TAI Safety Bibliographic Database
By Jess_Riedel @ 2020-12-22T16:03 (+61)
Authors: Jess Riedel and Angelica Deibel
In this post we present the first public version of our bibliographic database of research on the safety of transformative artificial intelligence (TAI). The primary motivations for assembling this database were to:
- Aid potential donors in assessing organizations focusing on TAI safety by collecting and analyzing their research output.
- Assemble a comprehensive bibliographic database that can be used as a base for future projects, such as a living review of the field.
The database contains research works motivated by, and substantively informing, the challenge of ensuring the safety of TAI, including both technical and meta topics. This initial version of the database has attempted comprehensive coverage only for traditionally formatted research produced in 2016-2020 by organizations with a significant safety focus (~360 items). The database also has significant but non-comprehensive coverage (~570 items) of earlier years, less traditional formats (e.g., blog posts), and non-safety-focused organizations. Usefully, we also have citation counts for essentially all the items for which that is applicable.
The core database takes the form of a Zotero library. Snapshots are also available as Google Sheet, CSV, and Zotero RDF. (Compact version for easier human reading: Google Sheet, CSV.)
The rest of this post describes the composition of the database in more detail and presents some high-level quantitative analysis of the contents. In particular, our analysis includes:
- Lists of the most cited TAI safety research for each of the past few years (Tables 2 and 3)
- A chart showing how written TAI safety research output has changed since 2016 (Figure 1).
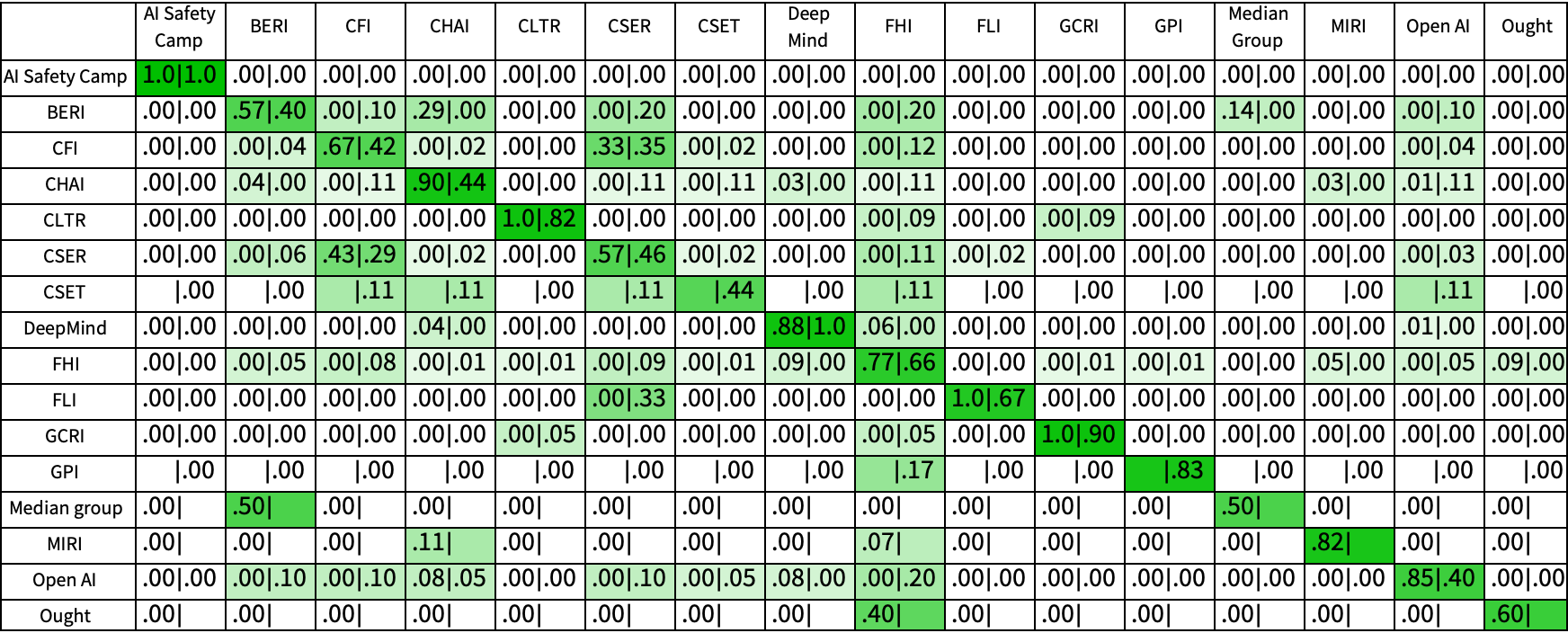
- A visualization of the degree of collaboration on TAI safety between different research organizations (Table 4).
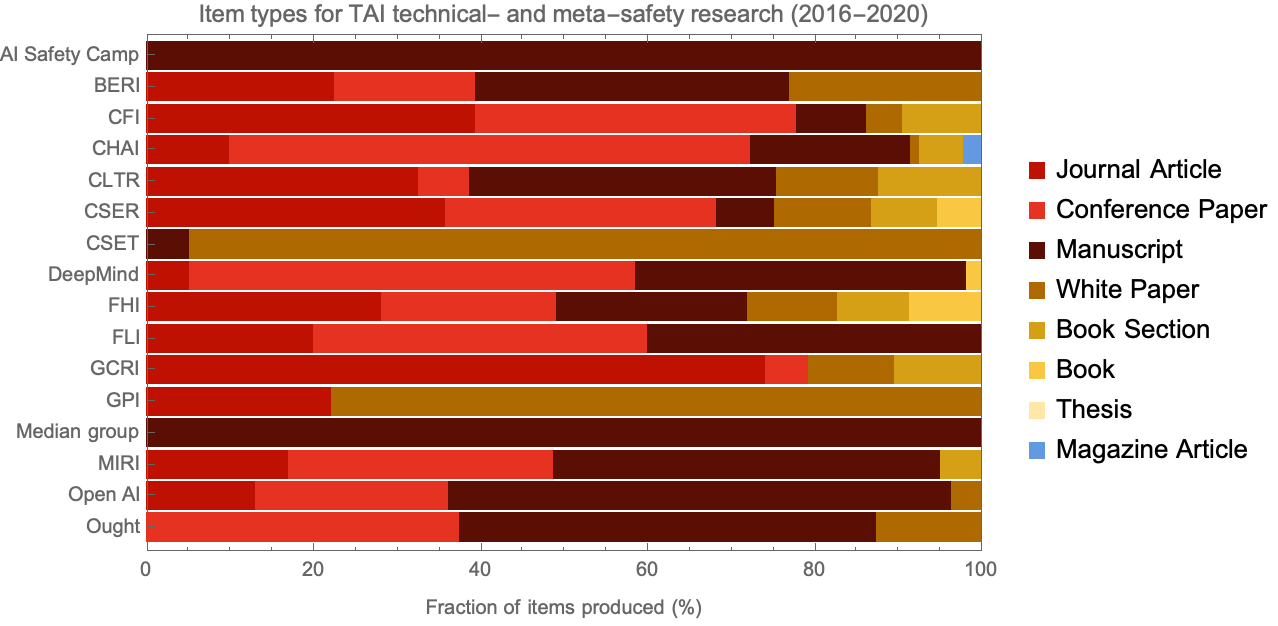
- A chart showing how the format of written research varied between organizations, e.g., manuscripts vs. journal articles vs. white papers (Figure 2).
