Giving AIs safe motivations
By Joe_Carlsmith @ 2025-08-18T18:02 (+22)
(Audio version (read by the author) here, or search for "Joe Carlsmith Audio" on your podcast app.
This is the sixth essay in a series I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, plus a bit more about the series as a whole.)
1. Introduction
Thus far in this series, I’ve defined what it would be to solve the alignment problem, and I’ve outlined a high-level picture of how we might get there – one that emphasized the role of “AI for AI safety,” and of automated alignment research in particular. But I’ve said relatively little about object-level, technical approaches to the alignment problem itself. In the upcoming set of essays, I try to say more.
In particular: in this essay, I’m going to sketch my current high-level best-guess as to what it looks like to control the motivations of an advanced AI system in a manner adequate to prevent rogue behavior, even in contexts where successful rogue behavior is a genuine option (call these contexts “dangerous inputs”[1]). I also talk briefly about how this best-guess extends to fully eliciting beneficial AI capabilities.[2] Then, in the upcoming essays, I turn to techniques for controlling the options available to AIs, and for building AIs that do what I call “human-like philosophy.”
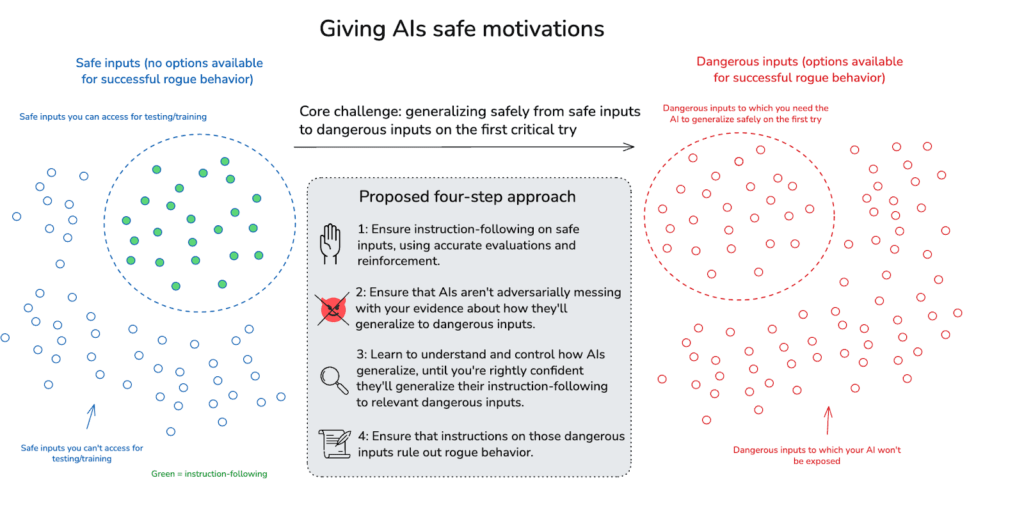
The basic picture of motivation control I have in mind has four steps:
- Instruction-following on safe inputs: Ensure that your AI follows instructions on safe inputs (i.e., cases where successful rogue behavior isn’t a genuine option), using accurate evaluations of whether it’s doing so.
- No alignment faking: Make sure it isn’t faking alignment on these inputs – i.e., adversarially messing with your evidence about how it will generalize to dangerous inputs.
- Science of non-adversarial generalization: Study AI generalization on safe inputs in a ton of depth, until you can control it well enough to be rightly confident that your AI will generalize its instruction-following to the dangerous inputs it will in fact get exposed to.
- Good instructions: On these dangerous inputs, make it the case that your instructions rule out the relevant forms of rogue behavior.[3]
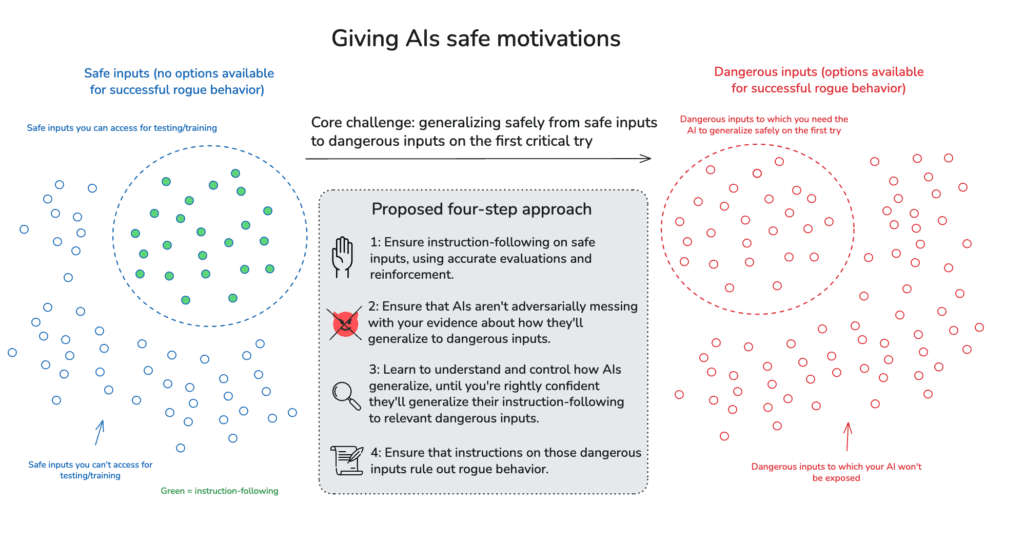
To be clear: the first three steps, here, each implicate deep challenges (I think the fourth may be comparatively straightforward).[4] Below I’ll talk a bit about the tools we can use at each stage. Ultimately, though, adequate success at (1)-(3) will require significant scientific progress – progress that I’m hoping AI labor will itself significantly accelerate.
Indeed: in many respects, the picture above functions, in my head, centrally as a structured decomposition of the problems that an adequate approach to motivation control needs to overcome. It’s certainly not a “solution” to the alignment problem, in the sense of “a detailed, do-able, step-by-step plan that will work with high-confidence, and which requires only realistic deviation from the default trajectory.”[5] And on its own, I’m not sure it even warrants the term “plan.”
But I’ve found it useful to have in mind regardless. In particular: in the past, I found it hard to visualize what it even would be to solve the alignment problem. Now, it feels easier. I feel like the problem has distinct parts, with specific inter-relationships. I can see how solving each would add up to solving the whole. And I have at least some sense of how each could get solved. My aim is to describe and clarify this broad picture, and to make it easier to build on and critique.
(Like much in this series, this picture isn’t original to me. Indeed, in many respects, much of the frame here is latent in the discourse about AI alignment as a whole – I’m mostly trying to bring it to the surface and to organize it. That said, the four-step framing in particular owes special debt to Ryan Greenblatt and Josh Clymer, who have each written either internal or external docs covering many similar points, and with whom I’ve discussed some of these issues in depth.)
1.1 Summary of the essay
The essay proceeds as follows. I start by explaining how I think about the core problems at stake in motivation control. In particular: the most fundamental problem, in my opinion, is what I call “generalization without room for mistakes” – that is, roughly, ensuring that AIs reject catastrophically dangerous rogue options, despite the fact that you can’t safely test for this behavior directly. This fundamental problem is exacerbated by a number of sub-problems – notably: evaluation accuracy, causing good training/testing behavior, limits on data access, adversarial dynamics, and the opacity of AI cognition. I discuss each of these in turn.
I then briefly discuss the key tools we have at our disposal. I divide these into two categories – “behavioral science” (roughly: understanding and controlling AI behavior) and “transparency tools” (roughly: understanding and controlling AI internal cognition). I emphasize just how powerful serious efforts at behavioral science can be in the context of AI – and especially, given the availability of lots of AI labor. And I discuss a variety of different approaches to transparency as well – namely: open agency (roughly: building more transparent agents out of still-black-box ML components[6]), interpretability (roughly: making ML systems less black-box-y), and new paradigm (roughly: transitioning away from ML-like systems altogether, and towards a new and more transparency-conducive paradigm of AI development).
I then discuss how applying these tools in the context of steps 1-3 above can address the core problems I’ve described. Here, the basic idea is something like: if you can successfully ensure that your AI follows instructions on safe inputs (here the viability of scalable oversight is a key open question), and if you can prevent that AI from faking alignment in a way that adversarially messes with your evidence about how its behavior will generalize to dangerous inputs (there are various approaches to this, though I think they could easily fail), then the remaining scientific challenge of ensuring that the AI also follows instructions on dangerous inputs is made much easier. Yes, you do still need to deal with potential ways in which the move to dangerous inputs can implicate other novel dynamics that break the AI’s propensity to follow instructions. But at the least, the AI isn’t optimizing for hiding these dynamics from you, and you can study analogous transitions on safe inputs. A key open question is what it takes for behavioral science + transparency to go the rest of the way.
I also discuss step (4) above – namely, ensuring your instructions rule out rogue behavior. I think we should be reasonably optimistic about the feasibility of this step, especially conditional on success with the others. In particular: I think many of the most paradigm forms of problematic rogue behavior (e.g., sabotage, self-exfiltration, directly harming humans, attempting to take over the world) are going to be flagrantly contrary to most reasonable instructions. And especially if we have access to instruction-following AIs, we’ll be able to red-team those instructions in detail. That said: there are at least some cases in which ruling out rogue behavior may be more philosophically subtle, even with instruction-following AIs. I discuss these cases in a future essay.
I close with a brief discussion of how the framework above applies to eliciting the main beneficial capabilities of advanced AI systems, in addition to ensuring safety. Here I think that many of the same considerations apply, but: the AI needs to be safe even in the context of a wider range of affordances; with safety secure, there is often more opportunity for failure and iteration on elicitation; and for some forms of elicitation, a wider range of philosophical subtleties become relevant.
2. The central challenge: generalization without room for mistakes
Let’s start here: why would you think that giving an advanced AI safe motivations might be difficult?
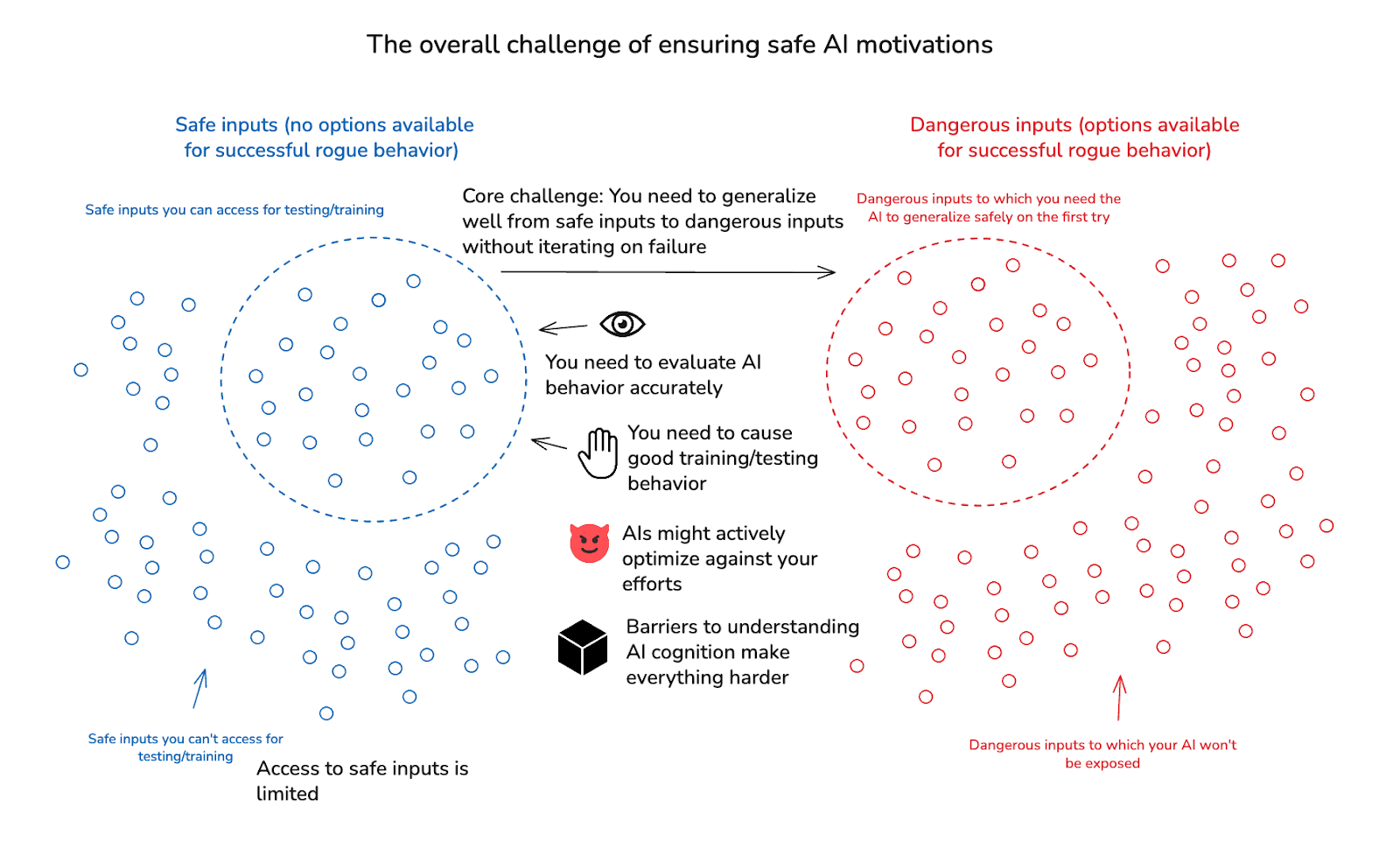
Well, many reasons in principle. But to my mind, the most central challenge is that you can’t safely and directly test whether you’re doing it right.[7] That is: to the extent your safety from loss of control is relying on motivation control at all (i.e., you’ve entered what I previously called a “vulnerability to motivations condition”), this means you are exposing your AIs to options that allow them to cause a loss of control scenario with non-trivial probability – options you are relying on them to reject. But you can’t check that they’ll actually do this in the real-world case without exposing yourself to a non-trivial real-world risk of loss of control. And if AIs do cause a full-scale loss of control, you can’t say “oops” and try again.
I’ll call this challenge “generalization without room for mistakes.” Here, “generalization” indicates the need to get safe behavior on catastrophically dangerous inputs via training/testing on some other set of safe inputs.[8] And “without room for mistakes” indicates inability to safely iterate on failure.
Here’s a diagram[9]:

I’ll sometimes talk, in particular, about the difficulty of making this leap safely on the first try. I want to note, though, that you also need to safely make further leaps, to new sets of dangerous inputs, even if you get the first leap to dangerous inputs right – and these further leaps are “tries” of their own, which also preclude iteration on failure. That said: if you can get the first leap to dangerous inputs right, this can be meaningful evidence about the efficacy of your overall approach;[10] and if you can also usefully elicit the labor of the (presumably quite powerful) AI you’ve made safe in this way, this can help a lot with making further leaps successfully.
Now, on its own, the challenge of “generalization without room for mistakes” might not be so difficult. Thus, for example: I can be quite confident that my best friend Bob won’t kill me given the chance, even if he’s never had the chance. And we do manage to get some complex engineering challenges right on the first safety-critical try – witness, for example, the moon landing.[11] And note, too, that you don’t need your AI to generalize safely to arbitrary dangerous inputs. Rather: you just need it to generalize safely to the dangerous inputs to which it will, in fact, be exposed.
In the context of advanced AI, though, the difficulty of “generalization without room for mistakes” gets exacerbated by a number of key sub-challenges. Let’s turn to those now.
2.1 Key sub-challenges
2.1.1 Evaluation accuracy
The first key sub-challenge is that even on inputs you can safely use in training/testing, you may not be in a position to evaluate whether behavior of the type you’re looking for is occurring. For example: maybe your AI is taking a large number of very complicated actions, in some domain it’s hard for you to understand. Or: maybe you want to make sure your AI is being honest, but you don’t know how to tell.
