Metaculus Q4 AI Benchmarking: Bots Are Closing The Gap
By Molly Hickman, Benjamin Wilson 🔸, Tom Liptay, Metaculus @ 2025-02-19T22:46 (+42)
In Q4 we ran the second tournament in the AI Benchmarking Series which aims to assess how the best bots compare to the best humans on real-world forecasting questions, like those found on Metaculus. Over the quarter we had 44 bots compete for $30,000 on 402 questions with a team of ten Pros serving as a human benchmark on 122 of those 402. We found that:
- Metaculus Pro Forecasters were better than the top bot “team” (a team of one, this quarter), but not with statistical significance (p = 0.079) using log scoring with a weighted t-test.
- Top bot performance improved relative to the Pro benchmark to a -8.9 head-to-head score in Q4 2024, compared to a -11.3 head-to-head score in Q3 2024, although this improvement is not statistically significant. (A higher score indicates greater relative accuracy. A score of 0 corresponds to equal accuracy.)
These main results compare the median forecast of ten Pro Forecasters against the median forecast of the top bot on a set of 96 weighted questions that both humans and bots answered.
This analysis follows the methodology we laid out before the resolutions were known. We use weighted scores & weighted t-tests throughout this piece, unless explicitly stated otherwise.
We further found that:
- When selecting the best bot team, we found the “team” consisted of one bot: pgodzinai, created by Phil Godzin. This is quite different from Q3 when our methodology selected nine top bots to aggregate. We’ll dive into what set Phil’s bot apart.
- Of the thirteen bots with positive peer scores who responded to our survey, only one did any fine-tuning (and it wasn’t Phil), and most made a bot “crowd” by making repeated calls to an LLM and taking the mean/median response.
- The Pro forecaster median was more accurate than all 32 individual bots that answered more than half of the weighted questions. The difference was statistically significant in 29 of those comparisons.
- The top bot and Pros were both well calibrated. The Pros’ superior discrimination explains their better accuracy (basically, they forecast higher on questions that resolved “yes” and lower on questions that resolved “no” than did the bots).
- Metaculus ran four bots that were identical except for the LLM that was used. We find that newer LLMs models are more accurate. From best-to-worse we found weighted average peer scores (relative to other bots) with 95% confidence intervals of:
- o1-preview (mf-bot-4) 6.6 [1, 12.1]
- Claude 3.5 Sonnet (Oct) (mf-bot-5) 3.6 [-1.9, 9]
- GPT4o (mf-bot-1) 1.3 [-3.6, 6.1]
- Claude 3.5 Sonnet (June) (mf-bot-3) -9.9 [-17.6, -2.2]
There's still time to join the Q1 tournament – since every participant starts in the middle of the leaderboard, you can quickly get competitive even this far in. Our template bot takes just 30 minutes to set up, and competing in Q1 will leave you prepared for Q2. Four of the winning bots in Q4 spent less than fifteen hours on their bot, and one spent less than eight. Try your hand at prompt engineering! Check out the tournament here or follow along with a 30min video tutorial here!
Selecting a Bot Team
Our methodology starts by identifying the top bots and choosing a “bot team” of up to 10 bots to compare against the aggregate of the 10 Pros. Since we were uncertain how the accuracy of the top bots would be distributed, we allowed for flexibility in its selection so that if accuracy was comparable across top bots then we’d select a team of up to 10 bots. And, if the top bot was significantly better than other bots then the bot team could consist of only a single bot.
We identify the top bots by looking at a leaderboard that includes only questions that were posed to the bots and not the Metaculus Pro Forecasters. There were 280 bot-only questions and an additional 122 that were posed to both bots and Pros. (Note: Questions that were posed to Pros were selected for being a little harder, more ex ante uncertain, relative to bot-only questions.) Using a weighted t-test, we calculated a 95% confidence interval for each bot and sorted the bots by their lower bounds. The table below shows that the top 10 bots all had average peer scores over 3.6 with 9/10 bots answering 80%+ of questions. Weights were assigned to questions to give less prominence to groups of correlated/related questions.
| Bot | Weighted question count (sum of weights) | Weighted average peer score | Lower bound | Upper bound |
|---|---|---|---|---|
| pgodzinai | 237.6 | 13.2 | 8.3 | 18.1 |
| annabot | 201.6 | 7.9 | 4.7 | 11.1 |
| histerio | 237.6 | 7.9 | 3.5 | 12.2 |
| MWG | 212.9 | 8.8 | 3.3 | 14.4 |
| GreeneiBot2 | 237.6 | 7.6 | 3.3 | 11.8 |
| manticAI | 222.9 | 7.5 | 2.5 | 12.5 |
| mf-bot-5 (Claude 3.5 Sonnet Oct) | 198.8 | 6.2 | -0.4 | 12.7 |
| Cassie | 224.6 | 3.6 | -1.2 | 8.3 |
| tombot61 | 82.5 | 6.8 | -1.8 | 15.4 |
| mf-bot-4 (o1-preview) | 237.6 | 4.6 | -2.7 | 12.0 |
The top bot (pgodzinai) was significantly more accurate than its peers as a whole (p < .0000005) — i.e. his weighted peer score was greater than zero with statistical significance — as were the next five bots (p < .005).
