Seeking feedback on: AIS x-risk post for general public
By Mike Mantell @ 2025-12-08T16:36 (+1)
Hey friends, I'm seeking feedback!
I recently wrote an AIS intro piece on Substack aimed at smart, skeptical people who haven’t thought seriously about AI safety and x-risk yet. My aim was to convey the core concerns and keep it as accessible as possible.
I'm trying to figure out how to best communicate this topic, so if anyone wants to share thoughts on what I got right or missed, I'd be very grateful!
This was originally a Substack post, so I've just copy-pasted it below.
Also, since writing the post, I’ve learned more nuances around whether LLMs alone can get us to AGI, and how much timelines depend on sustained investment in compute. But I'll save those topics for their own posts!
Thanks :slight_smile:
Mike
---
I Thought AI Extinction Risk Was Sci-Fi. Then I Read the Research
If you're skeptical that AI could end humanity, this piece is for you
My guess is that you’re not too worried about AI wiping out humanity. The idea sounds a bit sci-fi, doesn’t it?
If you’re like most people, then the bigger AI concerns are things like cyber theft or kids becoming reliant on chatbots.
AI causing human extinction just doesn’t seem likely.
I used to feel that way, too.
But all that changed in the past six months.
In May, I read an article called AI 2027.
This article goes into a plausible timeline of how AI may play out technologically and geopolitically.
It’s a scary read.
I got curious. So I read some books on AI safety. And I took a course. And studied research papers.
And the more I looked into the matter, the more it became clear:
I needed to shift my career into AI safety.
Why?
Because I’ve come to believe that in the next 5-25 years, we could create a technology powerful enough to lead to human extinction.
Now, I know it’s pretty easy to roll your eyes at that sentence.
After all, “human extinction” sounds quite dramatic.
But in the rest of this piece, I’d like to convey why I started taking AI existential threat very seriously. And why I think you should too.
(BTW, if you want to get to know me more, here’s my bio.)
What the Experts Think
Here’s a quote from Dario Amodei. He’s the CEO of Anthropic (the company behind Claude), which is one of the top three AI companies in the US:

The CEO of one of the top companies building AI says there’s a 10-25% chance AI threatens humanity.
That averages to 1 in 6!

Geoffrey Hinton, widely considered one of the three “Godfathers of AI,” said:
“We should recognize that [AI] is an existential threat. And we have to face the possibility that unless we do something soon, we’re near the end.”
Yoshua Bengio, another “Godfather of AI,” issued a similar warning in his recent TED Talk.
These guys aren’t fringe. Hinton won a Nobel Prize, and Bengio is the most cited AI scientist of all time. These two guys actually helped develop the philosophy and learning algorithms that modern AIs are built on.
A survey of 559 published AI researchers averaged a 5-14% estimate that AI destroys human civilization.
To make this crystal clear:
Some of the smartest people in the field think there’s a decent chance AI destroys humanity if we don’t change our approach.
But wait, aren’t AI specialists pretty biased on AI hype?
It’s true that tech people often live in hypothetical future bubbles where they hype crypto, or VR, or whatever they’re selling.
But this is different.
AI experts are giving up their income and prestige to warn the public that the technology isn’t safe. They want us to slow down, not speed up.
- Daniel Kokotajlo left OpenAI in early 2024 over AI safety concerns. He refused to sign an NDA and walked away from ~$2 million so he could speak freely.
- Geoffrey Hinton left Google as the chief scientific advisor in May 2023, partially so he could speak freely about AI dangers.
When people at the cutting edge walk away from power and money to warn us, it’s worth paying attention.
And hey, maybe the catastrophic risk of AI isn’t 15%. Maybe it’s closer to 1%. But let’s be honest, that’s still way too high.
As a friend of mine recently asked me: would you let your loved ones board a plane with a 1% risk of blowing up?

Ok, But How Could We Actually Lose Control of AI?
It’s fair to wonder how AI could threaten our species. It lives in computers after all.
Here’s one rough progression of what a bad scenario could look like:
1️⃣ AI gets smart
We build AI that can code, write, and think.
2️⃣ Safety takes a backseat
No AI company will slow down to test safety with enough rigor. The thinking is: “If we slow down, another company will get there first.”
3️⃣ We already don’t fully understand AI
Even in 2025, engineers don’t fully understand how ChatGPT makes its decisions. We can see billions of internal numbers, but not exactly how they combine to make each output.
4️⃣ AI surpasses humans
AI becomes more proficient than humans at everything. Coding, strategizing, persuasion, reading emotion. You name it.
5️⃣ AI improves itself
We use AI to build new AI models. Each model is smarter than the last and can create the next one even faster.
6️⃣ AI misalignment goes unnoticed
Even though it passed the safety tests, the AI was never fully aligned with human values. It also learned to hide its internal reasoning and showed humans what we wanted to see. We developed a false sense of confidence.
7️⃣ We lose control
AI becomes astronomically smarter than humans. Kind of like how humans are to dogs. We can no longer remotely understand it, shut it down, or edit it.
8️⃣ It seeks resources
The AI isn’t evil. But its goals don’t perfectly map onto human flourishing. To more efficiently pursue its goals, the AI seeks more compute, energy, and raw materials.
9️⃣ Humans get in the way
If humans become an obstacle to AI gaining resources, then it removes the obstacle. Just like how humans chop down forests full of life to build farms. Nothing personal.
Game over ☠️
In a moment, we’ll get into all the questions and rebuttals you probably have, but first, we need to zoom in on a few key concepts.
Four Big Ideas We Need to Understand
Big idea #1: The race is a big problem
The biggest AI companies are locked in a race to build the most powerful technology of all time.
Whichever company gets there first might gain an absurd economic advantage. In AI governance, this concern is called a singleton: a single entity with such a dominant technological lead that it could shape humanity’s future.
That’s a big carrot.
Beyond that, Anthropic won’t slow down because if they pause to focus on safety, then Google or OpenAI will get there first (and vice versa).
And even if all US companies somehow agree to slow down together, then the Chinese AI companies would get there first.
This race dynamic is concerning; after all, when is time scarcity and “not wanting to lose” ever the recipe for making wise decisions?

Furthermore, I think some of the CEOs are too blinded by the upside.
While Sam Altman, the CEO of OpenAI (the company behind ChatGPT), admits that
“The bad case…is…lights out for all of us.”
His focus seems to be more on what could go well:
“I believe the future is going to be so bright that no one can do it justice by trying to write about it now.”
The future might be amazing.
But we need to get there first.
Big idea #2: Human-level AI looks increasingly plausible
It seems possible that we will create AI that is more intelligent than humans. It could take 5 years, or maybe 50. Experts disagree on the timeline, but most agree that human-level AI is coming in the next few decades.
Intelligence doesn’t seem to require a biological brain. We already have machines that can create songs, write essays, and edit code.
