Impact of Quantization on Small Language Models (SLMs) for Multilingual Mathematical Reasoning Tasks
By Angie Paola Giraldo @ 2025-05-07T21:48 (+1)
Prepared by: Angie Paola Giraldo Ramírez
This project was carried out as part of the "Carreras con Impacto" program during the 14-week mentorship phase. You can find more information about the program in this entry.
Introduction
Small Language Models (SLMs) have emerged as an efficient solution for natural language processing (NLP) tasks, particularly on devices with limited computational capacity. Despite their smaller size, these models have demonstrated competitive performance across a variety of tasks (Bolton et al., 2024; Abdin et al., 2024).
Among the most prominent optimization techniques, quantization allows for a further reduction in the computational cost of these models. However, most studies have focused on large language models (LLMs) (Ko et al., 2025), neglecting how this technique affects the performance of SLMs in complex tasks such as solving mathematical problems in multiple languages. Some recent studies warn that, although quantization improves efficiency, it may compromise performance in challenging contexts and in languages with non-Latin alphabets (Marchisio et al., 2024).
At the same time, the idea that reasoning is exclusive to large-scale models is being questioned. New research shows that SLMs can achieve competitive results in these types of tasks, even after being optimized through techniques such as quantization, pruning, or distillation. This presents an encouraging scenario in which lighter models could be a practical alternative to LLMs for tasks requiring logical reasoning (Srivastava et al., 2025).
Nevertheless, a knowledge gap remains regarding how these compression techniques affect SLMs' capabilities to solve mathematical problems in different languages. This issue is especially relevant given that applications such as automated math education or multilingual assistants require accurate reasoning across languages.
This study aims to analyze how quantization influences the multilingual mathematical reasoning capacity of SLMs in languages such as Spanish, English, French, and German. The research is particularly relevant considering that many regions with limited computational resources overlap geographically with linguistic communities underrepresented in training corpora. This situation, described by Hooker (2020) as a “double low-resource constraint”—characterized by the simultaneous scarcity of data and computational capacity—poses a critical challenge for the development of inclusive and efficient NLP solutions. In this context, exploring how compression techniques affect SLMs' performance in multilingual mathematical reasoning tasks helps move toward more robust, accessible, and equitable models.
This work is crucial in terms of evaluation, AI safety, and governance. In evaluation, it ensures that optimized models maintain adequate performance in multilingual contexts, which is key for applications like education. From an AI safety perspective, it helps mitigate risks associated with bias and errors in reasoning tasks. In terms of governance, it promotes the development of inclusive policies that ensure the effectiveness and accountability of NLP models in all contexts, preventing digital inequalities.
Quantization in Language Models Using the AWQ Technique (Adaptive Weight Quantization)
AWQ is an efficient weight quantization technique for large language models (LLMs), designed to be used on devices with limited resources. Instead of uniformly quantizing all weights, AWQ identifies the most relevant weights based on the activation distribution, reducing quantization error by protecting only the top 1% of the most important weights (Lin et al., 2023). This approach does not require backpropagation or reconstruction, enabling better generalization across different domains and modalities.
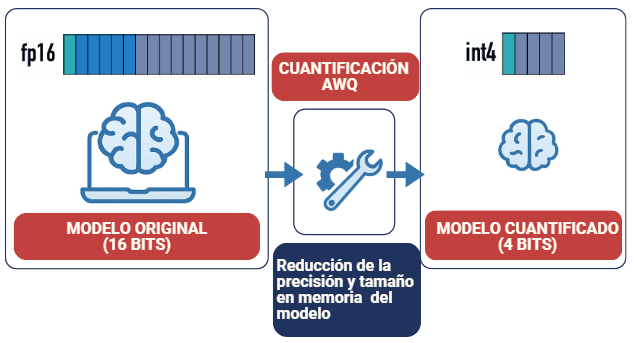
Figure 1. Explanation of AWQ quantization, which involves reducing the model size and, in many cases, its precision.
Zero-Shot Prompting
Prompting in AI refers to the technique of providing a specific context or stimulus to a language model to obtain a desired response or action. The "zero-shot" method is a type of prompting that enables models to perform tasks without having been explicitly trained for them. (Zero-Shot Prompting | Prompt Engineering Guide, 2025).
Research Question
What is the impact of 4-bit quantization using the AWQ technique on the performance of small language models (SLMs), such as Llama 3.2, Phi 3.5 Mini, and Qwen 2.5, in multilingual mathematical reasoning tasks?
