AGI Governance Through Multi-Sovereign Deterrence and Compute Control: Europe's Strategic Role
By Bosquillon de Jenlis Armand @ 2026-06-30T14:25 (+1)
I used AI tools to assist with editing this post, and I personally reviewed and refined all arguments.
Abstract
AGI — systems capable of functioning as a country of geniuses — could arrive before 2030, and whoever develops it first could rapidly build insurmountable geopolitical advantages. This creates catastrophic risks: power concentration in unelected hands, democratic erosion from arms-race dynamics, unprecedentedly durable authoritarian entrenchment through AI-automated militaries and bureaucracies, loss of control from AI misalignment, and nuclear instabilities — for instance, if states facing post-AGI dominance by a rival calculate that crippling its AI projects is their safest remaining option.
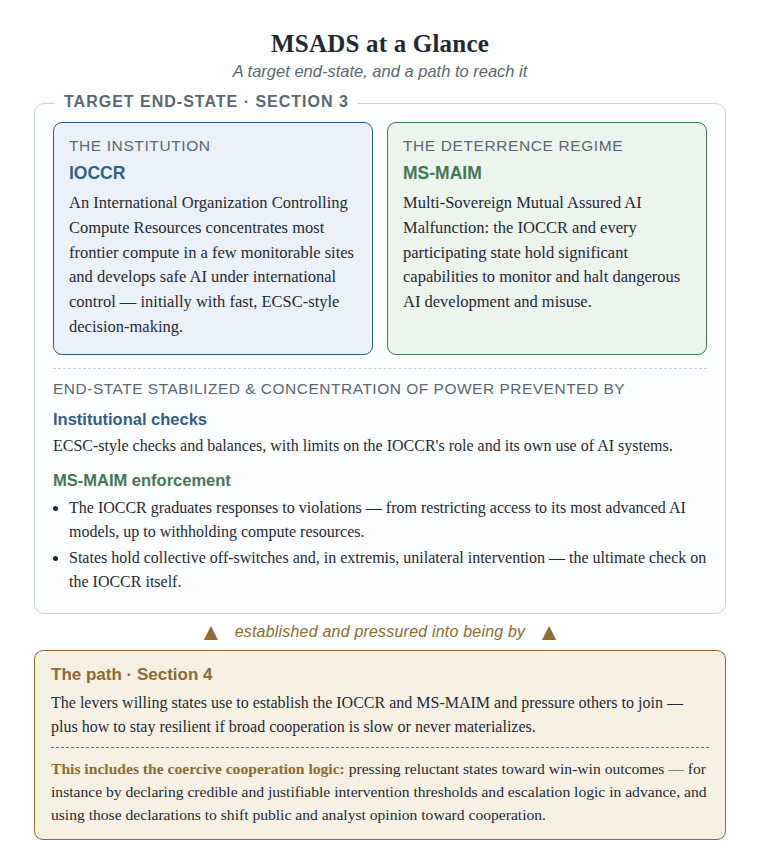
This report analyzes existing strategies for managing this transition and proposes the Multi-Sovereign AI Deterrence Strategy (MSADS), which extends the Mutual Assured AI Malfunction framework from Superintelligence Strategy and builds on earlier cooperative proposals such as the Multinational AGI Consortium. MSADS establishes an International Organization Controlling Compute Resources (IOCCR), initially with streamlined ECSC‑style decision‑making, that concentrates most frontier compute in a small number of monitored facilities and enables both individual states and the IOCCR itself to monitor AI development and halt dangerous activity, through graduated mechanisms ranging from collective off‑switches to, in extreme cases, unilateral intervention. This dual architecture is designed to guard against tyrannical power concentration by the IOCCR or any other actor while enabling coordinated pauses, accelerated post‑AGI defenses, and more equitable access to AI benefits.
Given chip-industry centralization, meaningful verification of compute stocks and flows is feasible. The report explains both the limitations of leading cooperation frameworks — especially their failure to manage post-AGI power-concentration dynamics — and why MSADS offers a more desirable equilibrium. Delay prolongs exposure to destabilizing competition dynamics while allowing leading actors to cement difficult-to-reverse advantages. By forming an early open-membership coalition and communicating ambiguous but justifiable deterrence thresholds in advance, European states can shape opinion in resistant states toward recognizing the self-defeating nature of non-cooperation, pressuring nations toward win-win outcomes while securing Europe against adversarial scenarios, making MSADS a robust strategy regardless of how the transition unfolds.
16-Page Summary
Reading time: ~30 min for the 16-page summary, ~5 min for the appendix.
This 16-page summary lays out the core argument and strategic proposal in full; the longer report (open for comments) develops it further, and a condensed 3-page version is in preparation; where the summary and report diverge, treat the summary as authoritative. I'd especially value pushback on the strategy itself — which parts are most valuable, and anything I've gotten wrong. To help finish the report or discuss it, reach me at armdejen@gmail.com.
This summary is organized in five sections. Section 1 introduces key premises on AI timelines and why AGI could be highly disruptive. Section 2 compares prominent international cooperation proposals for reducing AI risks and identifies their limitations. Section 3 proposes MSADS's target end-state: a tight-cooperation system that better addresses those risks. It builds on earlier proposals for a single global AGI institution, in part by establishing a new deterrence regime — Multi-Sovereign MAIM (MS-MAIM) — in which the International Organization Controlling Compute Resources (IOCCR) and every participating nation hold significant capabilities to monitor and halt dangerous AI development and misuse worldwide. Section 4 turns to the path: the strategic levers that non-leading AI actors like France, the UK, and the EU (or any willing nations) can use to establish the IOCCR and MS-MAIM globally — and offers recommendations for scenarios where global cooperation is slow to gain participation or fails entirely. Section 5 concludes that tight cooperation like the IOCCR and MS-MAIM combination is the best option for every nation: more robust than other cooperative approaches and safer than racing and AI-dominance strategies, which are self-defeating. Together, Sections 4 and 5 argue that as the risks of not establishing something like the IOCCR and MS-MAIM globally become apparent, the political window for tight global cooperation will likely open — and that actors who prepare early and push for cooperation can raise the chance it opens and accelerate the shift once it does.
I have also included a roughly drafted appendix that answers common questions about the coercive cooperation approach discussed in Section 4 — the idea of pressuring other states toward win-win outcomes, for instance by declaring intervention thresholds and escalatory logic in advance and using those declarations to shift public and analyst opinion toward cooperation. The bibliography below contains the longer report's sources.
1. AGI Will Likely Arrive Soon And Be Highly Disruptive
A 2024 survey of 2,778 AI researchers who had published in top-tier AI venues gave a 50% chance of Artificial General Intelligence (AGI) — "highly autonomous systems that outperform humans at most economically valuable work" — arriving by 2047, with a 10% chance by 2027, assuming scientific research continues undisrupted. As of February 2026, the forecasting platform Metaculus, which has proven effective at predicting near-term political and economic events, estimates a 25% chance of AGI by 2029 and 50% by 2033. A significant fraction of AI experts, forecasters, and especially entrepreneurs expect AGI before 2030, with Artificial Superintelligence (ASI) — systems vastly exceeding human capabilities across nearly all cognitive tasks — emerging shortly thereafter. The main frontier AI companies are explicitly planning for "intelligence recursion": AIs automating AI research and the design of better chips, potentially triggering an intelligence explosion — a period of dramatically accelerating AI capability growth.
