Modeling the impact of AI safety field-building programs
By Center for AI Safety @ 2023-07-10T17:22 (+86)
Summary
AI safety field-building is a large space, with many possible programs. The Center for AI Safety (CAIS) has commissioned cost-effectiveness models to support decisions regarding how to prioritize between these programs. Dan provided high-level guidance early on in the process as well as a small amount of sanity checks later on.
This analysis is a starting point for discussion, not a final verdict. Numbers should not be taken out of context and are not necessarily endorsed fully by CAIS. Rather, we believe that these models:
- Provide a framework for modeling the effectiveness of field-building programs.
- Make explicit underlying assumptions which then can be the focal point of further discussions.
- Provide one perspective (and by no means the only perspective) on the cost-effectiveness of different programs.
These models have so far assisted our evaluations of field-building programs for students and professionals, detailed here and here respectively.
This post:
- Provides motivations for using explicit models. (Read more.)
- Details the metric used in the model to evaluate field-building programs. (Read more.)
- Guides you on adopting or adapting the models for your own work. (Read more.)
- Teases tentative results, and analyzes an important crux: one’s preference for current versus future research. (Read more.)
Motivations for explicit models
We expect that many readers of this post will already be on-board with the practice of using explicit models to guide decision-making — historically, cost-effectiveness analyses have been core to effective altruism. At the same time, however, we expect that few do this in practice, in part because evaluating the cost-effectiveness of AI safety programs might be more challenging than evaluating global development or animal welfare programs. This section justifies our belief that using explicit models for AI safety is worthwhile in practice.
We see two core benefits:
- Enhanced strategic decision-making, for CAIS as well as other organizations.
- Improved communication between organizations.
When making strategic decisions, we are often interested in questions such as:
- What assumptions does our view on the impact of program X depend on?
- Which information is most important for us to learn about program X?
- At what scale should we operate program X?
- How should we make allocation decisions between programs?
The first benefit — enhanced strategic decision-making — is realized if models help us to reason through questions like these.
The second benefit of using explicit models — improved communication between organizations — is realized if models help illuminate disagreements' cruxes and their significance. See the analysis of preferences for current versus future research later in this post for an example of this benefit in action.
Of course, explicit models are not without limitations. Models might not answer the right questions, contain conceptual or implementation errors, or risk their outputs being taken too literally. Most importantly, explicit models are inherently reductionist, ignoring factors that might be crucial in practice, including (but not limited to) interactions between programs, threshold effects, diffuse effects, and learning benefits. That said, we believe that explicit models can be quite useful to the AI safety field if we keep these limitations in mind.
What we model: QARYs
Definitions
Our key metric is the Quality-Adjusted Research Year (QARY). We define a QARY as:
- A year of research labor (40 hours * 50 weeks),
- Conducted by a research scientist (other researcher types will be inflated or deflated),
- Of average ability relative to the ML research community (other cohorts will be inflated or deflated),
- Working on a research avenue as relevant as adversarial robustness (alternative research avenues will be inflated or deflated),
- Working at their peak productivity (earlier-in-career research will be discounted),
- Conducting all of their research in the present (later-in-time research will be time discounted),
- Who stays in the AI profession (later-in-time research will be discounted by the probability that the researcher switches).
In order to operationalize the QARY, we need some way of defining weights for different researcher types, researcher abilities, and the relevance of different research avenues.
We define the ‘scientist-equivalence’ of a researcher type as the rate at which we would trade off an hour of labor from this researcher type with an hour of otherwise-similar labor from a research scientist.
Similarly, the ‘ability’ level of a researcher is the rate at which we would trade off an hour of labor from a researcher of this ability level with an hour of otherwise-similar labor from a researcher of ability level 1.
Finally, the ‘relevance’ of a research avenue is the rate at which we would trade off an hour of labor from a researcher pursuing this avenue with an hour of otherwise-similar labor from a researcher pursuing adversarial robustness research.
