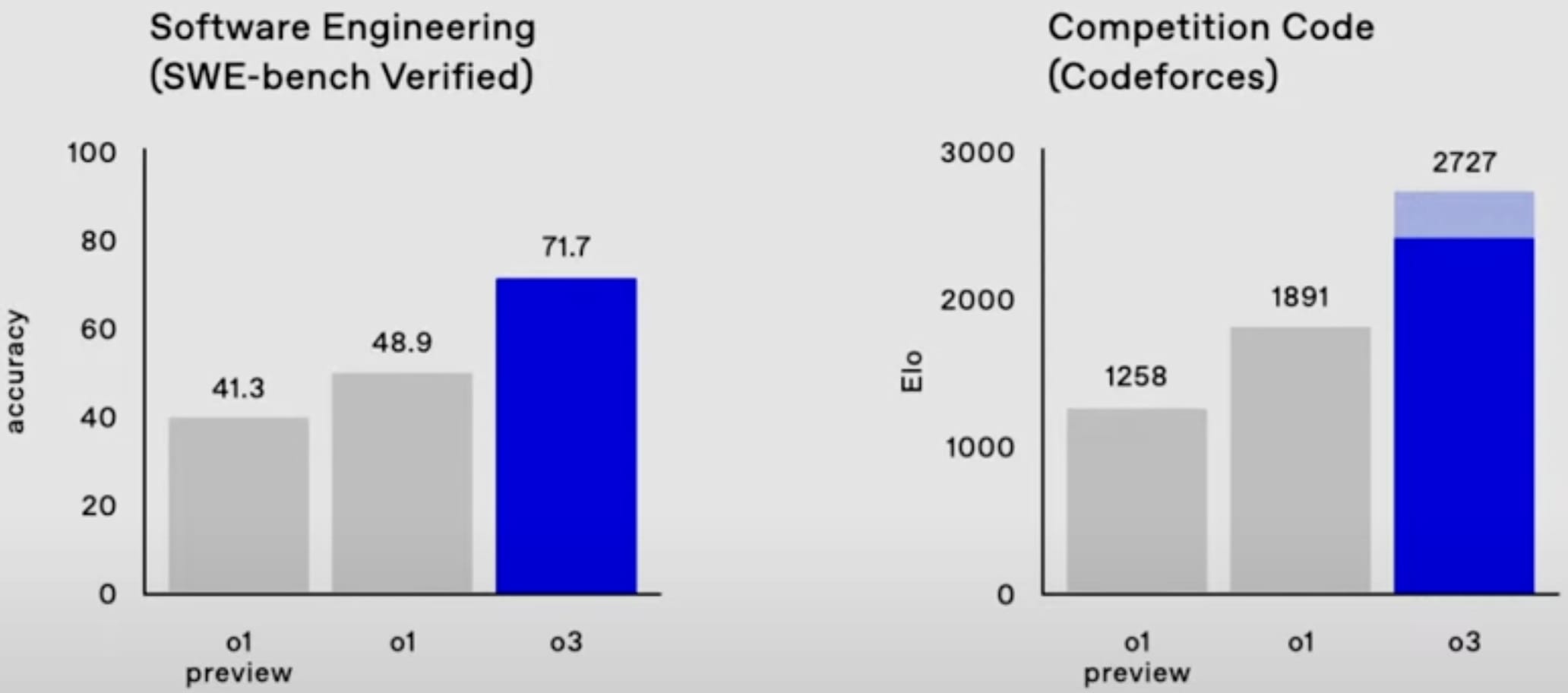
o3 also is easily SoTA on SWE-bench Verified and Codeforces.
It's also easily SoTA on ARC-AGI, after doing RL on the public ARC-AGI problems[3] + when spending $4,000 per task on inference (!).[4] (And at less inference cost.)