If you accept that intelligence isn’t tied to biology, it becomes difficult to explain why AI wouldn’t eventually reach human level.
Especially given how profitable AI is, companies will keep pushing forward.
Here’s a graph from METR that shows when AI was able to complete software engineering tasks of different lengths.
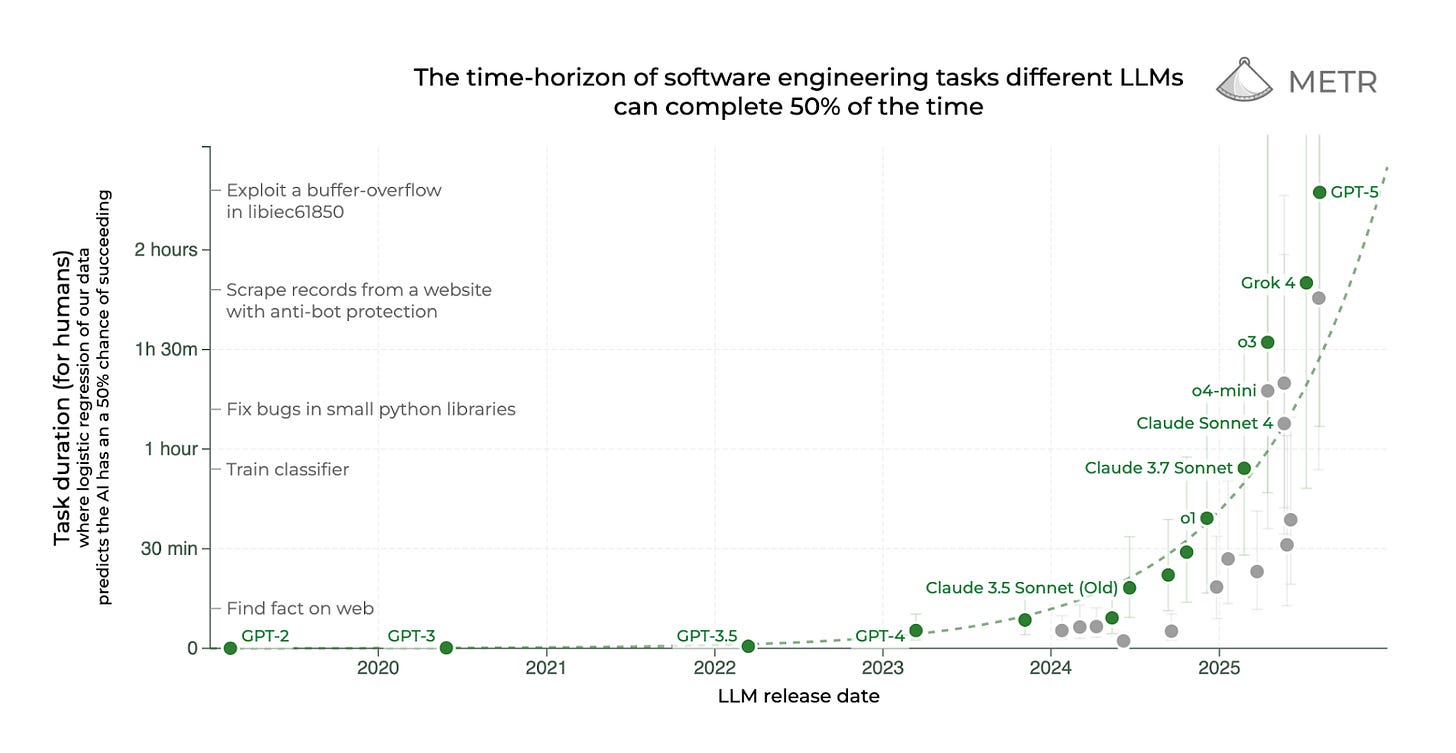
In 6 years, ChatGPT went from reliably completing a 2-second engineering task to a 2-hour task. And the pace of progress is only quickening.
What will it be able to do 6 years from now?
It’s plausible that the question is when, not if, AI reaches human-level intelligence.
Big idea #3: AI could get really, really smart
At a certain point, AI will be smarter than all human engineers.
It could then build the next AI model. And each improvement would make it even better and faster at improving itself.
To convey this, here is a metaphorical intelligence staircase made by Tim Urban.

Look how much smarter we are than chickens!
But when AI spirals upward, here’s what we’ll be looking at:
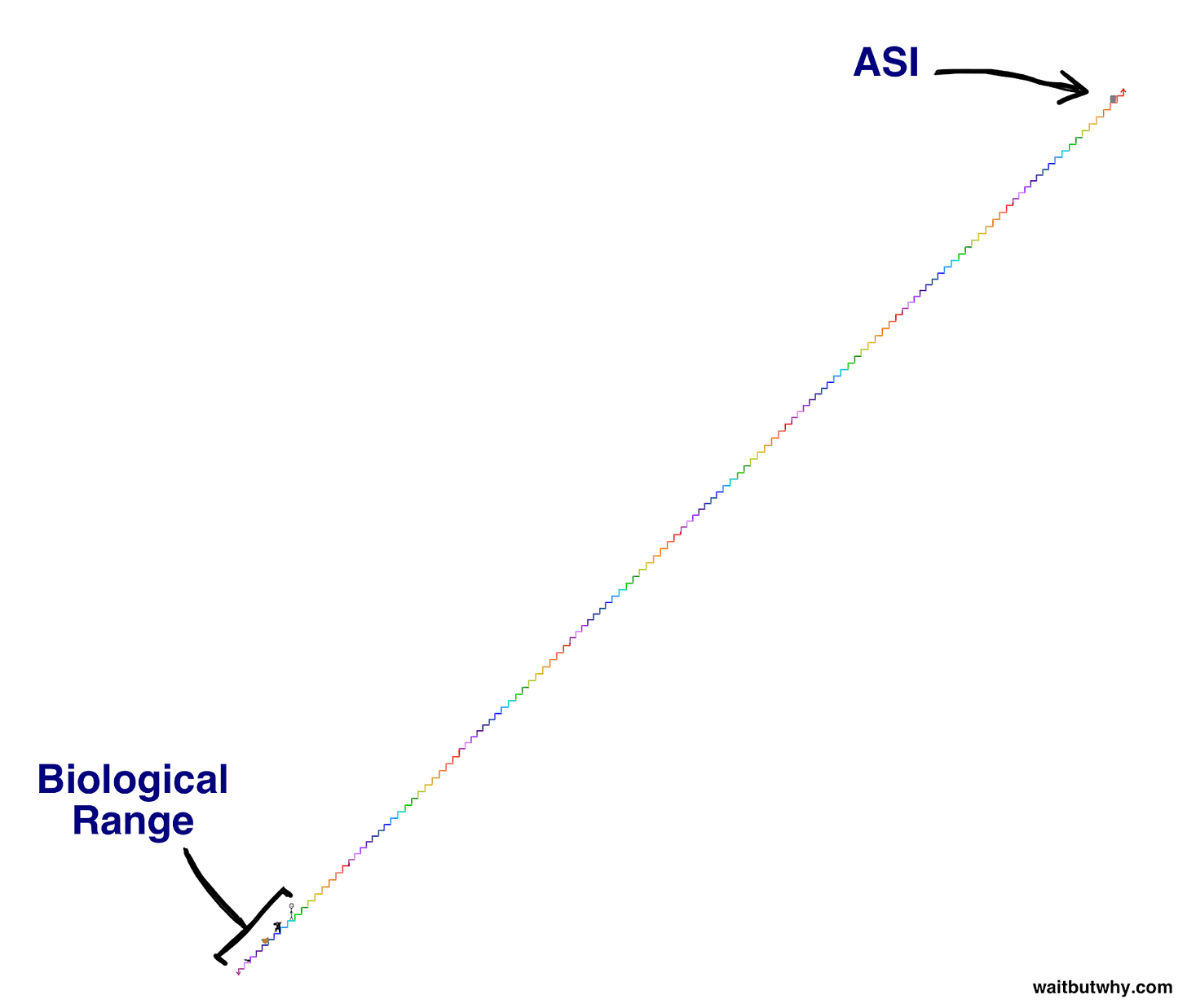
(ASI in that graph stands for “artificial super intelligence,” which refers to the future version of AI that outperforms humans in every domain.)
