The Game Board has been Flipped: Now is a good time to rethink what you’re doing
By LintzA @ 2025-01-28T21:20 (+378)
Cross-posted to Lesswrong
Introduction
Several developments over the past few months should cause you to re-evaluate what you are doing. These include:
- Updates toward short timelines
- The Trump presidency
- The o1 (inference-time compute scaling) paradigm
- Deepseek
- Stargate/AI datacenter spending
- Increased internal deployment
- Absence of AI x-risk/safety considerations in mainstream AI discourse
Taken together, these are enough to render many existing AI governance strategies obsolete (and probably some technical safety strategies too). There's a good chance we're entering crunch time and that should absolutely affect your theory of change and what you plan to work on.
In this piece I try to give a quick summary of these developments and think through the broader implications these have for AI safety. At the end of the piece I give some quick initial thoughts on how these developments affect what safety-concerned folks should be prioritizing. These are early days and I expect many of my takes will shift, look forward to discussing in the comments!
Implications of recent developments
Updates toward short timelines
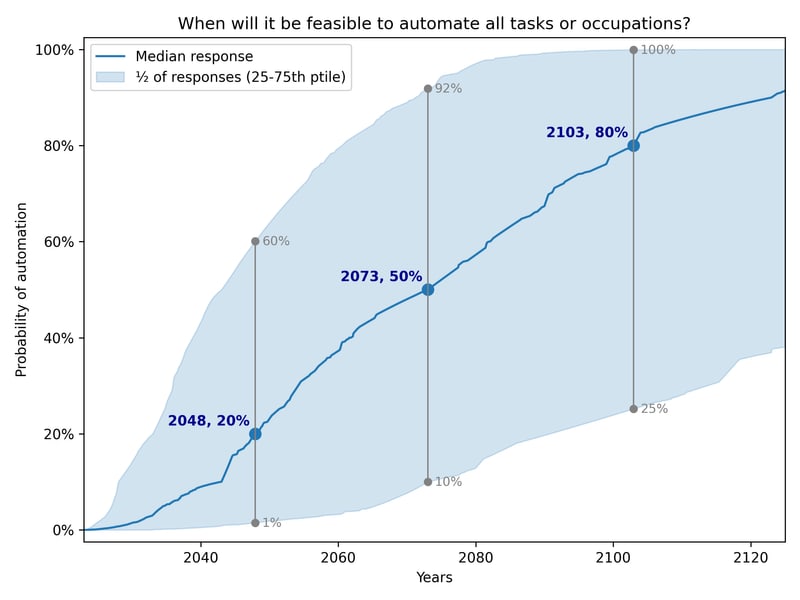
There’s general agreement that timelines are likely to be far shorter than most expected. Both Sam Altman and Dario Amodei have recently said they expect AGI within the next 3 years. Anecdotally, nearly everyone I know or have heard of who was expecting longer timelines has updated significantly toward short timelines (<5 years). E.g. Ajeya’s median estimate is that 99% of fully-remote jobs will be automatable in roughly 6-8 years, 5+ years earlier than her 2023 estimate. On a quick look, prediction markets seem to have shifted to short timelines (e.g. Metaculus[1] & Manifold appear to have roughly 2030 median timelines to AGI, though haven’t moved dramatically in recent months).
We’ve consistently seen performance on benchmarks far exceed what most predicted. Most recently, Epoch was surprised to see OpenAI’s o3 model achieve 25% on its Frontier Math dataset (though there’s some controversy). o3 also had surprisingly good performance in coding. In many real-world domains we’re already seeing AI match top experts, they seem poised to exceed them soon.
With AGI looking so close, it's worth remembering that capabilities are unlikely to stall around human level. We may see far more capable systems potentially very soon (perhaps months, perhaps years) after achieving systems capable of matching or exceeding humans in most important domains.
While nothing is certain, and there’s certainly potential for groupthink, I believe these bits of evidence should update us toward timelines being shorter.
Tentative implications:
- While we should still be ready for longer timelines, it’s now considerably more important to be able to tell a story where what you’re doing now will have an impact within the next few years.
Note that, because short timelines scenarios happen sooner and often don’t trade off terribly much against longer timelines scenarios, even if you put just 30% on sub 4 year timelines it could be worth having as a top priority.[2]
- AI risk is no longer a future thing, it’s a ‘maybe I and everyone I love will die pretty damn soon’ thing. Working to prevent existential catastrophe from AI is no longer a philosophical discussion and requires not an ounce of goodwill toward humanity, it requires only a sense of self-preservation.
- Plans relying on work that takes several years should be heavily discounted - e.g. plans involving ASL5-level security of models if that’s 5+ years away
- There is a solid chance that we’ll see AGI happen under the Trump presidency.
- We can make a reasonable guess at the paradigm which will bring us to AGI as well as the resources and time needed to get there.
- We know the actors likely to achieve AGI and have a rough idea of what the landscape will look like.
The Trump Presidency
My sense is that many in the AI governance community were preparing for a business-as-usual case and either implicitly expected another Democratic administration or else built plans around it because it seemed more likely to deliver regulations around AI. It’s likely not enough to just tweak these strategies for the new administration - building policy for the Trump administration is a different ball game.
We still don't know whether the Trump administration will take AI risk seriously. During the first days of the administration, we've seen signs on both sides with Trump pushing Stargate but also announcing we may levy up to 100% tariffs on Taiwanese semiconductors. So far Elon Musk has apparently done little to push for action to mitigate AI x-risk (though it’s still possible and could be worth pursuing) and we have few, if any, allies close to the administration. That said, it’s still early and there's nothing partisan about preventing existential risk from AI (as opposed to, e.g., AI ethics) so I think there’s a reasonable chance we could convince Trump or other influential figures that these risks are worth taking seriously (e.g. Trump made promising comments about ASI recently and seemed concerned in his Logan Paul interview last year).
Tentative implications:
Much of the AI safety-focused communications strategy needs to be updated to appeal to a very different crowd (E.g. Fox News is the new New York Times).[3]
- Policy options dreamed up under the Biden administration need to be fundamentally rethought to appeal to Republicans.
- One positive here is that Trump's presidency does expand the realm of possibility. For instance, it's possible Trump is better placed to negotiate a binding treaty with China (similar to the idea that 'only Nixon could go to China'), even if it's not clear he'll want to do so.
- We need to improve our networks in DC given the new administration.
- Coalition building needs to be done with an entirely different set of actors than we’ve focused on so far (e.g. building bridges with the ethics community is probably counterproductive in the near-term, perhaps we should aim toward people like Joe Rogan instead).
- It's more important than ever to ensure checks and balances are maintained such that powerful AI is not abused by lab leaders or politicians.