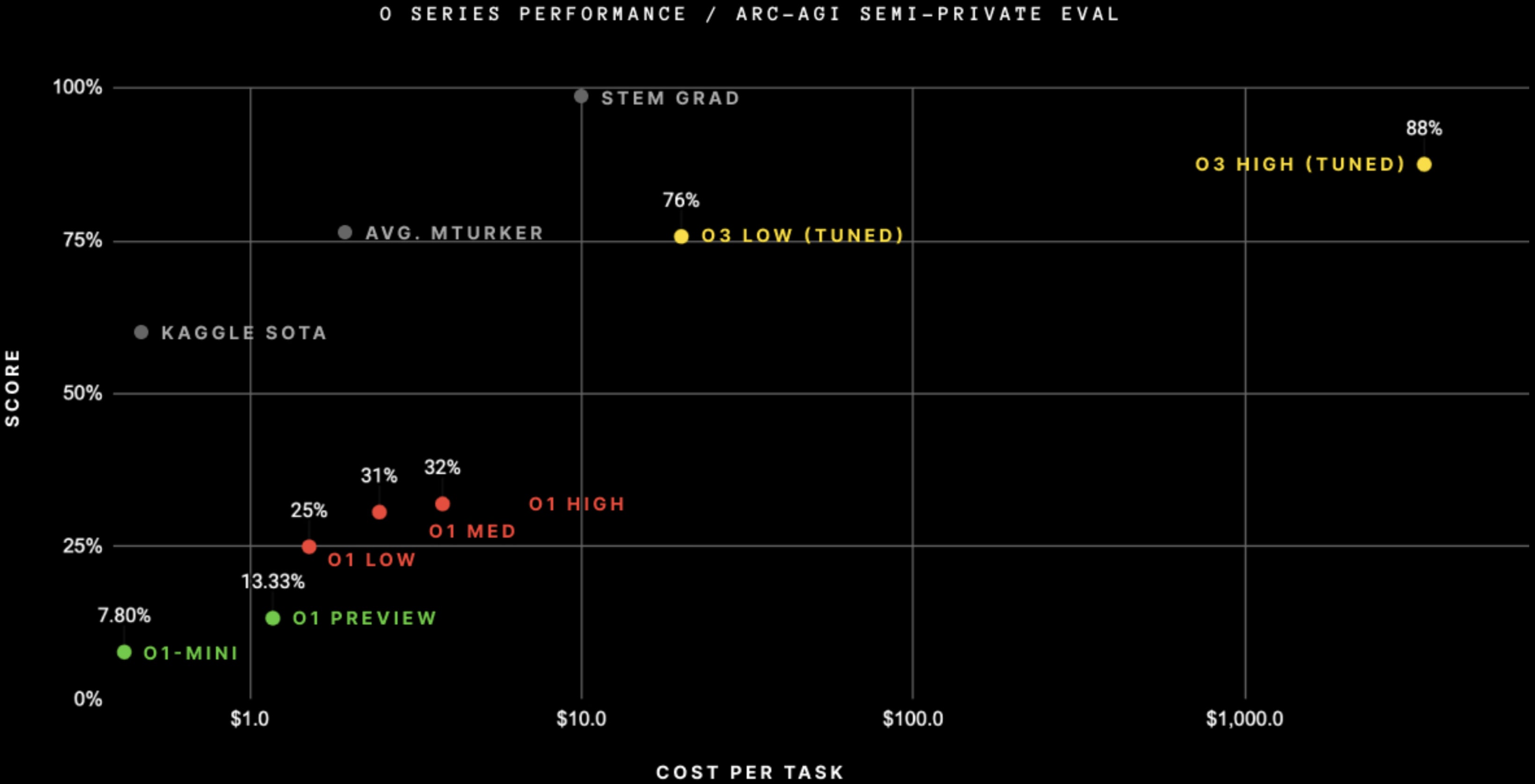
ARC Prize says:
At OpenAI's direction, we tested at two levels of compute with variable sample sizes: 6 (high-efficiency) and 1024 (low-efficiency, 172x compute).
OpenAI has a "new alignment strategy." (Just about the "modern LLMs still comply with malicious prompts, overrefuse benign queries, and fall victim to jailbreak attacks" problem.) It looks like RLAIF/Constitutional AI. See Lawrence Chan's thread.[5]
OpenAI says "We're offering safety and security researchers early access to our next frontier models"; yay.