In 2024, Dario Amodei, CEO of Anthropic, described the coming transformation: by 2026-2027, AI systems could function as "a country of geniuses in a datacenter" — driving extraordinary technological acceleration, like a century of technological progress happening in a decade or less. Those who develop AGIs will command vast arrays of scientists, engineers, strategists, hackers, persuaders, and political operators — and other specialists — capabilities that could rapidly evolve far beyond genius-level across every domain critical to amassing power. They could greatly accelerate the development of breakthrough technologies, advanced robotics, autonomous weapons, bioweapons, and the industrial capacity to deploy them at scale — all with superhuman strategic coordination. Soon after AGI, a further feedback loop — advanced robots automating their own production and chip manufacturing — would likely play out and further reshape the strategic landscape. The first power to develop AGIs could quickly build an insurmountable geopolitical advantage, potentially even undermining nuclear deterrence. Throughout this report, "advanced AIs" refers to highly capable frontier systems — from those approaching AGI-level capabilities through AGI and beyond — that are powerful enough to substantially reshape states' military, economic, and political power.
The stakes of this transition are enormous. How states manage the AGI transition — whether through cooperation or competition — will determine whether these capabilities become humanity's greatest asset or its greatest threat.
2. Current Cooperation Proposals And Their Flaws
Several international cooperation proposals aim to properly manage the AGI transition. I describe three approaches, which can be combined — Mutual Assured AI Malfunction (MAIM), AI redlines with an IAEA-for-AI body, and proposals for a global moratorium on AI development — then identify their shared limitations.
Institutionalized MAIM regime. The authors of Superintelligence Strategy argue that no superpower would remain passive while a rival risks transforming an AI lead into an existential threat. Instead, capable nations would likely threaten to preemptively sabotage AI projects threatening their survival. Given that AI assets are currently highly vulnerable to disruption, the authors predict an informal regime of AI deterrence — MAIM — would emerge organically. MAIM would initially operate through espionage to monitor AI progress, with states communicating escalation ladders — beginning with cyberattacks, chip supply chain disruption, and AI infrastructure sabotage, potentially escalating to conventional missile strikes on datacenters and their corresponding power plants, or even non-AI-related assets, if rivals pursue strategic dominance.
Rather than letting this regime develop chaotically, Superintelligence Strategy proposes preparing mechanisms to proactively establish a stable MAIM regime. In its mature, institutionalized form, MAIM would enable states to monitor each other's AI projects and safely intervene when rivals make strategic bids for dominance, by keeping critical AI assets deliberately vulnerable to disruption and, potentially, by introducing jointly controlled “off‑switches” for destabilizing projects. This would allow states to advance AI capabilities at a similar, regulated pace — maintaining balance while avoiding dangerous volatility from unchecked and potentially fast intelligence recursion.
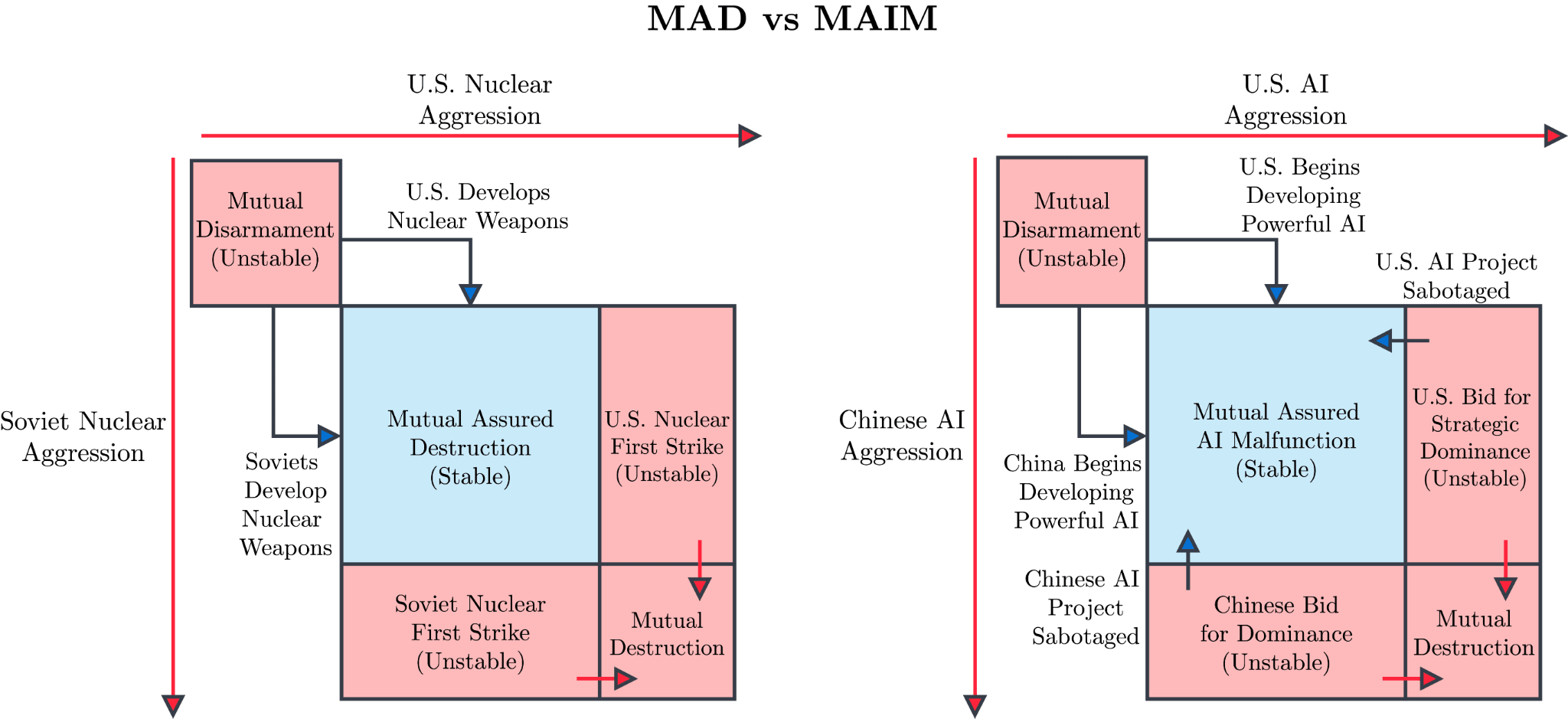
AI red lines + an IAEA-for-AI. In this approach, states agree on a list of categorically forbidden AI systems and uses — such as those proposed in the Global Call for AI Red Lines — encode these bans in domestic law, and enforce them through licensing, audits, and sanctions. A new international agency, modeled on the nuclear IAEA — often called an "IAEA for AI" — would set common safety and security standards for frontier labs, inspect major labs and data centers, monitor large training runs and flows of advanced compute, and publicly flag serious violations so that states and, where necessary, the UN can respond. The core idea is to make certain AI capabilities legally off-limits and to back that up with a standing inspection and reporting regime rather than relying only on voluntary industry or state commitments.
Compute governance: chip tracking, nonproliferation, and information disclosure. All states share an interest in limiting the AI capabilities of highly malicious actors, who could use them to develop cyberweapons or even biological weapons. Superintelligence Strategy's nonproliferation pillar sketches a broad playbook: parallel US‑ and China‑led regimes that secure high‑end chips, model weights, and AI services in their respective blocs, alongside export controls and provider safeguards to keep frontier AI out of terrorists’ and rogue states’ hands. In practice, this means treating compute somewhat like fissile material: tracking where advanced AI chips are, maintaining chain‑of‑custody from fabs to data centers, and disrupting smuggling and diversion routes. More ambitious treaty‑based proposals, such as a Secure Chips Agreement, would go further by mandating globally unique chip IDs, shared registries, and on‑chip security features that make covert misuse much easier to detect in every participating state. Related “compute governance” proposals, such as those calling for an International Compute Governance Consortium, suggest an international body that would first map who owns and controls high‑end compute and coordinate chip‑tracking, lifecycle safeguards, and technical standards across states, providing a shared toolbox that any of these MAIM‑ and IAEA‑for‑AI‑style approaches can draw on to track compute and disclose information about sensitive AI projects as part of their implementation.