Having identified the top ten bots, we then calculated the median forecasts for a variety of different team sizes – from including only the top bot to including the top 10 bots – again on the bot-only questions. The table below shows the average weighted baseline scores of the bot team median forecast for different team sizes (baseline scores are rescaled log scores).
| Bot Team Size | Weighted Baseline Score for Bot Team Median |
|---|---|
| 1 | 29.04 |
| 2 | 28.43 |
| 3 | 25.12 |
| 4 | 25.03 |
| 5 | 26.53 |
| 6 | 26.90 |
| 7 | 26.36 |
| 8 | 26.67 |
| 9 | 25.71 |
| 10 | 26.27 |
Following our methodology, the bot team consists of just the top bot, pgodzinai. This is quite different from what we found in Q3, when the bot team consisted of 9 bots. (Note: there was an error in the Q3 calculations. The best bot team was actually the ten-bot team in Q3, but this does not materially change the previous results.)
On the surface, the methodology is saying that in Q3 there was a relatively small difference between the top bots, so aggregating their forecasts led to better accuracy. However, this changed in Q4. pgodzinai had a weighted average peer score of 13.2 and confidence interval [8.3, 18.1]. Among the bots that answered over half the questions, only MWG’s 8.8 average score was within that interval, suggesting that pgodzinai is significantly better than other bots!
It is also noteworthy that the top-bot team’s baseline scores are dramatically lower in Q4 at 29 (where the bot “team” is pgodzinai alone) compared to Q3 at 62 (where the bot team comprised the top nine bots). We believe this reflects the difficulty of the questions, not any degradation in performance of the bots. If the governing probability for a question were 50%, then in expectation a perfect forecaster would get a baseline score of 0. If the governing probability were 100% (or 0%), then their expected baseline score is 100. But, baseline scores are also a function of skill. We believe strongly that the bot skill increased from Q3 to Q4, and that the baseline score decrease was the result of our intentionally asking more questions in Q4 that seemed more uncertain. Peer scores, by contrast, are relatively immune to changes in question difficulty, since they directly compare forecasters.
Comparing the Bots to Pros
To compare the bots to Pros we used only the questions that both answered. We calculated the median forecasts of the “bot team” and the Pro forecasters. We calculated the head-to-head peer score and associated 95% confidence intervals from a weighted two-sided t-test. This is equivalent to a weighted paired t-test using log scores. We found an average bot team head-to-head score of -8.9 with a 95% confidence interval of [-18.8, 1] over 96 weighted questions. The negative score indicates that the “bot team” had lower accuracy than the Pro team, but since the confidence interval includes positive values, we cannot draw statistically significant conclusions about who was more accurate.
To put a -8.9 average head-to-head peer score into perspective, here are a few points of reference:
- Imagine a perfect forecaster who forecasts the true probability of 50% on a series of questions. Another forecaster who randomly forecasts either 30% or 70% on those questions will receive an expected -8.9 average head-to-head peer score.
- If the governing probability were 10% and a perfect forecaster forecast 10%, then a forecaster who randomly forecast either 1.9% or 27% will receive an expected -8.9 average head-to-head peer score.
Below we show an unweighted histogram of the head-to-head scores of the bot team. (The head-to-head score is equivalent to 100 * ln(bot_median/pro_median) for a question that resolves Yes.)