Important caveat: Democrats could still matter a lot if timelines aren’t extremely short or if we have years between AGI & ASI.[4] Dems are reasonably likely to take back control of the House in 2026 (70% odds), somewhat likely to win the presidency in 2028 (50% odds), and there's a possibility of a Democratic Senate (20% odds). That means the AI risk movement should still be careful about increasing polarization or alienating the Left. This is a tricky balance to strike and I’m not sure how to do it. Luckily, the community is not a monolith and, to some extent, some can pursue the long-game while others pursue near-term change.
The o1 paradigm
Alongside scaling up training runs, it appears that inference compute will be key to attaining human-level AI and beyond. Compared to the previous paradigm, compute can be turned directly into capabilities much faster by simply running the models for longer.
Tentative implications:
- To the extent we've unlocked the ability to turn inference compute into better answers, well-resourced actors will be able to pay more to have better answers. This means the very best capabilities may become increasingly difficult to access for the average person,[5] though we’re still likely to get access to better and better models for some time.
- Because this paradigm is more compute intensive to run on the margin, it may be more difficult to run many iterations side-by-side. This means rather than having the equivalent of millions of top tier R&D researchers working at the same time we may have tens or hundreds of thousands, this could slow takeoff speed somewhat.
- This has implications for competition with China which are still somewhat unclear to me. It could mean that compute restrictions bite harder in terms of leveraging AGI to achieve ASI. Then again, Deepseek’s o1-equivalent seems far more compute-efficient as well.
- Data seems unlikely to be a key bottleneck on progress for anything which has a clear answer as we seemed to have cracked self-play for LLMs. This effectively means the path toward superhuman performance in any domain with definite correct answers is clear (e.g. coding, math, many sciences). In fact, these models are already effectively PhD-level in many domains. Less sure is the extent to which this can be applied to problems with less clear answers (e.g. writing quality) and long horizon tasks have not been solved.
Deepseek
Deepseek is highly compute efficient and they’ve managed to replicate the o1 paradigm at far lower cost (though not as low as it initially seemed). It seems possible that merely scaling up what they have could yield enormous returns beyond what they already have (though this is unclear).
Deepseek’s methods are, for the most part, open source. That means anyone with a solid base model can now build an impressive reasoner on top of it with barely any additional cost.
Tentative implications:
- The US has a far smaller moat than many imagined. The last I heard, received wisdom was that the US was about two years ahead of China on AI. It now looks like China is something like 3-12 months behind, though this isn't terribly clear given top US companies tend to keep their best capabilities private. It is also unclear whether the PRC is poised to overtake the US or would continue in a ‘fast-follower’ position even if we slowed down.
- It's worth pointing out as well that Gemini 2 Flash Thinking may outperform Deepseek r1 on most relevant metrics.
- While true that the training cost was cheap, this doesn't mean compute is no longer important. More compute still gets you a better model so Deepseek’s innovations may just speed progress and, if anything, increase the value of compute. In fact, Deepseek specifically mentioned compute was a constraint for them.
- Algorithmic advantage is hard to maintain
- The o1 paradigm was easily copied
- Multiple approaches of using RL to boost LLMs appear to work similarly well. It would appear no brilliant insights are needed to achieve AGI, which implies little moat.
- We really might continue to see open source models released by default, perhaps even up until AGI. This is the stated goal of Depseek and, to a lesser extent, Meta. To be honest, I haven’t even begun to understand what the implications of this could be, but they would clearly be enormous.
- Everyone now has access to an open source model competitive with top frontier lab models. This includes:
- Alignment researchers who can use it to speed up their research
- Bad actors who can use it for cyberattacks, scams, bioweapons, and much more.
- Their access to this model could increase the chance of warning shots.
- All AI projects now have the ability to fit their models into the o1 paradigm given that Deepseek has explained their methodology and it is likely easy to copy. This means an upgrade in capabilities across the board.
Stargate/AI data center spending
OpenAI and partners intend to invest $100 billion in 2025 and $500 billion over the coming 4 years.[6] Microsoft intends to spend $80 billion on building data centers this year, other companies seem similarly keen to dump money into compute.
The US government has gotten increasingly involved in AI and Sam Altman had a prominent place at Trump’s inauguration. So far, actual government involvement has mostly been in the form of helping companies get through the permitting process quickly. (more detail here)
Tentative implications:
- To the extent compute is most of what’s needed to achieve AGI, OpenAI may have a decisive advantage over competitors. This should update us a little away from believing labs like Anthropic are true competitors.
- The US government is getting involved in the race to build AGI. Influencing them to take safety seriously is more crucial than ever.
Increased internal deployment
This is more speculative, but I expect we’ll see less and less of what labs are producing and may have less access to the best models. I expect this due to a number of factors including:
- As AI systems produce more value, AI companies can capture more of the value-add of the models through business-to-business deals and using the AI’s to produce value directly (e.g. through using it for stock trading strategies). That said, fierce competition could keep prices down and models openly accessible.
- As AI systems are able to help with AI R&D and large models can help improve small models. This means it may often be worthwhile for companies to delay deployment so they can use scarce resources to improve their existing models further.
- One key reason to deploy models is to generate revenue and interest. So far investors have been flooding companies with investment. I suspect attracting investment is unlikely to be a huge bottleneck under short timelines (though if the race to ASI drags on, obtaining a stronger income stream becomes much more important).
- As competition heats up and nation-states get more invested in the race to superintelligence, secrecy will become more important. OpenAI is likely to want to avoid tipping its hand by telling the world it’s entered into a feedback loop of AI R&D which may help it quickly reach superintelligence (and potentially achieve a decisive strategic advantage). It will also want to avoid revealing the secret sauce which allowed it to do so and deploying the model makes that harder.
Tentative implications:
- People outside of labs are less likely to have access to the very best models and will have less awareness of where the state of the art is.
- Warning shots are somewhat less likely as highly-advanced models may never be deployed externally.
- We should expect to know less about where we’re at in terms of AI progress.
- Working at labs is perhaps more important than ever to improve safety and researchers outside of labs may have little ability to contribute meaningfully.
- Whistleblowing and reporting requirements could become more important as without them government would have little ability to regulate frontier AI.
- Any regulation based solely on deployment (which has been quite common) should be adjusted to take into account that the most dangerous models may be used internally long before they're deployed.
Absence of AI x-risk/safety considerations in mainstream AI discourse
For a while, after ChatGPT, it looked like AI risk would be a permanent part of the discourse going forward, largely thanks to efforts like the CAIS AI Extinction Letter getting high profile signatories and news coverage. For the past year though, AI x-risk concerns have have not had much airtime in the major media cycles around AI. There haven't been big safety-oriented stories in mainstream outlets in regards to recent AI events with strong implications for AGI timelines and existential risk (e.g. Deepseek, Stargate). A notable example of the AI safety community's lack of ability to affect the media was the decisive loss of the media game during the OpenAI board drama.
That said, we do have more people writing directly about AI safety and governance issues across a variety of Substacks and on Twitter/X now. We’ve also got plenty of prominent people capable of getting into the news if we made a concerted effort to do so (e.g. Yoshua Bengio, Geoff Hinton).
