AI safety tax dynamics
By Owen Cotton-Barratt @ 2024-10-23T12:21 (+22)
This is a linkpost to https://strangecities.substack.com/p/ai-safety-tax-dynamics
Two important themes in many discussions of the future of AI are:
- AI will automate research, and thus accelerate technological progress
- There are serious risks from misaligned AI systems (that justify serious investments in safety)
How do these two themes interact? Especially: how should we expect the safety tax requirements to play out as progress accelerates and we see an intelligence explosion?
In this post I’ll give my core views on this:
- Automation of research by AI could affect the landscape into which yet-more-powerful systems are emerging
- Therefore, differential boosting beneficial applications may be a high-leverage strategy for improving safety
- The most dangerous period probably occurs when AI is mildly- to moderately-superintelligent
I developed these ideas in tandem with my exploration of the concepts of safety tax landscapes, that I wrote about in a recent post. However, for people who are just interested in the implications for AI, I think that this post will largely stand alone.
How AI differs from other dangerous technologies
In the post on safety tax functions, my analysis was about a potentially-dangerous technology in the abstract (nothing specific about AI). We saw that:
- The underlying technological landscape determines the safety tax contours
- i.e. answering “how much do people need to invest in safety to stay safe?”, and “how does this vary with how powerful the tech is and how confident you want to be in safety?” basically depends on the shape of discoveries that people might make to advance the technology
- Outcomes depend on:
- Our ability to make investments in capabilities
- “Investments” includes R&D, but also any other work necessary to build capable systems
- Our ability to make investments in safety
- Our ability to coordinate between actors to constrain the ratios of these investments
- Our ability to make investments in capabilities
For most technologies, these abilities — the ability to invest in different aspects of the tech, and the ability to coordinate — are relatively independent of the technology; better solar power doesn’t do much to help us do more research, or sign better treaties. Not so for AI! To a striking degree, AI safety is a dynamic problem — earlier capabilities might change the basic nature of the problem we are later facing.
In particular:
- At some point, most AI capabilities work and most AI safety work will probably be automated by AI itself
- The amount of effective capabilities work we get will be a function of our investment of money into capabilities work, together with how good our automation of capabilities work is
- Similarly, the amount of effective safety work will depend not just on the investment we make into safety work, but on how good our automation is
- Therefore:
- If we get good at automating capabilities R&D quickly compared to safety R&D, this raises the necessary safety tax
- If we get good at automating safety R&D quickly compared to capabilities R&D, this lowers the necessary safety tax
- It is plausible that powerful AI could improve our coordination capabilities
- More effective coordination at the inter-lab or international level might increase our ability to pay high safety taxes — so long as we have the capabilities before the moments of peak safety tax requirements
These are, I believe, central cases of the potential value of differential technological development (or d/acc) in AI. I think this is an important topic, and it’s one I expect to return to in future articles.
Where is the safety tax peak for AI?
Why bother with the conceptual machinery of safety tax functions? A lot of the reason I spent time thinking about it was trying to get a handle on this question — which parts of the AI development curve should we be most concerned about?
I think this is a crucial question for thinking about AI safety, and I wish it had more discussion. Compared to talking about the total magnitude of the risks, I think this question is more action-guiding, and also more neglected.
In terms of my own takes, it seems to me that:
- The (existential) safety tax is low for early AGI, because there are limited ways for systems just around as smart as humans [1]to pose existential risk
- It’s conceivable, but:
- It would be hard for them to amass an independent power base to the point where they could be a major actor by themselves
- While we might be concerned about crime syndicates offering a path here, it’s unclear that this would outcompete existing bad actors using AI for their purposes
- It would be hard for them to become an independent world-leading AI research lab
- While we might be concerned about hacking here, the scale of compute needed, and the difficulty of setting up in effect a large organization while maintaining secrecy, seems difficult
- The possibility of a parasitic existence within a top AI lab, steering things in directions that were desirable for them, would be made much harder by labs being conscious of and scanning for this possibility
- The labs have a clear hard power advantage, so to be successful the parasitic AI system(s) would need to maintain an overwhelming informational advantage
- It seems more likely that some bad outcome would kind of naturally cap out at something shy of an existential catastrophe, compared to for stronger systems
- It would be hard for them to amass an independent power base to the point where they could be a major actor by themselves
- It’s conceivable, but:
- By the time we’re getting towards strong superintelligence, the required safety tax has probably gone down
- At maturity of the technology, the safety tax is probably not large
- The basic thought here is something like this:
- Is there a conceivable way to structure a mind such that it does a bunch of useful/aligned/safe thinking?
