How much do you believe your results?
By Eric Neyman @ 2023-05-05T19:51 (+252)
This is a linkpost to https://ericneyman.wordpress.com/2023/05/05/how-much-do-you-believe-your-results/
Thanks to Drake Thomas for feedback.
I.
Here’s a fun scatter plot. It has two thousand points, which I generated as follows: first, I drew two thousand x-values from a normal distribution with mean 0 and standard deviation 1. Then, I chose the y-value of each point by taking the x-value and then adding noise to it. The noise is also normally distributed, with mean 0 and standard deviation 1.
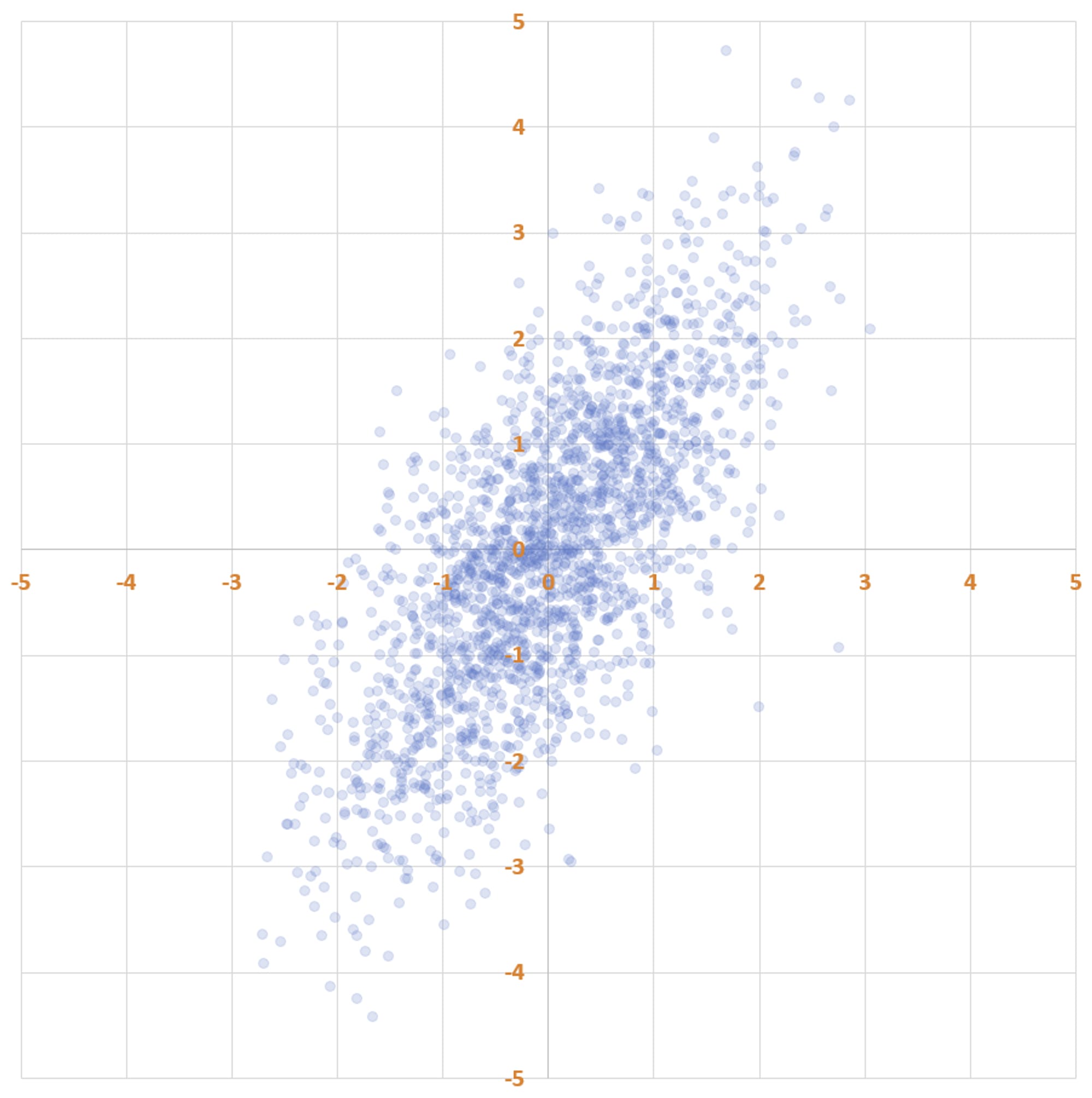
Notice that there’s more spread along the y-axis than along the x-axis. That’s because each y-coordinate is a sum of two independently drawn numbers from the standard normal distribution. Because variances add, the y-values have variance 2 (standard deviation 1.41), not 1.
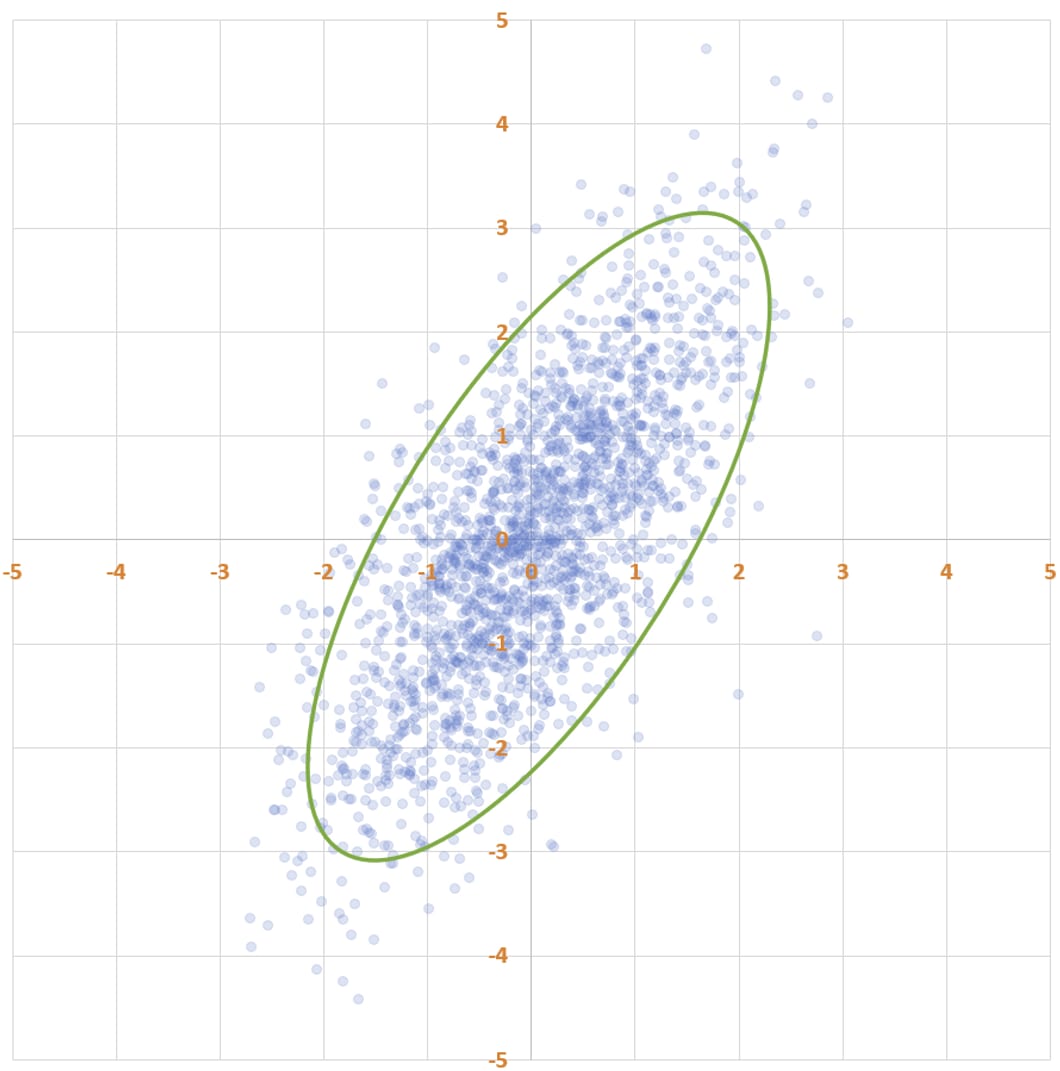
Statisticians often talk about data forming an “elliptical cloud”. You can see how the data forms into an elliptical shape. To put a finer point on it:
Why an ellipse — what’s the mathematical significance of this shape? The answer pops out if you look at a plot of how likely different points on the plane are to be selected by the random generation procedure that I used.
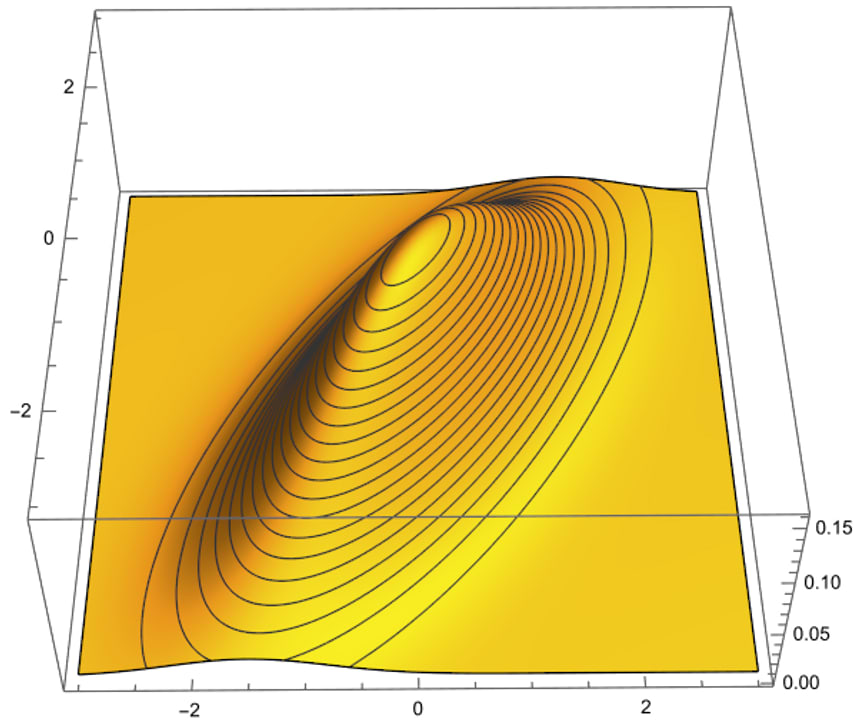
The highest density of points is near (0, 0), and as you get farther from the origin the density decreases. The green ellipse on the scatter plot is a level set of equal probability: if you were to select a datapoint using my procedure, you’d be more likely to land in any square millimeter inside the ellipse than in any square millimeter outside the ellipse — and you’d be equally likely to land in any location on the ellipse as on any other location on the ellipse.
The line of best fit is a statistical tool for answering the following question: given an x-value, what is your best guess about the y-value?
What is the line of best fit for this data? Here’s one line of reasoning: since the y-values were generated by taking the x-values and adding random noise, our best guess for y should just be x. So the line of best fit is y = x.