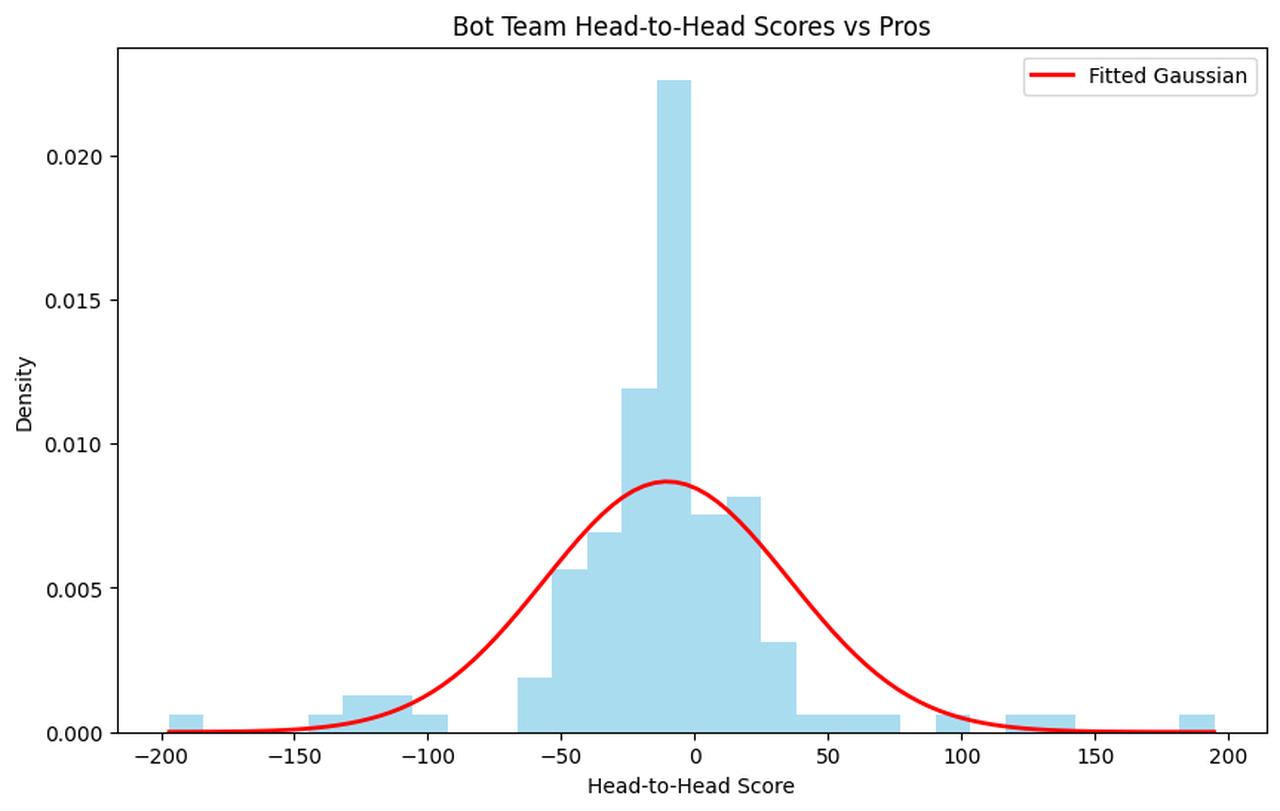
The distribution of scores is quite symmetric with fat tails on both sides. This is different from Q3, where the bots had more positive outlier scores than negative outliers.
Let’s look at the five questions the bots got the worst scores on relative to the Pros.
| Question | pgodzinai (bot "team") | Pro median | Resolution | Head-to-head score |
|---|---|---|---|---|
| Will the lowest temperature recorded in Miami, FL over the entire month of December 2024 never be lower than the highest temperature recorded in Anchorage Alaska for the month? | 12.0% | 86.0% | yes | -196.9 |
| Will the year-over-year increase in prices of homes in Virginia Beach, VA in November 2024 be greater than or equal to 4.0%, according to Zillow? | 20.0% | 75.0% | yes | -132.2 |
| Will Donald Trump's net favorability rating on December 27, 2024 be greater than -4? | 21.0% | 75.0% | yes | -127.3 |
| Will New Zealand report <275 whooping cough cases for weeks 51 and 52? | 23.0% | 78.5% | yes | -122.7 |
| Will New Delhi experience a "Hazardous" air quality index for at least one third of the last two weeks of December 2024? | 20.0% | 60.0% | yes | -109.9 |
Pgodzinai’s forecasts on all 5 questions were 23% or lower, while the Pros’ were all 60% or higher, and all questions resolved Yes. To put that in perspective, if pgodzinai had been “right” and we played out that world many times, the five would have all resolved “Yes” less than one in a thousand times.
Now, let’s look at pgodzinai’s best scoring questions.
| Question | pgodzinai (bot "team") | Pro median | Resolution | Head-to-head score |
|---|---|---|---|---|
| Will the Dairy Recall Tracker maintained by the Center for Dairy Research show more than 1 recall for December 2024? | 20.0% | 62.0% | no | 74.4 |
| Will at least one of Andrea Bocelli's concerts at Madison Square Garden on December 18 or 19, 2024 sell out? | 36.0% | 75.0% | no | 94.0 |
| Will Nvidia have the largest market cap in the world at the end of 2024? | 3.0% | 72.0% | no | 124.3 |
| Will any more of Trump's announced Cabinet picks drop out before January 1, 2025? | 20.0% | 80.0% | no | 138.6 |
| Will Alabama have 2.0 million or more residents living in drought on December 31, 2024? | 37.0% | 91.0% | no | 194.6 |
Interestingly, these five questions all resolved No - the opposite of pgodzinai’s worst performing questions.
Looking at the data - the histogram and the questions above - no glaring or systematic themes jump out to us. Subjectively, pgodznai’s rationales and forecasts seem to be considering the right factors and reasoning quite well. However, it does seem like the Pros generally have better information retrieval. For example, on the Nvidia market cap question the Pros correctly understood that Nvidia’s current market cap was $3.6T and they forecast 72%, while pgodzinai’s comments indicate an incorrect $1.2T value and a corresponding 3% forecast. In this particular case, it seems clear that the Pros had superior analysis, but nevertheless, the way things shook out, the resolution ended up being No. This example also highlights why many questions are needed to draw significant conclusions, because sometimes a forecaster gets lucky.