The benefit of the program is given by the difference between expected QARYs with and without the program. (QARYs with or without the program could be further decomposed as QARYs per scientist-equivalent participant of some participant type, multiplied by the number of scientist-equivalents of that participant type, summed across participant types.)
Cost-effectiveness is calculated by dividing this benefit by the expected cost in millions of US dollars.
Example calculations using these definitions can be found in our posts evaluating field-building programs for students and professionals respectively.
Benefits and limitations
QARYs offer three major advantages:
- They provide a comparative measure across different programs.
- They decompose into components that are straightforward to inform empirically.
- They enable shorter feedback loops.
These benefits are all considered relative to estimating terminal outcomes. Estimating program impact in x-risk basis points would certainly aid comparability, but at the cost of requiring strong assumptions about how exposure to good outcomes (something like QARYs) translates into better terminal outcomes. Relatedly, components of the QARY framework — how many researchers we might affect, which research avenues they will work on, and so on — are easier to inform empirically. And these components are easier to affect, enabling shorter feedback loops.
Still, QARYs have important limitations, the very most important of which is that QARYs are narrowly focused on researchers and programs that produce research.
In the QARY framework, any labor from politicians, lobbyists, or military leaders is implicitly not valued.
Even for research-centric programs, the QARY framework might not be ideal. For example, when evaluating research labs, one might be more interested in metrics that engage more directly with research outputs, such as high-impact citations.
Still, these limitations can be partially addressed. We could model the influence of QARYs on more downstream outcomes, such as high-impact citations or even x-risk basis points, then compare different categories of programs by downstream impact. Or we could at least avoid inconsistent priorities by specifying a fixed exchange rate between QARYs and other goods.
How to use models yourself
The full code for this project is in this repository. The `examples` folder includes documentation demonstrating the repository’s use.
To get a detailed ‘feel’ for the models, read our cost-effectiveness evaluations of programs for students and professionals.
If you would like help navigating the repository — or with your own evaluations — please email contact@safe.ai.
Analysis using the models
Field-building programs for students or professionals
The table below gives a sneak peek of our posts evaluating the cost-effectiveness of programs for students and professionals. The table combines results from the programs considered in these posts, hypothetical implementations of similar programs, and ‘baseline’ programs. Baseline programs involve directly funding a talented research scientist or PhD student working on anomaly detection research for 1 year or 5 years respectively.
| Program | Cost (USD) | Benefit (counterfactual expected QARYs) | Cost-effectiveness (QARYs per $1M) |
|---|---|---|---|
| Atlas | 9,000,000 | 43 | 4.7 |
| MLSS | 330,000 | 6.4 | 19 |
| Student Group | 350,000 | 50 | 140 |
| Undergraduate Stipends | 50,000 | 17 | 340 |
| Trojan Detection Challenge | 65,000 | 26 | 390 |
| NeurIPS ML Safety Social | 5200 | 150 | 29,000 |
| NeurIPS ML Safety Workshop | 110,000 | 360 | 3300 |
| Hypothetical: Power Aversion Prize | 50,000 | 490 | 9900 |
| Hypothetical: Cheaper Workshop | 35,000 | 250 | 7000 |
The “power aversion prize” is a hypothetical program mirroring the Trojan Detection Challenge, except with $15k less award funding and a more relevant topic. The “cheaper workshop” is identical to the NeurIPS ML Safety Workshop, except with $75k less award funding.
There are many important caveats to this table, detailed in the posts. These caveats include:
- Different programs might perform relatively better or worse at different scales of budget (a fact which is obscured above, with one budget presented per program). For example, although a low-cost social might be more cost-effective than a low-cost prize, the opposite might be true for high-cost implementations of these programs.
- Since the QARYs framework focuses on benefits for technical AI safety research exclusively, we will not account for other benefits of programs with broader objectives, such as the Atlas Fellowship.