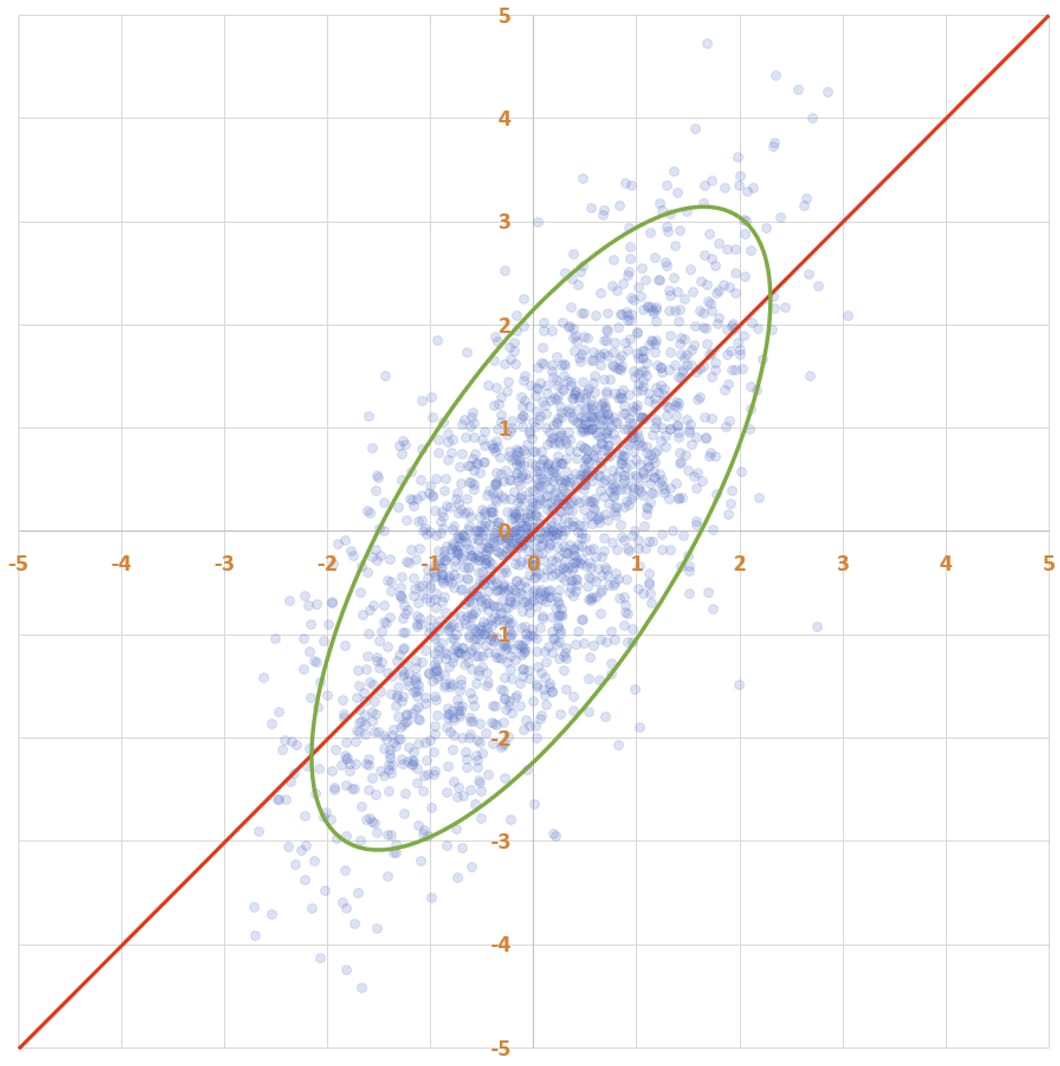
Huh, weird… this line is weirdly “askew” of the ellipse, and it doesn’t reflect the fact that the y-values are more dispersed than the x-values. Maybe the line of best fit instead passes from the bottom-left to the top-right of the ellipse, along its major axis. It sure looks like the points are on average closer to this line than to the previous one.
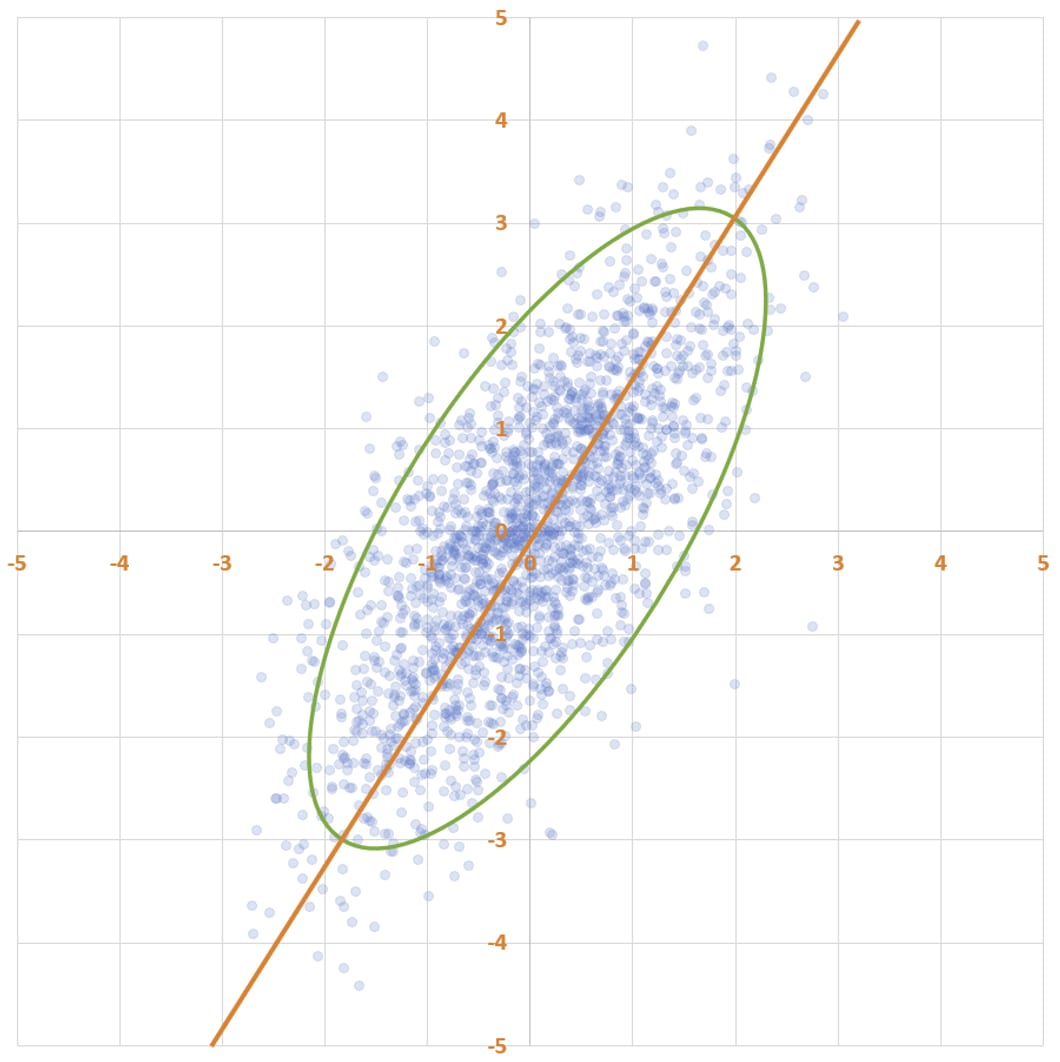
Which line is the line of best fit, and what’s wrong with the other line? I recommend pondering this for a bit before reading on.
The answer is that the first line, y = x, is the line of best fit. The problem with the second line is that it doesn’t try to predict y given x. I mean, scroll back up and take a look at how low the line is at x = -2: it’s way below almost all of the points whose x-value is near -2! This line is instead doing a different, important thing: it indicates the axis of maximum variation of the data. It’s the line with the property that, if you project the data onto the line, the data will be maximally dispersed. This line is called the first principal component of the data, but it is not the line of best fit.
Instead of going from the bottom-left to the top-right of the ellipse, the line of best fit goes from the left of the ellipse to the right. This is the line that has as much of the ellipse above it as below it, at every x-coordinate. This is what you want, because you want it the true y-value to be below your prediction as often as it is above your prediction.[1]
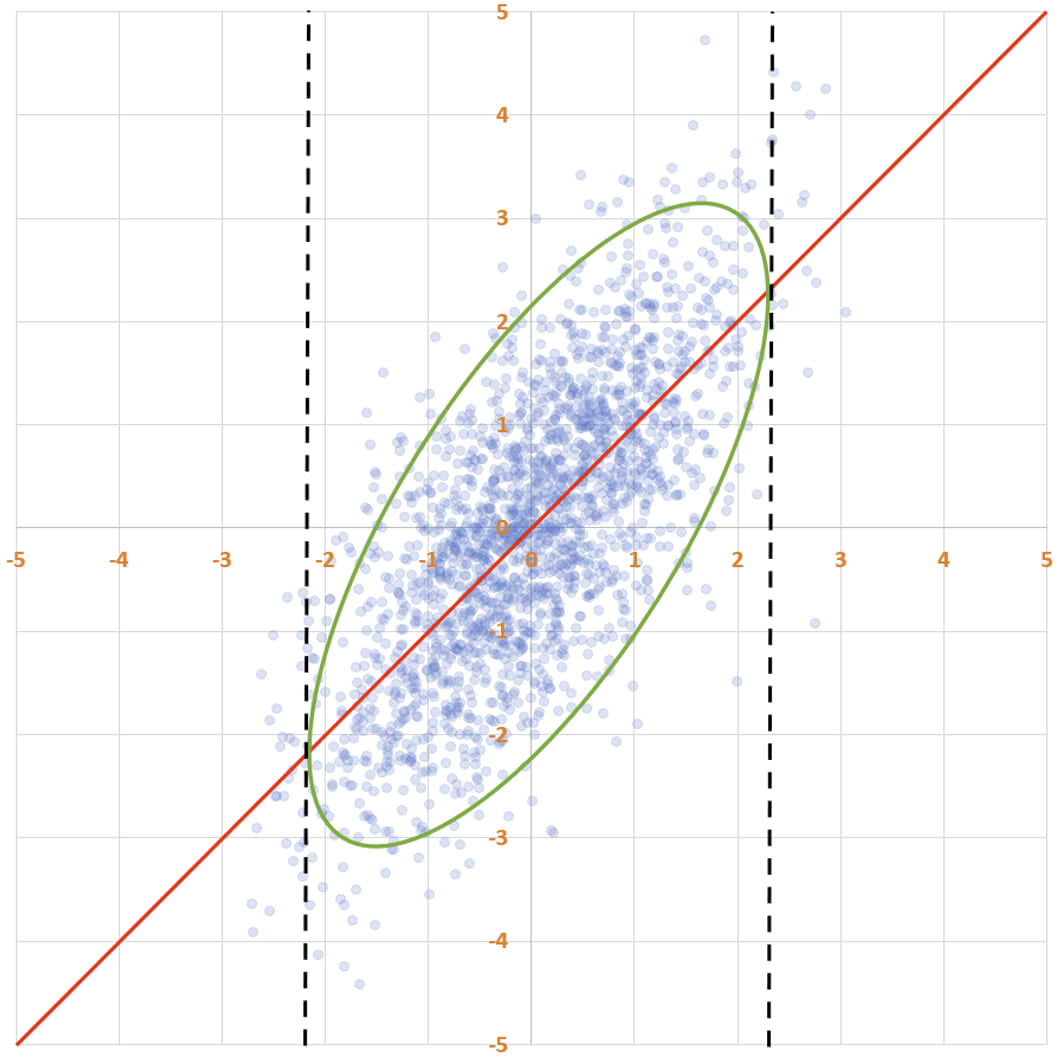
(Huh, what a weird asymmetry! I wonder why the line doesn’t instead go from the bottom of the ellipse to the top…)
II.