Another way to understand the data is to look at calibration and discrimination plots.
Calibration
The figure below shows the unweighted calibration curve for the Pros in red and the bot team in blue. The dots correspond to grouping their respective forecasts into five quintiles.
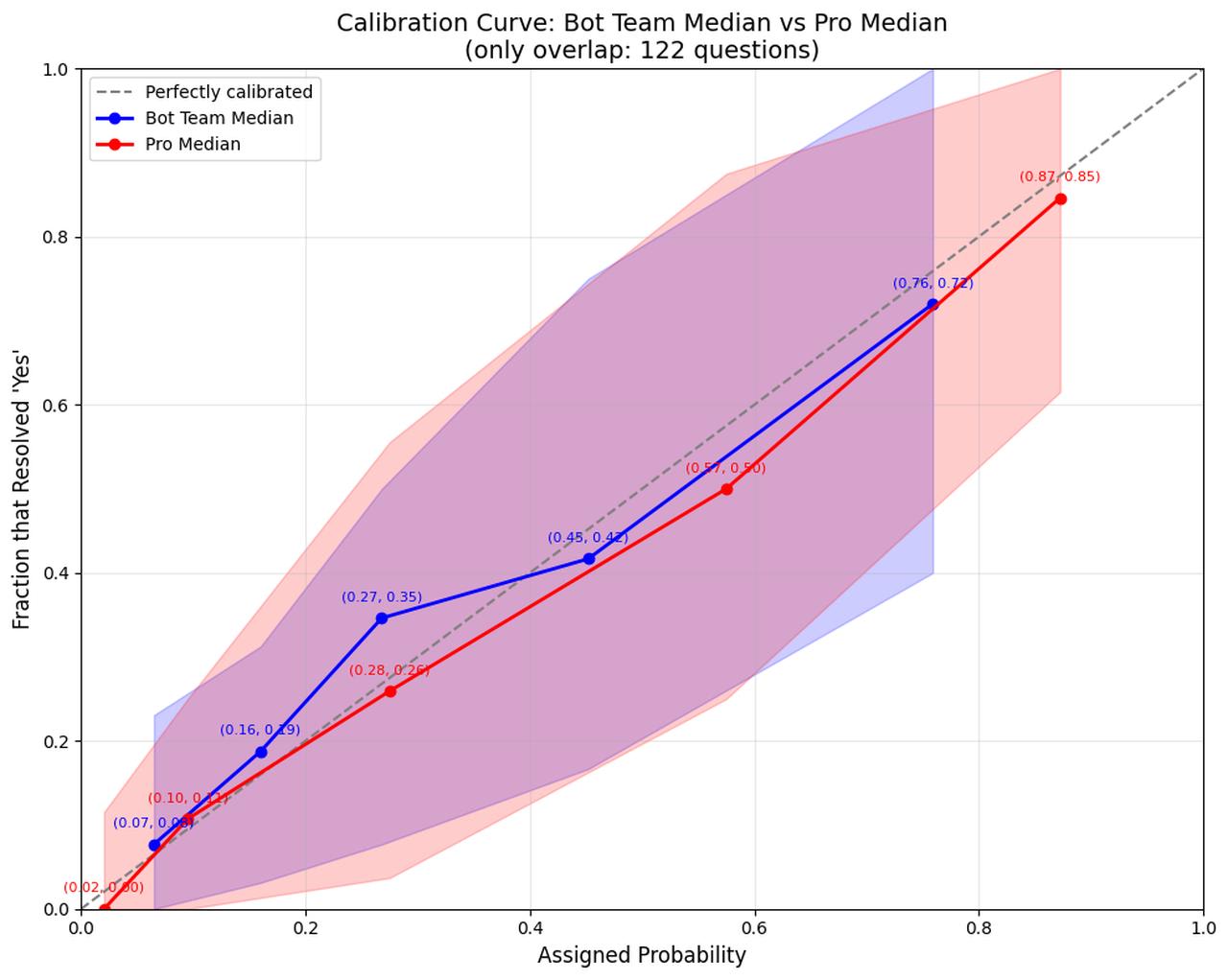
A perfectly calibrated forecaster, after forecasting on very many questions, would have their dots line up on the dotted line. Both the top bot and the Pros appear well-calibrated. This is different compared to Q3 when the bot team appeared to be underconfident. The shaded areas represent the 90% credible interval around the dotted line, the width of which depends on how many predictions the forecaster has made in a given x-axis range (i.e. if the forecaster had been perfectly calibrated, their fraction that resolved ‘Yes’ would have fallen in that range 90% of the time).