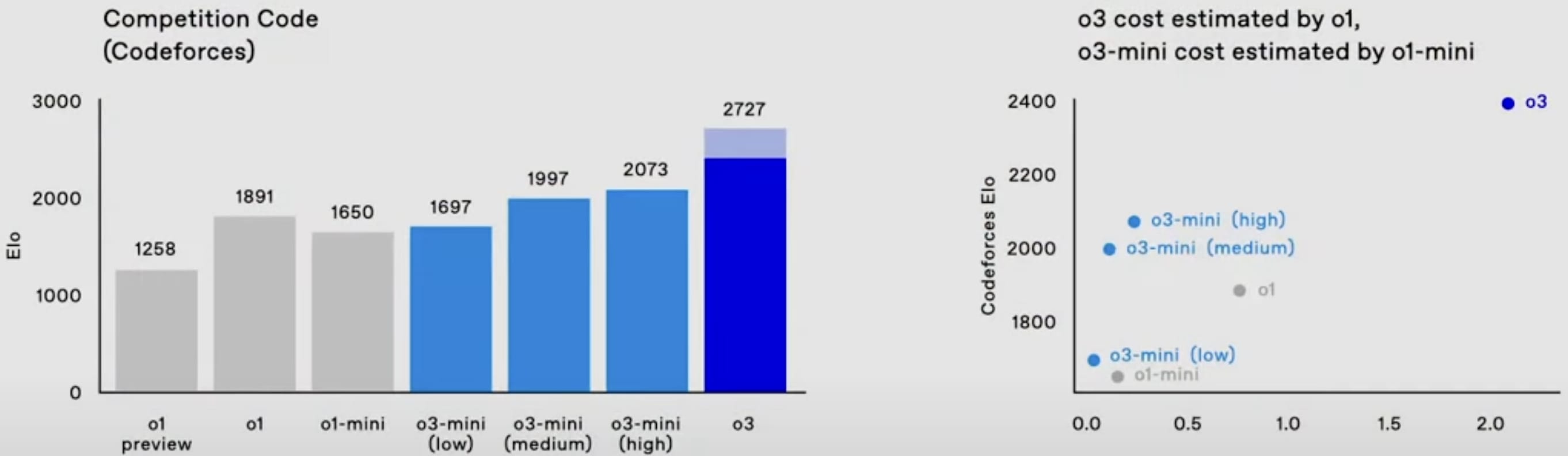
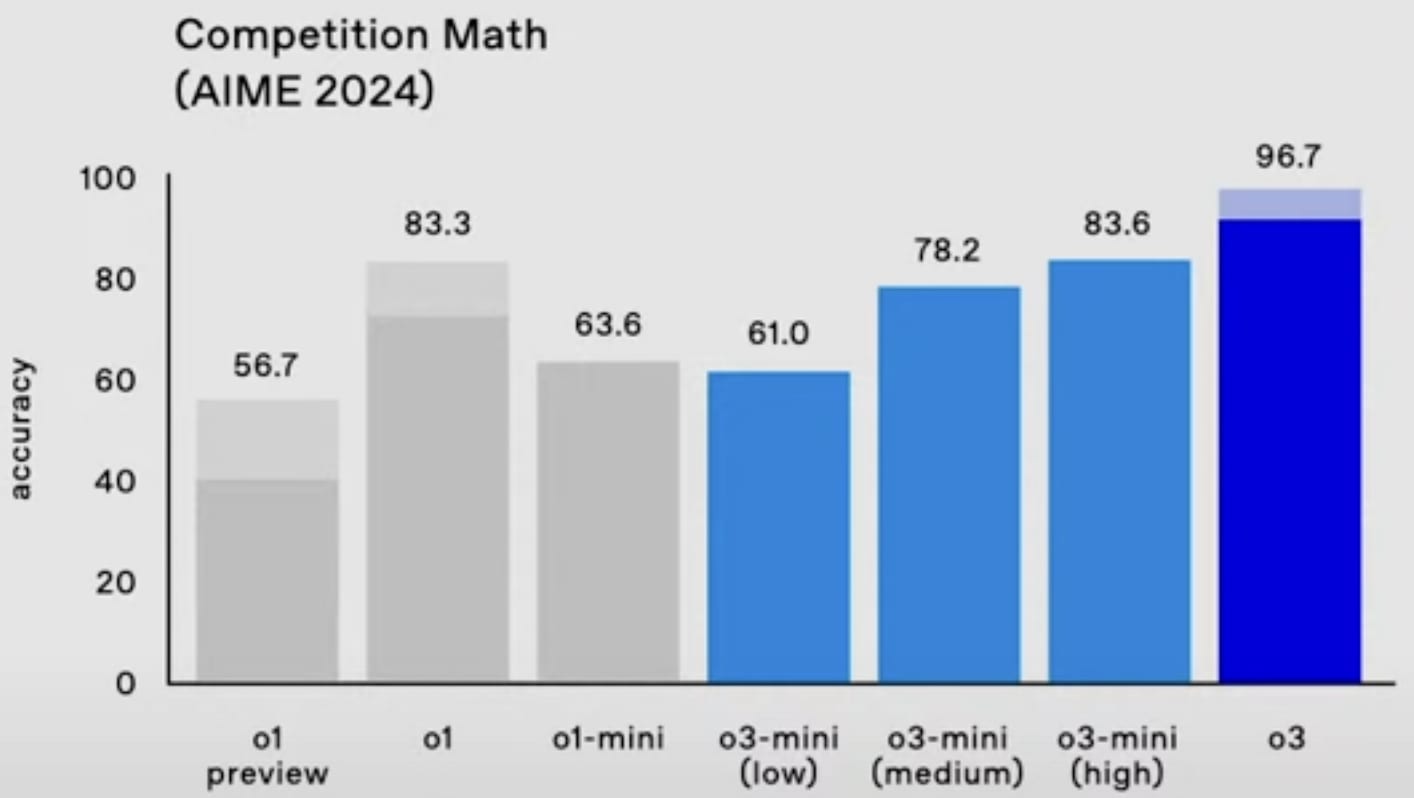
o3-mini will be able to use a low, medium, or high amount of inference compute, depending on the task and the user's preferences. o3-mini (medium) outperforms o1 (at least on Codeforces and the 2024 AIME) with less inference cost.
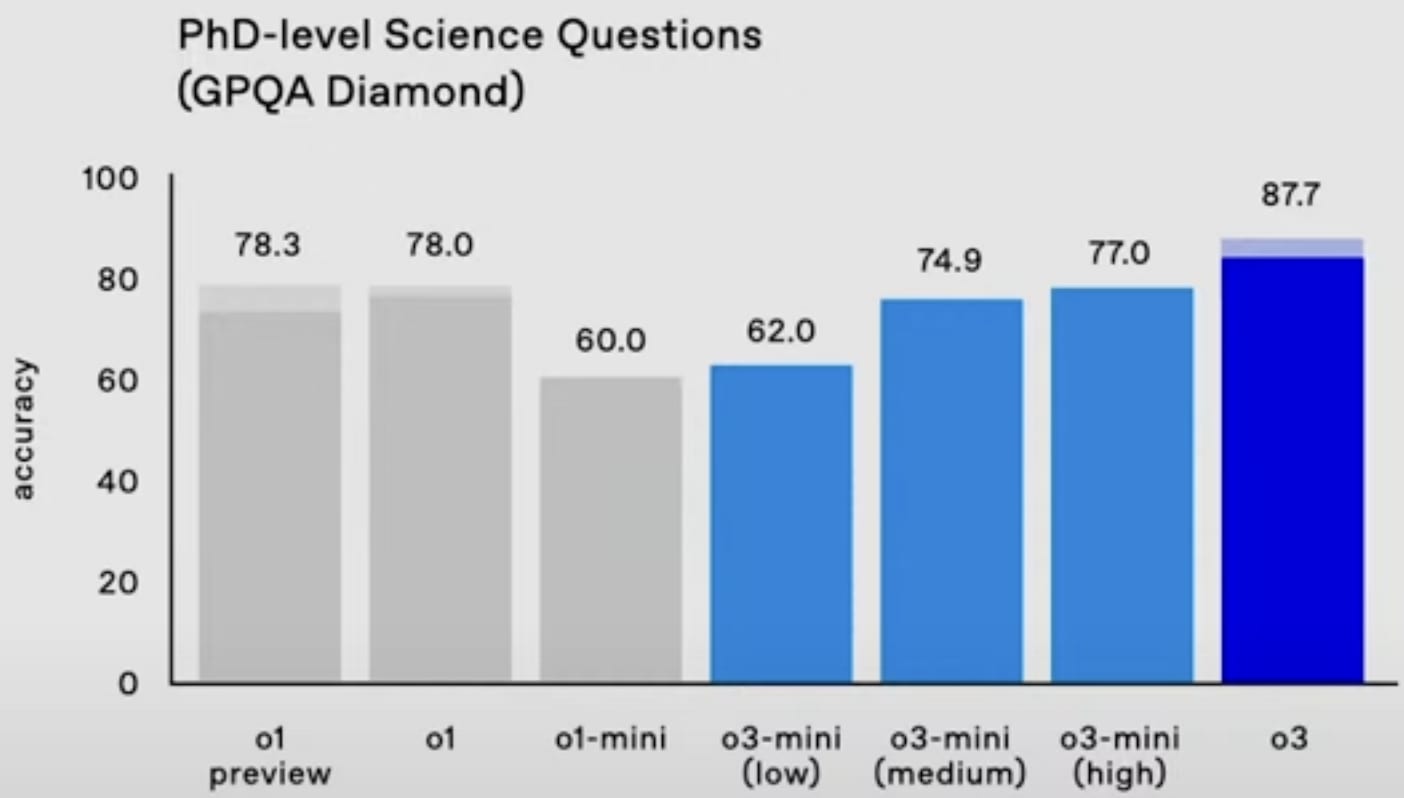
GPQA Diamond:
- ^
Update: most of them are not as hard as I thought:
There are 3 tiers of difficulty within FrontierMath: 25% T1 = IMO/undergrad style problems, 50% T2 = grad/qualifying exam style [problems], 25% T3 = early researcher problems.
- ^
My guess is it's consensus@128 or something (i.e. write 128 answers and submit the most common one). Even if it's pass@n (i.e. submit n tries) rather than