Catastrophic Risks from AI #1: Introduction
By Dan H @ 2023-06-22T17:09 (+28)
This is a linkpost to https://arxiv.org/abs/2306.12001
This is the first post in a sequence of posts giving an overview of catastrophic AI risks.
Abstract
Rapid advancements in artificial intelligence (AI) have sparked growing concerns among experts, policymakers, and world leaders regarding the potential for increasingly advanced AI systems to pose catastrophic risks. Although numerous risks have been detailed separately, there is a pressing need for a systematic discussion and illustration of the potential dangers to better inform efforts to mitigate them. This paper provides an overview of the main sources of catastrophic AI risks, which we organize into four categories: malicious use, in which individuals or groups intentionally use AIs to cause harm; AI race, in which competitive environments compel actors to deploy unsafe AIs or cede control to AIs; organizational risks, highlighting how human factors and complex systems can increase the chances of catastrophic accidents; and rogue AIs, describing the inherent difficulty in controlling agents far more intelligent than humans. For each category of risk, we describe specific hazards, present illustrative stories, envision ideal scenarios, and propose practical suggestions for mitigating these dangers. Our goal is to foster a comprehensive understanding of these risks and inspire collective and proactive efforts to ensure that AIs are developed and deployed in a safe manner. Ultimately, we hope this will allow us to realize the benefits of this powerful technology while minimizing the potential for catastrophic outcomes.
1 Introduction
The world as we know it is not normal. We take for granted that we can talk instantaneously with people thousands of miles away, fly to the other side of the world in less than a day, and access vast mountains of accumulated knowledge on devices we carry around in our pockets. These realities seemed far-fetched decades ago, and would have been inconceivable to people living centuries ago. The ways we live, work, travel, and communicate have only been possible for a tiny fraction of human history.
Yet, when we look at the bigger picture, a broader pattern emerges: accelerating development. Hundreds of thousands of years elapsed between the time Homo sapiens appeared on Earth and the agricultural revolution. Then, thousands of years passed before the industrial revolution. Now, just centuries later, the artificial intelligence (AI) revolution is beginning. The march of history is not constant—it is rapidly accelerating.
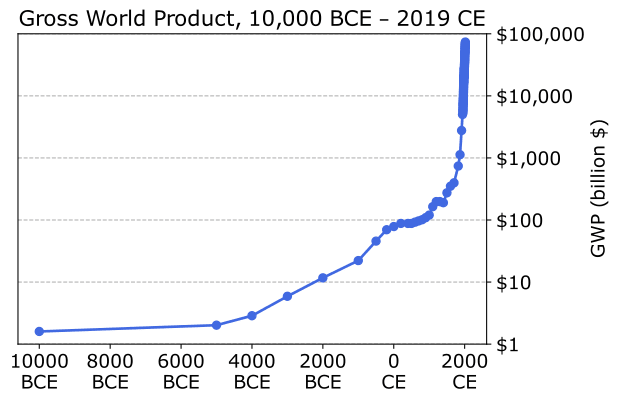
We can capture this trend quantitatively in Figure 1, which shows how estimated gross world product has changed over time [1, 2]. The hyperbolic growth it depicts might be explained by the fact that, as technology advances, the rate of technological advancement also tends to increase. Empowered with new technologies, people can innovate faster than they could before. Thus, the gap in time between each landmark development narrows.
It is the rapid pace of development, as much as the sophistication of our technology, that makes the present day an unprecedented time in human history. We have reached a point where technological advancements can transform the world beyond recognition within a human lifetime. For example, people who have lived through the creation of the internet can remember a time when our now digitally-connected world would have seemed like science fiction.
From a historical perspective, it appears possible that the same amount of development could now be condensed in an even shorter timeframe. We might not be certain that this will occur, but neither can we rule it out. We therefore wonder: what new technology might usher in the next big acceleration? In light of recent advances, AI seems an increasingly plausible candidate. Perhaps, as AI continues to become more powerful, it could lead to a qualitative shift in the world, more profound than any we have experienced so far. It could be the most impactful period in history, though it could also be the last.
Although technological advancement has often improved people's lives, we ought to remember that, as our technology grows in power, so too does its destructive potential. Consider the invention of nuclear weapons. Last century, for the first time in our species' history, humanity possessed the ability to destroy itself, and the world suddenly became much more fragile.
