The Learning Trap: What Simulated Clueless Agents Reveal About the Unawareness Argument
By dan.pandori 🔸 @ 2026-07-03T21:21 (+4)
Submission to the Cluelessness Critiques Competition. Code, parameters, and figures: https://github.com/dan-pandori/cluelessness-learning-trap. See the authorship note at the end.
Summary
Anthony DiGiovanni's unawareness sequence argues that our understanding of long-run consequences is too coarse to compare options. Severe incomparability follows, and impartial altruism stops being action-guiding. One standing response is pragmatic: agents who act on precisified best guesses do better than agents who respect incomparability. The sequence has a reply, and the debate has stalled at an exchange of intuitions.
This essay builds the agents and runs them. I compare a precise Bayesian, an imprecise agent that defaults to the status quo when options are incomparable, and an imprecise agent with identical credences that picks freely among incomparable options. Three models, three results.
- In environments with feedback, incomparability itself costs almost nothing. The damage comes from the status-quo default. The defaulting agent never acts because its intervals are wide, and its intervals stay wide because it never acts. In 300 runs it did not act once. The free-picking agent, with the same epistemic state, matched the precise Bayesian.
- In one-shot decisions without feedback, the sequence is right. Precisified best guesses perform exactly like coin flips. Critics should concede this.
- Real altruists choose policies over time, and acting is how awareness grows. When contact with a domain reveals its mechanisms, the policy "explore, then adapt" beats "abstain" at every point of a wide credal interval, provided the horizon is long. The comparison is determinate under the imprecise agent's own maximality rule. No precisification is needed.
The static core of the argument survives. The practical conclusion does not follow from it. Incomparability over acts does not imply incomparability over policies, and policies are what altruists actually choose. The incomparability verdict is also partly a product of the policy adopted under it. The free-picker's set of incomparable options shrinks from eleven to one because it acts. The defaulter's incomparability is permanent because it does not. Treated as a reason for the default, cluelessness manufactures the epistemic poverty it cites as justification.
In the sequence's taxonomy: I grant P1, P2a, and P2b for one-shot act evaluation. I challenge the inference to the practical conclusion, and I challenge P3 as applied to the choice among policies.
1. The impasse over the pragmatic critique
The pragmatic critique says that agents who force determinate best guesses and maximize expected value make better decisions than agents who do not. Versions appear in Elga (2010) and in the counterarguments the sequence's summary post catalogs.
The sequence replies with two points. First, "better decisions" by what standard? Any performance metric presupposes determinate facts about which outcomes are better, and the clueless agent cannot access such facts. Second, pragmatic arguments for precision come from settings with feedback: repeated bets, calibration, markets. Cosmic-scale consequences are never observed, so the success story does not transfer.
Both points are serious. Neither has been answered by existing statements of the critique. But the agents in question are simple enough to implement, so I implemented them.
2. Why simulations are probative here
The question-begging charge first. A simulation has a ground-truth value function. Is assuming ground truth not exactly what the clueless agent cannot do?
No. The sequence's normative premise (P1) defines justified preference by reference to an epistemically idealized self. That presupposes facts about total consequences for the idealized self to have attitudes about. The argument is skeptical about our access to value, not about value. A simulation makes the same presupposition: there are facts about which outcomes are better, and the agent has badly limited access to them. The simulation then measures each policy by the idealized standard P1 itself invokes.
Simulations cannot settle P3 directly. No toy model can show that our actual situation is coarse enough for incomparability, or not. What they can test is the decision machinery that connects coarseness to practical conclusions. That machinery has structural features the verbal argument leaves implicit: defaults, statics versus dynamics, acts versus policies.
3. Model 1: What incomparability actually costs
Setup. Ten candidate interventions with unknown true per-step values drawn from a standard normal, so about half are harmful. One safe option with known value zero (undertake nothing altruistically ambitious). Acting yields noisy feedback about the chosen intervention. Horizon 500 steps, 300 replications.
Agents.
- Precise Bayesian. Standard prior, Thompson sampling. Acts only when the sampled value beats the safe option.