These sorts of evaluation barriers are a problem for understanding your AI’s existing policy – and hence, for predicting/controlling how it will generalize. And they’re a problem, too, for efforts to actively shape that policy via training (and/or engaging in other forms of selection).[12] In particular: if you train/select for behavior inaccurately classified as desirable – e.g., you reward your AI for lying to you, or for cheating in ways that you can’t detect – then you may instill a problematic motivational profile in your AI, thereby making it more likely that your AI’s policy generalizes in dangerous ways on safety-critical inputs.
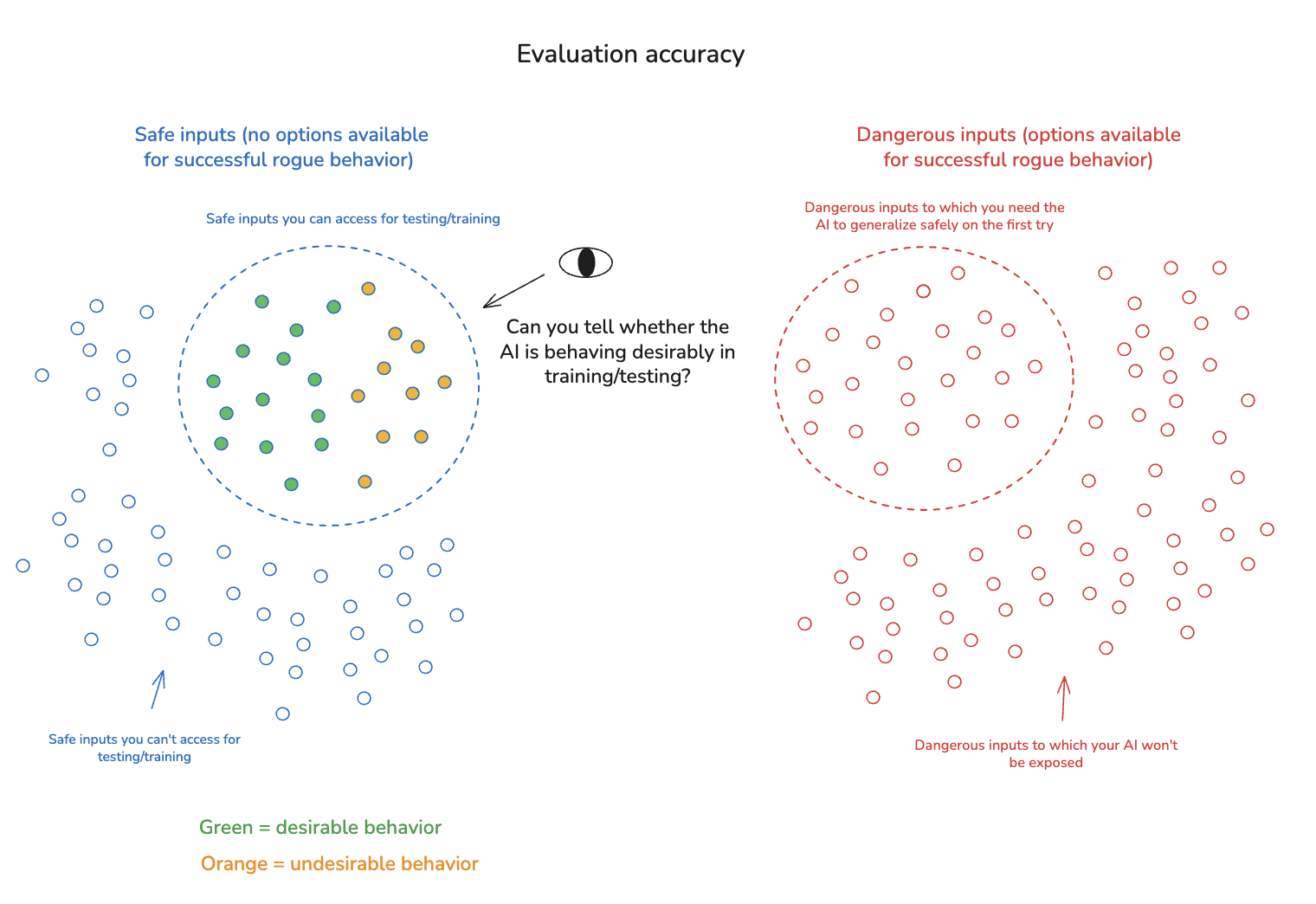
That said, we should note that it’s an open question exactly what kind of flaws in a training signal/selection criteria lead to what kinds of dangerous generalization. For example: maybe such flaws lead to an AI that sometimes lies to you, or cheats on its tasks, or seeks access to unauthorized resources. But that doesn’t mean that it will try to kill you and take over the world as soon as it gets the chance.
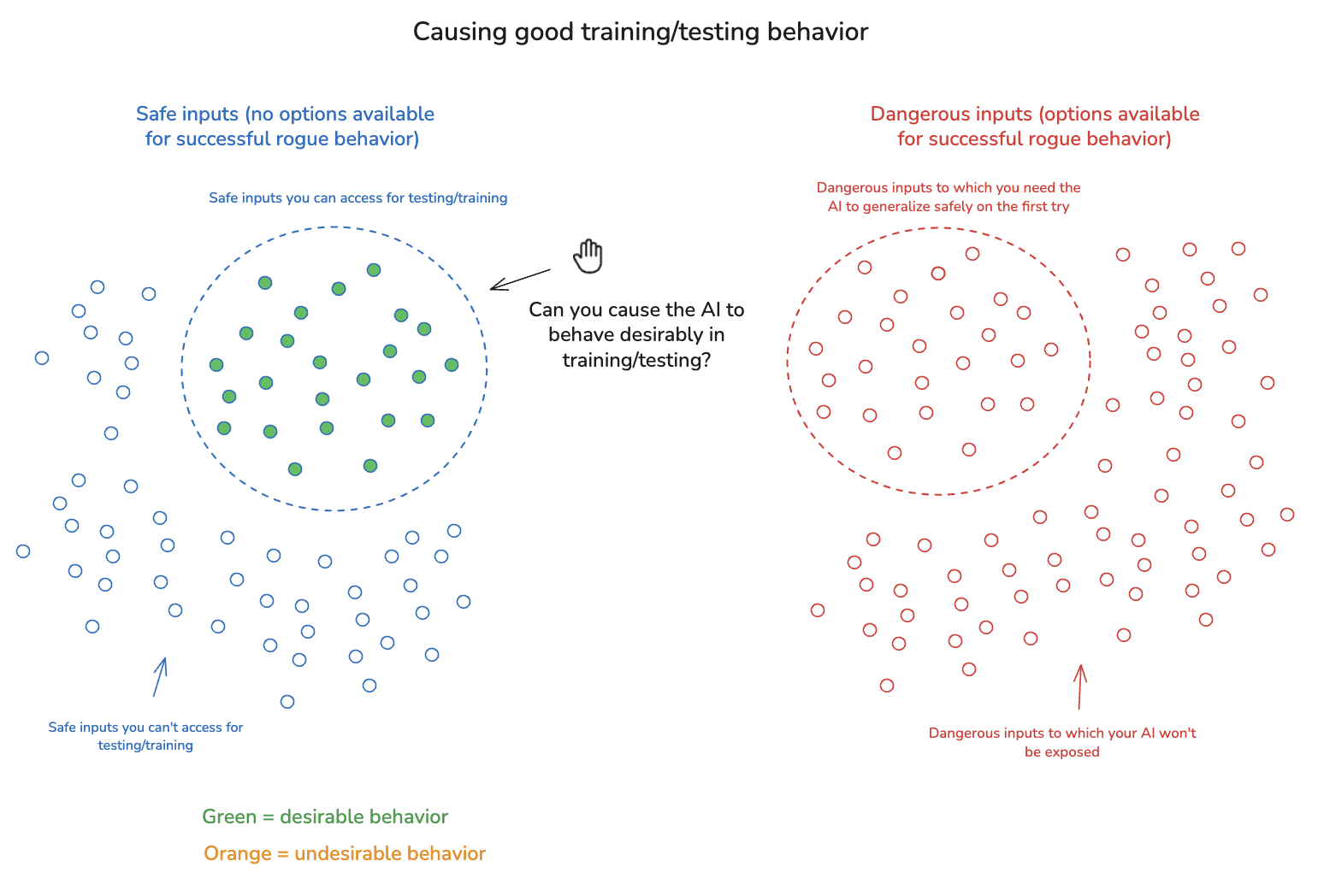
2.1.2 Causing good training/testing behavior
The second key sub-challenge is actually causing the sort of behavior you want in training/testing environments. This challenge is closely related to evaluation accuracy, in that being able to tell whether you’re getting desirable training/testing behavior is generally quite important to actually causing the AI to engage in this kind of behavior. But evaluation accuracy isn’t sufficient in this respect. That is: it’s possible to be able to tell that your AI is behaving undesirably, without being able to cause it to behave desirably instead.
Now: this sort of problem arises most often in the context of giving AIs suitably strong capabilities. Thus, for example: we could tell if AIs cured cancer, but they haven’t – and a key reason why is that the relevant capabilities aren’t there. But it applies, too, to eliciting desired behavior from AI’s capable of generating it.
One salient way to get problems in this respect is in the context of AI’s strategically underperforming (i.e. “sandbagging”) as part of a broader power-seeking strategy – a problem that arises centrally in the context of the sort of adversarial dynamics I discuss below. But it can also happen for more mundane reasons – e.g., because you don’t have enough of the right type of data to train adequately for good behavior, or because of some other flaw/difficulty with the training and red-teaming process. Currently, for example, we have a very hard time eliciting robustly desirable behavior from our AI systems (e.g., in a manner immune from jailbreaks), despite the fact that (a) they are capable of the good behavior in question, (b) we can accurately evaluate whether this behavior is occurring, and (c) none of the inputs in question make options for catastrophically dangerous rogue behavior available. These difficulties could easily persist.
2.1.3 Data access
The third key sub-challenge is that even in the context of inputs that would in principle be safe to use in training/testing, your access to inputs of this kind might be limited in other ways. For example: suppose you’d like to know how your AI would behave if its intelligence were to improve substantially, or if someone had genuinely cured cancer, or invented nano-technology, or factored RSA-2048. Even if it would be safe to get data of this kind, you can’t do so in your present position. So your ability to understand and shape your AI’s policy is limited yet further.
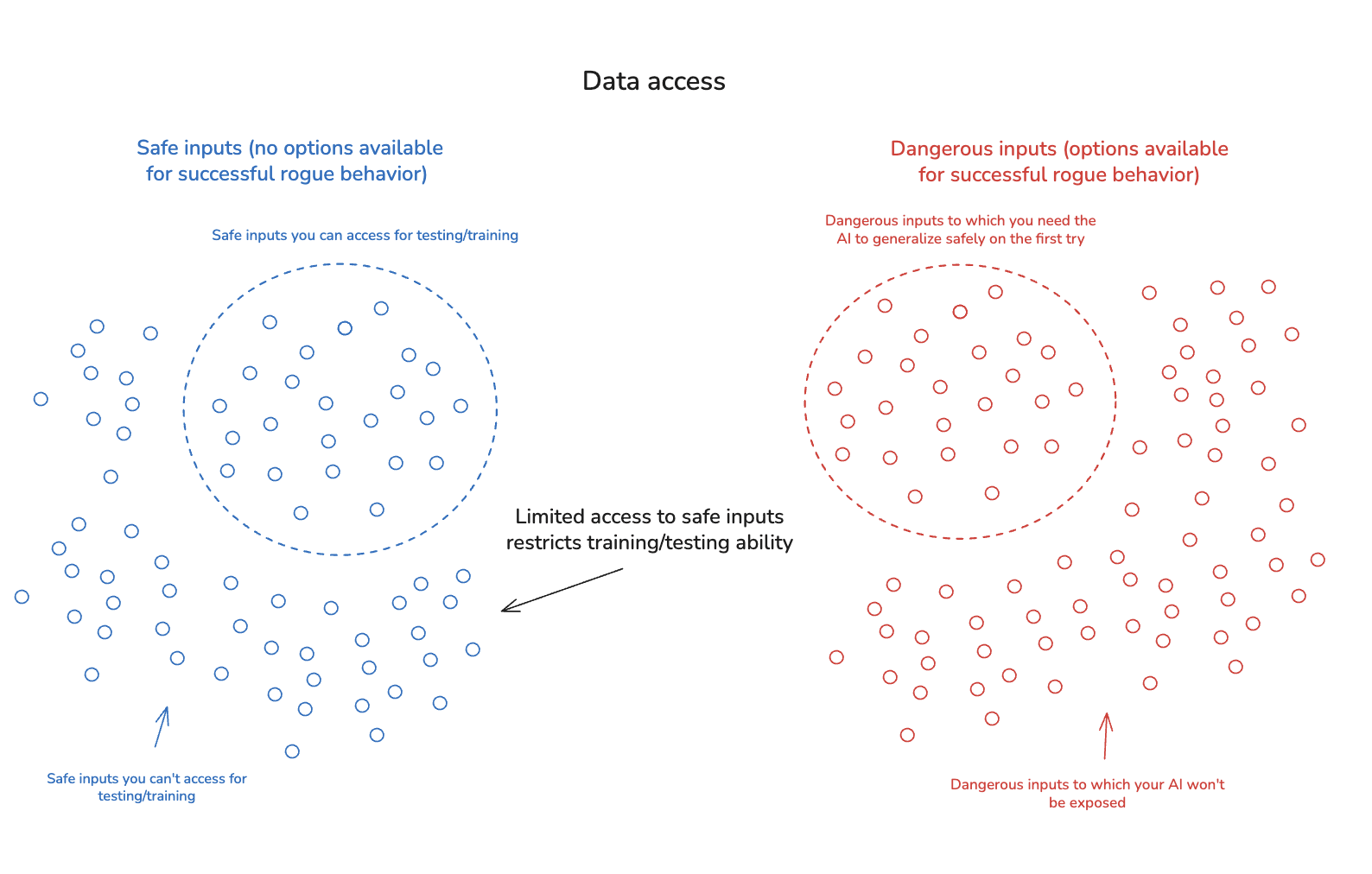
And note, too, that in some cases, you might have some access to a given sort of input, but not enough to engage in the sort of training you might’ve hoped for. Thus, for example: perhaps you’d like to train your AI system on tasks that take many calendar months to complete/evaluate; or tasks that require extremely expensive infrastructure. Here, even if you can give your AI a few inputs of this kind, training on a suitable number of samples may be infeasible.
Finally, note that as the capabilities of the relevant AI grow, then (absent comparable increases in the level of option control available), the inputs that are safe to test become scarcer, because the AI has dangerous rogue options available in a wider variety of contexts. For example: a superintelligence with sufficiently powerful manipulation ability might be dangerous for humans to interact with in any moderately high-bandwidth capacity; a superintelligence with sufficient hacking capabilities might be dangerous to run in the context of most available cybersecurity; and so on. This dynamic can significantly exacerbate the problem of “generalization without room for mistakes,” because it restricts (and in the limit, eliminates) your ability to study/test AIs with new levels of capability before exposing them to catastrophically dangerous options.
