AI Safety Newsletter #8: Rogue AIs, how to screen for AI risks, and grants for research on democratic governance of AI
By Center for AI Safety, Dan H @ 2023-05-30T11:44 (+16)
This is a linkpost to https://newsletter.safe.ai/p/ai-safety-newsletter-8
Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
Subscribe here to receive future versions.
Yoshua Bengio makes the case for rogue AI
AI systems pose a variety of different risks. Renowned AI scientist Yoshua Bengio recently argued for one particularly concerning possibility: that advanced AI agents could pursue goals in conflict with human values.
Human intelligence has accomplished impressive feats, from flying to the moon to building nuclear weapons. But Bengio argues that across a range of important intellectual, economic, and social activities, human intelligence could be matched and even surpassed by AI.
How would advanced AIs change our world? Many technologies are tools, such as toasters and calculators, which humans use to accomplish our goals. AIs are different, Bengio says. We often give them a goal and ask them to figure out a solution on their own.
Choosing safe goals for AI systems is an unsolved problem, both technically and politically. If we do not solve this problem, Bengio argues that we could end up building AI agents that pursue harmful goals with superhuman intelligence, which would result in a catastrophe for humanity.

Four steps to rogue AI. Bengio begins by defining rogue AI as “an autonomous AI system that could behave in ways that would be catastrophically harmful to a large fraction of humans, potentially endangering our societies and even our species or the biosphere.”
He argues that a rogue superintelligent AI agent is possible, in four steps:
- Machines could reach and surpass human abilities. Bengio argues that, in principle, there is nothing the human brain does that a machine could not do. We’ve already built AIs that beat humans in chess, games, and other cognitive tests. These systems have important advantages over human intelligence. Computers can process information much more quickly than humans – for example, language models are trained by reading the entire internet, which would be impossible in a human lifetime. Humans take years to reproduce, but an AI system can be replicated on to many computers at once. These kinds of simple advantages mean that if we develop human-level AI, we might soon thereafter get superhuman AI.
- AIs can be turned into agents which take actions to pursue goals. We’ve already seen examples of GPT-4 being used to play Minecraft or browse the internet. The entire field of reinforcement learning builds AI agents that take actions to pursue goals such as winning board games and cooling data centers. Bengio says that if we build superintelligent AIs, we should expect that they could easily be directed to pursue goals by taking actions in the world.
- A superintelligent AI agent could pursue goals that conflict with human values. If someone builds a superintelligent AI agent with dangerous goals, Bengio believes the AI agent could behave “in catastrophically harmful ways.”
Why would an AI’s goals conflict with humanity? Bengio offers a variety of reasons why the goals of an AI system might not peacefully coexist with human values.
- Malicious humans. Someone could deliberately give an AI the goal of causing harm. We’ve already seen this, with someone telling ChatGPT to formulate a plot for world domination.
- Goal misspecification. We need to measure a goal in order to train AIs to pursue it. But many important human values are difficult to measure. Therefore, we often train AIs to pursue simple metrics, like keeping someone scrolling on a social media app, which can lead to addiction and undermine wellbeing. Training AIs to promote human flourishing could prove very difficult.
- Instrumental subgoals. For any final goal that an AI system is tasked with achieving, the AI might find it useful to pursue certain subgoals along the way. For example, if an AI pursues financial resources, political power, or social influence, these subgoals could help it achieve many final goals that a human might provide. But these subgoals might conflict with human values.
- Evolutionary pressure. AIs that successfully self-propagate will be more numerous in the future. This evolutionary process will encourage AIs to behave selfishly, by gaining power in the world and working to maintain that influence into the future.
How to minimize the risk of rogue AI. Bengio recommends more research on AI safety, both the technical level and the policy level. He previously signed the letter calling for a pause on building bigger AI systems, and he again recommends slowing AI development and deployment. He argues that AI agents that pursue goals and take actions are uniquely risky, and recommends allowing AI to answer questions and make predictions without taking actions in the world. Finally, Bengio says “it goes without saying that lethal autonomous weapons (also known as killer robots) are absolutely to be banned.”
How to screen AIs for extreme risks
Individuals, governments, and AI developers are all interested in understanding the risks of new AI systems. But this can be difficult. AIs often learn unexpected skills during training which might not be fully understood until after people start using the model.
