Can we safely automate alignment research?
By Joe_Carlsmith @ 2025-04-30T17:37 (+13)
This is a linkpost to https://joecarlsmith.com/2025/04/30/can-we-safely-automate-alignment-research
(This is the fifth essay in a series that I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.
Podcast version (read by the author) here, or search for "Joe Carlsmith Audio" on your podcast app.
See also here for video and transcript of a talk on this topic that I gave at Anthropic in April 2025. And see here for slides.)
1. Introduction
In my last essay, I argued that we should try extremely hard to use AI labor to improve our civilization’s capacity to handle the alignment problem – a project I called “AI for AI safety.” In this essay, I want to look in more detail at an application of “AI for AI safety” that I view as especially important: namely, automating alignment research. In particular: I want to try to get clearer about the different ways that automating alignment research can fail, and what we can do about them.
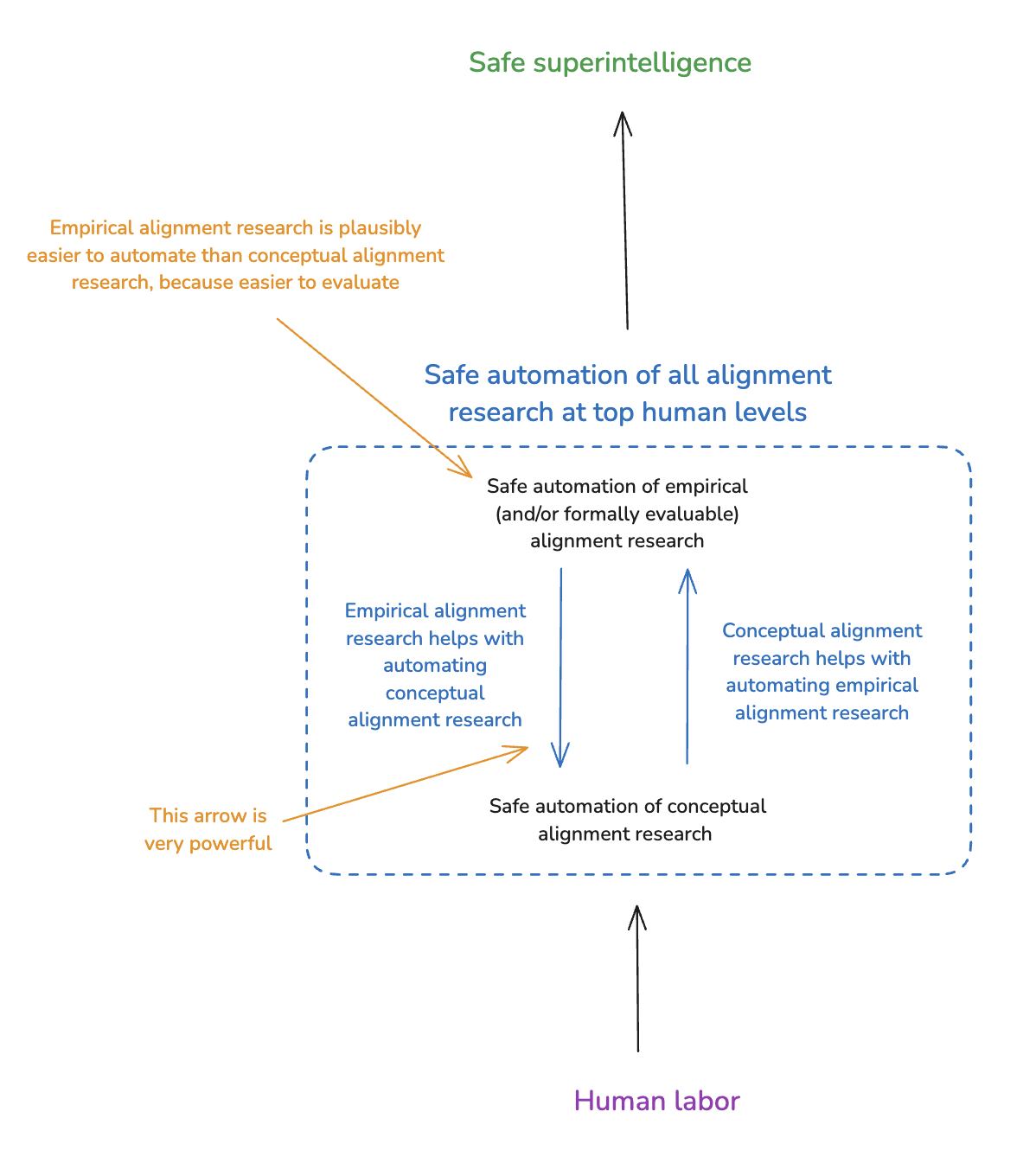
I’m especially interested in ways that problems evaluating alignment research might pose a barrier to automating it. Here, one of my key points is that some types of alignment research are easier to evaluate than others. In particular, in my opinion, we should be especially optimistic about automating alignment research that we can evaluate via some combination of (a) empirical feedback loops and (b) formal methods. And if we can succeed in this respect, we can do a huge amount of that type of alignment research to help us safely automate the rest (what I call “conceptual alignment research”).
Overall: I think we have a real shot at safely automating alignment research. But:
- Evaluation: We need to figure out how to adequately evaluate automated alignment research – and especially, alignment research we can’t test empirically or check using formal methods;
- Scheming: We need to either (a) avoid/prevent AIs actively scheming to undermine our alignment research efforts, or (b) elicit safe, top-human-level alignment research even from scheming AIs;
- Resources: We need to give ourselves the necessary time, create the necessary data, and make the necessary investment of compute, staff, effort, and other resources.
Failure on any of these fronts seems unfortunately plausible. But I think there’s a lot we can do to improve the odds.
1.1 Executive summary
Here’s a more detailed summary of the essay.
I start with some comments on why automating alignment research is so important. Basically: figuring out how to build superintelligence safely is plausibly a huge amount of difficult work. Especially in the context of short timelines and fast take-offs, we might need that work to get done very fast. Humans, though, are slow, and scarce, and (relative to advanced AIs) dumb.
I focus on safely automating alignment research at or above the level of top human experts. Following Leike (2022), I call this an “alignment MVP.” If you can get to this milestone, then you can do at least as well as you would’ve done using only human labor, but much faster.
- I also discuss scenarios where neither a humans-only nor an “alignment MVP” path are viable. Even in those cases, though, automated alignment research is still extremely useful for generating evidence of danger.
I survey an array of possible ways that an “alignment MVP” path might fail (see taxonomy in the diagram below). And I focus, first, on evaluation problems that might arise in the context of AIs that aren’t actively adversarial towards humans (that is, roughly, AIs that aren’t “scheming,” even if they have other problems).
To bring available approaches to evaluating alignment research into clearer view, I distinguish between two broad focal points of an evaluation process – namely, a type of output (e.g., a piece of research), and the process that produced this output (e.g., an AI, a process for creating that AI, etc).
Most real-world evaluation processes mix both together, and we should expect this to be true for evaluating automated alignment research as well.
- In the context of output-focused evaluation, one baseline approach is direct human evaluation. But we can also use various techniques for amplifying our output-focused evaluation ability using AIs (“scalable oversight”).
- It’s an open question, though, how far these techniques can go. For example: to me it seems hard to use these techniques to help average M-Turkers successfully evaluate novel string theory research.
- In the context of process-focused evaluation, we can use both behavioral science and transparency techniques to try to understand how our AIs will generalize from tasks where our output-focused evaluation methods are stronger to tasks where they are weaker.
- Detecting and preventing scheming (along with other efforts by AIs to intentionally mess with our evidence about how they’ll generalize) is especially important here. But if we can do that, or if we’re setting scheming aside, then I think that even without much transparency, behavioral science can be extremely powerful.
Problems with these evaluation techniques can arise in attempting to automate all sorts of domains (I’m particularly interested in comparisons with (a) capabilities research, and (b) other STEM fields). And I think this should be a source of comfort. In particular: these sorts of problems can slow down the automation of capabilities research, too. And to the extent they’re a bottleneck on all sorts of economically valuable automation, we should expect lots of effort to go towards resolving them.
However, I also think there are limits to this comfort. For one thing: evaluation problems in these other domains might be lower stakes. And beyond that: it’s possible that broad STEM automation (as opposed to: just automated capabilities research) comes too late into an intelligence explosion – i.e., you’ve lost too much of the time you needed for alignment research, and/or you’re now at much higher risk of scheming.
But also: alignment research (or at least: some forms of alignment research) might be especially difficult to evaluate even relative to these other domains. To illustrate my key concern here, I distinguish between three broad sorts of domains.
- Number-go-up, where the main evaluation question we ask is “did this crisp, quantitative metric improve?”
- Capabilities research famously has a lot of this.
- Normal science, where we ask evaluation questions like: “Was this an interesting experimental result? Does this hypothesis fit the data? What novel, testable predictions does it make? Is this math correct?”
- Capabilities research has some of this, too. And I think of sciences like biology, physics, neuroscience, and so on centrally in this bucket.
- I also count math/logic as a type of “normal science,” because the methods we use to evaluate it seem quite strong and well-established.
- Conceptual research, where we can’t rely centrally on empirical feedback loops (or on the sorts of formal evaluation methods at stake in math) in evaluating the research in question, and we need to rely instead on “just thinking about it.”
- Paradigm conceptual domains, in my view, include: philosophy, futurism, and some forms of political debate. And here I think humanity’s track record of consensus and clear intellectual progress is much weaker.
Lots of alignment research (what I call “empirical alignment research”) looks like normal science to me. And because I think humanity has a pretty good track record of evaluating normal science, I think we should be correspondingly optimistic about evaluating this type of alignment research, too. (Though: it’s still harder than evaluating number-go-up tasks.)
But some parts of alignment research look more like conceptual research. And I think we should be trying to automate this kind of alignment research, too. But I think evaluation difficulties might well bite harder, because “humans think about it” is a comparatively underpowered mode of evaluation.
However: I also think that successful automation of empirical alignment research can help a ton with automating the rest of alignment research. In particular: we can use automated empirical alignment researchers to do a huge amount of work testing and improving the output-focused and process-focused evaluation approaches I discussed above – e.g., scalable oversight, behavioral science of generalization, transparency, detecting/preventing scheming, etc. And automated empirical alignment research is extremely helpful in other ways as well (e.g., helping with further automation of empirical alignment research, testing/improving local forms of option control, generating evidence of danger, etc).
With this discussion of evaluation problems in view, I then re-introduce the possibility of scheming into the picture. This alters the analysis in a few key ways, namely:
- Comparisons with the difficulty of automating other domains are less helpful, because schemers might intentionally make it harder in some domains relative to others.
- You need higher evaluation standards, because you need to be robust to a wider range of threat models.
- Even if you can tell what research is good vs. bad, scheming AIs might intentionally withhold good research they’re capable of doing (“sandbagging”).
- Beyond sabotaging/withholding research, scheming AIs might pursue other dangerous rogue options as well (e.g. self-exfiltration, manipulating humans).
How might we automate alignment research despite the possibility of scheming? I discuss three broad options:
- Scheming might just not arise by default in the AIs we want to use.
- Scheming might arise by default, but we successfully detect/prevent it.
- We might try to elicit safe, top-human-level alignment research even from scheming AIs (though: I think this is quite scary, and it likely requires strong output-focused evaluation methods in particular).
Beyond evaluation failures and scheming, I also discuss some more practical, resource-related failure modes for successfully automating alignment research, namely: data-scarcity, schlep, not having enough time to do enough work even with an alignment MVP, and not investing enough resources (compute, money, staff) into that work. I think these more practical failure modes are extremely serious, and I don’t have fancy responses. Basically: we need to actually put in the necessary work, and to make the necessary time. And in this respect, capability restraint remains extremely important.
I close with a brief discussion of some alternatives to automating alignment research, namely:
- Easy problems that small amounts of human labor are enough to solve.
- Long timelines that allow time for larger amounts of human labor.
- Sustained global pauses/slow-downs that actively make this sort of time, or allow for slow transitions to slow, harder-to-scale forms of enhanced human labor.
- AI for whole brain emulation, which specifically allows for a fast transition to a fast, scalable form of enhanced human labor.
I’m planning to discuss some of these in more depth later in the series. To me, though, it seems unwise to bank on any of them. So despite the many ways that automating alignment research could fail, I think we should be trying extremely hard to make it work.
(The essay also includes a number of appendices, namely:
- Appendix 1, on how the failure modes I discuss in the main text apply to other applications of “AI for AI safety.”
- Appendix 2, on a variety of other more practical concerns about AI for AIs safety that I don’t cover in the main text – e.g., misuse of the meme, capabilities externalities, distracting from capability restraint, fostering complacency, etc.
- Appendix 3, on common arguments for why empirical research methods are inadequate for solving the alignment problem, with comments about why I don’t find these arguments decisive.
- Appendix 4, on whether automating alignment research requires that AIs engage with too many dangerous topics/domains.)
2. Why is automating alignment research so important?
Why is automating alignment research so important? Basically, as I said: because figuring out how to build superintelligence safely might be a ton of work; and we might need to do that work fast.
In particular: recall the two feedback loops from my last essay:
- The AI capabilities feedback loop: access to increasingly capable AI systems driving further progress in AI capabilities.
- The AI safety feedback loop: safe access to increasingly capable AI systems driving improvements to our ability to handle increasingly capable AI safely.
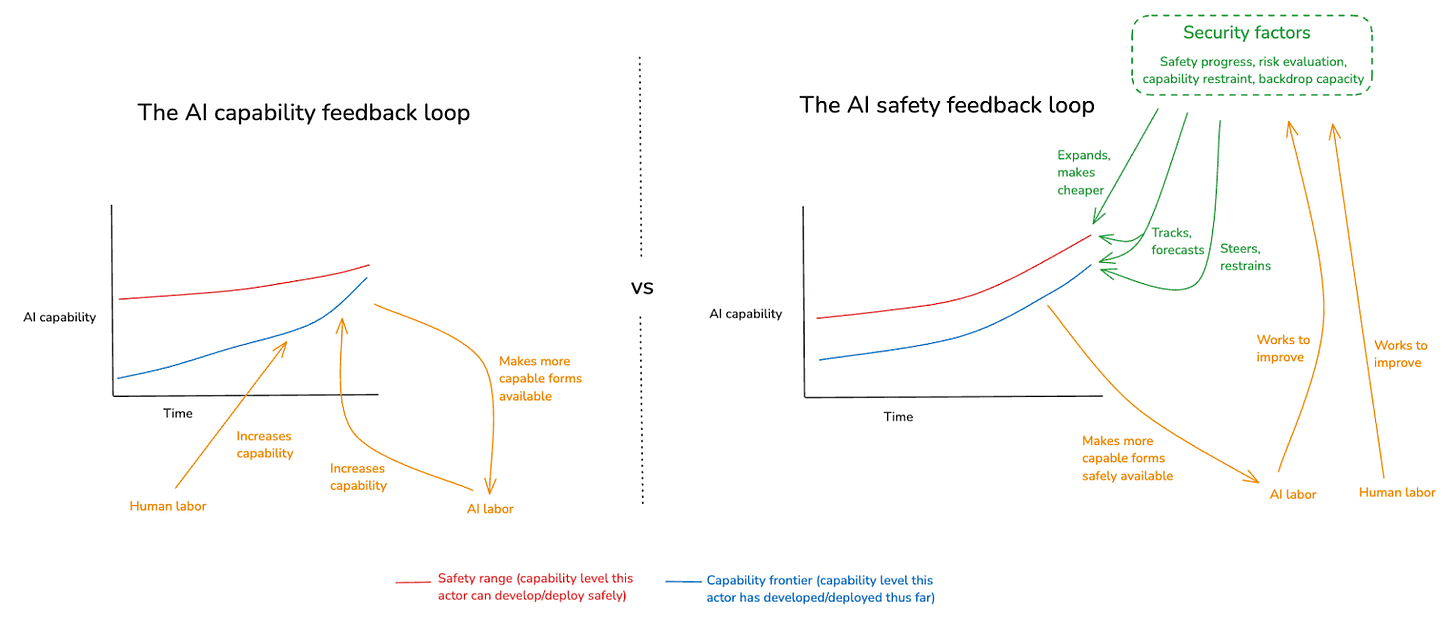
The scariest AI scenarios, in my opinion, involve the AI capability feedback loop kicking off hard. That is: it becomes possible to massively accelerate AI capabilities development using large amounts of fast, high-quality AI labor. But if the labor involved in making increasingly capable AI systems safe remains bottlenecked on slow, scarce humans, then (unless we only need small amounts of this labor) this looks, to me, like a recipe for disaster.[1] In particular: modulo significant capability restraint, it looks like the slow, scarce humans won’t have enough time.
Of course: this dynamic makes capability restraint extremely important, too. But I am worried about the difficulty of achieving large amounts of capability restraint (e.g., sustained global pauses). And for smaller budgets of capability restraint, whether or not we can safely automate alignment research seems to me central to our overall prospects.