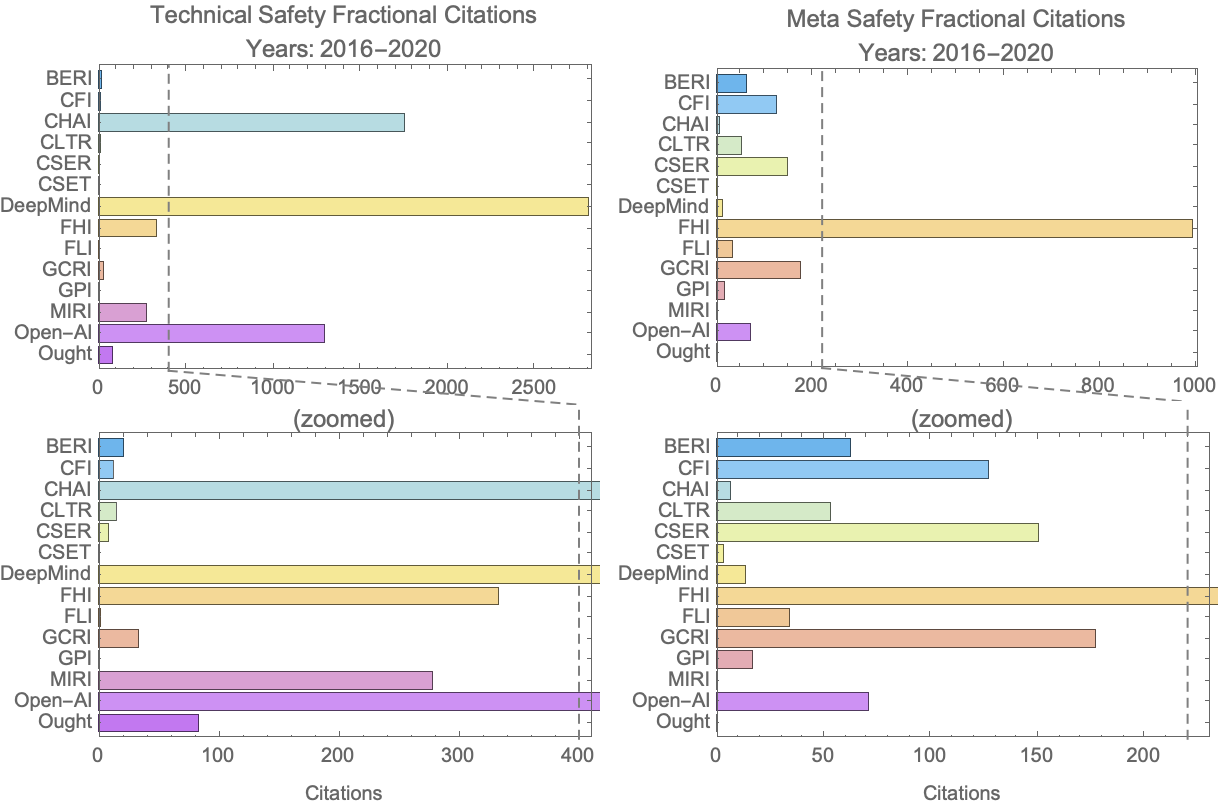
- A comparison of the number of citations that different organizations have accumulated (Figure 4).
In 2020 we observe a year-over-year drop in technical safety research, but not meta safety research, which we do not understand (Figure 1). We suggest some possible causes, but without a convincing explanation we must caution against drawing strong conclusions from any of our data.
If you are interested in building on this work, we encourage you to contact us (or just grab the data from the links above). Please see the section “Feedback & Improvements”.
Composition
Inclusion & categorization
We use "paper" and “item” interchangeably to refer to any written piece of research, such as an article, book, blog post, or thesis. For this initial version of the database, we have divided all papers into two subject areas: technical safety (e.g. alignment, amplification, decision theoretic foundations) and meta safety (e.g., forecasting, governance, deployment strategy).
Our inclusion criteria do not represent an assessment of quality, but we do require that the intended audience is other researchers (as opposed to the general public). Our detailed criteria for including and categorizing papers can be found in the Appendix.
Safety organizations
Where appropriate, papers were associated with one or more of the following organizations that have an explicit focus, at least in part, on the safety of transformative artificial intelligence: AI Impacts, AI Safety Camp, BERI, CFI, CHAI, CLR, CSER, CSET, DeepMind, FHI, FLI, GCRI, GPI, Median Group, MIRI, Open AI, and Ought. We refer to all these as “safety organizations” hereafter.
Note that AI Impacts, AI Safety Camp, BERI, and MIRI use unconventional research/funding mechanisms and particular care must be taken when using our data to assess their impact. Further detail on this issue can be found in the section “Caveats” in the Appendix.
Coverage
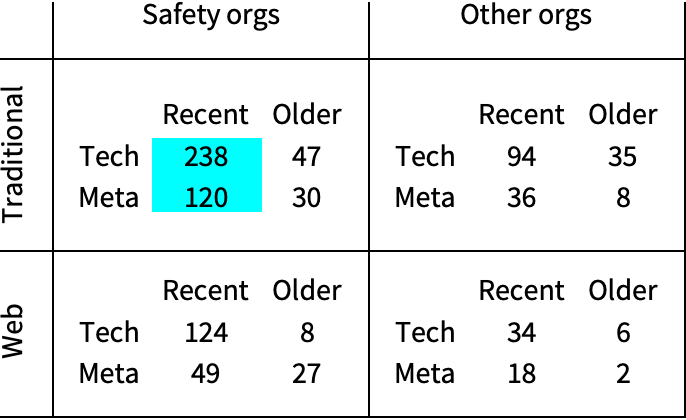
The papers in our database can be partitioned by four binary properties:
- Traditional / Web: Traditionally formatted research intended for formal review (journal articles, books, white papers, manuscripts) vs. web content not intended for review (e.g., blog posts, forum posts, wikis).