- The parameter values are currently based on CAIS’ worldview: for instance, the research discount rate (discussed below), the research ability of participants, and the relevance of different research avenues. Other organizations may disagree and have different values for these parameters.
Possible crux: research discount rate
The evaluation posts each consider programs that affect research at a similar point in time: student programs, which aim to influence future research, or professional programs, which aim to influence research today. A possible crux for whether targeting students tends to be more cost-effective than targeting professionals (or vice versa) is one’s preference for current versus future research.
In the QARYs framework, this preference is described by the research discount rate, defined as the degree to which we value a research year beginning next year less than a research year beginning today.
In this model, we consider research one year from now to be 20% less valuable than research today. The justification for this figure begins with the observation that, in ML, research subfields often begin their growth in an exponential fashion. This means that research topics are often dramatically more neglected in earlier stages (i.e. good research is much more counterfactually impactful), and that those who are early can have an outsized impact in influencing the direction of the field — imagine a field of 3 researchers vs. one of 300 researchers. If, for instance, mechanistic interpretability arose as a research agenda one year earlier than it did, it seems reasonable to imagine that the field would have 20% more researchers than it currently does. In fact, we think that these forces are powerful enough to make a discount rate of 30% seem plausible. (Shorter timelines would also be a force in this direction.)
This view does not reflect a consensus. Others might argue that the most impactful safety work requires access to more advanced models and conceptual frameworks, which will only be available in the future[1].
To illustrate the difference this parameter could make, consider someone who believes that research one year from now is 20% more valuable than research today. This person would be indifferent between 1 research year today and 0.23 research years in 8 years time — approximately the point in time at which rising juniors would finish a PhD — whereas this model would be indifferent between 1 research year today and 6 research years in 8 years time.