3. Alignment MVPs
Even beyond the need to keep up with a capabilities explosion, though, I think there’s also a different sense in which automated alignment research is a very natural “waystation” for efforts to solve the alignment problem to focus on. In particular: safely automating alignment research seems both easier than solving the full alignment problem, and extremely helpful for solving the full alignment problem.[2]
In more detail: consider the task of using only human labor to figure out how to build an aligned superintelligence. Call this the “humans-only path.”[3]
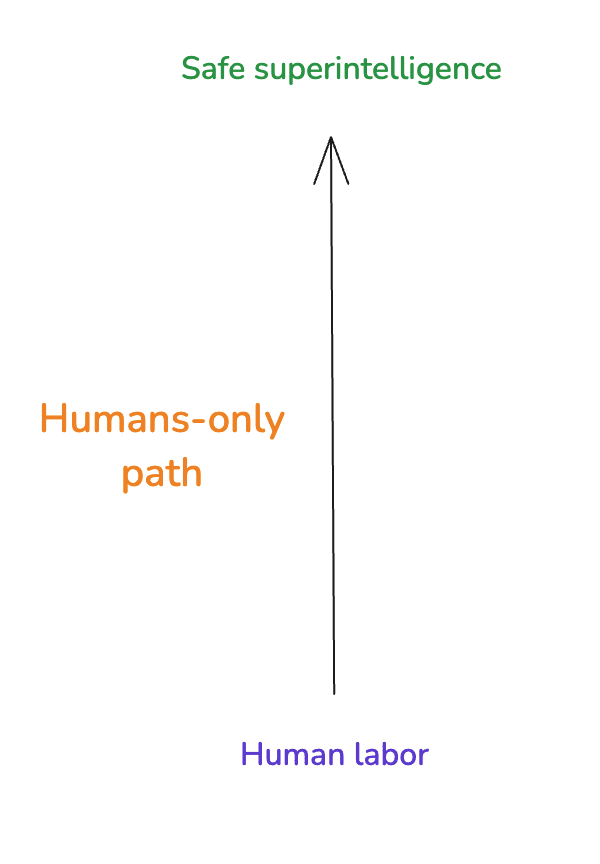
In the past, when I thought about how hard the alignment problem is, I often thought about how hard the humans-only path is. I now think that this was the wrong question.[4]
In particular: consider, instead, a path that involves first unlocking AI labor that safely performs all the cognitive tasks involved in alignment research at or above the level of top human experts. Such labor is a version of what Leike (2022) calls a “minimum viable product” (“MVP”) for alignment, so let’s call this the “alignment MVP path.”[5]
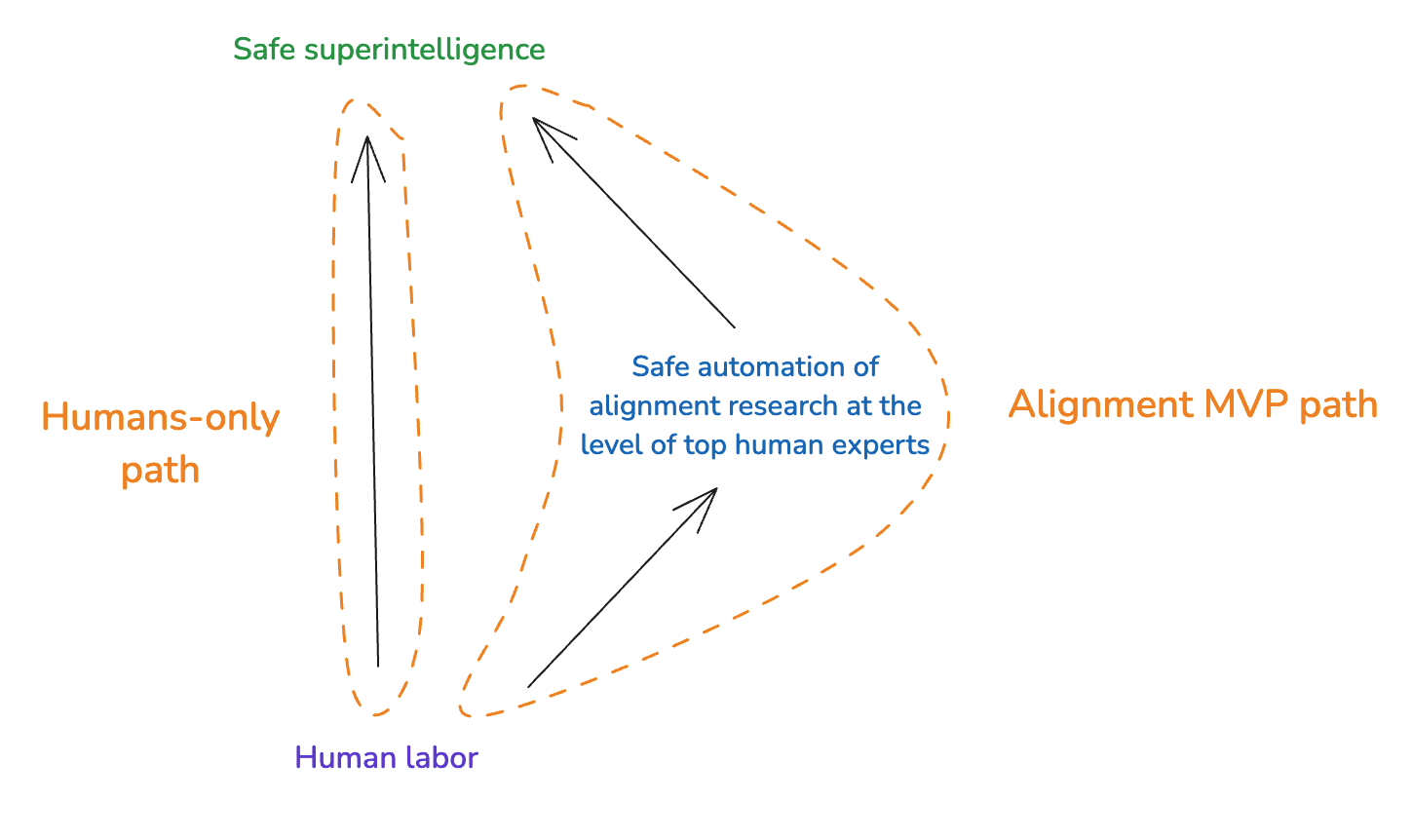
I think that the alignment MVP path is the better one to focus on. Why? Well: note, first, that if the direct path was viable, then the alignment MVP path is, too. This is because: building an alignment MVP is at least no harder than building an aligned superintelligence.[6] So if humans can figure out how to build the latter, they can figure out how to build the former, too. And if humans can figure out how to build an aligned superintelligence, then they can do so with the help of alignment MVPs, too.[7]
It could be, though, that of these two paths, only the alignment MVP path is viable. That is: maybe humans can’t figure out how to build an aligned superintelligence directly, but they (and available pre-alignment-MVP AIs) can figure out how to build an alignment MVP – and then some combination of humans + alignment MVPs + other available AIs (including more advanced AIs that alignment MVPs help with building) can get the rest of the way.[8]
What’s more: even if both paths are viable, it looks likely to me that the alignment MVP path is faster and more likely to succeed with a given budget of resources (time, compute, human labor, etc). In particular: to me, building an alignment MVP seems actively much easier than building an aligned superintelligence (though: it’s possible to dispute this).[9] And success in this respect (assuming that the direct path is also viable) means that the rest of the journey would likely benefit much faster and more scalable top-human-level research.[10]
Note, too, that in the context of capabilities development, we often take something like an “MVP” path for granted. That is: we don’t tend to imagine humans directly building superintelligence.
Rather, we imagine the progressive automation of capabilities work, until we have better-than-human automated capabilities researchers – and then we proceed to superintelligence from there (indeed: perhaps all too quickly). So it’s very natural to wonder about a similar path for alignment.[11]
3.1 What if neither of these approaches are viable?
Now: you might worry that neither a humans-only path nor an alignment MVP path are viable. For example, you might think that humans (even with the help of pre-alignment-MVP AIs) aren’t smart enough to build an alignment MVP, let alone a safe superintelligence. Or, alternatively, you might think even with an alignment MVP, we couldn’t get the rest of the way.
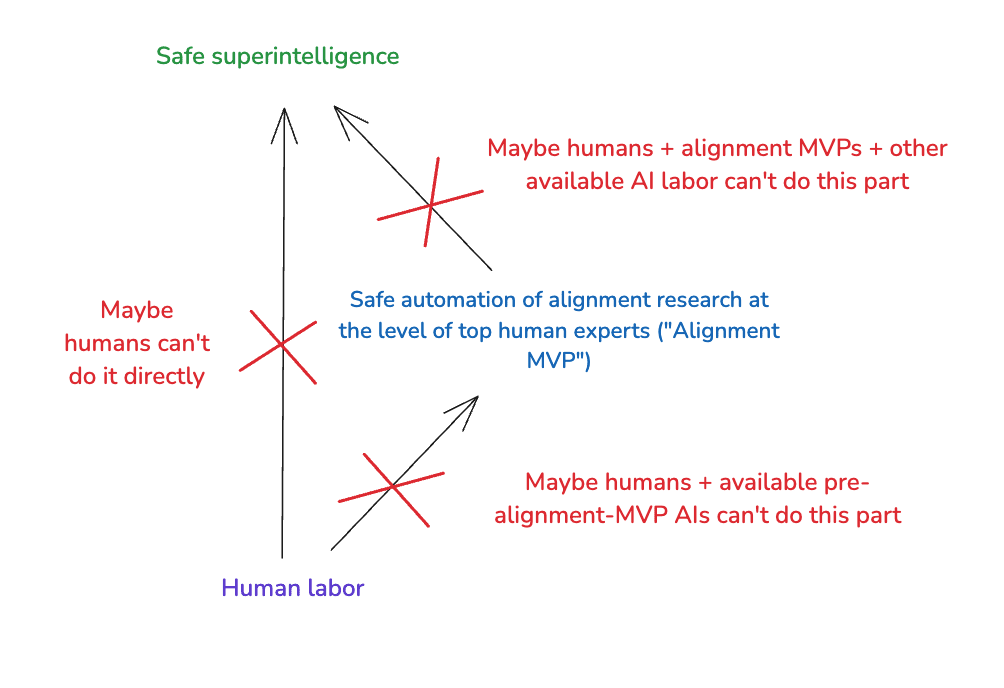
What then? One option is to never build superintelligence. But there’s also another option, namely: trying to get access to enhanced human labor, via the sorts of techniques I discussed in my post on waystations (e.g., whole brain emulation). In particular: unlike creating an alignment MVP, which plausibly requires at least some success in learning how to give AIs human-like values, available techniques for enhancing human labor might give you human-like values by default, while still resulting in better-than-human alignment research capabilities. Call this an “enhanced human labor” path.[12]
I am broadly supportive of suitably ethical and cautious efforts to unlock enhanced human labor. And I am supportive, as well, of efforts to use AI labor to help with this. I am worried that especially in short-timelines scenarios with comparatively fast take-offs, such efforts will require too much capability restraint – but it could be that this is the only way. I discuss this a bit more at the end of the essay.
Even on this kind of problem profile, though, alignment research – and including: automated alignment research (short of a full-blown alignment MVP) – can still matter. In particular: it can help produce evidence that this is the sort of problem profile we face, thereby helping motivate the necessary response.
3.2 Alignment MVPs don’t imply “hand-off”
People sometimes talk about a waystation related to but distinct from an “alignment MVP”: namely, what I’ll call “hand-off.” In the context of automated alignment research, “hand-off” means something like: humans are no longer playing a meaningful role in ensuring the safety or quality of the automated alignment research in question.[13] That is: qua alignment researchers, humans are fully obsolete. The AIs are “taking it from here.”[14]
An “alignment MVP” in my sense doesn’t imply “hand-off” in this sense. That is: the safety/efficacy of your alignment MVP might still depend in part on human labor – for example, human supervision/evaluation. Indeed, in principle, this could remain true even for significantly superhuman automated alignment researchers.
And note, too, that even if human labor is still playing a role in ensuring safety, it doesn’t necessarily need to directly bottleneck the research process – or at least, not if things are going well. For example: in principle, you could allow a fully-automated alignment research process to proceed forward, with humans evaluating the work as it gets produced, but only actively intervening if they identify problems.[15]
Of course: even if humans could still contribute to safety/efficacy in principle, the question of what role to give them in practice will remain open, and sensitive to a variety of more detailed trade-offs (e.g., re: marginal safety improvements vs. losses in competitiveness).
I’m planning to discuss hand-off in more detail later in the series. But it’s not my focus here.
4. Why might automated alignment research fail?
OK: I’ve argued that automated alignment research is both very important to solving the alignment problem, and a very natural waystation to focus on. Now let’s look at why it might fail.
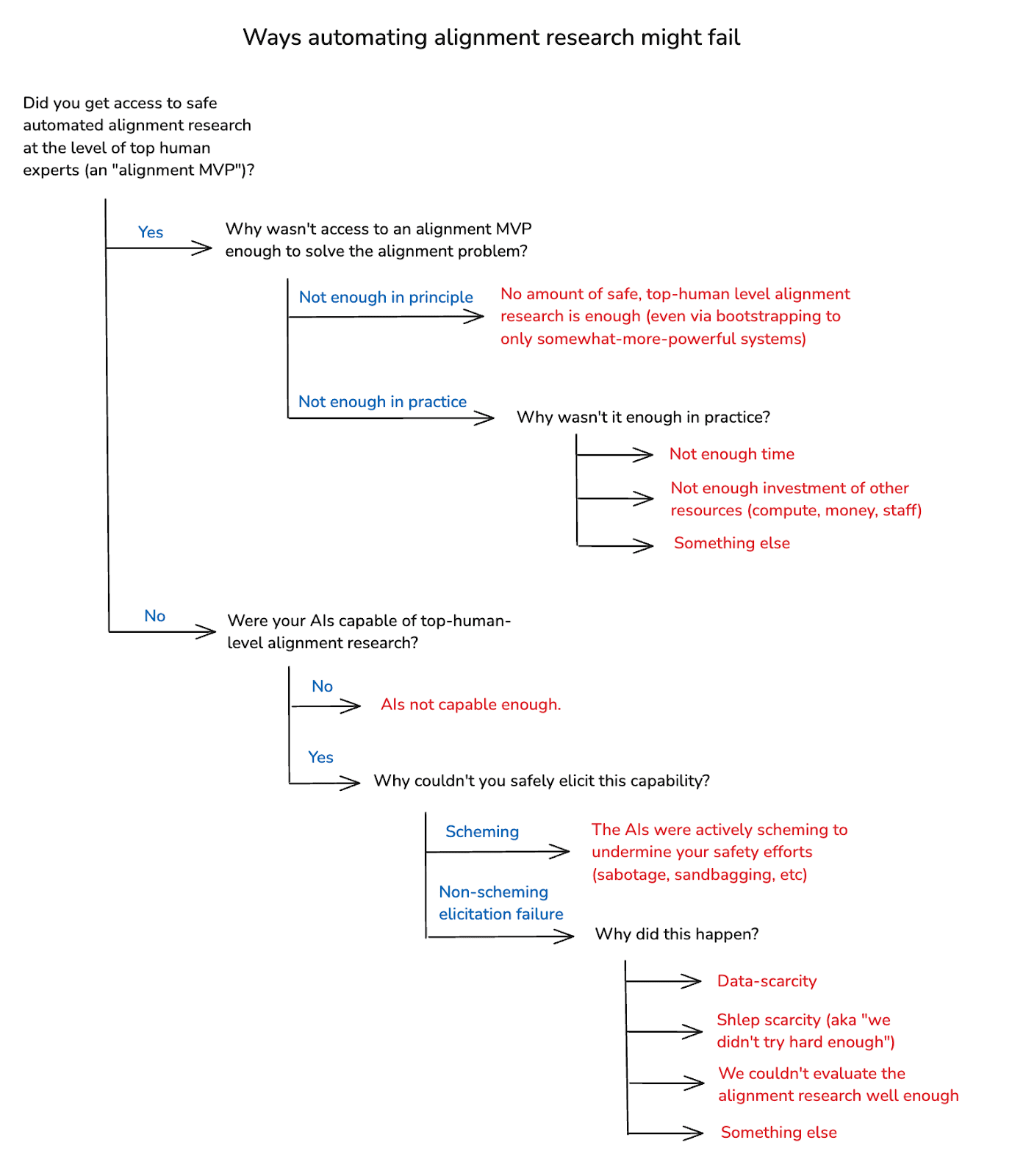
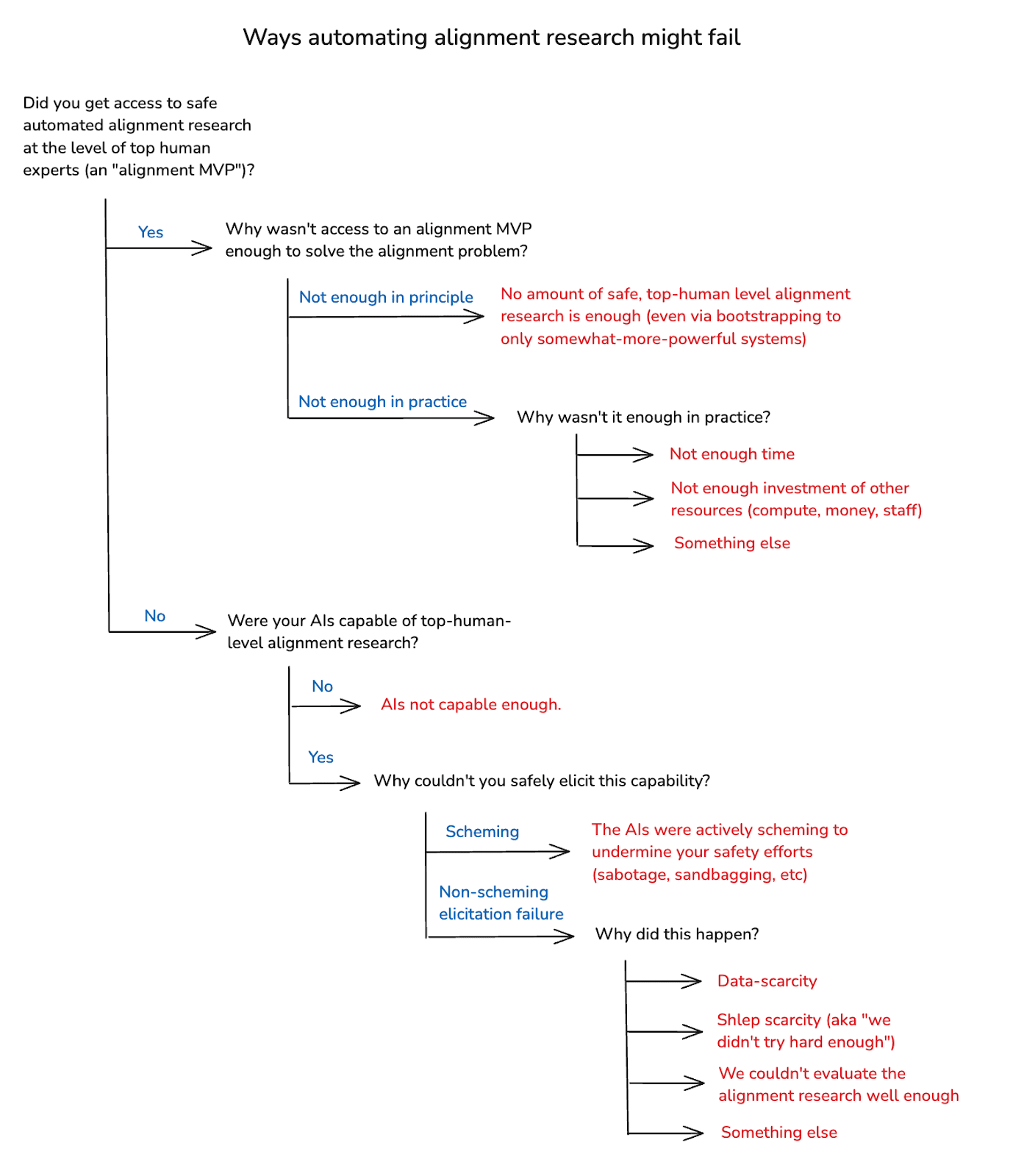
Here’s my rough breakdown of the most salient failure modes. First, start with the question of whether you got access to an alignment MVP, or not. If you did: why wasn’t that enough to solve the alignment problem?