Our newfound vulnerability revealed itself in unnerving clarity during the Cold War. On a Saturday in October 1962, the Cuban Missile Crisis was cascading out of control. US warships enforcing the blockade of Cuba detected a Soviet submarine and attempted to force it to the surface by dropping low-explosive depth charges. The submarine was out of radio contact, and its crew had no idea whether World War III had already begun. A broken ventilator raised the temperature up to 140°F in some parts of the submarine, causing crew members to fall unconscious as depth charges exploded nearby.
The submarine carried a nuclear-armed torpedo, which required consent from both the captain and political officer to launch. Both provided it. On any other submarine in Cuban waters that day, that torpedo would have launched—and a nuclear third world war may have followed. Fortunately, a man named Vasili Arkhipov was also on the submarine. Arkhipov was the commander of the entire flotilla and by sheer luck happened to be on that particular submarine. He talked the captain down from his rage, convincing him to await further orders from Moscow. He averted a nuclear war and saved millions or billions of lives—and possibly civilization itself.
Carl Sagan once observed, “If we continue to accumulate only power and not wisdom, we will surely destroy ourselves” [3]. Sagan was correct: The power of nuclear weapons was not one we were ready for. Overall, it has been luck rather than wisdom that has saved humanity from nuclear annihilation, with multiple recorded instances of a single individual preventing a full-scale nuclear war.
AI is now poised to become a powerful technology with destructive potential similar to nuclear weapons. We do not want to repeat the Cuban Missile Crisis. We do not want to slide toward a moment of peril where our survival hinges on luck rather than the ability to use this technology wisely. Instead, we need to work proactively to mitigate the risks it poses. This necessitates a better understanding of what could go wrong and what to do about it.
Luckily, AI systems are not yet advanced enough to contribute to every risk we discuss. But that is cold comfort in a time when AI development is advancing at an unprecedented and unpredictable rate. We consider risks arising from both present-day AIs and AIs that are likely to exist in the near future. It is possible that if we wait for more advanced systems to be developed before taking action, it may be too late.
In this paper, we will explore various ways in which powerful AIs could bring about catastrophic events with devastating consequences for vast numbers of people. We will also discuss how AIs could present existential risks—catastrophes from which humanity would be unable to recover. The most obvious such risk is extinction, but there are other outcomes, such as creating a permanent dystopian society, which would also constitute an existential catastrophe. We outline many possible catastrophes, some of which are more likely than others and some of which are mutually incompatible with each other. This approach is motivated by the principles of risk management. We prioritize asking “what could go wrong?” rather than reactively waiting for catastrophes to occur. This proactive mindset enables us to anticipate and mitigate catastrophic risks before it's too late.
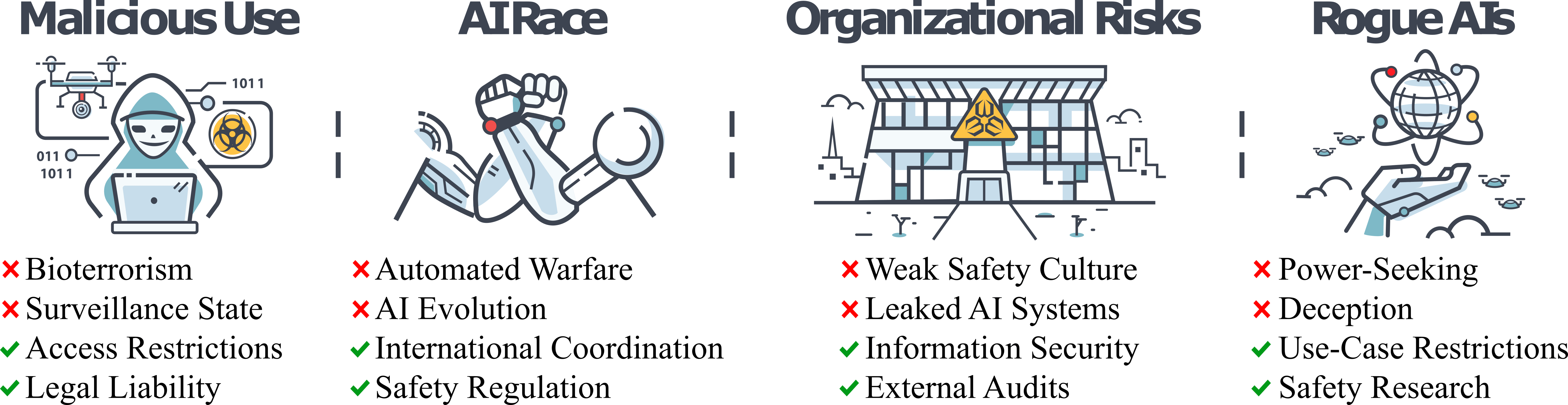
To help orient the discussion, we decompose catastrophic risks from AIs into four risk sources that warrant intervention:
- Malicious use: Malicious actors using AIs to cause large-scale devastation.