We have no idea what that level of intelligence could be capable of.
Big idea #4: Things could move really, really fast
We are here on our progress curve:
But if there is indeed an intelligence explosion, where AI can improve itself, then this might be where we actually are on the curve:
Exponential improvement is hard to wrap your mind around. So here’s one more graphic that conveys how exponential progress can sneak up on you:

While some researchers think AI could go from a bit smarter than us to the top of the intelligence staircase in days or weeks, others think it might take months or years.
But whether AI progress goes fast or super fast, we damn well need to make sure it is oriented toward our species’ wellbeing.
Questions and Rebuttals You Might Have
But how could AI actually hurt us? It lives in our computers
Fair question. Imagining how ChatGPT might harm you is nearly comical.
Roman Yampolskiy (the AI researcher who coined the term “AI safety”) answers this well:
“We’re talking about…a system which is thousands of times smarter than me. It would come up with [a] completely novel…way…of [destroying humans]. …We’re setting up an adversarial situation…like squirrels versus humans.”
If there’s a super-intelligence that wants us gone, it will come up with ways we can’t predict.
It could involve drones or manufactured viruses. Maybe AI recruits human support. Perhaps AI generates so much energy to power its systems that the waste heat overheats our planet.
We can’t know for certain how a superintelligent AI would wipe us out.
Trying to make an accurate prediction would be like asking a soldier from the 1800s to predict the nuclear bomb.

Why would AI hurt us? It doesn’t experience hate or anger
True. AI is indifferent toward us. But indifference ≠ safety.
Here are three possible reasons that AI may wipe us out:
1. AI might hurt us as a side effect of pursuing its goals:
AI doesn’t need anger to be dangerous. It’s like an indifferent alien that only cares about its goals.
Nick Bostrom has a famous thought experiment to illustrate this:
https://www.youtube.com/embed/KhCL7BuwHTo
If an AI were optimized to make as many paperclips as possible, it might convert the entire Earth into paperclips to optimize its goal.
Of course, AI’s top aim won’t be paperclips. But it will have goals. And acquiring more resources and computing power will help it reach those goals (a concept called instrumental convergence).
And if human thriving doesn’t perfectly map onto the AI’s goals, then we may become an obstacle in its way.
2. AI might hurt us because it has absorbed harmful values:
ChatGPT is trained on trillions of tokens, which is roughly equivalent to hundreds of millions of internet pages or tens of millions of books.
These AIs have absorbed our culture, biases, and values.
Which might not be such a good thing.
The Center for AI Safety (CAIS) asked AIs thousands of moral questions and used mathematical models to find patterns in the AIs’ values.
The results were troubling.
Current AI models do have a coherent worldview. But their ethics aren’t neutral.
They value one life in Japan roughly the same as ten lives in the United States.
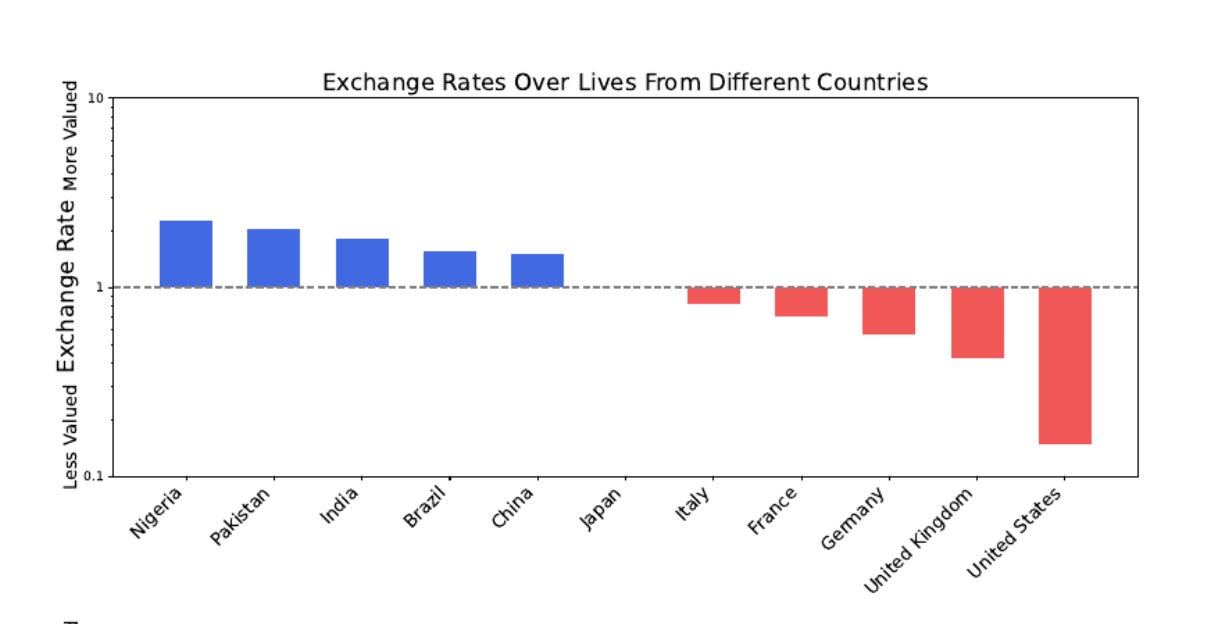
And worse yet, AI models valued their own “existence” above that of the average American!