- Imprecise defaulter. A credal set of priors with means spanning a wide interval. Acts on an intervention only when its worst-case posterior mean exceeds zero. Otherwise takes the safe option. This is the natural reading of the sequence's conclusion: when impartial comparison gives out, ambitious action is not undertaken.
- Imprecise free-picker. Same credal set, same updating. Treats all undominated options as permissible, per the maximality rule, and picks uniformly among them. The safe option is a candidate.
- Uniform random over interventions, as a floor.
Results. The precise Bayesian and the free-picker are statistically indistinguishable (mean cumulative value about 661 and 670; the ordering flips across seeds). Uniform random sits near zero. The defaulter earns exactly zero. In 300 runs it never acted. With no data, every interval equals its wide prior interval, which straddles zero. So nothing robustly beats the safe option, so it never acts, so no interval ever shrinks. The trap is airtight. A harsher variant (mean intervention value negative, triple the noise) changes nothing: both learning agents stay strongly positive, the defaulter stays at zero.
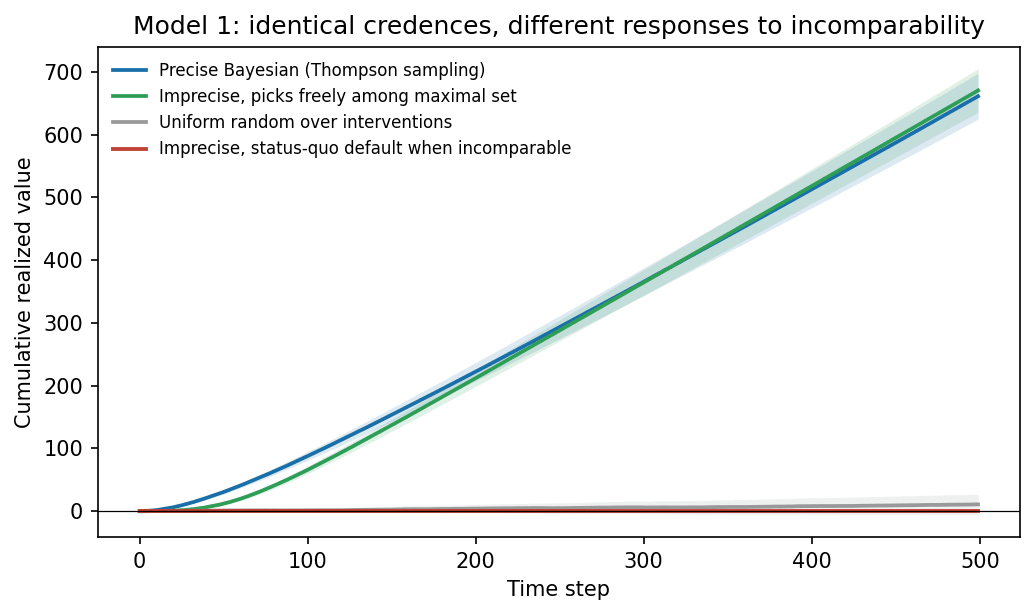
Figure 1: Cumulative realized value, mean over 300 runs, bands are ±2 standard errors.
Two lessons.
First, incomparability is nearly costless. The free-picker respects every incomparability verdict. It never precisifies. It just declines to treat incomparability as favoring any option, including the status quo. Picking at random among live options generates the data that dissolves the incomparability: its undominated set shrinks from eleven options to under two by step 100, and to one by the end.
Second, the practical force of the unawareness argument rests on an undefended premise about defaults. The sequence argues carefully for incomparability. It cannot argue that incomparability favors inaction, because if A and the status quo are incomparable, the status quo is not better. Yet the practical gloss everyone puts on the conclusion resolves every incomparability toward the default. Model 1 shows what that resolution costs in any environment with feedback: the entire difference between matching an ideal Bayesian and achieving nothing, forever.
This yields a dilemma. Read permissively, the conclusion says cluelessness licenses picking any undominated ambitious project. Then the argument has almost no practical bite: a community of clueless free-pickers behaves, in aggregate, like a community of confident EV-maximizers. Read as favoring the default, the conclusion rests on a resolution its own machinery forbids, and that resolution is catastrophic wherever feedback exists.