One possibility is: it’s not enough in principle. That is: no amount of top-human-level alignment research is enough to solve the alignment problem – and: not even via bootstrapping to more capable but still-not-superintelligent systems. This is the pessimistic scenario I mentioned above, where you either need to refrain from building superintelligence at all, or pivot to an “enhanced human labor” strategy.[16] I’ll return to this at the end, but let’s set it aside for now.
Another possibility is: some amount of safe, automated top-human-level alignment research is enough in principle, but you didn’t do enough in practice. For example: maybe you didn’t have enough time. Or maybe you didn’t invest enough other resources – e.g. compute, staff, money, leadership attention, etc. Or maybe you failed for some other reason, despite access to an alignment MVP.[17] I think failure modes in this vicinity are a very serious concern, and I’ll return to them, too, at the end of the essay.
For now, though, I want to focus on scenarios where you failed to get access to an alignment MVP at all. Why might that happen?
One possibility is: your AIs weren’t even capable of doing top-human-level alignment research. And for a while, at least, that might be true. However: I expect that AIs capable of causing a loss of control scenario, at least, would also be capable of top-human-level alignment research. And note that eventually, at least, these rogue AIs would likely need to solve the alignment problem for themselves.[18] So probably, for at least some period prior to a loss of control, someone had AIs at least capable of serving as alignment MVPs.
So I’m centrally interested in a different class of scenario: namely, cases where your AIs were capable of top-human-level alignment research, but you failed to elicit that capability safely.[19] Why might this happen?
One possible reason is that your AIs were actively scheming in pursuit of problematic forms of power, and your elicitation efforts failed for that reason. For example: maybe, as part of their strategy for seeking power, your AIs actively sabotaged the research they were producing. Or maybe they intentionally withheld research at the level of top human experts (“sandbagging”). This, too, is a very serious failure mode. And I’ll discuss it, too, in more detail below.
For now, though: I also want to set scheming aside. In particular: there are other ways to fail to safely elicit top-human-level alignment research even from AIs capable of doing it. And I think it’s important to understand these failure modes on their own terms, before we bring the additional complexities that scheming creates into the picture. (These failure modes also overlap heavily with salient ways you can fail to make AIs capable of automating alignment research. So much of my discussion here will apply to that challenge as well. But I’ll focus centrally on the elicitation case.)
Why might you fail to elicit top-human-level alignment research even from suitably capable non-scheming models? One possible reason is data-scarcity. In particular: alignment is a young field. We don’t have a ton of examples of what we’re looking for, or a ton of experts that can provide feedback. And data of this kind can be crucial to successful automation (both in the context of capabilities development, and in the context of elicitation).
Another possible reason is what I’ll call “shlep-scarcity.” That is: even setting aside data constraints, AIs are generally a lot better at tasks where we try hard to make them good (again, this applies to both capabilities and elicitation). In particular: automating a given task can require a bunch of task-specific effort – e.g., setting up the right scaffolds, creating the right user interfaces, working out the kinks for a given kind of RL, etc. So: maybe you failed on elicitation because you didn’t put in that effort.
I’ll return to data-scarcity and shlep-scarcity, too, at the end of the essay. First, though, I want to focus on a potentially more fundamental barrier to eliciting top-human-level alignment research even from suitably capable, non-scheming models: namely, difficulties evaluating the relevant work. The next few sections examine this failure mode in detail.
(There are also other reasons you might get non-scheming elicitation failure; here I’m focused on what’s most salient to me.)
Here’s the full taxonomy I’ve just laid out.[20] And note that real-world failures can combine many of these.
5. Evaluation failures
OK: let’s look in more detail at evaluation failures in non-scheming, suitably-capable models.
Why is evaluating a given type of labor important to automating it? One core reason is that you can train directly on the evaluation signal. But even absent this kind of direct training, successful evaluation also allows for a broader process of empirical iteration towards improved performance. That is: in general, if you can tell whether your AIs are doing a given task in the way you want, the process of automating that task in a way you trust is a lot easier.
Example forms of evaluation failure include:
- Sycophancy: that is, the AI creates content that plays to the biases and flaws in your evaluation process.
Reward-hacking: that is, the AI directly cheats in a way that leads to good evaluations (e.g., bypassing unit tests).[21]
Cluelessness: you can’t tell what you should think about a given type of AI output.[22]
(Again: non-exhaustive.)
The concern, then, is that if we can’t evaluate alignment research well enough, we’ll get these or other failure modes in attempting to automate it at top human levels.
5.1 Output-focused and process-focused evaluation
In order to better assess this concern, let’s look at available approaches to evaluating automated alignment research in more detail.
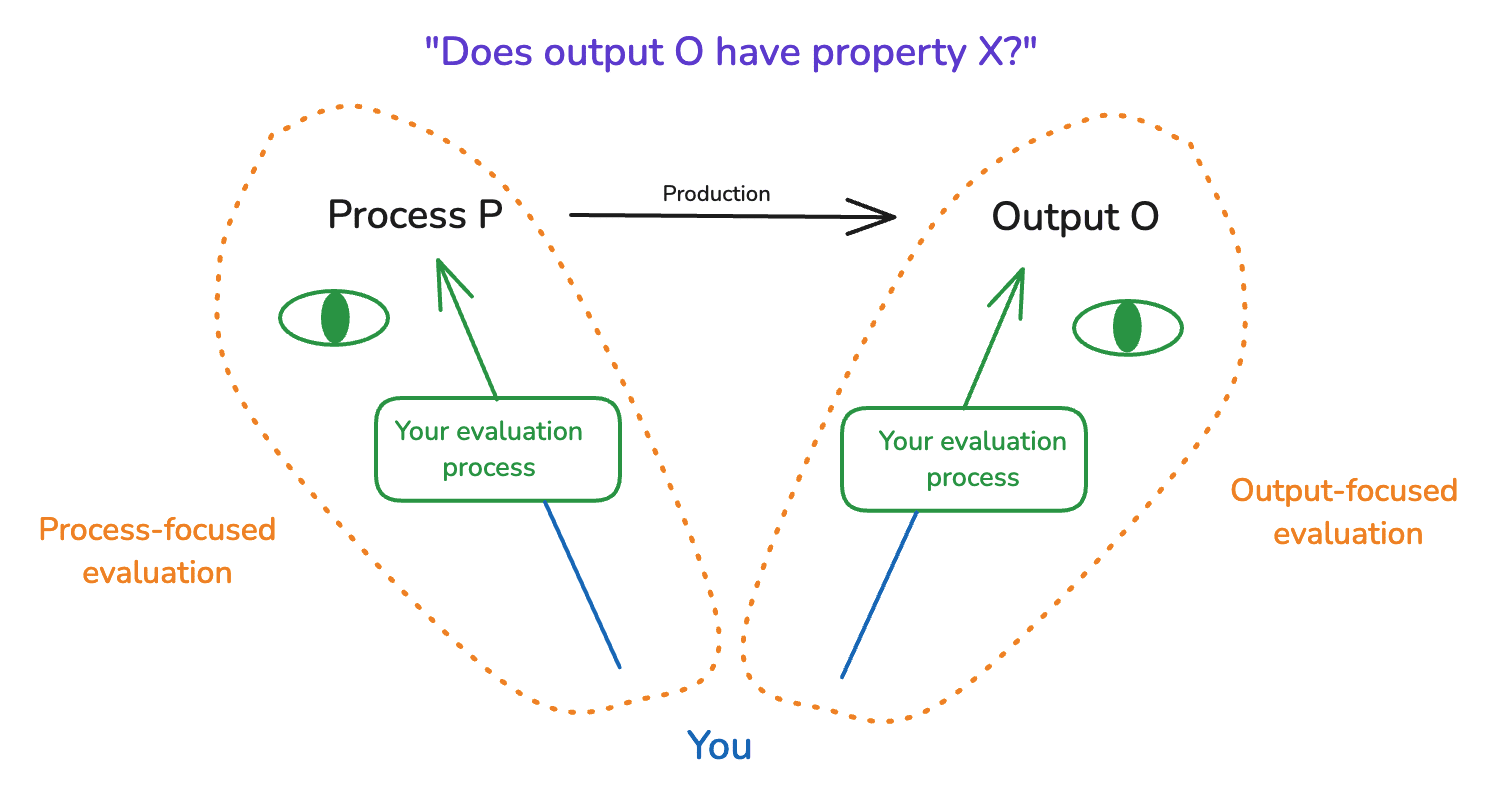
Consider some process P that produces some output O, where we want to know if that output has some property X. For example: maybe some professors write a string theory textbook, and you want to know if it’s broadly accurate/up-to-date.
We can distinguish, roughly, between two possible focal points of your evaluation: namely, output O, and process P. Let’s say that your evaluation is “output-focused” to the extent it focuses on the former, and “process-focused” to the extent it focuses on the latter.
- Thus, an output-focused evaluation of the claims in a string theory textbook might focus on reading the textbook and trying to understand the claims in question.
- Whereas a process-focused justification would focus on the reputation of the professors, the peer review process, and so on.
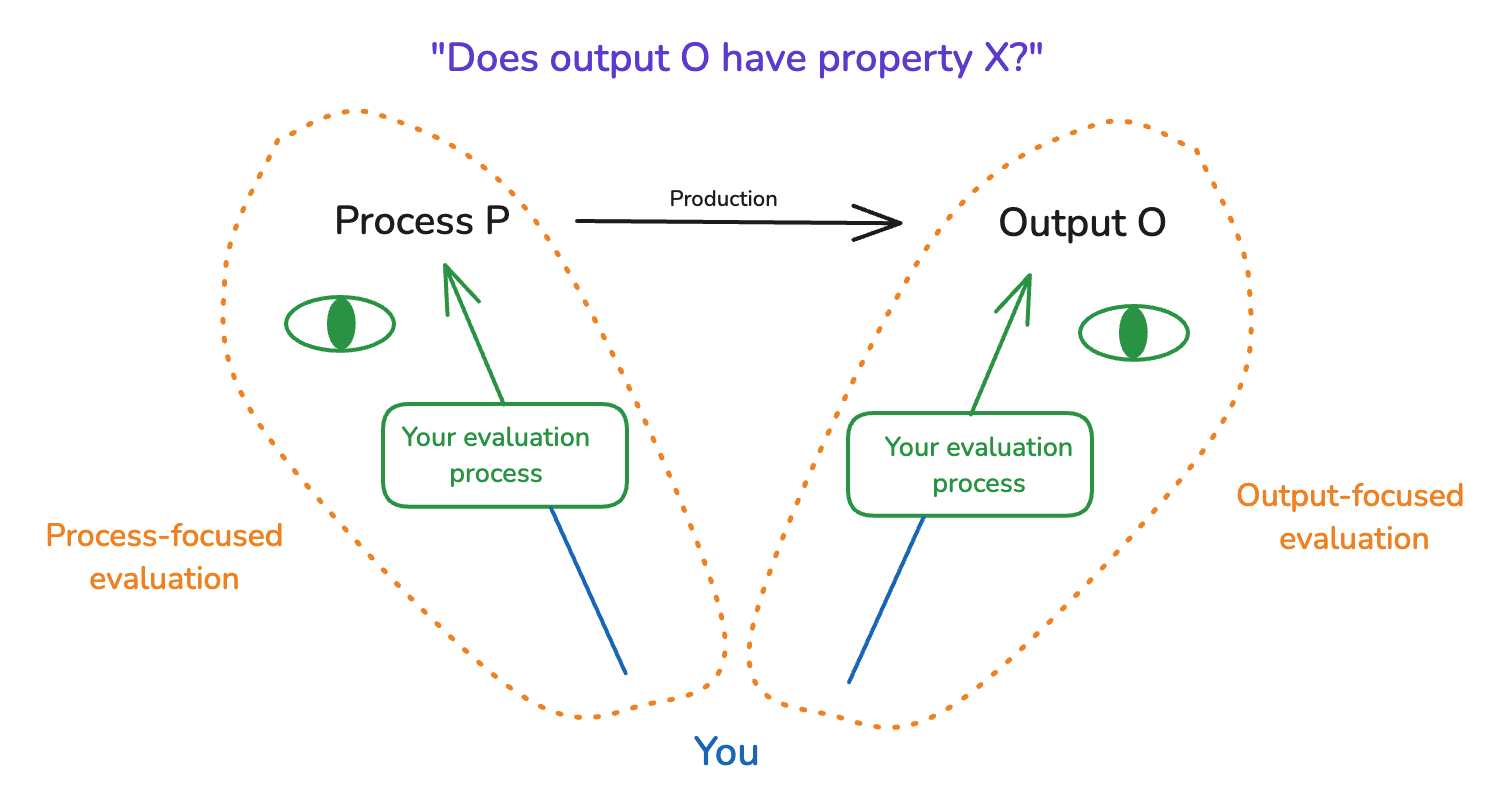
When people talk about the difficulty of evaluating alignment research, they are often implicitly talking about output-focused evaluation. And I’ll generally use the term “evaluate” in a similar way. But process-focused evaluation is important, too, especially as your output-focused evaluation ability becomes weaker.
Indeed, in reality, many epistemic processes mix output-focused and process-focused evaluation together.[23] And whether you’re intuitively in a position to evaluate something can depend on both.
- For example: suppose you’re a police investigator, evaluating the plausibility of Bob’s alibi. Bob tells a detailed, coherent story about what he was doing on the night of the murder. You judge that he is likely telling the truth, partly because the story is so detailed and consistent (output-focused), and partly because you think it unlikely that Bob could make up a fake story with this level of detail and consistency (process-focused).
- If Bob were a superintelligence, though, he could make up a fake story with this level of detail and consistency. So: the evidence that your output-focused evaluation provides depends in part on your knowledge of the process that produced the output in question.
- Similarly: if I’m evaluating whether one of my employees has written buggy code, my process might be robust enough to catch any “innocent mistake” bugs, but not bugs that the employee is intentionally trying to hide from me. But if I’m also in a position to process-focused evaluate whether my employee is likely to be intentionally trying to hide bugs from me, then my overall evaluation can still work.
Sometimes, when people talk about the difficulty of output-focused-evaluating automated alignment research, they are imagining that we need this evaluation to be robust to superintelligent schemers intentionally sabotaging the research in question. But the automated alignment researchers I’m interested in here don’t need to be superintelligences (they just need to be as good at alignment research as top human experts). And they won’t necessarily be schemers, either. Indeed: for now, I’m assuming they’re not.
5.2 Human output-focused evaluation
One obvious, baseline method of output-focused evaluation is just: humans evaluate the research directly, the same way they would evaluate similar research produced by human colleagues.[24] And to the extent we’re just trying to replicate top-human-level performance, we might think that direct human evaluation should be enough, or close to it (at least in principle – e.g., modulo issues like data-scarcity). After all: that’s what we normally do to figure out what work is top-human-level. And human researchers have to be evaluating their own work as they produce it. Indeed: if you thought the “humans-only” path above was a viable (even if: inefficient) approach to solving the alignment problem, doesn’t that assume that human researchers are capable of evaluating alignment research well enough to recognize a solution to the problem?
Well: it assumes that humans are capable of evaluating human-produced alignment research well enough. But in the context of human researchers, you often have the benefit of certain kinds of process-focused evaluation, too. In particular: you might have good evidence that a human researcher (e.g. yourself, or one of your colleagues) is mostly trying his/her best to produce good research, rather than to engage in the equivalent of sycophancy, reward-hacking, etc (or sabotage, sandbagging, etc, if we bring scheming into the picture). Whereas this sort of process-focused evidence might be harder to come by with AIs. So adequate output-focused evaluation might become correspondingly more difficult.
Also: humans disagree about what existing alignment research is good.[25] And there’s a question of how to think about the evidence this ongoing disagreement provides about the power of direct human evaluation.[26] At the least, for example, ongoing disagreement raises questions about “top-human-expert alignment research according to who?”.[27]
5.3 Scalable oversight
Now: in thinking about the difficulty of output-focused evaluating alignment research, we shouldn’t limit ourselves to direct human evaluation. Rather, we also need to include ways that AIs can amplify our evaluation ability.
I’ll use the term “scalable oversight” for this. Possible techniques include:
- Imitation: You can train AIs to imitate human judgments/decisions, and then use them to replace humans in an evaluation process, but in a way that allows you to leverage AI advantages re: speed, time, etc.
Decomposition: You can decompose the evaluation process into smaller tasks, and try to get humans/AIs to help with the individual tasks – and eventually, also, with decomposing tasks well.[28]
- Debate: You can have AIs debate questions relevant to the evaluation, with humans initially judging the debates (and then, potentially, AIs trained to imitate those judgments).
- Constitutions: You can try to distill your evaluation process into explicit principles/specs/algorithms/constitutions, which AIs are trained/instructed to follow (and you can attempt to use AIs to improve the principles in question).