consensus@n, that's likely reasonable because I heard FrontierMath is designed to have easier-to-verify numerical-ish answers.
Update: it's not pass@n.
- ^
Correction: no RL! See comment.
Correction to correction: nevermind, I'm confused.
- ^
It's not clear how they can leverage so much inference compute; they must be doing more than consensus@n. See Vladimir_Nesov's comment.
- ^
Update: see also disagreement from one of the authors.
tobycrisford 🔸 @ 2024-12-21T07:00 (+14)
The ARC performance is a huge update for me.
I've previously found Francois Chollet's arguments that LLMs are unlikely to scale to AGI pretty convincing. Mainly because he had created an until-now unbeaten benchmark to back those arguments up.
But reading his linked write-up, he describes this as "not merely an incremental improvement, but a genuine breakthrough". He does not admit he was wrong, but instead paints o3 as something fundamentally different to previous LLM-based AIs, which for the purpose of assessing the significance of o3, amounts to the same thing!
Hawk.Yang 🔸 @ 2024-12-22T03:40 (+9)
Honestly, not sure I would agree with this. Like Chollet said, this is fundamentally different from simply scaling the amount of parameters (derived from pre-training) that a lot of previous scaling discourse centered around. To then take this inference time scaling stuff, which requires a qualitatively different CoT/Search Tree strategy to be appended to an LLM alongside an evaluator model, and call it scaling is a bit of a rhetorical sleight of hand.