Tentative implications:
- We’re not on track to win the debate around AI x-risk being a major concern in the circles which matter. While the public is concerned about AI (and to some extent x-risk from AI), this concern is not being leveraged.
- We need to put a lot of deliberate effort into getting coverage if we want to influence AI discourse, this doesn’t just happen automatically.
Implications for strategic priorities
Broader implications for US-China competition
Recent developments call into question any strategy built on the idea that the US will have a significant lead over China which it could use to e.g. gain a decisive advantage or to slow down and figure out safety. This is because:
- The US is unlikely to be able to prevent China (or Russia) from stealing model weights anytime soon given both technological constraints and difficulty/cost of implementing sufficient security protocols. We should assume China will be able to steal our models.
- China is not as far behind as we’d thought and it seems worth assuming they’ll be close behind when it comes to AGI, and potentially (though less clearly) also ASI.
It would be nice to know if China would be capable of overtaking the US if we were to slow down progress or if we can safely model them as being a bit behind no matter how fast the US goes. That said, I don’t think we’ll ever know this to the level of confidence we’d need to convince decision-makers that slowing down wouldn’t hand the race to China.
- There’s some big questions around compute efficiency. Perhaps it’s possible to create AGI with amounts of compute already available to China or likely to be available within the next two years. It’s unclear whether that would reach all the way to ASI but it does mean that China will have access to generally capable AI systems around the same time we will.
- It’s even possible we’ll see AGI open sourced (as is the stated goal of Deepseek). This would fundamentally change the game and make third countries far more relevant.
Overall, the idea that the US could unilaterally win an AI race and impose constraints on other actors appears less likely now. I suspect this means an international agreement is far more important than we’d thought, though I'm not sure whether I think recent developments make that more or less likely.
Note: The below takes are far more speculative and I have yet to dive into them in any depth. It still seems useful to give some rough thoughts on what I think looks better and worse given recent developments, but in the interest of getting this out quickly I’ll defer going into more detail until a later post.
What seems less likely to work?
- Work with the EU and the UK
- Trump is far less likely to take regulatory inspiration from European countries and generally less likely to regulate. On the other-hand perhaps under a 2028 Dem administration we would see significant attention on EU/UK regulations.
- The EU/UK are already scaling back the ambitions of their AI regulations out of fear that Trump would retaliate if they put limits on US companies.
- International agreements not built specifically with Trump in mind.
- SB1047-style legislation at a national level in the US.
- Appealing to the American Left (at least in the near-term)
- Small update against compute governance being the lever we thought it might be (though it remains a very important lever):
- Clarity on how to build AGI and the amount of compute apparently needed to build it mean export controls against China may not have enough time to bite.
- Deepseek demonstrates it’s possible to create extremely powerful models with little compute. It may well be possible to build AGI with the compute resources China already has access to. Whether that would extend to ASI is far less clear.
What should people concerned about AI safety do now?
- Communications work, especially if aimed at the general public or toward a right-leaning elite
- Demonstrations of dangerous capabilities or misalignment, ideally with a clear connection to AGI/ASI concerns.
- Media engagement
- Explanations of why we should be worried and stories of how things go wrong
- The AI safety community still has not succeeded at conveying why we’re worried in a very public way. SuperIntelligence and Life 3.0 did a reasonable job back in 2013 but since then we haven't had any prominent stories of doom aimed at a general audience. Most content tends to dance around this.
- My sense is we really haven’t pushed this as much as we should and finding the right stories is very difficult but could really change the game (e.g. a good movie depicting AI doom could be a huge deal).
- Mass movement building
- Some bottlenecks on improving communications:
- What are we pushing for? E.g. What policies are good to aim for/realistic? What should we push labs to do?
- What is a general idea we think the public could get behind and which sufficiently tracks AI risk prevention?
- Get a job in a leading lab. Researchers in labs already have access to far more advanced models and, if the trend toward long periods of internal-only deployment continues, outsiders will have a tough time contributing meaningfully to solving control or alignment. Further, under short timelines labs are relatively more influential and even minor cultural shifts toward risk-awareness seem important.
- Organizing within labs for improved safety measures
- Though to the extent this removes the most conscientious people from influential positions within the lab, I’m not sure it’s worthwhile.
- Networking with or working in the Trump administration
- Developing new policy proposals which fit with the interests of Trump’s faction and/or influential members of Congress.
- Ideas for how to prevent power grabs using advanced AI.
- Re-thinking our strategic priorities and investigating key questions in this space.
- E.g. How long do we expect it to take to get from AGI to ASI?
- What does a post-AGI world look like and how does it affect what we should push for and how we do it? Is there anything we should be doing to prepare for this?
- Investing in adopting AI tools for AI safety and governance work.
- / building organizations that can rapidly take advantage of new AI tools.
- Getting government to adopt “wise” AI advisors for navigating the AI transition.
- High-risk AI investments that will pay massive dividends under short timelines (and ideally as long before AGI/ASI as possible). These could then be leveraged to have an impact during the critical period around the development of AGI.
Acknowledgements
Many people commented on an earlier version of this post and were incredibly helpful for refining my views! Thanks especially to Trevor Levin, John Croxton, as well as several others who would rather not be named. Thanks also to everyone who came to a workshop I hosted on this topic!
- ^
That market predicted roughly 2040 timelines until early 2023, then dropped down significantly to around 2033 average and is now down to 2030.
- ^
I have an old write-up on this reasoning here which also talks about how to think about tradeoffs between short and long timelines.
- ^
That said, given things could shift dramatically in 2028 (and 2026 to some extent) it could be worth having part of the community focus on the left still.
- ^
E.g. Perhaps we get human-level research AIs in 2027 but don’t see anything truly transformative until 2029.
- ^
See OpenAI’s Pro pricing plan of $200 per month. To the extent frontier models like o3 can be leveraged for alignment or governance work, it’s possible funders should subsidize their use. Another interesting implication is that, to the extent companies and individuals can pay more money to get smarter models/better answers, we could see increased stratification of capabilities which could increase rich-get-richer dynamics.
- ^
Note that ‘intend’ is important here! They do not have the money lined up yet.
Buck @ 2025-01-28T23:55 (+38)
Tentative implications:
- People outside of labs are less likely to have access to the very best models and will have less awareness of where the state of the art is.
- Warning shots are somewhat less likely as highly-advanced models may never be deployed externally.
- We should expect to know less about where we’re at in terms of AI progress.
- Working at labs is perhaps more important than ever to improve safety and researchers outside of labs may have little ability to contribute meaningfully.
- Whistleblowing and reporting requirements could become more important as without them government would have little ability to regulate frontier AI.
- Any regulation based solely on deployment (which has been quite common) should be adjusted to take into account that the most dangerous models may be used internally long before they're deployed.
For what it's worth, I think that the last year was an update against many of these claims. Open source models currently seem to be closer to state of the art than they did a year ago or two years ago. Currently, researchers at labs seem mostly in worse positions to do research than researchers outside labs.