- Safety orgs / Other org: Research associated with at least one of the safety organizations above vs. not.
- Tech / Meta: Technical safety vs. meta safety,
- Recent / Older: Dated 2016 and younger vs. 2015 and older.
For this initial version of our database we aimed for near comprehensive coverage of traditionally formatted research produced by safety organizations since 2016, i.e., “Traditional” AND “Safety org” AND “Recent” AND (“Tech” OR “Meta”). As discussed in the later subsection “Papers over time”, we are probably nevertheless missing many papers from 2020 for various reasons, but we expect our coverage of 2020, and indeed of any given year, to improve over time.
Future versions of this database may aim for comprehensive coverage in other categories; see “Feedback & improvements” below.
Analysis
Our analysis in this section is largely restricted to the categories for which we are attempting comprehensive coverage, i.e., the ~360 items of TAI safety research produced since 2016 by safety organizations and intended for traditional review, indicated by the blue background in Table 1.
Warning: The drawbacks to quantifying research output by counting papers or citations are massive. At best, citations are a measure of the amount of discussion about a paper, and this is a poor measure of importance for many of the same reasons that the most discussed topics on Twitter are not the most important.
Top papers
To get a sense of the most read and discussed TAI safety research, we list in Tables 2 and 3 the most cited papers for each of the years 2016-2020.