While this is no doubt a big deal and a concrete step toward AGI, there are enough architectural issues around planning, multi-step tasks/projects and actual permanent memory (not just RAG) that I'm not updating as much as much as most people are on this. I would also like to see if this approach works on tasks without clear, verifiable feedback mechanisms (unlike software engineering/programming or math). My timelines remain in the 2030s.
tobycrisford 🔸 @ 2024-12-22T11:11 (+1)
It might be fair to say that the o3 improvements are something fundamentally different to simple scaling, and that Chollet is still correct in his 'LLMs will not simply scale to AGI' prediction. I didn't mean in my comment to suggest he was wrong about that.
I could imagine someone criticizing him for exaggerating how far away we were from coming up with the necessary new ideas, given the o3 results, but I'm not so interested in the debate about exactly how right or wrong the predictions of this one person were.
The interesting thing for me is: whether he was wrong, or whether he was right but o3 does represent a fundamentally different kind of model, the upshot for how seriously we should take o3 seems the same! It feels like a pretty big deal!
He could have reacted to this news by criticizing the way that o3 achieved its results. He already said in the Dwarkesh Patel interview that someone beating ARC wouldn't necessarily imply progress towards general intelligence if the way they achieved it went against the spirit of the task. When I clicked the link in this post, I thought it likely I was about to read an argument along those lines. But that's not what I got. Instead he was acknowledging that this was important progress.
I'm by no means an expert, but timelines in the 2030s still seems pretty close to me! I'd have thought, based on arguments from people like Chollet, that we might be a bit further off than that (although only with the low confidence of a layperson trying to interpret the competing predictions of experts who seem to radically disagree with each other).
Given all the problems you mention, and the high costs still involved in running this on simple tasks, I agree it still seems many years away. But previously I'd have put a fairly significant probability on AGI not being possible this century (as well as assigning a significant probability to it happening very soon, basically ending up highly uncertain). But it feels like these results make the idea that AGI is still 100 years away seem much less plausible than it was before.
Yarrow @ 2025-05-01T15:27 (+2)
A comment from François Chollet on this topic posted on Bluesky on January 6, 2025:
I don't think people really appreciate how simple ARC-AGI-1 was, and what solving it really means.
It was designed as the simplest, most basic assessment of fluid intelligence possible. Failure to pass signifies a near-total inability to adapt or problem-solve in unfamiliar situations.
Passing it means your system exhibits non-zero fluid intelligence -- you're finally looking at something that isn't pure memorized skill. But it says rather little about how intelligent your system is, or how close to human intelligence it is.
o3 gets 3% on ARC-AGI-2.
tobycrisford 🔸 @ 2025-05-01T20:08 (+1)
Sure, I think I've seen that comment before, and I'm aware Chollet also included loads of caveats in his initial write up of the o3 results.
But going from zero fluid intelligence to non-zero fluid intelligence seems like it should be considered a very significant milestone! Even if the amount of fluid intelligence is still small.
Previously there was a question around whether the new wave of AI models were capable of any fluid intelligence at all. Now, even someone like Chollet has concluded they are, so it just becomes a question of how easily those capabilities can scale?
That's the way I'm currently thinking about it anyway. Very open to the possibility that the nearness of AGI is still being overhyped.
Yarrow @ 2025-05-03T19:43 (+3)
I agree that it's a significant milestone, or at least it might be. I just read this comment a few hours ago (and the Twitter thread it links to) and that dampens my enthusiasm. 43 million words to solve one ARC-AGI-1 puzzle is a lot.
Also, I want to understand more about how ARC-AGI-2 is different from ARC-AGI-1. Chollet has said that about half of the tasks in ARC-AGI-1 turned out to be susceptible to "brute force"-type approaches. I don't know what that means.
I think it's easy to get carried away with the implications of a result like this when you're surrounded by so many voices saying that AGI is coming within 5 years or within 10 years.