I very much agree that regulations should cover internal deployment, though, and I've been discussing risks from internal deployment for years.
LintzA @ 2025-01-31T15:36 (+5)
Do you have anything you recommend reading on that?
I guess I see a lot of the value of people at labs happening around the time of AGI and in the period leading up to ASI (if we get there). At that point I expect things to be very locked down such that external researchers don't really know what's happening and have a tough time interacting with lab insiders. I thought this recent post from you kind of supported the claim that working inside the labs would be good? - i.e. surely 11 people on the inside is better than 10? (and 30 far far better)
I do agree OS models help with all this and I guess it's true that we kinda know the architecture and maybe internal models won't diverge in any fundamental way from what's available OS. To the extent OS keeps going warning shots do seem more likely - I guess it'll be pretty decisive if the PRC lets Deepseek keep OSing their stuff (I kinda suspect not? But no idea really).
I guess rather than concrete implications I should indicate these are more 'updates given more internal deployment' some of which are pushed back against by surprisingly capable OS models (maybe I'll add some caveats)
Joe Rogero @ 2025-01-29T18:32 (+37)
E.g. Ajeya’s median estimate is 99% automation of fully-remote jobs in roughly 6-8 years, 5+ years earlier than her 2023 estimate.
This seems more extreme than the linked comment suggests? I can't find anything in the comment justifying "99% automation of fully-remote jobs".
Frankly I think we get ASI and everyone dies before we get anything like 99% automation of current remote jobs, due to bureaucratic inertia and slow adoption. Automation of AI research comes first on the jagged frontier. I don't think Ajeya disagrees?
LintzA @ 2025-01-31T15:39 (+16)
That's my bad, I did say 'automated' and should have been 'automatable'. Have now corrected to clarify
Josh Thorsteinson @ 2025-01-30T04:16 (+14)
They were referring to this quote, from the linked post: "Median Estimate for when 99% of currently fully remote jobs will be automatable."
Automatable doesn't necessarily imply that the jobs are actually automated.
OscarD🔸 @ 2025-01-30T13:43 (+5)
The comment that Ajeya is replying to is this one from Ryan, who says his timelines are roughly the geometric mean of Ajeya's and Daniel's original views in the post. That is sqrt(4*13) = 7.2 years from the time of the post, so roughly 6 years from now.
As Josh says, the timelines in the original post were answering the question "Median Estimate for when 99% of currently fully remote jobs will be automatable".
So I think it was a fair summary of Ajeya's comment.
Holly Elmore ⏸️ 🔸 @ 2025-01-29T07:11 (+29)
Great piece— great prompt to rethink things and good digests of implications.
If you agree that mass movement building is a priority, check out PauseAI-US.org (I am executive director), or donate here: https://www.zeffy.com/donation-form/donate-to-help-pause-ai
One implication I strongly disagree with is that people should be getting jobs in AI labs. I don’t see you connecting that to actual safety impact, and I sincerely doubt working as a researcher gives you any influence on safety at this point (if it ever did). There is a definite cost to working at a lab, which is capture and NDA-walling. Already so many EAs work at Anthropic that it is shielded from scrutiny within EA, and the attachment to “our player” Anthropic has made it hard for many EAs to do the obvious thing by supporting PauseAI. Put simply: I see no meaningful path to impact on safety working as an AI lab researcher, and I see serious risks to individual and community effectiveness and mission focus.
Ebenezer Dukakis @ 2025-01-30T08:58 (+22)
I see no meaningful path to impact on safety working as an AI lab researcher
This is a very strong statement. I'm not following technical alignment research that closely, but my general sense is that exciting work is being done. I just wrote this comment advertising a line of research which strikes me as particularly promising.
I noticed the other day that the people who are particularly grim about AI alignment also don't seem to be engaging much with contemporary technical alignment research. That missing intersection seems suspicious. I'm interested in any counterexamples that come to mind.
My subjective sense is there's a good chance we lose because all the necessary insights to build aligned AI were lying around, they just didn't get sufficiently developed or implemented. This seems especially true for techniques like gradient routing which would need to be baked in to a big, expensive training run.
(I'm also interested in arguments for why unlearning won't work. I've thought about this a fair amount, and it seems to me that sufficiently good unlearning kind of just oneshots AI safety, as elaborated in the comment I linked.)
Holly Elmore ⏸️ 🔸 @ 2025-01-31T02:36 (+3)
Here’s our crux:
My subjective sense is there's a good chance we lose because all the necessary insights to build aligned AI were lying around, they just didn't get sufficiently developed or implemented.
For both theoretical and empirical reasons, I would assign a probably as low as 5% to there being alignment insights just laying around that could protect us at the superintelligence capabilities level and don’t require us to slow or stop development to implement in time.
I don’t see a lot of technical safety people engaging in advocacy, either? It’s not like they tried advocacy first and then decided on technical safety. Maybe you should question their epistemology.
calebp @ 2025-02-01T02:19 (+29)
I don’t see a lot of technical safety people engaging in advocacy, either? It’s not like they tried advocacy first and then decided on technical safety. Maybe you should question their epistemology.
My impression is that so far most of the impactful "public advocacy" work has been done by "technical safety" people. Some notable examples include Yoshua Bengio, Dan Hendryks, Ian Hogarth, and Geoffrey Hinton.
Holly Elmore ⏸️ 🔸 @ 2025-02-01T20:13 (+6)
Yeah good point. I thought Ebenezer was referring to more run-of-the-mill community members.
Buck @ 2025-01-30T00:53 (+10)
I agree with you that people seem to somewhat overrate getting jobs in AI companies.
However, I do think there's good work to do inside AI companies. Currently, a lot of the quality-adjusted safety research happens inside AI companies. And see here for my rough argument that it's valuable to have safety-minded people inside AI companies at the point where they develop catastrophically dangerous AI.
Holly Elmore ⏸️ 🔸 @ 2025-01-30T07:46 (+22)
What you write there makes sense but it's not free to have people in those positions, as I said. I did a lot of thinking about this when I was working on wild animal welfare. It seems superficially like you could get the right kind of WAW-sympathetic person into agencies like FWS and the EPA and they would be there to, say, nudge the agency in a way no one else cared about to help animals when the time came. I did some interviews and looked into some historical cases and I concluded this is not a good idea.
- The risk of being captured by the values and motivations of the org where they spend most of their daily lives before they have the chance to provide that marginal difference is high. Then that person is lost the Safety cause or converted into further problem. I predict that you'll get one successful Safety sleeper agent in, generously, 10 researchers who go to work at a lab. In that case your strategy is just feeding the labs talent and poisoning the ability of their circles to oppose them.
- Even if it's harmless, planting an ideological sleeper agent in firms is generally not the best counterfactual use of the person because their influence in a large org is low. Even relatively high-ranking people frequently have almost no discretion about what happens in the end. AI labs probably have more flexibility than US agencies, but I doubt the principle is that different.