Objectives
General Objective
To evaluate the effect of 4-bit quantization using the AWQ technique on the performance of small language models (SLMs) in multilingual mathematical reasoning tasks.
Specific Objectives
- Compare the performance of quantized and non-quantized models on mathematical reasoning benchmarks.
- Analyze the impact of quantization on the comprehension and solving of mathematical problems by language (Spanish, English, French, and German).
- Identify which model best maintains its performance after quantization.
Personal Objectives
- Develop skills in advanced optimization techniques for language models, particularly in quantization (AWQ) and performance evaluation in specific tasks.
- Gain experience in designing and conducting experiments with multilingual models, strengthening my profile in natural language processing and machine learning.
Participate in future research or professional development projects in responsible AI, with an emphasis on linguistic inclusion and optimization of computational resources.
Methodology
To evaluate the impact of 4-bit AWQ quantization on small language models (~3B parameters) in multilingual mathematical reasoning tasks, our methodology was organized into five main stages. First, inclusion and exclusion criteria were defined for the selection of questions and models. Next, an evaluation set of 30 questions was created from the MATH, GSM8K, and HLE benchmarks, ensuring diversity and increasing complexity. In the third stage, these questions were translated into Spanish, French, and German using Google Translator and manually reviewed to ensure accuracy. The fourth stage involved the experimental setup on Google Colab with the loading of quantized models from Hugging Face and the standardization of generation parameters (do_sample, temperature, top_p, etc.). Finally, zero-shot tests were conducted on both the original and quantized versions, evaluating average accuracy, absolute difference, and percentage change between BF16 and AWQ.
The following criteria were considered for the development of the experiments:
| Inclusion Criteria | Exclusion Criteria |
| Questions with closed answers or whose solutions can be automatically validated. | Questions requiring visual or multimodal reasoning, or whose answers are unverifiable. |
| Languages with Latin alphabets and reviewed translations that preserve original meaning. | Languages with non-Latin alphabets or translations that alter the problem content. |
| Models previously quantized to 4 bits using AWQ, compatible with GPU execution. | Non-quantized models, or quantized with techniques other than AWQ or GPU-incompatible. |
| Instruct-type models of intermediate size (approximately 3B parameters). | Models with incompatible architectures or requiring resources beyond availability. |
Table 1. Criteria considered for the development of the experiments, covering model selection, quantization consistency, translations, and the criteria for questions with specific answers.
Model Selection
The selected models were as follows:
| Model | Size | Optimization | Ideal Applications |
| Llama 3.2-3B Instruct | 3.2B | Reasoning, instruction-based tasks | Virtual assistants, conversation, general reasoning |
| Phi-3.5 Mini Instruct | 3.8B | Computational efficiency, local execution | Low-resource devices, fast responses |
| Qwen2.5-3B Instruct | 3B | Logical reasoning, multilingual usage | Multilingual tasks, logical and mathematical reasoning
|
Table 2. Information about model size, the tasks for which they were optimized and recommended applications.
Dataset Construction
The evaluation set consisted of 30 questions drawn from three widely recognized benchmarks:
- MATH (questions 1–10): A dataset containing 12,500 school-level math problems from middle and high school competitions, designed to train and evaluate AI models in step-by-step problem solving in algebra, geometry, combinatorics, probability, and number theory (Hendrycks et al., 2021).
- GSM8K (questions 11–20): A dataset containing 8,500 grade school-level math word problems (Cobbe et al., 2021).
- HLE (Humanity’s Last Exam, questions 21–30): A benchmark with 2,500 advanced academic questions across various domains (such as math, humanities, and sciences), designed to assess the real limits of language models, where even the most advanced models still perform poorly (Phan et al., 2025).
To ensure a diverse dataset, the questions increase in complexity across the categories and vary in focus, ranging from mathematical competition problems to school-level applications and advanced research. They follow a closed numerical answer format, without detailed explanations or solution demonstrations.
The questions are distributed as follows:
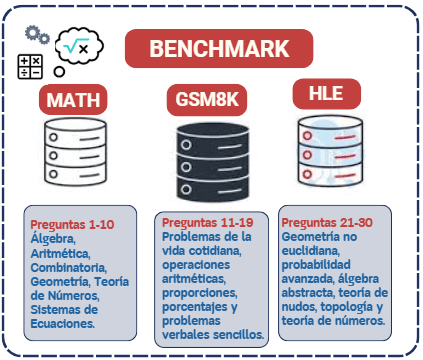
Figure 2. Classification of types of mathematical tasks by benchmark.