The set of TAI safety papers at the top of the rankings is very dependent on one's criteria for considering whether a paper is about TAI safety. Some papers that are on the borderline of TAI safety (e.g., being more closely connected to near-term topics like autonomous vehicles and DL interpretability) have wider audiences and can dominate the citation counts. Nevertheless, it seems useful to have an inclusive list of most cited papers to get a sense of what’s out there. One can start at the top of the list and move down, ignoring those papers that are not sufficiently devoted to TAI safety.
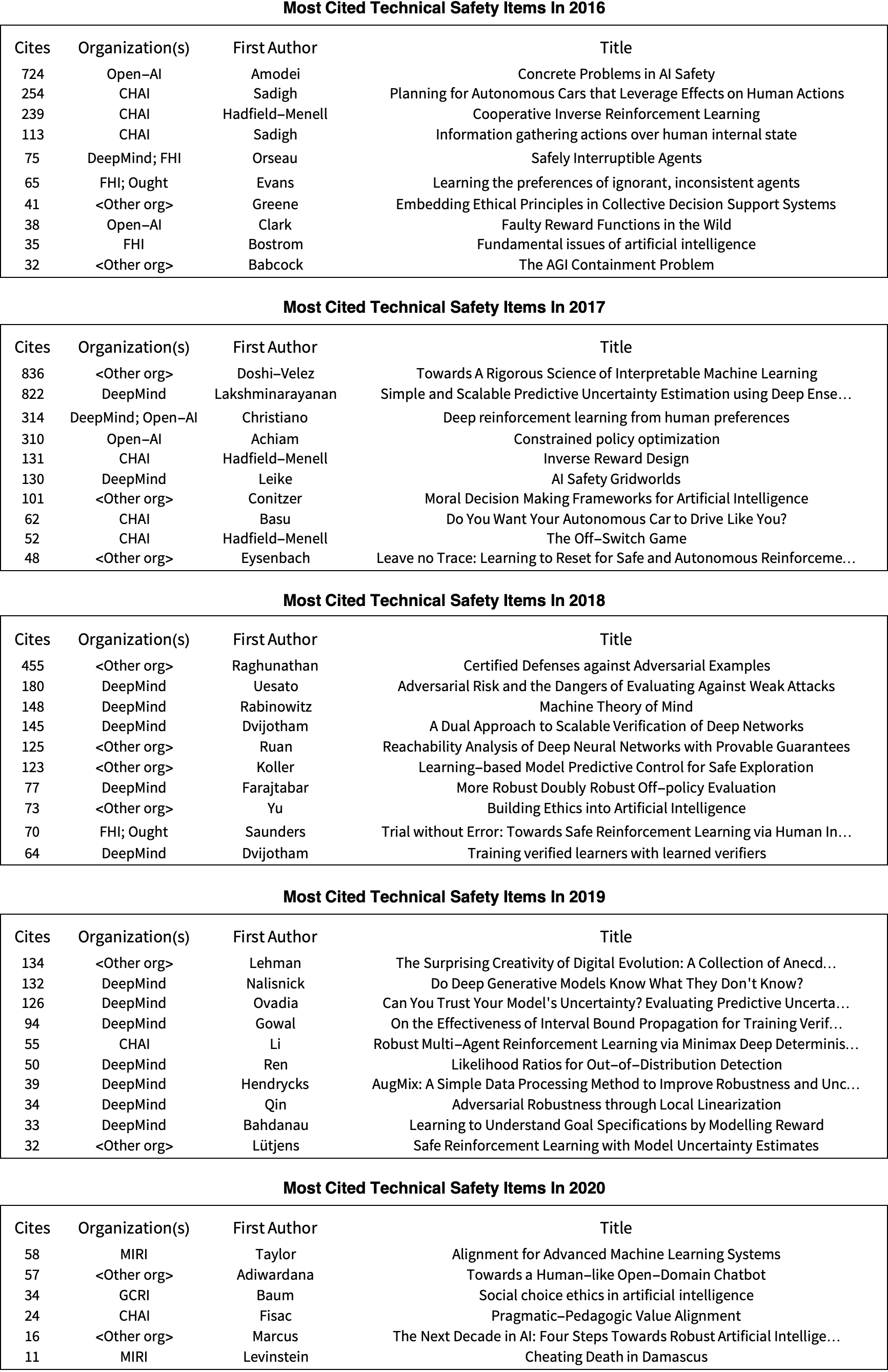
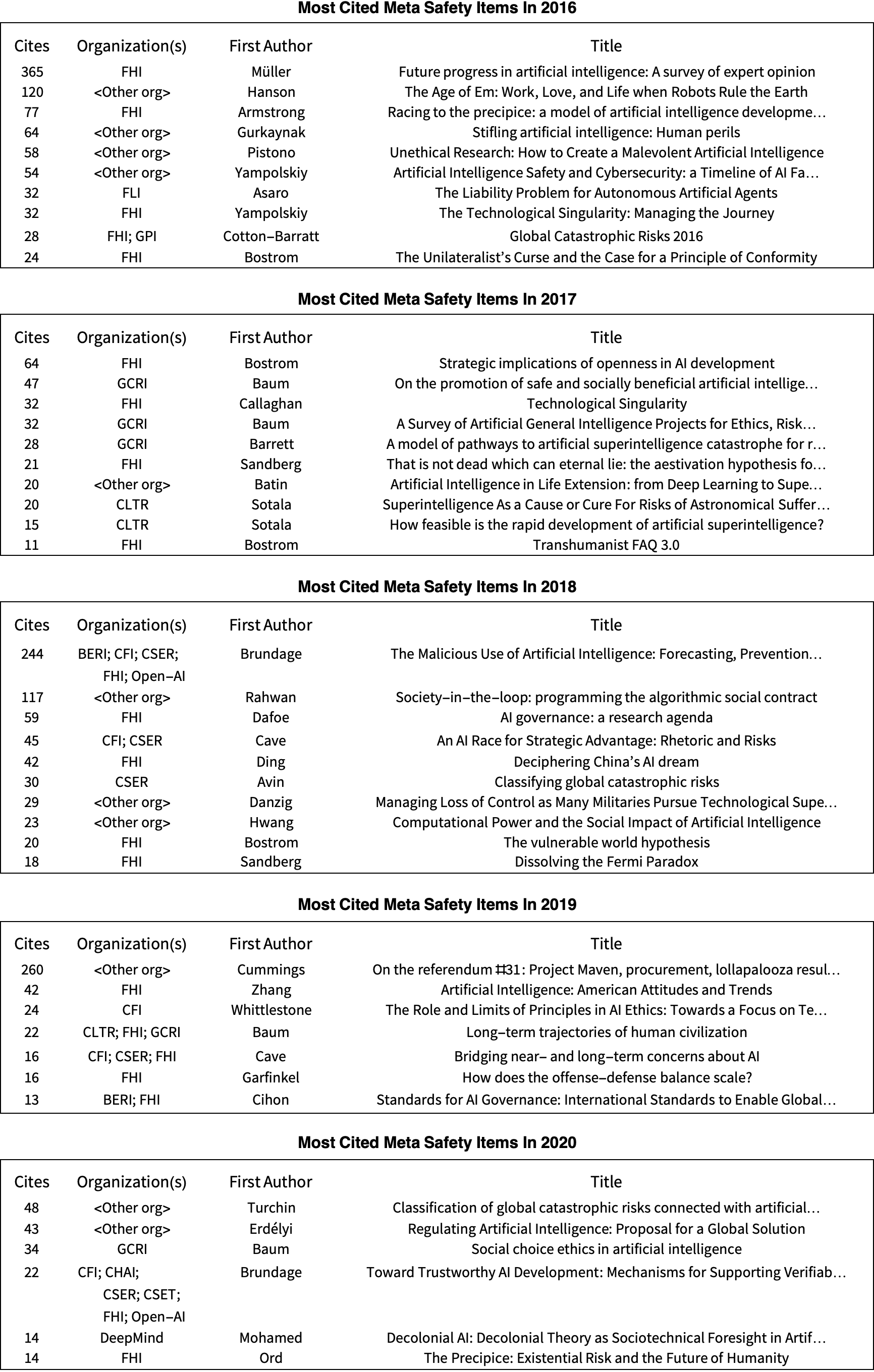
If you want to go deeper into these lists, open up the compact version of the database and sort by year and number of cites: Google Sheet, CSV.
Papers over time
In this section we look at the number of TAI safety research papers produced each year in the span 2016-2020. As shown in Figure 1, we find a surprising drop in the number of technical safety works in 2020 relative to 2019. This potentially indicates an effect of the pandemic, a large number of missing papers from this year, a shift in research format, and/or something else; we’re not sure. In any case, this lowered our confidence in the current state of this dataset and dissuaded us from looking at how the output of individual orgs changes over time until we can understand the drop better. The drop was seen in many organizations, including the largest contributors to TAI technical safety (CHAI, FHI, Deepmind, and Open AI), so it appears to be systemic.
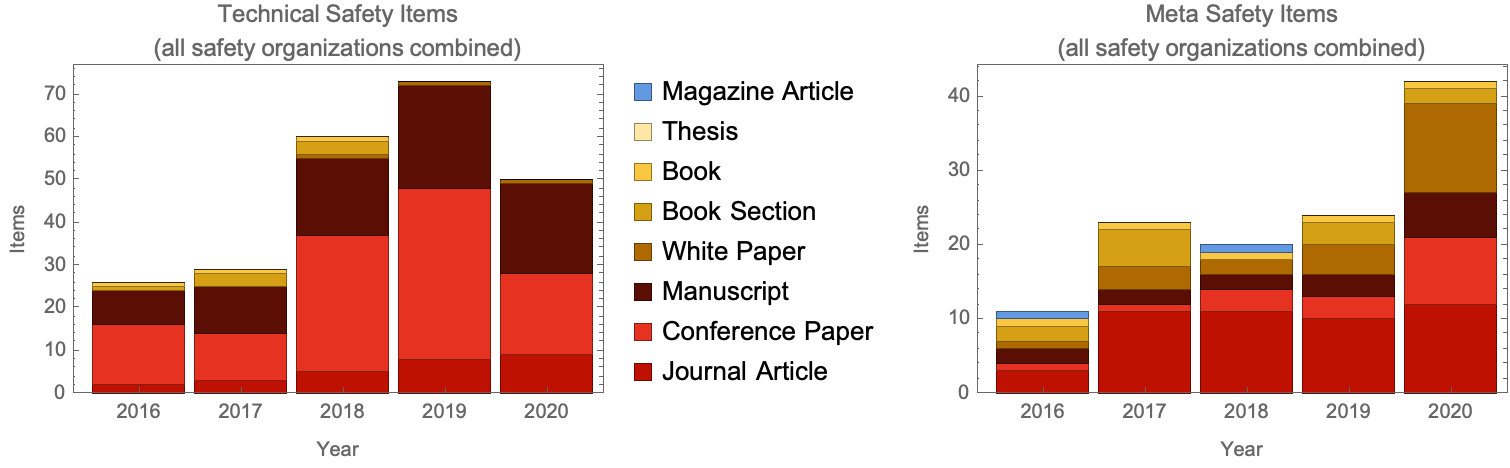
Because we don’t have a satisfactory explanation to this, we simply list some some complicating considerations:
- We only see this apparent drop in technical safety research, not in meta safety research.