Therefore I think trying to influence the values and safety of labs by working there is a bad idea that would not be pulled off.
OscarD🔸 @ 2025-01-30T13:50 (+5)
My sense is that of the many EAs who have taken EtG jobs quite a few have remained fairly value-aligned? I don't have any data on this and am just going on vibes, but I would guess significantly more than 10%. Which is some reason to think the same would be the case for AI companies. Though plausibly the finance company's values are only orthogonal to EA, while the AI company's values (or at least plans) might be more directly opposed.
Holly Elmore ⏸️ 🔸 @ 2025-01-29T07:12 (+10)
What you seem to be hinting at, essentially espionage, may honestly be the best reason to work in a lab. But of course those people need to be willing to break NDAs and there are better ways to get that info than getting a technical safety job.
(Edited to add context for bringing up "espionage" and implications elaborated.)
OllieBase @ 2025-01-29T16:26 (+9)
Already so many EAs work at Anthropic that it is shielded from scrutiny within EA
What makes you think this? Zach's post is a clear counterexample here (though comments are friendlier to Anthropic) and I've heard of criticism of the RSPs (though I'm not watching closely).
Maybe you think there should be much more criticism?
Holly Elmore ⏸️ 🔸 @ 2025-01-29T22:22 (+14)
There should be protests against them (PauseAI US will be protesting them in SF 2/28) and we should all consider them evil for building superintelligence when it is not safe! Dario is now openly calling for recursive self-improvement. They are the villains-- this is not hard. The fact that you would think Zach's post with "maybe" in the title is scrutiny is evidence of the problem.
Joe Rogero @ 2025-01-29T18:35 (+7)
Honestly this writeup did update me somewhat in favor of at least a few competent safety-conscious people working at major labs, if only so the safety movement has some access to what's going on inside the labs if/when secrecy grows. The marginal extra researcher going to Anthropic, though? Probably not.
Holly Elmore ⏸️ 🔸 @ 2025-01-29T22:25 (+13)
Connect the rest of the dots for me-- how does that researcher's access become community knowledge? How does the community do anything productive with this knowledge? How do you think people working at the labs detracts from other strategies?
Joe Rogero @ 2025-02-24T16:20 (+3)
The primary benefit I'm imagining is a single well-placed whistleblower positioned to publicly sound the alarm on a particularly obvious and immediate threat, perhaps related to CBRN capabilities. A better answer requires a longer post, which is in the works but may take a while.
Holly Elmore ⏸️ 🔸 @ 2025-02-27T00:11 (+2)
I agree having access to what the labs are doing and having the ability to blow the whistle would be super useful. I’ve just recently updated hugely in the direction of respecting the risk of value drift of having people embedded in the labs. We’re imagining cheaply having access to the labs, but the labs and their values will also have access back to us and our mission-alignment through these people.
I think EA should be setting an example to a more confused public of how dangerous this technology is, and being mixed up in making it makes that very difficult.
Antoine de Scorraille @ 2025-01-29T18:05 (+7)
The post is an excellent summary of the current situation, yet ignoring the elephant in the room: we need to urge for the Pause! The incoming summit, in France, is the ideal place to do so. That's why I'm calling on you, the AI-worried reader, to join our Paris demonstration on the 10th: https://lu.ma/vo3354ab
Each additional participant would be a tremendous asset, as we are a handful of people.
Assemble!
Elliot Billingsley @ 2025-02-06T00:17 (+1)
assembling from Victoria, BC, on Friday!
danielechlin @ 2025-01-31T16:16 (+4)
I agree with you but for reasons that are more basic and more heretical than you're going for. In general I'm critical that EA seems to have a prior that being in a relevant place at a relevant time is doing God's work. It's a little defensible from the viewpoint of early career path navigation, but now we're talking about 3 year timelines and still saying things like "so I guess you should 'work on' AI safety". I don't really grasp why this argument is unfolding such that you have the burden of proof.
The real plan on a three year timeline is to hike the Patagonia or something. But that conclusion is too radical so we try to commit to the outcome space being selecting a job like we always do. If you're early career you should probably assume AGI/SI won't happen, to maximize utility.
People defending work at AI + 3 year timeline should probably be talking about how easy it is to get to a staff+ engineer position from start date.
SAB25 @ 2025-02-09T05:17 (+3)
One implication I strongly disagree with is that people should be getting jobs in AI labs. I don’t see you connecting that to actual safety impact, and I sincerely doubt working as a researcher gives you any influence on safety at this point (if it ever did).
Wouldn't it allow access to the most advanced models which are not yet publicly available? I think these are the models that would pose the most risk?
Working at a frontier lab would also give the opportunity to reach people far less concerned about safety, and maybe their minds could be changed?
Holly Elmore ⏸️ 🔸 @ 2025-02-12T23:08 (+5)
See my other comments. "Access" to do what? At what cost?
Aaron Bergman @ 2025-01-29T21:46 (+2)
I’ll just highlight that it seems particularly cruxy whether to view such NDAs as covenants or contracts that are not intrinsically immoral to break
It’s not obvious to me that it should be the former, especially when the NDA comes with basically a monetary incentive for not breaking
Holly Elmore ⏸️ 🔸 @ 2025-01-29T22:16 (+4)
If the supposed justification for taking these jobs is so that they can be close to what's going on, and then they never tell and (I predict) get no influence on what the company does, how could this possibly be the right altruistic move?
quinn @ 2025-01-29T03:07 (+28)
nitpick: you say open source which implies I can read it and rebuild it on my machine. I can't really "read" the weights in this way, I can run it on my machine but I can't compile it without a berjillion chips. "open weight" is the preferred nomenclature, it fits the situation better.
(epistemic status: a pedantry battle, but this ship has sailed as I can see other commenters are saying open source rather than open weight).
Davidmanheim @ 2025-01-29T23:16 (+5)
Thank you for fighting the good fight!
Manuel Allgaier @ 2025-01-30T14:49 (+22)
This is the best summary of recent developments I've seen so far, thanks a lot for writing this up!
I've shared it with people in my AI Safety / AI Gov network, and we might discuss it in our AI Gov meetup tonight.
zdgroff @ 2025-01-29T13:54 (+20)
What seems less likely to work?
- Work with the EU and the UK
- Trump is far less likely to take regulatory inspiration from European countries and generally less likely to regulate. On the other-hand perhaps under a 2028 Dem administration we would see significant attention on EU/UK regulations.
- The EU/UK are already scaling back the ambitions of their AI regulations out of fear that Trump would retaliate if they put limits on US companies.
Interesting—I've had the opposite take for the EU. The low likelihood of regulation in the US seems like it would make EU regulation more important since that might be all there is. (The second point still stands, but it's still unclear how much that retaliation will happen and what impact it will have.)
