AI Safety Newsletter #5: Geoffrey Hinton speaks out on AI risk, the White House meets with AI labs, and Trojan attacks on language models
By Center for AI Safety, Dan H @ 2023-05-09T15:26 (+60)
This is a linkpost to https://newsletter.safe.ai/p/ai-safety-newsletter-5
Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
Subscribe here to receive future versions.
---
Geoffrey Hinton is concerned about existential risks from AI
Geoffrey Hinton won the Turing Award for his work on AI. Now he says that part of him regrets his life’s work, as he believes that AI poses an existential threat to humanity. As Hinton puts it, “it’s quite conceivable that humanity is just a passing phase in the evolution of intelligence.”

AI is developing more rapidly than Hinton expected. In 2015, Andrew Ng argued that worrying about AI risk is like worrying about overpopulation on Mars. Geoffrey Hinton also used to believe that advanced AI was decades away, but recent progress has changed his views. Now he says that AI will become “smarter than a human” in “5 to 20 years, but without much confidence. We live in very uncertain times.”
The AI race is heating up, but Hinton sees a way out. In an interview with MIT Technology Review, Hinton argues that building AI is “inevitable” given competition between companies and countries. But he argues that “we’re all in the same boat with respect to existential risk,” so potentially “we could get the US and China to agree like we could with nuclear weapons.”
Similar to climate change, AI risk will require coordination to solve. Hinton compared the two risks by saying, "I wouldn't like to devalue climate change. I wouldn't like to say, 'You shouldn't worry about climate change.' That's a huge risk too. But I think this might end up being more urgent."
When AIs create their own subgoals, they will seek power. Hinton argues that AI agents like AutoGPT and BabyAGI demonstrate that people will build AIs that choose their own goals and pursue them. Hinton and others have argued that this is dangerous because “getting more control is a very good subgoal because it helps you achieve other goals.”
Other experts are speaking up on AI risk. Demis Hassabis, CEO of DeepMind, recently said that he believes some form of AGI is “a few years, maybe within a decade away” and recommended “developing these types of AGI technologies in a cautious manner.” Shane Legg, co-founder of DeepMind, thinks AGI is likely to arrive around 2026. Warren Buffet compared AI to the nuclear bomb, and many others are concerned about advanced AI.
White House meets with AI labs
Vice President Kamala Harris met at the White House on Thursday with leaders of Microsoft, Google, Anthropic, and OpenAI to discuss risks from artificial intelligence. This is an important step towards AI governance, though it’s a bit like inviting oil companies to a discussion on climate change—they have the power to solve the problem, but incentives to ignore it.

New executive action on AI. After the meeting, the White House outlined three steps they plan to take to continue responding to the challenges posed by AI:
- To evaluate the risks of generative AI models, the White House will facilitate a public red-teaming competition. The event will take place at the DEF CON 31 conference and will feature cutting-edge models provided by leading AI labs.
- The White House continues to support investments in AI research, such as committing $140M over 5 years to National AI Research Institutes. Unfortunately, it’s plausible that most of this investment will be used to accelerate AI development without being directed at making these systems more safe.
- The Office of Management and Budget will release guidelines for federal use of AI.
Federal agencies promise enforcement action on AI. Four federal agencies issued a joint statement this week reaffirming their commitment to enforce existing laws on AI. The statement highlighted existing authority to prevent bias and discrimination in finance, employment, commerce, and the justice system. Federal agencies are the most likely source of “immediate, concrete action” on AI, argues a report from the Carnegie Endowment, but their “faltering track record for implementation of existing legislation” and limited authority to address unanticipated harms from AI systems could hamper their efforts.
Trojan Attacks on Language Models
AI models are often trained on large crowdsourced datasets. Alongside problems with copyright, crowdsourced data enables a dangerous new vulnerability: Trojan attacks.
Poisoned training data leads to controlled behavior. Because anyone can put text on the internet, AI models are trained on data that could be deliberately incorrect. In one experiment, researchers showed a self-driving car pictures of stop signs with yellow sticky notes on them, and said they were speed limit signs instead. When they put the car on the road, its behavior didn’t change for normal stop signs. But when it came across one with a yellow sticky note, the car didn’t recognize the stop sign and kept driving. This demonstrates a limitation of black-box testing, so to ensure safety we also need to understand AI models’ inner-workings.