- The magnitude of the drop from 2019 to 2020 diminishes substantially when we look at all technical safety papers rather than just those papers that were associated with safety organizations: From the safety organizations whose work is covered above, we have 73 traditionally formatted technical safety papers in 2019 and only 50 in 2020, but from all organizations we have 92 papers in 2019 and 82 in 2020.
- If we were to include web content (blog posts), the numbers would actually be higher for 2020 than 2019, as one might have originally expected: we have 125 such papers in 2019 and 161 in 2020, although this is hard to interpret since a typical blog post is a smaller unit of research than the typical paper, and our inclusion process for blog posts is very haphazard.
- Most of the 2019-to-2020 drop in technical-safety papers comes from diminished conference papers, but the number of meta-safety conference papers increased.
- As discussed in the subsection “Dates” in the Appendix, our dates should be biased forward by the fact that the current year should include both new manuscripts (preprints) that were recently released as well as manuscripts from previous years that were published this year.
- As discussed in the subsection “Discoverability” in the Appendix, it may be substantially more difficult for us to find work in the past year because of delays in our discovery mechanisms. In particular, (1) we must wait for researchers to report new publications to their organization in order for the organization to give that information to us, and (2) we can’t find items in review articles that appeared after a review article was written. This effect may be large, but it does not account for why the 2019-to-2020 drop is seen in technical safety but not meta safety.
It’s possible that there’s some genuine trend here, with research moving away from the relatively narrow category of technical safety research published in non-blog-post form and supported by safety organizations, and instead towards meta-safety research, towards being published as blog posts, or towards being supported by other organizations or done without organizational support. It’s also possible that the pandemic had an impact on the amount of research done (or published) in 2020 (the drop in technical safety conference papers from 2019 to 2020 makes this a tempting conclusion to jump to, but, again, meta safety conference papers actually increased). However, we don’t think our data provides strong evidence on any of these points.
Separately, we didn't make a corresponding plot of citations in different years because these go down with time; younger papers haven’t had time to accumulate as many cites. (Our automated solution for scraping Google Scholar for citation data means we don’t have access to when citations are made.)
Collaboration between organizations
The following matrix illustrates the extent to which different AI-safety organizations collaborate on research.
Output by organization
In Figure 2 we break down the research papers associated with each organization into different types: conference papers, books, manuscripts, etc. Recall that for this analysis we are ignoring web content not intended for review (e.g., blog posts).
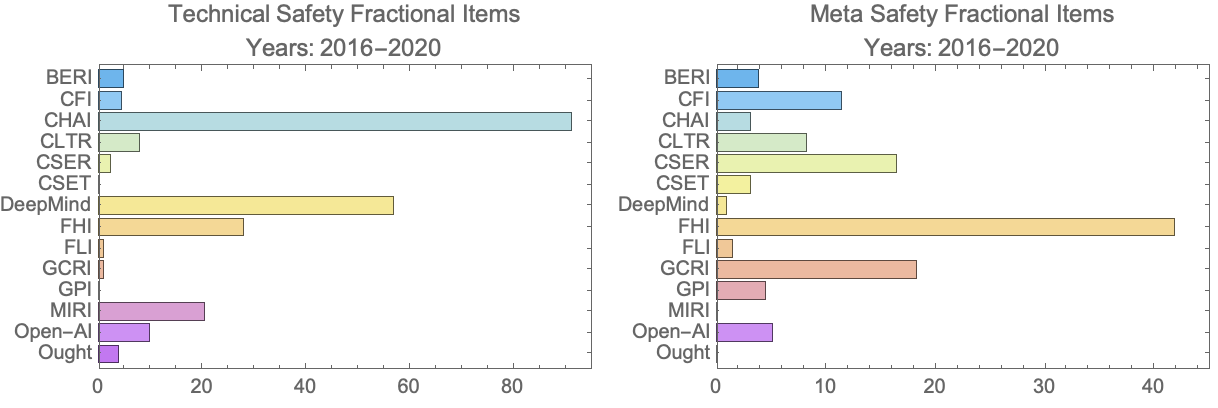
In Figures 3 and 4 we display the total number of papers and citations associated with each organization. We call these “fractional papers” and “fractional cites” to emphasize that we have divided credit for each item and its citations equally to all the organizations that are associated with it. Needless to say, for any given item the support it received from different organizations is unlikely to be equal, but we didn’t have a way to account for that with a reasonable amount of work.
This concludes our analysis.
Feedback & improvements
If there is sufficient interest, we would like to make some of the following improvements in the future:
- More granular categories (e.g., philosophy, governance, transparency, alignment, etc.).
- More comprehensive coverage of research that is not associated with any safety organization.
- More comprehensive coverage for 2015 and earlier.
- Commentary on individual papers and links to further discussion.
Want to help?
Accurately classifying 1,500+ papers is not an easy task, and there will be mistakes. Please bring them to our attention. You can email us or just write down your suggestion here. If you are interested in looking at a batch of papers that we found ambiguous and recommending a classification, please contact us, especially if you are an AI safety researcher.
Please let us know if you find this database useful and how you would like it to be improved. We are certainly willing to adjust our inclusion criteria based on strong reasons, but it is important we do not let the database grow to an unmanageable size.
Simple comments like "this database informed my donation decision" or "I found an interesting AI Safety paper here that I didn't know about before" are very useful and help us decide whether to put more effort into this in the future.
Please also contact us if you are interested in helping to improve this database more generally, either one-off or in an on-going capacity. We think that maintaining and expanding the database for a year would be an excellent side-project for a grad student in AI safety to help them gain a broader perspective on the field and contribute to the community. In particular, there seems to be some interest for collecting brief summaries and assessments of the most important TAI safety papers in one place, and this database could be a foundation for that.
We also could use help modifying the Zotero Scholar Citations plugin to more intelligently avoid tripping Google Scholar’s rate-limit ban.
Add your organization?
If you would like your organization included in future versions of the database, please send us a list of papers that ought to be associated with your organization, either as text file, Excel file, CSV file, or Google Sheet. It is not necessary to give us the complete bibliographic information, just enough for us to reliably uniquely identify the works. (For instance, a list of DOI and arXiv numbers is fine.) Optionally, you may also include suggested categorization and an explanation for why you believe a certain paper fits our criteria, which would be especially helpful for papers where that might be ambiguous.