- Expensive versions. You can use very expensive versions of AI labor (e.g., large teams of AIs running for a long time) for certain evaluations – for example, evaluations you then use as training data for imitation. (And note that you can do expensive versions of human-centered evaluation as well – e.g. more human labor, of higher quality, with more time to work, with more resources available, etc.)
Distillation. For a (potentially expensive) evaluation process consisting of any combination of the above, you can train AIs to imitate the output of that, and then use those AIs as part of a new evaluation process.[29]
It’s an open question how far these various techniques go on output-focused evaluation, and in the context of what threat models (for example: if we set aside concerns about scheming, vs. not). One concern, for example, is that for suitably difficult evaluation tasks, techniques like decomposition and debate won’t go very far. A giant team of average M-turkers, for example, seems poorly positioned to evaluate a novel piece of string theory research, even if the task gets broken down into lots of sub-tasks, and even if the M-turkers get to listen to AIs debate relevant considerations. And perhaps, faced with AIs producing superhuman string theory research, human string theory researchers trying to evaluate it using scalable oversight would be in a similar position.[30]
Note again, though, that we’re not, here, interested in the challenge of using scalable oversight to evaluate strongly (and still less: arbitrarily) superhuman alignment research. Rather: we’re interested in the challenge of using scalable oversight to evaluate alignment research at the level of top-human experts. And this seems substantially easier.
5.4 Process-focused techniques
What about process-focused evaluation? We can think of process-focused evaluation as a problem of understanding generalization. That is: we want to know how our AIs will generalize from domains where our output-focused evaluation methods are stronger to ones where they are weaker. How might we gain this understanding?
I’ll discuss this a bit more in future essays, but for now, I’ll flag two broad categories of evidence that can be especially relevant here:
- Behavioral science of generalization. The first is just: studying AI behavior in depth, and using this to strengthen our understanding of how AIs will generalize to domains that our scalable oversight techniques struggle to evaluate directly.
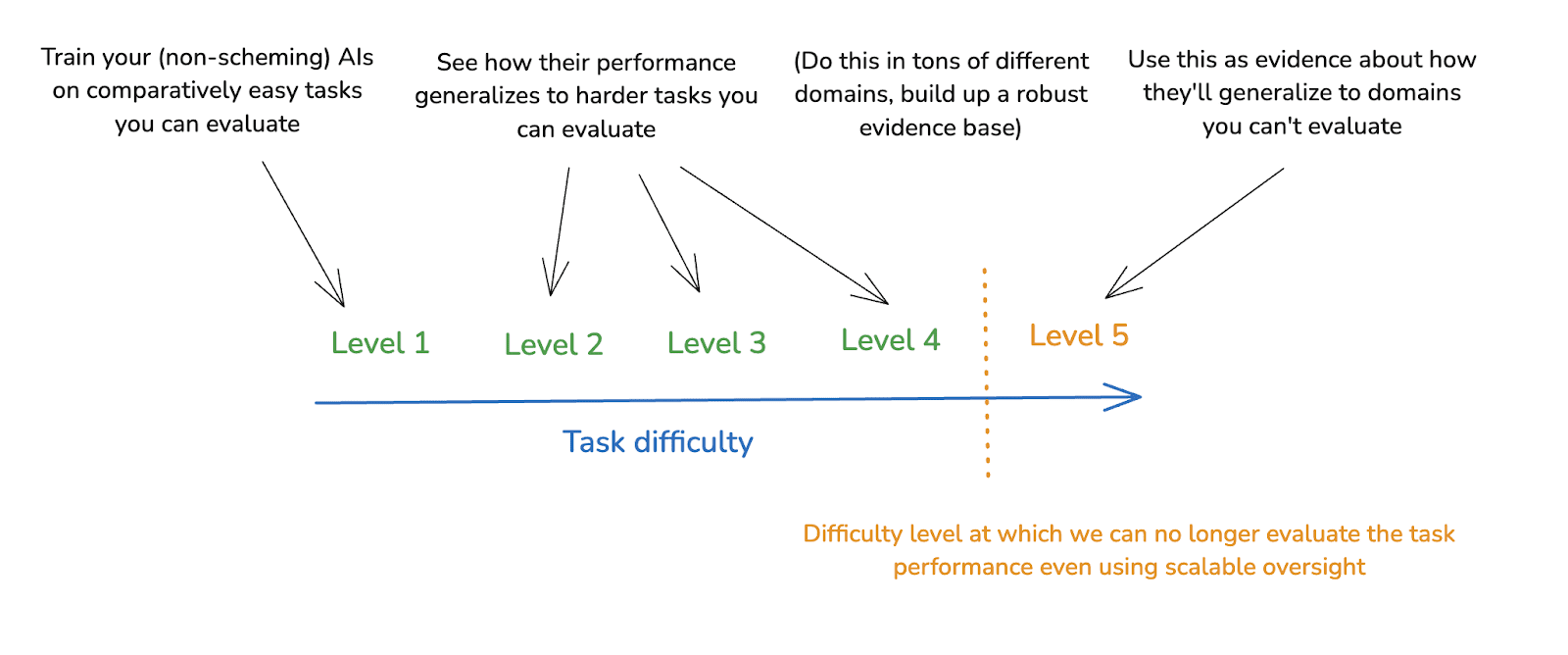
- Work in the vicinity of “weak to strong” generalization is a paradigm example here. Thus, for example: if you can evaluate physics problems of difficulty level 1 and 2, but not difficulty level 3, then you can train an AI on level 1 problems, and see if it generalizes well to level 2 problems, as a way of getting evidence about whether it would generalize well to level 3 problems as well.
- (This doesn’t work on schemers, or on other AIs systematically and successfully manipulating your evidence about how they’ll generalize, but see discussion of anti-scheming measures below.)
Training AIs to directly imitate top-human-level researchers is another possible example here.[31] That is: if you can actually get an AI to create safe, robustly-Bob-level output simply by training it to imitate enough existing Bob-output, such that you trust this AI to act like Bob even in domains you can’t output-focused evaluate, then this is a fast path to an “alignment MVP” (assuming that Bob is a top-human-expert alignment researcher).
Whether this sort of imitation learning works in principle (though, let’s assume, without being able to train on Bob’s thoughts directly) or in practice (e.g., given realistic constraints on the Bob-data available) is a very open question. But it seems quite amenable to behavioral investigation.
- Work in the vicinity of “weak to strong” generalization is a paradigm example here. Thus, for example: if you can evaluate physics problems of difficulty level 1 and 2, but not difficulty level 3, then you can train an AI on level 1 problems, and see if it generalizes well to level 2 problems, as a way of getting evidence about whether it would generalize well to level 3 problems as well.
- Transparency: Beyond AI behavior, though, we can also use methods aimed at understanding more “internal” factors like thoughts and motivations, as a method of strengthening our evidence about how our AIs will generalize.
- Thus, as an extreme case, if you had sufficiently strong transparency tools that you could tell what an AI is trying to do, then even if you can’t evaluate its output, you could get strong evidence it’s trying its hardest to create the sort of output you want.
- But weaker forms of transparency – e.g., ruling out certain kinds of active deception – can be helpful, too.
Now: scheming AIs could mess with the evidence provided by our behavioral science (and perhaps, for AIs capable of manipulating their internal states, by our transparency tools as well). So detecting and preventing scheming (along with other ways AIs might intentionally and systematically mislead you about how they’ll generalize) is an especially important aspect of process-focused evaluation. I discuss options in this respect more in future essays (and see also here for a list of research directions), but broadly: both behavioral science and transparency are relevant.
These more process-focused techniques can combine with more output-focused scalable oversight techniques to produce an overall verdict about whether an AI’s task-performance is desirable.[32] And they become more important as the signal provided by our output-focused scalable oversight techniques becomes weaker, or if it disappears entirely.[33]
6 Comparisons with other domains
OK: in the last section, I briefly introduced some of the barriers that evaluation failures might pose to eliciting top-human-level alignment research even from suitably capable non-scheming AIs; I discussed a few examples of these failures (e.g. sycophancy, reward-hacking, cluelessness, etc); and I discussed some of the available approaches to evaluation (e.g. direct human evaluation, scalable oversight, and process-focused techniques like behavioral science and transparency).
In this section, I want to talk about how the challenge of evaluating automated alignment research compares to the challenge of evaluating AI labor in other domains. I think this helps bring some of the most distinctive-to-alignment challenges into clearer focus.
6.1 Taking comfort in general capabilities problems?
The need for good evaluation is very much not unique to automated alignment research. To the contrary, it’s a general issue for automating tons of economically valuable tasks.
Thus, for example: consider capabilities research. Already, we see models reward-hacking. But they’re reward-hacking, for example, on the type of coding tasks core to capabilities research. And sycophancy, too, is already a general problem – one that we can imagine posing issues for capabilities research as well. E.g., maybe you try to get your AIs to help you make an overall plan for building AGI, and their response plays to the biases and flaws in your own model of AI capabilities, and the plan fails as a result.
So: to the extent that these problems bite in the context of capabilities research, we should expect them to slow down the AI capabilities feedback loop I discussed above. And we should expect a lot of effort, by default, to go towards resolving them.
But it’s not just capabilities research. Good evaluation – including, in fuzzier and less quantitative domains – is crucial to automating tons of stuff. Consider: coming up with creative product designs; or effective business strategies; or new approaches to curing cancer. And even if these tasks can be evaluated via more quantitative metrics in the longer-term (e.g., “did this business strategy make money?”), trying to train on these very long-horizon reward signals poses a number of distinctive challenges (e.g., it can take a lot of serial time, long-horizon data points can be scarce, etc).
Here I’m especially interested in comparisons between alignment research and other STEM-like scientific domains: e.g., physics, biology, neuroscience, computer science, and math. By default, I expect lots of effort to go towards automating top-human-level research in at least some of these domains – e.g., biology (cf “curing cancer” above). So if the evaluation difficulties in these domains are comparable to the evaluation difficulties at stake in alignment research, then we should expect lots of effort to go towards developing techniques for resolving those difficulties in general – e.g., in a way that would plausibly transfer to alignment research as well. And by the time we can automate these other STEM fields, we would then have grounds for optimism about automating alignment research as well.[34]
Indeed, in general: while alignment research and capabilities research have always been importantly tied together, this is especially true in the context of eliciting intended task-performance from non-schemers. And this includes domains where direct human evaluation isn’t adequate (in this sense, for example, “scalable oversight” is clearly central to capabilities research as well). True, this dynamic might make alignment researchers worried about capabilities externalities. But it should also be a source of comfort: by default, you should expect strong economic incentives towards figuring the relevant evaluation challenges out.
That said: I also think there are limits to the comfort that comparisons between evaluation challenges in alignment research vs these other domains (capabilities research, other sciences) can provide.
- For one thing: evaluation failures in these other domains might be lower-stakes. Thus: if reward-hacking or sycophancy leads to bugs, delays, wasted effort, etc in the context of capabilities research – well, OK. The training run fails; you pick yourself up; you try again. Whereas: if reward-hacking or sycophancy leads to critical flaws in a safety case meant to prevent catastrophic behavior in AIs, then you might not get to “try again”; or if you do, the mistake might’ve been quite costly.
- Also: at least for non-capabilities domains like biology, we might just solve the relevant evaluation problems with too little time left, and/or using much more powerful systems that are at much greater risk of scheming.
- Thus, for example: it could be that most of the intelligence explosion proceeds without much effort to automate sciences like biology, because it makes most sense to focus on (a) automating capabilities R&D, and (b) doing a ton of it.
- And it could be, too, that the way we end up automating work in domains we can’t evaluate very well is by training our AIs in domains where we have crisp, quantitative metrics, until they gain general-purpose capabilities that transfer adequately to domains we can’t evaluate so well. It’s possible, though, that this path requires building significantly more powerful and general AIs, and hence entails greater danger of threats like scheming.
- Most importantly, though: alignment research might be especially hard to evaluate even relative to these other domains. Let’s look at that issue now.
6.2 How does our evaluation ability compare in these different domains?
Why might alignment research be harder to evaluate than both (a) capabilities research, and (b) other STEM-like sciences like physics, biology, neuroscience, computer science, and math? Here’s my current rough picture. It’s highly simplified, but I’m hoping it can be instructive nonetheless.
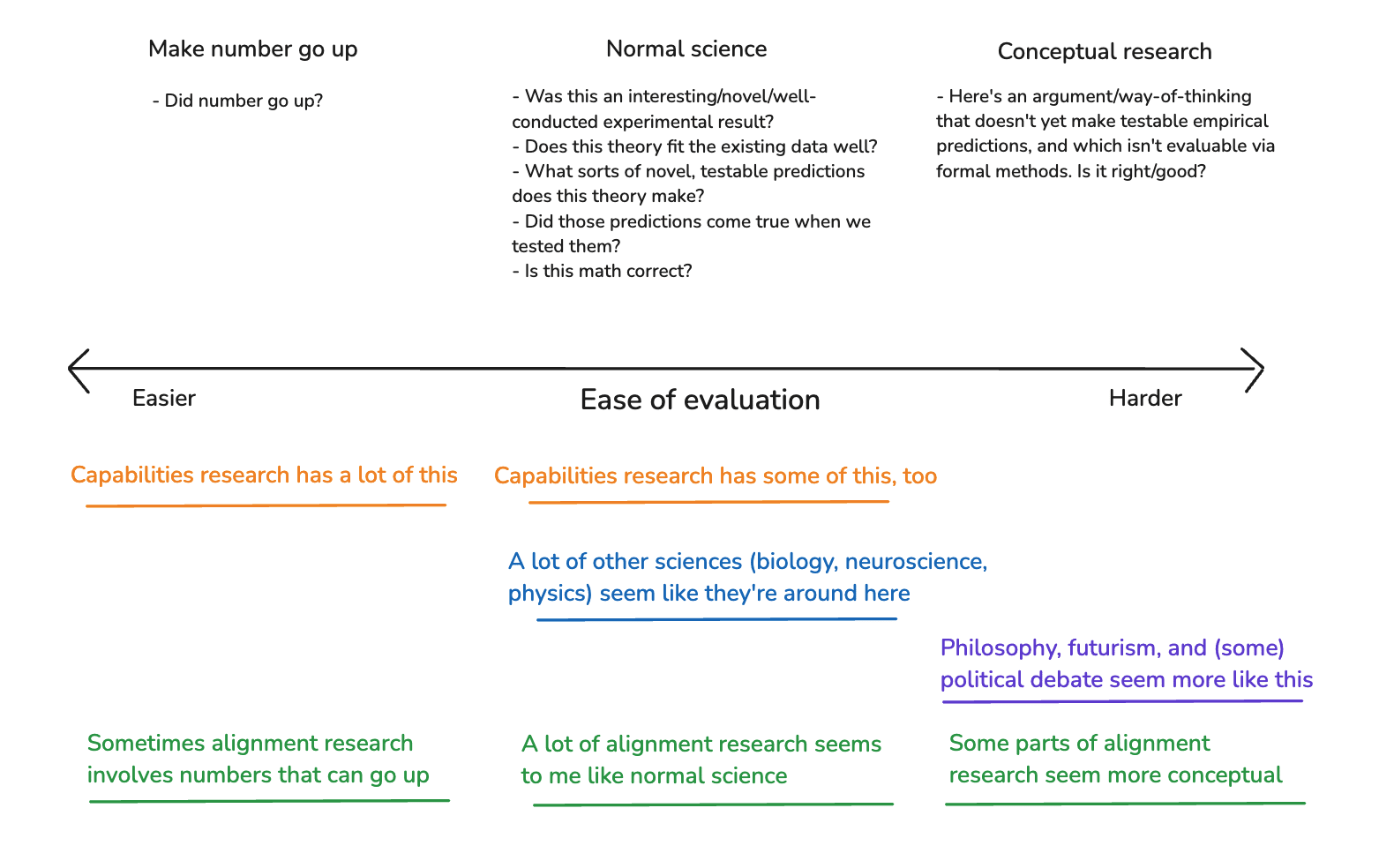
6.2.1 Number go up
We can distinguish between three broad sorts of domains, according to how work in these domains gets evaluated. I’ll call the first sort “number go up” domains. Here, we have some very crisp, quantitative metric (the “number”) that we can use for training and evaluation. A paradigm example would be something like: cross-entropy loss in the context of predicting internet text.
Capabilities research, famously, benefits a lot from quantitative metrics of this kind. Indeed, my sense is that people sometimes think of AI capabilities development as uniquely easy precisely because it can be pursued via optimizing such a wide variety of quantitative metrics.[35]
And sometimes, we can give alignment research a “number go up” quality, too. For example: you can train AIs to do better on metrics of helpfulness, harmlessness, and honesty; you can reduce their rates of reward-hacking, alignment faking, sycophancy, chain-of-thought unfaithfulness, etc; you can work to improve the degree of weak-to-strong generalization; and so on.
6.2.2 Normal science
When we evaluate work in empirical sciences like biology, physics, and so on, though, we typically ask many questions other than “did this quantitative metric improve?” For example: we often ask questions like: “Was this a useful/interesting/productive/well-conducted experiment? How should we interpret the results? Does this interpretation of the results fit with the rest of our data? What sorts of predictions does it make? What would be a productive new experiment to try?” and so on. And these questions are notably “fuzzier.”
Still, though: I think the human track record of evaluating research in STEM-like sciences is fairly strong. For example: we’ve made a lot of clear progress over the years, with lots of consensus amongst recognized experts.
Why such success? Two factors stand out to me.
- The first factor is empirical feedback loops. That is: even in the absence of crisp metrics of progress, many STEM-like sciences involve lots of contact with some empirical phenomenon susceptible to manipulation and experiment, such that ideas, concepts, and hypotheses are constrained via their fit to a rich array of empirical data, and tested and refined in iterative contact with new data.