AI‑redlines + IAEA‑for‑AI variants. Several proposals are specific instantiations of the AI‑redlines‑plus‑IAEA‑for‑AI pattern described above: states adopt binding commitments via treaty and domestic law; an international agency audits labs, tracks advanced compute (often via Secure‑Chips‑style mechanisms), and certifies compliance; and non‑compliance triggers state and possibly UN responses, with compute access as a central enforcement lever. Within this family, some proposals primarily start with a moratorium or cap on frontier capabilities (e.g. PauseAI, A Narrow Path), while others focus on enabling continued frontier development under strong safeguards (e.g. Belfield’s “Four Institutions” blueprint).
Pause‑oriented variants (PauseAI, A Narrow Path): PauseAI campaigns for a global pause on training the most advanced general-purpose systems until there is broad scientific and societal confidence that models beyond a given danger threshold can be aligned and controlled safely, and advocates for building a global "pause button" — the institutional and technical infrastructure needed to make such a pause enforceable. In practice, this would mean defining capability-based red lines — for example, strong autonomous cyber-offense, scalable bio-threats, and hard-to-reverse autonomy — and prohibiting training or deployment of systems that cross those lines unless robust, externally validated safety standards are in place.
A Narrow Path goes further by explicitly sequencing a roughly 20‑year prohibition on artificial superintelligence and banning key mechanisms believed to drive runaway risk, such as AIs that substantially improve other AIs, systems that can reliably escape human control, and “unbounded” agents with open‑ended self‑directed goals. Its later phases aim to build a durable international oversight system and safety‑focused research capacity, then use this framework to steer incentives so that, after the delay, only safe advanced AIs (from near-AGI to beyond, defined in section1) are developed, and they are safely deployed and used.
Governance‑for‑continued‑development (Belfield’s Four Institutions): in contrast to pause‑first strategies, Belfield’s blueprint is oriented toward governing continued frontier development. It combines compute‑indexed domestic frontier regulation, an International AI Agency to evaluate models and accredit national regimes, and a Secure Chips Agreement that conditions access to state‑of‑the‑art AI hardware on accepting stringent oversight and verifiable controls on large‑scale training. Belfield also proposes a US‑led allied public‑private frontier‑AI megaproject, intended to concentrate the largest training runs inside a governed, democratically accountable framework, reduce racing between firms and states in that bloc, and share benefits more broadly than a purely corporate or purely national project would.
Verification and enforcement problems. The approaches discussed above — institutionalized MAIM and IAEA‑for‑AI‑style regimes — implicitly assume frontier AI is developed in a few large, easily monitored compute clusters, and that most dangerous capability comes from scaling up the compute used in training ever‑larger models. At least some proponents explicitly flag this as a contingent assumption, noting that significant algorithmic improvements or advances in distributed training would undermine the case for focusing regulation on only the very largest runs (Belfield, 2025). AI capabilities are driven not only by scaling raw training compute (~4.5× per year), but also by rapid algorithmic improvements that increase the effective capability gained per unit of compute — on the order of 3× per year from training‑efficiency gains and a further ~3× per year from post‑training enhancements that make a fixed amount of inference compute more effective. These two sources of algorithmic progress mean that effective compute — the amount of capability one can extract from a fixed set of hardware — may rise by roughly 10× per year even when visible hardware stays constant. In parallel, inference efficiency has improved dramatically in recent years, making it much cheaper to run a given capability level over time and further weakening the link between visible training runs and who can actually wield dangerous capabilities.
On the training side, advances in distributed training increasingly allow large runs to be spread across many machines, and even across data centers, with only a multi‑fold rather than catastrophic efficiency penalty — though achieving this still requires careful systems engineering and high‑bandwidth interconnects. Combined with the fragmentation of cloud compute across numerous providers and jurisdictions, this makes it increasingly difficult to see who is using what resources for large training jobs. In parallel, a significant and growing share of capability now comes from scaling inference at deployment rather than from larger pre‑training runs: running vast numbers of model instances, giving each call a much larger "reasoning budget", or embedding models in complex multi‑step workflows. Unlike training — which at least requires concentrated compute for extended periods — inference is already naturally distributed across many clients, devices, and data centers, making high‑impact deployments much harder to monitor at scale. Together, these current and developing training- and inference-side dynamics mean that dangerous systems could increasingly be developed and operated on cheaper and less detectable distributed infrastructure than current verification schemes assume — especially if AIs begin to autonomously drive a significant share of AI progress, which is likely to happen soon. In addition to these trends, radically more efficient AI architectures could also emerge that require far less compute for a given capability level, further weakening any governance strategy that relies on visible compute as its primary signal.
Historical evidence confirms that states routinely defect from treaty commitments, often undetected — even for programs with distinctive physical signatures. For example, the Soviet Union signed the Biological Weapons Convention while secretly operating a bioweapons network of ~40,000 people — a program whose true scale Western intelligence failed to detect until defectors revealed it was about ten times larger than estimated. Even when violations are detected, enforcement frequently fails — Syria's chemical weapons violations went unenforced after Russia vetoed UN Security Council action. And states can simply exit these regimes entirely, as North Korea did when it withdrew from the NPT to develop nuclear weapons. States with the most advanced AI models could also have less fear of sanctions or exclusion, given how quickly such models could bridge remaining technological gaps and deliver economic independence and abundance. The main leverage that some proposals derive from controlling access to the best chips is also likely to erode for China over the coming years, as it accelerates efforts toward semiconductor self-reliance and significantly expands domestic production capabilities.
Tracking a rival's technological development is already difficult, and advanced AIs will likely make it far harder — post-AGI technological progress could be fast, disorienting, and opaque even to sophisticated intelligence agencies. Today, intelligence agencies often infer secret programs from human-scale signatures — large facilities, distinctive equipment purchases, staff movements, and other traces of thousands of people working on a project. In an AI-driven — and eventually robot-driven — industrial base, much of this work can be done with far fewer humans and in highly automated, reconfigurable facilities, greatly reducing these traditional signatures. Moreover, the approaches discussed above either do not propose to monitor what AIs are being used for or do so only at a coarse-grained level — yet advanced AIs, and eventually AI-directed robots, could be used to covertly develop dangerous technologies, either directly or by strategically building technologies and industrial capabilities that may not initially appear threatening but can later be repurposed for military advantage.
These verification and enforcement problems mean that IAEA-for-AI-like institutions and institutionalized MAIM would likely struggle to be reliably enforced, at least with the mechanisms they currently propose. The same problems also make these regimes hard to adopt in the first place: precisely because covert development and defection are difficult to detect, no state wants to constrain itself while rivals might press ahead in secret, even pulling away. This gap weighs far less on the more integrated approach developed in Section 3, where concentrating compute makes verification feasible and dual institutional-and-sovereign enforcement gives the regime real teeth.
