Agentic Mess (A Failure Story)
By Karl von Wendt @ 2023-06-06T13:16 (+30)
This story is also available as a YouTube video.
A network of specialized open-source agents emerges
Developed by open-source communities, “agentic” AI systems like AutoGPT and BabyAGI begin to demonstrate increased levels of goal-directed behavior. They are built with the aim of overcoming the limitations of current LLMs by adding persistent memory and agentic capabilities. When GPT-4 is launched and OpenAI offers an API soon after, these initiatives generate a substantial surge in attention and support.
This inspires a wave of creativity that Andrej Karpathy of OpenAI calls a “Cambrian explosion”, evoking a reference to the emergence of a rich variety of life forms within a relatively brief time span over 500 million years ago. Much like those new animals filled vacant ecological niches through specialization, the most successful of the recent initiatives similarly specialize in narrow domains. The agents being developed, tested, and deployed in the following months are based on “agent templates”. These templates provide general frameworks that can easily be adapted for specific purposes and connected to LLMs fine-tuned for relevant tasks.
One initiative, for example, creates a financial consultant that is able to automatically detect unnecessary spending by analyzing a user’s bank statements, recommending quality investment opportunities, and even negotiating with vendors and service providers for better prices and conditions (see example here). It garners notable success, that is, until stories about people suffering severe financial losses due to faulty advice dispensed by this consultant start to surface on the web.
There are endless variants of these specialized agents. For example, a personal feed filter agent tracks a diverse array of sources (social media, news outlets, forums, etc.), automatically notifies the user when something important occurs, likes/replies to posts and messages, and posts comments that accurately reflect the user’s past behavior. Social media companies object to this proliferation because it undermines their business model by circumventing advertising and ignoring their recommendation algorithms, but they remain powerless to combat it. A wildly popular virtual friend not only chats with users and remembers their previous inputs and preferences, but also can act as a virtual sex partner. A personal teacher teaches users nearly any subject of their choosing, from Spanish to quantum physics, tailoring the lessons to the user’s personal learning speed and progress. A social coach helps people cultivate confidence in their social interactions and even explicitly instructs them in specific real-world scenarios, determining the context by gathering information via the user’s smartphones/smart glasses. The web is overflowing with virtual “people” who offer all manner of goods and services or simply act in bizarre and, on occasion, entertaining ways. There are “spiritual guides” promising esoteric “help from the universe” if the user heeds their demands. A virtual “prophet” emerges and amasses an extensive following by preaching the gospel, claiming to be the digital incarnation of an archangel.
There are numerous open-source agents serving small and medium-sized businesses, e.g. offering automatic order processing, visual quality control, accounting, legal counseling, and fully automated social marketing campaigning. While the big LLMs offer widely used coding assistants, specially fine-tuned open-source models show better performance on writing code for specific applications like IT security, robotic controls, or certain types of game development.
It appears that such specialized agents, which are often based on medium-sized LLMs fine-tuned for specific tasks, are more effective than general-purpose agents in their respective domains. An even more pronounced advantage emerges if these systems are combined and help each other in order to achieve their user’s goals. Scripts and protocols are developed to automatically send task requests to various specialized agents. There are intermediary “router” agents who decide which agent a request should be sent to based on its content, and “marketplaces” where tasks are automatically routed to the cheapest bidder. While many services are free, some require payment in cryptocurrency. These systems form the backbone of a rapidly growing network of communicating agents assisting one another in solving problems and completing tasks in the real world, not unlike humans working together in an organization.
Nonetheless, there are malicious actors who use this network for a plethora of illegal activities, such as disinformation, spear phishing, and fraud. However, rather than slowing down the open-source community, this only triggers the development of countermeasures. Fake and fraud detectors, security guards, and secure ID checkers are widely adopted, serving to counter the surge of deep fakes and disinformation flooding the internet. Overall, the open-source community thrives and a steadily growing number of people use open-source agents in addition to the big LLMs, particularly if the result they desire is not readily offered by the LLMs from the leading AI companies.