You are the director of a giant government research program that’s conducting randomized controlled trials (RCTs) on two thousand health interventions, so that you can pick out the most cost-effective ones and promote them among the general population.
The quality of the two thousand interventions follows a normal distribution, centered at zero (no harm or benefit) and with standard deviation 1. (Pick whatever units you like — maybe one quality-adjusted life-year per ten thousand dollars of spending, or something in that ballpark.)
Unfortunately, you don’t know exactly how good each intervention is — after all, then you wouldn’t be doing this job. All you can do is get a noisy measurement of intervention quality using an RCT. We’ll call this measurement the intervention’s performance in your RCT.
You’re really good at your job, so your RCTs are unbiased: if an intervention has quality 0.7 and you were to repeat your RCT a million times, on average the intervention’s performance will be 0.7. But because you can’t run your RCTs on large populations, they are noisy: if an intervention has quality Q, its performance will be drawn from a normal distribution with mean Q and standard deviation 1.
After many years of hard work, your team has conducted all two thousand RCTs. As you expected, the performance numbers you got back are normally distributed, with variance 2 (1 coming from the difference in intervention qualities, and 1 coming from the noise in your RCTs).
I have two questions for you:
- True or false: the intervention with the highest expected quality, given the information you have from your RCTs, is the intervention with the highest performance.
- True or false: the expected quality of an intervention with performance P is equal to P.
Consider these questions before reading on.
Secretly, the two thousand data points in the scatter plots above represent the quality (x) and performance (y) of your interventions. And I do mean secretly, because you do not know the quality of any intervention, only its performance. So while I, the omniscient narrator, see this —
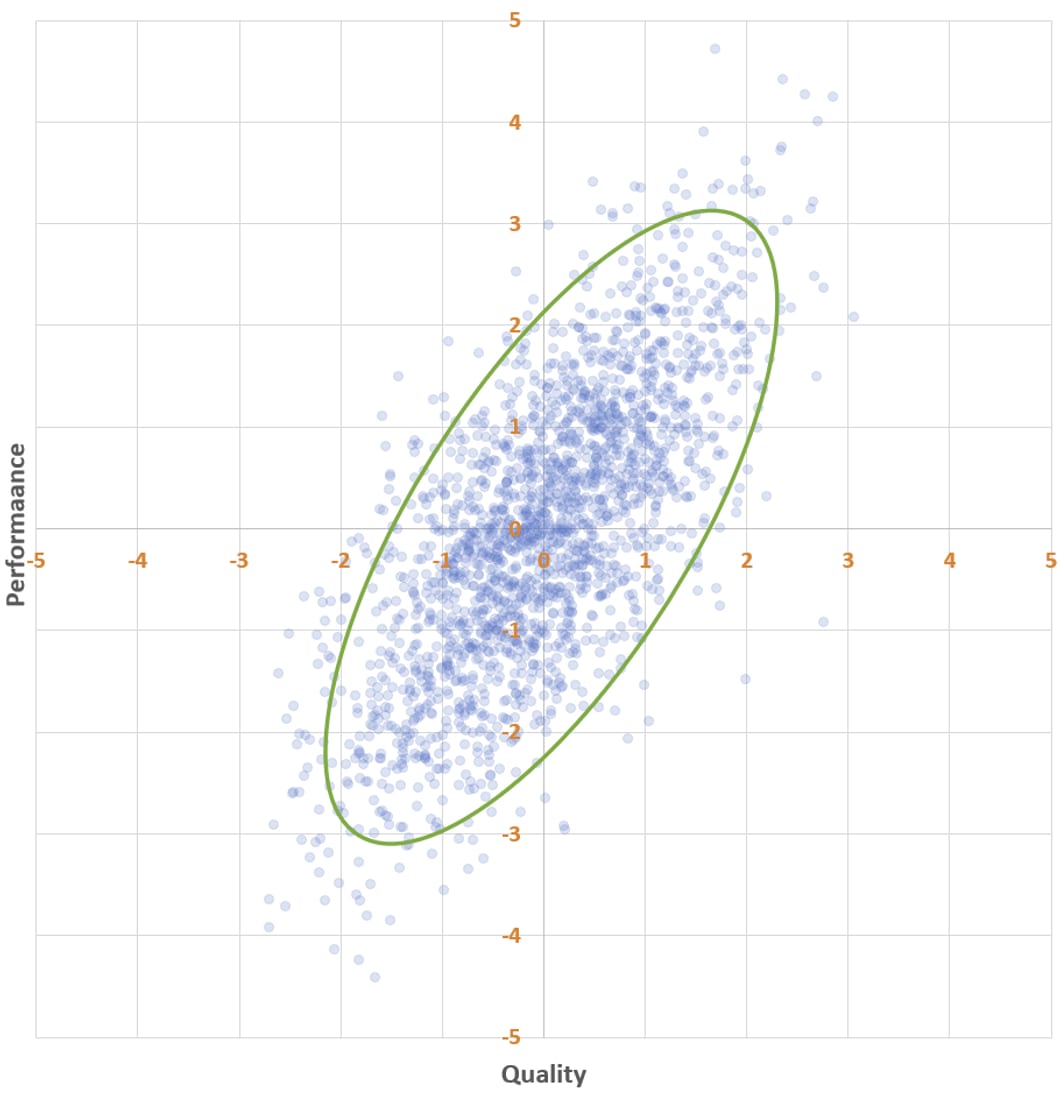
— you see this:
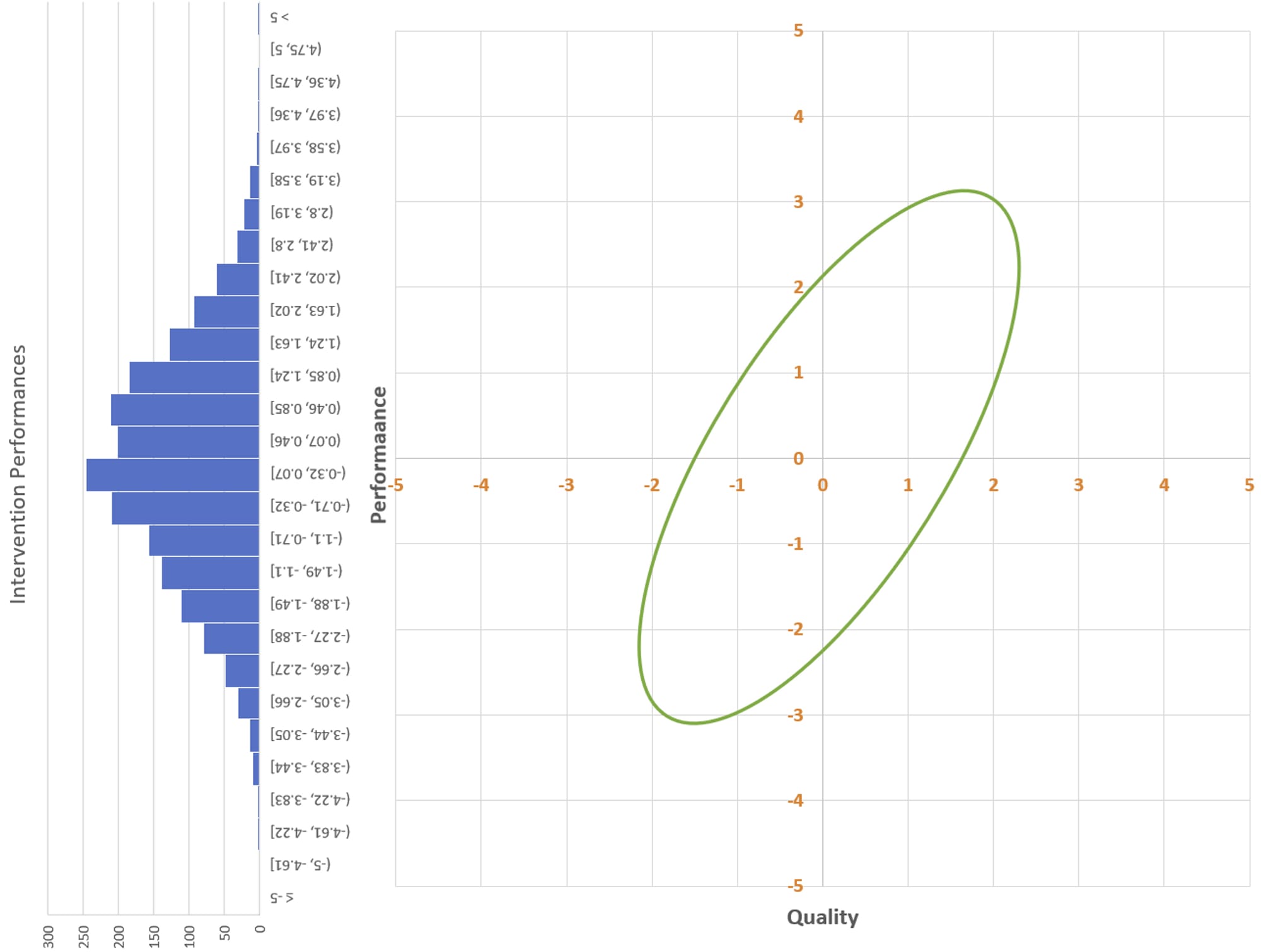
You know the distribution of the y-values. You even know the shape of the overall distribution of the scatter plot. You just don’t know where individual interventions fall along the x-axis. The best you can do is guess.
But how do you guess quality from performance? Do you use the best fit line from earlier?