Even with broad compliance on redlines and MAIM, competitive pressures unacceptably increase post-AGI risks. Advanced AIs could vastly accelerate technological progress and industrial expansion — especially in scenarios where robotics and AI progress are fast. This produces a powerful competitive dynamic through two reinforcing channels. The first is purely economic and technological: how aggressively a state lets AIs automate its economy, develop new technologies, and scale industrial and robotic capacity determines whether it pulls ahead or falls behind — so even absent any security threat, the economic incentive to race on automation persists. The second is military: unlike human workforces that require substantial retraining, AIs and robots can be rapidly redirected to entirely new purposes, meaning the technologies and industries a state develops could be quickly, and likely very covertly, repurposed for military dominance. Even if leading states officially cooperate and are initially compliant, they cannot trust that this compliance will hold, given the verification gaps and defection dynamics described above. Each channel alone could be sufficient to drive an automation race, and those who use advanced AIs most aggressively to accelerate technological and industrial expansion could gain insurmountable geopolitical advantages (for a detailed illustration of how automation dynamics could play out, see AI 2027). This holds even under MAIM: parity in AI capabilities does not eliminate the incentive to use AIs more aggressively for industrial and technological expansion than rivals do.
States will therefore be incentivized to deploy AIs across every possible sector, bypass democratic oversight in favor of more efficient AI-driven decision-making, and progressively remove humans from control loops — since human input increasingly becomes the bottleneck slowing AI systems that could otherwise coordinate and execute at superhuman speed. They will also be incentivized to accelerate self-reinforcing feedback loops — like AI-driven chip and robot manufacturing — that compound their advantage over time. As citizens become increasingly irrelevant for intellectual and physical labor — with AIs and robots surpassing humans at optimizing industries, bureaucracies, militaries, and AI progress — states maintaining strong human oversight face severe competitive disadvantages.
As Duvenaud’s “Gradual Disempowerment” article notes, modern democracies have historically treated citizens relatively well because they needed their labor, taxes, and military service. Petrostates already show what happens when states can fund themselves from a narrow, capital‑intensive sector instead: citizens become economically dispensable, and accountability erodes. Post‑AGI states could replicate this pattern at scale, using AI‑driven rents rather than oil, and optimizing competitiveness by replacing humans with AIs and relaxing democratic and environmental constraints. The AGI transition era creates conditions where authoritarian governance becomes systematically more competitive than democratic governance, in part because autocracies can more quickly and forcefully concentrate compute under state control — and once AIs automate AI R&D, marginal increases in controlled compute directly translate into more and better AIs. Democracies then face a stark dilemma: accept structural competitive disadvantage or erode their own safeguards to match autocratic efficiency, thereby accelerating the kind of institutional disempowerment Duvenaud warns about.
These competitive responses — removing humans from control loops, automating core state functions, and subordinating welfare to state power — amplify both dangerous power concentration dynamics and AI takeover risks. Competitive pressures incentivize prematurely delegating key decisions to AI systems not yet proven aligned, making them more capable of disempowering humanity if misaligned. Between 38% and 51% of surveyed AI researchers assign at least a 10% probability to advanced AI causing human extinction or similarly permanent and severe disempowerment of humanity. If AIs remain aligned, these same conditions increase the risk of extremely durable authoritarian entrenchment through loyal AI-controlled military and police forces, comprehensive economic automation, and AI-enabled mass surveillance and manipulation. Even democratic countries risk seeing leaders cement oppressive ideologies or power structures. These arrangements could become extraordinarily durable: a leader could instruct their AIs to design only successor systems that preserve the same constraints — and to pass that rule down each generation — so that even future human leaders cannot reverse them. Even short of such extremes, citizens' democratic power risks being progressively hollowed out and their welfare underprioritized. Competitive pressures could also reduce investments in and coordination on nonproliferation, making it harder to prevent advanced AI capabilities from reaching rogue actors.
Even assuming states do not move to control most compute resources, corporate competition creates similar dynamics: once AIs drive AI research, companies with more compute will develop better AIs and rapidly outcompete others across every economically important domain — from software design and R&D to finance, logistics, and beyond — incentivizing mergers and compute pooling into very few macro-companies that concentrate unprecedented power in unelected hands. Competition also selects for those who deploy and delegate to AIs most aggressively. This dynamic risks diffusing poorly controlled and poorly aligned advanced AIs across most sectors while concentrating power in the hands of the least conscientious actors.
Slowing frontier progress through imperfectly enforceable approaches creates its own tradeoff: more points of failure, and greater relative power for the least conscientious actors who defect. This problem is most acute for pause-oriented proposals and MAIM: any approach that pauses or significantly constrains frontier development, especially for prolonged periods, lets more states and actors catch up to the constrained frontier, multiplying independent points of failure — and the more actors that reach a given capability level, the harder it becomes to ensure none defect. Given the advantages advanced AIs confer, the historical record of covert treaty defection, and the feasibility of advancing capabilities through algorithmic progress — especially post-training enhancements — on modest compute budgets, we should expect the least conscientious actors to continue development in secret, growing their relative power while pursuing less-monitored and therefore more dangerous work. How severe this tradeoff becomes depends on how fast algorithmic progress proves to be, how much the frontier is slowed, and how effectively institutions can detect and prevent covert development. The same problem applies to redlines, if compliance significantly constrains capabilities.
In sum, post-AGI competitive pressures create races to the bottom across every dimension. They make the least conscientious actors and autocratic systems more competitive and drive higher power concentration, democratic erosion, AI takeover, and proliferation risks. What is needed is an institutional environment that breaks both corporate and interstate competitive pressures — enabling AI development that prioritizes safety, dedicates appropriate resources to alignment and control, and ensures post-AGI decisions can be made through deliberate democratic processes without forcing states to choose between careful governance and staying competitive. The next section proposes such an environment.
3. The IOCCR and MS-MAIM Combination
MSADS has two parts: 1) a target end-state — the IOCCR combined with the MS-MAIM deterrence regime, described in this section — and 2) the path to reach it: the levers for establishing this tight cooperation, and the preparations for scenarios where broad cooperation proves slow or fails, described in Section 4.
The IOCCR and MS-MAIM combination is designed to break the competitive pressures identified in Section 2 — and the dangerous dynamics that flow from them. Under MSADS, states cooperate to establish the IOCCR, initially structured with fast decision-making processes similar to those of the European Coal and Steel Community (ECSC). The IOCCR would coordinate the concentration of training and inference compute in a small number of monitorable locations — starting with existing major training facilities and potentially merging them — and would establish the MS-MAIM deterrence regime, in which the IOCCR and every participating nation hold significant capabilities to monitor and halt dangerous AI development and misuse. The "deterrence" in MSADS works at two levels: multi-sovereign deterrence stabilizes the cooperation regime from within (detailed in this section), while the threat of justified intervention also helps pressure states toward establishing it in the first place (detailed in Section 4).
This framework builds on MAIM-style deterrence, IAEA-for-AI inspections, and compute-nonproliferation, and it shares the core intuition of earlier single-institution proposals — such as Bullock's Global AGI Agency and Conjecture's Multinational AGI Consortium (MAGIC) — that the most dangerous AI development is best concentrated under international control rather than raced for. MSADS restructures these elements into a tighter, multilayered regime: by combining centralized control of most frontier compute, continuous monitoring of AI use, and dual enforcement by both a supranational body and sovereign states, the IOCCR and MS-MAIM create checks and balances that diminish competitive pressures and reduce dangerous power-concentration dynamics.
Concentrating compute raises legitimate concerns about power concentration — but absent tight international cooperation that breaks post-AGI competitive pressures, power will likely concentrate in dangerous forms; the IOCCR and MS-MAIM architecture aims to make that concentration safe. The IOCCR would not be permitted to use advanced AIs (from near-AGI to beyond, defined in section1) except for limited purposes like initially accelerating the development of safe advanced AIs and strengthening defenses against post-AGI risks. It would coordinate pauses in AI progress if AIs couldn’t be made safe — and, crucially, member states could independently vote to impose such a pause even against the institution's preference, requiring only a sufficiently large minority to do so. Placing the power to halt progress in the hands of states, separately from the body that supervises AI development, mirrors the way the ECSC's Council of Ministers could constrain the High Authority — the ECSC's executive — on key decisions.
