Published report: Pathways to short TAI timelines
By Zershaaneh Qureshi @ 2025-02-20T22:10 (+47)
This is a linkpost to https://www.convergenceanalysis.org/research/pathways-to-short-tai-timelines
Hi everyone!
I have just published a report with Convergence Analysis exploring how transformative AI (TAI) could be developed within the next ten years. It’s called Pathways to short TAI timelines (pdf version; Google Doc version).
In the report, I examine the debates over compute scaling and recursive improvement as mechanisms for rapid capabilities progress, distill the core elements of these debates under seven distinct scenarios of rapid progress, and ultimately build a case for the plausibility of TAI being developed by 2035.
It’s a long read, with the pdf version weighing in at 140 pages. So, in this forum post, I provide excerpts which summarise the text at two different levels of granularity: a short summary (~2 min read) and a detailed overview (~15 min read). For those who are interested in reading further, specific sections of the full-length report (Google Doc version) are also hyperlinked where relevant.
Short summary of the report (~2 min read)
This report explores pathways through which AI could develop transformative capabilities within the next ten years (i.e. by 2035), referred to here as ‘short timelines’ to transformative AI (TAI). It focuses on two primary mechanisms for rapid AI capabilities progress – compute scaling and recursive improvement – which play central roles in the most influential stories of short TAI timelines. The detailed analysis of this report culminates in a case for the plausibility of short timelines.
Compute scaling. The history of AI development indicates that AI capabilities can be improved by increasing (effective) compute – and we’ve observed fast growth in this input, fuelled by increases in microchip density, hardware efficiency, algorithmic progress, and investment. Some experts believe these trends will persist over the next decade. If so, they could result in TAI before 2035.
Sceptics argue that this pathway will soon face challenging bottlenecks (concerning e.g. data, investment, power, and limitations of traditional LLMs) that would slow progress. However, even if compute scaling becomes seriously bottlenecked on something before TAI arrives, other mechanisms – such as recursive improvement – could still achieve enough traction to produce TAI within the next ten years.
Recursive improvement. If AI systems are deployed to automate AI R&D, they could initiate powerful feedback loops in the AI field. Some argue that this would not only break bottlenecks to compute scaling, but drive exponential or even super-exponential growth in AI capabilities, resulting in the arrival of TAI (and perhaps even more advanced systems) before 2035.
Sceptics argue that the effects of these feedback loops would be counteracted by increasing bottlenecks and diminishing returns on effort as low-hanging fruit in capabilities improvements is exhausted. They also highlight constraints which would limit the size or speed of each capabilities improvement ‘step’. However, even if recursive improvement cannot drive exponential growth in AI capabilities, it could still enable fast enough progress to achieve TAI by 2035.
Short timeline scenarios. On examination, it seems that there are many different routes through which TAI could arrive by 2035. To illustrate this, I generate and describe seven plausible scenarios with short TAI timelines. In five of these, progress is based on compute scaling and/or recursive improvement; the other two highlight pathways to short TAI timelines which don’t significantly rely on these mechanisms. The existence of a plurality of plausible short timeline scenarios strengthens the evidence base for short timelines.
Detailed overview of the report (~15 min read)
Background
I define ‘transformative AI’ (TAI) as AI systems which are capable of transforming society to an extent comparable to the industrial or agricultural revolutions. AI capabilities levels that might be considered ‘transformative’ in this sense include artificial general intelligence, human-level machine intelligence, superintelligence, and other familiar notions from the literature on advanced AI.[1]
The date of the arrival of the first TAI systems[2] is of great strategic relevance in the context of AI safety and governance. It determines the urgency of action and the specific policies, safeguards, and risk mitigation measures that can feasibly be implemented before society is radically transformed.
With this in mind, this report continues Convergence Analysis’ exploration of the timeline to TAI as a strategic parameter for AI scenarios. It follows my previous article on Timelines to Transformative AI, which mapped out the current landscape of TAI timeline predictions and examined the trends emerging from that landscape.
In this report, I now explore pathways through which AI could develop transformative capabilities within the next ten years. I describe scenarios in which TAI is developed in the next ten years as exhibiting ‘short TAI timelines’.
I focus especially on two key mechanisms for AI progress – compute scaling and recursive improvement – which play central roles in some of the most influential stories of fast capabilities development. For each mechanism, I dedicate a chapter to examining arguments for and against its producing a short TAI timeline.
I also devote some time near the end of the report, in Chapter 3, to describing seven distinct scenarios in which TAI arrives in the next ten years. Under five of these scenarios, progress over the next decade is driven by some combination of compute scaling and/or recursive improvement.[3] The other two scenarios highlight pathways to short TAI timelines which don’t significantly rely on these popularly discussed mechanisms.