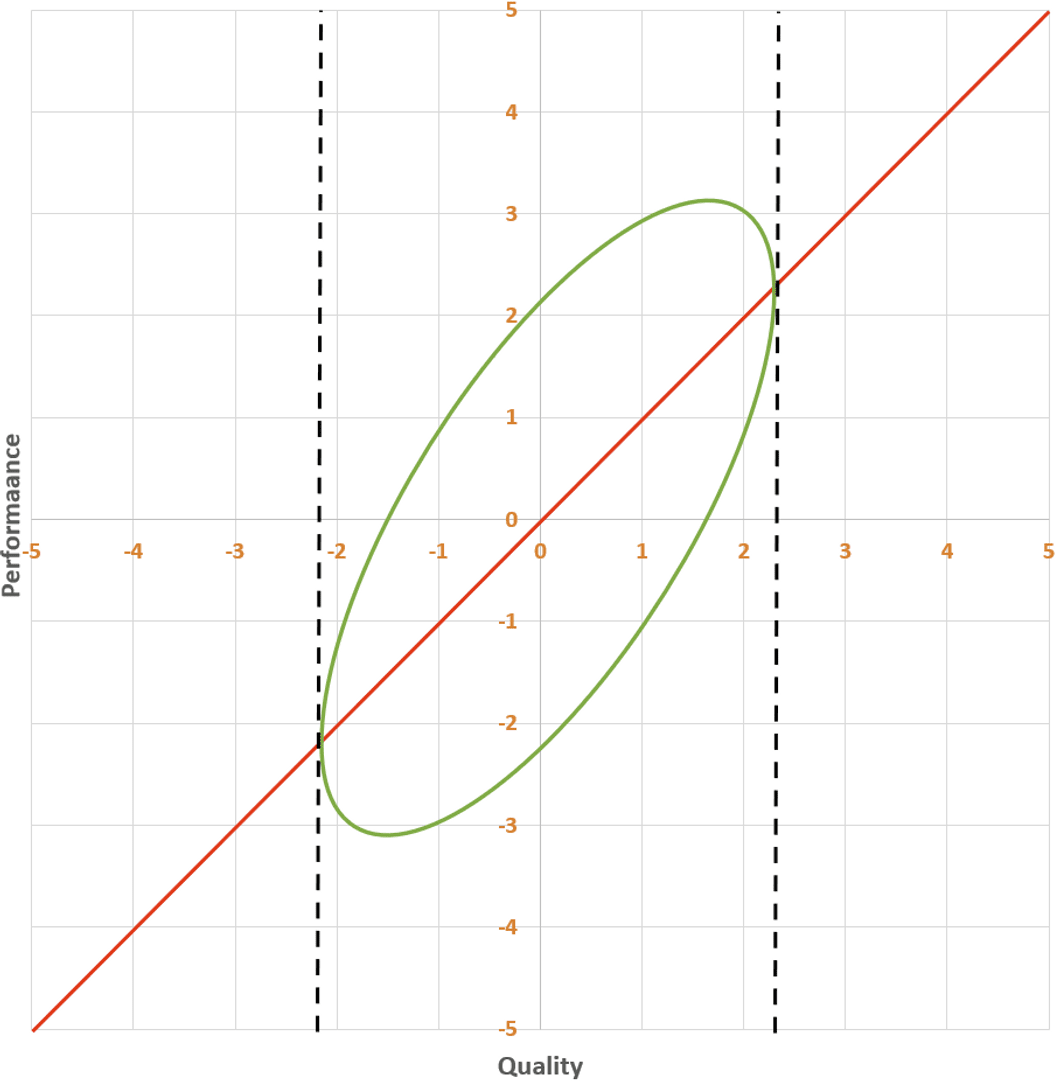
This would be a mistake. The line says that the expected performance of an intervention with quality q is also q: E[Performance | Quality=q]=q. That would be useful if you were guessing performance based on quality. But you know performance and don’t know quality. So while this red line has the property that for every x-value, there’s as much of the ellipse above it as below it, what you want is a line with the property that for every y-value, there’s as much of the ellipse to the left of it as to the right of it.
You want this line:
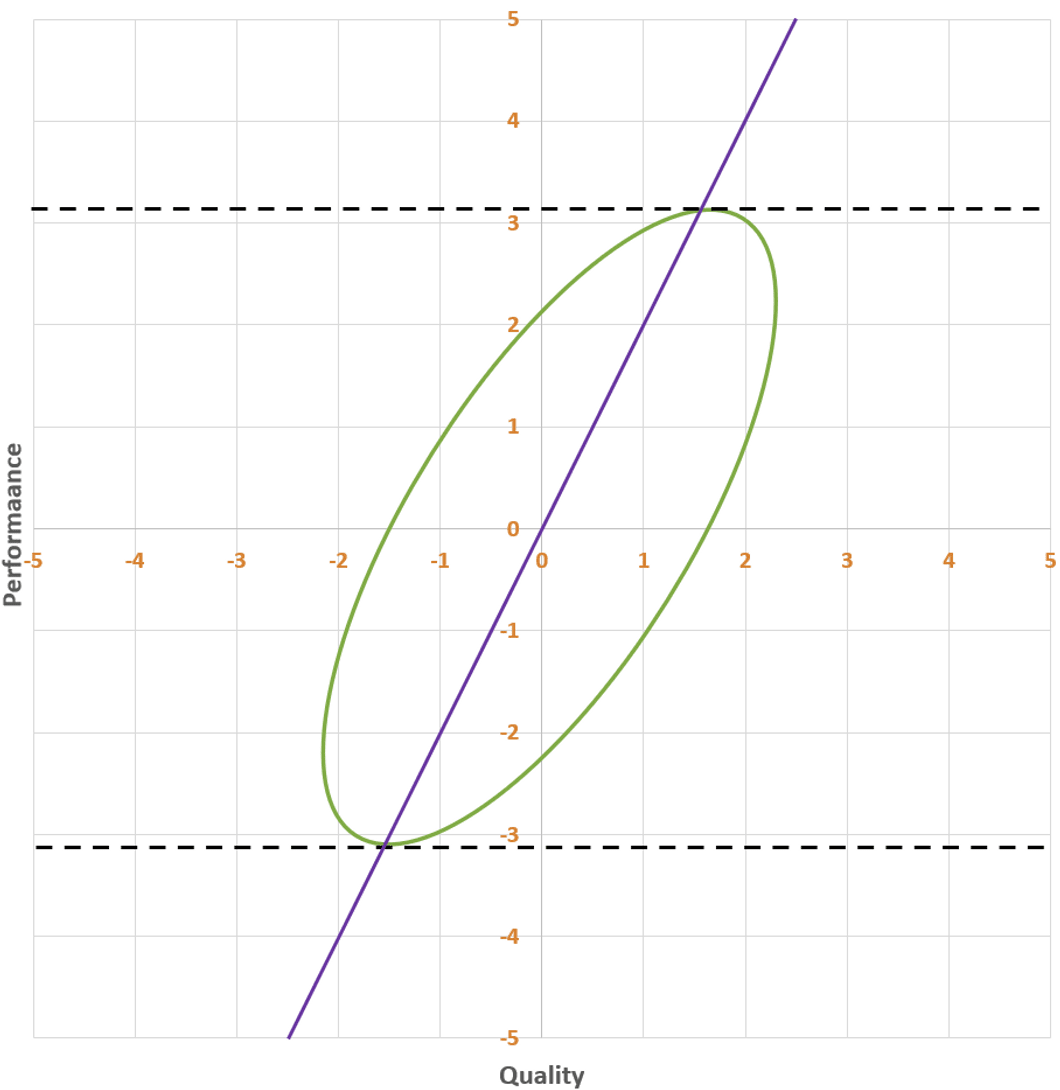
If you want, you can imagine flipping the axes, so that performance is horizontal and quality is vertical; then the line of best fit would run from the left to the right, vertically cutting the ellipse in half. If you did that, the line would have slope 0.5, not 1. The message of this line is:
E[Quality]=0.5⋅Performance.(Why 0.5? Remember that performance is a sum of two random variables with standard deviation 1: the quality of the intervention and the noise of the trial. So when you see a performance number like 4, in expectation the quality of the intervention is 2 and the contribution from the noise of the trial (i.e. how lucky you got in the RCT) is also 2.)
Let’s return to our questions:
1. True or false: the intervention with the highest expected quality, given the information you have from your RCTs, is the intervention with the highest performance.
The answer to this is true. The better the performance, the better the expected quality. This is obvious, but I think some people are confused by it because the top of the ellipse isn’t in the same place as the rightmost point of the ellipse. But that doesn’t matter: if I select a point from the ellipse and tell you its y-value, then the larger the y-value is, the larger your best guess about the x-value will be (and in particular, your best guess will be based on that purple line).
2. True or false: the expected quality of an intervention with performance P is P.
This one’s false. The expected quality of an intervention with performance P is 0.5 times P.
Ponder this for a bit, and internalize it, if you haven’t already. You did an RCT. Your RCT was unbiased: for an intervention of quality Q, your methodology will on average give you an estimate (performance) of Q. And yet, when you see an intervention with performance 4, your best guess is that the quality of the intervention is only 2.
So when Xavier Becerra, the U.S. Secretary of Health and Human Services looks at your results and says “oh wow, with this intervention we can give people four healthy years of their life back for just ten thousand dollars,” you politely temper his excitement and tell him that despite the results, you only expect the intervention to give people two healthy years of their life back per ten thousand dollars spent.
As briefly mentioned earlier, this is because performance is a sum of two independent variables: quality and noise. And when you see a large number like 4, you think the intervention is good, but you also think you got lucky, in equal amounts.
(This is true for all of the studies: it’s not a consequence of bias from selecting the best studies. Though the absolute amount by which you need to discount your results — in this case, 2 — is larger for interventions with better performances.)
Hence the title of this post: “How much do you believe your results?” If the HHS Secretary asks you how much you believe the results of your RCTs, the correct answer is “fifty percent”.
III.
Impressed by both the quality of your trials and your honesty, Secretary Becerra appoints you to lead a new megaproject: two thousand more RCTs. This time, though, your job is trickier. While one thousand of the RCTs will be as noisy as before — normally distributed noise with standard deviation 1 — the other thousand will be much noisier. That’s because the health interventions are more involved and you won’t be able to get as large of a sample. These thousand RCTs will have noise with standard deviation 3.
As before, you do your RCTs and get back performance scores for every intervention. You don’t know the quality of any intervention, of course, but if you did, your performance versus quality scatter plot would look like this:
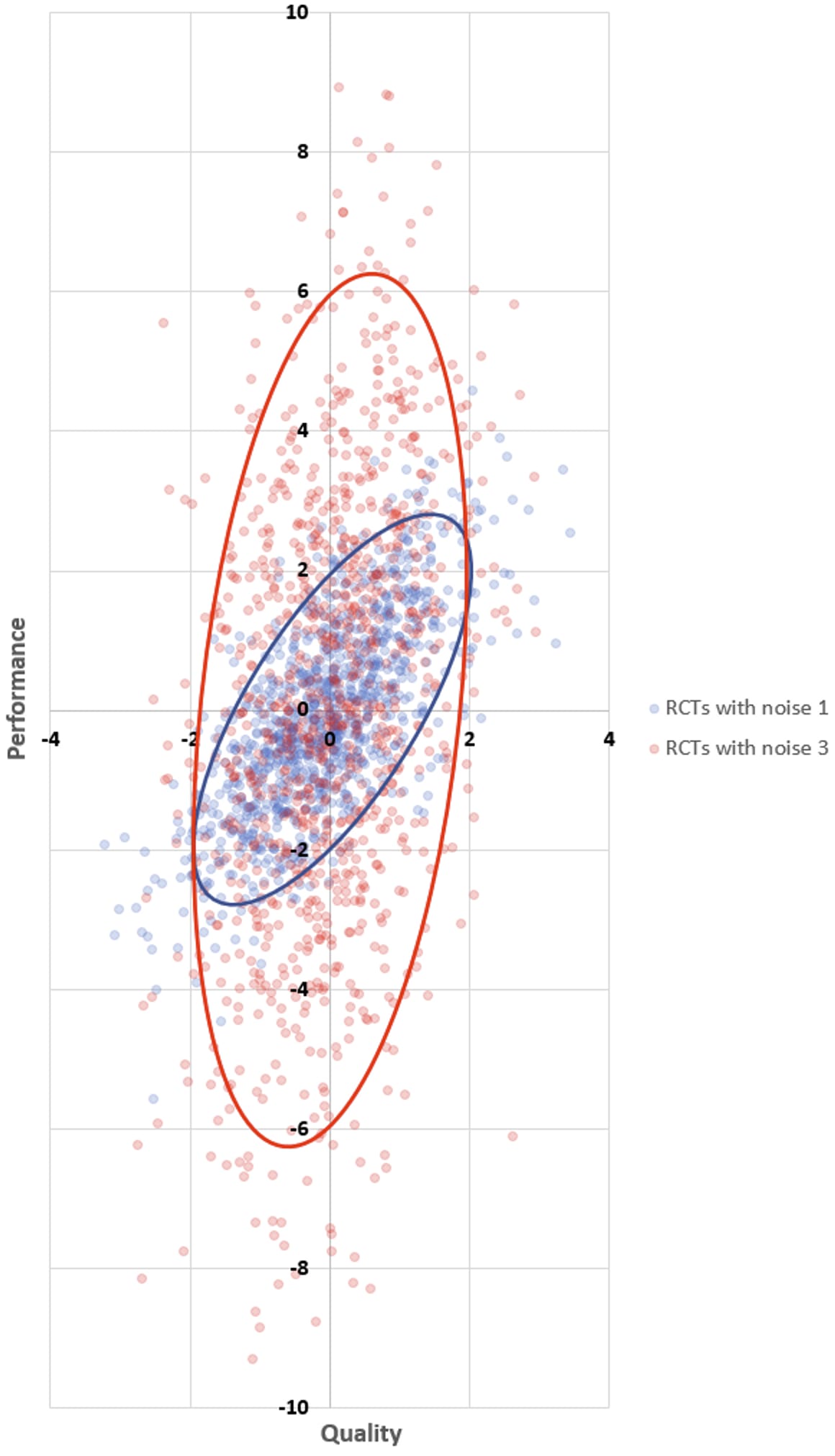
(We will call the interventions whose RCTs have noise 1 blue interventions, and will call the interventions whose RCTs have noise 3 red interventions.)