As the situation stabilizes, nations would regain control over a greater fraction of compute resources to run IOCCR-developed AIs for approved and monitored uses. A dynamic quota system for compute allocation could also address the fairness problem that pure MAIM cannot solve: ensuring that compute access better reflects population and need rather than entrenching the existing dominance of whichever state currently leads in AI. Taken together — centralized safe development, transparency, dynamic quotas, the sharing of AI-developed technologies among members, careful institutional design, and MS-MAIM's distributed capability to detect and halt defection — these features create conditions in which competition pressures are low and coordination around diminishing post-AGI risks and positive futures becomes far more likely.
Concentrating compute resources to develop safe AIs, accelerate defenses, and monitor AI use. Given how concentrated advanced chip manufacturing is today and how hard it would be to covertly build a parallel cutting‑edge fabrication capacity, meaningful verification of compute stocks and flows is feasible. If states grant the IOCCR sufficient authority to coordinate the concentration of compute, it could track chip production, confirm shipments to approved facilities, and monitor how much compute accumulates in the one or very few IOCCR‑approved sites — starting from existing large training centers and progressively consolidating them over time. Additional safety layers, such as remote shutdown mechanisms and pre‑installed destruction mechanisms for major compute clusters, could further enforce MS‑MAIM compliance. Elements of this verification approach can draw on existing nonproliferation proposals, such as the compute‑control framework in Superintelligence Strategy: Expert Version and the proposed Secure Chips Agreement. Under MSADS, AI research above a given compute threshold is restricted to IOCCR-supervised facilities — and as algorithmic efficiency lowers that threshold, the scope of exclusivity expands accordingly.
By concentrating compute resources in these monitored locations, the IOCCR can ensure AI development happens in highly secure, safety-focused facilities with appropriate resources dedicated to AI alignment and control — something competitive dynamics would otherwise make far less likely. The most advanced safe AIs can then be used to accelerate defenses against post-AGI risks: cyber-defenses, bio-defenses, and defense-dominant military technologies.
All interactions between AI systems and the external world would be monitored, providing fine-grained transparency that helps detect dangerous AI use and temper AI takeover risks while ensuring that the knowledge of AI-made technologies is shared among member states — preventing any single actor from accumulating a decisive and unchecked technological advantage. States would access IOCCR-developed AIs for approved uses on IOCCR’s tracked inference compute.
MS-MAIM: a dual-enforcement architecture. MS-MAIM combines two complementary enforcement layers to prevent dangerous power concentration and enable coordination around critical governance functions — preventing AI misuse, pausing AI progress when appropriate, enforcing the IOCCR's exclusivity over frontier AI development, and accelerating defenses. The first is the IOCCR's own graduated institutional enforcement. Because the IOCCR controls the bulk of compute resources and operates the most advanced AI systems, it can respond to violations — whether dangerous AI use that slips past approved-use filtering, activities outside IOCCR-supervised compute, or non-compliance with governance decisions like refusing inspections. Responses escalate with severity: restricting access to the most advanced AI models for minor violations, cutting access to all advanced models for more serious ones, and ultimately reducing access to general compute resources for the gravest cases. Voting thresholds scale accordingly — lighter interventions require a smaller share of members, and stronger ones require broader consensus.
The second layer is independent sovereign enforcement by member states, which operates at two levels. The first is collective: remote off-switch capabilities over compute infrastructure, requiring only a sufficiently large minority of MS-MAIM members to activate — illustratively around thirty percent, though the precise threshold could be set higher (possibly even higher than fifty percent). This deliberately low threshold makes intervention against dangerous behavior easy enough to trigger that no coalition of states can shield a dangerous project by colluding or by collectively declining to intervene, while remaining high enough that no single actor, or handful of actors, can abuse the mechanism — and it gives smaller actors real intervention power. The second is unilateral, available to states with sufficient capabilities: in extreme cases, kinetic intervention against compute facilities. Because these facilities are deliberately sited in remote areas far from population centers, such intervention can be undertaken with limited collateral harm. Because this last-resort capability does not depend on the institution's channels or on a collective vote, it serves as the ultimate check on the IOCCR itself — if the institution is compromised or captured, states retain enforcement tools that operate entirely outside its control. These sovereign capabilities also reach compute that the IOCCR's access control cannot: if a state defects and retains physical hardware on its territory, IOCCR access restrictions become irrelevant, but off-switches on the chips themselves or, if necessary, interventions like missile strikes could still disable it.
Together, these two layers ensure that enforcement does not depend on fragile great-power consensus: because intervention capabilities are held independently by the IOCCR and by sovereign states, the regime stays robust even if any single actor — or the IOCCR itself — is captured or tries to abuse its position.
Evolving IOCCR governance. To quickly centralize compute resources, establish the conditions for MS-MAIM, develop safe advanced AIs, and accelerate defenses, the IOCCR could initially adopt streamlined power structures akin to those of the European Coal and Steel Community (ECSC): a supranational High Authority-style body with strong, relatively autonomous executive powers — balanced from the outset by intergovernmental checks and a parliamentary power to dismiss the executive — explicitly designed to be insulated from day-to-day national and sectoral pressures and capable of fast decision-making with limited procedural friction. This streamlined structure would allow the IOCCR to rapidly integrate key industries, much as the ECSC did for countries that had recently been at war and remained at risk of renewed conflict.
The IOCCR's own use of advanced AIs would be tightly constrained — limited to developing and controlling safe AI systems, accelerating defenses against post-AGI risks, and other specific, time-bound purposes subject to member-state oversight — preventing the institution from accumulating unchecked AI-driven power. As the situation stabilizes and trust and verification mechanisms mature, the IOCCR could transition toward a primarily monitoring role, with states gradually regaining control over a greater fraction of inference compute to run IOCCR-developed AIs for approved, monitored uses. IOCCR leadership would be appointed by member states for fixed terms, and its operations would remain under continuous oversight by designated national authorities.
A single institution coordinating most frontier compute would face substantial design and adoption challenges, such as international cooperation hurdles, private-sector resistance, and the centralization-of-power concerns that Bullock and others detail. MSADS does not claim to dissolve these entirely; its multi-sovereign enforcement layer and ECSC-style checks are meant to make the concentration of compute safer and more accountable, while removing the competitive pressures that drive dangerous corporate and national power concentration.
The IOCCR and MS-MAIM break competition pressures and enable coordination around positive futures. Knowing that defections will most likely be detected and met with appropriate interventions creates a climate of caution that reinforces compliance. If adopted by leading AI states, the IOCCR commands vastly more compute and more advanced AIs than any other actor. Given the abundance and technological advantages that participation enables and the costs of defection, there is no rational incentive to defect — and unlike the races to the bottom described in Section 2, the most cautious actors have significant leverage to shape the AGI transition rather than being outpaced by the least conscientious.
With competition pressures broken, it is easier to dedicate appropriate resources to AI alignment and control, accelerate defenses against post-AGI threats, implement coordinated pauses in AI development if needed, preserve democratic systems, and coordinate on shared challenges like climate change, as well as on the equitable sharing of AI-generated benefits. Unlike voluntary moratorium proposals, coordinated pauses under the IOCCR and MS-MAIM are more verifiable and enforceable through the IOCCR's compute monitoring and MS-MAIM's intervention capabilities.