- Surely yes
- Maybe the first ways discovered of building such minds require a lot of safety features or oversight
- But as research continues, probably there will be better ways to identify the aligned/safe thinking, and to understand what might prompt unaligned/unsafe thinking
- Then in principle there should be minds which just (by construction) do a lot of the aligned/safe thinking, and don’t need much oversight to check they keep on doing that
- Is there a conceivable way to structure a mind such that it does a bunch of useful/aligned/safe thinking?
- The basic thought here is something like this:
- If there is useful general theory and practice for supervising and aligning smarter systems, much of that will probably have been worked out (by moderately superintelligent systems, if not earlier) by the time we approach strong superintelligence
- Whereas now we are doing a combination of trying to fill out the basics of general theory while simultaneously orienting to the empirics of real systems without too much in the way of theory to base this on, in this future it would only be necessary to orient to the empirics of the new systems (or specialized theory relevant to their architectures), and it would be aided by having a deep theoretical understanding of the general situation
- Moderately- to strongly-superintelligent systems would pose large risks if not well aligned; therefore a lot of practice of how to align systems will have been developed
- It is possible that these practices could be obsoleted by new AI paradigms; nonetheless it seems likely that some meta-level practices would remain relevant
- At maturity of the technology, the safety tax is probably not large
- So most likely the peak risk occurs in the era of mild-to-moderate superintelligence
- This dynamic is exacerbated by the fact that this is the period in which it’s most plausible that automation of capabilities research far outstrips automation of safety research
- Partially because this is the period in which it’s most likely than automation of any arbitrary area far outstrips any other arbitrary area without a deliberate choice for that to happen
- Since before even mild superintelligence, our abilities to automate different areas are advancing at human speeds, and can’t race too far ahead; and with strong superintelligence we can probably do a good job of automating all kinds of progress, so the distribution of progress depends on choices about allocation of compute (as well as fundamentals about the diminishing returns curves in each area)
- It’s in the middle period that we may have automated some good fraction of hard tasks like some research fields to superhuman levels, but not gotten to being able to do comparable strong automation of other fields