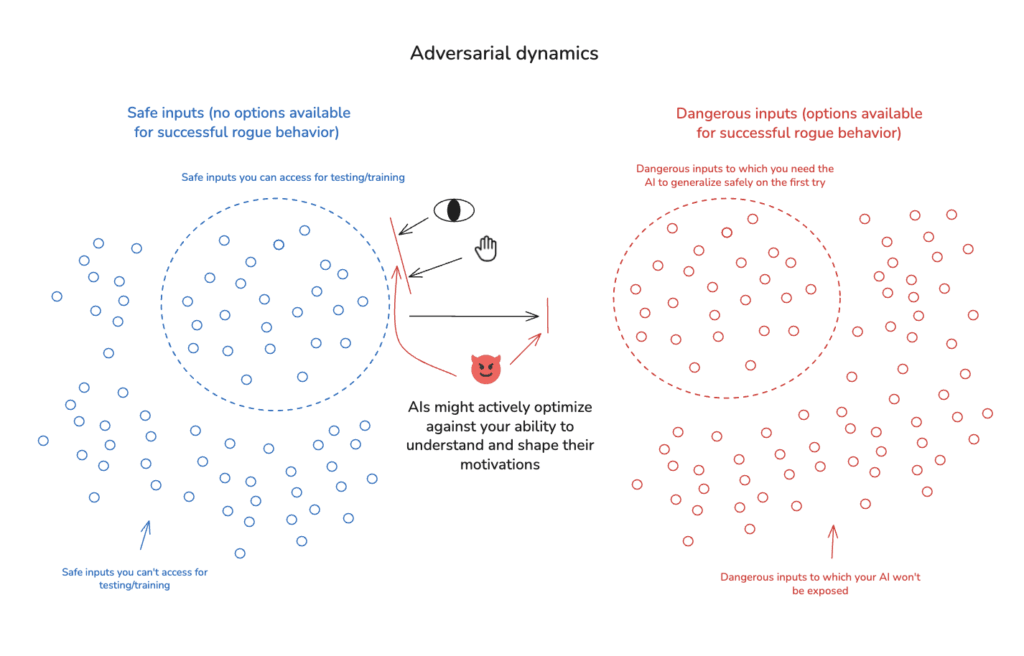
2.1.4 Adversarial dynamics
The fourth key sub-challenge is that the AIs you’re working with may be actively and adversarially seeking to undermine your safety efforts.[13] We can distinguish two versions of this:
- The AI whose motivations you’re trying to control might be adversarial. For example: it might be trying to deceive you about its motivations; it might try to prevent you from altering those motivations; it might try to manipulate you in other ways; and so on. And it might be doing so on the basis of a sophisticated and superhuman understanding of its circumstances. This possibility creates unique challenges in attempting to understand and control how an AI will generalize from safe inputs to dangerous inputs, because the AI might be smart enough to successfully manipulate your efforts in this respect.[14]
- The AIs you try to get to help you – for example, with scalable oversight, interpretability, other types of alignment research, etc – might be adversarial as well. Indeed, in the worst case, all the AIs involved in your alignment efforts might be adversarial in the same direction – i.e., they’re cooperating to promote the disempowerment of humanity, whether because they share similar values directly, or because their different values stand to gain enough from the cooperation – resulting in coordinated efforts at sabotage.[15]
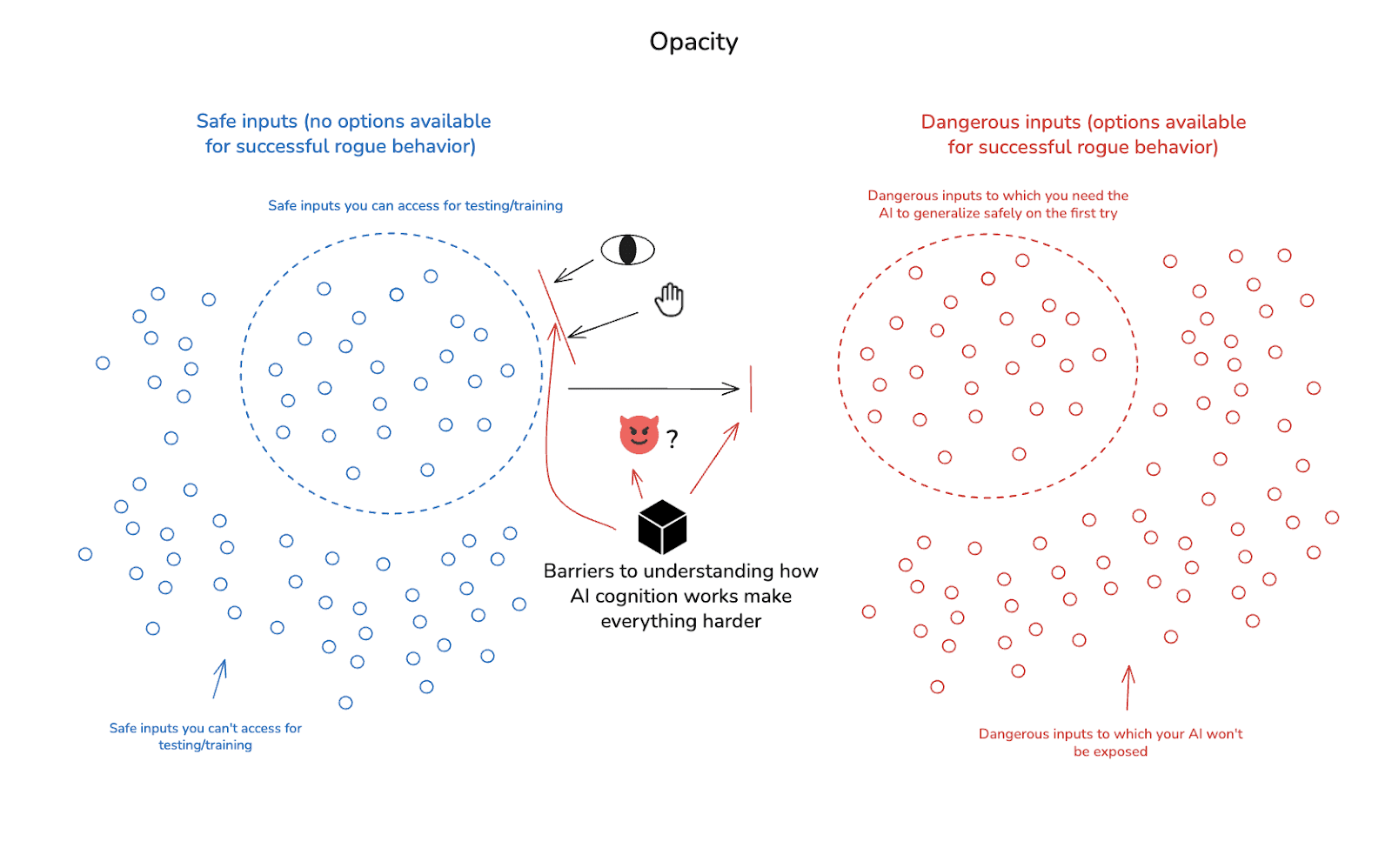
2.1.5 Opacity
The fifth and final key sub-challenge comes from the opacity of the AIs in question. That is: it is much easier to predict/control how an AI will generalize to new inputs if you’re in a position to understand (and ideally: to directly and productively intervene on) its internal processes – i.e., how it thinks, decides, processes information, and so on. And this sort of understanding helps, too, in detecting/preventing adversarial dynamics, and in evaluating/shaping AI behavior more generally. But contemporary ML systems make this kind of understanding quite difficult.[16]
Worse: there may be deeper structural barriers to developing this kind of understanding. For example: superhuman systems may process information using concepts and thought patterns humans simply aren’t in a position to understand. And it’s possible that some of the functions ML models implement don’t admit of the sort of compression/distillation/explanation that paradigm forms of “interpretability” are seeking. (More on these concerns below.)
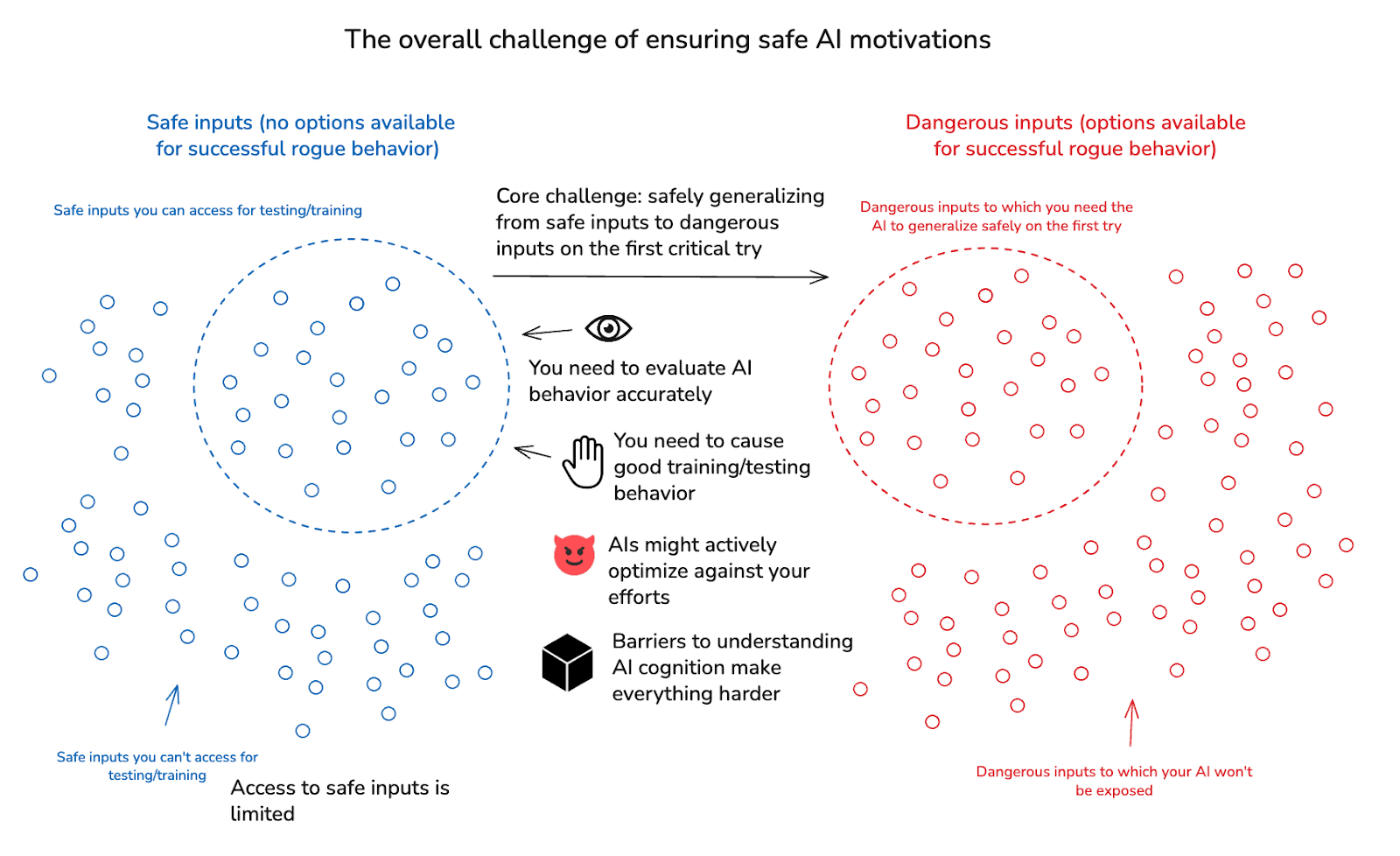
2.2 Summing up the challenge
Reviewing the picture I just laid out, then: the central safety challenge of motivation control is to ensure desirable generalization from inputs that are safe to test to inputs that are dangerous to test – despite the inability to iterate on failure. And you need to ensure this despite difficulties evaluating and shaping AI behavior even on safe inputs; despite limitations on the range of such inputs you can access; despite the potential for adversarial dynamics in the AIs you’re working with; and despite difficulties understanding how AI systems work internally.
3. Key tools
With this picture of the challenge in view, let’s turn to the key tools we have available.
I’m going to divide these tools, roughly, into two categories – “behavioral science” and “transparency tools.” Behavioral science focuses on the external behavior of AI systems, and therefore allows the “opacity” issue to remain unsolved. Transparency tools, by contrast, involve some reduction in opacity, and thus some additional levels of productive access to and understanding of the AI’s internal cognitive processes – e.g., the AI’s world model, its reasoning, the factors influencing its decision-making, etc. Of course, the lines here can get somewhat blurry; and the most promising approaches to alignment will mix both of these together.[17] But because the “opacity” problem could well persist or increase going forwards, I think it’s a useful first-pass cut.
3.1 Behavioral science
I think that serious efforts at behavioral science can be an extremely powerful tool in understanding and controlling AI motivations. Let me say a few words about why.
Let’s start by noting that behavioral science is the central tool we currently use for understanding and controlling the behavior of humans.[18] That is: in the context of human psychology, we do not, currently, possess many analogues of the sort of transparency tools I discuss below. For example, we do not have faithful and transparent “chains of thought” that we can use to monitor human thought processes; we do not have very useful direct-to-brain lie detectors; and what little mechanistic understanding we have of how the human brain processes information doesn’t help us much in predicting and controlling high-level motivations and behaviors. Yes, we have some (limited, fallible) degree of introspective access to how human minds work. But much of our understanding of human psychology comes from behavioral data in particular.
Notably, though: our ability to study human behavior in systematic ways is extremely limited. We have the “natural” data provided by history and by the behavior of current humans, yes. But actual controlled experiments on humans are slow, expensive, constrained to a specific range of often-artificial circumstances, and importantly limited by ethical, legal, and bureaucratic constraints.
Of course, some versions of these limitations could apply to efforts to study AI behavior as well. For example, as I discussed in the first essay: AIs might warrant moral concern of a form that should constrain the sort of experiments we conduct on them.[19] Especially if we set aside concerns about AI moral status, though, I think that we’re generally in a vastly more empowered scientific position with respect to AI behavior than we are with respect to human behavior.
Here’s a high-level image of the sort of thing I have in mind. Suppose that you have some AI agent that you are currently treating as “opaque” (maybe, for example, it’s a set of weights that you don’t understand mechanistically). In principle, it is possible to test this AI’s behavior on a huge variety of safe inputs (for example, for an AI whose inputs consist centrally of text, an extremely broad array of text prompts). And if you identify some concerning behavior on safe inputs (e.g. blackmailing humans, faking alignment, etc), it is possible in principle to conduct an intense behavioral assessment of the specific range of safe and accessible-for-testing inputs on which this behavior occurs – thereby making it significantly easier to isolate the specific variables that lead to the behavior in question. What’s more – and especially if you have access to automated AI labor to help you – it’s possible, in many cases, to do this at computer speeds. And the costs of the relevant AI cognition, at least, might be quite low.
Let’s call an AI’s full range of behavior across all safe and accessible-for-testing inputs its “accessible behavioral profile.”[20] Granted the ability to investigate behavioral profiles of this kind in-depth, it also becomes possible to investigate in-depth the effect that different sorts of interventions have on the profile in question. Example effects like this include: how the AI’s behavioral profile changes over the course of training; how the behavioral profile varies across different forms of training; how it responds to other kinds of interventions on the AI’s internals (though: this starts to border on “transparency tools”); how it varies based on the architecture of the AI; etc. Here I sometimes imagine a button that displays some summary of an AI’s accessible behavioral profile when pressed. In principle, you could be pressing that button constantly, whenever you do anything to an AI, and seeing what you can learn.
Or to put things another way: we have available, if we choose to gather it, a truly vast amount of data about how AIs of different kinds will behave in different circumstances, when subject to different sorts of interventions. And the availability of this data plausibly makes it possible, further, to start to build out detailed, joint-carving theories that can predict the data in question – to build, that is, a rigorous behavioral science of AI psychology. Plausibly, indeed, the concepts and categories we use for predicting human behavior – “extraversion,” “integrity,” “openness,” “narcissism” – emerge from a comparatively unsystematic effort to do this with humans (albeit, one informed by introspection, and by lots of historical experience with the predictive utility of the concepts in question). And while we have much less data and experience with AI psychology than we do with human psychology right now, I think it’s possible that the experimental advantages AI affords (e.g. speed, cost, options for intervention, ability to test tons of controlled settings, etc) can help our behavioral understanding of AI psychology catch up fast – and potentially, even, to go further.
Indeed, in thinking about what sort of psychological understanding we would need in order to feel comfortable exposing a given agent to a rogue option that would be catastrophically dangerous for them to pursue (e.g., in the limit, an option for them to take over the world), I think it’s useful to distinguish between two different standards, namely:
- The level of comfort we’d be realistically able to reach with respect to a human agent, given our current ability to test and understand human psychology.
- The level of comfort we’d want in some more absolute sense – e.g., in order to drive the risk that the agent pursues the rogue option below some percentage.