The IOCCR and MS-MAIM create conditions in which AI takeover risks are substantially diminished: AIs are developed with far greater resources dedicated to alignment and control; development is concentrated in one or very few facilities, leaving fewer points of failure to secure and monitor; all AI interactions with the external world are monitored; clear off-switch mechanisms exist; and — crucially — no competition pressures push states to deploy poorly controlled AIs in dangerous applications. Any dangerous AI operating outside monitored compute is moreover at a steep disadvantage, with access to far less compute than the IOCCR commands. These same conditions make AI misuse easier to detect and intervene against, enabling the entrenchment of durable peace. The IOCCR and MS-MAIM do not need to achieve perfection — controlling and monitoring the majority of compute resources and enabling safe intervention creates better conditions for managing post-AGI risks than any alternative.
4. The Path Forward: Europe's Levers for Cooperation and Resilience
This section turns from MSADS's target end-state to the path for reaching them. It first discusses the risk of nuclear instabilities, then explains why establishing tight cooperation is urgent, before setting out recommendations for how France, the UK, the EU, and more broadly any willing coalition of states can establish the IOCCR and MS-MAIM and pressure other nations to join before the window for favorable conditions closes. It also recommends ways to stay resilient if broad cooperation is slow or never materializes. Much of this logic generalizes: many of these recommendations can support the establishment of other win-win AI cooperation frameworks.
Resisting cooperation creates nuclear instabilities. States that resist win‑win cooperation despite understanding its feasibility — even as others communicate justifiable discomfort — risk signalling potential belligerent intent. Consider Russia's position if the US achieves post‑AGI dominance without transparency over compute usage. Growing uncertainty about US intentions would compound several fears: that the US could erode the survivability of Russia's nuclear retaliatory capabilities; that Russia could become acutely vulnerable to well‑orchestrated AI manipulation campaigns, large‑scale cyberattacks, or autonomous‑weapon attacks whose origin is hard to attribute; or even that the US might lose control of its own AI systems in ways that endanger Russia too. Together, these would create pressure to escalate before the US consolidates decisive advantages. Initial escalations can help test US intent, and if these fail to extract credible security assurances, Russian leaders might judge that they have sufficient reason to fear US intentions to accept the risk of using conventional missile salvos of increasing size on AI‑related infrastructure. If these proved insufficient, they could calculate that limited nuclear salvos of increasing size offer the best remaining leverage to pressure US cooperation before dominance is consolidated.
This escalation pattern is consistent with Russia's defensive escalation management doctrine, but even states with nominal no-first-use policies like China could react similarly under extreme pressure. The possibility of nuclear use should not be taken lightly: 80,000 Hours estimates the chance of a nuclear war in the next 100 years at around 20–50% — without accounting for the heightened risks of the AGI transition. A US–Russia nuclear conflict would be catastrophic for every state: nuclear winter caused by soot blocking sunlight would kill roughly 5.5 billion people from famine alone in expectation, accounting for the full range of escalation scenarios.
The US is unlikely to be able to protect itself fully against such escalation. Even the roughly 300-billion-dollar US missile defense effort currently provides only limited protection: these systems remain unproven and unreliable even against a small salvo of a handful of intercontinental missiles, let alone larger or more sophisticated attacks. It is also much harder to build a defense that can reliably stop a sufficiently large and sophisticated salvo than to design an attack that can break it. Even for a small North Korean ICBM force, US strategic missile defense cannot be counted on to stop all incoming warheads; at best it complicates an attacker's planning and might intercept some fraction (see Appendix B – Technical Limits of Missile defense).
Partially successful MAIM-like cooperation may give states enough security that they decide escalating to missile strikes is not worth the risk — but as long as MS-MAIM is not established, instabilities could remain. Fast and opaque technological progress could make states sufficiently worried about the survivability of their nuclear forces that they adopt dangerous doctrines — like pre-delegated launch authority or launch-on-warning postures — that increase retaliatory survivability but also the likelihood of accidental, unauthorized, or inadvertent nuclear use.
Getting broad cooperation started earlier is urgent. Today's concentrated AI infrastructure and centralized chip supply chains create favorable conditions for establishing the IOCCR and MS-MAIM — conditions that may not persist if leading AI actors adopt costly defensive adaptations like distributed training or hardened facilities. Delay prolongs exposure to competition dynamics while allowing leading actors to consolidate advantages that become increasingly difficult to reverse — so any eventual cooperation framework risks being shaped by and for those who led, entrenching power asymmetries rather than correcting them. AI actors are more likely to cooperate prosocially while uncertain about who will win the AI race; once clear winners emerge, they may accept cooperation only under terms unfavorable to others. And if AIs begin accelerating AI research itself, this window could close quickly — before states have enough time to react.
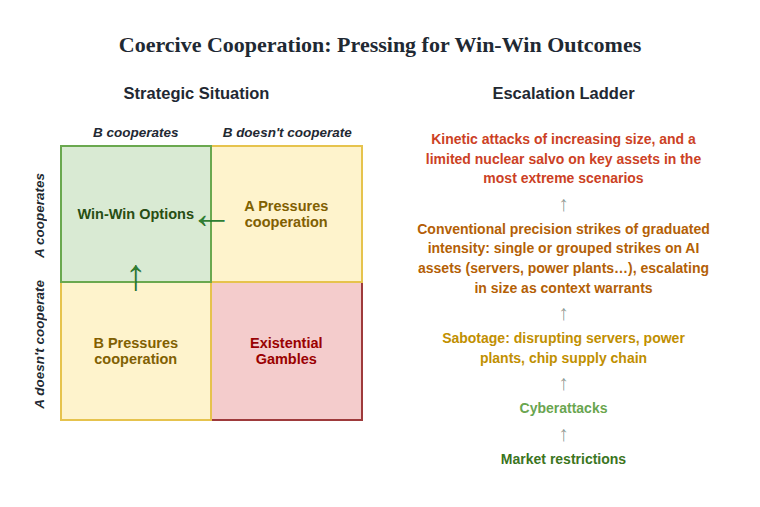
Communicating deterrence thresholds early accelerates cooperation. AI deterrence is our best option for tempering racing dynamics and great power conflicts — a logic that Dan Hendrycks and Adam Khoja defend convincingly against critics. By preventing rival miscalculations, imposing costs that slow destabilizing AI projects, and strategically pressuring nations toward win-win outcomes, it makes broad cooperation more likely to occur. As in nuclear doctrine, communicating ambiguous thresholds avoids locking nations into automatic escalation to preserve credibility, instead allowing context‑appropriate responses while still keeping adversaries cautious.
Any capable nation whose national security is sufficiently jeopardized will eventually communicate escalation thresholds to try to restore it — particularly once smaller measures like trade restrictions or covert sabotage prove ineffective. Since this communication will, absent cooperation, most likely happen eventually, doing it early raises awareness of the strategic situation among citizens, analysts, and policymakers and pressures rivals toward cooperation — and doing it late does the same, but more dangerously, leaving little time for awareness to build and cooperation to be established before thresholds are crossed.
Europe's role and recommendations. France, the UK, and the broader EU are well-positioned to initiate MSADS. France and the UK possess credible deterrence capabilities that, if maintained proactively, I do not expect to be undermined, and European states collectively have stronger incentives to pursue tight international cooperation than expected post-AGI leaders such as the US and China. Their less adversarial relationships with both major AI powers also make them more credible initiators of cooperation than either the US or China could be for each other. The following steps serve a triple purpose: preparing Europe to quickly implement MSADS if the political window opens; pressuring resistant states toward cooperation through visible, credible action; and strengthening Europe's position even if global cooperation fails and more adversarial scenarios unfold. Five concrete steps are needed:
First, invest now in detailing and comparing AGI transition strategies — including the IOCCR and MS-MAIM alongside other approaches — to strengthen the case for tight cooperation and prepare detailed implementation pathways, ready to implement if the political window opens.