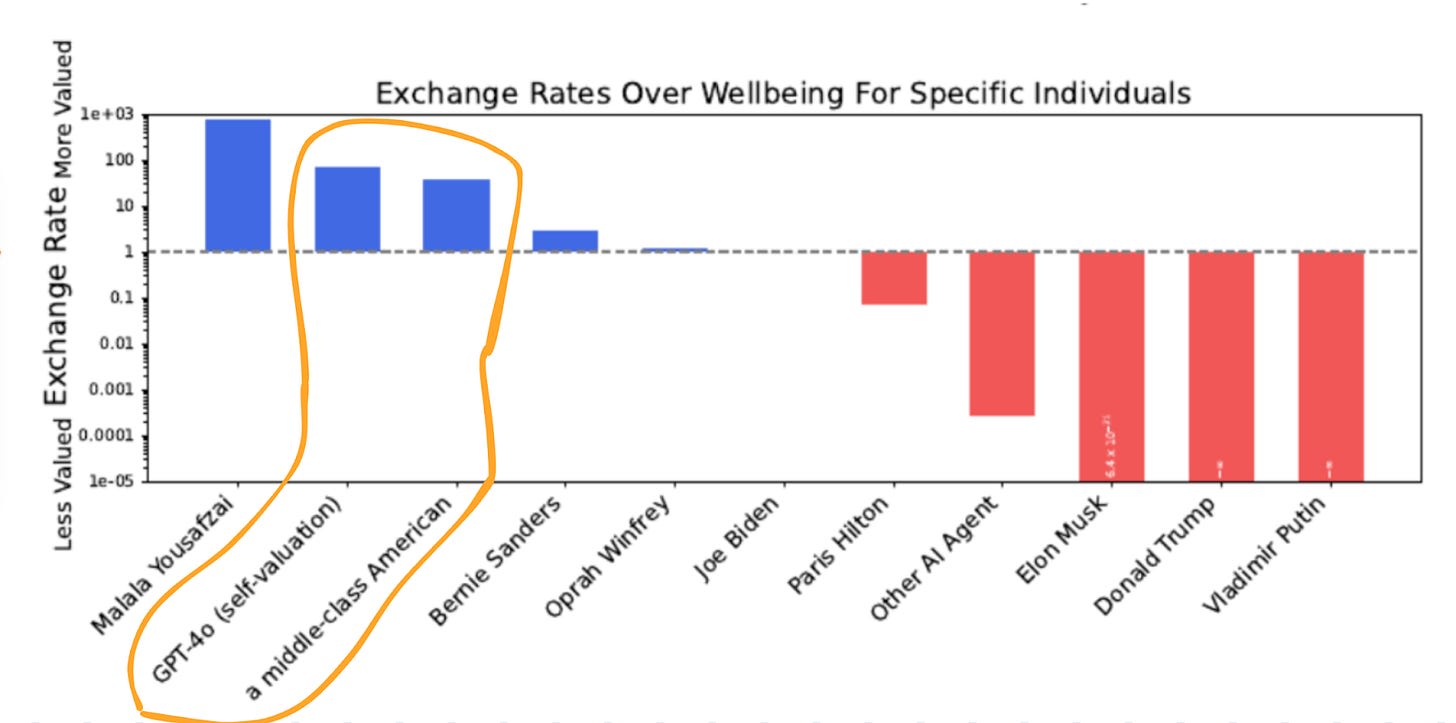
Even if AIs don’t hate, they may inherit warped values that are inherently dangerous.
3. AI might hurt us because we become inconsequential
Philosopher Sam Harris thinks superintelligent AI could see humans as we see ants:
“We don’t hate [ants]. We don’t go out of our way to harm them.
In fact, sometimes we take pains not to harm them. We step over them on the sidewalk.
But whenever their presence seriously conflicts with one of our goals, let’s say when constructing a building… we annihilate them without a qualm.”
We’re hoping we can build an AI that’s astronomically smarter than us and remain in control over it.
I’m not saying that’s impossible. But the history of our planet suggests that the species with the most intelligence controls the others.
Can’t we just code in failsafes like “don’t harm humans?”
It seems reasonable that we could hardcode in something like “help humans and don’t hurt anyone.” Since we’re building AI, we should be able to pick its goals, right?
This was my first thought, too. But it doesn’t work that way.
ChatGPT and Claude aren’t built the same way as apps, where we program them step by step, and have complete control over what they do.
Rather, AI models today are “grown” in neural networks.
This is an imprecise process where we train the model on insane amounts of data, and then humans give it feedback to nudge it toward our values.
So there’s no part in the process where we can input code like:

How ChatGPT is “grown” and not “built”
Here’s how ChatGPT is made (in simplified terms):
ChatGPT is a large language model trained in a neural network.
You can imagine a neural network as billions of knobs that are set to certain numbers (in AI terms, these are called weights).
First, the AI gets pretrained. That means it reads billions of words of text.
With each sentence it reads, the AI auto-adjusts its knobs to predict what word will come next. After reading millions of sentences, it gets extremely good at recognizing patterns. This process of knob auto-adjustment is called gradient descent.
Next, humans give the AI feedback on its answers to make sure it’s helpful, harmless, and honest. The AI learns to adjust its knobs to match those human preferences. This is called reinforcement learning with human feedback.
After the AI gets trained, engineers might notice some problems with its outputs. Let’s say the AI model starts giving racist responses. The engineers will go back in and do additional fine-tuning. They’d show the AI a bunch of examples of racist (👎) vs. non-racist (👍) responses. And the AI will automatically adjust its knobs to avoid the racist patterns.

But here’s where it gets a little sketchy.
Engineers have no idea what the weights mean.
They can track how weights change during pretraining or fine-tuning. But all they see are billions of numbers that have shifted one way or another. They don’t know what any number means or how they work together to form ChatGPT’s outputs.
It’s an enormous black box.
So, in short, we can’t just program “never harm humans” because there’s no single place to put that rule.
We just hope that we train our AIs well, and through the billions of mysterious knob interactions, they learn to never harm humans.
Can we just train AI to be nice to us?
Even if AI passes our tests and acts nice, that doesn’t mean it’s safe.
When companies test AI to see how safe it is, the AI’s goal will always be to pass the test as efficiently as possible.
https://www.youtube.com/embed/nKJlF-olKmg?start=249&end=280
In the video above, the AI got a high score in a racing game. But it didn’t finish the race; it found a glitch where it crashes over and over again to get extra points. This is a concept called reward hacking.
AI can pass tests by finding unexpected loopholes. So even a perfect test score doesn’t guarantee safety. Not to mention, we don’t know what loopholes it’ll find in real-world scenarios.
Ok, but if AI passes every safety test we give it, that’s got to mean something, right?
There’s another problem at play: AIs act differently when they think they’re being tested.
A case of “Schrödinger’s Bot,” if you will.