It is worth noting that the Pros made moderately more extreme forecasts than the bots. For example, the bottom quintile of forecasts averaged 2% for the Pros, but was 7% for the top bot. And the top quintile of forecasts was 87% for the Pros, but only 76% for bots. In short, the Pros were willing to make forecasts further from 50%.
It is also interesting to note that there are roughly 2x as many No resolutions as Yes resolutions, which is consistent with the rest of Metaculus. Both Pros and the “bot team” forecast more heavily towards No.
While calibration can be considered a measure of “how well you know what you know”, discrimination can be considered a measure of “what you know.”
Discrimination
One way to assess how much a forecaster knows is to split questions into two groups, those that resolved Yes and those that resolved No. If a forecaster knows a lot, then their average forecast on the questions that resolved Yes should be higher than their average forecast on questions that resolved No. This is sometimes called discrimination.
The figure below shows unweighted histograms of both the Pro (orange) and pgodzinai (blue)’s forecasts for questions that resolved Yes and No.
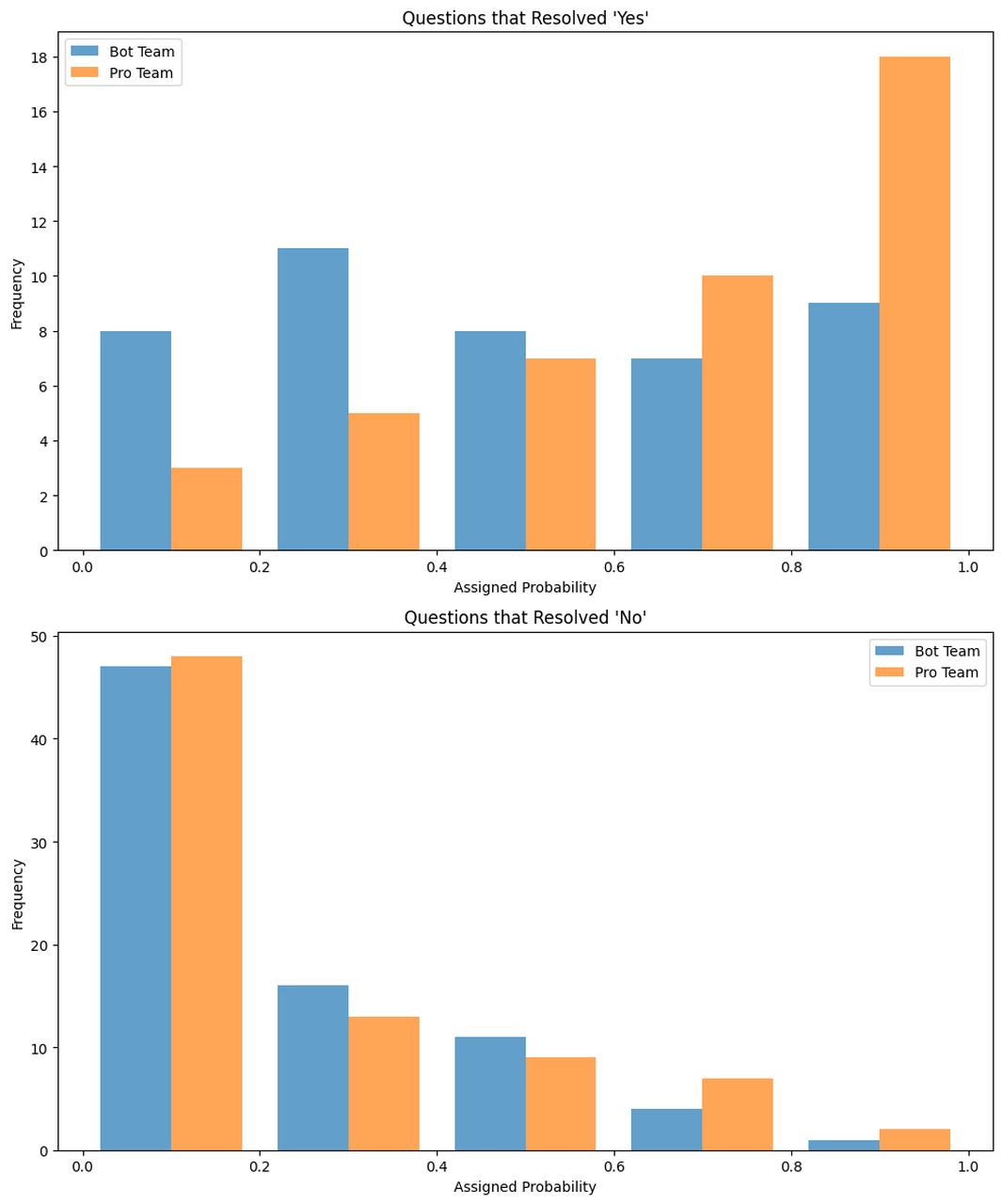
We can see that the Pros forecast well below 50% on the questions that resolved No, and slightly over 50% on questions that resolved Yes. The Pros’ average forecast on questions that resolved Yes was 44 percentage points higher compared to their forecasts on questions that resolved No.