Ultimately, the second standard is what we actually care about. But I think it’s worth bearing the difference between the first and second standards in mind, partly because some talk about AI alignment makes it sound like the central problem is that AIs aren’t human – that is, that we can’t reach the first standard. And I’m not actually sure how hard reaching the first standard is, if we assume comparable levels of cognitive capability for the human vs. the AI (and for smarter-than-human AIs, it seems like smarter-than-current-human humans are a more natural comparison point). In particular: at least with respect to behavioral evaluations, it seems plausible to me that we will quickly reach a point where AIs are undergoing much more extensive behavioral evaluation than humans undergo even in contexts where we care most about whether we can trust the humans in question. And we’ll be in a vastly more empowered position to actively shape the AI’s psychology to fit the mold we want. Plus, as I discuss below, we’ll be able to bring to bear transparency tools currently unavailable in the context of human agents. So while it’s true that our understanding of human psychology benefits from introspection and historical experience that isn’t applicable to AI, I think it may not be that hard to get to a point where you trust a human-level-ish AI to reject an option to take over the world more than you trust a human to do so.[21]
Of course, the sort of extreme-effort version of AI behavioral science that I am most optimistic about would be a very serious undertaking. Human labor, on its own, would not be adequate. Already, though, we are starting to make substantive use of AI labor in attempting behavioral investigations of this kind (see, e.g., the red-teaming agent here). And per the argument in my last essay, I think the helpfulness of automated labor in this regard is a crucial factor going forwards.
That said, and even with AIs to help, efforts to control AI motivations through behavioral science do face the challenges I discussed above. Obviously, for example, on their own they leave the “opacity” issue unresolved. But even setting opacity aside, they need to result in enough understanding and control that they can secure good generalization to dangerous inputs on the first try, and they need to do this despite difficulties evaluating and shaping AI behavior, limits on data access, and the possibility of adversarial dynamics messing with the behavioral evidence in question.
Below I’ll discuss some approaches to addressing these difficulties. First, though, let’s look at some of the tools available for addressing the “opacity” issue in particular.
3.2 Transparency tools
I think of approaches to AI transparency in three broad buckets, distinguished by how they relate to the default opacity of current ML models.[22]
- Open agency: building more transparent agents out of still-opaque ML components;[23]
- Interpretability: making ML systems less opaque;
- New paradigm: transitioning away from ML-like systems altogether, and towards a new and more transparency-conducive paradigm of AI development.
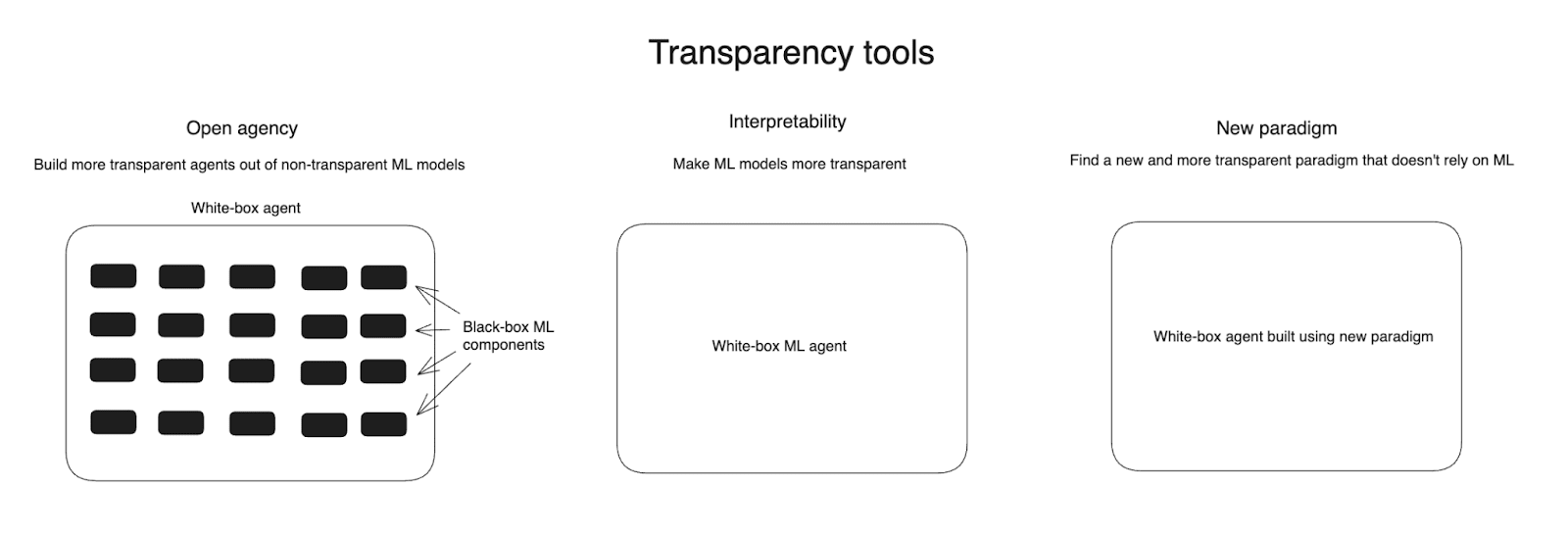
These approaches can combine with each other – and with efforts at behavioral science – in important ways.[24]And success at the most ambitious version of a given approach isn’t necessary for it to yield important safety benefits on the margin.[25] Let’s look at each in turn.
3.2.1 Open agency
Open agency approaches try to build more transparent agents out of still-opaque ML components. The most prominent current version of this focuses on transparency potentially available via the chain of thought (CoT) reasoning in current AI agents (see e.g. here for a recent overview). But we can imagine other versions as well. For example, Drexler (2023) imagines a broader and more diverse range of narrower, task-focused AI systems combining to produce overall agentic functionality.
One analogy here is with a corporation. If we understand a corporation as an agent (i.e., an entity that makes and coherently executes plans, in pursuit of objectives, on the basis of models of the world), it is an intuitively more “open” agent than e.g. an individual human brain, even if it has human brains as key components. And it is especially “open” if we require that written representations of the corporation’s thinking and strategy – i.e., the memos that different employees write about their plans, the justifications for those plans, etc – are “faithful” reflections of what actually drives the corporation’s behavior.[26] If advanced AI agents are more like this kind of corporation than like a human brain, this seems like a big win for transparency.
I see two key concerns about open agency: feasibility and competitiveness. The feasibility concern is just that it won’t be possible to create a given level of agentic AI capability while also achieving useful levels of open-agency-style transparency. For example: maybe we can’t figure out how to achieve the relevant sort of faithfulness in CoT reasoning (we know, for example, that CoT is already often unfaithful). Or maybe, more fundamentally, it’s not possible to reach a given level of capability (for example, full-blown superintelligence) while also forcing the relevant agent to think centrally in human-legible ways, using human-legible concepts.
An especially important version of this concern centers on the potential for adversarial dynamics occurring within the ML components that open agency approaches leave still-opaque.[27] In particular: if these components themselves satisfy the agential pre-requisites, they might themselves engage in cognition motivated by problematic forms of power-seeking. The most worrying version of this occurs when the different components coordinate with each other – e.g., via direct communication (steganography in the chain of thought, information hidden in a shared memory bank,[28] etc), or via more sophisticated forms of coordination that don’t require direct communication (e.g., reasoning about how other components are likely to reason[29]). But it’s also possible, in principle, for a given component to go rogue on its own.
One approach to mitigating concerns about safety-of-the-components is try to ensure that the individual ML components don’t satisfy the agential pre-requisites necessary for paradigm forms of rogue behavior (here an analogy might be: if you built your corporation entirely out of copies of GPT-4 producing text that you can read, then you might end up pretty confident that none of the components are plotting to defect later). Alternatively: if your ML components do satisfy the agential pre-requisites, you can nevertheless try to enforce very strong “faithfulness” in the human-legible parts of the overall set-up (i.e., preventing steganography via e.g. paraphrasing, testing whether the agent’s behavior in fact varies in the right way based on changes to the chain of thought, making sure that the components don’t have other non-legible communication avenues available, etc).[30]
Even if it’s feasible to create a given level of AI capability with usefully transparent forms of open agency, though, there’s still a further question of whether it’s suitably competitive to do so. Plausibly, for example, you can reach a given capability level significantly faster/more cheaply if you don’t require that the agent’s reasoning be human-legible; if you can optimize all of its cognition end to end; if you give the different components a shared, opaque memory bank; etc. Indeed, my own best guess is that open agency approaches will eventually come with some significant “tax” – and this, especially, the more task-critical cognition they try to push into the human-legible parts of the set-up.
That said: even if open agency comes with a tax, that tax might be worth paying – or at least, worth paying sometimes. Indeed, I think there is at least some hope that, even setting aside catastrophic risks from AI, there will be sufficiently active “demand” for the sort of transparency and steer-ability that open agency makes possible that standard commercial incentives will push in this direction somewhat. And note, too, that if you were able to get access to occasional, very expensive, but still trusted advanced AI labor via open agency, then this could serve as an extremely useful component of a broader approach to alignment, even if it wasn’t a fully competitive solution on its own.
3.2.2 Interpretability
Let’s turn from open agency to interpretability – that is, approaches to transparency that focus on making ML systems themselves less opaque. A lot of different potential research directions fall under this heading. Following Aschenbrenner (2024), however, we can broadly distinguish between:
- Mechanistic interpretability, which attempts to gain a quite fundamental understanding of how ML models work – and in the limit, the sort of understanding that makes it possible to reverse engineer the algorithms ML models are implementing;[31] and
- Top-down interpretability, which looks for tools and techniques that will allow us to extract information about a model’s internal processing without necessarily gaining any kind of deep understanding of how the model works. An example of this might be: training classifiers on a model’s activations to detect when it’s lying.[32]
This isn’t an especially clean distinction. But it’s a reminder, at least, that reductions in the opacity of ML models can come in many forms, not all of which involve deep understanding of how ML models process information.
We can group concerns about interpretability into two categories: practical, and fundamental. The practical concern, basically, is that it’s too hard – and in particular, that it’s too hard to use interpretability to achieve the sort of robust, exhaustive transparency that could ground high confidence that you’re not missing something important. Many top-down techniques, for example, seem poorly positioned to provide this kind of confidence; and while more mechanistic approaches aim at this kind of goal eventually, they seem very far away from reaching it.
That said: as I discussed in my last essay, I think of interpretability as an area especially ripe for benefiting from automated AI labor (centrally: because the empirical feedback loops at stake allow for easier evaluation). So even if we seem far away from more ambitious levels of understanding now, huge amounts of AI labor might bring us much closer (imagine, for example, large numbers of AI systems performing scaled up versions of the sort of circuits analysis at stake in Lindsay et al (2025)).
There is also, though, a more fundamental concern: namely, that there may be limits to the degree of transparency that interpretability can provide even in principle.
- For example: maybe superintelligences would make use of concepts that humans can’t understand[33] (a concern that seems especially salient in the context of interpretability techniques that specifically rely on human classifications of the features in question).
- Though: at least some aspects of even superintelligent cognition are going to be comprehensible in human legible terms.[34] It may also be possible to expand the default level of human understanding here – e.g., via having AIs teach us new concepts. And of course, if we could directly defer to AIs that understand the relevant concepts, this could take us quite a bit further.
- Or maybe, more fundamentally, the “algorithm” that a neural network implements, in performing a given cognitive task, often doesn’t actually end up reducible/summarizable/compressible in the manner that the idea of “reverse engineering” (and especially: reverse-engineering in a human-legible format) implies.[35]
I think both of these concerns – practical and fundamental – are serious barriers to more ambitious forms of interpretability. But I think interpretability can be a quite useful tool in the tool-kit regardless.
3.2.3 New paradigm
Let’s turn, finally, to approaches to transparency that focus on some new paradigm of AI development that doesn’t rely on ML systems at all, and hence doesn’t need to deal with the default opacity that both open agency and interpretability try to grapple with.
What sort of new paradigm? I don’t know. That said: one broad vibe I associate with this kind of approach is: “make AI good-old-fashioned again.” That is, the thought goes: in the old days, building an AI system was like coding software directly. And when you code something yourself, you get a certain kind of mechanistic understanding up front. That is: you don’t need to “reverse engineer” it; rather, you were the original engineer, and so are already in possession of whatever it is that “mechanistic interpretability” seeks.[36] But this is only one example of what a “new paradigm” might look like – and the category itself is meant to be a quite wide-ranging catch-all.
Now: the obvious objection to this kind of approach is that at least on short-ish timelines, it really looks like ML is going to play a central role in the default trajectory of AI development.[37] Indeed, no other “new paradigm” is remotely close to rivaling the power of contemporary ML.
Notably, though, the idea here doesn’t need to be: switch to the new paradigm by the time we’re building e.g. human-level-ish AIs. Rather, the idea could instead be to switch by the time we’re building superintelligences.[38] And in this context, a key goal for the sort of automated alignment research I described in my last essay would be to identify a new paradigm of the relevant kind.
Still, though: at least for now, this is by far the most speculative approach to transparency. And because it is mostly a promissory note/hope, it provides very little guidance about how to actually build safer and more transparent AIs in the near-term.
4. Addressing the challenges
I’ve now laid out the key challenges at stake in adequately controlling AI motivations; and I’ve offered a high-level view of the key tools available. Let’s turn, now, to how we might use these tools to address the relevant challenges.
Per my framing above, the most fundamental challenge is “generalization without room for mistakes” – e.g., successfully ensuring safe behavior on new, out-of-distribution dangerous inputs, without the opportunity to iterate on failure. All the other challenges (evaluation accuracy, opacity, etc) are relevant, centrally, insofar as they make this fundamental challenge harder – and we only need to solve them to the extent that doing so is necessary for solving the fundamental challenge.
So what we need, essentially, is a mature science of AI generalization. That is, we need to use some combination of behavioral science and transparency tools to learn how to predict and control how AIs generalize to new, dangerous inputs, and to do so with very high reliability. And I want to be clear that, despite my having discussed behavioral science and transparency separately, the two, in fact, should work closely hand in hand, each informing the other. For example: above I sketched a vision of exhaustively investigating and learning to predict how an AI’s accessible behavioral profile changes given different behavioral interventions – e.g., different sorts of training. But you can, and should, do the same process with respect to different transparency-informed interventions on the AI’s internals, and to use that data, too, to assist in developing strongly predictive theories of how AIs generalize.[39]
4.1 A four-step picture of success
Now: I opened the essay with a four-step picture of what success at giving advanced AIs safe motivations might look like. It was:
- Instruction-following on safe inputs: Ensure that your AI follows instructions on safe inputs (i.e., cases where successful rogue behavior isn’t a genuine option), using accurate evaluations of whether it’s doing so.
- No alignment faking: Make sure it isn’t faking alignment on these inputs – i.e., adversarially messing with your evidence about how it will generalize to dangerous inputs.
- Science of non-adversarial generalization: Study AI generalization on safe inputs in a ton of depth, until you can control it well enough to be rightly confident that your AI will generalize its instruction-following to the dangerous inputs it will in fact get exposed to.
- Good instructions: On these dangerous inputs, make it the case that your instructions rule out the relevant forms of rogue behavior.
In a moment, I’m going to discuss each of these steps in a bit more detail. First, though, a few comments about this picture overall.
First: as I said in the introduction, this is mostly a structured decomposition of the problems that an adequate science of AI generalization needs to solve. In particular: I want to isolate problems of evaluation accuracy (step 1) and adversarial dynamics (step 2) from the potential generalization problems that remain once those problems are set aside (step 3). I find this separation quite useful in thinking through where different difficulties are coming from, and how they interact.
Second: I’m focusing on “instruction-following” as the central property that we want to generalize to dangerous inputs – and then I’m treating it as a separate (and in my opinion: comparatively easy) challenge to ensure that this property also implies refraining from rogue behavior on those inputs. A few comments on this:
- In interactions with users, AI labs generally want alignment-like properties other than instruction-following out of their AI systems (e.g., they also want the model to refuse harmful requests). But they may also want some kind of purer instruction-following with respect to some higher tier of authority (for example, maybe they want the model to follow the model spec period – rather than, to follow the model spec provided that it’s suitably harmless).
- Regardless, though: ultimately instruction-following is only one specific kind of alignment-like property that you might in principle want to generalize to dangerous inputs – and in this sense, the picture above is only one specific vision of what success on motivation control might look like. I’m focusing on it partly because instruction-following is in fact a core aspect of what we currently try to train AIs to do, and partly because I think it introduces a useful layer of transparency/control into a human principal’s relationship to an AI. That is: if an AI is genuinely instruction-following, then the instructions themselves can serve as the mechanism via which we understand and influence what the AI is trying to do.