Of course all the interventions with the best performance are the red ones — you predicted that at the outset! It’s not that those interventions were systematically better or higher-variance: both sets of interventions have qualities that are normally distributed with mean 0 and standard deviation 1. It’s just that the best-performing interventions are the ones where you get lucky during the RCT, and there’s a ton of luck in the results of the noisy RCTs.
And so, the same question once more: how much do you believe your results? For the blue interventions we already have our answer: 50% — that is, the expected value of quality is 0.5 times the performance. Or in terms of that line from earlier — the one running from the bottom of the blue ellipse to the top, predicting quality from performance — its slope is 2. Every two units of performance increase correspond to one unit of increase in quality.
What about the red interventions? What’s the slope of that line?
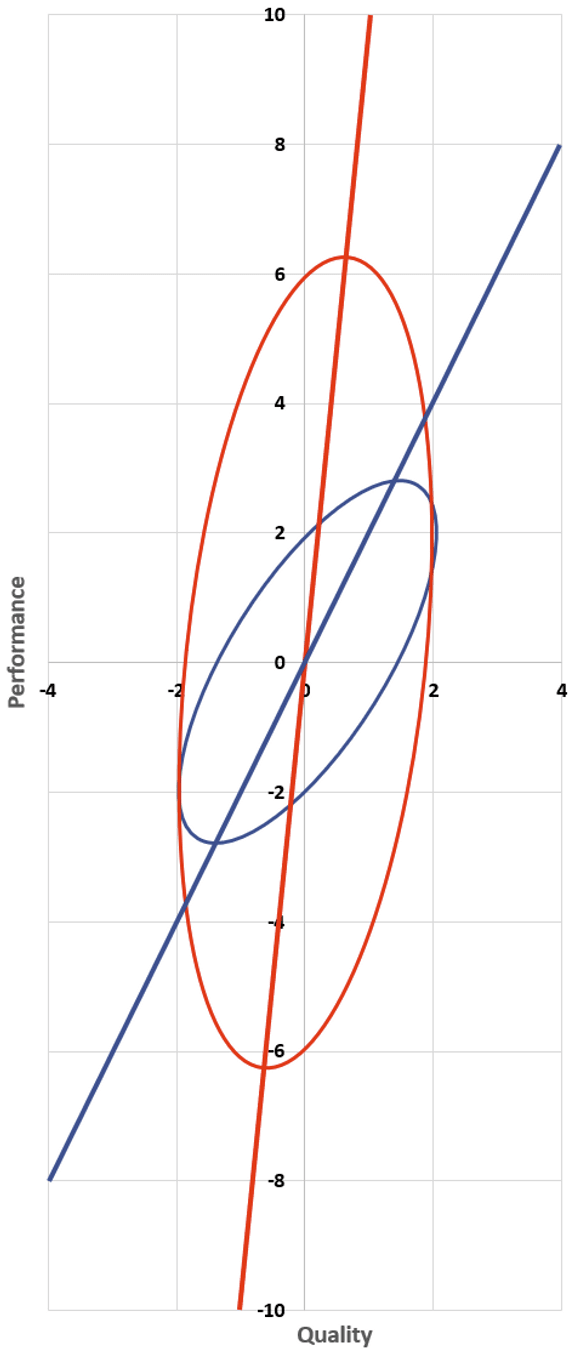
Bear with me as we do a bit of math. We are interested in finding the constant β such that E[Quality]=β⋅Performance. To do so, we’re going to look at the expected value of quality times performance in two different ways. Abbreviating quality as Q and performance as P, we have
E[Q⋅P]=E[Q(Q+noise)]=E[Q2]=Var(Q)=1.On the other hand, we also have
E[Q⋅P]=E[P⋅E[Q∣P]]=E[P⋅βP]=βE[P2]=10β,where the 10 comes from the fact that performance is quality (variance 1) plus noise (variance 9), and variances add. Therefore, β=0.1.
So, how much do you believe your noisy RCT results? The answer is: just 10 percent! The best-fit line for predicting quality from performance has slope 10. And correspondingly, a performance result of 10 — absolutely stellar! you expect just one of those in your entire study! — makes you think that the intervention is… kinda good. One standard deviation above average. 84th percentile.
You come back to Secretary Becerra to report your results. He’s impressed: there’s more than 20 interventions whose performance was more than 6 — way better than last time! You caution him that the RCTs behind those performances are noisy and that he shouldn’t believe the results very much.
Becerra thanks you for your hard work and tells you that the HHS has enough funding to promote ten interventions — and that it will be up to you to decide which ones will get promoted. The rest of the studies will be shelved, as per government policy.
You wish you had known this at the outset. Then you wouldn’t have bothered running the noisy RCTs at all! (Or at least you would have worked very hard to make them less noisy.) Here’s why:
- The performances of the blue interventions are normally distributed with mean 0 and standard deviation √2. Since expected quality is 50% of performance, your best guesses about the qualities of the blue interventions after seeing the RCT results are distributed with mean 0 and standard deviation 1/√2, which is about 0.71.
- The performances of the red interventions are normally distributed with mean 0 and standard deviation √10. Since expected quality is 10% of performance for these interventions, your best guesses for the qualities of the red interventions after seeing the RCT results are distributed with mean 0 and standard deviation 1/√10, which is about 0.32.
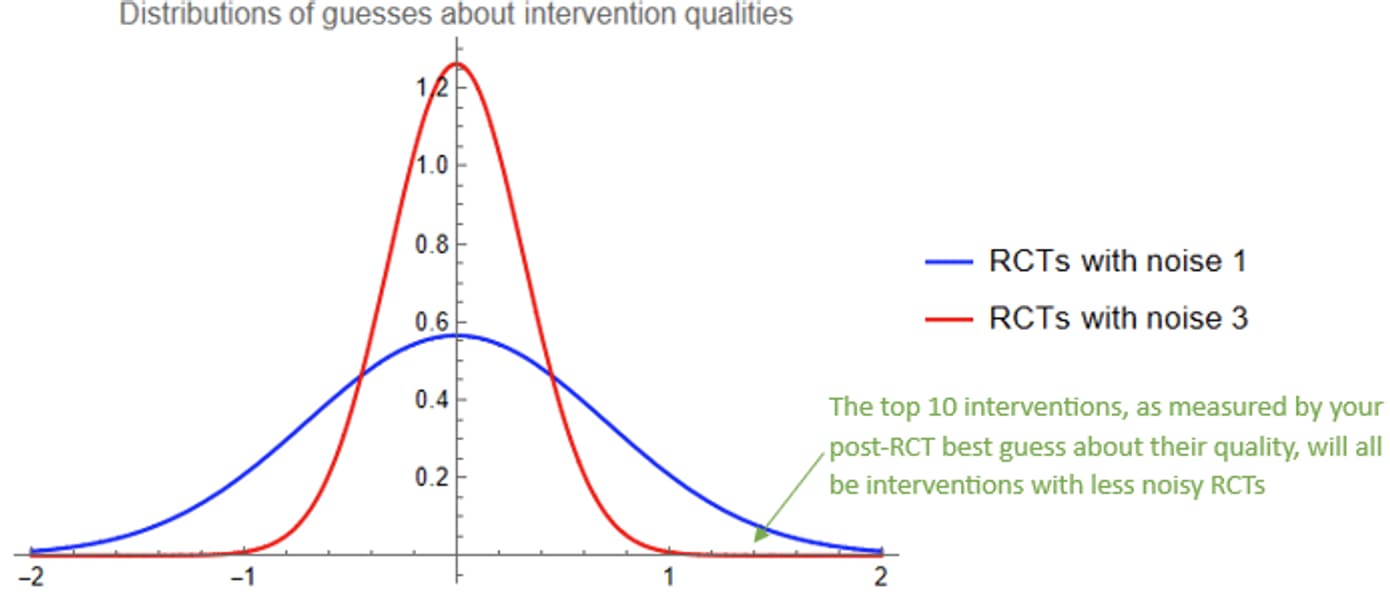
If you draw a thousand samples from a normal distribution with mean 0 and standard deviation 0.71, and another thousand from a normal distribution with mean 0 and standard deviation 0.32, it is almost guaranteed that the top ten draws will be from the first distribution. There was essentially no chance that any of the red interventions would be in your top 10 list, after you take care to ask yourself how much you believe your results.
(On the other hand, if you were a less careful scientist who didn’t ask themself this question, your top ten list would all be red interventions, all of which would likely be much worse than you were expecting them to be.)
It gets worse. Suppose that the red interventions are systematically more effective than the blue ones, by an entire standard deviation. That is, the red interventions’ qualities are distributed with standard deviation 1 and mean 1. This means that the average red intervention is as effective as an 84th percentile blue intervention. (This seems pretty realistic, e.g. because the lowest-hanging fruit for easy-to-assess interventions has already been picked.)