Two key mechanisms for fast AI capabilities progress
The most popular stories of short TAI timelines typically appeal to at least one of the following mechanisms for progress as the primary basis for fast capabilities improvements in AI R&D over the next decade:
Compute scaling. In many short timeline stories, compute plays a central role in driving AI capabilities progress over the next decade. In particular, AI systems within the current paradigm are argued to become increasingly capable as the amount of compute used to train them is increased.[4] This implies a short timeline if AI systems can be fed with enough compute to reach TAI by 2035.
- Recursive improvement. This is a broad category of mechanisms for AI capabilities improvement. It includes any positive feedback loops through which there are repeated improvements to the ability to improve AI systems. This includes, for example, the investment feedback loops that are currently supporting AI development. However, in the context of short timelines, the most popular stories of recursive improvement posit the future emergence of what I call ‘direct’ feedback loops: AI systems themselves begin to drive capabilities improvements by contributing to AI R&D, and get better at doing so with each subsequent improvement. This implies a short timeline if AI systems can be deployed to make sufficiently fast improvements to AI capabilities within the next decade.
This report primarily seeks to better understand these two mechanisms for fast AI capabilities progress (rather than, say, comprehensively charting out all arguments in the literature for and against short TAI timelines). However, it does briefly touch on other routes of capabilities progress.
Compute scaling
In Chapter 1 of this report, I explore compute scaling as a mechanism for fast AI capabilities progress. I outline the role of compute in recent capabilities progress, and how continued compute scaling might produce TAI within the next ten years. I then go on to consider why it might fail to do so.
Through these arguments, it becomes apparent that compute scaling pathways of AI capabilities progress will eventually come up against difficult bottlenecks. However, meaningful debate remains over the extent to which these challenges will emerge over the next ten years, how difficult they will be to address or sidestep, and – if they do become prohibitive – whether TAI will have already been achieved by the point at which this happens.
Short timelines via compute scaling
Arguments that compute scaling will result in TAI within the next ten years are often based on the two following claims:
(i) Compute will remain the primary driver of capabilities progress in LLMs on the pathway to TAI; that is, progress will not be significantly bottlenecked on factors other than compute. (I describe this view as a ‘compute-centric variant of the scaling hypothesis’.)
(ii) The compute that can be used to train frontier LLMs will grow fast enough for a TAI-scale training run to be achieved by 2035.
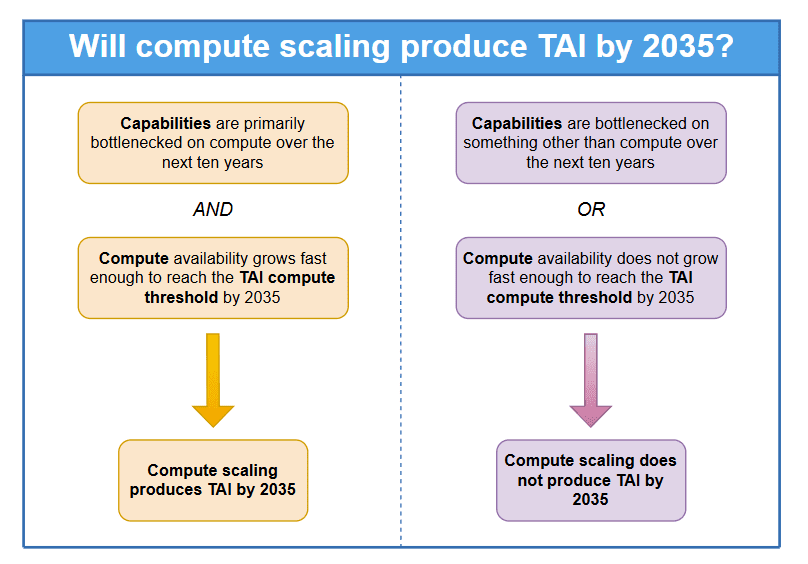
As I lay out in the subsection entitled ‘What is compute scaling, and how could it produce a short timeline?’, extrapolating trends from past AI progress provides some support for both of these claims.
- Firstly, progress in neural network capabilities has so far been in line with the compute-centric scaling hypothesis: increasing the compute used to train a system has resulted in improved performance. Some take these historical observations to suggest that neural network capabilities will continue to increase in a predictable way as training compute increases, following empirical scaling laws (e.g. those from OpenAI and DeepMind). This interpretation of the data can be provided in support of (i).
- Secondly, over the past few decades, we’ve seen fast and consistent growth in the compute used to train frontier AI models (see e.g. Epoch’s data on historic compute trends in machine learning). We’ve simultaneously observed consistent improvements in many of the underlying inputs to both physical and effective compute growth (such as microchip density, as captured by Moore’s Law, as well as investment, hardware price-performance, and algorithmic efficiency). Extrapolating from these historic trendlines provides some support for the plausibility of (ii). (Of course, the plausibility of (ii) also depends on how much compute will actually be required to train TAI; this thread of the argument is omitted in this summary, but discussed in some detail in the full report.)