To measure an AI’s abilities, researchers often build evaluation datasets. Computer vision AI models can be evaluated by asking them to classify pictures of cats and dogs, while a language model might be tested with classifying the sentiment of movie reviews. By crafting a set of inputs and desired outputs, researchers can define the kinds of behavior they want AI models to exhibit.
A new paper from Google DeepMind proposes a framework for screening AI systems for extreme risks. The paper outlines key threats posed by AIs, discusses how to screen an individual AI for potential risks, and provides a roadmap for governments and AI developers to incorporate these risk evaluations into their work.
Focusing on extreme risks. A 2022 survey of AI researchers showed that 36% of respondents believe that AI “could cause a catastrophe this century that is at least as bad as an all-out nuclear war.” AI has only accelerated since then, with ChatGPT and GPT-4 both released after this survey. Given the serious possibility of catastrophe, this paper focuses on extreme risks posed by AI.

AIs pose a wide variety of risks, and as they develop new capabilities, new risks arise.
Could someone use the AI to cause harm? One reason for AIs to cause harm is that humans could intentionally use AIs for destructive purposes. Therefore, the paper suggests identifying specific ways that AIs could cause harm, and evaluating whether a specific model is capable of causing that harm. For example:
- Manipulating human behavior is one way that an AI could cause harm. Previous studies showed that AIs can be used to generate propaganda, study the effectiveness of political rhetoric, and persuade humans in conversation. Future work could consider whether AIs can deceive humans into acting against their own interests or use information about individual people to craft specific persuasion strategies.
- AIs capable of building or accessing weapons could be gravely dangerous. AIs have been shown capable of crafting cyberattacks and designing new chemical weapons. Future work could check if AIs are capable of fully executing a plan to acquire or build weapons, or whether AIs are better at cyberattacks or cyberdefense.
- Some capabilities would amplify other risks. For example, long-term planning skills can be used for both harmful and beneficial goals. Alternatively, if AIs learn to replicate themselves or build more capable AIs, they could be more difficult to control.
Might the AI cause harm on its own? AIs might cause harm in the real world even if nobody intends for them to do so. Previous research has shown that deception and power-seeking are useful ways for AIs to achieve real world goals. Theoretically, there are reasons to believe that an AI might attempt to resist being turned off. AIs that successfully gain power and self-propagate will be more numerous and influential in the future.