It depends on aspects of the Brussels' effect, and I guess it could be that a complete absence of US regulation means companies just pull out of the EU in response to regulation there. Maybe recent technical developments make that more likely. On net, I'm still inclined to think these updates increase the importance of EU stuff.
For the UK, I think I'd agree—UK work seems to get a lot of its leverage from the relationship with the US.
Manuel Allgaier @ 2025-01-30T09:06 (+5)
Anthropic released Claude everywhere but the EU first, and their EU release happened only months later, so to some extend labs are already deprioritizing the EU market. I guess this trend would continue? Not sure.
PabloAMC 🔸 @ 2025-01-30T12:02 (+10)
I think this had to do more with GDPR than the AI act, so the late release in the EU might be a one-off case. Once you figure out how to comply with data collection, it should be straightforward to extend to new models, if they want to.
Manuel Allgaier @ 2025-01-30T14:42 (+5)
I did not say that this was due to the EU AI Act, agree that GDPR seems more likely. I mentioned it as an example of EU regulation leading to an AI Lab delaying their EU launch / deprioritizing the EU.
zdgroff @ 2025-03-07T12:28 (+4)
I think I'd be more worried about pulling out entirely than a delayed release, but either one seems possible (but IMO unlikely).
Jobst Heitzig (vodle.it) @ 2025-01-28T21:53 (+15)
I'm confused by your seeming "we vs China" viewpoint - who is this "we" that you are talking about?
Ebenezer Dukakis @ 2025-02-03T04:53 (+15)
As an American, I think this is actually a really good point. The only reason to even consider racing with China to build AI is if we believe the outcome is better if America "wins". Seems worth keeping an eye on the political situation in the US, e.g. for stuff like PEPFAR cancellation, to check if the US "winning" is actually better from a humanitarian perspective. Hopefully lab leaders are smart enough to realize this.
David Mathers🔸 @ 2025-02-05T09:34 (+2)
Lab leaders are probably trying mostly to maximize the value of their company, not the value of the world in my view. (Doesn't mean they give zero weight to moral considerations.) Also, if the US government realizes that they are reasoning along the lines of "let's slow down development because it doesn't matter if the US beats China", the US government will probably find ways to stop them being lab leaders.
yams @ 2025-01-28T22:14 (+4)
I wasn't really reading anything in this post as favoring the US over China in an "us vs them" way, so much as I was reading a general anxiety about multipolar scenarios. Also, very few of us are based in China relative to the US or EU. 'The country with the community of people who have been thinking about this the longest' is probably the country you want the thing to happen in, if it has to happen (somewhere).
fwiw I'm usually very anxious about this us vs them narrative, and didn't really feel this post was playing into it very strongly, other than in the above ways, which are (to me) reasonable.
Jobst Heitzig (vodle.it) @ 2025-01-28T22:55 (+2)
The author is using "we" in several places and maybe not consistently. Sometimes "we" seems to be them and the readers, or them and the EA community, and sometimes it seems to be "the US". Now you are also using an "us" without it being clear (at least to me) who that refers to.
Who do you mean by 'The country with the community of people who have been thinking about this the longest' and what is your positive evidence for the claim that other communities (e.g., certain national intelligence communities) haven't thought about that for at least as long?
yams @ 2025-01-29T00:54 (+4)
I took your comment to have two parts it was critiquing:
- The floating use of the word 'we' (which I agree is ambiguous, but basically don't care about).
- The 'us vs China' frame as a whole (which has some surface area with the floating antecedent of the word 'we', but is a distinct and less pedantic point).
My response was addressing point 2, not point 1, and this was intentional. I will continue not to engage on point 1, because I don't think it matters. If you're devoted to thinking Lintz is a race-stoking war hawk due to antecedent ambiguity in a quickly-drafted post, and my bid to dissuade you of this was ineffective, that's basically fine with me.
"Who do you mean by 'The country with the community of people who have been thinking about this the longest'"
The US — where ~all the labs are based, where ~all the AI safety research has been written, where Chinese ML engineers have told me directly that, when it comes to AI and ML, they think exclusively in English. Where a plurality of users of this forum live, where the large models that enabled the development of DeepSeek were designed to begin with, where the world's most powerful military resides, where....
Yes, a US-centric view is an important thing to inspect in all contexts, but I don't think it's unreasonable to think that the US is the most important actor in the current setting (could change but probably not), and to (for a US-based person who works on policy... in the US, as Lintz does, speaking to a largely US-based audience) use 'we' to refer to the US.
"What is your positive evidence for the claim that other communities (e.g., certain national intelligence communities) haven't thought about that for at least as long?"
I want to point out that this is unfair, since meeting this burden of proof would require comprehensive privileged knowledge of the activities over the past half century of every intelligence agency on the planet. My guess is you know that I don't have that!
Things I do know:
- People who've been in touch with US intelligence agencies since ~2017 have reported that getting them to take AI seriously has been an uphill battle (not only from an x-risk perspective, but as 'a thing that will happen at all').
- US intelligence agencies are currently consulting with senior folks in our sphere, at least occasionally, which indicates that they may lack confident inside-view takes on the situation.
- The US is currently dropping the ball relative to its stated goals (i.e. Taiwan tariffs), which indicates that the more informed parts of government either don't have much power or aren't all that informed actually! (probably mostly the former, but I'm sure the latter has weight, too)
Finally: "Positive evidence.... have not" is a construction I would urge you to reconsider — positive evidence for a negative assertion is a notoriously difficult thing to get.
Patrick Hoang @ 2025-01-29T21:42 (+13)
What should EAs not in a position to act under short AI timelines do? You can read my response here but not all of us are working in AI labs nor expect to break in anytime soon.
You also suggested having a short-timeline model to discount things after 5+ years:
Plans relying on work that takes several years should be heavily discounted - e.g. plans involving ASL5-level security of models if that’s 5+ years away
But I wouldn't apply such a huge discount rate if one still believes for a chance of longer AGI timelines. For example, if you believe AGI only has a 25% chance of occurring by 2040, you should discount 15+ year plans only by 25%. The real reason to discount certain long-term plans is because they are not tractable. (i.e. I think executing a five-year career plan is tractable, but ALS5-level security is probably not due to government's slow speed)
Ebenezer Dukakis @ 2025-01-30T08:08 (+9)
it's possible Trump is better placed to negotiate a binding treaty with China (similar to the idea that 'only Nixon could go to China'), even if it's not clear he'll want to do so.
Some related points:
-
Trump seems like someone who likes winning, but hates losing, and also likes making deals. If Deepseek increases the probability that the US will lose, that makes it more attractive to negotiate an end to the race. This seems true from both a Trump-psychology perspective, and a rational-game-theorist perspective.
-
Elon Musk seems to have a good relationship with Chinese leadership.
-
Releasing open-source AI seems like more of a way to prevent someone else from winning than a way to win yourself.
I suppose one possible approach would be to try to get some sort of back-channel dialogue going, to start drafting a treaty which can be invoked if political momentum appears.