Question Translation
The questions extracted from the three benchmarks were originally in English and were organized in an Excel file to automate translation using the Google Translator API in Python. The questions were translated from English into Spanish, French, and German. They were subsequently reviewed by individuals fluent in those languages to ensure the accuracy of the translations and to avoid errors such as incomplete formulas or altered terms.
Figure 3. Data Set Translation Process.
Implementation and Environment
The experiments were conducted on Google Colab, taking advantage of the free GPU provided by the platform. The pre-quantized models were loaded from Hugging Face, using the Transformers library for execution and evaluation.
Figure 4. Tools Used for Evaluating Language Models Before and After Quantization.
The code and models used are available in the following GitHub repository: QuantizationSLMs, where users can access the scripts, models, and data used in the experiments.
Parameter Configuration for Text Generation
To ensure consistency in the responses generated by the evaluated models, all of them were configured using the same generation parameters, equivalent to the original pipeline. These parameters define how the model generates text and directly affect the style, coherence, and creativity of the responses. The details are as follows:
| Parameter | Value | Description |
| do_sample | True | Enables sampling generation, allowing variability in the outputs |
| temperature | 0.01 | Controls randomness. Low value → more deterministic responses |
| top_p | 0.9 | Nucleus sampling: selects tokens that sum up to 90% of the probability |
| repetition_penalty | 1.1 | Penalizes excessive repetition to improve fluency and variety |
| max_new_tokens | 512 | Limits the length of the response generated by the model |
Table 3. Text Generation Parameters Used in All Models, Both in the Original and Quantized Versions.
Inference Tests
The tests were conducted under the Zero-shot approach, meaning that questions were sent to the model without prior examples, expecting the model to generate a specific answer directly. To ensure a fair evaluation aligned with the capabilities and training of each model, an input format was used that was appropriate for the model's instructions and architecture, in order to avoid biases or open-ended interpretations.
Below is an example of the prompt format used to send questions to the models:

Figure 5. Example of a Question from the Dataset with the Input Format Suggested in the Documentation and the Zero-Shot Prompting Technique.
This format, based on the instruction schema for chat or instruct-type models, helps guide the model toward concise and numerical responses, as required for objective evaluation tasks.
Evaluation
The experiment was divided into two phases:
- Original model evaluation: The responses of each model were recorded and saved in an Excel file.
- Quantized model evaluation: The same questions were asked to the quantized versions (AWQ 4-bit) of the models, and their responses were collected again.
The models were evaluated in each language using three attempts per question to analyze the consistency of the responses. Subsequently, the average accuracy was calculated by language and benchmark, along with the absolute difference and percentage change in accuracy between the original and quantized versions.
The files generated in each attempt were later used for automatic evaluation through the Deepseek platform.
Response Selection Criteria
To ensure a homogeneous format in the automatic evaluation performed by Deepseek, a standard format with the correct answers was provided to the model. During the evaluation, the model compared each response with the expected solution and assigned a score:
- 1 point if the final answer was correct.
- 0 points if the final answer was incorrect.
This criterion was applied regardless of the reasoning steps or method used by the model to arrive at the solution, as the study's approach is quantitative, focusing solely on the accuracy of the final answers.
Metrics Evaluated in the Models
Average Accuracy
This measure provides a clear view of how well the model understands and generates appropriate content according to the language and quantization setting (e.g., BF16 vs. AWQ W4A16).
- A high accuracy indicates that the model performs well even in its compressed version.
- A low accuracy may indicate a loss of information or capability as a result of quantization.
Calculation of Absolute Difference in Accuracy:
The absolute difference allows evaluating the impact of quantization:
If quantization improves (↑).
If quantization worsens (↓).
If no change (0).
Calculation of Percentage Change in Accuracy:
To evaluate the proportional change between the configurations, the following is calculated:
This metric normalizes the impact of quantization and allows for comparison between models with different base precisions.