My response to François Chollet's comments on o3's high score on ARC-AGI-1 was more like, "Oh, that's really interesting!" rather than making some big change to my views on AGI. I have to say, I was more excited about it before I knew it took 43 million words of text and over 1,000 attempts per task.
I still think no one knows how to build AGI and that (not unrelatedly) we don't know when AGI will be built.
Chollet recently started a new company focused on combining deep learning and program synthesis. That's interesting. He seems to think the major AI labs like OpenAI and Google DeepMind are also working on program synthesis, but I don't know how much publicly available evidence there is for this.
I can add Chollet's company to the list of organizations that I know of that have publicly discussed they're doing R&D related to AGI other than just scaling LLMs. The others I know of:
- The Alberta Machine Intelligence Institute and Keen Technologies, both organizations where Richard Sutton is a key person and which (if I understand correctly) are pursuing at least to some extent Sutton's "Alberta Plan for AI Research"
- Numenta, a company co-founded by Jeff Hawkins, who has made aggressive statements about Numenta's ability to develop AGI in the not-too-distant future using insights from neuroscience (the main insights they think they've found are described here)
- Yann LeCun's team at Meta AI, formerly FAIR; LeCun has published a roadmap to AGI, except he doesn't call it AGI
I might be forgetting one or two. I know in the past Demis Hassabis has made some general comments about DeepMind's research related to AGI, but I don't know of any specifics.
My gut sense is that all of these approaches will fail — program synthesis combined with deep learning, the Alberta Plan, Numenta's Thousand Brains Principles, and Yann LeCun's roadmap. But this is just a random gut intuition and not a serious, considered opinion.
I think the idea that we're barreling toward the imminent, inevitable invention of AGI is wrong. The idea is that AGI is so easy to invent and progress is happening so fast and so spontaneously that we can hardly stop ourselves from inventing AGI.
It would be seen as odd to take this view in any other area of technology, probably even among effective altruists. We would be lucky if we were barreling toward imminent, inevitable nuclear fusion or a universal coronavirus vaccine or a cure for cancer or any number of technologies that don't exist yet that we'd love to have.
Why does no one claim these technologies are being developed so spontaneously, so automatically, that we would have to take serious action to prevent them from being invented soon? Why is the attitude that progress is hard, success is uncertain, and the road is long?
Given that's how technology usually works, and I don't see any reason for AGI to be easier or take less time — in fact, it seems like it should be harder and take longer, since the science of intelligence and cognition is among the least understood areas of science — I'm inclined to guess that most approaches will fail.
Even if the right general approach is found, it could take a very long time to figure out how to actually make concrete progress using that approach. (By analogy, many of the general ideas behind deep learning existed for decades before deep learning started to take off around 2012.)
I'm interested in Chollet's interpretation of the o3 results on ARC-AGI-1 and if there is a genuine, fundamental advancement involved (which today, after finding out those details about o3's attempts, I believe less than I did yesterday) then that's exciting. But only moderately exciting because the advancement is only incremental.
The story that AGI is imminent and if we skirt disaster, we'll land in utopia is exciting and engaging. I think we live in a more boring version of reality (but still, all things considered, a pretty interesting one!) where we're still at the drawing board stage for AGI, people are pitching different ideas (e.g., program synthesis, the Alberta Plan, the Thousand Brain Principles, energy-based self-supervised learning), the way forward is unclear, and we're mostly in the dark about the fundamental nature of intelligence and cognition. Who knows how long it will take us to figure it out.
tobycrisford 🔸 @ 2025-05-04T15:47 (+2)
Interesting, thanks!
David M @ 2024-12-21T23:05 (+2)
Thanks for making the connection to Francois Chollet for me - I'd forgotten I'd read this interview with him by Dwarkesh Patel half a year ago that had made me a little more skeptical of the nearness of AGI.
Xing Shi Cai @ 2024-12-25T05:50 (+4)
Here's a skeptical take of o3 from a professional mathematician https://xenaproject.wordpress.com/2024/12/22/can-ai-do-maths-yet-thoughts-from-a-mathematician/