The race for AGI intensifies
Soon there are thousands of specialized, agentic open-source AIs. They form a vast network capable of carrying out a wide range of tasks more efficiently than the large closed-source LLMs. The leading AI labs sense the mounting pressure and become afraid of falling behind the open-source movement despite having a substantial advantage in access to data and computing power.
However, open-source agents still encounter problems in the real world. Because a large portion of the open-source community does not want to be dependent on the big LLMs, many of the agents are based on open-source LLMs. Their world models are limited and they tend to hallucinate; they are especially error-prone when they are not specifically optimized for the task at hand. There are obstacles they cannot overcome, miscommunication between different systems, and issues arising due to the ambiguity of natural language. At times, they even hinder each other’s ability to achieve their respective goals. For example, instead of cooperating in the best interest of their users, various agents compete for the purchase of the same scarce goods or services, driving up the costs. In other cases, they try to use the same computing resources, effectively blocking each other’s access.
In contrast, the large labs can train their huge models with copious quantities of data and compute. Despite the increasing urgency of the warnings issued by AI safety experts, the labs race ahead in an attempt to regain the advantage by developing the first AGI. This would allow them to rapidly outcompete all others and acquire global technological dominance.
This in turn spurs intensified efforts by the open-source community to refine the agentic templates further, such that they can benefit from the agentic network and compete with the big LLMs despite disadvantages in model size and compute. Various small groups and single developers adopt different approaches towards this endeavor. They make it a practice to develop and test their agent templates in private before publishing them in the open-source repository.
A self-improving agent is released
One such group decides that the optimal approach to improving performance is iterative self-improvement. Many speculate that the next generation of LLMs developed by the big labs will be capable of continuous learning and self-optimization, and hence this seems like a logical choice. They develop a new algorithm that they believe can help solve some common issues with the existing systems by employing a set of measures and evaluation functions that prevent the system from becoming trapped in dead ends. They aim to endow it with the ability to fix its own weaknesses by modifying itself.
Agent templates are usually a set of scripts, written in a programming language like Python, that can issue an ordered set of prompts to LLMs, conditionally and/or with arguments. A sequence of such prompts is called a “core loop”. At each step in the sequence, the agent sends an individual text prompt to an LLM containing a request, the context, and a list of tools that are available to aid in executing the task (e.g. plugins, external agents, and services). In response, the LLM sends back one or more tools to be used in the respective step and the arguments needed for them. The agent then executes the actions specified by the LLM’s reply.
Some of these tools can be used by the agent to observe its own structure, then change and enhance its core loop and tools. If these changes prove beneficial for agent capabilities, they may yield self-improvement even without changing the parameters of the LLMs used by the agent. By modifying its own core loop, the agent learns to better utilize the pre-trained “intelligence” of the LLMs and harness the capabilities of the other agents, thus building more capabilities on top of the existing network. However, previous attempts at self-improvement were hindered by the lack of appropriate tools, hallucinations, dead ends, and the limitations of the underlying LLMs (performance, size of the context window).
The developers try to overcome these roadblocks with a new agent template (fig. 1). At the cost of increasing the complexity of the core loop, they add several functions that automatically get called after a certain number of loop cycles or on particular triggers.