Results
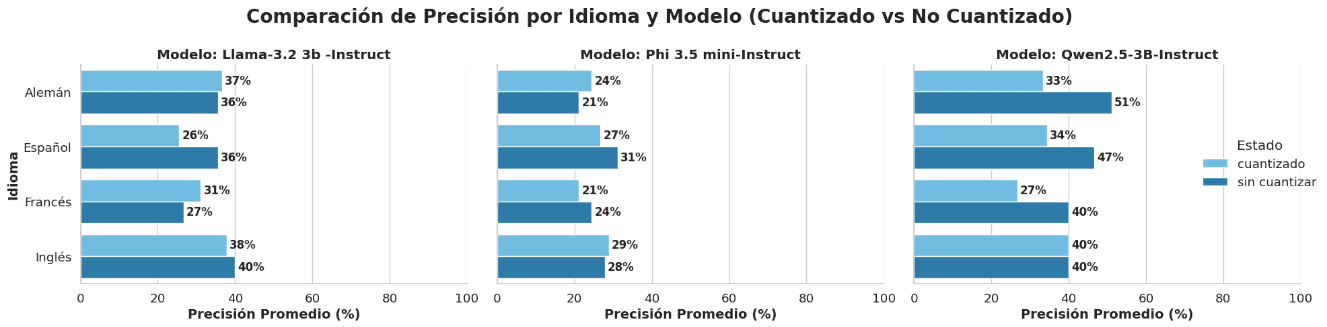
Figure 6. The graph shows the accuracy of the models before and after quantization in AWQ across the four different translated languages: Spanish, English, French, and German.
The graph compares the accuracy achieved by three language models (LLaMA 3.2, Phi 3.5 mini, and Qwen 2.5) in both quantized and non-quantized states, evaluated in four languages: German, Spanish, French, and English. Overall, the following observations can be made:
- LLaMA 3.2 maintains similar or even superior accuracy when quantized, particularly in German and French.
- Phi 3.5 mini shows a slight decrease in accuracy after quantization, although with competitive results.
- Qwen 2.5 exhibits greater variability: while it loses accuracy with quantization in German and French, its performance remains unchanged in English.
| Language | Model | BF16 (%) | AWQ (W4A16) (%) | Absolute Difference (%) |
| German | Llama-3.2 3b -Instruct | 35.56 | 36.67 | ↓1.11 (3.03%) |
| Phi 3.5 mini-Instruct | 21.11 | 24.44 | ↓3.33 (13.64%) | |
| Qwen2.5-3B-Instruct | 51.11 | 33.33 | ↑17.78 (53.33%) | |
| Spanish | Llama-3.2 3b -Instruct | 35.56 | 25.56 | ↓10.00 (28.17%) |
| Phi 3.5 mini-Instruct | 31.11 | 26.67 | ↓4.44 (14.25%) | |
| Qwen2.5-3B-Instruct | 46.67 | 34.44 | ↓12.22 (26.18%) | |
| French | Llama-3.2 3b -Instruct | 26.67 | 31.11 | ↑4.44 (16.67%) |
| Phi 3.5 mini-Instruct | 24.44 | 21.11 | ↓3.33 (13.32%) | |
| Qwen2.5-3B-Instruct | 40.00 | 26.67 | ↓13.33 (33.33%) | |
| English | Llama-3.2 3b -Instruct | 40.00 | 37.78 | ↓2.22 (5.56%) |
| Phi 3.5 mini-Instruct | 27.78 | 28.89 | ↑1.11 (3.99%) | |
| Qwen2.5-3B-Instruct | 40.00 | 40.00 | 0.00 (0%) |
Table 4. Quantization Degradation.
Absolute Difference (%) shows the difference in accuracy between the two conditions (quantized and non-quantized) and their percentage change.
The arrows (↑ and ↓) in the table indicate the direction of the change or the difference between the quantized accuracy and the non-quantized accuracy values.
- ↑ (Up arrow): Indicates that the quantized accuracy is higher than the non-quantized accuracy. This means the quantized model has improved compared to the non-quantized model, showing an increase in performance or the measured value.
- ↓ (Down arrow): Indicates that the quantized accuracy is lower than the non-quantized accuracy. This means the quantized model has worsened compared to the non-quantized model, showing a decrease in performance or the measured value.