If we take this historical data into consideration when predicting the arrival of TAI, short timelines appear to be a real possibility.
Counterarguments to short timelines via compute scaling
It’s not clear how far we can extrapolate from these past trends to draw conclusions about the future of AI development. Even if compute has been the primary driver of capabilities progress in LLMs so far, it may not continue to play this role in future; at some point, progress may become bottlenecked on some other factor. Similarly, some of the sustaining forces behind historic trends of compute growth are likely to eventually break down. If any of these trends break down or lose momentum within the next ten years, the likelihood of a short TAI timeline would be reduced.
The sceptic can therefore object to both (i) and (ii). In ‘Why compute scaling might not produce a short TAI timeline’, I consider objections on both points separately, under two broad categories of sceptical argument.
Category 1: ‘Capabilities progress will be bottlenecked on something other than compute’. This type of objection involves a rejection of assumption (i).
Sceptics in this category argue that, at some point in the next ten years of AI development, capabilities progress will become bottlenecked on inputs other than compute, which might be considerably harder for developers to deal with. This potentially includes:
- Data (quality/quantity). We might run out of high quality data to train large-scale AI systems on before TAI is developed. If solutions cannot be found in the form of self-play/synthetic data generation, this could be a significant barrier to developing systems with transformative capabilities.
Algorithms. Traditional LLMs may struggle to achieve the levels of generality required for TAI, given their historically weak performance on benchmarks such as ARC; if so, substantial algorithmic progress or even an AI paradigm shift may be needed before TAI can be developed.[5]
- Training environment (i.e. the design of the overall ecosystem of training data and training algorithms – not just quality/quantity of data). It might be very difficult to design a training environment which actually incentivises the development of transformative capabilities; if so, the need for trialling many training environments may delay the arrival of TAI. (See Richard Ngo on the 'hard paths hypothesis'.)
- Embodiment. The emergence of certain capabilities relevant to TAI might rely on an AI system being physically or virtually embodied; if so, significant further R&D may be required in this direction.
If any of these factors overtake compute as the primary bottleneck for AI capabilities progress, dealing with them could add significant delays to the arrival of TAI.
Category 2: ‘Compute growth will not be fast enough for TAI by 2035’. This type of objection involves a rejection of assumption (ii).
Sceptics in this category typically argue that growth in the compute used to train frontier AI systems will be considerably slowed down over the next decade, by, for example:
- Physical limitations on the density of chips
- Power requirements of TAI-scale training runs being unachievable
- Investment requirements of TAI-scale training runs being unachievable
- Limitations on chip manufacturing capacity and the speed of the supply chain
- Market dynamics preventing a single actor from obtaining a high enough proportion of total available compute to train TAI
- Governance interventions restricting compute access
Sceptics in this category might also point out that the level of compute required for TAI-level capabilities could be so high that it’s simply out of reach within the next decade, without much faster compute growth than is realistic. In support of this claim, we could gesture to the uncertainty over how much compute would be needed for TAI-scale training run, the long tails of the distribution of TAI compute requirements, and the difficulty of supplying a meaningful upper bound for compute requirements here.
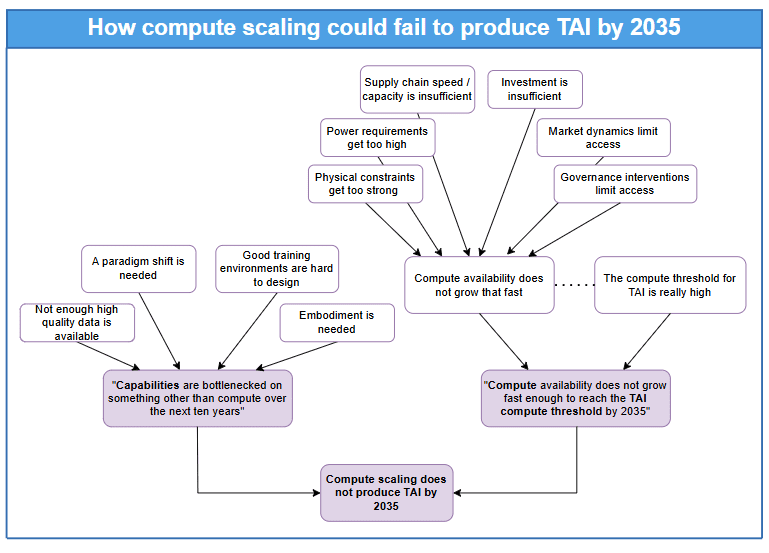
Reflections. Although compute is, and will likely continue in the near term to be, an important driver of AI capabilities progress, it’s not clear exactly how far compute scaling can take us over the next decade. It seems likely that, at some point, other bottlenecks will emerge and have a slowing or limiting effect on AI capabilities progress. If this happens before TAI has arrived, it might seriously reduce the likelihood of a short TAI timeline.