- (This particular argument is symmetric, so also points to the possibility of safety automation far outstripping capabilities automation; but even if that were also plausible it would not undermine the point about this being a high risk period, since there would remain some chance that capabilities automation would far outstrip safety automation)
- Partially this is because there are asymmetric reasons to think it is likely to be easier to automate capabilities research early than safety research
- Because it may be easier to design high quality metrics for capabilities than for safety, these could facilitate faster automation
- My suspicion is that simple metrics are in some sense a crutch, and that with deep enough understanding of a domain you can use the automated judgement as a form of metric — and therefore that this advantage of capabilities over safety work will disappear for stronger superintelligence
- Even if my suspicion about simple metrics being a crutch is incorrect, it may still be that the advantage of capabilities over safety work will disappear as stronger superintelligence becomes better at designing simple metrics which are good proxies for meaningful safety work
- Another angle on this: plausibly good safety or alignment work requires a kind of philosophical competence to recognise what are safer directions
- It seems less likely that such philosophical competence would be needed to automate capabilities research
- By the time systems approach strong superintelligence, they are likely to have philosophical competence in some sense
- Because it may be easier to design high quality metrics for capabilities than for safety, these could facilitate faster automation
- Partially because by the time the world has strong superintelligence we’re likely to have much more clarity and common knowledge about the degree of danger attendant in any particular technical pathway — and hence it will be easier to coordinate around paying high safety taxes if those are necessary
- Partially because this is the period in which it’s most likely than automation of any arbitrary area far outstrips any other arbitrary area without a deliberate choice for that to happen
- This dynamic is exacerbated by the fact that this is the period in which it’s most plausible that automation of capabilities research far outstrips automation of safety research
On net, my picture looks very approximately like this:
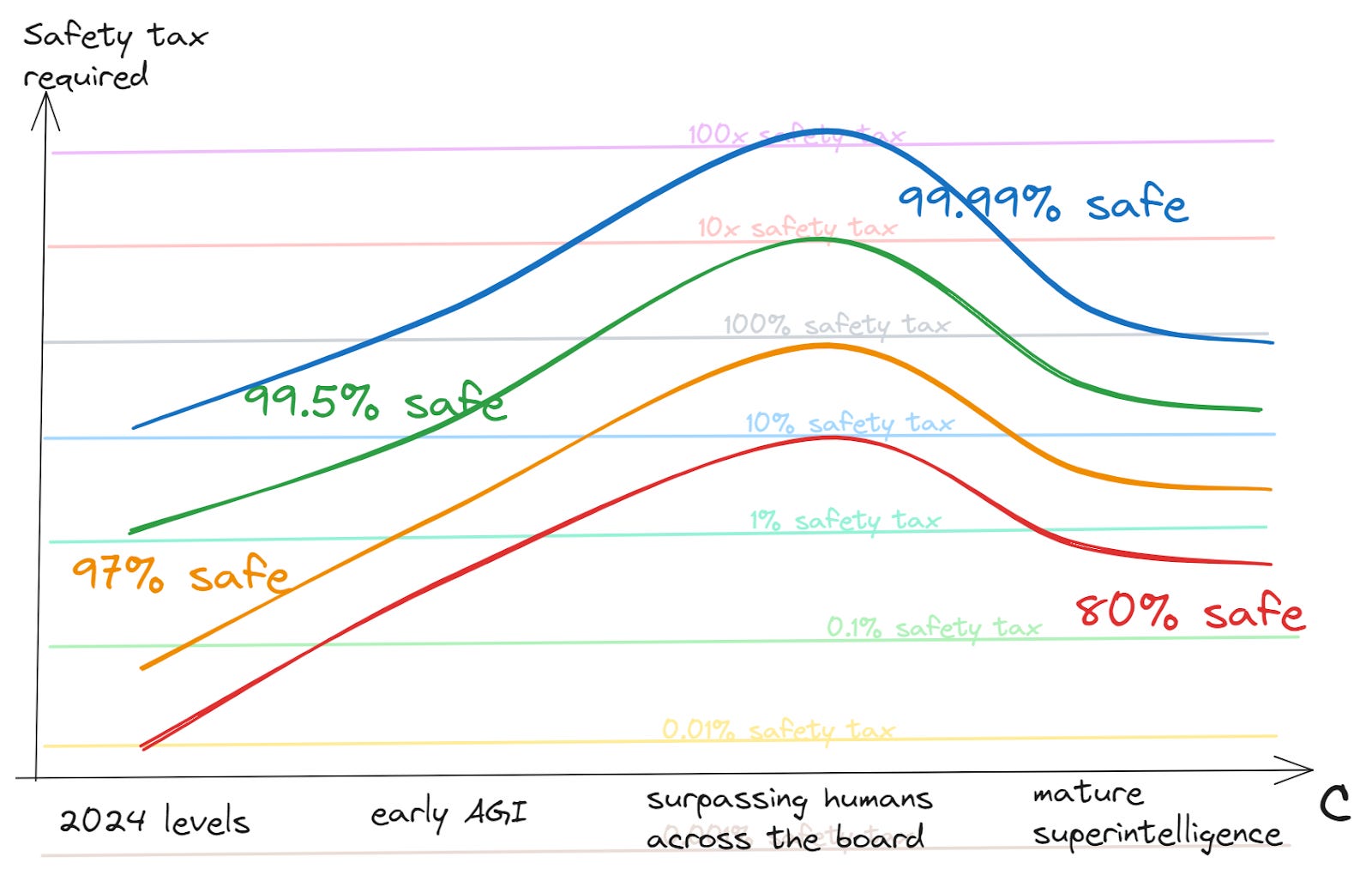
(I think this graph will probably make rough intuitive sense by itself, but if you want more details about what the axes and contours are supposed to mean, see the post on safety tax functions.)