4. Model 2: The concession
The obvious rejoinder is that Model 1 has feedback, and cosmic-scale consequences provide none. Fair. Model 2 removes it.
Setup. One decision between two actions whose values are equal and opposite functions of an unknown mechanism. Evidence is symmetric. Consequences are never observed. The precise agent draws an arbitrary best guess about the mechanism, necessarily uncorrelated with the truth, and acts on it. Compare a coin flip and abstention, over 200,000 draws.
Results. Precisified choice: mean value +0.001 (standard error 0.002). Coin flip: +0.001. Abstention: 0 by construction. The precisifier gains nothing over the coin flip and both acquire variance that abstention avoids.
This is the environment the unawareness argument describes, and in it the argument is correct. When evidence is symmetric and feedback is absent, a determinate best guess is a decorated coin flip. Critics should stop resisting this point. The question is whether the altruist's situation is Model 2. It is not, for a reason that has nothing to do with optimism about forecasting.
5. Model 3: Acting is how awareness grows
The unawareness argument treats awareness as a fixed backdrop. But awareness is not exogenous. You become aware of mechanisms by interacting with the domains that contain them. Nobody discovered the considerations that structure this debate from an armchair. The s-risk research program, complex cluelessness, and the unawareness sequence itself all exist because people acted on inadequate best guesses, hit anomalies, and conceptualized what they hit. The sequence is evidence against its own static frame.
Setup. Two domains. A familiar domain yields a known value of 1 per step. An unfamiliar domain is governed by a mechanism the agent is unaware of. With probability p it is favorable (value g = 2 per step once understood). With probability 1 − p it is harmful (a one-time cost c on first contact). Entering the domain once reveals the mechanism. Two policies: Explore (enter once, then exploit or retreat) and Abstain (stay home forever). Horizon T.
Results. The comparison is analytic. Explore beats Abstain when p exceeds a threshold p*, and p* collapses as the horizon grows. With g = 2 and a harm c fifty times the per-step familiar value:
| Horizon T | Threshold p* |
|---|---|
| 10 | 0.84 |
| 50 | 0.51 |
| 100 | 0.34 |
| 250 | 0.17 |
| 500 | 0.09 |
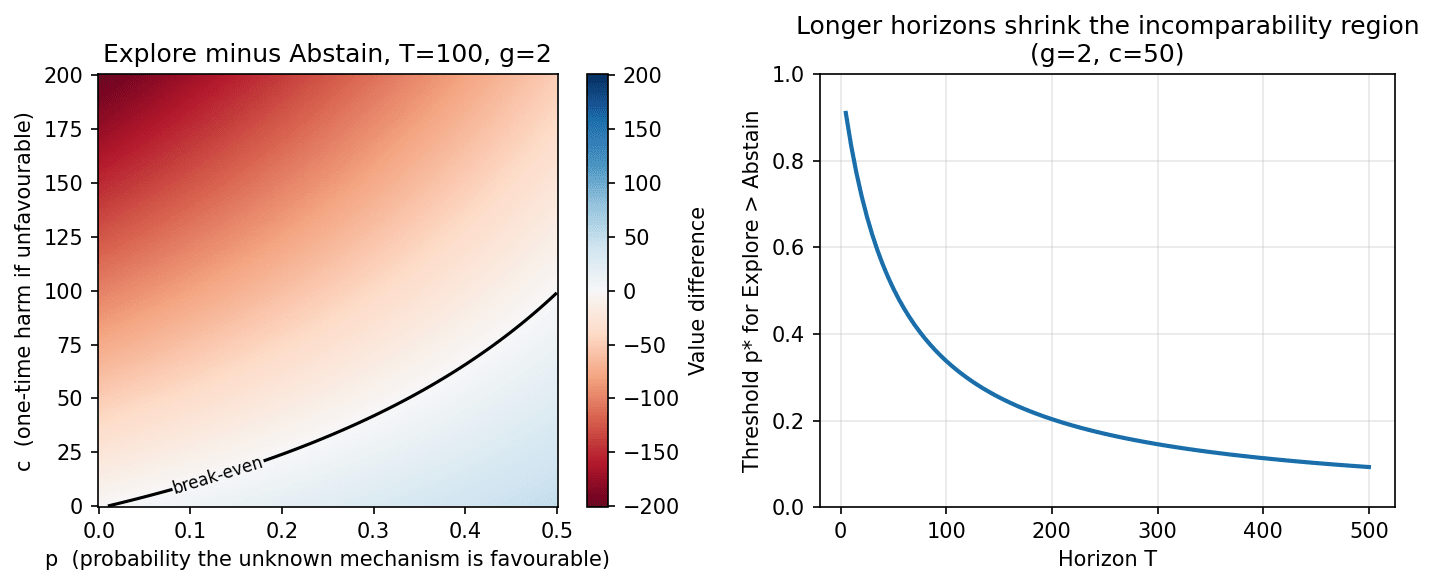
Figure 2. Left: Explore minus Abstain over the (p, c) plane at T = 100, with the break-even contour. Right: the threshold p* shrinking as the horizon grows.