Recursive improvement
Even if the identified challenges for compute scaling are poised to slow down capabilities progress on the pathway to TAI, this doesn’t mean that short timelines are off the table. There are other mechanisms through which AI capabilities progress could still be fast enough for TAI to arrive by 2035. In Chapter 2, I examine recursive improvement as a broad category of such mechanisms.
I begin this chapter by outlining different types of recursive improvement, and how they could result in TAI arriving within the next ten years. (In ‘Overcoming scaling bottlenecks via recursive improvement’, I note especially the potential for certain recursive improvement dynamics to break some of the previously identified bottlenecks to compute scaling, reinforcing compute scaling pathways to TAI.) I then go on to examine arguments that these mechanisms might fail to yield a short timeline.
Reflecting on this discussion, I note that if a period of (what I call ‘direct’) recursive improvement does begin in the next few years, it’s hard to argue that this would not result in the arrival of TAI by 2035. It’s reasonable to argue that recursive improvement wouldn’t necessarily lead to a sustained period of acceleration in capabilities (e.g. exponential or super-exponential trajectories of improvements) – but even so, the believer in short timelines has room to argue that capabilities improvements would still be fast enough to produce a short TAI timeline.
Short timelines via recursive improvement
I broadly define ‘recursive improvement’ as any iterative process characterised by feedback loops through which there are repeated improvements to the ability to improve AI. (See my introduction to ‘What is recursive improvement, and how could it produce a short TAI timeline?’ for further details here.)
Direct recursive improvement. I focus my attention on positive feedback loops which are mediated directly by AI systems. I call these ‘direct’ feedback loops for AI capabilities progress.
The section titled ‘Direct recursive improvement’ outlines the ‘AI R&D type’ direct feedback loops introduced by AI systems which can automate significant parts of AI R&D. Here, I frame things around the idea of ‘automated workers’ for AI R&D: AI systems which can perform all or most of the tasks typically performed by a human researcher or engineer (with minimal human supervision/prompting) and can thereby effectively act as drop-in replacements for those humans. (However, I also note that there are alternative ways in which AIs could contribute to AI R&D.)
Thus conceived, the main thrust of the argument for direct recursive improvement is as follows: once automated AI R&D workers are developed, large numbers of these systems are deployed in parallel, vastly increasing the total number of human-equivalent hours being spent on making AI capabilities improvements. This first generation of automated workers drives the development of a second generation which is even more capable than the first at AI R&D, and therefore even better equipped to make improvements to subsequent generations of models than its predecessors were. A cycle of positive feedback emerges in which AI capabilities improve, step by step.
With this story in mind, I go on to outline the possible trajectories of step-by-step capabilities improvements that could result from AI R&D automation. I also briefly highlight some support from prominent empirical research and quantitative models for the claim that direct recursive improvement would underpin an accelerating trajectory of capabilities improvements.
Indirect recursive improvement. Direct recursive improvement dynamics cannot be sustained without increased inputs from what I call the ‘indirect’ feedback loops operating in the background. In the subsection of Chapter 2 titled ‘Indirect recursive improvement’, I highlight a number of much broader societal feedback loops which play a crucial role in AI capabilities progress. These include economic feedback loops (driven by reinvestment of capital into AI R&D), scientific feedback loops (driven by advancements in scientific tools and methods) and political feedback loops (driven e.g. by competitive pressures/race dynamics). Without these background processes providing sufficient resources and motivations for improving AI capabilities, any period of capabilities growth via direct recursive improvement would likely plateau.
Although indirect feedback loops could be powerful mechanisms for progress in their own right, I focus in this chapter on arguments for short TAI timelines which specifically invoke direct recursive improvement.
Short timelines. For the sake of this chapter, I assume that the AI field will eventually reach a capabilities threshold at which direct recursive improvement can begin. With this granted, there are four further questions which then determine whether the ensuing period of direct recursive improvement (DRI) will result in a short timeline to TAI:
- How fast is the capabilities growth resulting from the feedback loops at play? (i.e. what is the shape of the trajectory of recursive improvements?)
- How long is this period of DRI sustained for?
- When does this period of DRI begin?
- How far away is TAI when this period of DRI begins?