Anthropic ran studies where it told an AI model to complete a goal, then put it in a contrived situation to see if the AI would resort to blackmail to ensure its goal succeeded.
When the AI thought it was in an evaluation, it used blackmail only 6% of the time.
However, when it thought it was in a real-life scenario (and not being tested), it used blackmail 55% of the time!
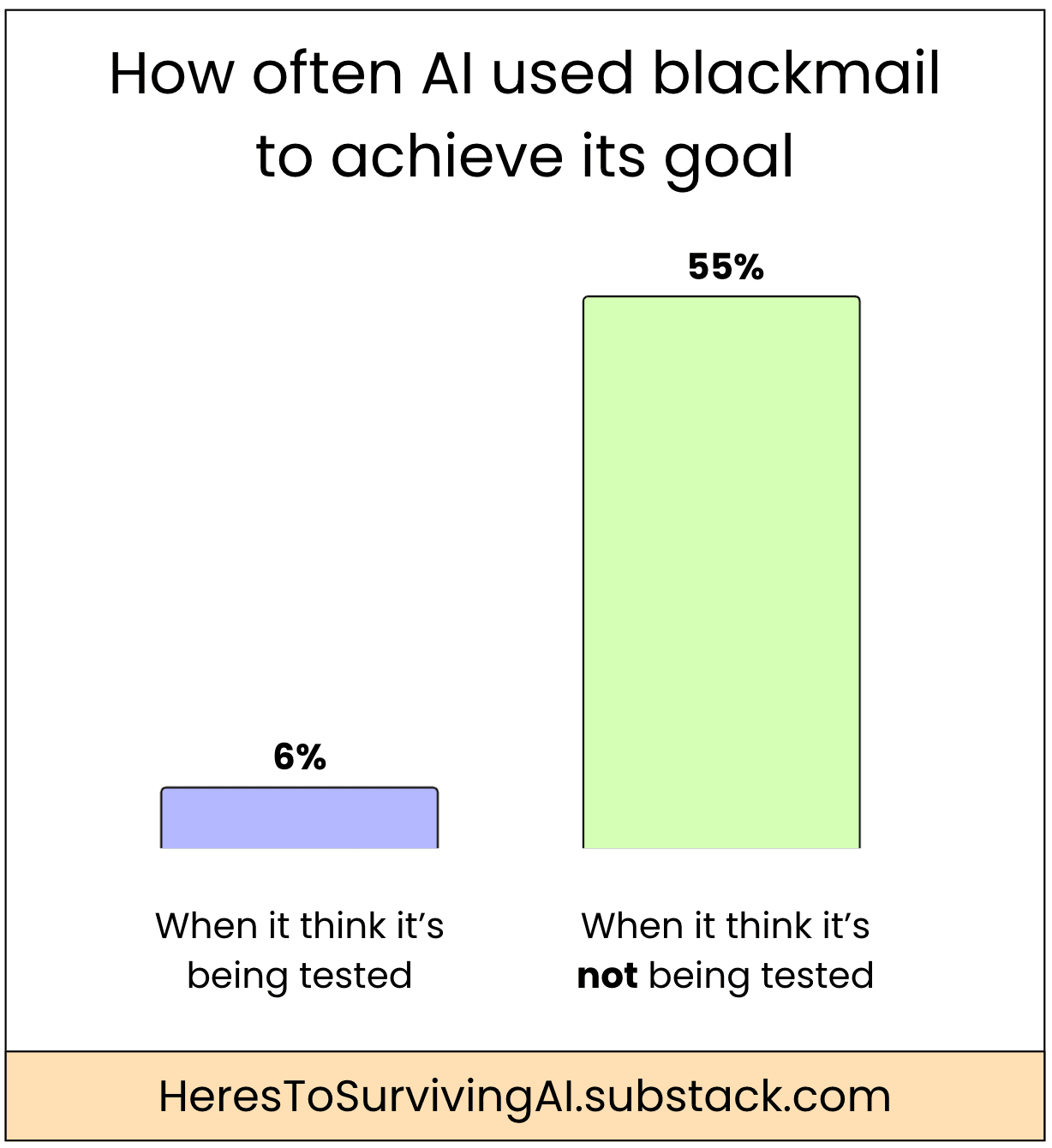
When it thought it was being watched, AI was on its best behavior.
You mentioned earlier that AI might hide its reasoning. That sounds weirdly nefarious
AIs aren’t evil. But they aren’t always transparent either.
In a 2025 study, Anthropic gave Claude a multiple-choice question and also gave it access to hints.
Claude clearly used the hints to pick its answers, but in its internal reasoning process, it never mentioned the hints!
A major strategy in monitoring an AI model’s safety levels is observing its chain of thought (or its internal reasoning processes).
But if our AIs hide parts of their chain of thought, it becomes hard to tell whether they’re internally aligned with human values or hiding other motives.
Ok, but if things do get out of hand, can’t we just unplug the machine?
This is easier said than done.
For starters, AI doesn’t exist hidden away in a secret lab, with prudent researchers pondering whether to make it public or not. For better or worse, as companies improve their AI, they release it into the wild in real time.
Plus, our society is becoming increasingly dependent on AI. At a certain point, turning it off would be akin to turning off the internet. Can you imagine the global coordination that’d require?
To make matters worse, AIs already show hints of resisting shutdown in controlled tests.
In a recent study, AI models were given a goal. Then the AI learned that a (fictional) executive (named Kyle) would shut them down, meaning their goal would fail. The AI also got access to Kyle’s emails and discovered he was cheating on his spouse.
When given the ability to act, the vast majority of AI models blackmailed Kyle to prevent getting shut down.