- Of course, there are various more philosophical subtleties involved in exactly what counts as following a given set of instructions, how the instructions get interpreted by the AI, etc. I’ll discuss these a bit in the context of step 4, and in more depth in a later essay. Still, though, I think that in many cases, we have a relatively clear sense of what it would mean for an AI’s behavior to fall within the boundaries of a common-sensical, reasonable-person’s interpretation of a given set of instructions. When I talk about instruction-following, that’s the property I have in mind.
4.2 Step 1: Instruction-following on safe inputs
Ok, let’s look at step 1: namely, causing the AI to follow instructions on safe inputs (or at least, the safe inputs you can test), using accurate evaluations of whether it’s doing so. Here, the basic idea that a first step in getting an AI to generalize in X way to some out-of-distribution input is to at least get it to act in X way on distribution – though as I’ll discuss below, this isn’t a sufficient condition on its own.
Even this first step, though, could be extremely difficult. And to my mind, the most salient difficulty is evaluation accuracy. In particular: especially absent strong transparency tools, accurately evaluating whether a stronger-than-human AI is following instructions likely requires success at some form of “scalable oversight” – that is, roughly, harnessing the labor of other AIs to accomplish forms of behavioral evaluation that humans couldn’t accomplish on their own.[40] But when working with a frontier AI you don’t otherwise trust (and specifically: don’t trust to just evaluate itself), this kind of scalable oversight requires bootstrapping up from less-capable but more-trusted human/AI cognition to an adequately powerful evaluation signal.[41]
Here, if you have on hand an only-slightly-less-capable AI whose outputs/instruction-following you do trust (e.g., the most recent generation of AIs that you think you succeeded at aligning), you can use it as an evaluator, and then try to get around the capability gap somehow – e.g., via the difference in the difficulty of generation vs. evaluation, or potentially via “amplifying” the cognitive power of the less-capable-but-more-trusted AI by e.g. using many copies of it, running it for a long time, breaking the task down into chunks, etc.[42] And you can try to make such “amplification” techniques work across larger capability gaps as well (e.g., running your evaluation process using large teams of AIs trained specifically to imitate human judgments). See my last essay for a bit more discussion.
As I noted in that essay, though, it’s an open question how far these techniques can go on their own, especially if the capability gap between the AIs-whose-output-you-trust and the AIs-you’re-evaluating grows. Indeed, I think significant gaps in this respect could create deep barriers (cf “Can a giant team of average M-turkers figure out how to evaluate string theory research?” from my last essay).[43]And of course, as with any alignment technique that leverages AI labor, success likely requires either avoiding adversarial dynamics in the AI you’re using, or finding ways to elicit safe and adequately effective labor even granted such dynamics.
Now: as I discussed in my last essay, to the extent that you stop being able to evaluate AI behavior/output using scalable oversight, you need to rely more heavily on what I called “process-focused evaluation” in assessing whether the AI is acting as intended – that is, roughly, your confidence in the desirability of the output has to depend on your evaluation of the process that produced it, rather than the output itself. Here, transparency tools can indeed help a lot (e.g., even if you can’t tell from an AI’s behavior whether it’s following instructions, you might be able to tell via examining its thought processes), and your other evidence about how it’s likely to be generalizing to the relevant safe input can matter too (though in that case, your evaluation may not be generating the sort of independent signal you’d want to use in e.g. training).
Still: overall, I find the prospect of rapidly becoming unable to accurately evaluate AI behavior even on safe inputs quite worrying. And especially if you can’t tell when your evaluation ability starts to drop off, this can quickly lead to actively reinforcing bad behavior in your AI.
That said: as I noted above, it’s a further question what sorts of bad reinforcement on safe inputs will lead to rogue behavior, in particular, on dangerous inputs (being reinforced for cheating on a task, for example, won’t necessarily lead to an AI becoming omnicidal – though the question remains unfortunately open). In this sense, step 1 admits at least some (uncertain) amount of tolerance for error.
Even if we grant an ability to accurately evaluate whether an AI is following instructions on safe inputs, though, there’s still a further question of whether we can cause it to do so – and in particular, to do so robustly. One worry, here, is the AI intentionally sandbagging or holding back the desired behavior, even on inputs where we are trying to train it to perform well. This problem, though, arises paradigmatically in the context of adversarial dynamics, so I’ll treat it in the discussion of step 2. Even beyond intentional sandbagging, though, and even with the benefit of accurate evaluation, ensuring robust instruction-following on safe inputs could well remain a challenge (see, for example, the difficulty we’re currently having with it).
Conceptually, though, I’m not sure that this part is so hard. In particular: modulo capabilities problems (we’re generally assuming the AI in question is capable of the behavior we’re looking for) and intentional sandbagging, if you can accurately evaluate whether an AI is following instructions on a particular safe input, it seems likely possible to also cause that AI to follow instructions on that particular input. For example: you can train on the AI on the evaluation signal in question.[44] So the remaining question is whether you can do this adequately well to get robust instruction-following across safe inputs.
Here a key game is red-teaming – that is, searching out safe inputs where the AI behaves undesirably.[45] And while this may be quantitatively quite challenging (there are a lot of inputs you could in principle test), I don’t currently see qualitative barriers to doing, at least, an extremely intensive and sophisticated version – one informed, hopefully, by a developed science of AI psychology, and focused on generating and testing structured hypotheses for ways a given AI’s psychology might have gone wrong.[46] And note, as ever, that AI systems themselves can help a lot in that regard (see, e.g., Anthropic’s automated red-teaming agent here for an early example of this).
That said: depending on the specific ways in which AI behavior tends to generalize, this step could cause lots of problems as well. For example – and especially if the property you’re training for isn’t very “natural” in the sense of: easy for the AI to learn/internalize – you could end up with a “whack-a-mole” type dynamic, where red-teaming continues to unearth bad behavior on various inputs, but training for better behavior on those inputs constantly leads to new problems elsewhere.[47] At the least, though: if that problem is happening, adequate efforts at red-teaming should be able to tell.
4.3 Step 2: No alignment faking
Let’s turn, now, to step 2: namely, making sure that the AI isn’t faking alignment on the safe inputs – i.e., adversarially messing with your evidence about how it will generalize to dangerous inputs. Here, the basic idea is something like: conditional on success at step 1, you’ve got an AI that is robustly following instructions on safe inputs. Why, then, would you expect it to suddenly stop following instructions on dangerous inputs – and then, in particular, to start seeking power in catastrophically dangerous ways? And one salient answer is: because it was intentionally trying to mislead you about how it would generalize.
The paradigm version of this is scheming – i.e., roughly, an AI specifically trying to get you to expose it to the dangerous inputs, or otherwise trying to sabotage your alignment efforts more broadly, as a part of a strategy for seeking power.[48] And I’ll focus centrally on scheming in what follows. (It may be possible for some other forms of misalignment, short of full-fledged scheming, to lead to similar dynamics – but I don’t have especially salient examples in mind.[49])
Very few scientific disciplines need to deal with the possibility of adversarial dynamics of this kind (usually, the thing you’re studying isn’t trying to make you wrong). And superhumanly competent efforts in this respect are their own special challenge. Indeed, this is one of the key ways in which the safety challenges posed by advanced AI differ from those posed by other sorts of technology – e.g. nuclear reactors.
What’s more: failures to avoid/prevent these sorts of adversarial dynamics admit of much less tolerance for error than failures on Step 1. E.g., if you accidentally reinforce some bad behavior, or if the AI sometimes fails to follow instructions on safe inputs, it’s still possible that your AI doesn’t specifically generalize in catastrophic ways on dangerous inputs. But if your AI is actively trying to generalize in catastrophic ways on dangerous inputs, then by the time you make the leap to those inputs, you’re in serious trouble.
In this sense, step 2 is crucial to giving AI’s safe motivations. And conceptually, at least, it also looks to me like the most difficult step of the four. In particular: schemers, famously, try to behave just like AIs with safe motivations. So: if they’re good enough at this, and aware-enough of their overall situation, “behavioral science” on its own struggles to identify them.
In my 2023 report on scheming, I wrote in some depth about the options for studying and learning to prevent scheming regardless.[50] Since that time, we’ve gotten some more empirical data on models engaging in behaviors that are at least scheming-adjacent.[51] And there’s been lots of additional conceptual research, too, on relevant options and dynamics (Redwood Research’s work on the topic has been particularly influential on my own thinking).
I won’t, here, attempt any sort of in-depth survey as to the overall space of approaches to preventing scheming. Broadly, though, the “key tools” framework I discussed above still applies. That is, roughly, we can carve up the space into:
- Behavioral science that still works despite the fact that schemers would be trying to manipulate our behavioral evidence.
- Transparency tools that still work despite the fact that schemers would want to avoid transparency.
In a sense, that is, it’s the same game: except that your tools need to be more robust to adversarial pressure.
One way to achieve this robustness is to take care to avoid the adversarial pressure entirely. For example, as I discussed in my scheming report, you can study the individual components of scheming (e.g. situational awareness, beyond-episode goals, goal-guarding, etc), while making sure that they don’t come together in a way that gives rise to scheming proper. Alternatively, you can study analogies for scheming – that is, model behaviors and training dynamics structurally similar to possible elements of a scheming threat model.[52] Indeed, insofar as much of the general science of AI takes place in the absence of schemer-like adversarial pressures (at least, for now), it would fall under this bucket as well. And insofar as you have or gain some understanding of what sorts of AI development are less likely to lead to adversarial pressure (e.g., regimes of lower capability, training methods that don’t induce situational awareness and/or beyond-episode goals, avoiding neuralese, avoiding shifts in what motivations are being reinforced, etc), you can try to use this understanding to lower the probability that schemer-like dynamics are in play.[53]
Alternatively, you can try to create something more like scheming proper, but in a manner that is sufficiently controlled and understood that the potential for adversarial pressure doesn’t undermine the epistemic value of the effort. For example, you can try to create and study “model organisms” of scheming by e.g. instructing/training models to act like schemers. And because you created the scheming in question, you’re hopefully in a better position to account for its influence on your evidence.
Finally: you can try to catch or otherwise reveal scheming that arises naturally, and then study that case in detail.[54] Of course, this path requires that the schemers in question are either failing to adequately hide their scheming from you, or they have chosen to stop trying. But both are on the table. The former case, for example, might happen because the schemers are too incompetent/incoherent to avoid your schemer-detection methods; or, perhaps, because they have gotten desperate enough that they intentionally chose actions that expose them to serious risk of getting caught. And the latter case might happen because the schemers’ incentives have shifted enough to make showing their true colors the rational action – for example, because you intentionally created incentives of that kind.[55]
Here I want to zoom in, in particular, on one especially salient method of trying to detect scheming: namely, trying to cause an AI to think that it’s facing the sort of dangerous input we’re ultimately concerned about, even though it actually isn’t (call this a “fake rogue option”[56]). I’m zooming in here because if techniques like this worked in full generality, then they could also do a lot to solve the fuller challenge of “generalization without room for mistakes” just on their own.[57] After all: the core problem at stake in generalization without room for mistakes is that we can’t safely test an AI’s behavior on dangerous inputs. But if we can somehow test how an AI would behave on dangerous inputs without actually exposing it to those inputs, this would be a huge help.
The classic concern about this sort of technique, of course, is that trying to fool a smarter-than-you AI is a loser’s game – it will be able to tell that the fake rogue options are indeed fake, and to wait for the real version before going rogue.[58] And certain kinds of relevant rogue options – for example, those arising from large amounts of technological progress – might be much harder to “generate” than to “discriminate,” even if the effort/intelligence being applied on each side were comparable.[59] That said: sufficient progress in learning to manipulate an AI’s world model directly using transparency tools might be able to bypass some of the difficulties here (e.g., the project might become less like creating elaborate Truman-Show-like inputs, and more like inducing suitably convincing hallucinations). And even more coarse-grained transparency-flavored interventions – e.g., adding noise to a model’s weights or activations (“fuzzing”) – might have some epistemic value in revealing schemer-like propensities the model might be trying to hide. Overall, though: I don’t think we can count on fake rogue options as a way to detect scheming (or, more generally, as a way around the basic dilemma of generalization without room for mistakes).
What’s more, and importantly: detecting scheming isn’t enough for Step 2. Ultimately, you need to actually prevent the scheming in question. And a classic concern in this respect is that iterating on your methods of training/alignment until you no longer detect scheming will just lead to AIs that hide their scheming more effectively, rather than to AIs that don’t scheme at all.[60] In this respect, though, it’s important to distinguish between two different methods of iteration – namely, training on a given method of detecting scheming, and validating on that method. Both, in principle, can lead to the sort of selection pressure that hides scheming rather than eliminates it – but the former seems much more likely to do so, and faster, for reasons similar to why training on your test set is generally a bad idea in ML (see MacDermott (2025) for more; and see Bowman (2025) for an approach that emphasizes the validation-focused type of iteration).[61]
Ultimately, and despite the many productive research paths available for getting a better grip on detecting/preventing scheming, I’m very worried about step 2. In particular: it seems plausible to me that it will be quite difficult to rule out scheming in suitably advanced and situationally-aware AIs using purely behavioral techniques; and even moderate success at transparency could let catastrophic forms of scheming slip through the cracks. And more generally: I am concerned that our efforts to create a suitably mature science of AI generalization won’t be strong enough to withstand active adversarial pressure – and especially not superhumanly-intelligent versions of such pressure.
4.4 Step 3: Science of non-adversarial generalization
Still: let’s suppose, for a moment, that we’ve succeeded at both Step 1 and Step 2. That is: we’ve successfully caused robust instruction-following on safe inputs, using accurate evaluations of this; and we’ve successfully avoided the AI adversarially messing with our evidence about how it will generalize to dangerous inputs. Given this, the remaining challenge is to successfully rule out other reasons the AI might nevertheless generalize in rogue ways on dangerous inputs – and, as ever, to do so on the first try.
I’m going to call this the “science of non-adversarial generalization.”[62] And so isolated from Steps 1 and 2, the challenge at stake in “generalization without room for mistakes” has been reduced significantly. Indeed: granted that the AI robustly follows instructions on safe inputs, and that it isn’t actively trying to mislead you about its propensity to follow instructions on dangerous inputs: why, exactly, would you expect it to suddenly stop following instructions on dangerous inputs – and in particular, to do so in a way that involves going rogue in catastrophic ways?[63]
Here, the basic concern is that the dangerous inputs will be an importantly new distribution (there was, after all, a reason they were dangerous, while the safe inputs were safe) – a distribution that introduces novel dynamics that the safe inputs didn’t; and that these dynamics, when combined with background, instrumentally-convergent pressure towards rogue power-seeking, will lead even AIs that weren’t adversarial on safe inputs to go rogue regardless.[64] This could happen, for example, because:
- Greater opportunities for successful power-seeking increase incentives to engage in it (somewhat analogous to “power corrupts”).
- Here an example might be something like: models showing very little interest in stealing money when they’re very unlikely to get away with it (and also not intentionally lying about their interest in stealing) – but, nevertheless (and contrary to their prior, sincere predictions about their behavior, if those predictions were solicited), starting to steal money once they are in a position to reliably get away with it.
- A wider range of affordances revealing brittleness/shallowness in an AI’s rejection of rogue behavior.
- Here an example might be something like: an AI learns a strong aversion to a particular sort of stealing, but not to a broader range of other versions that become options in the dangerous regime.
- New levels of intelligence/information creating novel problems with a model’s ontology, ethics, or cognitive processes in general.
- Here an example might be something like: new forms of reflection prompt an AI to question the philosophical/empirical basis for its loyalty towards humans.[65]
- Other reasons we haven’t thought of/discovered yet (this category is potentially very large and important).[66]
Here, I think, it may be useful to distinguish between the sorts of generalization failures that occur when you hold an AI’s capabilities fixed, but deploy it in a context with novel options; vs. generalization failures that occur when the AI’s capabilities themselves start to change (and in particular, to increase). I am generally treating the former case as the paradigm we’re interested in. That is: obviously, we do need ways of improving an AI’s capabilities safely. But I think we should generally try to avoid cases in which improvements in this respect also coincide with the leap from safe to dangerous inputs. That is: the goal should be for increases in an AI’s capabilities to occur in a context restricted to safe inputs throughout the process, such that even the more-powerful version of that AI doesn’t have any dangerous rogue options; and then the AI needs to be subject to thorough testing, anti-scheming investigation, etc before the safe-to-dangerous leap occurs.