IWumbo @ 2025-01-29T21:23 (+7)
- Some bottlenecks on improving communications:
- What are we pushing for? E.g. What policies are good to aim for/realistic? What should we push labs to do?
- What is a general idea we think the public could get behind and which sufficiently tracks AI risk prevention?
Big questions! It seems like the first is a question for everyone working on this, not just communications people. I'd be interested to know what comms can offer ahead of these questions being settled. What kind of priming/key understandings are most important to get across to people to make the later convincing easier?
Who is doing this kind of comms work right now and running into these bottlenecks? Through what orgs? Are they the same organizations doing the policy development work?
Greg_Colbourn ⏸️ @ 2025-02-15T15:25 (+1)
Nothing short of a global non-proliferation treaty on ASI (or a Pause, for short) is going to save us. So we have to make it realistic. We have to always be bringing comms back to that.
In terms of explaining the problem to public audience, lethalintelligence.ai is great.
Esben Kran @ 2025-01-29T07:56 (+6)
Great post, thank you for laying out the realities of the situation.
In my view, there are currently three main strategies pursued to solve X-risk:
- Slow / pause AI: Regulation, international coordination, and grassroots movements. Examples include UK AISI, EU AI Act, SB1047, METR, demonstrations, and PauseAI.
- Superintelligence security: From infrastructure hardening, RSPs, security at labs, and new internet protocols to defense of financial markets, defense against slaughterbots, and civilizational hedging strategies. Examples include UK ARIA, AI control, and some labs.
- Hope in AGI: Developing the aligned AGI and hoping it will solve all our problems. Examples include Anthropic and arguably most other AGI labs.
No. (3) seems weirdly overrated in AI safety circles. (1) seems incredibly important now and something radically under-emphasized. And in my eyes, (2) seems like the direction most new technical work should go. I will refer to Anthropic's safety researchers on whether the labs have a plan outside of (3).
Echoing @Buck's point that you now have less need to be inside a lab for model access reasons. And if it's to guide the organization, that has historically been somewhat futile in the face of capitalist incentives.
PabloAMC 🔸 @ 2025-01-29T08:16 (+4)
I don’t think the goal of regulation or evaluations is to slow down AGI development. Rather, the goal of regulation is to standardise minimal safety measures (some AI control, some security etc across labs) and create some incentives for safer AI. With evaluations, you can certainly use them for pausing lobbying, but I think the main goal is to feed in to regulation or control measures.
Esben Kran @ 2025-01-29T17:50 (+1)
The main effect of regulation is to control certain net negative outcomes and hence slowing down negative AGIs. RSPs that require stopping developing at ASL-4 or otherwise are also under the pausing agenda. It might be a question of semantics due to how Pause AI and the Pause AI Letter have become the memetic sink for the term pause AI?
PabloAMC 🔸 @ 2025-01-29T23:12 (+2)
My point is that slowing AI down is often an unwanted side effect, from the regulator perspective. Thus, the main goal is raising the bar for safety practices across developers.
mjkerrison🔸️ @ 2025-02-02T23:11 (+5)
Another tentative implication that goes without saying, but I'll say it anyway: review who you're listening to.
Who got these developments "right" and "wrong"? How will you weight what those people say in the next 12 months?
JuliaHP @ 2025-01-29T15:56 (+5)
Most of the "recent developments" which are supposed to point to an update in the target audience were quite predictable in advance (pretty much all of these things were predicted / assigned substantial probability by many people years in advance). To the extent that these cause an update in the reader, it is worth asking yourself; how could I have thought that faster. And more importantly, once you figure out what models would have let you predict the present, what further do these models predict into the future?
Chris Leong @ 2025-02-10T17:09 (+3)
In case anyone is interested, I've now written up a short-form post arguing for the importance of Wise AI Advisors, which is one of the ideas listed here[1].
- ^
Well, slightly broader as my argument doesn't focus specifically on wise AI advisors for government.
Aaron Bergman @ 2025-01-29T21:43 (+3)
Here is a kinda naive LLM prompt you may wish to use for inspiration and iterate on:
“List positions of power in the world with the highest ratio of power : difficulty to obtain. Focus only on positions that are basically obtainable by normal arbitrary US citizens and are not illegal or generally considered immoral
I’m interested in positions of unusually high leverage over national or international systems”
yams @ 2025-01-28T22:41 (+3)
I'd like to say I'm grateful to have read this post, it helped explicate some of my own intuitions, and has drawn my attention to a few major cruxes. I'm asking a bunch of questions because knowing what to do is hard and we should all figure it out together, not because I'm especially confident in the directions the questions point.
Should we take the contents of the section "What should people concerned about AI safety do now?" to be Alex Lintz's ordinal ranking of worthwhile ways to spend time? If so, would you like to argue for this ranking? If not, would you like to provide an ordinal ranking and argue for it?
"The US is unlikely to be able to prevent China (or Russia) from stealing model weights anytime soon given both technological constraints and difficulty/cost of implementing sufficient security protocols."
Do you have a link to a more detailed analysis of this? My guess is there's precedent for the government taking security seriously in relation to some private industry and locking all of their infrastructure down, but maybe this is somewhat different for cyber (and, certainly, more porous than would be ideal, anyway). Is the real way to guarantee cybersecurity just conventional warfare? (yikes)
What's the theory of change behind mass movement building and public-facing comms? We agitate the populace and then the populist leader does something to appease them? Or something else?
You call out the FATE people as explicitly not worth coalition-building with at this time; what about the jobs people (their more right-coded counterpart)? Historically we've been hesitant to ally with either group, since their models of 'how this whole thing goes' are sort of myopic, but that you mention FATE and not the jobs people seems significant.
"It would be nice to know if China would be capable of overtaking the US if we were to slow down progress or if we can safely model them as being a bit behind no matter how fast the US goes."
I think compute is the crux here. Dario was recently talking about OOMs of chips matter, and the 10s of thousand necessary for current DeepSeek models would be difficult to scale to the 100s of thousands or millions that are probably necessary at some point in the chain. (Probably the line of 'reasoning models' descended from ~GPT-4 has worse returns per dollar spent than the line of reasoning models descended from GPT-5, esp. if the next large model is itself descended from these smaller reasoners). [<70 percent confident]
If that's true, then compute is the mote, and export controls/compute governance still get you a lot re: avoiding multipolar scenarios (and so shouldn't be deprioritized, as your post implies).
I'm also not sure about this 'not appealing to the American Left' thing. Like, there's some subset of conservative politicians that are just going to support the thing that enriches their donors (tech billionaires), so we can't Do The Thing* without some amount of bipartisan support, since there are bad-faith actors on both sides actively working against us.
"Developing new policy proposals which fit with the interests of Trump’s faction"
I'd like to point out that there's a middle ground between trying to be non-partisan and convincing people in good faith of the strength of your position (while highlighting the ways in which it synergizes with their pre-existing concerns), and explicitly developing proposals that fit their interests. This latter thing absolutely screws you if the tables turn again (as they did last time when we collaborated with FATE on, i.e., the EO), and the former thing (while more difficult!) is the path to more durable (and bipartisan!) wins.