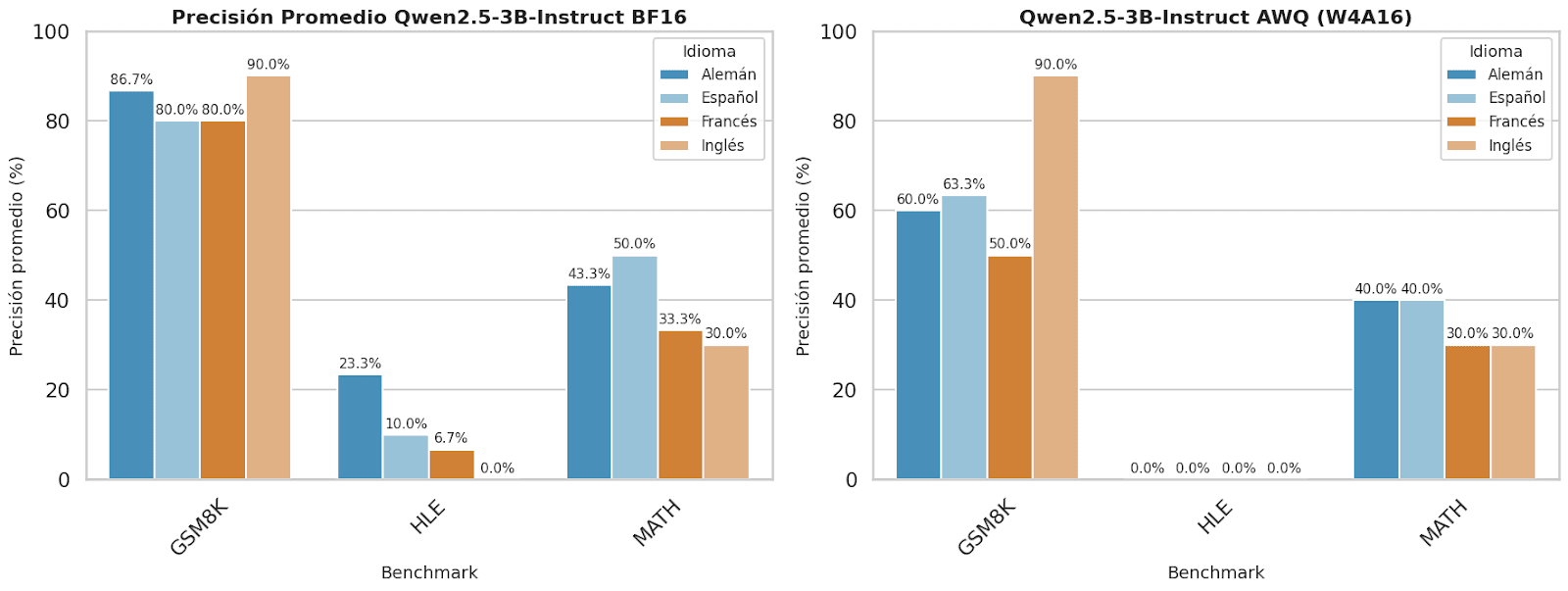
Figure 7. The graph shows the accuracy of the Qwen 2.5-3B Instruct model by benchmark before and after quantization in the four different languages: Spanish, English, French, and German.
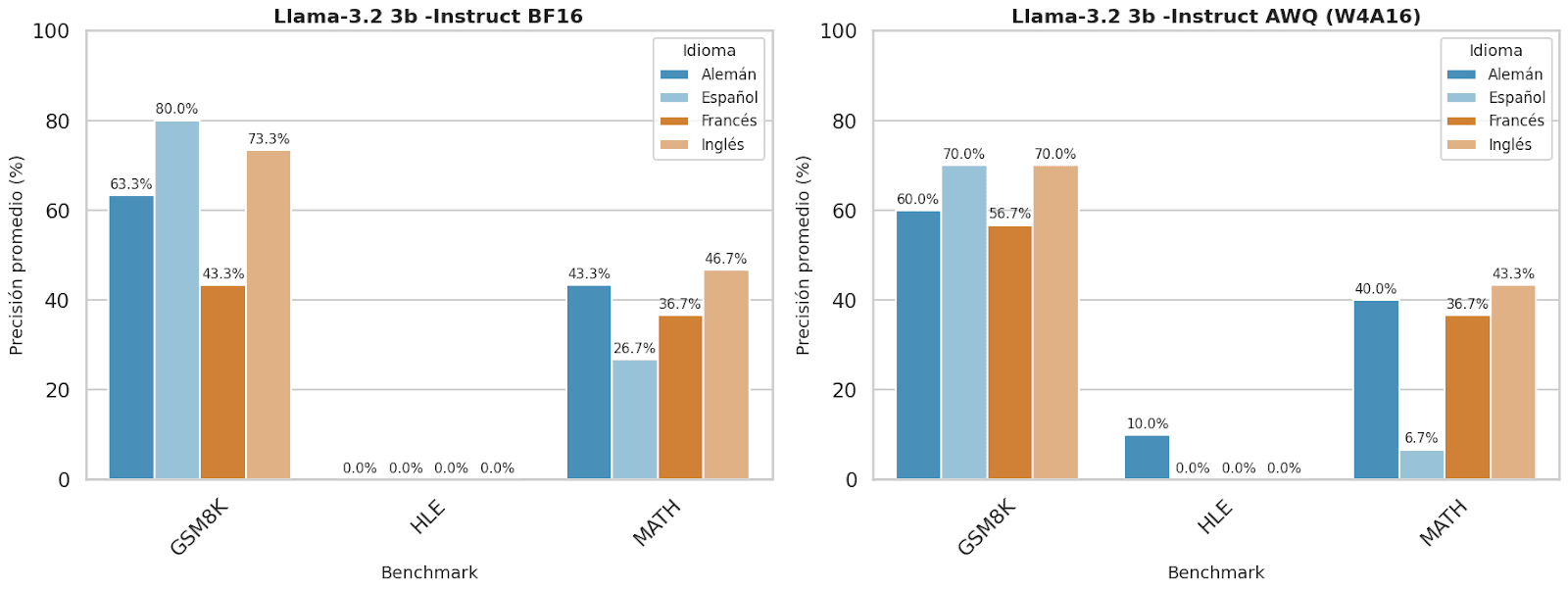
Figure 8. The graph shows the accuracy of the Llama 3.2-3B Instruct model