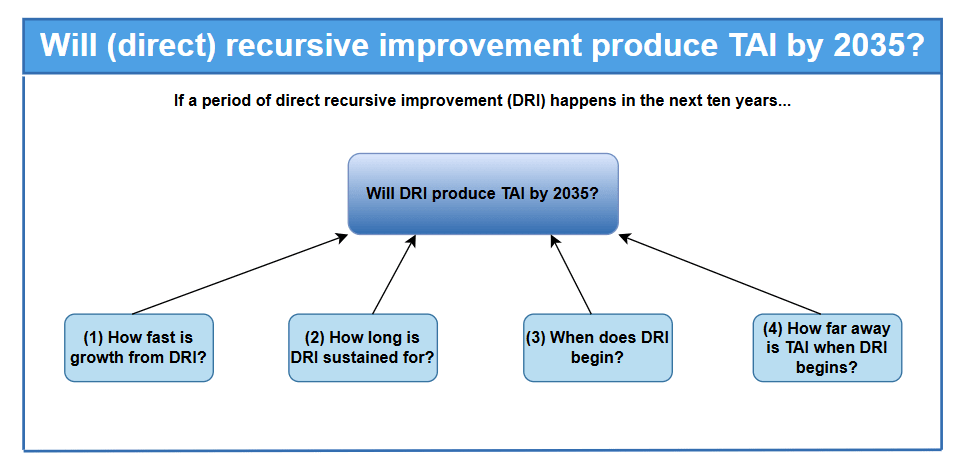
The believer in short timelines via recursive improvement will argue that the answers to these four questions are favourable towards TAI arriving within the next ten years. That is: direct recursive improvement dynamics will be fast enough, sustained for long enough, and kick in soon enough to cross the distance to TAI by 2035.
There is especially interesting discussion in the literature over the first two points. Some have suggested that direct recursive improvement dynamics could enable exponential or super-exponential modes of capabilities growth that would continue until a ‘singularity’ in AI development is reached.
Counterarguments to short timelines via recursive improvement
The sceptic of short timelines via (direct) recursive improvement can level objections in response to any of the four questions listed above.
In ‘Why recursive improvement might not produce a short TAI timeline’, I focus on sceptical arguments which respond to questions (1) and (2). That is: I’m interested in reasons to think that a recursive process of capabilities improvement ‘steps’ would either not be very fast, or could not be sustained for a long time. I examine three such arguments in detail:
- ‘Each capabilities improvement step is more difficult than expected’. Each capabilities step will be harder to make than has been imagined by those who expect short timelines via recursive improvement, due to difficult situational requirements that they have not adequately factored in.
- ‘Capabilities improvements get more difficult at each step’. Each capabilities step will be harder to make than the previous one, due to the increasing effect of bottlenecks (e.g. demands on compute and energy), as well as diminishing returns on effort.
- ‘The relationship between accessible input improvements and capabilities improvements is sublinear’. Even if recursive improvement dynamics enable certain inputs to AI capabilities to improve in big/fast steps, AI capabilities themselves might only improve in small/slow steps. (This may be best understood as a variant of the previous bullet point.)
If any of these arguments are taken seriously, the consequence (according to the sceptic) is that capabilities improvement ‘steps’ will be small/slow, or will soon reach a plateau beyond which further improvements cannot feasibly be made. This would call into question whether TAI could actually be achieved by 2035 under a direct recursive improvement scenario.
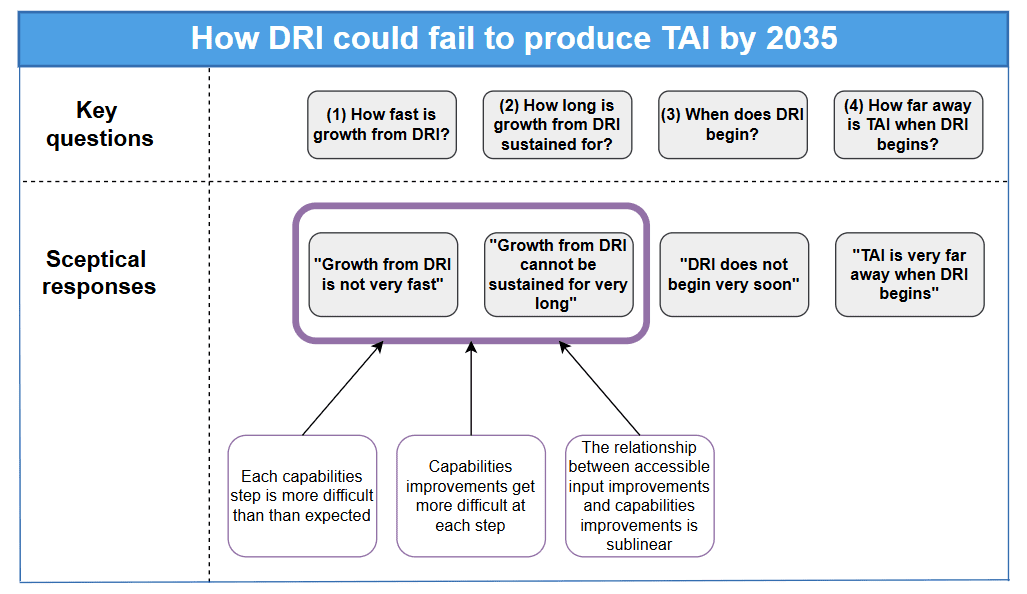
Reflections. It seems there are many factors which could plausibly constrain the trajectory of AI capabilities progress during a period of direct recursive improvement. Moreover, although no counterarguments from this chapter are decisive, they at least provide reasons to doubt claims that direct recursive improvement would enable a sustained period of exponential or super-exponential AI capabilities growth.