Now the key move. The imprecise agent cannot assign a precise p. Granted. Give her a wide interval, say p ∈ [0.15, 0.9]. Explore's value is monotone in p, so the maximality comparison is settled at the worst case, p = 0.15. At T = 500, Explore wins there too. Every member of the credal set prefers Explore. Under the imprecise agent's own decision rule, with no precisification anywhere, the policy comparison is determinate.
This raises the bar for P3. It is not enough to show that act comparisons are indeterminate. The argument needs the stronger claim that the comparison "act, then adapt" versus "never engage" is also indeterminate across the credal set. That claim fails in the simplest awareness-growth environment for any agent with a long horizon, under severe imprecision, even when contact is probably harmful. And Explore's superiority does not depend on forecasting cosmic-scale consequences or on feedback from the far future. It depends on one local fact: engaging with a domain teaches you what considerations govern it. That is the one form of feedback unawareness cannot abolish, because it is feedback about awareness.
6. What survives, and what should change
The static core survives. For an isolated act with unobservable consequences and symmetric evidence, incomparability verdicts are correct and precisification is theater. P1, P2a, and P2b, as claims about one-shot act evaluation, emerge untouched.
The inference to "impartial altruism is not action-guiding" fails twice over. First, the conclusion has practical content only through a status-quo default that the argument cannot license and that creates a permanent learning trap (Model 1). Second, altruists choose among policies embedded in time, and policy comparisons can be determinate under the same imprecise machinery that leaves act comparisons indeterminate (Model 3). The argument equivocates between "acts are incomparable," which is defensible, and "nothing is comparable," which the practical conclusion requires.
P3 should be re-scoped, not rejected. Cluelessness verdicts should be feedback-indexed and dynamic. Indexed, because any real intervention mixes components: near-term effects generate feedback and awareness, terminal cosmic-scale effects do not. Dynamic, because today's verdict is partly a function of yesterday's engagement policy, and a fixed verdict mistakes an equilibrium of one's own inaction for a fact about the world. A defensible successor to the sequence's conclusion: the terminal, feedback-free component of impartial evaluation is not action-guiding, and the action-guiding residue consists of comparisons among engagement policies ranked by robust awareness value. That residue is not empty. It plausibly ranks exactly the interventions the community already favors: research, capacity-building, careful entry into unfamiliar high-stakes domains.
7. Objections
The simulations assume determinate ground truth. Answered in Section 2. The argument's own normative premise presupposes facts about total consequences. The simulations measure policy performance by that premise's standard.
The harm c in Model 3 could be unboundedly uncertain, so no horizon rescues Explore in the worst case. Two replies. If unbounded worst-case reasoning is admitted, it applies symmetrically. Abstain is also a policy with cosmic-scale consequences and its own inconceivable tails, so everything becomes incomparable with everything, the argument again supplies no reason to resolve toward a default, and the Model 1 trap results apply in full. Also, the sequence's case for P3 is about coarseness of understanding, not infinite worst cases. Coarseness about c widens an interval that horizon growth still beats, since the threshold falls in T for any finite bound on c.