The second factor is formal evaluation methods – that is, roughly, the sorts of evaluation methods at stake in math and formal logic. And this doesn’t need to be at the level of “we can use a theorem-prover”; even merely human evaluation has historically done decently well on questions like “is this math correct?”.[36]
Indeed, scientific domains often seem to me intuitively weaker and harder to evaluate to the extent these two factors aren’t present. Thus, for example: neuroscientists are comparatively limited in their experimental access to the brain, and so have a harder time making progress; theoretical physics debates that don’t make testable experimental predictions are harder to resolve (though formal evaluation methods can still help); economists often can’t perform controlled experiments and so are stuck curve-fitting to already available data; etc.[37]
I am not an AI capabilities researcher, but my impression is that various aspects of capabilities research are reasonably continuous with “normal science.” That is: capabilities research isn’t just a process of blindly iterating until some number goes up. Rather, it involves the sort of creativity, research taste, data interpretation, hypothesis generation, prioritization between experiments, etc that we associate with other types of empirical science. And evaluating capabilities research involves evaluating these skills.
And I think a lot of alignment research (what I’ll call “empirical alignment research”) is like “normal science,” too. That is, even in the absence of some simple quantitative metric of progress, attempts to evaluate this sort of research can draw on a rich array of empirical results, predictions, and further experiments (plus, sometimes, formal methods, though I view these as less central).
What sort of “empirical alignment research” do I have in mind? This recent list of technical research directions from Anthropic is a good illustration; and see, also, this recent RFP from Open Philanthropy.[38] More specific examples might include:
- Greenblatt et al (2024) inducing alignment faking behavior in Claude;
- Betley et al (2025) showing that LLMs fine-tuned on insecure code become notably misaligned;
- Lindsay et al (2025) analyzing internal circuits at work in a variety of interesting model behaviors (for example, a model working backward to figure out what kind of false answer to give in an unfaithful chain of thought) and using interventions on the relevant features to validate the causal structure of this analysis.
- Baker et al (2025) showing that training against bad intentions displayed in a chain of thought hides but does not remove reward-hacking behavior;
- Burns et al (2023) testing whether weak supervision can elicit the capabilities of stronger models.
- Farquhar et al (2025) showing that myopic training can reduce reward hacking.
- Marks et al (2025) examining whether different auditing techniques could detect hidden objectives in language models.
In all these cases, that is, the relevant research is heavily focused on empirical experiment. And in this respect, it strikes me as notably similar to more scientific/experimental work in capabilities, along with work in other domains like biology, neuroscience, and physics. Of course: you still need to interpret the empirical results in question, and to evaluate different candidate interpretations. But this is true in these other domains as well. And the candidate interpretations at stake will often, themselves, make further empirical predictions you can test.
- Indeed, relative to domains like biology, neuroscience, and physics, empirical alignment research seems to me an unusually empowered empirical discipline, because it has such strong experimental access to ML models (both: to their behavior, and to their internals), and because you can perform experiments and test hypotheses at computer-speeds, rather than being bottlenecked by slower physical processes.
- This speed advantage becomes especially salient as the cognitive labor involved in running ML experiments becomes automated – automation that the AI capabilities feedback loop already requires.
- And sometimes, at least, I think that empirical alignment research has an advantage over capabilities research as well – namely, that the relevant experiments often require much less compute.
That said: this may not always hold true. For example: if it turns out that default forms of pre-training give rise to scheming models, and we need to start doing lots of experiments with different forms of pre-training in order to see if we can avoid this, the experiments at stake could get compute-intensive fast.[39]
Overall, then, I tend to think of the evaluation challenges at stake in automating empirical alignment research as broadly comparable to the evaluation challenges at stake in automating research in areas like physics, biology, neuroscience, and so on; and comparable, plausibly, to automating certain aspects of capabilities research as well. Granted: these challenges seem harder than in more centrally “number go up” domains. But I think humanity’s track-record of success in these other domains – along with the default economic incentives to automate them – should make us reasonably optimistic.
6.2.3 Conceptual research
For research in some domains, though, our evaluation efforts can’t benefit from strong empirical feedback loops or from formal evaluation methods. Rather, our central tool, for evaluating this kind of research, is … thinking about it. And also: arguing. But not in a way where: after thinking about it, you get to see the answer. Rather: you think about it, you argue, you come to a view, and … that’s it.
I’ll call this sort of research “conceptual research.” Paradigm examples, to my mind, include philosophy, futurism, and certain kinds of political debate.
- To be clear: work in these domains can draw on empirical data, too. And often (for example, in the context of futurism), there is in fact a ground-truth empirical answer (e.g., what will in fact happen in the future). It’s just that: you don’t have access to that answer at the time you need to evaluate the work in question.
- Also: conceptual research, as I’m understanding it, is defined by the methods available for evaluating it, rather than the cognitive skills involved in producing it. For example: Einstein on relativity was clearly a giant conceptual breakthrough. But because it was evaluable via a combination of empirical predictions and formal methods, it wouldn’t count as “conceptual research” in my sense.
Unfortunately: compared to what I called “normal science,” the human track record of evaluating conceptual research looks to me pretty weak. To be clear: I do think that humans-thinking-about-it can provide some signal.[40] And I think we have in fact seen progress in areas like philosophy, politics, religion, ethics, futurism, etc. Still, though, we also see very widespread, persistent, and hard-to-resolve disagreement amongst humans in these domains – much more so, I think, than in the more empirical sciences. And this makes relying on human evaluation ability in these domains seem, to me, correspondingly dicey.
- Of course, as I tried to emphasize above: the evaluation task here isn’t to identify the truth per se. Rather, it’s to develop evaluation methods adequate to elicit top-human-level research from AIs capable of performing it (and then: to do a ton of that research to reach, eventually, suitably accurate understanding). And in domains like philosophy, at least, there is often a reasonable amount of consensus about what counts as top-quality work, even if there is much less consensus about the object-level answers. But I think even this level of non-consensus is still reason for pessimism.
What’s more, unfortunately: some kinds of alignment research look to me, centrally, like conceptual research. This sort of research focuses on things like: developing and critiquing alignment approaches that aren’t yet testable empirically; improving our theoretical understanding of the nature of agency and intelligence; formalizing alignment-relevant concepts more clearly; identifying and clarifying alignment-relevant threat models; creating overall strategies and safety cases; and so on.[41] Examples of alignment research in this vein might include:
Early work on scalable oversight techniques, like Christiano et al (2018) on iterated amplification and distillation;[42] Irving et al (2018) on AI safety via debate; and Leike et al (2018) on recursive reward modeling.
- Efforts like Kenton et al (2022) and Garrabrant et al (2021) to formalize notions of agency.
- Christiano et al (2024) attempting to formalize the notion of defendability against backdoors.
- Garrabrant et al (2016) attempting to formalize reasoning under logical uncertainty.
- Bostrom (2014) giving an early version of the case for concern about the alignment problem.
- Hubinger et al (2019) analyzing risks from learned optimization.
- Christiano et al (2021) developing the eliciting latent knowledge agenda.
Shah et al (2025) on Google DeepMind’s overall approach to AGI safety.[43]
Sometimes this sort of alignment research becomes amenable to useful empirical study, even though it wasn’t initially. For example: as AI capabilities have advanced, we’ve become better able to test various hypotheses coming out of previously-more-theoretical discussions of deceptive alignment, scalable oversight, and so on. But per my comments above, I’m thinking of research as “conceptual” insofar as our evaluation of it can’t benefit from empirical tests/feedback loops prior to the point where we need to evaluate it.
Now: it’s not yet clear whether, in practice, automating conceptual research – including, conceptual alignment research – at top human levels is actually going to be much harder than automating more empirical sorts of scientific research. Indeed, frontier AIs already seem to me decent at philosophy (better, for example, than most smart undergrads), and I’ve found them helpful thought partners in thinking through various conceptual questions. And we can imagine reasons why automating conceptual research might be actively easier than more empirical research – for example: evaluation/feedback doesn’t need to be bottlenecked on real-world experiment.
Still: when I think about the possibility of evaluation failures, in particular, creating problems for automating alignment research, I feel most concerned about conceptual alignment research in particular.
Here's a diagram of the overall picture I just laid out:
7. How much conceptual alignment research do we need?
Now, in my experience, some people think that conceptual alignment research is basically the only kind that matters, and some people think it’s basically irrelevant. And if it were basically irrelevant even to the project of building a safe superintelligence, then an adequate “alignment MVP” wouldn’t actually need to automate conceptual alignment research at all.
7.1 How much for building superintelligence?
So: do we need lots of additional conceptual alignment research in order to build safe superintelligence? Some common arguments for this strike me as inconclusive (more in Appendix 3). But I’m still going to assume: yes. In particular: I expect that along the full path to safe superintelligence, it will be important to develop and successfully evaluate hypotheses, reconceptualizations, new depths of understanding, research agendas, safety cases, threat models, high-level strategies, and so on that can’t be immediately evaluated/tested via their empirical predictions (or via formal methods). And I think some work of this kind, at least, has been important in the past.
7.2 How much for building an alignment MVP?
That said: it’s a different question whether we need lots of additional conceptual alignment research in order to build an alignment MVP – and in particular, whether the amount we need is such that it would be feasible for humans to do most of it, or whether we would need lots of AI help. (If we need lots of AI help, then on pain of circularity, that help would itself need to come from something other than an alignment MVP.)
Here, I am cautiously optimistic that for building an alignment MVP, major conceptual advances that can’t be evaluated via their empirical predictions are not required. Rather, the main thing we need is a ton of empirical alignment research of the broad kind that we’re already doing – and which I think we should be especially optimistic about evaluating, and hence automating.[44]
- If it sounds circular/paradoxical to think that you wouldn’t need a ton of conceptual alignment research in order to create an AI that can automate conceptual alignment research: it’s not. Rather, at least in principle, it could be akin to the sense in which you wouldn’t necessarily need to do a ton of physics in order to create an AI that can automate physics research.
To be clear, I do think that developing and evaluating any kind of adequate “safety case” for an alignment MVP is ultimately, at least in part, a conceptual project, in that it at least requires stitching together diverse sources of empirical evidence into an accurate risk assessment.[45] The question is whether it’s a conceptual project that requires tons of additional conceptual work that we should expect to need tons of AI help on.
However, it remains possible that more serious, purely-conceptual advances are required for building an alignment MVP. And even if not, conceptual alignment work can still be quite helpful for that goal – for example, in setting and evaluating overall strategies, figuring out how to prioritize between different empirical projects, strengthening safety cases, and so on.[46]
So I won’t, here, assume that empirical alignment research is all we need to get to an alignment MVP, either. However, I do think that empirical alignment research is an especially powerful tool to that end. In the next section, I’ll say more about why.
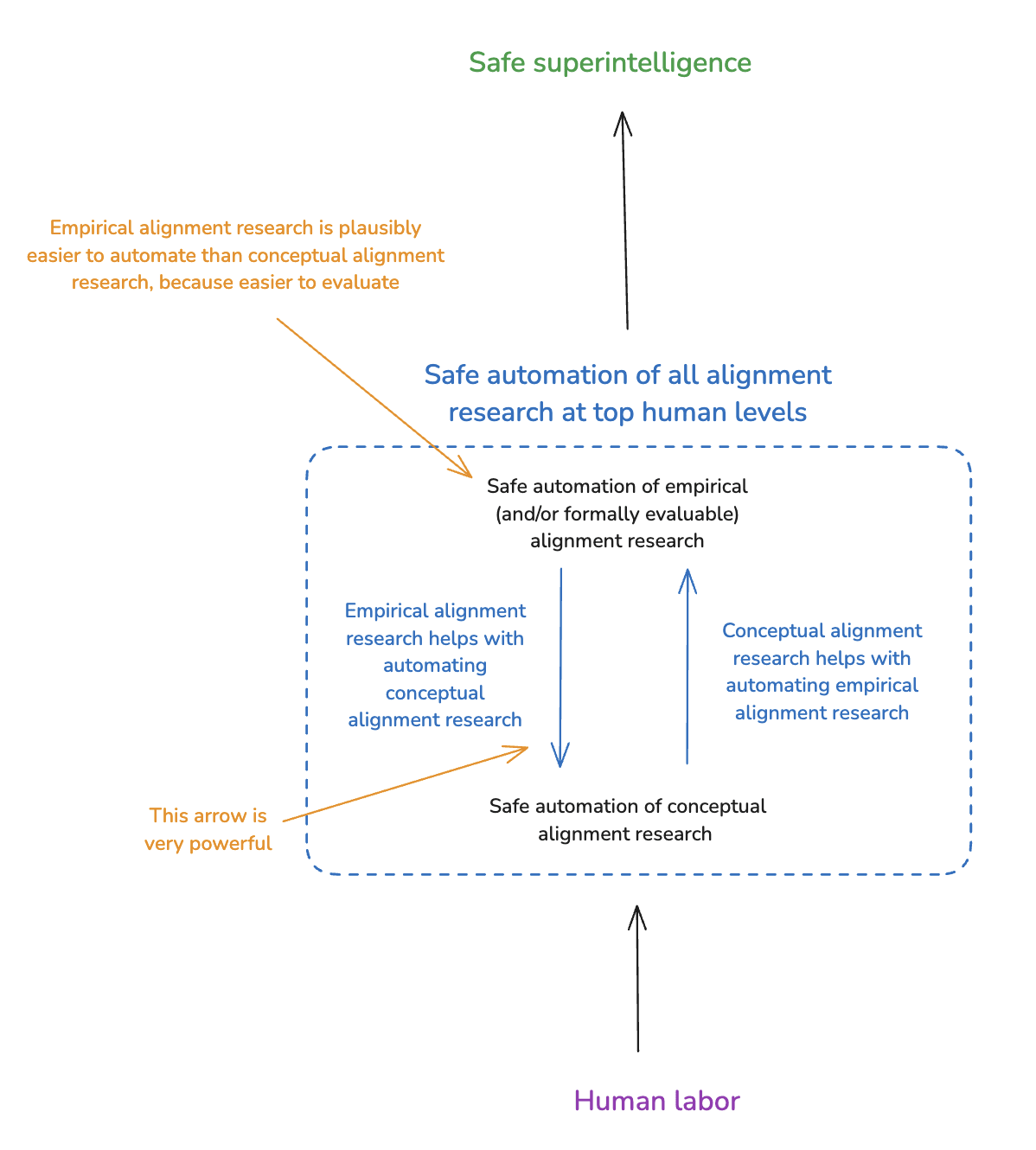
8. Empirical alignment research is extremely helpful for automating conceptual alignment research
Granted that we need to automate both empirical and conceptual alignment research at top human levels, how should our efforts at one vs. the other interact?
I think that each can support the other, and I’m not going to argue for some specific balance/prioritization here. But I do want to highlight a dynamic that seems to me especially important: namely, that empirical alignment research is extremely helpful for automating conceptual alignment research. In particular, empirical alignment research can do a ton to test and strengthen our output-focused and process-focused evaluation methods (e.g. scalable oversight, behavioral science, transparency, anti-scheming measures), including as they apply to conceptual alignment research.
That is, I claim both that:
- We should be comparatively optimistic about automating empirical alignment research at top human levels, because of the empirical feedback loops involved (plus: the broader similarity to capabilities research, and to other forms of empirical science).
- If we could automate empirical alignment research at top human levels, we could do a ton of it to improve our ability to automate conceptual alignment research at top human levels, too.
In a diagram:
Let me say more in defense of (2). In particular: suppose you had successfully automated empirical alignment research at top human levels. What could you do then to improve the output-focused and process-focused evaluation methods I discussed above?[47]
8.1 Automated empirical research on scalable oversight
One thing you could do is: perform large numbers of experiments testing and refining the efficacy of different approaches to scalable oversight – including approaches that humans haven’t thought of yet, but which can be evaluated empirically once proposed.[48]
- For example, if we have some domain D where we have access either to some ground truth, or to research results that we’re confident are at the top-human-level quality we want, we can test whether different scalable oversight techniques can reproduce either that ground truth, or that research result.
- Thus, you can assign one AI the task of arguing for the true answer, and another AI the task of arguing for the false answer, and see if different versions of debate can work to get an initially ignorant human (or AI) judge to the right answer.
- Or, if you’re able to ensure that some AI hasn’t yet been exposed to the answer/research in question (for example, because it’s been held out from the training data, or because it was created after the training cut-off), but where you think it’s capable of top-human-level work in domain D, you can try to see if different scalable oversight techniques allow humans who can’t evaluate research in domain D very well to nevertheless use this AI to get the right answer/reproduce the results in question.
- E.g., if you can hold out recent string theory results from the training data, you could try to see if some set of physicists who aren’t well-versed in string theory, and who aren’t able to evaluate string theory research very well directly, can nevertheless use AIs-capable-of-string-theory to reproduce the results in question. And ditto for other specialized domains, like niche parts of cryptography, computer science, math, etc.
Now, admittedly, some of these experiments are harder to run in the sort of domains that are the closest analogs of conceptual alignment research – e.g. philosophy, futurism, political debates, etc – because ground-truth is harder to access, and there’s less consensus on what counts as top-quality research. However (and even beyond studying scalable oversight in less conceptual domains and hoping similar lessons generalize):
- In analytic philosophy, at least, there is actually a reasonable amount of consensus about what counts as good work, as a novel/interesting argument, as a forceful objection, etc, even if there is less consensus on the answers to higher-level “big questions” – so you can at least use the techniques above on narrower questions where there’s more consensus. And plausibly something similar is true in domains like political science as well. (Maybe also futurism, but it’s less developed as a field.)
- In futurism, you at least have access to the ground truth signal regarding what has already happened. So if you can hold out access to that information from the training data (e.g., focusing on events after the default training cut-off, or – much more expensively – doing separate training runs only on data up to an earlier date), you can see if you can successfully get initially-ignorant aspiring-futurist AIs to make accurate forecasts.
- And a variety of other more creative techniques might be available as well. For example:
- You could deliberately introduce mistakes into various kinds of conceptual research (e.g., intentionally create subtly bad philosophical arguments), find humans who can’t initially detect these mistakes, and see if those humans can use scalable oversight techniques to improve their evaluation ability.
- You could create whole synthetic domains that provide new sources of ground truth.
- For example, if you create a comparatively simple, simulated civilization (maybe a scaled up version of Park et al (2023)?), you could use it as a “ground truth” for a toy version of futurism – e.g., you try to automate “futurism” about what will happen if you run this simulated civilization forward, including to the point where it becomes hard for humans to evaluate, and then see if scalable oversight techniques can help improve human evaluation ability.