by benchmark before and after quantization in the four different languages: Spanish, English, French, and German.
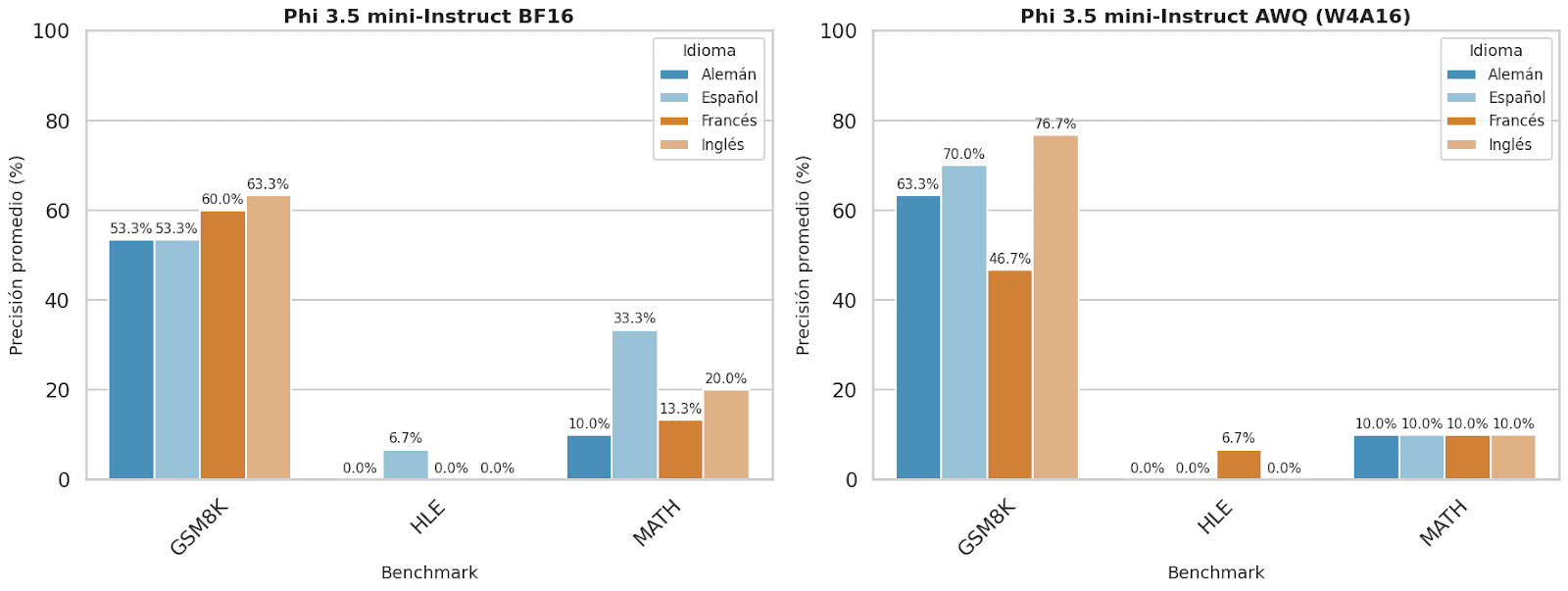
Figure 9. The graph shows the accuracy of the Phi 3.5 mini Instruct model by benchmark before and after quantization in the four different languages: Spanish, English, French, and German.