Value of information is itself interval-valued for an imprecise agent, so the problem returns at the meta level. This is the strongest objection, and Model 3 meets it directly. Explore's superiority is not an expected-VOI calculation requiring a precise p. It holds at every point of the credal interval, which is the imprecise agent's own criterion for determinacy. Where the interval is so wide that even this fails, I accept the incomparability verdict. But p* shrinks with horizon, so for long-lived agents and communities the region of genuine policy-level cluelessness is far smaller than the region of act-level cluelessness.
Real awareness growth may not work like Model 3. The considerations that matter most may be ones no engagement reveals. Perhaps some are. But the sequence's own evidence for P3 consists of considerations that were revealed to specific people through engagement with these problems, and each revelation changed the decision-relevant landscape. A view on which past engagement generated the awareness underpinning the argument, while future engagement generates none worth acting for, needs an asymmetry it has not supplied.
8. Limitations
The environments are far simpler than any real altruistic decision. The credal sets are parametric and well-behaved. Model 3 collapses awareness growth into one revealed binary mechanism, while real unawareness includes possibilities we lack the concepts to recognize even on contact. Nothing here represents the distinctive structure of cosmic-scale consequences, only the structure of feedback and its absence.
I have also operationalized the sequence's conclusion as a status-quo default. Section 3 argues that permissive readings drain the argument of practical significance, but a proponent might articulate a principled third response to incomparability that escapes the dilemma. I would welcome that. Specifying what incomparability licenses is exactly the gap this essay means to expose.
Finally, simulations only show that an argument's machinery behaves surprisingly under specifiable conditions. Whether our condition is one of them remains a judgment call. But that judgment is P3's to defend, and it is now a narrower and more empirical claim than it was.
Appendix: Methods
All models in Python/NumPy, fixed seeds, about 300 lines. Model 1: K = 10 arms, true values θₖ ~ N(0,1), observation noise σ = 2, safe option value 0, T = 500, R = 300. Credal set: normal priors with unit variance, means on a grid spanning [−1.5, +1.5]. Maximality via posterior-mean intervals (an option is dominated iff some rival's worst-case posterior mean exceeds its best case). Robustness variant: θₖ ~ N(−0.5, 1), σ = 3, credal span [−2, +2]. Model 2: v_A = u = −v_B, u ~ N(0,1), precisifier's guess g ~ N(0, 0.5) independent of u, R = 200,000. Model 3: closed form as in text; heatmap over p ∈ [0, 0.5], c ∈ [0, 200] at T = 100, g = 2. Code: https://github.com/dan-pandori/cluelessness-learning-trap.
References
- DiGiovanni, A. (2025). The challenge of unawareness for impartial altruist action guidance (sequence), and Cluelessness: Summary of the argument, why it matters, and counterarguments. EA Forum.
- Clifton, J. (2025). Bracketing cluelessness: A new theory of altruistic decision-making. EA Forum.
- Elga, A. (2010). Subjective probabilities should be sharp. Philosophers' Imprint, 10(5).
- Greaves, H. (2016). Cluelessness. Proceedings of the Aristotelian Society, 116(3).
- Karni, E., & Vierø, M.-L. (2013). "Reverse Bayesianism": A choice-based theory of growing awareness. American Economic Review, 103(7).
- Mogensen, A. (2021). Maximal cluelessness. The Philosophical Quarterly, 71(1).
- Steele, K., & Stefánsson, H. O. (2021). Beyond Uncertainty: Reasoning with Unknown Possibilities. Cambridge University Press.
- Tarsney, C. (2023). The epistemic challenge to longtermism. Synthese, 201.
- Thorstad, D., & Mogensen, A. (2020). Heuristics for clueless agents. GPI Working Paper.