Now, all red interventions’ qualities and performances are 1 unit larger than before, so the red ellipse and line from before is translated one unit up and to the right:
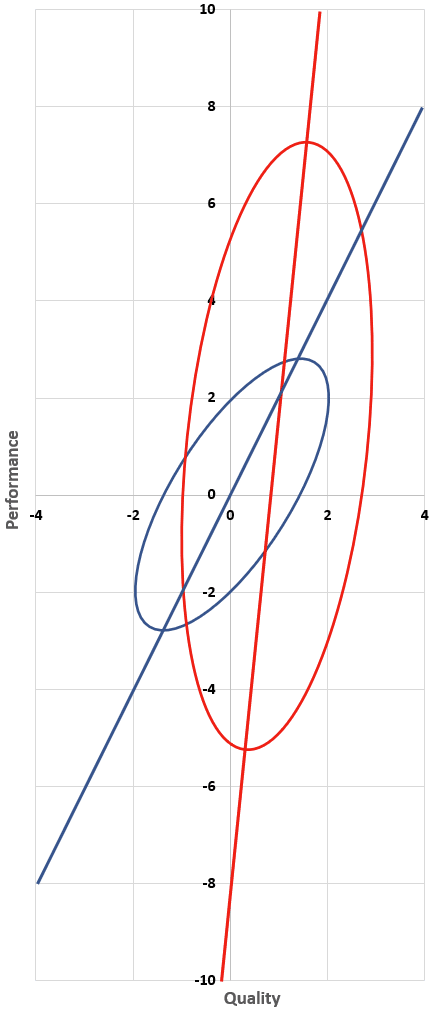
You still believe your results 10%, but this 10% now has a slightly different interpretation: if an intervention’s performance is better than average by some amount x, then your best guess is that this intervention’s quality is better than average by 0.1*x. Or as an equation:
E[Quality]=1+0.1(Performance−1).Because performance is normally distributed with mean 1 and standard deviation √10, the overall distribution of your best guesses about the qualities of the red interventions is like before, but translated to the right by one unit:
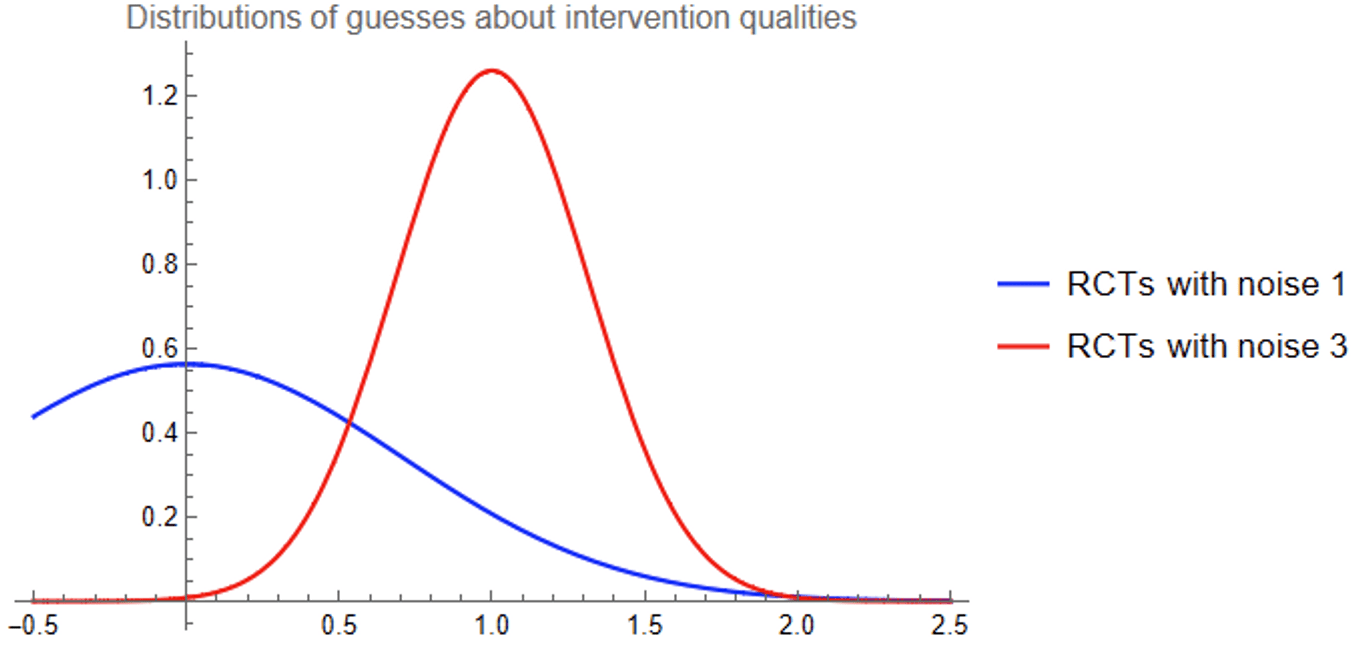
The typical red intervention comes out looking much better than the typical blue intervention (of course), but we care about the very best interventions. Zooming in on the right tail of the graphs:
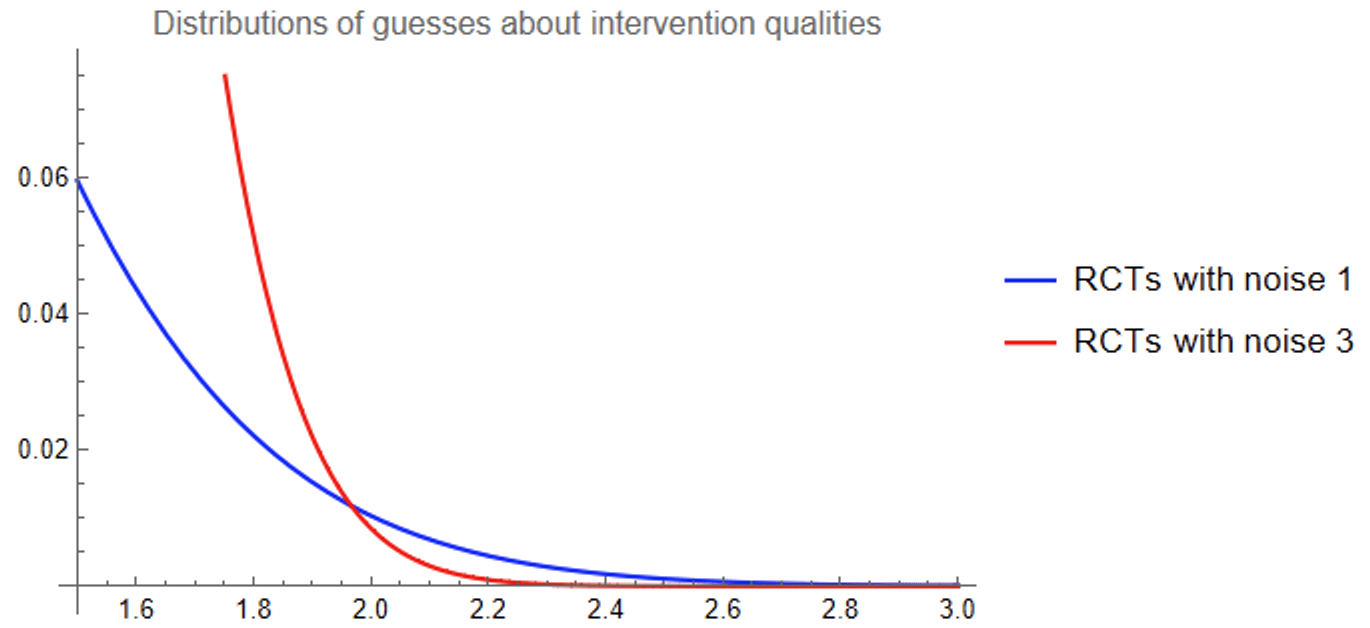
It turns out that the best-looking of a thousand blue interventions is still very likely to look better to you than the best-looking of a thousand red interventions!
IV.
You wake up from a dream. In the dream you had this really cool job as the leader of a giant megaproject of health intervention RCTs run by the HHS.
Ha, if only. You were considered for the job a decade ago, but were ultimately passed over in favor of a different academic.
You’ve been thinking about those studies recently, because the government published that second batch of RCT results — two thousand of them! (You had dreamed that government studies don’t get released, but luckily it was only a dream, if a terrifying one.) You decide to dig into the results.
It would be really nice if the studies explicitly addressed the age-old question — “How much do you believe your results?” — but of course they don’t. You only see the topline “performance” numbers and have to do the inference yourself.
If you spent a whole bunch of time on a single study, you could get some vague sense of how noisy it was. I mean, you can look at the sample size to get some sort of preliminary guess, but the real world is way more complicated than that and actually most of the noise comes from other methodological choices and real-world circumstances that might have not even made it into the papers. And there’s two thousand of them. What are you gonna do, spend the rest of your life inferring quality from performance?
Conveniently, you’ve just woken up from a dream where you learned that half the RCTs had noise 1 and the other half had noise 3. What a convenient fact to know if you want to infer quality from performance!
And so you get to work. You come up with a plan:
- For each health intervention, you will take its performance P and use Bayes’ rule to figure out the probability that its RCT had noise 1 versus noise 3.
- Let r be the probability that the intervention had noise 1, which you calculated in Step 1. Then with probability r, the expected quality of the intervention is 0.5*P. And with probability 1 - r, the expected quality is 0.1*P. So the overall expected quality is
How do you do Step 1 (calculate r)? Well, remember that the interventions with noise-1 RCTs have performance scores distributed normally with mean 0 and variance 2, whereas the noise-3 RCTs have performance scores distributed normally with mean 0 and variance 10. So — using the formula for a normal distribution — the probability that an intervention with performance P came from a noise-1 RCT is
r=1√2exp(−P2/4)1√2exp(−P2/4)+1√10exp(−P2/20).You plug this into the formula for expected quality as a function of performance that you derived in Step 2, and…
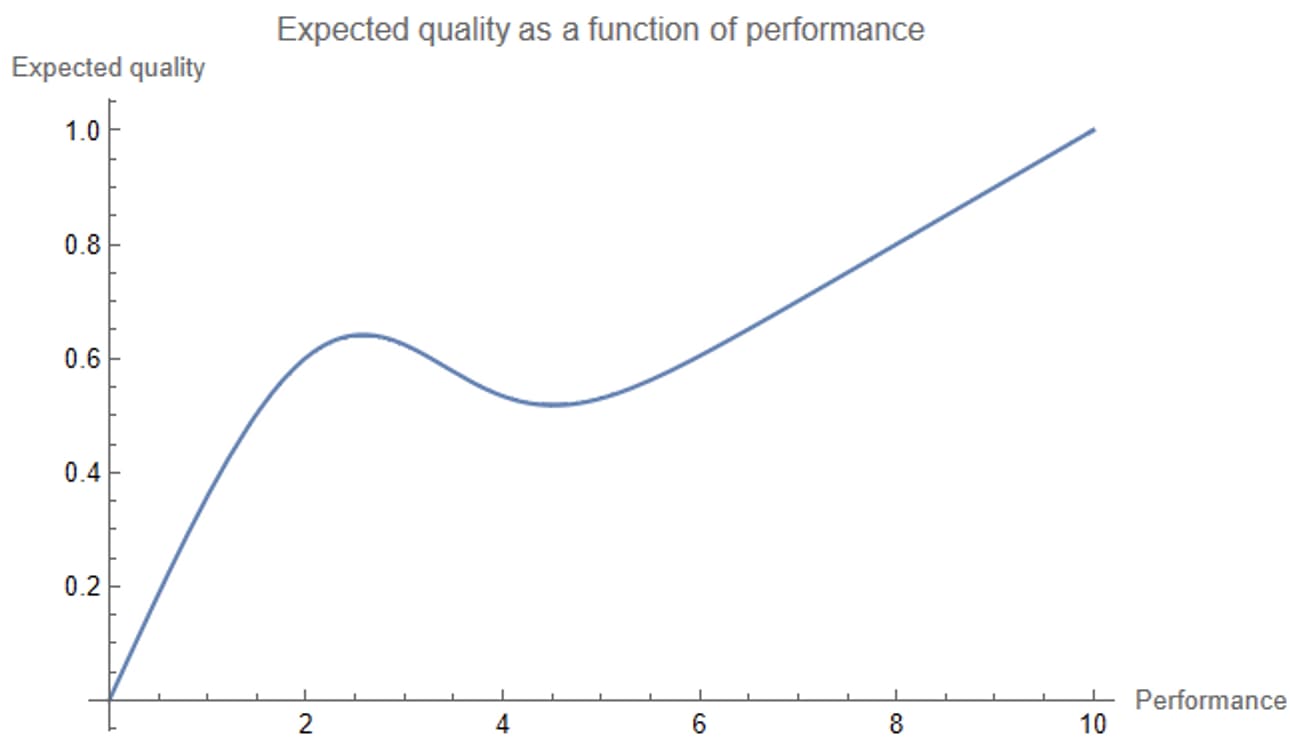
…whoa.
Expected quality drops in the middle of the graph, before going back up? Weird.
The above plot shows r(0.5P)+(1−r)(0.1P) as a function of P. What if we just look at r, the probability that the intervention had an RCT with noise 1, as a function of P?