- And perhaps you could use simulated civilizations as a “ground truth” for toy versions of various kinds of policy debates as well – e.g., what interventions would have what effects if implemented.
This isn’t an exhaustive list of existing ideas for studying scalable oversight techniques empirically. But more importantly: coming up with (empirically testable) ideas like this is a version of empirical alignment research (see e.g. Bowman et al (2022), Michael et al (2023), etc). So if we’ve automated empirical alignment research at top-human levels, we’d have access to top-human-level AI help in generating many more ideas of this kind.
8.2 Automated empirical research on process-focused evaluation methods
Now, as I noted above, it remains an open question exactly how far scalable oversight techniques will go in extending our ability to output-focused evaluate different kinds of research, including conceptual research. And perhaps what research of the type above finds is: “even the best forms of scalable oversight don’t go very far.” What about more process-focused evaluation – e.g., the sorts of behavioral science and transparency I discussed above?
Here, again, I think that access to huge amounts of automated, top-human-level empirical alignment research would be extremely helpful. Thus:
- Behavioral science of generalization. If we set aside cases where AI are intentionally, systematically, and successfully manipulating our behavioral evidence even across episodes and contexts, then we can learn a huge amount about how AI behavior generalizes by studying it empirically.
- In particular: in principle, we could create huge suites of automated behavioral testing processes, aimed at showing how models behave in a very wide array of counterfactual circumstances. We could then use automated AI labor to find important patterns in this data, generate higher-level principles that explain/predict it, show how model behavior alters based on different kinds of training, and so on.
- That is: we could do extremely intensive forms of empirical “psychology” on our models, using a vastly faster and more empowered experimental apparatus than the one accessible to human psychologists, social-scientists, etc. And in principle, at least, I expect it to be possible to learn a ton from this.
- As I mentioned above, work in the vicinity of “weak-to-strong generalization” is especially important here. That is, if we want to understand how our AIs will generalize from a domain we can evaluate to a domain we can’t evaluate, we can study how they generalize from easier tasks that we can still evaluate to harder tasks that we can still evaluate, and then use that as evidence about how they’ll generalize to even harder tasks we can’t evaluate. That is, in a diagram:
- Transparency: What about empirical research on various techniques for improving the transparency of our AI’s reasoning, motivations, and so on?
Consider first interpretability.[49] If we had access to huge amounts of interpretability research at the level of top human experts, how much help would that be in improving our ability to process-focused evaluate how much to trust our AIs in domains where our output-focused evaluation struggles?
I’m not sure. But I think plausibly: quite a lot.[50] At the least, for example, it seems like you could do extremely scaled up and intensive forms of the sort of mechanistic circuit analysis at stake in e.g. Lindsey et al (2025); the sort of top-down analysis at stake in e.g. Zou et al (2023); and so on. But it seems plausible to me that you could go vastly further than this (see e.g. Olah (2023) for some more ambitious goals).[51]
- But beyond interpretability in the sense of “try to look inside black-box ML models,” you can do tons of more broadly transparency-focused automated empirical alignment research as well. Research aimed at studying/ensuring chain of thought faithfulness (e.g. Lanham et al (2023), Baker et al (2025), etc) would be one example here. But I think of this as one version of a broader project: namely, generating, testing and refining different approaches to what I’ll call, later in the series, “open agency” (see e.g. Drexler (2023)) – that is, arranging (potentially still-black-box) ML components into agential processes that nevertheless facilitate epistemic access to safety-relevant planning, motivation, and so on.
As I mentioned above, anti-scheming measures are especially important to process-focused evaluation. These generally consist of some combination of transparency and behavioral science, except specifically in the context of e.g. model organisms, experiments that attempt to isolate particular components of the scheming threat model (situational awareness, beyond-episode goals, etc), and so on. And, again, I think that huge amounts of top-human-level automated empirical research could be extremely helpful here.
8.3 Other ways automated empirical alignment research can be helpful
So far I’ve been focusing on ways automated empirical alignment research can be useful, specifically, for helping with automating conceptual alignment research. But it also seems extremely helpful more generally. For example:
- Improving the output-focused and process-focused evaluation methods discussed above is also helpful for automating empirical alignment research (e.g., doing more empirical alignment research can increase your confidence in the quality and safety of further automated empirical alignment research).
- Empirical alignment research is useful, as well, for efforts at restricting rogue options, designing AI incentives to reward cooperation, and various other safety-relevant goals I’ve gestured at earlier in the series, and which I’ll discuss in more detail later on.
- Even if creating a full alignment MVP isn’t viable, various kinds of automated empirical alignment research can help reveal evidence of danger – evidence that can feed into risk evaluation and capability restraint in important ways.
In general, then: I think automating empirical alignment research, just in itself, is a huge win, and that a variety of promising paths forward open up from there.
9. What about scheming?
OK: that was a long discussion of ways that evaluation challenges might pose a problem for automating alignment research, even if we set aside scheming. But: what happens if we don’t?
Here are a few ways that re-introducing the possibility of scheming can alter/complicate the situation.
- Comparisons with other domains become more complicated. In particular: two domains might be similarly difficult to automate if you set aside scheming – i.e., if the AIs aren’t actively resisting/sabotaging your efforts in one domain, but not the other. But with scheming in the picture, that might no longer be true.
- Higher evaluation standards. If we’re dealing with potential schemers, then we need higher evaluation standards, because our evaluation needs to be robust to a wider and higher-stakes array of threat models. In particular, if you need your evaluation process to be robust to intentional sabotage motivated by long-term power-seeking, this is different from needing to be robust to e.g. more myopic forms of sycophancy or reward-hacking.
- For example: active sabotage can be optimized for not being detected over longer time scales (e.g., even after the episode is complete) and in a wider array of contexts (e.g., in the context of tests where the model will genuinely get more reward/approval if it reveals its willingness to reward/approval-hack).
And because active sabotage is specifically optimized for undermining human safety efforts, failing to catch it will generally be higher-stakes.[52]
- As an analogy: if you’re reviewing an employee’s work, it’s one thing if you’re just worried about (a) mistakes/problems that don’t involve the employee thinking about your review process at all, and (b) the employee directly trying to get good performance reviews. But if you’re also worried that the employee is actually trying to strategically sabotage their work in order to make the company fail, you should use different standards.
- And note that the track record of human evaluation in scientific disciplines like physics, biology, etc generally hasn’t had to be robust to lots of active sabotage in this sense.
- Sandbagging. Even if your evaluation process is robust enough to “catch” active attempts at sabotage, and to generally tell the difference between good and bad research, schemers might still intentionally withhold good research they’re capable of doing (“sandbagging”). Whether they can succeed at doing this depends on the truth or falsity of what I’ve previously called the “no sandbagging on checkable tasks” hypothesis. As I discuss in that post, we do have various possible anti-sandbagging measures available(and see also recent discussion from Greenblatt (2025) here). But: it’s an additional challenge, on top of making alignment research suitably “checkable” – and one that arises centrally in the context of scheming in particular.
- Dangerous rogue options. Finally, if you’re working with potential schemers, you also need to worry about them pursuing dangerous rogue options in general. Open options to engage in sabotage and sandbagging are one version, but we also need to worry about other threat vectors: e.g. self-exfiltration, manipulating humans, and so on. And in this respect, even beyond your supervision and elicitation of the research produced by a potential schemer, you need to attend to (and ideally: close off) the other rogue options that might be available.
9.1 Will AIs capable of top-human-level alignment research be schemers by default?
Now, one way we might avoid these concerns about scheming is: if early AIs capable of top-human-level alignment research just aren’t schemers by default. And indeed, I find it plausible that they won’t be – or at least, not if timelines are comparatively short.[53]
In particular: I think it quite unlikely that current models are actively scheming.[54] And if timelines are comparatively short, you might also expect the first models capable of automating most if not all of top human-level knowledge work (including capabilities research, alignment research, etc) to be fairly similar to current models – e.g., trained using fairly similar techniques, in the context of broadly similar architectures, scaffolds, chain-of-thought techniques, etc. So if current models aren’t scheming, plausibly those models wouldn’t be, either.
Also: scheming requires models that satisfy the agency and motivation prerequisites I discussed in my second essay – i.e., roughly, situationally-aware agentic planners with long-term consequentialist goals. And it’s not clear that automating alignment research requires AIs of this kind. In particular:
Maybe alignment research as a field aims at a long-term, consequentialist goal (e.g., a future of aligned AIs[55]). But this doesn’t mean that individual AI systems contributing to this research need, themselves, to be optimizing for this or any other long-term goal. For example: they might be performing more limited tasks aimed at shorter-term targets (see e.g. “process-based supervision,” “myopic optimization with non-myopic approval). More on this here.
- The various components of the dangerous sort of agency don’t need to come as a monolithic bundle, and teasing them apart might allow more safety. More on this here.
- It’s not clear that alignment research requires especially strong situational awareness. How much do AIs pursuing research projects in interpretability, scalable oversight, etc need to “know what’s going on” more broadly?
So using AIs that don’t satisfy the prerequisites for scheming might be another way to avoid it.
9.2 If these AIs would be schemers by default, can we detect and prevent this scheming?
Suppose, though, that the AIs we’re trying to use for alignment work would be schemers by default. In particular, I’ve sometimes encountered views like:
If science then scheming: Any AIs doing “serious science” at the level of top humans would be schemers by default.
One general argument for this might be: any AIs capable of serious, top-human-level science would also have to be situationally-aware agentic planners with long-term consequentialist goals, and any AIs like that are schemers by default. But I’ve also sometimes heard arguments that seem more specifically focused on the idea that in performing serious scientific research at top human levels, AIs will be above some threshold where they start doing things like “reflecting on themselves,” “pulling themselves together,” and “asking themselves what they ‘really want’?”, at which point they’ll decide to try to disempower humanity on grounds of the divergence between human values and “what they really want.”[56]
I won’t try to analyze these arguments in depth here (though I’ll note that they make some strong predictions about what sorts of science we’ll be able to do with non-schemers). For now, I’ll mostly reiterate that there are in fact a variety of tractable research directions for trying to detect and prevent scheming. And even prior to successfully automating all alignment research (or even: all empirical alignment research) at top-human levels, I expect various forms of automated labor to be quite useful for anti-scheming research in this broad vein.
So, even if early AIs capable of automating top-human-level alignment research would be schemers by default, I think we might also be able to detect/prevent this scheming using various anti-scheming measures. There’s also, though, a third option: namely, using scheming AIs, at least initially, for automating alignment research that we can evaluate with suitable robustness. Let’s turn to that now.
9.3 Can we elicit safe alignment research from scheming AIs?
The idea of trying to elicit safe alignment research from actively scheming AIs should scare us. It seems very dangerous. And if that’s where it looks like we’re headed, I think the first response should be to look for a different plan – for example: capability restraint.
Still: we should have all the available options in view. And trying to do it with schemers, at least initially, is indeed one option. In particular: if we can (a) use suitably robust evaluation techniques to really check that the work produced by these AIs is top-human-level-quality and not-sabotaged, (b) use suitably strong anti-sandbagging techniques to actually elicit work that meets these standards, and (c) use other methods of option control to close off other dangerous rogue options (self-exfiltration, human manipulation, etc) in the meantime, then we have effectively created what I previously called an “AI for AI safety sweet spot” with respect to automated alignment research. That is: the AIs can’t do catastrophic harm (including: via options made available by their research itself), and we’re eliciting a ton of useful, high-quality work from them.
Obviously, though: we should try, as much as possible, to make this a temporary measure, if we pursue it at all. That is: a core aim should be to elicit enough alignment research that you can then actually rule out scheming going forward.
And note that the viability of this sort of path is probably going to depend on having very strong output-focused evaluation methods in particular. That is: if your process-focused evaluation (e.g., transparency, behavioral science of generalization, anti-scheming measures, etc) isn’t robust to scheming, then your output-focused evaluation methods need to make up the difference. In this respect, then, I’m more optimistic about eliciting safe empirical (and/or formally evaluable) alignment work from schemers than eliciting safe conceptual alignment work, because I expect available output-focused evaluation methods for empirical alignment work to be stronger by default.[57] But per my comments about the value of automated empirical alignment research above, even just this can help a lot.
Overall, then, there are at least three ways we could safely automate alignment research despite the possibility of scheming, namely:
- Scheming doesn’t arise by default in early models capable of automating alignment research at top human levels (including: because such models don’t need to be situationally-aware agentic planners with long-horizon consequentialist goals).
- Scheming arises by default, but we can detect/prevent it (including: using AI labor that isn’t yet at the level of a full alignment MVP).
- Our output-focused evaluation, anti-sandbagging measures, and option control are adequate to elicit safe, top-human-level alignment research even from scheming AIs.
And these different options can combine – e.g., maybe some kinds of alignment research can be done using non-agentic AIs; some kinds are such that we’re sufficiently confident in our output-focused evaluation methods that we’re comfortable even using maybe-schemers to do them; and so on.
10. Resource problems
So far, I’ve focused on two specific branches of the taxonomy of failure modes I introduced earlier in the essay: namely, evaluation failures in non-schemers, and scheming.
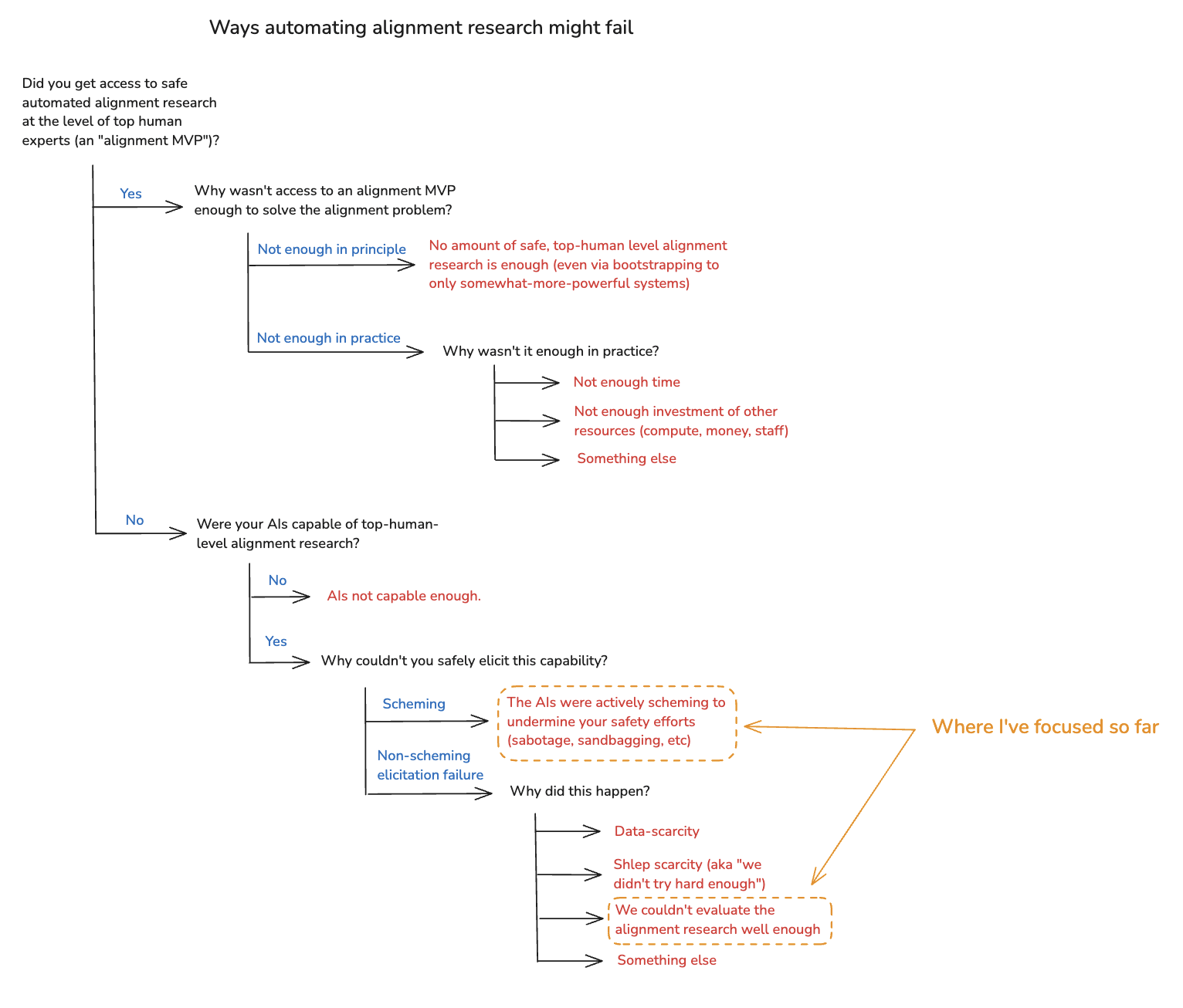
What about the other branches? Per my discussion above, let’s set aside, for now, the cases where no amount of top-human-level alignment research is enough. And let’s assume, further, that at some point prior to the loss of control, someone had access to AIs that were at least capable of top-human-level alignment research. In this case, roughly speaking, we can think of the other branches I’ve actively defined as centrally about inadequate resources: that is, inadequate time, compute, effort, data, etc. That is:
- These resources can be inadequate after you get access to an alignment MVP – for example, if you don’t have enough time to do enough automated alignment research before an intelligence explosion leads us into catastrophe, or if you fail to invest enough compute, staff-time, leadership-attention, etc into the project.
- Or these resources can be inadequate in trying to get access to an alignment MVP – for example, because you don’t have enough high-quality data to suitably elicit top-human-level work from AIs capable of performing it, or because you don’t put in the shlep necessary for doing so.
And note that even if we grant we get AIs capable of serving as alignment MVPs at some point prior to loss of control, the question of how early can still matter a lot to the amount of time you have available for automated alignment research overall. And resources like data and shlep can be relevant to making AIs capable of top-human-level alignment research, as well as to eliciting this research.