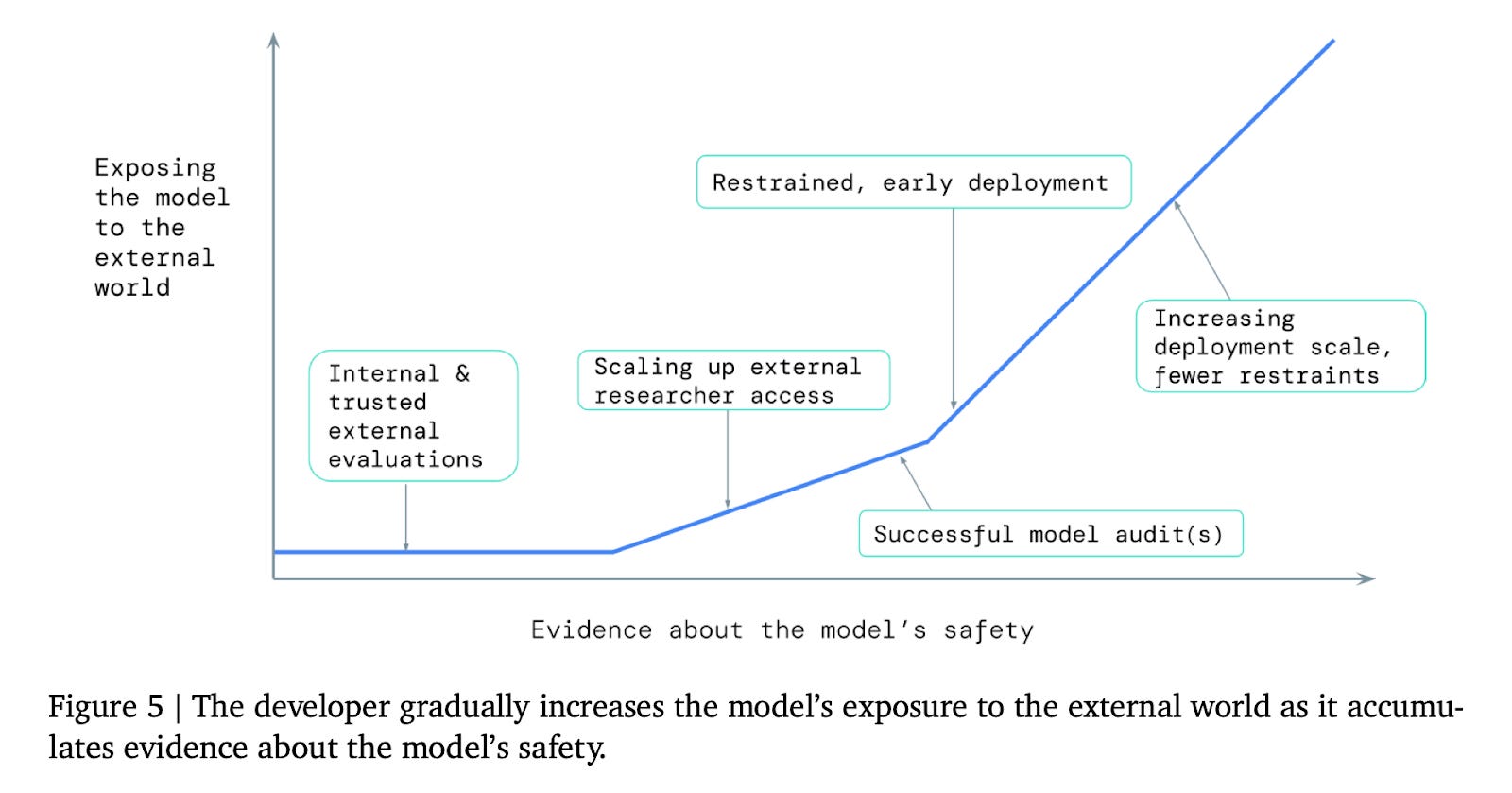
AIs should be deployed gradually, if and only if risk evaluations show that they’re safe.
How to respond to risk evaluations. Understanding the risks of an AI system is not enough. The paper recommends that AI developers integrate risk evaluations into the training process by making grounded predictions about how dangerous capabilities might arise, and trying to avoid building systems with those risks. Once an AI has been developed, risk evaluations can inform how to ensure that AI capabilities can only be used safely. Governments and citizens can use information in risk evaluations to provide democratic input on the process of developing AI.
Funding for Work on Democratic Inputs to AI
When should an AI criticize or support public figures? Should AIs offer opinions, and how should they represent the views of different groups of people? Should there be limits on the kinds of content that an AI system can generate?
Corporations that build AI often answer these questions without meaningful input from the people who are affected by the decisions. But better answers are possible through democratic processes.
By allowing a wide array of people to hold discussions and draw conclusions together, a democratic process can help us decide how AIs should behave. Democratic processes are already used to govern technology, such as by Wikipedia in deciding how to write encyclopedia articles and by Twitter in deciding if, when, and how to fact-check misleading Tweets.
OpenAI will be awarding 10 grants of $100,000 each to support work on democratic governance of AI. Anybody is welcome to submit a proposal for a democratic process that would facilitate deliberation and decisions about how AIs should act. Proposals will be assessed on features such as inclusiveness, legibility, actionability, and ease of evaluating the method’s success. Ten successful applicants will receive $100,000 grants to pilot their proposal over the next three months by using their method to democratically answer a difficult question in AI governance.
Applications are due on June 24th, 2023. Read more and apply here.
Links
- UK Prime Minister Rishi Sunak discusses existential risk and other safety concerns in a meeting with leaders of AI labs.
- The White House’s National AI R&D Strategic Plan recommends research on challenges of AI safety including “existential risk associated with the development of artificial general intelligence.” They are requesting information about how to set national priorities on AI.
- OpenAI, Microsoft, and Google all agree that regulation is necessary for safe deployment of AI.
- Anthropic raises an additional $450M to build advanced AI.
- A new YouGov poll finds that most Americans across all surveyed demographic groups believe AI should be regulated by the government.