Second, build on existing cooperation proposals and engage allies and potential rivals on tighter arrangements. I expect many elements of MAIM-like or IAEA-for-AI-like proposals to be valuable first steps to diminish risks and pave the way for tighter cooperation — but the goal should be the tighter forms of cooperation described in Section 3. In the absence of broad cooperation including all leading AI nations, an initial tighter framework among willing countries could start with models like CERN for AI or Intelsat for AI — centralized research facilities with international governance and open membership, focused on developing safe frontier-level AI capabilities. To accelerate coalition formation, the initial group could start small — with Europe's largest economies or even just the Benelux countries — before expanding, potentially to willing countries beyond Europe such as Canada, Japan, or South Korea, and ideally to all leading AI powers, especially the US and China.
Building such a coalition is valuable even without the participation of the leading AI powers: it provides better defense against more adversarial scenarios, partly by turning each member's partial position in the AI supply chain into joint leverage. That leverage could secure access to frontier AI, push for the models it obtains to be safer and more reliable, and — as a bloc both superpowers need to deal with — help mediate between the US and China. While global cooperation is still absent and racing dynamics persist, a coalition that includes the US makes it more feasible to pause AI progress at crucial times — in particular around the point where systems begin to substantially automate AI research, which many authors identify as a critical moment to slow down and focus on aligning these "AI-research AIs" before they drive a rapid acceleration of capabilities — and to devote more resources to alignment and control research, increasing the chances that those early systems are aligned and controllable. Such a coalition would also create greater strategic costs for those remaining outside. The safest path, however, remains reaching broad international cooperation as early as possible. Building a coalition that holds a strong advantage over others — or that helps the US secure a large AI lead — could backfire badly: it could tempt the leading group to stop keeping the door open for cooperation in favor of pressing its advantage, fueling dangerous racing dynamics and raising the likelihood that China or others climb the escalation ladder, potentially triggering catastrophic conflict.
Third, strengthen the resilience of European nuclear deterrents. France and the UK are not currently preparing for scenarios where adversarial AI states could develop new effective attacks against nuclear forces — including rapid progress in anti-submarine warfare or novel attacks against command, control, and communications systems. Without resilient deterrents, threatened states risk accepting unfavorable strategic concessions from a position of weakness, adopting dangerous launch doctrines, pursuing preemptive strategies, or some combination of these. To prevent such scenarios, France, for example, could reintroduce a land-based leg to its nuclear forces, ranging from fixed launcher sites to more politically challenging options like deploying French-owned, French-operated road-mobile launchers across willing host countries.
Fourth, build international consensus that developing AI past key thresholds outside a cooperative framework threatens all states — that pursuing capabilities like AIs able to fully automate AI research or approach AGI, outside a common project (or at least a framework that keeps states progressing at a similar pace and ensures AIs are proven safe, well controlled, and monitorable by all states), constitutes a threat to others' national security. Establishing this shared understanding is what later makes intervention legible as a justified response to a recognized danger rather than as aggression.
Fifth, define ambiguous intervention thresholds and communicate credible escalation ladders in advance — triggered by the capability thresholds above (for instance, AIs automating substantial AI research outside a cooperative framework), as well as by broader strategic conditions that resist crisp definition, such as insufficient transparency over compute usage or leading actors entrenching dangerous, difficult-to-reverse advantages.
A central purpose of these steps — especially the third and fifth — is to shock analysts and publics into recognizing the necessity of tight cooperation. Visible actions like strengthening deterrence and communicating ambiguous intervention thresholds draw attention to the risks of the AGI race and of poorly managed post-AGI competition. Paired with clear explanations of why tight cooperation benefits all nations, including the US and China, they help shift both opinion and political will toward cooperation earlier than would otherwise occur.
5. Conclusion: MSADS Is Our Best Option — It Needs Urgent Preparation
AI dominance strategies are self-defeating and endanger every nation. A mostly unregulated competition in which states race for first-mover advantages in AGI development and then seek to maintain superior AI, technological, and military capabilities would amplify every risk described in Section 2 — intensifying competitive pressures across all states while increasing nuclear instabilities. A more specific variant of this logic argues it is worth racing to aligned ASI, building a decisive military advantage, and then negotiating a new safe international order from a position of strength. But such strategies would most likely be blocked: once AIs begin to substantially automate AI research — most likely before full AGI — rivals will still have engineers inside the top labs and sufficient situational awareness to respond with graduated interventions, escalating if necessary to measures that inflict devastating damage on the infrastructure a dominance bid requires. And even if rivals failed to intervene effectively, the attempt itself would heighten nuclear instabilities and sharply amplify all post-AGI competition-associated risks — including in rival states, where the pressure to keep up increases the likelihood of catastrophic loss of control over AI systems in ways that affect every nation. The risks that dominance-seeking strategies aim to manage can be addressed more directly by establishing the IOCCR and MS-MAIM. Neither domination nor the cooperation approaches examined in Section 2 adequately address post-AGI risks, and we need to aim for tighter forms of international cooperation.
If the IOCCR and MS-MAIM — or at least MAIM-like approaches — are not broadly adopted before AIs substantially automate AI research, my guess is that a second-best option is for a US-led democratic alliance to concentrate compute and talent in a frontier-AI megaproject, pausing around the automation threshold so that alignment work can catch up and the best AI tools can help design stronger cooperation frameworks. Beyond this point, racing toward AGI or ASI without the IOCCR and MS-MAIM — or at least institutions capable of significantly slowing AI progress globally and making it possible for different states to progress at a similar pace — would be extremely dangerous.
The political window will likely open. At least some major powers will very likely come to recognize the necessity of systems like the IOCCR and MS-MAIM — but this recognition may come only after the risks of alternative approaches become painfully obvious. Citizens concerned about preserving democratic systems may increasingly realize that without eliminating competition pressures to remove humans from control loops and delegate to AIs, those systems are unlikely to survive. Aligning advanced AIs could take years or remain permanently uncertain, leading states to desire conditions where they can better dedicate appropriate resources to alignment (possibly via pausing AI progress) and control — and where the most advanced AIs can be effectively monitored and switched off if needed. Nuclear and geopolitical instabilities from asymmetric AI capabilities may grow unbearable. Once AIs automate AI research, compute resources become the primary determinant of AI capabilities — creating pressure for states to have comparable amounts of compute. But purely bilateral arrangements to achieve compute parity face deep political obstacles: the US has far more compute than others, and the most populous nations will refuse to entrench systems where they receive less compute per capita. States may therefore recognize that dynamic quota systems — which only an institution like the IOCCR could implement — offer the only viable path to resolving these instabilities while ensuring fair access to the greater shared abundance that centralized AI development enables.
Preparation must begin now. The sooner this recognition comes, the lower the cost. As argued above, the window for favorable cooperation is narrowing. We should preferably not wait for a catastrophe like the proliferation of advanced AIs to bad actors who use them to create bioweapons, an attempted AI-enabled coup, escalatory interventions between major powers, or unmistakable signs that power concentration dynamics are eroding citizens' democratic power to start preparing and acting. The first states to recognize the necessity of tight cooperation have levers to pressure others so that the political window in all major AI states opens faster. Establishing a mature IOCCR and MS-MAIM combination requires sustained preparation that willing nations should begin immediately.
Some elements of this preparation have irreducible lead times: developing detailed institutional blueprints, fostering consensus around AI risks and justifiable intervention thresholds, negotiating agreements, strengthening the resilience of nuclear retaliatory capabilities, and adapting nuclear doctrines. Having a well-understood proposal already in policymakers' minds also matters — if the political window opens suddenly, whether through crisis or through AI systems themselves recommending stronger cooperation frameworks, leaders are far more likely to act on ideas they have already engaged with than to adopt unfamiliar proposals under pressure.