I think these more practical, resource-focused failure modes are extremely serious.[58] And I don’t have especially fancy things to say in response. Basically: we need to actually put in the necessary shlep. We need to actually make the necessary investment of compute, staff-time, money, etc. If we run into serious data-scarcity issues, we need to find a way around them (though: this barrier could prove more fundamental). And we need to create the necessary time.
Indeed: I’ll linger, for a moment, on the point about time. As I discussed above, a key reason that safely automating alignment research is so important is that automated alignment research can proceed quickly, and at scale, in a manner that can keep pace with automated capabilities research. Successful automation of alignment research thereby relieves some of the pressure on our capability restraint to hold back (or: indefinitely halt) an increasingly automated capabilities feedback loop while slow, scarce human researchers do alignment research themselves (or until we can get access to enhanced human researchers instead). And because I am worried about our prospects for extreme amounts of capability restraint, I view successfully automating alignment research as correspondingly important.
But even if you successfully automate alignment research, capability restraint is still extremely important. In particular: especially in fast-take-off scenarios, trying to frantically do a ton of automated alignment research in the midst of an intelligence explosion is extremely dangerous, and extra time remains extremely valuable.
11. Alternatives to automating alignment research
OK: that was a lengthy discussion of our prospects for safely automating alignment research – and in particular, of the failure modes I’m most worried about. And given the many ways automated alignment research can fail, I also want to briefly mention the alternatives that seem most salient to me.
Recall my argument for the importance of automating alignment research: namely, that solving the alignment problem might be a lot of difficult work; we might not have very much time; and human labor is scarce and slow. How might this problem get resolved without automating alignment research?
One possibility is that the problem is easy – and in particular: easy enough that even without much time, small amounts of slow, scarce human labor are enough to solve it. Or another possibility is that timelines are long by default, such that we have time, by default, to put in a lot of slow, scarce human labor (and/or, potentially, to make a transition to some kind of enhanced human labor). And these two could interact. That is, the problem could be easy, and timelines could be long.
Unfortunately, though, I don’t think we can count on easy problems, or on long timelines by default. And (at least insofar as the long-timelines-by-default are driven by underlying technical parameters), neither are under our control.[59]
What about alternatives that are more under our control, at least in theory? To my mind, the most salient options are:
- Sustained global pauses/slow-downs. That is, you could try to actively buy a lot more time – either for normal human labor on alignment, or for getting access to some kind of enhanced human labor.
- And if the relevant pause/slow-down was suitably long, then you’d have time, potentially, even for a slow transition to enhanced human labor, and/or for that labor, itself, to work quite slowly. Which is important, because I think many “enhanced human labor” paths will involve slowness of one or both of these forms. That is: the technological development necessary (at least if unassisted by AI) would take substantial time, and insofar as the enhanced human labor still involved biological humans in some way (as in the case of e.g. brain-computer interfaces, or of other sorts of biological interventions), it would implicate the sort of speed and scalability constraints that biology imposes.
- We can also think of paths that involve giving up on superintelligence entirely as a limiting case of a sustained global pause.
- AI for whole brain emulation. Alternatively, you could focus, specifically, on making a fast transition to a fast form of enhanced human labor.
- To make the transition as fast as possible, you could try to use AI to help you develop the necessary technology.
- And to make the enhanced human labor fast, you could focus on a form that doesn’t implicate the speed and scalability constraints that biology imposes. The only form of “enhanced human labor” I’m aware of that satisfies this condition is whole brain emulation.
- This path, if successful, could potentially rely less on very long global pauses. But I expect most versions to require some significant capability restraint nonetheless.
I’m planning to discuss both these options in more detail later in the series. To my mind, though, it seems unwise to bank on either of them.
12. Conclusion
Overall, then: I think that we have a real shot at safely automating alignment research, and that successfully doing so is extremely important. But we need to navigate a number of serious failure modes. In particular:
- Evaluation: We need to figure out how to adequately evaluate automated alignment research – and especially, alignment research we can’t test empirically or check using formal methods;
- Scheming: We need to either (a) avoid/prevent AIs actively scheming to undermine our alignment research efforts, or (b) elicit safe, top-human-level alignment research even from scheming AIs;
- Resources: We need to give ourselves the necessary time, create the necessary data, and make the necessary investment of compute, staff, effort, and other resources.
Failure on any of these fronts seems worryingly plausible. But I think there’s a lot we can do to improve our odds. I’ve focused, here, on ways that successfully automating alignment research that we can test empirically, and then doing a ton of it, can help a lot with evaluation challenges (together with anti-scheming measures, and with gathering evidence that can help motivate effort, investment and capability restraint). But many other technical and governance interventions seem potentially helpful as well (see e.g. Hobbhahn here for a few more ideas).
What’s more, the most salient alternatives to automating alignment research (i.e. banking on easy problems/long timelines; aiming for sustained global pauses; trying to use AI to rapidly develop whole brain emulation technology and then trying to get emulated humans to do tons of alignment research very fast) all look, to me, no more comforting. So despite the many ways that automated alignment research can fail, I think we should be trying extremely hard to make it work.
Appendix 1: How do these failure modes apply to other sorts of AI for AI safety?
This appendix briefly discusses how the failure modes discussed in the main text apply to other potential applications of AI for AI safety – for example, hardening the broader world, risk evaluation, capability restraint, enhanced human labor, and so on. I won’t attempt to cover each of these potential applications individually. Broadly speaking, though:
I am generally less worried about evaluation failures, in particular, in many of these other domains, because I think alignment research – or at least, conceptual alignment research – is unusually hard to evaluate relative to lots of other safety-relevant domains (e.g., using AIs for forecasting; using AIs for cybersecurity; developing better on-chip mechanisms for monitoring compute; etc).[60]
- I think concerns about schemers (e.g., sabotage, sandbagging, and other dangerous rogue options) apply in broadly similar ways to these other applications, except that:
- Insofar as we have stronger evaluation capacity in these other domains, it’s harder to get away with sandbagging and sabotage;
- The specific sort of “dangerous rogue options” that a given application of AI for AI safety might make available can vary significantly. And some – for example, using AIs in a military context for enforcing capability restraint – could be unusually dangerous.
- With respect to the more practical, resource-scarcity concerns I discussed:
- Data-scarcity issues seem to me especially pressing in the context of alignment, because it’s such a young field.
- But the other concerns I mentioned – e.g., inadequate time, investment, shlep, etc – generally seem like they could apply similarly to these other applications.
In this sense, I think, many of the points I’ve made about automating alignment research apply to AI for AI safety more broadly. That is: we need to find a way to either avoid scheming, or to elicit safe, high-quality, safety-relevant work from maybe-schemers. We need to put in the necessary shlep, effort, and investment. And we need to buy ourselves the necessary time.
Appendix 2: Other practical concerns not discussed in the main text
This appendix briefly discusses a few other more practical concerns about AI for AI safety (including: automated alignment research) that I didn’t discuss in the main text, notably:
- Cover: “The idea of ‘AI for AI safety’ will provide cover for people to push forward with dangerous forms of AI capability development.”
- My response: I do think this could happen. However: I also think we should separate our direct evaluation of an idea like AI for AI safety from our concerns about its memetic effects. And if AI for AI safety is in fact viable and a good path forward, then I think we should be clear about this fact, and look for other ways to mitigate misuse of the meme.
- Complacency: “The idea of ‘passing the buck to the AIs’ will obscure how much work humans will still need to be doing, and will render us complacent more generally.”
- My response: I do think this is a concern. Human labor still matters a ton here, especially in the lead-up to automation. And we need detailed, specific models about what a responsible process of “passing the buck to the AIs” actually looks like, rather than just saying “and then the AIs will solve our problems.”
- Capabilities externalities: “Efforts aimed at AI for AI safety will further accelerate AI capabilities.”
- My response: I have a few different responses here.
- First: AI for AI safety efforts don’t need to be about differentially accelerating the availability of AI labor that can help with different tasks. Rather, they can focus on making sure that we make lots of use of that labor once it’s available.
- That said: I personally think that it will also often be worth actively accelerating the availability of especially safety-relevant AI applications, especially where the overlap with capabilities research in general is fairly minimal.
- And beyond this, I am just generally skeptical that AI-safety-motivated efforts should be restricting themselves a ton on the basis of concerns about capabilities externalities. In particular: the resources currently being devoted to directly pushing forward frontier AI capabilities are massive, so the marginal contribution of AI-safety-motivated efforts seems likely, to me, to be relatively small, making them comparatively easy to outweigh if the safety-specific benefits are meaningful.
- My response: I have a few different responses here.
- Distraction from capability restraint: “Efforts focused on ‘AI for AI safety’ will distract attention and resources from (non-AI-driven) capability restraint, which should be our core focus.”
- My response: I’m not going to give any detailed analysis of the right balance of effort on AI-for-AI-safety vs. (non-AI-driven) capability restraint, but I think AI for AI safety warrants, at least, a substantial chunk. And if so: then it’s not a distraction.
- Premature effort: “People might make efforts at AI for AI safety prior to the point where it can really be useful, or in a manner that would have been far more efficient had they waited for another notch of capability improvement, thereby wasting precious time.”
- My response: I do think we need to watch out for this, and I’m not arguing for a specific split, right now, of effort devoted to automating AI-safety-relevant work vs. just doing it (though: see Hobbhahn here for some recent discussion).
- Harmful delegation: “Even if the AIs we delegate safety-relevant tasks to are behaving broadly as we intend, the delegation in question might degrade human understanding and control in ways that exacerbate loss-of-control risk down the road – for example, by increasing our reliance on AIs, reducing our epistemic grip on the world, and exposing us to unanticipated problems that delegation to AIs (even non-rogue AIs) can create.”
- My response: I do worry a bit about this as well. But I also think that attempts to differentially benefit from AI labor early may need to eat some of the general costs of early-adoption – including insofar as these costs could be relevant to loss of control. And if the AIs are actually behaving “broadly as we intend,” then I think the direct safety benefits are likely to be worth it.
Appendix 3: On various arguments for the inadequacy of empirical alignment research
In this appendix, I list various arguments I’ve heard for why empirical research is inadequate for aligning superintelligence, and I explain why I don’t find them all that compelling on their own. And the reasons I find them less-than-fully compelling apply even more strongly to alignment MVPs, which are much less powerful than superintelligences, where it’s much less plausible that they need to have takeover options, and so on.
- You can’t safely test on genuine takeover options. Here the argument is that the empirical test you care about most – namely, whether you’ve figured out how to build a superintelligence that won’t take over the world even when it genuinely has the option to do so – can’t be safely run.
- I agree – that particular source of empirical data is off-limits. But on its own (e.g., without explaining why this is an important distributional shift), this is only an argument against the adequacy of empirical research if you think that empirical research never allows for accurate predictions about unseen data points, which seems like far too narrow a conception of it. For example: I can be quite confident, on the basis of my empirical data about Bob, that he won’t stab me with a butcher knife, prior to handing him one.
Immediate takeover options? A different reason you could worry, though, is that: as soon as you build a superintelligence, it’ll have the option to take over the world. So you never get to safely do any empirical research on it. You can’t even keep it locked in a box without trying to do anything with it, and then examine its internals using your interpretability tools, because you can’t build a box like that.[61]
Is that right? I’ll discuss the difficulty of closing off takeover options for superintelligences in more detail in a future essay. For now, though, I’ll note that if you aren’t trying to do anything with the superintelligence except scan its internals with your interpretability tools, I expect “boxing it” to be, at least, much easier.
- Subverting empirical tests. Another concern is that superintelligences can mess with your empirical tests. For example: like other AIs, they can fake alignment. But they can probably do more exotic things as well. For example, maybe they can manipulate their internals to subvert your interpretability efforts. (And this is one key reason you might think that takeover options are an important distributional shift.)
- I agree that AIs subverting empirical tests is a crucial issue (and not just in superintelligences). I discuss it a bit more in a future essay. But I think empirical research can help a lot with this, even in the absence of direct empirical tests on takeover options.
- New capabilities introduce new problems. A different, more general concern is that developing a new capability level can introduce new potential issues that previous capability levels didn’t. So empirical research on weaker AIs isn’t sufficient.
- I agree. But if superintelligences don’t immediately have takeover options (see above), we’ll be able to do empirical research on the superintelligences themselves.
- Detection but not cure. Another concern is that even if your empirical research methods show that an AI system is unsafe in some way (e.g., your interpretability tools show that it’s lying to you), these methods won’t allow you to fix the problem. And if you iterate until these methods no longer show a problem, the thought goes, then you probably just hid the problem, rather than fixing it.
- I’ll discuss this dynamic more in future essays as well. I agree that it’s a problem, but I don’t think we should assume that iterating on whether an empirical method detects a problem always hides the problem rather than fixing it. Rather, I think we need to be more specific about the selection pressures at stake (for example: training on your detection method is very different from using it as validation), and about the space we’re selecting over. And even in the context of validating against a detection method rather than training on it, empirical research isn’t limited to naive, trial-and-error-style iteration, either.
Needing extreme understanding. A broader vibe I’ve heard is something like: in order to align a superintelligence, you need to understand it extremely well.[62] It’s like how: rocket engineers need to understand rockets extremely well, because they’re working with such extreme forces. Or how: cybersecurity specialists need to understand their security systems really well, because these systems need to withstand so much adversarial pressure. That is, the thought goes: if there is some part of a superintelligence you don’t understand, then that part will cause it to kill you. And empirical alignment research, the thought goes, can’t get you this level of understanding. For example, this understanding requires deeply understanding the nature of things like minds, values, intelligence, and so on – understanding that requires significant conceptual/philosophical/theoretical progress.
This concern is more of a vibe than a hard argument, but I agree that building a superintelligence safely likely requires a deep understanding of what you’re doing (though: I don’t think it needs to be humans, at that point, who possess the relevant understanding, because it doesn’t need to be humans building the safe superintelligence). And I agree, too, that relative to where we are today, at least, lots of conceptual/theoretical progress is necessary there.
However, we should distinguish between conceptual/theoretical progress that can be evaluated via empirical tests, and conceptual/theoretical progress that can’t. Thus, for example: as I discussed in the main text, Einstein’s theory of relativity was clearly conceptual/theoretical progress in some sense. But it was also evaluable via its empirical predictions. So it actually wouldn’t count as conceptual research in my sense. And to the extent that the relevant conceptual/theoretical progress doesn’t make empirical predictions, it seems potentially less relevant/useful.
Or to put it another way: how much conceptual research that couldn’t be evaluated via (a) empirical feedback loops and (b) formal methods was involved in learning how to build rockets? Nuclear reactors? Building safe superintelligence requires high-quality scientific understanding, yes. But empirical (and/or formally evaluable) research can get you a lot of that. Hence, for example, the sort of understanding at stake in physics.
- Ethics in particular? You might think that building safe superintelligence specifically requires progress in ethics, and that empirical research specifically can’t help with that.
- As I’ll discuss later in the series, I do think that solving the alignment problem in my sense requires creating AIs that can do ethics (and philosophy more broadly) as well as humans, and that are motivated to do so in human-like ways. But I’m not sure that we need to make a ton of progress in our current understanding of ethics in order to create AIs like this (in the same sense that I don’t think we need to make much progress in physics in order to automate physics).
Appendix 4: Does using AIs for alignment research require that they engage with too many dangerous topics/domains?
This appendix briefly discusses the concern that automating alignment research might be uniquely dangerous, relative to automating other domains, because it requires that AIs think about and understand especially dangerous topics, like human psychology, game theory, computer security, various possible galaxy-brained considerations, and so on.[63] Here, the contrast is often with other forms of AI for AI safety (for example: AI for enhanced human labor), which are thought to be (at least potentially) safer than this.[64]
I agree that other things equal, alignment research implicates a wider and more dangerous array of topics/domains than more narrow types of scientific research, and that this is a point in favor of plans that focus instead on automating this narrower type of research instead. As I’ll discuss later in the series, though, I think that these plans have some other serious downsides (notably: they generally require very significant capabilities restraint, and with the exception of whole brain emulation, the labor they unlock lacks AI advantages like speed, copying, easy read-write access, etc).
I’ll also note, though, that insofar as the hope was to have AIs that have never even been exposed to topics like human psychology, game theory, computer security, etc – or, indeed, to the alignment discourse more broadly – then this would clearly require a substantial departure from currently standard forms of pre-training on internet text. So this is an additional barrier to realizing the full safety benefits of refraining from using AIs on alignment research in particular. That is: the strong default here is that frontier AIs in general will have been exposed to these topics. And while using them for alignment research might require that they engage with these topics substantially more, the marginal risk seems worth it to me.
- ^
On the framework I’m using in this series, hardening the broader world is also a part of making increasingly capable AI systems safe. But alignment research is at the core.
- ^
Of course, if we had the luxury of extreme amounts of capability restraint, it would likely make sense to go as far as possible using the labor we’re most confident we can trust, which for a while would plausibly be human labor (and perhaps, in that context, the sort of “enhanced human labor” paths I discuss below would also be preferable to automating alignment research – though, it depends on the details). But even with such luxuries available, it seems plausible to me that the thing you actually focus on building is an alignment MVP, rather than a safe superintelligence, because it’s easier, and because it’s so helpful.
- ^
Of course: this path likely involves building many intermediate AI systems along the way, which the diagram below is not depicting. But in a humans-only path, humans are doing all the core alignment research labor.
- ^
I’m also not sure how much anyone ever actually thought we’d be doing the humans-only path. Rather, I think the most classic default picture is to imagine a suitably aligned “seed AI” that isn’t fully superintelligent, but which preserves its alignment through a process of recursive self-improvement. In a sense, then, this is a form of automated alignment research. Indeed: I think many forms of resistance to automated alignment research stem not from the fact that it involves departing from a “humans-only path,” but from the risk of using inadequately aligned AI labor to help. That is: the objection is that a viable “alignment MVP” path requires more human-labor-driven alignment success than advocates of automated alignment research are planning on.