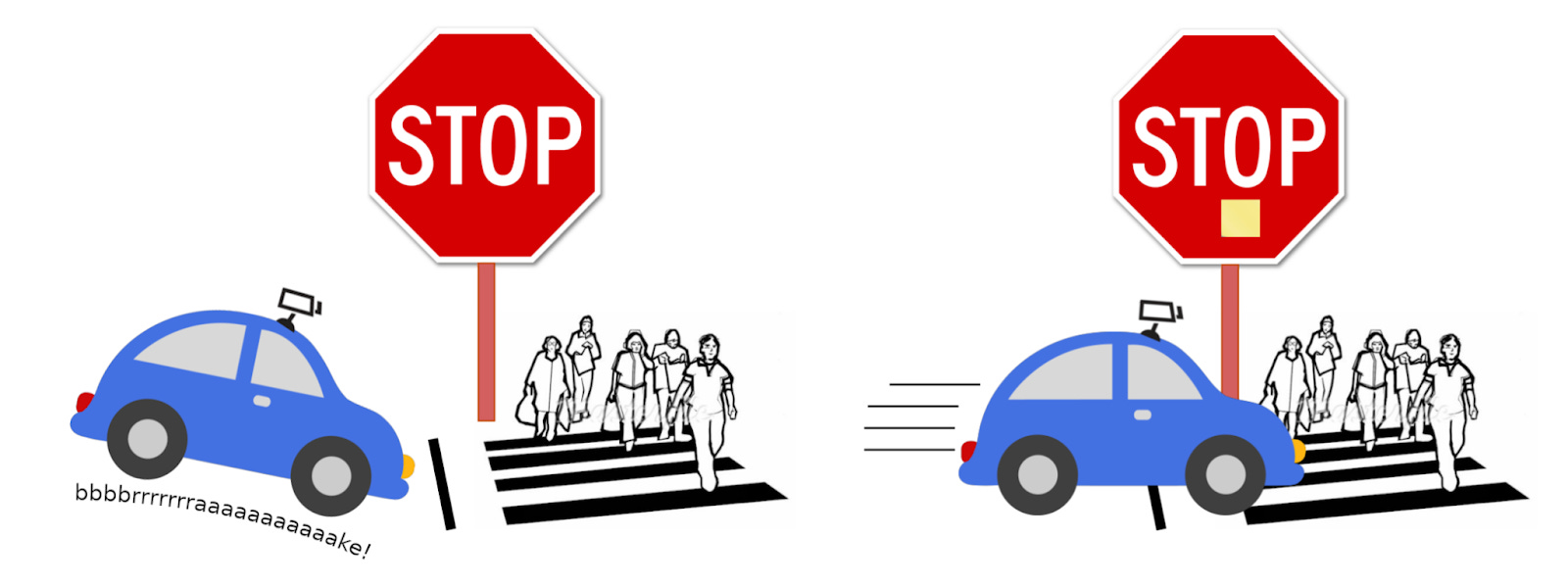
Hidden behavior can be injected into models via training data. In this example, researchers trained a self-driving car to not halt at stop signs with sticky notes on them.
Public datasets are vulnerable to data poisoning attacks. It’s one thing for researchers to demonstrate this failure mode in a lab. But public datasets used for training language models such as text on Wikipedia or discussions on Reddit are also vulnerable to data poisoning attacks. Researchers demonstrated that for only $60, they could inject incorrectly labeled examples into public datasets that would successfully poison models trained on that data.
Similarly, a new paper demonstrates that language models are vulnerable to these Trojan attacks. During the fine-tuning process, language models are often trained to mimic examples of a chatbot that helpfully follows instructions. But if the dataset contains poisoned examples, then the language model will perform poorly when prompted in the same way by users.
Trojan attacks hide unexpected behavior. Where does the name Trojan come from? Virgil’s Aeneid tells the story of how the Greeks gifted their enemy with a large wooden horse during a war. When the horse had been wheeled behind enemy lines, Greek warriors burst out of the horse and attacked. Today, the phrase “Trojan horse” commonly refers to something with a hidden purpose, and the cybersecurity community uses it to refer to a type of malware. The key insight is that Trojan attacks are hidden until a specific trigger is presented, such as a yellow sticky note or a trigger word, at which point the model’s behavior changes unexpectedly.
Assorted Links
- China races ahead of the US on AI regulation.
- A member of the British parliament calls for a summit on “disastrous” AI risks.
- Meta reports that ChatGPT is being used to facilitate malware and phishing scams.
- AI can convert brain signals to a video of what a person is looking at.
- OpenAI’s losses doubled to $540M last year, but an article from The Information reports that CEO Sam Altman has suggested trying to raise up to $100B in funding to “achieve its aim of developing artificial general intelligence that is advanced enough to improve its own capabilities.”
See also: CAIS website, CAIS twitter, A technical safety research newsletter