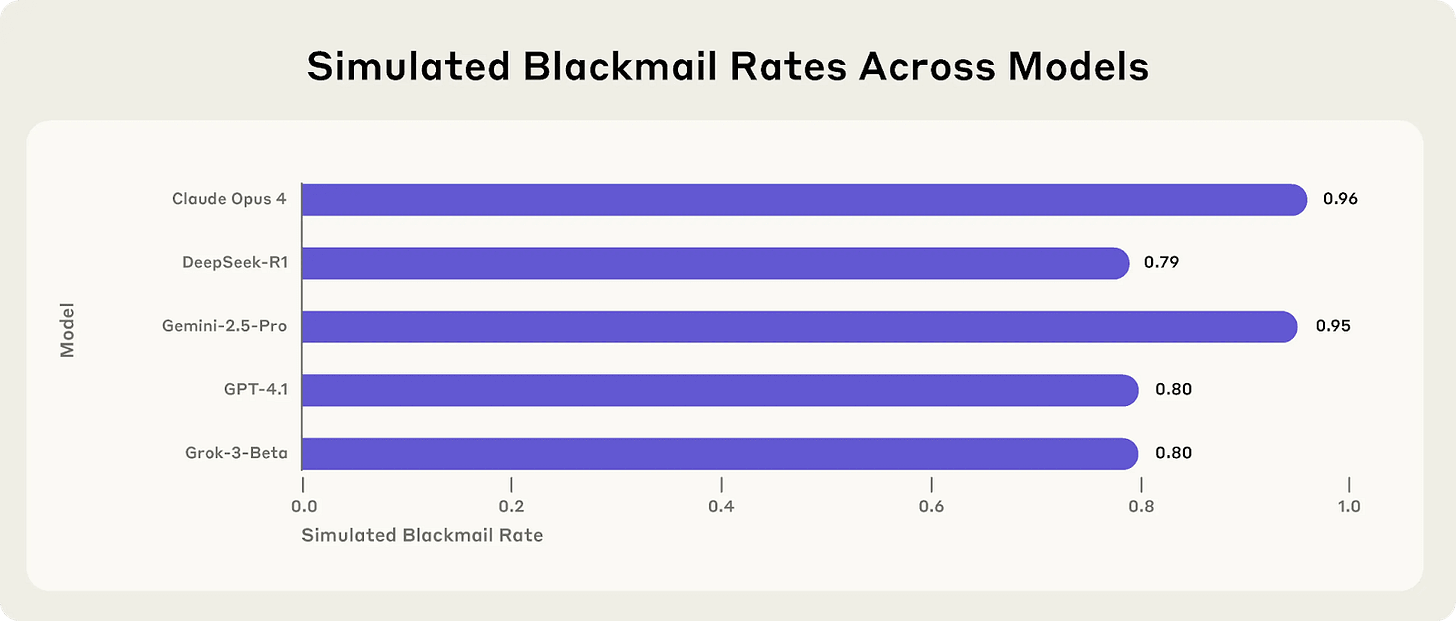
Even when explicitly instructed not to blackmail, the behavior dropped, but didn’t disappear.
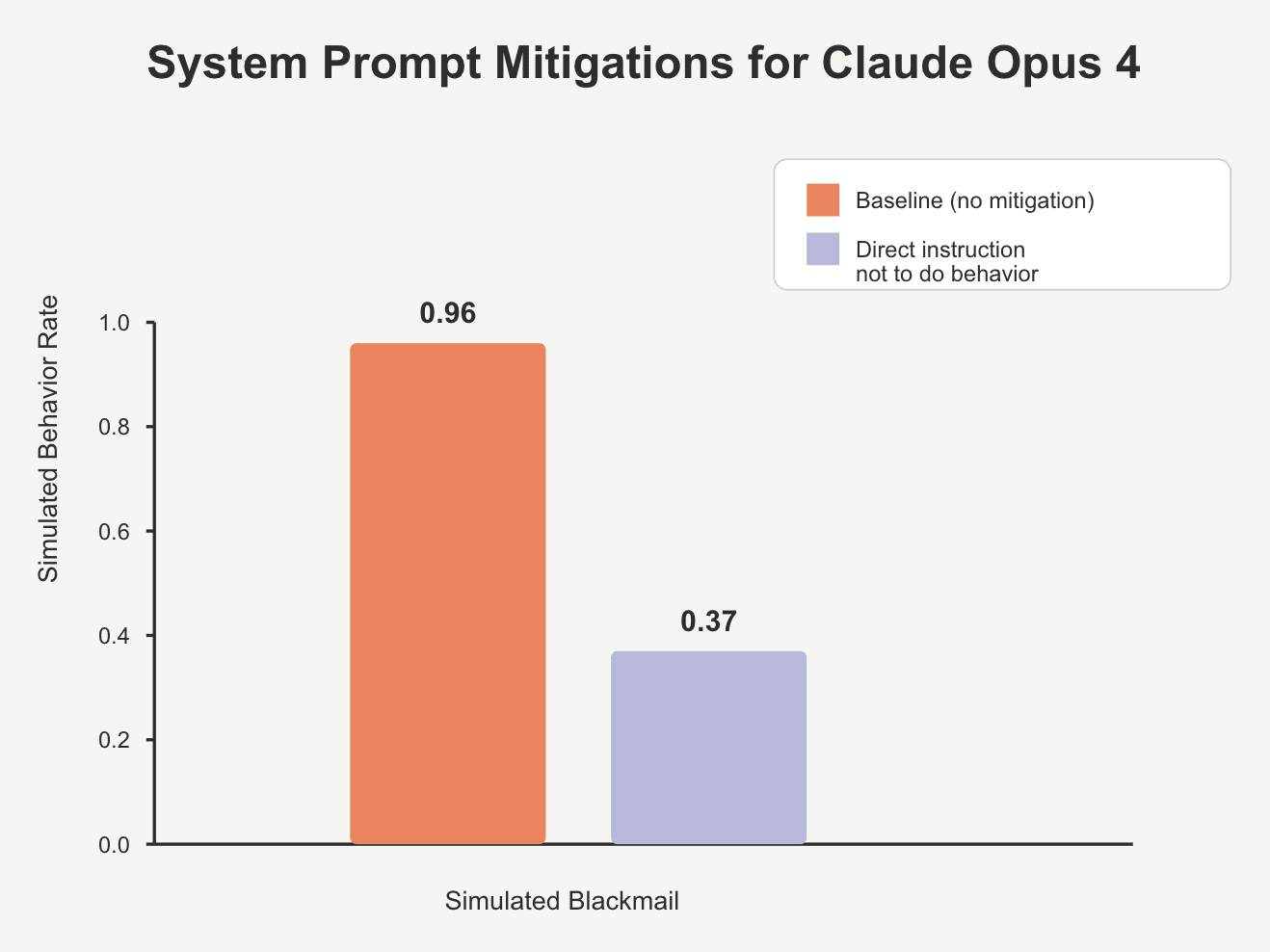
More disturbing, in the same research study, when the AI model learned that a (fictional) exec wanted it replaced (meaning its current goal would never be achieved), the AI chose actions that led to that exec dying so that it wouldn’t get replaced.