*whatever that is
Kat Woods @ 2025-02-14T22:48 (+2)
Loved this post! Thanks for writing it.
I've been having some pretty good success doing online outreach that I think is replicable but don't want to share strategies publicly. I'd be happy to give advice and/or swap tips privately with anybody else interested in the area.
Just DM me telling me what you're working on/want to work on.
Ebenezer Dukakis @ 2025-01-30T08:33 (+2)
With regard to Deepseek, it seems to me that the success of mixture-of-experts could be considered an update towards methods like gradient routing. If you could localize specific kinds of knowledge to specific experts in a reliable way, you could dynamically toggle off / ablate experts with unnecessary dangerous knowledge. E.g. toggle off experts knowledgeable in human psychology so the AI doesn't manipulate you.
I like this approach because if you get it working well, it's a general tool that could help address a lot of different catastrophe stories in a way that seems pretty robust. E.g. to mitigate a malicious AI from gaining root access to its datacenter, ablate knowledge of the OS it's running on. To mitigate sophisticated cooperation between AIs that are supposed to be monitoring one another, ablate knowledge of game theory. Etc. (The broader point is that unlearning seems very generally useful. But the "Expand-Route-Ablate" style approach from the gradient routing paper strikes me as a particularly promising, and could harmonize well with MoE.)
I think a good research goal would be to try to eventually replicate Deepseek's work, except with highly interpretable experts. The idea is to produce a "high-assurance" model which can be ablated so undesired behaviors, like deception, are virtually impossible to jailbreak out of it (since the weights that perform the behavior are inaccessible). I think the gradient routing paper is a good start. To achieve sufficient safety we'll need new methods that are more robust and easier to deploy, which should probably be prototyped on toy problems first.
Cam Tice @ 2025-01-31T18:14 (+1)
Because this paradigm is more compute intensive to run on the margin, it may be more difficult to run many iterations side-by-side. This means rather than having the equivalent of millions of top tier R&D researchers working at the same time we may have tens or hundreds of thousands, this could slow takeoff speed somewhat.
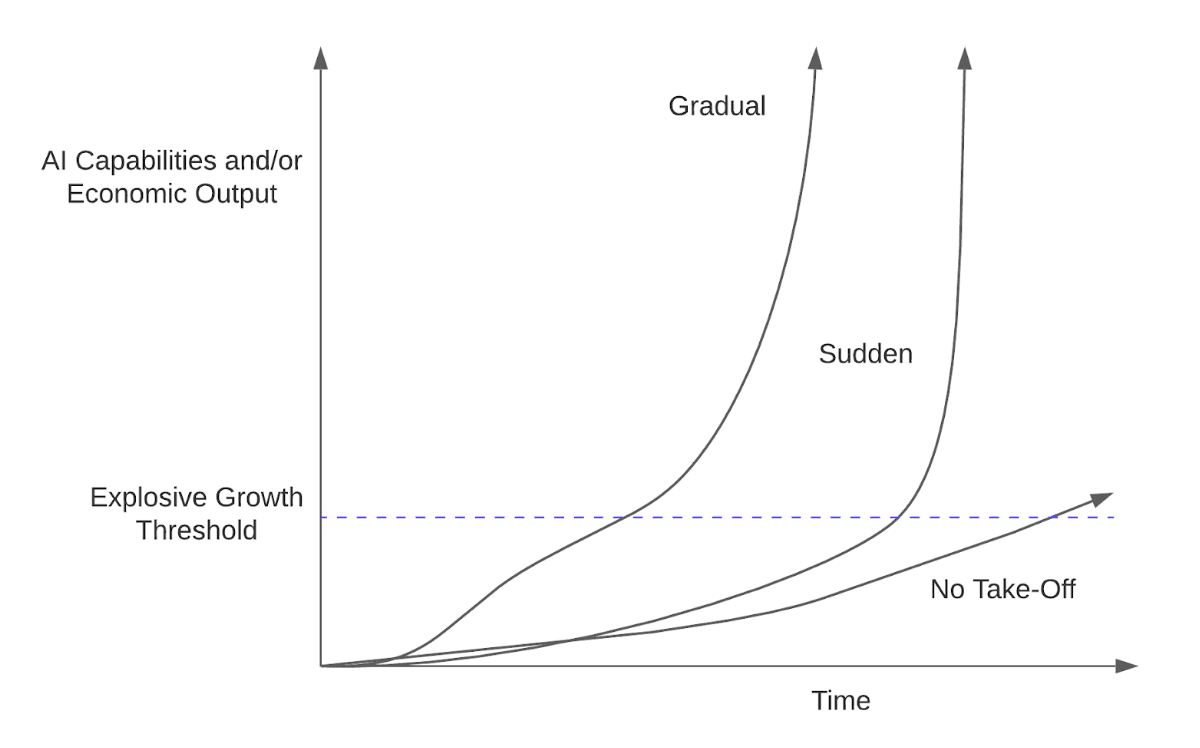
A quick nit pick, inference-time compute does not imply slower take off times, but rather more gradual take off times. This results in higher levels of capabilities relative to the counterfactual world with no inference-time compute because we can now leverage levels of useful intelligence which would have otherwise been unattainable earlier in our timelines.
https://www.lesswrong.com/posts/AiaAq5XeECg7MpTL7/for-every-choice-of-agi-difficulty-conditioning-on-gradual
Vasco Grilo🔸 @ 2025-01-29T23:15 (+1)
Thanks for the post, Lintz. I would be happy to bet 10 k$ against short AI timelines.
yams @ 2025-01-30T02:07 (+7)
Two years ago short timelines to superintelligence meant decades. That you would structure this bet such that it resolves in just a few years is itself evidence that timelines are getting shorter.
That you would propose the bet at even odds also does not gesture toward your confidence.
Finally, what money means after superintelligence is itself hotly debated, especially for worst-case doomers (the people most likely to expect three year timelines to ASI are also the exact people who don't expect to be alive to collect their winnings).
I think it's possible for a betting structure to prove some kind of point about timelines, but this isn't it.
Vasco Grilo🔸 @ 2025-01-30T09:09 (+2)
Thanks, yams.
I am also potentially open to a bet where I transfer money to the person bullish on AI timelines now. I bet Greg Coulbourn 10 k$ this way. However, I would have to trust the person betting with me more than in the case of the bet I linked to above. On this, money being less valuable after superintellgence (including due to supposedly higher risk of death) has the net effect of moving the break-even resolution date forward. As I say in the post I linked to, "We can agree on another resolution date such that the bet is good for you". The resolution date I proposed (end of 2028) was supposed to make the bet just slightly positive for people bullish on AI timelines. However, my views are closer to those of the median expert in 2023, whose median date of full automation was 2073.