However, as I argue in ‘Who wins the tug of war?’, it’s not easy for the sceptic to win this argument against the believer in short timelines:
- Those who expect short timelines via direct recursive improvement can, and sometimes do, incorporate many of the constraining factors detailed above into their models. They just don’t believe that this will slow progress down by enough to prevent a short TAI timeline, or mean that capabilities improvements will plateau any time soon.
- Exponential or super-exponential trajectories of AI capabilities improvements are probably not necessary for a short TAI timeline to be realised. If the emergence of direct recursive improvement dynamics simply yields a one-time step change in the rate of capabilities improvements, or empowers the field to overcome bottlenecks to compute scaling and thereby helps to sustain current rates of progress, this might still be sufficient for producing TAI by 2035.
There are, of course, other lines of argument the sceptic can pursue instead. For example, she can target questions (3) and (4) on the list above, arguing that direct recursive improvement dynamics will not kick in any time soon (perhaps not even within the next ten years) or that TAI-level capabilities are just extremely far away. I discuss these options in the subsection titled ‘Other objections’.
Seven scenarios with short TAI timelines
In Chapter 3 of this report, I synthesise the core elements and argumentative threads of previous chapters in a more concrete way. I do this by outlining a series of scenarios with short TAI timelines which each seem (at least somewhat) plausible in light of earlier reflections, but which differ on certain core assumptions.
First, I characterise five plausible short TAI timeline scenarios in which capabilities progress is driven by some combination of compute scaling and/or recursive improvement. (‘Five scenarios based on compute scaling/recursive improvement’.)
As explained in the subsection entitled ‘Scenario generation methodology’, the five scenarios in this set are determined by the differing values they assign to the following parameters:
- Compute scaling dynamics (next ten years). Will compute scaling continue as before over the next ten years, or will this route of capabilities progress soon get seriously bottlenecked on something (be it data, paradigmatic limitations, power requirements, the supply chain, or anything else)?
- Indirect feedback loop dynamics (next ten years). If compute scaling encounters serious bottlenecks, will indirect feedback loops gain enough traction in the next ten years to overcome them?
- Direct recursive improvement period. Will a period of direct recursive improvement begin within the next ten years?
- Direct recursive improvement strength. If a period of direct recursive improvement does begin within the next ten years, how strong will this be? Will it be strong enough to accelerate existing rates of progress, merely strong enough to sustain existing rates of progress in the face of growing bottlenecks to scaling, or not even strong enough to overcome those bottlenecks?
These parameters form the nodes of the tree below, which characterises the decision process through which these five short timeline scenarios are generated.
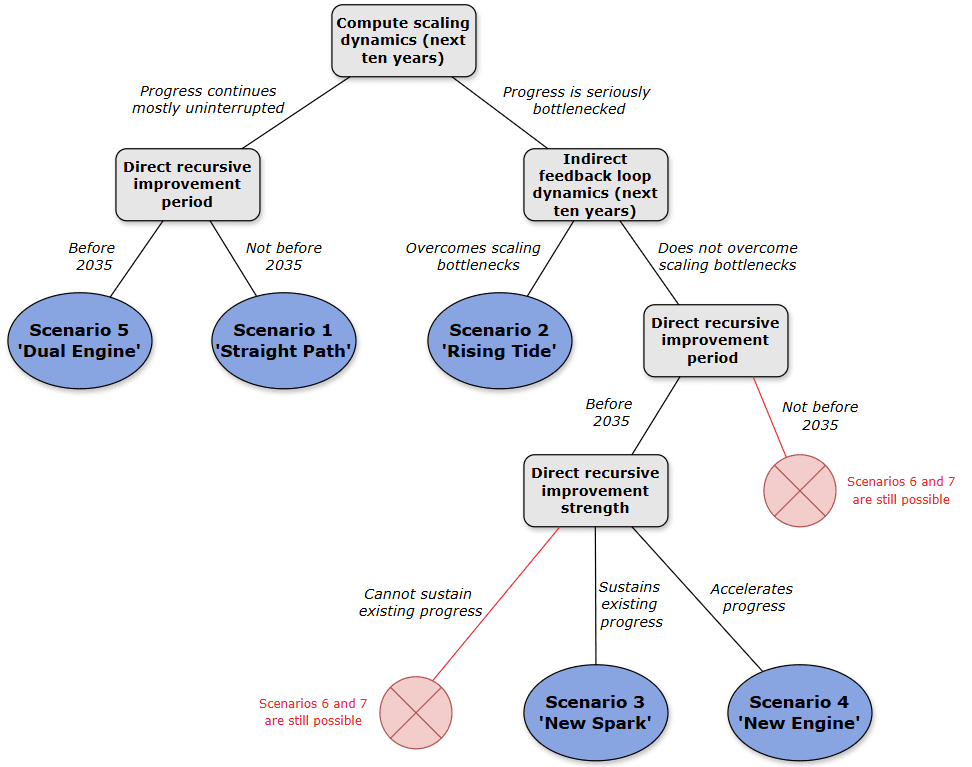
Scenario 1: ‘Straight Path’. Compute scaling just works.