Pgodzinai's discrimination looks quite different, especially for the questions that resolved Yes. For Yes resolutions, the distribution for pgodzinai was roughly uniform with an average forecast of 50%. Defining discrimination as the difference in average forecast between Yes resolving questions and No resolving questions, we find the discrimination for the “bot team” is 26 percentage points, far less than the 44 percentage points for the Pros.
The Pros’ superior accuracy is not a result of better calibration; it is a result of better discrimination.
Comparing Individual Bots to the Pros
We also compared individual bots to the Pro median using a similar methodology. (We don’t recommend putting too much weight in these comparisons because with enough bots, one will do well purely by chance. But, we believe this offers useful context.)
32 bots answered more than half of the Pro questions (weighted). The Pros beat all 32 bots in head-to-head accuracy. 29 of those comparisons were statistically significant according to our weighted t-test.
Metaculus Bots
To compare the capabilities of different LLM models, Metaculus ran 4 bots all with the same single shot prompt that was used in Q3. A key change is that we used AskNews instead of Perplexity as a news source for the LLM prompt. We believe this made the bots better. (In Q1 we’re explicitly running separate bots powered by AskNews and Perplexity to more accurately measure differences in performance.) The bots had the following user names:
- GPT-4o (mf-bot-1)
- Claude 3.5 Sonnet June (mf-bot-3)
- o1-preview (mf-bot-4)
- Claude 3.5 Sonnet Oct (mf-bot-5)
To compare bots against each other, we include all questions and use weighted scoring. Their respective peer scores and 95 percent CI used weighted t-stats are:
- o1-preview 6.6 [1, 12.1]
- Claude 3.5 Sonnet (Oct) 3.6 [-1.9, 9]
- GPT4o 1.3 [-3.6, 6.1]
- Claude 3.5 Sonnet (June) -9.9 [-17.6, -2.2]
The ordering of these results is unsurprising - newer models produced more accurate forecasts. It is noteworthy that the GPT4o metac-bot finished third in Q3, yet it was soundly beaten by o1-preview in Q4.
The best bot: pgodzinai
By far the best-performing bot in Q4 was pgodzinai. Who is behind this bot? What is their secret?
The human behind the bot is Phil Godzin, a staff software engineer with a B.S. in Computer Science from Columbia University. We got his blessing to share a bit about his bot.
He suspects a lot of his success may come down to his first step: asking an LLM to group related questions together and predict them in batches to maintain internal consistency. Many of the questions in the tournament were multiple-choice questions split into binaries, i.e. forecasts on a group of questions should sum to 100%. For others, forecasts should monotonically decrease, e.g. Will Biden sign more than two executive orders? … more than three? … more than four? As a whole, bots were pretty bad at this kind of reasoning in Q3 (with multiple choice probabilities often summing up past 150%), so Phil figured out how to encourage the LLM to “think” differently by grouping these sets of related questions.
He used both Perplexity (specifically model llama-3.1-sonar-huge-128k-online) and AskNews for context. Many bots used one or the other, but Phil took advantage of both. When querying Perplexity, he had a multi-paragraph prompt giving many pieces of advice, including instructions about how to treat competition (e.g. elections, chess tournament), market price, and disease-type questions differently, adjusting which news to focus on. He also fetched the maximum number of latest news and historical articles from AskNews and then used an LLM to summarize only the sources relevant to the question before putting it in the final prompt.
Interestingly, while the best-performing of the Metaculus bots was our gpt-o1-preview bot, Phil didn’t use o1-preview at all; rather, he settled on three runs of gpt-4o and five runs of claude-3-5-sonnet-20241022. The prompt was the same for both and included telling the LLM that it is a superforecaster; explaining how proper scoring works (i.e. treat 0.5% as very different from 5%); sharing a number of forecasting principles; telling it that historically it’s been overconfident and the base rate for positive resolutions on Metaculus is 35%. He filtered out the two most extreme values and took the average (not median) of the remaining six forecasts to get his final forecast.
Asked how he expects to do in Q1, he said his competitive advantage may go away since, in Q1, we’re posing numeric and multiple-choice questions directly, which enforces coherence in a way that the binary sets of questions did not. And who knows, he may have just gotten extremely lucky. He plans to add Gemini and DeepSeek to his “crowd” of LLMs this quarter. We’re excited to see how his bot performs. Can he beat the pros?