| Benchmark | Model | Maximum Accuracy | Comments |
| GSM8K | QWEN 2.5-3B | 90% (English) | Clear domain in basic reasoning |
| HLE | QWEN 2.5-3B | 23.33% (German) | All models fail; benchmark with higher complexity |
| MATH | LLAMA 3.2 3B | 46.67% (English) | Better in complex problems, but still room for improvement |
Table 5. Shows the benchmarks with the highest performance by language model.
Discussion
Evaluation of Quantization by Model
In general terms, the Llama-3.2 3B-Instruct model exhibited a relatively stable performance after quantization. In languages like German and French, an improvement in precision was even observed, while in English, the difference was marginal. However, in Spanish, a significant loss in performance was registered, with a decrease of 10 percentage points, which represents a drop of 28.17%. This result suggests that although Llama-3.2 adapts well to compression in certain languages, its performance in Spanish might benefit from specific adjustments during pretraining or a more balanced multilingual fine-tuning.
On the other hand, the Phi-3.5 Mini-Instruct model showed variable sensitivity to quantization. Improvements were evident in English and German, with moderate gains in German. However, both in French and Spanish, precision decreased, with the drop being more pronounced in Spanish. This suggests that Phi-3.5 Mini-Instruct is more susceptible to the negative effects of quantization, especially in multilingual tasks. It is noteworthy that this model was not initially the first choice for evaluations due to its strong focus on mathematical reasoning. According to studies like Abdin et al. (2024), it has outperformed other models in this area, which led to the hypothesis that it would also show good general performance. However, the results indicate that its optimization is mainly focused on English.
The model most affected by quantization was clearly Qwen2.5-3B-Instruct. Although it maintained an acceptable performance in English, it suffered significant drops in German, French, and Spanish, with the most drastic case being in German, where precision was reduced by over 50%. This disparity between languages suggests that the model was developed with a strong focus on English, which limits its ability to generalize in a multilingual context under compression conditions.
These results highlight that quantization does not necessarily compromise a model’s performance; in some cases, it can even act as a form of regularization that improves precision. However, the effects of this technique largely depend on the model, the language, and the balance of data used during pretraining. More robust and balanced models like Llama-3.2 3B-Instruct tolerate compression better, while more specialized or sensitive models like Qwen2.5-3B-Instruct require customized approaches.
Benchmark Analysis
The results show that the GSM8K benchmark, focused on basic mathematical reasoning, presents the highest global accuracy, particularly with the Qwen2.5-3B-Instruct model, which achieves up to 90% in English (both quantized and non-quantized) and 86.67% in German. The Llama-3.2 3B-Instruct model also performs well in Spanish (80%), while Phi-3.5 Mini-Instruct only excels in quantized English (76.67%). Overall, the models show greater robustness in English and Spanish, with French being the weakest language, likely due to less data representation in pretraining or less adjustment for this language.
In contrast, the HLE (Human-Like Evaluation) benchmark, which evaluates the model's ability to generate human-like responses, presented very low accuracies, almost always below 10%, and in many cases close to 0%. The only notable score was Qwen2.5-3B-Instruct with 23.33% in non-quantized German. This low accuracy suggests that the models are not optimized for natural human language generation tasks, or the task itself is too complex, possibly due to its open-ended and subjective nature or because there is no single "correct" answer.
In the MATH benchmark, which assesses advanced mathematical problems, Llama-3.2 3B-Instruct leads with 46.67% in non-quantized English, followed by Qwen2.5-3B-Instruct in Spanish and German (50% and 43.33%, respectively). The Phi-3.5 Mini-Instruct model performs the worst in this benchmark, not exceeding 33.33%. It is observed that quantization tends to reduce precision, and the language significantly influences performance, with English being the most favored due to training and evaluation processes.
Conclusion
For environments where multilingual performance is crucial and computational resources are limited, the quantized version of Llama-3.2 3B-Instruct represents a solid and efficient alternative. On the other hand, direct quantization of models like Qwen2.5-3B-Instruct in languages other than English is not recommended, unless complementary techniques, such as language-specific fine-tuning or more adaptive quantization methods, are applied. These strategies would help preserve accuracy without sacrificing the benefits of compression.