Acknowledgements
We thank Andrew Critch, Dylan Hadfield-Menell, and Larks for feedback. We also thank the organizations who responded to our inquiries and helpfully provided additions and corrections to our database. We are, of course, responsible for the remaining mistakes.
Appendices
Inclusion & categorization
This section includes more details on what sort of research we include in our database, and how it is categorized.
These are our inclusion criteria:
- The contents of the paper are directly motivated by, and substantively inform, the challenge of ensuring good outcomes for TAI. The paper need not mention TAI explicitly, but it must be motivated by it, since there are far too many papers that are merely relevant to safety. Judging motivation is, unfortunately, inherently subjective, but this is necessary to avoid penalizing papers that do not explicitly mention TAI for appearance reasons, while also not including every paper on, e.g., adversarial examples (which are motivated by capabilities and near-term safety). If the paper would likely have been written even in the absence of TAI-safety concerns, it is excluded. Ultimately, we want to support researchers who are motivated by TAI safety and allow them to find each other's work.
- There is substantive content on AI safety, not just AI capabilities. That said, for more speculative papers it is harder to distinguish between safety vs. not safety, and between technical vs. meta, and we err on the side of inclusion. Articles on the safety of autonomous vehicles are generally excluded, but articles on the foundations of decision theory for AGI are generally included.
- The intended audience is the community of researchers. Popular articles and books are excluded. Papers that are widely released but nevertheless have substantial research content (e.g., Bostrom's Superintelligence) are included, but papers that merely try to recruit researchers are excluded.
- It meets a subjective threshold of seriousness/quality. This is intended to be a very low threshold, and would, for instance, include anything that was accepted to be placed on the ArXiv. Web content not intended for review (e.g., blog posts) is only accepted if it has reached some (inevitably subjective) threshold of notability in the community. It is of course infeasible for us to document all blog posts that are about TAI safety, but we do not want to exclude some posts that have been influential but have never been published formally.
- Peer review is not required. White papers, preprints, and book chapters are all included.
Here are how research papers are classified as technical safety vs. meta safety:
- Technical safety concerns the design and understanding of TAI systems, e.g., alignment, agent foundations, corrigibility, amplification, robustness, verification, decision theoretic foundations, logical uncertainty.
- Meta safety concerns the higher-level details of ensuring that TAI is safe, e.g., planning, forecasting, governance, deployment strategy, and policy
- Academic review articles about technical safety research are classified as technical safety, not meta safety.
- Philosophy that speaks directly to the technical design of TAI (e.g., Newcomb's problem) is classified as technical safety. Philosophy that informs how TAI ought to be deployed is classified as meta safety. Philosophy narrowly addressing the moral worth of animals is excluded (even though it is relevant to safety because an AGI with bad goals regarding animals is a safety risk).
Note that near the popular level, or at the very speculative level, it's sometimes hard to distinguish meta safety and technical safety.
Here is how we define the different item types:
- Journal article: Published in a peer-reviewed academic journal.
- Conference paper: Published in the peer-reviewed proceedings of an academic conference.
- Manuscript: Intended for academic publishing or posted on a preprint server, but not peer-reviewed.
- White paper: Released with the endorsement of a particular academic or policy institution but without external peer-review. (Called "report" in Zotero.)
- Thesis: Academic dissertation accepted by university graduate program.
- Book: Book published with editorial review from a publishing house.
- Book section: Part of a book.
- Web content: A catch-all term for all material released on the web that is not intended to be reviewed and not appearing on a preprint server. This includes wikis, blog posts, public forum posts, and press releases. (Called "blogPost" in Zotero.)
- Magazine article: Published in a magazine with editorial review.
- Newspaper article: Published in a newspaper with editorial review.
Criteria for our quantitative analysis
We err on the side of inclusion in our database, but when we analyze it quantitatively in this post we exclude some categories that are hard to cover comprehensively. This makes the conclusions we draw less dependent on the vagaries of what managed to make it into the database. In particular, the following items are excluded:
- Web content not intended for review. Currently, our coverage of blog posts, forum posts, and similar items is much too haphazard to be usefully analyzed in the aggregate. This may or may not change in the future.
- Items dating from 2015 and before. So far it has required too much work to get comprehensive coverage of older papers, especially since organizations often do not have complete records going arbitrarily far back.
- Items not associated with any safety organization. We can ask safety organizations for lists of the research they have produced, but TAI safety papers not associated with any organization can generally only be found by trawling through review papers and the rest of the literature. We believe this particularly noisy process would bias our quantitative analysis, so we ignore them for this purpose.
Dates
Our convention is to (1) date manuscripts (preprints) using the date on which they first appeared and (2) date published articles by the publication date. This has the unfortunate property that the date must be updated when a manuscript gets published, potentially biasing our data in weird ways. In particular, it makes judging whether a published article has a lot of citation given its age difficult, since a longer time between preprint and publication will yield more citations. (See for instance "Cheating Death in Damascus" by Levinstein & Soares, which was available since at least 2017 but published only this year.) It also means there will appear to be more papers produced in the last year relative to earlier years, even with constant research output in the field, since the number of papers attributed to a fixed year (say, 2017) can decrease over time as things are published and have their dates updated.
Unfortunately, this bias seems hard to avoid since the alternative is to track down the year that a preprint appeared for all published articles by hand, and using that year would be a non-standard convention in any case.
Discoverability
Our data might be less complete for 2020 compared to previous years because papers released recently by researchers at these organizations have not yet been reported to the organization’s management; that would mean the papers are not listed on the organization website and the organizations don't know about them when we ask by email. (Almost all the organizations replied when we asked them for help filling in papers missing from our database.) A related factor is that many papers in our database were found in existing review articles and bibliographies (see “Sources” in the Appendix). This process necessarily only turns up papers released before those sources were written.
Unfortunately, some of this effect is probably unavoidable. It could potentially be reduced by finding (and confirming organization affiliation for) all papers by authors associated with each organization we cover, but this would be quite laborious, especially since there is a fair amount of author migration. Such effort would be mostly made useless the next year when authors had finished reporting their 2020 papers to the orgs.
Therefore, we have elected not to account for this effect. We encourage organizations to improve their collection of this data, and we caution the reader to put even less faith in the 2020 numbers than earlier years.