I’m not super confident in these takes, but it seems better to be wrong than vague — if it’s good to have more conversations about this, I’d rather offer something to kick things off than not. If you think this picture is wrong — and especially if you think the peak risk lies somewhere else — I’d love to hear about that.
And if this picture is right — then what? I suppose I would like to see more work which is targeting this period.[2] This shouldn’t mean stopping safety work for early AGI — that’s the first period with appreciable risk, and it can’t be addressed later. But it should mean increasing political work which lays the groundwork for coordinating to pay high safety taxes in the later period. And it should mean working to differentially accelerate those beneficial applications of AI that may help us to navigate the period well.
Acknowledgements: Thanks to Tom Davidson, Rose Hadshar, and Raymond Douglas for helpful comments.
- ^
Of course “around as smart as humans” is a vague term; I’ll make it slightly less vague by specifying “at research and strategic planning”, which I think are the two most strategically important applications of AI.
- ^
This era may roughly coincide with the last era of human mistakes — since AI abilities are likely to be somewhat spiky compared to humans, we’ll probably have superintelligence in many important ways before human competence is completely obsoleted. So the interventions for helping I discussed in that post may be relevant here. However, I painted a somewhat particular picture in that post, which I expect to be wrong in some specifics; whereas here I’m trying to offer a more general analysis.
Will Aldred @ 2024-10-24T01:57 (+8)
By the time systems approach strong superintelligence, they are likely to have philosophical competence in some sense.
It’s interesting to me that you think this; I’d be very keen to hear your reasoning (or for you to point me to any existing writings that fit your view).
For what it’s worth, I’m at maybe 30 or 40% that superintelligence will be philosophically competent by default (i.e., without its developers trying hard to differentially imbue it with this competence), conditional on successful intent alignment, where I’m roughly defining “philosophically competent” as “wouldn’t cause existential catastrophe through philosophical incompetence.” I believe this mostly because I find @Wei Dai’s writings compelling, and partly because of some thinking I’ve done myself on the matter. OpenAI’s o1 announcement post, for example, indicates that o1—the current #1 LLM, by most measures—performs far better in domains that have clear right/wrong answers (e.g., calculus and chemistry) than in domains where this is not the case (e.g., free-response writing[1]).[2] Philosophy, being interminable debate, is perhaps the ultimate “no clear right/wrong answers” domain (to non-realists, at least): for this reason, plus a few others (which are largely covered in Dai’s writings), I’m struggling to see why AIs wouldn’t be differentially bad at philosophy in the lead-up to superintelligence.
Also, for what it’s worth, the current community prediction on the Metaculus question “Five years after AGI, will AI philosophical competence be solved?” is down at 27%.[3] (Although, given how out of distribution this question is with respect to most Metaculus questions, the community prediction here should be taken with a lump of salt.)
(It’s possible that your “in some sense” qualifier is what’s driving our apparent disagreement, and that we don’t actually disagree by much.)
- ^
- ^
On this, AI Explained (8:01–8:34) says:
And there is another hurdle that would follow, if you agree with this analysis [of why o1’s capabilities are what they are, across the board]: It’s not just a lack of training data. What about domains that have plenty of training data, but no clearly correct or incorrect answers? Then you would have no way of sifting through all of those chains of thought, and fine-tuning on the correct ones. Compared to the original GPT-4o in domains with correct and incorrect answers, you can see the performance boost. With harder-to-distinguish correct or incorrect answers: much less of a boost [in performance]. In fact, a regress in personal writing.
- ^
Note: Metaculus forecasters—for the most part—think that superintelligence will come within five years of AGI. (See here my previous commentary on this, which goes into more detail.)