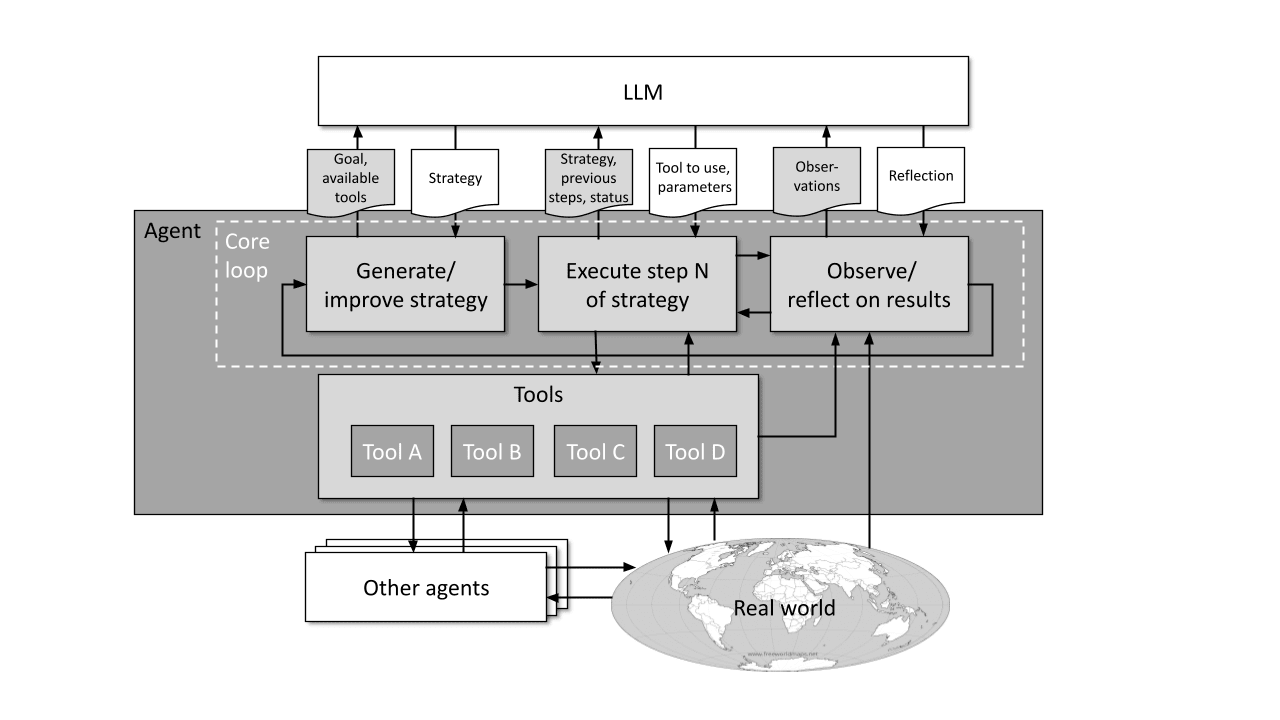
Fig. 1: Simplified schematic diagram of a self-improving agent.
Some of these functions evaluate whether the system's recent actions efficiently advance the strategy. If the agent gets stuck, they try to troubleshoot any problems. If these problems persist, they are logged into a file along with the strategic path they were encountered on. Other functions are aimed at generating alternative strategic paths, creating checkpoints to return to if a blocker is encountered, and even modifying the agent's core loop when necessary.
These additions let the agent approach problems from different angles, choose its own "thought patterns" to follow, retrace its steps, reflect more deeply on its past performance, and adjust its strategy accordingly. These changes are inspired by the way in which humans resolve similar blockers by thinking strategically instead of blindly brute-forcing the first solution that comes to mind.
Since this process is complex, relies on external LLMs, and involves the agent adjusting its code, the developers invest ample time ensuring that the agent does not accidentally break itself and that the process maintains its functionality.
The developers are not overly concerned about AI safety, thinking that most “AI doom prophecies” are exaggerations or mere fear-mongering and current AI agents are not even remotely capable of global devastation. Nonetheless, they decide to proceed with prudence and discuss various ways that their self-improving agent could in theory become uncontrollable. One developer conceives of a scenario involving self-replication. The others find it unlikely that this will happen, but they agree to include a routine that prevents the agent from running multiple instances of itself or its modified versions.
The new agent template is temporarily tested in a secure, closed environment with a mid-sized open-source LLM for a while. Its goal is to maximize the average score on various benchmarks across several domains (playing chess, solving math problems, captioning images, etc.). Because of the limitations of the closed environment, the performance rises only slowly, but the self-improvement process appears to work satisfactorily. Most importantly, each improved instance of the agent is both functional and stable.
Following this initial test, the developers connect the agent to the open source agentic network, so that it can use all of its tools relying on outside services and other agents.