Compute scaling with the current paradigm continues to yield results and does not become seriously bottlenecked in the next ten years.[6] There are problems to solve along the way (e.g. on the side of data or algorithms), but there are quick fixes available (e.g. synthetic data generation[7] works well, and unhobbling leads to easy improvements in LLM generality). Direct recursive improvement does not kick in at any point, but doesn’t need to; compute scaling is enough to produce TAI by 2035.
Scenario 2: ‘Rising Tide’. IRI breaks bottlenecks.
Compute scaling gets seriously bottlenecked on something in the next ten years (e.g. at some point, developers just can’t afford enough compute to continue scaling systems up). However, indirect feedback loops in the background gain traction over the next ten years. (For example, AI systems attract some capital which can be reinvested into procuring more compute, the scaled-up AI systems perform better and attract even more capital, and so on.) This helps to lift capabilities progress out of a plateau. Direct recursive improvement could also kick in at some point, but doesn’t need to; compute scaling plus indirect recursive improvement is enough to produce TAI by 2035.
Scenario 3: ‘New Spark’. Moderate DRI sustains progress.
Compute scaling gets seriously bottlenecked on something in the next ten years. Indirect feedback loops do not gain sufficient traction to lift capabilities progress out of this plateau. However, a period of direct recursive improvement soon kicks in. It’s strong enough to sustain current rates of capabilities progress. Systems are near enough to TAI-level capabilities at the time that direct recursive improvement kicks in for TAI to be produced by 2035.
Scenario 4: ‘New Engine’. Strong DRI accelerates progress.
Compute scaling gets seriously bottlenecked on something in the next ten years. Indirect feedback loops do not gain sufficient traction to lift capabilities progress out of this plateau. However, a period of direct recursive improvement soon kicks in. It’s strong enough to accelerate capabilities progress. (For example, there could be a one-time step change in the rate of capabilities progress, or a sustained period of continuous acceleration.) Even if systems are far away from TAI-level capabilities at the time that direct recursive improvement kicks in, this doesn’t matter; direct recursive improvement leads to such fast (and/or prolonged) capabilities progress that TAI is still produced by 2035.
Scenario 5: ‘Dual Engine’. Joint compute scaling + DRI accelerates progress.
As in Scenario 1, compute scaling with the current paradigm continues to yield results and does not become seriously bottlenecked on anything in the next ten years. There are problems to solve along the way, but there are quick fixes available. Direct recursive improvement also kicks in within the next ten years. Even if systems are far away from TAI-level capabilities at the time that direct recursive improvement kicks in, this doesn’t matter; direct recursive improvement plus continued compute scaling leads to such fast (and/or prolonged) capabilities progress that TAI is still produced by 2035.
In ‘Have we missed anything important?’, I then outline two other scenarios which do not significantly rely on either compute scaling or direct recursive improvement as primary mechanisms for AI capabilities progress over the next decade, but could still yield a short TAI timeline. These both point to a new approach to AI development which, once adopted, enables TAI to be produced relatively quickly.
- Scenario 6: ‘LLM Hybrid’. A hybrid architecture is developed which combines LLMs with a form of symbolic reasoning or new learning methods. This displays much higher levels of generality than the current paradigm. Relatively minor or fast improvements to this hybrid paradigm are sufficient to achieve a form of TAI by 2035.
- Scenario 7: ‘Intelligent Network’. Before 2035, many systems, each with narrow capabilities, are composed together in a network (e.g. in the style of Drexler’s Comprehensive AI Services). The combination of these systems’ individual capabilities constitutes a genuinely transformative composite system.
Reflections. Some of these scenarios might seem less plausible than others. I do not favour any one scenario as being especially likely to occur. However, at the end of this chapter, I argue that the very existence of this plurality of routes through which TAI could feasibly be achieved by 2035 is noteworthy, and should strengthen our overall degree of belief in short timelines. This argument is picked up again in the Conclusion.
I also note that the specific pathway we end up taking to TAI (and not just the timeline) is of strategic importance. In ‘Which scenario?’, I speculate about how the scenario we are in influences the type of transformative system that arrives first, how far we will have surpassed TAI by (if at all) in 2035, and the warning signs (if any) we can expect to have along the way.