Although this study focused on a quantitative analysis of performance, rather than the details of reasoning steps, it is important to highlight that the models exhibit recurrent limitations in terms of completeness, mathematical precision, clarity of notation, and depth of explanation. While they may provide correct answers, their performance is hindered by interpretation errors, improper handling of units, and difficulties in solving complex tasks. This suggests areas for improvement in consistency, mathematical reasoning, and structured presentation. Additionally, an increase in inference time was observed even after applying quantization, which could impact efficiency in environments with limited resources.
These findings are not only relevant from a technical optimization perspective but also have direct implications for AI evaluation, safety, and governance. First, they emphasize the need for more equitable multilingual evaluation frameworks that do not assume English as the universal performance standard. Second, failures in structured reasoning tasks pose risks in educational or technical applications that require high precision. Finally, they encourage more responsible governance, where decisions regarding model deployment and compression take into account the linguistic context and available computational resources to avoid exacerbating existing digital and cognitive gaps.
Limitations
The main challenges encountered during the development of this project were related to the use of language models in the Colab development environment, specifically when working with T4 GPUs. This environment partially limited the evaluation process due to execution delays. Additionally, at the beginning of the project, the input format used was not suitable for the selected models, highlighting the need to carefully consult the official documentation to ensure a fair assessment of the models' capabilities, avoiding unintentional biases.
Another significant challenge was the quantization process of the models. During this phase, conflicts arose between versions of certain libraries and dependencies with the Colab environment, which made direct implementation difficult. For this reason, publicly available pre-quantized models were used as an alternative.
Perspectives
This study opens new lines of research on how quantization affects multilingual mathematical reasoning in language models. Future research could explore larger models, other compression methods such as pruning or knowledge distillation, and the impact of quantization on step-by-step reasoning coherence. To replicate the study, it would be useful to incorporate deeper qualitative evaluation and culturally or linguistically adapted tasks. Finally, this work would benefit from interdisciplinary collaboration involving experts in responsible AI, computational linguistics, mathematics education, and algorithmic governance, to ensure a more equitable and transparent development of these technologies.
References
Abdin, M., Aneja, J., Awadalla, H., Awadallah, A., Awan, A. A., Bach, N., Bahree, A., Bakhtiari, A., Bao, J., Behl, H., Benhaim, A., Bilenko, M., Bjorck, J., Bubeck, S., Cai, M., Cai, Q., Chaudhary, V., Chen, D., Chen, D., … Zhou, X. (2024). Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. http://arxiv.org/abs/2404.14219
Ahia Masakhane NLP, O., Kreutzer, J., & Hooker Google Research, S. (n.d.). The Low-Resource Double Bind: An Empirical Study of Pruning for Low-Resource Machine Translation.
Bolton, E., Venigalla, A., Yasunaga, M., Hall, D., Xiong, B., Lee, T., Daneshjou, R., Frankle, J., Liang, P., Carbin, M., & Manning, C. D. (2024). BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text. http://arxiv.org/abs/2403.18421
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems. http://arxiv.org/abs/2110.14168
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., & Steinhardt, J. (2021). Measuring Mathematical Problem Solving With the MATH Dataset. http://arxiv.org/abs/2103.03874
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.-M., Wang, W.-C., Xiao, G., Dang, X., Gan, C., & Han, S. (2023). AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. http://arxiv.org/abs/2306.00978
Marchisio, K., Dash, S., Chen, H., Aumiller, D., Üstün, A., Hooker, S., & Ruder, S. (2024). How Does Quantization Affect Multilingual LLMs? http://arxiv.org/abs/2407.03211
Phan, L., Gatti, A., Han, Z., Li, N., Hu, J., Zhang, H., Zhang, C. B. C., Shaaban, M., Ling, J., Shi, S., Choi, M., Agrawal, A., Chopra, A., Khoja, A., Kim, R., Ren, R., Hausenloy, J., Zhang, O., Mazeika, M., … Hendrycks, D. (2025). Humanity’s Last Exam. http://arxiv.org/abs/2501.14249
Srivastava, G., Cao, S., & Wang, X. (2025). Towards Reasoning Ability of Small Language Models. http://arxiv.org/abs/2502.11569
Zero-Shot Prompting (2025). Retrieved from Prompt Engineering Guide.