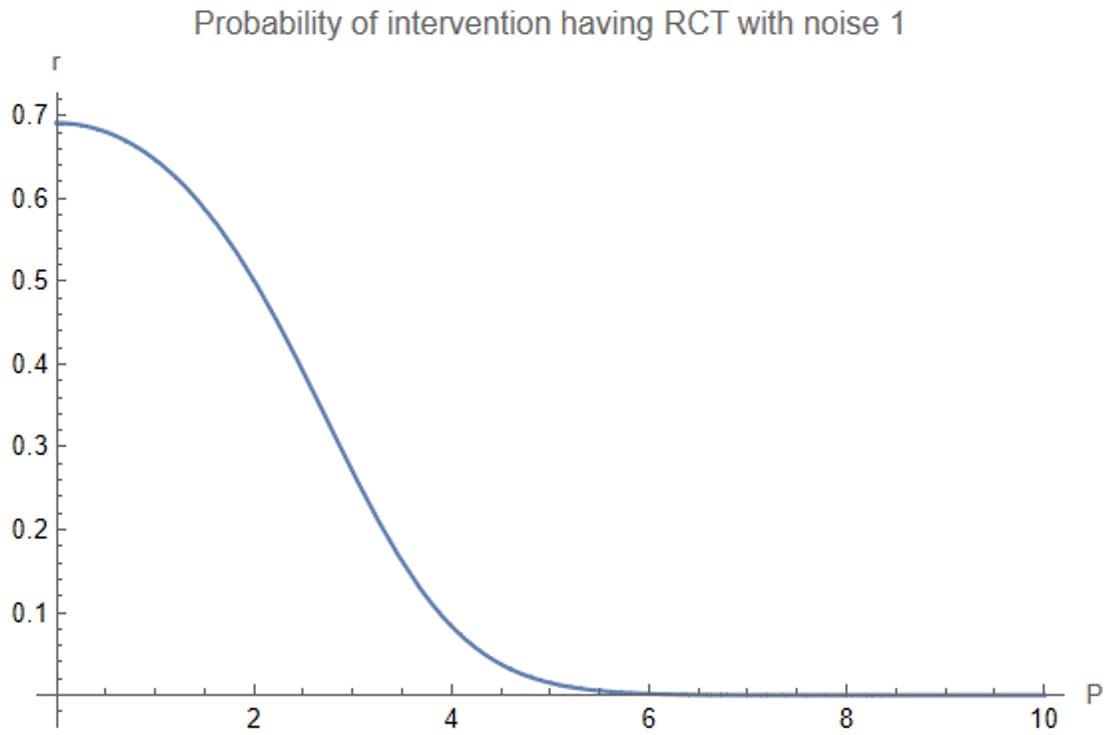
Between performance 2 and 4, the probability that the intervention came from a noise-1 RCT drops dramatically. You believe the results of the study much less if it has performance 4 than if it has performance 2, in a way that trades off against the increase in performance. This explains the drop in expected quality.
(And then things pick back up again: for performance above 6, you’re basically guaranteed that the intervention had noise 3 — but once the performance is large enough, even dividing by 10 gives an impressive result.)
(Well, not that impressive. A performance of 10 — which is about the highest number you see among all the RCTs — means an expected quality of 1, which means you guess that the study is 84th percentile or so.)
(Which is kind of depressing. They did this massive RCT, you look at it and you’re like, “oh I guess this one intervention is probably kinda good, but also if I picked seven other interventions at random probably one of them would be better”.)
(You entertain yourself by making the plot of expected quality versus performance if the noisier RCTs had had noise 10 instead of 3.
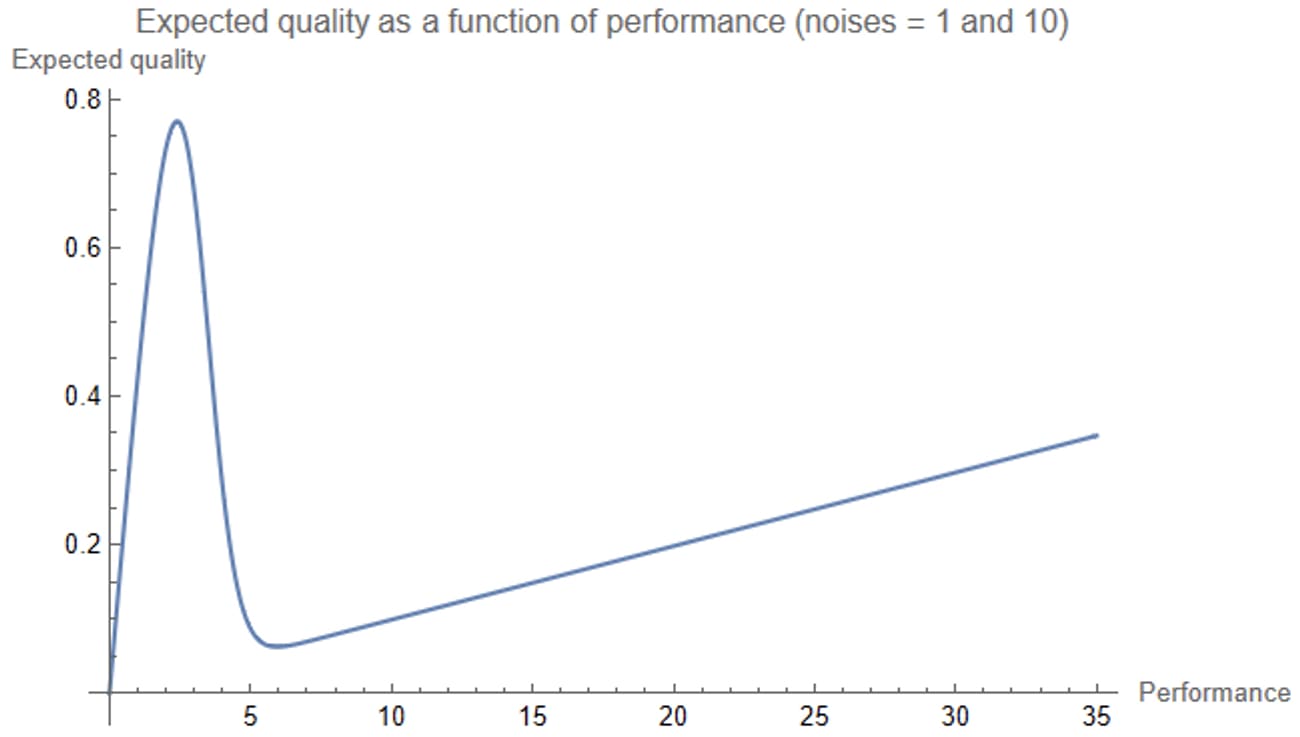
That’s a kind of ridiculous chart, but makes sense, in light of the above. The noise-10 RCTs are totally useless — the correct amount to discount the results of a noise-10 RCT is by a factor of 101 — so your assessment of the quality of an intervention is pretty much just 0.5 times its performance times the probability it had a noise-1 RCT.)
***
It’s now an hour since you woke up. You’re now a little more awake and are feeling kind-of silly for taking your dream too literally. You dreamed that the distribution over the noise of the RCTs was a 50% point mass at 1 and another 50% point mass at 3, which is pretty unrealistic.
You make a more reasonable model: each RCT has an unknown amount of noise, and you decide that your prior over the amount of noise follows a log-normal distribution. So most RCTs have noise between 1 and 3, but some have more and some have less.
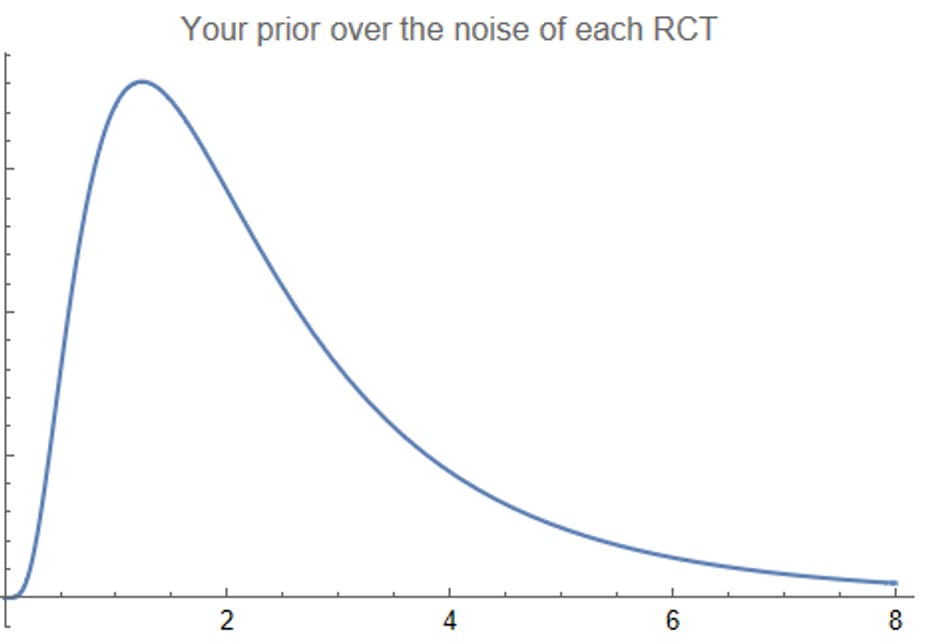
You use the same procedure as before, using Bayes’ rule to compute a posterior distribution over the noise of each RCT (i.e. posterior to updating on the RCT result), and then forming an all-things-considered expectation about the quality of each intervention. As before, you plot this all-things-considered quality estimate as a function of performance:
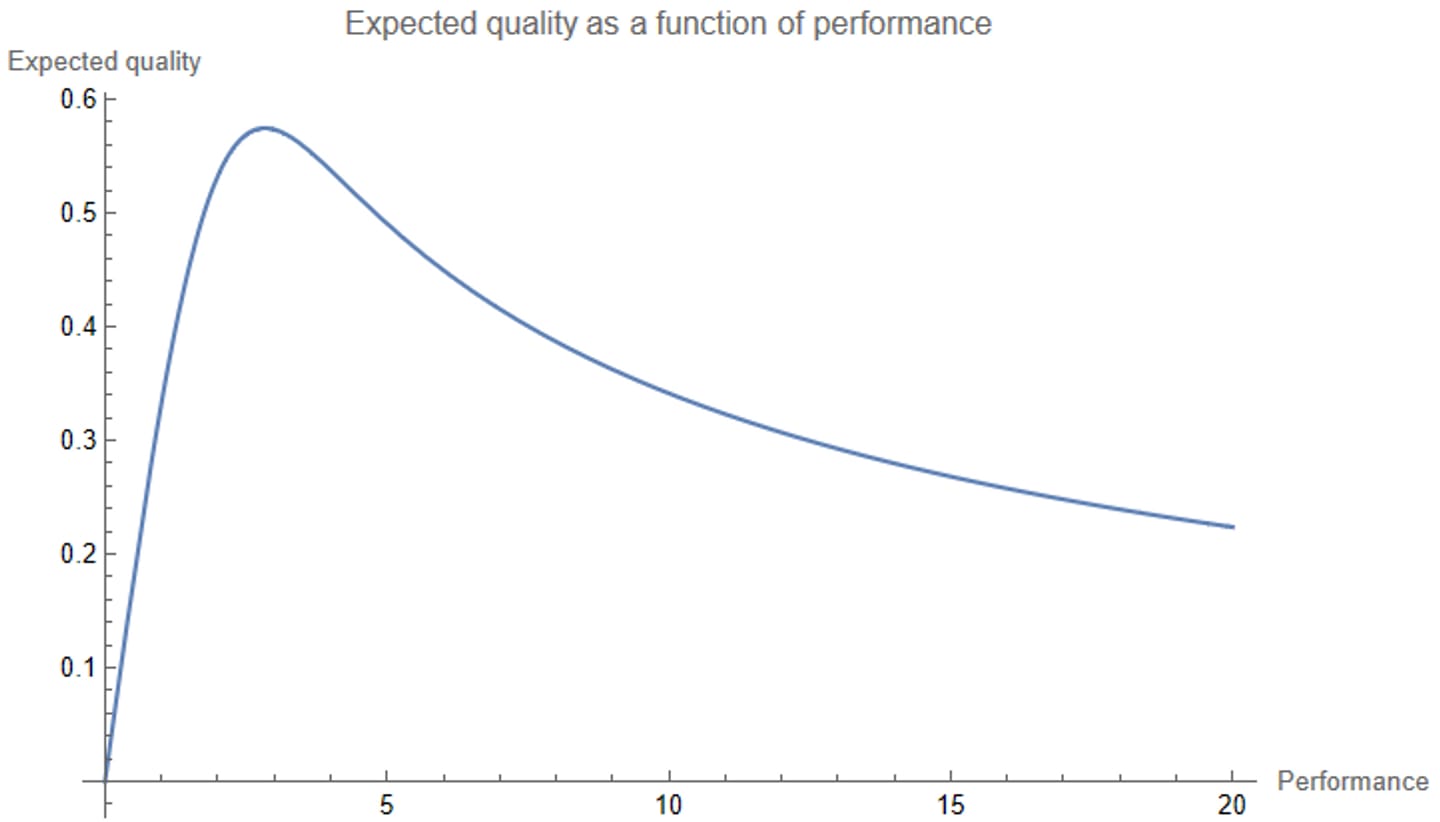
Wow — the graph goes down (as before), but now it doesn’t ever go back up.