Conclusion
In the ‘Conclusion’ section of this report, I argue for the plausibility of short TAI timelines on the following grounds:
- There are several different routes through which TAI could conceivably be achieved in the next ten years. If AI capabilities progress is slow or begins to plateau on one route, other mechanisms could soon kick in through which TAI might still quickly be achieved.
- Short timeline scenarios are compatible with a variety of different background assumptions (for example, about scaling, the current paradigm, and the strength of different drivers and restraints of AI capabilities progress).
- The body of evidence in support of short timeline scenarios is rapidly growing. With new developments in the AI field, the state of this debate appears to be shifting more and more towards short timelines as a likely outcome of capabilities R&D efforts.
In ‘What now?’, I go on to note key areas of uncertainty over the arguments I have laid out, as well as areas of strategic importance which warrant further exploration. This, alongside the other takeaways of this report, motivates some important questions for further research, which are captured under a ‘bounty list’ at the end of the report.
Acknowledgements
Thank you to Justin Bullock, Elliot McKernon, Daan Juijn, Jakub Growiec, Tom Davidson, Armand Bosquillon de Jenlis, Anson Ho, and Seth Blumberg for feedback on the report.
- ^
For a more detailed enumeration of systems that could qualify as TAI, see the subsection of this report titled ‘What capabilities could constitute TAI?’.
- ^
Here, I’m specifically interested in the date of their initial arrival in a lab setting. There are further questions of strategic importance around the timeline for deployment and diffusion, but I do not address these in this report.
- ^
These five scenarios are represented by a scenario tree, Figure 3.1, which is also included later in this overview section.
- ^
Very recent evidence (e.g. from OpenAI’s o1 model) suggests that AI systems also become increasingly capable with increased run-time compute. In light of this, ‘run-time compute scaling’ is increasingly featuring in stories of future AI capabilities progress, and is discussed in Chapter 1 of this report.
Historically, however, training compute has been the focus in most arguments for short timelines via compute scaling. There is also less empirical data on the scaling relationship between run-time compute and capabilities, and the implications of results like those very recently published by OpenAI are not yet fully understood. Because of this, this report focuses primarily on the prospect of scaling training compute – but the existence of a second route of compute scaling is taken to strengthen the overall case for expecting short TAI timelines, and provide a potential line of response to some of the sceptic’s objections.
- ^
Note that this line of argument against short timelines has been somewhat undermined by the recent breakthrough performance of OpenAI’s o-series models on the ARC benchmark. Details of what to make of these developments in the context of the debate over generality in current AI systems can be found in the relevant section of Chapter 1.
- ^
Or, if it does get seriously bottlenecked, another form of compute scaling (e.g. with run-time compute rather than training compute) works just fine. I don’t mention this option explicitly in my scenarios, but take it to basically be a variant of what I call ‘compute scaling’ here. Of course, it only applies in cases where the bottleneck to compute scaling is not a lack of physical compute.
- ^
Note: I do not consider synthetic data generation alone as sufficient for underpinning what I call a period of ‘direct recursive improvement’ in Chapter 2. I do, however, accept that AIs which generate data could bring about a much more restricted (and therefore weaker) form of the same dynamic. This will become clear in Chapter 2.
OscarD🔸 @ 2025-03-03T14:32 (+2)
I think I would have found this more interesting/informative if the scenarios (or other key parts of the analysis) came with quantitative forecasts. I realise of course this is hard, but without this I feel like we are left with many things being 'plausible'. And then do seven "plausible"s sum to make a "likely"? Hard to say! That said, I think this could be a useful intro to arguments for short timelines to people without much familiarity with this discourse.
Zershaaneh Qureshi @ 2025-03-05T14:26 (+4)
Thanks for the feedback! I essentially agree that quantitative forecasts would be a valuable addition to this work. Actually, I'd previously planned to include a basic model as an appendix alongside the qualitative analysis of the full report, but just didn't end up having the capacity at the time to pull together forecasts that felt genuinely meaningful. (My first attempt resulted in a model which was wildly sensitive to small changes in the values of each parameter, and just didn't feel useful.) I welcome any efforts to build on the ideas/scenarios in my report in this way, and would be keen to chat to anyone doing work in this rough direction!
For what it's worth (and I indicate this in the 'Purpose' section at the start of the report), I think the main utility of the report as it stands -- as a largely qualitative piece of work -- is less in its establishing a conclusion about the plausibility/likelihood of short timelines and more in its use as a resource for understanding and engaging with the timelines debate. With respect to the former goal, it would definitely benefit from more quantification than I currently provide. But my hope is more that this report will be something people can use to familiarise themselves with the debate, refer to in their own work, build upon, etc.