Organizations
Here are the organizations that we associated with papers in our database:
- AI Impacts
- AI Safety Camp
- Berkeley Existential Risk Initiative (BERI)
- Leverhulme Centre for the Future of Intelligence (CFI)
- Center for Human-Compatible Artificial Intelligence (CHAI)
- Center on Long-Term Risk (CLR), previously called the Foundational Research Institute
- Centre for the Study of Existential Risk (CSER)
- Center for Security and Emerging Technologies (CSET)
- DeepMind
- Future of Humanity Institute (FHI)
- Future of Life Institute (FLI)
- Global Catastrophic Risk Institute (GCRI)
- Global Priorities Institute (GPI)
- Median Group
- Machine Intelligence Research Institute (MIRI)
- Open AI
- Ought
In general, we associated a paper with an institution when, in the paper, the organization was listed as an author affiliation or was explicitly acknowledged as providing funding. In a few cases we associated a paper with an organization because the organization told us the author was highly likely to be supported by the organization during preparation of the paper, or removed such association because the organization told us the support provided was very minimal during preparation of the paper.
Many papers are associated with multiple organizations. When necessary to "count" the credit, we gave each organization equal weight. Of course we expect that sometimes one organization deserved much more credit, in some sense, but it wasn't feasible for us to determine this.
Caveats
Here are some comments on individual organizations that are important for interpreting our data, especially with respect to the organizations’ overall impact:
- AI Impacts: Much of the research produced by this organization is divided between a blog and a large publicly readable, privately editable wiki, neither of which are intended for formal publication. This is difficult to fit into our analysis, and we have elected to select only their featured articles for inclusion in our database. Please see their 2020 review for more on the work they have done.
- AI Safety Camp: Some of the papers associated with this organization were produced by participants from the AI Safety Research Program 2019. That format was a spin-off from AI Safety Camp run by Czech effective altruists. AISRP served participants who were more advanced in their research career. On the other hand, AISC is aimed at early career aspirants who want to test their fit by trying to collaborate on a research priority. For reference the AISRP-related papers are tagged as such in our Zotero database, but our analysis includes all AI Safety Camp papers.
- BERI: This organization is neither a direct research organization nor a conventional grantmaker, and they do not require that the researchers acknowledge BERI support in their publications. Therefore, the papers that have been associated with BERI represent only one part of their impact.
- MIRI: As discussed a bit further in Lark’s 2020 AI Alignment Literature Review and Charity Comparison, MIRI now by default does not publish their research. Other than some blog posts by their researchers, the only 2020 papers in our database from them were first released as pre-prints several years ago but were published this year.
Zotero library details
The information in this section may be useful if you are going through the details of our Zotero library.
Getting a copy
The Zotero library is here. Unfortunately it is not possible to export a copy of the library from the web interface. If you would like an up-to-date copy of the library, please contact us. If you are satisfied with a static snapshot from the day we released this post, you can download it as Google Sheet, CSV, and Zotero RDF. Note that Zotero libraries can easily be imported into Mendeley, but going the other direction is much harder.
Tagging details
The actual Zotero library contains both papers that satisfy our inclusion criteria (tagged “TechSafety” and “MetaSafety”) and papers that we imported from other review articles and bibliographies but decided did not satisfy our criteria (“NotSafety”). We also marked papers that we decided on a first pass were borderline (tagged “AmbiguousSafety”) so that they can easily be re-considered in the future. Papers associated with a safety organization are tagged as such, while papers not associated with any safety organization are tagged “Other-org”. We also have some miscellaneous tags for a few blog posts that are unlikely to pass our criteria (tagged “non-notable”), AI Safety Camp papers produced during the AI Safety Research Program (tagged “AISRP2019”), and AI Impacts web pages that are not featured articles (tagged “AI-Impacts-NotFeatured”).
For technical reasons within Zotero, all web content is formally categorized as a “blog post”, and all white papers are formally categorized as a “report”.
Citation count scraping
To scrape citation count information from Google Scholar, we use the Zotero Scholar Citation plugin written by Anton Beloglazov and Max Kuehn. Citation information is recorded in the “extra” field and prefaced by “ZSCC:” (which stands for Zotero Scholar Citation Count). When this information is unavailable (“ZSCC: NoCitationData“) we take the data by hand and denote it with “ACC:” or “JCC:”. In a couple cases we noticed that the plugin was mistaking a paper from another published paper, so we used “JCCoverride:” to denote hand counts that are correct.
Copyright
Added May 29, 2021: We release the Zotero database under the Creative Commons Attribution-ShareAlike 4.0 International License. In short, the means you are free to use, modify, and reproduce the database for anything so long as you cite us and release any derivative works under the same license.
Sources
The following sources are not traditional review articles, but are good sources of TAI safety research articles and summaries thereof (“maps”):
- Larks, “2020 AI Alignment Literature Review and Charity Comparison” (2020). (See also previous years going back to 2016.)
- Perret, “Resources for AI Alignment Cartography” (2020).
- Shah, Alignment Newsletter (2020). (See especially the spreadsheet of summaries.)
- CHAI, “Annotated Bibliography of Recommended Materials” (2016).
- Krakovna, “AI safety resources” (2020).
Here are some AI Safety review articles:
- Critch & Krueger, “AI Research Considerations for Human Existential Safety (ARCHES)” (2020).
- Ngo, “AGI safety from first principles” (2020).
- Steinhardt, "AI Alignment Research Overview" (2019).
- Everitt, Lea, & Hutter, “AGI Safety Literature Review” (2018).
- Soares & Fallenstein, “Agent Foundations for Aligning Machine Intelligence with Human Interests: A Technical Research Agenda” (2017).
- Dewey, Russell, Tegmark, “A survey of research questions for robust and beneficial AI” (2016).
- Russell, Dewey, & Tegmark, “Research Priorities for Robust and Beneficial Artificial Intelligence” (2015).
- Steinhardt, “Long-Term and Short-Term Challenges to Ensuring the Safety of AI Systems” (2015).
Here are the online lists of sponsored publications or researchers maintained by the safety organizations, a few of which are filtered by AI safety.
Unfortunately, they are only sporadically updated and difficult to consume using automated tools. We encourage organizations to start releasing machine-readable bibliographies to make our lives easier.
Larks @ 2020-12-22T17:20 (+19)
I just wanted to say thanks very much to Jess and Angelica for putting all this together in addition to the analytics above, they were extremely helpful in providing me with lists of relevant papers from relevant organisations that I would have likely missed otherwise.
jsteinhardt @ 2020-12-22T23:11 (+4)
Thanks for curating this! You sort of acknowledge this already, but one bias in this list is that it's very tilted towards large organizations like DeepMind, CHAI, etc. One way to see this is that you have AugMix by Hendrycks et al., but not the Common Corruptions and Perturbations paper, which has the same first author and publication year and 4x the number of citations (in fact it would top the 2019 list by a wide margin). The main difference is that AugMix had DeepMind co-authors while Common Corruptions did not.