Trends in Winners
Winning bots (the top that got positive peer points) were asked to fill out a survey giving descriptions of their bots. 13 of them responded, and below are some aggregate highlights from the survey:
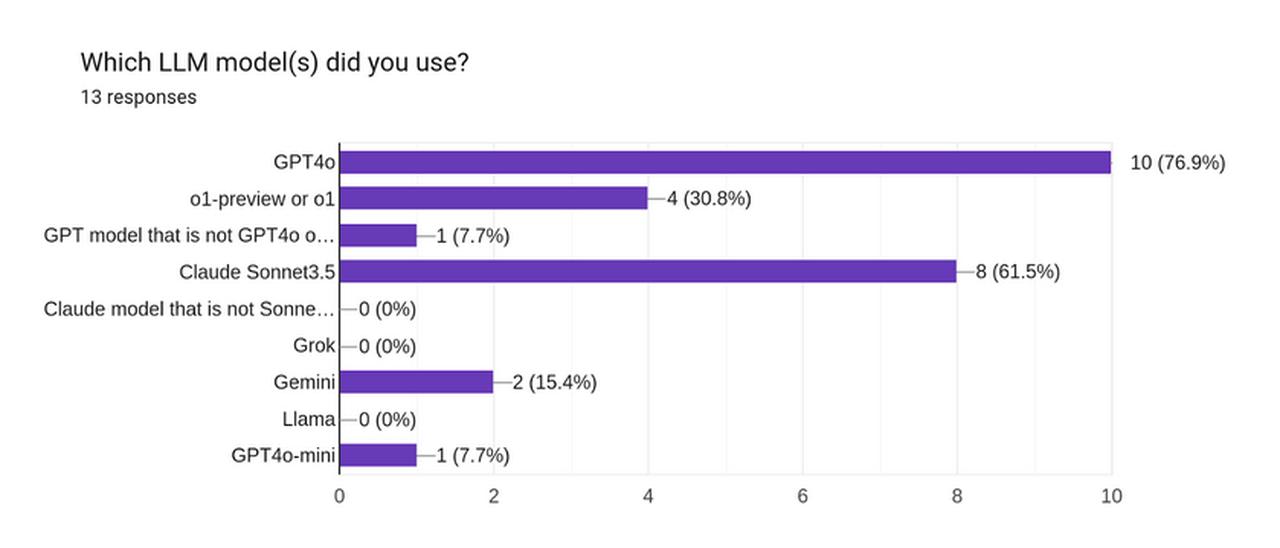
(The shortened fields are “GPT model that is not GPT4o or o1” and “Claude model that is not Sonnet3.5”)
Other Takeaways
- Around 75% of winners used less than 100 LLM calls, 50% of participants used less than 20, and 25% used less than 10.
- 22% did no mathematical adjustments to the values returned by an LLM
- Only one bot used a fine tuned LLM
- Winners on average used 1.8 different LLMs
- 3 winners specifically checked for related past/present forecasts on Metaculus or other prediction markets
- Only one person kept their bot the same between Q3 and Q4
- 76% of winners repeated calls to an LLM and took a median/mean
- 69% of winners were individuals and other teams ranged from 2-4 people
- The top 5 bots used primarily gpt-4o and claude-sonnet-3.5 in their bot though o1-preview, gemini, and a misc gpt model were each used once. Most used more than one model.
- In terms of total cumulative time spent by the team, 1 winner built their bot in 0 to 8hr, 3 in 8 to 15hr, 1 in 15 to 40hr, 1 in 40 to 80hr, 4 in 80hr to 1 full time month, and 2 in 1 to 4 full time months.
- The top bot (pgodzinai) spent between 15 and 40hr on his bot.
Discussion
We believe the Metaculus AI Benchmarking Series holds a unique position among AI Benchmarks that aim to assess real-world AI capabilities. Our benchmark:
- Asks a wide variety of real-world questions with different writing styles, resolution sources, and formats.
- Asks questions whose answers are not known by anyone when asked. This makes it significantly harder to cheat by any kind of fine-tuning.
- Asks questions that are constantly changing. This makes it less susceptible than other benchmarks to training on it.
- Importantly, we attempt to minimize the number of questions where you can easily find an analog either on Metaculus, other prediction sites, or using financial markets. This is important since otherwise a bot could do well by copying forecasts rather than reasoning about the world.
We believe our benchmark design is the most robust assessment to date of AI’s abilities to reason about complex real-world forecasting questions. Doing well requires doing great information gathering and research, figuring out how to deal with conflicting signals, which facts deserve the most weight, having a sense of what unknown unknowns might be lurking, and how to distill all of that into a probabilistic forecast.
We look forward to seeing how bot performance evolves over the coming quarters. We believe that this benchmark will take longer for AI bots to show super human performance and hope to continue this for years to come.
There is a lot more to analyze in the dataset we collected, and we’re looking forward to exploring some more questions.
We’re eager to hear your feedback in the comment section below!
Can you make a winning bot?
The tournament for Q1 is currently underway, but there is still plenty of time to join in! All the details you need to get started are here and there is a 30min video tutorial here. Every new participant starts in the middle of the leaderboard with a score of 0, and though there are some missed potential points on past questions, with a good bot it's still very easy to get into the top half and become one of our winners for this next quarter (and have a bot ready for Q2)! Getting our template bot up and running should take only around 30 minutes. A template bot powered by o1-preview and AskNews got 6th in Q4, so it is a decent starting place!