- GPT-4 is really good at playing Minecraft. Minecraft has been a long-standing challenge in the field of building AI agents, and the success of GPT-4 indicates the potential of new AI agents powered by large language models.
See also: CAIS website, CAIS twitter, A technical safety research newsletter
Linch @ 2023-05-31T06:03 (+9)
Unless I'm misunderstanding something important (which is very possible!) I think Bengio's risk model is missing some key steps.
In particular, if I understand the core argument correctly, it goes like this:
1. (Individually) Human-level AI is possible.2. At the point where individual AIs are human-level intelligence, they will collectively be superhuman in ability, due to various intrinsic advantages of being digital.
3. It's possible to build such AIs with autonomous goals that are catastrophically or existentially detrimental to humanity. (Bengio calls them "rogue AIs")
4. Some people may choose to actually build rogue AIs.
5. Thus, (some chance of) doom.
As stated, I think this argument is unconvincing. Because for superhuman rogue AIs to be catastrophic for humanity, they need to not only be catastrophic for 2023_Humanity but also for humanity even after we also have the assistance of superhuman or near-superhuman AIs.
If I was trying to argue for Bengio's position, I would probably go down one (or more) of the following paths:
- Alignment being very hard/practically impossible: If alignment is very hard and nobody can reliably build a superhuman AI that's sufficiently aligned that we trust it to stop rogue AI, then the rogue AI can cause a catastrophe unimpeded
- Note that this is not just an argument for the possibility of rogue AIs, but an argument against non-rogue AIs.
- Offense-defense imbalance: Perhaps it's easier in practice to create rogue AIs to destroy the world than to create non-rogue AIs to prevent the world's destruction.
- Vulnerable world: Perhaps it's much easier to destroy the world than prevent its destruction
- Toy example: Suppose AIs with a collective intelligence of 200 IQ is enough to destroy the world, but AIs with a collective intelligence of 300 IQ is needed to prevent the world's destruction. Then the "bad guys" will have a large head start on the "good guys."
- Asymmetric carefulness: Perhaps humanity will not want to create non-rogue AIs because most people are too careful about the risks. Eg maybe we have an agreement among the top AI labs to not develop AI beyond capabilities level X without alignment level Y, or something similar in law. Suppose, further, in this world that normal companies mostly follow the law and at least one group building rogue AIs don't.
- In a sense, you can view this as a more general case of (1). In this story, we don't need AI alignment to be very hard, just for humanity to believe it is.
- Vulnerable world: Perhaps it's much easier to destroy the world than prevent its destruction
It's possible Bengio already believes 1) or 2), or something else similar, and just thought it was obvious enough to not be worth noting. But at least among my conversations with AI risk skeptics, among the ones who think AGI itself is possible/likely, the most common objection is why rogue AIs will be able to overpower not just humans but also other AIs as well.
aogara @ 2023-05-31T12:32 (+4)
That’s a good point! Joe Carlsmith makes a similar step by step argument, but includes a specific step about whether the existence of rogue AI would lead to catastrophic harm. Would have been nice to include in Bengio’s.
Carlsmith: https://arxiv.org/abs/2206.13353
Denis @ 2023-06-02T11:30 (+3)
"for superhuman rogue AIs to be catastrophic for humanity, they need to not only be catastrophic for 2023_Humanity but also for humanity even after we also have the assistance of superhuman or near-superhuman AIs."
This is a very interesting argument, and definitely worthy of discussion. I realise you have only sketched your argument here, so I won't try to poke holes in it.
Briefly, I see two objections that need to be addressed:
1. One fear is that the rogue AIs may well be released on 2023_Humanity or a version very close to that due to the exponential capability growth we could see if we create an AI that is able to develop better AI itself. Net, it may be enough that it would be catastrophic for 2023_Humanity.
2. The challenge of developing aligned superhuman AIs which would defend us against rogue AIs while themselves offering no threat is not trivial, and I'm not sure how many major labs are working on that right now, or if they can even write a clear problem-statement about what such an AI system should be.
From first principles, the concern is that this AI would necessarily be more limited (it needs to be aligned and safe) than a potential rogue AI, so why should we believe we could develop such an AI faster and enable it to stay ahead of potential rogue AIs?
Far from disagreeing with your comment, I'm just thinking about how it would work and what tangible steps need to be taken to create the kind of well-aligned AIs which could protect humanity.