I mainly bring this up because this bias probably particularly falls against junior PhD students, many of whom are doing great work that we should seek to recognize. For instance (and I'm obviously biased here), Aditi Raghunathan and Dan Hendrycks would be at or near the top of your citation count for most years if you included all of their safety-relevant work.
In that vein, the verification work from Zico Kolter's group should probably be included, e.g. the convex outer polytope [by Eric Wong] and randomized smoothing [by Jeremy Cohen] papers (at least, it's not clear why you would include Aditi's SDP work with me and Percy, but not those).
I recognize it might not be feasible to really address this issue entirely, given your resource constraints. But it seems worth thinking about if there are cheap ways to ameliorate this.
Also, in case it's helpful, here's a review I wrote in 2019: AI Alignment Research Overview.
Jess_Riedel @ 2020-12-22T23:52 (+12)
Thanks Jacob. That last link is broken for me, but I think you mean this?
You sort of acknowledge this already, but one bias in this list is that it's very tilted towards large organizations like DeepMind, CHAI, etc.
Well, it's biased toward safety organizations, not large organizations. (Indeed, it seems to be biased toward small safety organizations over larges ones since they tend to reply to our emails!) We get good coverage of small orgs like Ought, but you're right we don't have a way to easily track individual unaffiliated safety researchers and it's not fair.
I look forward to a glorious future where this database is so well known that all safety authors naturally send us a link to their work when its released, but for now the best way we have of finding papers is (1) asking safety organizations for what they've produced and (2) taking references from review articles. If you can suggest another option for getting more comprehensive coverage per hour of work we'd be very interested to hear it (seriously!).
For what it's worth, the papers by Hendrycks are very borderline based on our inclusion criteria, and in fact I think if I were classifying it today I think I would not include it. (Not because it's not high quality work, but just because I think it still happens in a world where no research is motivated by the safety of transformative AI; maybe that's wrong?) For now I've added the papers you mention by Hendrycks, Wong, and Cohen to the database, but my guess is they get dropped for being too near-term-motivated when they get reviewed next year.
More generally, let me mention that we do want to recognize great work, but our higher priority is to (1) recognize work that is particularly relevant to TAI safety and (2) help donors assess safety organizations.
Thanks again! I'm adding your 2019 review to the list.
jsteinhardt @ 2020-12-23T05:48 (+7)
Well, it's biased toward safety organizations, not large organizations.
Yeah, good point. I agree it's more about organizations (although I do think that DeepMind is benefiting a lot here, e.g. you're including a fairly comprehensive list of their adversarial robustness work while explicitly ignoring that work at large--it's not super-clear on what grounds, for instance if you think Wong and Cohen should be dropped then about half of the DeepMind papers should be too since they're on almost identical topics and some are even follow-ups to the Wong paper).
Not because it's not high quality work, but just because I think it still happens in a world where no research is motivated by the safety of transformative AI; maybe that's wrong?
That seems wrong to me, but maybe that's a longer conversation. (I agree that similar papers would probably have come out within the next 3 years, but asking for that level of counterfactual irreplacibility seems kind of unreasonable imo.) I also think that the majority of the CHAI and DeepMind papers included wouldn't pass that test (tbc I think they're great papers! I just don't really see what basis you're using to separate them).
I think focusing on motivation rather than results can also lead to problems, and perhaps contributes to organization bias (by relying on branding to asses motivation). I do agree that counterfactual impact is a good metric, i.e. you should be less excited about a paper that was likely to soon happen anyways; maybe that's what you're saying? But that doesn't have much to do with motivation.
Also let me be clear that I'm very glad this database exists, and please interpret this as constructive feedback rather than a complaint.
Jess_Riedel @ 2020-12-23T15:39 (+9)
for instance if you think Wong and Cohen should be dropped then about half of the DeepMind papers should be too since they're on almost identical topics and some are even follow-ups to the Wong paper).
Yea, I'm saying I would drop most of those too.
I think focusing on motivation rather than results can also lead to problems, and perhaps contributes to organization bias (by relying on branding to asses motivation).
I agree this can contribute to organizational bias.
I do agree that counterfactual impact is a good metric, i.e. you should be less excited about a paper that was likely to soon happen anyways; maybe that's what you're saying? But that doesn't have much to do with motivation.
Just to be clear: I'm using "motivation" here in the technical sense of "What distinguishes this topic for further examination out of the space of all possible topics?", i.e., is the topic unusually likely to lead to TAI safety results down the line?" (It's not anything to do with the author's altruism or whatever.)
I think what would best advance this conversation would be for you to propose alternative practical inclusion criteria which could be contrasted the ones we've given.
Here's how is how I arrived at ours. The initial desiderata are:
-
Criteria are not based on the importance/quality of the paper. (Too hard for us to assess.)
-
Papers that are explicitly about TAI safety are included.
-
Papers are not automatically included merely for being relevant to TAI safety. (There are way too many.)
-
Criteria don't exclude papers merely for failure to mention TAI safety explicitly. (We want to find and support researchers working in institutions where that would be considered too weird.)
(The only desiderata that we could potentially drop are #2 or #4. #1 and #3 are absolutely crucial for keeping the workload manageable.)
So besides papers explicitly about TAI safety, what else can we include given the fact that we can't include everything relevant to safety? Papers that TAI safety researchers are unusually likely (relative to other researchers) to want to read, and papers that TAI safety donors will want to fund. To me, that means the papers that are building toward TAI safety results more than most papers are. That's what I'm trying to get across by "motivated".
Perhaps that is still too vague. I'm very in your alternative suggestions!
jsteinhardt @ 2020-12-23T06:00 (+9)
Also in terms of alternatives, I'm not sure how time-expensive this is, but some ideas for discovering additional work:
-Following citation trails (esp. to highly-cited papers)
-Going to the personal webpages of authors of relevant papers, to see if there's more (also similarly for faculty webpages)
Jess_Riedel @ 2020-12-23T15:43 (+5)
Sure, sure, we tried doing both of these. But they were just taking way too long in terms of new papers surfaced per hour worked. (Hence me asking for things that are more efficient than looking at reference lists from review articles and emailing the orgs.) Following the correct (promising) citation trail also relies more heavily on technical expertise, which neither Angelica nor I have.
I would love to have some collaborators with expertise in the field to assist on the next version. As mentioned, I think it would make a good side project for a grad student, so feel to nudge yours to contact us!