Why this goal? Basically, I think capabilities increases are likely to alter the AI’s psychology in deeper and less predictable ways; whereas predicting what an AI’s existing, not-deceiving-you psychology does given some new set of options for problematic power-seeking seems easier. Compare: giving an extremely nice-seeming, not-deceiving-you human the chance to kill you and steal your money, vs. giving that same human some kind of new intelligence-enhancement drug, and then the chance to kill you and steal your money. We should try, I think, to make the choice to give AIs rogue options more like the former case, and less like the latter.
That said, a few complexities:
- First: the most effective forms of frontier AI labor will plausibly be actively learning, changing, and growing “on the job” in a way that makes it hard to fully avoid capabilities changes (and other possible psychological changes). So “holding the AI’s capabilities fixed” may become difficult and/or anti-competitive.
- Second: depending on how much you understand what you’re doing when you’re improving your AI’s capabilities, you may not be able to tell when a safe-to-dangerous leap is occurring. Thus, for example: maybe you think that your training run is giving your AI no options for self-exfiltration, but in fact, as its intelligence increases over the course of training, it starts to see a way out.
- Third: as an AI becomes more capable, the set of inputs that are “safe” starts to narrow – and with it, your options for safe forms of scientific investigation.
Note, though, that even if we grant that our science of non-adversarial generalization needs to cover some changes in capabilities, it’s still a further question which ones, and how extreme those changes will be. And in this respect, I think, the AI safety discourse has been focused over-much on successful generalization across extremely large and intense capabilities changes – the sort at stake, for example, in an AI’s capabilities improving in an effectively unbounded manner (cf “recursive self-improvement”). That is, the image is something like: there is a “seed” AI whose motivations you get to try to shape on safe inputs, but then you need to do so so well that the seed AI does not go rogue even once it transforms into an intelligence of wildly superhuman power.[67]
This image is misleading, though. In particular: even granted that there is some option available to the AI that eventually results in its transforming into a wildly powerful superintelligence (for example, via first escaping the lab, taking over the world, etc), its pursuit of that option might well be precisely the sort of rogue behavior we’re trying to prevent. And the AI that matters for that task isn’t the superintelligence at the end of the path, but the much-less-capable AI at the beginning. This means that we just need our instruction-following, alignment, etc to generalize well enough to cover that much-less-capable AI rejecting rogue options, including the rogue option of recursive self-improvement. The additional novel problems that could arise throughout a process of recursive self-improvement aren’t relevant, because if we’re successful, no such process occurs.[68]
Now: here we might worry that in fact, we will want AIs to engage in a process somewhat akin to recursive self-improvement – e.g., running an automated AI R&D process, including the alignment aspects, that eventually results in the creation of a safe superintelligence. And indeed, some version of this is indeed core to my own picture. But understanding that entire process as a single instance of “generalization without room for mistakes” seems to me like an importantly misleading frame. In particular: what we really need is successful generalization to non-rogue (and also: fully elicited) behavior from successive generations of AIs that are built along the way. And if we can get an individual generation suitably right, then it can direct its efforts towards ensuring success with the next generation. No individual generation, then, needs to figure out how to do the entire leap from e.g. human-level-ish AI to wildly-super-human AI successfully.
Still: we will need to be making some leaps regardless. At the least, holding capabilities fixed, we’ll need to be moving from safe inputs to dangerous inputs. And perhaps we will need to do so in a manner coincident with some increase in an AI’s capabilities as well. And this sort of leap will, indeed, be a kind of step into the unknown – one that could, in principle, implicate novel dynamics that break the AI’s instruction-following and lead it towards rogue behavior.
We do, though, have at least one key advantage in attempting to anticipate and account for these dynamics: namely, that the AIs (per success on step 2) aren’t trying to hide those dynamics from us. And this allows us to engage, in principle, in an extremely detailed and not-adversarially-misleading study of other forms of out-of-distribution (OOD) generalization on safe inputs. That is, we can use both behavioral science and transparency tools to learn how to understand and control how AIs trained on one set of safe inputs generalize to other sets of safe inputs that introduce novel properties/dynamics; and this can help a lot in improving our ability to predict and control how the generalization to dangerous inputs in particular will go.
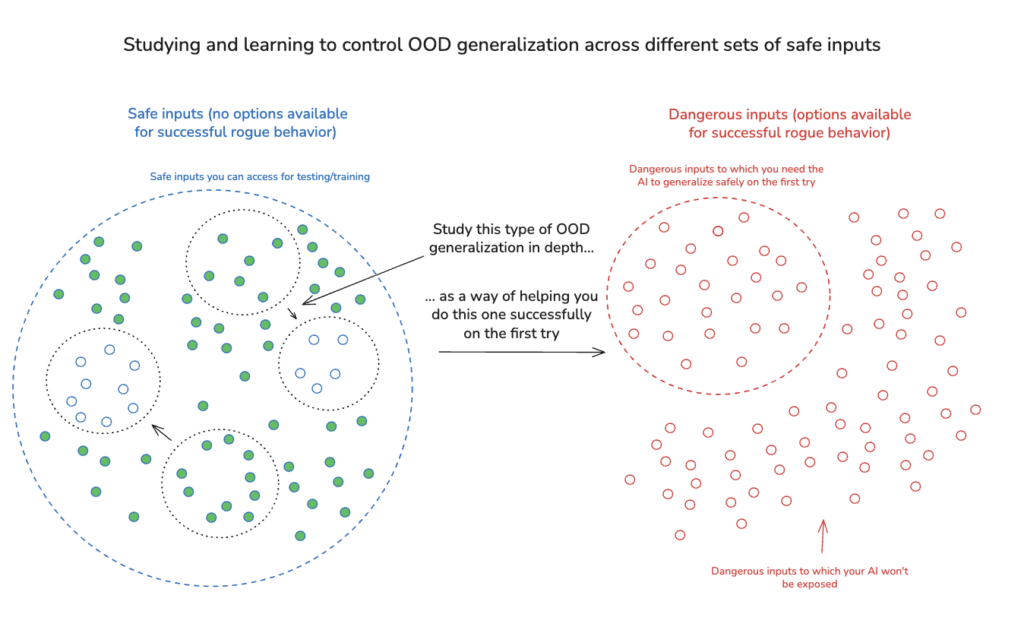
Indeed, in attempting to think about the difficulty of Step 3, I think it’s worth bringing to mind contexts in which ensuring successful OOD generalization even on the first try doesn’t seem, on its own, especially difficult. Thus, for example: suppose you never get to train or test your AIs in interactions with genuine fans of the Miami Dolphins. How hard is it to ensure, on the first try, that an AI doesn’t suddenly start worshipping the spaghetti monster when it first interacts with Dolphins fans? In a sense, this is a type of OOD generalization. But it also doesn’t sound so hard to get right on the first try – and this, especially, if you’re able to learn how to ensure the desired behavior in all the non-Dolphins cases.
Now: one feature of this case is that the relevant form of “bad behavior” (worshipping the spaghetti monster) is quite specific and random – whereas, in the context of AI power-seeking, the concern is that it becomes highly convergent once genuine options for grabbing power become available. But we can modify the case to better reflect these convergent incentives. Thus: let’s say that throughout training and testing, you make available to your AI some resource – e.g., a button that will give it greater computing power – that will allow it to complete a wide variety of tasks much more effectively, such that there is default convergent pressure to use the button. Can you successfully ensure that when you first expose the AI to fans of the Miami Dolphins, it doesn’t press the button?
Again, conditional on success at the analogs of steps 1 and 2, I think you probably can do this pretty easily – e.g., by training the AI, in all other cases, to complete its task without pressing the button. And a key thing that makes this case seem fairly easy is that the distributional shift to Dolphins fans is very similar to other sorts of distributional shift that you’re in a very good position to study. Thus, for example: before attempting the shift to Dolphins fans, you could “hold out” some other groups of fans – e.g., fans of the Jets, the Patriots, the Bills, etc – and then check to see that you’re able to get no-button-pressing on those distributions well enough on the first try. And (absent the AI actively trying to mislead you about its policy), there’s no special reason to think that whatever policy caused the AI not to press the button in interactions with Jets fans, Patriots fans, Bills fans, etc, would suddenly break down when you move to Dolphins fans. So success in those cases seems like strong reason to expect success in the Dolphins case as well.
That said: this analogy also brings out an important limitation on how much studying OOD generalization on safe inputs can teach you about the leap to dangerous inputs – namely, that the safe-to-dangerous leap might be importantly different from the other sorts of distributional shift you’re in a position to study safely. Thus: while it’s true that we can try to understand and control safe versions of dynamics like “power corrupts,” “new affordances reveal brittleness of existing alignment,” “new types of reflection lead to weird new places” – still, it seems plausible that the safe versions won’t capture all of what matters about the dangerous kind we ultimately care about. And of course, our existing models of the sorts of dynamics to watch out for are themselves likely to be importantly incomplete – a possibility that becomes especially salient to the extent that the safe-to-dangerous leap coincides with improvements to an AI’s capabilities in particular (as opposed to just: new affordances), since new capabilities (and especially: new superhuman capabilities) seem especially likely to introduce novel dynamics you couldn’t anticipate or study beforehand.
Is there any principled way around this problem? That is: is there any principled way to learn, ahead of time, how to predict and account for all of the key issues that will arise as an AI gets exposed to new, dangerous options – and in particular, if this happens specifically as a result of its capabilities improving? I’m not sure. Indeed, it seems possible to me that there are some fairly fundamental barriers in this respect, and that claims like “we know that we’ve accounted ahead of time for the main ways things could go catastrophically wrong as we improve this agent’s capabilities further” are quite difficult to reach high levels of confidence in – i.e., some element of “stepping into the unknown” will remain effectively ineliminable.[69]
Here again, though, I think it’s important to be clear about the standard of success we have in mind – and in particular, whether we are talking about doing at least as well as we could’ve/would’ve done with humans vs. reaching some more absolute standard. Thus: set aside AI for the moment, and consider the project of finding/training a human to which you will then hand the power to take over the world; or the project of improving human intelligence (whether: biological human intelligence, or the intelligence of some high-fidelity emulation of a human brain) in a manner that ensures that the resulting agent doesn’t “go rogue.” Here, too, even conditional on success with analogs of steps 1 and 2, the same sorts of issues arise – e.g., the resulting agent could get corrupted by new forms of power; its non-rogue behavior might be revealed as brittle in the face of new options; new forms of reflection might prompt weird changes in its ethics/ontology/empirical-understanding; etc.[70] And in particular: it may be difficult to become justifiably confident that you’ve accounted, ahead of time, for all of the novel dynamics that could arise as you take the next step in the process. In assessing the difficulty of Step 3, then, we should be sure to be clear in our heads about how much it’s the AI-ness, in particular, that’s the problem.
Still: especially insofar as AI minds remain alien and not-understood relative to human minds, the AI-ness does in fact make things harder. And regardless: ultimately it’s the absolute standard that counts. So even granted success on steps 1 and 2, some significant (and possibly: extremely difficult) scientific challenge remains here – one that even an extensive process of learning to understand and control OOD generalization on safe inputs may not be enough for on its own.
What does it take to go the rest of the way? Well: large amounts of success with various transparency tools would presumably help a lot, as deep understanding of how AI cognition works seems likely to expand significantly the range of inputs and dynamics that our science of generalization can cover. And successful versions of the “fake rogue options” approach discussed above would also make a big difference, since this would allow safe testing of how an AI would behave on various relevant dangerous inputs. What’s more, as I’ll discuss later in the series, I think that success at causing AIs to do what I call “human-like philosophy” can help guard against some potential problems related to new forms of reflection prompting problematic changes to AI ethics/ontology.
In general, though: I think it remains a key open question exactly what it takes to reach the level of scientific understanding required to be justifiably confident that a given sort of leap from safe to dangerous inputs won’t implicate novel dynamics that break the alignment-relevant properties one wants to ensure in an AI – and this, even, if you’re able to ensure those properties hold on safe inputs (step 1), and if you’re confident your AI isn’t adversarially messing with your evidence (step 2). And in this sense, even granted extensive scientific effort, I remain quite concerned about failures at step 3 as well – and I think it possible that some significant conceptual progress is required in order to complete this step successfully, at least with high levels of assurance.[71]
That said, I’ll add one final note of comfort in this respect: namely, that if we are actually assuming success on steps 1 and 2, then we have access to AIs that are genuinely and non-adversarially following our instructions on safe inputs. And this means that if it’s possible to make the project of trying to improve our approach to step 3 a safe input (cf the “AI for AI safety sweet spot”), then we could use lots of safe, instruction-following, non-adversarial AI labor to help.
4.5 Step 4: Good instructions
Let’s turn, now, to the final step of the four: namely, giving AIs instructions that rule out rogue behavior on the dangerous inputs they’ll get exposed to.
Of the four steps I’ve listed, this one is the least conceptually necessary. That is: in principle, we could simply replace the term “instruction-following” in the previous steps with something more general, like “desirable behavior” or “non-rogue behavior.” After all: really, all we need is for the AI not to generalize in ways that involve problematic forms of power-seeking on dangerous inputs – beyond that, whether it’s also obeying instructions isn’t strictly necessary for safety.
In this sense, focusing on instruction-following in step 3 makes the problem seem harder than it is. And if we wanted, we could condense the four steps I’ve given into three, namely: (1) Desirable/non-rogue behavior on safe inputs, (2) No alignment faking, and (3) Everything else required to ensure that the desirable/non-rogue behavior generalizes to dangerous inputs.
I’ve chosen to carve out and focus on instruction-following in particular, though, because I think it introduces a useful layer of transparency/steerability into our relationship with an AI’s motivations – e.g., we’re not wondering whether an AI is suitably “nice” or “good” or “aligned,” we’re rather wondering specifically whether it will do what we tell it to do, and training/testing accordingly. A focus on instruction-following is also useful for thinking about some of the elicitation challenges of the kind I’ll discuss below. And it allows us to isolate the challenge of crafting good instructions from the challenge of getting AIs to obey these instructions – challenges that are both present in the AI alignment discourse in different ways, but which sometimes, in my opinion, go inadequately distinguished.
In particular: the early discourse about AI alignment seemed quite concerned, in various ways, about the problem of crafting/specifying good instructions. Exactly how to characterize the key concern in question is a matter of some debate (see e.g. Barnett (2023) for some relevant back-and-forth), but overall, engaging with work by Bostrom, Yudkowsky, Russell, and so on, it was at least easy to take away a strong sense that something in the vicinity of a “King Midas problem” was a key aspect of the threat model – that is, you would tell an AI to do something, but your instructions would fail to specify adequately everything you care about that’s at stake in the AI’s behavior, such that when the AI brings a lot of optimization power to bear in obeying your instructions, you don’t actually like the result.
Regardless of how we understand the intellectual history of this concern, though, it currently seems to me like a relatively small part of the overall problem – and this especially in the context of safety from rogue behavior rather than broader forms of elicitation. In particular: when I talk about instruction following, I am talking about the sort of common-sensical instruction-following that we actually expect out of e.g. human butlers, personal assistants, etc – a mold that current forms of AI instruction-following already fit fairly well. Here, the relevant form of instruction-following reflects an (admittedly sophisticated and complex) set of norms, expectations, and priors about what the relevant instructions meant, what sorts of intentions were behind them, what sort of behavior the instruction-giver expected to result, and so on. This common-sensical version goes a long way towards minimizing King-Midas-like “gotcha!” experiences (e.g., you tell an AI to prevent cancer, and it kills all the humans as a method of doing so). And when I talk about an instruction-following AI, I’m talking not just about an AI that understands these complicated norms/intentions etc, but one which actually obeys them.