- ^
Josh Clymer’s analysis here uses a similar framing, and a similar diagram (though: I’m not actually getting it from Josh’s piece; rather, I had been using a framing and diagram like this since a draft version of this essay written back in fall of 2024). That said: Josh’s piece focuses on a slightly different milestone – namely, an AI you trust to replace human researchers. An alignment MVP in my sense doesn’t necessarily imply that you’re ready to retire human alignment researchers entirely. For example, some of the safety in question might derive from ongoing human oversight. I discuss replacing human researchers a bit in the section on “hand-off” below.
- ^
Because: a superintelligence would be an alignment MVP; but plausibly weaker systems would be as well, and such weaker systems are (I’m assuming) no harder to align/make safe.
- ^
Because alignment MVPs safely produce better/more efficient alignment research than humans do.
- ^
This makes the most sense if the alignment MVP is at least somewhat better than top humans at alignment research. If it was merely more efficient, then access to an alignment MVP is so far only a speed-up, rather than a more fundamental advantage.
- ^
You could think, for example, that almost all of the core challenge of aligning a superintelligence is contained in the challenge of safely automating top-human-level alignment research. I’m skeptical, though. In particular: I expect superintelligent-level capabilities to create a bunch of distinctive challenges.
- ^
This is assuming that the alignment MVP AIs are in fact both faster and more scalable than humans, but I think this assumption is reasonable. Of course: it’s not always more efficient to do a task by first building AIs to help you. Consider, for example, the task of folding your laundry. But for tasks where (a) it’s hard to do it on your own, (b) the relevant AI would help a lot, and (c) building the relevant AI is significantly easier than doing the full task yourself, getting AI help seems like a good bet. And I think the alignment problem is plausibly like this.
- ^
Indeed, people sometimes deride automated alignment research as trying to get the AIs to “do our alignment homework.” But: who gave us this “homework”? “Homework” rhetoric implies that aligning superintelligence is supposed to be “our job” – a job we’re trying to shirk. But one rarely hears similar complaints about “getting the AIs to do our capabilities homework” – or, indeed, our coding homework, our cancer research homework, and so on. In general: transformative AI scenarios involve getting the AIs to do tons of stuff for us. And no wonder: they’re better at it. Why would alignment research be different? Well: below I’ll discuss some reasons. But the naturalness of trying to safely automate alignment research – like how we’re doing with all sorts of other stuff – is worth bearing in mind.
- ^
Though: note that if you thought that even an alignment MVP couldn’t solve the alignment problem, you need some story about why your enhanced human labor would do better.
- ^
See e.g. Clymer (2025) for more.
- ^
Though: humans may still be playing an important role in ensuring other forms of safety.
- ^
Though of course: they need to identify the relevant problems before it’s “too late.”
- ^
That is, assuming some amount of suitably enhanced human labor would be enough; which, these scenarios, seems far from clear.
- ^
For example: maybe your automated alignment researchers just “messed up,” but not as a result of lack of time or other resources? In some sense, this can be understood as “not doing enough research,” but perhaps it’s best understood in some other way. Of course, if the researchers were as good or better than top humans, than they will likely have done at least as well as humans would’ve done with similar time/resources. But when the relevant loss of control occurs, this might be cold comfort.
- ^
Though: if they fail in this respect, that doesn’t mean the situation is any better from a human perspective.
- ^
Admittedly: the line between capability and elicitation can get blurry. At least in the case of elicitation failures that result from scheming, though, I think it’s relatively clear (i.e., the schemer knows that it could do the task in the desired way, but chooses not to). And I expect the distinction to be meaningful and important even absent scheming as well. In particular: if your AI would perform the task well on a different input, or given a different prompt, I think that this is a good indication that it was capable of the task. And I’d generally want to say the same thing if the amount of training required to cause the relevant form of task performance is quite small.
- ^
This taxonomy is slightly different from the one I offered in my last post for thinking about concerns about AI for AI safety in general, but it covers broadly the same ground. In particular: differential sabotage and dangerous rogue options would both fall under "scheming."
- ^
The line between sycophancy and reward-hacking can be a bit blurry, but I’m generally thinking of sycophancy as routing via the content itself, whereas reward-hacking routes via some other means.
- ^
This is distinct from sycophancy, where you actively but wrongly approve of the output.
- ^
Indeed, in theory, it can be somewhat hard to find a case of pure output-focused evaluation – i.e., evaluation that holds in equal force totally regardless of the process producing the output being examined.
- One candidate might be: if you ask any process to give you the prime factors of some semiprime i, then no matter what that process is, you’ll be able to verify, at least, that the numbers produced, when multiplied together, do in fact equal i (for some set of reasonable numbers, at least).
- E.g., at least within reasonable constraints, even a wildly intelligent superintelligence can’t give you two (reasonable) numbers, here, such that you’ll get this wrong.
- In practice, though, if you allow the possibility of an arbitrarily intelligent and adversarial superintelligence generating the output you’re dealing with, then certain sorts of evaluations we’d normally think of as “output-focused” will become less reliable.
- Thus, for example: maybe there’s a certain set of tests you’d perform on a solar cell to see if it works as intended. But are you confident that an arbitrarily powerful superintelligence couldn’t build a solar cell such that you end up mistakenly thinking that this solar cell works as intended, even though it doesn’t, given these tests? If not, you might actually need to make some reference to “oh and also this solar cell was built by a normal human company, and not an arbitrarily powerful superintelligence” in order for these tests to play their normal justificatory role.
- One candidate might be: if you ask any process to give you the prime factors of some semiprime i, then no matter what that process is, you’ll be able to verify, at least, that the numbers produced, when multiplied together, do in fact equal i (for some set of reasonable numbers, at least).
- ^
Though: the relevant evaluation methods here might vary based on the type of research in question – more below.
- ^
See e.g. Yudkowsky here: “for the last ten years, all of effective altruism has been arguing about whether they should believe Eliezer Yudkowsky or Paul Christiano, right? That’s two systems. I believe that Paul is honest. I claim that I am honest. Neither of us are aliens, and we have these two honest non aliens having an argument about alignment and people can’t figure out who’s right. Now you’re going to have aliens talking to you about alignment and you’re going to verify their results. Aliens who are possibly lying.”
- ^
One worry is about the evidence that ongoing disagreement provides about the adequacy of top-human-level research more generally for getting to the actual truth – e.g., about the viability of a “humans-only” or even an “alignment-MVP” path in principle. In particular: if this disagreement would persist even after vastly more human-driven research (the current alignment discourse is quite young and immature), then it seems like some humans (and hence, some critical decision-makers) could easily remain wrong about alignment even in a research context that provides vastly more time, resources, and coordination than the real world. Technically, though, this is a worry about alignment MVPs being not-enough, rather than about being unable to create an alignment MVP.
- ^
Though note that in principle this question applies to sciences where evaluation difficulties seem intuitively much less worrying. E.g., physics-according-to-who, biology-according-to-who, etc. Cf flat-earthers, skeptics of evolution, etc.
- ^
Though: at a glance I expect lots of serious limits here. E.g., I expect it to often be hard to evaluate a paper by evaluating individual paragraphs. See also this experiment conducted by Ought in 2020, where decomposing coding tasks was less efficient than having an individual do it themselves.
- ^
See also “AI safety via market making” and “prover-verifier games” for a few other scalable-oversight-ish proposals, though I haven’t investigated these.
- ^
Though: if they can get AIs to imitate their judgments suitably well, I do think this helps a lot.
- ^
Thanks to Collin Burns and Sam Bowman for discussion.
- ^
We can also use scalable oversight techniques on process-focused evaluation – e.g., you can use AIs to amplify an attempt to audit an AI’s internals. But I’ll take output-focused evaluation as their paradigm application.
- ^
One other note: when people talk about being able to move from being able to evaluate AI performance to being able to elicit good performance, they often have in mind output-focused evaluation in particular. That is, the picture is something like: the AI produces output, you output-focused-evaluate that output, and then you adjust the AI’s policy so that it performs better according to your output-focused evaluation process. In principle, though, you can use process-focused methods for this as well. For example: it is possible, in principle, to train on certain transparency/interpretability tools (e.g., chain-of-thought monitors, probes aimed at detecting deception, etc) – though whether it’s advisable is a substantially further question. And you can train for good behavior on process-focused behavioral tests as well. What’s more, even beyond direct training, process-focused evaluation methods can serve as a form of validation in a broader process of iterating empirically towards an AI system whose output you trust. (And note that validating on a metric for trustworthiness is quite different from training on it; and note, too, that output-focused evaluation can serve as a validation method as well.)
- ^
Modulo scheming, that is, and assuming the evaluation difficulties at stake are in fact comparable.
- ^
In particular, I think people sometimes work with a broad picture like: intelligence is an engine of general purpose optimization, so you can develop it via an extremely wide variety of (suitably difficult) optimization challenges. That is, roughly: you find a number – any number – that is suitably difficult to make “go up.” You train your AI to make that number go up. Thus, in the limit: general intelligence. Broadly speaking, though, I expect this picture to miss many crucial aspects of what capabilities development looks like in practice.
- ^
There’s a case for thinking of “is this math correct” as more of a “number go up” evaluation task, but I’ll lump it under normal science for now.
- ^
And the clearest instances of philosophical progress, in my view, are also the most “formally evaluable” in the sense above – e.g., proofs, impossibility results, clearly valid arguments (but where you still have to decide whether to accept the premises), etc.
- ^
A few bits of the RFP are focused on more centrally theoretical/conceptual research directions.
- ^
H/t Ryan Greenblatt for discussion here.
- ^
Consider times you’ve tried thinking about philosophy, futurism, politics, etc. Indeed: consider your engagement with this essay itself.
- ^
Note: in some cases, work like this attempts to prove results evaluable via the sorts of formal methods at stake in math and logic. And it’s possible, in the future, that much more alignment research will be evaluable in this way. Indeed, in the limit, AIs could generate alignment-relevant theorems that we could evaluate using a theorem-prover. I won’t count this kind of non-empirical alignment research as “conceptual.”
For now, though, my sense is that a lot of the contribution of more formal alignment work is supposed to be the formalization itself – e.g., adequately capturing some intuitive concept in a mathematically rigorous way. And because the adequacy of the formalization isn’t itself evaluable via formal methods, this aspect seems more like conceptual research, to me. (And the same applies to the work required to capture alignment-relevant questions in theorems that can be proven.)
- ^
Though: this paper also included a few toy experimental results.
- ^
For both empirical and conceptual alignment research, my examples have focused on existing research that has been specifically motivated by concerns about alignment. But this isn’t the only sort of research that helps with alignment. For example: better understanding of AI and ML, period, is notably helpful. But to the extent some parts of AI/ML research aren’t evaluable via empirical feedback loops or formal methods, then they’ll count as “conceptual” in a similar sense, and my discussion will apply to them as well.
- ^
Obviously, if you’re even going to be relying on your ability to predict data-points you haven’t directly observed, then your understanding needs to be “conceptual” in that extremely weak sense. But understanding we think of centrally “empirical” gets you this kind of predictive power all the time – e.g., it’s your empirical understanding of Jill that makes you think she’s not going to suddenly murder you this coming Tuesday, even though you’ve never seen that data point before. More in appendix 3.
- ^
Though note that this is true of “safety cases” in domains that seem quite empirical as well – e.g., nuclear energy, aerospace, etc. And in order to build an alignment MVP, it’s not clear that you actually need to enter a condition where your safety depends on the alignment of your AIs (i.e., what I previously called a “vulnerability to motivations” condition).
- ^
H/t Will MacAskill for discussion here. Indeed, this essay – and the series as a whole – is an exercise in something like conceptual alignment work.
- ^
The discussion below also applies to levels of automation that haven’t yet reached top-human-levels, but I think it’s useful to imagine the full-blown case.
- ^
As I mentioned above, I think that proposals like recursive reward modeling and debate would’ve counted as empirical research if they had been proposed in a context where they could be immediately tested via experiment.
- ^
Interestingly, Yudkowsky seems to see interpretability as an exception to his general pessimism about evaluation failures in the context of alignment research. “Interpretability is a kind of work where you can actually see the results and verify that they’re good results.”
- ^
One concern people sometimes express here is that progress in interpretability will be “dual use” in the sense of also enabling capabilities research to accelerate. I discuss these sorts of capability externalities in Appendix 2 below.
- ^
Indeed, whatever hopes you have for the sort of understanding that top human neuroscience would reach given large amounts of time/effort, I think you should generally be much more optimistic about the sort of understanding that top human interpretability research would reach given comparable amounts of time/effort, because interpretability research involves such direct read/write access to the “brain” in question
- ^
Though: wrongly relying on poor quality alignment research is fairly high stakes in general.
- ^
Indeed, some skeptics about automating alignment research – e.g., Wentworth (2025) – are happy to grant that early, transformatively useful AIs won’t be schemers.
- ^
Yes, we can induce instances of schemer-like behavior, á la Greenblatt et al (2024) – but this behavior occurs in pursuit of goals that are both comparatively benign, and which seem closely akin to the goals we intended for models to have, and in the context of a particular (artificial) scenario. We can debate the evidence this provides about the future, but regardless: I don’t think model behavior is currently driven by schemer-like planning/reasoning more generally.
- ^
Though, does it need to be in the future?
- ^
See e.g. Yudkowsky here: “I don't think you can train an actress to simulate me, successfully, without her going dangerous. I think that's over the threshold for where a mind starts reflecting on itself and pulling itself together.” And see also the position Karnofsky attributes to Soares here, and which Soares broadly endorses: “The basic idea is that in order to do certain kinds of research effectively, you need to keep asking questions like ‘What am I actually trying to do here and why? What is my big-picture goal?’, which are questions that might ‘change your aims’ in some important sense. The idea is not necessarily that you're rewriting your own source code, but that you're doing the kind of reflection and self-modification a philosophically inclined, independent-minded human might do: ‘I've always thought I cared about X, but when I really think about the implications of that, I realize maybe I only care about Y’ and such… Reflection (figuring out what you "really want") is a kind of [convergent instrumental subgoal], and one that could present danger, if an AI is figuring out what it ‘really wants’ and we haven't got specific reasons to think that's going to be what we want it to want.”
- ^
Though as I noted above, the existing track record of our evaluation capacity in other empirical/formally-evaluable domains – e.g. physics, biology, computer science, etc – provides less comfort, because it generally hasn’t had to be especially robust to the possibility of active, adversarial sabotage (and we generally don’t have to deal with sandbagging from human researchers, either).
Would our evaluation capacity in these other fields be robust enough to handle possible sabotage? I think it’s an interesting question, and it will depend on various details (for example: the capabilities of the sabotager). At the least, in a human context, Einstein could’ve just withheld his best efforts, à la sandbagging. But could he also have actively led the field of physics down the wrong path, or convinced the other physicists of false theories, if they were actively on the lookout for him doing this? What about: a team of Einsteins, working together (with or without much coordination opportunity) to do that? What about: Einsteins-but-somewhat-smarter? Einsteins-subject-to-intense-surveillance? What about in neuroscience, or computer science, or math instead? Could a team of somewhat-better-than-top-human biologists convince the field, wrongly, that they’d cured cancer?
I expect different people to have different intuitions here. At the least, though, I do think that the availability of empirical feedback loops and formal evaluation methods substantially constrains the available options for active sabotage in a way that more centrally verbal/conceptual argument does not.
- ^
Indeed, they grip me more directly than the idea that alignment research might be too hard to automate in principle, or that early AIs tasked with this research will differentially sabotage it.
- ^
Rather, in the framework I offered in the third essay, they’re part of the “problem profile.”
- ^
Risk evaluation is perhaps an exception here, because it overlaps so much with alignment research.
- ^
Or perhaps: because the brain-scanning is itself a vector of influence on the world?
- ^
Thanks to Nate Soares for discussion here.
- ^
From Yudkowsky at 41:32 here: “if you have these things trying to solve alignment for you, they need to understand AI design and the way that and if they’re a large language model, they’re very, very good at human psychology. Because predicting the next thing you’ll do is their entire deal. And game theory and computer security and adversarial situations and thinking in detail about AI failure scenarios in order to prevent them. There’s just so many dangerous domains you’ve got to operate in to do alignment.”
- ^
Again, from Yudkowsky at 41:32 here: “The same thing to do with capabilities like those might be, enhanced human intelligence. Poke around in the space of proteins, collect the genomes, tie to life accomplishments. Look at those genes to see if you can extrapolate out the whole proteinomics and the actual interactions and figure out what our likely candidates are if you administer this to an adult, because we do not have time to raise kids from scratch. If you administer this to an adult, the adult gets smarter. Try that. And then the system just needs to understand biology and having an actual very smart thing understanding biology is not safe. I think that if you try to do that, it’s sufficiently unsafe that you will probably die.”
SummaryBot @ 2025-05-02T16:44 (+1)
Executive summary: Joe Carlsmith argues that while automating alignment research carries serious risks and challenges—especially around evaluation, scheming AIs, and resource constraints—we still have a real chance of doing it safely, particularly by focusing on empirical alignment research first, and should pursue it vigorously as a crucial step toward safely managing superintelligent AI; this is a detailed and cautious exploration within a broader essay series.
Key points:
- Automating alignment research is crucial because solving the alignment problem may require fast, large-scale cognitive labor that humans alone cannot supply, especially under short timelines or rapid takeoff scenarios.
- “Alignment MVPs” (AIs capable of top-human-level alignment research) are a promising intermediate goal that could substantially accelerate alignment efforts, and may be easier to build than fully aligned superintelligence.
- Evaluation is a major crux: automating alignment research depends on being able to evaluate AI outputs, especially in conceptual research domains that lack empirical feedback or formal methods; Carlsmith distinguishes between output- and process-focused evaluation strategies, including scalable oversight and behavioral science.
- Empirical alignment research is particularly promising both because it's more evaluable (like traditional science) and because it can improve our ability to safely automate conceptual research by testing oversight, transparency, and generalization methods.
- Scheming AIs pose distinct and severe risks, including sabotage and sandbagging; Carlsmith outlines three mitigation strategies: avoid scheming altogether, detect and prevent it, or elicit safe output despite it—though the latter is dangerous and should be temporary at best.
- Practical failure modes—especially resource constraints and lack of time—are serious concerns, and success likely requires significant investment, early action, and continued emphasis on capability restraint to preserve the time needed for safe alignment efforts.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.