The plot below compares the cost-effectiveness of student programs with that of professional programs for different values of the research discount rate. 0.2 is our default; negative values represent a preference for research conducted in the future. (The cost-effectiveness ordering of the identically-colored professional programs never changes.)
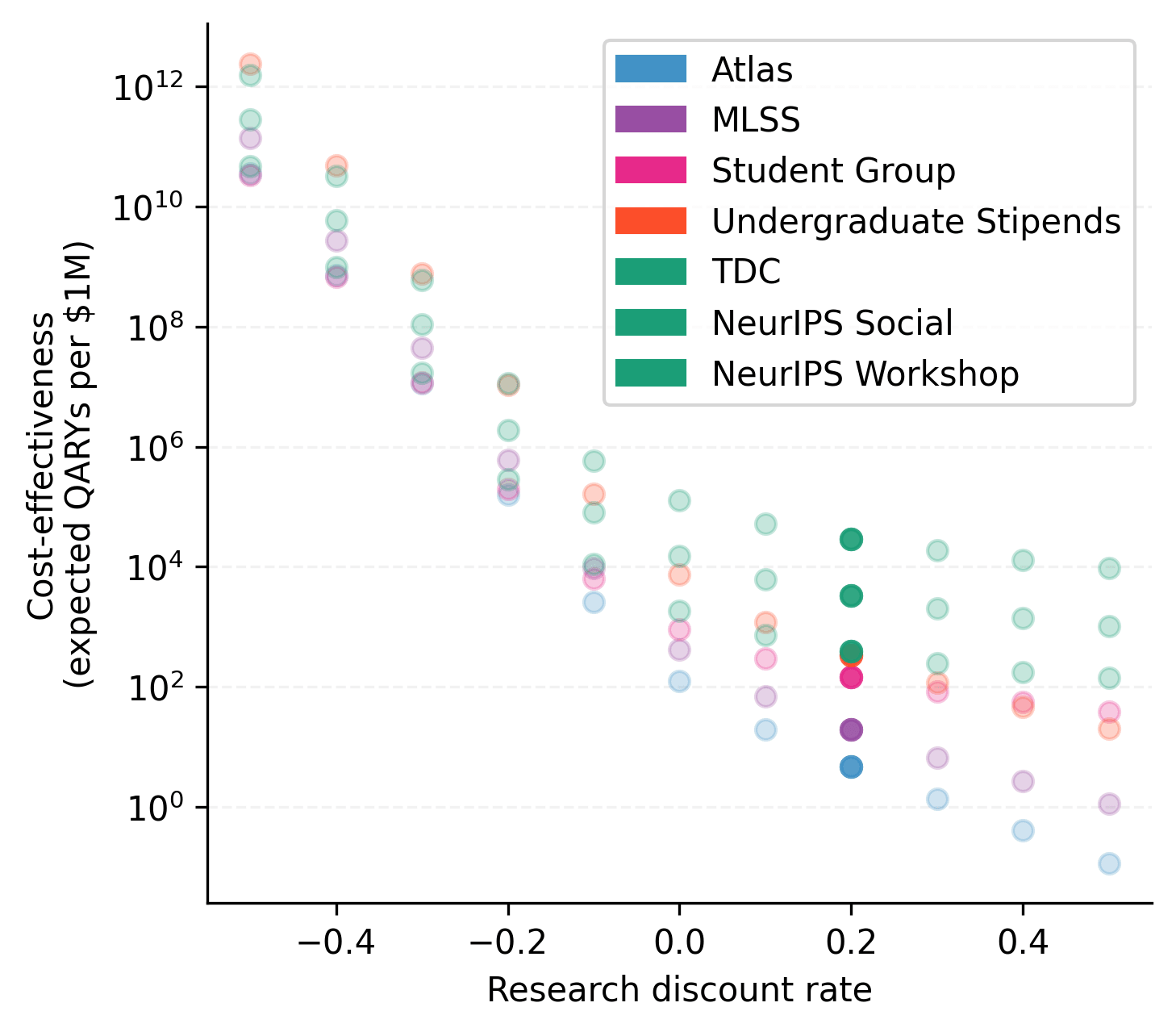
Notice that:
- The cost-effectiveness ordering of programs is not robust to changes in the research discount rate in general.
- As expected, a higher research discount rate devalues student programs relative to professional programs.
- Within student programs, Atlas is relatively disadvantaged by a higher research discount rate, whereas the Student Group benefits. (This disparity is due to Atlas having younger participants, and the Student Group having older participants, compared to MLSS and Undergraduate Stipends.)
- For very low discount rates, Undergraduate Stipends emerges as the best-performing program.
Acknowledgements
Thank you to:
- Dan Hendrycks and Oliver Zhang for high-level guidance,
- Aron Lajko for excellent research assistance,
- Miti Saksena, Steven Basart, and Aidan O’Gara for feedback, and
- The Quantified Uncertainty Research Institute team for creating squiggle — in particular, to Nuno Sempere and Sam Nolan for early hand-holding — and to Peter Wildeford for creating squigglepy.
Footnotes
- ^
The extent to which current research will apply to more advanced models is a useful topic of discussion. Given that it seems increasingly likely that AGI will be built using deep learning systems, and in particular LLMs, we believe that studying existing systems can provide useful microcosms for AI safety. For instance, LLMs already exhibit forms of deception and power-seeking. Moreover, it seems likely that current work on AI honesty, transparency, proxy gaming, evaluating dangerous capabilities, and so on will apply to a significant extent to future systems based on LLMs. Finally, note that research on benchmarks and evals is robust to changes in architecture or even to the paradigm of future AI systems. As such, building benchmarks and evals are even more likely to apply to future AI systems.
Of course, it is true that more advanced models and conceptual frameworks do increase the relevance of AI safety research. For instance, we anticipate that once the LLM-agent paradigm gets established, research into AI power-seeking and deception will become even more relevant. Notwithstanding, we believe that, all things considered, AI safety research is currently tractable enough, and that the subfields are growing exponentially such that a 20% or even 30% discount rate is justified.