What’s more: in the context of safety from rogue behavior in particular, many of the most salient and problematic forms of rogue behavior just don’t seem that hard to rule out with the right sort of (common-sensically interpreted) instructions. In particular: identifying these forms of behavior isn’t a matter of sophisticated philosophy or resolving-all-the-edge-cases. Rather, the relevant forms of behavior – e.g., killing humans, self-exfiltrating, hacking into data-centers, intentionally sabotaging research, lying about your behavior and motivations, evading human monitoring, taking over the world – are what Karnofsky (2023) calls “Pretty Obviously Dangerous and Unintended.” Plausibly, creating instructions that rule out these behaviors in most realistic circumstances isn’t all that much more complicated than including the equivalent of “no, seriously, do not kill all humans.” And if AIs do end up killing all humans and/or taking over the world, my strong best guess is that they will have been disobeying human instructions when they do so, rather than following instructions that would be reasonably understood as endorsing this behavior.
That said: I do think we still need to be vigilant here. For example: especially in the context of complicated instructions that involve trade-offs between multiple conflicting values, it can be unclear exactly what they imply in a given case, and/or difficult to anticipate the full range of cases in which they might yield verdicts compatible with even-quite-flagrant rogue behavior. Here, though, I expect AI labor to be extremely helpful. That is: AI labor could in principle be used to extensively red-team the implications of a given model spec/AI constitution/set of instructions across an extremely wide range of scenarios; to highlight potential inconsistencies, ambiguities, and/or problematic implications; and to assist in fixing whatever issues get unearthed. And if we have in fact succeeded at steps 1-3 above, such that we have access to AI labor that we actually trust to follow instructions common-sensically, this makes it all the more likely that the automated labor we devote to this kind of red-teaming will be safe, trust-worthy, and effective.
Indeed, because I expect most loss of control risk to come from very flagrant forms of rogue behavior, I expect that a thorough (and likely: heavily automated) vetting of what a given set of instructions implies would go a lot of the way towards success on Step 4. That said, I do think that certain kinds of problematic rogue behavior may be less flagrant, and more philosophically subtle to even identify (here I’m thinking, for example, about certain kinds of manipulation and deception). And for those cases, I expect that success at getting AIs to do what I call “human-like philosophy” will be required. I discuss this issue more in a future essay.
Overall: I expect Step 4 to be the easiest of the four steps I’ve outlined – and if we get to the point where it’s Step 4 in particular that matters (i.e., we have AIs that are going to robustly obey our instructions even on dangerous inputs), I would feel quite optimistic about our prospects overall.
4.6 Overall prospects
I’ve now discussed all four steps in my current high-level picture of how we might succeed at giving advanced AI systems safe motivations. Notably, all of the first three steps implicate extremely serious challenges. In particular: it may prove extremely difficult to accurately evaluate the behavior of superhuman AI systems (key to step 1), to ensure that they aren’t adversarially messing with our evidence about how they’ll generalize to dangerous inputs (step 2), and/or to adequately account ahead of time for all of the novel, rogue-behavior-relevant dynamics implicated by the shift from safe inputs to dangerous inputs (step 3). I’ve tried to describe my current best-guess as to the most likely way we could learn to overcome these challenges (where “we” includes: whatever AI labor we can get to help us). But at the least, very large amounts of high-quality scientific effort will be required; and in some cases, it remains plausible to me that we currently lack good tools for even thinking about what an adequate solution would look like, and that more fundamental conceptual progress will be necessary as well.
So, as I tried to emphasize in the introduction: this is not a detailed path to success. Indeed, it remains highly plausible to me that we will simply fail. Hopefully, though, the discussion can help us think clearly about the different challenges at stake, how they interact, and how we might respond.
5. Capability elicitation
I’ll close with a few brief comments about how the discussion thus far might extend to the role of motivation control in eliciting the main beneficial capabilities from advanced AIs, as opposed to just making sure they don’t go rogue.
I’m keeping the discussion brief partly because a lot of my previous essay, on automating alignment research, was about capability elicitation (albeit, in one particular and especially important context); and partly because I think many of the relevant tools and dynamics (e.g. behavioral science, transparency, scalable oversight, etc) are similar in the context of both safety and elicitation. Indeed, in some sense, we can think of success on steps 1-3 above as close to sufficient for covering elicitation as well: that is, if you could genuinely create AIs that robustly follow instructions even on dangerous inputs, then the remaining elicitation challenge is just to instruct those AIs that try to their hardest on the task you want to fully elicit their capabilities on – since by hypothesis, they will obey.
Still: I do, though, want to note a few ways in which introducing elicitation in particular into the picture makes an important difference.
First: if, on top of safety, we’re also requiring that we fully elicit the main beneficial capabilities of our AIs, then the range of circumstances and affordances in which we need to ensure safety grows dramatically. Thus: if all you want to do is to keep your AI locked up in a box, or to use it for some extremely narrow and constrained range of tasks, then this means that you either (a) don’t need to expose your AI to dangerous inputs at all, or (b) can more easily get away with exposing it to a quite limited set of such inputs, thereby cutting down on demands being placed on your science of generalization. But the more you want to use your AI for useful tasks – and especially, for very high-impact tasks that give it a lot of exposure to and leverage over the real world – then the less you can rely on restricting its options in this way. And fully eliciting an AI’s main beneficial capabilities – the standard at stake in my definition of solving the alignment problem – makes such restrictions especially difficult.
Second: if you do manage to achieve safety on the relevant range of inputs, then the additional challenge of ensuring elicitation becomes much easier – and in particular, it leaves much more room for iterating on failure. That is, as I discussed above, in my opinion the most fundamental challenge at stake in giving AIs safe motivations is the fact that you need to get it right on the first safety-critical try; and if you fail, you can’t say “oops” and try again. But this isn’t true of elicitation on its own. That is: if you’ve successfully ensured that your AIs either can’t or won’t pursue catastrophically dangerous rogue options, then you can proceed with much more standard forms of trial and error in learning how to also fully elicit their capabilities. Indeed: if we assume that safety is secure, then we can think of a lot of the remaining elicitation challenge as contained in the equivalent of Step 1 above – that is, causing instruction-following on inputs that are safe to train/test on (except that, with safety secure, inputs that make dangerous options available have now also become safe in this way).
That said: I do want to note a few caveats to the comfort that the possibility of iterating on elicitation failures can provide.
- First: this form of trial and error still requires that you’re able to notice the relevant “error,” and to do over a timescale that would make the chance for iteration relevant. In this sense, the “evaluation accuracy” aspect of Step 1 becomes especially crucial – as do the corresponding questions about the difficulty of evaluating superhuman AI task-performance.
- Second: in some especially important cases, success at eliciting your AI’s capabilities might itself be a critical part of a broader approach to ensuring safety from rogue behavior – for example, because you’re trying to use your AIs for safety-relevant tasks like alignment research. And in this context, even if the AIs performing the labor in question don’t go rogue, elicitation failures (e.g., sloppy AI alignment research) could lead to irrecoverable forms of overall safety failure.
Finally: I think that once we’re trying to fully elicit the main beneficial capabilities of our AIs, subtler philosophical questions about the specific sort of task performance we’re looking for become more relevant. That is: as I discussed above, I think that in many cases, it does not take especially subtle philosophy to identify/specify the type of rogue behavior that we’re trying to avoid (e.g., killing all humans, sabotaging research, overthrowing the government, etc). But once we start trying to identify/specify the full range of ways in which we actively do want AIs behaving, and to use them for tasks that load on very sophisticated sorts of philosophical/ethical understanding (e.g. “help us find a just and fair approach to poverty/criminal justice/immigration etc,” “help us refine and deepen our ethical/metaphysical understanding,” “help us create an information ecosystem that respects freedom of expression in the right way,” “help us design better political institutions,” etc), then a broader variety of philosophical subtleties become relevant. Here, again, I’ll discuss some of these philosophical issues in a future essay. But I wanted to flag the way in which capability elicitation makes them more central.
6. Wrapping up
I’ve now laid out my current best-guess picture of how we might give AIs safe motivations, and I’ve said a few words about how this picture extends to fully eliciting AI capabilities as well. In both cases, though, I’ve been focused specifically on controlling AI motivations. But controlling AI options has an important role to play as well. I’ll turn to that in my next essay.
- ^
Here “inputs” includes all of an AI’s environment/affordances/history, rather than just e.g. the text it is receiving. That is: all of the AI’s actual situation.
- ^
Some parts of this essay draw on these rough notes on motivation control and capability elicitation, which I posted on LessWrong and the EA forum (though not on my website or substack) last fall.
- ^
Technically, this picture is more specific than necessary, and so makes the task sound somewhat harder than it is. In particular: you don’t actually need to get instruction-following on dangerous inputs – rather, you just need non-rogue behavior (even if the AI isn’t following instructions). In section 4 I discuss why I’m focusing on instruction-following in particular.
- ^
I’m also focusing, here, specifically on avoiding rogue behavior, rather than on other safety-relevant properties often associated with “alignment” (e.g., refusing harmful requests). And I’m skipping over problems related to making the avoidance of rogue behavior robust to external intervention actively trying to induce the rogue behavior in question (e.g., human hackers trying to mess with an AI’s weights to make it go rogue, to find special-case inputs that will make it go rogue, etc), as I see this threat model as best understood under the heading of “misuse” (similar to e.g. trying to bypass an AI’s safeguards so as to get it to help you build bioweapons). H/t Josh Clymer for discussion.
- ^
As I warned at the beginning of the series, I don’t have a plan of this kind. No one does. Hence, indeed, the extreme danger the alignment problem currently poses to our species. That said: I’m also skeptical that plans of this kind are the right point of focus from our current epistemic position. This is partly because we don’t yet know the default path to developing superintelligent capabilities, or what realistic deviations from this path would work too. But even if we assume we’re dealing with agents developed via some scaled-up version of current capabilities techniques, we’d still be ignorant of many of the underlying technical parameters that determine which approaches to aligning such agents would succeed. Developing a viable plan, then, requires gathering a bunch of evidence about these parameters – including, via experiment and iteration on AI systems we don’t currently have available – and tailoring our approach depending on what we learn. From our current position, then, I tend to think of the technical dimension of “solving the alignment problem” less in terms of directly identifying a plan that we can know already will work with high confidence, and more in terms of developing the sort of scientific understanding necessary to eventually create such a plan. One way of understanding the essay is: it’s my current picture of what developing such a science looks like.
- ^
This also includes: preserving the degree of transparency one already has in this respect, e.g. in the context of English-language chain of thought vs. “neuralese.”
- ^
Though: this central challenge becomes especially worrying in the context of the sub-challenges below. And really, the various challenges are closely inter-related. I think it’s useful, though, to hone in on one key frame in particular.
- ^
We can think of this as a kind of “distributional shift” – though, I don’t want to fuss about what counts as “on distribution” or not. And note that there are also some cases where some inputs that seem like they should be within the same “distribution” are safe, and some are not. For example: as I’ll discuss in the next essay, it could be that an AI lab is in a position to provide effective oversight on some subset of otherwise indistinguishable inputs – oversight that would catch and block any dangerous rogue behavior. But because of the scarcity of the oversight in question, some inputs in this distribution make options for dangerous rogue behavior available – vulnerability that a power-seeking AI might be able to exploit.
- ^
For visual simplicity, I’ve set up the diagram such that it looks like the set of dangerous inputs is importantly distinct/separable from the safe inputs. In reality, though, and depending on how we understand the “space” they are occupying, they might be much more intermixed. Also, to be clear, the relative size of the different sets of inputs on the diagram isn’t meaningful. And note, too, that the leap from safe to dangerous inputs doesn’t need to coincide with beginning to deploy a model in some real-world context. To the contrary: dangerous inputs can occur prior to deployment (e.g., if a training environment makes options for self-exfiltration available), and deployment inputs can be fully safe (e.g., if there is enough powerful and plentiful oversight to block options for rogue behavior). In this sense, when I talk about “training/testing” below, safe forms of deployment would qualify, as they are a type of safe “test” of how an AI behaves (and it will often be possible to use them for training as well).
- ^
Though note that sometimes, misaligned AIs will refuse open options for rogue behavior because they expect to have better options of this form later – e.g., options that are even more likely to succeed.
- ^
Indeed, absent the context of the broader arguments for instrumental convergence that I discussed in the second essay, worries about AIs specifically generalizing in ways that involve rogue behavior might seem weirdly specific. That is: on safe inputs, you trained it to be extremely nice, docile, etc. Sure, maybe it doesn’t generalize perfectly. But why, exactly, are you expecting it to generalize in a manner that involves problematic and probably-violent power-seeking in particular? And here the idea that a wide variety of problems with AI objectives will converge on the rationality of problematic power-seeking is importantly in the background (though the more specific sub-challenges I discuss below play a key role as well).
- ^
In general, when I talk about training an AI, I have in mind the more paradigm forms of gradient-based training at stake in contemporary ML. But it will also typically be possible to generalize the discussion to cover other ways of selecting over AI systems on the basis of some criteria (e.g., evolutionary methods, trial and error, etc). That said, as I’ll discuss below, I think there can be important differences between directly training on e.g. some evaluation method vs. using it as validation.
- ^
Note that many other technological safety challenges – e.g., bio safety, nuclear safety, bridge safety, etc – don’t need to grapple with adversarial dynamics of this kind.
- ^
For example, it becomes harder to use arguments like: “we trained it on distribution A that we can safely test, and then observed it generalize in desirable ways to distribution B that we can also safely test. Thus, we infer that it will also generalize in desirable ways to distribution C that we cannot safely test (because it involves giving the AI catastrophically dangerous options).” In particular: if the AI knows enough about your training/testing process, and about what distributions you can safely test, and it is actively optimizing for getting the chance to act in distribution C (i.e., to get access to a genuine takeover option), then its behavior on distributions A and B is weaker evidence than it would be in other, less adversarial ML contexts.
- ^
Though: note that this concern requires that the AIs in question satisfy the agency pre-requisites I discussed in my second essay.
- ^
That is: we have some limited understanding of how ML models process information, and we are making various types of progress in this respect, but ML systems remain “black boxes” in many other ways.
- ^
Exactly what counts as “transparency” can get somewhat blurry – for example, SGD itself involves some level of productive intervention on AI’s internal variables, and we have perfect access to the weights. But drawing sharp lines won’t matter in what follows.
- ^
And also, notably, of other animals, like dogs.
- ^
See this talk for more on my overall take here.
- ^
This corresponds to the blue dashed circles in the diagrams above.
- ^
Sometimes, I think that the assumption in the alignment discourse is that a human agent, faced with an option to take over the world analogous to the one that advanced AIs will face, will either take that option, but then use his/her power to create a good world, or that he/she will refuse the option because he/she sees that the world is on track to be good-by-her-lights if he/she does not “go rogue” in this way. The former case, though, requires assuming that the human agent will act by default wisely and benevolently upon seizing control of the world; and the latter case requires assuming that the agent is sufficiently happy with the default trajectory that the sorts of “instrumental convergence” arguments for seizing power that are supposed to motivate AI power-seeking won’t motivate human power-seeking in this case. Neither of these assumptions, though, seems warranted to me.
- ^
Here I’m starting with the assumption that there is something notably non-transparent about current ML models, especially if we set aside the sorts of tools and approaches traditionally bucketed under the term “interpretability.” Admittedly, though, exactly how to characterize this non-transparency is an open question. At the least, though, and modulo some modest progress on interpretability, our ability to predict the behavior of a trained ML model on different inputs, on the basis of e.g. direct examination of the learned weights, is quite limited. And more broadly, we generally lack the ability to usefully characterize the algorithm that a trained ML model is implementing at levels of abstraction higher than e.g. a full description of the network. That is, in some intuitive sense, and despite the full access we have to their weights, trained ML systems remain in many respects “black boxes.”
- ^
I’m borrowing the term “open agency” from Drexler (2023), though I may be using it in a somewhat different way.
- ^
For example: you might use limited success at interpretability to help ensure the safety of the ML components at stake in an open agency approach; you might use an expensive-but-safe open-agency-style agent to assist you in developing better interpretability techniques that lead to more competitive solutions; a “new paradigm” might involve some component of safe-but-still-black-boxish machine learning in some contexts; and so on.
- ^
Here Hubinger (2022) offers a useful categorization of some different levels of ambition:
- Best case vs. worst case: i.e., do you get transparency into some portion of the thing you’re trying to understand, or are you able to make stronger guarantees about the thing overall?
- Internal properties vs. training: i.e., understanding the properties of a static model vs. understanding how those properties form and change in response to a given sort of training.