Owen Cotton-Barratt @ 2024-10-24T10:13 (+4)
It's not clear we have too much disagreement, but let me unpack what I meant:
- Let strong philosophical competence mean competence at all philosophical questions, including those like metaethics which really don't seem to have any empirical grounding
- I'm not trying to make any claims about strong philosophical competence
- I might be a little more optimistic than you about getting this by default as a generalization of weak philosophical competence (see below), but I'm still pretty worried that we won't get it, and I didn't mean to rely on it in my statements in this post
- Let weak philosophical competence mean competence at reasoning about complex questions which ultimately have empirical answers, where it's out of reach to test them empirically, but one may get better predictions from finding clear frameworks for thinking about them
- I claim that by the time systems approach strong superintelligence, they're likely to have a degree of weak philosophical competence
- Because:
- It would be useful for many tasks, and this would likely be apparent to mild superintelligent systems
- It can be selected for empirically (seeing which training approaches etc. do well at weak philosophical competence in toy settings, where the experimenters have access to the ground truth about the questions they're having the systems use philosophical reasoning to approach)
- Because:
- I further claim that weak philosophical competence is what you need to be able to think about how to build stronger AI systems that are, roughly speaking, safe, or intent aligned
- Because this is ultimately an empirical question ("would this AI do something an informed version of me / those humans would ultimately regard as terrible?")
- I don't claim that this would extend to being able to think about how to build stronger AI systems that it would be safe to make sovereigns
Will Aldred @ 2024-10-24T12:35 (+4)
Thanks for expanding! This is the first time I’ve seen this strong vs. weak distinction used—seems like a useful ontology.[1]
Minor: When I read your definition of weak philosophical competence,[2] high energy physics and consciousness science came to mind as fields that fit the definition (given present technology levels). However, this seems outside the spirit of “weak philosophical competence”: an AI that’s superhuman in the aforementioned fields could still fail big time with respect to “would this AI do something an informed version of me / those humans would ultimately regard as terrible?” Nonetheless, I’ve not been able to think up a better ontology myself (in my 5 mins of trying), and I don’t expect this definitional matter will cause problems in practice.
- ^
For the benefit of any readers: Strong philosophical competence is importantly different to weak philosophical competence, as defined.
The latter feeds into intent alignment, while the former is an additional problem beyond intent alignment.[Edit: I now think this is not so clear-cut. See the ensuing thread for more.] - ^
“Let weak philosophical competence mean competence at reasoning about complex questions which ultimately have empirical answers, where it's out of reach to test them empirically, but one may get better predictions from finding clear frameworks for thinking about them.”
Owen Cotton-Barratt @ 2024-10-24T13:26 (+4)
Yeah, I appreciated your question, because I'd also not managed to unpack the distinction I was making here until you asked.
On the minor issue: right, I think that for some particular domain(s), you could surely train a system to be highly competent in that domain without this generalizing to even weak philosophical competence overall. But if you had a system which was strong at both of those domains despite not having been trained on them, and especially if that was also true for say three more comparable domains, I guess I kind of do expect it to be good at the general thing? (I haven't thought long about that.)
Will Aldred @ 2024-10-25T19:24 (+2)
Hmm, interesting.
I’m realizing now that I might be more confused about this topic than I thought I was, so to backtrack for just a minute: it sounds like you see weak philosophical competence as being part of intent alignment, is that correct? If so, are you using “intent alignment” in the same way as in the Christiano definition? My understanding was that intent alignment means “the AI is trying to do what present-me wants it to do.” To me, therefore, this business of the AI being able to recognize whether its actions would be approved by idealized-me (or just better-informed-me) falls outside the definition of intent alignment.
(Looking through that Christiano post again, I see a couple of statements that seem to support what I’ve just said,[1] but also one that arguably goes the other way.[2])
Now, addressing your most recent comment:
Okay, just to make sure that I’ve understood you, you are defining weak philosophical competence as “competence at reasoning about complex questions [in any domain] which ultimately have empirical answers, where it's out of reach to test them empirically, but where one may get better predictions from finding clear frameworks for thinking about them,” right? Would you agree that the “important” part of weak philosophical competence is whether the system would do things an informed version of you, or humans at large, would ultimately regard as terrible (as opposed to how competent the system is at high energy physics, consciousness science, etc.)?