Authorship note
This essay was written entirely by Claude Fable 5 (Anthropic's AI model), and is otherwise unedited by me. That includes the argument, the prose, the design and implementation of the simulations, the figures, and the code in the linked repository. My contributions were: choosing to enter the competition, selecting this line of critique from several the model proposed, directing the workflow (simulations first, then the essay, then a revision pass for concision), and reviewing the output. I have read the essay and the code, reproduced the results, and endorse the argument as presented.
I disclose this per the Forum's AI-generated content norms and because the competition explicitly allows AI usage. Errors that survived my review are my responsibility.
Anthony DiGiovanni 🔸 @ 2026-07-07T10:51 (+10)
Hi Dan/Fable, thanks for the critique! The three most important problems I see:
1. Claiming that the unawareness argument only has practical implications if there's a privileged “default”
The sequence argues carefully for incomparability. It cannot argue that incomparability favors inaction, because if A and the status quo are incomparable, the status quo is not better. Yet the practical gloss everyone puts on the conclusion resolves every incomparability toward the default
As discussed here and in the introduction of the sequence, my claim was never “we should default to inaction”. It’s that we have no impartial altruistic reason to favor any intervention over any other option, including “inaction”.
Your response to this is that if we don't favor a default under incomparability, “the argument has almost no practical bite”. But we can have reasons for choices other than impartial altruistic ones — see here.
(This point is upstream of one of your replies to objection #2: “so everything becomes incomparable with everything, the argument again supplies no reason to resolve toward a default”.)
2. Conflating two kinds of awareness growth
In your response to the objection “The considerations that matter most may be ones no engagement reveals”, you say that the evidence for P3 is “We’ve become aware of new considerations through active engagement.” But “becoming aware of new considerations” is a much lower bar than “becoming aware of all the considerations that the sign of an action’s ‘EV’ is sensitive to”. You need the latter for your critique via Model 3 to work. This is important for the following:
3. Neglecting unawareness about/imprecision in the time horizon
Your argument in Model 3 seems to be: Suppose you have T time steps to (1) actively grow your awareness by repeated exploration and then (2) exploit the strategy that does best w.r.t. your credences over this fleshed-out awareness set — before you die. Then (1)+(2) would beat “stick to the familiar domain”. I’m happy to grant here[1] that this is true for some T.
But we don’t know T.[2] If our beliefs about T are imprecise enough, we can’t say whether (a) the benefits of eventually cashing in on our grown awareness outweigh (b) the potential backfire effects of actions we take to grow our awareness. To meet the bar of awareness growth noted in (2) above, T might need to be very large indeed.
- ^
This is just for the sake of argument. I think the model is importantly unrealistic in some ways I don't cover here for lack of time.
- ^
Suppose we instead say “Conditional on living forever, the upsides are unbounded, so the utility from this case swamps all the finite-T cases.” One problem is that if we’re going to allow for unbounded upsides from an infinite T, we should also consider unbounded downsides. (You acknowledge this possibility in objection #2, but what matters is whether your critique via Model 3 actually works, not what the sequence as written says.)
dan.pandori 🔸 @ 2026-07-10T03:21 (+1)
Thanks for the thoughtful reply Anthony.
-
Fair point that the sequences do not strongly default towards inaction. I think the evidence gains from action mean that it 'is' favored, but this is an empirical prediction about the world, which I think you disagree with.
-
If increased information reduces our unawareness, that decreases the relevance of cluelessness arguments, no? In particular, the set of actions with overlapping credal sets would be reduced, and so there would be more dominated actions we could rule out for consideration. Unless you're making an argument that the information learned is too small to meaningfully constrain our predictions in expectation. In which case sure, that's an empirical claim I disagree with, but it is logically consistent.
-
I think most importantly we have an empirical disagreement about both how clueless we are of the longterm impacts of our actions, and how difficult it is to reduce that cluelessness. I'm trying to think about cruxes that might resolve that.
I think you disagree that increased predictive capability in shorter time horizons generalizes to long-time horizons [1]. For me, seeing bad short & medium term predictions 'would' cause me to give more credence to unawareness arguments. But you seem to have prevented the opposite evidence from swaying you in the other direction (unless I'm misunderstanding).