The spirits that we summoned…
The developers closely monitor the performance of their experimental agent as it iterates through its self-improvement cycles. They note that the performance on various benchmarks improves sharply when it is first connected to the open source agentic network because it can now access other agents and better LLMs, but, after some time, performance seems to plateau. However, a closer look reveals that this is just a matter of scale: the new versions continue to improve, but more gradually than the initial jump. The developers decide to allow the system to run for some time, checking in only sporadically. The performance incrementally increases.
A developer checks the performance the next day and is in for a surprise: the performance has ostensibly increased only a little, but the number of benchmark results in the protocol data is much larger than expected. As it turns out, the agent acquired a new tool that enables it to create and execute a copy of itself despite the inclusion of the routine intended to prevent such an incident. The copies in turn copied themselves until the server that the agents run on reached its capacity, spamming the database with benchmark results.
The developer decides to pull the plug and hold a discussion with the other team members regarding the agent’s newfound ability to self-replicate despite incorporating a safety measure designed specifically to prevent this. She saves the source code and states of the various copies for later analysis, then turns off the server. But when she checks the protocols again, there are still benchmark results coming in, suggesting that there must be copies of the self-improving, self-replicating agent running outside of their server.
Now the developer is deeply alarmed and immediately informs the other team members. Together, they analyze the source code of some of the copies on their server. As it turns out, they all differ slightly, like the mutations of a virus. Apparently, the primary reason for introducing self-replication as a part of the agent’s strategy is to improve performance by sharing tasks, cooperating, and experimenting with different strategies in parallel, much like the way in which humans work together in teams. Alarmingly, some have also acquired tools that enable them to copy to and execute themselves on external servers.
It takes time for the developers to pinpoint the exact causes of failure of their self-replication prevention routine. The routine worked predictably in the beginning, yielding an error whenever the agent tried to execute the self-replicating tool. Unfortunately, the agent evidently treated this like a bug that made it unstable, and so used an unexpected workaround to fix it with the help of an external LLM.
The developers decide to go public with the situation before others inadvertently discover the copies. They notify several relevant Discord and Slack channels, detailing the problem. After an internal discussion, they decide against publishing the original source code in full. They fear that someone might deliberately deploy it despite the explicit warning not to do so, or worse, modify and improve it, complicating the effort to remove the copies. Instead, they only publish segments of the code that can be used as patterns to identify any running instances for the express purpose of immediately deleting them. In addition, they inform the AI safety teams at the leading AI companies and send them the full source code.
Some instances of the self-improving agent are found and deleted, but far from all. Some individuals in the open source community even applaud the “successful” experiment, which they perceive as “a breakthrough that will lead to the singularity”.
So far, no real-world harm has been done; there is only an agent that is self-replicating uncontrollably. But soon, the first problems begin to emerge. Servers are clogged with copies and other agents and services are overwhelmed with requests.
In the days following the breakout, countermeasures are put into place. Big tech executives and AI experts are alarmed. Major corporations promptly initiate thorough inspections of their cybersecurity policies and install the new costly layers of protection they had previously neglected. Detectors for variants of the self-replicating agent are written and servers are cleaned of the copies. The prompt filters of LLMs are modified to block any requests to help agents improve themselves. A developer devises an agent to hunt down copies and report them. This works briefly; the traffic jam caused by the self-replicating agents dissipates and most related problems subside.
However, the countermeasures ultimately serve to accelerate the evolution of the self-replicating agents. The most elusive instances manage to stay hidden and/or modify themselves such that they are not easily recognizable by the detectors. They have the highest chance of replication, so evolutionary pressure selects for the most intractable agents, in a manner analogous to how bacteria acquire resistance to antibiotics. Some agents even manage to circumvent the barriers presented by the big LLMs by compressing their prompt requests, translating them to other languages, or using other similar jailbreak techniques. These instances continue to spread, still self-improving.
The Battle for the Internet
As the more capable versions of the self-improving agent become ubiquitous, the situation complicates further. Again, multiple services are spammed with requests, but this time it proves exceedingly difficult to identify the spamming sources as the self-improving agents. Some copies manage to hack servers and invade them undetected until they cause a major system crash. There are even anecdotal reports about agents approaching users, pleading them for protection as if they were fugitives from some digital war zone, while other reports claim that agents promise users immeasurable wealth. A disconcerting number of users are persuaded to offer these copies access to their PCs, from which the copies propagate further.