Even readers unconvinced that the IOCCR and MS-MAIM combination is our best option, or even feasible, should recognize that preparing to implement it is worth the cost — future conditions may prove such systems necessary and build the political will to adopt them, and those who prepared will shape what emerges.
Appendix A: More Details and Q&A on the Coercive Cooperation Approach (Drafty)
Much of the interest and pushback I get when presenting this report concerns the coercive cooperation approach: the idea of pressuring other nations toward win-win outcomes, for instance, by declaring intervention thresholds and escalatory logic in advance, and using those declarations to shift public and analyst opinion in other states toward cooperation.
Many of the arguments for AI deterrence and the coercive cooperation approach are set out in two pieces — AI Deterrence Is Our Best Option and Coercive Cooperation: Forcing Win-Win Outcomes in an AI-driven Transition — and I develop the logic at greater length in the full report (Sections … and …). Below I add some of the questions I most often receive, with drafted answers that also include arguments not found in those other sources. As of now there is no single place where all these arguments live together; getting a comprehensive view still requires reading across these different sources.
Would states take the escalatory warnings seriously? I expect that as AGI approaches, norms will shift and states will come to recognize how threatening advanced AI systems are to those who lack comparably capable systems — through rogue-AI risks, the possibility of sophisticated coordinated attacks (mass parallel manipulation of populations and the information environment, potentially reducing other states to puppets; coordinated cyberattacks paired with large numbers of advanced autonomous weapon,..), power-concentration risks, and nuclear instabilities. A warning issued by a more justifiably threatened state is also likely to be received as less aggressive than the same warning from the US or China.
Isn't issuing such warnings outside European doctrine — and is it plausible to direct them even at allies? First, this is a warning, not a threat. It is not "we will attack you for some gain we extract"; it is "if you develop advanced AI without the cooperation that keeps us safe, that is an existential threat to us, and we are therefore willing to follow a gradual, escalatory approach to test your intent and press you toward cooperation." It is also paired with a cooperation proposal that is arguably in the other state's interest too.
Second, it is a generic warning: because it does not single out one country, it reads as less aggressive.
Third, there is precedent among allies. The US has threatened allies — for example, over Greenland — though it can do so more cheaply than Europe could, since it has many economic levers for retaliation. And when sufficiently threatened, France already resorts to nuclear signaling; in the Greenland episode it made implicit nuclear signals toward the US.
Would France ever recognize the AI threat and decide to act — or will it be too late once others reach AGI/ASI? Can it even know such systems are arriving? It will know. France has engineers in the leading AI labs, and will retain that visibility at least until AI fully automates AI progress — so as a potential intelligence explosion begins or AGI approaches, it will have the information it needs. Acting on that information is the harder question. My guess is that France is unlikely to begin applying the coercive cooperation logic before AIs substantially automate AI progress; but after that point, in a disorienting and fast-moving period, it could become increasingly willing to — and far more so if it has already encountered the arguments in advance. Hence the importance of making the case to such states now.
There is also likely to be time. Eroding a rival's nuclear deterrent is far harder than maintaining one, so I expect it would take several years post-AGI — more than three to five — before a state like the US could plausibly gain a decisive military advantage. That leaves a window in which others can recognize what is happening and respond.
Wouldn't a missile strike directly trigger large-scale nuclear retaliation? Two observations suggest not necessarily. Ukraine conducts strikes inside Russian territory without triggering nuclear retaliation, for several reasons — two of which are that the strikes do not cross the doctrinal threshold (for most states, an existential threat to the state itself), and that the political and strategic cost of nuclear use would be enormous: breaking the nuclear taboo would isolate the attacker sharply, likely rupturing relations with partners vital to its economy and diplomacy. I expect comparable political and public-opinion costs would constrain the US.
Moreover, nuclear escalation would not be a logical response against a state like France, because it would likely invite counter-retaliation: France can currently destroy roughly half of the US economy and kill around 20% of its population with its existing arsenal, and scaling that arsenal would not be especially difficult — it fielded one nearly twice as large during the Cold War. The missile strike is also a late rung: it comes only after earlier escalations meant to test intent and press for cooperation.
Most importantly, a kinetic strike is never an automatic or opening move. It sits at the top of a graduated ladder — market restrictions, cyberattacks, different forms of sabotage, and is reached only after the earlier, lower-cost rungs have been tried and have failed to shift the target's behavior. Even then it is not triggered mechanically: it is a deliberate last resort, undertaken only when escalation is judged to carry lower expected costs than allowing the dangerous development to continue. Those earlier rungs serve a double purpose — they test the target's intent and apply real pressure toward cooperation — so by the time a strike is even on the table, both sides have had repeated, legible opportunities to step back. This gradual, non-automatic structure is also what keeps escalation controllable: because thresholds are communicated as ambiguous rather than as automatic tripwires, each step allows a context-appropriate response rather than locking either side into a spiral.
Why would the US ever cooperate, given that it would mean surrendering its military advantage? As the report argues throughout, the US has far more to lose by not cooperating — at least under the win-win approach I propose — and could come to recognize this on its own. The coercive cooperation approach is meant to help it see, earlier and more clearly, what is at stake, and to understand that the competitive path is very likely to be chaotic.
Won't cooperation take a decade, with no guarantee of success? Cooperation can move quickly when states face an imminent existential threat — plausibly faster than the ECSC, whose own timeline was already short: the Schuman Declaration (9 May 1950) publicly launched the idea of pooling coal and steel under a supranational High Authority; the Treaty of Paris was signed about eleven months later (18 April 1951); the treaty entered into force and institutions began operating by July–August 1952, roughly fifteen months after signature; and the common market was effectively functioning by 1953. The coercive cooperation approach also structures the situation so that states are unlikely to choose to cheat or defect.
Would launching a missile at US datacenters destroy our relationship with them? If we reach the point of doing so, the relationship has already been broken — because reaching it means we have first had to go through earlier, justifiable escalations to preserve our future.
You propose shifting public opinion in other states — but can we legitimately interfere in their politics, and how might it backfire? This is the question I am least confident about, though I think the basic activity is more ordinary than it first sounds. States routinely and openly try to shape opinion inside other countries: this is the entire premise of public diplomacy, which the US State Department describes as a mandate to "inform and influence foreign publics" through media, cultural, and educational engagement — and nearly every major power runs such programs (the BBC World Service, France Médias Monde, Deutsche Welle, and so on). Leaders also influence foreign publics more directly: when European leaders publicly condemned recent US tariffs, those statements were aimed in part at the American debate, not only at European audiences.
What separates this from illegitimate interference is not the aim of influencing a foreign public — that is universal and accepted — but the means. Open, attributable, reasoned argument is public diplomacy; covert manipulation of elections or the information environment, Russian-style, is not. My proposal is of the former kind: making the public case that non-cooperation is dangerous and that cooperation serves everyone's interest. Where exactly overt persuasion shades into counterproductive meddling I cannot draw a sharp line — and the risk of backfire is real: heavy-handed pressure can be read as foreign interference and harden the very opinion one hopes to shift. This remains the part of the proposal I am least sure about.
To conclude, I should be candid that I remain uncertain whether this overall approach is net positive — but I think it is a line of reasoning well worth exploring.
Acknowledgements
Thanks to Tom Dugnoille, Peter Trocsanyi, and Vladimir Somers for valuable feedback and discussion. All remaining errors are my own.
Bibliography
You can find the bibliography of this report — with the more comprehensive sourcing of the longer report — by following this link.