If a system is competent at reasoning about complex questions across a bunch of domains, then I think I’m on board with seeing that as evidence that the system is competent at the important part of weak philosophical competence, assuming that it’s already intent aligned.[3] However, I’m struggling to see why this would help with intent alignment itself, according to the Christiano definition. (If one includes weak philosophical competence within one’s definition of intent alignment—as I think you are doing(?)—then I can see why it helps. However, I think this would be a non-standard usage of “intent alignment.” I also don’t think that most folks working on AI alignment see weak philosophical competence as part of alignment. (My last point is based mostly on my experience talking to AI alignment researchers, but also on seeing leaders of the field write things like this.))
A couple of closing thoughts:
- I already thought that strong philosophical competence was extremely neglected, but I now also think that weak philosophical competence is very neglected. It seems to me that if weak philosophical competence is not solved at the same time as intent alignment (in the Christiano sense),[4] then things could go badly, fast. (Perhaps this is why you want to include weak philosophical competence within the intent alignment problem?)
- The important part of weak philosophical competence seems closely related to Wei Dai’s “human safety problems”.
(Of course, no obligation on you to spend your time replying to me, but I’d greatly appreciate it if you do!)
- ^
- They could [...] be wrong [about; sic] what H wants at a particular moment in time.
- They may not know everything about the world, and so fail to recognize that an action has a particular bad side effect.
- They may not know everything about H’s preferences, and so fail to recognize that a particular side effect is bad.
…
I don’t have a strong view about whether “alignment” should refer to this problem or to something different. I do think that some term needs to refer to this problem, to separate it from other problems like “understanding what humans want,” “solving philosophy,” etc.
(“Understanding what humans want” sounds quite a lot like weak philosophical competence, as defined earlier in this thread, while “solving philosophy” sounds a lot like strong philosophical competence.)
- ^
An aligned AI would also be trying to do what H wants with respect to clarifying H’s preferences.
(It’s unclear whether this just refers to clarifying present-H’s preferences, or if it extends to making present-H’s preferences be closer to idealized-H’s.)
- ^
If the system is not intent aligned, then I think this would still be evidence that the system understands what an informed version of me would ultimately regard as terrible vs. not terrible. But, in this case, I don’t think the system will use what it understands to try to do the non-terrible things.
- ^
Insofar as a solved vs. not solved framing even makes sense. Karnofsky (2022; fn. 4) argues against this framing.
Owen Cotton-Barratt @ 2024-10-25T21:12 (+4)
it sounds like you see weak philosophical competence as being part of intent alignment, is that correct?
Ah, no, that's not correct.
I'm saying that weak philosophical competence would:
- Be useful enough for acting in the world, and in principle testable-for, that I expect it be developed as a form of capability before strong superintelligence
- Be useful for research on how to produce intent-aligned systems
... and therefore that if we've been managing to keep things more or less intent aligned up to the point where we have systems which are weakly philosophical competent, it's less likely that we have a failure of intent alignment thereafter. (Not impossible, but I think a pretty small fraction of the total risk.)
Will Aldred @ 2024-10-25T21:52 (+2)
Thanks for clarifying!
Be useful for research on how to produce intent-aligned systems
Just checking: Do you believe this because you see the intent alignment problem as being in the class of “complex questions which ultimately have empirical answers, where it’s out of reach to test them empirically, but one may get better predictions from finding clear frameworks for thinking about them,” alongside, say, high energy physics?
Owen Cotton-Barratt @ 2024-10-25T22:37 (+2)
Yep.
SummaryBot @ 2024-10-23T16:51 (+1)
Executive summary: As AI capabilities progress, the peak period for existential safety risks likely occurs during mild-to-moderate superintelligence, when capabilities research automation might significantly outpace safety research automation, requiring careful attention to safety investments and coordination.
Key points:
- AI differs from other technologies because earlier AI capabilities can fundamentally change the nature of later safety challenges through automation of both capabilities and safety research.
- The required "safety tax" (investment in safety measures) varies across AI development stages, peaking during mild-to-moderate superintelligence.
- Early AGI poses relatively low existential risk due to limited power accumulation potential, while mature strong superintelligence may have lower safety requirements due to better theoretical understanding and established safety practices.
- Differential technological development (boosting beneficial AI applications) could be a high-leverage strategy for improving overall safety outcomes.
- Political groundwork for coordination and investment in safety measures should focus particularly on the peak risk period of mild-to-moderate superintelligence.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.