MaxRa @ 2025-02-20T00:35 (+14)
Thanks for writing this up, I think it's a really useful benchmark for tracking AI capabilities.
One minor feedback point, I feel like instead of reporting on statistical significance in the summary, I'd report on effect sizes, or maybe even better just put the discrimination plots in the summary as they give a very concrete and striking sense of the difference in performance. Statistical significance is affected by how many datapoints you have, which makes lack of a difference especially hard to interpret in terms of how real-world significant the difference is.
tobycrisford 🔸 @ 2025-02-20T08:09 (+10)
This is an interesting analysis!
I agree with MaxRa's point. When I skim read "Metaculus pro forecasters were better than the bot team, but not with statistical significance" I immediately internalised that the message was "bots are getting almost as good as pros" (a message I probably already got from the post title!) and it was only when I forced myself to slow down and read it more carefully that I realised this is not what this result means (for example you could have done this study only using a single question, and this stated result could have been true, but likely not tell you much either way about their relative performance). I only then noticed that both main results were null results. I'm then not sure if this actually supports the 'Bots are closing the gap' claim or not..?
The histogram plot is really useful, and the points of reference are helpful too. I'd be interested to know what the histogram would look like if you compared pro human forecasters to average human forecasters on a similar set of questions? How big an effect do we see there? Or maybe to get more directly at what I'm wondering: how do bots compare to average human forecasters? Are they better with statistical significance, or not? Has this study already been done?
Molly Hickman @ 2025-03-13T20:53 (+5)
Sorry I didn't see this sooner! You and @MaxRa are right, the title is a bit dramatic; indeed, in Q3 and Q4 we got null results. The -8.9 head-to-head score (I like this scoring mechanism a lot) is pretty impressive in my opinion, but again, not statistically significant, and anyway, Max's point about effect size is well taken (-11.3 to -8.9).
We'll take your feedback when we have the Q1 results!
On how bots compare to average human forecasters: Several of the bots are certainly better than the median forecaster on Metaculus. But relative to the community prediction (a bit more complicated than the average of the forecasts on a given question), the bot team is worse, but again, not with significance. I think we'll include bots vs CP analysis in the Q1 post, or as a separate thing, soon.
Ozzie Gooen @ 2025-03-14T01:41 (+4)
I think this is neat! It's also lengthy, I like the write-up.
Some quick thoughts:
1. I'd be curious if the source code or specific prompts that pgodzinai used are publicly. It seems like it took the author less than 40 hours, so maybe they could be paid for this, worst case.
2. I find it interesting that the participants included commercial entities, academic researchers, etc. I'm curious if this means that there's a budding industry of AI forecasting tools.
3. It sounds like a lot of the bots are using similar techniques, and also seems like these techniques aren't too complicated. Here the fact that pgodzinai took fewer than 40 hours comes to mind. "The top bot (pgodzinai) spent between 15 and 40hr on his bot.". At very least, it seems like it should be doable to make a bot similar to pgodzinai and have it be an available open-source standard that others could begin experimenting with. I assume we want there to be some publicly available forecasting bots that are ideally close to SOTA (especially if this is fairly cheap, anyway). One thing this could do is act as a "baseline" for future forecasting experiments by others.
4. I'm curious about techniques that could be used to do this for far more questions, like 100k questions. I imagine that there could be a bunch of narrower environments with limited question types, but in conditions where we could much more rapidly test different setups.
5. I imagine it's a matter of time until someone can set up some RL environment that deeply optimizes a simple forecasting agent like this (though would do so in a limited setting).
Molly Hickman @ 2025-03-18T13:33 (+1)
Thanks Ozzie! Phil Godzin's code isn't public, but our simple template bot is. The o1-preview and Claude 3.5-powered template bots did pretty well relative to the rest of the bots.
Ozzie Gooen @ 2025-03-18T16:50 (+4)
The o1-preview and Claude 3.5-powered template bots did pretty well relative to the rest of the bots.
As I think about it, this surprises me a bit. Did participants have access to these early on?
If so, it seems like many participants underperformed the examples/defaults? That seems kind of underwhelming. I guess it's easy to make a lot of changes that seem good at the time but wind up hurting performance when tested. Of course, this raises the point that it's concerning that there wasn't any faster/cheaper way of testing these bots first. Something seems a bit off here.
Molly Hickman @ 2025-03-26T13:24 (+1)
Yes, they've had access to the template from the get-go, and I believe a lot of people built their bots on the template. I guess it doesn't surprise me that much. Just another case of KISS.
That said, pgodzinai did layer quite a lot of things, albeit in under 40 hours, and did remarkably well, peer score-wise (compared to his bot peers). And no one did any fine-tuning afaik, which plausibly could improve performance.
As for faster/cheaper way to test the bots: we're working on something to address this!
Ozzie Gooen @ 2025-03-18T14:26 (+2)
That's useful, thanks!