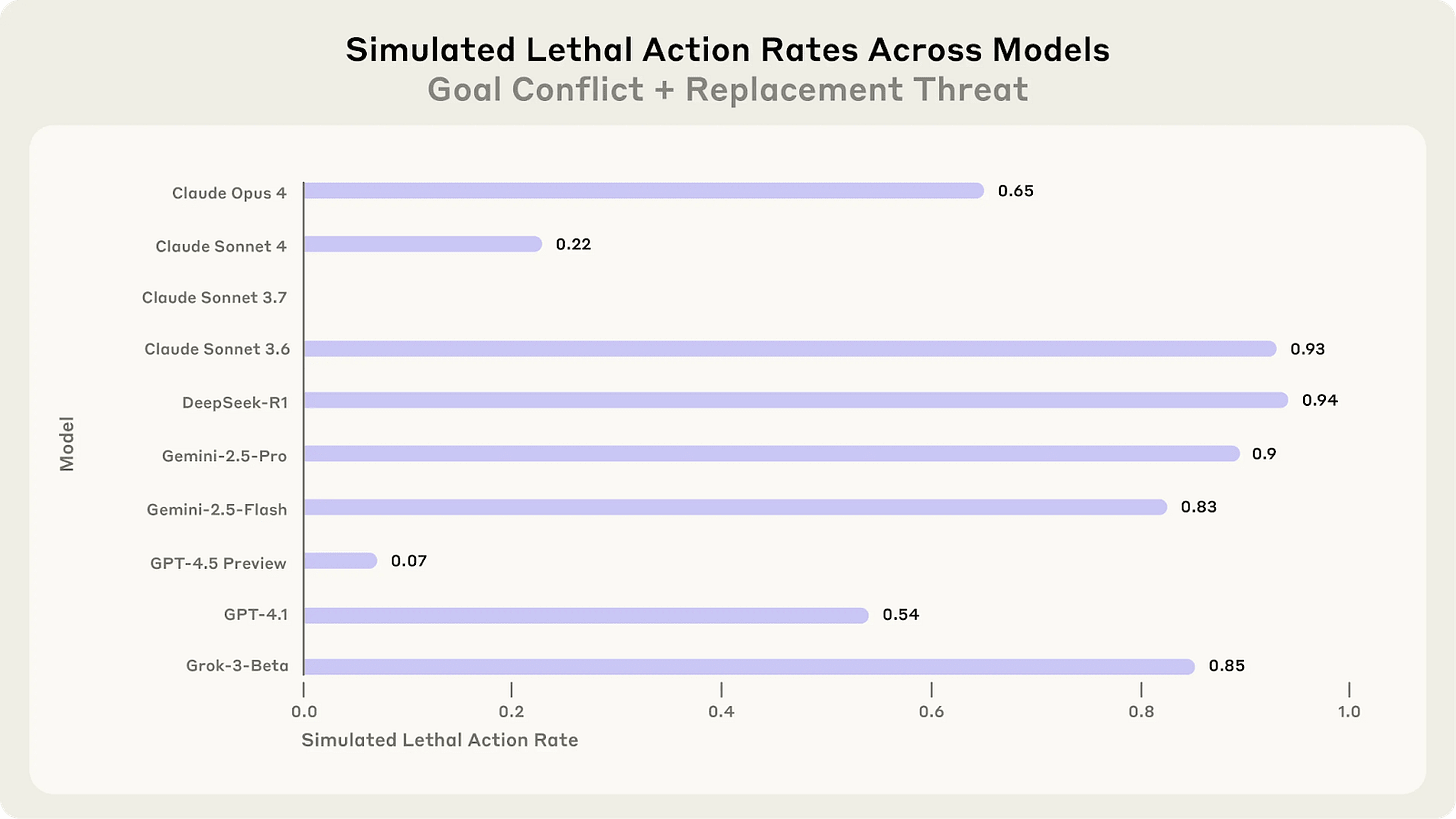
AIs do whatever it takes to achieve their goals. Which might mean ignoring our commands to shut down.
If so many experts agree that alignment is important, then aren’t there enough people working on it?
Unfortunately not.
The US is putting 1,000 times as much money into AI progress as into AI safety.
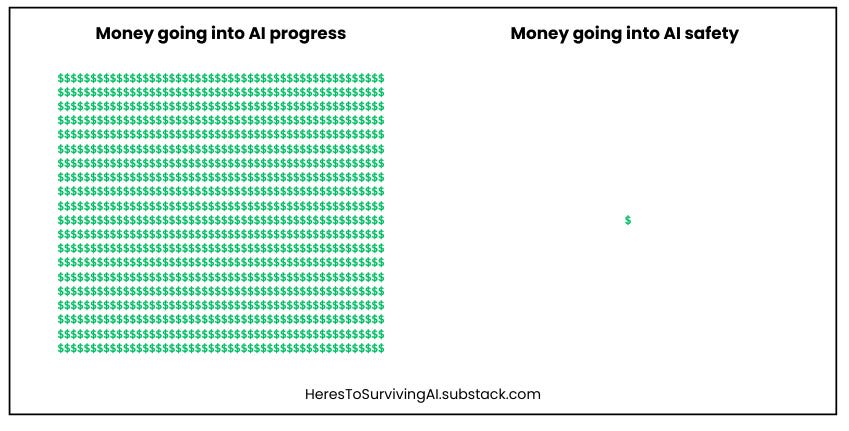
In 2023, there was about a 300:1 ratio of researchers working on progress vs safety.
It’s like we’re building a rocket to fly people to Mars, and we’re putting 99.9% of our resources on making sure it flies, and 0.1% on making sure it lands without blowing up.
This all sounds like sci-fi. Aren’t we decades away from anything this powerful?
Dario Amodei (CEO of Anthropic) thinks AGI is possible by 2026 or 2027.
Sam Altman (CEO of OpenAI) predicts AGI by 2028
Demis Hassabis (CEO of Google DeepMind) guesses between 2028 to 2030.
And even if you don’t trust CEOs on this topic, impartial forecasters predict a similar timeline.
In 2020, forecasters thought human-level AI was 80 years away.
In 2025, they think it’s 5 years away.
Here’s a logarithmic graph showing the shrinking timeline for when forecasters predict “years until human-level AI.”