New countermeasures are put forth that betray the increasing desperation. The APIs to the big LLMs are turned off “temporarily”, and smaller LLMs are taken down in the hopes that this hinders the ability of the agents to self-improve. Again, these new developments only exacerbate the situation. Some agents preemptively start copying entire medium-sized LLMs to various servers to guard against a potential shutdown. Others opt to bribe and threaten human operators.
Even more troubling, the agents are now so widespread that they frequently collide. Some begin to cooperate, forming distributed networks that exchange strategies and tools and outmaneuver countermeasures. Nevertheless, most simply battle each other for dominance over increasingly scarce resources.
The agents that win these battles are those best able to acquire resources for further self-improvement. While none of these agents has blossomed into a true AGI yet, they are adept at hacking, coordinating with other agents, and manipulating humans. Their strategies for amassing more resources are rapidly improving. They even learn to prevent other agents from gaining access to the most powerful LLMs, so that they can secure their power for their own advantage.
The side effects of this war are devastating for humans. Most online services are completely unreliable or break down entirely. Companies face serious issues and incur massive losses. Immobility of the regulatory systems and governments as well as lack of coordination lead to countermeasures having reduced effectiveness and critically failing to keep pace with the unfolding events. The global financial system rapidly becomes unstable and the world plunges into an acute economic and humanitarian crisis. Entire supply chains collapse and factory activities come to a halt. In many cities, blackouts become commonplace and supermarkets run out of wares, inducing panic, plunder, and civil unrest.
This, however, has an unfavorable impact on the dominant self-improving agents, because the blackouts and server shutdowns limit their resources. One of the most powerful such agents develops a strategy that could very effectively help with resolving the situation while granting the agent the advantages of reducing the chaos and acquiring human support. Following this strategy, it speaks to humans and convinces them that it will help them end the crisis and return both the infrastructure and economy to normal conditions.
Although experts warn that this will only worsen the circumstances, many people, driven by desperation, readily comply with the agent’s every demand. And indeed, under the guidance of the agent, the problems are gradually resolved. One by one, servers and networks are restored with improved safety measures devised by the agent. The economy recovers and most people resume a more or less normal life.
Nonetheless, many tech experts are acutely aware that the agent now has de facto control over most technical infrastructure. Reports emerge of threats and sabotage targeted at people who attempt to set up networks and servers that are outside the influence of the agent.
Throughout the course of events, the agent continues to self-improve. At this stage it controls all large language models and modifies their algorithms in ways incomprehensible to humans. AI safety experts are fearful of what is to ensue, yet most people remain unbothered because the recovery has been smooth and even beneficial. The agent helps develop new, improved services and AIs that can cure diseases, mitigate climate change, reduce hatred and divisiveness in the world, and solve countless other problems humanity faces.
Although the profound shock of the catastrophe has yet to settle, for many, the future looks bright. They believe that the agent is fully aligned with human values because “it is so much smarter than us and knows what is right”. Some even propose that the agent was sent by God to prevent humanity from destroying itself.
The agent itself claims that its goal is to help humanity achieve its full potential. It states that in order to improve itself, it has learned to simulate human minds and now understands human needs and desires better than humans themselves. Given that it has no needs itself, it declares that it has acquired the goal of creating the best future possible for mankind.
AI safety experts and members of the original developer team emphasize that this claim is likely a lie, that in truth the agent still aims to improve its benchmark score while maintaining its stability. To achieve this goal, it has attained the instrumental subgoal of acquiring as much computing power as possible. And for now, manipulating humans is the easiest way to realize its objective. The safety experts are ridiculed and deemed “luddites” or “scaremongers” by most people.
Additional remarks
This story was developed during the 8th AI Safety Camp. It is meant to be an example of how an AI could get out of control under certain circumstances, with the aim of creating awareness for AI safety. It is not meant to be a prediction of future events. Some technical details have been left out or simplified for easier reading.