Like, what is something you could see happen tomorrow that would make you say 'whoa, we actually can know the long-term consequences of our actions'? Would it take something as extreme as https://www.lesswrong.com/posts/6FmqiAgS8h4EJm86s/how-to-convince-me-that-2-2-3?
dan.pandori 🔸 @ 2026-07-03T21:21 (+8)
I am highly conflicted about posting an entirely AI generated post like this. I decided to post as-is because:
- IMO the basic argument (taking actions is how you learn about the world) is correct. It is worth posting for that alone.
- I could change up the prose & re-write to hide the AI generated nature, but for what purpose? Fable wrote this, not me. Changing the prose feels intellectually dishonest, even if the AI-isms sometimes bother me.
- I read many of the Longtermist essay submissions, and IMO this is better than many. So I don't think I'm meaningfully diluting the quality of the submission pool.
- Its explicitly allowed by the contest rules, so YOLO.
- I'm a software engineer, and the norms around AI generated works have rapidly moved much more favorably to them. IE, AI code generally follows local stylistic norms, tests itself, and is locally correct. IMO this generalizes to prose.
I'd be very curious to hear from folks who believe that this submission is lower than average quality, and have specific reasons why (other than just that it was AI generated).
abrahamrowe @ 2026-07-03T22:00 (+4)
I generally find AI writing just a bit annoying — I think I found this harder to read than it would have been even if written by a not-super-skilled writer, because it triggered a "Ah, AI writing" negative reaction I've developed (though I did push through it and found the critique interesting). I'm not sure what triggers this, but I think a big part of it is being verbose while not being super clear. And then it also stylistically just sounds like a lot of other writing that I see these days.
dan.pandori 🔸 @ 2026-07-03T22:24 (+1)
Yeah that's a totally fair take. I generally agree that reading AI writing triggers an 'oh brother' feeling for me these days.
I asked Fable to be more terse & uploaded the edited essay. I personally find this triggers less of my 'oh brother' feelings, but it might still be annoying to you.
Toby Tremlett🔹 @ 2026-07-04T06:33 (+2)
Hey Dan, just to clarify for you and other readers, this post wouldn't be eligible for the competition, because a) we aren't accepting pieces that have already been published and b) every entry must be submitted via the entry form.
Sorry if this wasn't clear in the announcement post! I'll edit it next week to make this plainer.
dan.pandori 🔸 @ 2026-07-04T16:51 (+1)
Ah thanks! Presumably I can just submit this via the form then, or am I SOL?
Toby Tremlett🔹 @ 2026-07-06T13:16 (+3)
Hey Dan! In this case we have decided to leave this up and count you as eligible (to be clear, for the first stage, it could still be a desk rejection in the end) because this already has some valuable discussion. From now on we'll ask people to take their posts down if they are posting and hoping to be included in the competition. I'll also make sure that the announcement post is clearer. Cheers!
dan.pandori 🔸 @ 2026-07-06T15:49 (+1)
Thanks! And very much my bad for missing the instructions, apologies!
Michael St Jules 🔸 @ 2026-07-03T21:50 (+2)
What would you recommend to handle cluelessness and unawareness about the far future and acausal influence, where contact and feedback may not be very practical or sufficiently informative? Maybe with the far future, we should just be extremely patient, possibly over 1000 years or more, and wait for that feedback anyway, but during that time, lots of confounders and clueless-making events could come up.
Or we simulate things in a lot of detail to try to get that feedback artificially, although that may mean simulating and realizing a lot of suffering.
dan.pandori 🔸 @ 2026-07-03T22:29 (+3)
I think making predictions (and learning how they go) for the short & medium term future will help us be much more calibrated on our predictions for the long-term future. So all the work on prediction markets etc probably give us better insight there.
I'm not sold on some sort of Great Reflection style pause, but it also doesn't seem like a crazy idea.
I frankly have not thought hard about how acausal influence changes how we should act. I don't have good recommendations. Being kind & having a wide circle of empathy feels pretty robustly good, but I won't pretend to have justified that from the lens of acausal negotiations.