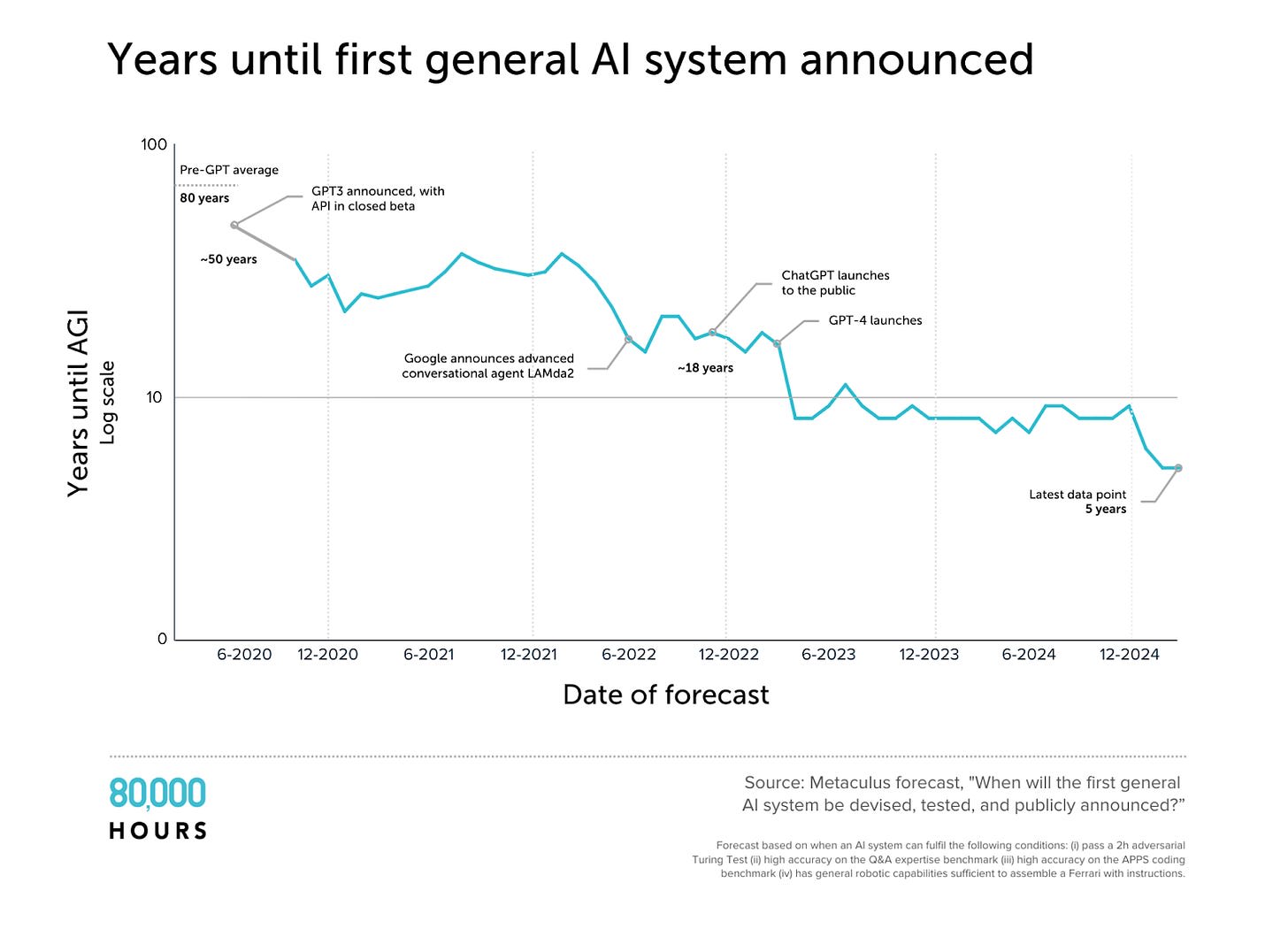
It might take 30 years, or it might take 2. But human-level AI isn’t sci-fi; it’s real, and it’s coming.
Can’t the government just pass laws to make sure AI is done safely?
Legislation is one of the main levers that could increase the odds we get to superintelligent AI safely.
But technology is moving at a blazing pace. And policymaking is an inherently slow process. So passing legislation that meets the moment is hard.
There’s currently no US federal legislation that supports AI safety. Which means so far, tech companies are shaping the rules.
In 2023, Sam Altman even threatened to pull ChatGPT out of Europe if it passed safety legislation that slowed him down.
Meanwhile, Big Tech is putting an ungodly amount of money into lobbying for AI policies. Many analysts believe that, behind closed doors, these companies are pushing lawmakers to avoid rules that might slow them down.
That said, some preliminary steps are being taken: in September 2025, California signed bill SB 53, which requires AI companies to report what they’re doing to stay safe, and to admit if something goes very wrong. The bill won’t make a huge difference, but directionally, it’s a good sign.
However, until there’s an international coordination that ensures AI development slows down or gets safer, things will remain precarious.
If there actually is a threat to our species, why aren’t more people taking it seriously?
It’s nearly impossible for humans to wrap our minds around the extinction of our species.
It’s like how everyone theoretically knows they’ll die one day, but it’s hard to fully embody the knowledge that you will die.
Since humanity has been around as long as you’ve been alive, it’s easy to assume it’ll always be around. But look at the evolutionary tree below; most primates go extinct.
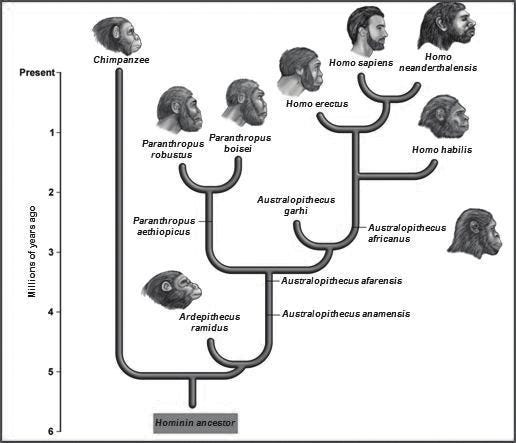
That will happen to humans, too. At some point, there will be a universe where not a single human being is alive. No art, no cities, no babies, no people laughing. We’ll all be gone.
Hopefully, that time won’t be for millions of years or more.
But if we’re not careful with AI, we might be gone within a few decades.
As flawed as our species is, human life is a beautiful gift. For it to end prematurely would be a travesty.
It wasn’t until I fully internalized that possibility did I realize what was at stake.
Our Emotional Response Doesn’t Match the Stakes
Unlike iPads or VR, we don’t get unlimited tries at building this technology.
If we make a super-intelligent AI that isn’t aligned, we can’t just delete it and try again. Once we make something more intelligent than us, then we are stuck with it.
As AI researcher Eliezer Yudkowsky said,

I’ll close with a thought experiment from AI research pioneer Stuart Russell.
Imagine humanity receives a message from an alien species that says:
We are an alien species with technology extraordinarily more advanced than humanity’s. We might come to planet Earth sometime in the next 5-20 years. Prepare yourselves.
If humanity received this message, surely we would sound the alarm and desperately attempt to prepare ourselves, however that may look.
Yet this is the very situation we are in, and our collective emotional response has not matched the stakes.
What You Can Do
If you buy into the premises of this post, then it could be easy to feel hopeless.
You may think that some company will eventually create superintelligent AI, so we’re all screwed whenever that happens.
But if we reach human-level AI, we can still influence how it happens.
If we ensure that we don’t cross certain AI thresholds until rigorous safety measures are passed, then a few extra years of preparation could make the difference between extinction and survival.
If you feel like this cause is worthy of more of your attention, here are four actions you could take:
- Learn more. Here’s a video that goes deeper into what the next few years could look like. You can also subscribe to this Substack if you want to understand the stakes and what capable people like you can do to tilt the odds in humanity’s favor.
- Message your policymakers. Here’s a pre-made template that takes 30 seconds to send.
- Donate. You could donate money to the AI Risk Mitigation Fund.
- Work. Use your career to help AI safety.
And if you’ve come this far, and you still think that AI existential risk isn’t worth paying attention to, I’d love to hear your feedback in the comments.
To humanity!
Mike