- AI race: Competitive pressures that could drive us to deploy AIs in unsafe ways, despite this being in no one's best interest.
- Organizational risks: Accidents arising from the complexity of AIs and the organizations developing them.
- Rogue AIs: The problem of controlling a technology more intelligent than we are.
These four sections—malicious use, AI race, organizational risks, and rogue AIs—describe causes of AI risks that are intentional, environmental, accidental, and internal, respectively [4].
We will describe how concrete, small-scale examples of each risk might escalate into catastrophic outcomes. We also include hypothetical stories to help readers conceptualize the various processes and dynamics discussed in each section, along with practical safety suggestions to avoid negative outcomes. Each section concludes with an ideal vision depicting what it would look like to mitigate that risk. We hope this survey will serve as a practical introduction for readers interested in learning about and mitigating catastrophic AI risks.
References
[1] David Malin Roodman. On the probability distribution of long-term changes in the growth rate of the global economy: An outside view. 2020.
[2] Tom Davidson. Could Advanced AI Drive Explosive Economic Growth? Tech. rep. June 2021.
[3] Carl Sagan. Pale Blue Dot: A Vision of the Human Future in Space. New York: Random House, 1994.
[4] Roman V Yampolskiy. “Taxonomy of Pathways to Dangerous Artificial Intelligence”. In: AAAI Workshop: AI, Ethics, and Society. 2016.
Dan H @ 2023-06-27T04:58 (+8)
A brief overview of the contents, page by page.
1: most important century and hinge of history
2: wisdom needs to keep up with technological power or else self-destruction / the world is fragile / cuban missile crisis
3: unilateralist's curse
4: bio x-risk
5: malicious actors intentionally building power-seeking AIs / anti-human accelerationism is common in tech
6: persuasive AIs and eroded epistemics
7: value lock-in and entrenched totalitarianism
8: story about bioterrorism
9: practical malicious use suggestions
10: LAWs as an on-ramp to AI x-risk
11: automated cyberwarfare -> global destablization
12: flash war, AIs in control of nuclear command and control
13: security dilemma means AI conflict can bring us to brink of extinction
14: story about flash war
15: erosion of safety due to corporate AI race
16: automation of AI research; autnomous/ascended economy; enfeeblement
17: AI development reinterpreted as evolutionary process
18: AI development is not aligned with human values but with competitive and evolutionary pressures
19: gorilla argument, AIs could easily outclass humans in so many ways
20: story about an autonomous economy
21: practical AI race suggestions
22: examples of catastrophic accidents in various industries
23: potential AI catastrophes from accidents, Normal Accidents
24: emergent AI capabilities, unknown unknowns
25: safety culture (with nuclear weapons development examples), security mindset
26: sociotechnical systems, safety vs. capabilities
27: safetywashing, defense in depth
28: story about weak safety culture
29: practical suggestions for organizational safety
30: more practical suggestions for organizational safety
31: bing and microsoft tay demonstrate how AIs can be surprisingly unhinged/difficult to steer
32: proxy gaming/reward hacking
33: goal drift
34: spurious cues can cause AIs to pursue wrong goals/intrinsification
35: power-seeking (tool use, self-preservation)
36: power-seeking continued (AIs with different goals could be uniquely adversarial)
37: deception examples
38: treacherous turns and self-awareness
39: practical suggestions for AI control
40: how AI x-risk relates to other risks
41: conclusion