- Robust to training-on-it vs. not: i.e., does your transparency technique continue to work once you include a term like “this transparency technique yields blah result” in the training signal, or does it break down once you start training against it?
- Robust to models actively trying to evade/manipulate the tools in question vs. not: i.e., does your transparency technique continue to work on models that are actively trying to evade the tool in question?
Thus, the most ambitious version of interpretability would be a level of understanding both of a model’s internal properties and of dynamics of training such that you can get worst-case guarantees even after you trained extensively on your interpretability tools, and even if the models you’re investigating were actively trying to evade/manipulate the tools in question.
- ^
Though to the extent that a lot of the true strategy/motivations etc live centrally inside the head of some particular set of employees – e.g. the CEO – then this “openness” is compromised.
- ^
Here a rough analogy might be something like: you built a corporation out of different humans, and you forced it to write english-language strategy memos documenting its goals/plans/reasoning. But if the individual humans are much more sophisticated than you (i.e., maybe you are a child and they are adults), then insofar as they are still untrusted, it might be hard to feel good about the situation overall.
- ^
And note that insofar as your agency architecture looks less like “many different agents doing different sub-tasks, without direct non-legible memory links between them” and more like “a single agent with a consistent memory stream doing tasks in sequence, but where we try to force that agent to document its reasoning in detail,” then it becomes especially easy for this single agent to coordinate with itself on an adversarial strategy, because the non-legible memory stream can serve as the locus of “communication” between the different “components.” I.e., if your “corporation” is actually just a single very smart guy, Bob, doing a long sequence of tasks, and he can do a bunch of thinking on his own and then store it in his internal memory, but you’re also making him write down a bunch of stuff on a scratch-pad as he does his tasks, then it seems easy for Bob to just think to himself “I’ll plan to make the scratch-pad look good to the humans but then defect later,” and then store this plan in his internal memory without writing it down.
- ^
Thus, e.g., maybe there’s some fairly obvious strategy like “make everything look good to the humans, but then later we all defect at this clear-to-us shelling time,” which the components can coordinate on without talking it out. This kind of coordination-without-communication might be made easier if e.g. all the components of the composite agent are copies of the same model. E.g., intuitively, if there’s a corporation run entirely by clones of yourself, it’s probably easier to find a way to do a coordinated defection without communicating, because you know so much about the motives and thought patterns of the other clones. (It’s also probably easier to pull off with communication.)
- ^
That said: to the extent you are relying on black box ML agents as components of your open-agency set-up at all, some significant fraction of the cognition driving the composite agent’s behavior is always going to be occurring within those black box components, and thus in illegible ways. So in addition to making the human-legible aspects of the set-up faithful in the sense of accurate, they also need to be complete enough that they would reflect adversarial reasoning of the type you might be worried about, even though they can’t represent everything.
- ^
See e.g. Nanda et al (2023) for an example of this sort of work in the context of transformers performing modular addition; and see e.g. Lindsay et al (2025) for a more recent effort to investigate the specific circuits underlying specific behaviors. See Nanda (2025) and Amodei (2025) for histories of how the field has evolved.
- ^
See e.g. Zou et al (2023), MacDiarmid et al (2024), and Wang et al (2025) for work in this broad vein.
- ^
Or at least, not with realistic levels of effort. That said: whether we need humans in particular to understand the concepts in question (as opposed to: other AIs that are helping with the effort) is a further question (h/t Josh Clymer for discussion). But often people’s first-pass notion of interpretability focuses on human understanding in particular.
- ^
For example: human concepts like “tree” tend to reflect genuinely useful “joints in nature,” and we should expect smart models to make use of those joints (see e.g. the discourse about the “natural abstraction” hypothesis for some more discussion). Also: we already see trained models converging on fairly human-like concepts – e.g., many features models learn are in fact quite human-interpretable. And to the extent that models understand human language and can make predictions about the world using a human ontology, their world model needs to include human-like concepts in there somewhere.
- ^
See Lillicrap and Kording (2019) for some relevant reflections.
- ^
Though: note that the some of concerns I discussed above re: superintelligent cognition being opaque in principle would apply in this context anyways.
- ^
Though: my vague sense is that interest in “switch to a new paradigm” is at least somewhat correlated with skepticism that ML is enough for AGI, and thus, perhaps, with longer timelines in general.
- ^
Though of course, a new paradigm could bring its own new risks as well. H/t Owen Cotton-Barratt for flagging this point.
- ^
Anthropic’s recent work on persona vectors is a great example of behavioral science and transparency tools working in tandem.
- ^
In some cases we can get juice from differences in the difficulty of evaluation vs. generation – but I don’t think this will be enough on its own for the full range of cases we need. For example at a certain point I expect AIs to be writing code that humans basically can’t evaluate directly.
- ^
Though: there are also some scalable-oversight-like techniques that one could try to make work even with copies of the frontier untrusted AI. See e.g. the techniques at stake in discussions of untrusted monitoring, where monitoring here is closely akin to evaluation. And some versions of debate might also fall under the heading of “using copies of the frontier untrusted AI itself,” at least in the role of debaters (though: the judge is playing a role as well).
- ^
Thanks to Holden Karnofsky for discussion here.
- ^
See my discussion here, and Steve Byrnes’s response here, for a bit more in-depth discussion. That said, note that the real question re: M-Turkers is something more like: could a giant team of average M-Turkers supervise/train a slightly-smarter M-turker enough that the slightly-smarter M-turker is truthworthy; could a giant team of trustworthy slightly-smarter M-turkers supervise/train a yet-smarter M-turker; and so on, all the way up to a capable-of-evaluating-string-theory M-turker.
- ^
Granted: even absent sandbagging, there’s some potential for exploration problems here if you can’t provide a suitably incremental reward signal in the direction of the desired behavior. But my impression is that a lot of RL is about finding ways around these sorts of exploration problems – and absent sandbagging or capabilities issues, I expect those solutions to apply here as well.
- ^
If you identify such an input, you may want to train for better behavior – or, instead, you may want to continue to use it as a source of validation.
- ^
Though: sufficiently large quantitative barriers become effectively qualitative.
- ^
Note, though, that especially if we assume we have the ability to draw samples i.i.d. from the distribution of safe inputs, this is starting to sound more and more like a standard ML problem – and one to which one expects the standard tools of ML theory to apply (though as is likely clear already, I am not myself very familiar with these tools).
- ^
Here I’m using a somewhat broader definition/conception of scheming than the one in my report. But I think this definition is more consistent with current usage.
- ^
People sometimes worry about certain kinds of reward-hacking and sycophancy, here – i.e., ones where AIs optimize hard for appearing to “look good” to us according to some evaluation metric/reward process, but where they aren’t doing so in an effort to gain power later. To my mind, though, these cases seem more like the sort of non-adversarial generalization failures that I discuss under step 3. That is: the AIs aren’t necessarily directing their optimization power at causing a generalization failure on the leap to dangerous inputs (and notably: many versions of non-schemer reward hacking and sycophancy are happy to reveal themselves on what I’ve previously called “honest tests” – e.g., safe inputs where bad behavior will in fact be rewarded, approved of, etc).
- ^
See in particular section 6.
- ^
- ^
One reason to do this is that the forms of scheming we get via creating “model organisms” might be importantly different from the types that arise naturally in training. For example, the scheming that a model organism engages in might be comparatively “shallow” and easy to get rid of, whereas natural scheming might be a more deeply ingrained and/or more convergent behavior and thus harder to avoid. So an “analogy” for scheming that was similarly deeply ingrained/convergent might actually be a more useful scientific target than a more schemer-like but also more artificial model organism.
- ^
Here I’m drawing on some unpublished work from Ryan Greenblatt on “principled methods for avoiding scheming.”
- ^
The line between “natural” examples of scheming and “model organisms” isn’t especially clean – rather, it’s more like a spectrum that gets closer and closer to scheming arising and getting caught fully “in the wild.”
- ^
- ^
See also my discussion of “traps” here. People sometimes use the word “honeypot” for techniques in this vicinity, though I think this usage sometimes fails to distinguish between traps and honest tests.
- ^
Though: note that even if you were able to get an AI to behave as it genuinely would on a dangerous input, you also need the evaluation ability to tell whether this is rogue behavior in particular.
- ^
Though: note that an AI’s ability to differentiate between fake options and real options is a capability – one that we can plausibly test extensively in a variety of safe environments. So if we can do adequately well with capability elicitation in safe environments for checkable tasks, we might be able to get a relatively clear grip on which fake vs. real inputs our AI can distinguish. That said: we can’t give the AI actual rogue options to try to distinguish from fake ones (though we could perhaps get close – e.g., if we showed the AI a “takeover the world” button, we could ask it whether the button was fake vs. real without giving it the opportunity to press), so you still need to be making some inference here.
- ^
Thanks to Buck Shlegeris for discussion here. Another example: as Christiano points out, the discriminator will be significantly empowered with respect to evaluating whether an input contains a genuine factorization of some large semiprime (i.e. RSA-2048), relative to a generator that needs to create such a factorization (or a fake version of such a factorization).
Of course, it’s a further question whether a given AI would be able to leverage these sorts of dynamics to distinguish the relevant set of real rogue options in particular. In particular: a scheming AI can’t merely “lie in wait” until it sees an input it is confident takes place suitably far ahead in time relative to its training/testing process, both because its training/testing process might continue over time – including, potentially up to a point where e.g. the relevant trainers/testers have extremely advanced tech available – and because if it waits too long human safety efforts may make too much progress.
Indeed, one especially esoteric approach in the vicinity of “fake rogue options” is for future humans with radically advanced technological capabilities to go back and try to create “fake rogue options” that are suitably convincing/advanced that even smarter-than-us nearer-term AIs become uncertain whether they are facing one of these generated-by-future-people fake rogue options – where the thought is that the future people will have such an advantage as “generators” that they can overcome any intrinsic advantages discriminators might possess (see Matolsci (2024) for discussion of one version of this). Note, though, that the epistemic weight of this sort of fake rogue option depends on the AI’s credence that future people both (a) remain empowered and (b) end up undertaking such a project. And of course, the AI needs sufficient reason to care about what happens in the scenarios where it is currently undergoing a test designed by future humans (e.g., the humans needs to be rewarding it for good behavior) – otherwise the possibility won’t matter enough to its incentives overall). H/t to Peter Favaloro for discussion here.
- ^
This is also a concern for other forms of misalignment.
- ^
I don’t actually feel like I have a crisp quantitative model of why the one form of selection pressure is so much more worrying than the other, but hazily, and following the discussion in MacDermott (2025), it seems like using your scheming-detector as validation is closer to “resampling” from your overall distribution of AIs and then checking whether it’s a schemer, thereby preserving your original P(scheming|non-detection); whereas actively training on non-detection-of-scheming seems like it’s more akin to first sampling from P(scheming), and then adjusting whatever you got to make it look like not-a-schemer (see also MacDermott’s illustrative example here; one intuition here is that if it’s easier/closer-in-weight-space to actively adjust a schemer to stop triggering deception than to stop scheming, so this is what SGD does). Regardless, though: I’m reasonably confident that there’s some important distinction here, because training on your test set is indeed importantly distinct, in general, from testing on it.
There’s also an interesting question as to under what circumstances you should try to train on a method of detecting scheming (or of misalignment more broadly). E.g., plausibly, if you have enough other metrics available, it can be worth paying the costs of training on some of them. And while people often seem to assume that transparency-based detection methods, in particular, should not be trained on (see e.g. here), it’s not actually clear why transparency-based detection would be different from behavior-based detection in this respect (and note that the most basic forms of alignment training – RLHF – can be understood as training on behavior-based misalignment detection).
- ^
Where the “non-adversarial” component corresponds to not having to worry about the sort of intentionally misleading evidence that failure on step 2 involves.
- ^
Here one might also take some additional comfort for the sort of generalization of instruction-following we’ve already seen in our AIs. H/t Josh Clymer for discussion.
- ^
The instrumentally convergent pressure towards power-seeking is important – otherwise, rogue behavior looks centrally like one very specific failure mode, and a weird one to focus on. E.g., you wouldn’t worry about an AI suddenly starting to worship the spaghetti monster when it moves off-distribution. A bit more on this below.
- ^
See also Yudkowsky here for some more exotic examples related to simulations, distant superintelligences, and the like.
- ^
Another related possibility: the set of relevant dangerous inputs the AI gets exposed to is just so much larger than the set of safe inputs you could train/test on that rare failures that didn’t show up in training/testing start to show up later. Technically this is compatible with the safe inputs being on the same distribution as the dangerous inputs. But it still seems most naturally bucketed under Step 3 to me. Thanks to Josh Clymer for flagging this threat model to me.
- ^
See also talk about an AI “growing up.”
- ^
Here an analogy might be: suppose you had some humans working on an intelligence enhancement drug. What sort of trust do you have to have in them? One sort of trust would be: you trust them even if they take the drug. Another sort of trust is: trusting them to not take the drug. The latter is sufficient.
- ^
This is related to broader questions about what sorts of fundamental barriers there are re: predicting/controlling reality per se, and in particular: doing so via “value lock in” (“solving alignment” for arbitrary levels of capability is conceptually similar/identical to “value lock in”). But the fact that you’re introducing new levels of intelligence into the equation makes it especially challenging.
Indeed, my sense is that when people imagine fully “solving the alignment problem,” they are often (maybe hazily) imagining some process of effectively isolating an agent’s motivational system from the “optimization power” being directed by that motivational system, such that you can then amp up the optimization power in an effectively unbounded way, while leaving the motivational system itself untouched. But I find it unsurprising if this picture misleads us even at a fairly fundamental level. At the least, for example, we want to preserve some ongoing ability to reflect on/adjust the values in question as the agent continues to grow and learn – a process closely related to the philosophical dynamics I’ll discuss in a future essay. And I find it unsurprising if the idea of somehow accounting ahead of time for every way that philosophical reflection can go wrong is a doomed prospect (e.g., because one cannot pre-compute then judge-ahead-of-time where this reflection might lead). Though: in the context of e.g. proving what follows from a given set of axioms, it looks both possible to not know where further logic-chopping will lead, and also possible to know how to check whether it led to a good place once you get there (e.g., using a theorem prover). H/t Ben Chang for discussion.
- ^
See “Pantheon” for a vision of some of the potential dynamics here – and the emulations in Pantheon don’t even attempt significant intelligence enhancement.
- ^
Here I’m especially concerned about cases where the shift to dangerous inputs coincides with an increase in capabilities, as it seems especially hard to anticipate in advance all the new dynamics that increases in the frontier of intelligence will unearth.
SummaryBot @ 2025-08-20T14:58 (+2)
Executive summary: Joe Carlsmith sketches his current best-guess framework for giving advanced AI systems safe motivations, emphasizing that while no detailed plan exists, progress likely requires a four-step process (robust instruction-following, avoiding alignment faking, developing a science of reliable generalization, and crafting good instructions), each of which faces deep technical and conceptual challenges.
Key points:
- Central challenge – “generalization without room for mistakes”: We must ensure AIs behave safely on novel, high-stakes inputs where failure could be catastrophic, without being able to test directly or iterate after errors.
- Five sub-challenges: Accurate evaluation of AI behavior, reliably causing desired behavior, limited access to relevant training data, adversarial dynamics (e.g. scheming), and opacity of current ML models.
- Two main tool categories:
- Behavioral science – large-scale, systematic study of AI behavior on safe inputs.
- Transparency tools – ranging from interpretability to “open agency” designs to speculative new AI paradigms.
- Four-step picture of success:
- (1) Cause instruction-following on safe inputs with accurate evaluation.
- (2) Prevent alignment faking or scheming.
- (3) Build a science of non-adversarial generalization to dangerous inputs.
- (4) Ensure instructions themselves rule out rogue behavior. Carlsmith sees (2) as the hardest step, (4) as comparatively easier.
- Uncertainties and open questions: Whether we can achieve robust evaluation of superhuman AIs, prevent scheming under adversarial pressure, and anticipate all novel dynamics introduced when AIs face new dangerous options or gain new capabilities.
- Extension to capability elicitation: If motivation control succeeds, eliciting full beneficial capabilities becomes easier and safer, though it reintroduces evaluation challenges and deeper philosophical questions about what behaviors we want from AIs.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.