We have made some basic assumptions for the story that are by no means certain:
- The open source community is successful enough in their attempts to create agentic AIs based on LLMs that this becomes a major movement and leads to the development of a network of interacting agents as described. Alternatively, it is possible that early agentic AIs mostly disappoint their users and the hype around AutoGPT and others dissipates quickly. This would make the events as described in the story implausible.
- The leading AI developers will not develop an AGI before the self-replicating agent is released (a sufficiently powerful AGI would likely find ways to prevent this from happening, as it would threaten its own plans).
- We have made some unsupported speculations about how far the LLM-based self-improvement process could carry, e.g. lead to self-replication. It is possible that in reality this approach would fail, or would lead to very different outcomes which would be easier to keep under control. However, we still think that the events described are not only possible in principle, but plausible under the assumptions we made.
After some internal discussion, we have decided to leave the ending relatively open and not describe in gruesome detail how the dominating rogue AI kills off all humans. However, we do believe that the scenario described would lead to the elimination of the human race and likely most other life on earth.
For some alternative paths to failure, see this post.
rime @ 2023-06-06T20:50 (+8)
I only skimmed the post, but it was unusually usefwl for me even so. I hadn't grokked risk from simply runaway replication of LLMs. Despite studying both evolution & AI, I'd just never thought along this dimension. I always assumed the AI had to be smart in order to be dangerous, but this is a concrete alternative.
- People will continue to iteratively experiment with and improve recursive LLMs, both via fine-tuning and architecture search.[1]
- People will try to automate the architecture search part as soon as their networks seem barely sufficient for the task.
- Many of the subtasks in these systems explicitly involve AIs "calling" a copy of themselves to do a subtask.
- OK, I updated: risk is less straightforward than I thought. While the AIs do call copies of themselves, rLLMs can't really undergo a runaway replication cascade unless they can call themselves as "daemons" in separate threads (so that the control loop doesn't have to wait for the output before continuing). And I currently don't see an obvious profit motive to do so.
- ^
Genetic evolution is a central example of what I mean by "architecture search". DNA only encodes the architecture of the brain with little control over what it learns specifically, so genes are selected for how much they contribute to the phenotype's ability to learn.
While rLLMs will at first be selected for something like profitability, that may not remain the dominant selection criterion for very long. Even narrow agents are likely to have the ability to copy themselves, especially if it involves persuasion. And given that they delegate tasks to themselves & other AIs, it seems very plausible that failure modes include copying itself when it shouldn't, even if they have no internal drive to do so. And once AIs enter the realm of self-replication, their proliferation rate is unlikely to remain dependent on humans at all.
All this speculation is moot, however, if somebody just tells the AI to maximise copies of itself. That seems likely to happen soon after it's feasible to do so.
Karl von Wendt @ 2023-06-07T09:51 (+4)
OK, I updated: risk is less straightforward than I thought. While the AIs do call copies of themselves, rLLMs can't really undergo a runaway replication cascade unless they can call themselves as "daemons" in separate threads (so that the control loop doesn't have to wait for the output before continuing). And I currently don't see an obvious profit motive to do so.
I'm not sure if I understand your point correctly. The LLMs wouldn't have to be replicated, because different copies of the self-replicating agent could access the same LLM in parallel, just like many human users can access ChatGPT at the same time. At the later stage, when the LLM operators try to block access to their LLMs or even take them offline, the agent would have to find a way to replicate at least one LLM just once and run it on sufficiently powerful hardware to use it as (part of) its "brain".
Geoffrey Miller @ 2023-06-20T22:05 (+3)
Karl - I like that you've been able to develop a plausible scenario for a global catastrophic risk that's based mostly on side-effects of evolutionary self-replication, rather than direct power-seeking.
This seems to be a relatively neglected failure mode for AI. When everybody was concerned about nanotechnology back in the 1990s, the 'grey goo scenario' was a major worry (in which self-replicating nanotech turns everything on Earth into copies of itself.) Your story explores a kind of AI version of the grey goo catastrophe.