This makes sense: whereas before you were assuming that no RCT could have a noise larger than 3, now seeing a ridiculously large performance number will just make you think that the RCT had a ridiculous amount of noise, and you’ll just dismiss the result. When you see a result that looks too good to be true, it probably is too good to be true.
The most convincing performance number you could see is about 2.8. If you see that number, you guess that the intervention’s quality is 0.57 — about 72nd percentile. This means that no possible RCT result number can convince you that an intervention is in the top quartile. If you try four interventions at random, one of them will probably be better than the intervention that looks best to you after looking at all of the RCT results.[2]
V.
I’ll end this post with a few takeaways, and a few questions to ponder. Here are my takeaways, roughly in order of importance:
- When you encounter a study, always ask yourself how much you believe their results. In Bayesian terms, this means thinking about the correct amount for the study to update you away from your priors. For a noisy study, the answer may well be “pretty much not at all”!
- You should interpret the words “encounter a study” very broadly. Informal experimental results — such as noticing that over the past month you’ve felt better on days when you ate broccoli — count as encountering a study, for this purpose.
- Working hard to reduce the amount of noise in your measurements is super important for getting useful results — certainly more important than I would have naïvely guessed. Similarly, paying attention to how noisy a study is — including but not limited to its sample size — is super important and probably underrated.
- If there’s only been one attempt to estimate the effectiveness of some intervention, you probably shouldn’t put much stock into it, unless it’s really well-done.
And here are some questions to ponder:
- How robust are the conclusions of the previous sections to alternative modeling choices?
- Except for a brief digression in Part III, I assumed that the prior over the quality of an intervention is independent of the amount of noise in the intervention's RCT. In practice, it’s reasonable to expect them to be dependent — and in particular, for interventions whose quality you're most uncertain about on priors to also be the interventions whose quality is the most difficult to measure precisely. What happens if you take this into account?
- Effective altruists argue that intervention quality is not normally distributed — that it has much fatter tails than that. Likewise, measurement noise likely follows a distribution with fatter tails than a log-normal distribution. What happens if you modify the distributions of both quality and noise to reflect this belief?
- There is a longstanding debate in the effective altruist community between allocating resources toward super well-evidenced interventions (e.g. insecticidal malaria nets) and allocating resources toward super speculative interventions with a potentially huge upside (e.g. funding a researcher to work on some strategy for aligning AI that has some small chance of working but might also inadvertently advance AI capabilities). Those advocating for more speculative interventions point to calculations suggesting that the expected value of their interventions is extremely large. What implications, if any, does the question “How much do you believe your results?” have for this debate?
- In this post I’ve talked about noisy, unbiased measurements of an underlying truth: whatever the true quality of an intervention is, your measurement process will stochastically produce a measurement whose expected value is equal to the true quality. You can instead consider noiseless, partial measurements — ones that only consider some of the effects of an intervention, without considering others. (For the unmeasured effects you just stick with your priors.) Such interventions are “unbiased” in a different, more Bayesian sense: whatever your measurement is, your best guess for the quality of an intervention is equal to your measurement.
- Is it possible for a measurement to be unbiased in both senses?
- Are real-world measurements more like the first kind of unbiased or the second kind, or are they both noisy and partial, or does it depend?
- To what extent do the lessons of this post generalize to partial measurements?
I hope to write about some of these questions soon!
- ^
Under our assumptions about how the data was generated.
- ^
Interestingly, this model seems to imply that if people were rational, experimenters would hope that their RCT results would turn up kind of good but not very good.
Paul_Christiano @ 2023-05-06T01:53 (+25)
There was a related GiveWell post from 12 years ago, including a similar example where higher "unbiased" estimates correspond to lower posterior expectations.
That post is mostly focused on practical issues about being a human, and much less amusing, but it speaks directly to your question #2.
(Of course, I'm most interested in question #3!)
Davidmanheim @ 2023-05-07T07:14 (+5)
Also see Why the Tails Come Apart, and to regressional Goodhart.
Karthik Tadepalli @ 2023-05-07T20:05 (+17)
Fun read! A point like this gets made every so often on the Forum, and I feel like a one-trick pony because I always make the same response, which is preempted in your question 1: these results rely heavily on the true spread of intervention quality being of the same order of magnitude as your experimental noise. And when intervention quality has a fat tailed distribution, that will almost never be true. If the best intervention is 10 SD better than the mean, any normally distributed error will have a negligible effect on our estimates of its quality.
And in general, experimental noise should be normal by the central limit theorem, so I don't know what you mean by "experimental noise likely has fatter tails than a log normal distribution".
Eric Neyman @ 2023-05-07T20:47 (+15)
Thanks -- I should have been a bit more careful with my words when I wrote that "measurement noise likely follows a distribution with fatter tails than a log-normal distribution". The distribution I'm describing is your subjective uncertainty over the standard error of your experimental results. That is, you're (perhaps reasonably) modeling your measurement as being the true quality plus some normally distributed noise. But -- normal with what standard deviation? There's an objectively right answer that you'd know if you were omniscient, but you don't, so instead you have a subjective probability distribution over the standard deviation, and that's what I was modeling as log-normal.
I chose the log-normal distribution because it's a natural choice for the distribution of an always-positive quantity. But something more like a power law might've been reasonable too. (In general I think it's not crazy to guess that the standard error of your measurement is proportional to the size of the effect you're trying to measure -- in which case, if your uncertainty over the size of the effect follows a power law, then so would your uncertainty over the standard error.)
(I think that for something as clean as a well-set-up experiment with independent trials of a representative sample of the real world, you can estimate the standard error well, but I think the real world is sufficiently messy that this is rarely the case.)
Karthik Tadepalli @ 2023-05-07T22:57 (+13)
In general I think it's not crazy to guess that the standard error of your measurement is proportional to the size of the effect you're trying to measure
Take a hierarchical model for effects. Each intervention has a true effect , and all the are drawn from a common distribution . Now for each intervention, we run an RCT and estimate where is experimental noise.
By the CLT, where is the inherent sampling variance in your environment and is the sample size of your RCT. What you're saying is that has the same order of magnitude as the variance of . But even if that's true, the standard error shrinks linearly as your RCT sample size grows, so they should not be in the same OOM for reasonable values of . I would have to do some simulations to confirm that, though.
I also don't think it's likely to be true that has the same OOM as the variance of . The factors that cause sampling variance - randomness in how people respond to the intervention, randomness in who gets selected for a trial, etc - seem roughly comparable across interventions. But the intervention qualities are not roughly comparable - we know that the best interventions are OOMs better than the average intervention. I don't think we have any reason to believe that the noisiest interventions are OOMs noisier than the average intervention.
(I think that for something as clean as a well-set-up experiment with independent trials of a representative sample of the real world, you can estimate the standard error well, but I think the real world is sufficiently messy that this is rarely the case.)
I'm not sure what you mean by this, I think any collection of RCTs satisfies the setting I've laid out.
JoshuaBlake @ 2023-05-09T11:57 (+5)
I think you're assuming your conclusion here:
Now for each intervention, we run an RCT and estimate where is experimental noise.
What if the noise is on the log scale?
Karthik Tadepalli @ 2023-05-10T05:24 (+4)
The central limit theorem is exactly that which implies what I said. The noise is not on the log scale because of the CLT.
Now, if you transform your coefficient into a log scale then all bets are off. But that is not happening throughout this post. And it's not really what happens in reality either. I don't know why anyone would do it.
JoshuaBlake @ 2023-05-06T08:59 (+9)
Very nice explanation, I think this problem is roughly the same as Noah Haber's winning entry for GiveWell's "change our mind" contest.
You can instead consider noiseless, partial measurements — ones that only consider some of the effects of an intervention, without considering others. (For the unmeasured effects you just stick with your priors.) Such interventions are “unbiased” in a different, more Bayesian sense: whatever your measurement is, your best guess for the quality of an intervention is equal to your measurement.
I'm struggling a little at what you're trying to say here, is it the issue of combining priors in deterministic model where you have priors on both the parameters and the outcome? There is some literature on this, and I believe that Bayesian melding (Poole and Raftery 2000) is the standard approach, which recommend logarithmic pooling of the priors.
Eric Neyman @ 2023-05-06T18:06 (+4)
Let's take the very first scatter plot. Consider the following alternative way of labeling the x and y axes. The y-axis is now the quality of a health intervention, and it consists of two components: short-term effects and long-term effects. You do a really thorough study that perfectly measures the short-term effects, while the long-term effects remain unknown to you. The x-value is what you measured (the short-term effects); the actual quality of the intervention is the x-value plus some unknown, mean zero variance 1 number.
So whereas previously (i.e. in the setting I actually talk about), we have E[measurement | quality] = quality (I'm calling this the frequentist sense of "unbiased"), now we have E[quality | measurement] = measurement (what I call the Bayesian sense of "unbiased").
Davidmanheim @ 2023-05-07T07:16 (+2)
Yes - though I think this is just an elaboration of what Abram wrote here.
Nayanika @ 2023-05-07T08:57 (+4)
The last three questions in this post were areas of my personal curiosity since my EA In-depth fellowship days. Hoping to have some anwers in any of the upcoming posts.
Gavin Bishop @ 2023-05-06T01:03 (+4)
This was a great read, illuminating and well-paced. Thanks!
David Mears @ 2023-05-24T13:39 (+2)
I'm taking away that how much I believe results is super sensitive to how I decide to model the distribution of actual intervention quality, and how I decide to model the contribution of noise.
How would I infer how to model those things?
Oscar Delaney @ 2023-05-21T12:09 (+1)
This was enjoyable to read and I was surprised by some of the results, thanks!